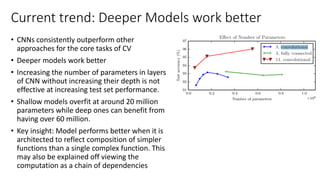
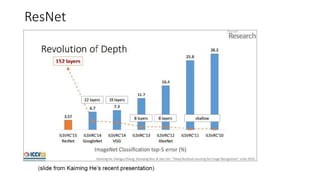
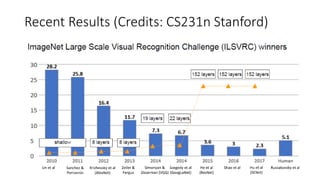
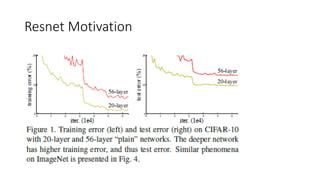
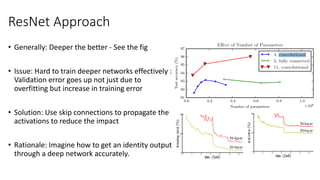
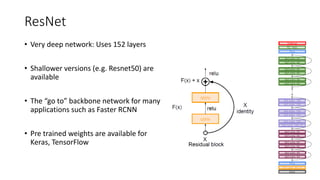
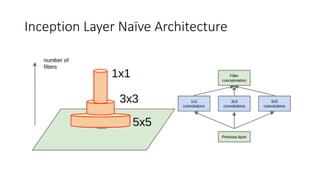
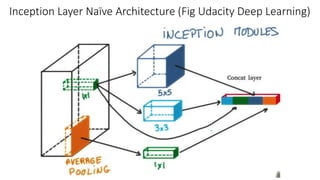
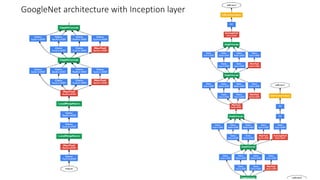
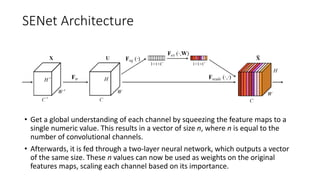
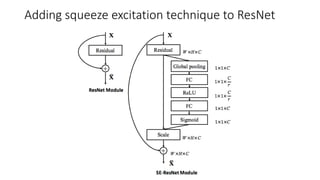
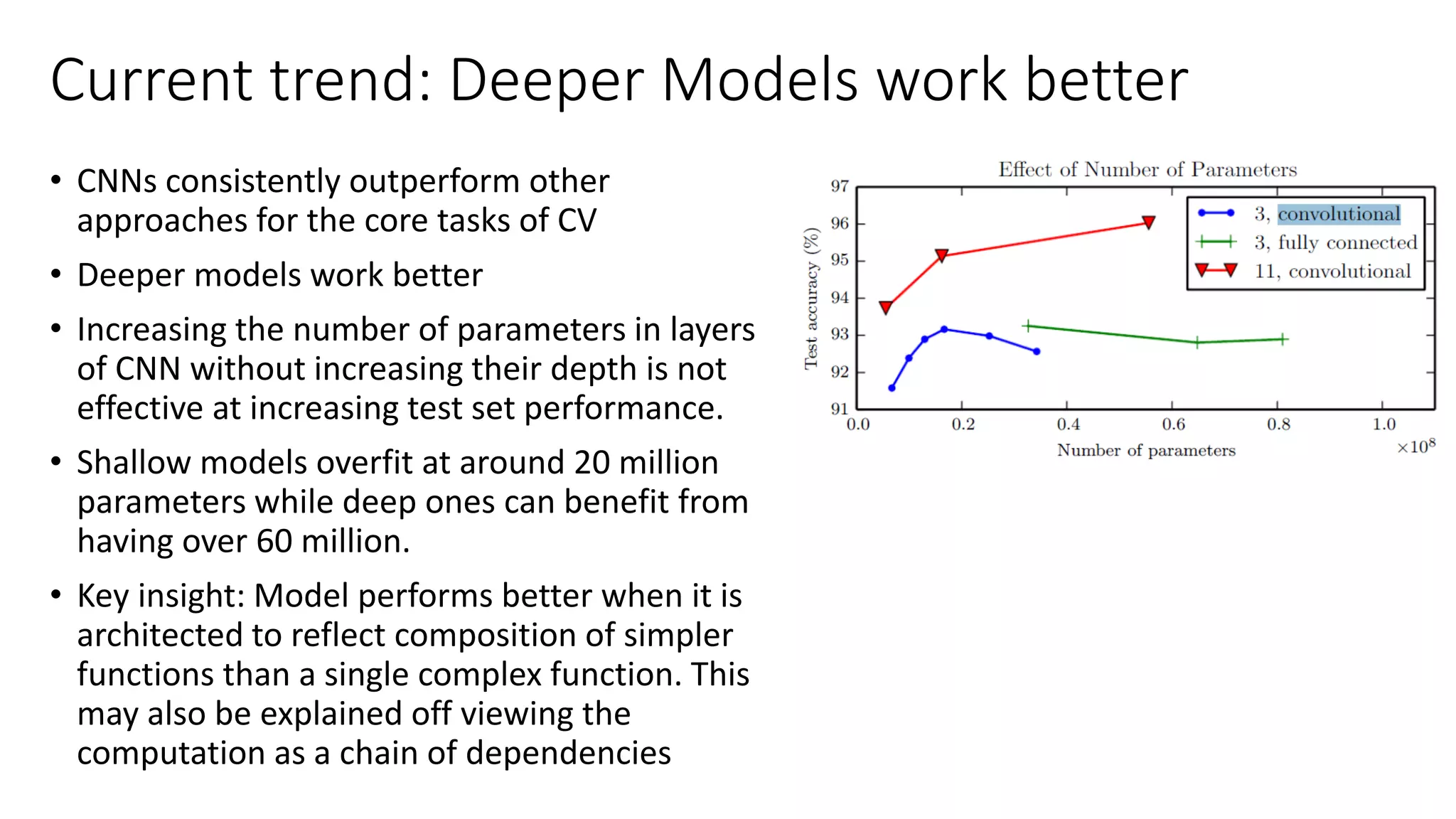
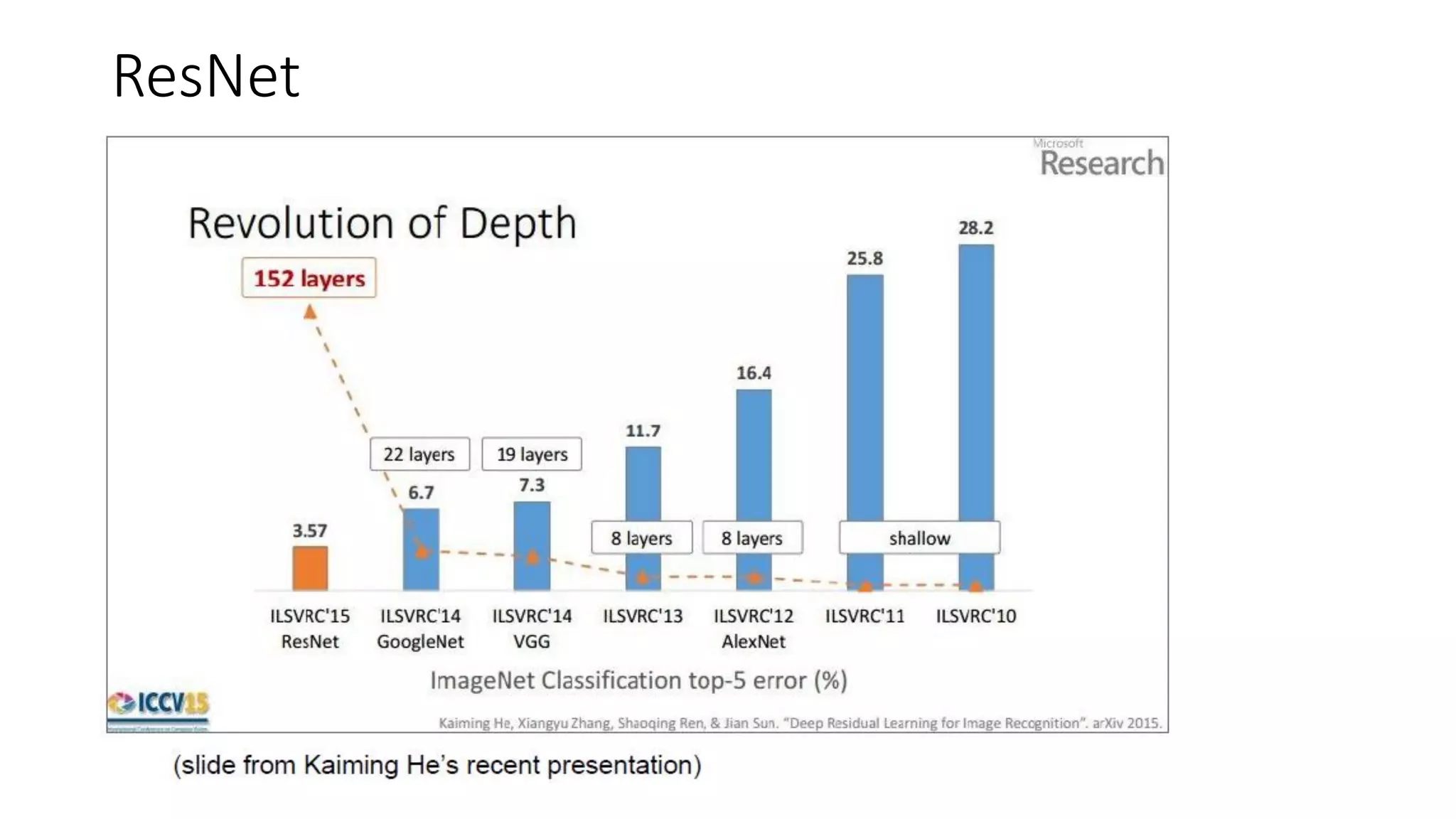
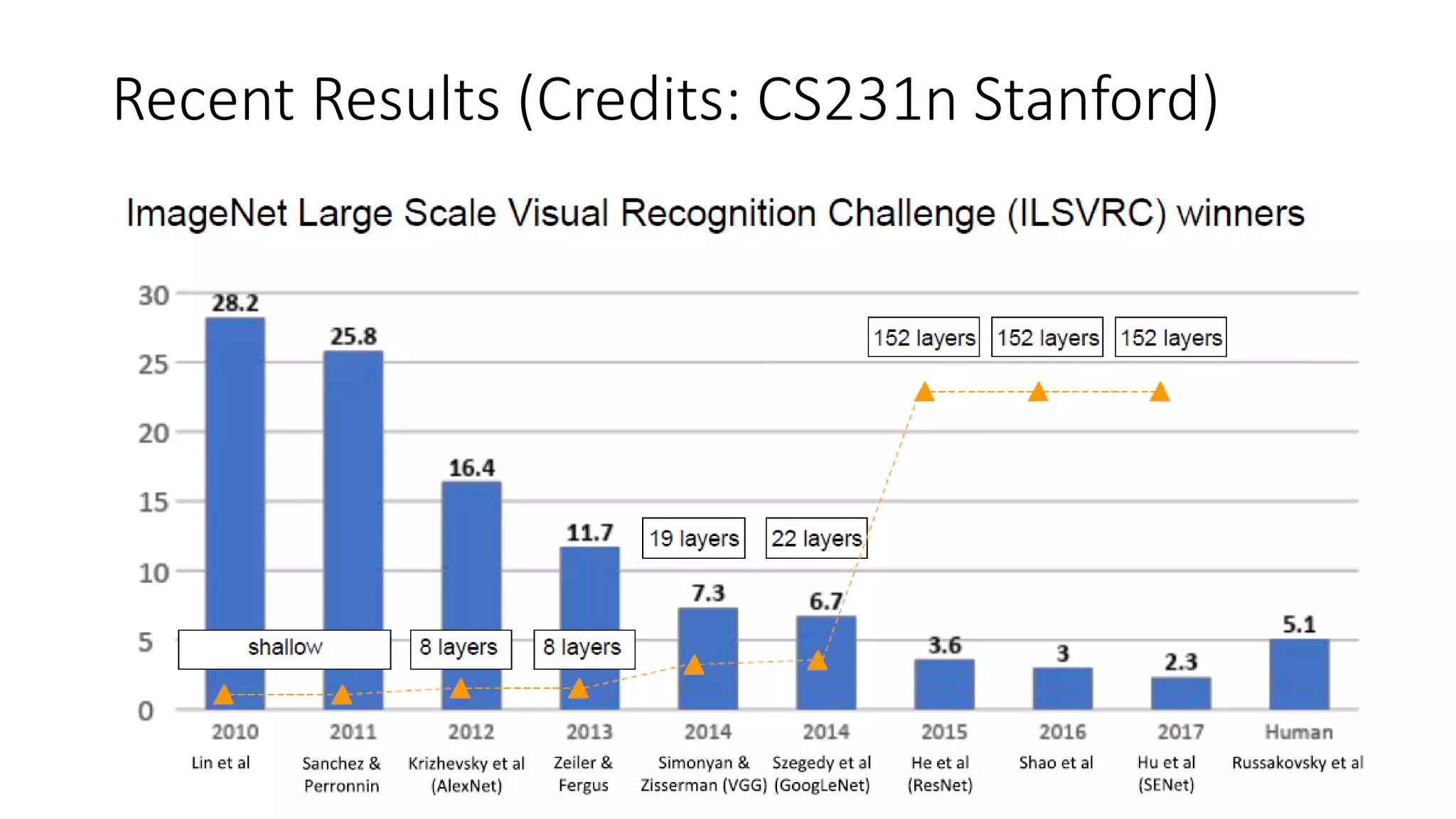
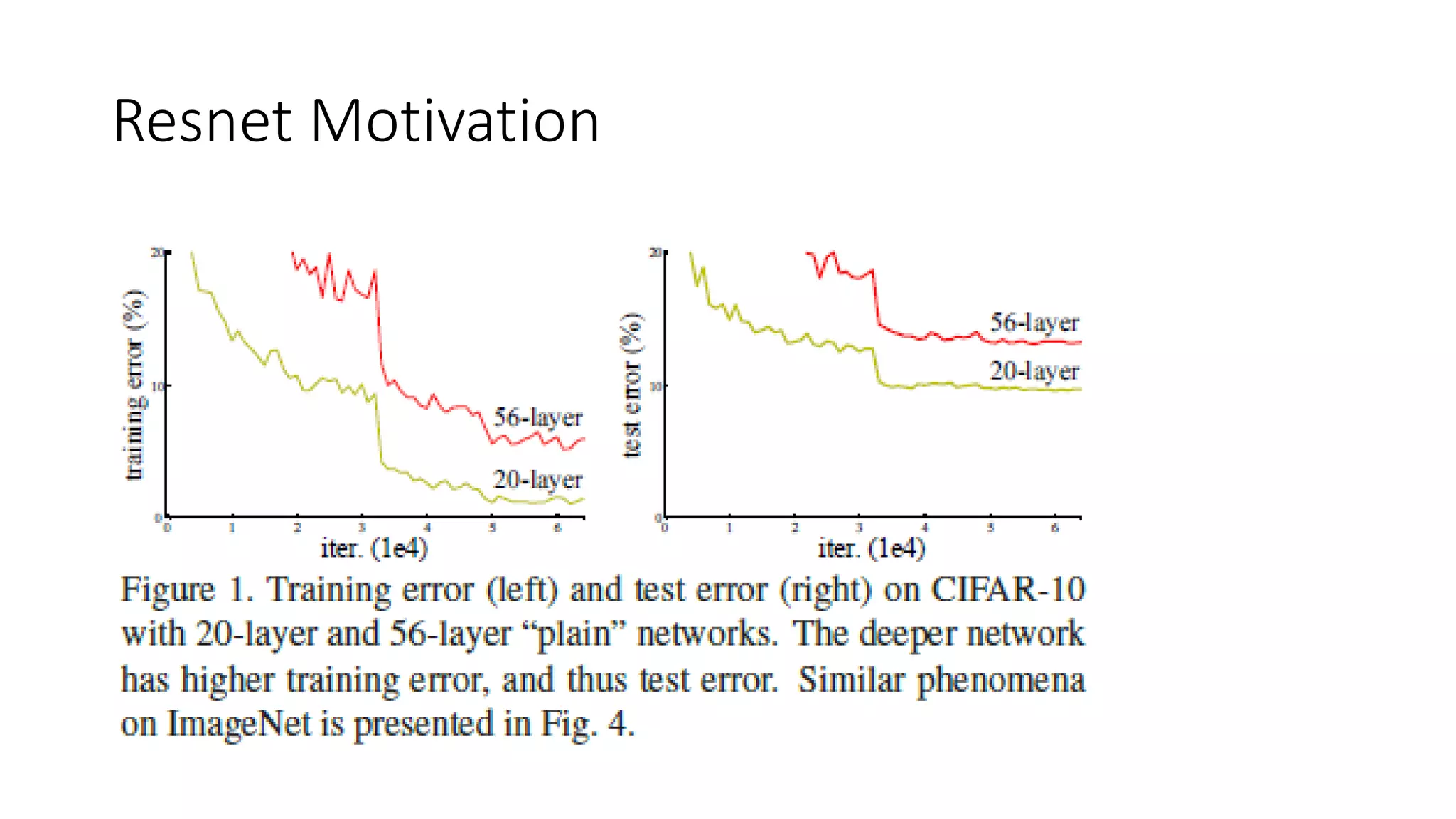
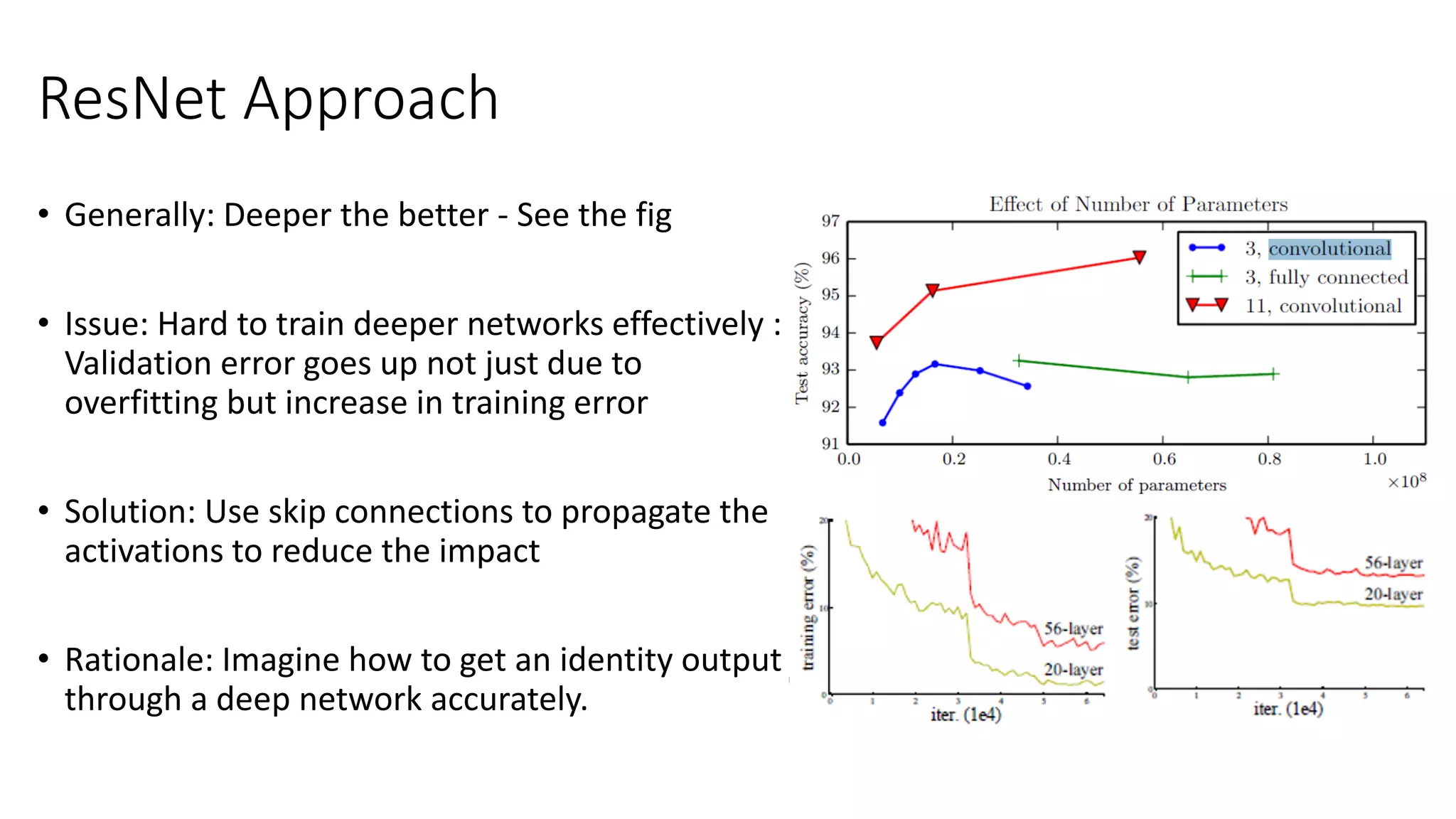
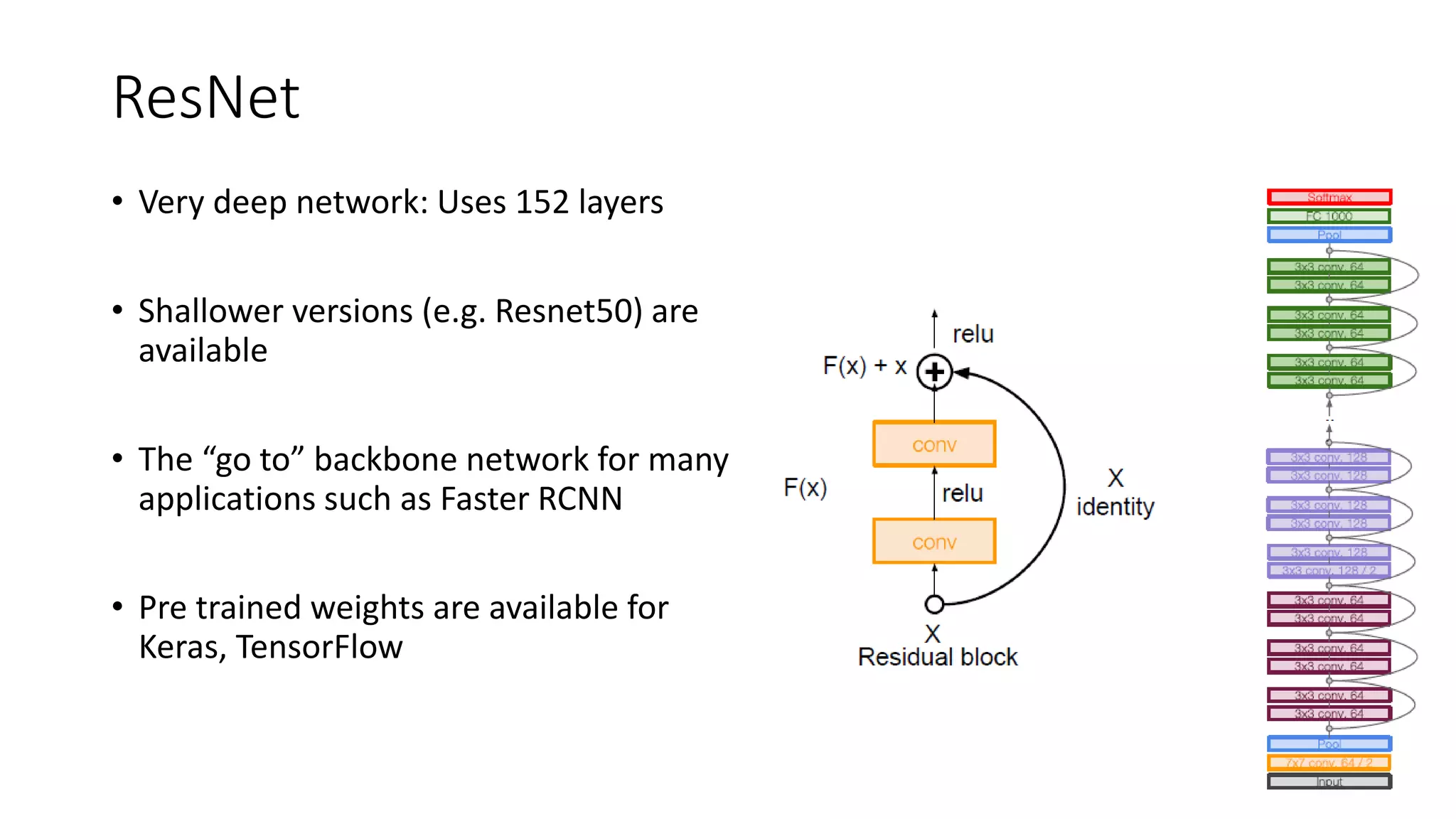
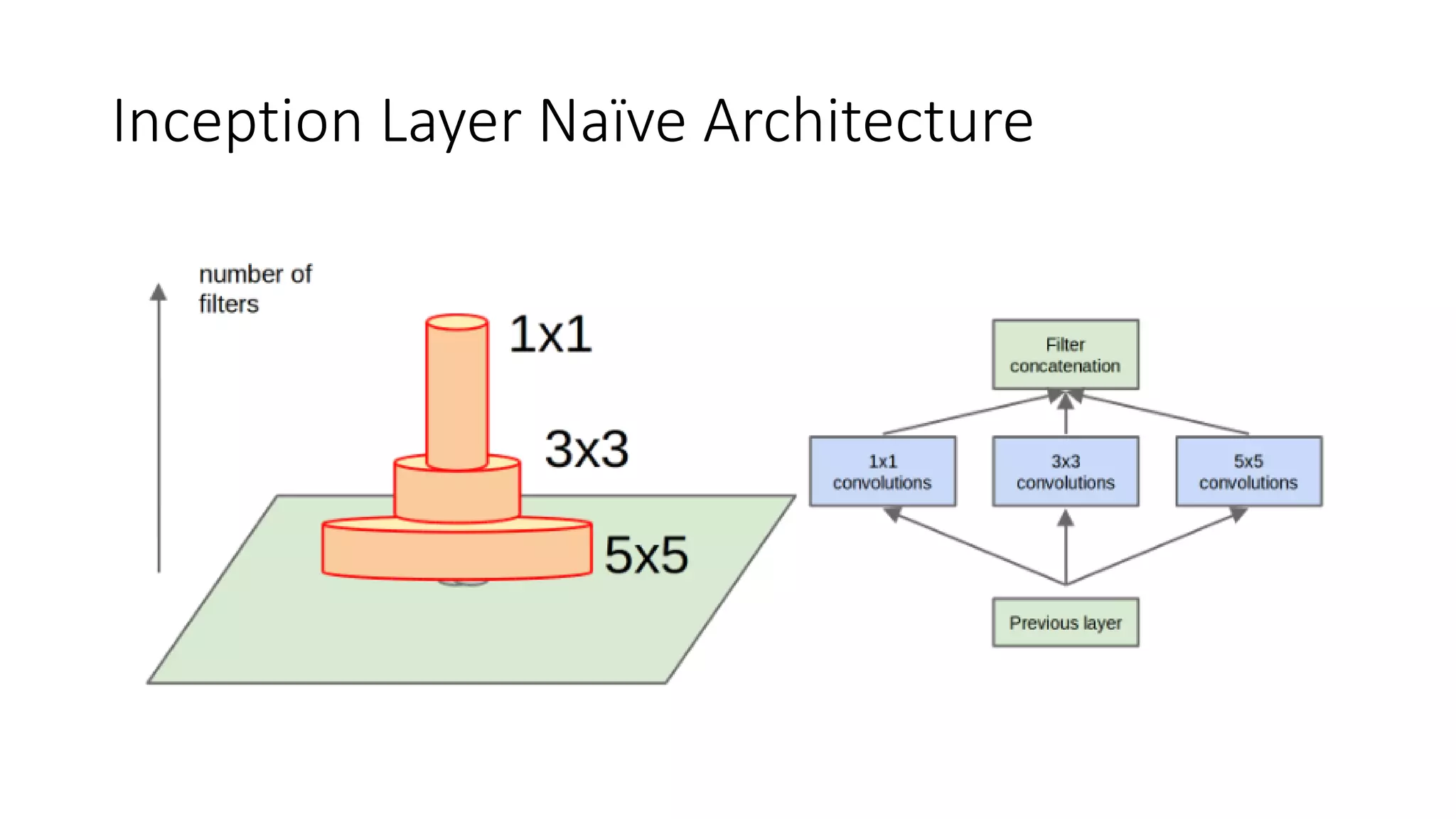
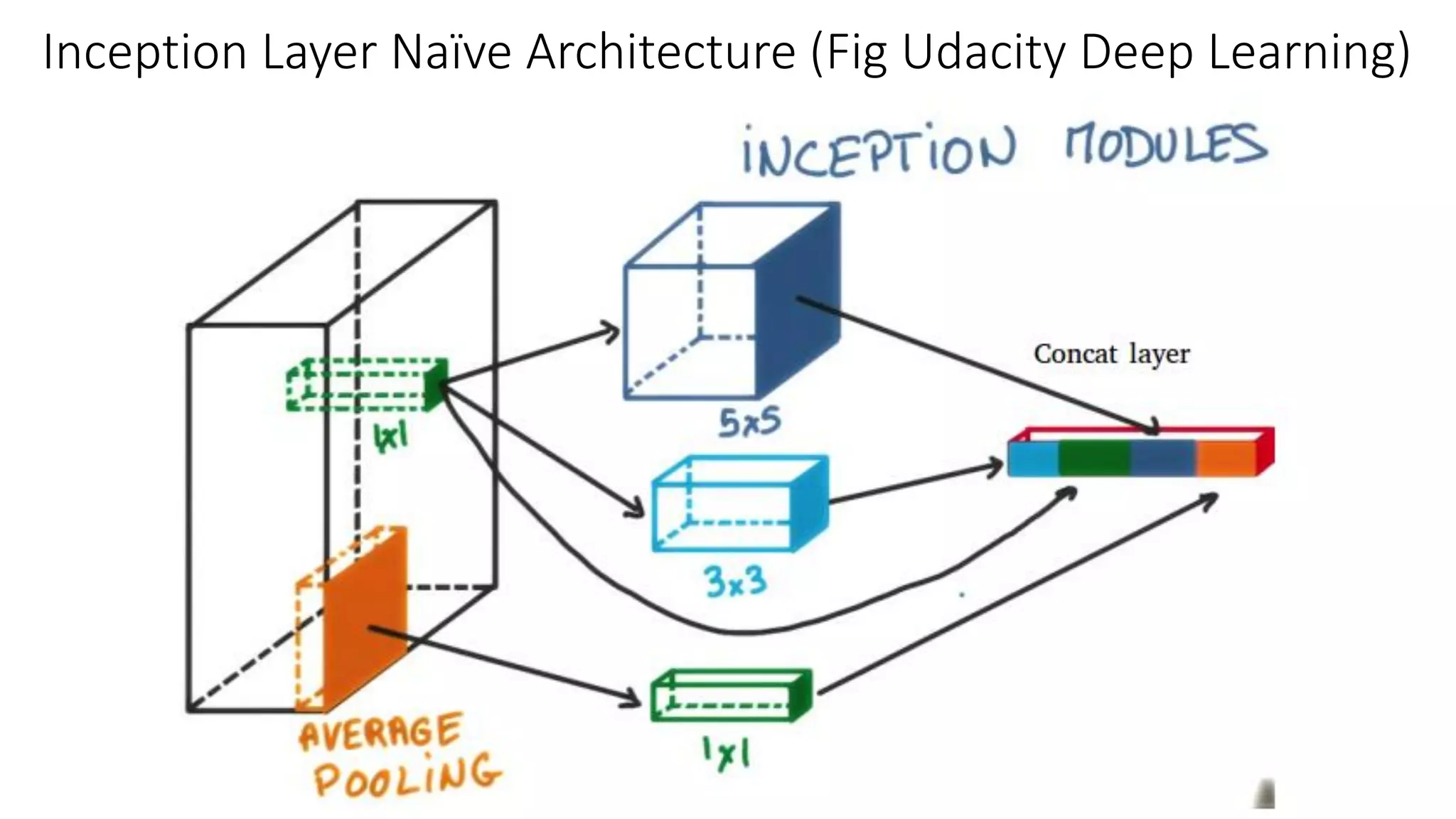
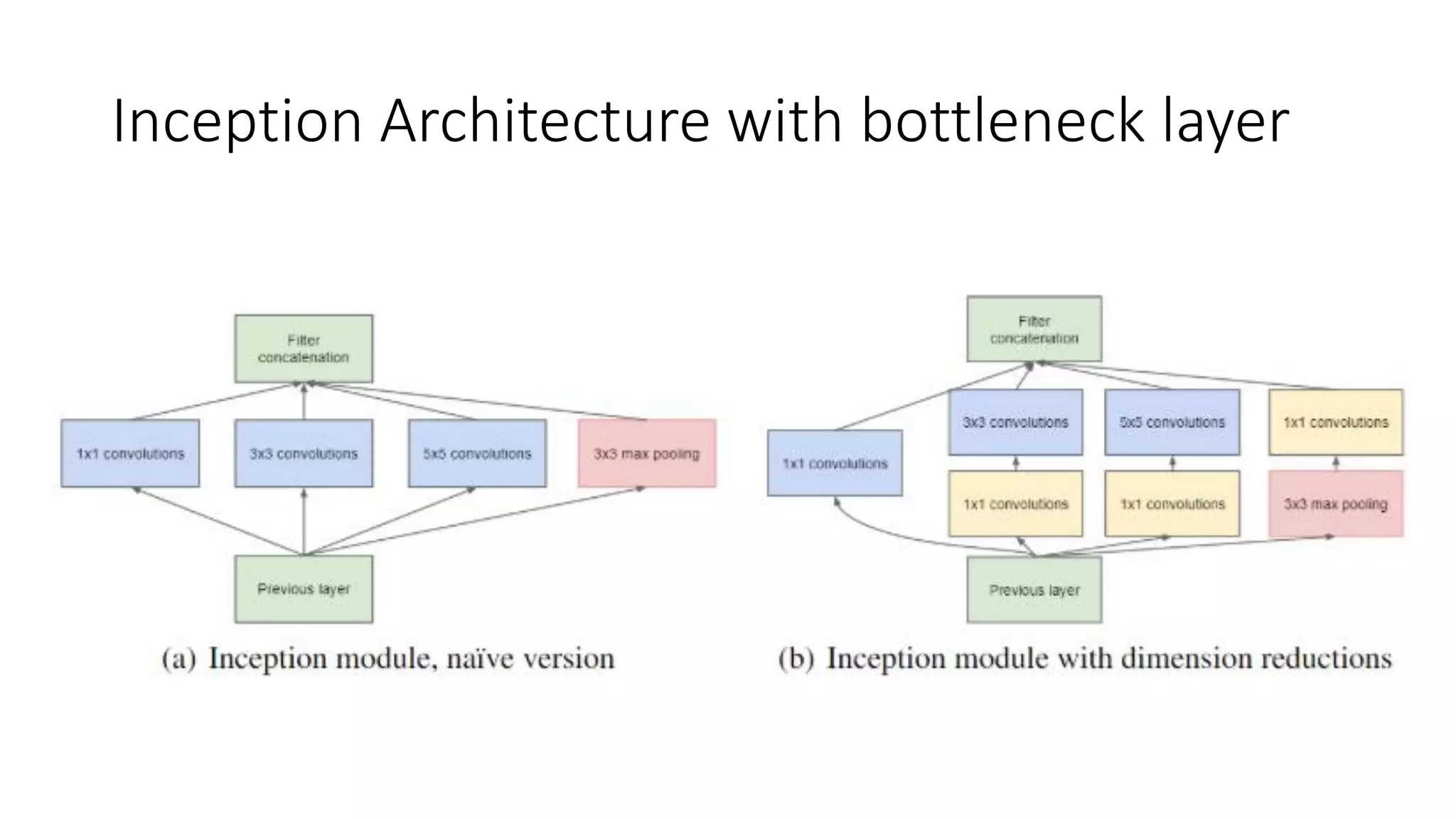
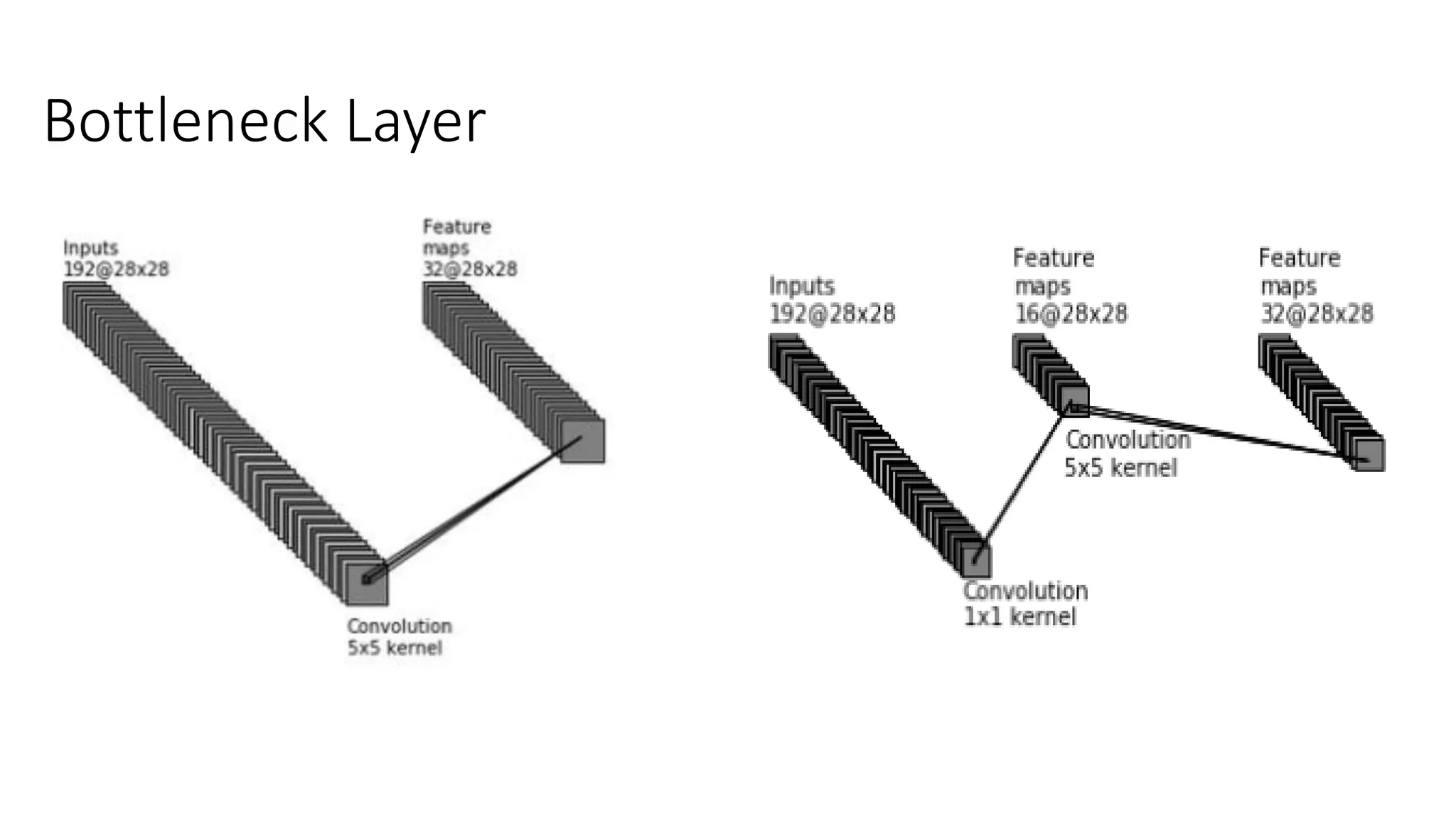
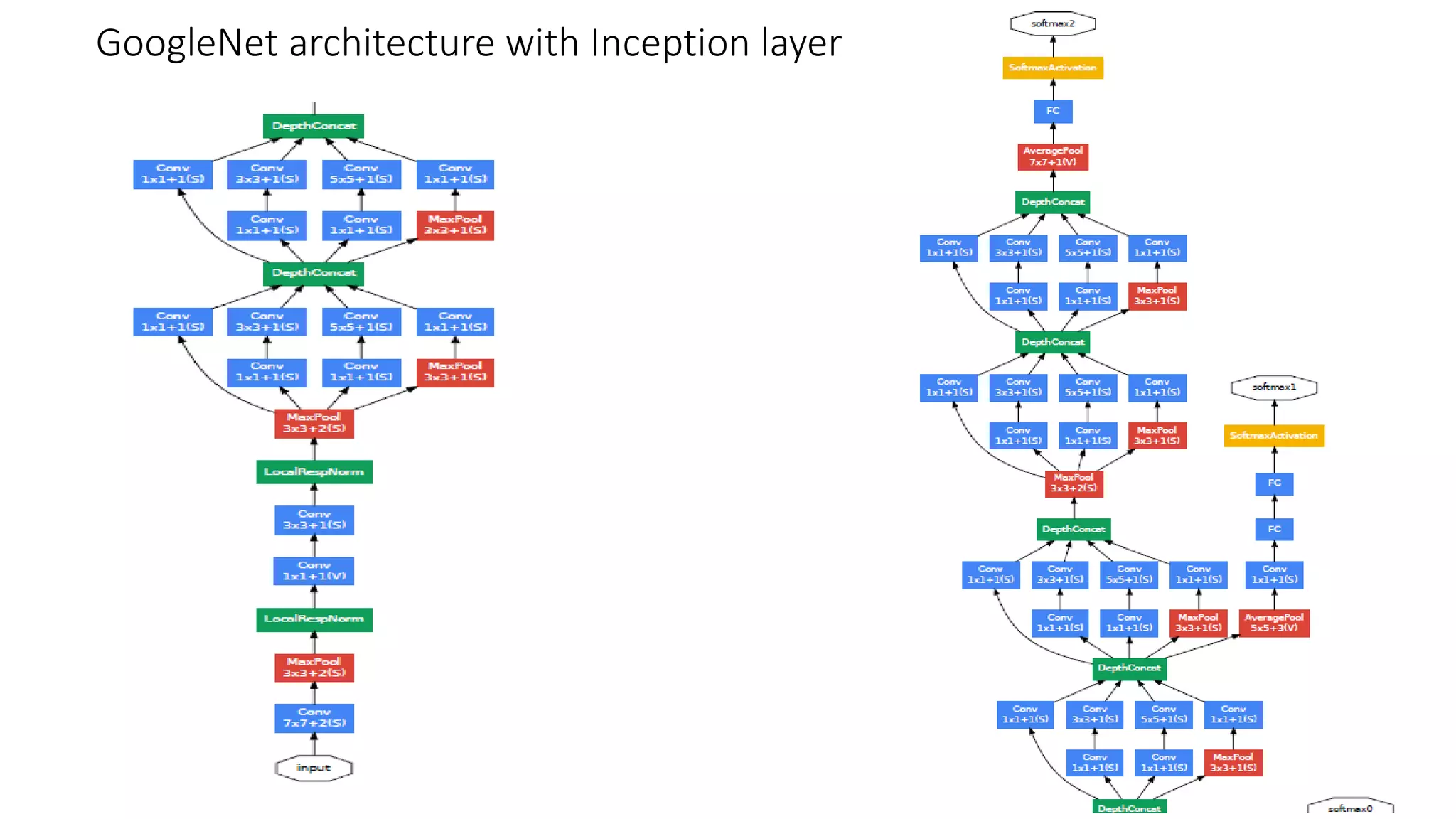
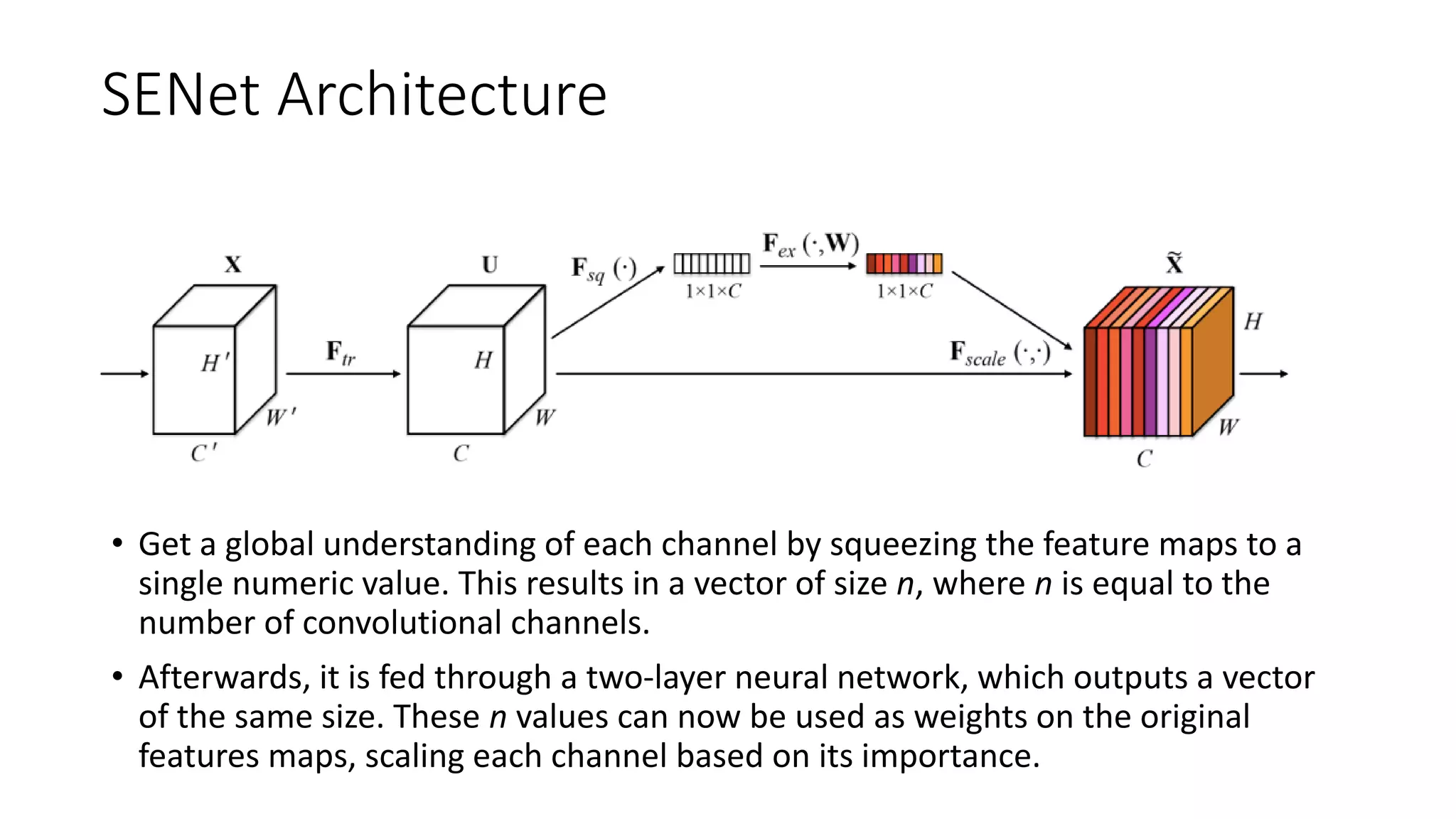
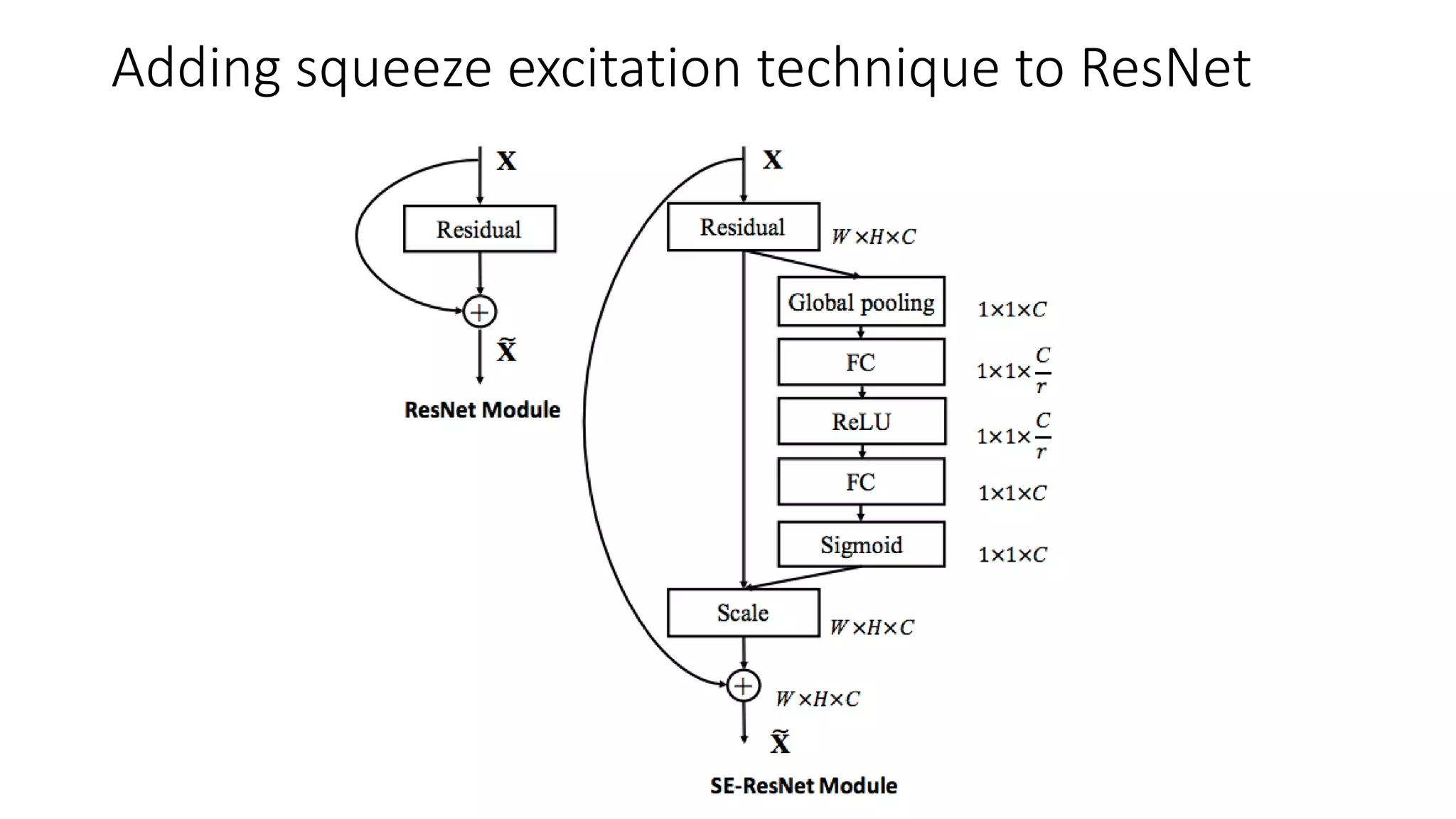
The document discusses the significance of studying popular architectures in deep learning, focusing on approaches such as ResNet and Inception layers for improving model performance. It highlights the advantages of deeper networks, the implementation of skip connections in ResNet, and introduces the SENet architecture, which enhances representational power by adjusting the weighting of convolutional layer channels. Overall, using these innovations can lead to more effective deep learning models and better transfer learning applications.