Download as PDF, PPTX

















![20
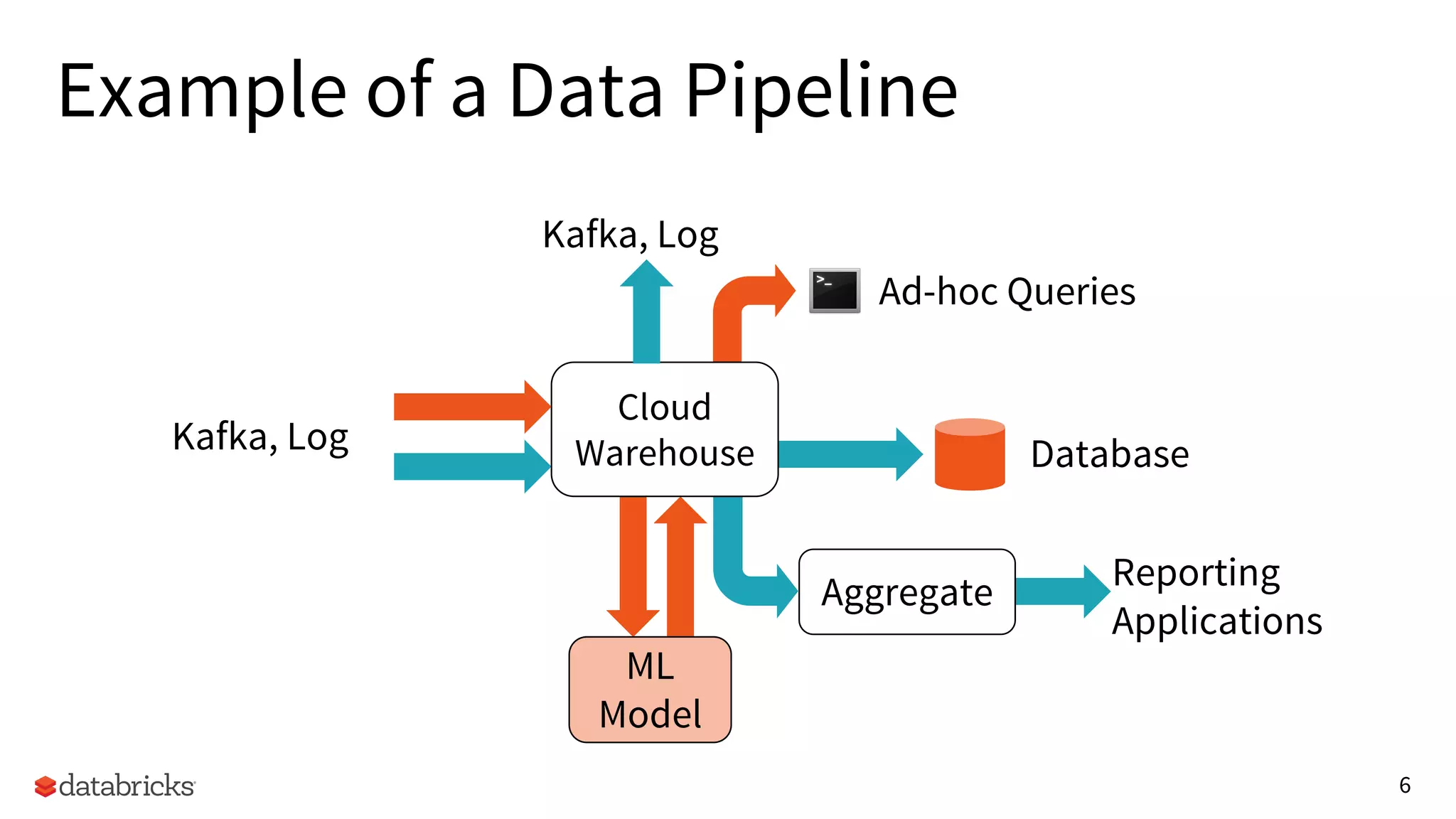
Corrupt
Files
java.io.IOException. For example, java.io.EOFException: Unexpected end of input
stream at org.apache.hadoop.io.compress.DecompressorStream.decompress
java.lang.RuntimeException: file:/temp/path/c000.json is not a Parquet file (too
small)
spark.sql.files.ignoreCorruptFiles = true
[SPARK-17850] If true, the Spark jobs will
continue to run even when it encounters
corrupt files. The contents that have
been read will still be returned.
Dealing with Bad Data: Skip Corrupt Files](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-20-320.jpg)
![21
Missing or
Corrupt
Records
[SPARK-12833][SPARK-
13764] TextFile formats
(JSON and CSV) support
3 different ParseModes
while reading data:
1. PERMISSIVE
2. DROPMALFORMED
3. FAILFAST
Dealing with Bad Data: Skip Corrupt Records](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-21-320.jpg)








![31
Functionality: Better JSON and CSV Support
[SPARK-18352] [SPARK-19610] Multi-line JSON and CSV Support
- Spark SQL currently reads JSON/CSV one line at a time
- Before 2.2, it requires custom ETL
spark.read
.option(”multiLine",true)
.json(path)
Availability: Apache Spark 2.2
spark.read
.option(”multiLine",true)
.json(path)](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-31-320.jpg)




![36
Availability: Apache Spark 2.2
Unified CREATE TABLE [AS SELECT]
CREATE TABLE t1(a INT, b INT)
USING ORC
CREATE TABLE t1(a INT, b INT)
USING hive
OPTIONS(fileFormat 'ORC')
CREATE Hive-serde tables CREATE data source tables
CREATE TABLE t1(a INT, b INT)
STORED AS ORC](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-36-320.jpg)
![37
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
[db_name.]table_name
USING table_provider
[OPTIONS table_property_list]
[PARTITIONED BY (col_name, col_name, ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[AS select_statement];
Availability: Apache Spark 2.2
Unified CREATE TABLE [AS SELECT]
Apache Spark preferred syntax](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-37-320.jpg)

![39
[SPARK-15689] Data Source API v2
1. [SPARK-20960] An efficient column batch interface for data
exchanges between Spark and external systems.
o Cost for conversion to and from RDD[Row]
o Cost for serialization/deserialization
o Publish the columnar binary formats
2. Filter pushdown and column pruning
3. Additional pushdown: limit, sampling and so on.
Target: Apache Spark 2.3](https://image.slidesharecdn.com/17-170608201527/85/Building-Robust-ETL-Pipelines-with-Apache-Spark-39-320.jpg)





















![20
Corrupt
Files
java.io.IOException. For example, java.io.EOFException: Unexpected end of input
stream at org.apache.hadoop.io.compress.DecompressorStream.decompress
java.lang.RuntimeException: file:/temp/path/c000.json is not a Parquet file (too
small)
spark.sql.files.ignoreCorruptFiles = true
[SPARK-17850] If true, the Spark jobs will
continue to run even when it encounters
corrupt files. The contents that have
been read will still be returned.
Dealing with Bad Data: Skip Corrupt Files](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-20-2048.jpg)
![21
Missing or
Corrupt
Records
[SPARK-12833][SPARK-
13764] TextFile formats
(JSON and CSV) support
3 different ParseModes
while reading data:
1. PERMISSIVE
2. DROPMALFORMED
3. FAILFAST
Dealing with Bad Data: Skip Corrupt Records](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-21-2048.jpg)









![31
Functionality: Better JSON and CSV Support
[SPARK-18352] [SPARK-19610] Multi-line JSON and CSV Support
- Spark SQL currently reads JSON/CSV one line at a time
- Before 2.2, it requires custom ETL
spark.read
.option(”multiLine",true)
.json(path)
Availability: Apache Spark 2.2
spark.read
.option(”multiLine",true)
.json(path)](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-31-2048.jpg)




![36
Availability: Apache Spark 2.2
Unified CREATE TABLE [AS SELECT]
CREATE TABLE t1(a INT, b INT)
USING ORC
CREATE TABLE t1(a INT, b INT)
USING hive
OPTIONS(fileFormat 'ORC')
CREATE Hive-serde tables CREATE data source tables
CREATE TABLE t1(a INT, b INT)
STORED AS ORC](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-36-2048.jpg)
![37
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
[db_name.]table_name
USING table_provider
[OPTIONS table_property_list]
[PARTITIONED BY (col_name, col_name, ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[AS select_statement];
Availability: Apache Spark 2.2
Unified CREATE TABLE [AS SELECT]
Apache Spark preferred syntax](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-37-2048.jpg)

![39
[SPARK-15689] Data Source API v2
1. [SPARK-20960] An efficient column batch interface for data
exchanges between Spark and external systems.
o Cost for conversion to and from RDD[Row]
o Cost for serialization/deserialization
o Publish the columnar binary formats
2. Filter pushdown and column pruning
3. Additional pushdown: limit, sampling and so on.
Target: Apache Spark 2.3](https://image.slidesharecdn.com/17-170608201527/75/Building-Robust-ETL-Pipelines-with-Apache-Spark-39-2048.jpg)





The document discusses building ETL (Extract, Transform, Load) pipelines using Apache Spark, highlighting its capabilities in data extraction and transformation, especially for dirty or complex datasets. It covers key features like multi-line JSON and CSV support, structured streaming, and performance improvements in Spark 2.3, along with examples of ETL queries. The session aims to illustrate how Spark simplifies the complexities of managing data pipelines and enhances data processing efficiency.
Introduction to ETL pipelines using Apache Spark, overview of the speaker, and background on Databricks.
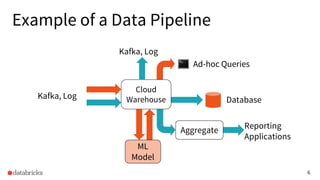
Defines ETL (Extract, Transform, Load) and explains data pipelines with examples and output data characteristics.
Describes the importance of ETL, complexities involved, and key challenges faced when executing ETL operations.
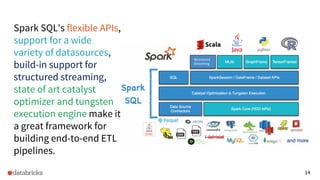
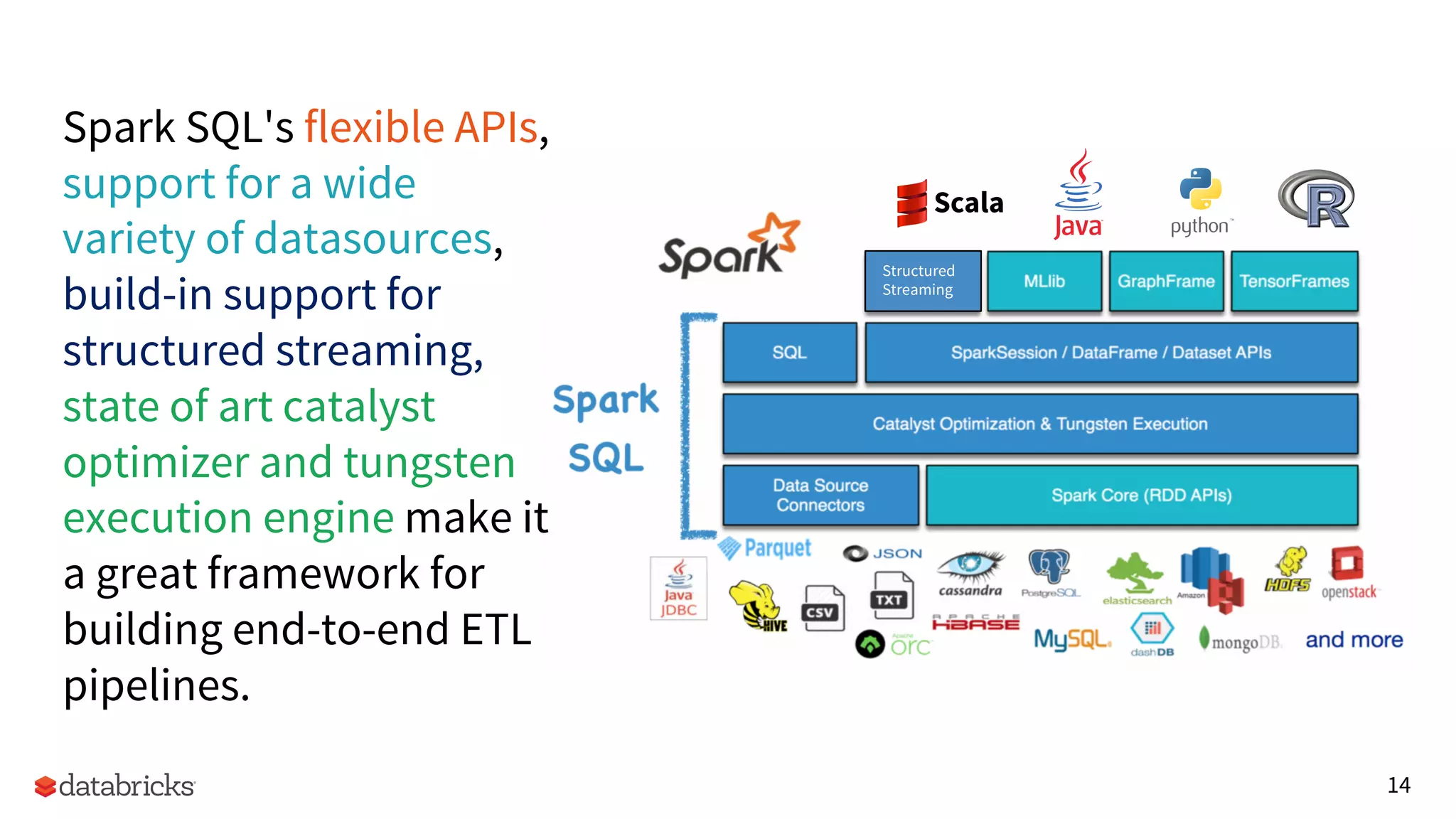
Overview of Spark SQL’s capabilities, advantages of its APIs for building ETL pipelines, and integration with structured streaming.
Discusses built-in connectors in Spark for various data types and schema inference from semi-structured files.
Methods for dealing with corrupt records and files in Spark, including various modes for JSON and CSV parsing.
Details on utilizing higher-order functions for transformations in SQL, including aggregate and filtering operations.
Improvements in Spark 2.3 related to ETL efficiency, including new table creation syntax and performance enhancements.
Promotes Databricks' platform for trying Apache Spark and provides speaker's contact information for further inquiries.























































































