Download as PDF, PPTX


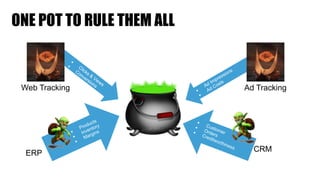
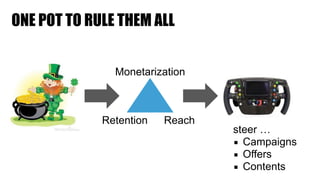

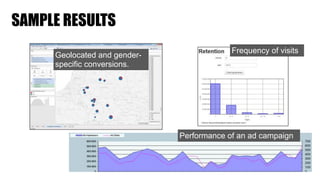

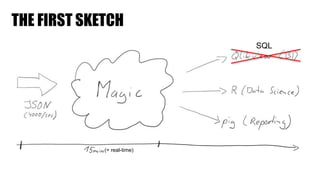

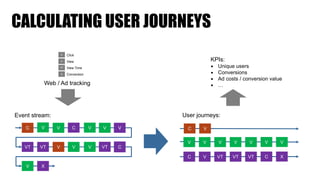

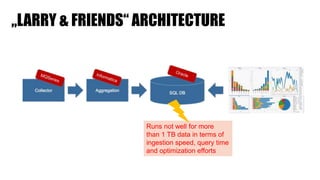

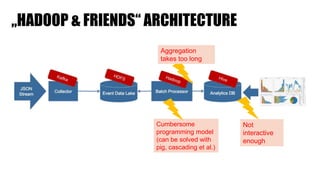

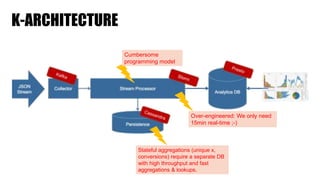
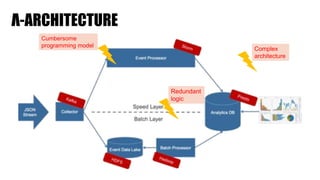


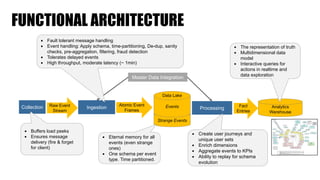
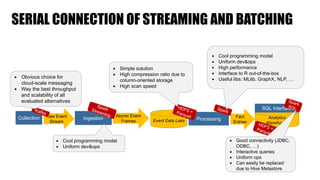
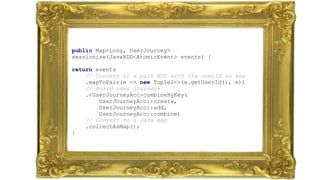



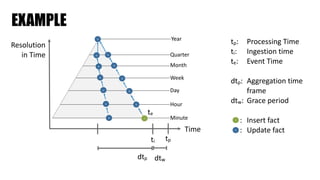


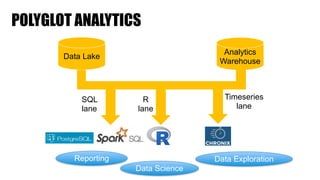
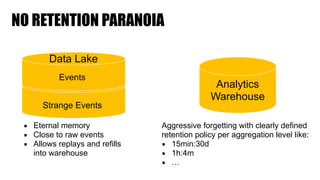


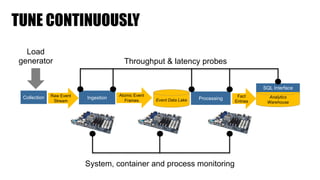





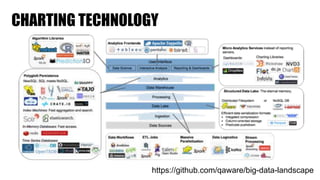
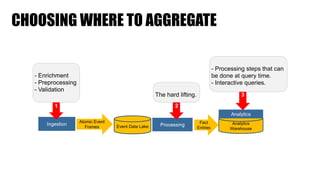


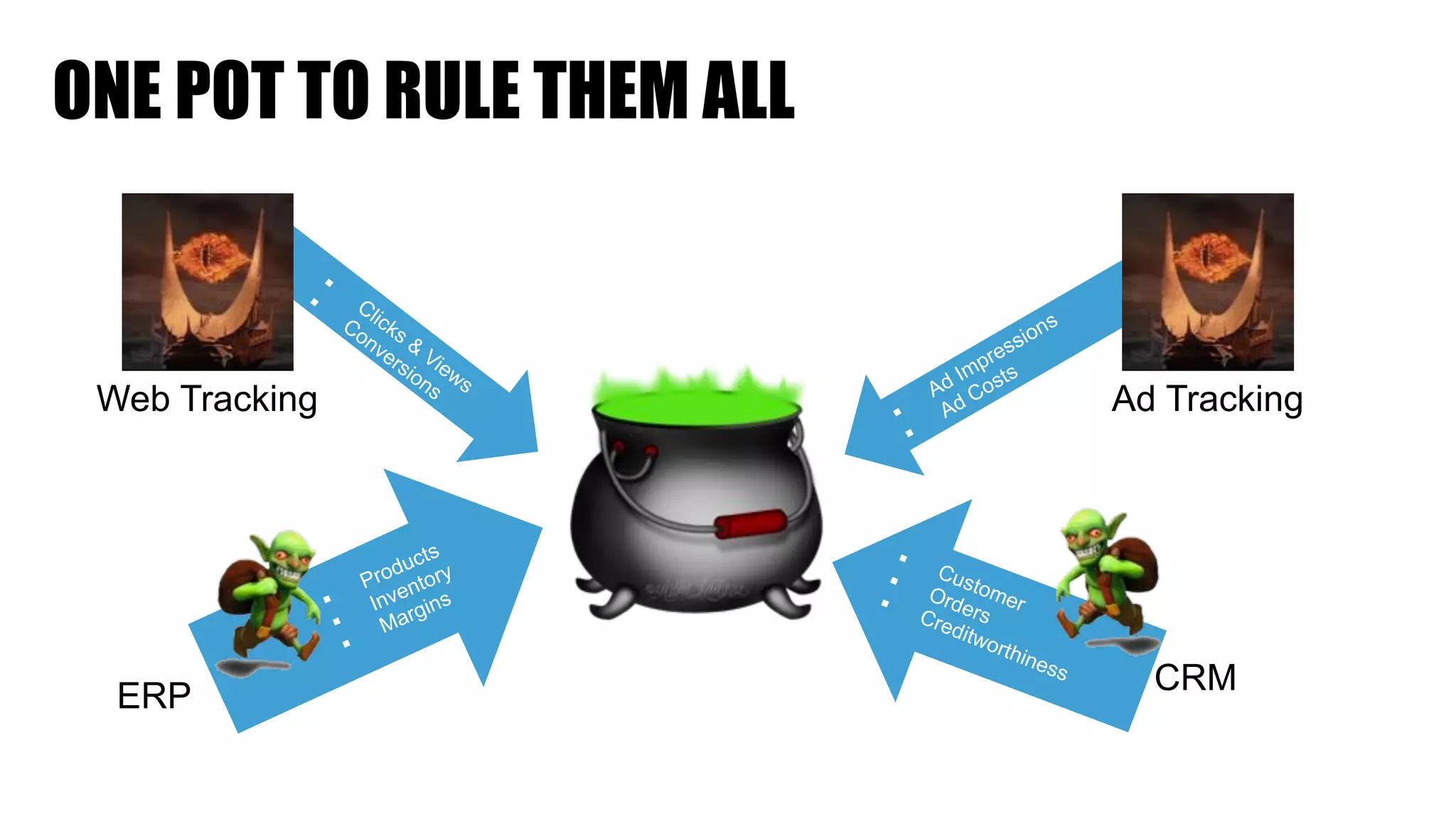

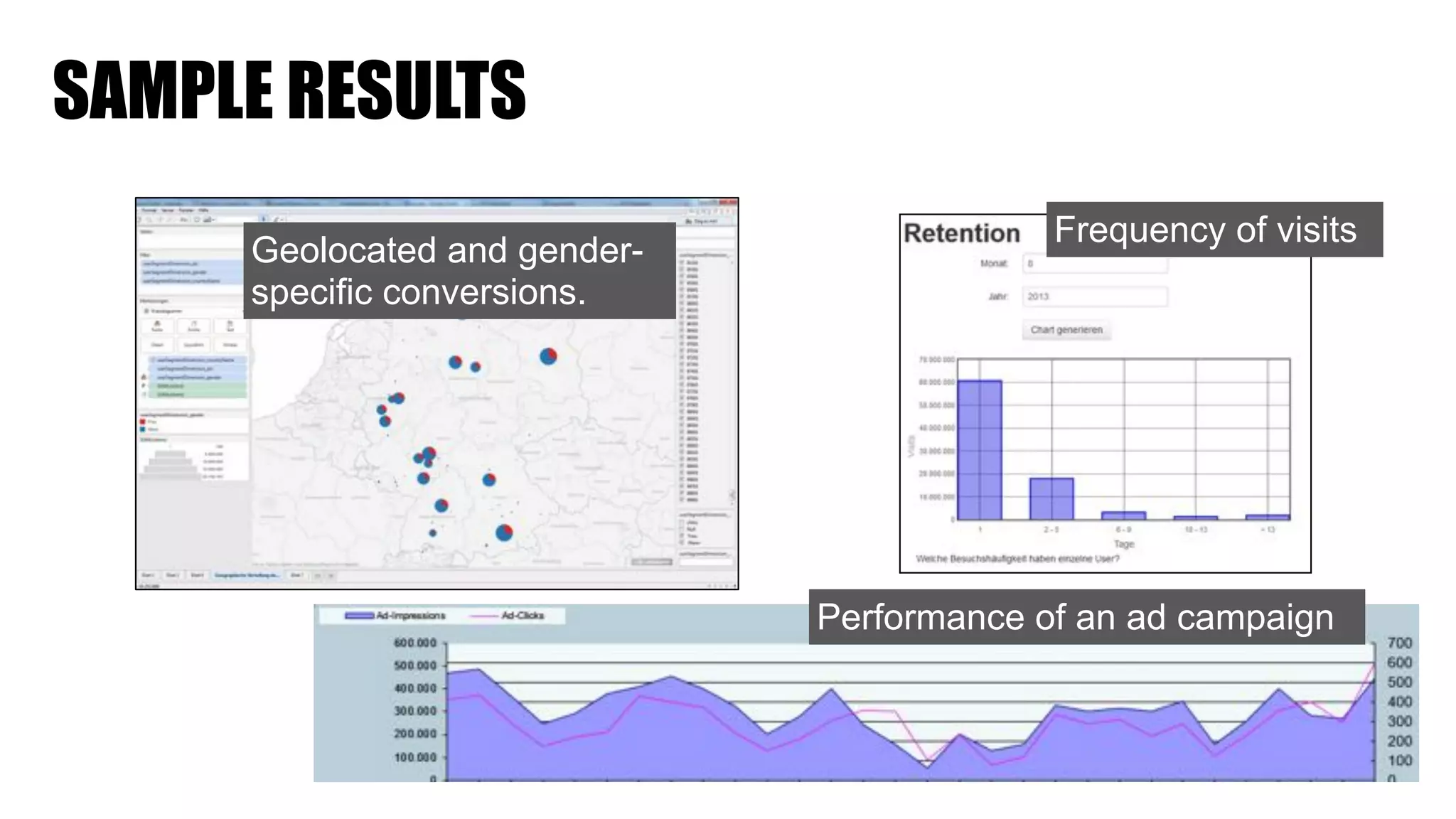

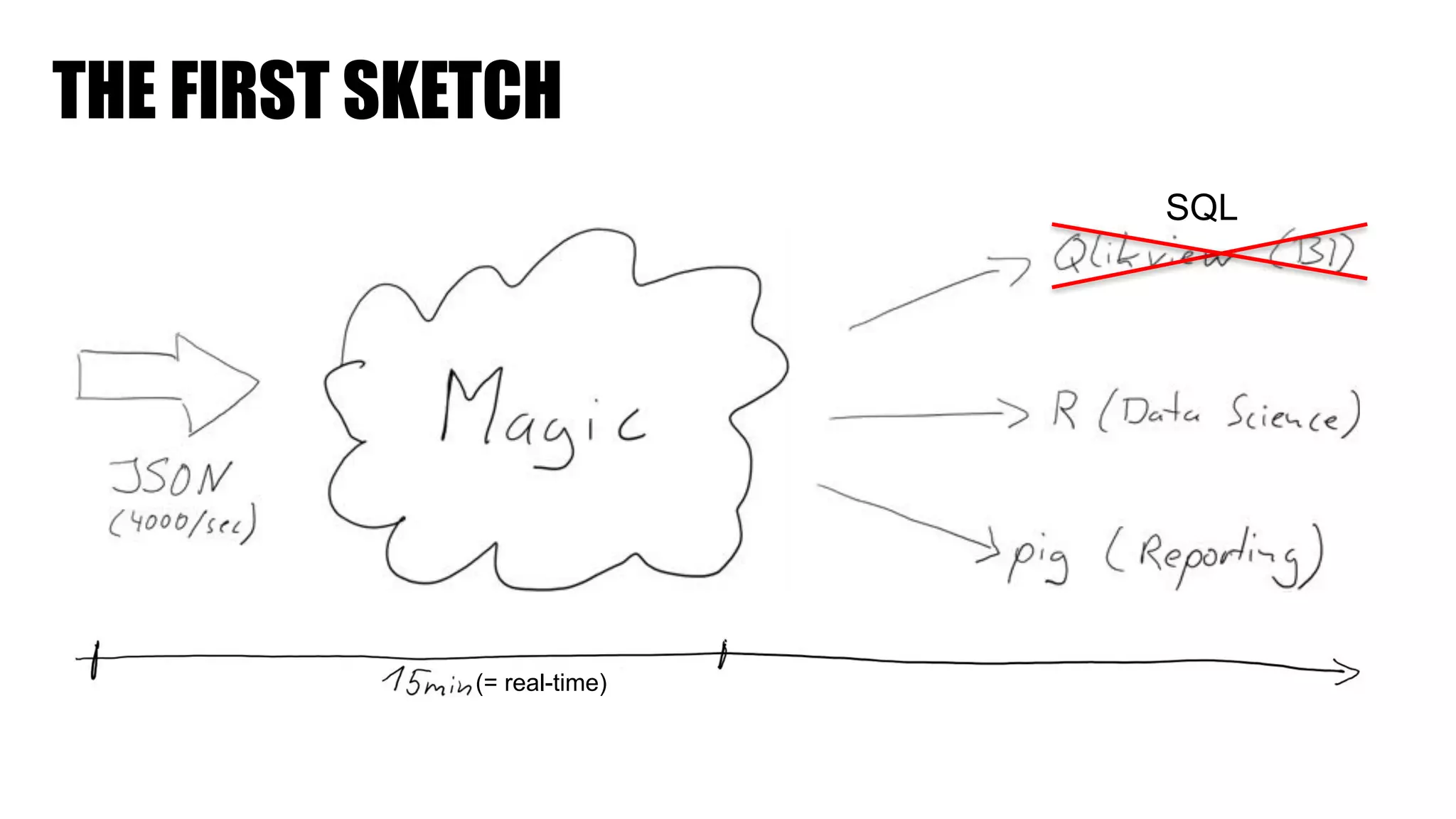

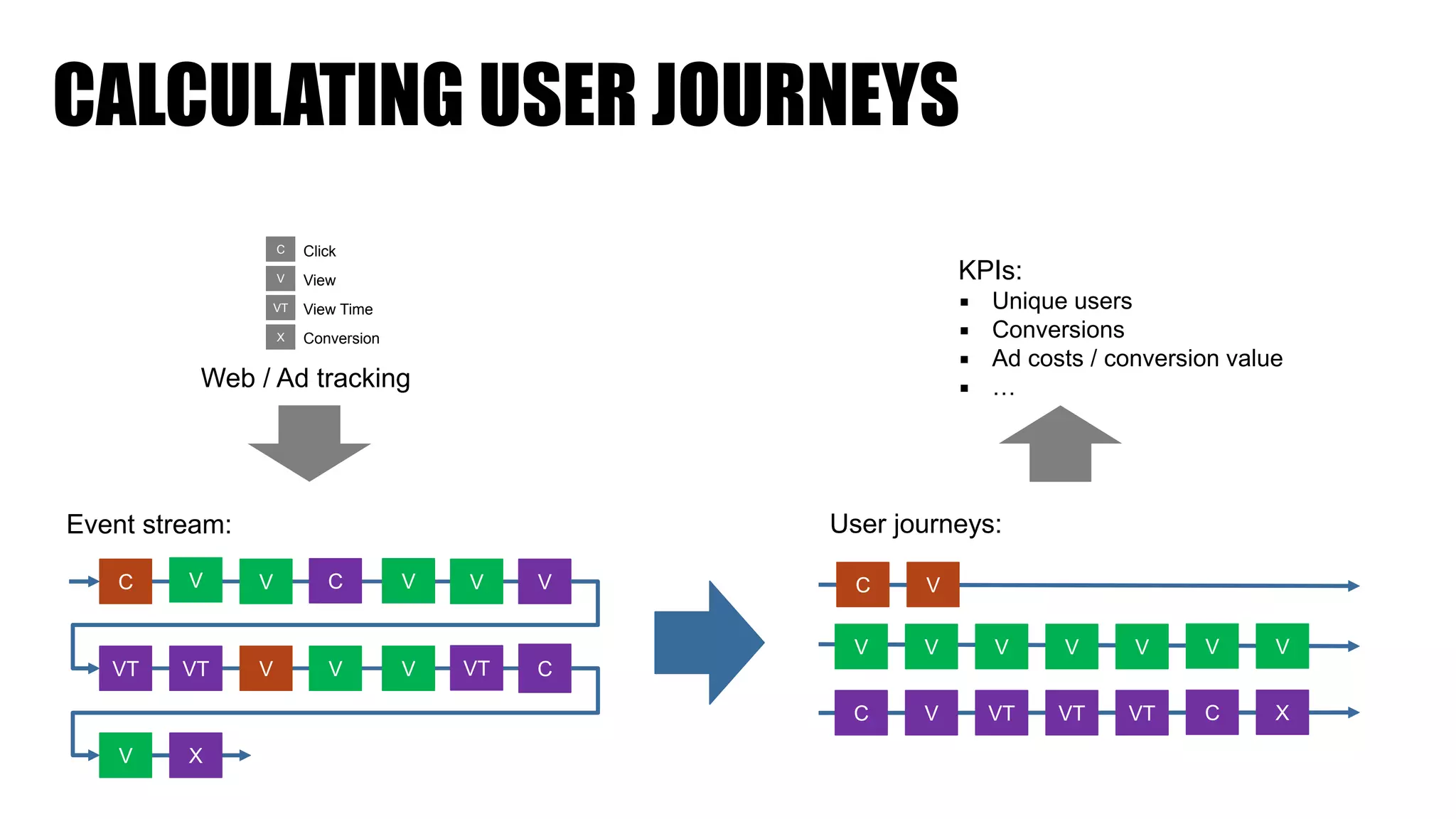

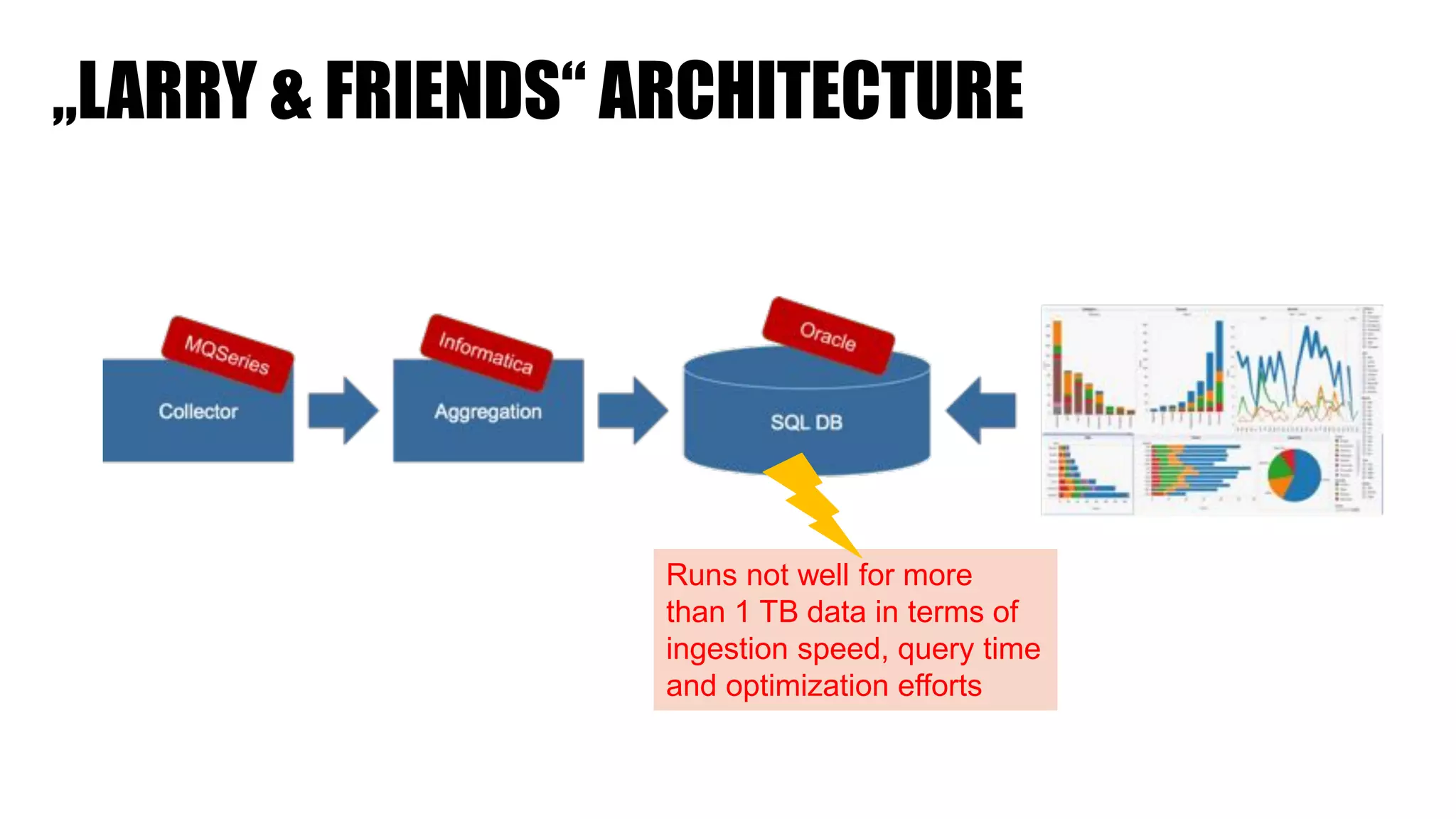

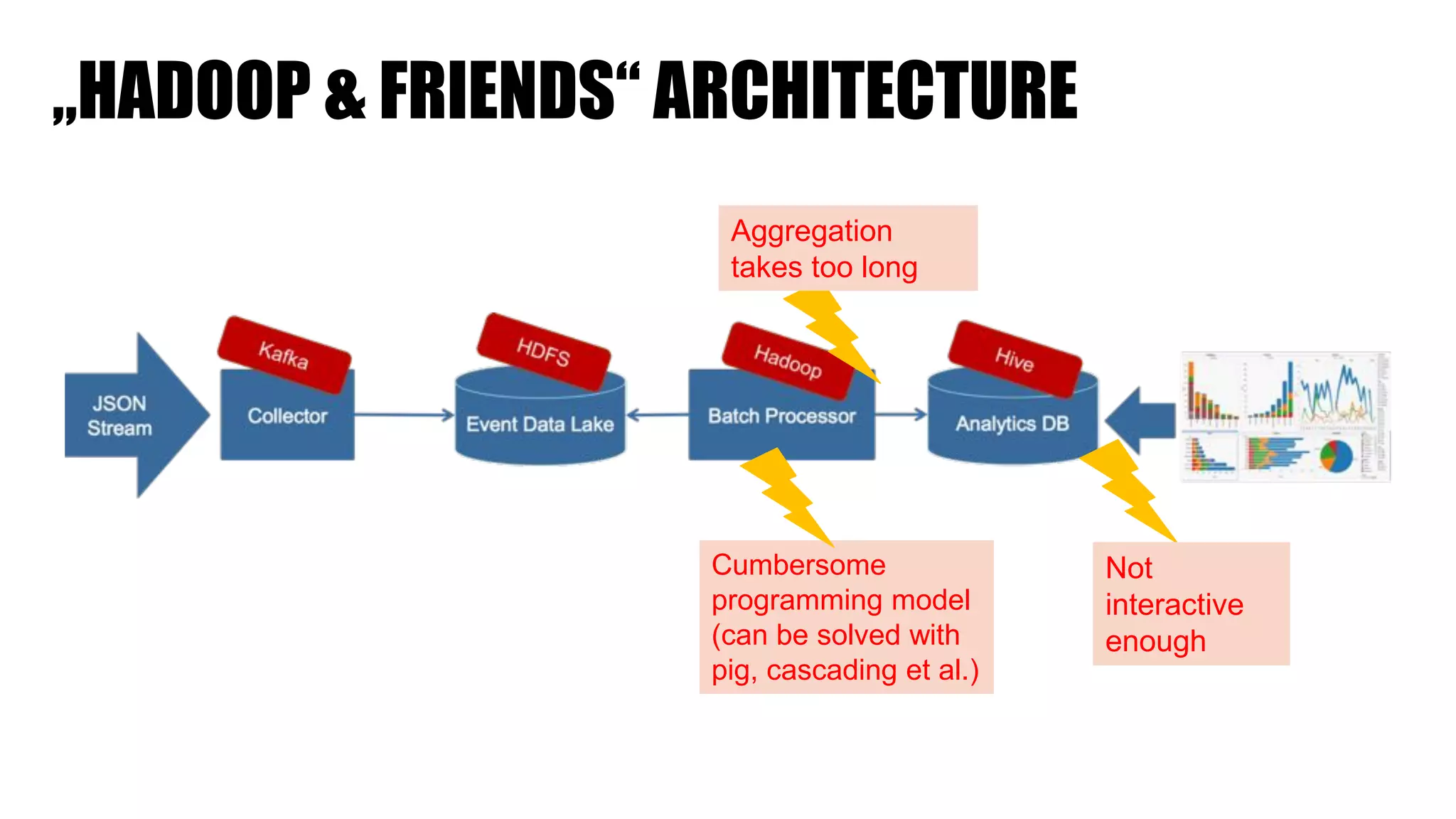

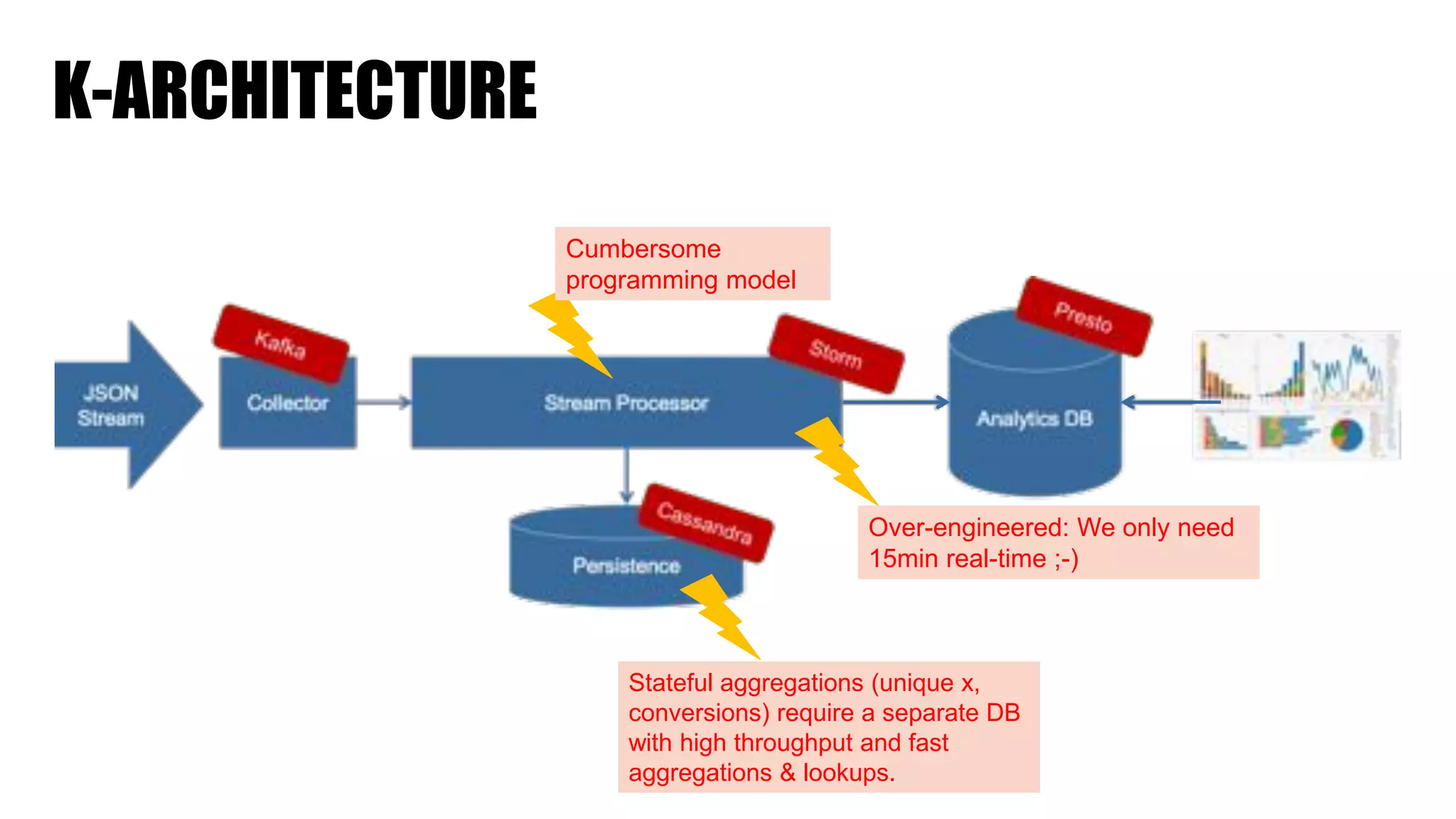
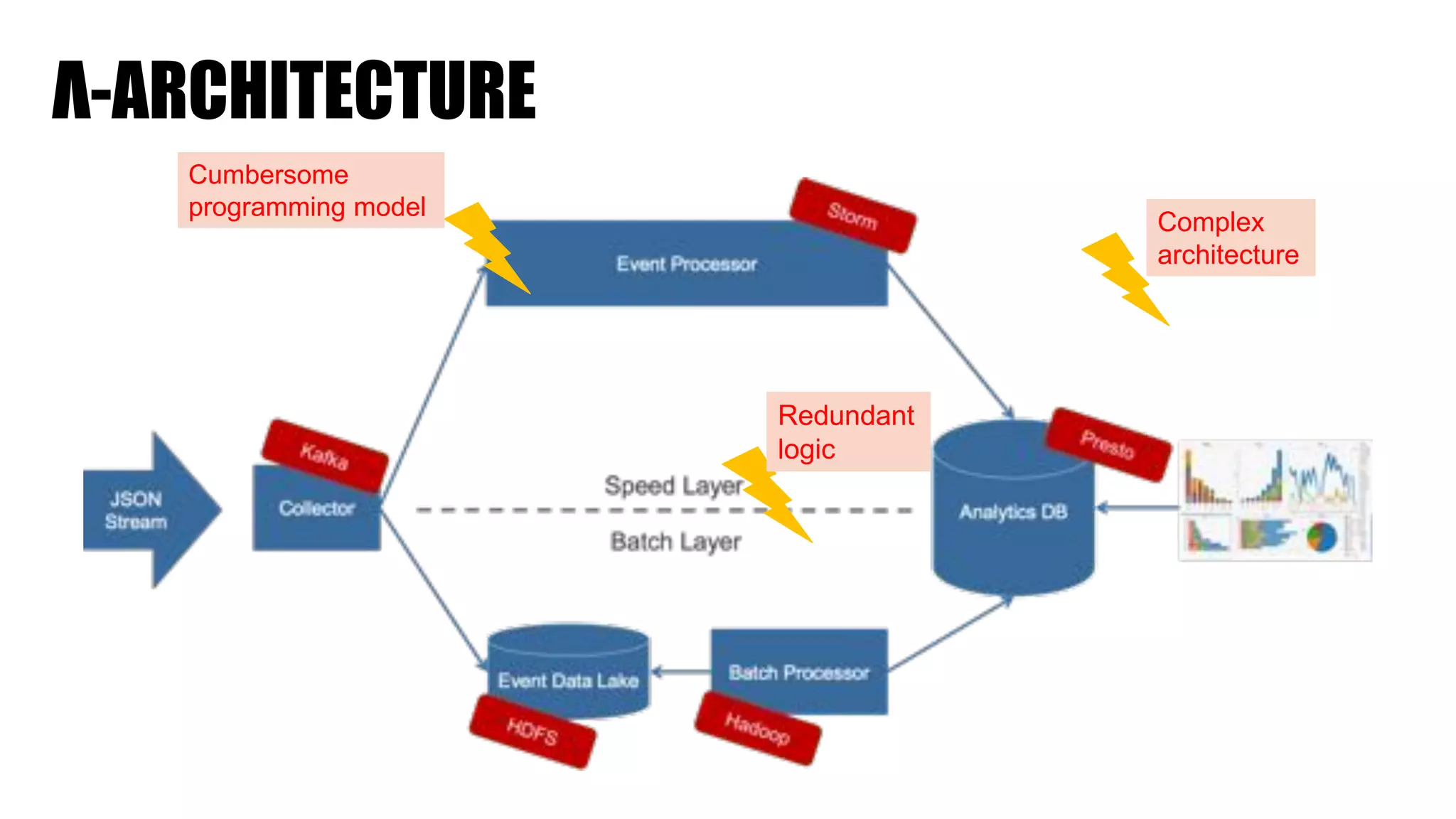


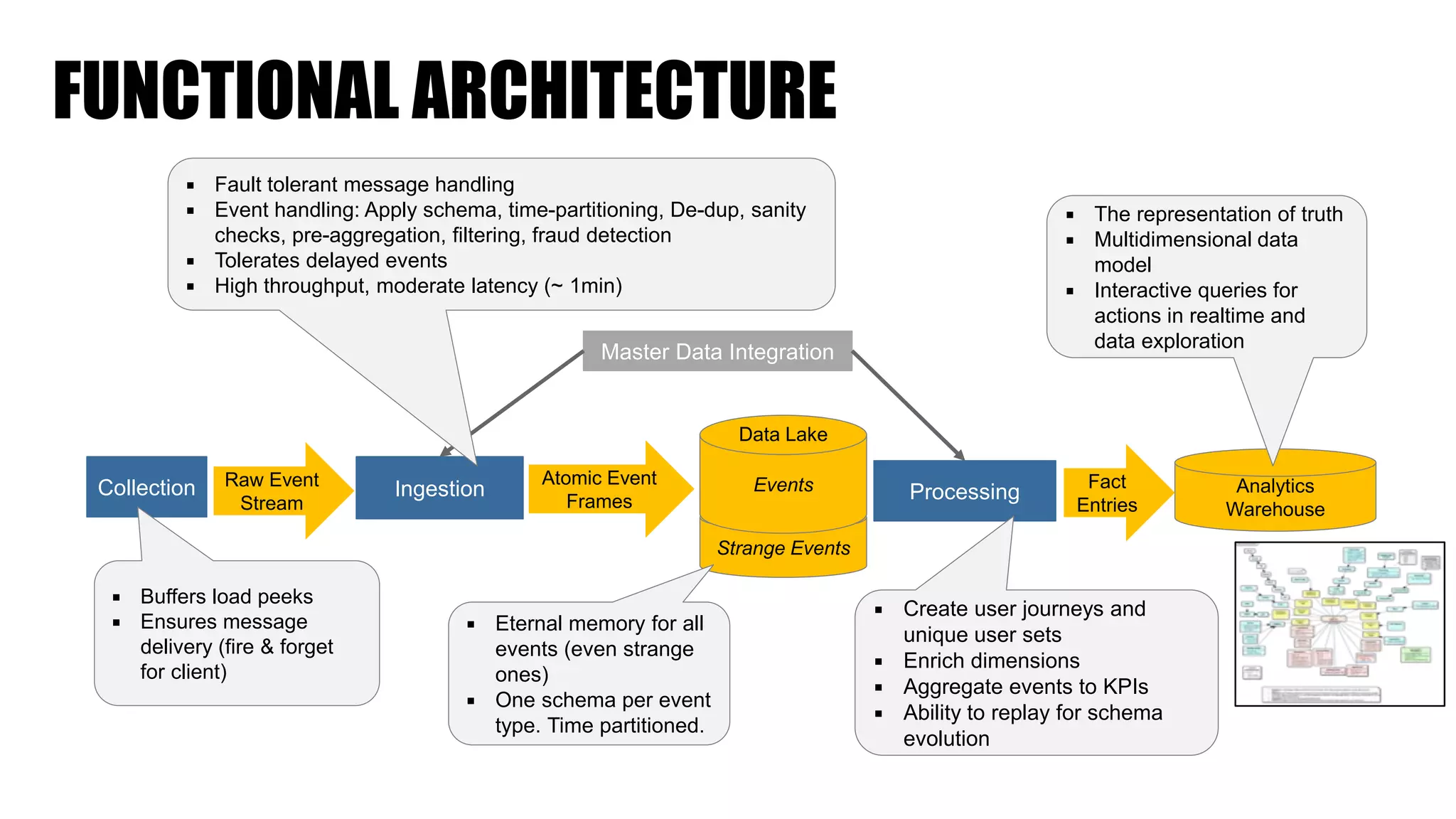
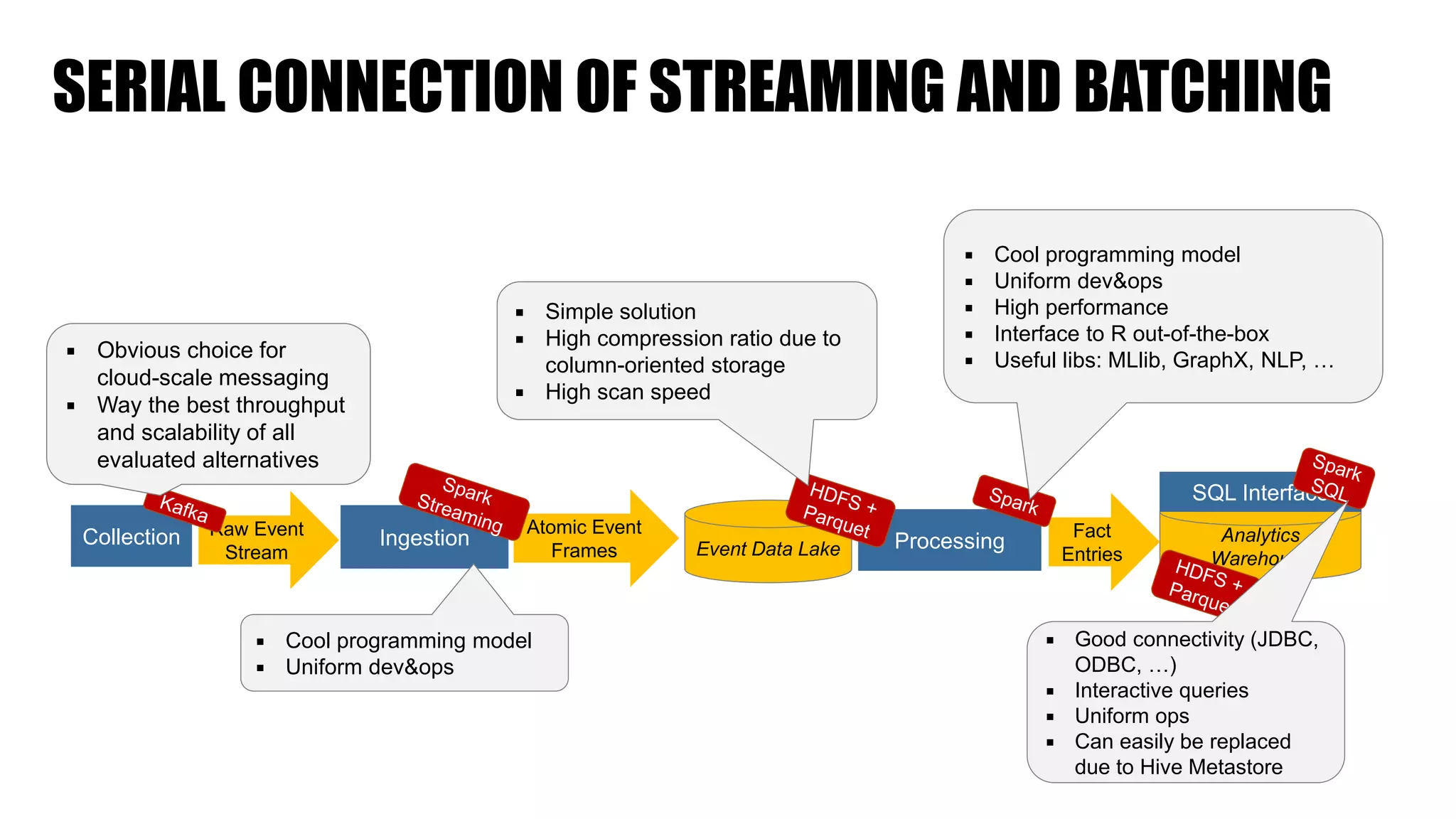
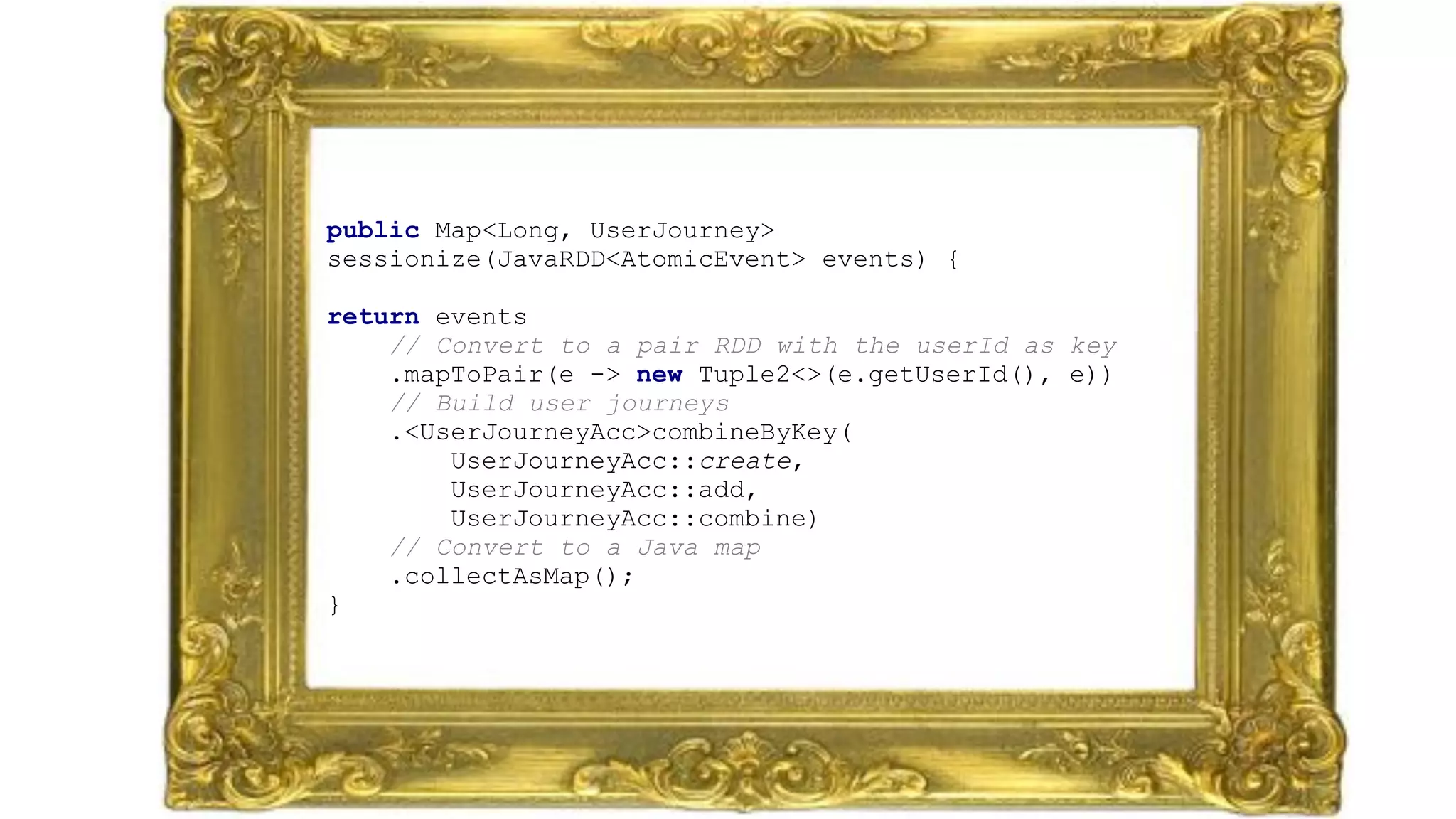



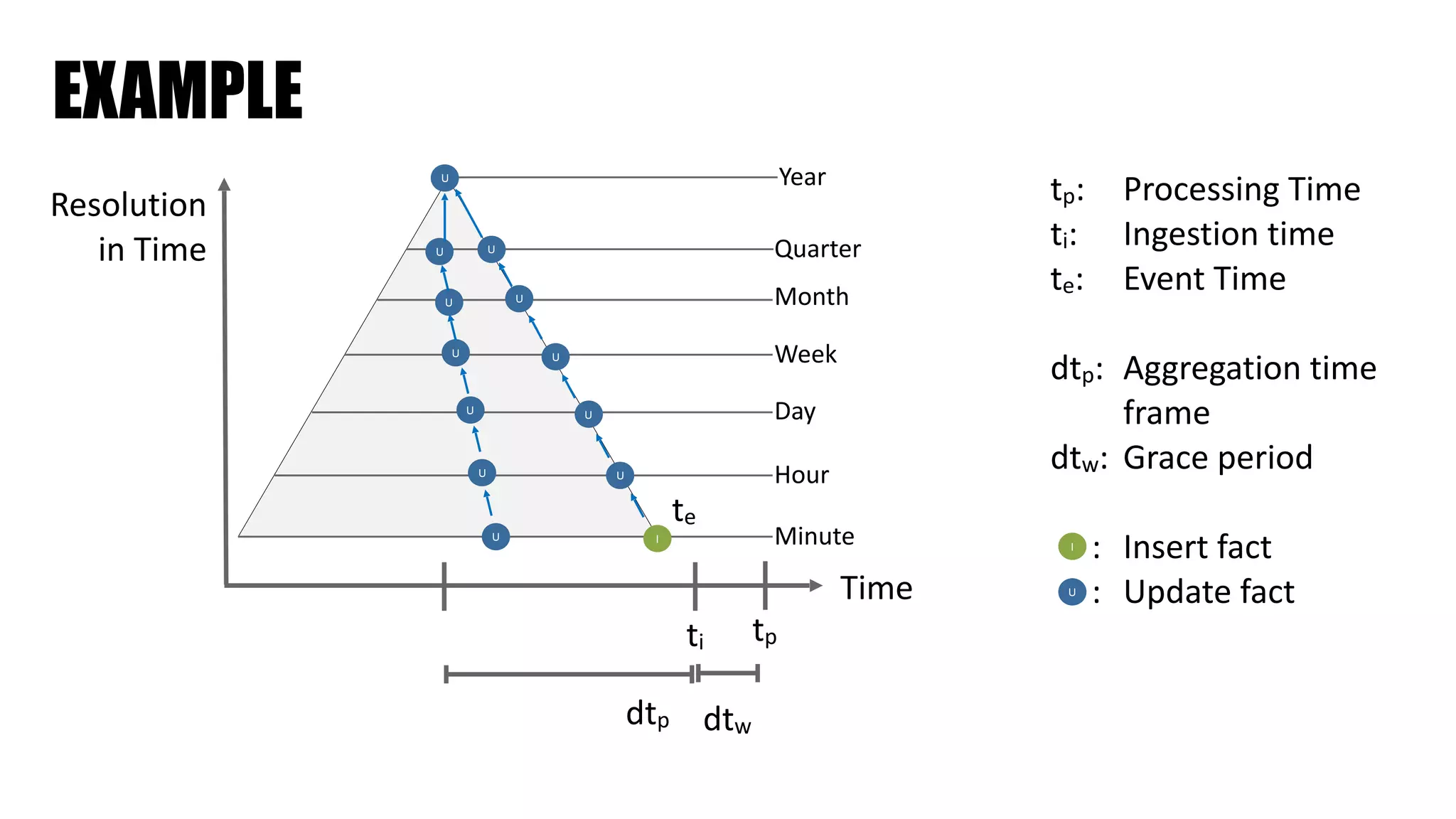

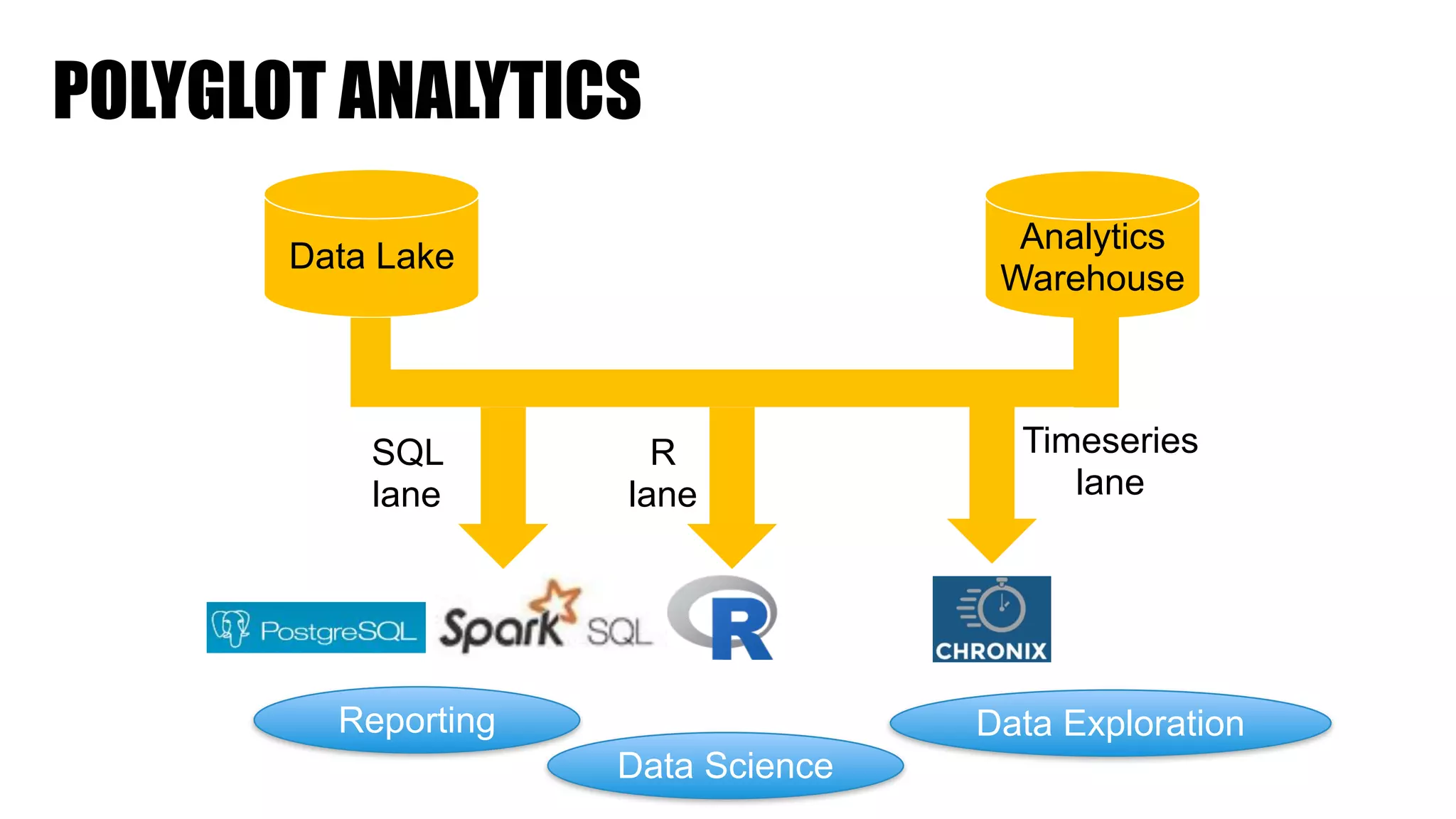
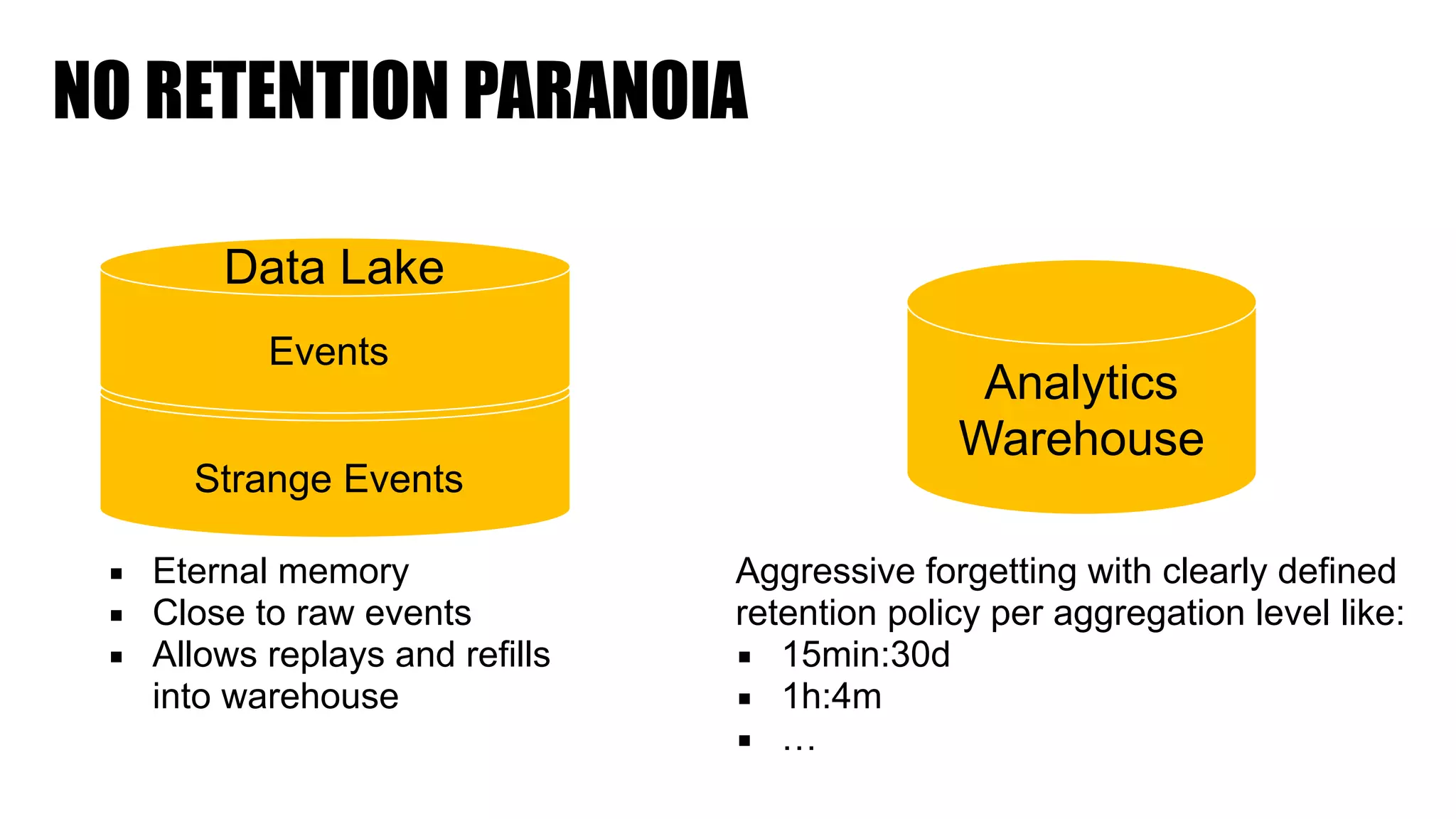


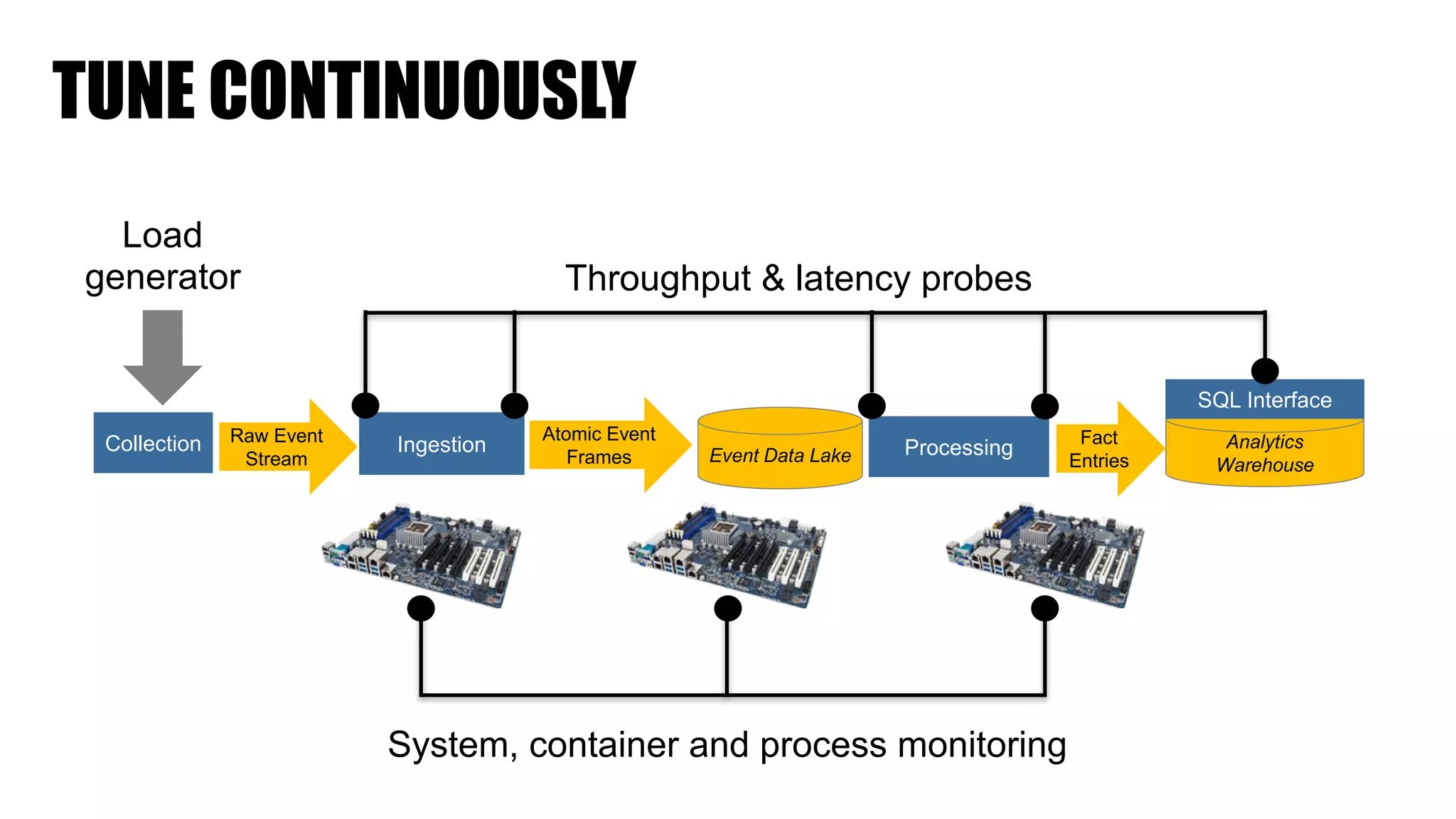





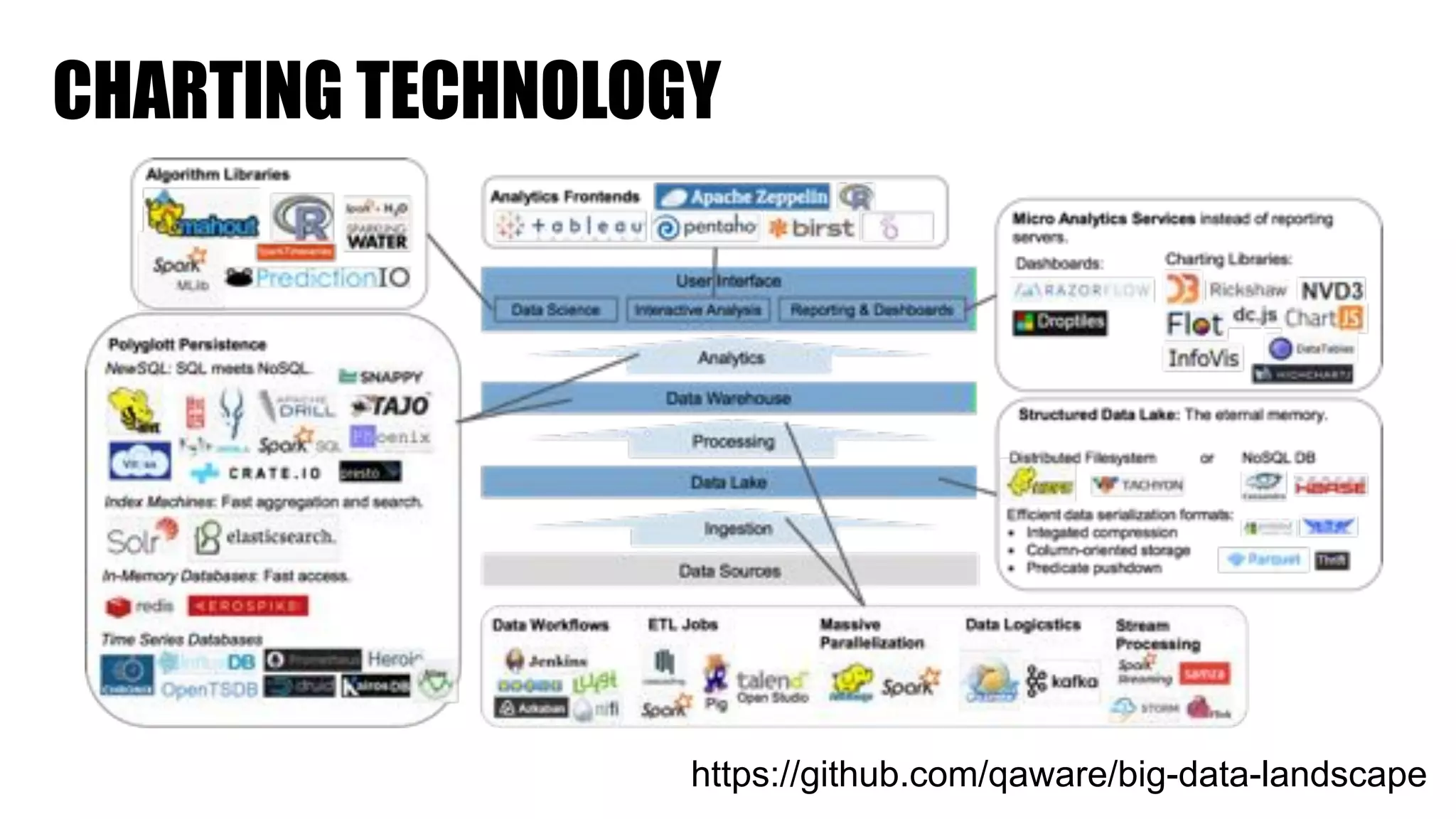
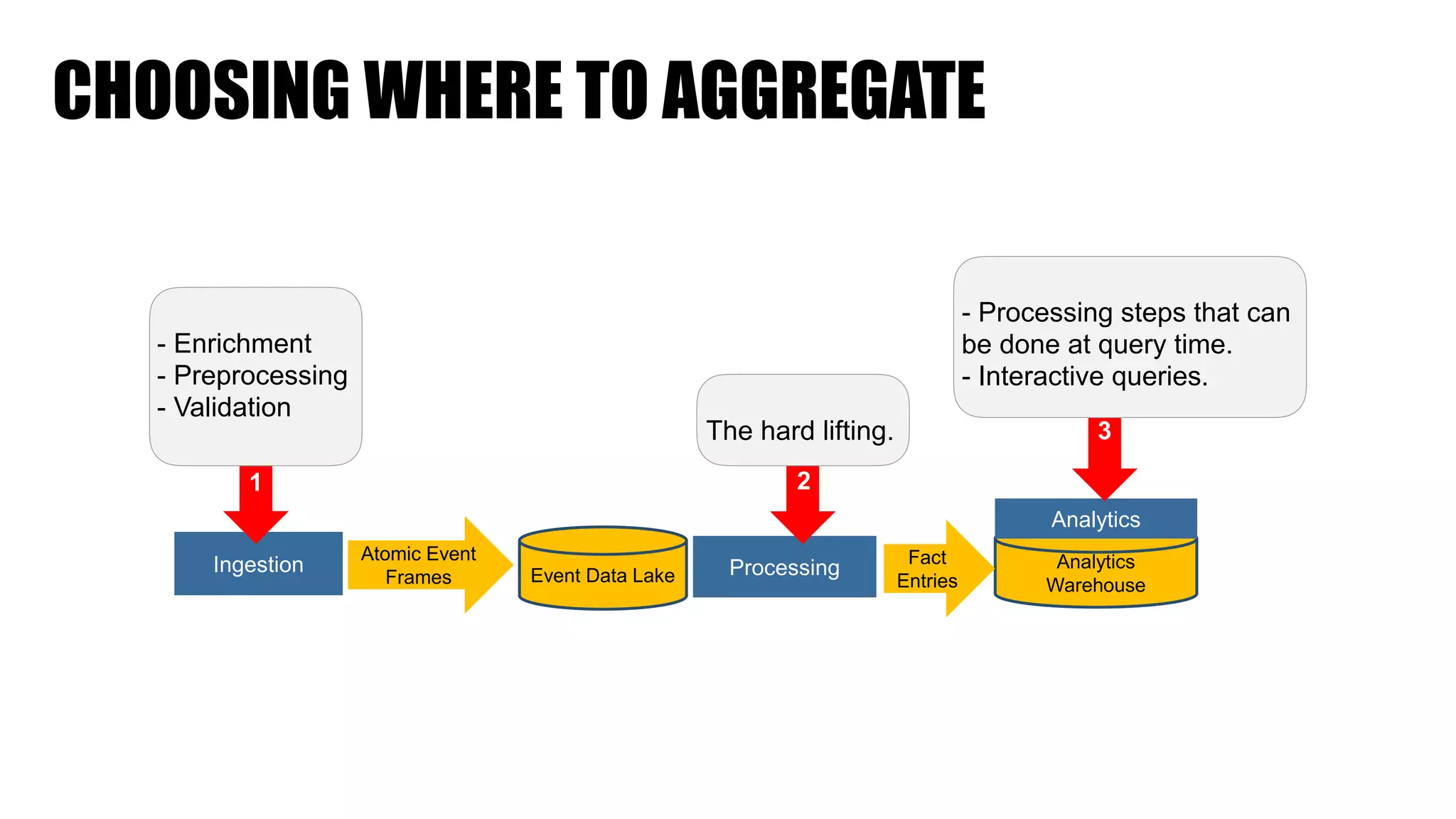

The document discusses clickstream analysis using Apache Spark, highlighting the challenges of handling large data volumes in real-time web and ad tracking. It introduces a proposed architecture for efficient data processing, incorporating aspects like event ingestion, user journey mapping, and real-time analytics. The document also emphasizes lessons learned regarding optimal architecture design, user counting techniques, and system monitoring for effective data management.























































































