Downloaded 53 times




















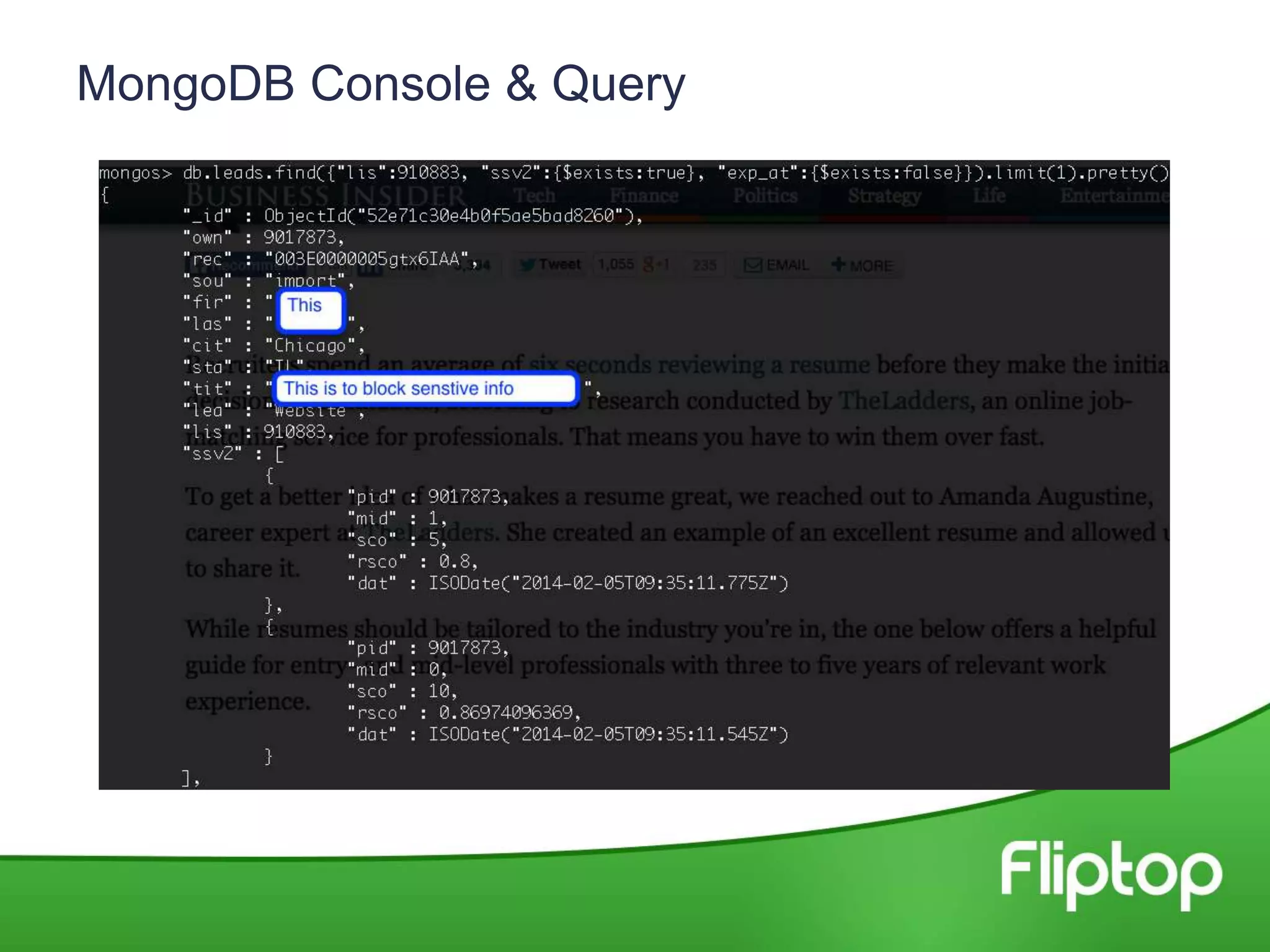
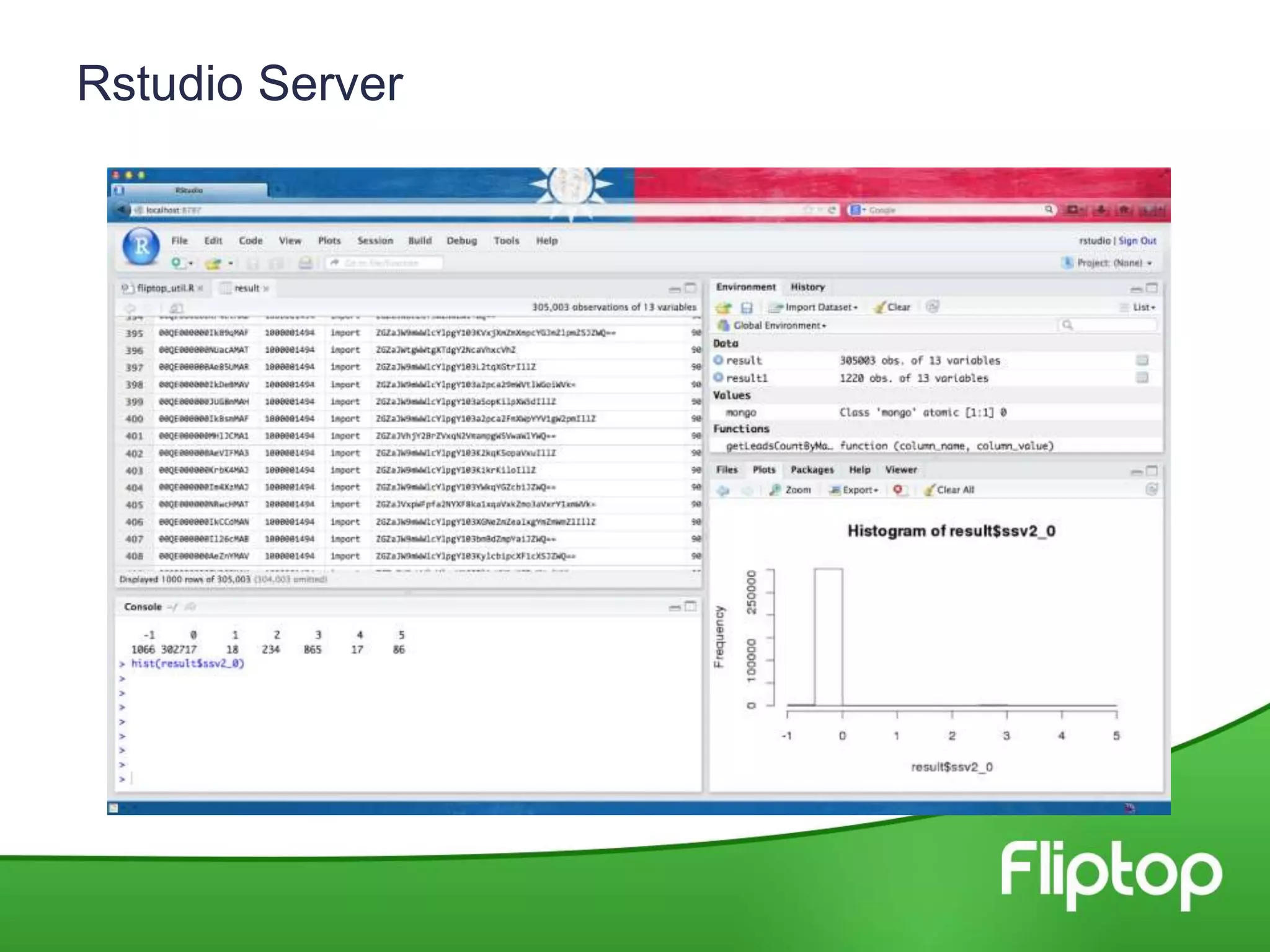











This document discusses using RStudio server with MongoDB to enable data science work on MongoDB data. Key points: - Fliptop uses MongoDB to store sales lead, opportunity, and contact data from their CRM. They also aggregate additional data sources. - They use RStudio server to pull MongoDB data into R data frames to enable exploring, analyzing, and prototyping machine learning algorithms on the data in an interactive way. - The rmongodb package allows transforming MongoDB data into R data frames. This allows working with the data in R for tasks like text processing, algorithm prototyping, and insights extraction.



































































