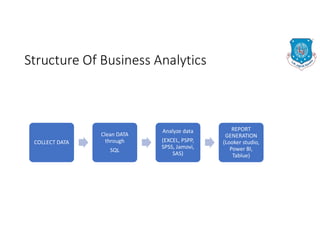
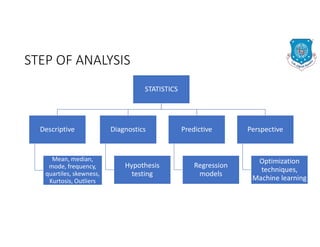
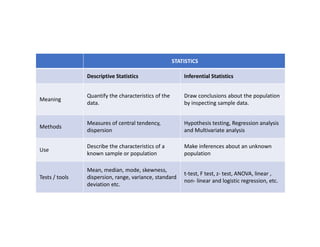
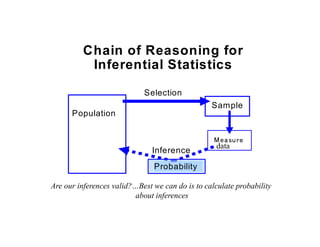
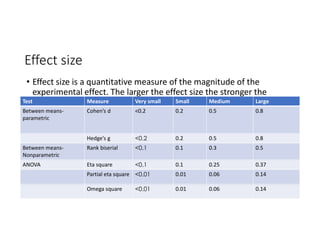
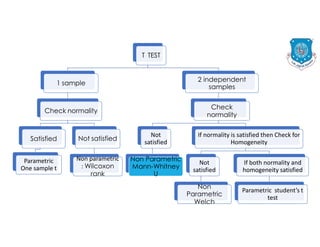
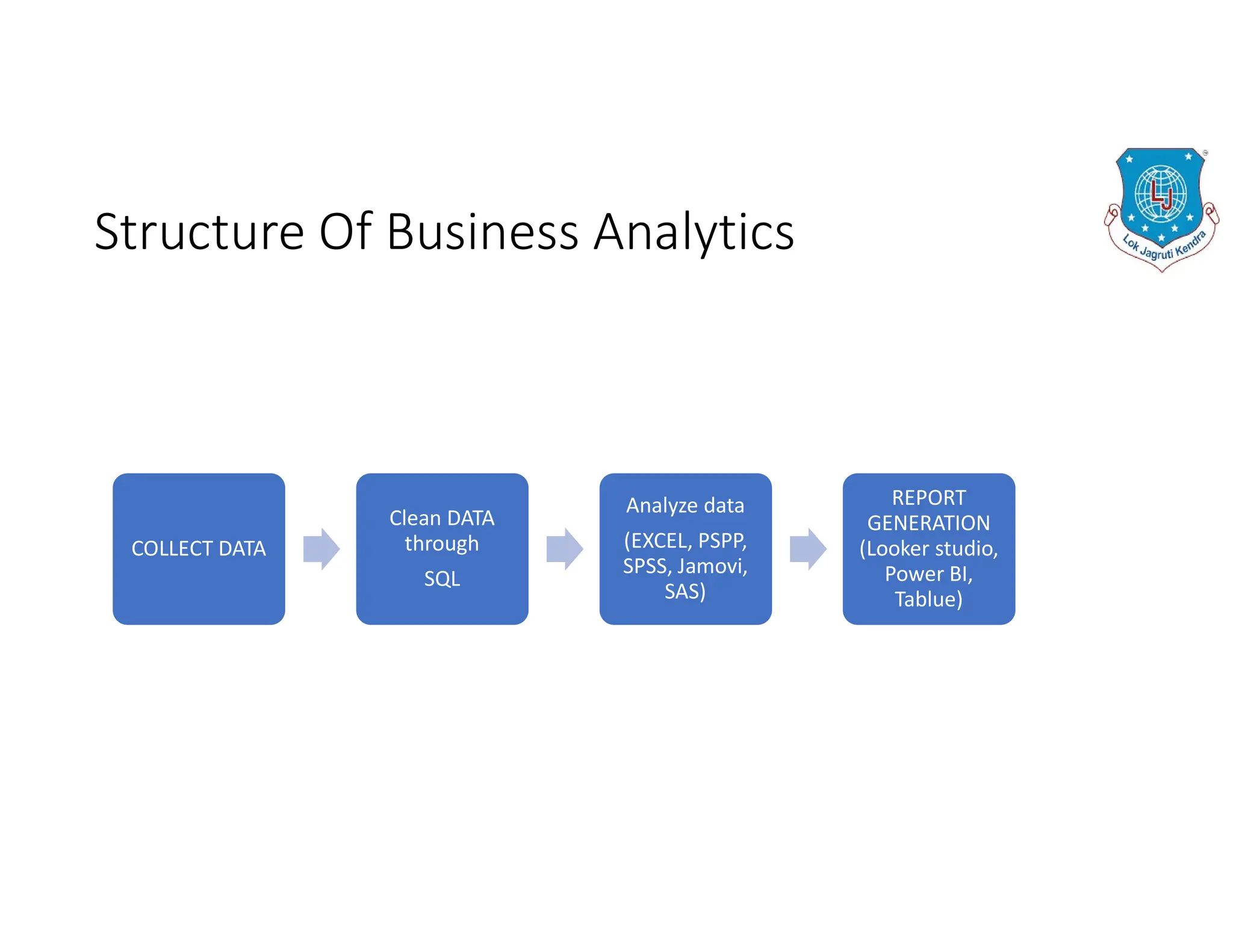
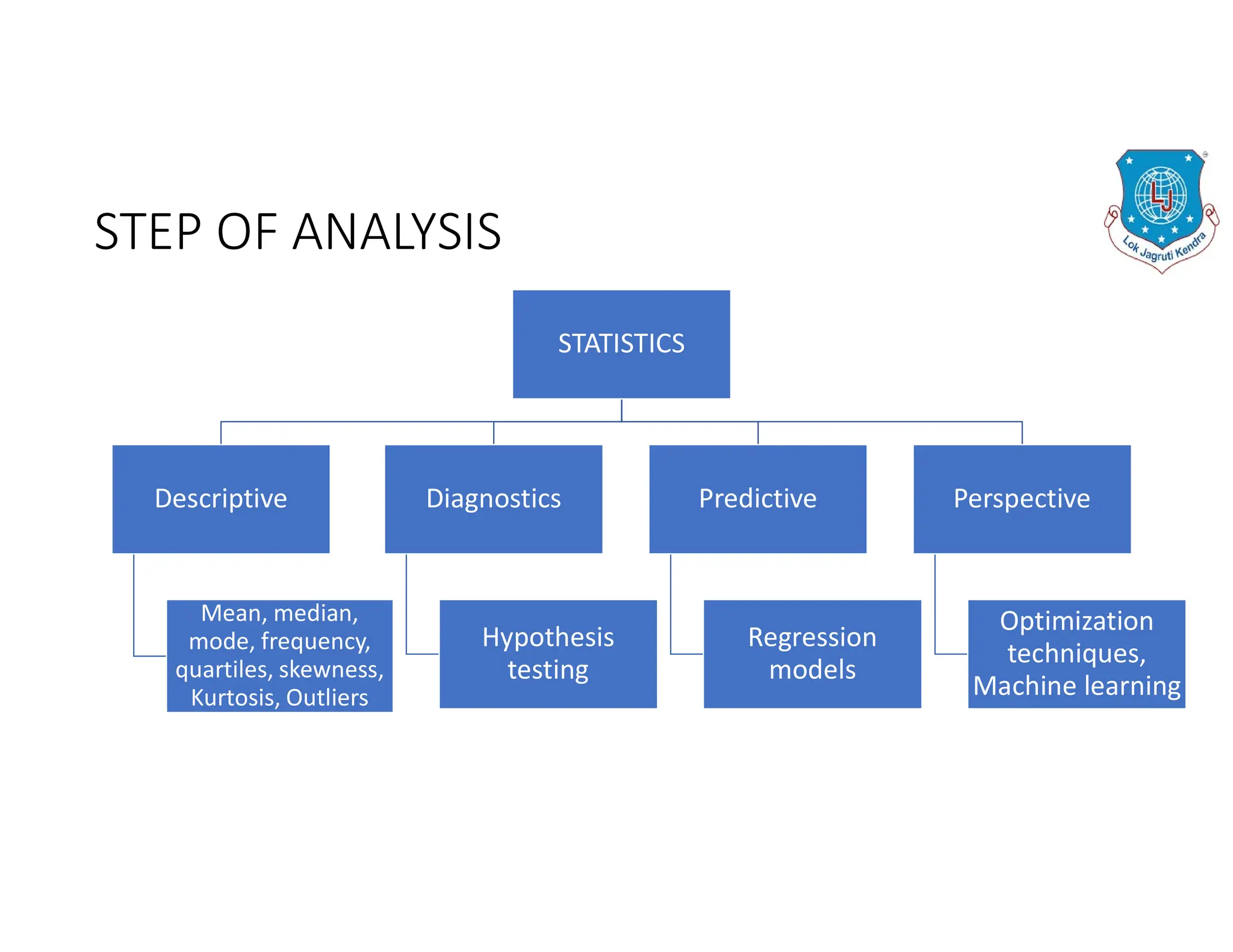
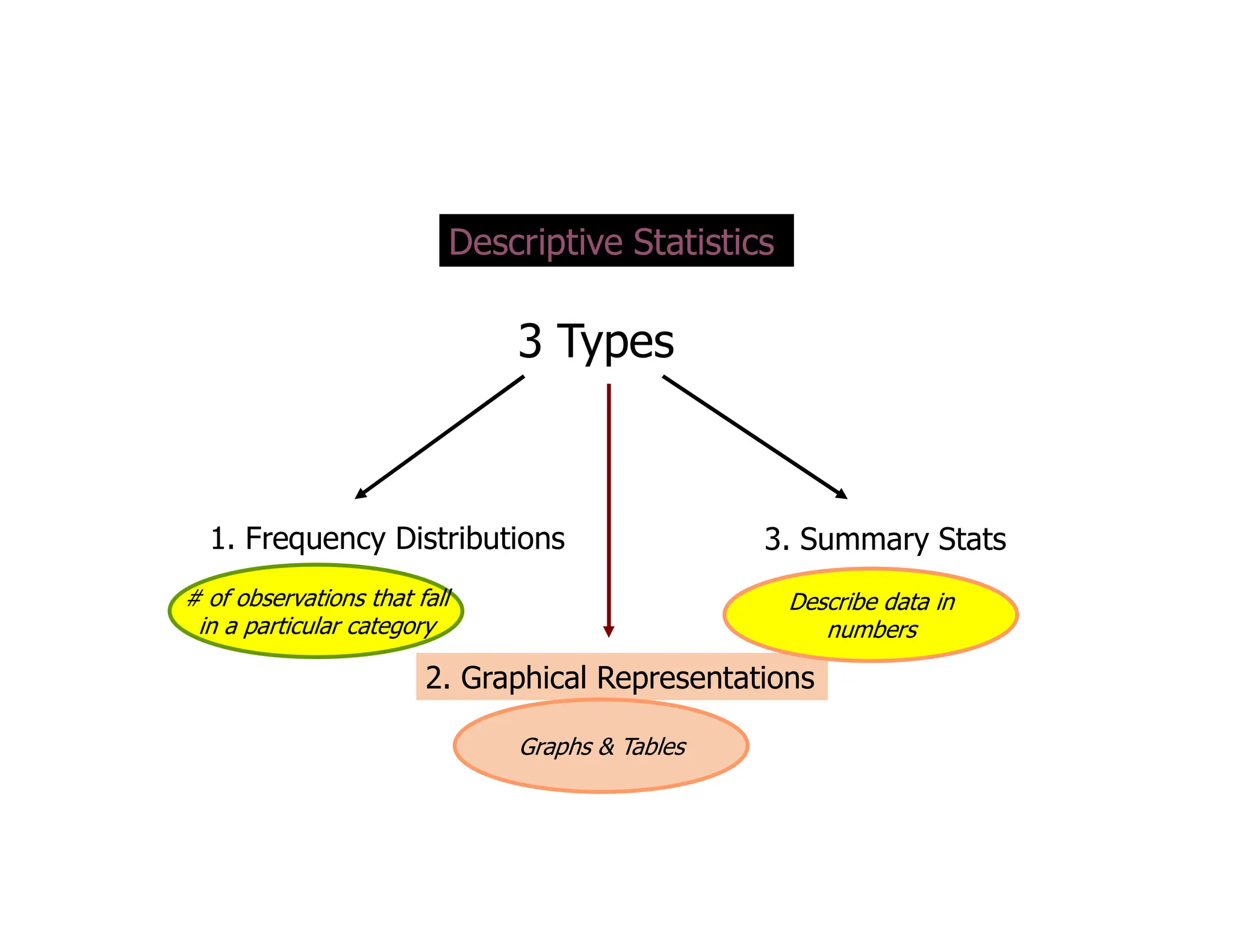
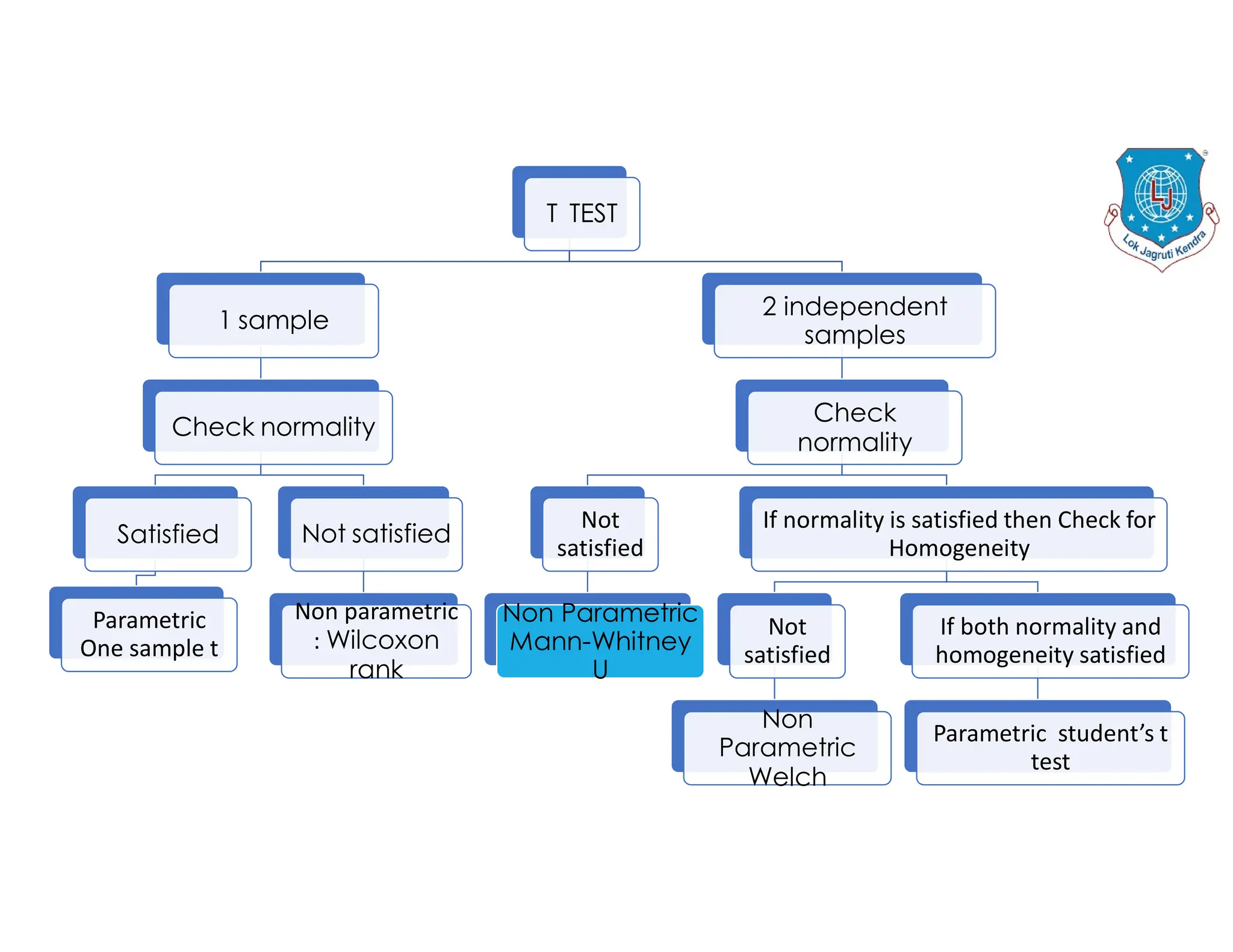
The document discusses the structure of business analytics which includes collecting data through various methods such as surveys, transactions, interviews, observations, online tracking, forms, and social media monitoring. It then discusses cleaning and analyzing the data using tools like SQL, Excel, SPSS, and Tableau. The final step is report generation using tools such as Looker Studio and Power BI.





































































![Introduction-to-Business-Research[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/introduction-to-business-research1-241115171824-57202799-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




