Download as PDF, PPTX








![Deep Learning at Salesforce
Discusses
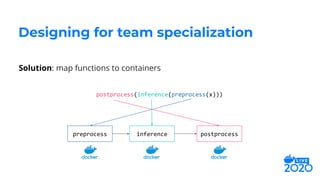
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/85/Distributed-Deep-Learning-with-Docker-at-Salesforce-9-320.jpg)
![Deep Learning at Salesforce
Discusses
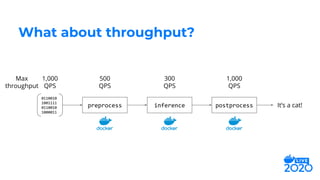
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”
Data Science Team](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/85/Distributed-Deep-Learning-with-Docker-at-Salesforce-10-320.jpg)
![Deep Learning at Salesforce
Discusses
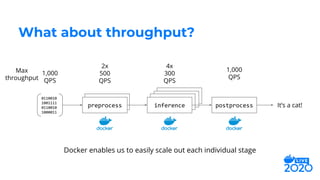
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”
Data Science Team Systems Team](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/85/Distributed-Deep-Learning-with-Docker-at-Salesforce-11-320.jpg)




















![Deep Learning at Salesforce
Discusses
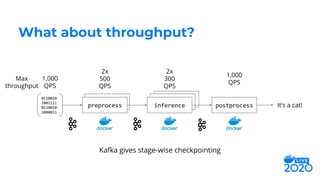
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/75/Distributed-Deep-Learning-with-Docker-at-Salesforce-9-2048.jpg)
![Deep Learning at Salesforce
Discusses
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”
Data Science Team](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/75/Distributed-Deep-Learning-with-Docker-at-Salesforce-10-2048.jpg)
![Deep Learning at Salesforce
Discusses
cat
preprocess
[0.2, 0.71, 0.89, 0.6]
[0.85, 0.15]
inference
postprocess“Hello! My
cat is
friendly.”
Data Science Team Systems Team](https://image.slidesharecdn.com/jeffhajewski-distributeddeeplearning-200529022235/75/Distributed-Deep-Learning-with-Docker-at-Salesforce-11-2048.jpg)



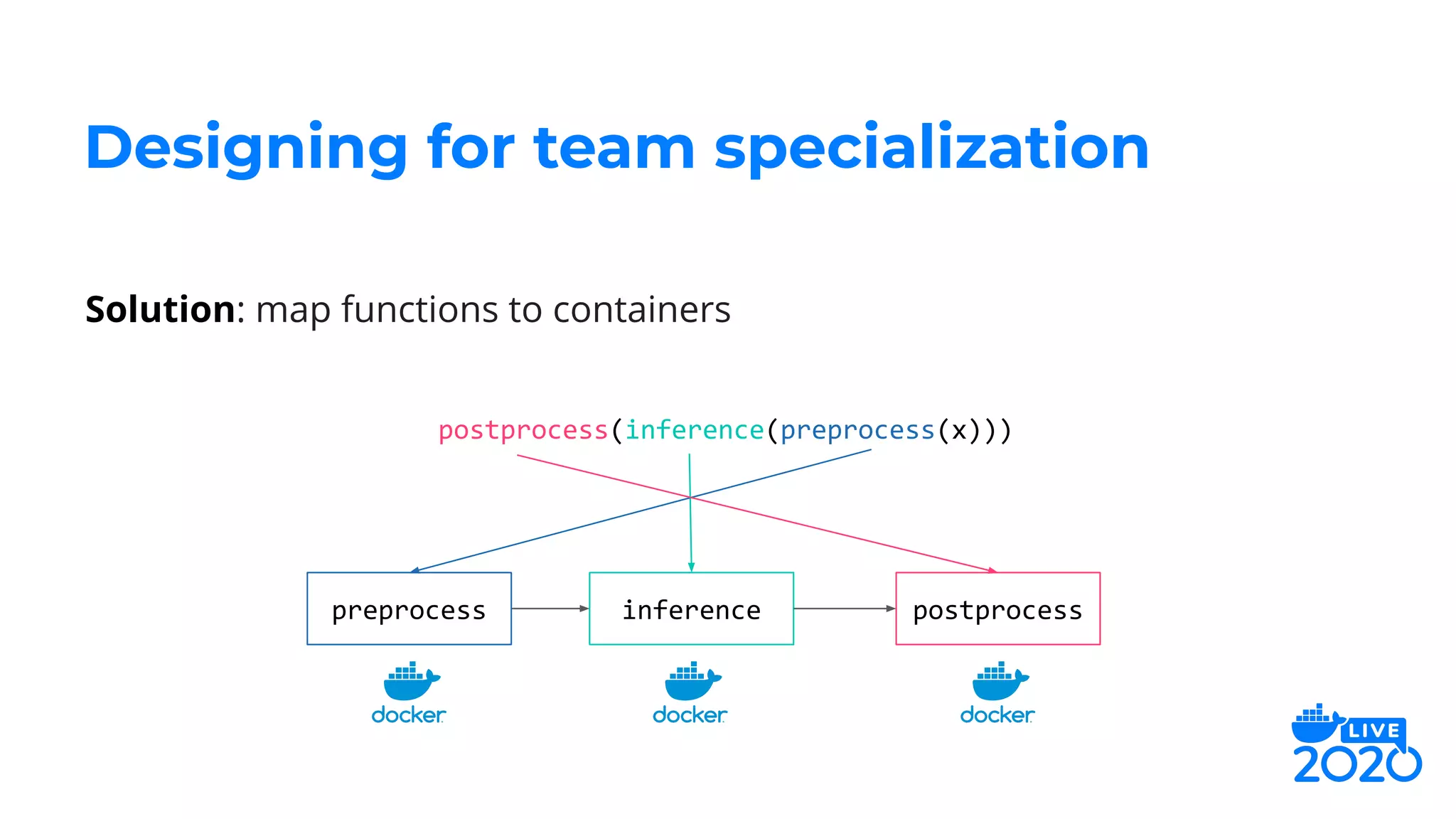
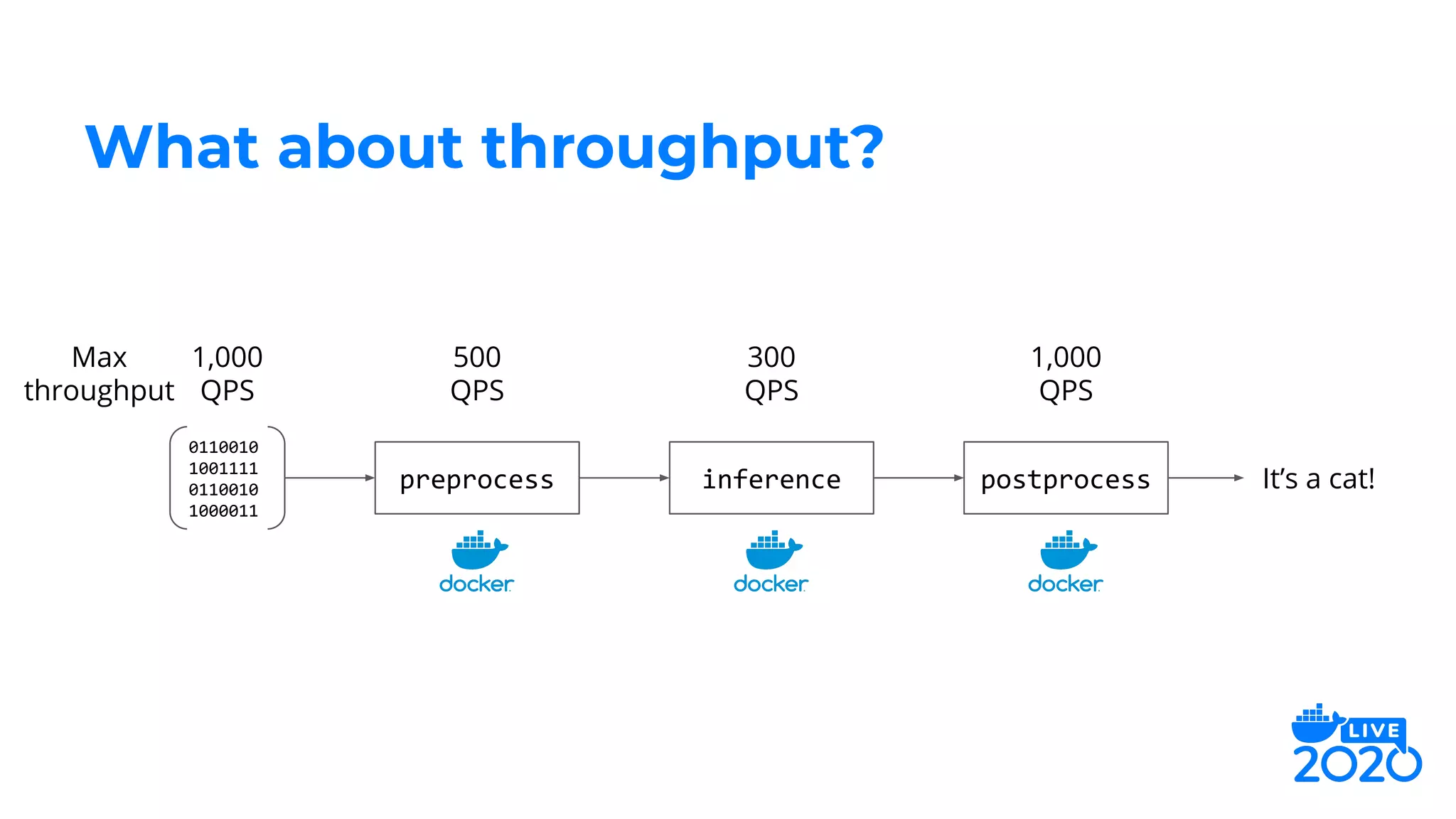
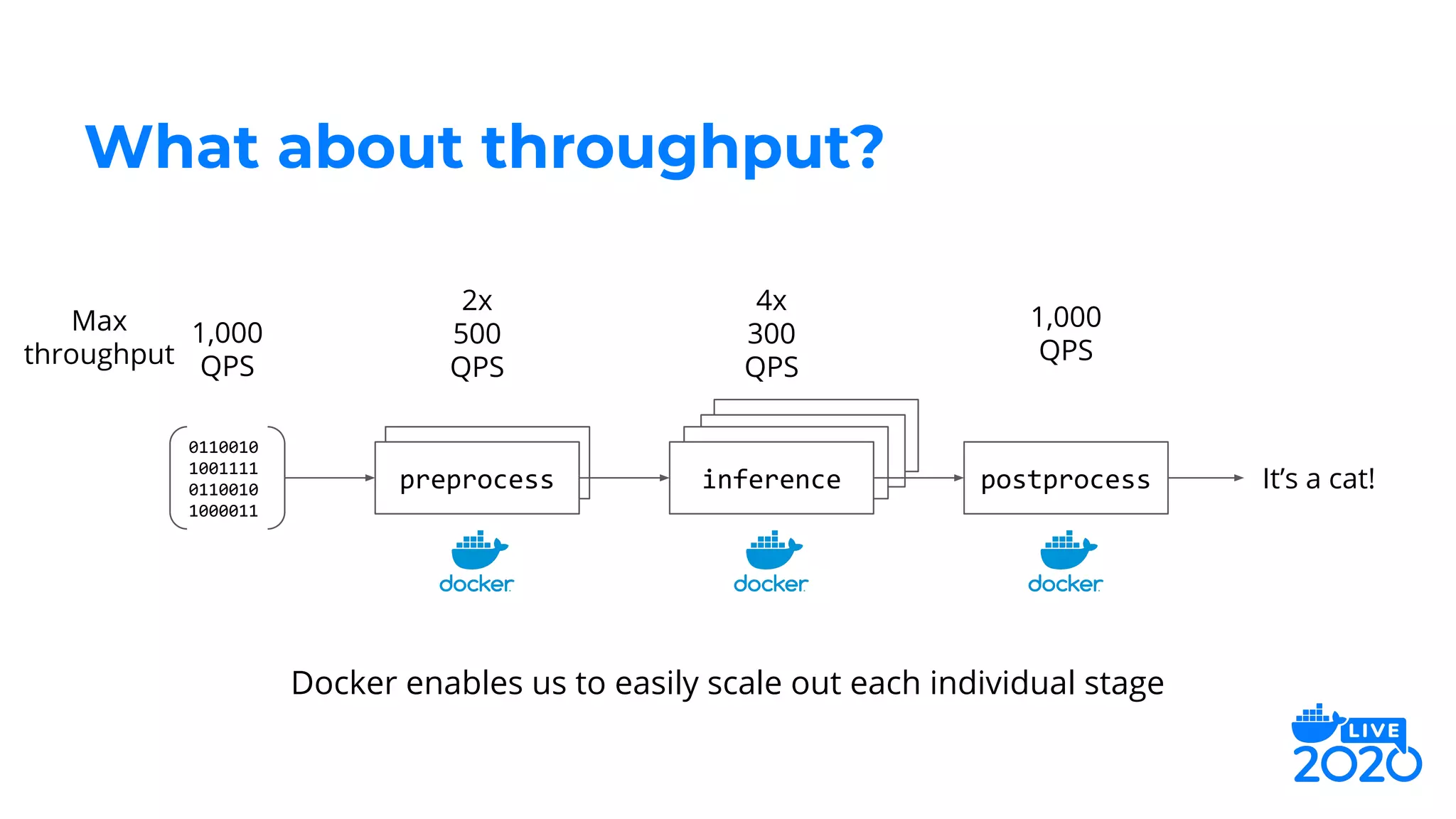
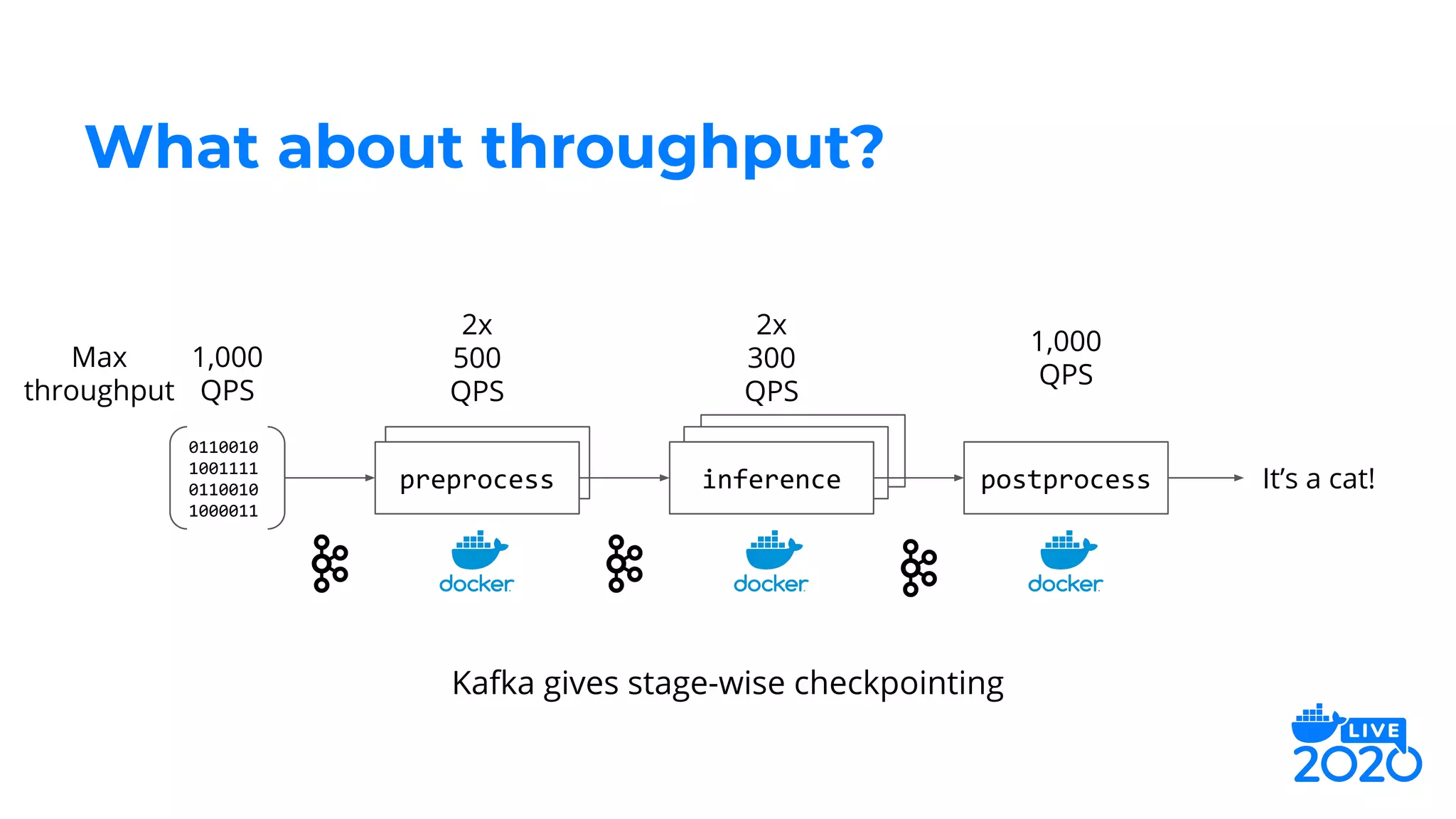



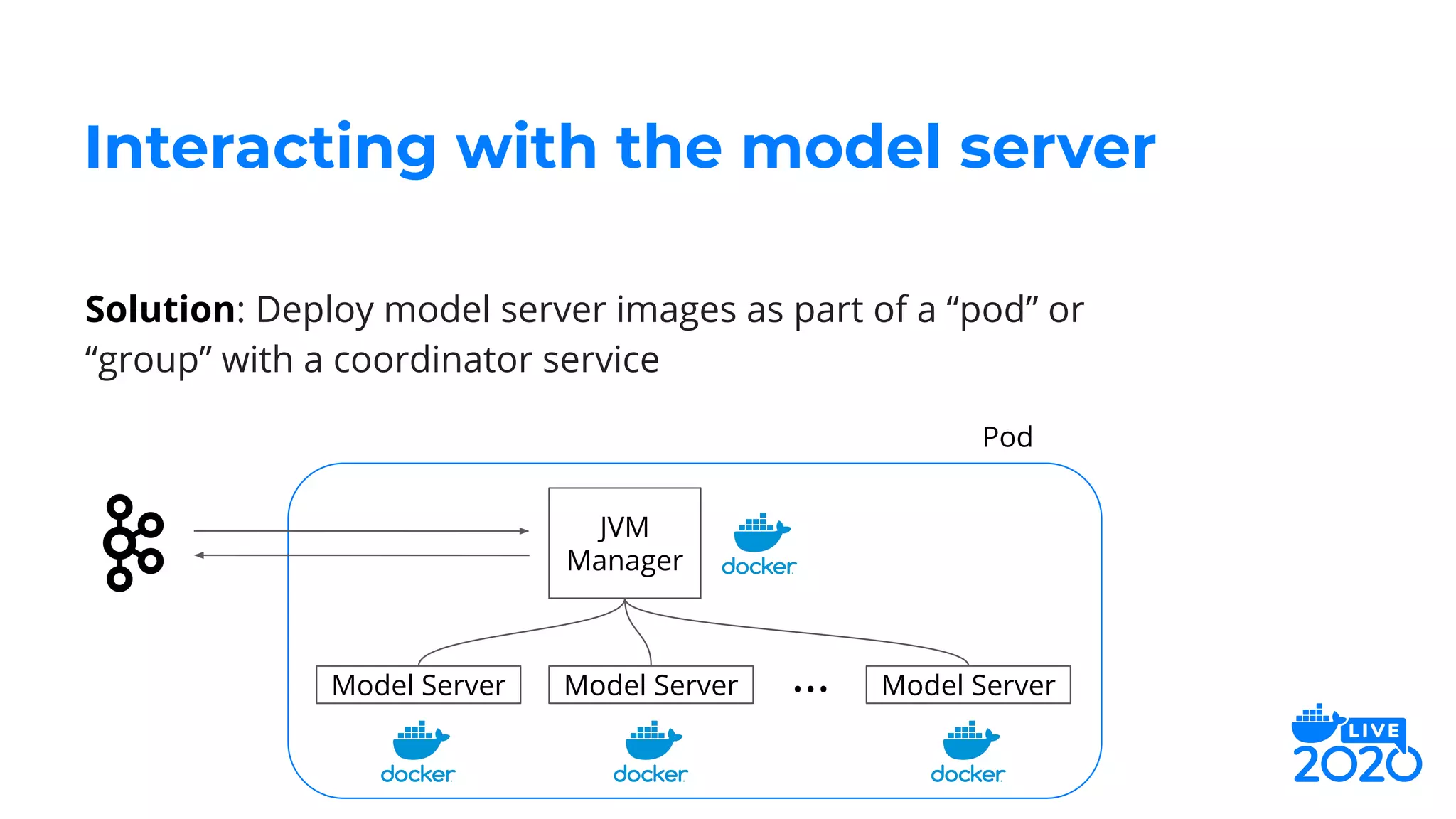







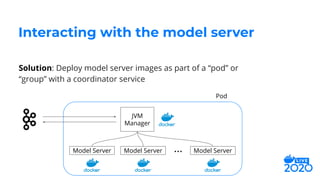
The document outlines how Salesforce employs Docker for distributed deep learning model deployment, addressing challenges such as team specialization, interaction with model servers, and testing. It emphasizes the importance of preprocessing, inference, and postprocessing in the deep learning workflow and presents solutions like containerizing functions and using Docker Compose for testing. Key takeaways include the scalability of deep learning processes through Docker and its ability to simplify complex systems.












































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










