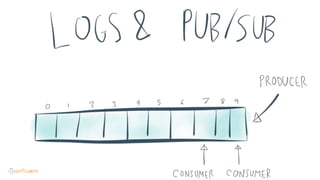
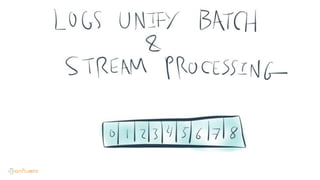
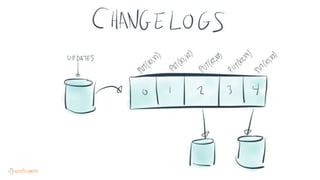
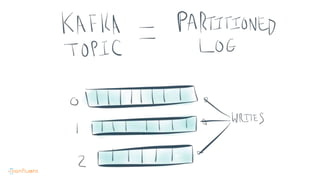
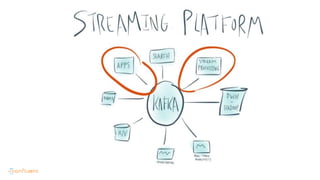
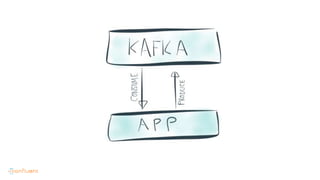
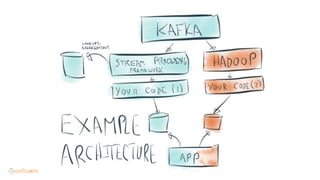
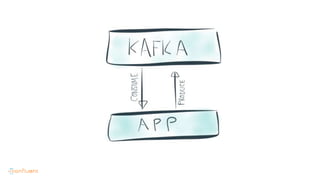
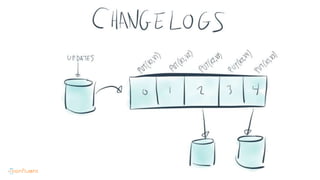
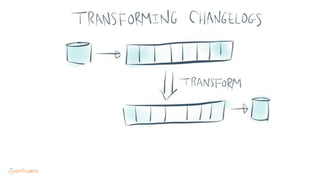
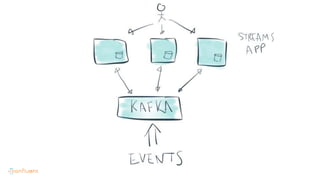
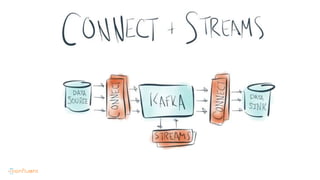
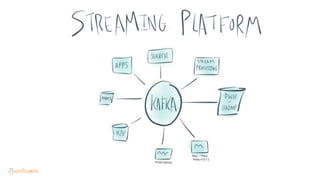
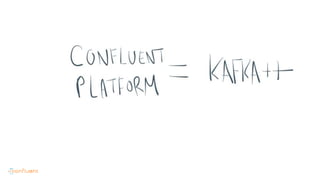
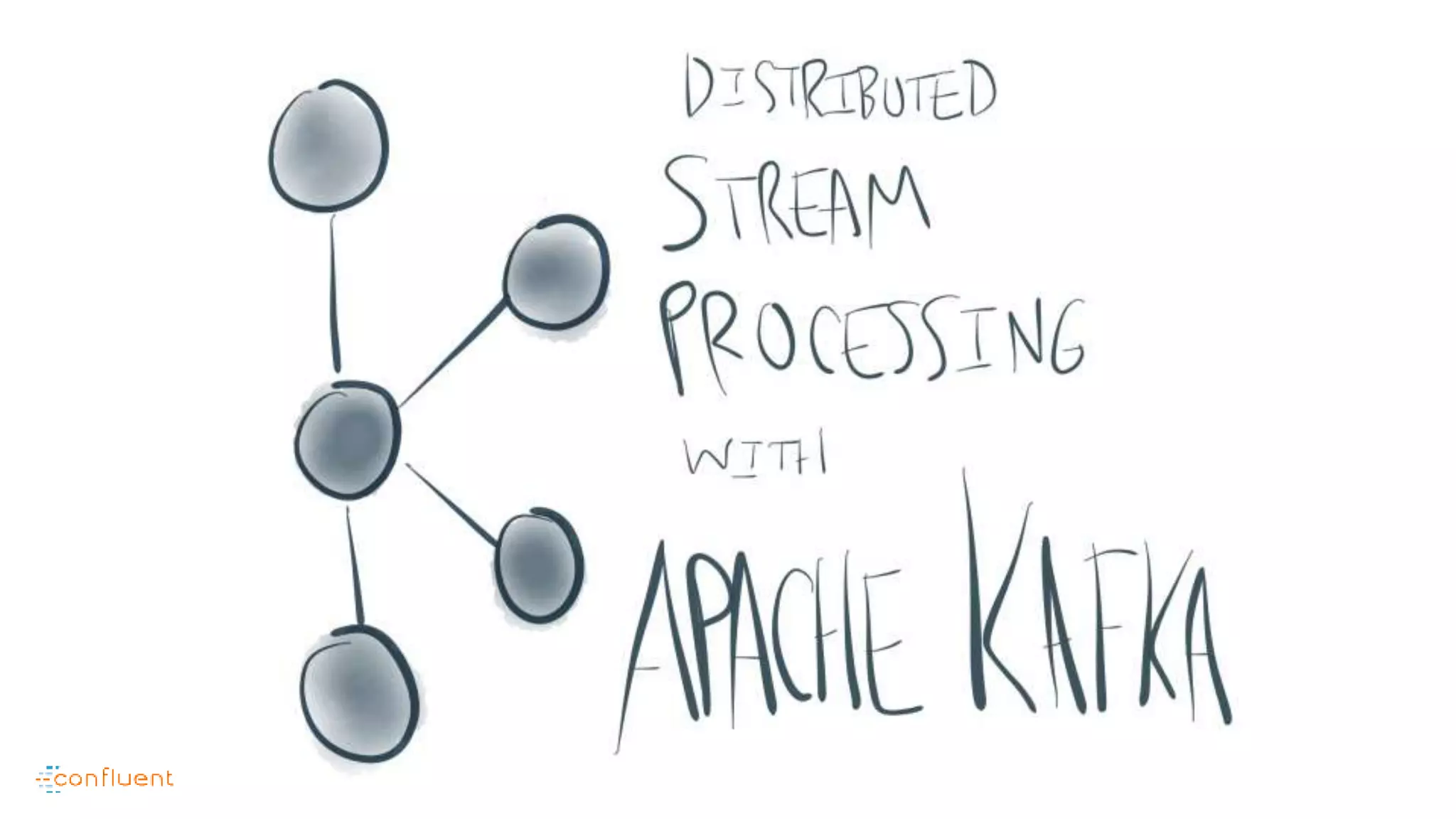
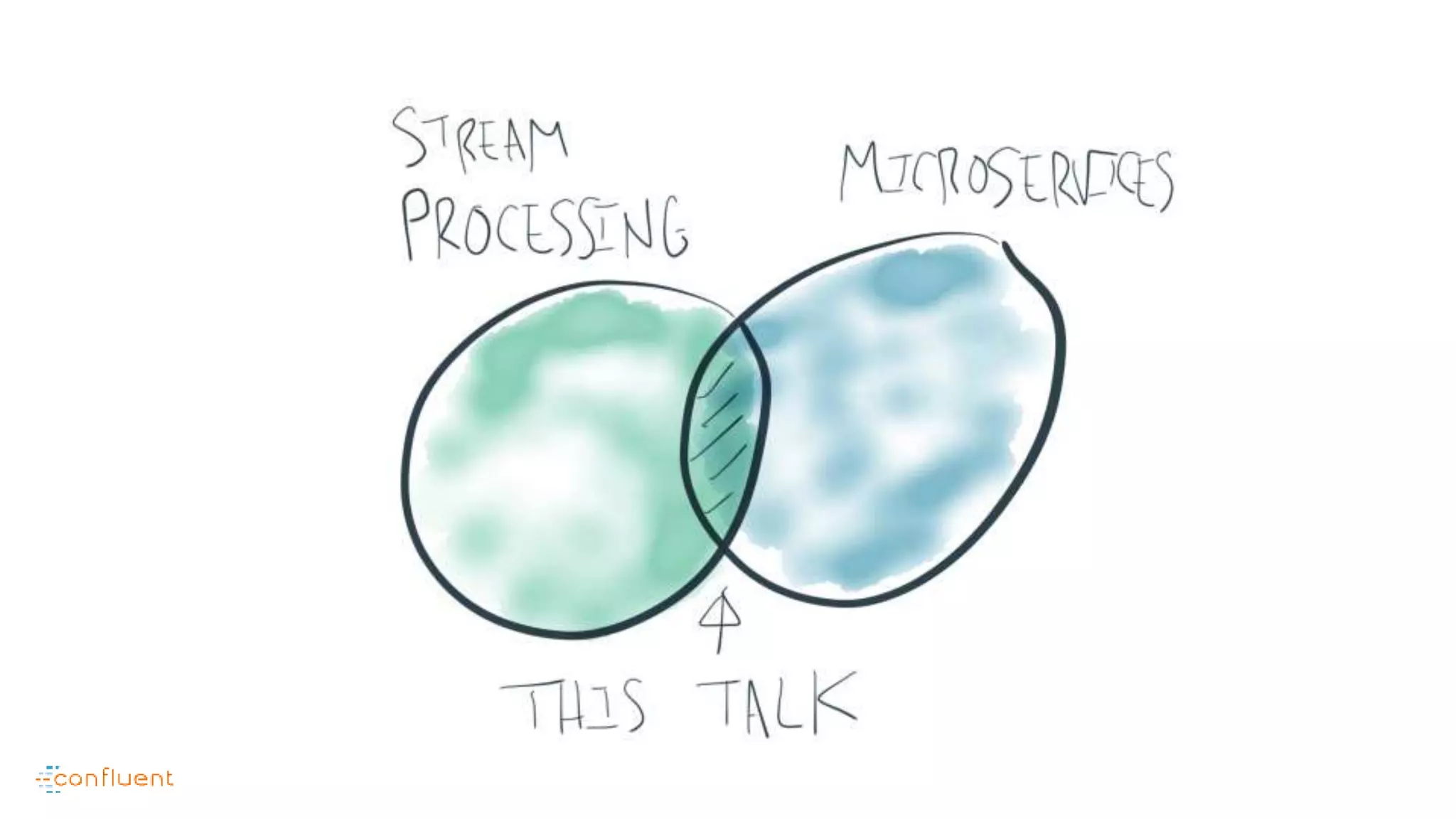
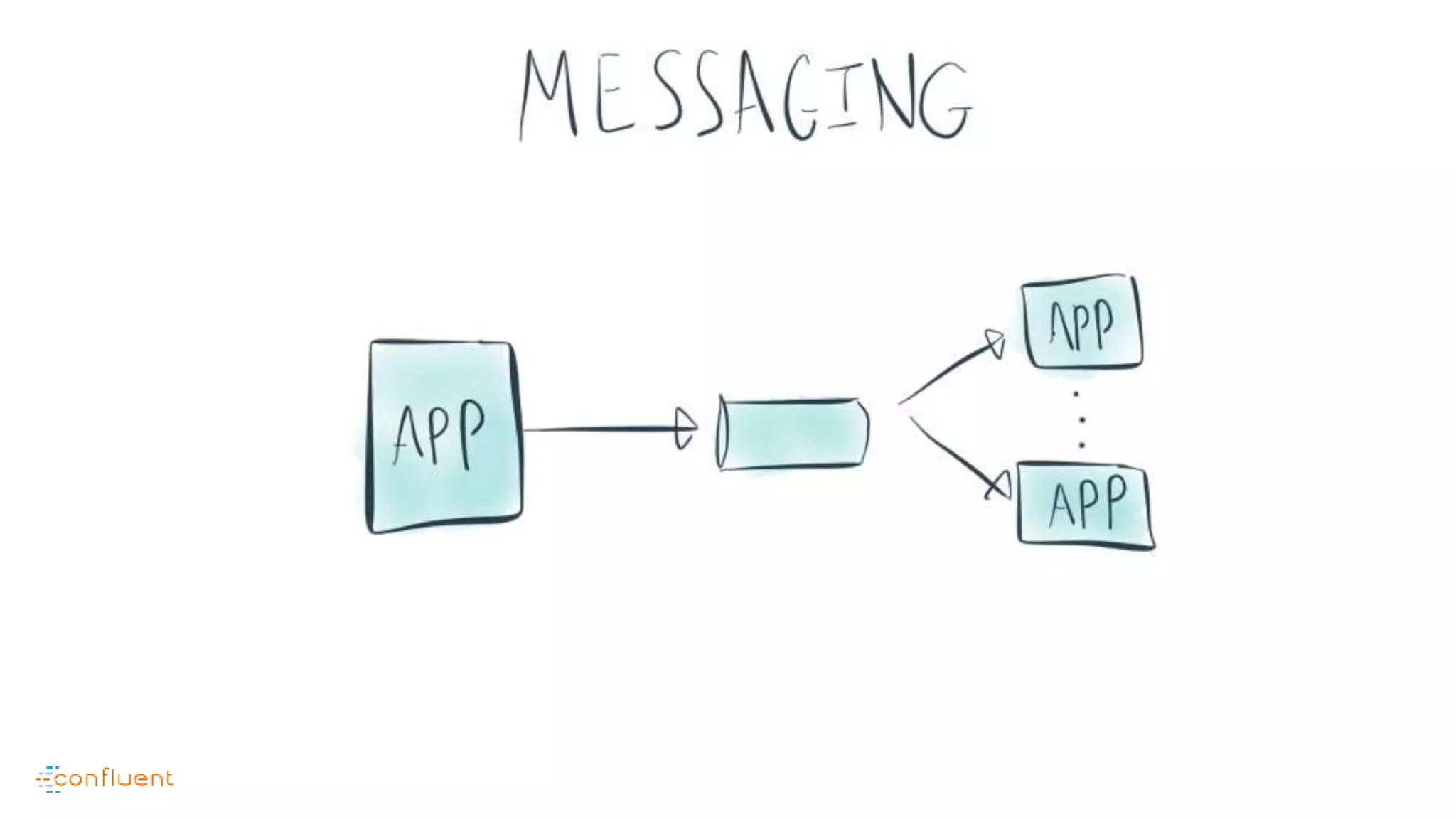
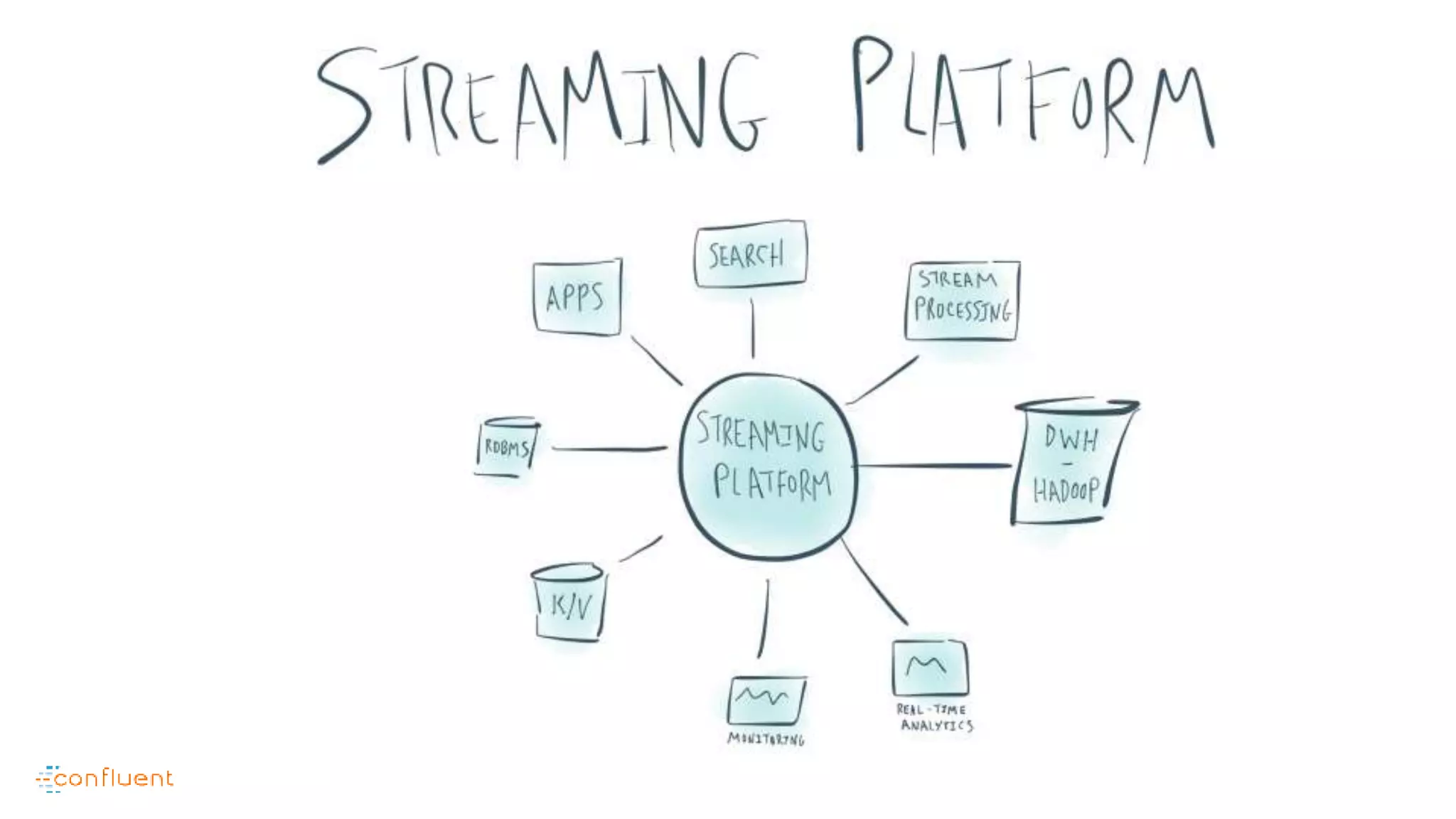
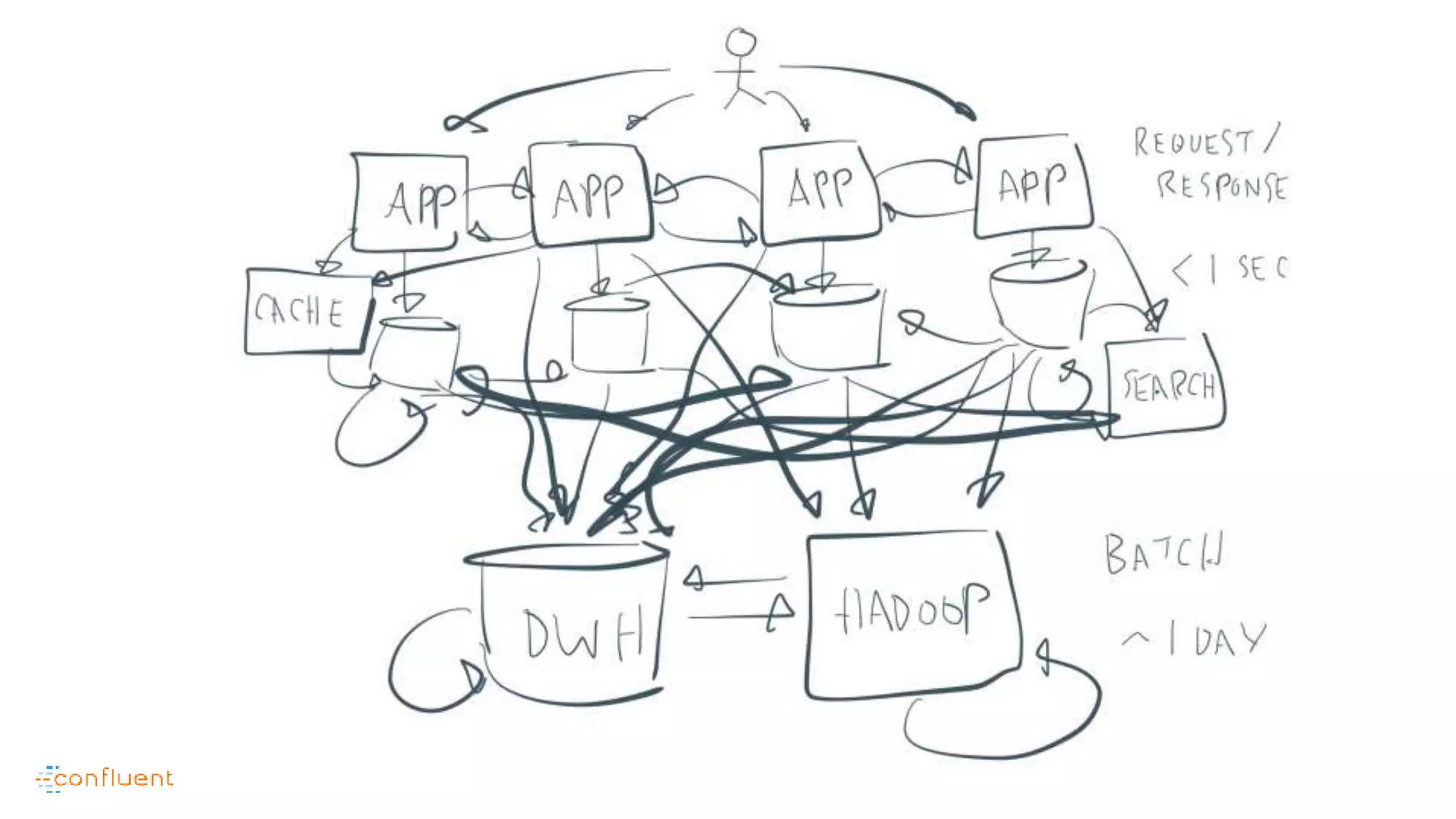
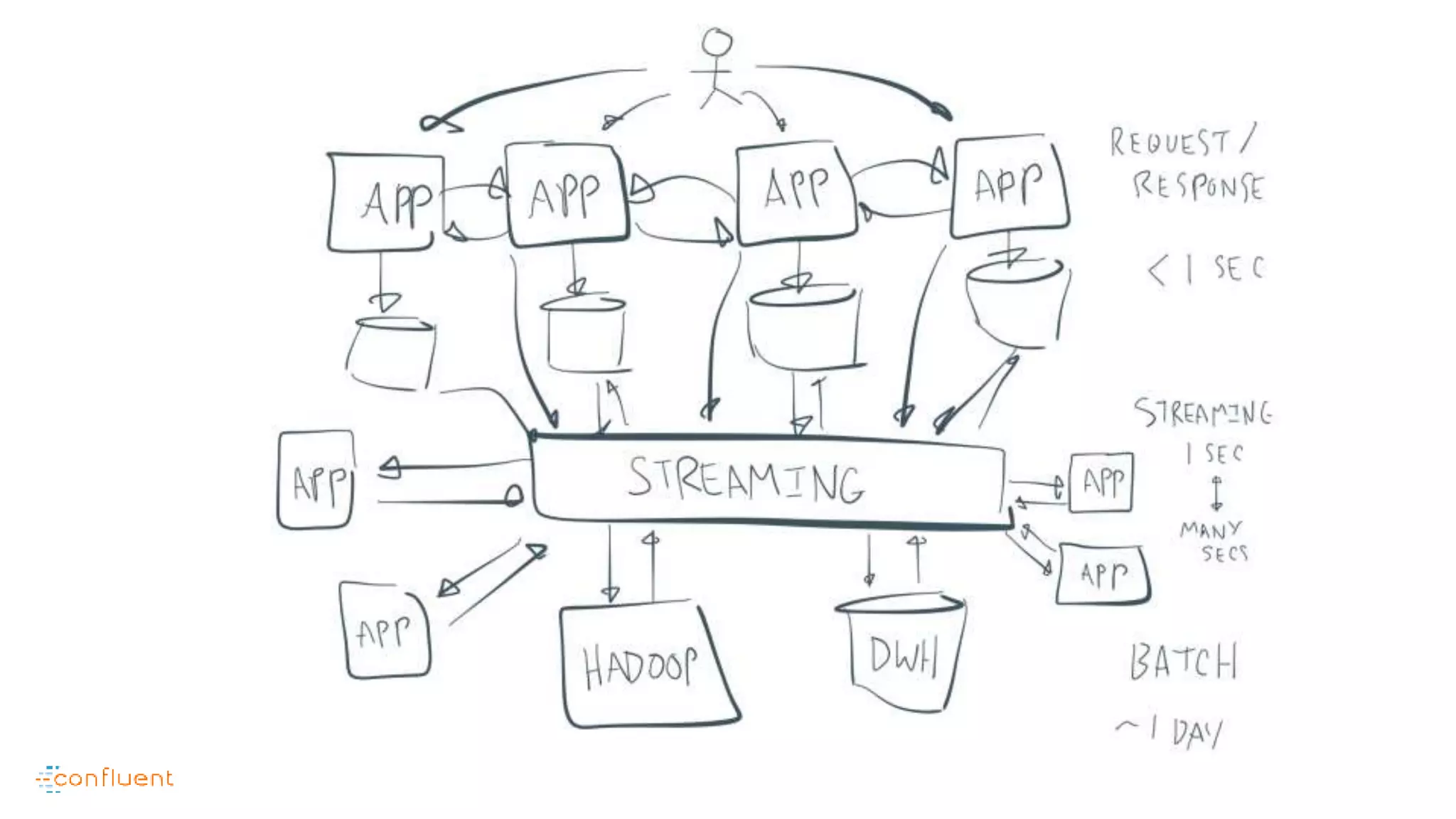
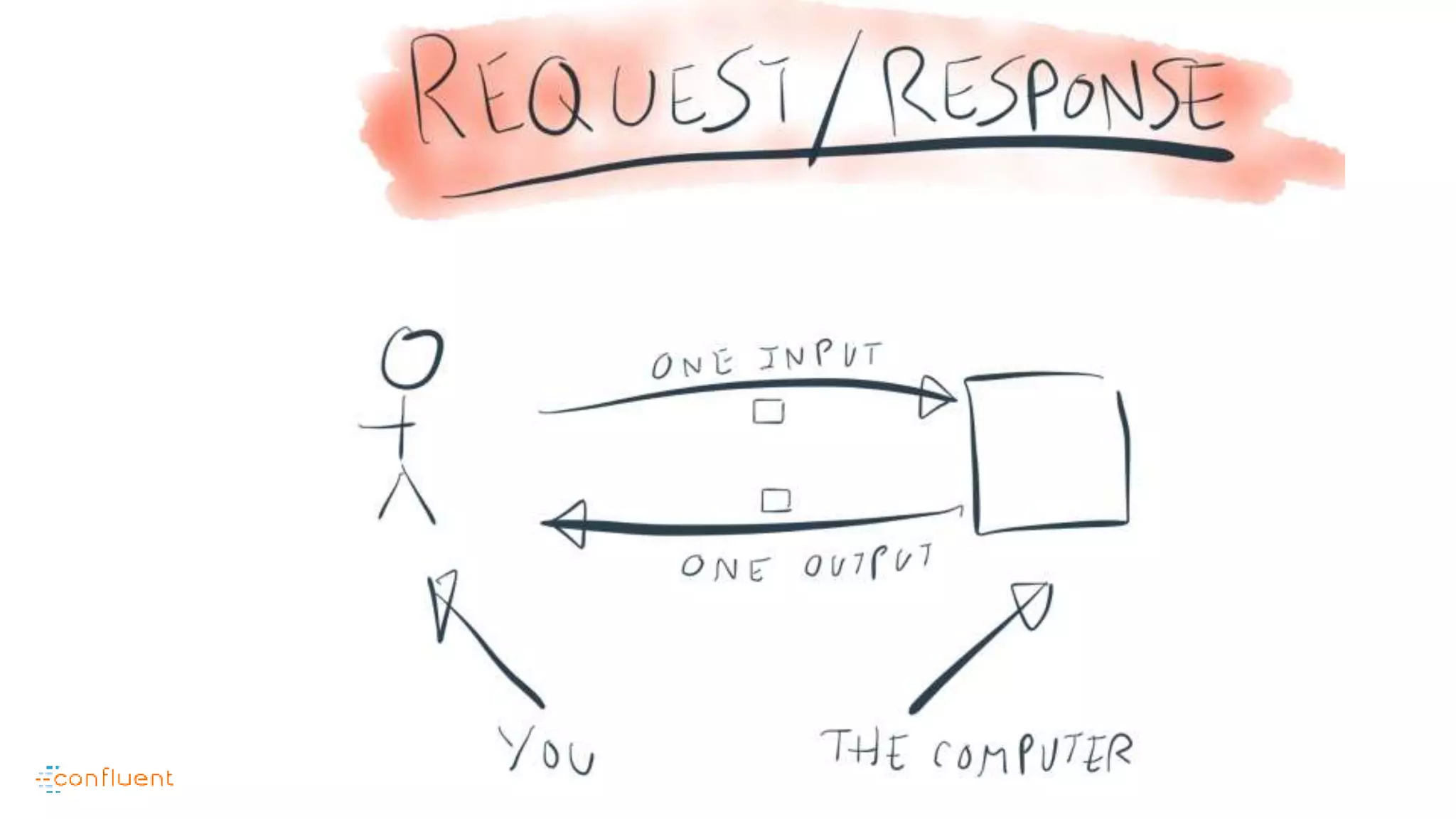
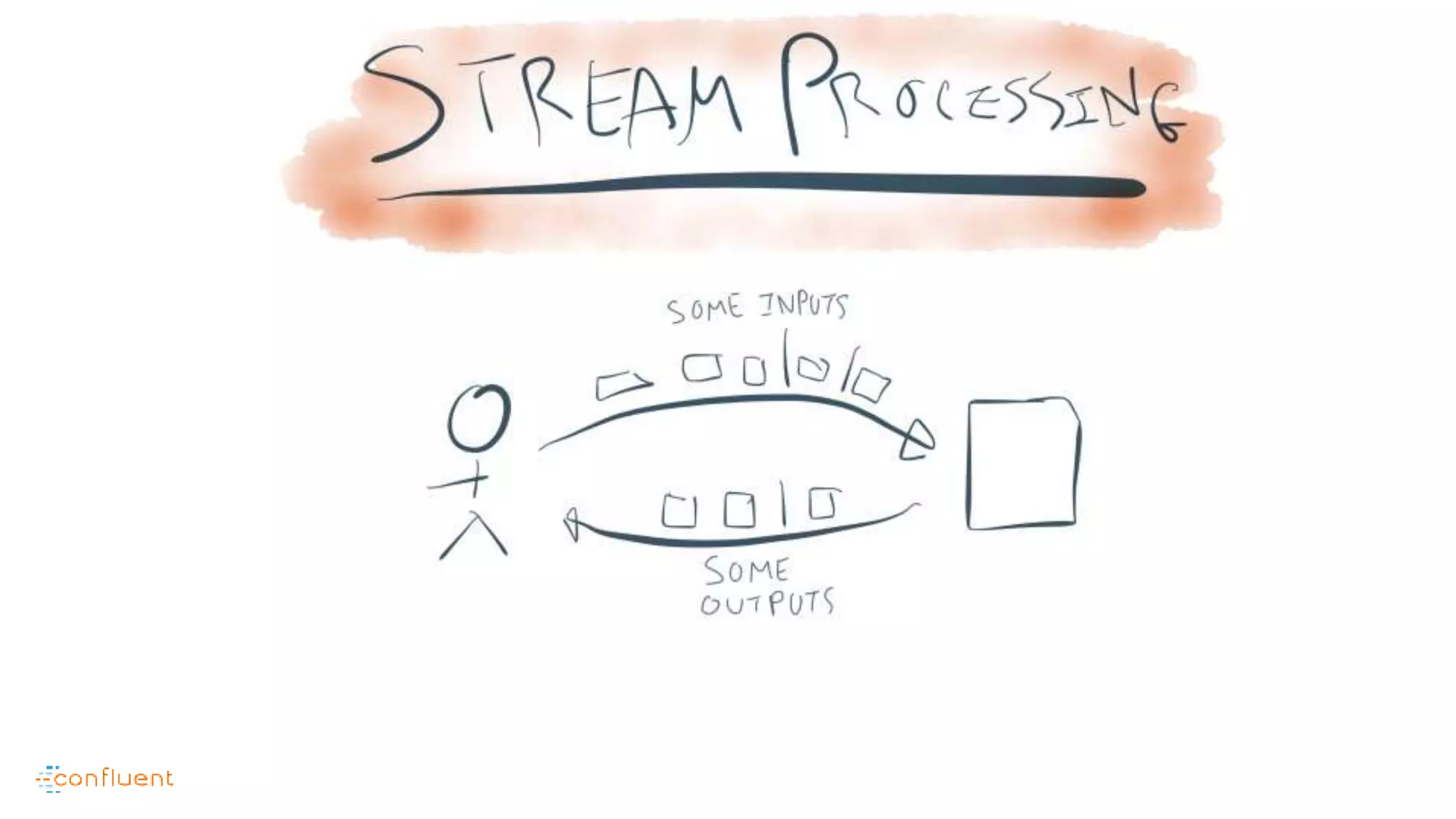
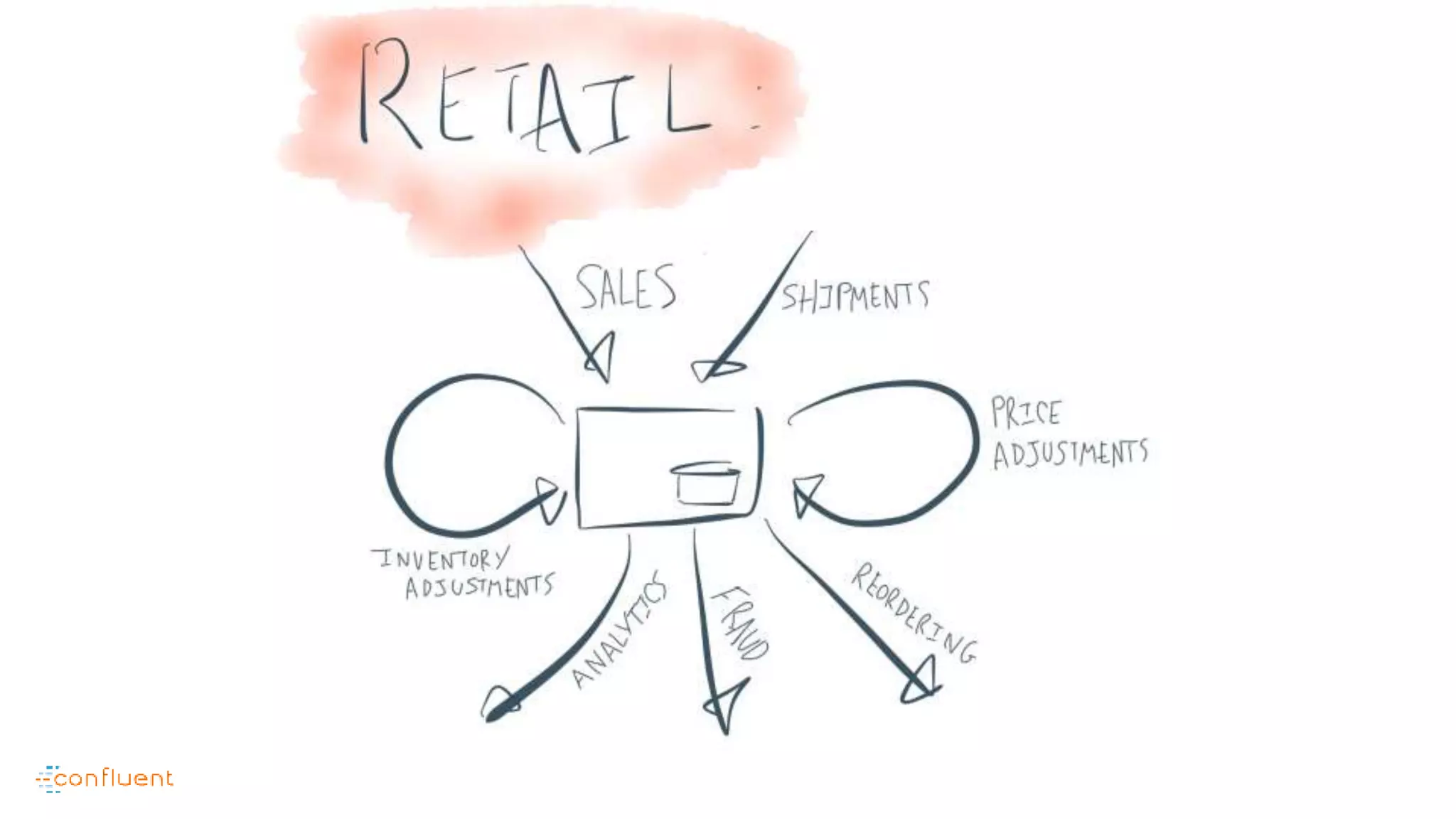
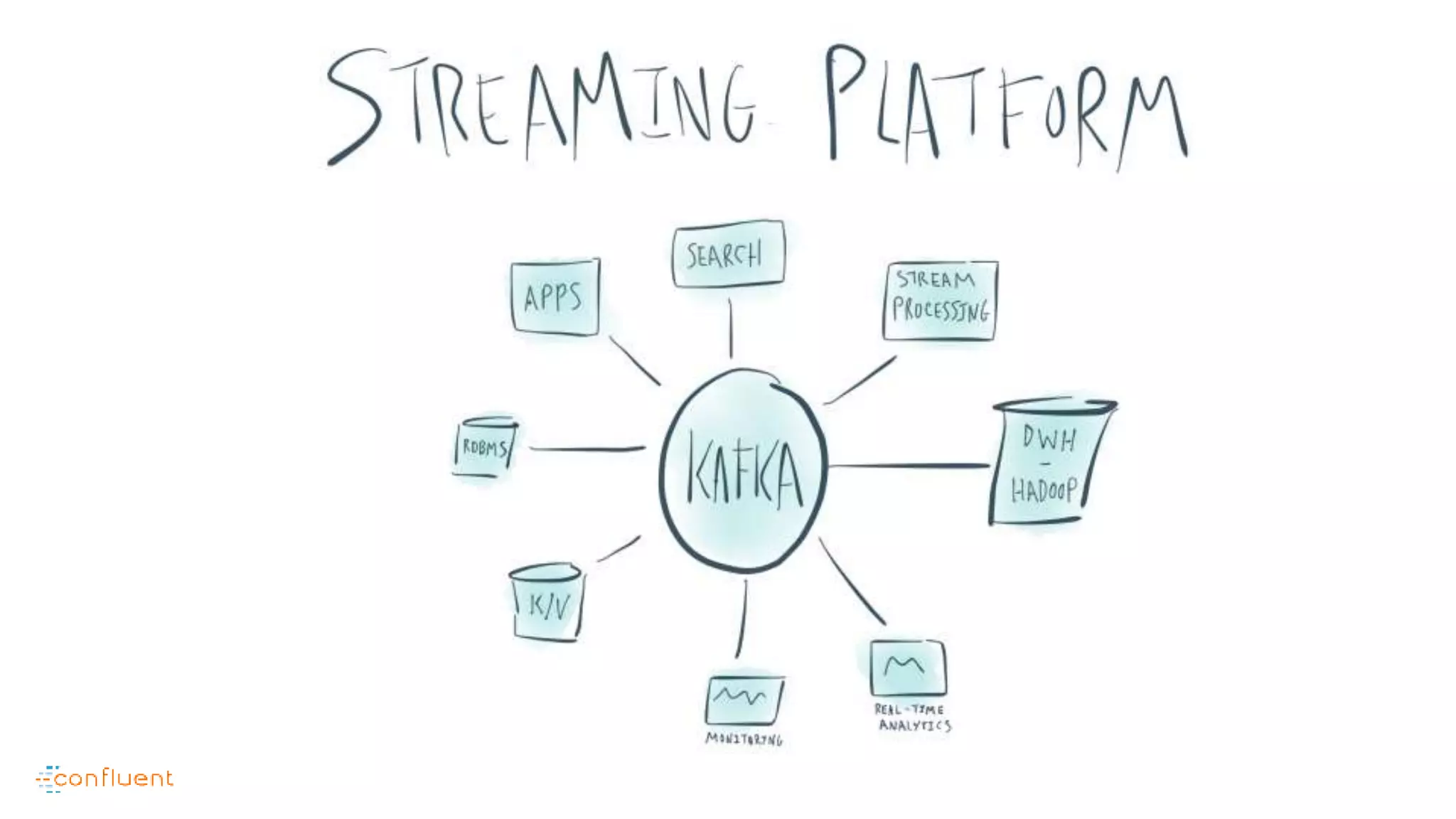
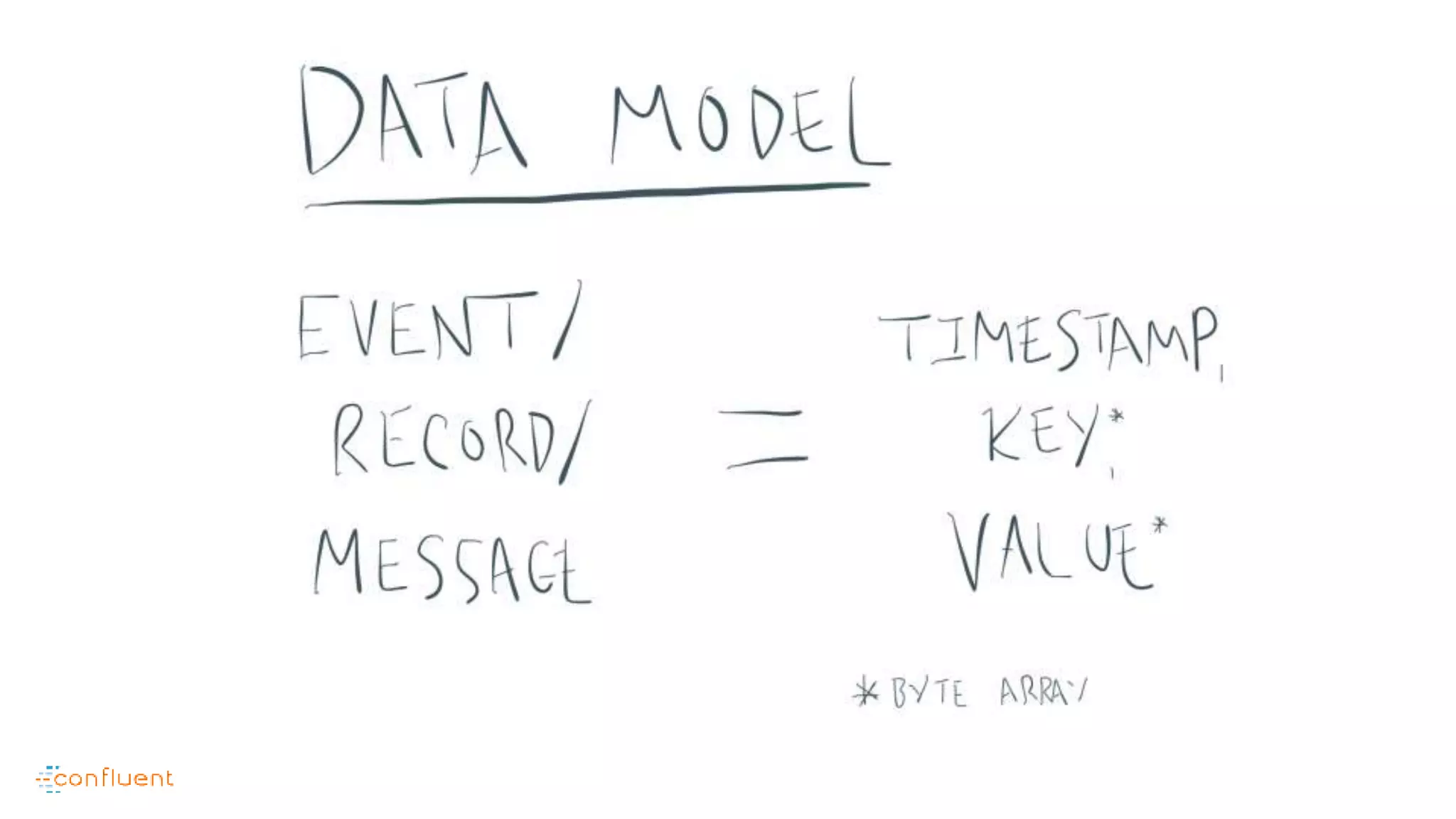
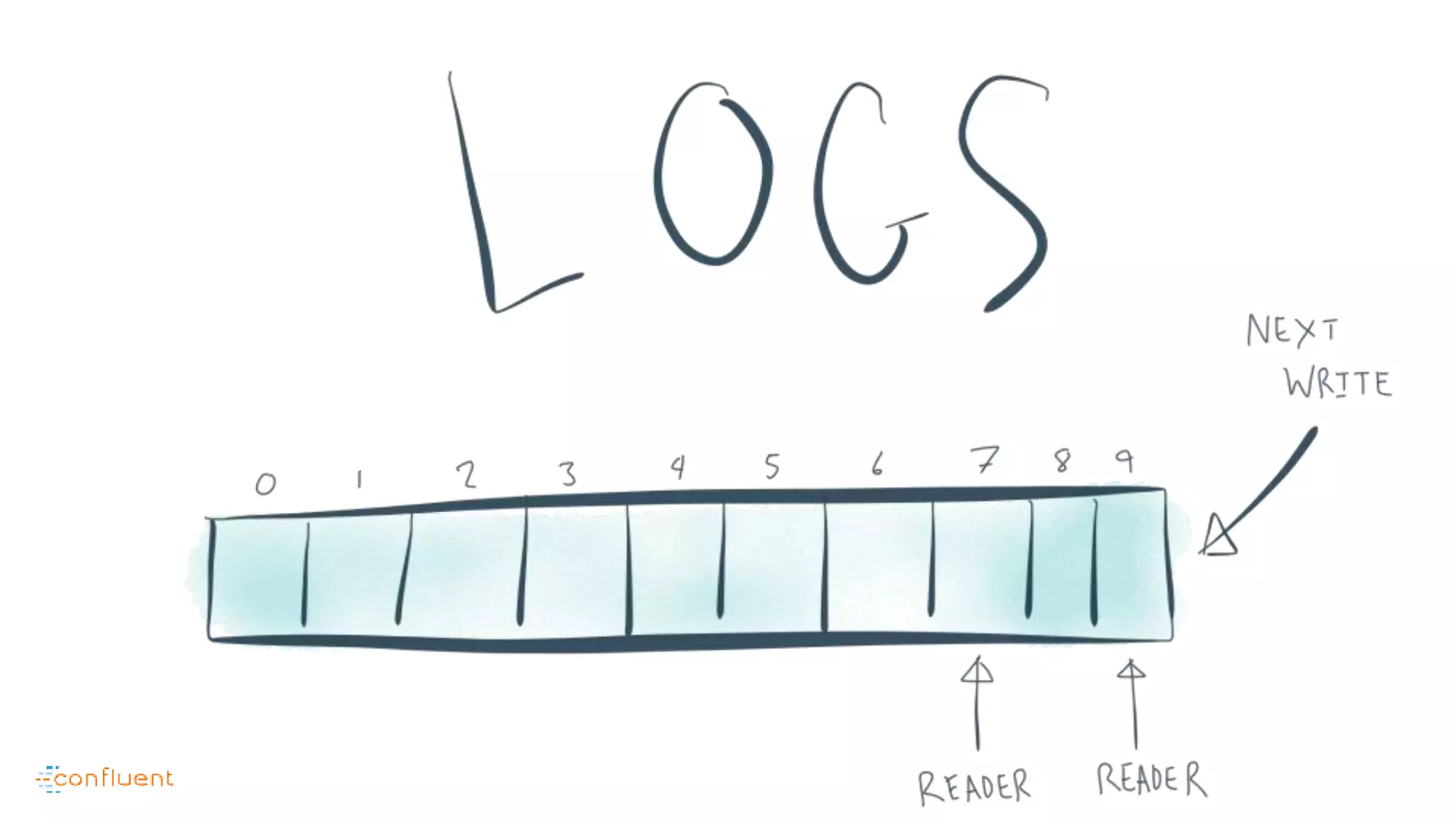
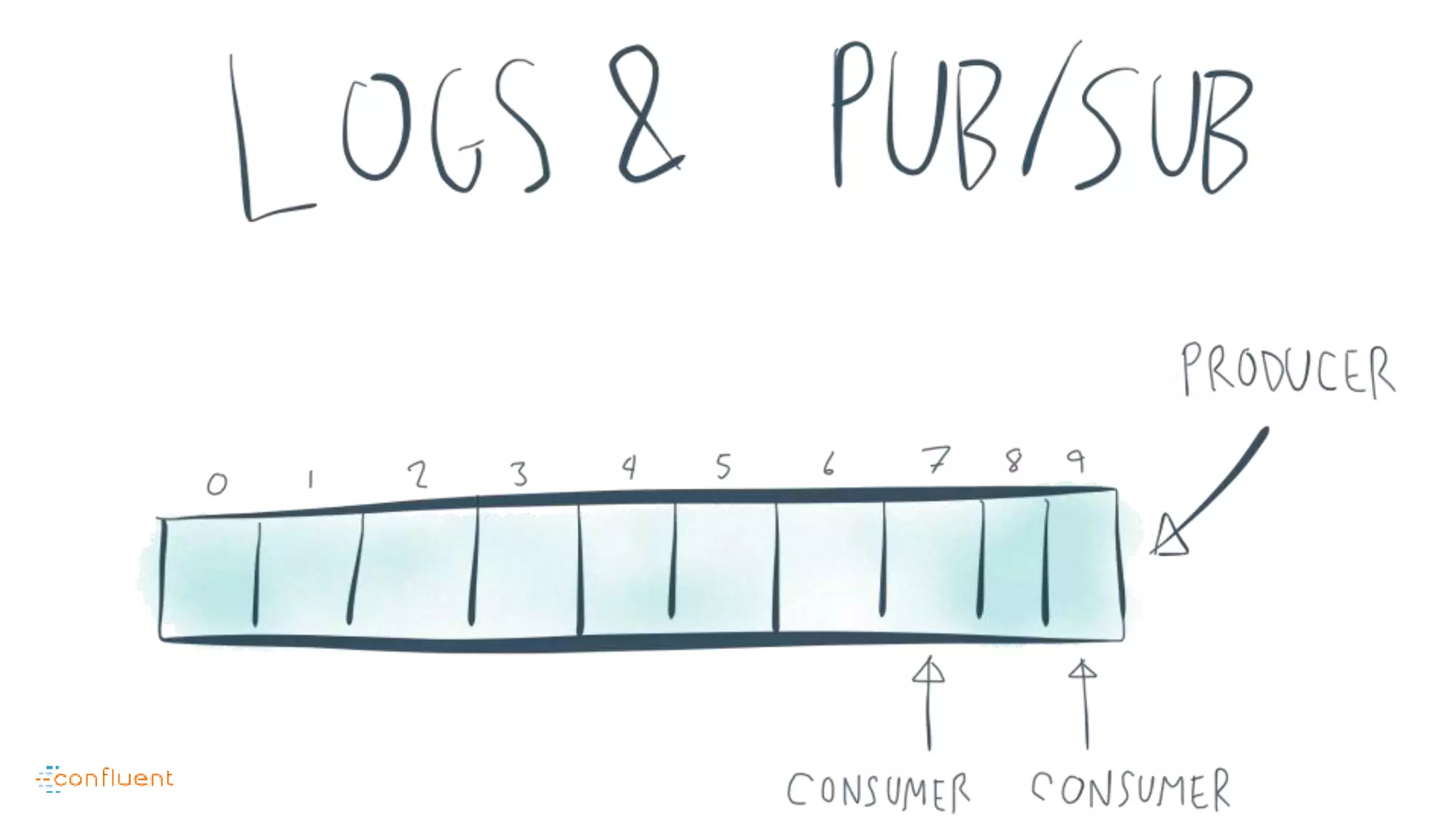
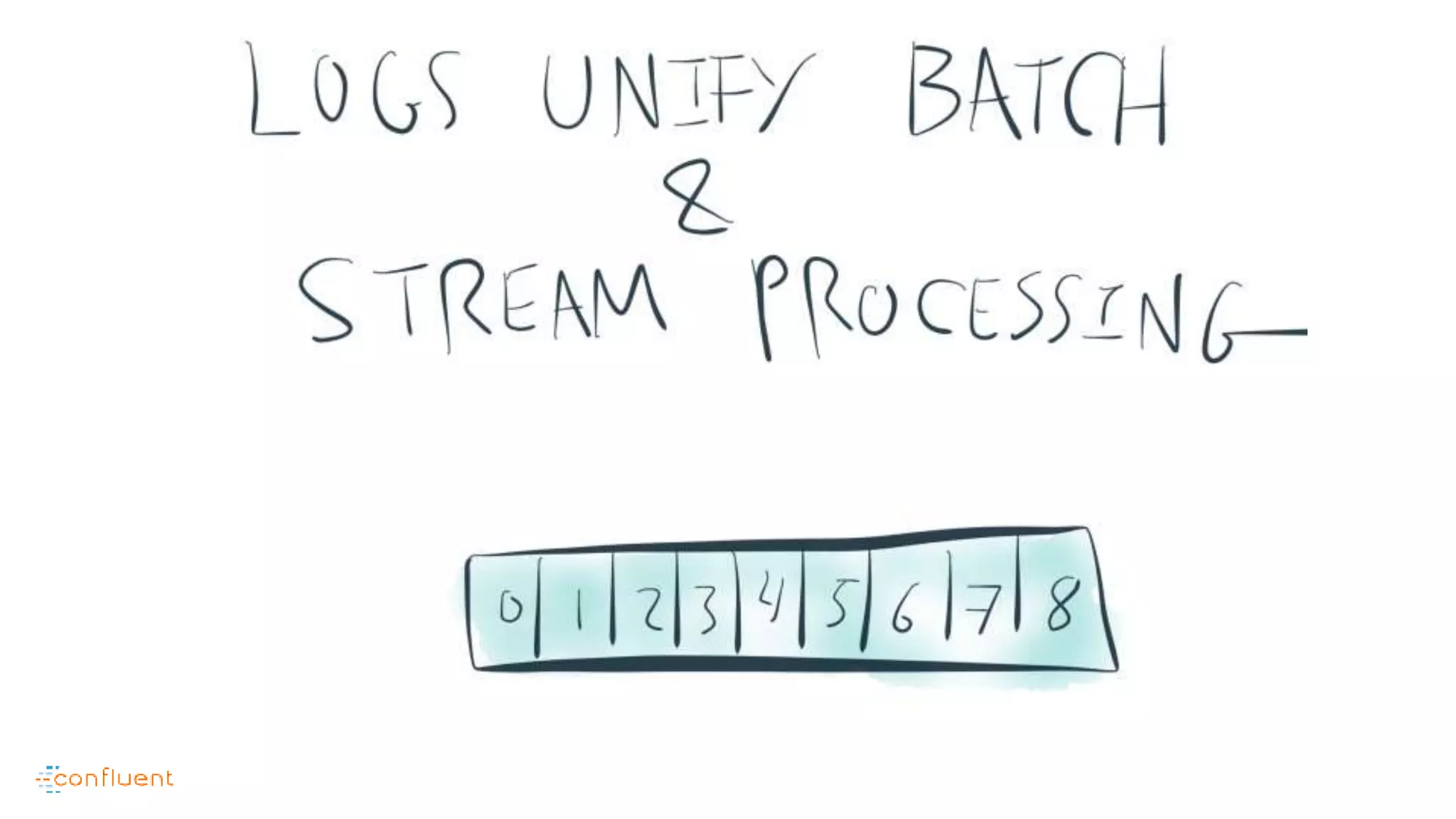
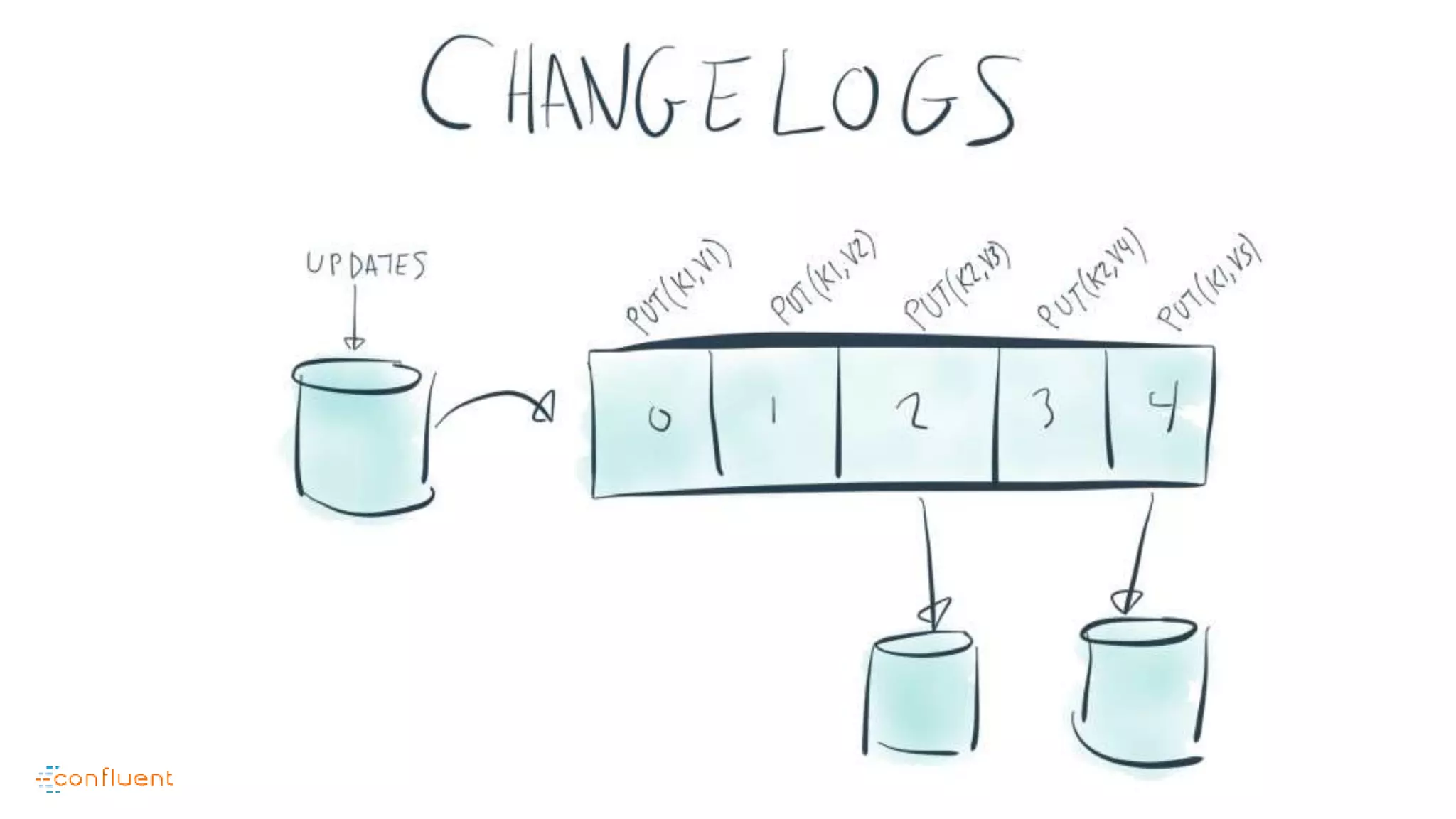
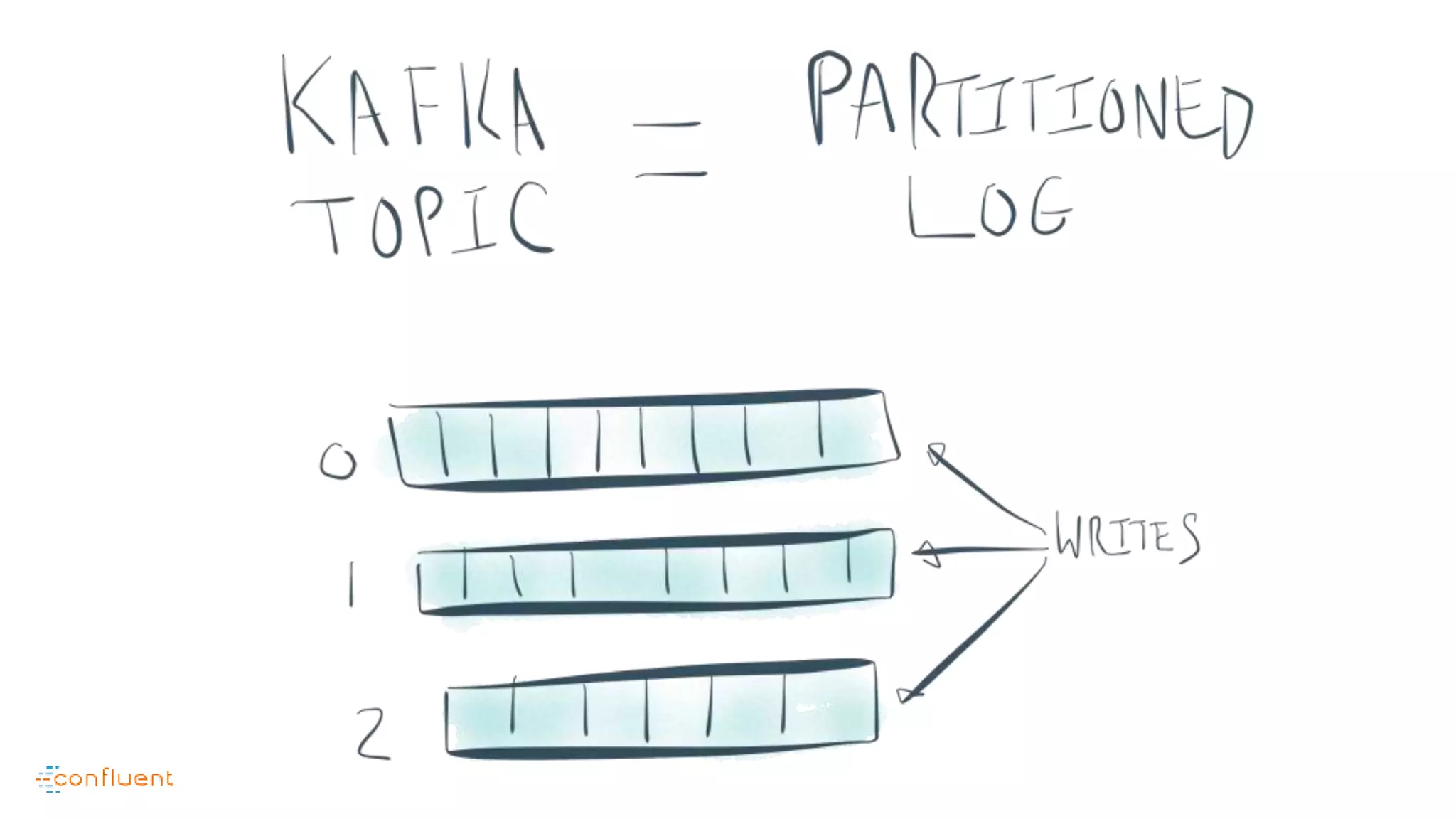
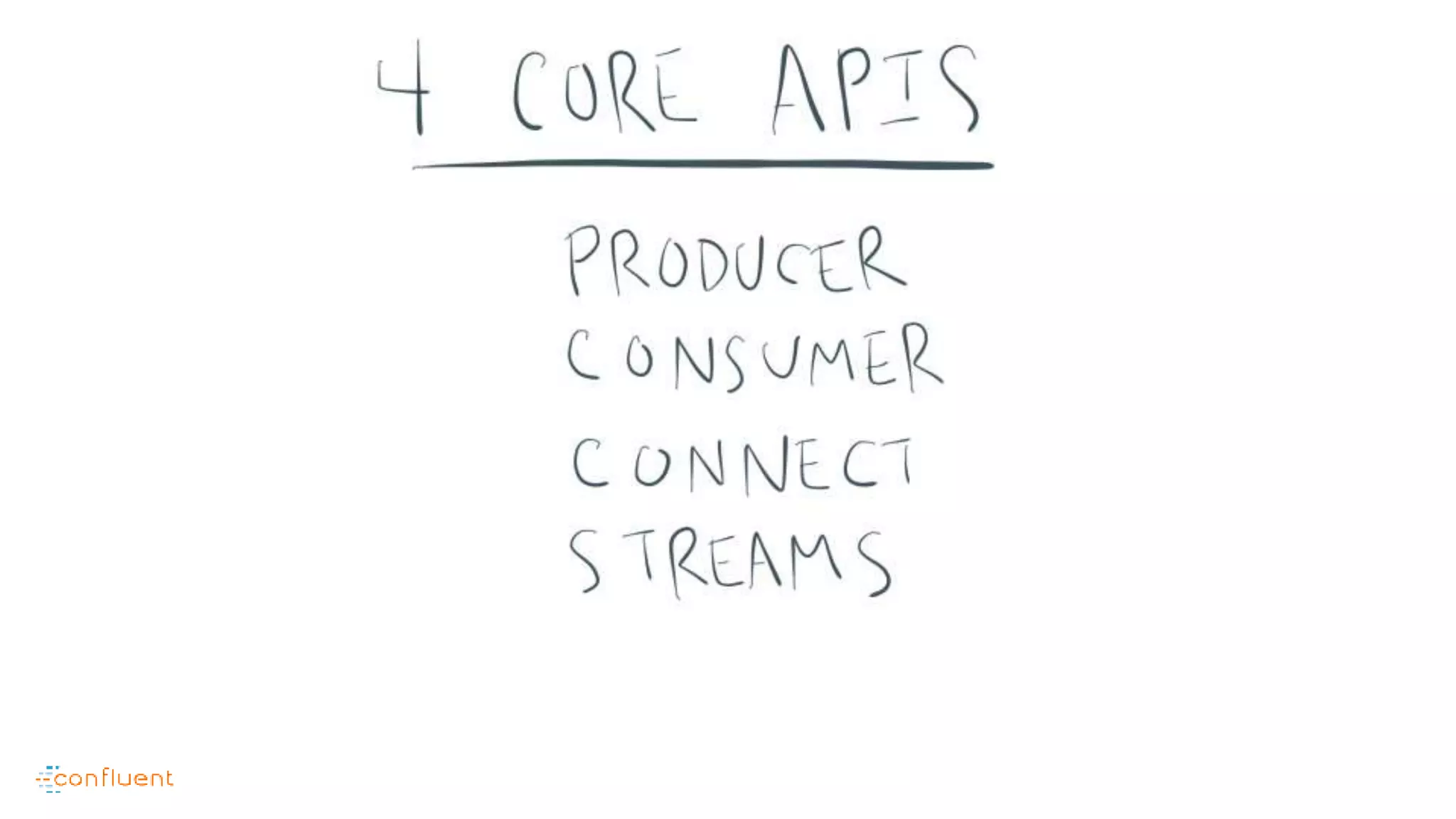
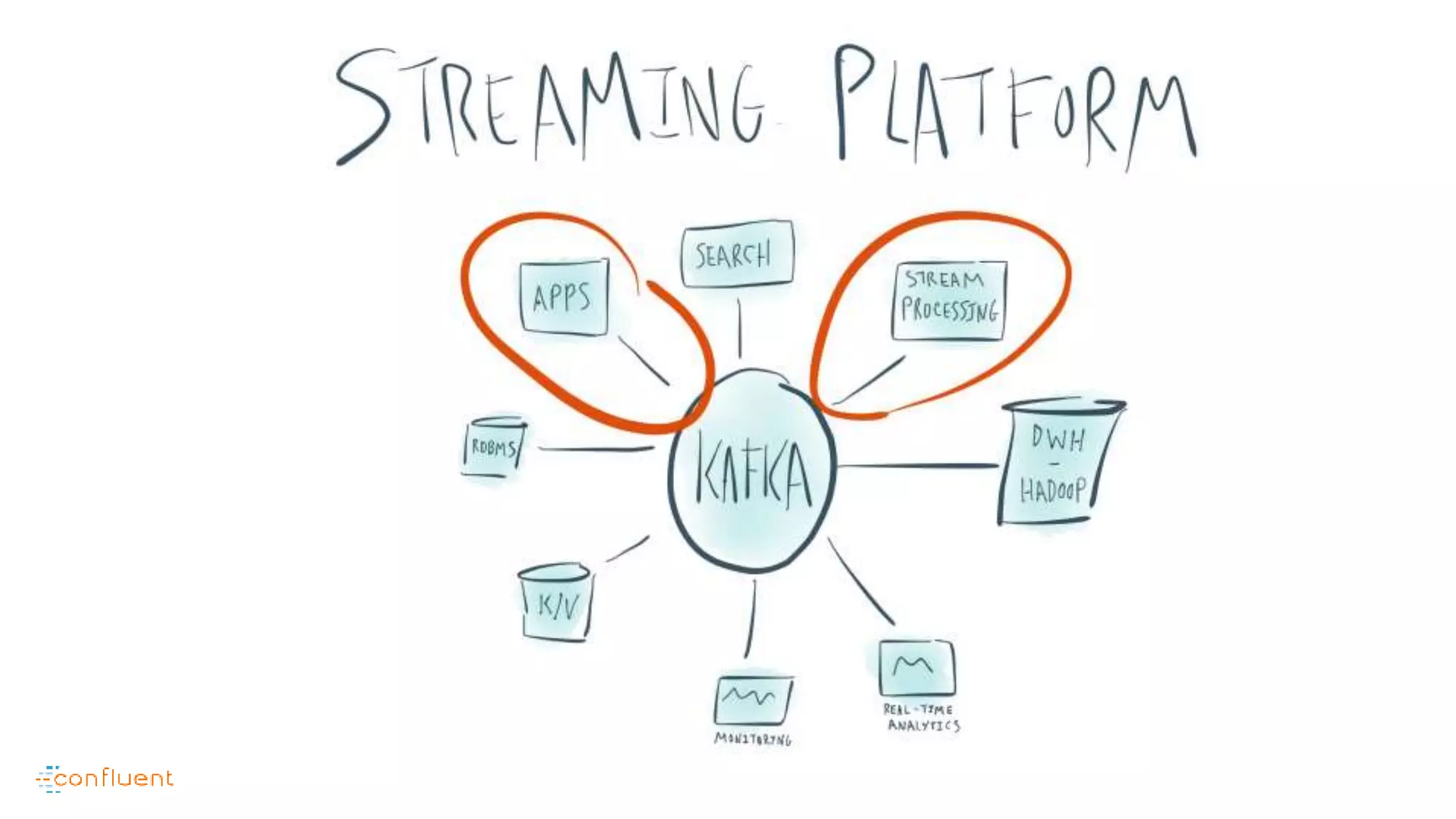
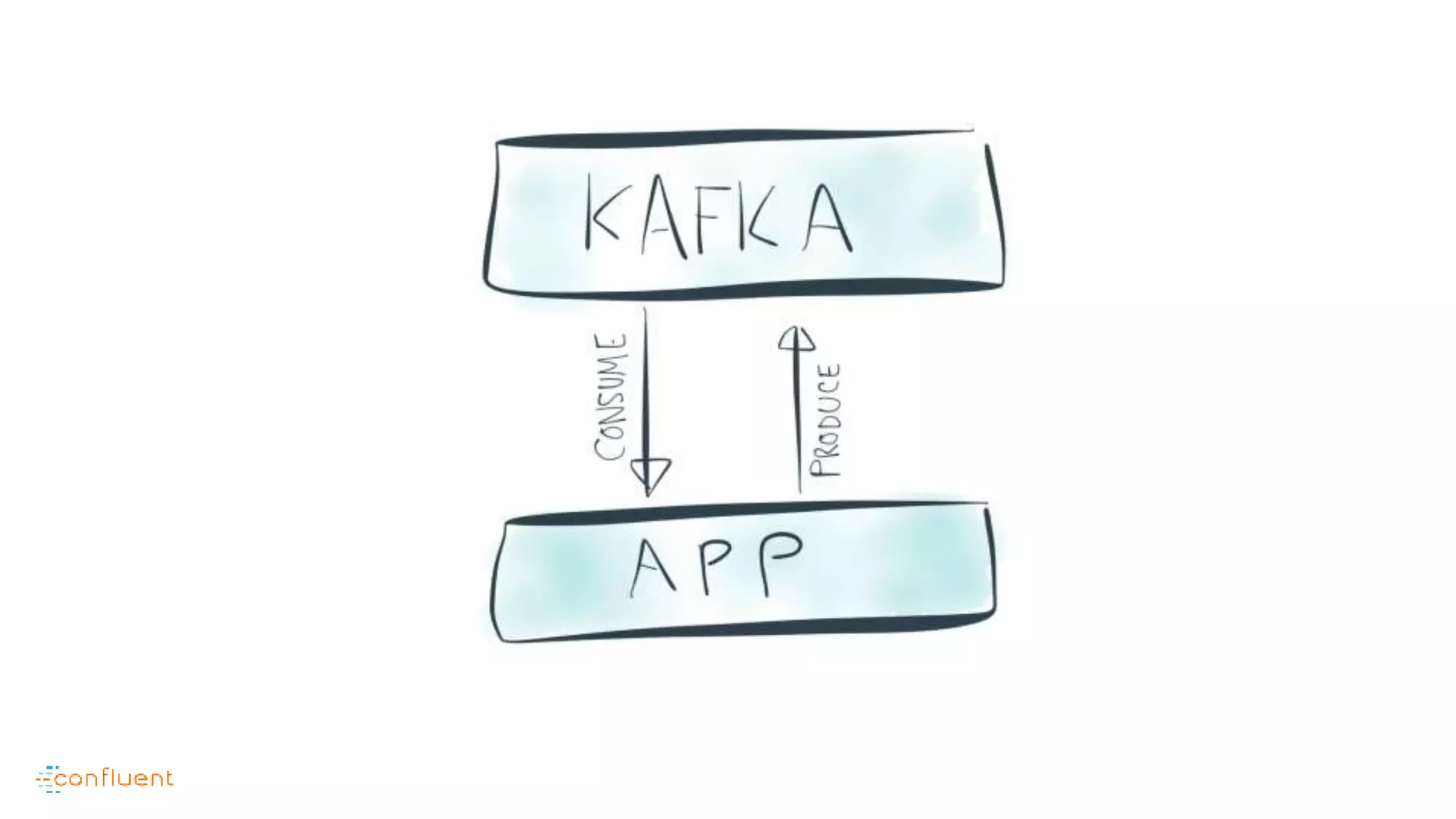
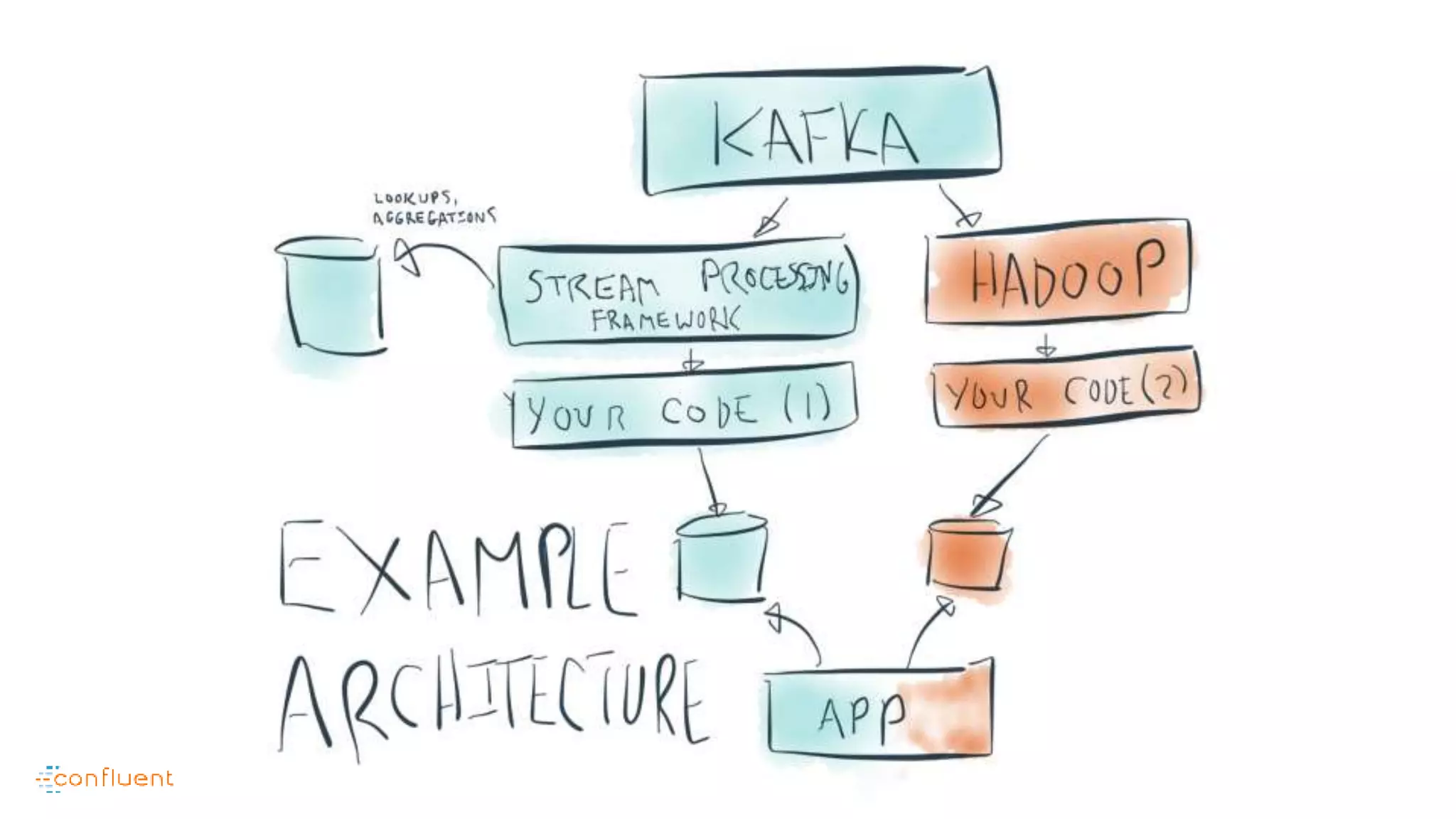
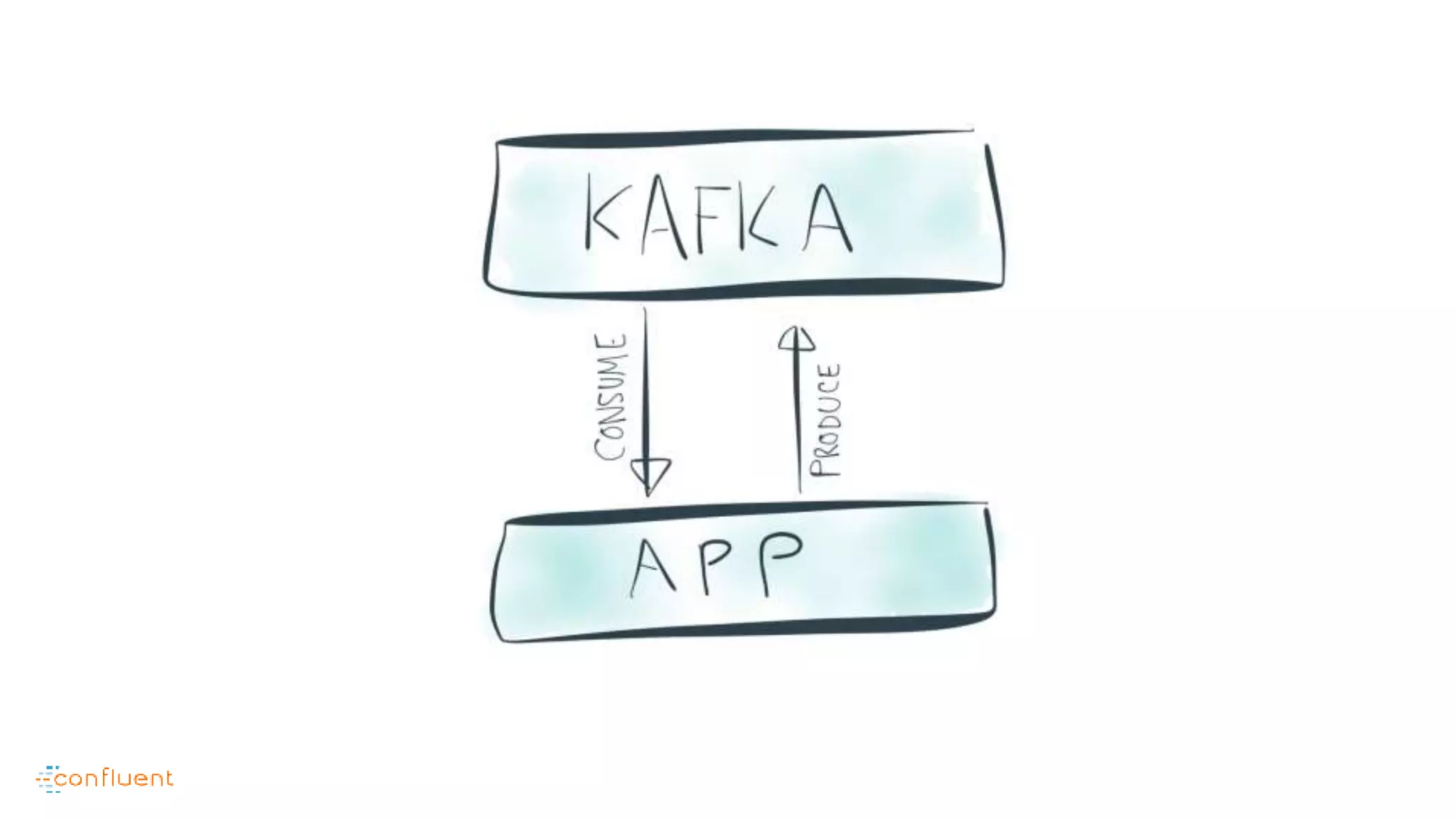
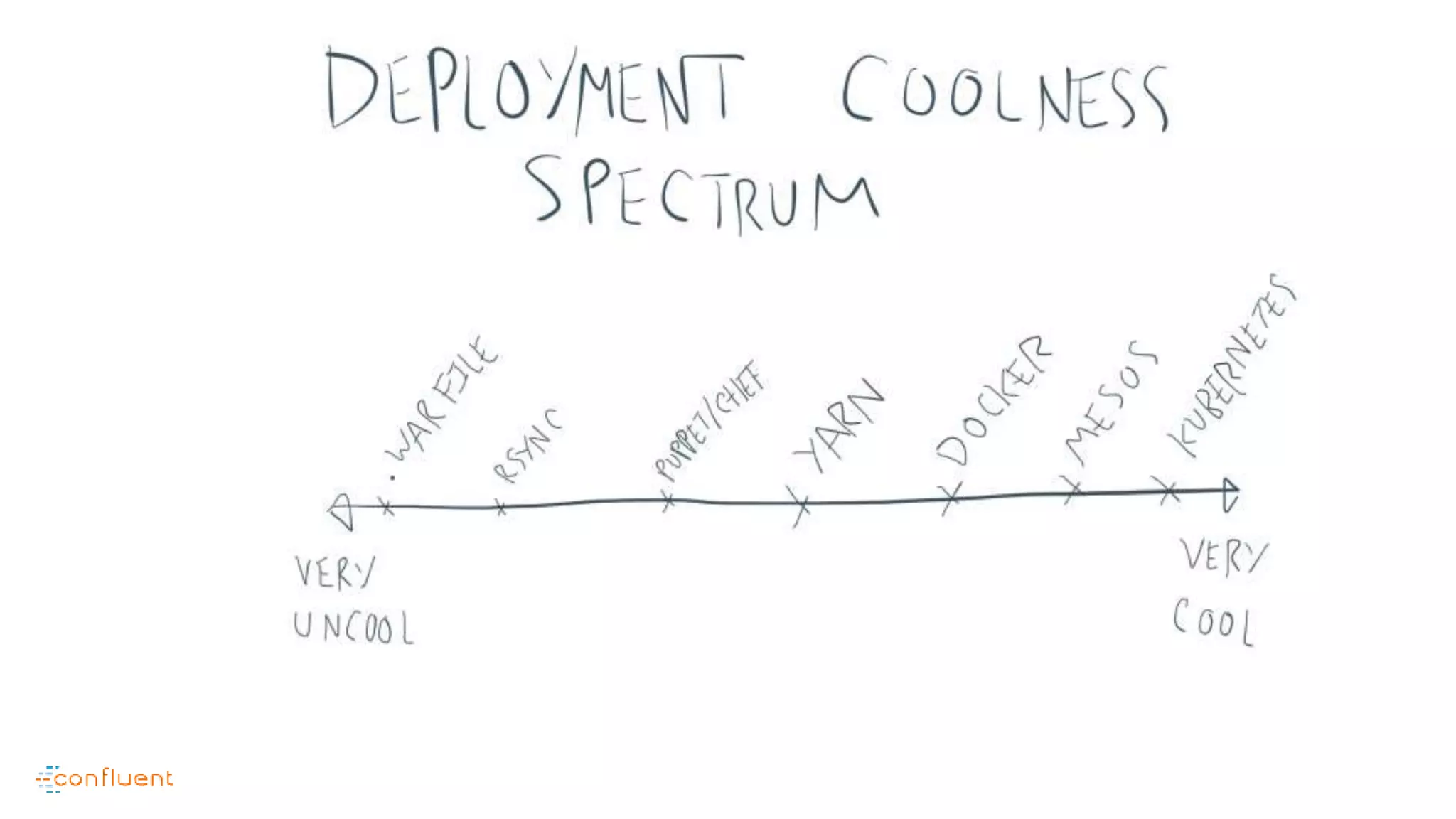
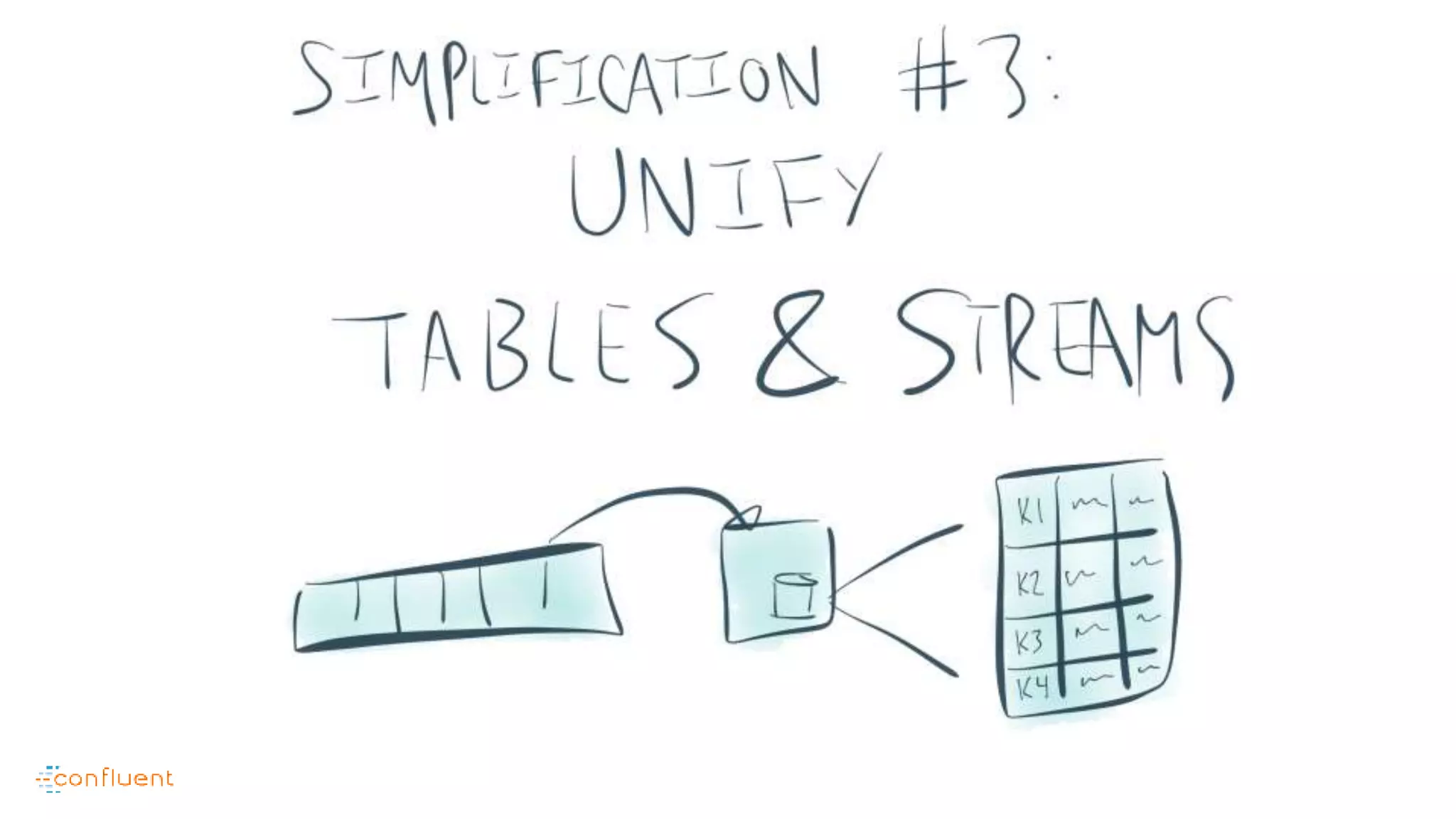
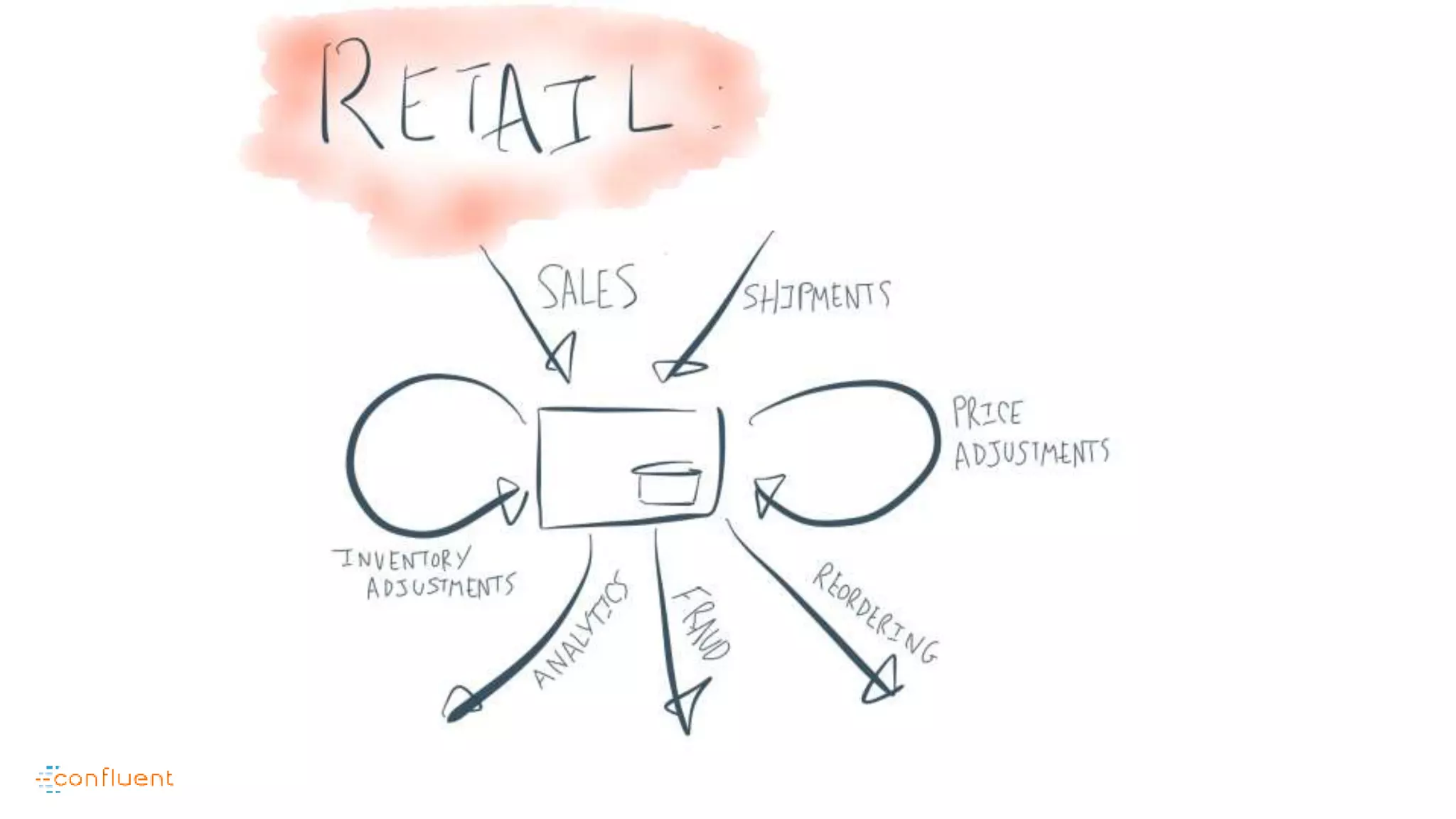
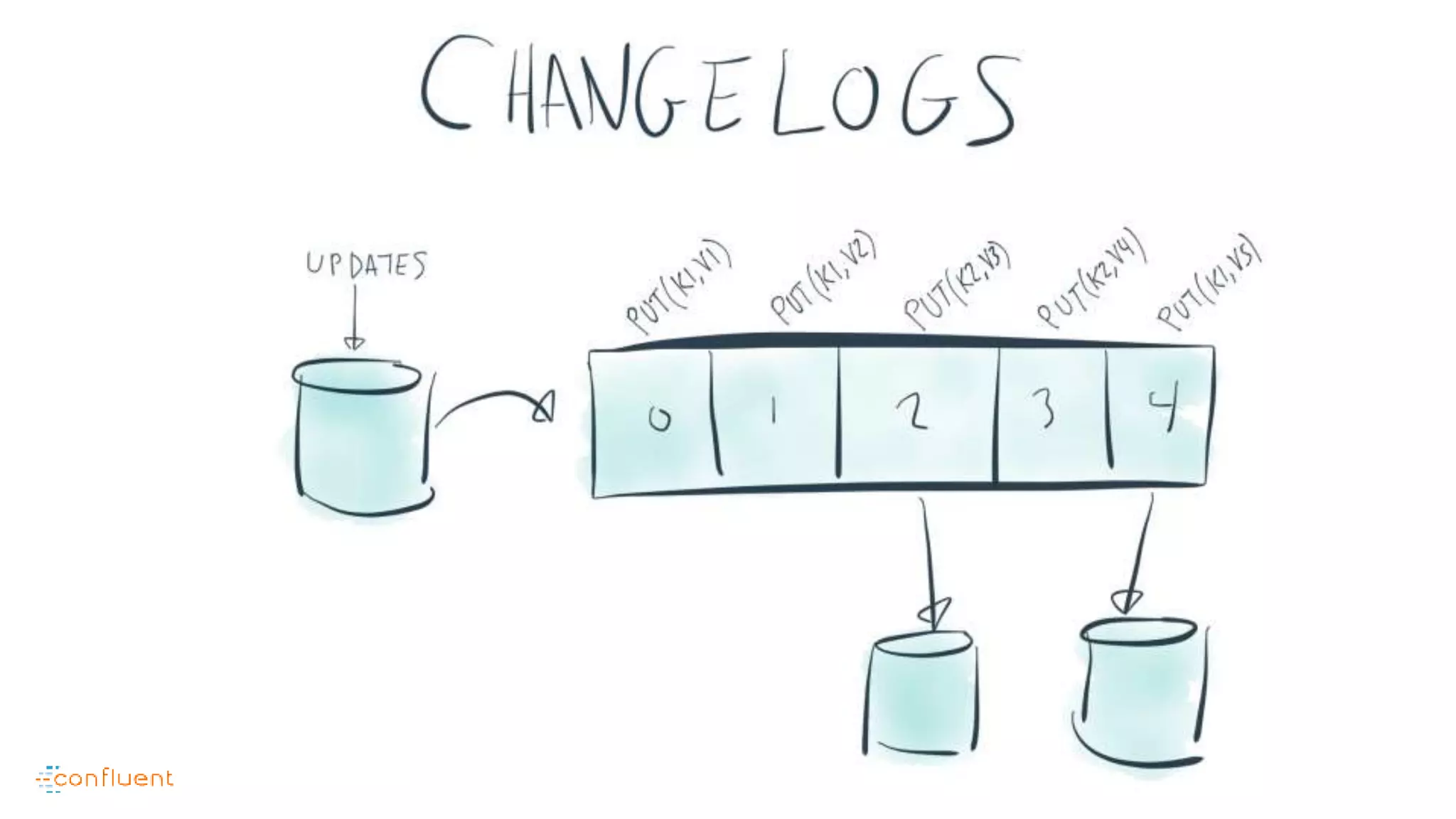
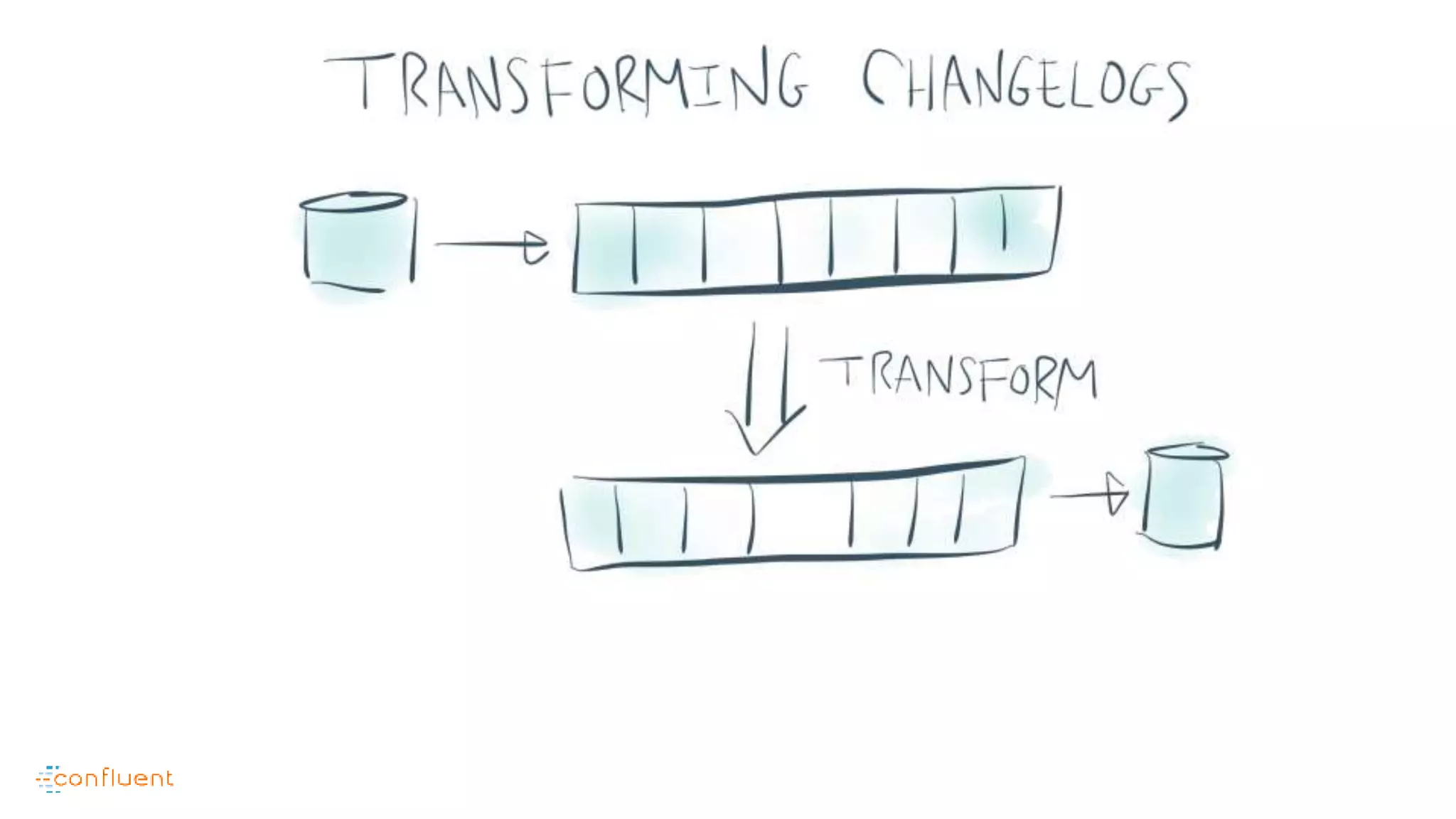
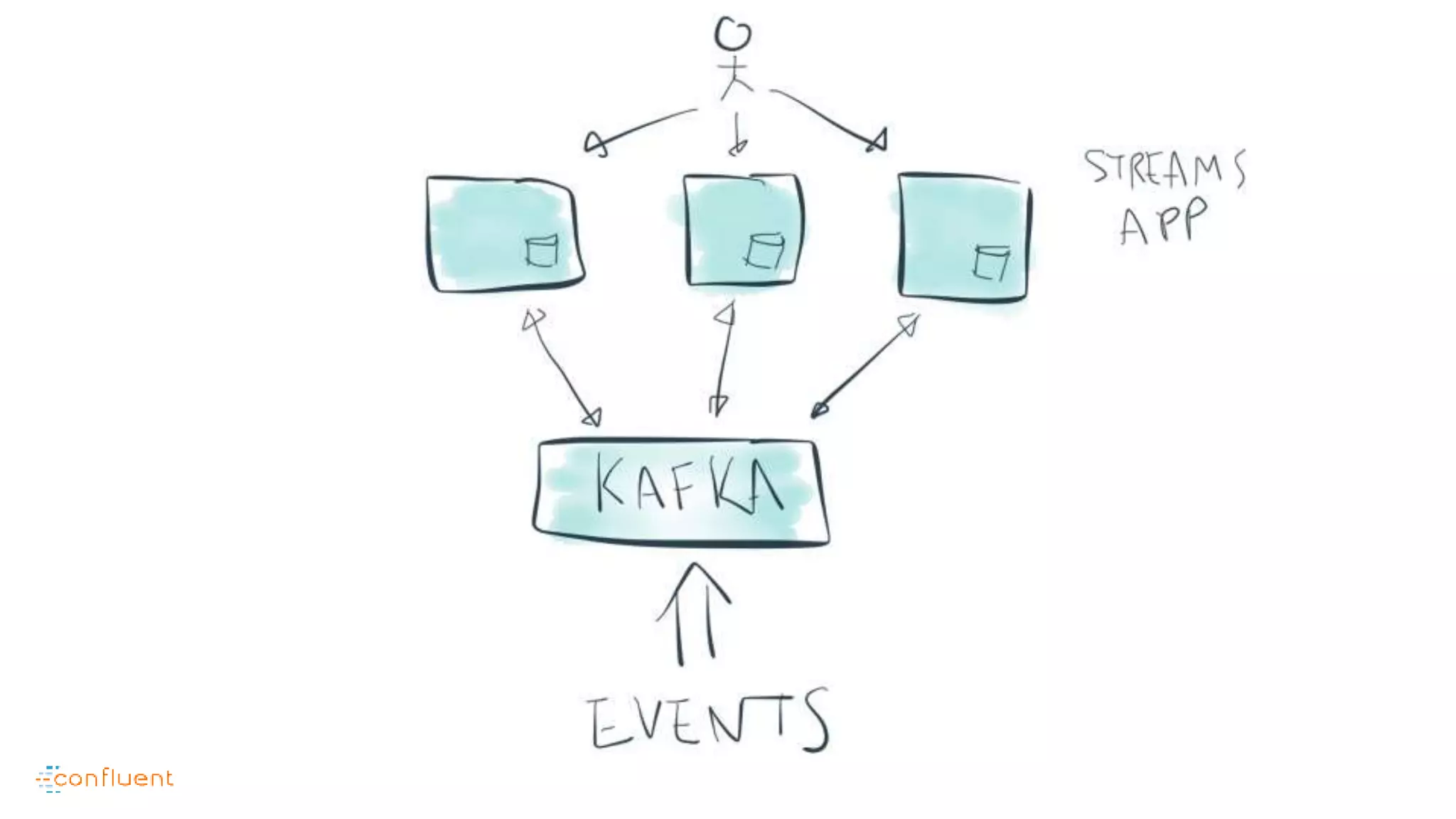
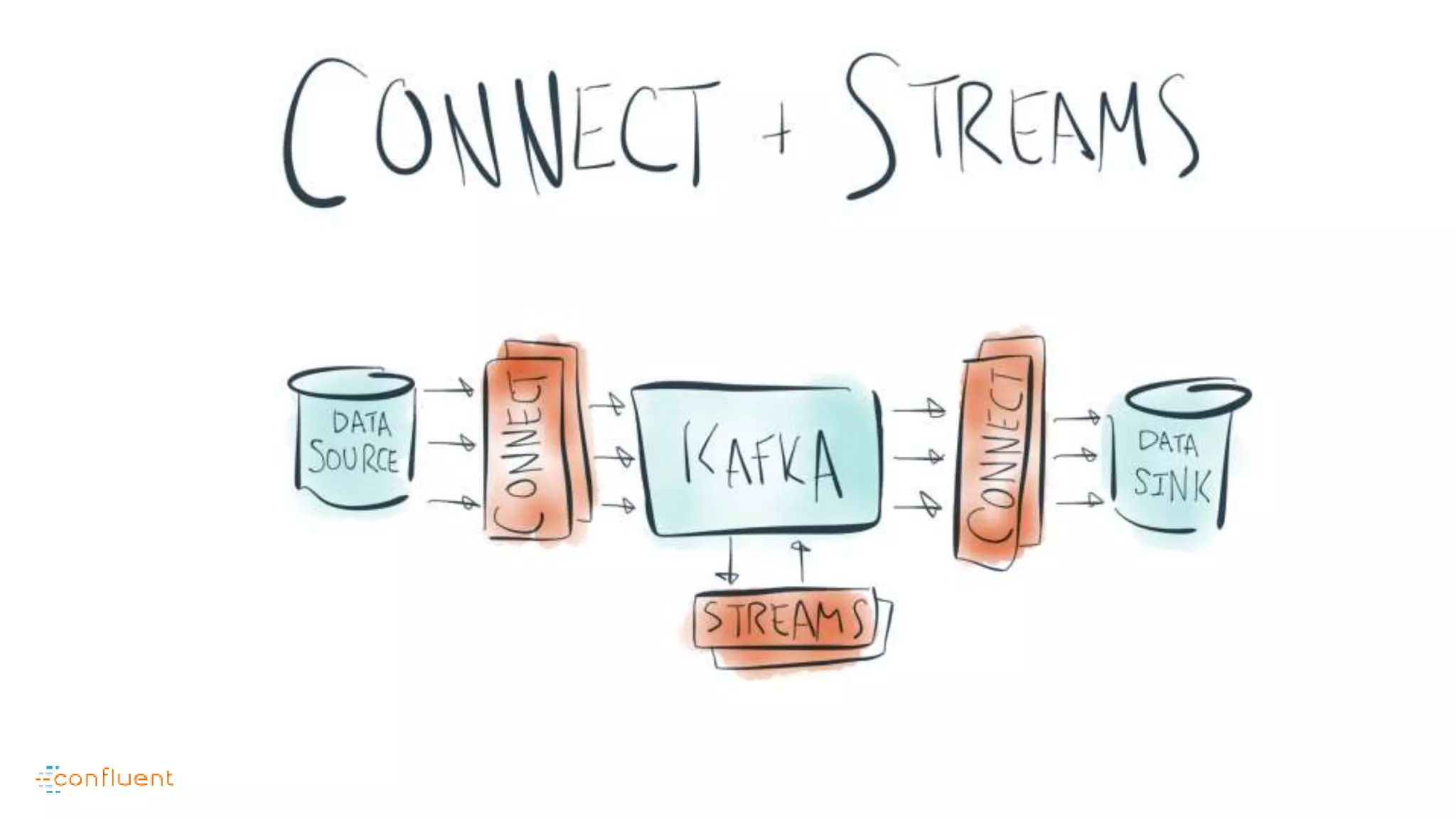
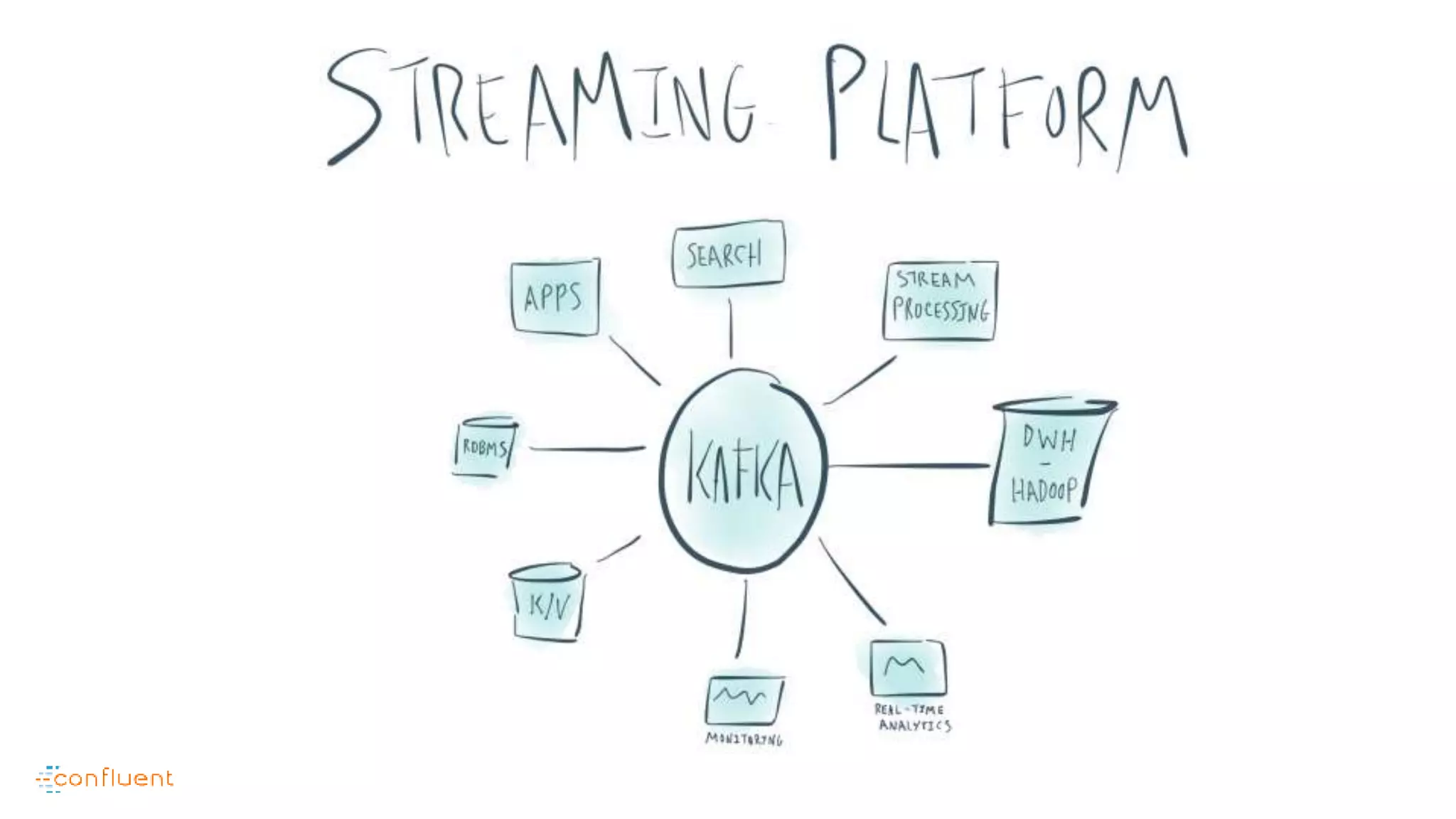
This document contains Twitter handles and URLs for individuals and companies involved with Apache Kafka and Confluent. It includes the Twitter handles for Jay Kreps, Apache Kafka, and Confluent, as well as the URLs for the Apache Kafka website and Confluent blog.