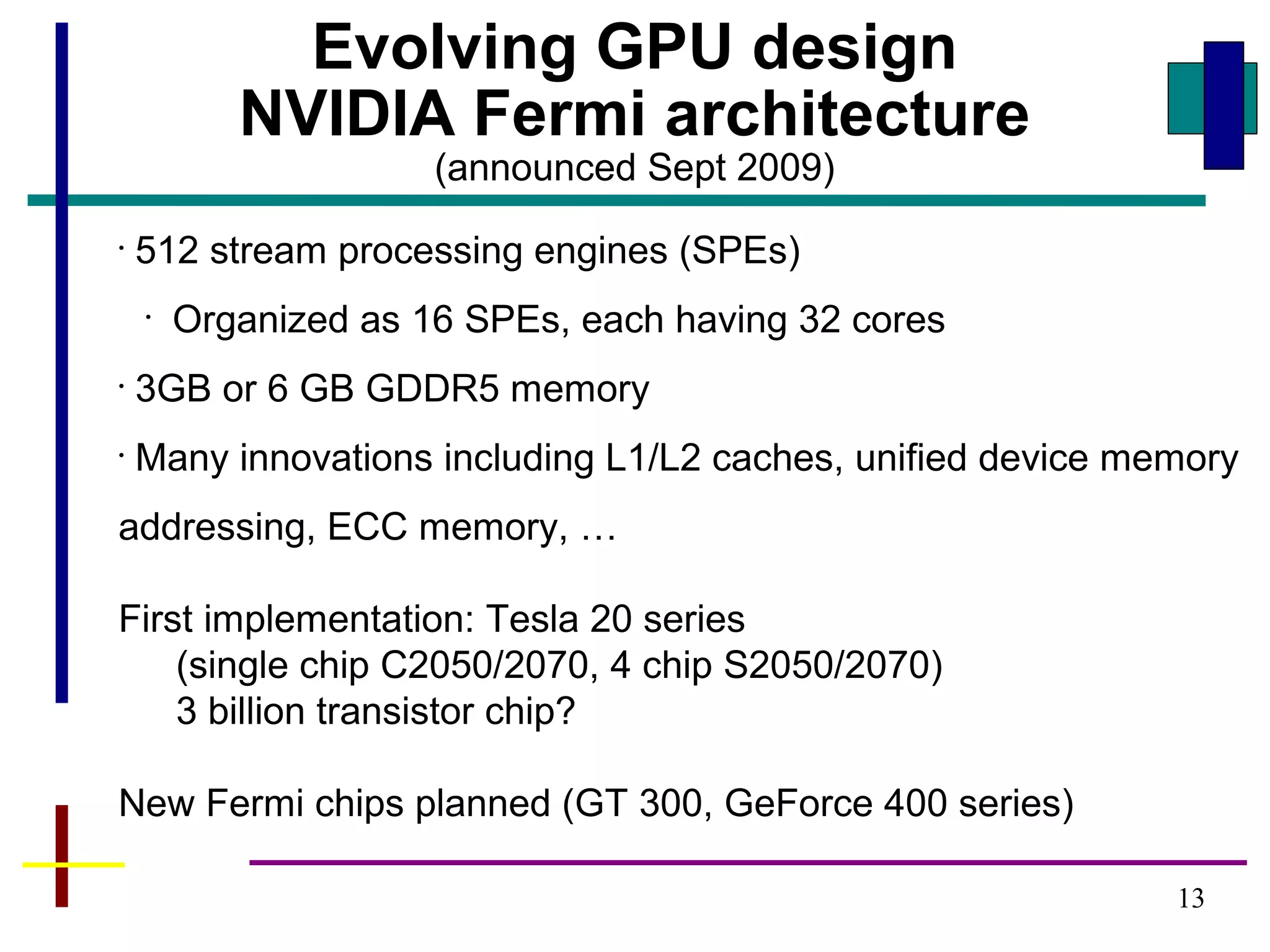
Downloaded 66 times








![19
2. Allocating memory space in
“host” (CPU) for data
Use regular C malloc routines:
int *a, *b, *c;
…
a = (int*)malloc(size);
b = (int*)malloc(size);
c = (int*)malloc(size);
or statically declare variables:
#define N 256
…
int a[N], b[N], c[N];](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-19-320.jpg)


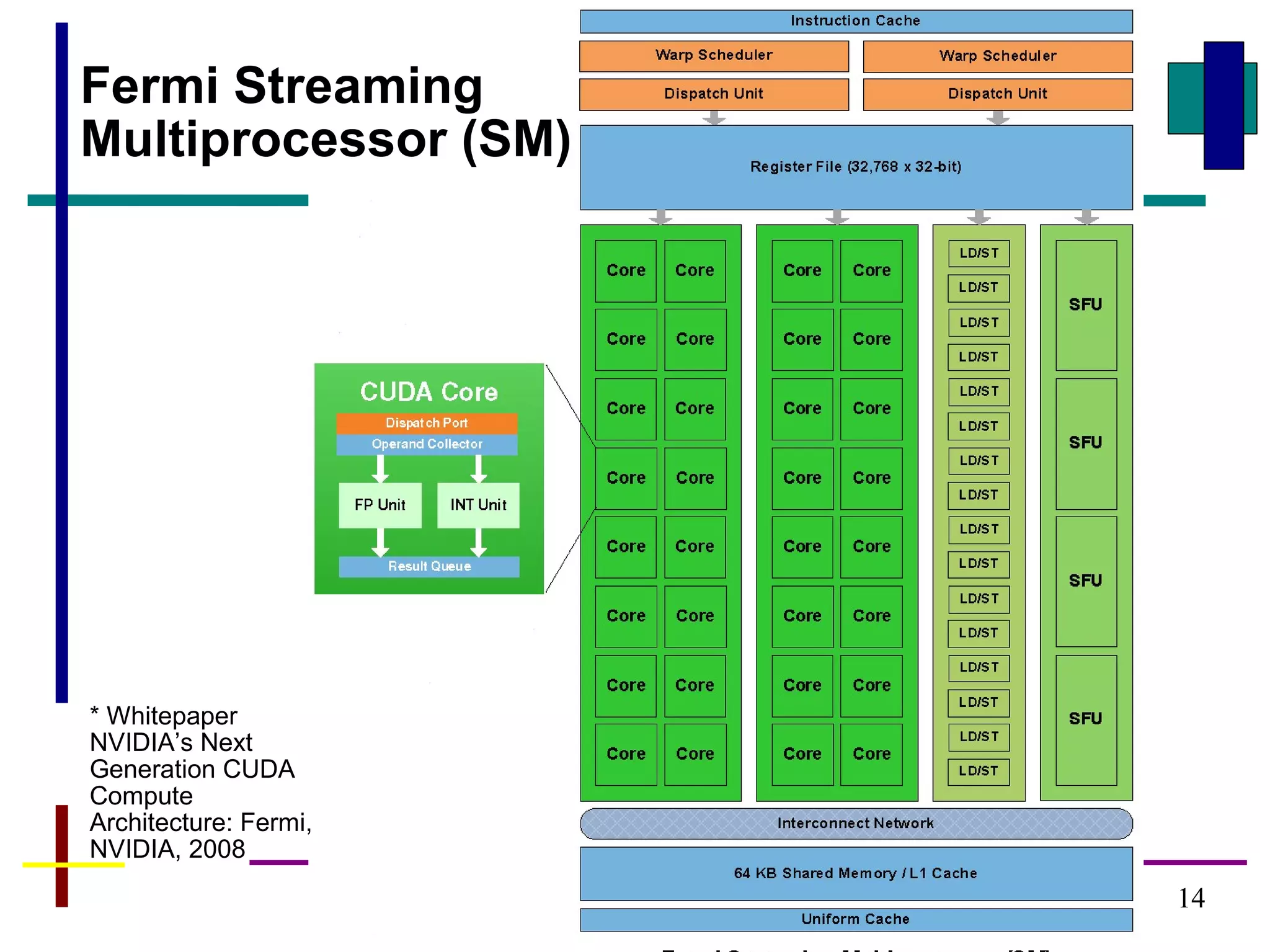
![22
A kernel defined using CUDA specifier __global__
Example – Adding to vectors A and B
#define N 256
__global__ void vecAdd(int *A, int *B, int *C) { // Kernel definition
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
// allocate device memory &
// copy data to device
// device mem. ptrs devA,devB,devC
vecAdd<<<1, N>>>(devA,devB,devC);
…
}
Loosely derived from CUDA C programming guide, v 3.2 , 2010, NVIDIA
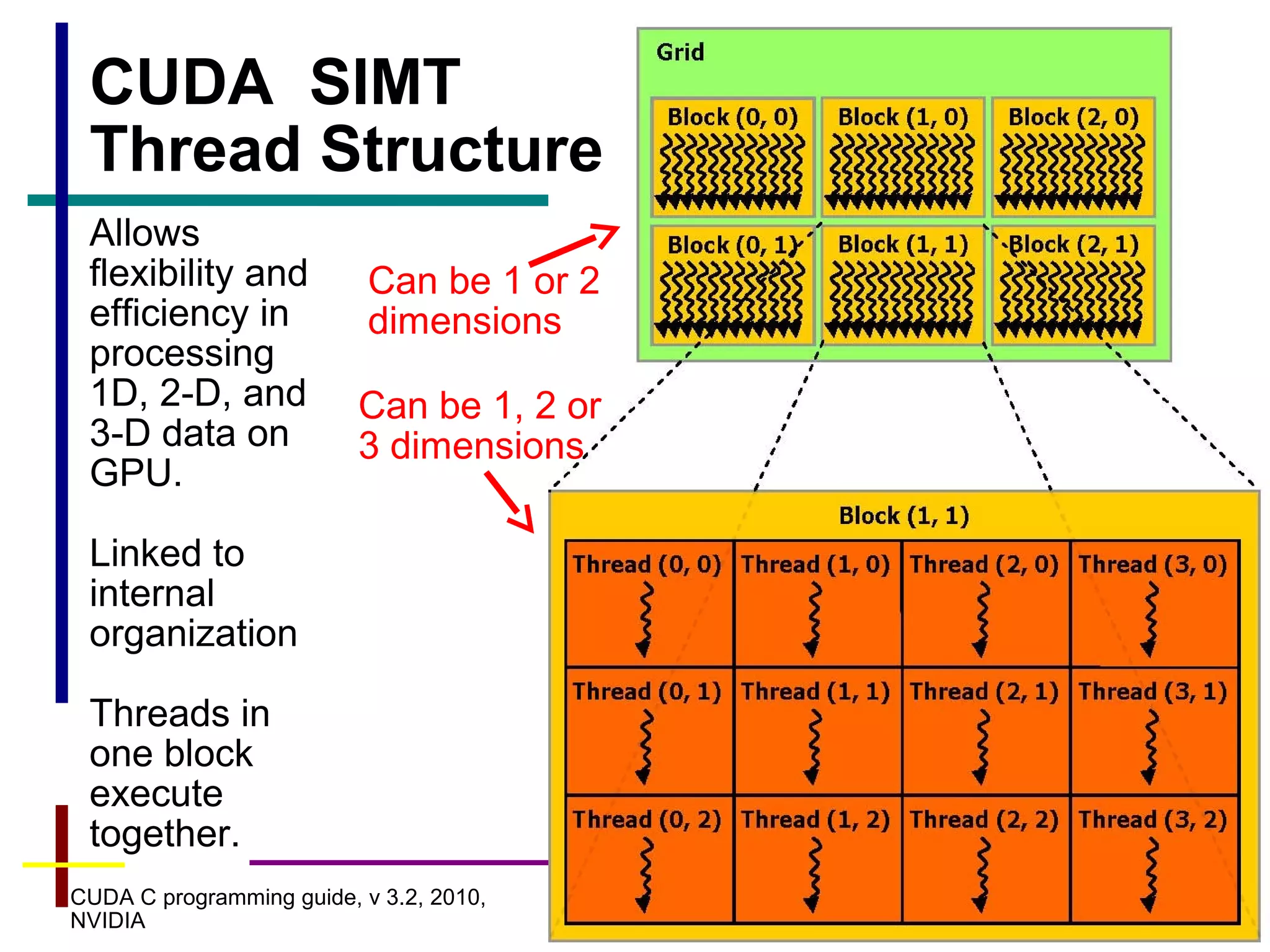
Declaring a Kernel Routine
Each of the N threads performs one pair-
wise addition:
Thread 0: devC[0] = devA[0] + devB[0];
Thread 1: devC[1] = devA[1] + devB[1];
Thread N-1: devC[N-1] = devA[N-1]+devB[N-1];
Grid of one block, block has N threads
CUDA structure that provides thread ID in block](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-22-320.jpg)


![26
Complete
CUDA
program
Adding two
vectors, A and B
N elements in A and
B, and N threads
(without code to load
arrays with data)
#define N 256
__global__ void vecAdd(int *A, int *B, int *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main (int argc, char **argv ) {
int size = N *sizeof( int);
int a[N], b[N], c[N], *devA, *devB, *devC;
cudaMalloc( (void**)&devA, size) );
cudaMalloc( (void**)&devB, size );
cudaMalloc( (void**)&devC, size );
a = (int*)malloc(size); b = (int*)malloc(size);c =
(int*)malloc(size);
cudaMemcpy( devA, a, size, cudaMemcpyHostToDevice);
cudaMemcpy( dev_B, b size, cudaMemcpyHostToDevice);
vecAdd<<<1, N>>>(devA, devB, devC);
cudaMemcpy( &c, devC size, cudaMemcpyDeviceToHost);
cudaFree( dev_a);
cudaFree( dev_b);
cudaFree( dev_c);
free( a ); free( b ); free( c );
return (0);
}
Derived from Jason Sanders,
"Introduction to CUDA C" GPU
technology conference, Sept. 20,](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-26-320.jpg)




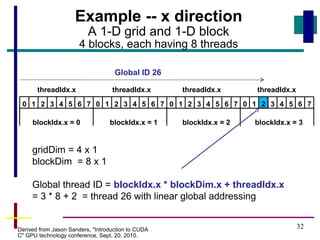
![33
#define N 2048 // size of vectors
#define T 256 // number of threads per block
__global__ void vecAdd(int *A, int *B, int *C) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
}
int main (int argc, char **argv ) {
…
vecAdd<<<N/T, T>>>(devA, devB, devC); // assumes N/T is an integer
…
return (0);
}
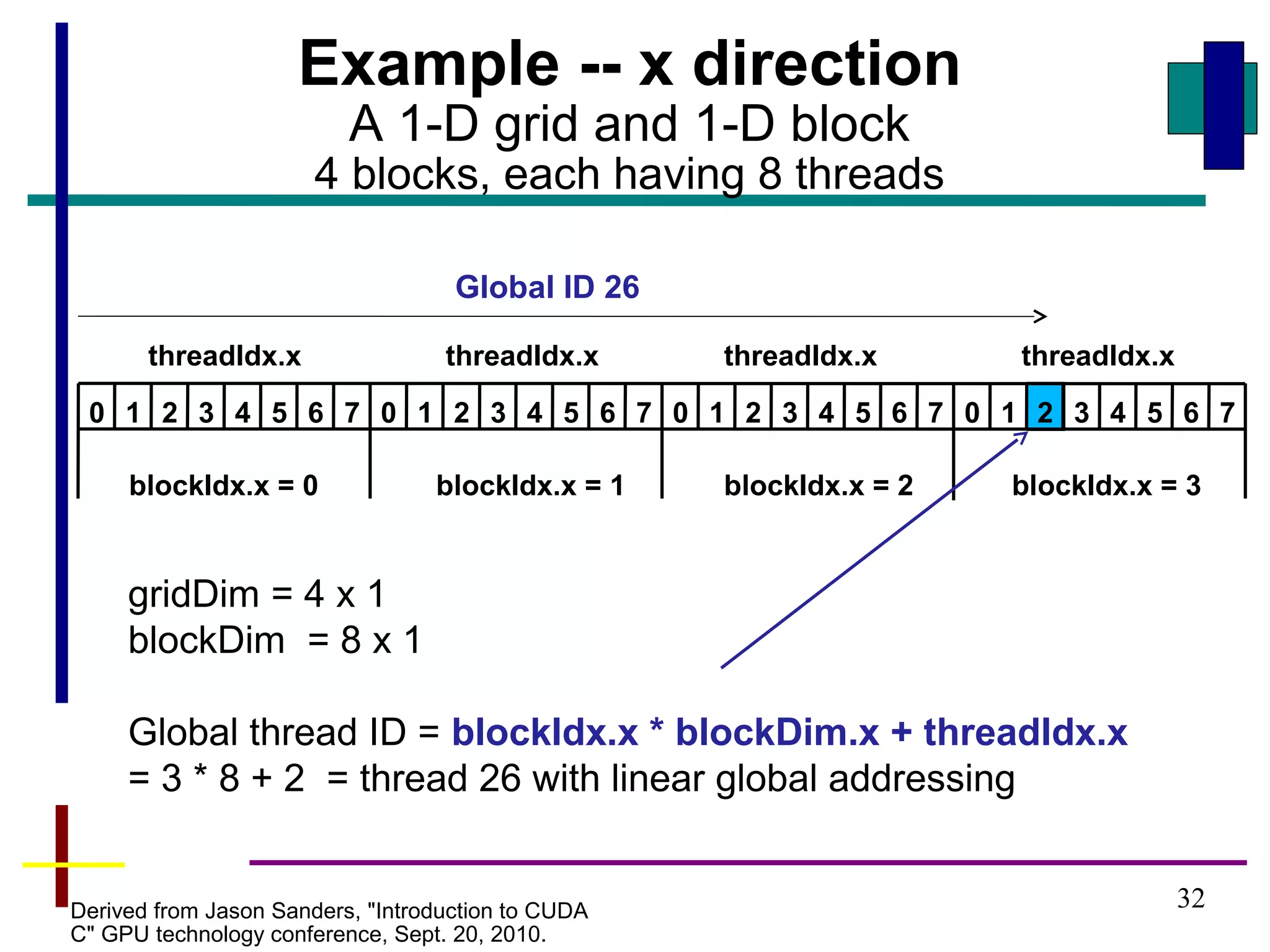
Code example with a 1-D grid
and 1-D blocks
Number of blocks to map each vector across grid,
one element of each vector per thread](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-33-320.jpg)
![34
#define N 2048 // size of vectors
#define T 240 // number of threads per block
__global__ void vecAdd(int *A, int *B, int *C) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i]; // allows for more threads than vector elements
// some unused
}
int main (int argc, char **argv ) {
int blocks = (N + T - 1) / T; // efficient way of rounding to next integer
…
vecAdd<<<blocks, T>>>(devA, devB, devC);
…
return (0);
}
If T/N not necessarily an integer:](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-34-320.jpg)
![35
Example using 1-D grid and 2-D blocks
Adding two arrays
#define N 2048 // size of arrays
__global__void addMatrix (int *a, int *b, int *c) {
int i = blockIdx.x*blockDim.x+threadIdx.x;
int j =blockIdx.y*blockDim.y+threadIdx.y;
int index = i + j * N;
if ( i < N && j < N) c[index]= a[index] + b[index];
}
Void main() {
...
dim3 dimBlock (16,16);
dim3 dimGrid (N/dimBlock.x, N/dimBlock.y);
addMatrix<<<dimGrid, dimBlock>>>(devA, devB, devC);
…
}](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/85/Cuda-intro-35-320.jpg)















![19
2. Allocating memory space in
“host” (CPU) for data
Use regular C malloc routines:
int *a, *b, *c;
…
a = (int*)malloc(size);
b = (int*)malloc(size);
c = (int*)malloc(size);
or statically declare variables:
#define N 256
…
int a[N], b[N], c[N];](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-19-2048.jpg)

![22
A kernel defined using CUDA specifier __global__
Example – Adding to vectors A and B
#define N 256
__global__ void vecAdd(int *A, int *B, int *C) { // Kernel definition
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
// allocate device memory &
// copy data to device
// device mem. ptrs devA,devB,devC
vecAdd<<<1, N>>>(devA,devB,devC);
…
}
Loosely derived from CUDA C programming guide, v 3.2 , 2010, NVIDIA
Declaring a Kernel Routine
Each of the N threads performs one pair-
wise addition:
Thread 0: devC[0] = devA[0] + devB[0];
Thread 1: devC[1] = devA[1] + devB[1];
Thread N-1: devC[N-1] = devA[N-1]+devB[N-1];
Grid of one block, block has N threads
CUDA structure that provides thread ID in block](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-22-2048.jpg)
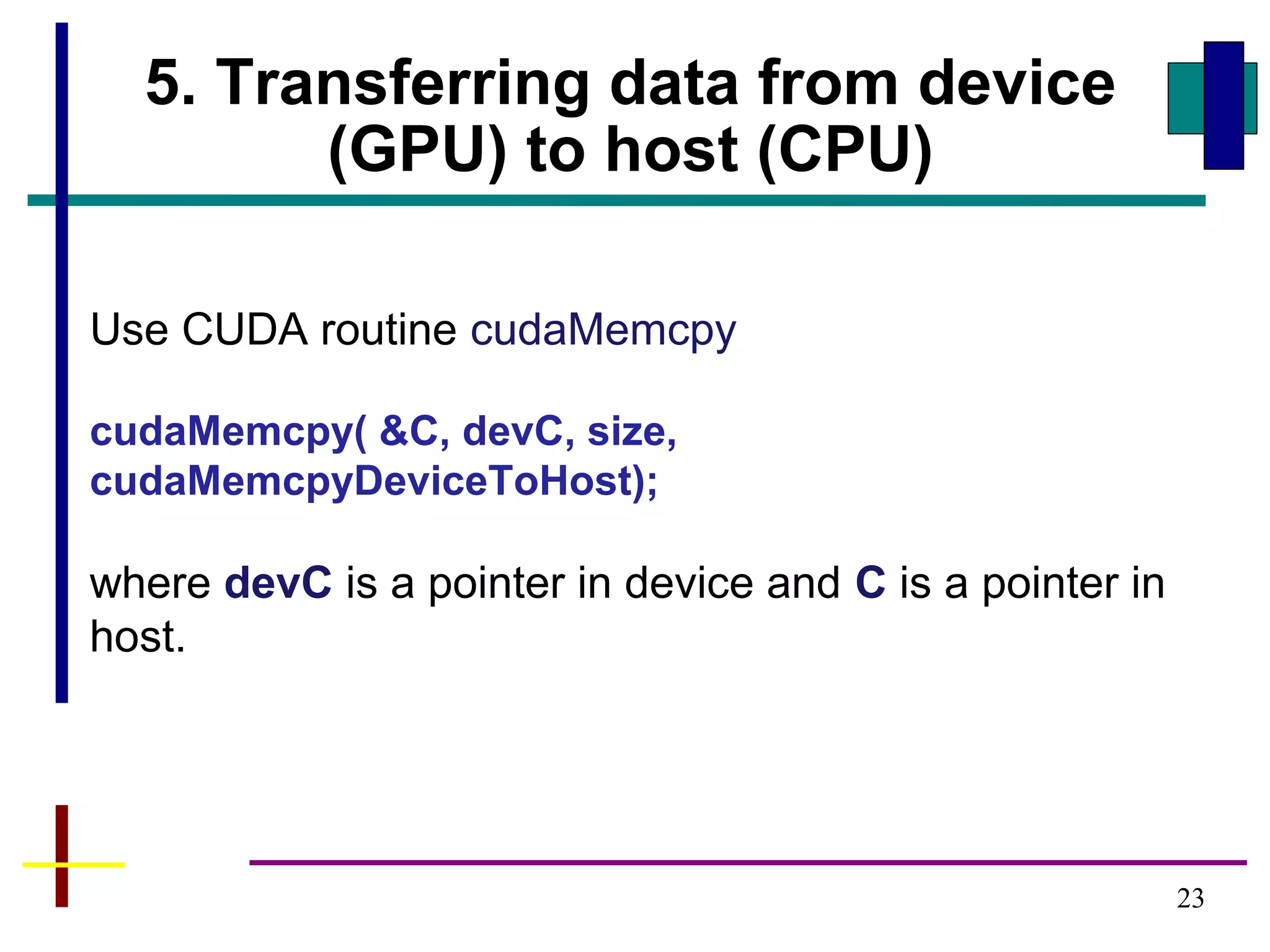


![26
Complete
CUDA
program
Adding two
vectors, A and B
N elements in A and
B, and N threads
(without code to load
arrays with data)
#define N 256
__global__ void vecAdd(int *A, int *B, int *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main (int argc, char **argv ) {
int size = N *sizeof( int);
int a[N], b[N], c[N], *devA, *devB, *devC;
cudaMalloc( (void**)&devA, size) );
cudaMalloc( (void**)&devB, size );
cudaMalloc( (void**)&devC, size );
a = (int*)malloc(size); b = (int*)malloc(size);c =
(int*)malloc(size);
cudaMemcpy( devA, a, size, cudaMemcpyHostToDevice);
cudaMemcpy( dev_B, b size, cudaMemcpyHostToDevice);
vecAdd<<<1, N>>>(devA, devB, devC);
cudaMemcpy( &c, devC size, cudaMemcpyDeviceToHost);
cudaFree( dev_a);
cudaFree( dev_b);
cudaFree( dev_c);
free( a ); free( b ); free( c );
return (0);
}
Derived from Jason Sanders,
"Introduction to CUDA C" GPU
technology conference, Sept. 20,](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-26-2048.jpg)



![33
#define N 2048 // size of vectors
#define T 256 // number of threads per block
__global__ void vecAdd(int *A, int *B, int *C) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
}
int main (int argc, char **argv ) {
…
vecAdd<<<N/T, T>>>(devA, devB, devC); // assumes N/T is an integer
…
return (0);
}
Code example with a 1-D grid
and 1-D blocks
Number of blocks to map each vector across grid,
one element of each vector per thread](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-33-2048.jpg)
![34
#define N 2048 // size of vectors
#define T 240 // number of threads per block
__global__ void vecAdd(int *A, int *B, int *C) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i]; // allows for more threads than vector elements
// some unused
}
int main (int argc, char **argv ) {
int blocks = (N + T - 1) / T; // efficient way of rounding to next integer
…
vecAdd<<<blocks, T>>>(devA, devB, devC);
…
return (0);
}
If T/N not necessarily an integer:](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-34-2048.jpg)
![35
Example using 1-D grid and 2-D blocks
Adding two arrays
#define N 2048 // size of arrays
__global__void addMatrix (int *a, int *b, int *c) {
int i = blockIdx.x*blockDim.x+threadIdx.x;
int j =blockIdx.y*blockDim.y+threadIdx.y;
int index = i + j * N;
if ( i < N && j < N) c[index]= a[index] + b[index];
}
Void main() {
...
dim3 dimBlock (16,16);
dim3 dimGrid (N/dimBlock.x, N/dimBlock.y);
addMatrix<<<dimGrid, dimBlock>>>(devA, devB, devC);
…
}](https://image.slidesharecdn.com/cudaintro-130504054037-phpapp01/75/Cuda-intro-35-2048.jpg)







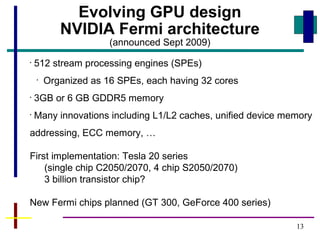
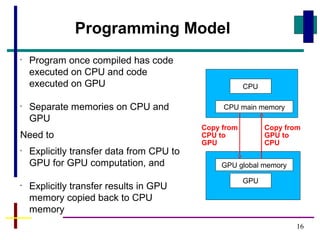
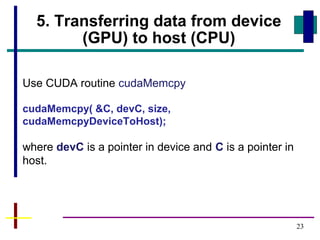
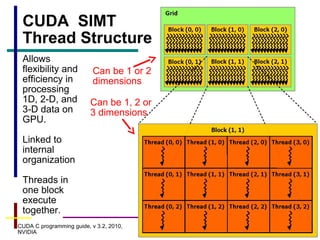
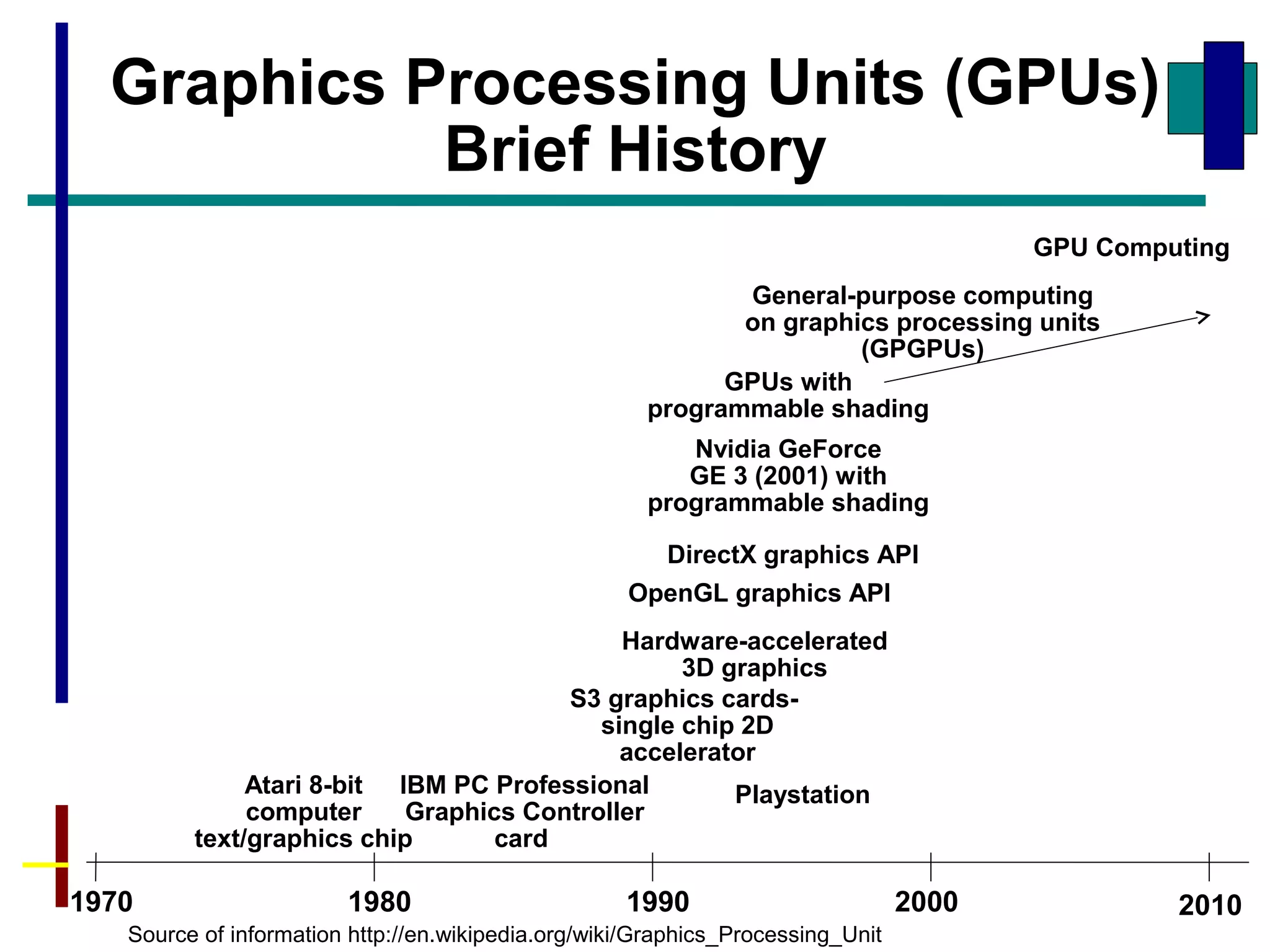
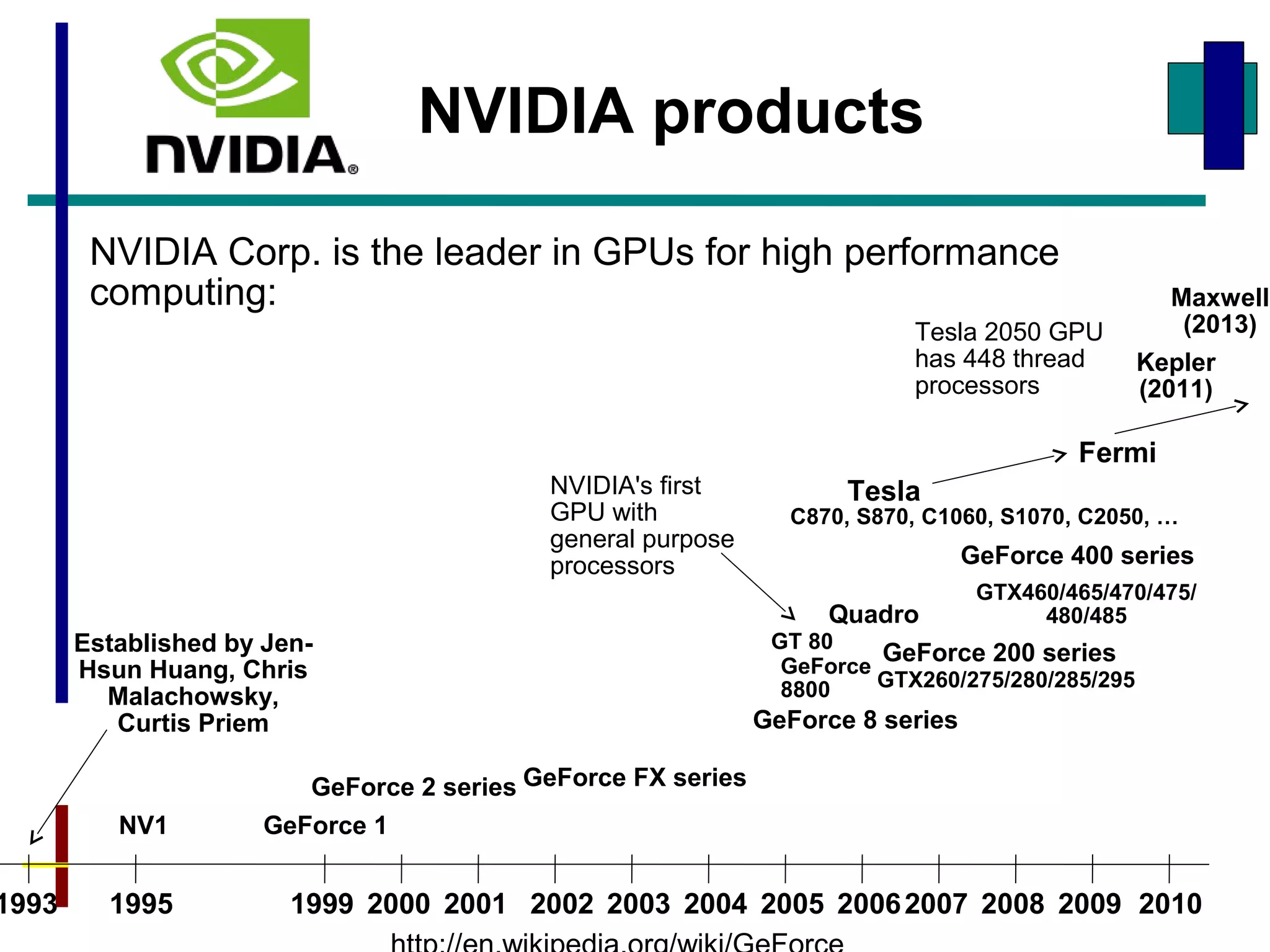
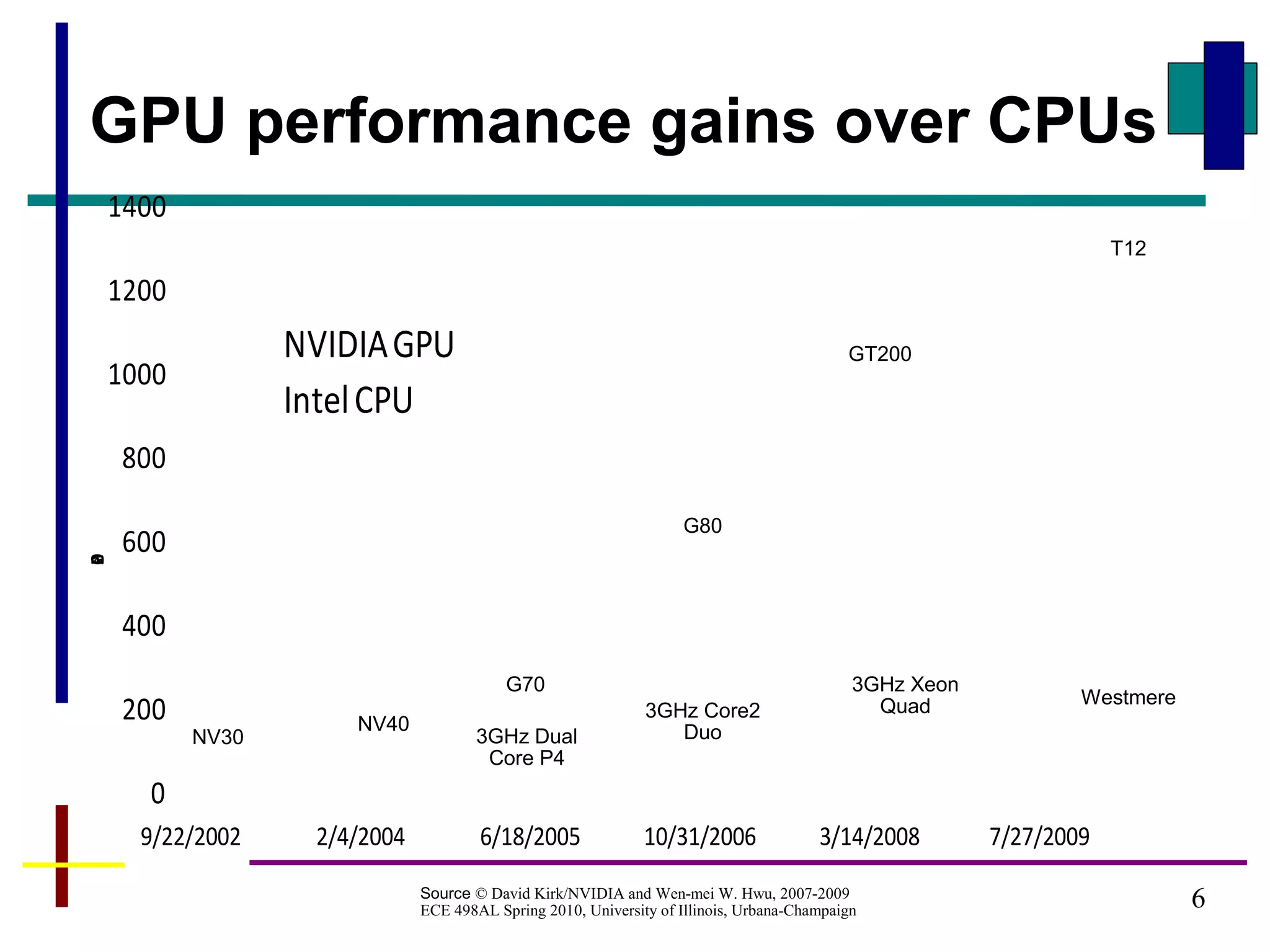
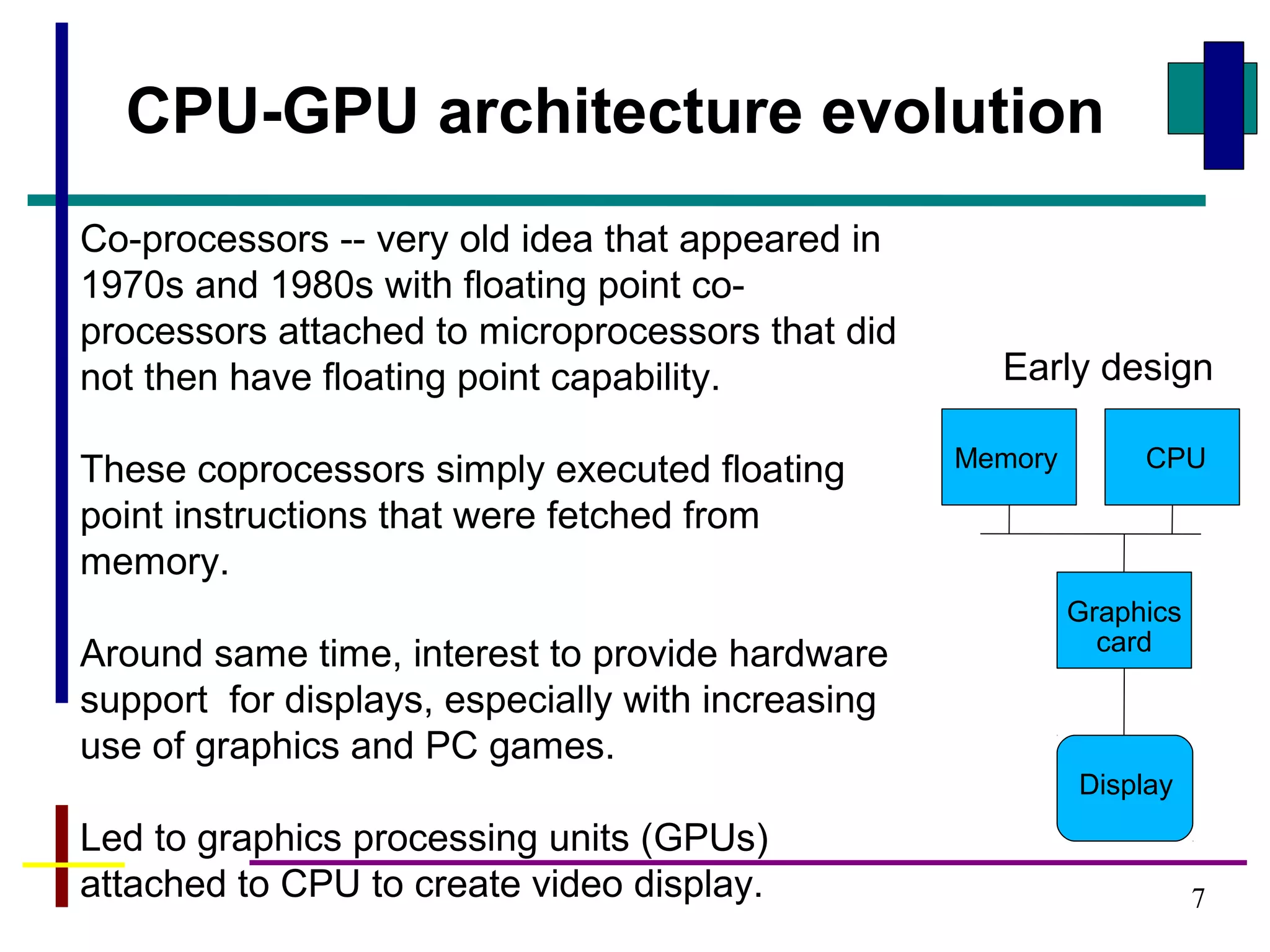
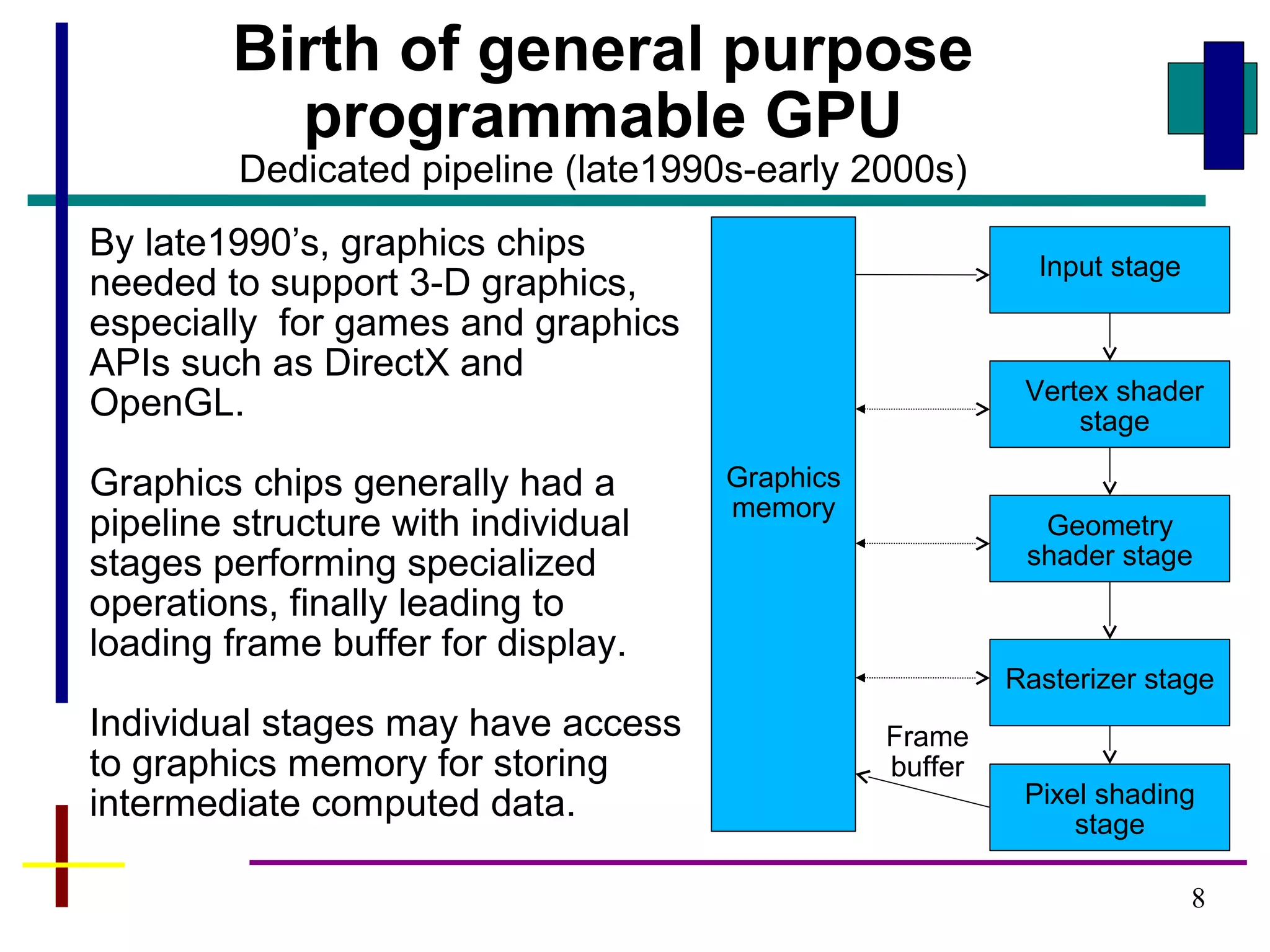
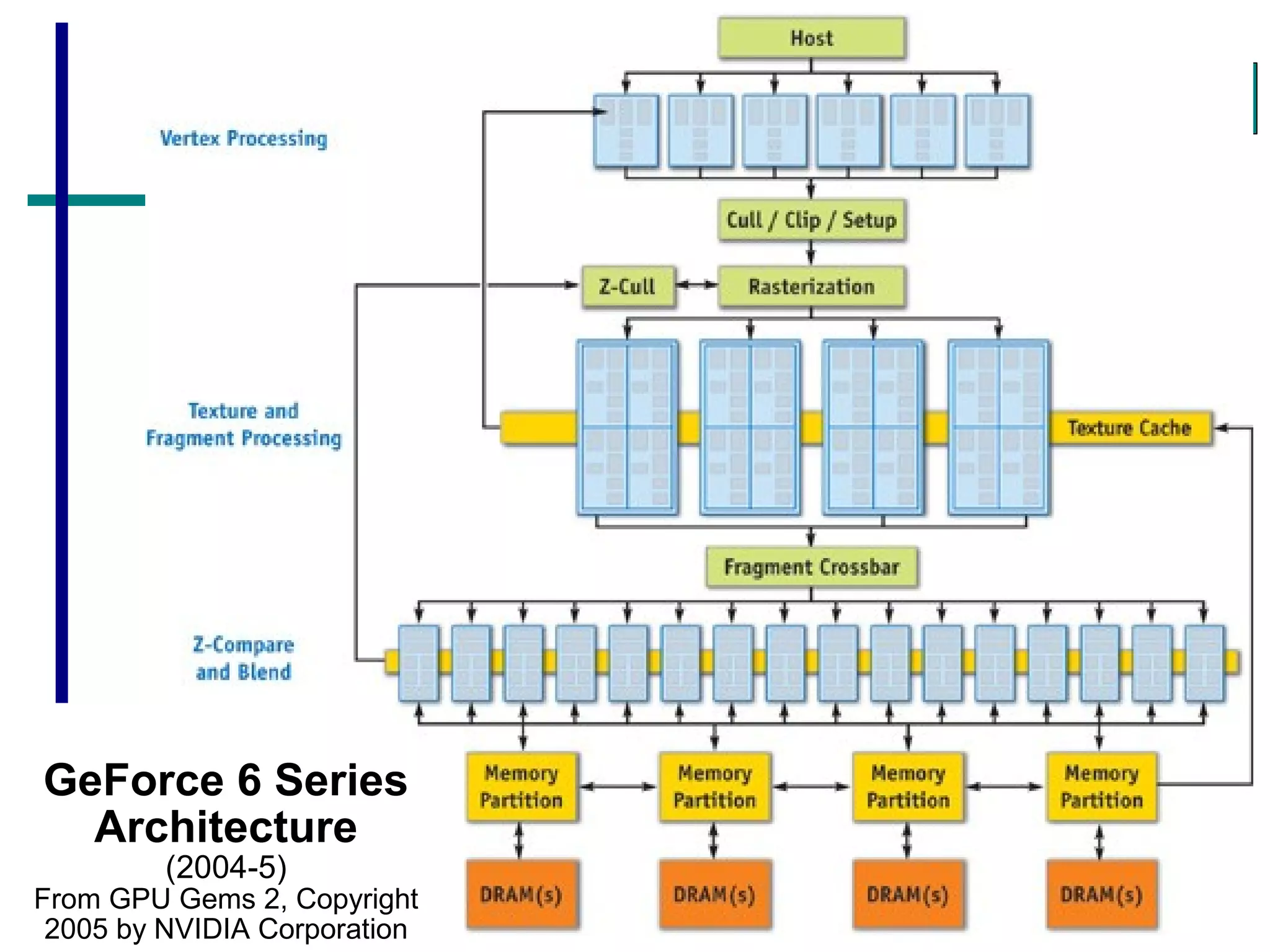
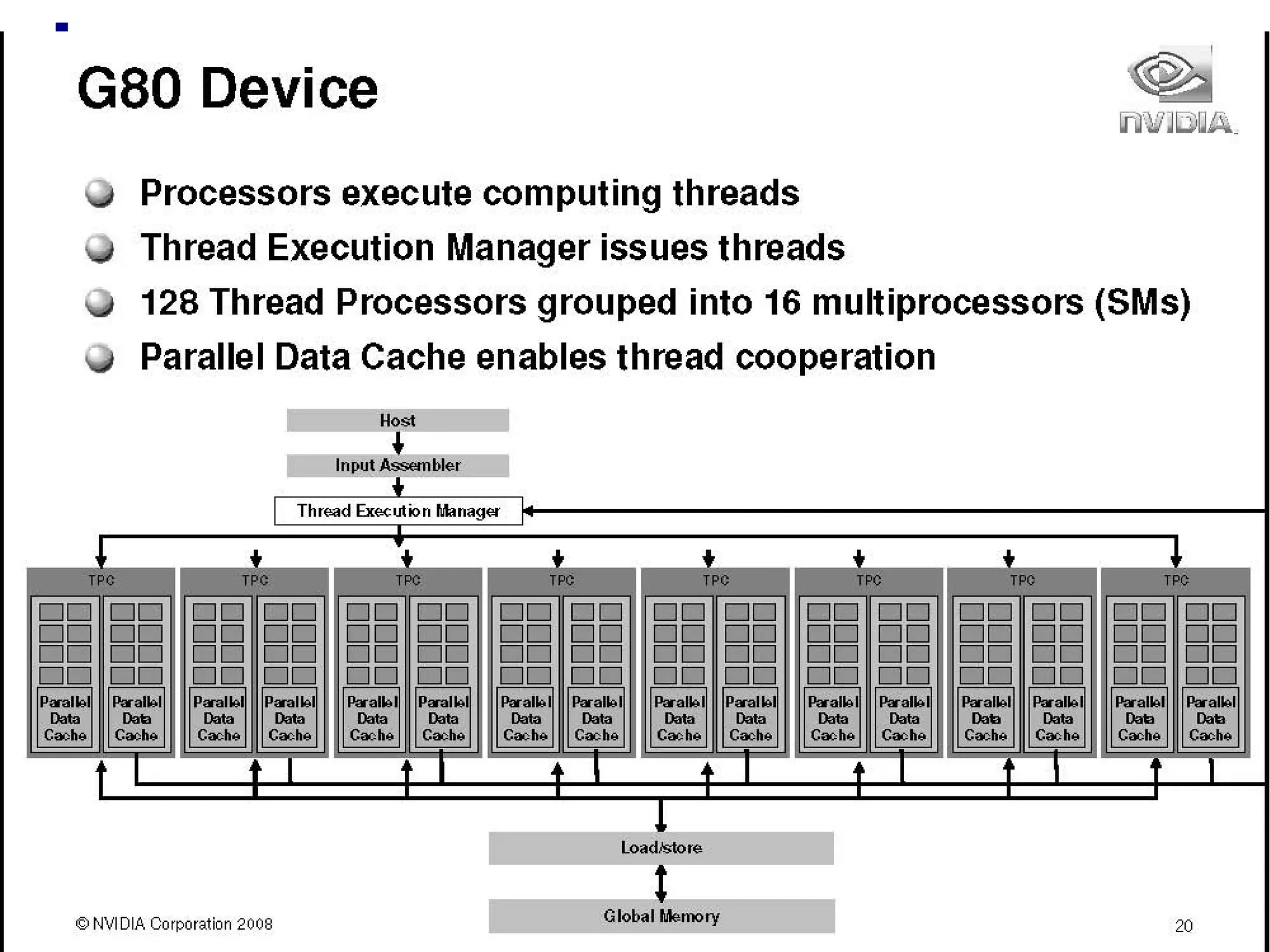
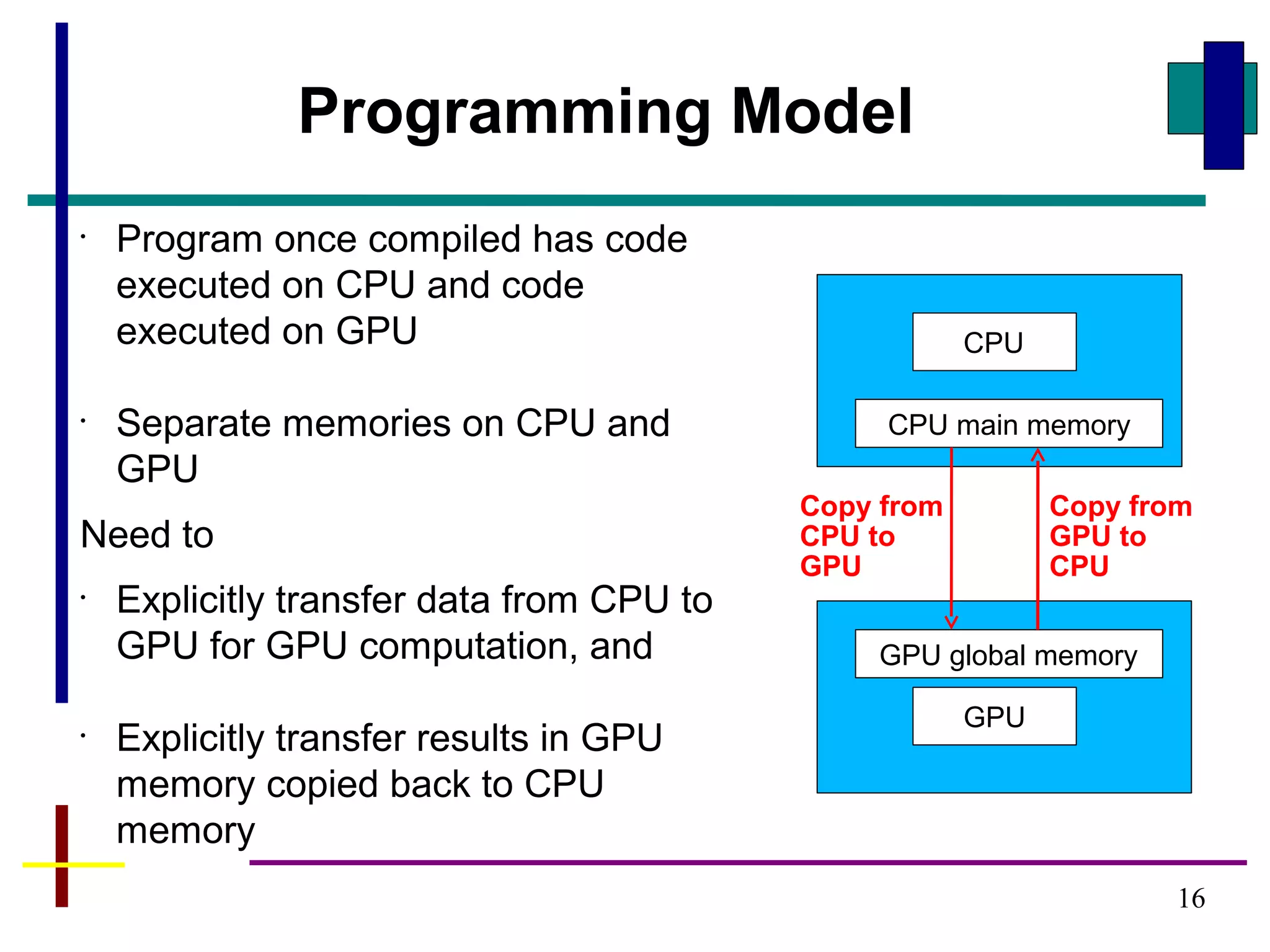
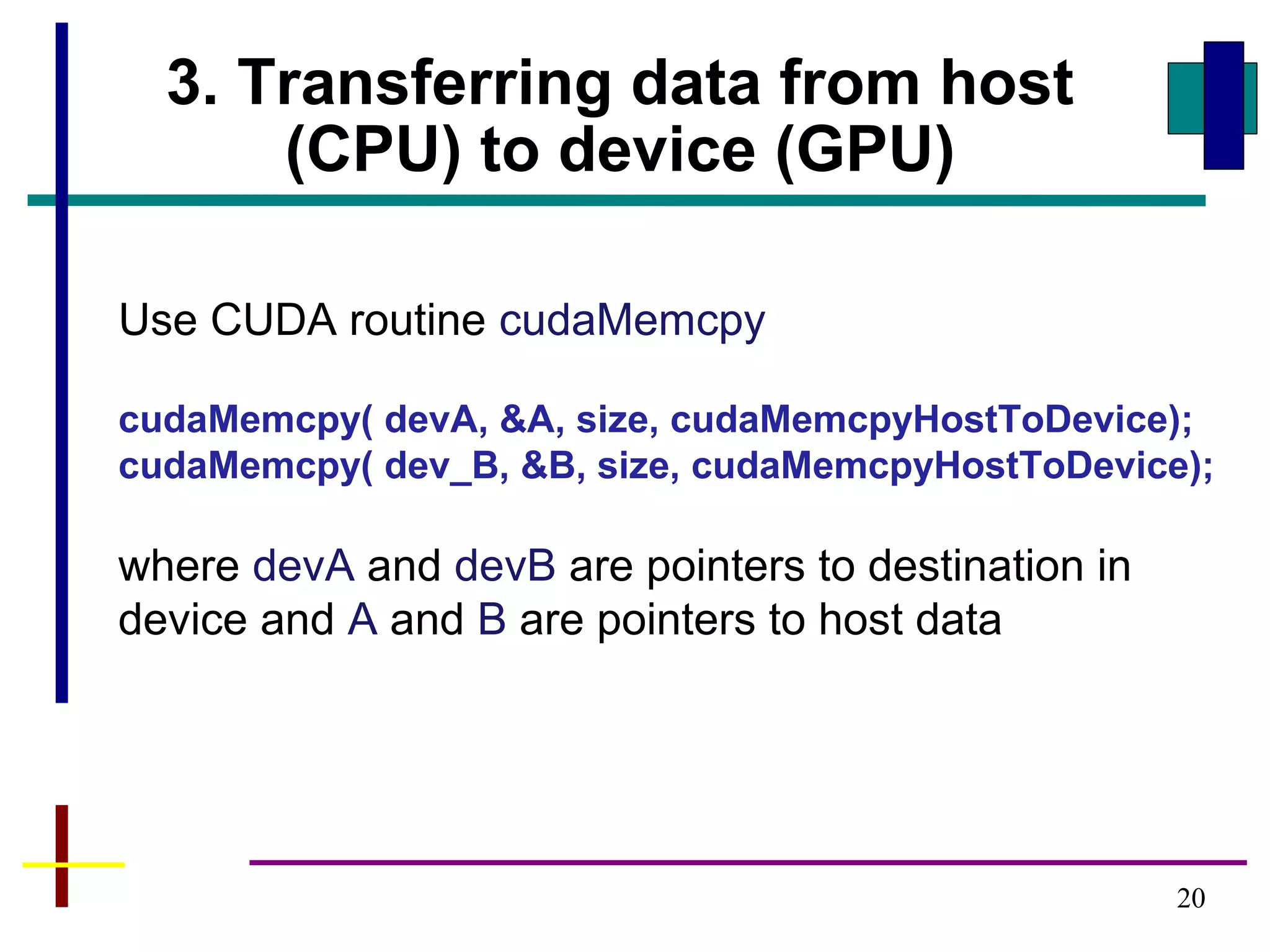
GPUs have evolved from graphics cards to platforms for general purpose high performance computing. CUDA is a programming model that allows GPUs to execute programs written in C for general computing tasks using a single-instruction multiple-thread model. A basic CUDA program involves allocating memory on the GPU, copying data to the GPU, launching a kernel function that executes in parallel across threads on the GPU, copying results back to the CPU, and freeing GPU memory.
































































































