






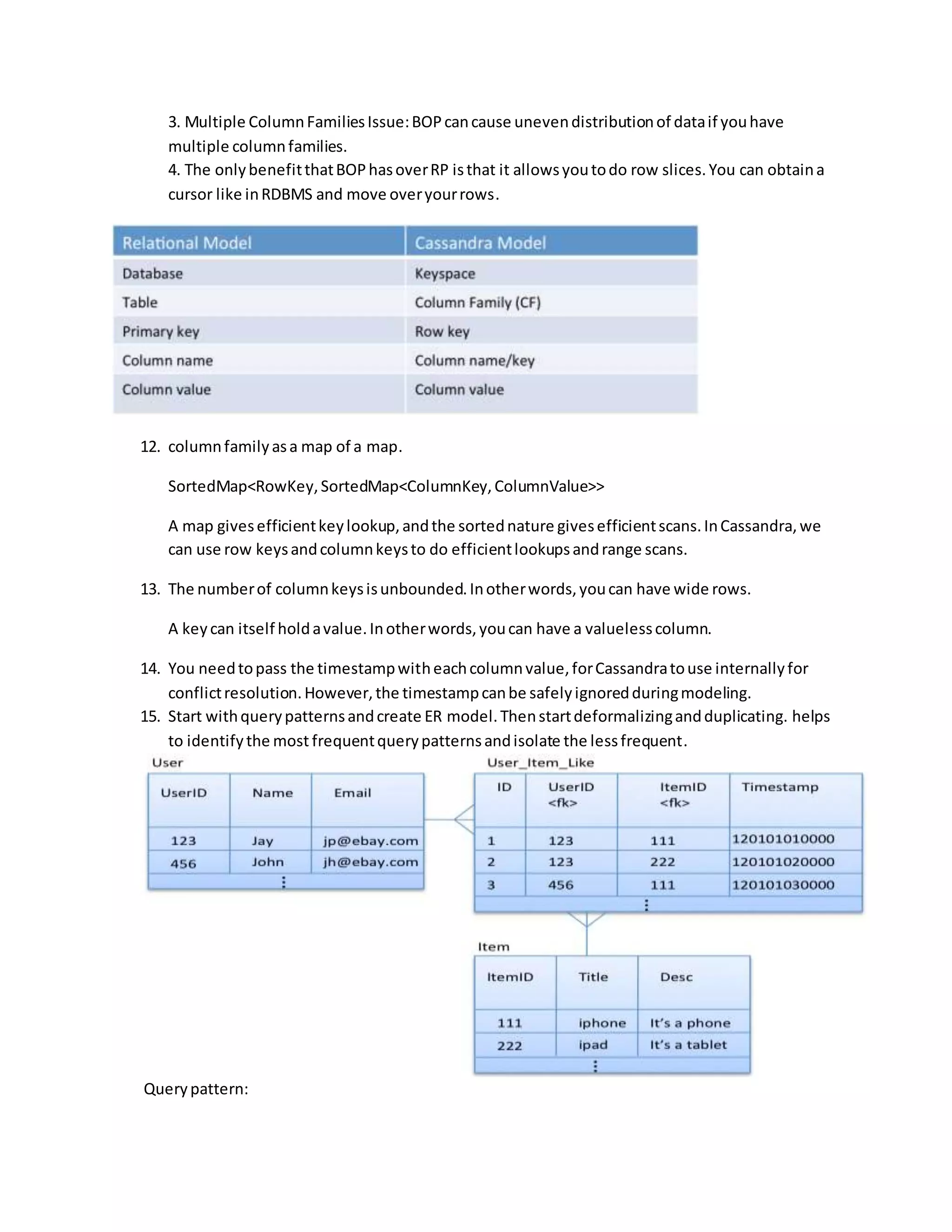



This document provides best practices and recommendations for modeling data in Cassandra. It discusses using composite types through APIs, supercolumns, wide and skinny rows, valueless columns, TTL for column expiration, counter columns, keyspaces, column families, row keys, columns, supercolumns, partitioners like RandomPartitioner and ByteOrderedPartitioner, partitioning and replication, commitlogs, memtables and SSTables, protocol types, advantages of RandomPartitioner, modeling query patterns, options for normalization, and time series patterns.























































































