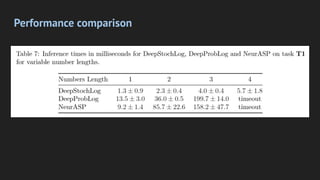
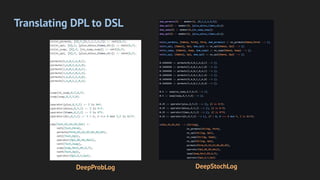
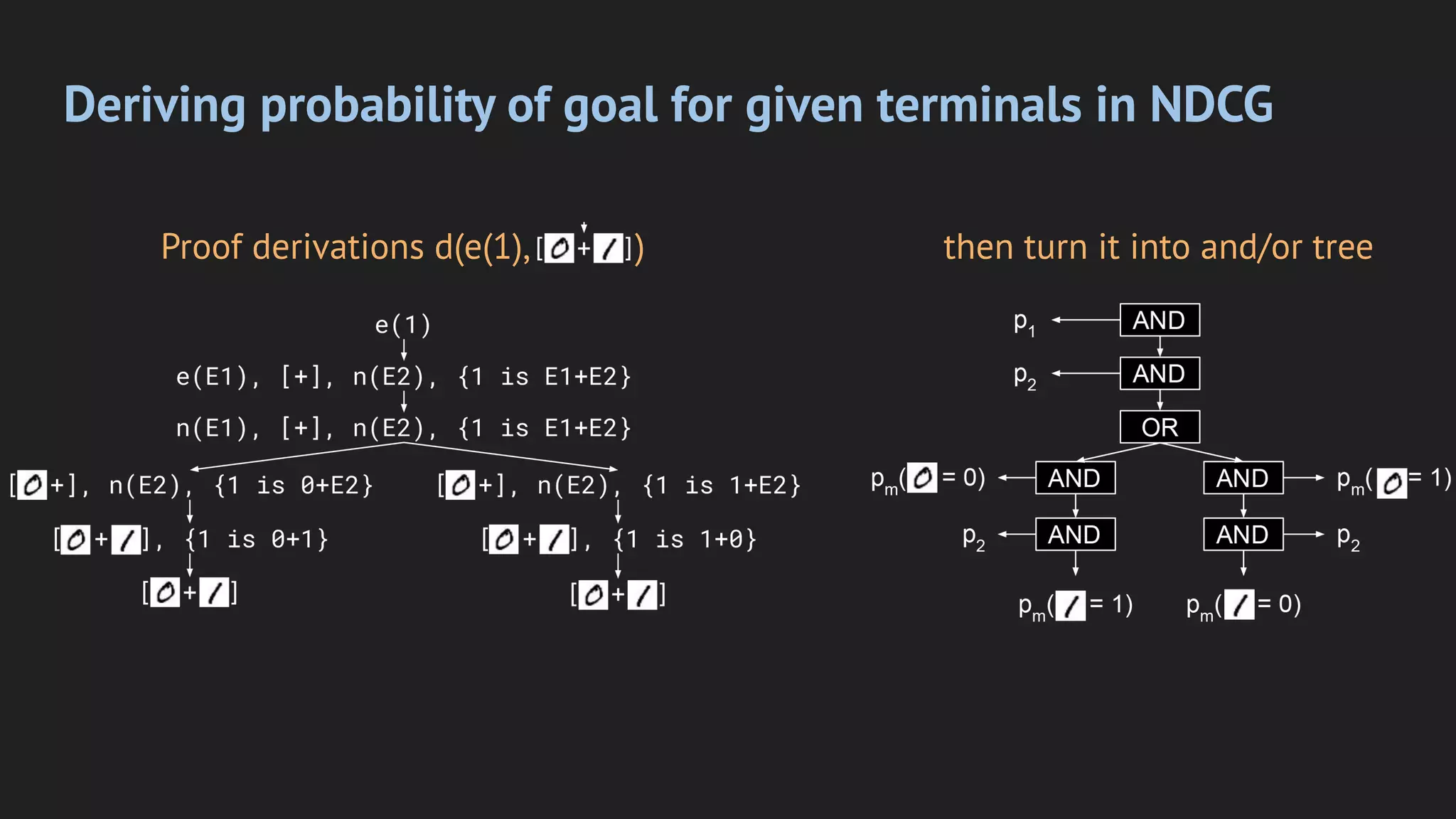
Deepstochlog is a neural-symbolic framework that introduces neural definite clause grammars, achieving state-of-the-art results in various tasks while offering improved scalability. It includes models like PCFG and SDCG, facilitating complex language generation and probabilistic parsing using neural networks. Future research aims to enhance structure learning, probability calculations, and perform larger-scale experiments.



![CFG: Context-Free Grammar
E --> N
E --> E, P, N
P --> [“+”]
N --> [“0”]
N --> [“1”]
…
N --> [“9”] 2 + 3 + 8
N
E
E
P N
E
P N
Useful for:
- Is sequence an element of the specified language?
- What is the “part of speech”-tag of a terminal
- Generate all elements of language](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-4-320.jpg)
![PCFG: Probabilistic Context-Free Grammar
0.5 :: E --> N
0.5 :: E --> E, P, N
1.0 :: P --> [“+”]
0.1 :: N --> [“0”]
0.1 :: N --> [“1”]
…
0.1 :: N --> [“9”] 2 + 3 + 8
N
E
E
P N
E
P N
Useful for:
- What is the most likely parse for this sequence of terminals? (useful for ambiguous grammars)
- What is the probability of generating this string?
0.5
0.1
1
1
0.1
0.1
0.5
0.5
Probability of this parse = 0.5*0.5*0.5*0.1*1*0.1*1*0.1 = 0.000125
Always
sums
to
1
per
non-terminal](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-5-320.jpg)
![DCG: Definite Clause Grammar
e(N) --> n(N).
e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
p --> [“+”].
n(0) --> [“0”].
n(1) --> [“1”].
…
n(9) --> [“9”]. 2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
Useful for:
- Modelling more complex languages (e.g. context-sensitive)
- Adding constraints between non-terminals thanks to Prolog power (e.g. through unification)
- Extra inputs & outputs aside from terminal sequence (through unification of input variables)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-6-320.jpg)
![SDCG: Stochastic Definite Clause Grammar
0.5 :: e(N) --> n(N).
0.5 :: e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
1.0 :: p --> [“+”].
0.1 :: n(0) --> [“0”].
0.1 :: n(1) --> [“1”].
…
0.1 :: n(9) --> [“9”]. 2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
Useful for:
- Same benefits as PCFGs give to CFG (e.g. most likely parse)
- But: loss of probability mass possible due to failing derivations
0.5
0.1
1
1
0.1
0.1
0.5
0.5
Probability of this parse = 0.5*0.5*0.5*0.1*1*0.1*1*0.1 = 0.000125](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-7-320.jpg)
![NDCG: Neural Definite Clause Grammar (= DeepStochLog)
Useful for:
- Subsymbolic processing: e.g. tensors as terminals
- Learning rule probabilities using neural networks
0.5 :: e(N) --> n(N).
0.5 :: e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
1.0 :: p --> [“+”].
nn(number_nn,[X],[Y],[digit]) :: n(Y) --> [X].
digit(Y) :- member(Y,[0,1,2,3,4,5,6,7,8,9]).
2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
0.5
pnumber_nn
( =2)
1
1
0.5
0.5
pnumber_nn
( =3)
pnumber_nn
( =8)
Probability of this parse =
0.5*0.5*0.5*pnumber_nn
( =2)*1*pnumber_nn
( =3)*1*pnumber_nn
( =8)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-8-320.jpg)
![DeepStochLog NDCG definition
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> g1
, …, gn
.
Where:
● nt is an atom
● g1
, …, gn
are goals (goal = atom or list of terminals & variables)
● I1
,…,Im
and O1
,…,OL
are variables occurring in g1
, …, gn
and are the
inputs and outputs of m
● D1
,…,DL
are the predicates specifying the domains of O1
,…,OL
● m is a neural network mapping I1
,…,Im
to probability distribution over
O1
,…,OL
(= over cross product of D1
,…,DL
)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-9-320.jpg)



![And/Or tree + semiring for different inference types
Probability of goal Most likely derivation
MAX
0.96
0.5
0.5
0.5 0.5 0.5 0.5
0.5
0.5
0.04
0.02
0.98
0.96 0.04
0.02
0.98
PG
(derives(e(1), [ , +, ]) = 0.1141 dmax
(e(1), [ , +, ] ) = argmaxd(e(t))=[ , +, ]
PG
(d(e(1))) = [0,+,1]](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-13-320.jpg)




![Sibling of DeepProbLog, but different semantic (PLP vs SLP)
DeepProbLog: neural predicate probability (and thus implicitly over “possible worlds”)
nn(m,[I1
,…,Im
],O,[x1
,…,xL
]) :: neural_predicate(X).
DeepStochLog: neural grammar rule probability (and thus no disjoint sum problem)
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> g1
, …, gn
.
PLP vs SLP ~ akin to difference between random graph and random walk](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-18-320.jpg)



![Classic grammars, but with MNIST images as terminals
T3: Well-formed brackets as input
(without parse). Task: predict parse.
T4: inputs are strings ak
bl
cm
(or
permutations of [a,b,c], and (k+l+m)%3=0).
Predict 1 if k=l=m, otherwise 0.
→ parse = ( ) ( ( ) ( ) )
= 1
= 0](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-23-320.jpg)
![Natural way of expressing this grammar knowledge
brackets_dom(X) :- member(X, ["(",")"]).
nn(bracket_nn, [X], Y, brackets_dom) :: bracket(Y) --> [X].
t(_) :: s --> s, s.
t(_) :: s --> bracket("("), s, bracket(")").
t(_) :: s --> bracket("("), bracket(")").](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-24-320.jpg)
![All power of Prolog DCGs (here: an
bn
cn
)
letter(X) :- member(X, [a,b,c]).
0.5 :: s(0) --> akblcm(K,L,M),
{K = L; L = M; M = K},
{K = 0, L = 0, M = 0}.
0.5 :: s(1) --> akblcm(N,N,N).
akblcm(K,L,M) --> rep(K,A),
rep(L,B),
rep(M,C),
{A = B, B = C, C = A}.
rep(0, _) --> [].
nn(mnist, [X], C, letter) :: rep(s(N), C) --> [X],
rep(N,C).](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-25-320.jpg)

![Word Algebra Problem
T6: natural language text describing algebra problem, predict outcome
E.g."Mark has 6 apples. He eats 2 and divides the remaining among his 2 friends. How many apples did each friend get?"
Uses “empty body trick” to emulate SLP logic rules through SDCGs:
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> [].
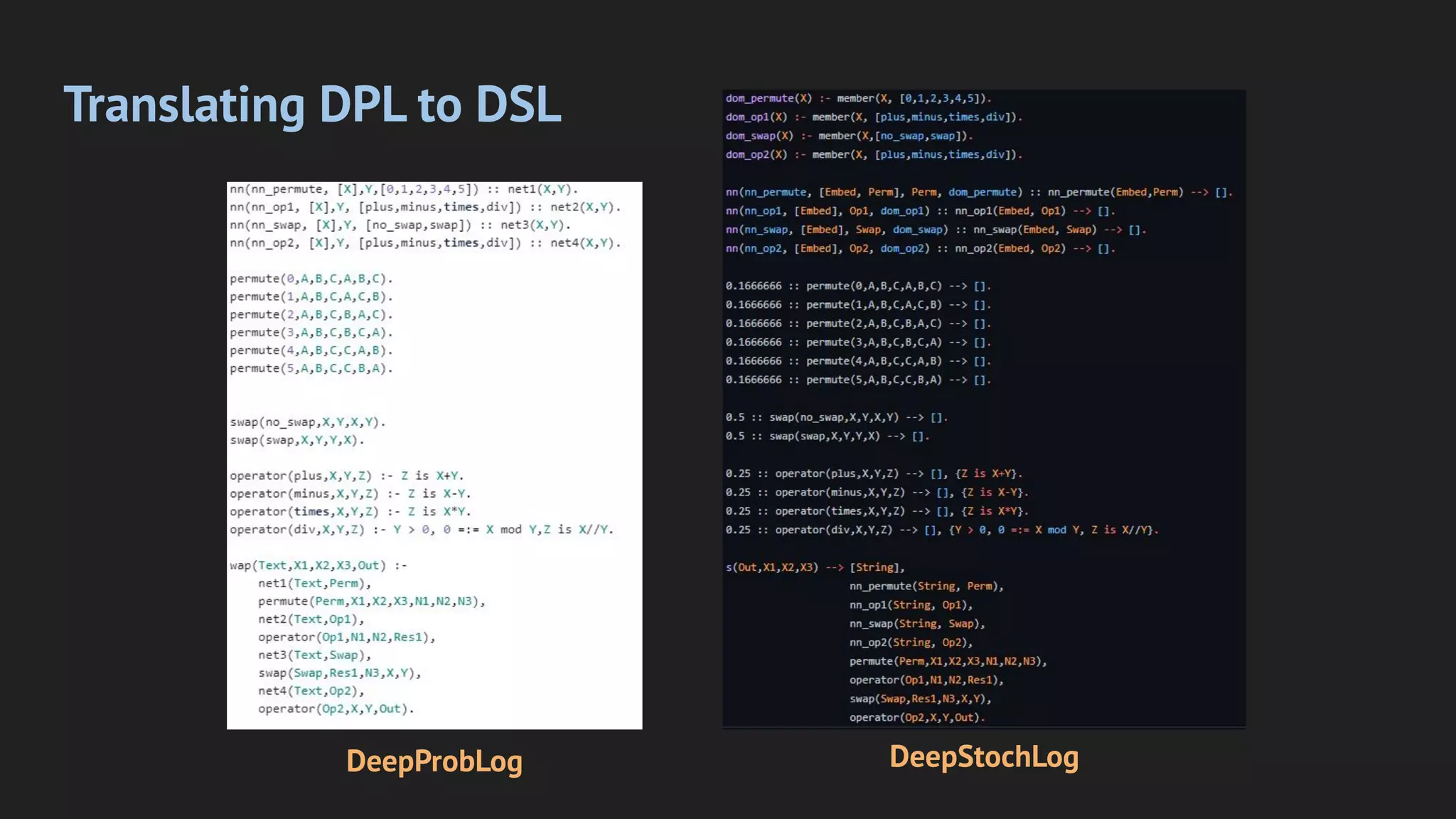
Enables fairly straightforward translation of DeepProbLog programs for a lot of tasks
DeepStochLog performs equally well as DeepProbLog: 96% accuracy](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/85/DeepStochLog-Neural-Stochastic-Logic-Programming-27-320.jpg)





![CFG: Context-Free Grammar
E --> N
E --> E, P, N
P --> [“+”]
N --> [“0”]
N --> [“1”]
…
N --> [“9”] 2 + 3 + 8
N
E
E
P N
E
P N
Useful for:
- Is sequence an element of the specified language?
- What is the “part of speech”-tag of a terminal
- Generate all elements of language](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-4-2048.jpg)
![PCFG: Probabilistic Context-Free Grammar
0.5 :: E --> N
0.5 :: E --> E, P, N
1.0 :: P --> [“+”]
0.1 :: N --> [“0”]
0.1 :: N --> [“1”]
…
0.1 :: N --> [“9”] 2 + 3 + 8
N
E
E
P N
E
P N
Useful for:
- What is the most likely parse for this sequence of terminals? (useful for ambiguous grammars)
- What is the probability of generating this string?
0.5
0.1
1
1
0.1
0.1
0.5
0.5
Probability of this parse = 0.5*0.5*0.5*0.1*1*0.1*1*0.1 = 0.000125
Always
sums
to
1
per
non-terminal](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-5-2048.jpg)
![DCG: Definite Clause Grammar
e(N) --> n(N).
e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
p --> [“+”].
n(0) --> [“0”].
n(1) --> [“1”].
…
n(9) --> [“9”]. 2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
Useful for:
- Modelling more complex languages (e.g. context-sensitive)
- Adding constraints between non-terminals thanks to Prolog power (e.g. through unification)
- Extra inputs & outputs aside from terminal sequence (through unification of input variables)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-6-2048.jpg)
![SDCG: Stochastic Definite Clause Grammar
0.5 :: e(N) --> n(N).
0.5 :: e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
1.0 :: p --> [“+”].
0.1 :: n(0) --> [“0”].
0.1 :: n(1) --> [“1”].
…
0.1 :: n(9) --> [“9”]. 2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
Useful for:
- Same benefits as PCFGs give to CFG (e.g. most likely parse)
- But: loss of probability mass possible due to failing derivations
0.5
0.1
1
1
0.1
0.1
0.5
0.5
Probability of this parse = 0.5*0.5*0.5*0.1*1*0.1*1*0.1 = 0.000125](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-7-2048.jpg)
![NDCG: Neural Definite Clause Grammar (= DeepStochLog)
Useful for:
- Subsymbolic processing: e.g. tensors as terminals
- Learning rule probabilities using neural networks
0.5 :: e(N) --> n(N).
0.5 :: e(N) --> e(N1), p, n(N2),
{N is N1 + N2}.
1.0 :: p --> [“+”].
nn(number_nn,[X],[Y],[digit]) :: n(Y) --> [X].
digit(Y) :- member(Y,[0,1,2,3,4,5,6,7,8,9]).
2 + 3 + 8
n(2)
e(2)
e(5)
p n(3)
e(13)
p n(8)
0.5
pnumber_nn
( =2)
1
1
0.5
0.5
pnumber_nn
( =3)
pnumber_nn
( =8)
Probability of this parse =
0.5*0.5*0.5*pnumber_nn
( =2)*1*pnumber_nn
( =3)*1*pnumber_nn
( =8)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-8-2048.jpg)
![DeepStochLog NDCG definition
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> g1
, …, gn
.
Where:
● nt is an atom
● g1
, …, gn
are goals (goal = atom or list of terminals & variables)
● I1
,…,Im
and O1
,…,OL
are variables occurring in g1
, …, gn
and are the
inputs and outputs of m
● D1
,…,DL
are the predicates specifying the domains of O1
,…,OL
● m is a neural network mapping I1
,…,Im
to probability distribution over
O1
,…,OL
(= over cross product of D1
,…,DL
)](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-9-2048.jpg)


![And/Or tree + semiring for different inference types
Probability of goal Most likely derivation
MAX
0.96
0.5
0.5
0.5 0.5 0.5 0.5
0.5
0.5
0.04
0.02
0.98
0.96 0.04
0.02
0.98
PG
(derives(e(1), [ , +, ]) = 0.1141 dmax
(e(1), [ , +, ] ) = argmaxd(e(t))=[ , +, ]
PG
(d(e(1))) = [0,+,1]](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-13-2048.jpg)




![Sibling of DeepProbLog, but different semantic (PLP vs SLP)
DeepProbLog: neural predicate probability (and thus implicitly over “possible worlds”)
nn(m,[I1
,…,Im
],O,[x1
,…,xL
]) :: neural_predicate(X).
DeepStochLog: neural grammar rule probability (and thus no disjoint sum problem)
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> g1
, …, gn
.
PLP vs SLP ~ akin to difference between random graph and random walk](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-18-2048.jpg)




![Classic grammars, but with MNIST images as terminals
T3: Well-formed brackets as input
(without parse). Task: predict parse.
T4: inputs are strings ak
bl
cm
(or
permutations of [a,b,c], and (k+l+m)%3=0).
Predict 1 if k=l=m, otherwise 0.
→ parse = ( ) ( ( ) ( ) )
= 1
= 0](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-23-2048.jpg)
![Natural way of expressing this grammar knowledge
brackets_dom(X) :- member(X, ["(",")"]).
nn(bracket_nn, [X], Y, brackets_dom) :: bracket(Y) --> [X].
t(_) :: s --> s, s.
t(_) :: s --> bracket("("), s, bracket(")").
t(_) :: s --> bracket("("), bracket(")").](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-24-2048.jpg)
![All power of Prolog DCGs (here: an
bn
cn
)
letter(X) :- member(X, [a,b,c]).
0.5 :: s(0) --> akblcm(K,L,M),
{K = L; L = M; M = K},
{K = 0, L = 0, M = 0}.
0.5 :: s(1) --> akblcm(N,N,N).
akblcm(K,L,M) --> rep(K,A),
rep(L,B),
rep(M,C),
{A = B, B = C, C = A}.
rep(0, _) --> [].
nn(mnist, [X], C, letter) :: rep(s(N), C) --> [X],
rep(N,C).](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-25-2048.jpg)

![Word Algebra Problem
T6: natural language text describing algebra problem, predict outcome
E.g."Mark has 6 apples. He eats 2 and divides the remaining among his 2 friends. How many apples did each friend get?"
Uses “empty body trick” to emulate SLP logic rules through SDCGs:
nn(m,[I1
,…,Im
],[O1
,…,OL
],[D1
,…,DL
]) :: nt --> [].
Enables fairly straightforward translation of DeepProbLog programs for a lot of tasks
DeepStochLog performs equally well as DeepProbLog: 96% accuracy](https://image.slidesharecdn.com/deepstochlogaaai-220403211729/75/DeepStochLog-Neural-Stochastic-Logic-Programming-27-2048.jpg)
















![[Pycon 2015] 오늘 당장 딥러닝 실험하기 제출용](https://cdn.slidesharecdn.com/ss_thumbnails/pycon2015-150913033231-lva1-app6892-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









































































