Downloaded 302 times

































































This document provides an overview of bioinformatics. It defines bioinformatics as the science of collecting, analyzing and conceptualizing biological data through computational techniques. It discusses that bioinformatics involves managing, organizing and processing biological information from databases, as well as analyzing, visualizing and sharing biological data over the internet. It also outlines some of the goals of bioinformatics like organizing the human and mouse genomes, as well as some applications like genomic and protein sequence analysis, protein structure prediction, and characterizing genomes.
Introduction to bioinformatics, which combines biological data with informatics techniques for analysis and conceptualization.
Discusses biological data quantities, including human genome size (3 billion base pairs), and goals of bioinformatics such as data management and visualization.
Bioinformatics defined through molecular biology aspects and central dogma, highlighting data processing and statistical analysis in biological contexts.
Details computational methods in bioinformatics, including algorithm development and the human genome project, emphasizing data integration and accessibility.
Information analysis processes in bioinformatics, focusing on data management, hypothesis derivation, and the significance of quick analysis.
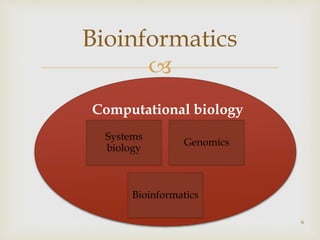
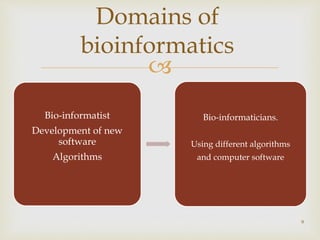
Different domains of bioinformatics applications including computational biology, medical informatics, and drug development.
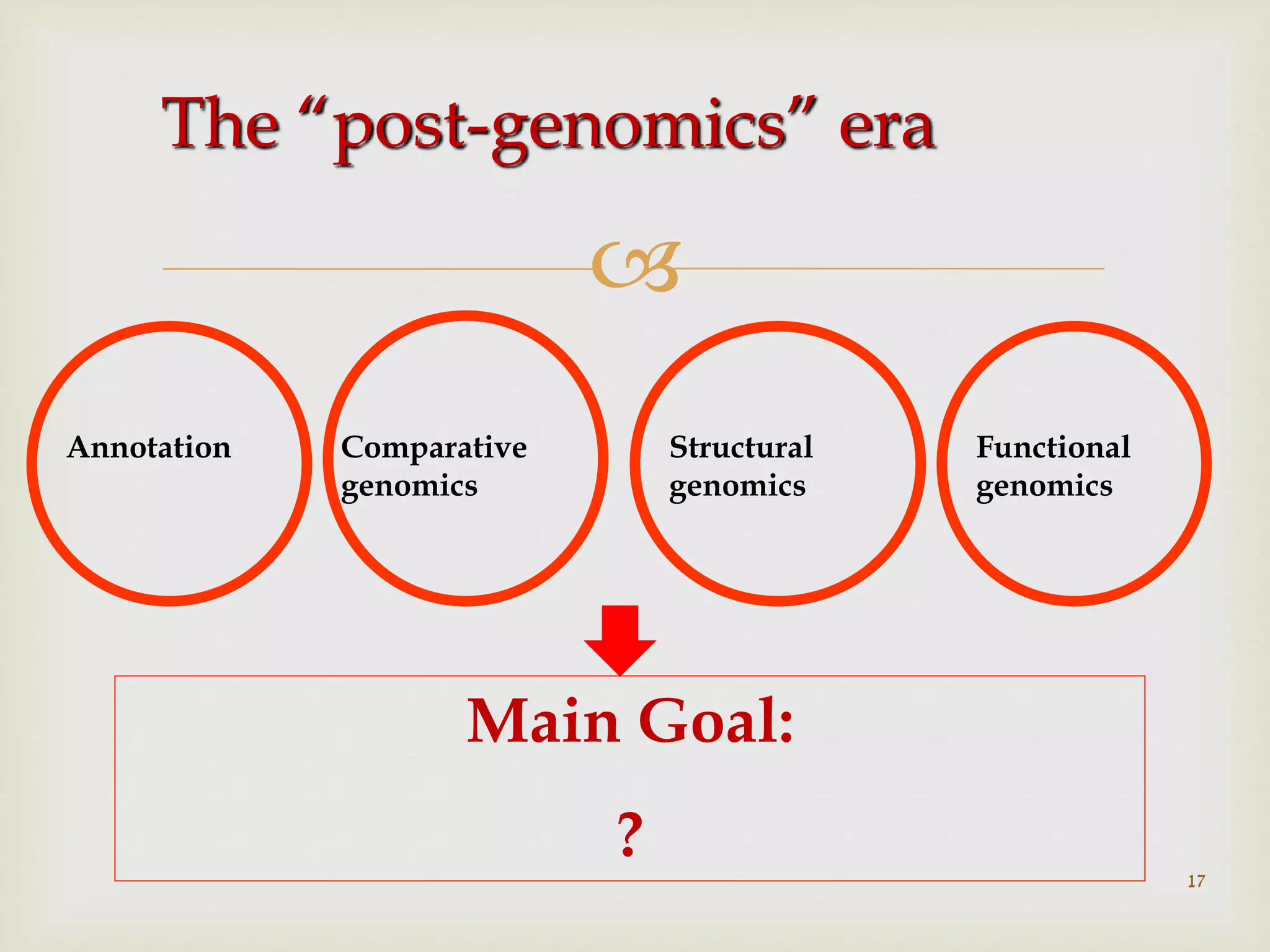
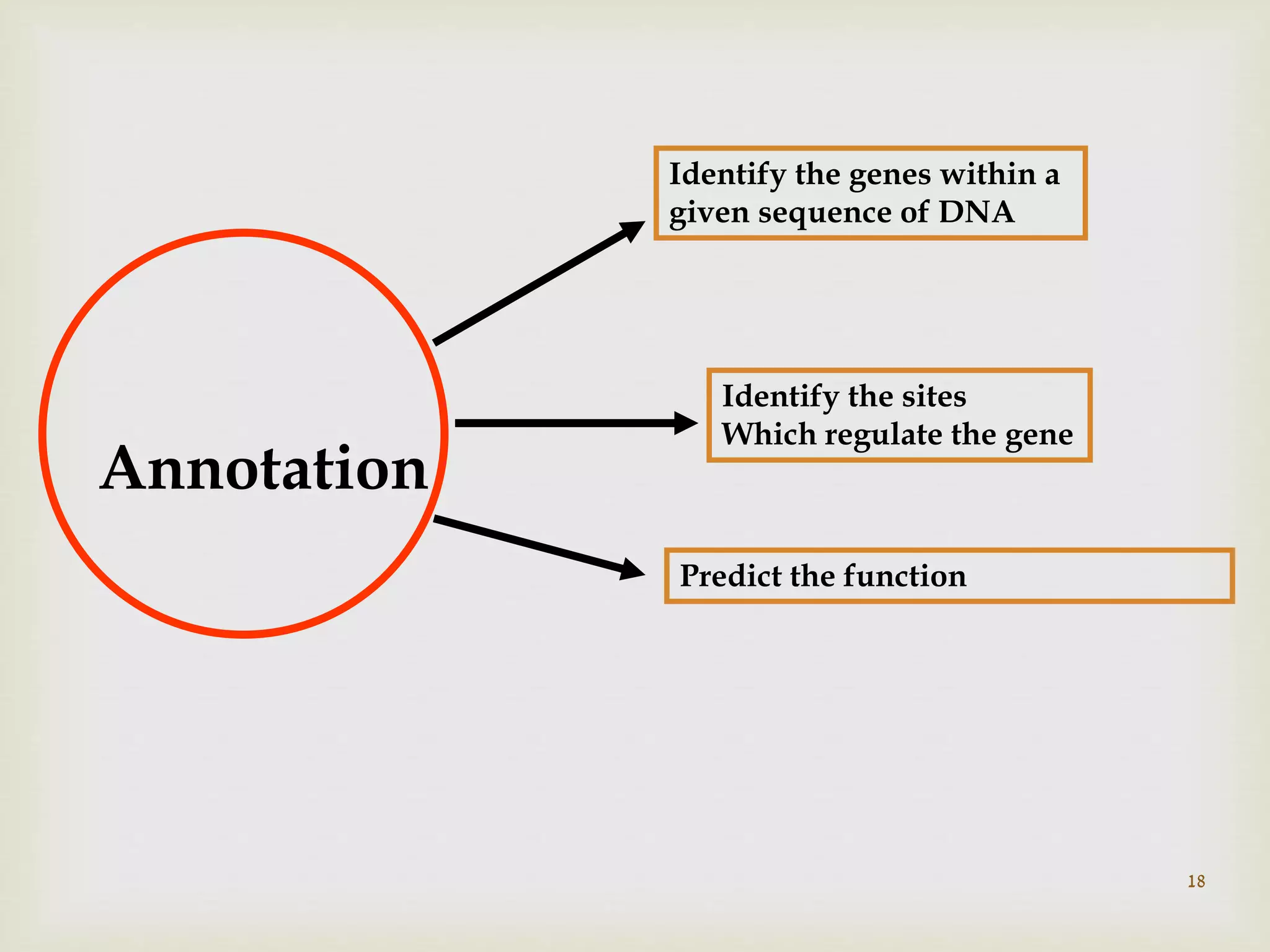
Main goals in the post-genomics era, including gene annotation and prediction of gene functions from DNA sequences.
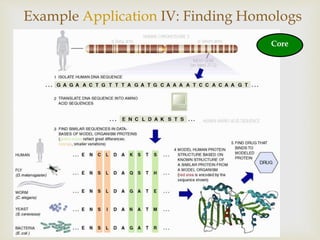
Assesses methods for gene identification within genomes and comparative genomics for evolutionary studies.
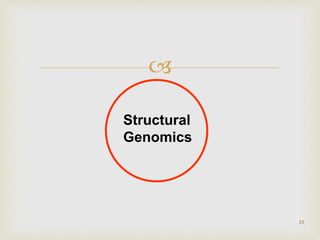
Focus on structural genomics, emphasizing protein structures, functionality, and evolutionary relationships derived from 3D structures.
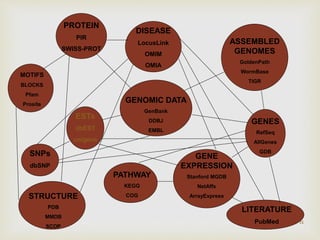
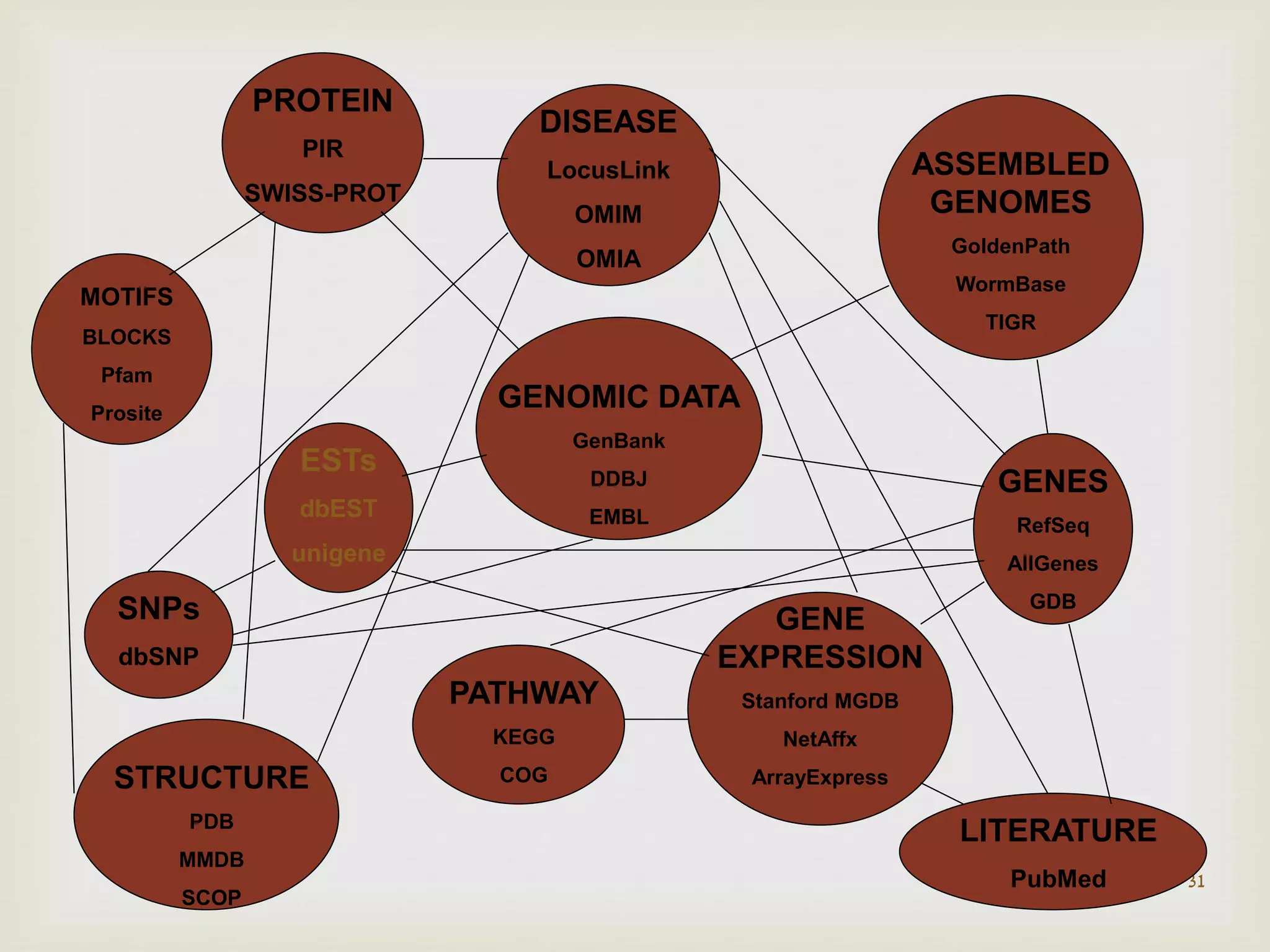
Different biological databases including sequence, structure, and literature databases, and their interrelation for data accessibility.
Applications in genomics, including gene finding, characterization of genomic elements, and comparative analyses across species.
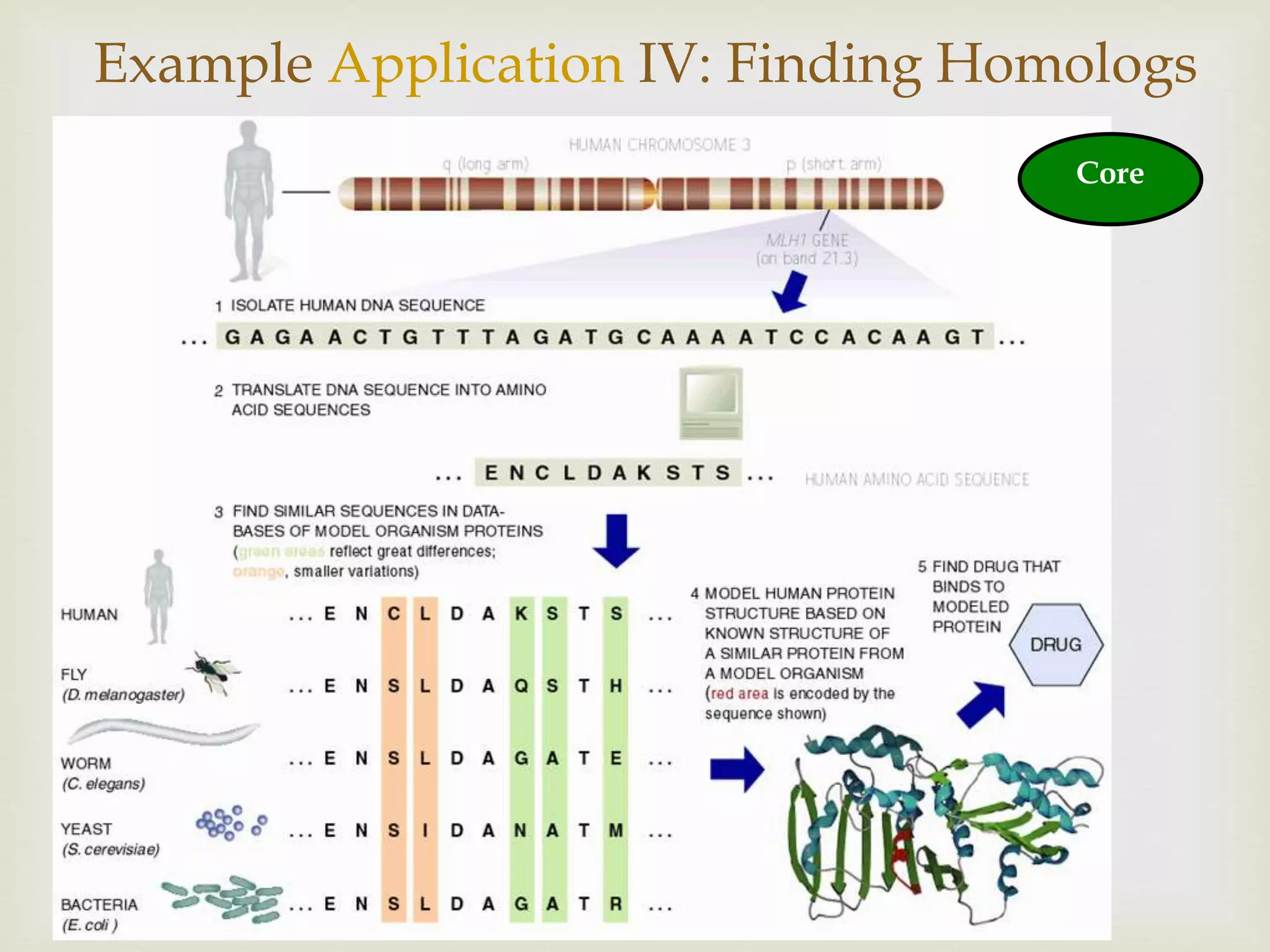
Applications in protein sequence analysis including alignment methods, prediction of secondary and tertiary structures, and evolutionary implications.
Overall characterization of genomes, including expression analysis, comparisons among organisms, and statistical evaluations.
Closure and thanks, likely summarizing the significance of bioinformatics in modern biological research.






























































































