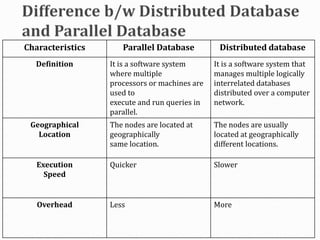
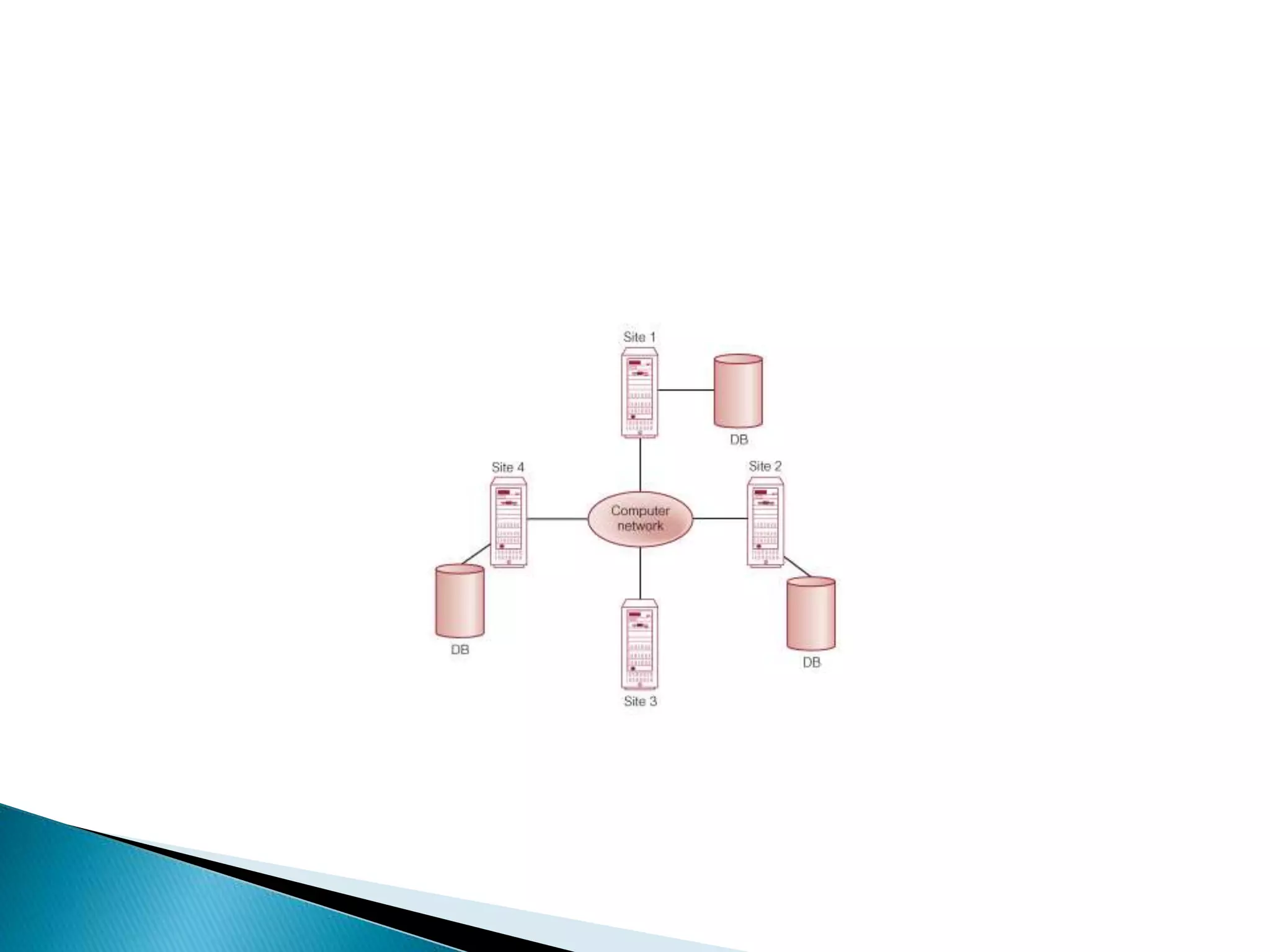
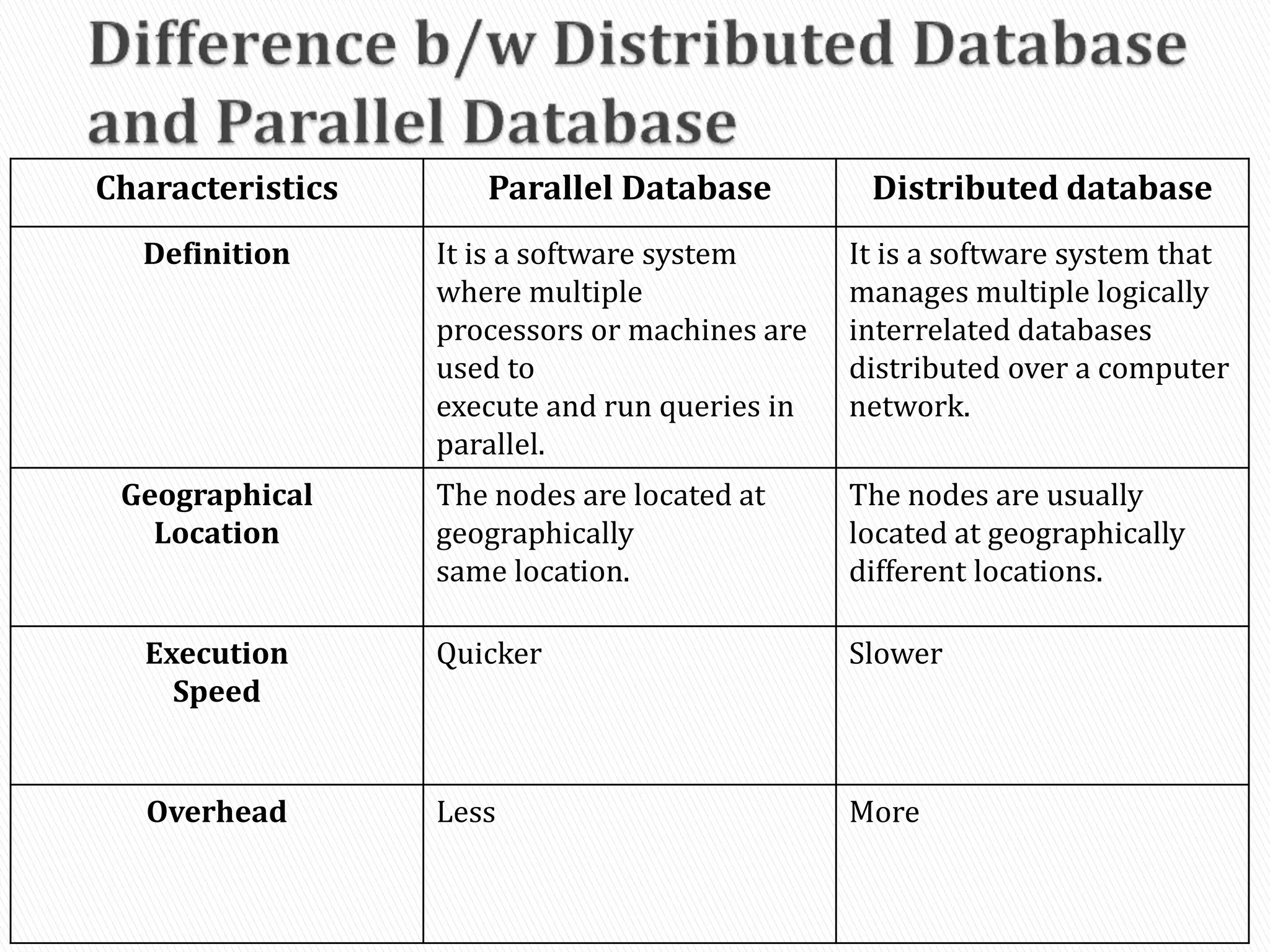
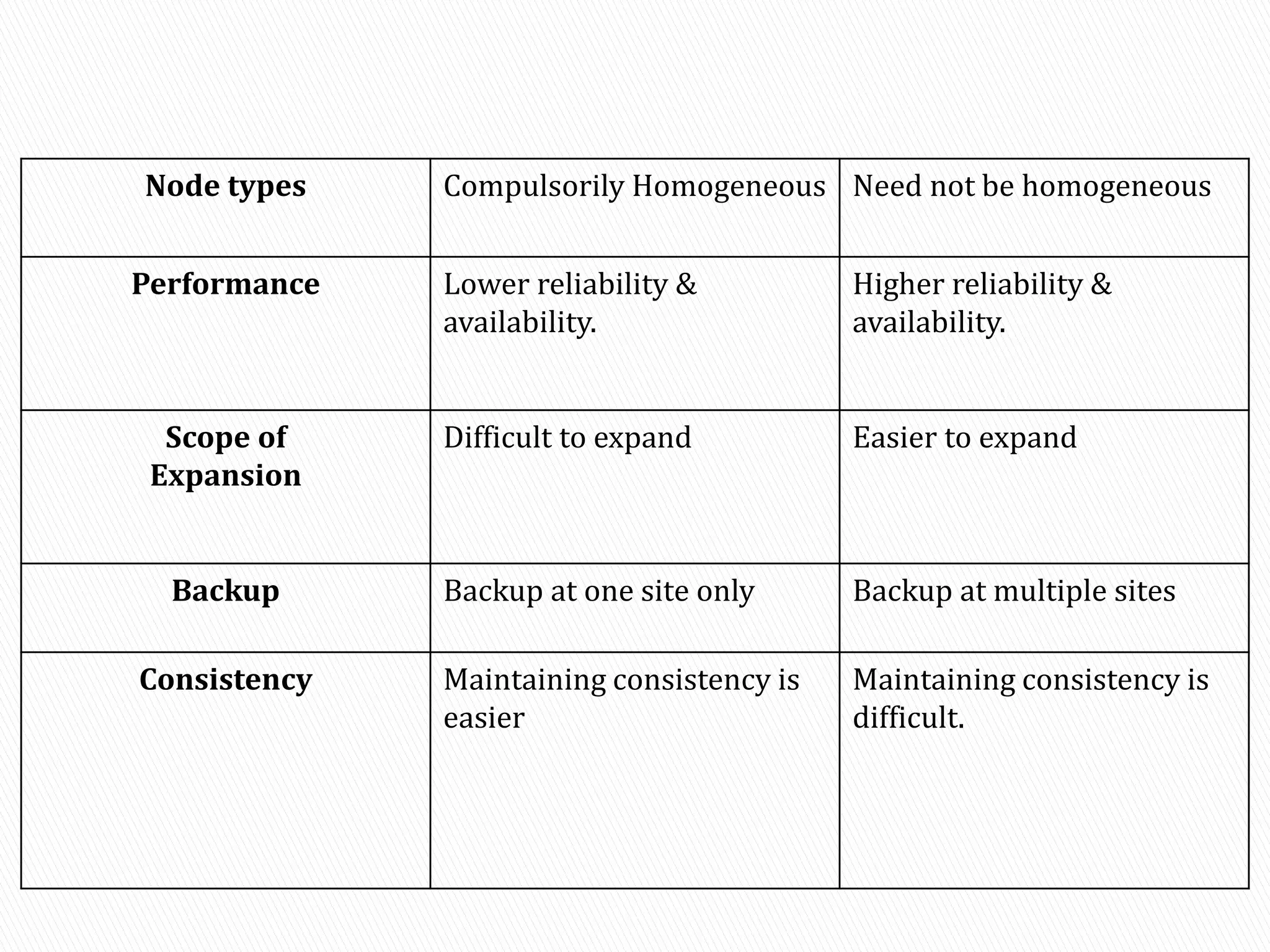
A distributed database is a collection of logically interrelated databases distributed over a computer network. A distributed database management system manages the distributed database and provides transparent access to users. Distributed databases can be either homogeneous, with identical software and compatibility across sites, or heterogeneous, with different schemas, software, and data structures at different sites. Key challenges of distributed databases include concurrency control, recovery from failures, and maintaining data consistency across multiple locations.