KEMBAR78
Daftar
Login
clustering of user | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Atsushi Hayakawa
1,565 views
clustering of user
Technology
◦
Related topics:
text-mining
•
Read more
4
Save
Share
Embed
Download
Downloaded 19 times
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
名古屋Ruby会議02 LT:Ruby中級への道
by
Shigeru UCHIYAMA
PDF
Executive-Assistant-Jobs
by
Ralph290Roman
PDF
Results Evaluation Mocktails 2015
by
Dianova
DOCX
Problemas de estadistica con spss
by
pedro_zapata_sanchez
PDF
SPLINFANTCOLLECTIONPPT
by
Emesure Mark
PPTX
Индивидуальное занятие по РРС и ФПСР
by
preemstvennost
PDF
Empresa Inserção Floricultura Dianova ISUP A3S 2016
by
Dianova
PDF
Open Source Outlook: Expected Developments for 2016
by
Black Duck by Synopsys
名古屋Ruby会議02 LT:Ruby中級への道
by
Shigeru UCHIYAMA
Executive-Assistant-Jobs
by
Ralph290Roman
Results Evaluation Mocktails 2015
by
Dianova
Problemas de estadistica con spss
by
pedro_zapata_sanchez
SPLINFANTCOLLECTIONPPT
by
Emesure Mark
Индивидуальное занятие по РРС и ФПСР
by
preemstvennost
Empresa Inserção Floricultura Dianova ISUP A3S 2016
by
Dianova
Open Source Outlook: Expected Developments for 2016
by
Black Duck by Synopsys
Viewers also liked
PDF
Dianova Results Evaluation Mocktails 2016
by
Dianova
PDF
Práctica de Creación de Máquina Virtual con LAMP en Amazon Web Services
by
Héctor Garduño Real
PPTX
(5)perubahan struktur ekonomi
by
Elisabeth Marina
PPTX
Presentation3- JC Premiere Compensation Plan
by
JC Premiere Business International
PPT
What is beauty? Final Project Dee-Dee-Slideshare
by
DEEDEENLU
PDF
Análisis del Whitepaper DB4O
by
Héctor Garduño Real
PPT
Cocktail and mocktail
by
Varun Rathore
Dianova Results Evaluation Mocktails 2016
by
Dianova
Práctica de Creación de Máquina Virtual con LAMP en Amazon Web Services
by
Héctor Garduño Real
(5)perubahan struktur ekonomi
by
Elisabeth Marina
Presentation3- JC Premiere Compensation Plan
by
JC Premiere Business International
What is beauty? Final Project Dee-Dee-Slideshare
by
DEEDEENLU
Análisis del Whitepaper DB4O
by
Héctor Garduño Real
Cocktail and mocktail
by
Varun Rathore
Similar to clustering of user
PDF
はじパタLT3
by
Tadayuki Onishi
PDF
各言語の k-means 比較
by
y-uti
PDF
第3回集合知プログラミング勉強会 #TokyoCI グループを見つけ出す
by
Atsushi KOMIYA
PPT
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
Section11 clustering
by
HiroyukiKosho
PDF
機械学習勉強会 #3
by
ketancho
PPTX
機械学習基礎(3)(クラスタリング編)
by
mikan ehime
PDF
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
by
antibayesian 俺がS式だ
PDF
クラスタリングとレコメンデーション資料
by
洋資 堅田
PDF
はじパタLT2
by
Tadayuki Onishi
PPTX
[第2版]Python機械学習プログラミング 第11章
by
Haruki Eguchi
PDF
「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#5資料
by
Shintaro Nomura
はじパタLT3
by
Tadayuki Onishi
各言語の k-means 比較
by
y-uti
第3回集合知プログラミング勉強会 #TokyoCI グループを見つけ出す
by
Atsushi KOMIYA
Tokyo r#10 Rによるデータサイエンス 第五章:クラスター分析
by
hnisiji
Sakusaku svm
by
antibayesian 俺がS式だ
Section11 clustering
by
HiroyukiKosho
機械学習勉強会 #3
by
ketancho
機械学習基礎(3)(クラスタリング編)
by
mikan ehime
あんちべのすべらない話~俺のツイートがこんなにウケないはずがない~
by
antibayesian 俺がS式だ
クラスタリングとレコメンデーション資料
by
洋資 堅田
はじパタLT2
by
Tadayuki Onishi
[第2版]Python機械学習プログラミング 第11章
by
Haruki Eguchi
「ビジネス活用事例で学ぶ データサイエンス入門」輪読会#5資料
by
Shintaro Nomura
More from Atsushi Hayakawa
PDF
tidyverse.orgの翻訳
by
Atsushi Hayakawa
PDF
Zepp play soccerで測ってみた
by
Atsushi Hayakawa
PDF
dataclassとtypehintを使ってますか?
by
Atsushi Hayakawa
PDF
トライアスロンとgepuro task views V2.0 Japan.R 2018
by
Atsushi Hayakawa
PPTX
バンクーバー旅行記
by
Atsushi Hayakawa
PPTX
Analyze The Community Of Tokyo.R
by
Atsushi Hayakawa
PPTX
Visual Studio CodeでRを使う
by
Atsushi Hayakawa
PDF
トライアスロンと僕 - Japan.R 2017
by
Atsushi Hayakawa
PDF
simputatoinで欠損値補完 - Tokyo.R #65
by
Atsushi Hayakawa
PDF
useR!2017 in Brussels
by
Atsushi Hayakawa
PPTX
Japan.R 2016の運営
by
Atsushi Hayakawa
PPTX
Rstudio上でのパッケージインストールを便利にするaddin4githubinstall
by
Atsushi Hayakawa
PDF
統計的学習の基礎 4.4~
by
Atsushi Hayakawa
PDF
Splatoon界での壮絶な戦い&Japan.Rの宣伝
by
Atsushi Hayakawa
PDF
最近のクラウドストレージの事情と私情
by
Atsushi Hayakawa
PDF
gepuro task views
by
Atsushi Hayakawa
PDF
nginxのログを非スケーラブルに省メモリな方法で蓄積する
by
Atsushi Hayakawa
PDF
implyを用いたアクセスログの可視化
by
Atsushi Hayakawa
PDF
イケてる分析基盤をつくる
by
Atsushi Hayakawa
PDF
らずぱいラジコン
by
Atsushi Hayakawa
tidyverse.orgの翻訳
by
Atsushi Hayakawa
Zepp play soccerで測ってみた
by
Atsushi Hayakawa
dataclassとtypehintを使ってますか?
by
Atsushi Hayakawa
トライアスロンとgepuro task views V2.0 Japan.R 2018
by
Atsushi Hayakawa
バンクーバー旅行記
by
Atsushi Hayakawa
Analyze The Community Of Tokyo.R
by
Atsushi Hayakawa
Visual Studio CodeでRを使う
by
Atsushi Hayakawa
トライアスロンと僕 - Japan.R 2017
by
Atsushi Hayakawa
simputatoinで欠損値補完 - Tokyo.R #65
by
Atsushi Hayakawa
useR!2017 in Brussels
by
Atsushi Hayakawa
Japan.R 2016の運営
by
Atsushi Hayakawa
Rstudio上でのパッケージインストールを便利にするaddin4githubinstall
by
Atsushi Hayakawa
統計的学習の基礎 4.4~
by
Atsushi Hayakawa
Splatoon界での壮絶な戦い&Japan.Rの宣伝
by
Atsushi Hayakawa
最近のクラウドストレージの事情と私情
by
Atsushi Hayakawa
gepuro task views
by
Atsushi Hayakawa
nginxのログを非スケーラブルに省メモリな方法で蓄積する
by
Atsushi Hayakawa
implyを用いたアクセスログの可視化
by
Atsushi Hayakawa
イケてる分析基盤をつくる
by
Atsushi Hayakawa
らずぱいラジコン
by
Atsushi Hayakawa
Recently uploaded
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
clustering of user
1.
第6回 さくさくテキストマイニング勉強会 ツイートから
ユーザーを クラスタリング できる?
2.
自己紹介 早川 敦士
電気通信大学 システム工学科三年
3.
ブログ http://d.hatena.ne.jp/gepuro/
自己紹介 Twitter @gepuro
4.
2011年度 S-PLUS学
生研究奨励賞の (^O^) 特別賞を 頂きました!
5.
ある日の事・・・・
6.
本を読んでいて、
これを やってみたいなあ っと感じた。
7.
これ?
8.
それが ユーザーの クラスタリング
です。
9.
既に、書き手が 分かっているものを、
注意 判別していきます。
10.
フォローしている ユーザから、
ツイートを 適当に取得
11.
ゴミ取り ●@ユーザー名 ●RT以降 ●ハッシュタグ
12.
クラスター分析で 書き手を
分けてみる。
13.
対象のデータ集合を
分割して, クラスター分析 いくつかの集合に 分ける
14.
? 分割して、分ける? クラス分類とは、 違うの?
15.
クラスタリングとクラス分類って違うらしい http://d.hatena.ne.jp/Kshi_Kshi/20110110/1294687656 クラスタリング:教師なし クラス分類 :教師あり
16.
クラスタリングは、 大きく2種類
あります。
17.
●階層的クラスタリング ●非階層的クラスタリング
18.
●階層的クラスタリング ●非階層的クラスタリング
19.
ユーザーのツイートを 2分割しておいて・・・
20.
文字の バイグラムを 使って・・・
21.
文字のバイグラム ●
今日は、さくテキだ! 2文字のセットを 作って、 今-日 その出現頻度を ● ● 日-は 利用しました。 ● は- 、 ● 、 -さ ● ・・・・・・・
23.
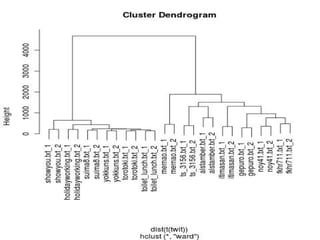
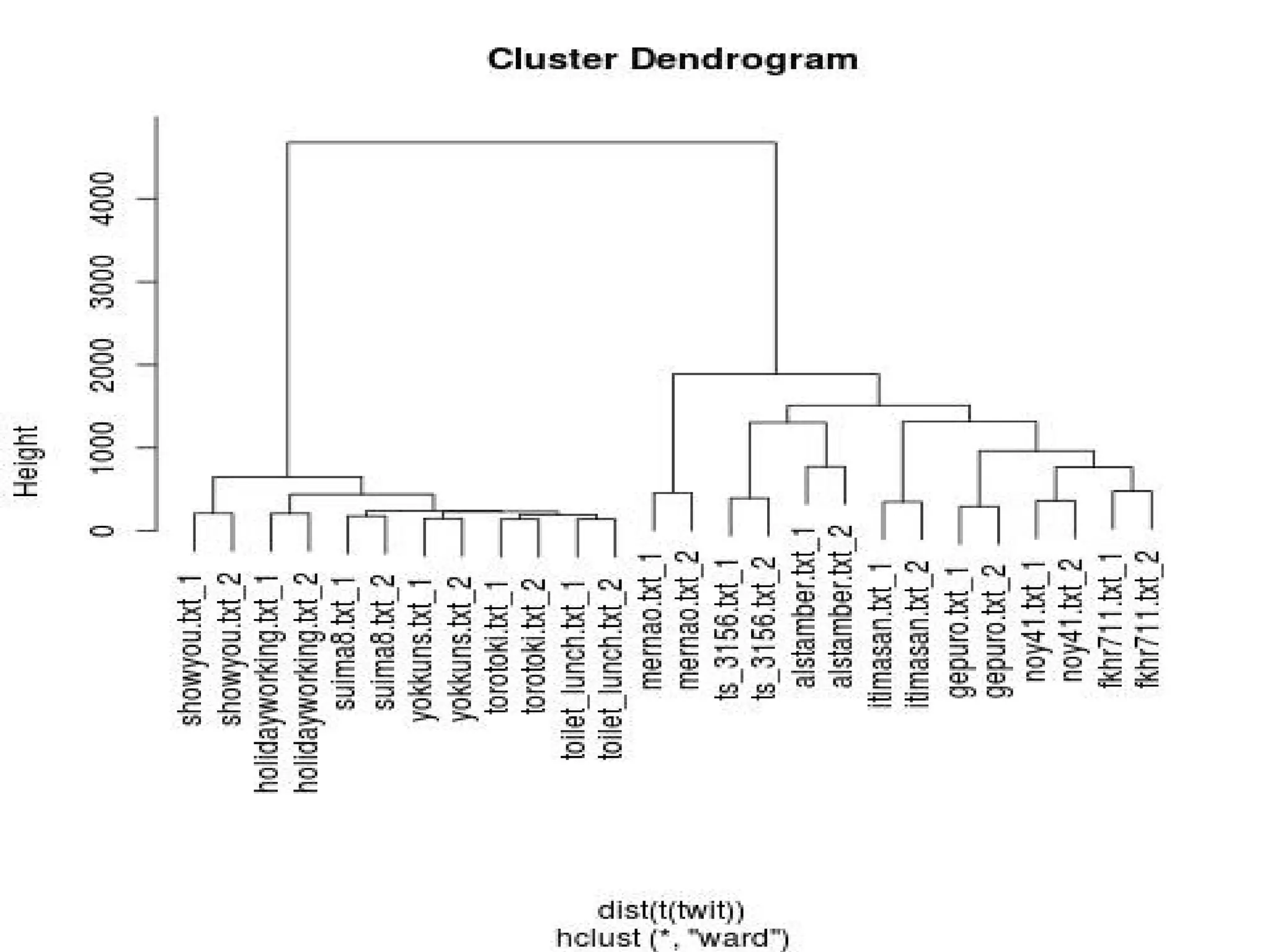
library(RMeCab) twit <- docNgram("./sep",type=0) plot(
hclust(dist(t(twit)),"ward"))
24.
書き手の判別には、 2万字以上必要と 言われているけど・・・
25.
多いのは、約3万字 少ないのは、約4500文字
だった。
26.
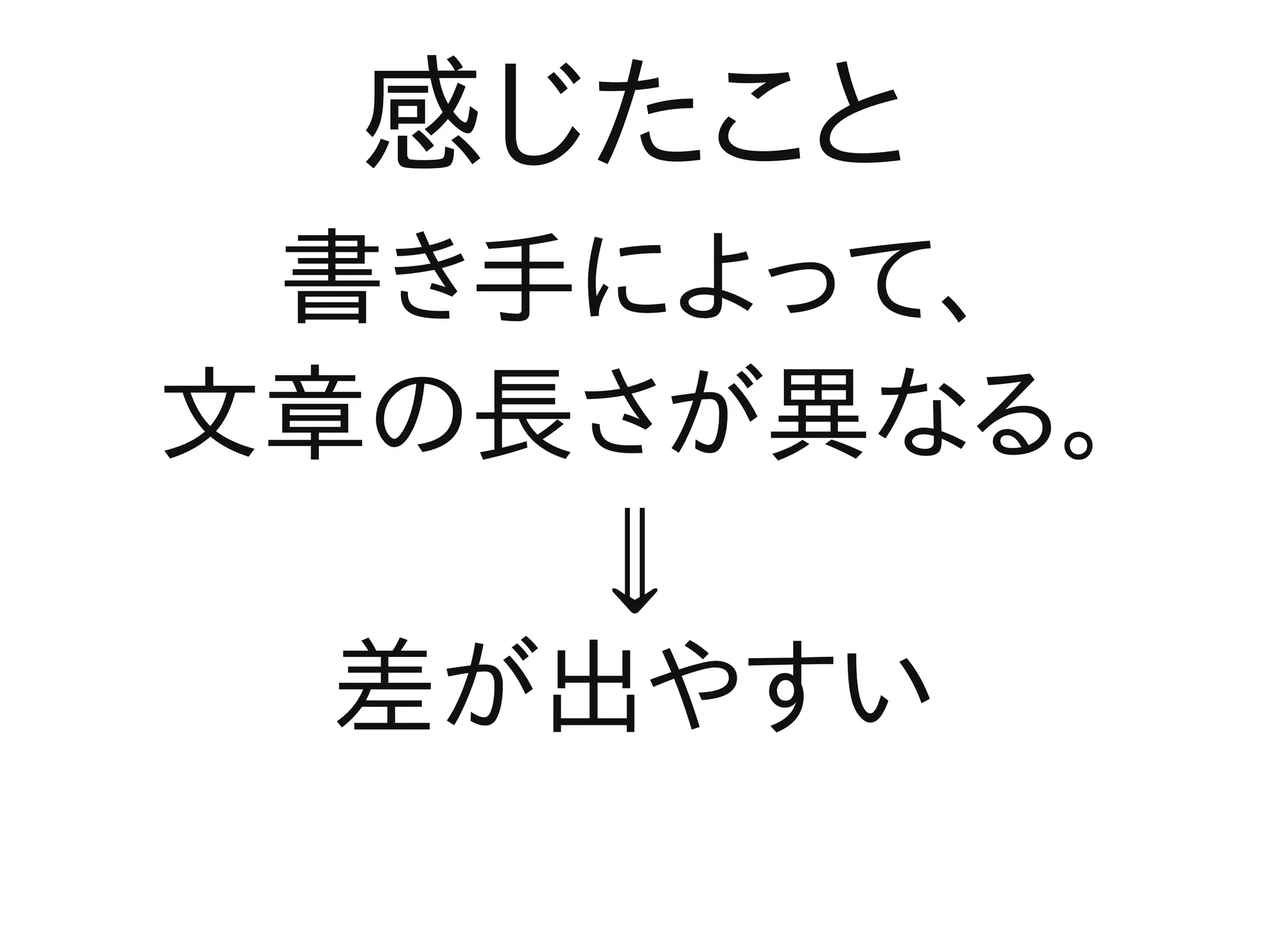
感じたこと 書き手によって、 文章の長さが異なる。
⇓ 差が出やすい
27.
相対度数で 見てみるかな
29.
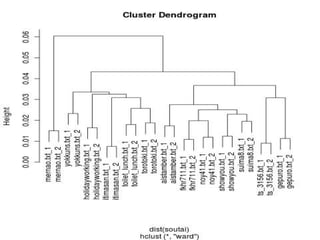
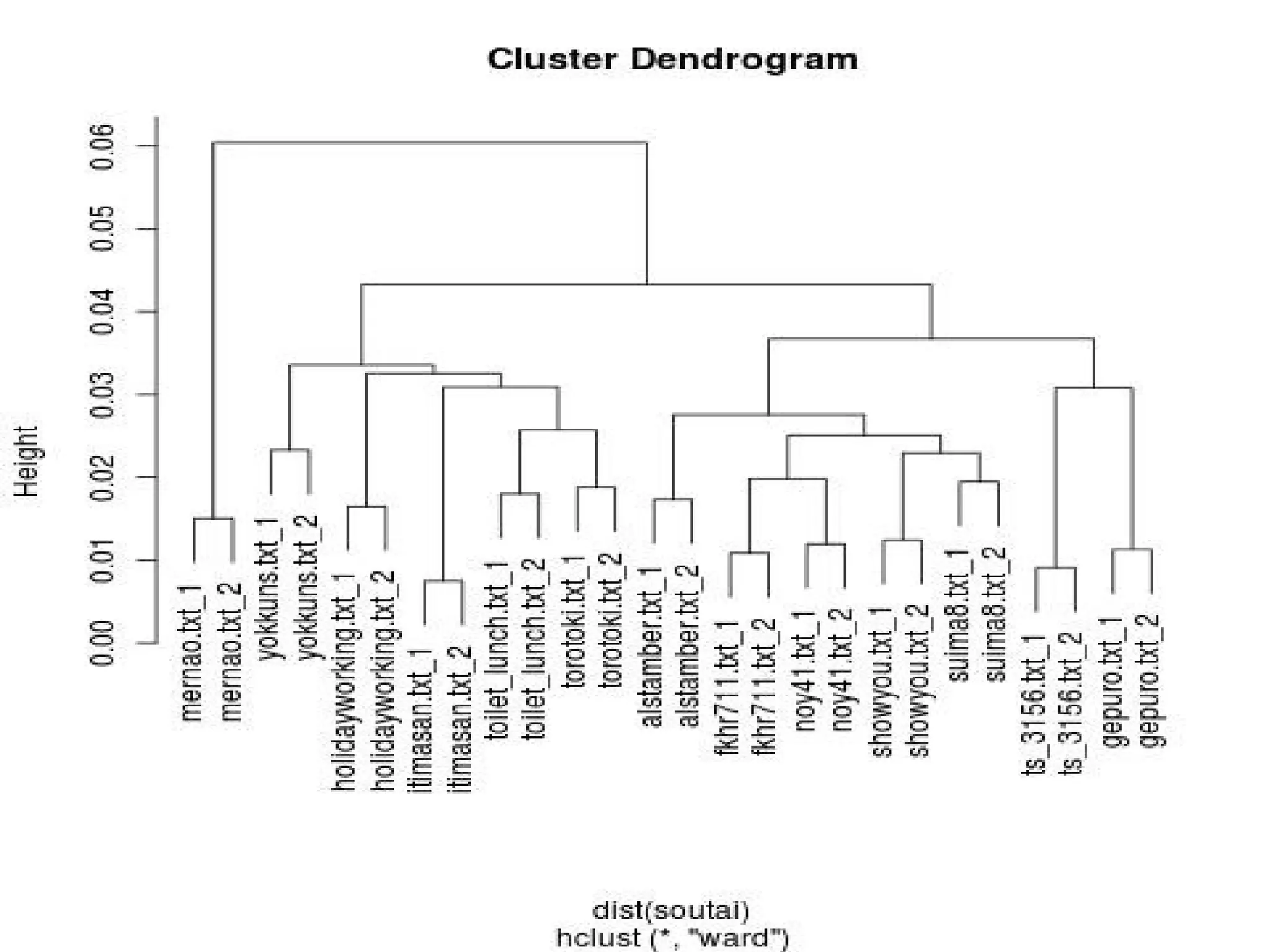
library(RMeCab) twit <- docNgram("./sep",type=0) soutai
<- t(twit) / rowSums(t(twit)) plot(hclust(dist(soutai),"ward"))
30.
一つ目が合わさる部分で
見たいけど、 高さの部分で区切るから、 クラスタリングが 希望通りにできない。
31.
●階層的クラスタリング ●非階層的クラスタリング
32.
kmeans
33.
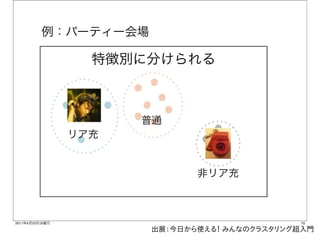
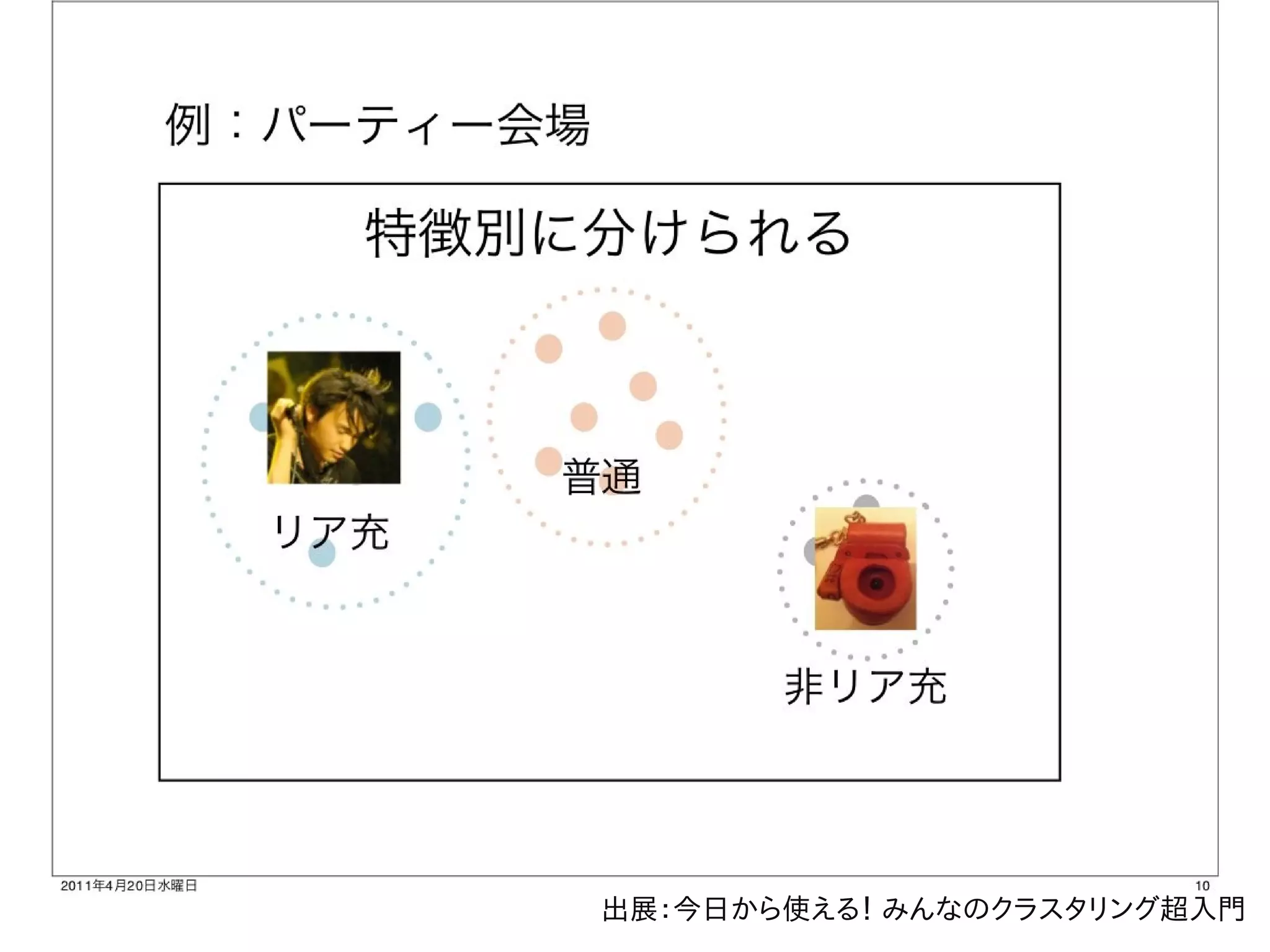
今日から使える! みんなのクラスタリング超入門
kmeans http://www.slideshare.net/toilet_lunch/ss-7684979 に分かりやすく書かれています。
34.
出展:今日から使える! みんなのクラスタリング超入門
35.
階層的クラスタリングと kmeans 同じコーパスを用いて
37.
上手くできてるかな
38.
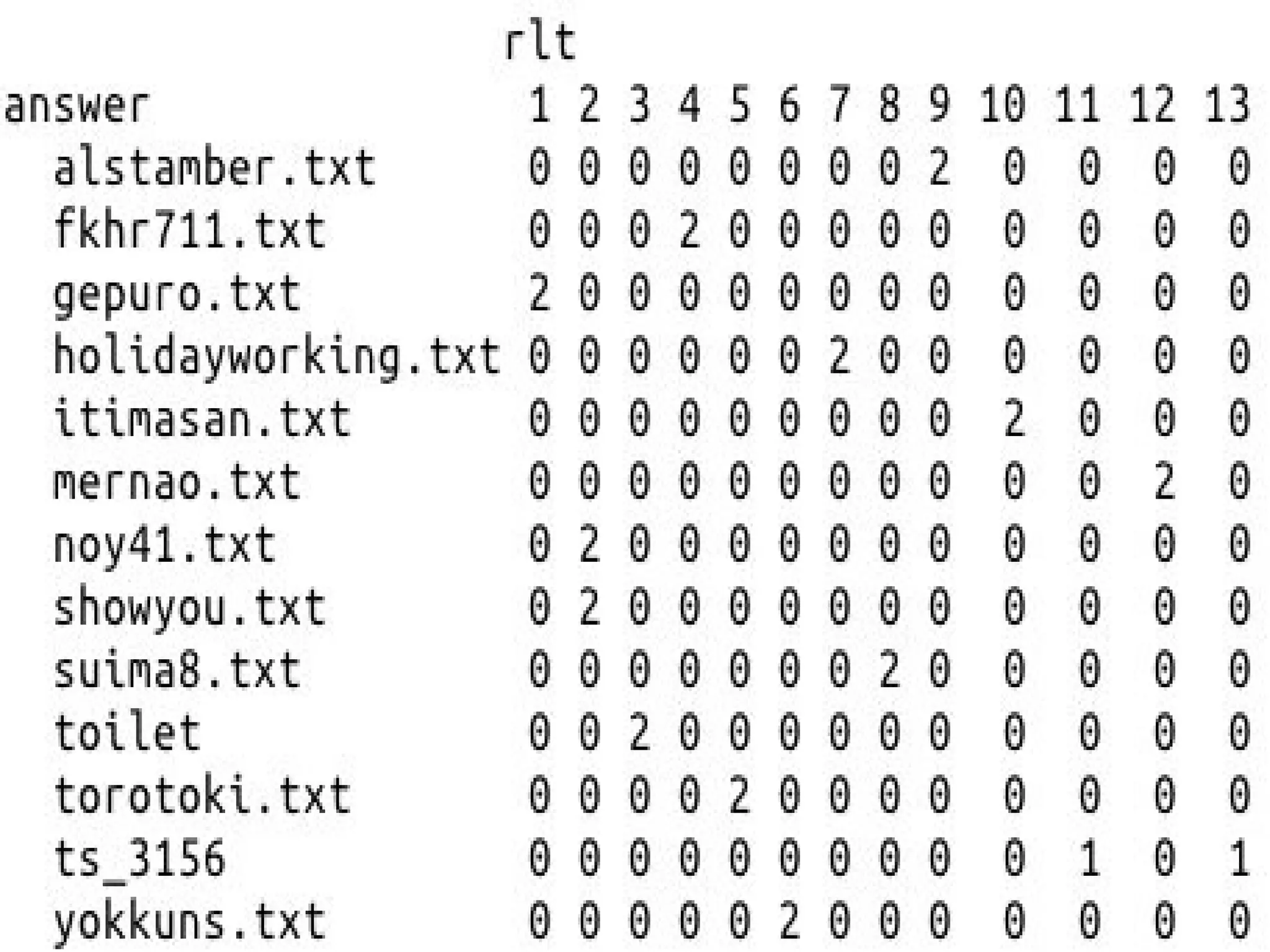
kmeans(soutai,centers=13) answer = c() for
( i in 1:26){ answer[i] = strsplit(names(rlt),split="_")[[i]][1] } ctbl <- table(answer,rlt) ctbl
39.
クラスタリングを使うと、 書き手の特徴を掴み、
それぞれを 分けることができた。
40.
参考 •
Rによるテキストマイニング入門 著:石田 基広 出版社:森北出版株式会社 • RとLinuxと・・・ http://rmecab.jp/wiki/index.php?RMeCab • 今日から使える! みんなのクラスタリング超入門 http://www.slideshare.net/toilet_lunch/ss-7684979 • クラスタリングとクラス分類って違うらしい http://d.hatena.ne.jp/Kshi_Kshi/20110110/1294687656
41.
ご清聴 ありがとうございました
Download

































![kmeans(soutai,centers=13)
answer = c()
for ( i in 1:26){
answer[i] = strsplit(names(rlt),split="_")[[i]][1]
}
ctbl <- table(answer,rlt)
ctbl](https://image.slidesharecdn.com/slide-111217210640-phpapp01/85/clustering-of-user-38-320.jpg)









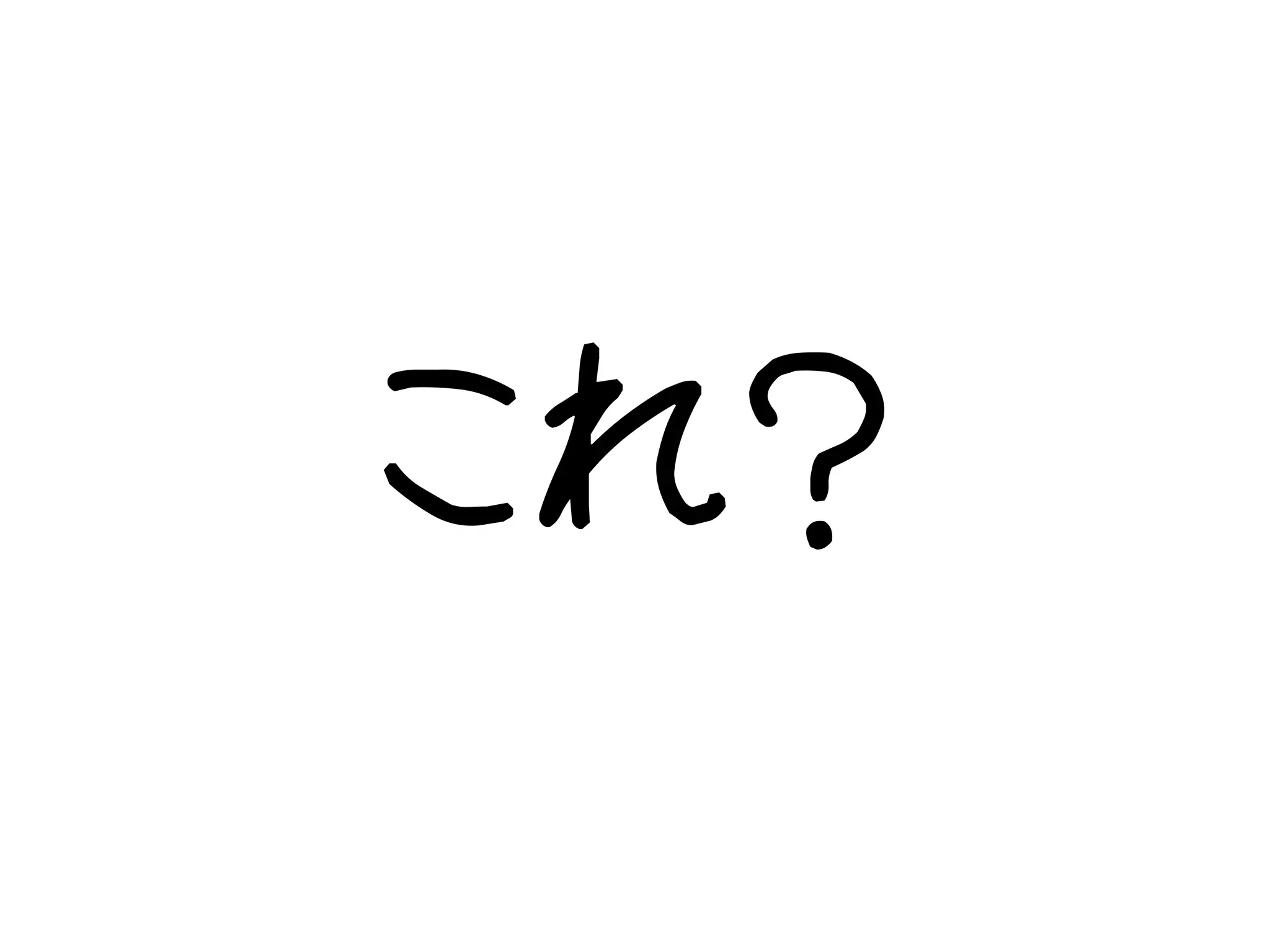

























![kmeans(soutai,centers=13)
answer = c()
for ( i in 1:26){
answer[i] = strsplit(names(rlt),split="_")[[i]][1]
}
ctbl <- table(answer,rlt)
ctbl](https://image.slidesharecdn.com/slide-111217210640-phpapp01/75/clustering-of-user-38-2048.jpg)





























![[第2版]Python機械学習プログラミング 第11章](https://cdn.slidesharecdn.com/ss_thumbnails/11-181212011918-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




























