


















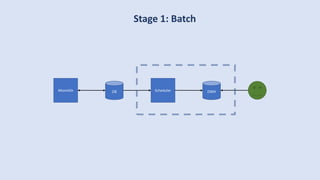




















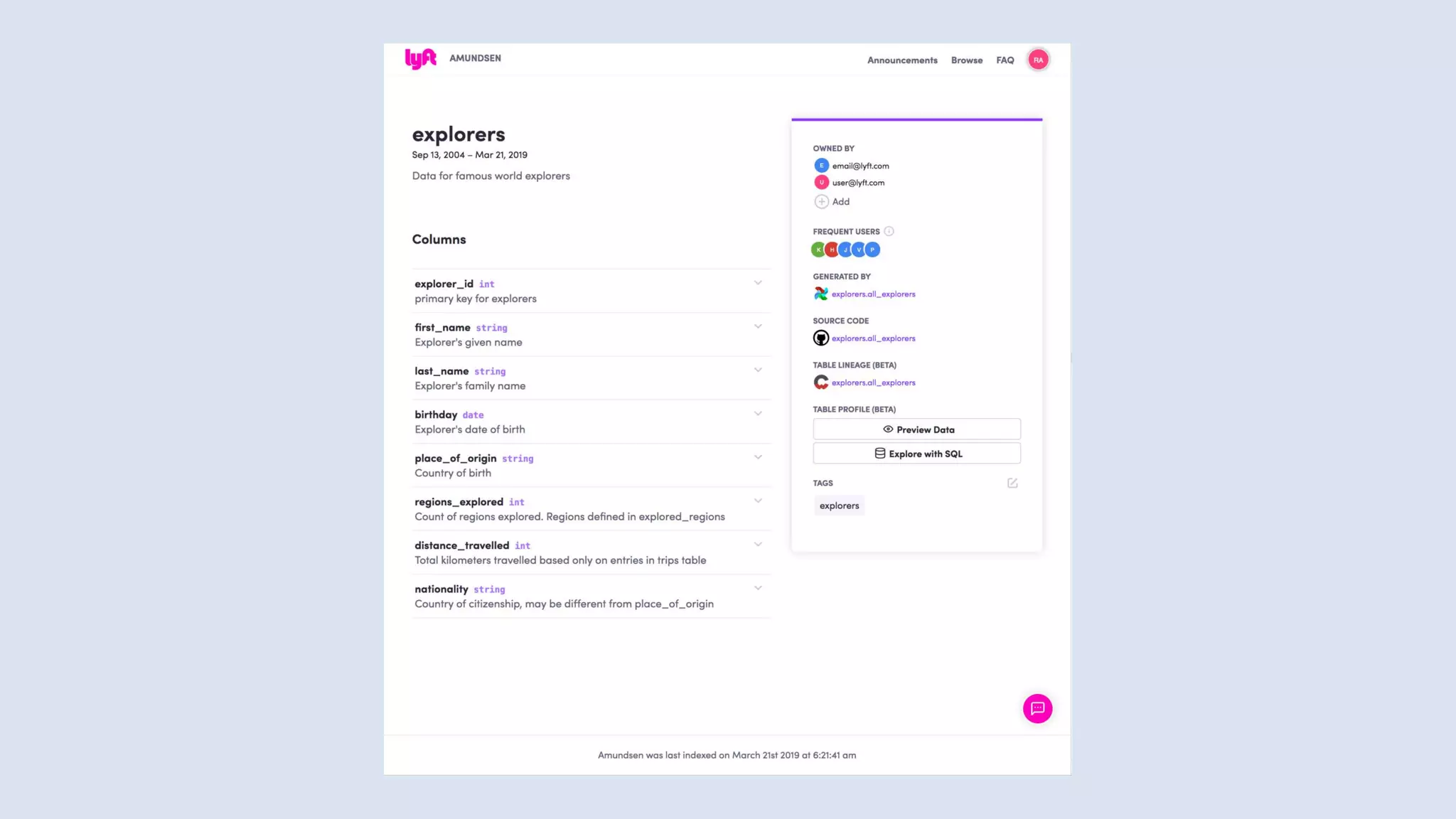
![Terraform
provider "kafka" {
bootstrap_servers = ["localhost:9092"]
}
resource "kafka_topic" "logs" {
name = "systemd_logs"
replication_factor = 2
partitions = 100
config = {
"segment.ms" = "20000"
"cleanup.policy" = "compact"
}
}](https://image.slidesharecdn.com/untitled-191206093354/85/Future-of-Data-Engineering-65-320.jpg)









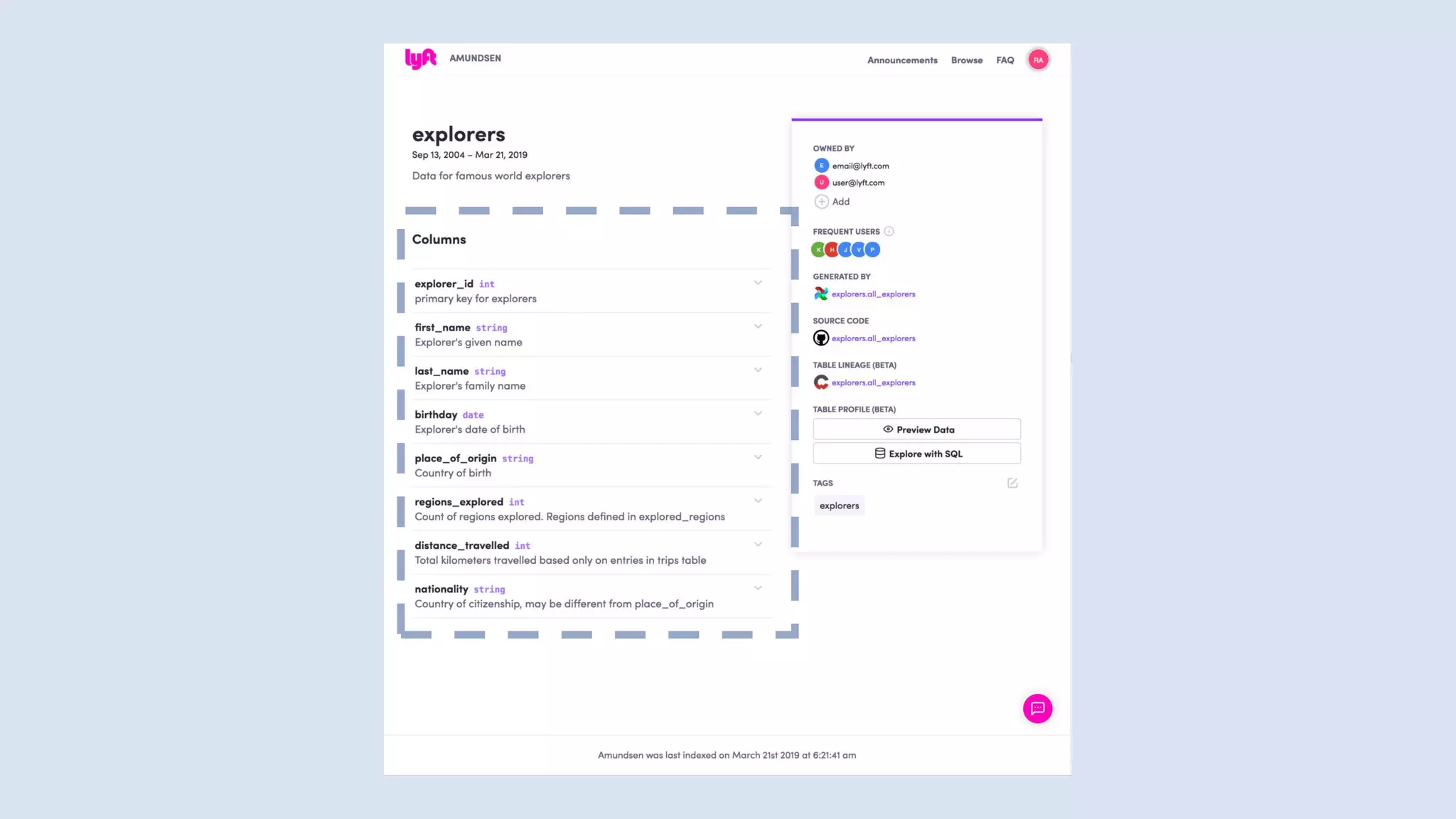
![Kafka ACLs with Terraform
provider "kafka" {
bootstrap_servers = ["localhost:9092"]
ca_cert = file("../secrets/snakeoil-ca-1.crt")
client_cert = file("../secrets/kafkacat-ca1-signed.pem")
client_key = file("../secrets/kafkacat-raw-private-key.pem")
skip_tls_verify = true
}
resource "kafka_acl" "test" {
resource_name = "syslog"
resource_type = "Topic"
acl_principal = "User:Alice"
acl_host = "*"
acl_operation = "Write"
acl_permission_type = "Deny"
}](https://image.slidesharecdn.com/untitled-191206093354/85/Future-of-Data-Engineering-82-320.jpg)


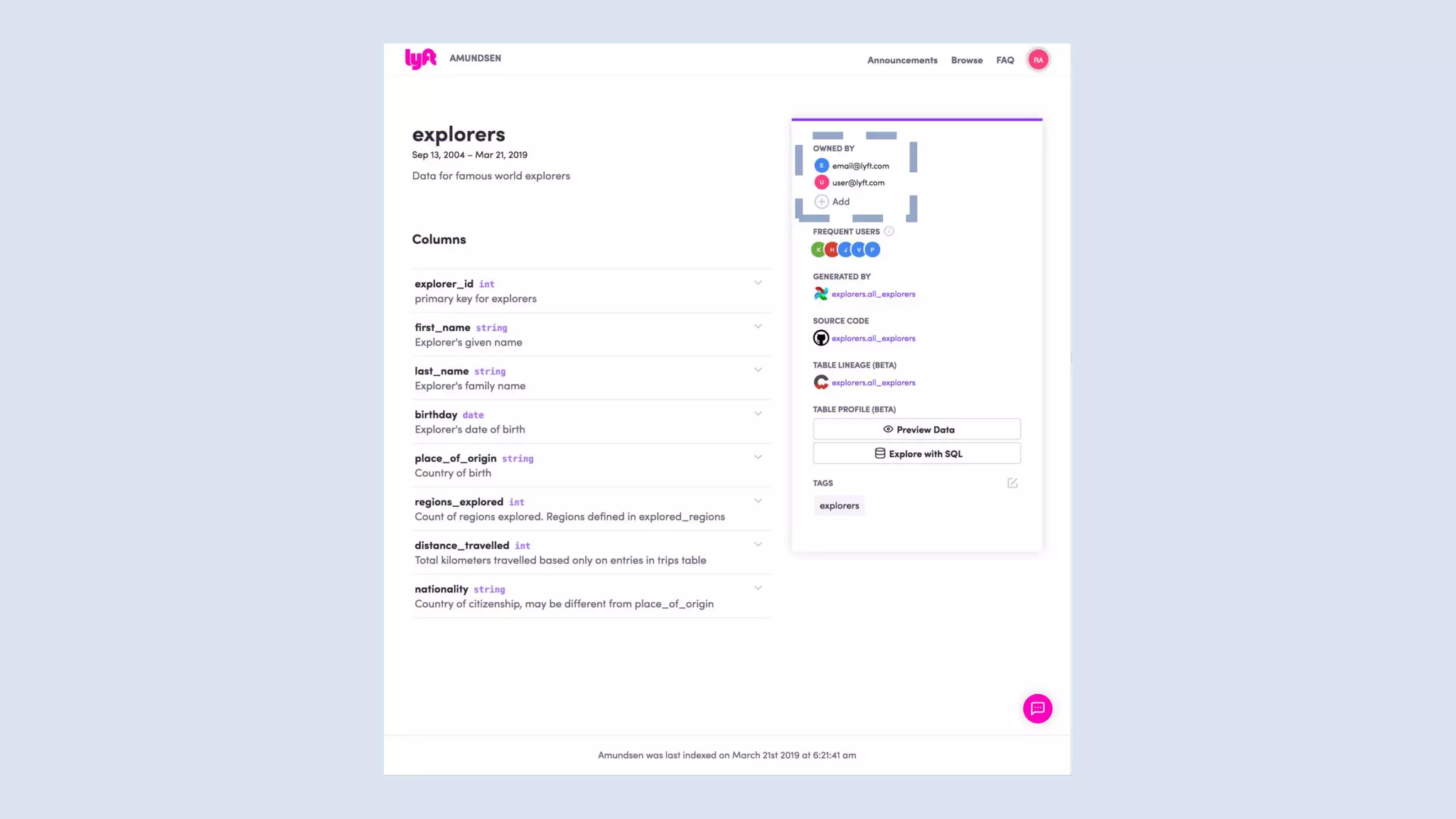
![Detecting sensitive data
{
"item":{
"value":"My phone number is (415) 555-0890"
},
"inspectConfig":{
"includeQuote":true,
"minLikelihood":"POSSIBLE",
"infoTypes":{
"name":"PHONE_NUMBER"
}
}
}
{
"result":{
"findings":[
{
"quote":"(415) 555-0890",
"infoType":{
"name":"PHONE_NUMBER"
},
"likelihood":"VERY_LIKELY",
"location":{
"byteRange":{
"start":"19",
"end":"33"
},
},
}
]
}
}](https://image.slidesharecdn.com/untitled-191206093354/85/Future-of-Data-Engineering-86-320.jpg)



















































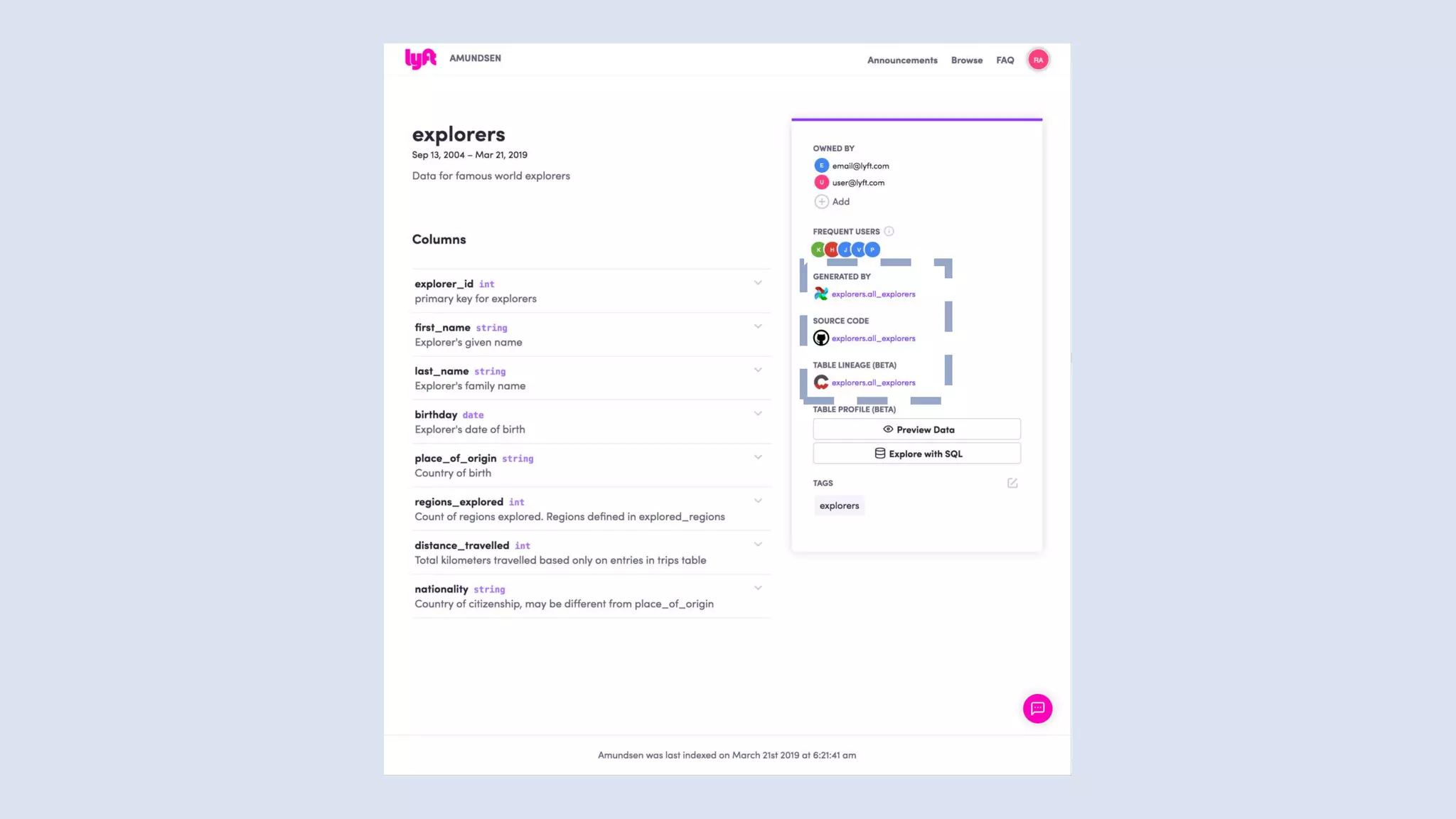
![Terraform
provider "kafka" {
bootstrap_servers = ["localhost:9092"]
}
resource "kafka_topic" "logs" {
name = "systemd_logs"
replication_factor = 2
partitions = 100
config = {
"segment.ms" = "20000"
"cleanup.policy" = "compact"
}
}](https://image.slidesharecdn.com/untitled-191206093354/75/Future-of-Data-Engineering-65-2048.jpg)









![Kafka ACLs with Terraform
provider "kafka" {
bootstrap_servers = ["localhost:9092"]
ca_cert = file("../secrets/snakeoil-ca-1.crt")
client_cert = file("../secrets/kafkacat-ca1-signed.pem")
client_key = file("../secrets/kafkacat-raw-private-key.pem")
skip_tls_verify = true
}
resource "kafka_acl" "test" {
resource_name = "syslog"
resource_type = "Topic"
acl_principal = "User:Alice"
acl_host = "*"
acl_operation = "Write"
acl_permission_type = "Deny"
}](https://image.slidesharecdn.com/untitled-191206093354/75/Future-of-Data-Engineering-82-2048.jpg)


![Detecting sensitive data
{
"item":{
"value":"My phone number is (415) 555-0890"
},
"inspectConfig":{
"includeQuote":true,
"minLikelihood":"POSSIBLE",
"infoTypes":{
"name":"PHONE_NUMBER"
}
}
}
{
"result":{
"findings":[
{
"quote":"(415) 555-0890",
"infoType":{
"name":"PHONE_NUMBER"
},
"likelihood":"VERY_LIKELY",
"location":{
"byteRange":{
"start":"19",
"end":"33"
},
},
}
]
}
}](https://image.slidesharecdn.com/untitled-191206093354/75/Future-of-Data-Engineering-86-2048.jpg)





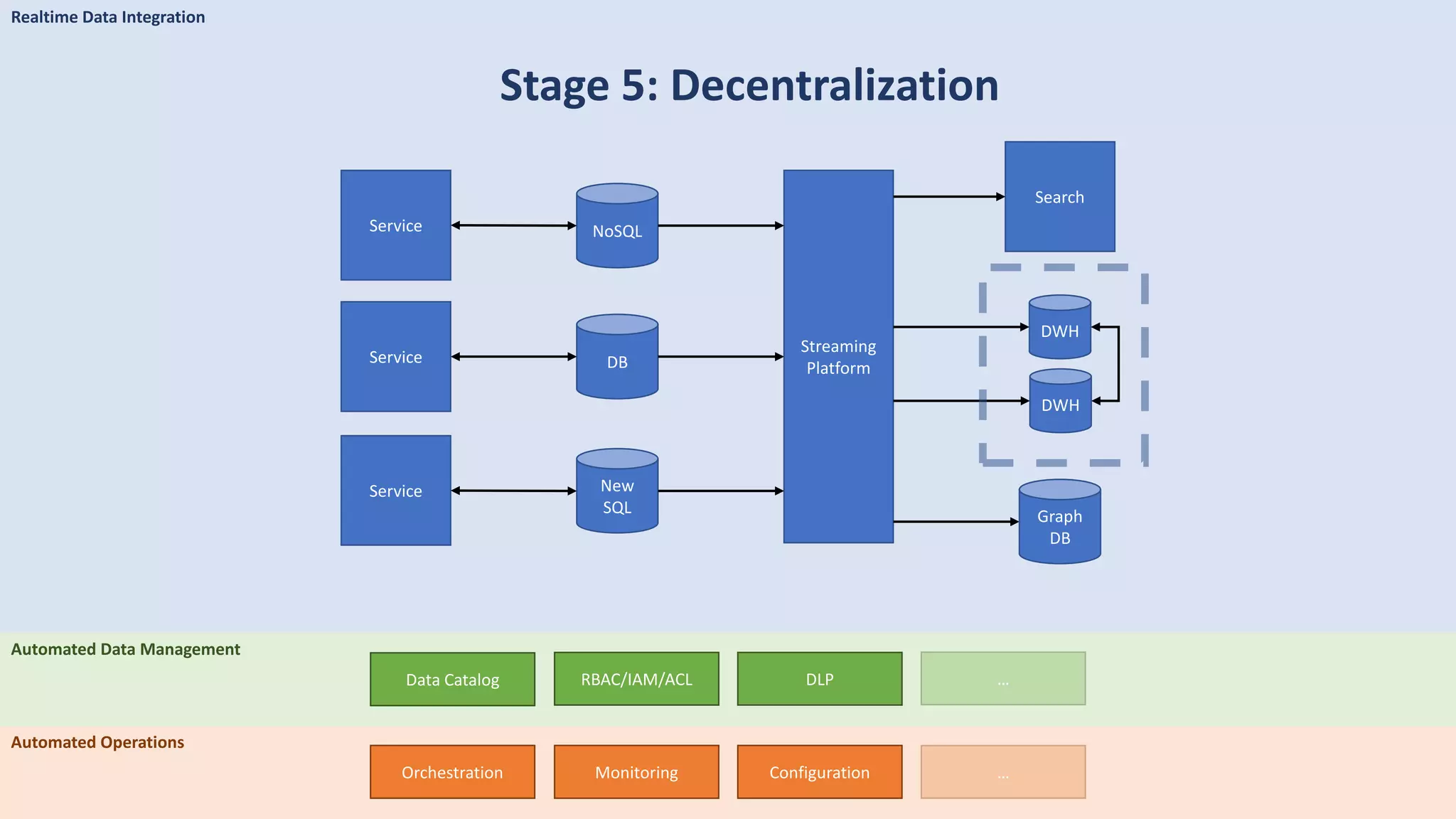



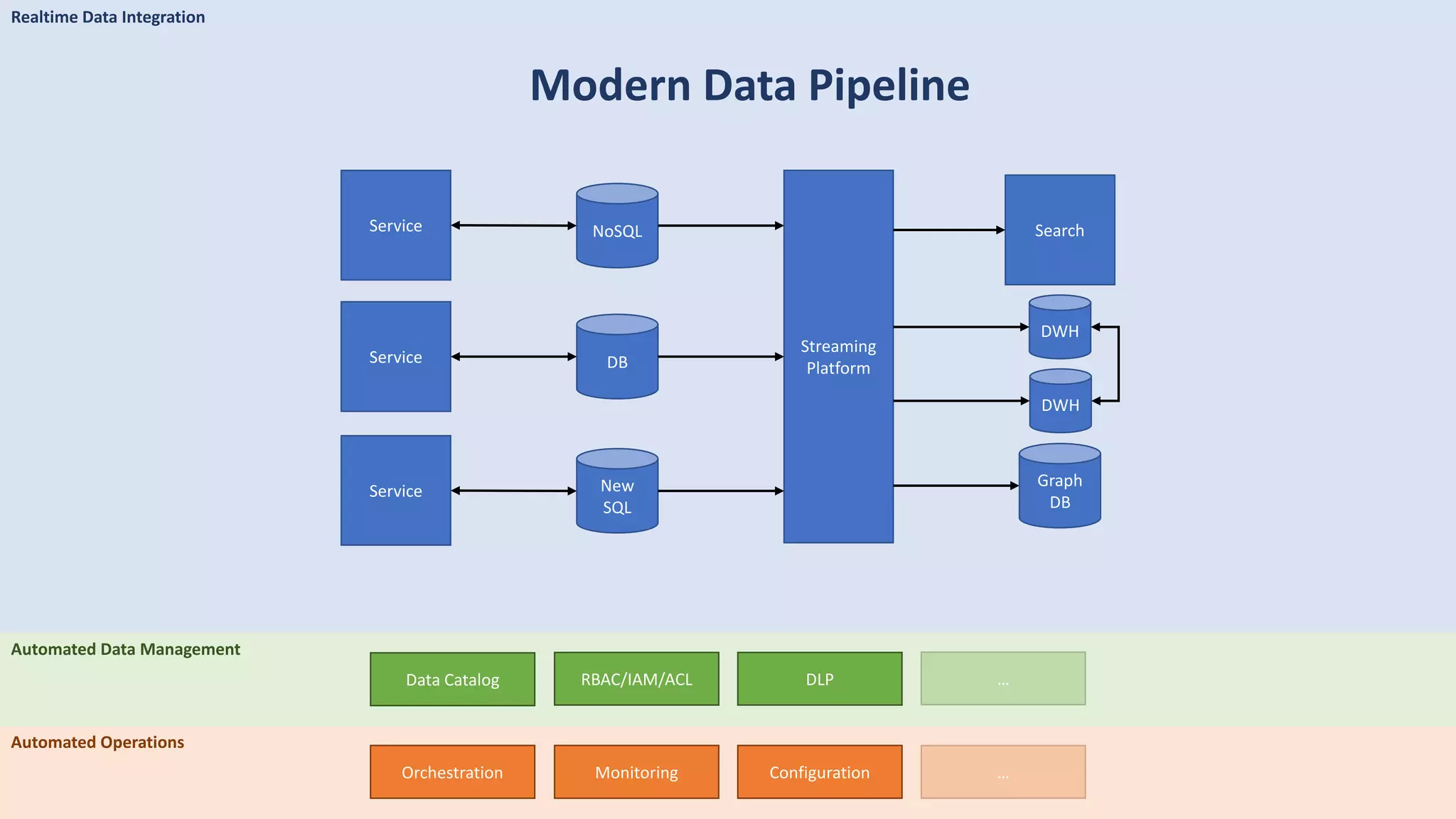



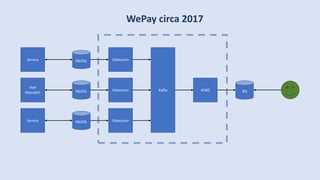
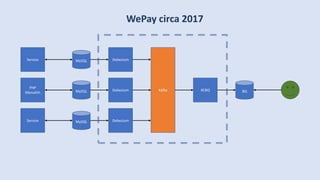
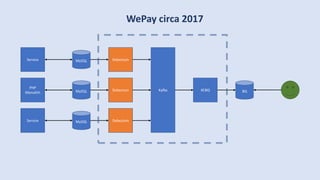
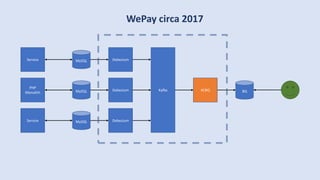
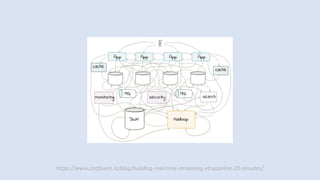
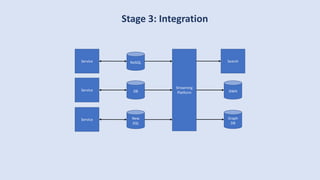
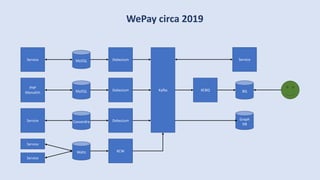
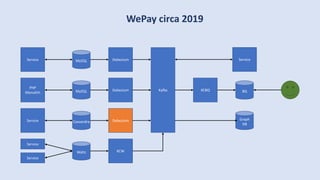
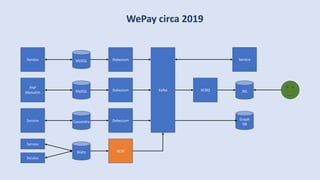
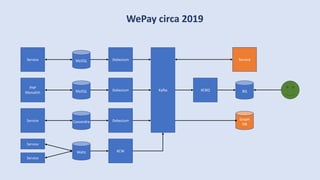
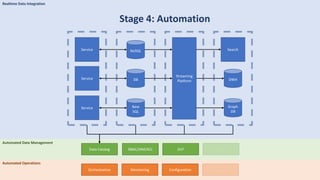
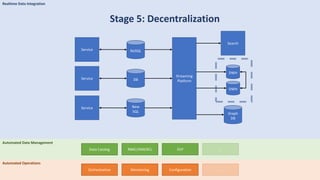
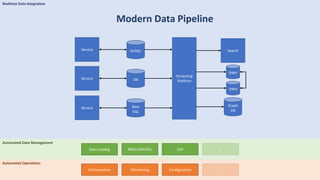
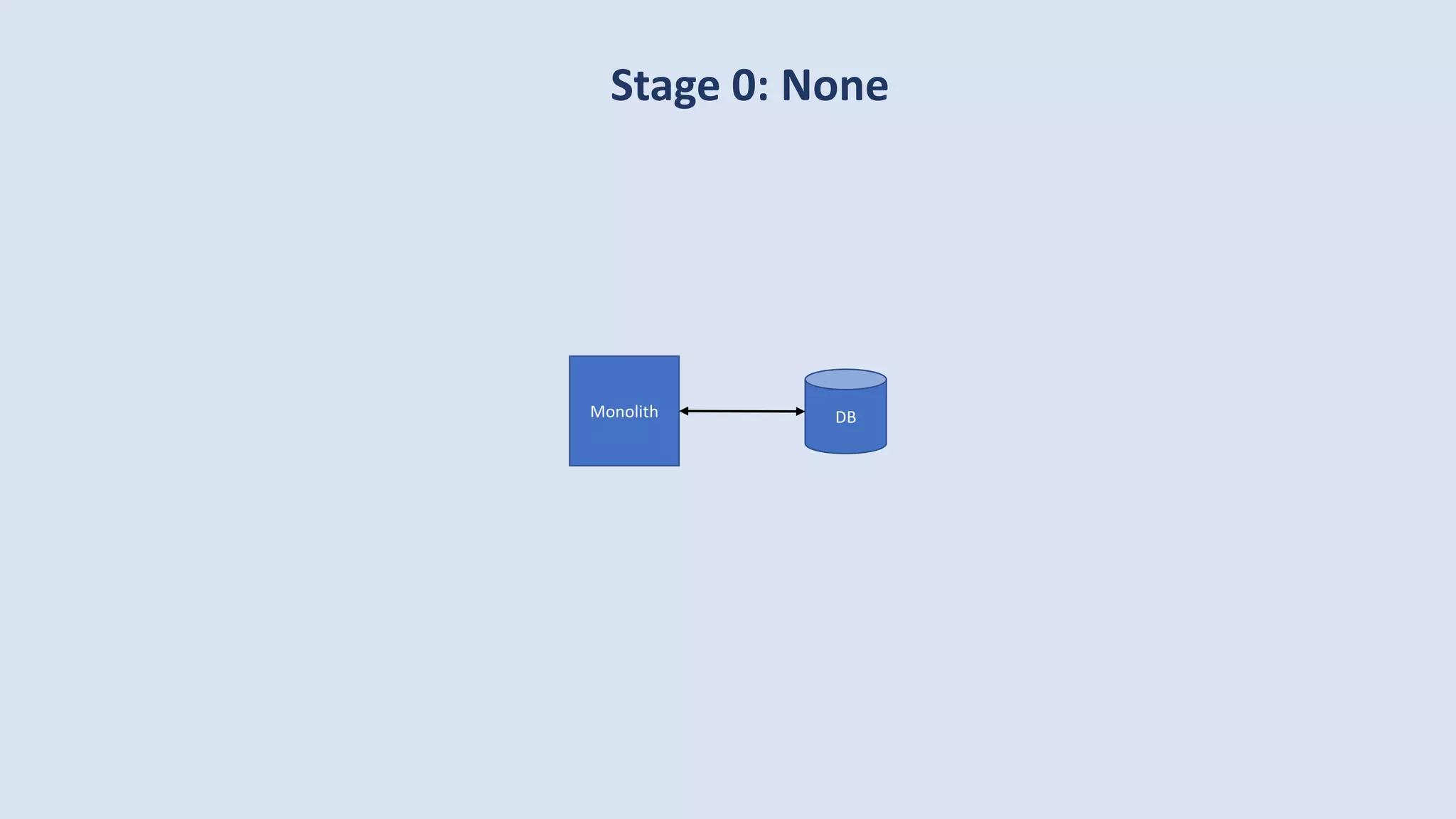
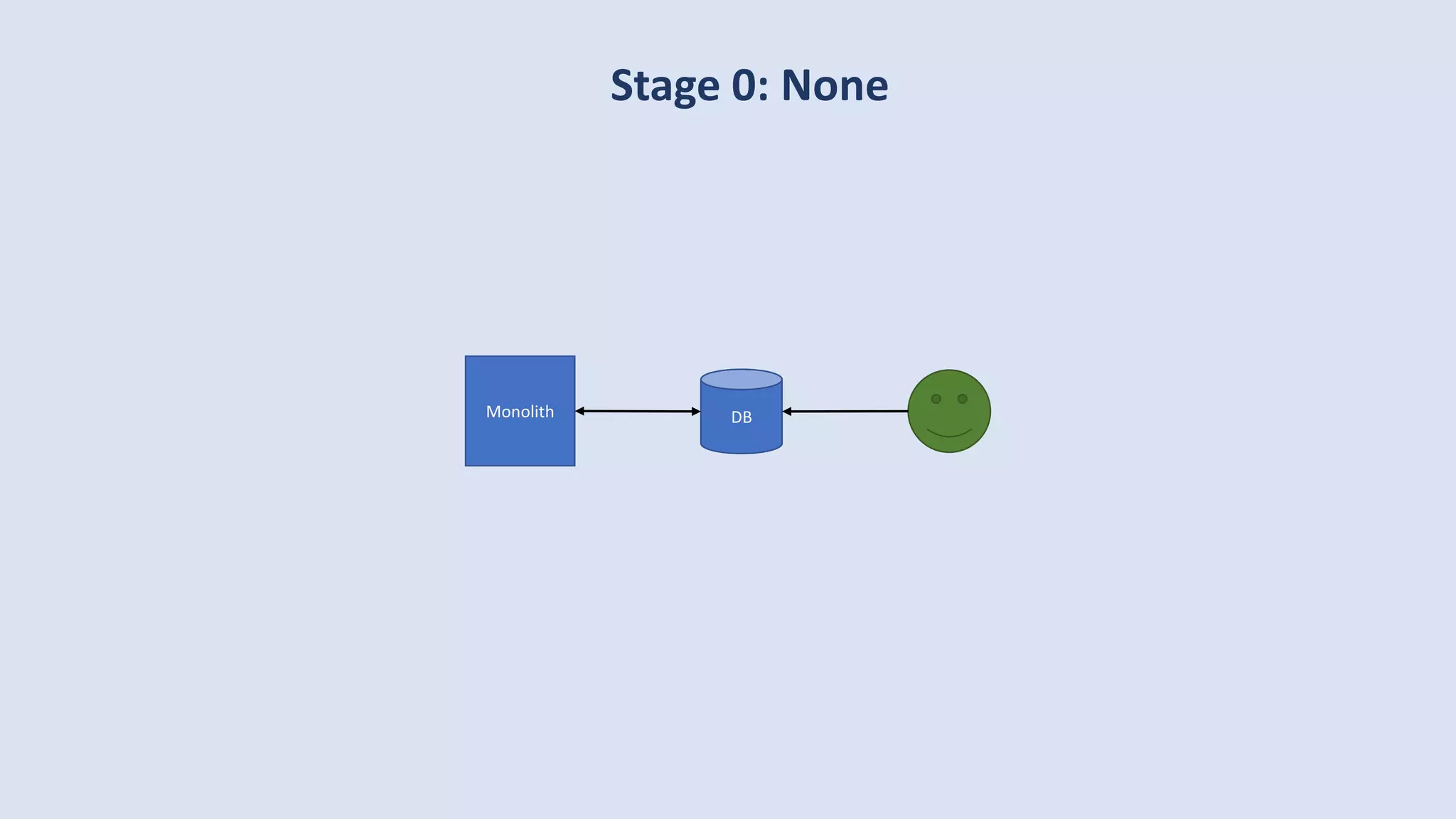
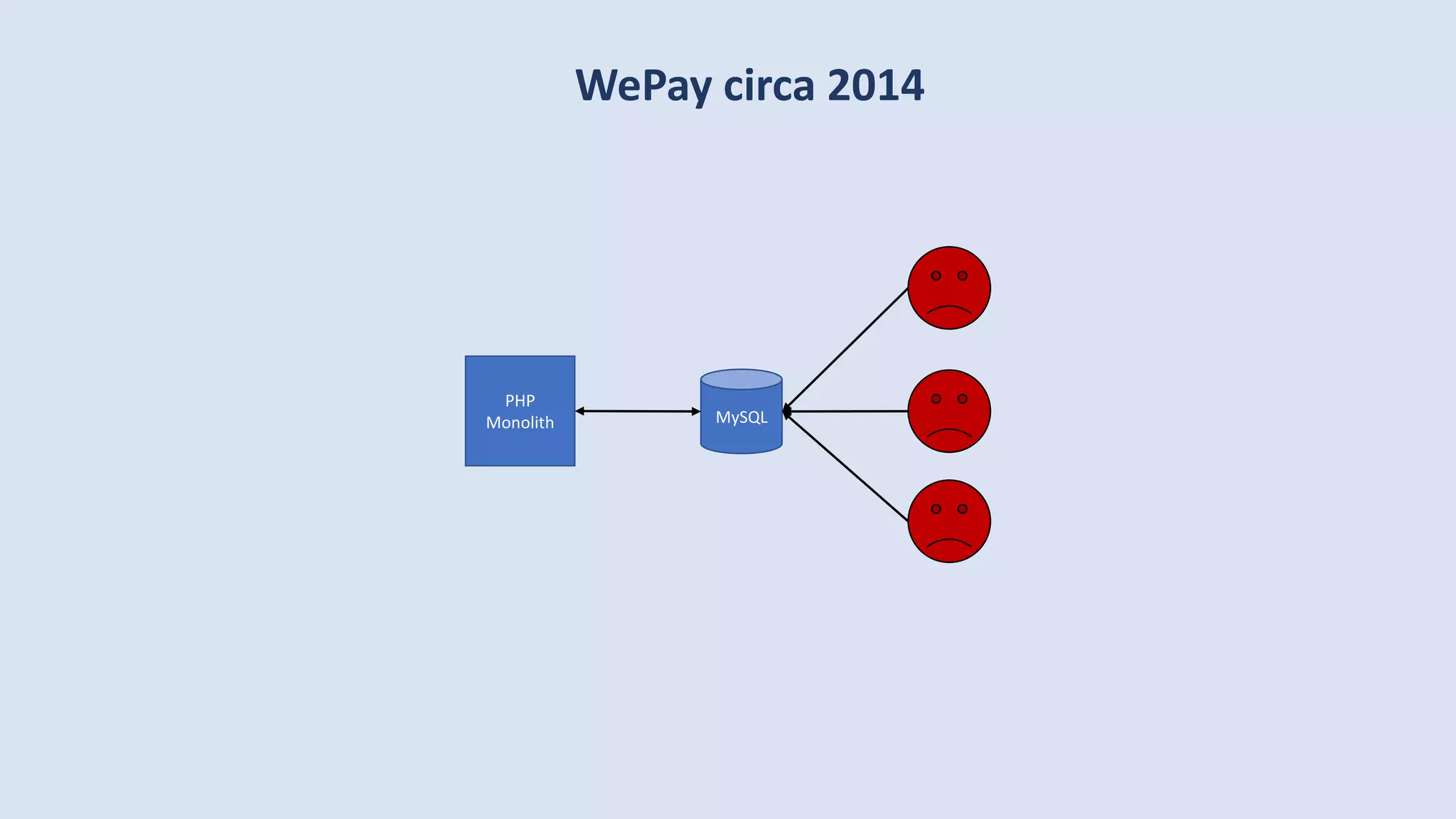
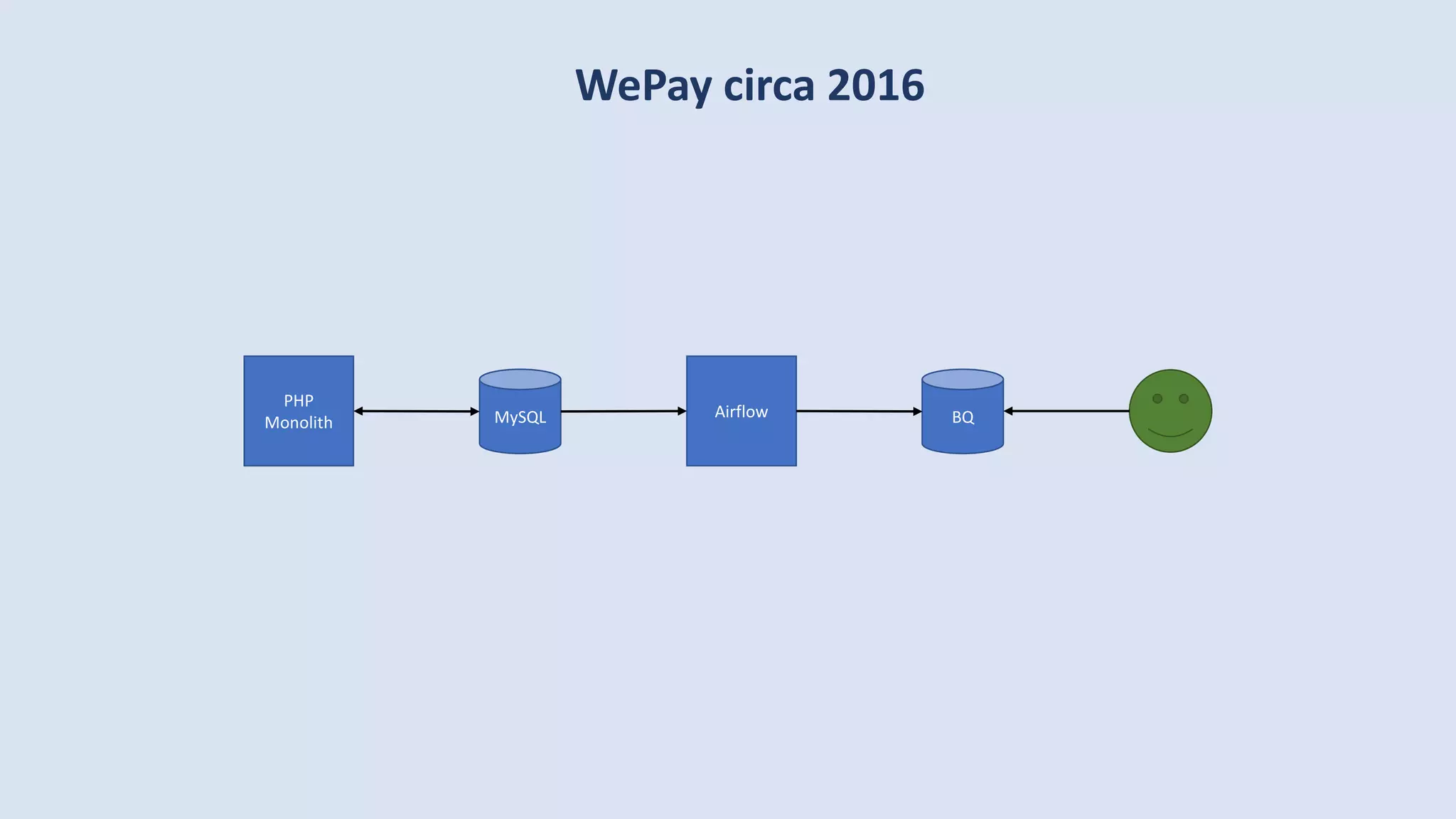
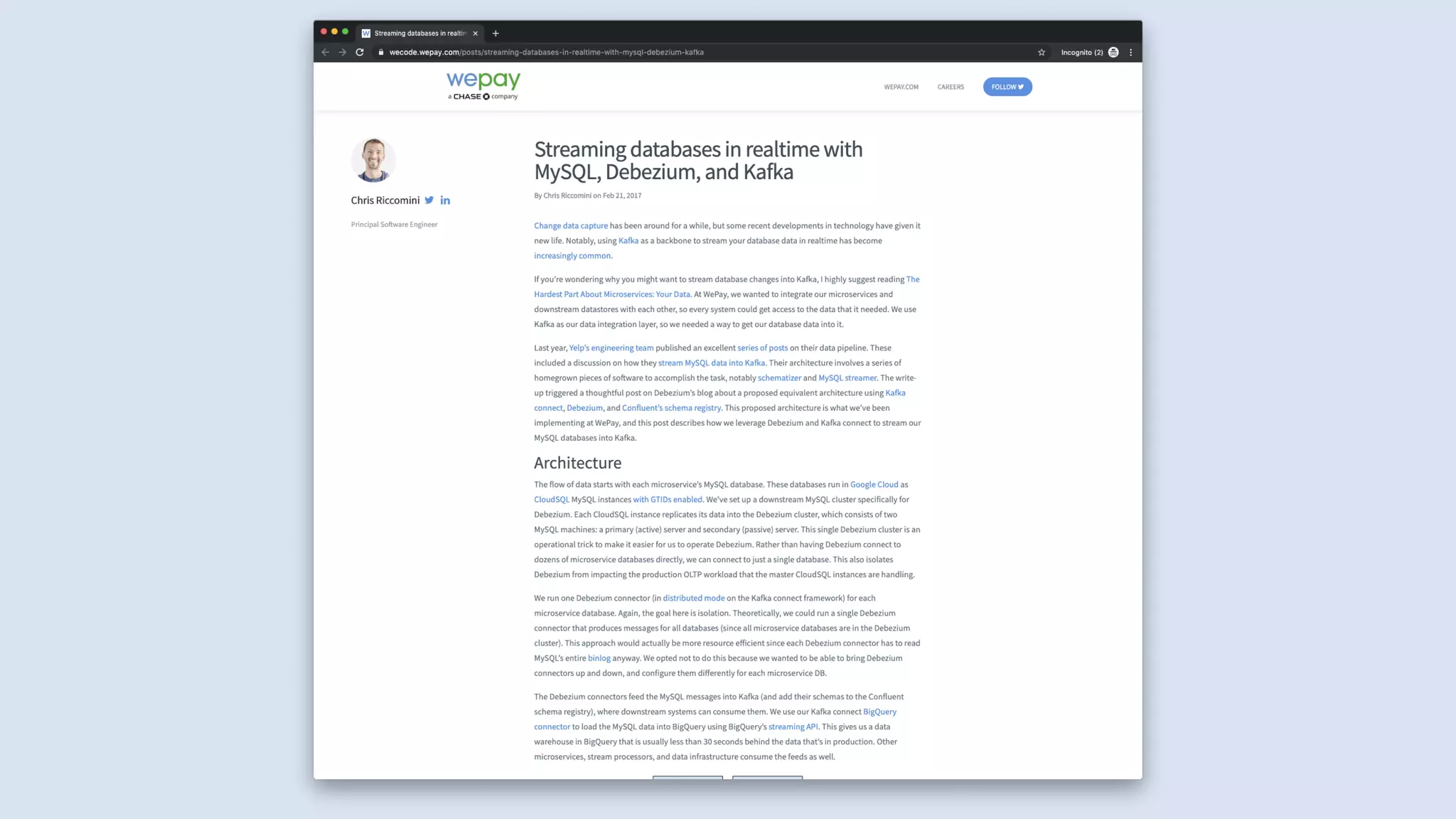
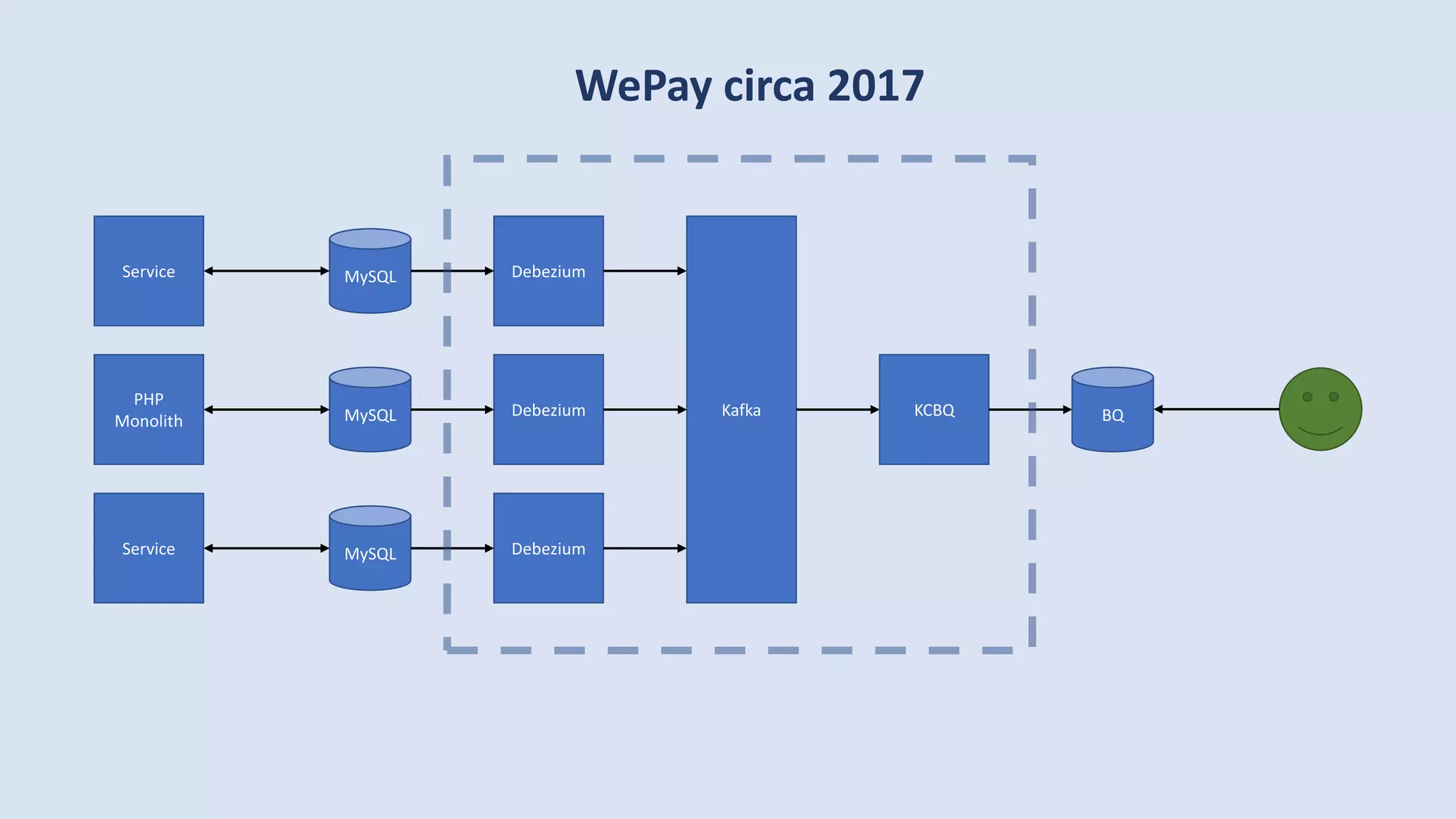
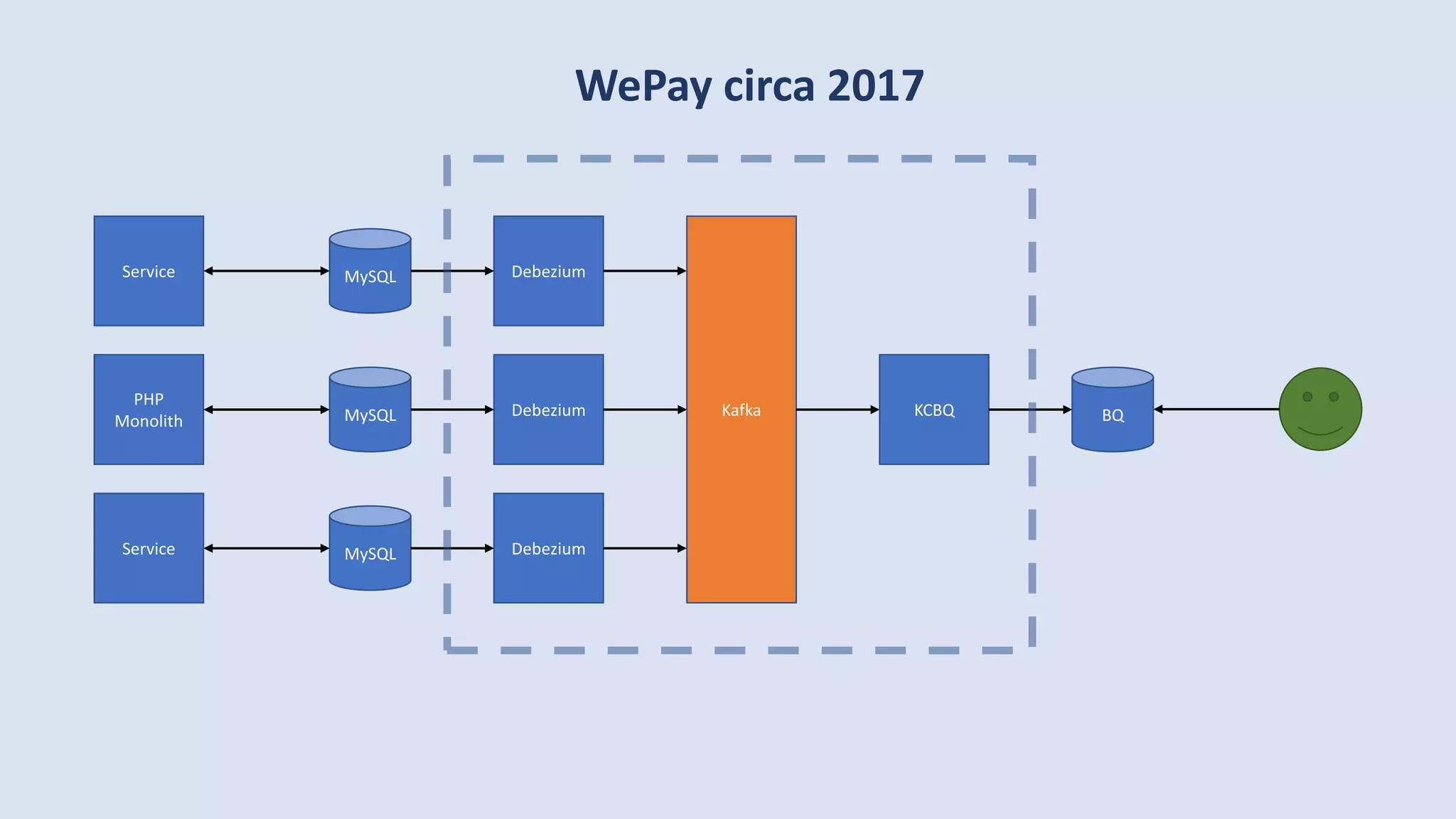
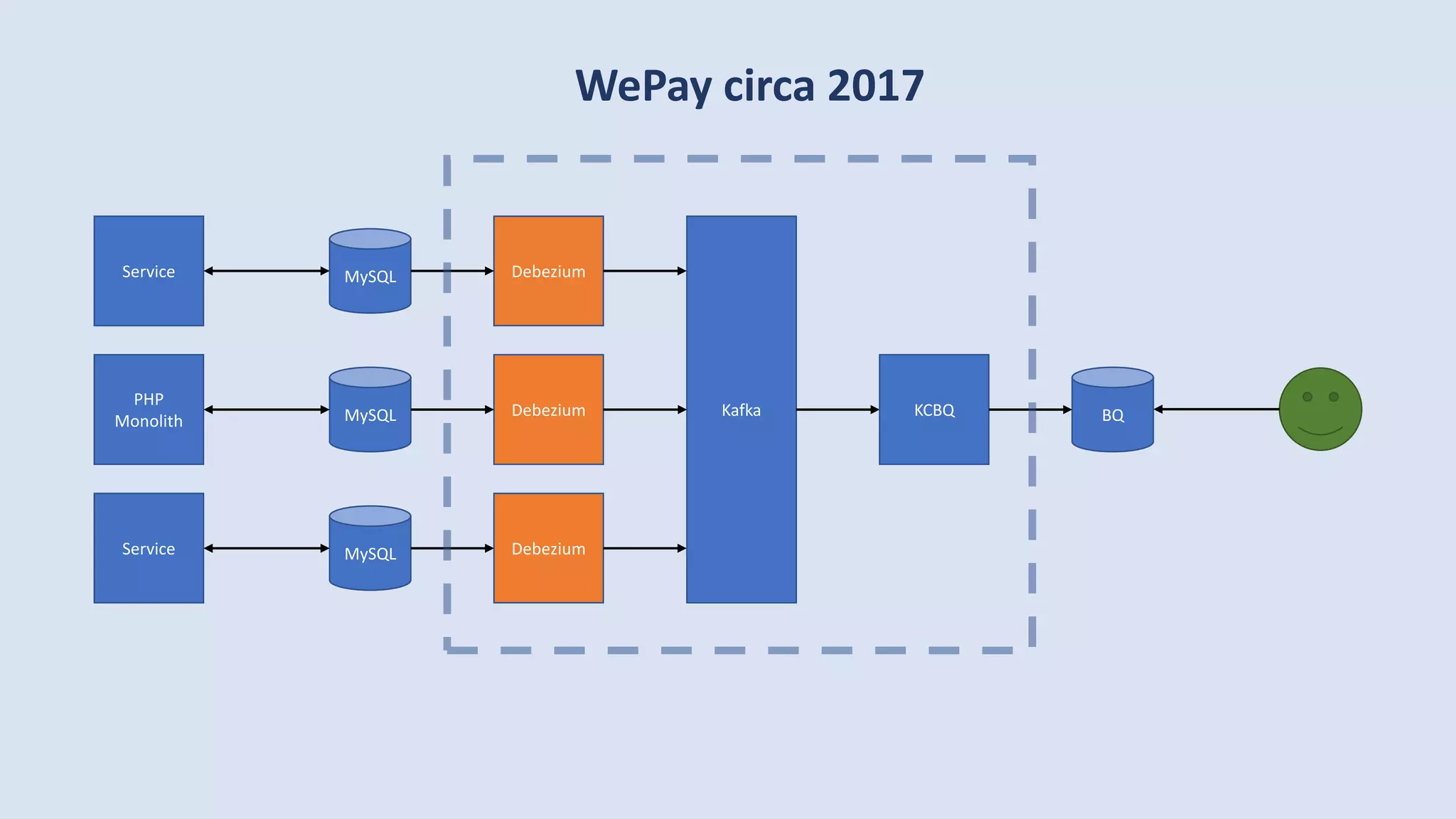
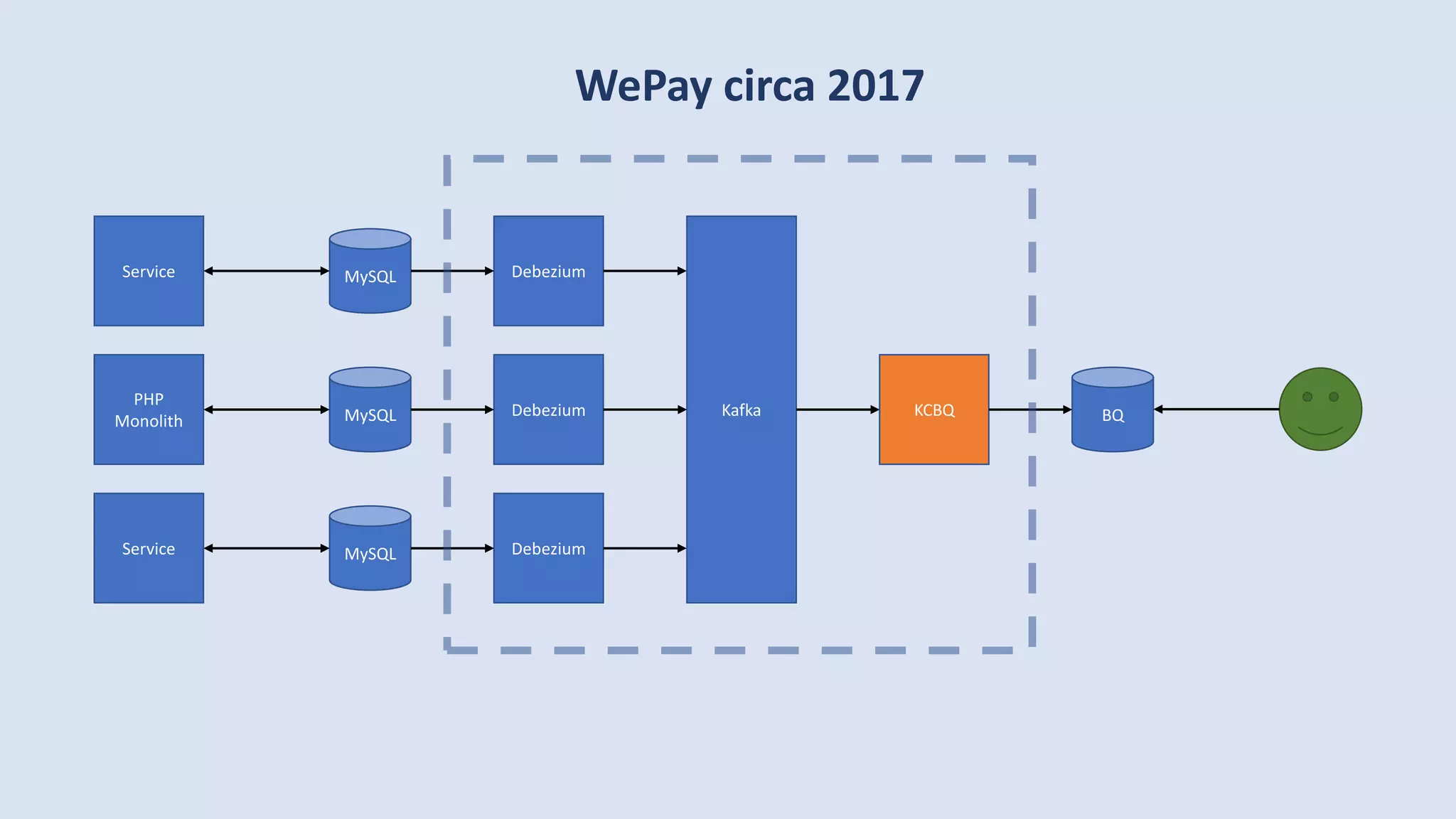
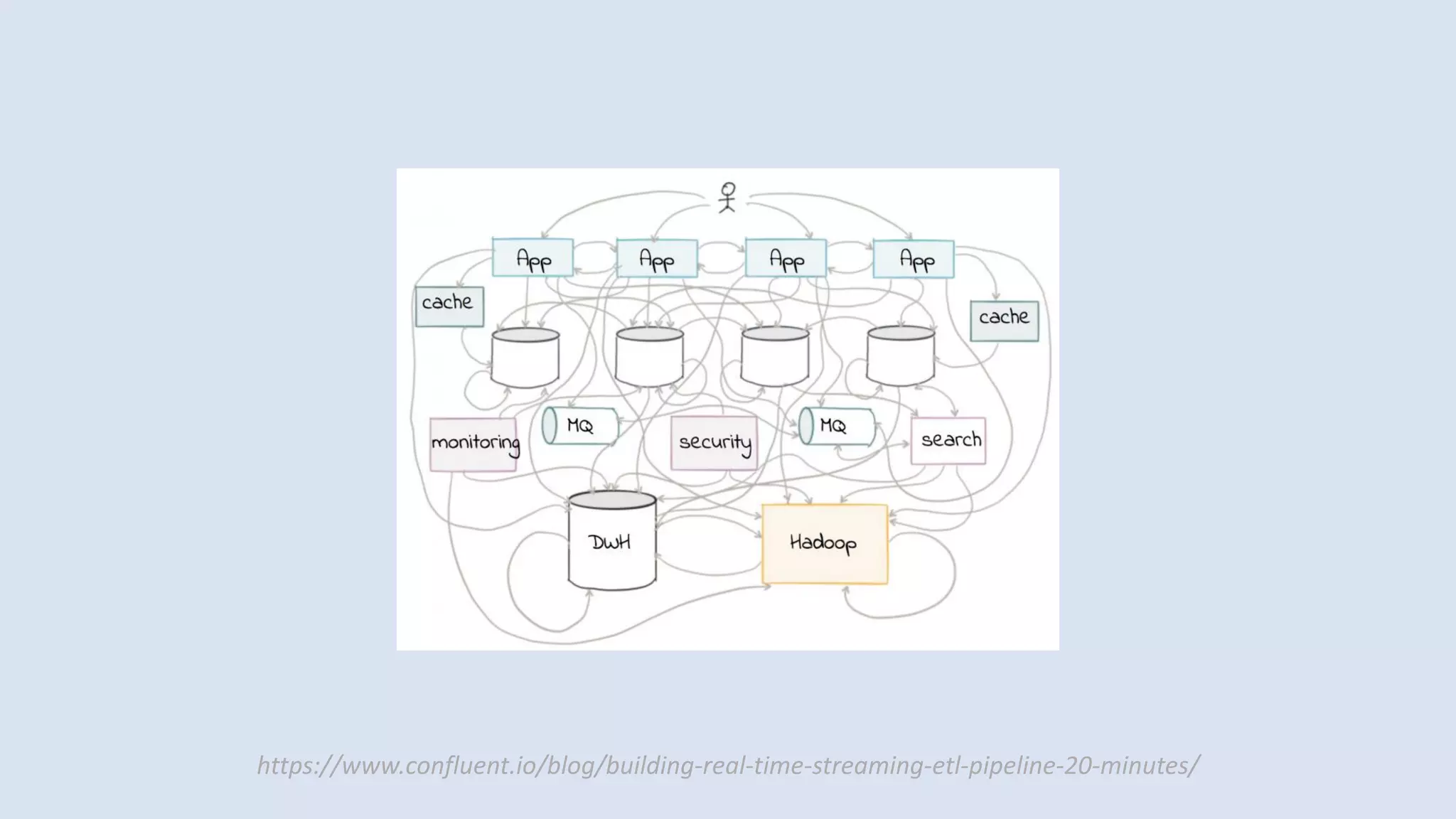
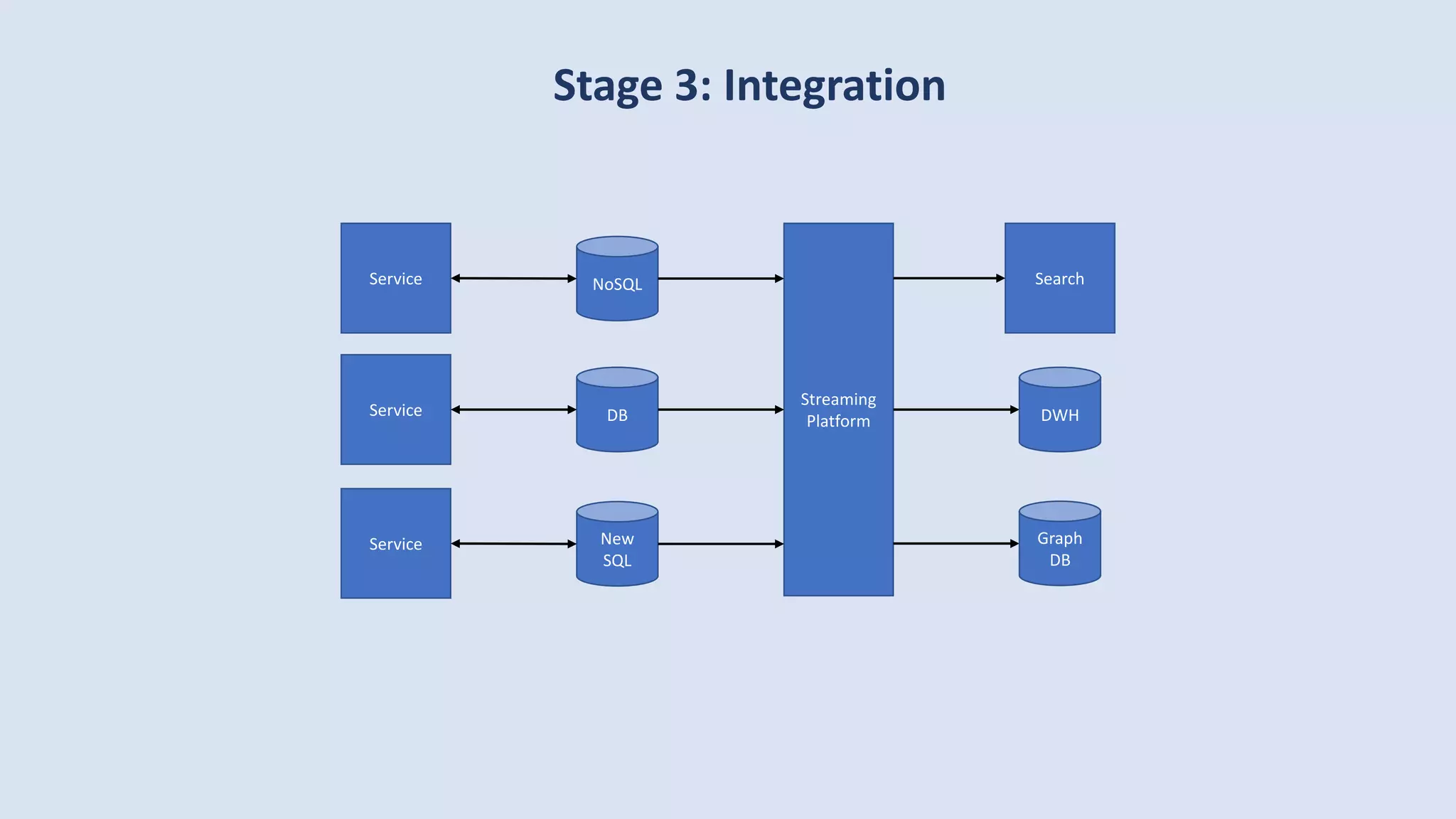
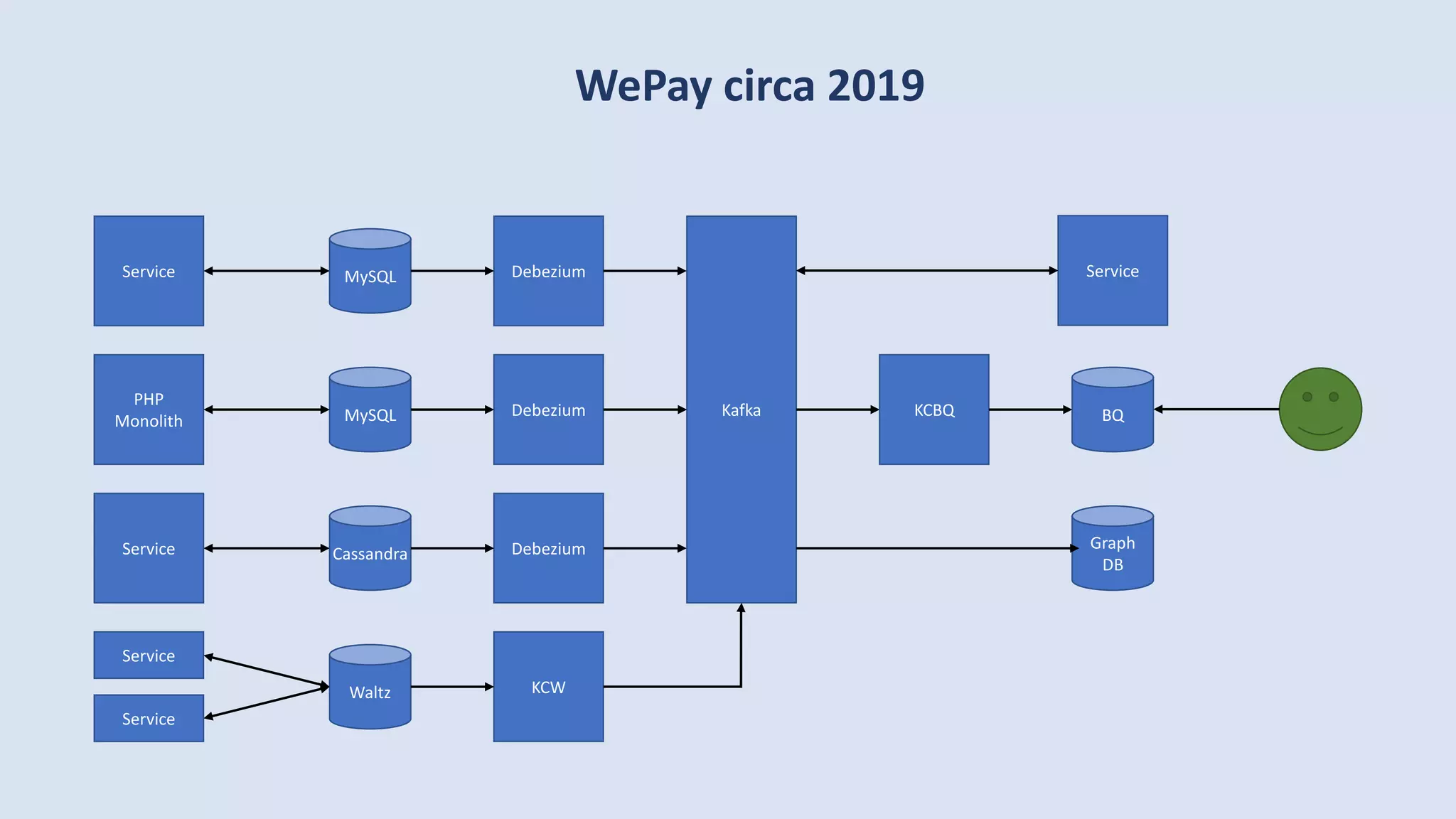
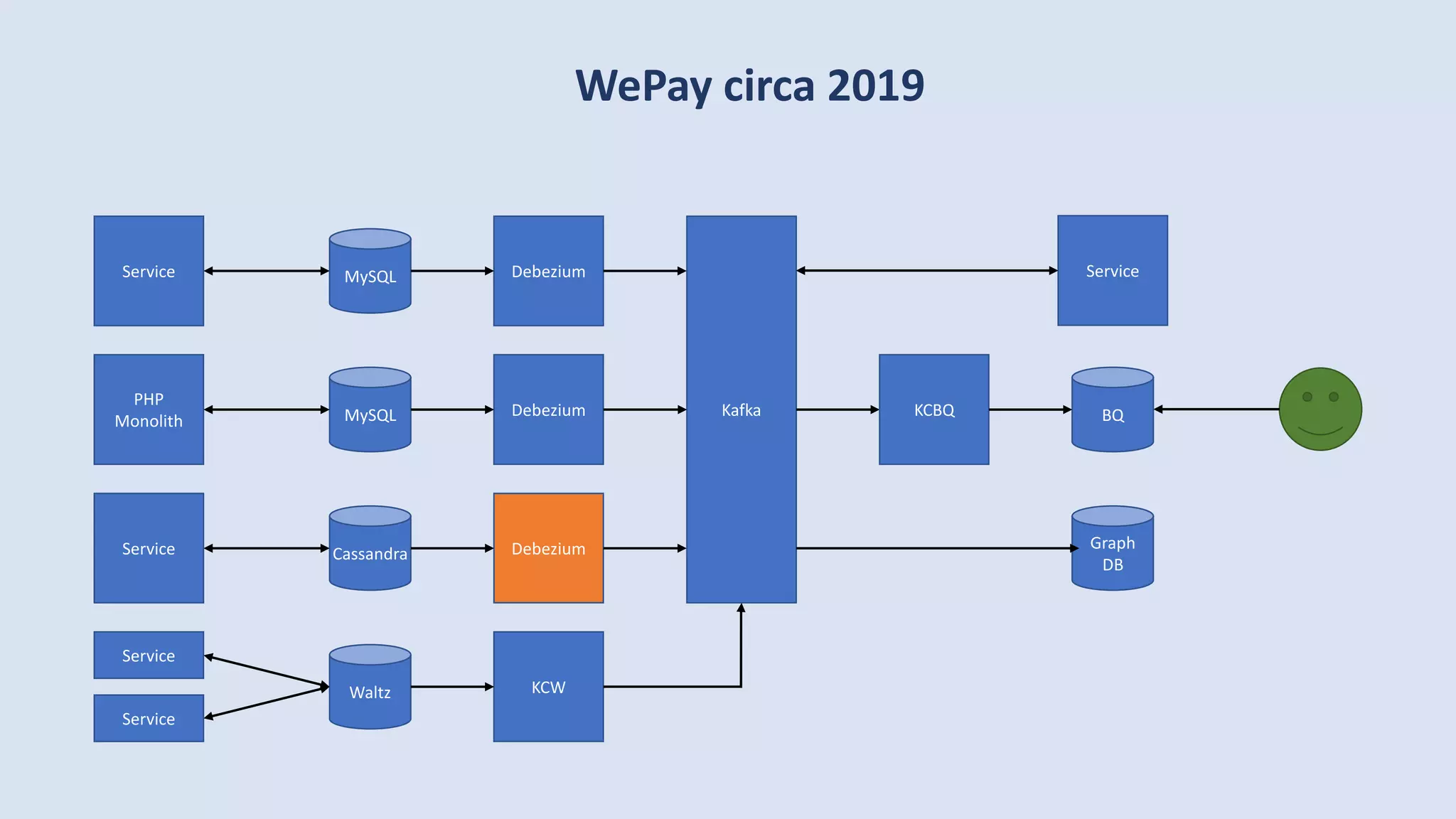
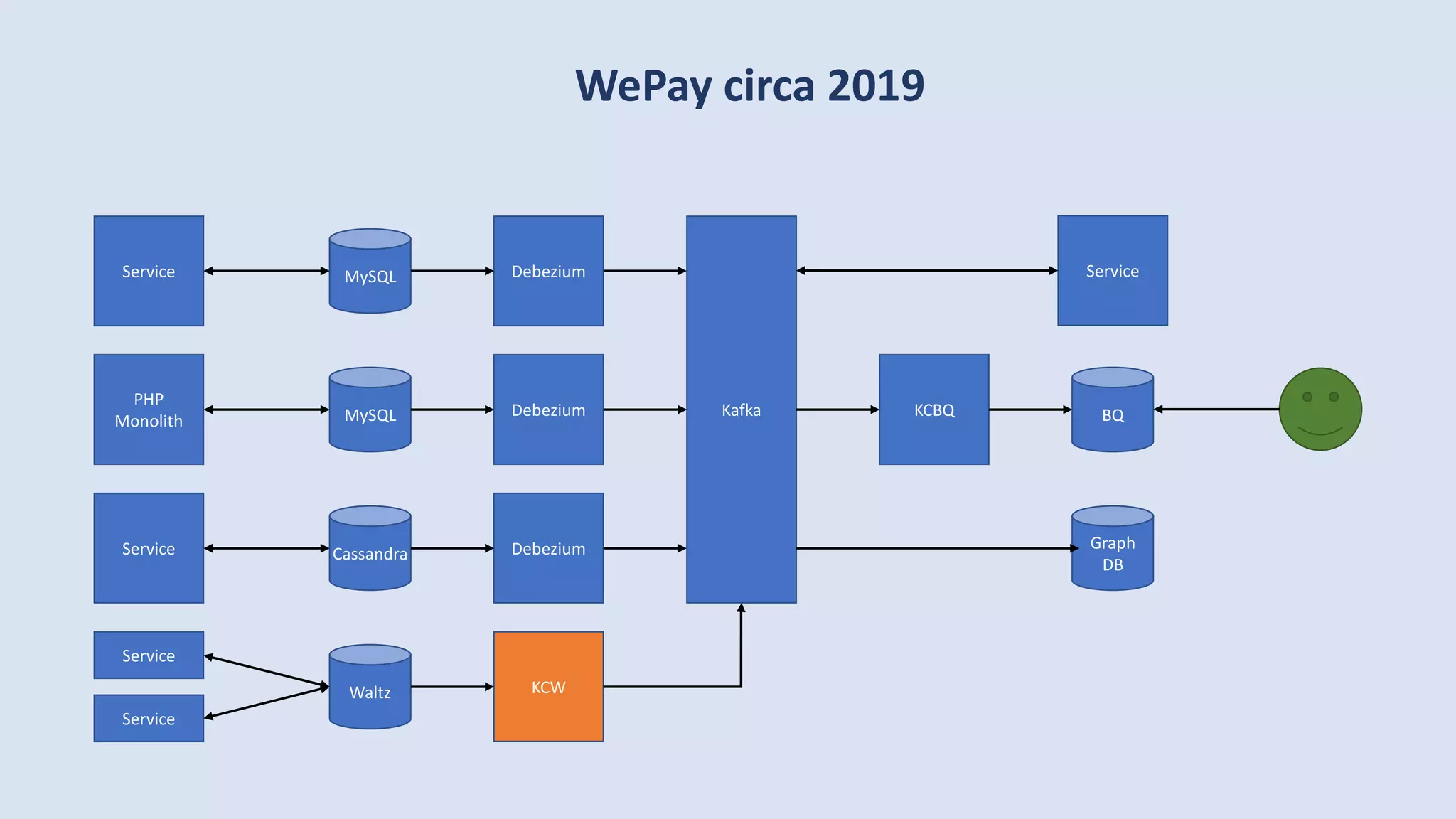
The document discusses data engineering and the evolution of data pipelines, highlighting six stages of maturity from none to decentralization. It emphasizes the roles and responsibilities of data engineers in building infrastructure and tools that facilitate data movement and processing across organizations. The talk also covers the importance of automation and integration in modern data engineering practices.
















































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






