Download to read offline













![STM Publishers prevent Mining
• FUD & disinformation about legality (Elsevier)
• Monopolies on infrastructure (“API”s, CCC
Rightfind)
• Technical obstruction (Wiley Captcha,
Macmillan Readcube)
• Restrictive contracts with libraries (ALL) [1]
• Wasting my/our time (ALL)
[1] [You may not] utilize the TDM Output to enhance … subject repositories
in a way that would [… ] have the potential to substitute and/or replicate
any other existing Elsevier products, services and/or solutions.](https://image.slidesharecdn.com/camlib-160108093231-160112171009/85/Content-Mining-of-Science-in-Cambridge-20-320.jpg)
![WILEY … “new security feature… to prevent systematic download of content
“[limit of] 100 papers per day”
“essential security feature … to protect both parties (sic)”
CAPTCHA
User has to type words](https://image.slidesharecdn.com/camlib-160108093231-160112171009/85/Content-Mining-of-Science-in-Cambridge-21-320.jpg)















![STM Publishers prevent Mining
• FUD & disinformation about legality (Elsevier)
• Monopolies on infrastructure (“API”s, CCC
Rightfind)
• Technical obstruction (Wiley Captcha,
Macmillan Readcube)
• Restrictive contracts with libraries (ALL) [1]
• Wasting my/our time (ALL)
[1] [You may not] utilize the TDM Output to enhance … subject repositories
in a way that would [… ] have the potential to substitute and/or replicate
any other existing Elsevier products, services and/or solutions.](https://image.slidesharecdn.com/camlib-160108093231-160112171009/75/Content-Mining-of-Science-in-Cambridge-20-2048.jpg)
![WILEY … “new security feature… to prevent systematic download of content
“[limit of] 100 papers per day”
“essential security feature … to protect both parties (sic)”
CAPTCHA
User has to type words](https://image.slidesharecdn.com/camlib-160108093231-160112171009/75/Content-Mining-of-Science-in-Cambridge-21-2048.jpg)


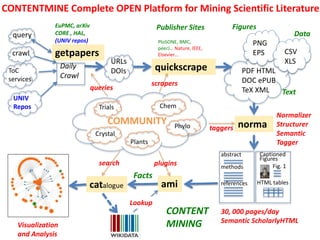
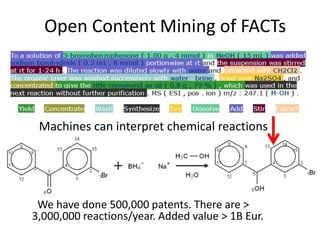
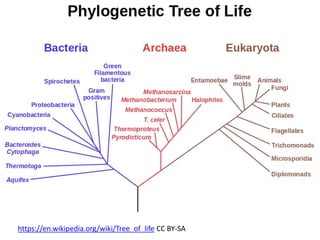
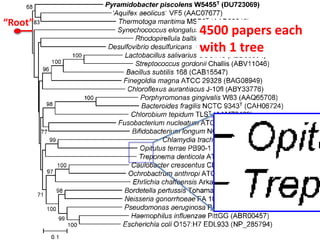
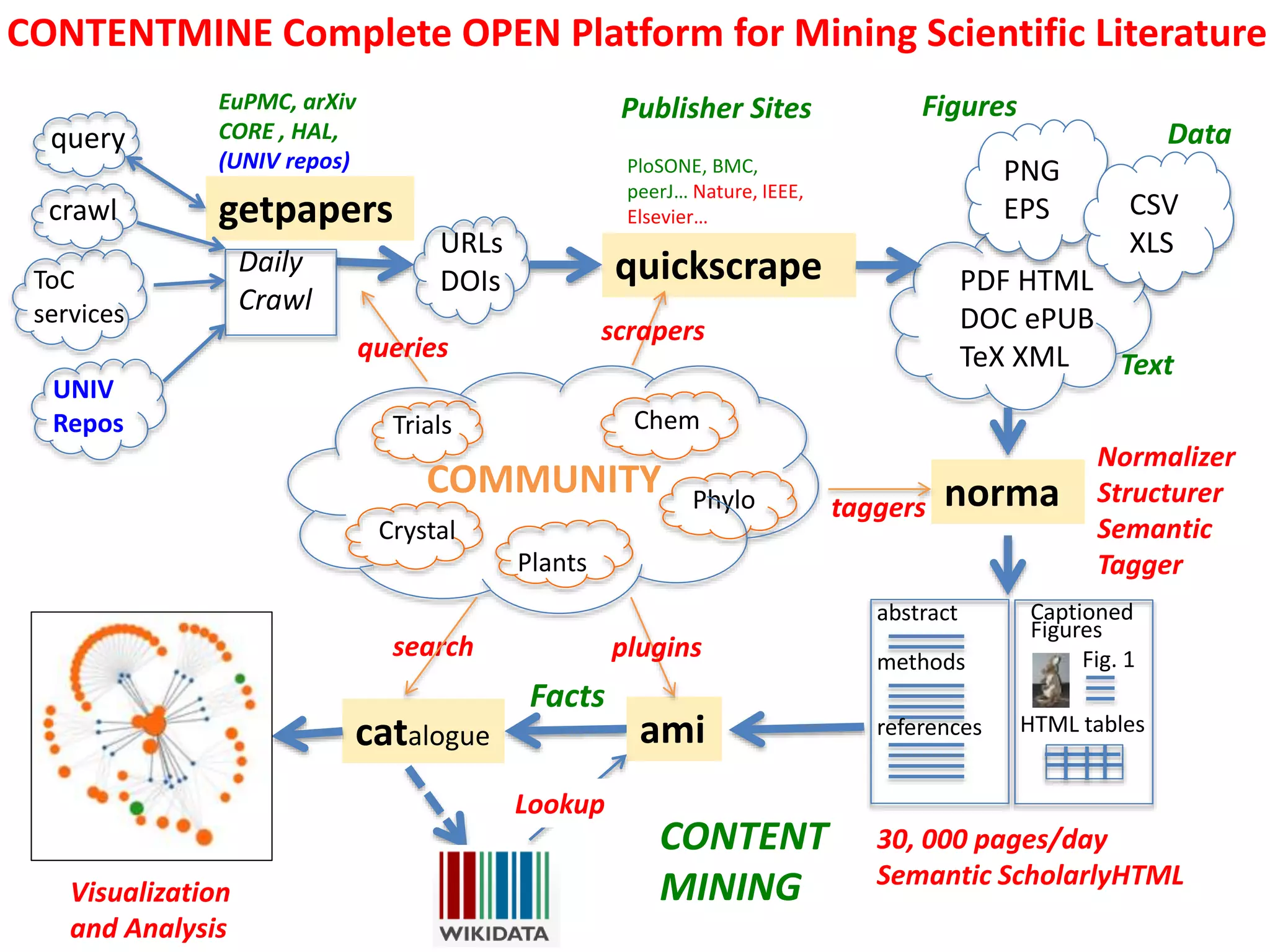
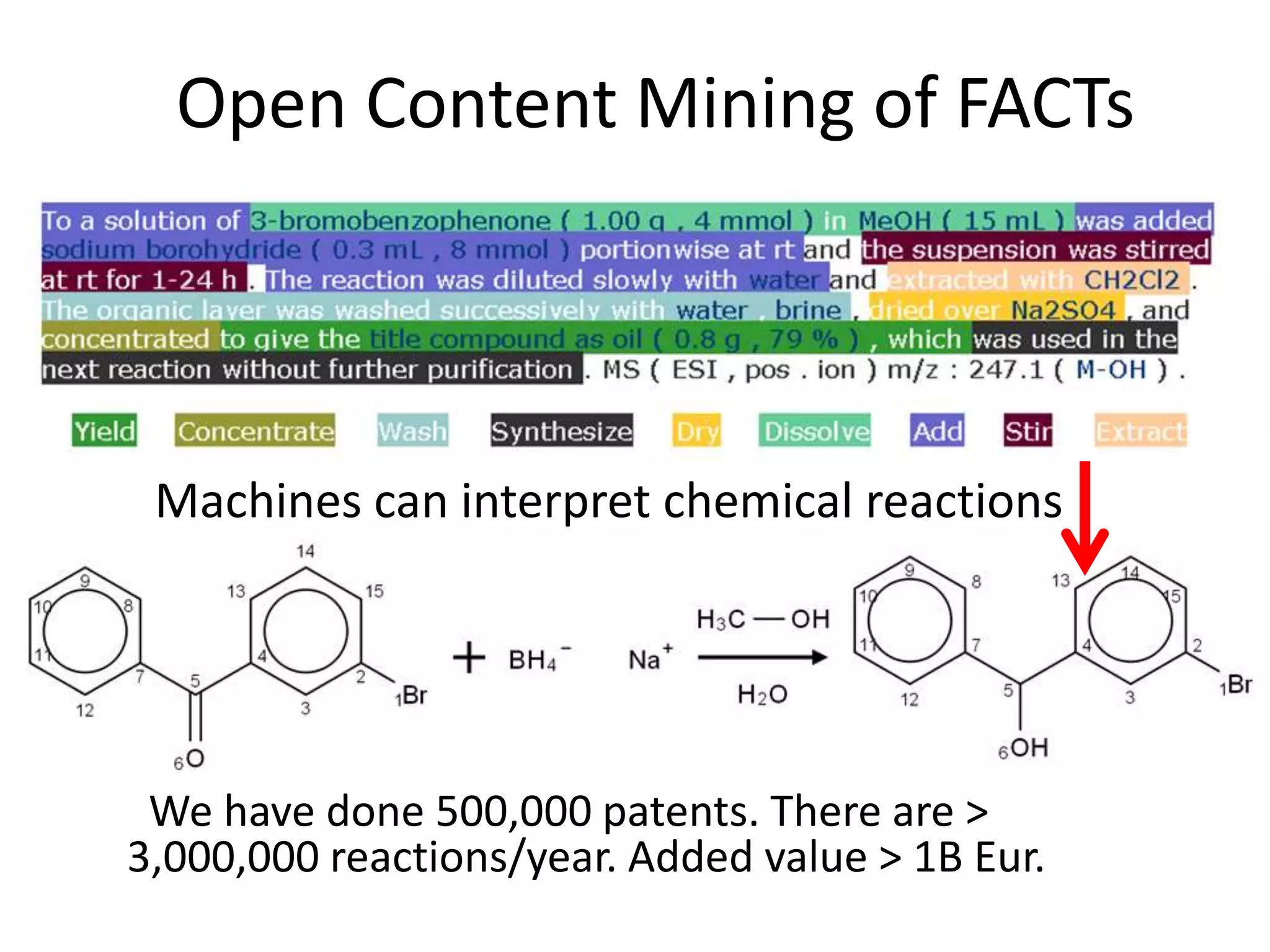
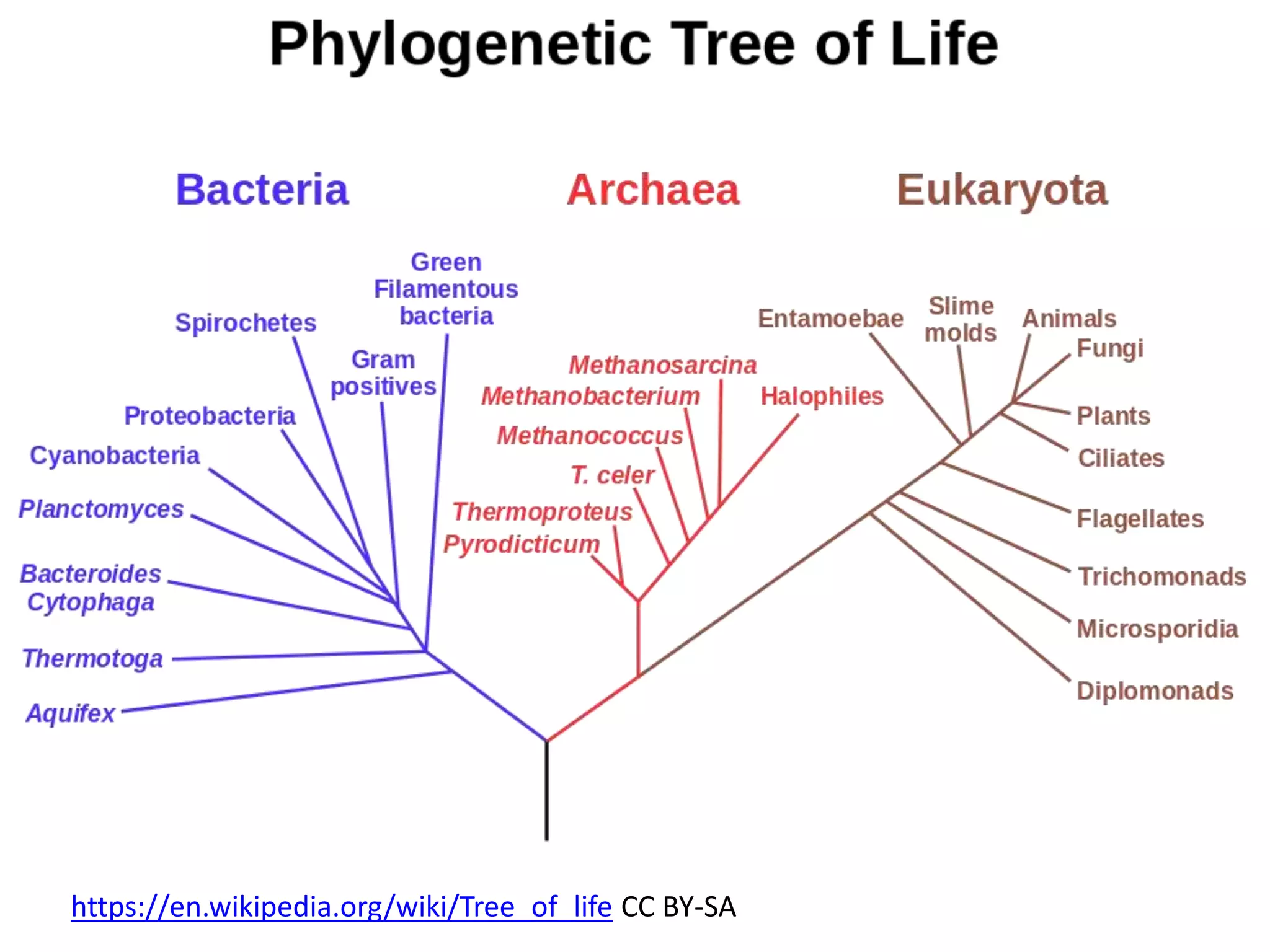
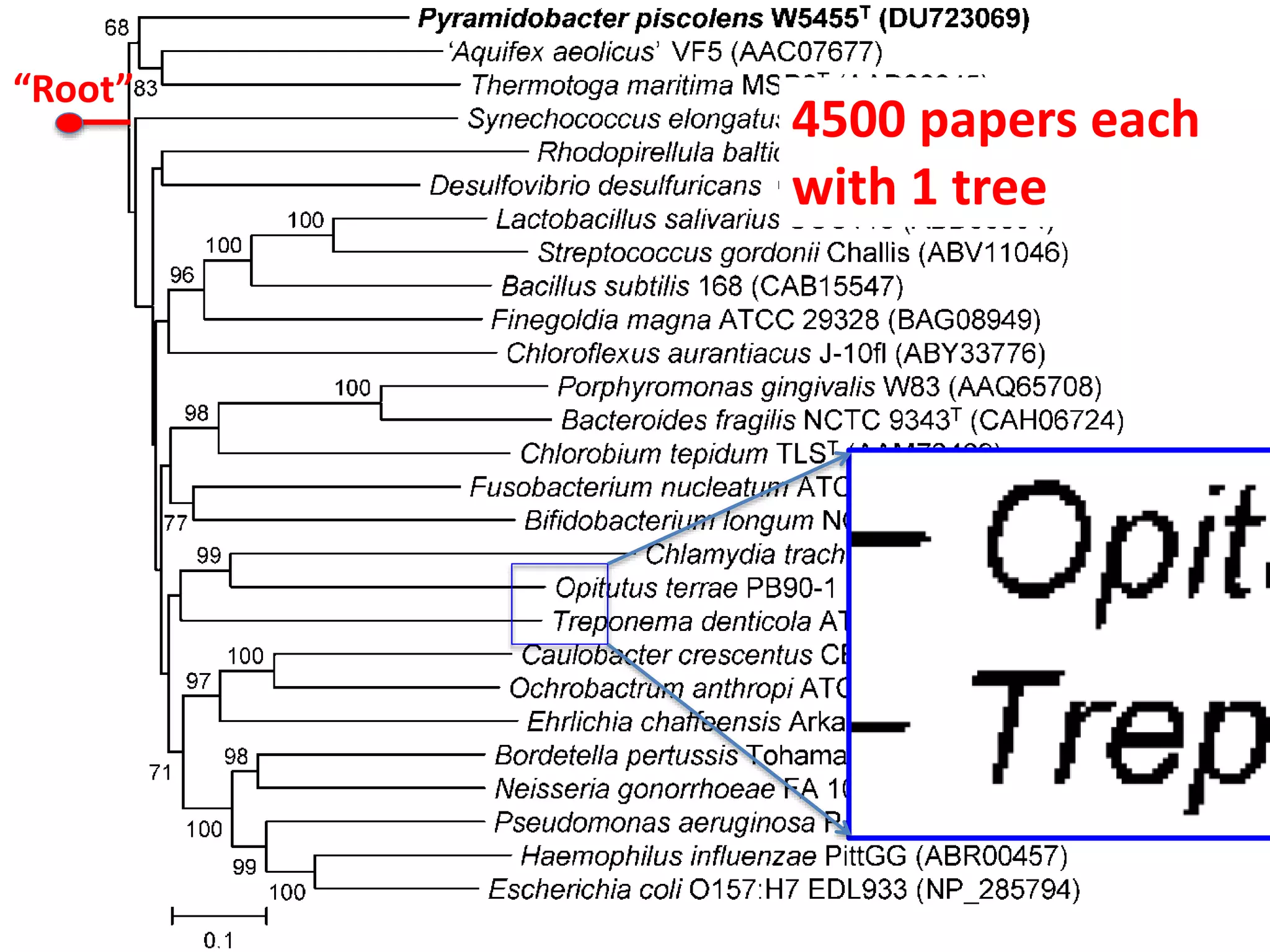
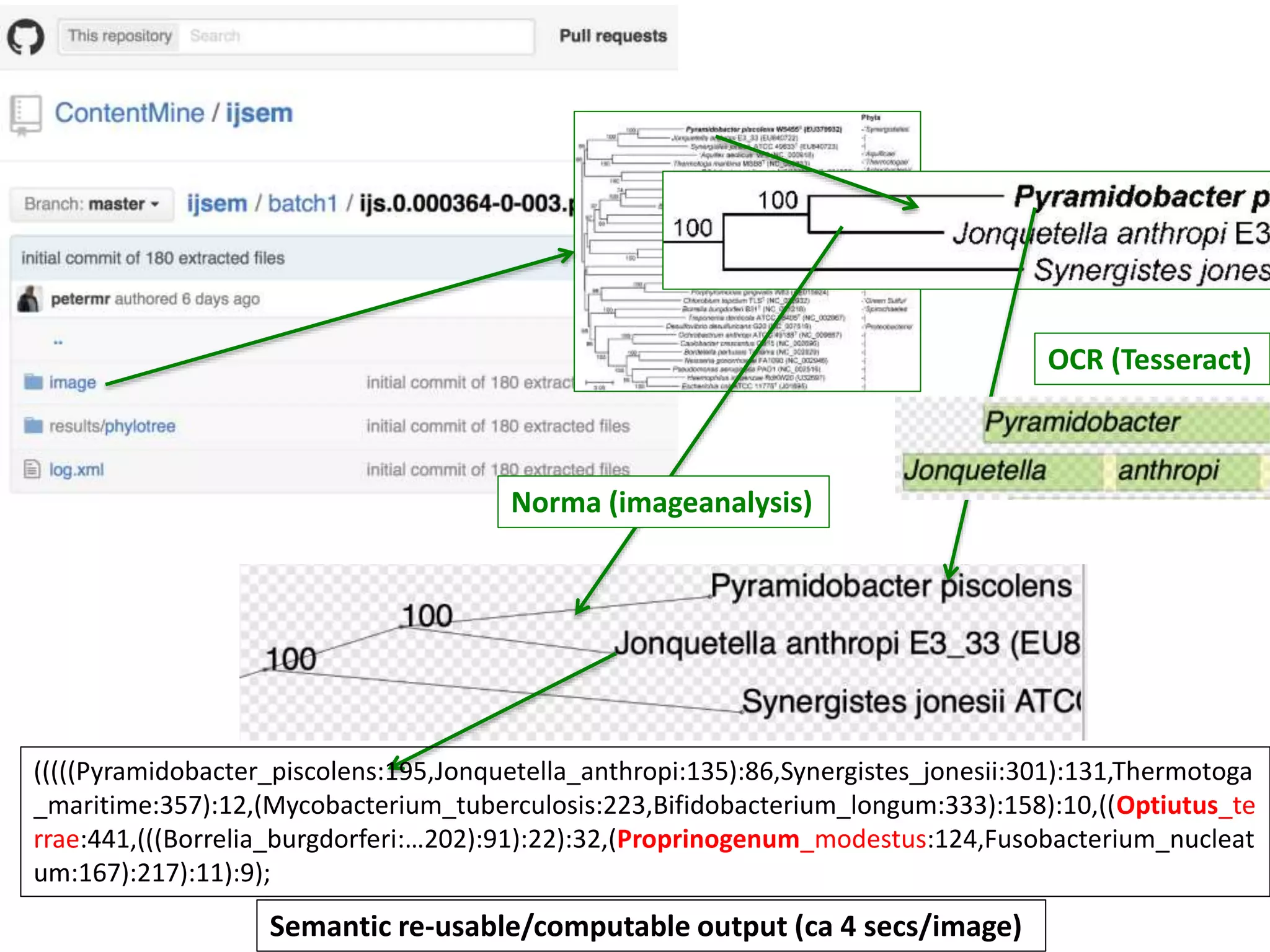
The document discusses the concept and utility of content mining in scientific literature, focusing on the efforts of Cambridge University to become a leader in this field. It outlines various applications, such as mapping clinical trials and extracting chemical reactions, while addressing challenges posed by publishers regarding mining legality and access. Contentmine is presented as a comprehensive platform for efficiently mining and analyzing scientific data from a large volume of publications.





















































































