Downloaded 70 times



























The document provides a detailed overview of Spark Shuffle, including its major components such as Shuffle Writers and Shuffle Readers, and different serialization strategies like JavaSerializer and KryoSerializer. It discusses various shuffle writer algorithms, their use cases, and the importance of optimizing shuffle operations to enhance performance. Key suggestions include minimizing shuffles, using caching judiciously, and leveraging KryoSerializer for improved efficiency.
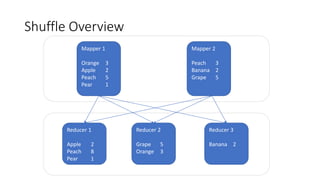
Overview of Spark Shuffle, including major classes and components involved in shuffle process.
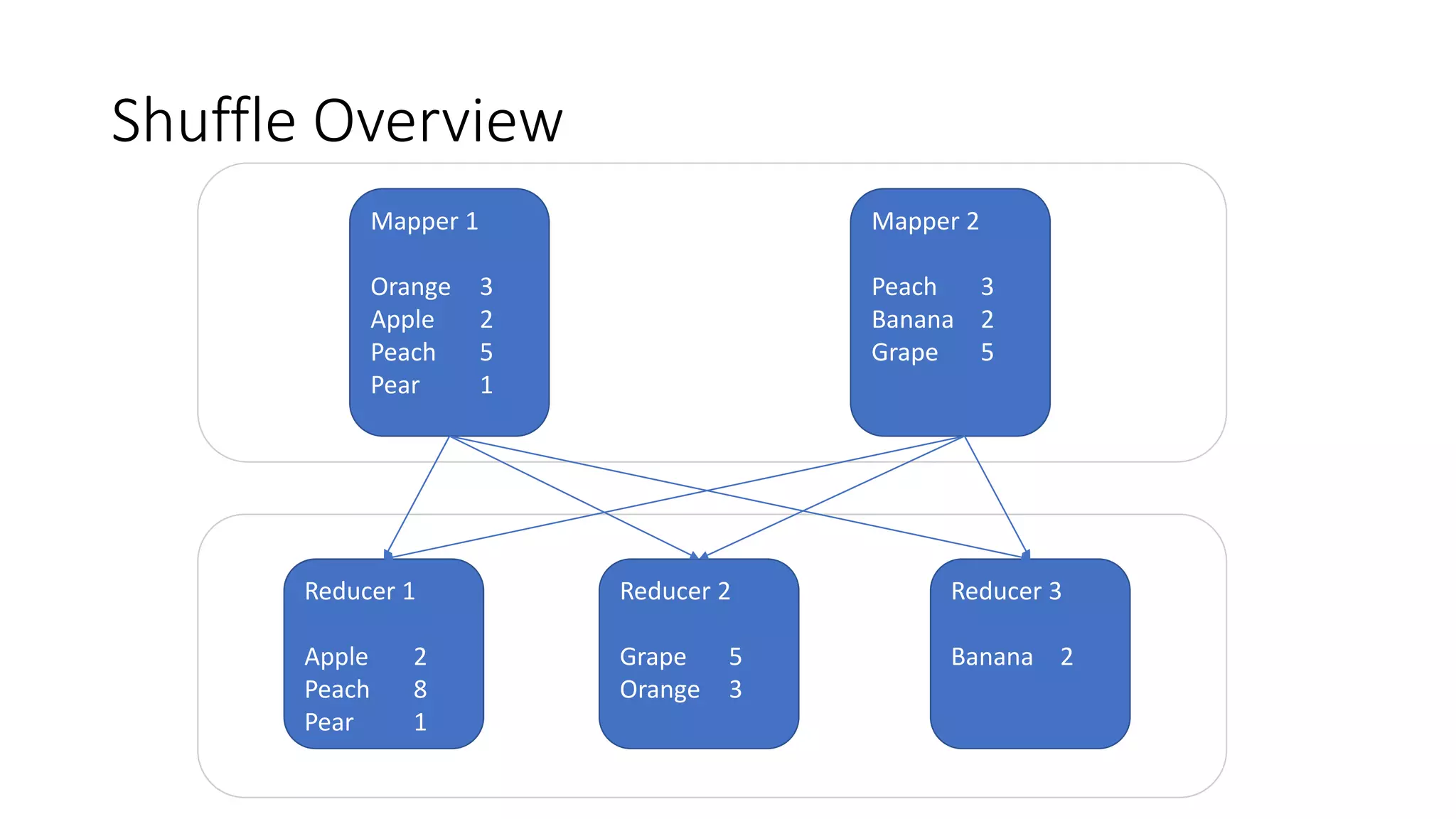
Insight into Shuffle Overview with data distribution and the pluggable interface regarding ShuffleManager.
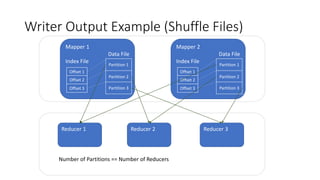
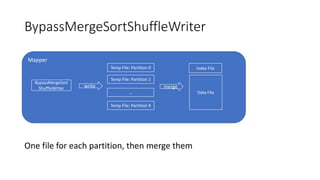
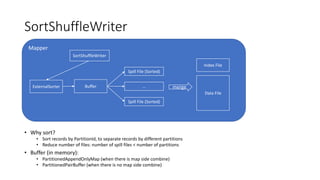
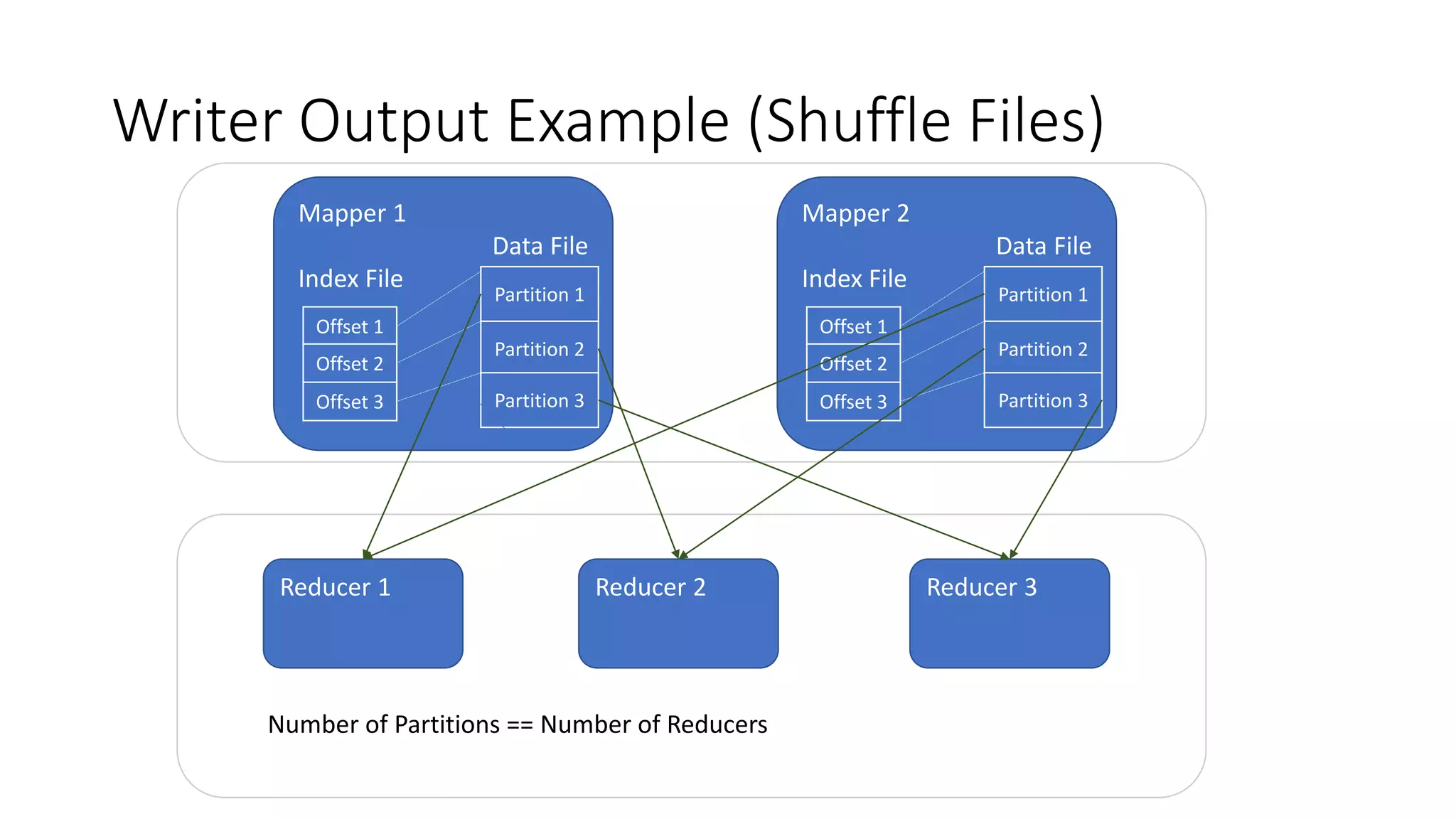
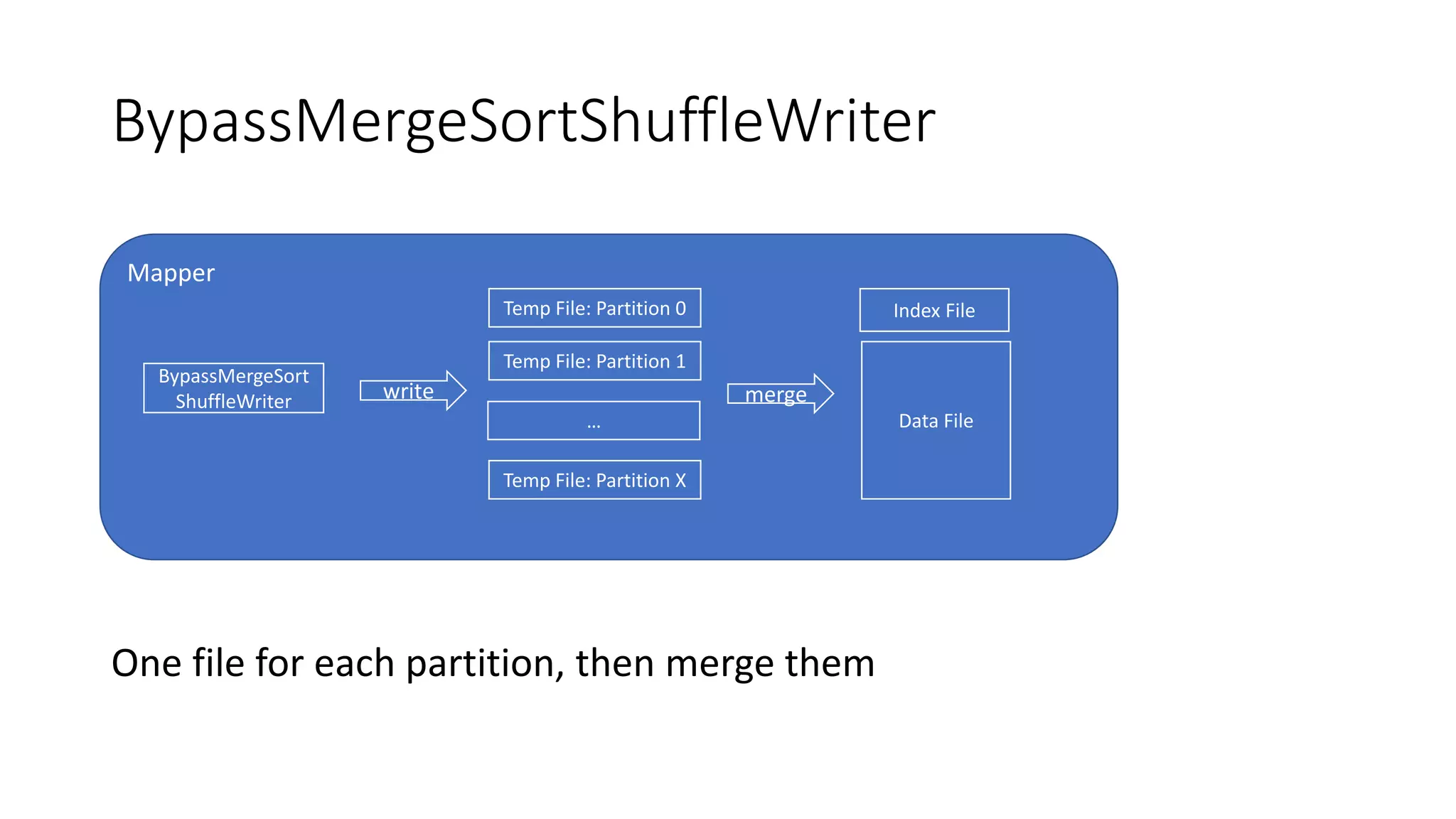
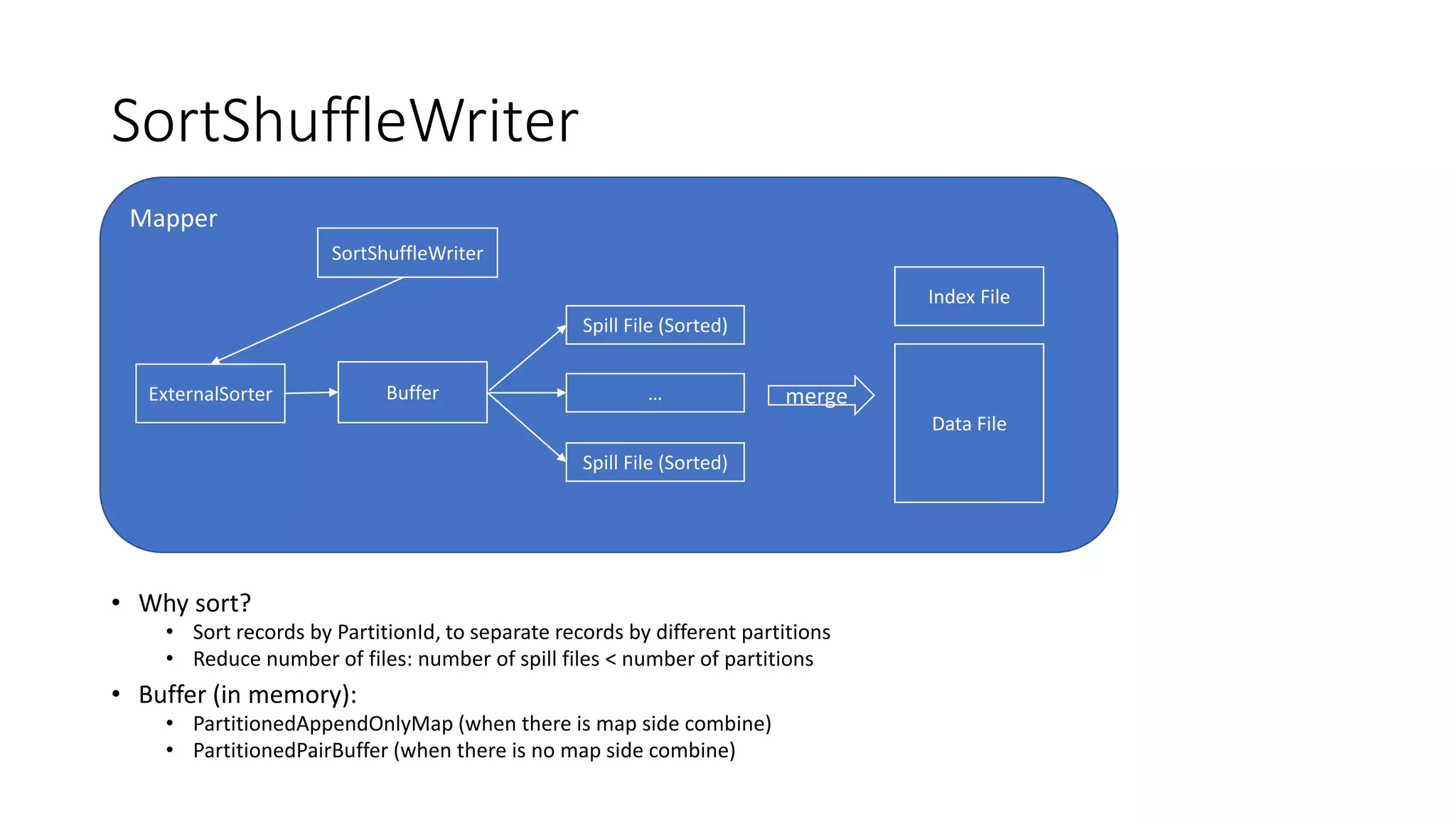
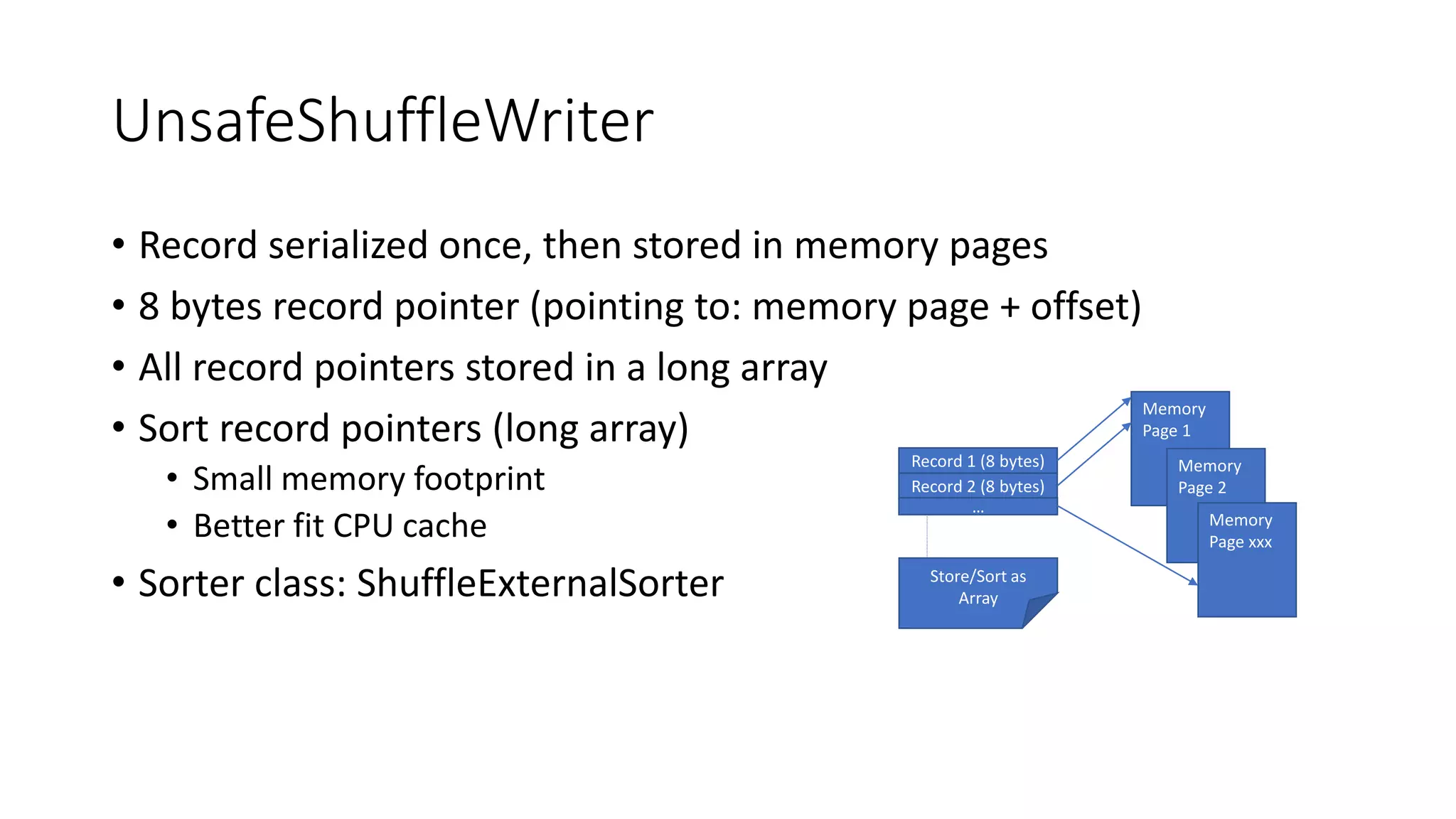
Different implementations of Shuffle Writers, algorithms used, and conditions for their utilization.
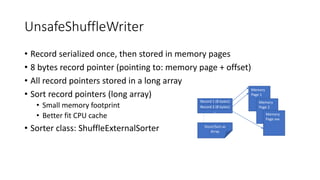
In-depth discussion on (BypassMergeSort, Sort, and Unsafe) Shuffle Writers and their characteristics.
Overview of JavaSerializer and KryoSerializer, their functionality, pros and cons in serialization.
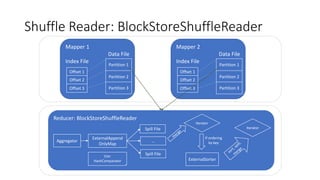
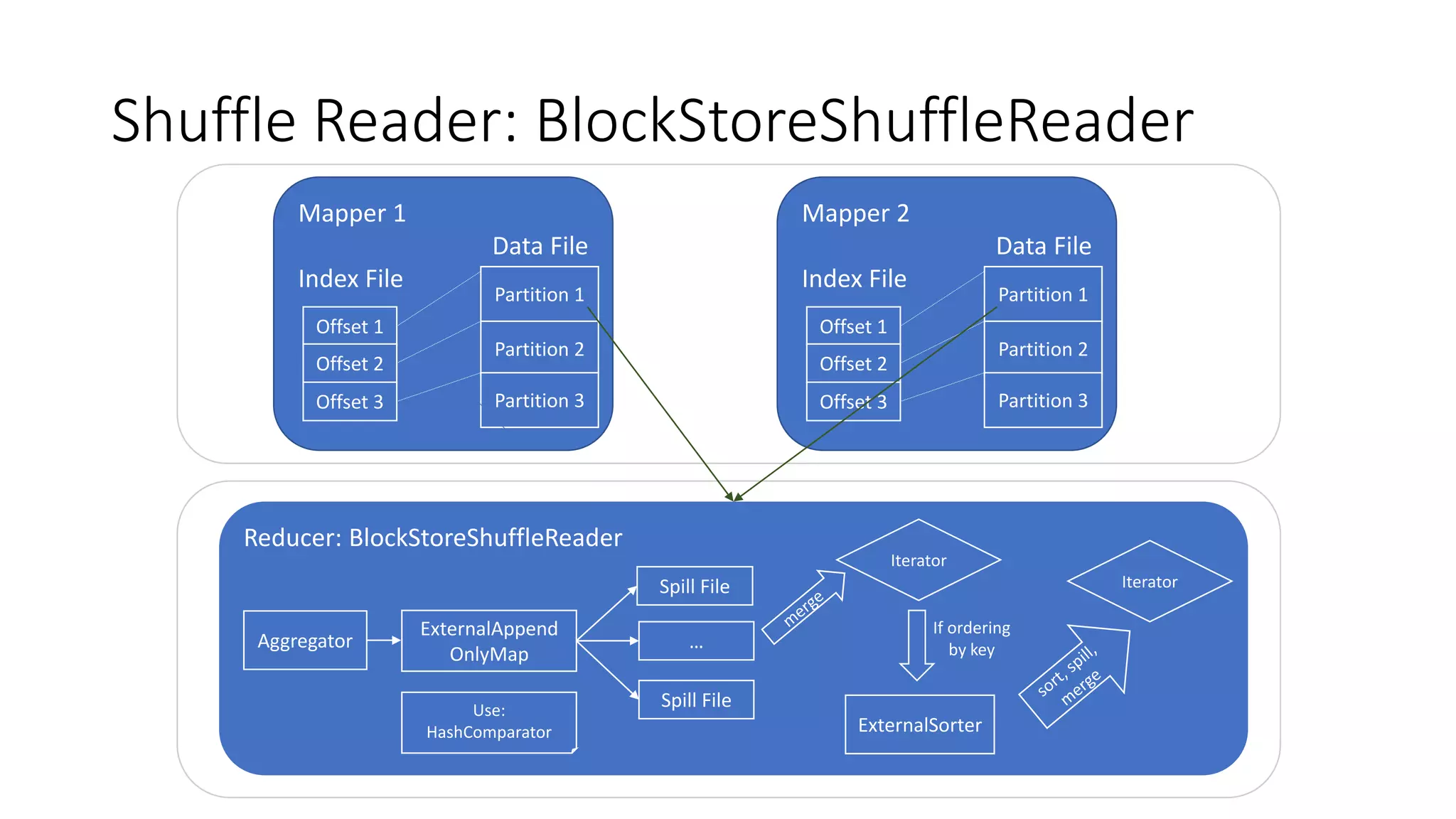
Explanation of BlockStoreShuffleReader, its functionality, and role of External Shuffle Service in managing shuffle files.
Guidelines for optimizing shuffle operations, including configuration tuning and comparison of shuffle vs caching.



































































