Distributed Database system in Computer Science.pptx
The document discusses distributed database systems, explaining their structure, goals, and the types, namely homogeneous and heterogeneous databases. It details data storage methods, including replication and fragmentation, along with their advantages and challenges, such as maintaining data consistency and recovery issues. Additionally, it highlights concurrency problems and various solutions, including locking mechanisms to manage multiple transactions effectively.
INTRODUCTION:
A distributedsystem is a collection of computer programs that utilize computational resources across
multiple, separate computation nodes to achieve a common, shared goal.
A Distributed System Contains multiple computers(nodes) that are separate but linked together using the
communication Network.
A distributed system is defined as set of autonomous Computers System that appears to its users as a single
coherent.
Example :Google search system. Each request is worked upon by hundreds of computers that crawl the web
and return the relevant results. To the user, Google appears to be one system, but it actually is multiple
computers working together to accomplish one single task (return the results to the search query).
Internet is a very large distributed System. -User at any location in network can use services email, file
transfer, www , etc.
Intranet is Small Part of Internet belonging to some organization separately administered to enforce local
Security Policies.
many small and Portable devices manufactured with advancement in technology is now integrated into
distributed System -Example Laptop, Mobile Phone, camera, Smart watch, etc.
mobile user can easily use resources available in network and services available in internet(e.g. google
drive ,Gmail, mobile connect to printer etc.)
4.
Goals of DistributedSystem :
Heterogeneity is hidden from the user .(operating systems , models(HP ,Dell ,Lenovo ,Apple ))
Heterogeneity: Hardware Devices, OS, Programming Language in DS must communicate with
each other and for that standard needs to be agreed and adopted middleware.(it is a s/w layer
which help distributed system to communicate with different heterogenous models.)
The manner in which Distributed system is Organized internally is hidden. Resources like Printer,
can be shared with multiple nodes rather than being restricted to just one.
Transparency: It means that any form of distributed System Should hide its distributed nature from
its user, appearing and functioning as a normal Centralized System.
Availability must be there rather than of failure.
Information / Load Sharing
5.
Different Types ofDistributed Database:
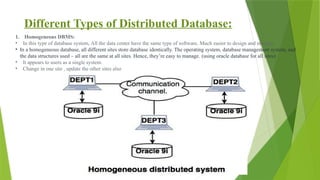
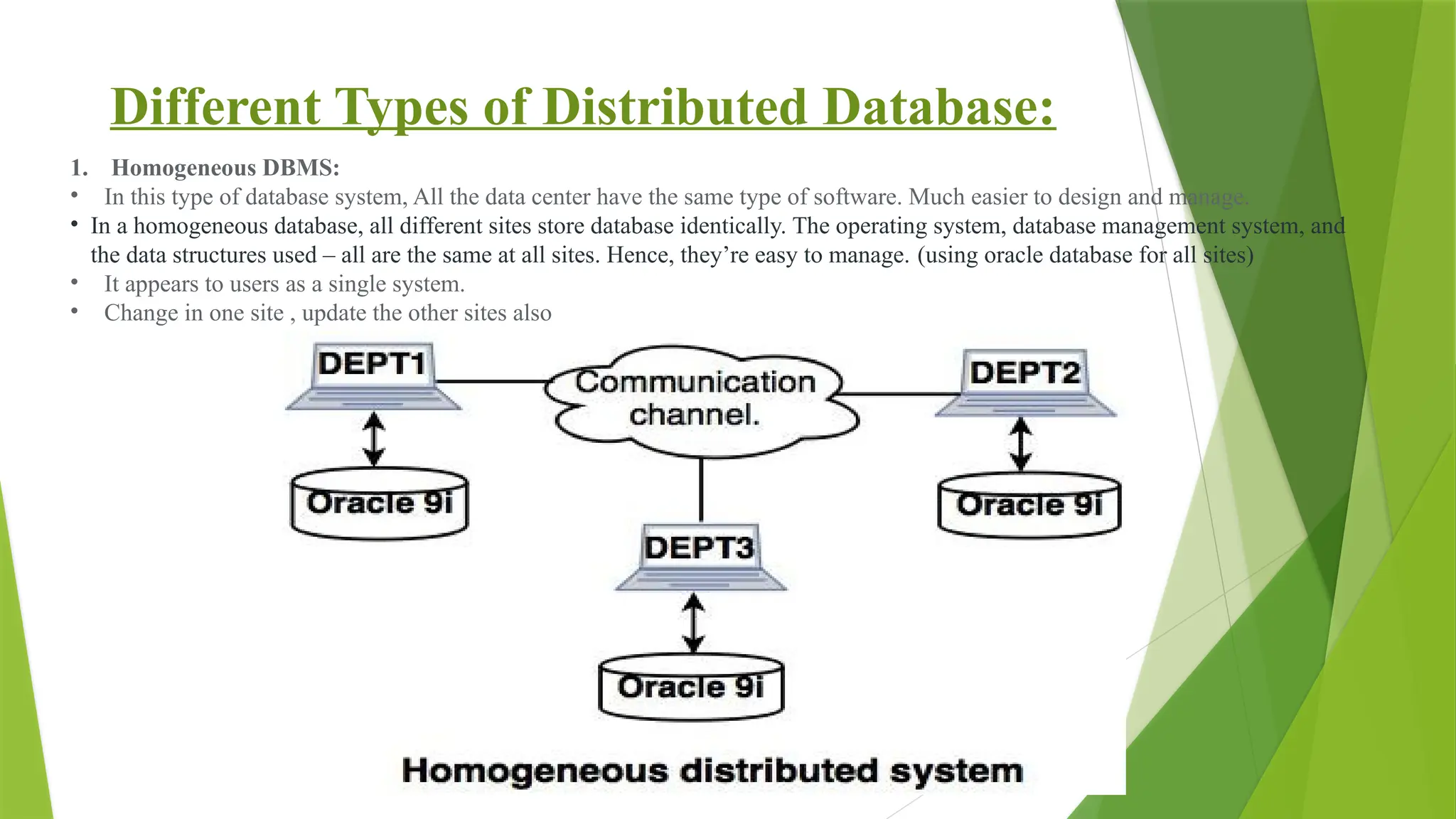
1. Homogeneous DBMS:
• In this type of database system, All the data center have the same type of software. Much easier to design and manage.
• In a homogeneous database, all different sites store database identically. The operating system, database management system, and
the data structures used – all are the same at all sites. Hence, they’re easy to manage. (using oracle database for all sites)
• It appears to users as a single system.
• Change in one site , update the other sites also
6.
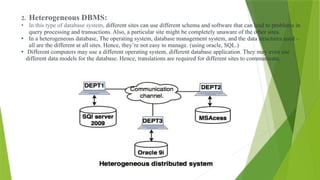
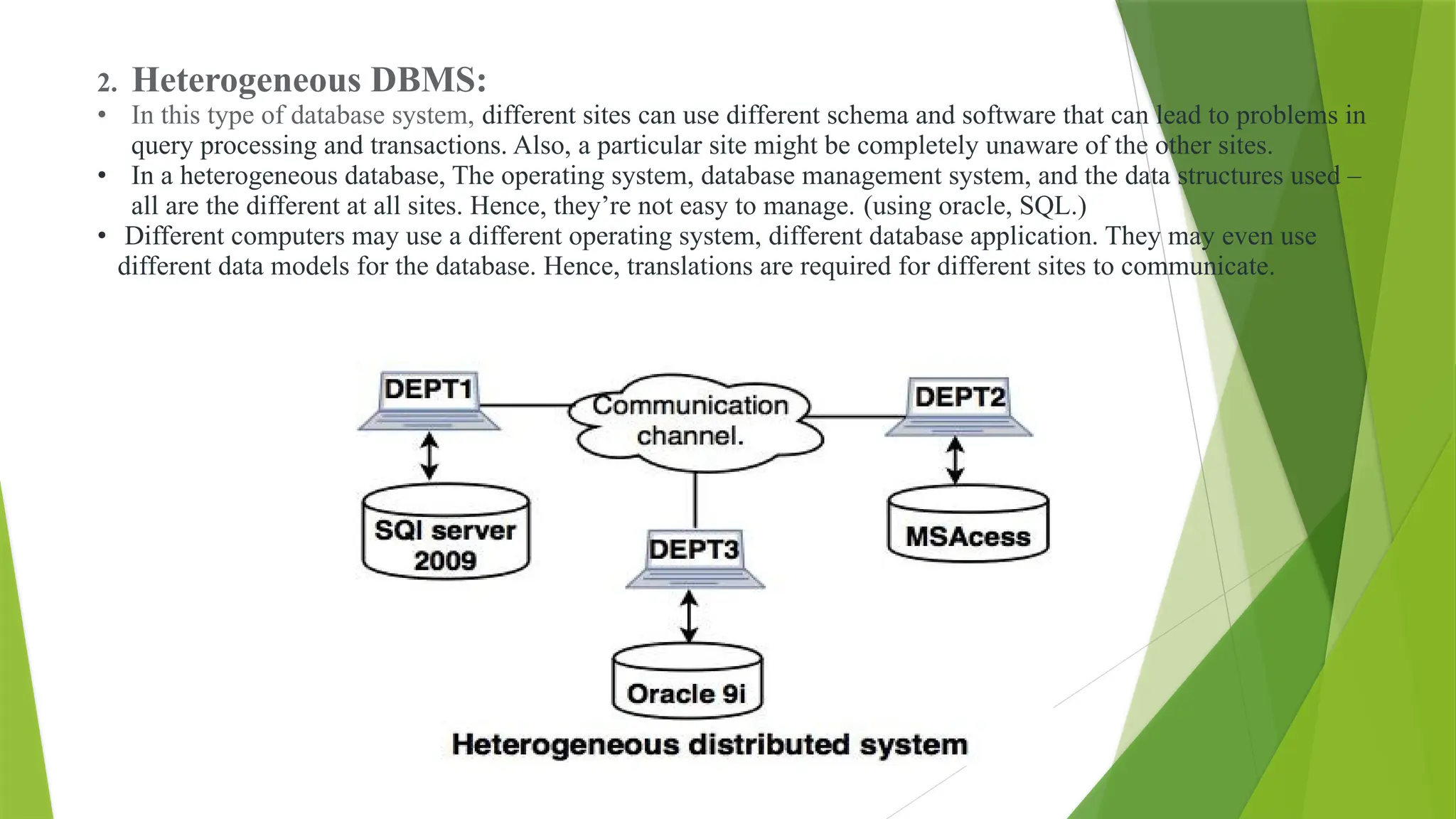
2. Heterogeneous DBMS:
•In this type of database system, different sites can use different schema and software that can lead to problems in
query processing and transactions. Also, a particular site might be completely unaware of the other sites.
• In a heterogeneous database, The operating system, database management system, and the data structures used –
all are the different at all sites. Hence, they’re not easy to manage. (using oracle, SQL.)
• Different computers may use a different operating system, different database application. They may even use
different data models for the database. Hence, translations are required for different sites to communicate.
7.
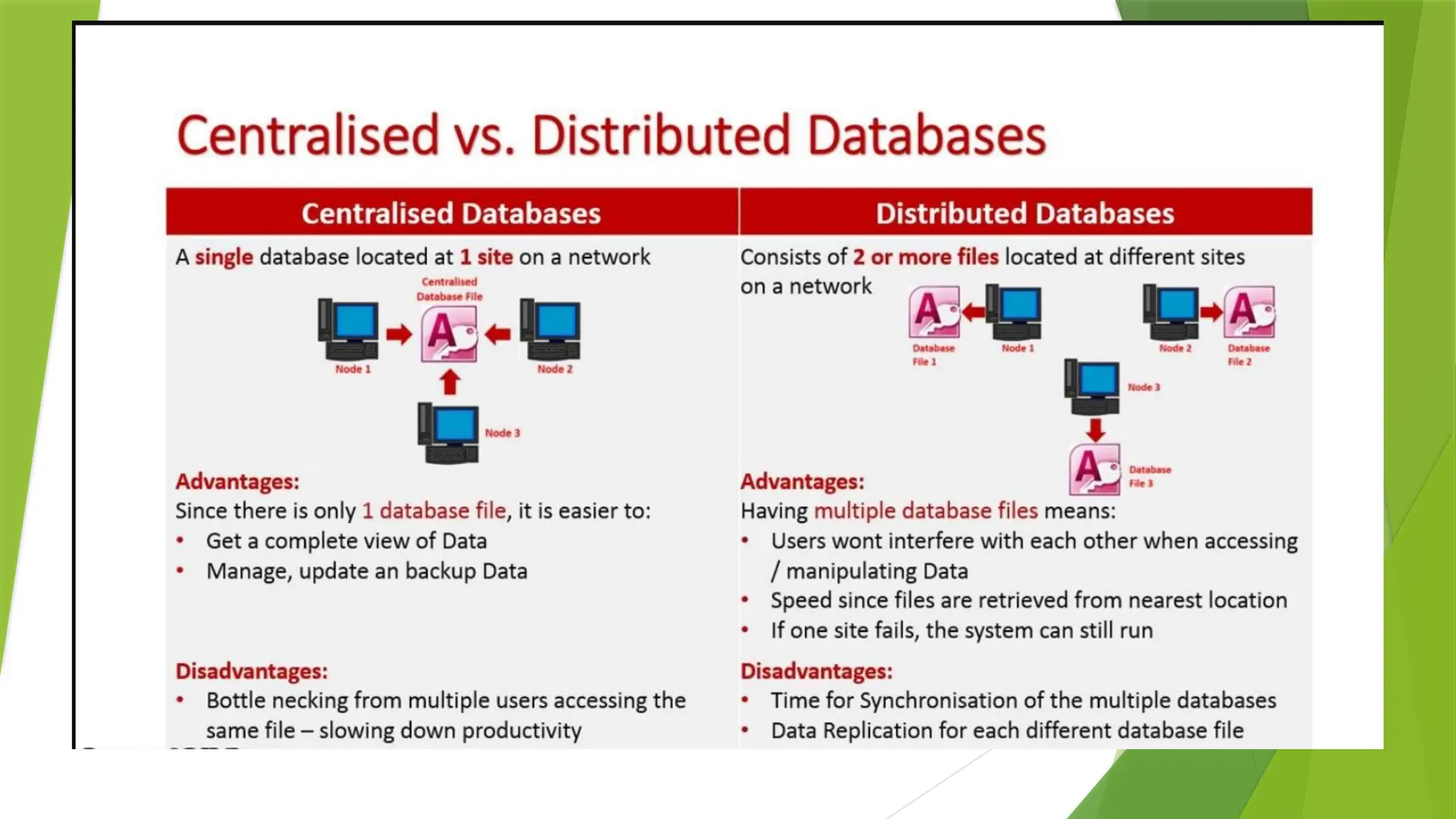
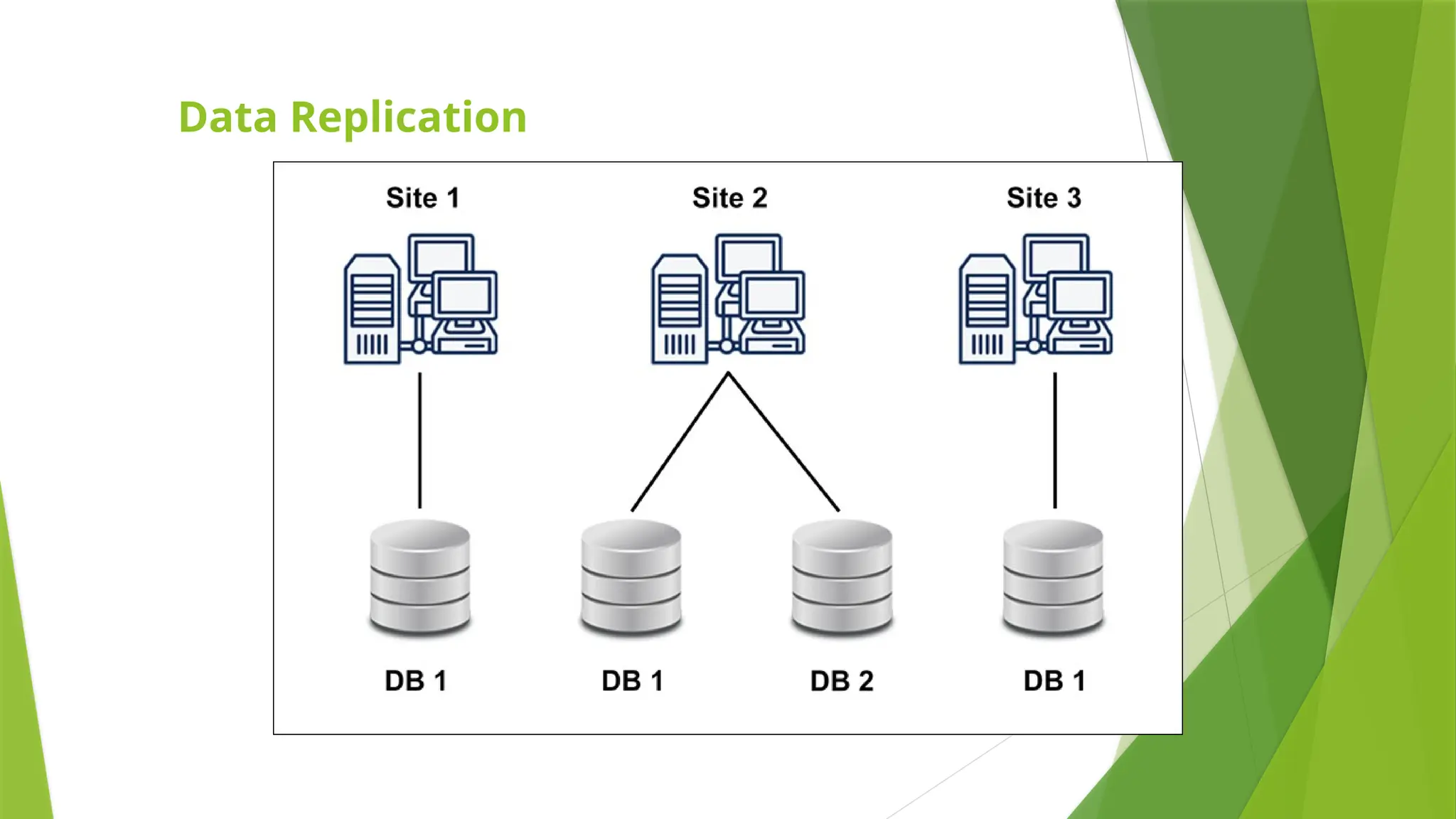
Distributed Data Storage:
•Thereare two ways in which data can be stored at different sites. These are,
• Replication.
• Fragmentation.
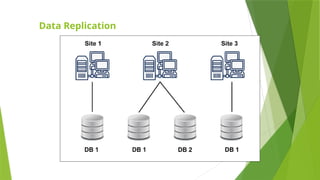
Replication
•As the name suggests, the system stores copies of data at different sites. If an entire database is
available on multiple sites, it is a fully redundant(having several copies of same data) database.
•The advantage of data replication is that it increases availability of data on different sites. As the data is
available at different sites, queries can be processed parallelly.
•However, data replication has some disadvantages as well. Data needs to be constantly updated and
synchronized with other sites, if any site fails to achieve it then it will lead to inconsistencies in the
database. Availability of data is highly benefitted from Replication.
•Constant updating complicates concurrency control and it is also overhead for the servers.
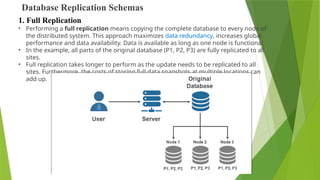
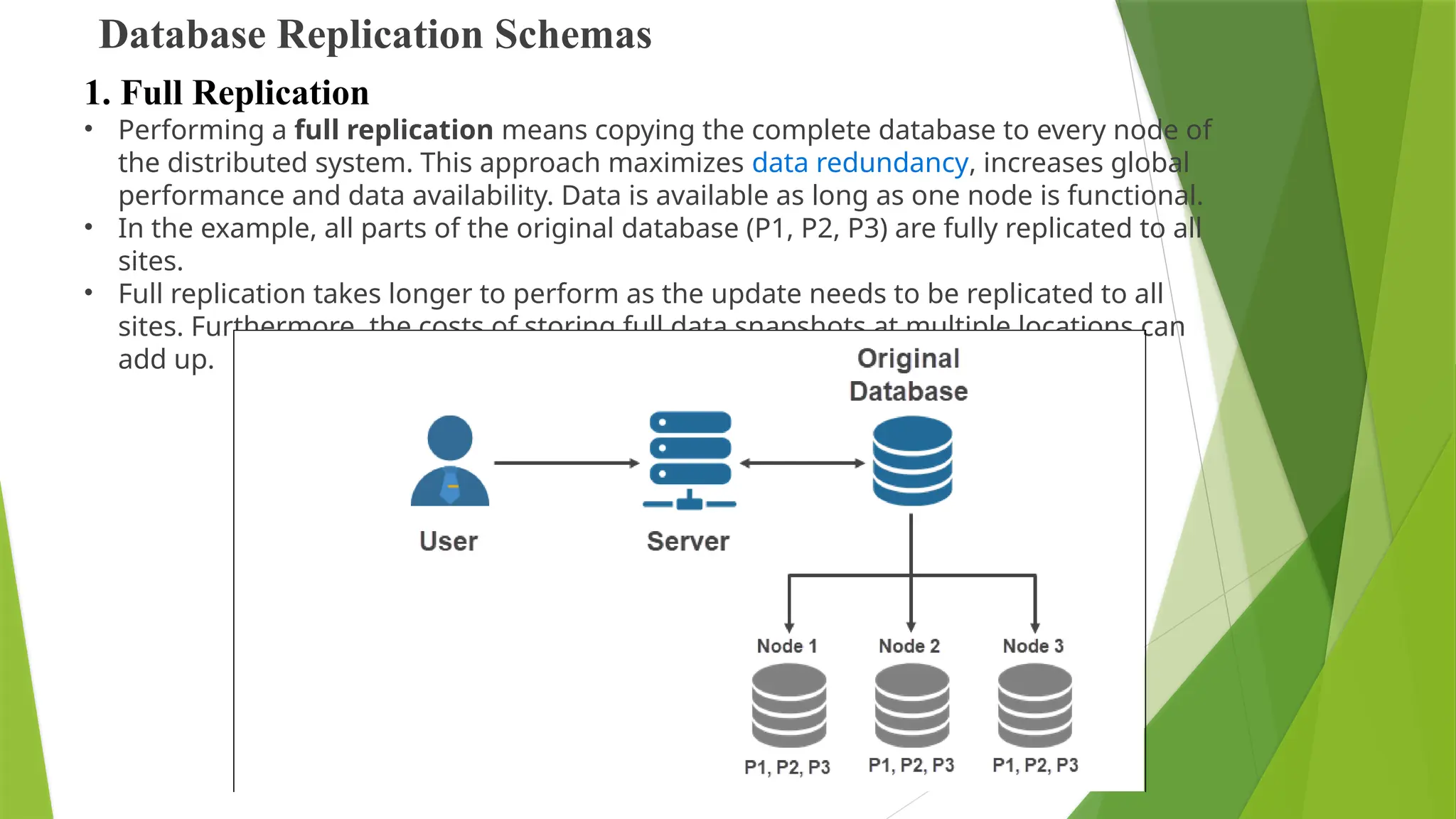
Database Replication Schemas
•Performing a full replication means copying the complete database to every node of
the distributed system. This approach maximizes data redundancy, increases global
performance and data availability. Data is available as long as one node is functional.
• In the example, all parts of the original database (P1, P2, P3) are fully replicated to all
sites.
• Full replication takes longer to perform as the update needs to be replicated to all
sites. Furthermore, the costs of storing full data snapshots at multiple locations can
add up.
1. Full Replication
10.
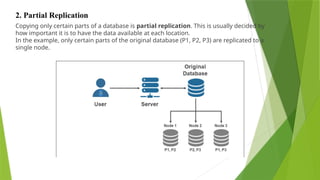
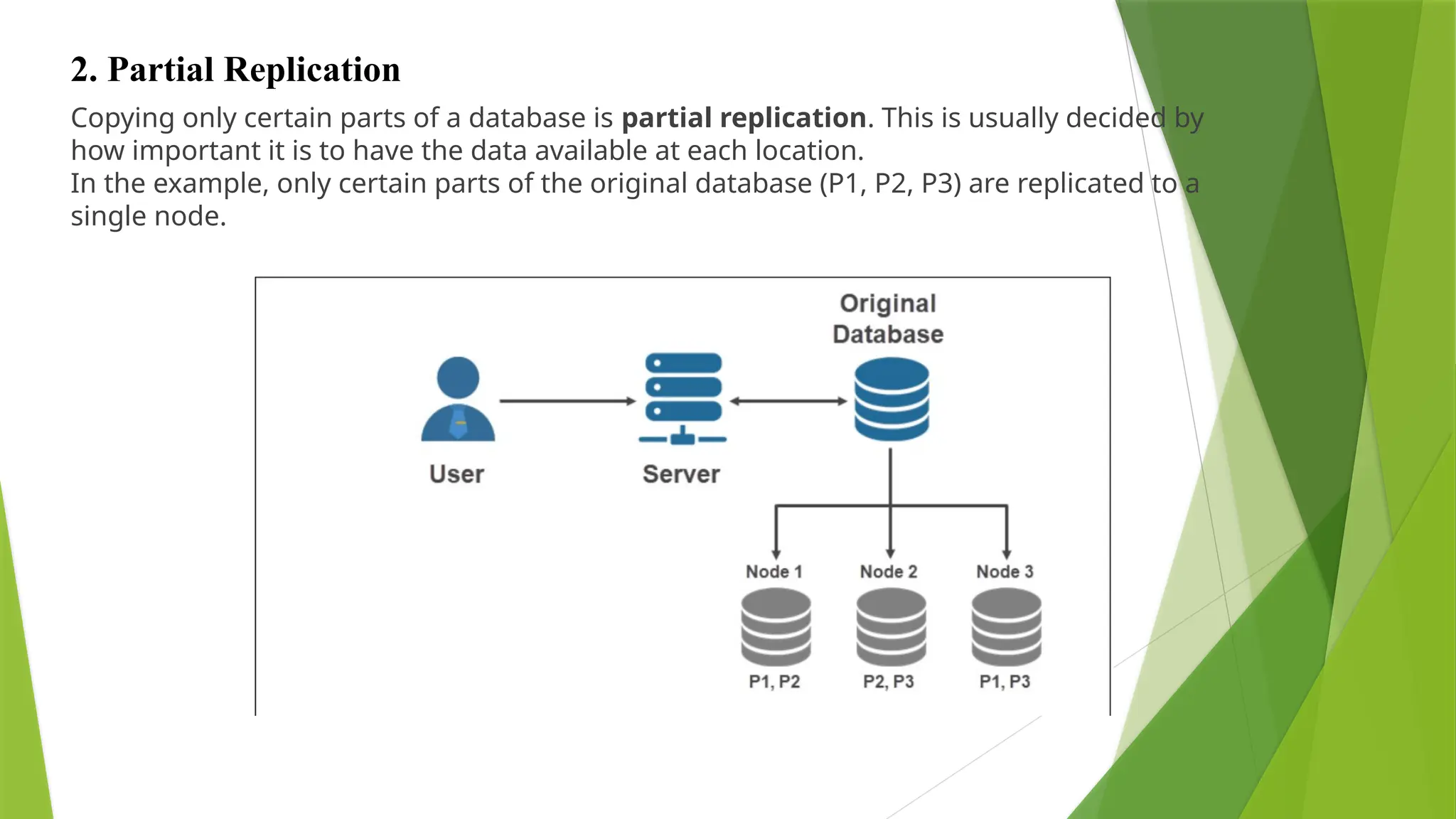
Copying only certainparts of a database is partial replication. This is usually decided by
how important it is to have the data available at each location.
In the example, only certain parts of the original database (P1, P2, P3) are replicated to a
single node.
2. Partial Replication
11.
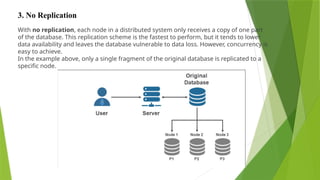
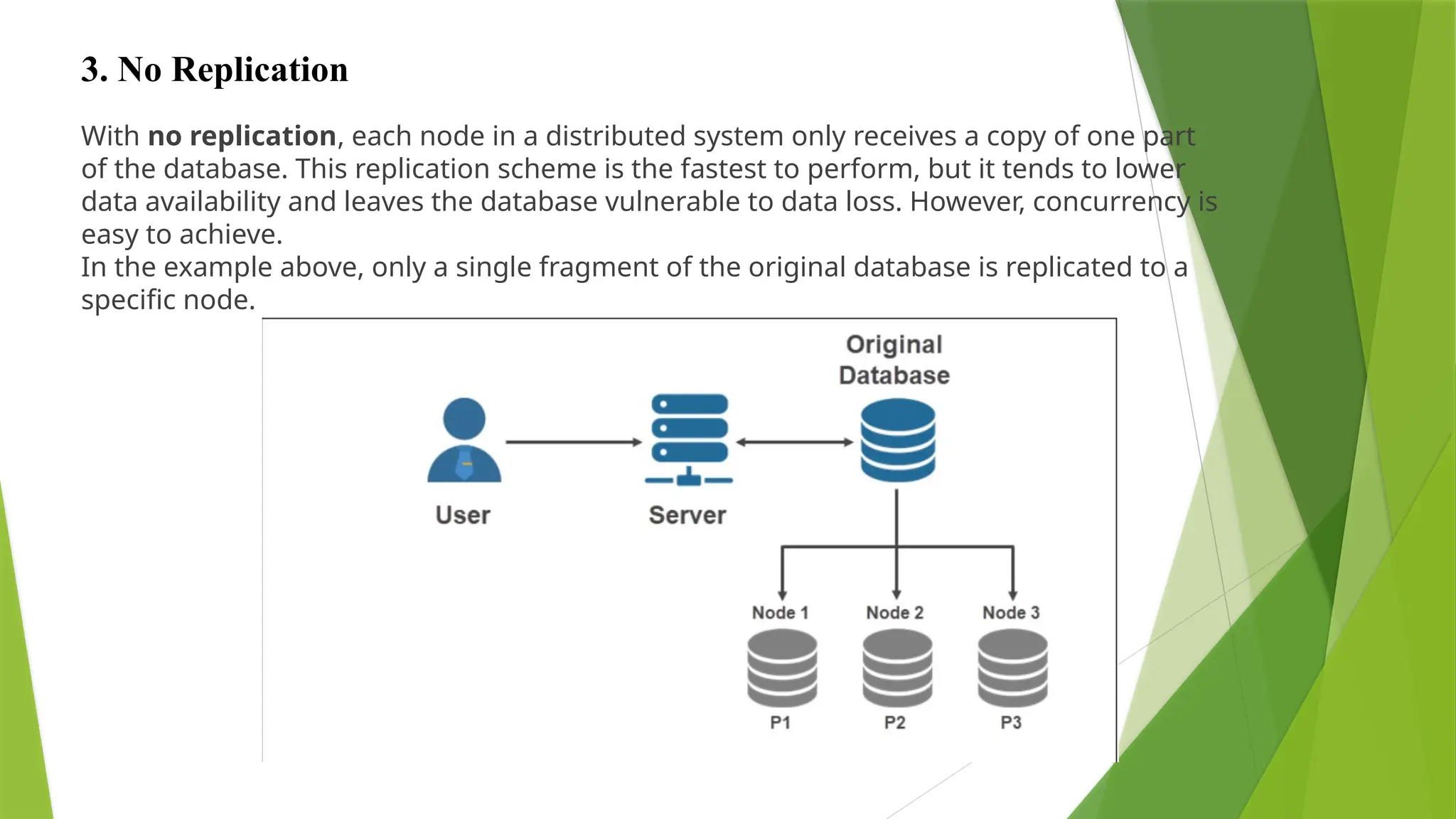
With no replication,each node in a distributed system only receives a copy of one part
of the database. This replication scheme is the fastest to perform, but it tends to lower
data availability and leaves the database vulnerable to data loss. However, concurrency is
easy to achieve.
In the example above, only a single fragment of the original database is replicated to a
specific node.
3. No Replication
12.
Advantages of DataReplication
•Improve performance. Having the same data in multiple locations means a user can
retrieve data from the nearest server and increasing performance.
•Improve multi-user support. Data replication helps with query execution, especially when
multiple users are accessing the database.
•Improve availability. Several users can access and manage data in a distributed database
without getting in each other's way.
Disadvantages of Data Replication
Data replication poses several challenges:
•It can require a lot of storage space, especially for full replications. This can create high
costs or reduce performance if many replicas need to be updated simultaneously.
•Maintaining data consistency is difficult when using methods like merge or peer-to-peer
replication.
13.
Distributed Data Storage:.
Fragmentation
•InFragmentation, the relations are fragmented, which means they are split into smaller parts.
•Each of the fragments is stored on a different site, where it is required. In this, the data is not
replicated, and no copies are created. Consistency of data(accuracy, completeness, and
correctness of data stored in a database) is highly benefitted from Fragmentation.
•The prerequisite for fragmentation is to make sure that the fragments can later be reconstructed
into the original relation without losing any data.
•Consistency is not a problem here as each site has a different piece of information.
•There are two types of fragmentation,
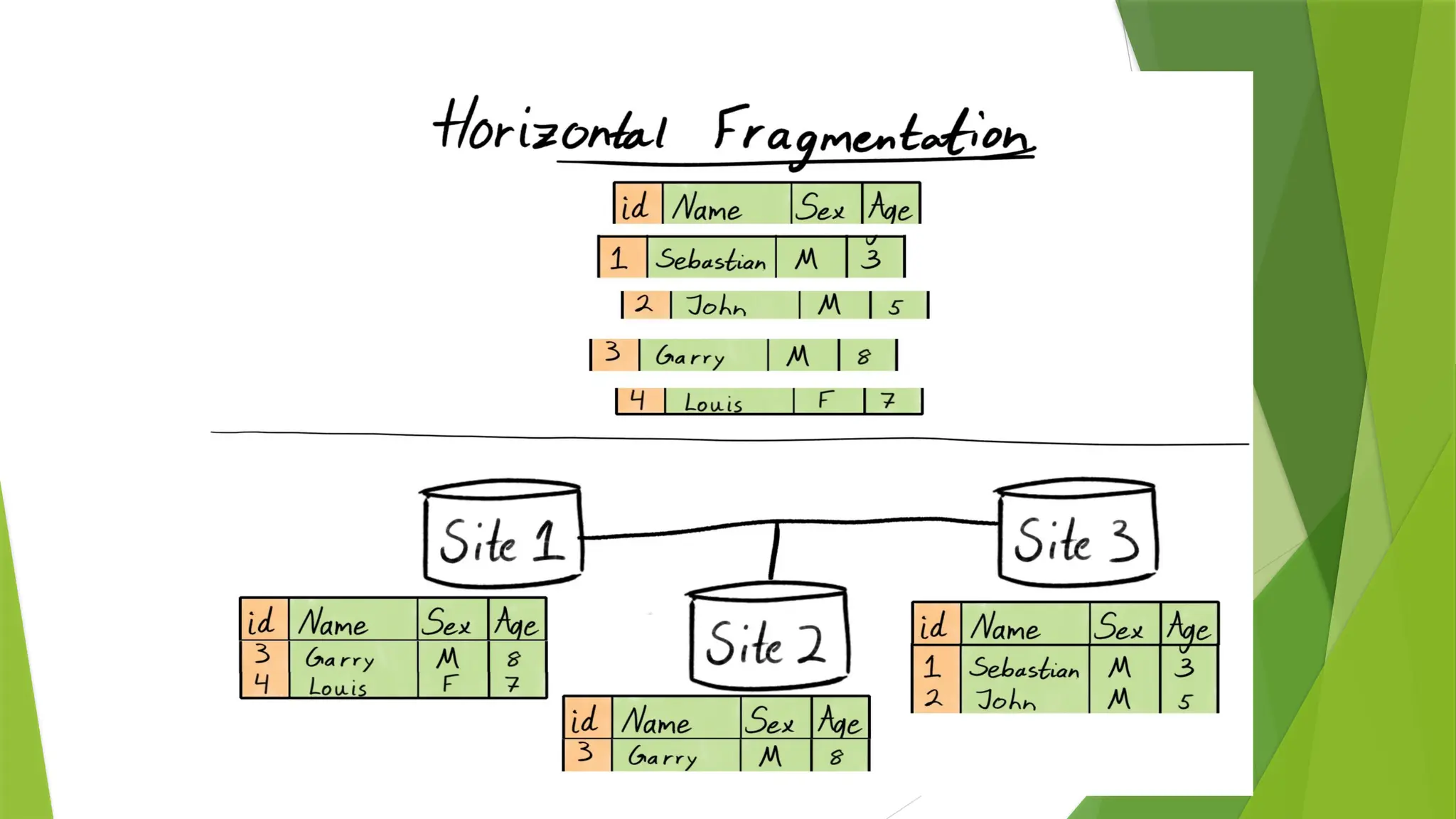
• Horizontal Fragmentation – Splitting by rows.
• Vertical fragmentation – Splitting by columns.
14.
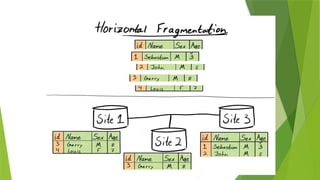
Horizontal Fragmentation –Splitting by rows.
•It divides a table horizontally into a group of rows to create subset of tables.
•Horizontal fragmentation refers to the process of dividing a table horizontally by assigning each row (or
a group of rows) of relation to one or more fragments. These fragments can then be assigned to different
sites in the distributed system.
E.g.- Account (ACC No, Balance, Branch_Name).
Select * from Account where Branch_Name = “Pune“;
here we select only one row. Means it is a process in which fragmenting a single/multiple row
using conditions.
The reconstruction of the original fragmentation by performing UNION.
16.
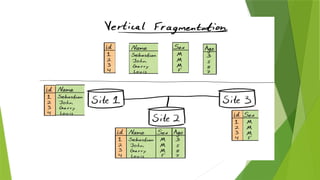
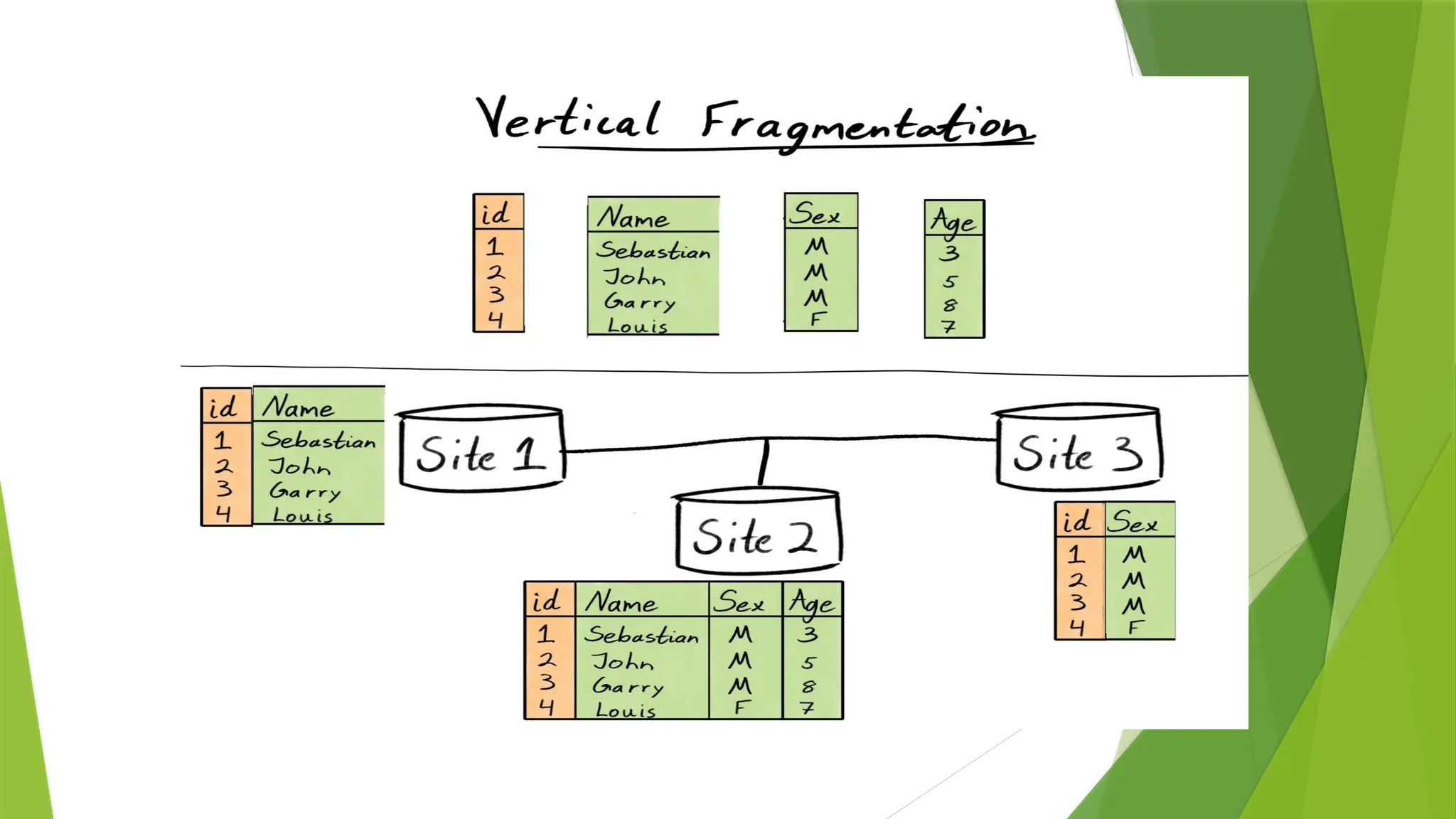
Vertical fragmentation –Splitting by columns.
•It divides a table vertically into a group of columns to create subset of tables.
•Vertical fragmentation refers to the process of dividing a table vertically by assigning
each column (or a group of columns) of relation to one or more fragments. These
fragments can then be assigned to different sites in the distributed system.
E.g.- Account (ACC_No, Balance, Branch_Name).
Select ACC_No, Branch_Name from Account;
here we select columns . Means it is a process in which fragmenting a single/multiple
columns using conditions.
Reconstruction of vertical fragmentation is performed by using FULL OUTER JOIN operation on
fragmentation.
18.
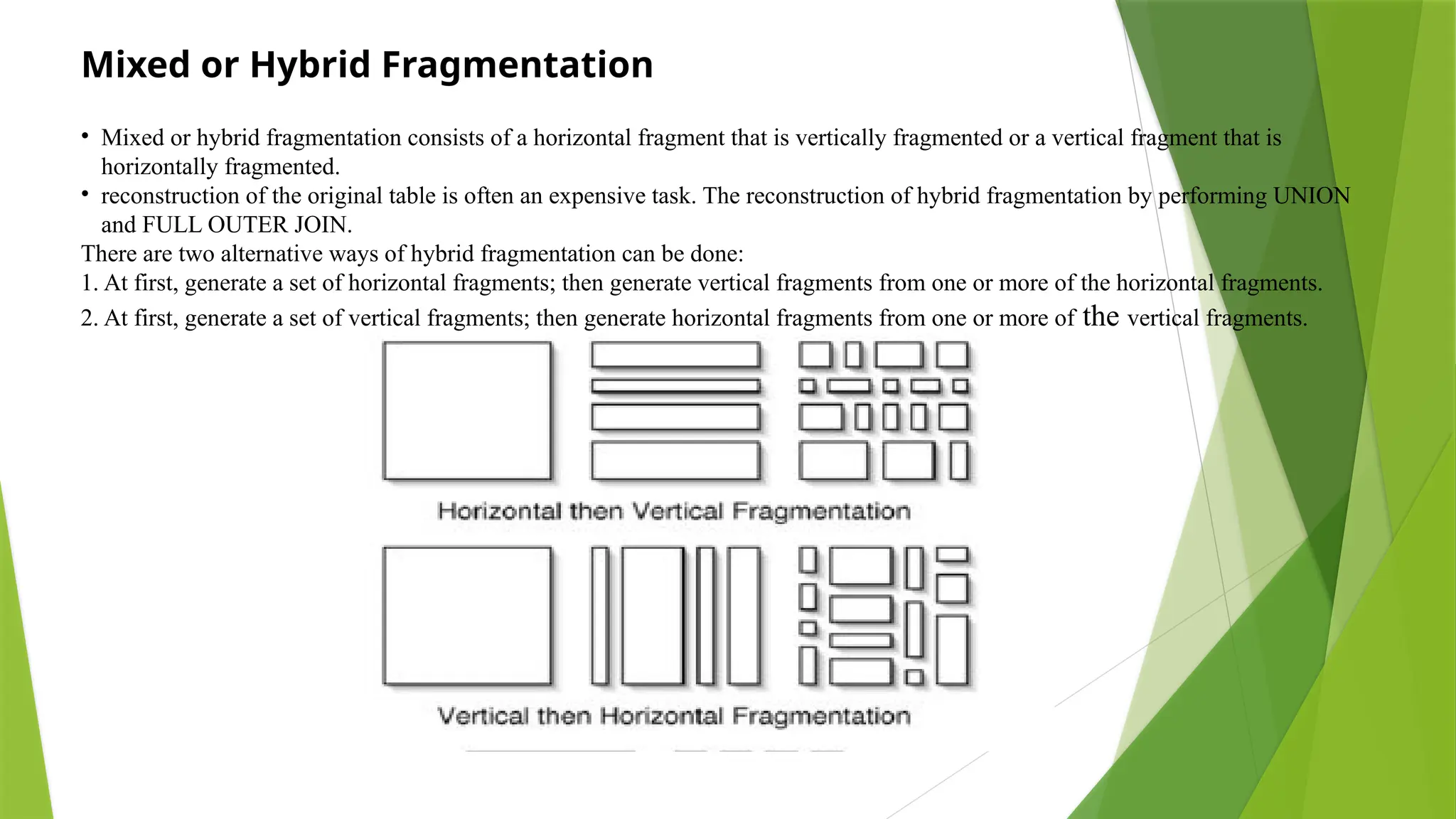
Mixed or HybridFragmentation
• Mixed or hybrid fragmentation consists of a horizontal fragment that is vertically fragmented or a vertical fragment that is
horizontally fragmented.
• reconstruction of the original table is often an expensive task. The reconstruction of hybrid fragmentation by performing UNION
and FULL OUTER JOIN.
There are two alternative ways of hybrid fragmentation can be done:
1. At first, generate a set of horizontal fragments; then generate vertical fragments from one or more of the horizontal fragments.
2. At first, generate a set of vertical fragments; then generate horizontal fragments from one or more of the vertical fragments.
19.
Recovery in Distributed
System:
•Recoveryis the most complicated process in distributed databases. Recovery of a
failed system in the communication network is very difficult.
For example:
Consider that, location A sends message to location B and expects response from B
but B is unable to receive it. There are several problems for this situation which are
as follows.
Message was failed due to failure in the network.
•Location B sent message but not delivered to location A.
•Location B crashed down.
•So it is actually very difficult to find the cause of failure in a large communication
network.
•Distributed commit in the network is also a serious problem which can affect the
recovery in a distributed databases.
20.
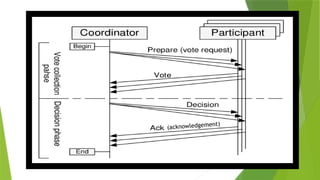
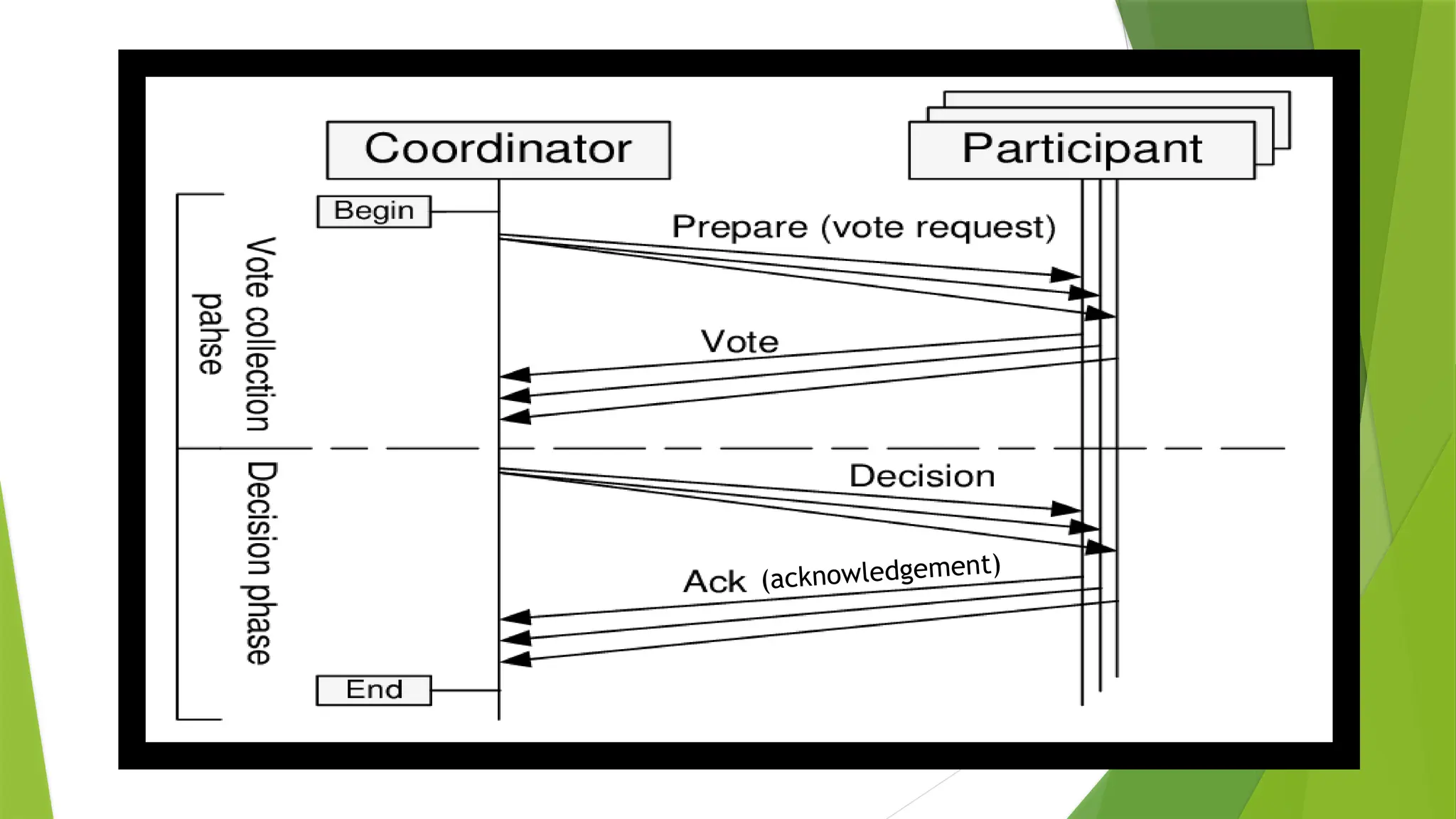
1. Two-phase commitprotocol in Distributed databases
•Two-phase protocol is a type of atomic commitment protocol. This is a distributed algorithm which can
coordinate all the processes that participate in the database and decide to commit or terminate the
transactions. The protocol is based on commit and terminate action.
•The two-phase protocol ensures that all participant which are accessing the database server can receive
and implement the same action (Commit or terminate), in case of local network failure.
•Two-phase commit protocol provides automatic recovery mechanism in case of a system failure.
•Commit request:
In commit phase the coordinator attempts to prepare all cohorts(a group of users ) and take necessary steps
to commit or terminate the transactions.
•Commit phase:
The commit phase is based on voting of cohorts and the coordinator decides to commit or terminate the
transaction.
Concurrency Problem: Concurrencyproblems are common problems faced while
maintaining any database management systems. Concurrency problems occur when
multiple transactions are being executed on the same database in unrestricted
problems. Types of concurrency problems in DBMS are as follows:
• i)Lost Update Problem
• ii)Temporary Update Problem(Dirty Read Problem)
• iii)Unrepeatable Read Problem
2. Concurrency control
problems
23.
I) Lost UpdateProblem:
•A lost update problem occurs due to the update of the same record by two different
transactions at the same time.
lost update problem using an example.
Here is a scenario, two transactions A and B are performing operations on the same
record in a Database.
Let's understand the transactions being performed in the above image:
1.X = 100
2.Transaction A is reading record X = 100 and adding 15 to X, but this transaction is not
yet reflected on DB. As write operation is not performed. (Result temp_X = 115)
3.Transaction B also reads X but here it is not getting updated value after transaction A.
Hence, X = 100. And subtracting 25 from X. And write commit operation is performed
on X. Hence, X = 75
4.Write commit operation for transaction A is performed. Hence X = 115
5.Here, the actual results of transactions A and B should be: X = 100, X after transaction
A: X = 115, Transaction B begins: X = 115, X after transaction B: X = 95.
6.After performing transactions A and B value of X should have been X = 95.
7.But due to a lost update problem the result of Transaction B is lost and the final
result is X = 115.
The dirty readproblem in DBMS occurs when a transaction reads the data that has been updated by
another transaction that is still uncommitted. It arises due to multiple uncommitted transactions
executing simultaneously.
Example: Consider two transactions A and B performing read/write operations on a data DT in
the database DB. The current value of DT is 1000: The following table shows the read/write
operations in A and B transactions.
Transaction A reads the value of data DT as 1000 and modifies it to 1500 which gets stored in the
temporary buffer. The transaction B reads the data DT as 1500 and commits it and the value of DT
permanently gets changed to 1500 in the database DB. Then some server errors occur in
transaction A and it wants to get rollback to its initial value, i.e., 1000 and then the dirty read
Time A B
T1 READ(DT) ------
T2 DT=DT+500 ------
T3 WRITE(DT) ------
T4 ------ READ(DT)
T5 ------ COMMIT
T6 ROLLBACK ------
II). Temporary Update Problem
26.
III). Unrepeatable ReadProblem
The unrepeatable read problem occurs when two or more different values of the same
data are read during the read operations in the same transaction.
Example: Consider two transactions A and B performing read/write operations on a data
DT in the database DB. The current value of DT is 1000: The following table shows the
read/write operations in A and B transactions.
Transaction A and B initially read the value of DT as 1000. Transaction A modifies the value
of DT from 1000 to 1500 and then again transaction B reads the value and finds it to be
1500. Transaction B finds two different values of DT in its two different read operations.
Time A B
T1 READ(DT) ------
T2 ------ READ(DT)
T3 DT=DT+500 ------
T4 WRITE(DT) ------
T5 ------ READ(DT)
27.
3. Concurrency Controlsin distributed databases
There are two different ways of making distinguish copy of data by applying:
Lock based protocol
A lock is applied to avoid concurrency problem between two transaction in such a way that the lock is
applied on one transaction and other transaction can access it only when the lock is released. The lock is
applied on write or read operations. It is an important method to avoid deadlock.
1) Shared lock system (Read lock)
The transaction can activate shared lock on data to read its content. The lock is shared in such a way that
any other transaction can activate the shared lock on the same data for reading purpose.
For example, consider a case where initially A=100 and there are two transactions which are reading A. If
one of transaction wants to update A, in that case other transaction would be reading wrong value.
However, Shared lock prevents it from updating until it has finished reading
2) Exclusive lock
The transaction can activate exclusive lock on a data to read and write operation. In this system, no other
transaction can activate any kind of lock on that same data.
In simple words if transaction T1 is reading a data item A, then same data item A can be read by another
transaction T2 but cannot be written by another transaction.