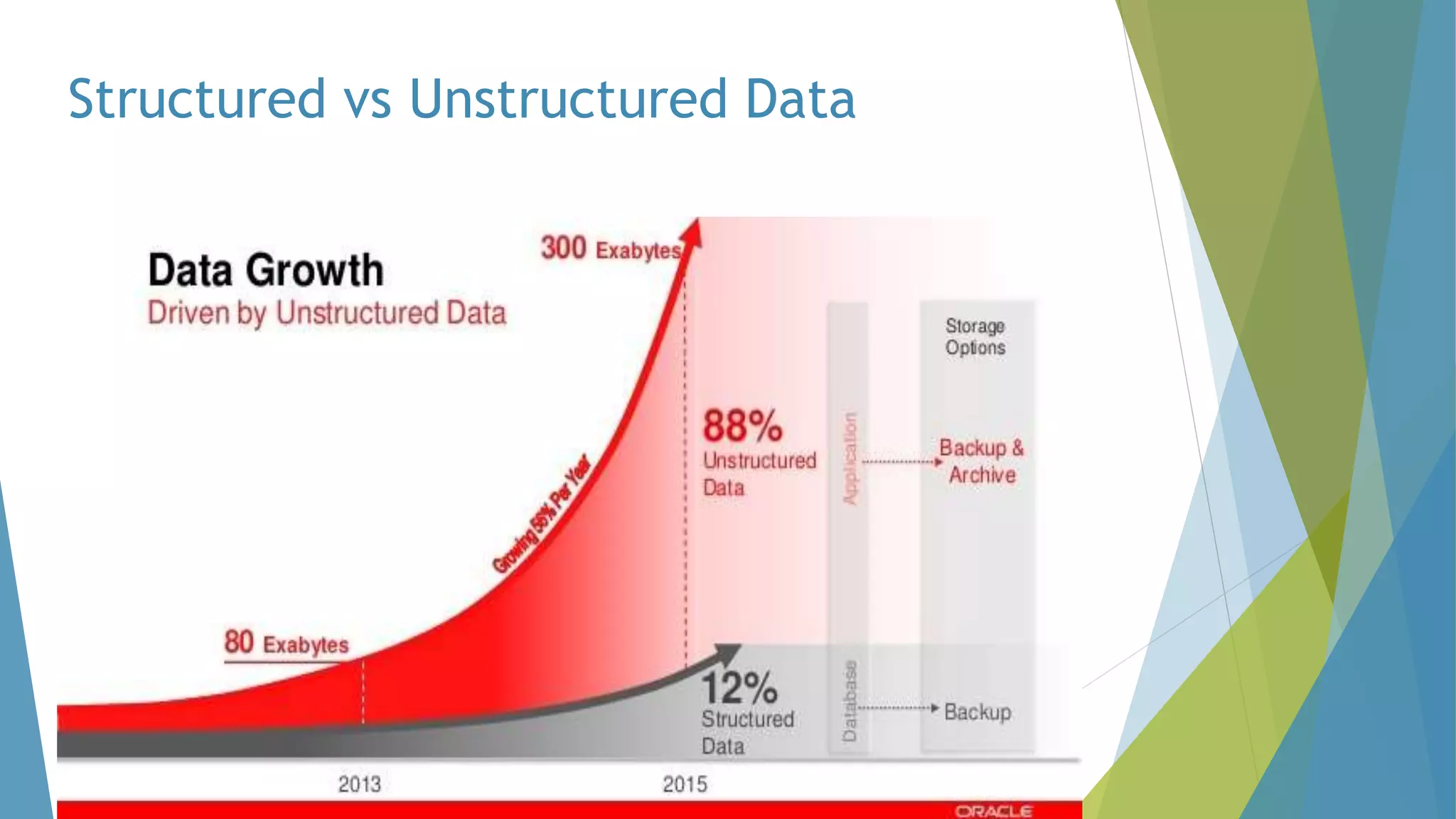
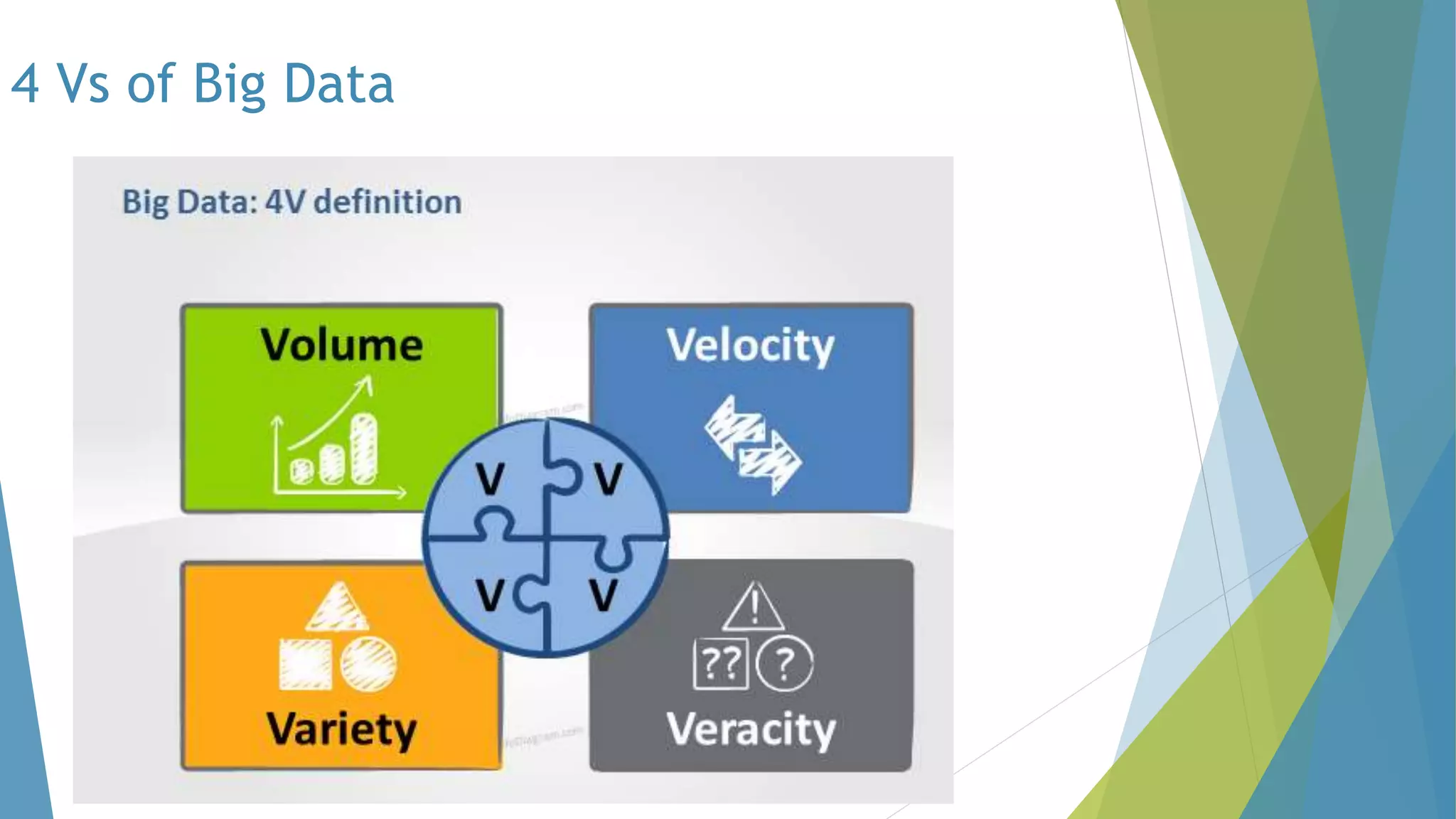
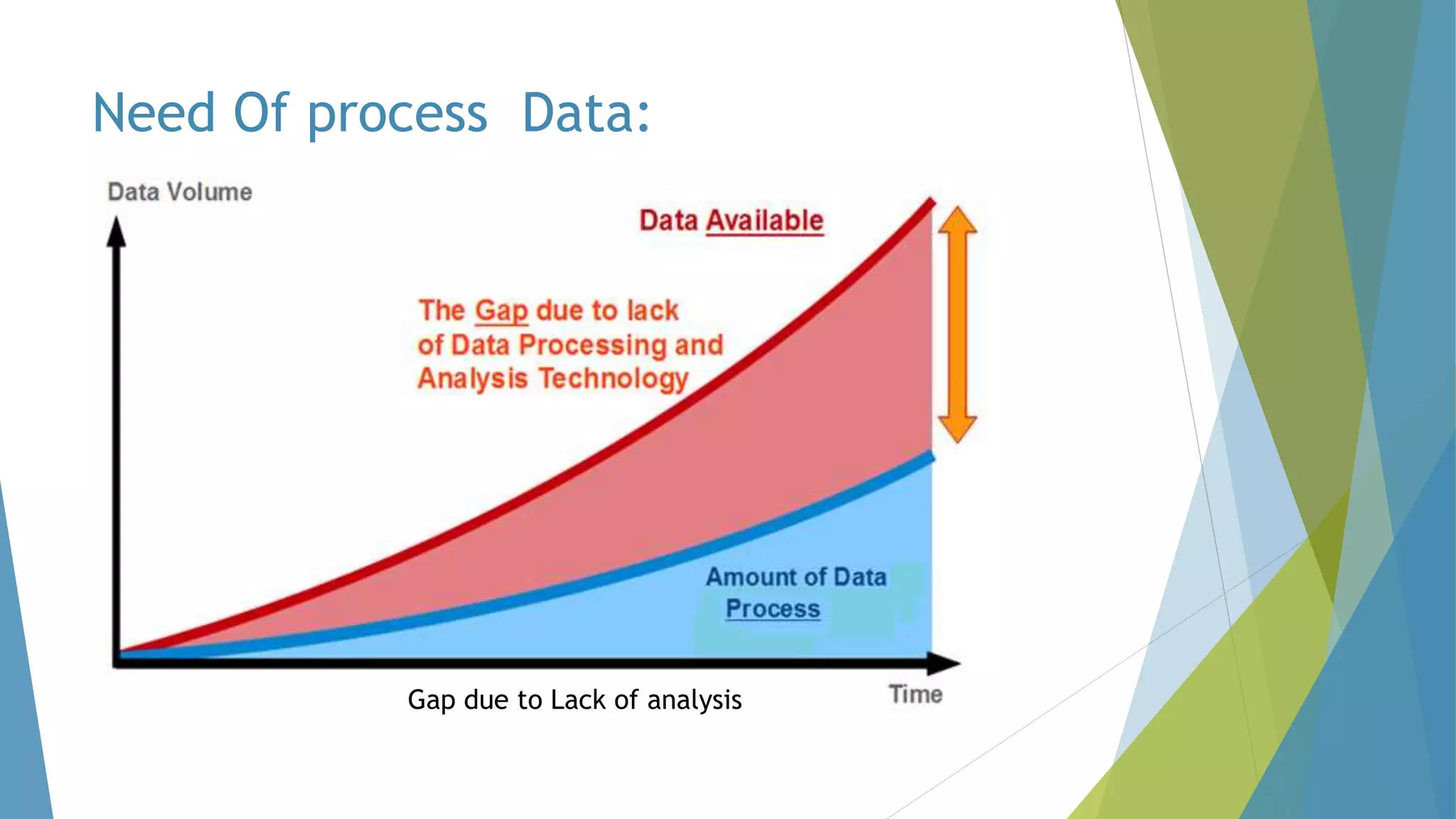
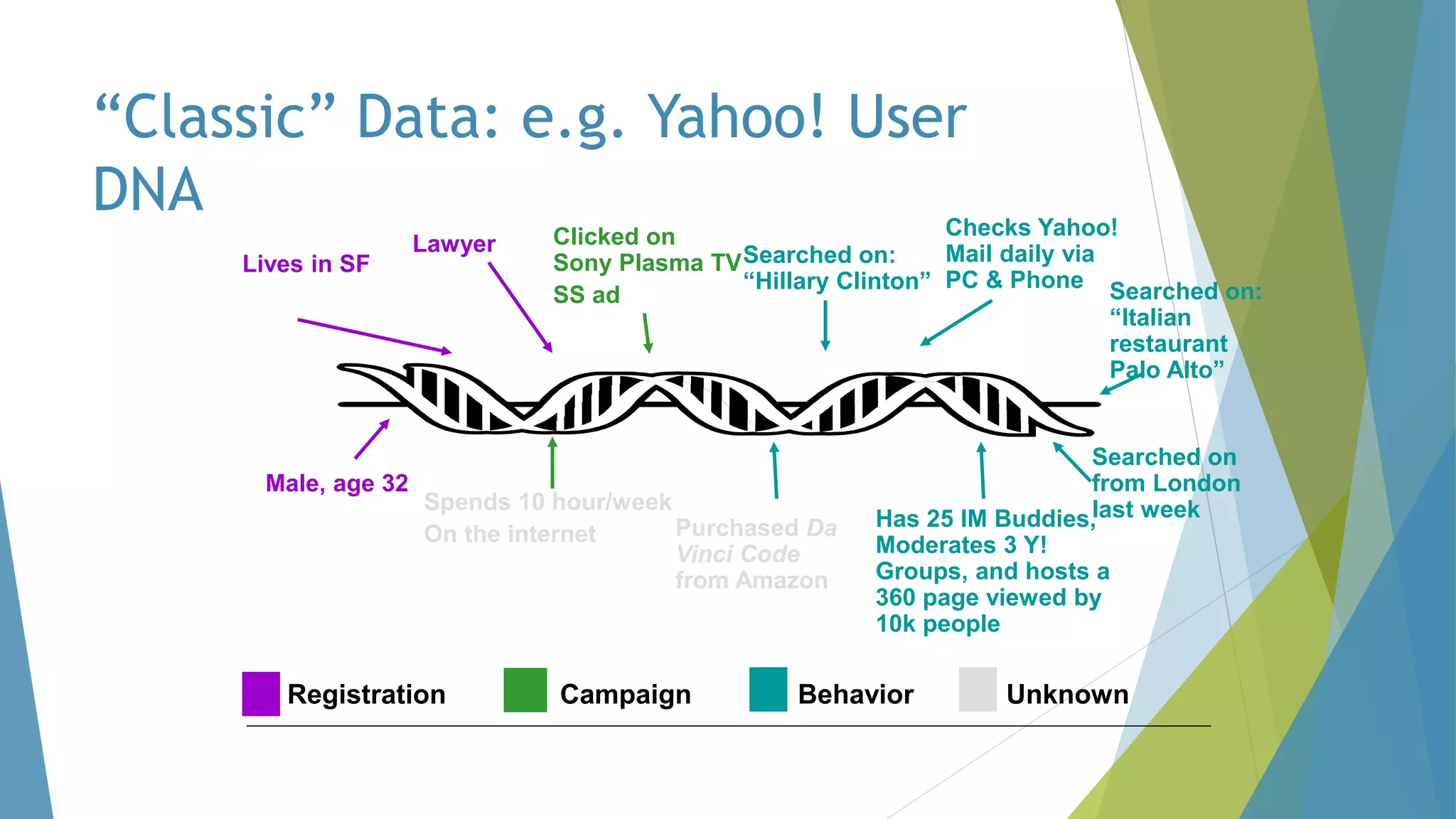
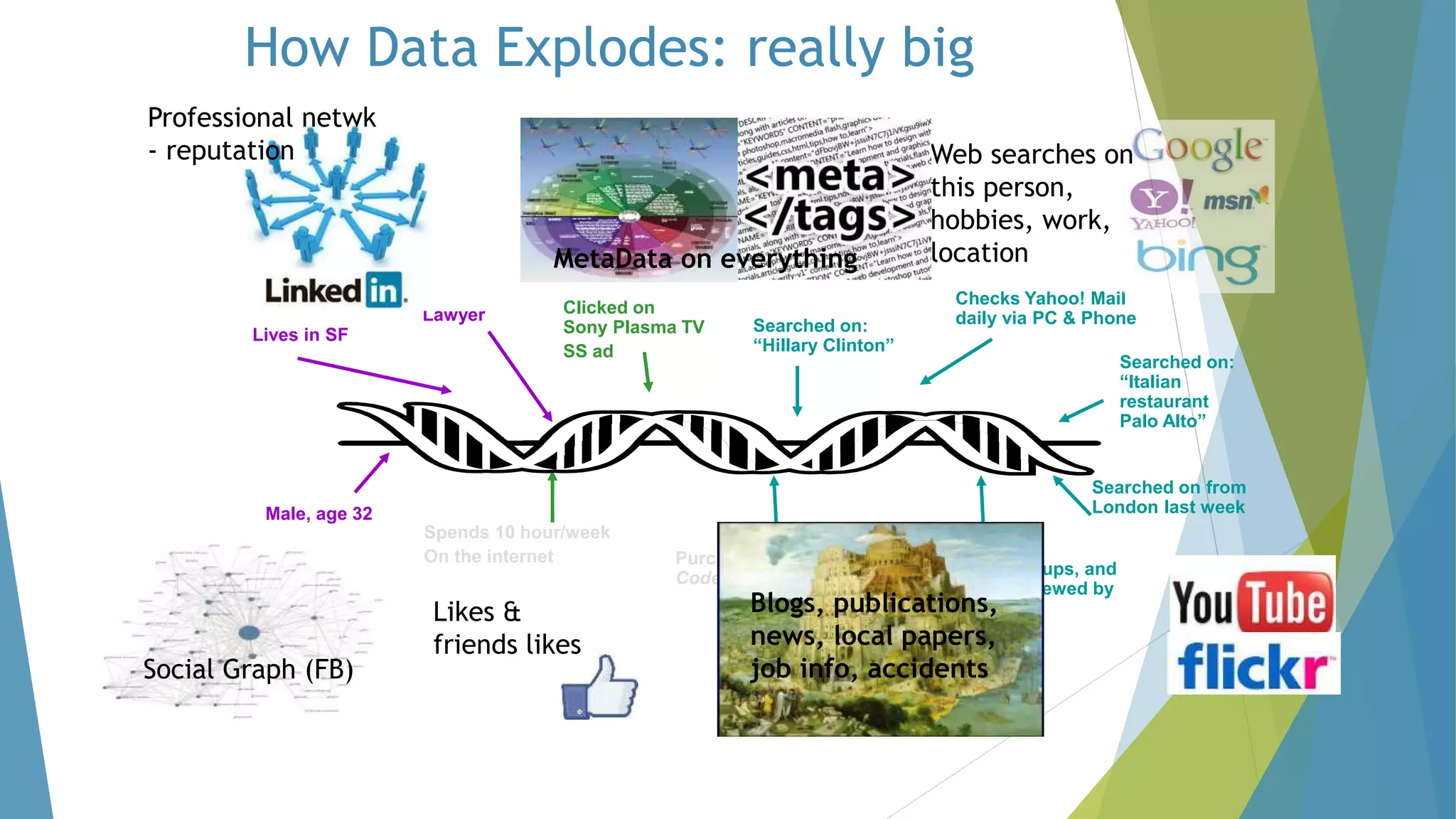
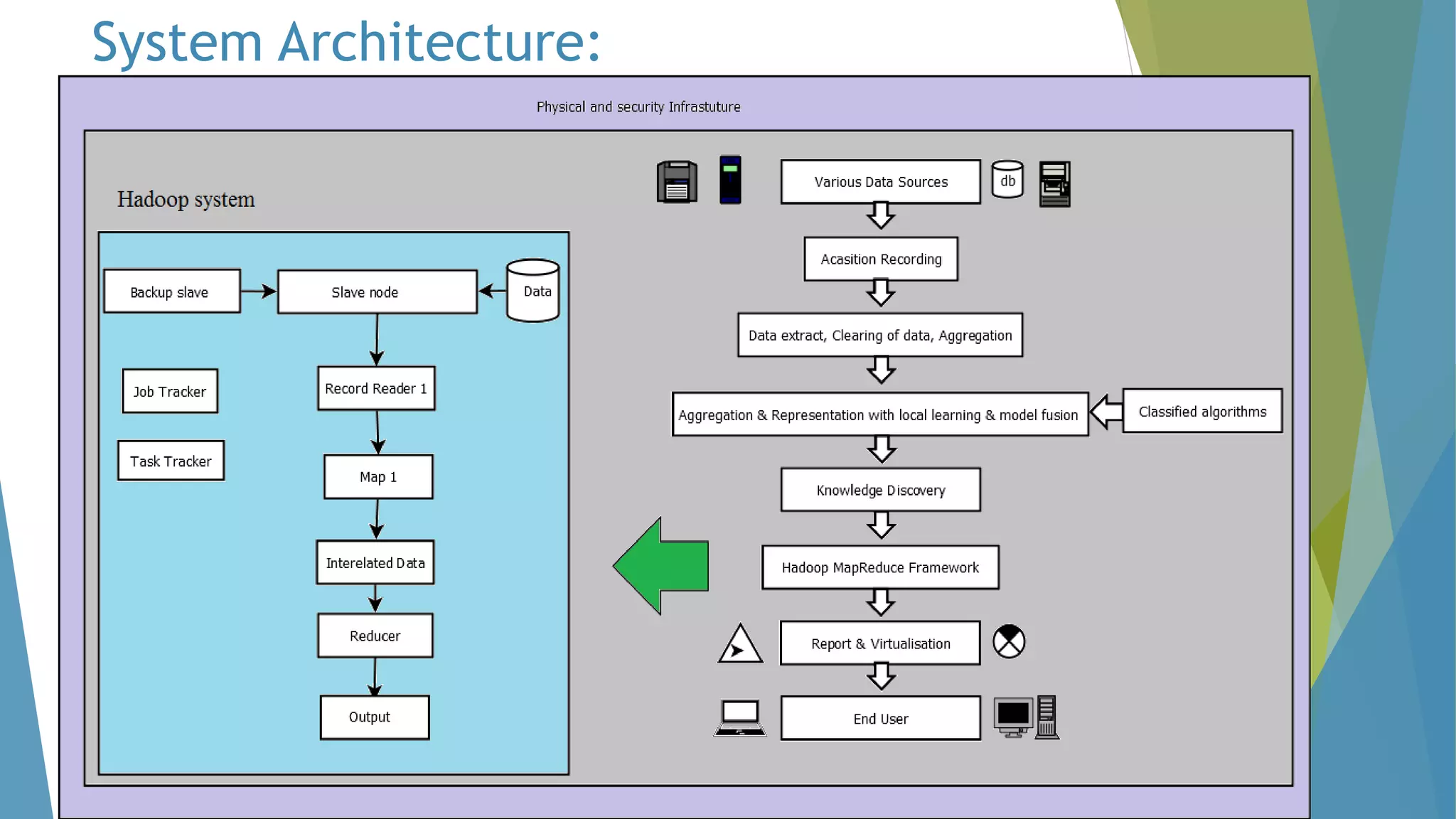
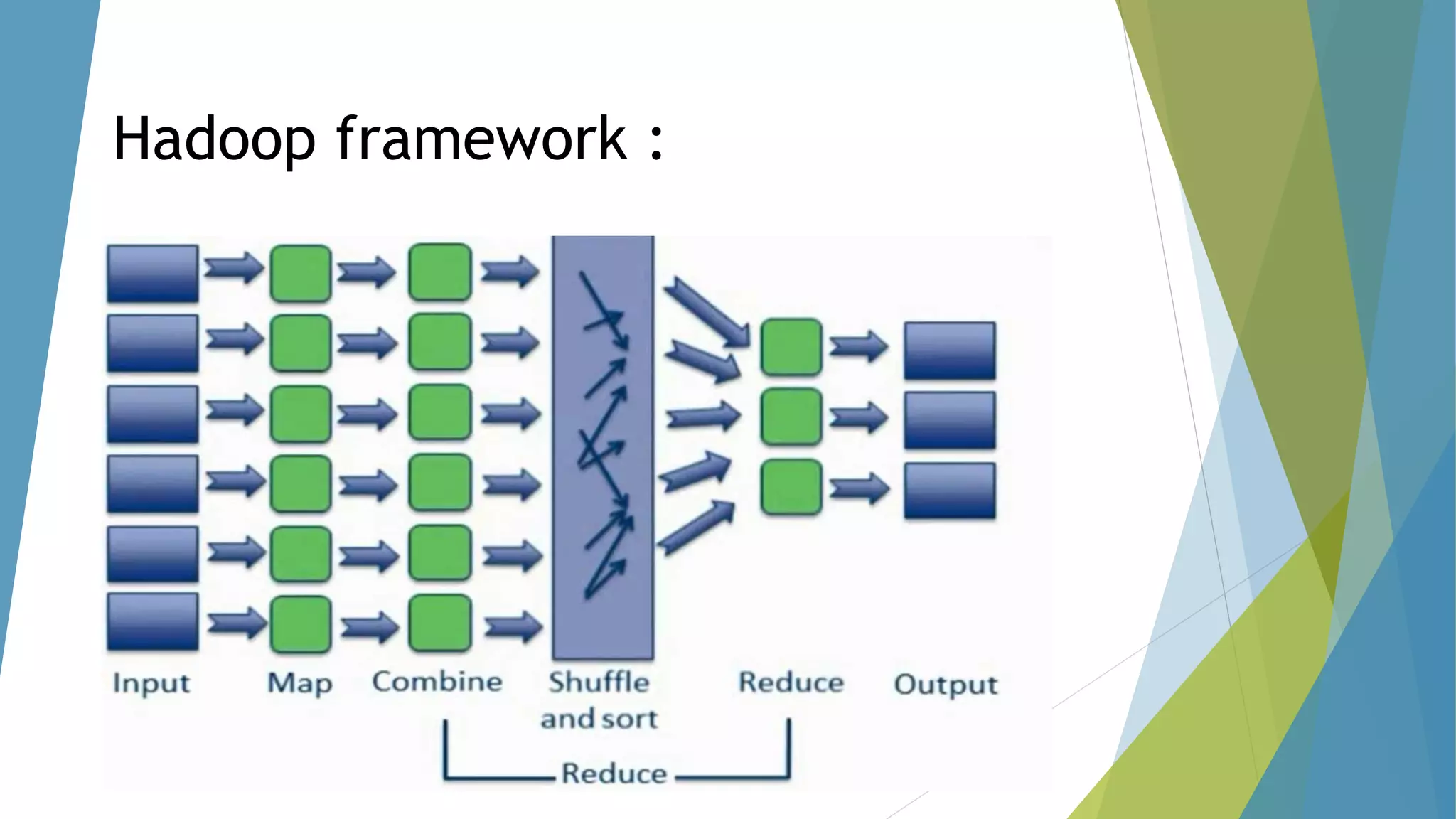
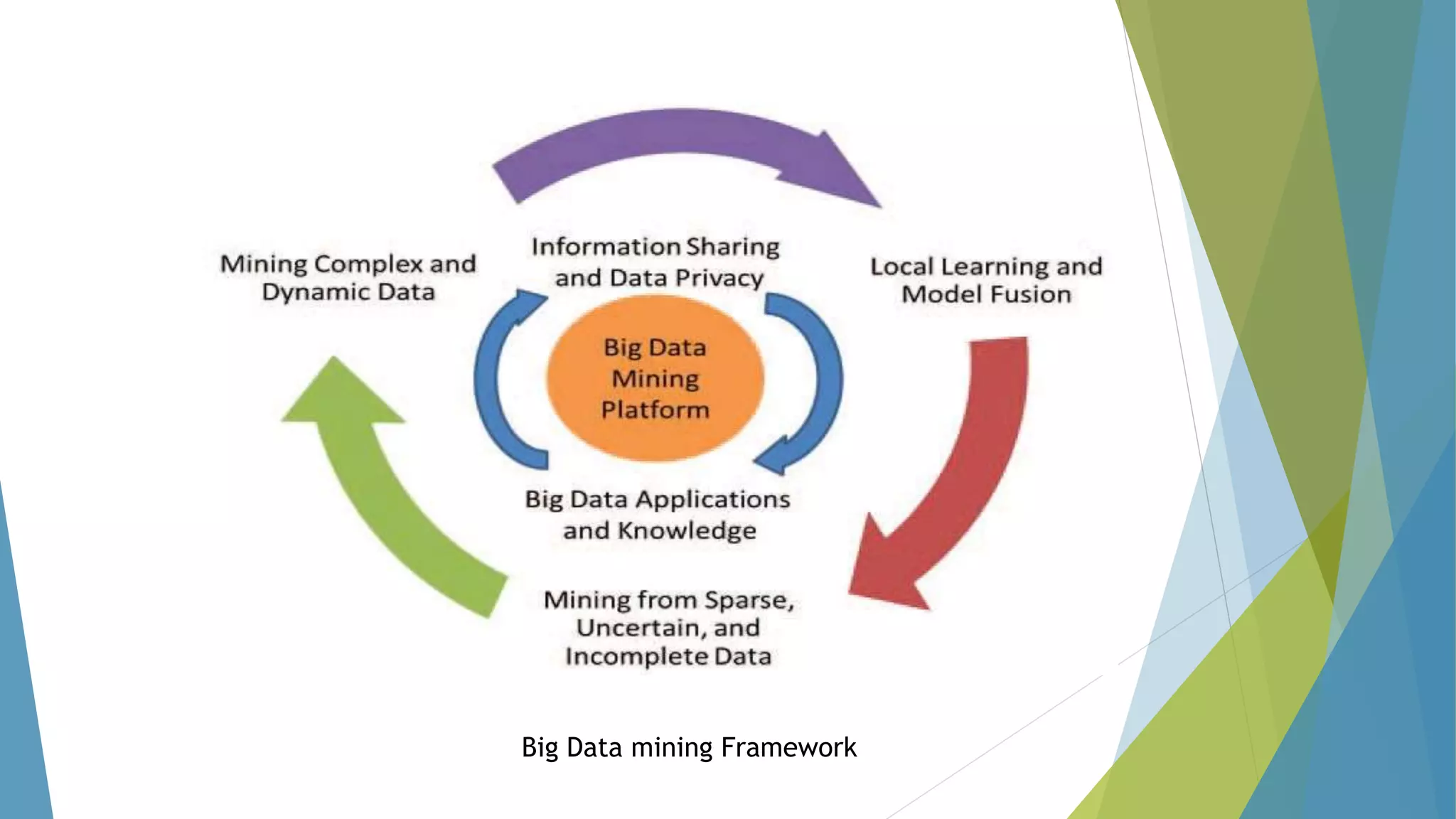
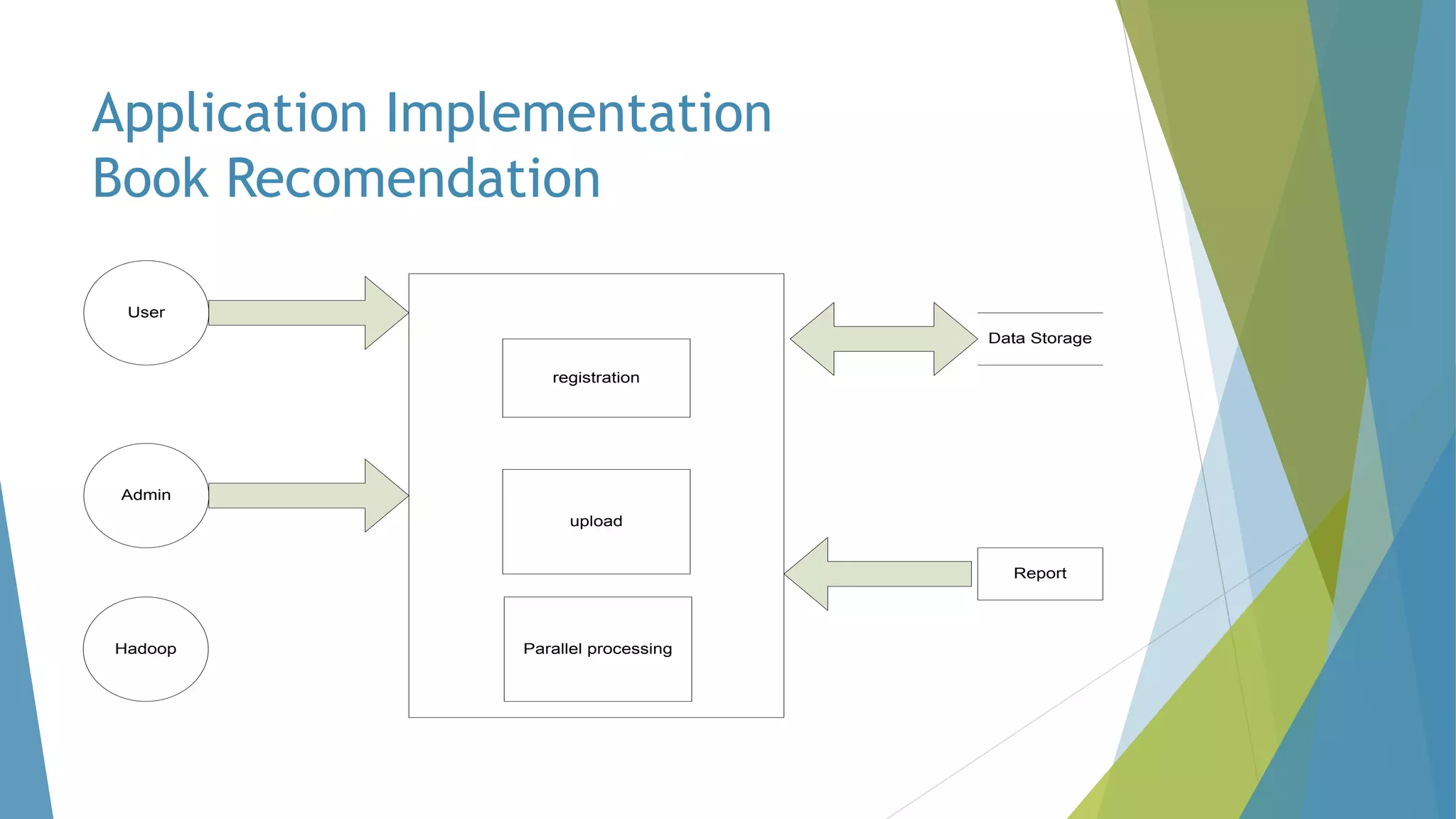
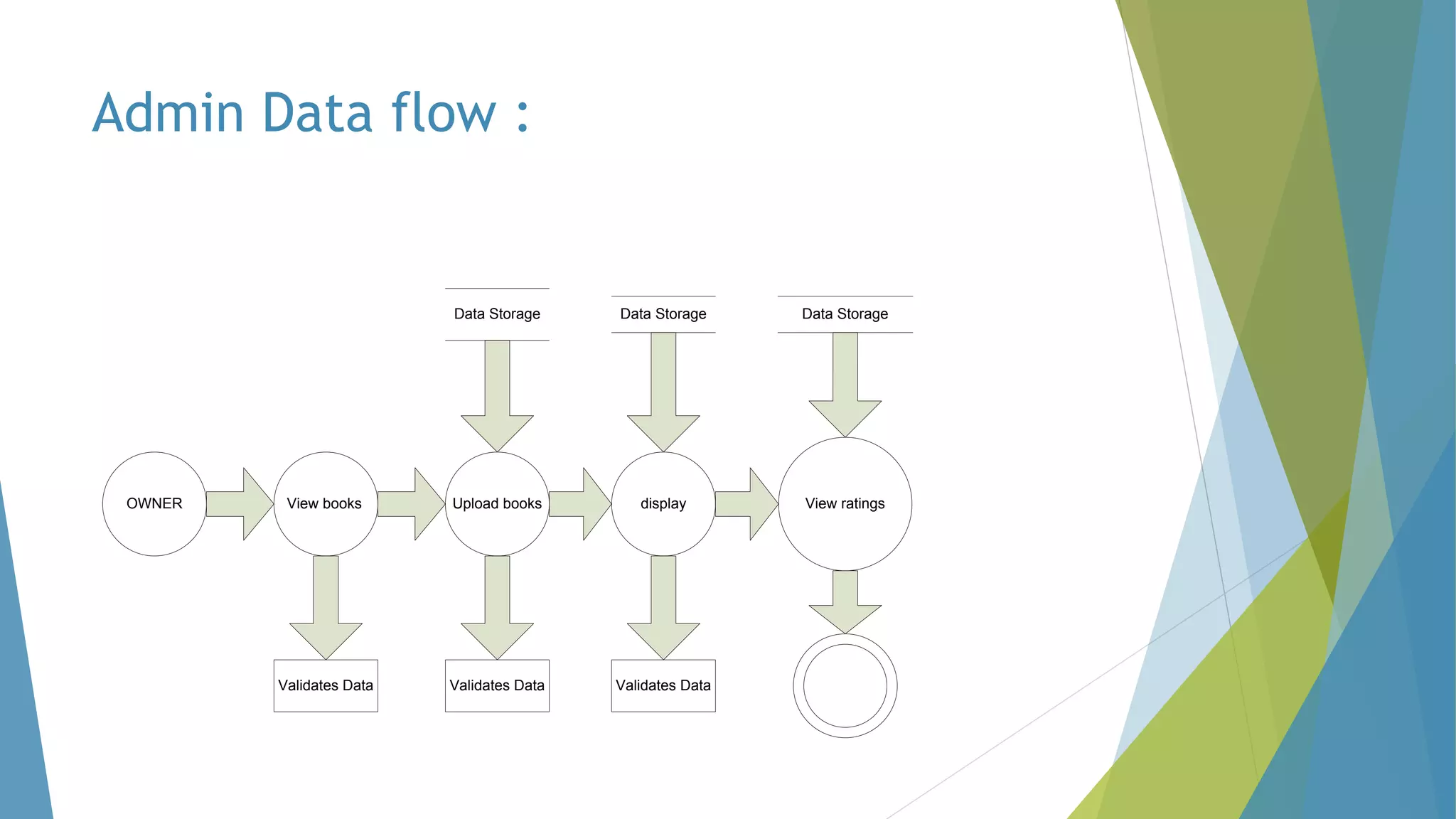
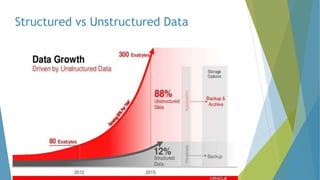
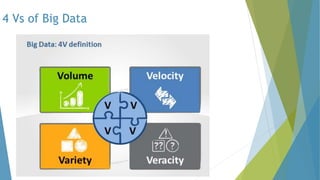
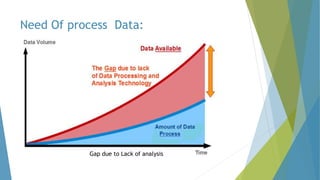
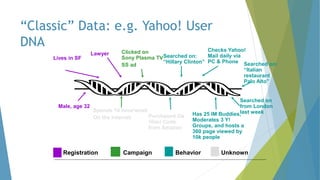
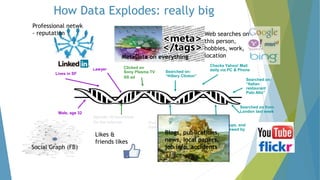
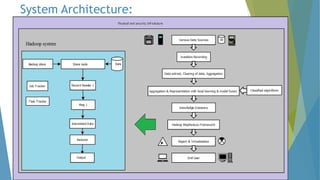
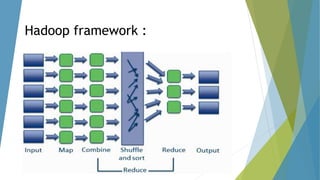
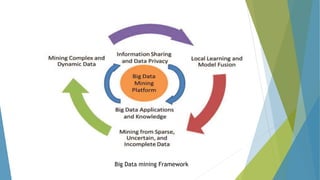
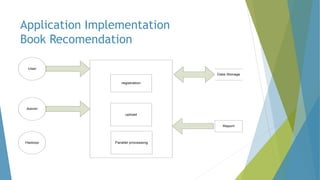
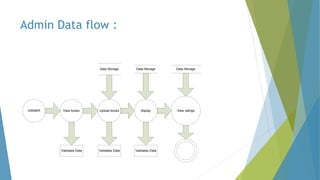
The dissertation by Sandip B. Tipayle Patil explores the intersection of data mining and big data, detailing definitions, frameworks, and challenges in managing vast amounts of information. It highlights the rapid growth of data, the characteristics of big data, and the necessity for improved tools and techniques like Hadoop for effective analysis. The conclusion emphasizes the potential of harnessing big data to drive advancements in various fields and improve business profitability.






![Data Mining Tasks
Classification [Predictive]
Clustering [Descriptive]
Association Rule Discovery [Descriptive]
Sequential Pattern Discovery [Descriptive]
Regression [Predictive]
Deviation Detection [Predictive]
Collaborative Filter [Predictive]](https://image.slidesharecdn.com/dataminingwithbigdataimplementation-150717102634-lva1-app6891/85/Data-mining-with-big-data-implementation-7-320.jpg)































![Data Mining Tasks
Classification [Predictive]
Clustering [Descriptive]
Association Rule Discovery [Descriptive]
Sequential Pattern Discovery [Descriptive]
Regression [Predictive]
Deviation Detection [Predictive]
Collaborative Filter [Predictive]](https://image.slidesharecdn.com/dataminingwithbigdataimplementation-150717102634-lva1-app6891/75/Data-mining-with-big-data-implementation-7-2048.jpg)