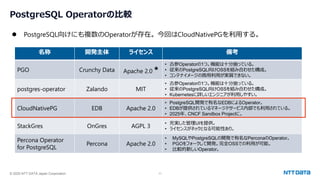
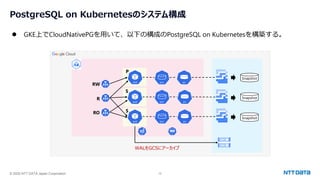
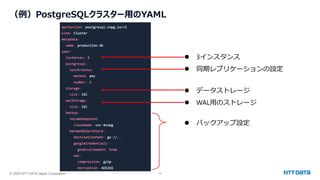
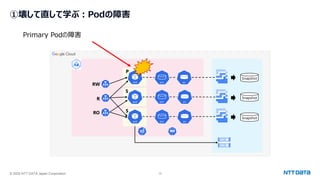
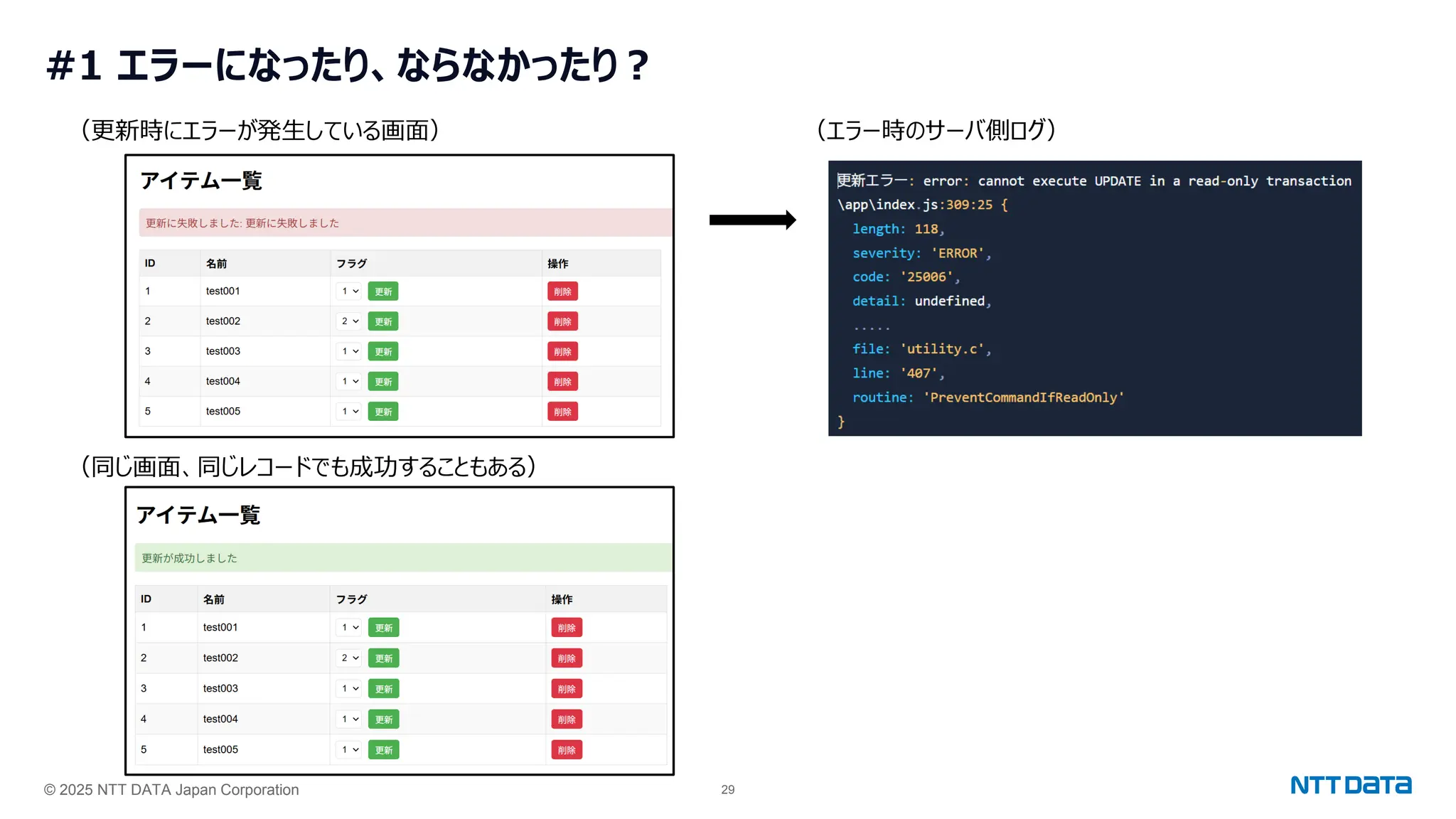
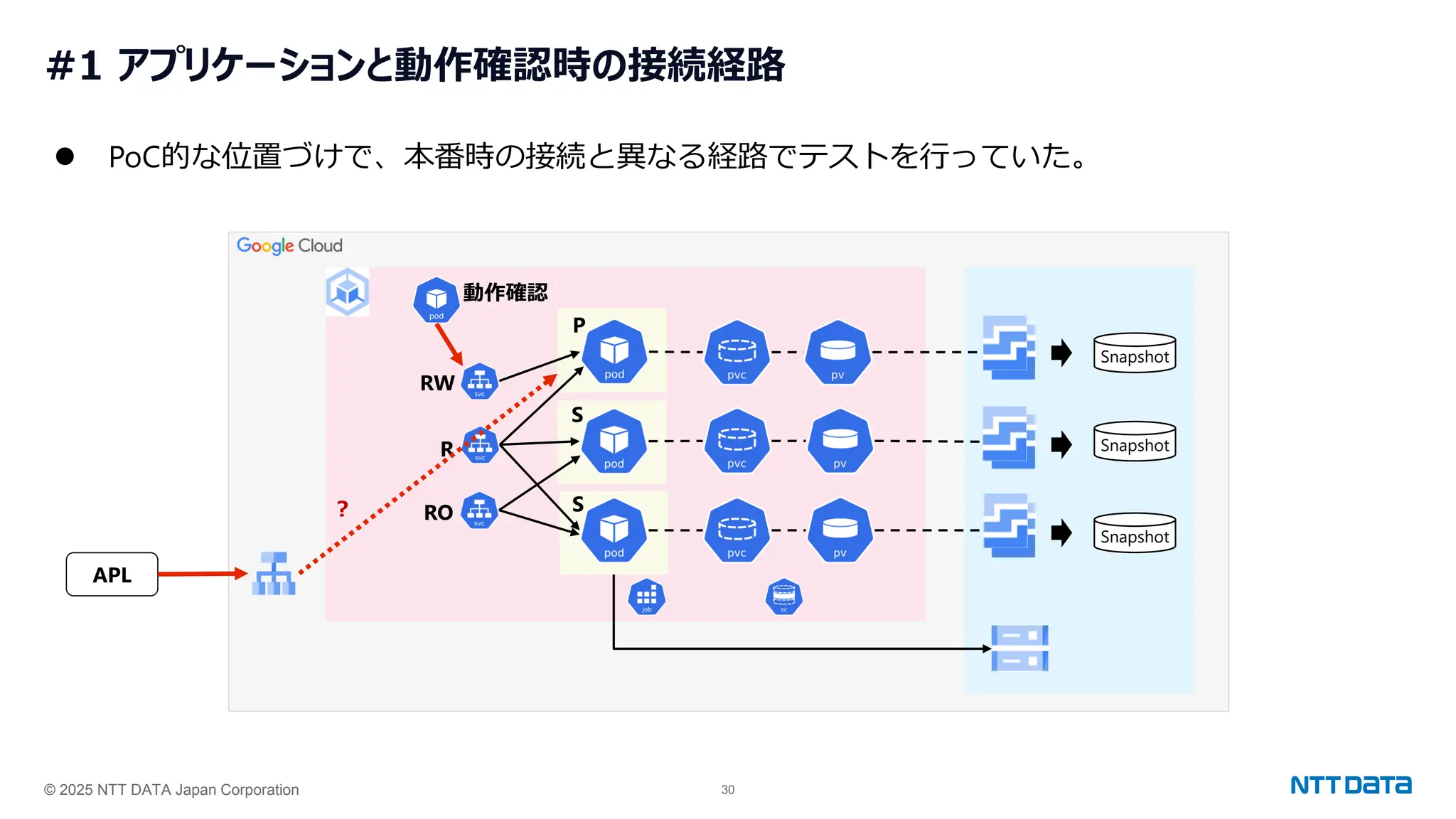
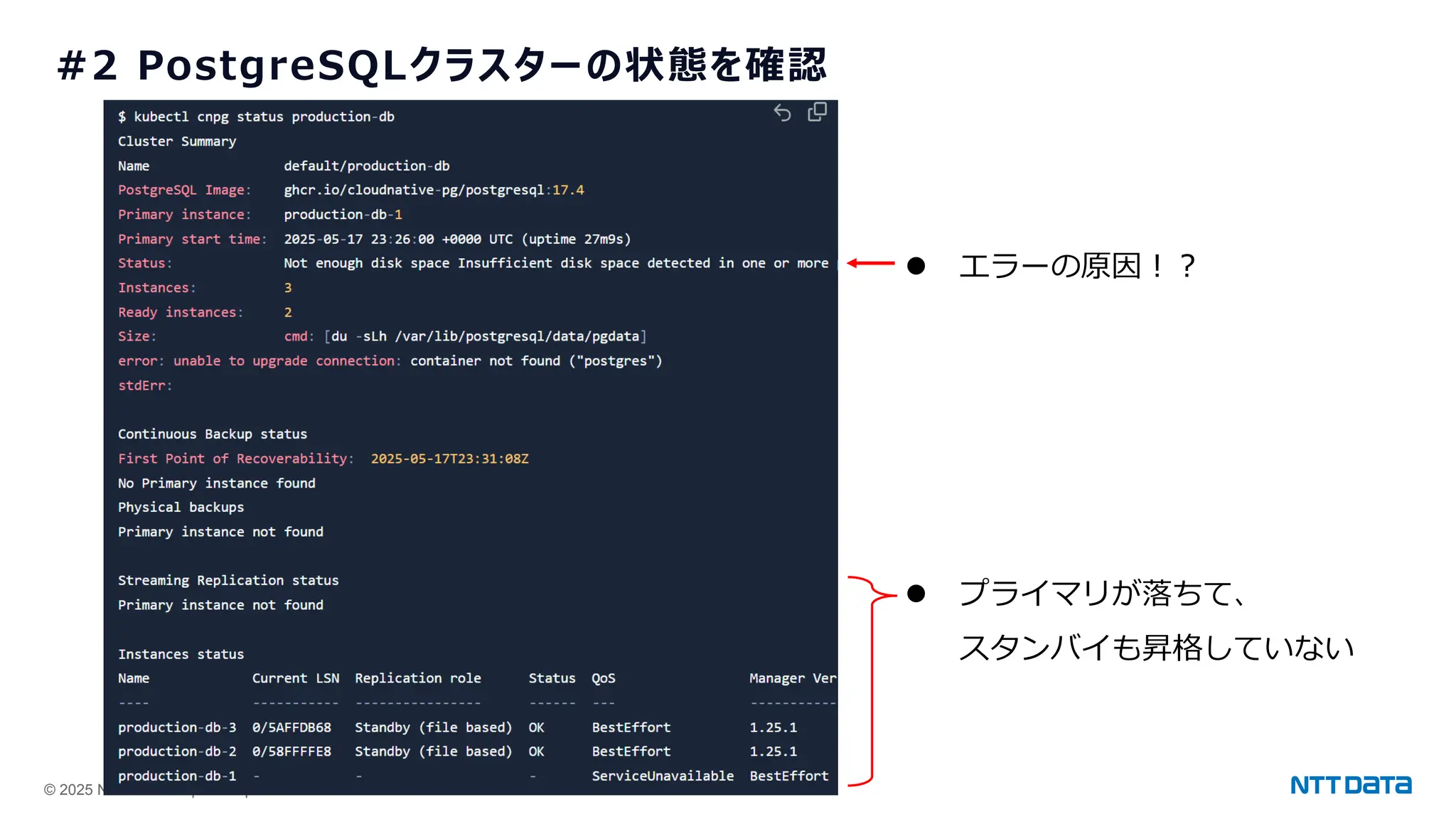
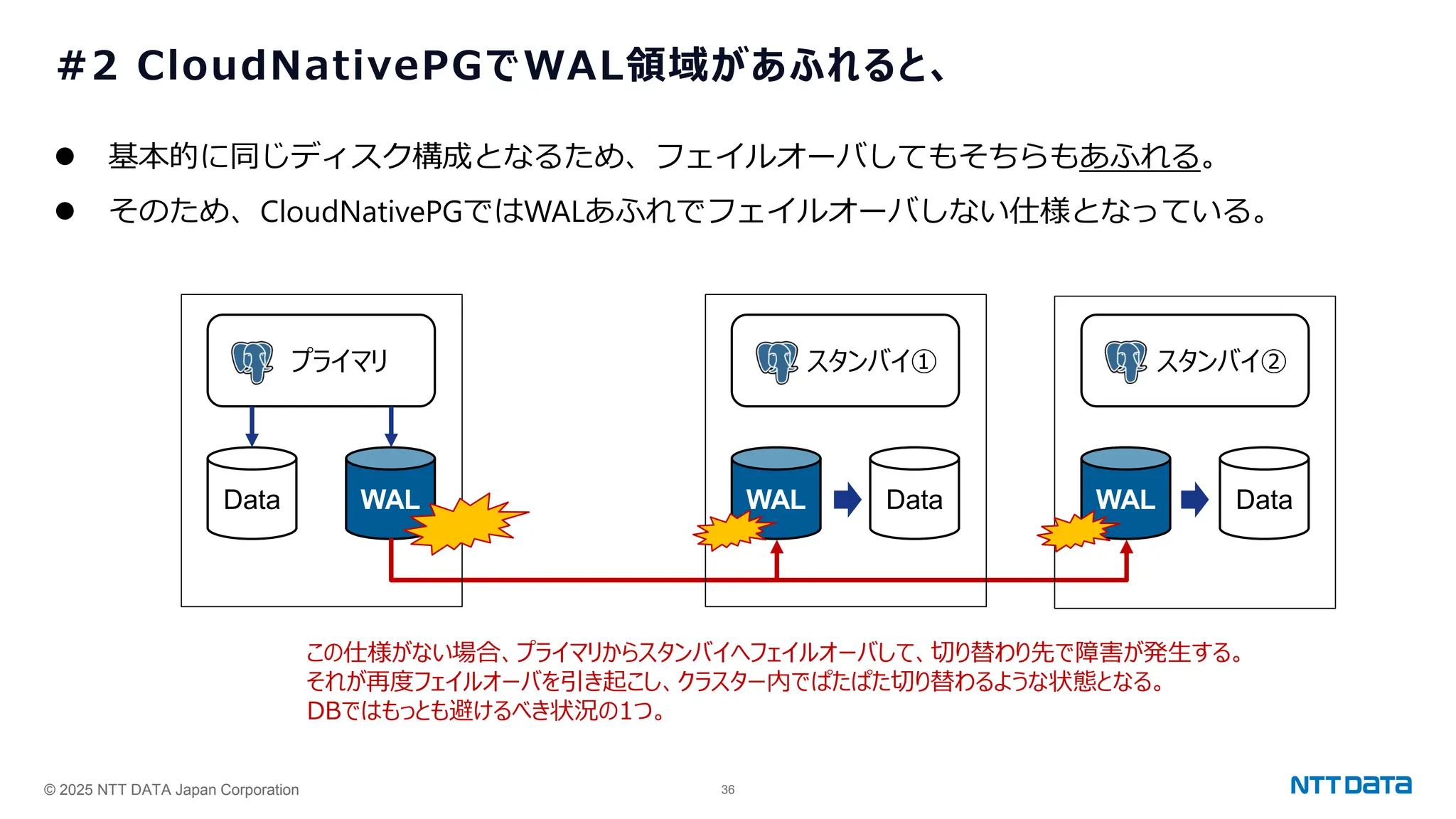
つくって壊して直して学ぶ Database on Kubernetes (CloudNative Days Summer 2025 発表資料) 2025年5月23日(金) NTTデータ OSSビジネス推進室 小林 隆浩、加藤 慎也




















































































![[db tech showcase Tokyo 2014] C31: PostgreSQLをエンタープライズシステムで利用しよう by PostgreS...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c31pgeconspostgresql-141120011520-conversion-gate01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



































