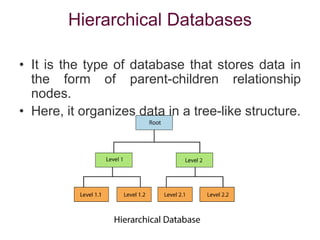
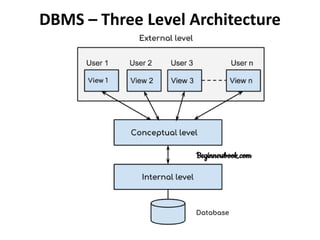
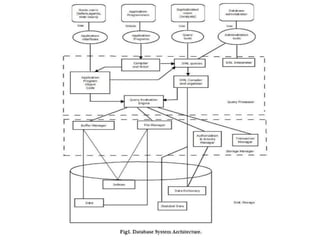
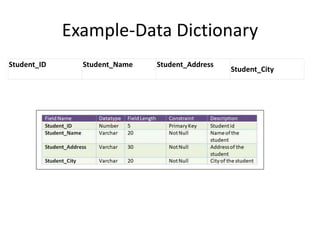
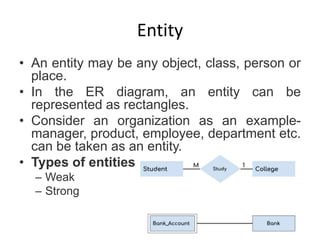
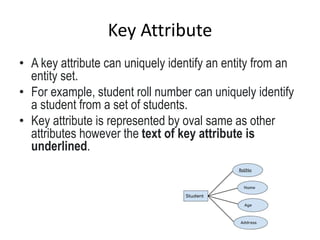
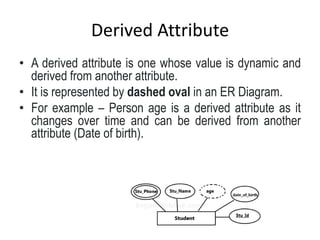
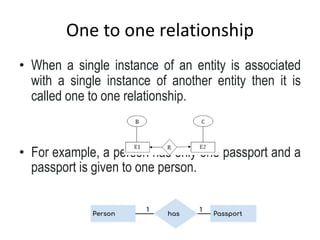
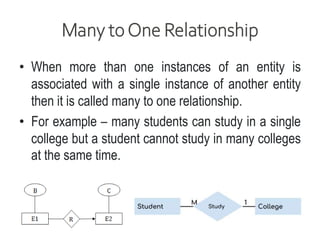
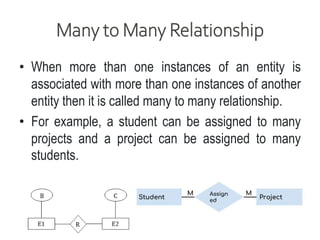
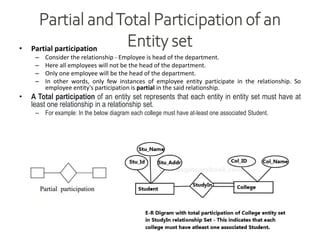
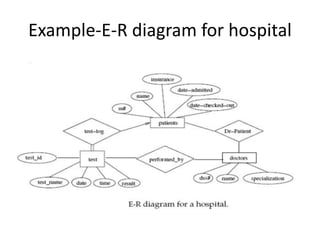
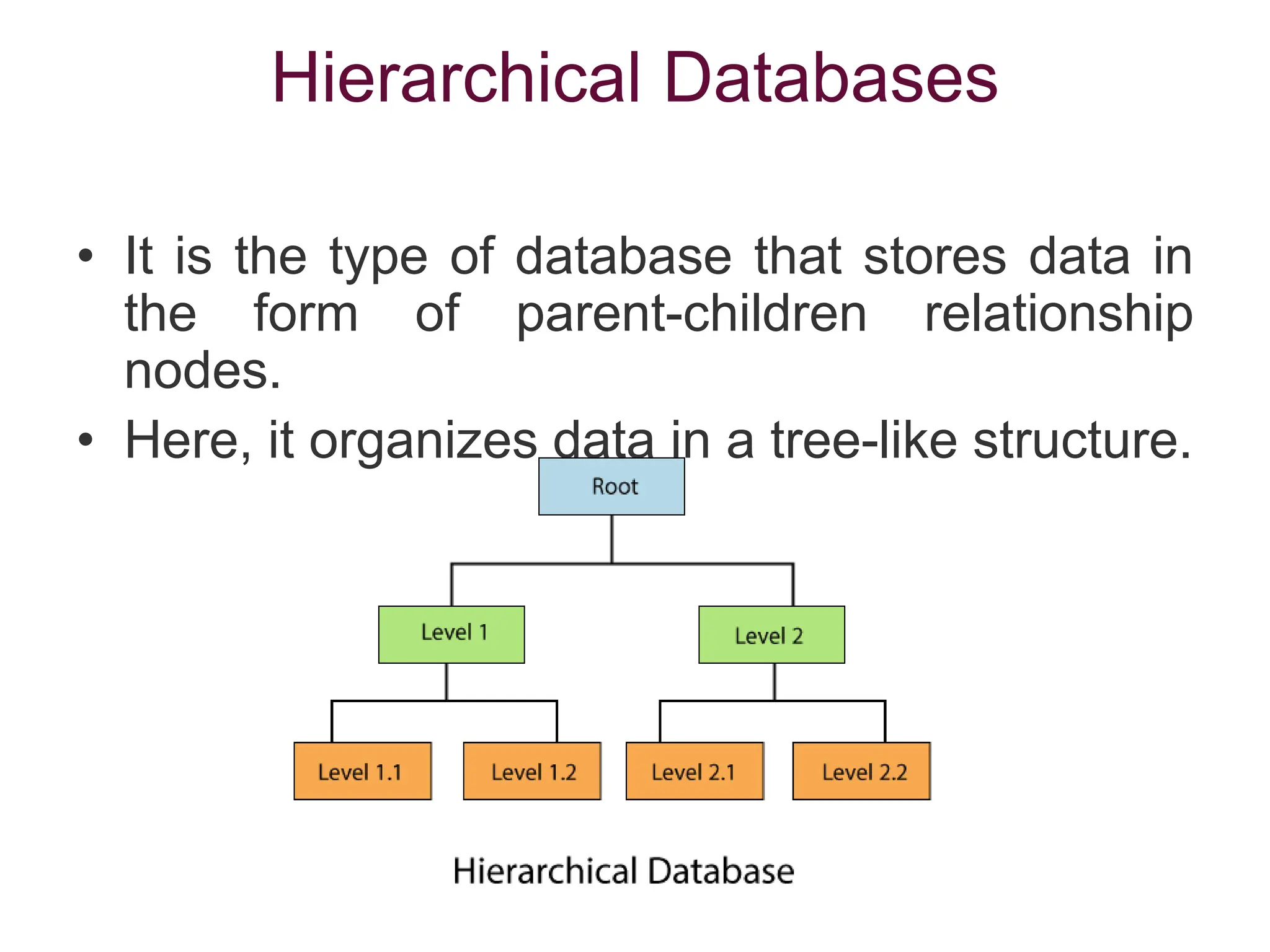
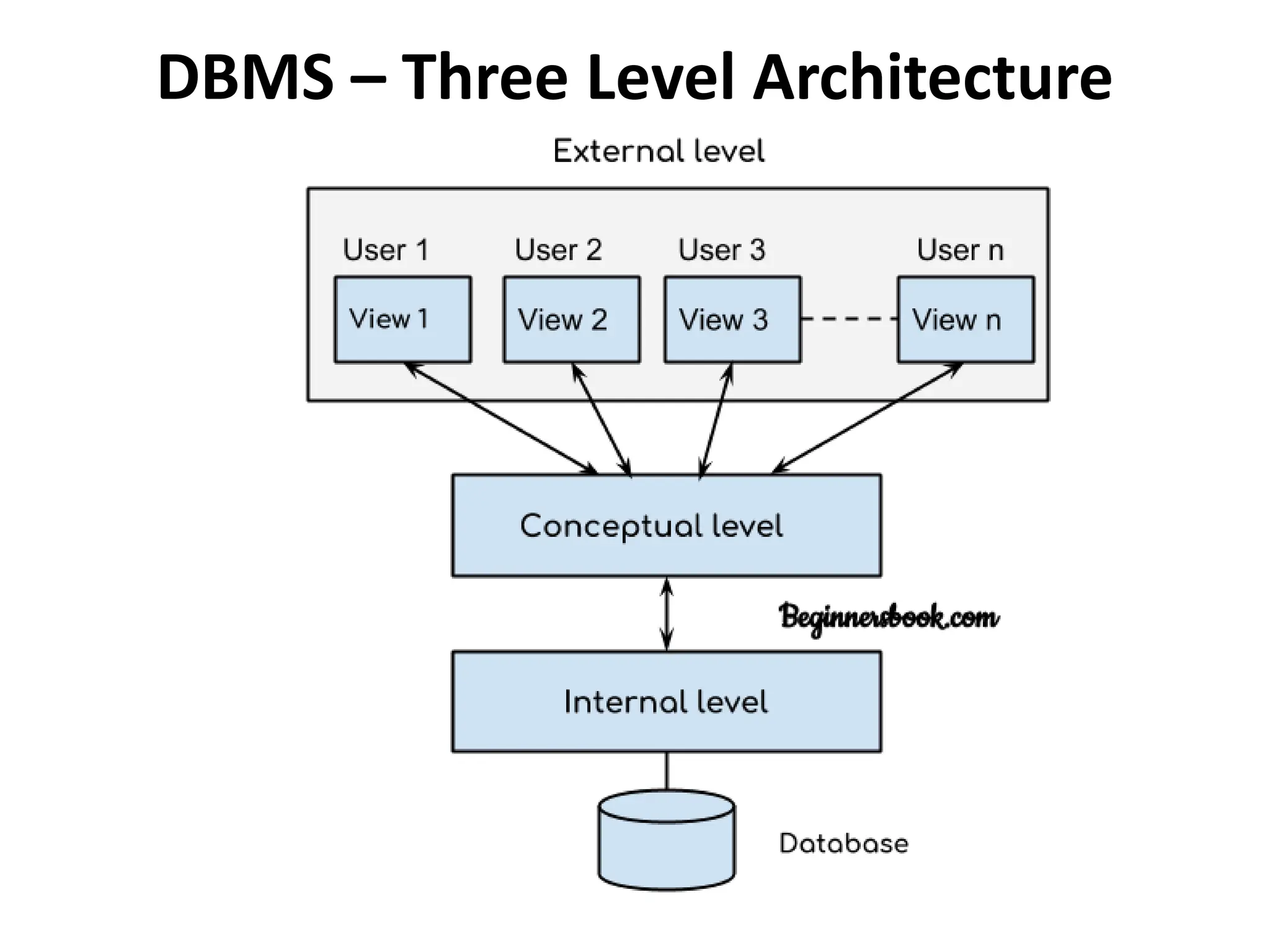
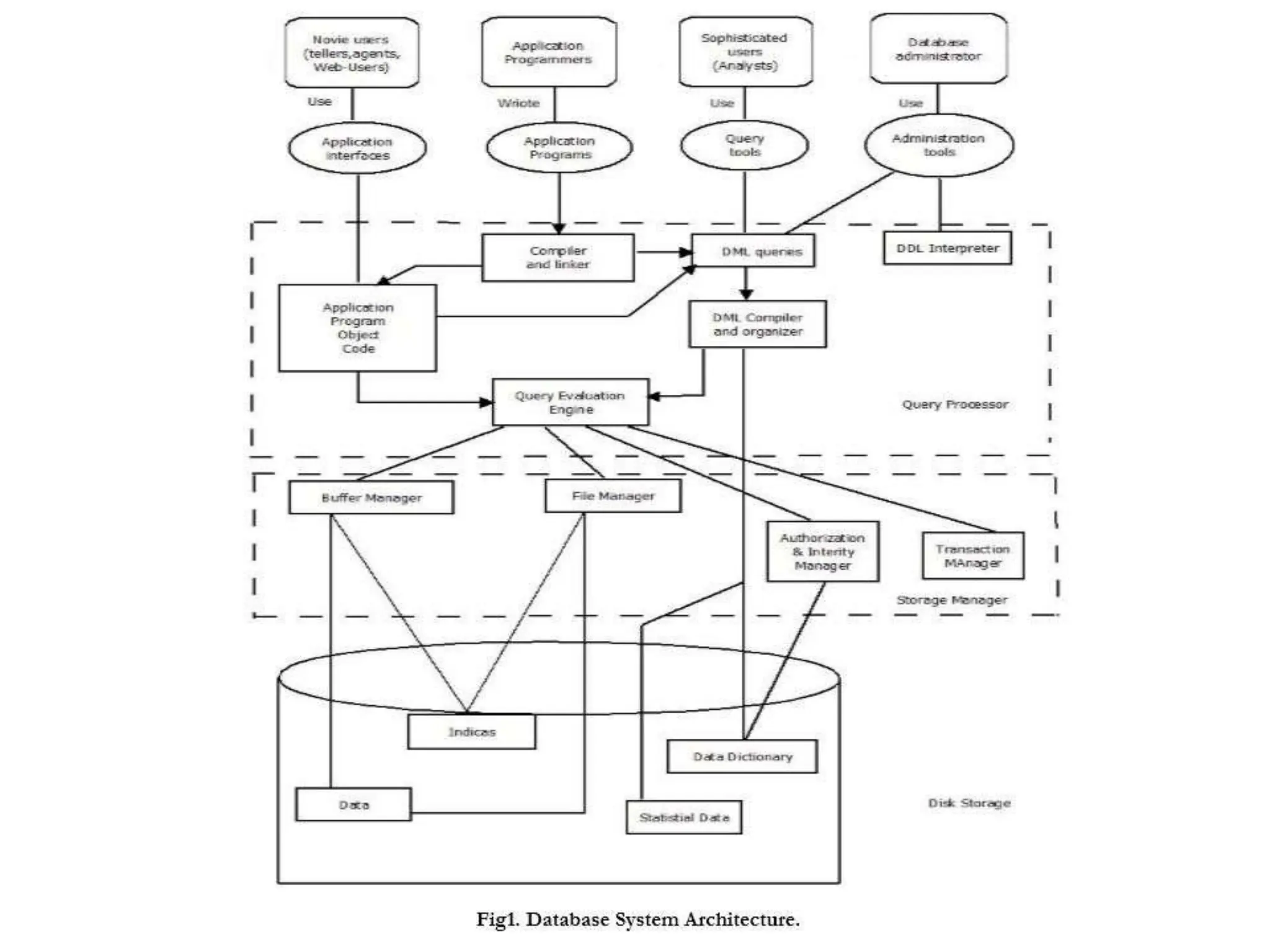
Data refers to a collection of distinct units of information, which can be organized in databases for easy access and management. Database Management Systems (DBMS) facilitate the creation, storage, updating, and retrieval of this data, offering advantages like reduced redundancy and improved data sharing while also presenting challenges such as complexity and costs. Various types of databases exist, including centralized, distributed, and NoSQL, each with unique characteristics tailored to different storage and organizational needs.












































































![Structure of DML statement
• Select [attributelist][*] from [relations/tables]
where [predicate/condition]
• Insert into tablename
([attributelist])values(value1,value2,....)
OR
• Insert into tablename
values(value1,value2,....))
• Delete * from tablename where predicate](https://image.slidesharecdn.com/dbms-iiiunit-240429164945-878ee90b/85/DBMS-basics-and-normalizations-unit-pptx-101-320.jpg)











![• SELECT column_name [, column_name ]
FROM table1 [, table2 ] WHERE column_name
OPERATOR (SELECT column_name [,
column_name ] FROM table1 [, table2 ]
[WHERE])](https://image.slidesharecdn.com/dbms-iiiunit-240429164945-878ee90b/85/DBMS-basics-and-normalizations-unit-pptx-113-320.jpg)

















































































![Structure of DML statement
• Select [attributelist][*] from [relations/tables]
where [predicate/condition]
• Insert into tablename
([attributelist])values(value1,value2,....)
OR
• Insert into tablename
values(value1,value2,....))
• Delete * from tablename where predicate](https://image.slidesharecdn.com/dbms-iiiunit-240429164945-878ee90b/75/DBMS-basics-and-normalizations-unit-pptx-101-2048.jpg)











![• SELECT column_name [, column_name ]
FROM table1 [, table2 ] WHERE column_name
OPERATOR (SELECT column_name [,
column_name ] FROM table1 [, table2 ]
[WHERE])](https://image.slidesharecdn.com/dbms-iiiunit-240429164945-878ee90b/75/DBMS-basics-and-normalizations-unit-pptx-113-2048.jpg)



















































