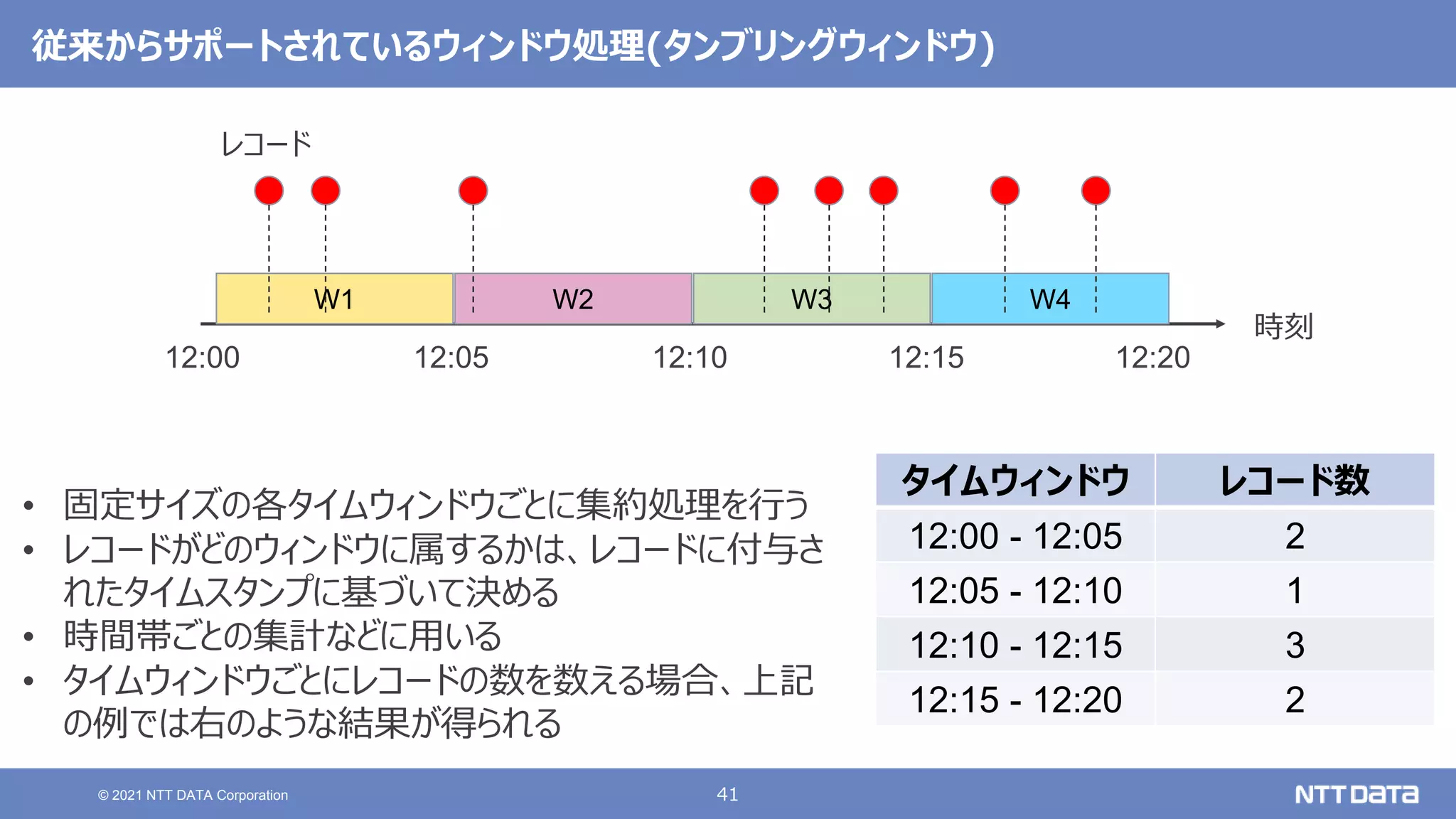
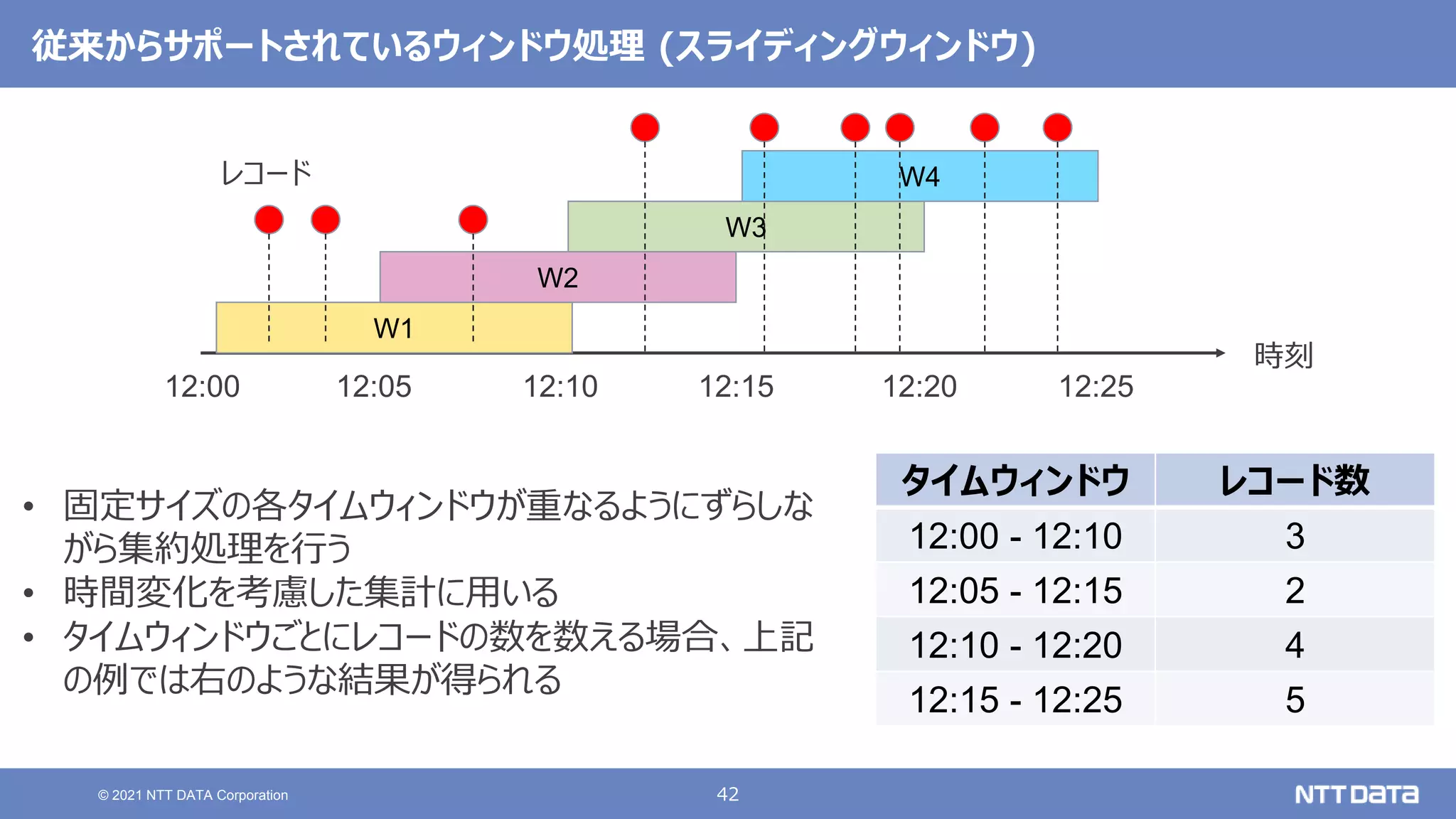
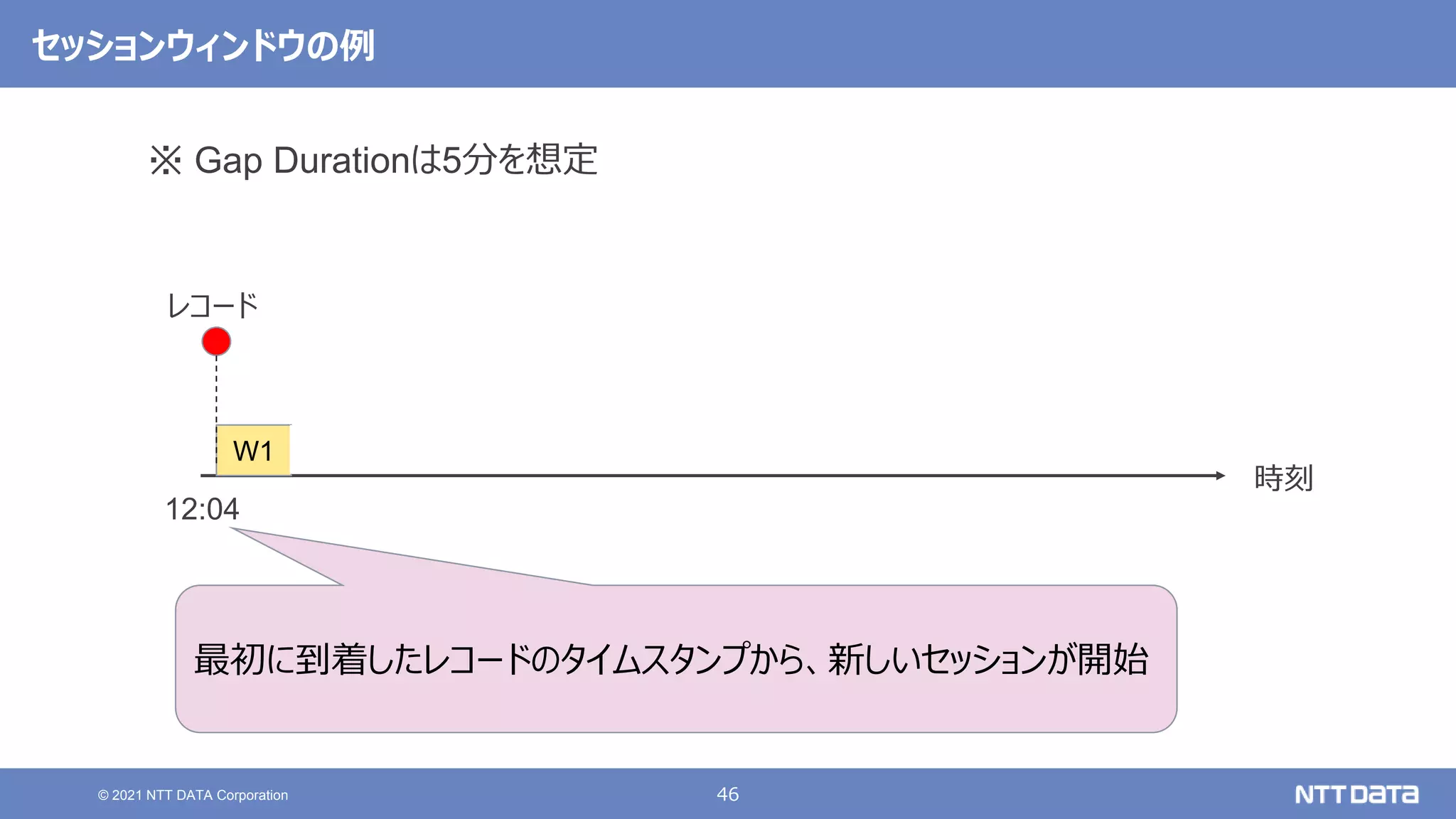
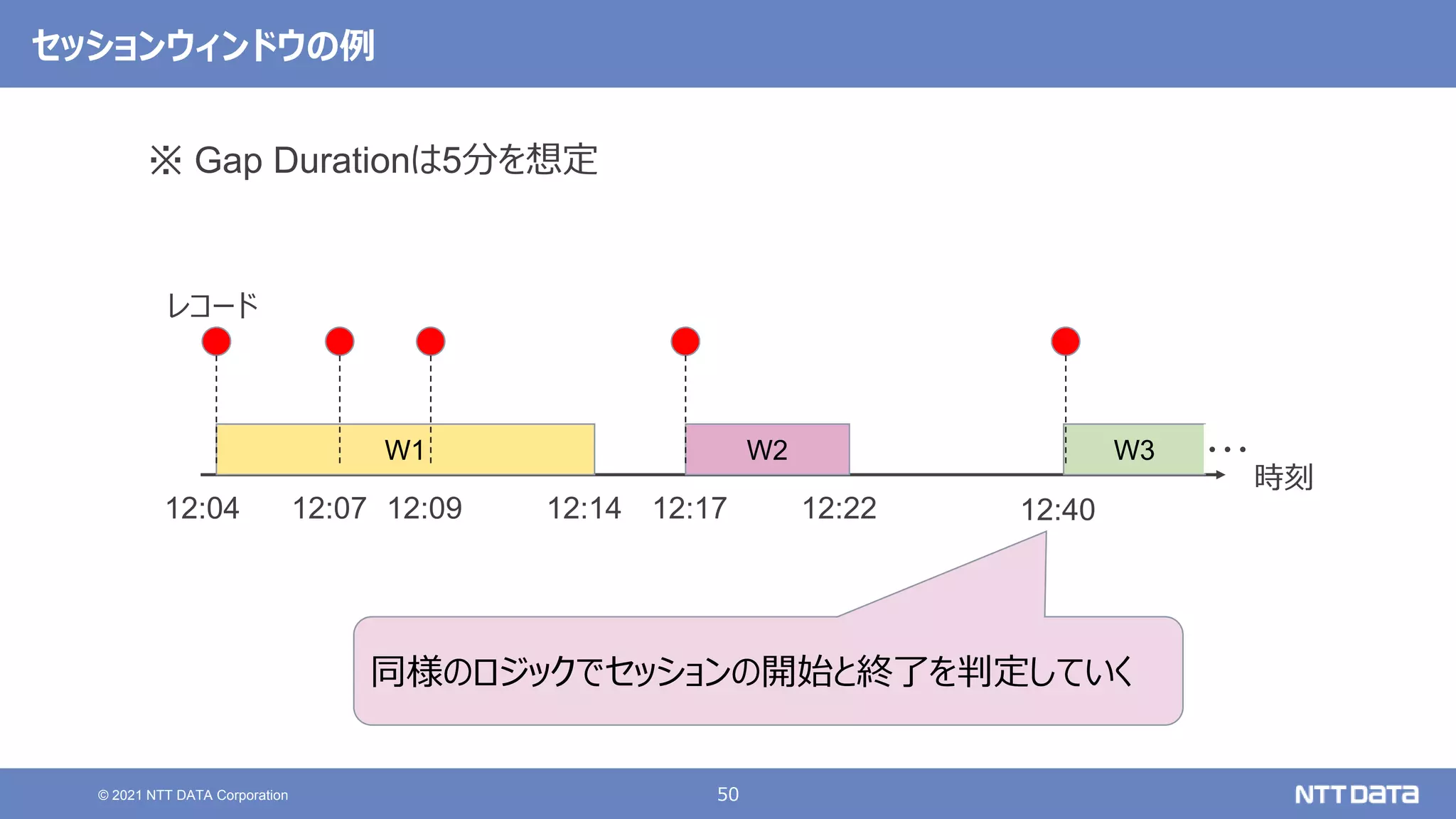
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 - (db tech showcase 2021 / ONLINE 発表資料) 2021年11月17日(水) NTTデータ 技術開発本部 岩崎 正剛 NTTデータ 技術開発本部 猿田 浩輔










![12
© 2021 NTT DATA Corporation
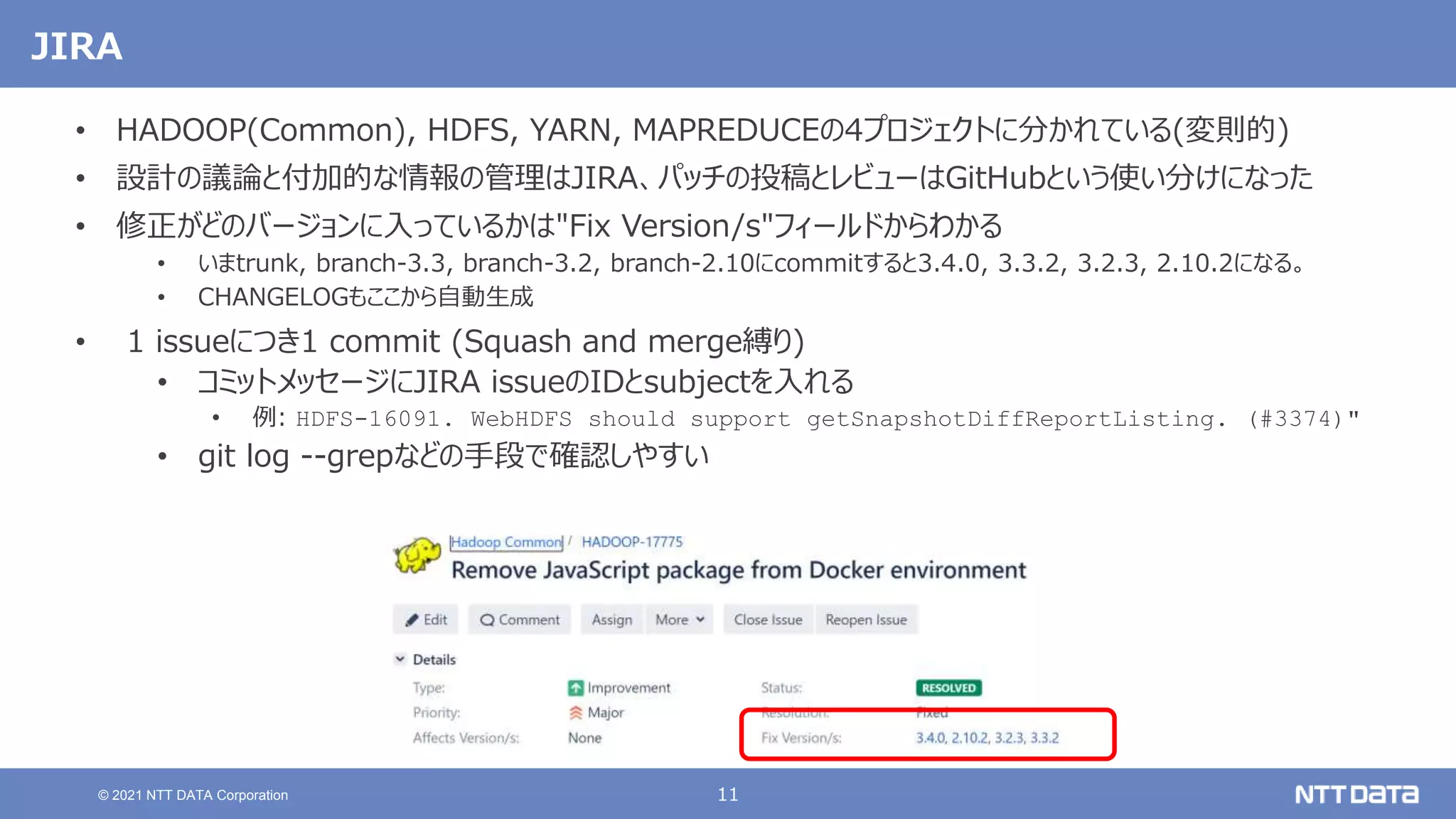
メーリングリスト
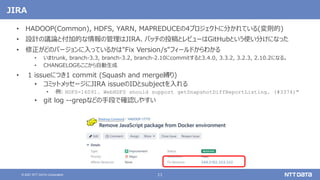
• 正式な意思決定はメーリングリストで行うポリシー
http://www.apache.org/theapacheway/
• [DISCUSS]スレッドで議論してから[VOTE]スレッドで投票する
https://www.apache.org/foundation/voting.html
• MLも4つ(common, hdfs, mapreduce, yarn)に分かれている...
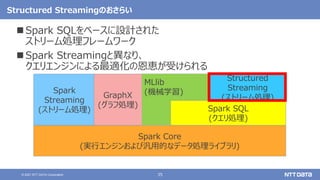
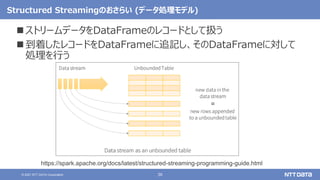
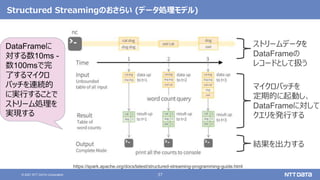
• User MLとDeveloper MLがあるが、動向を知りたい場合はDeveloper MLを見るとよい](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/85/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-12-320.jpg)













![29
© 2021 NTT DATA Corporation
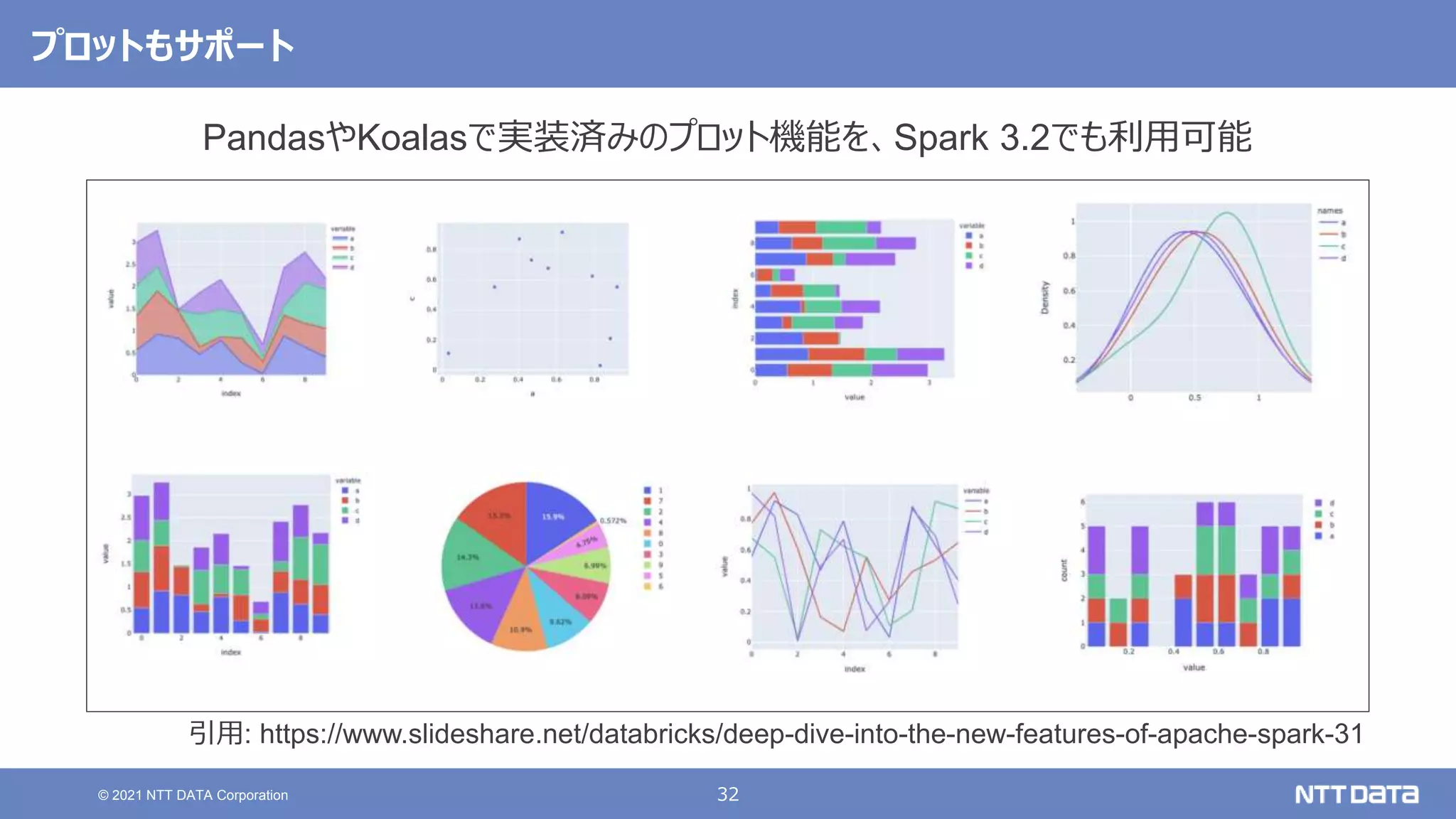
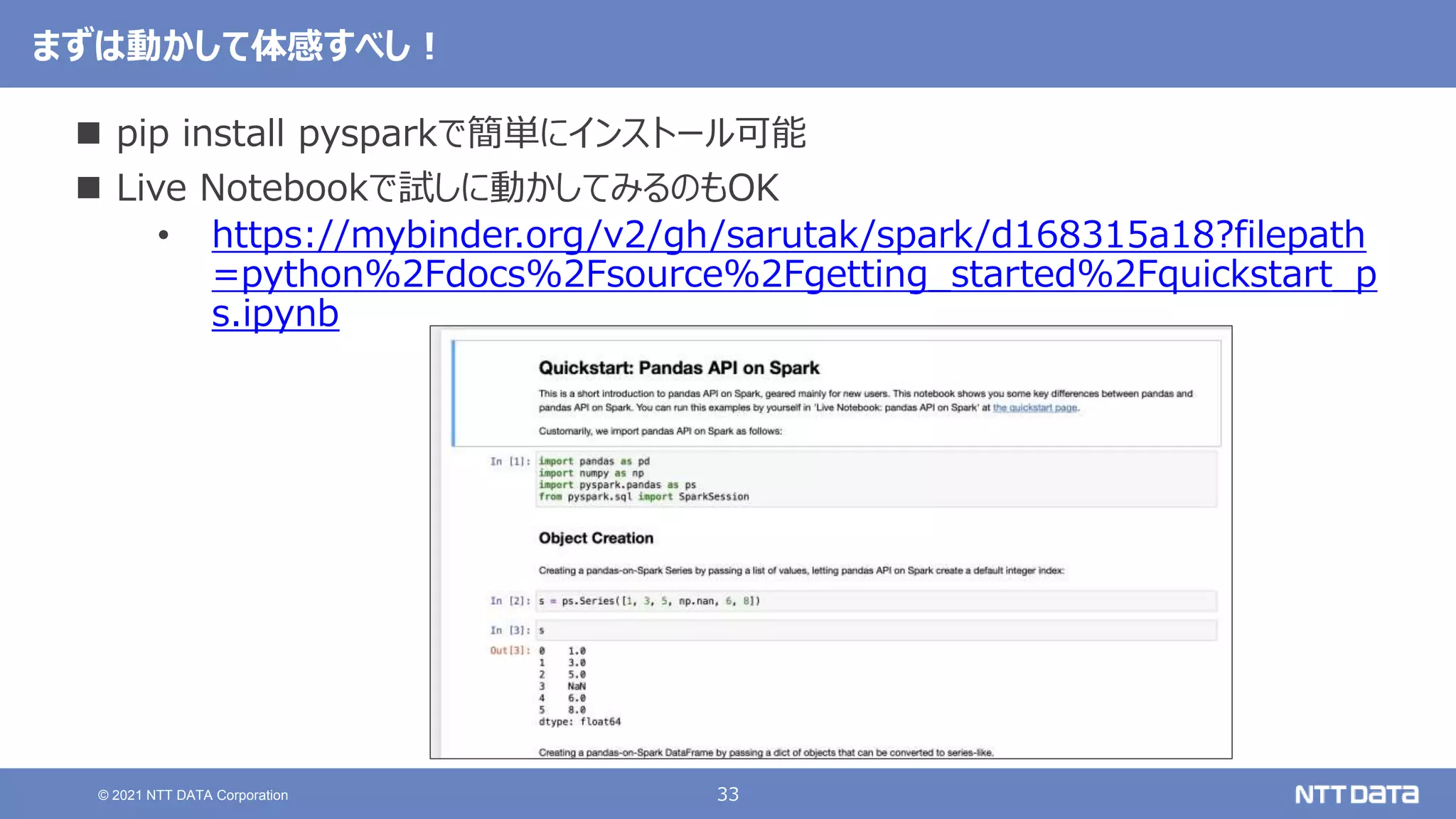
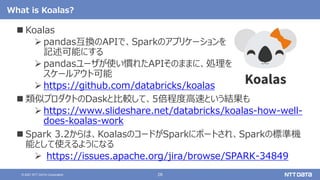
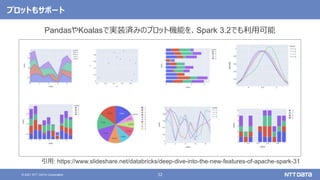
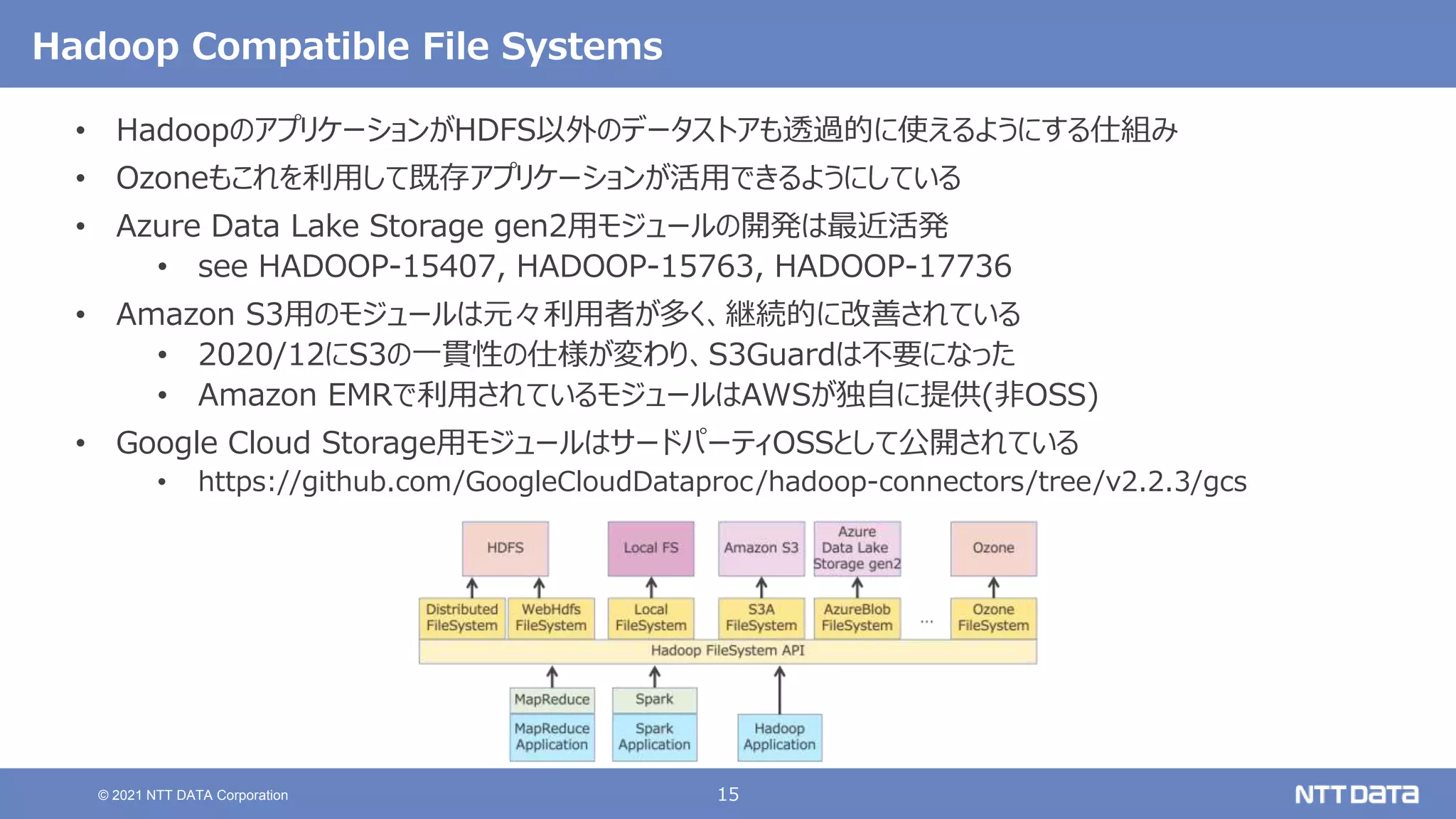
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/85/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-29-320.jpg)
![30
© 2021 NTT DATA Corporation
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/85/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-30-320.jpg)
![31
© 2021 NTT DATA Corporation
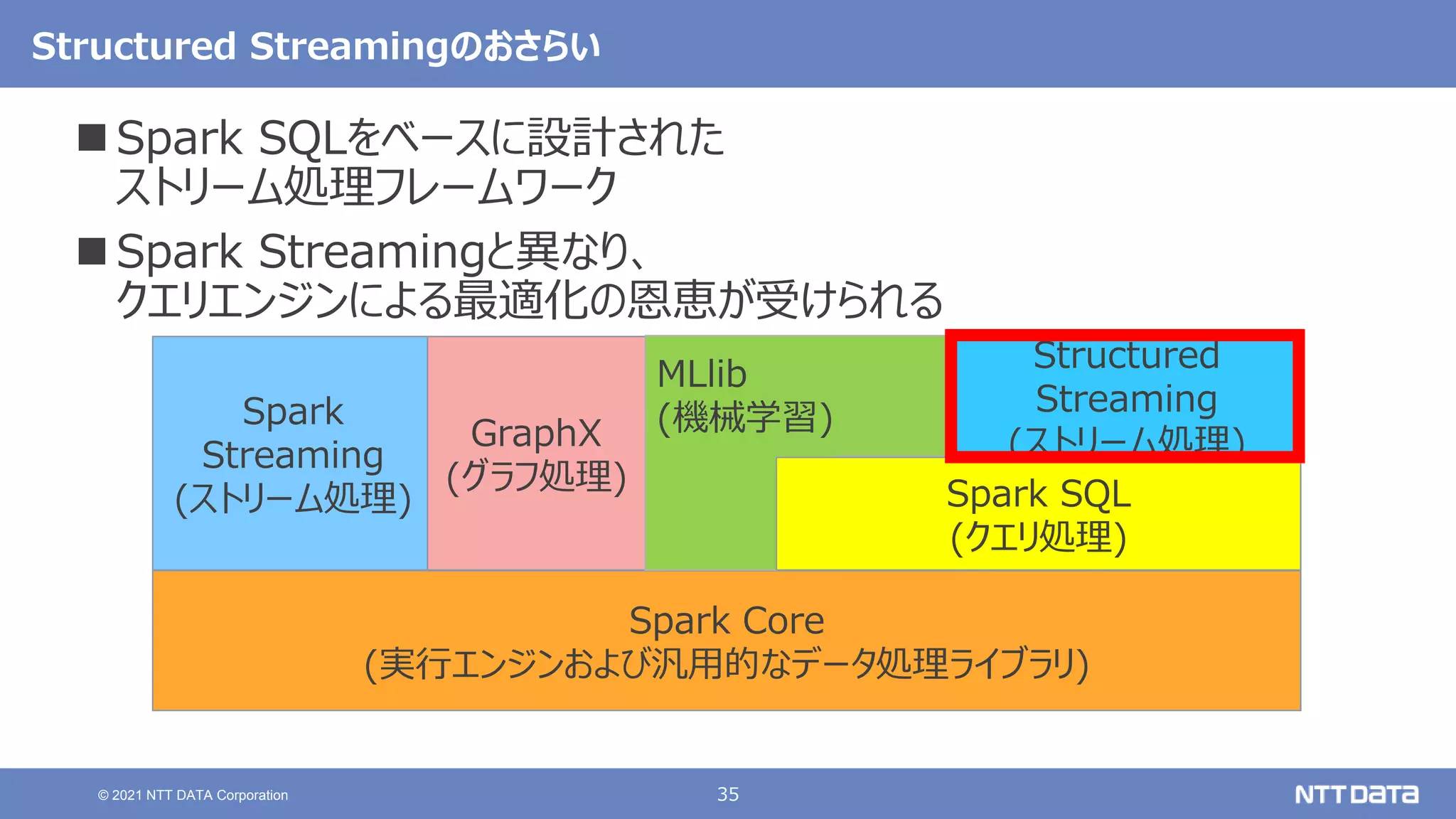
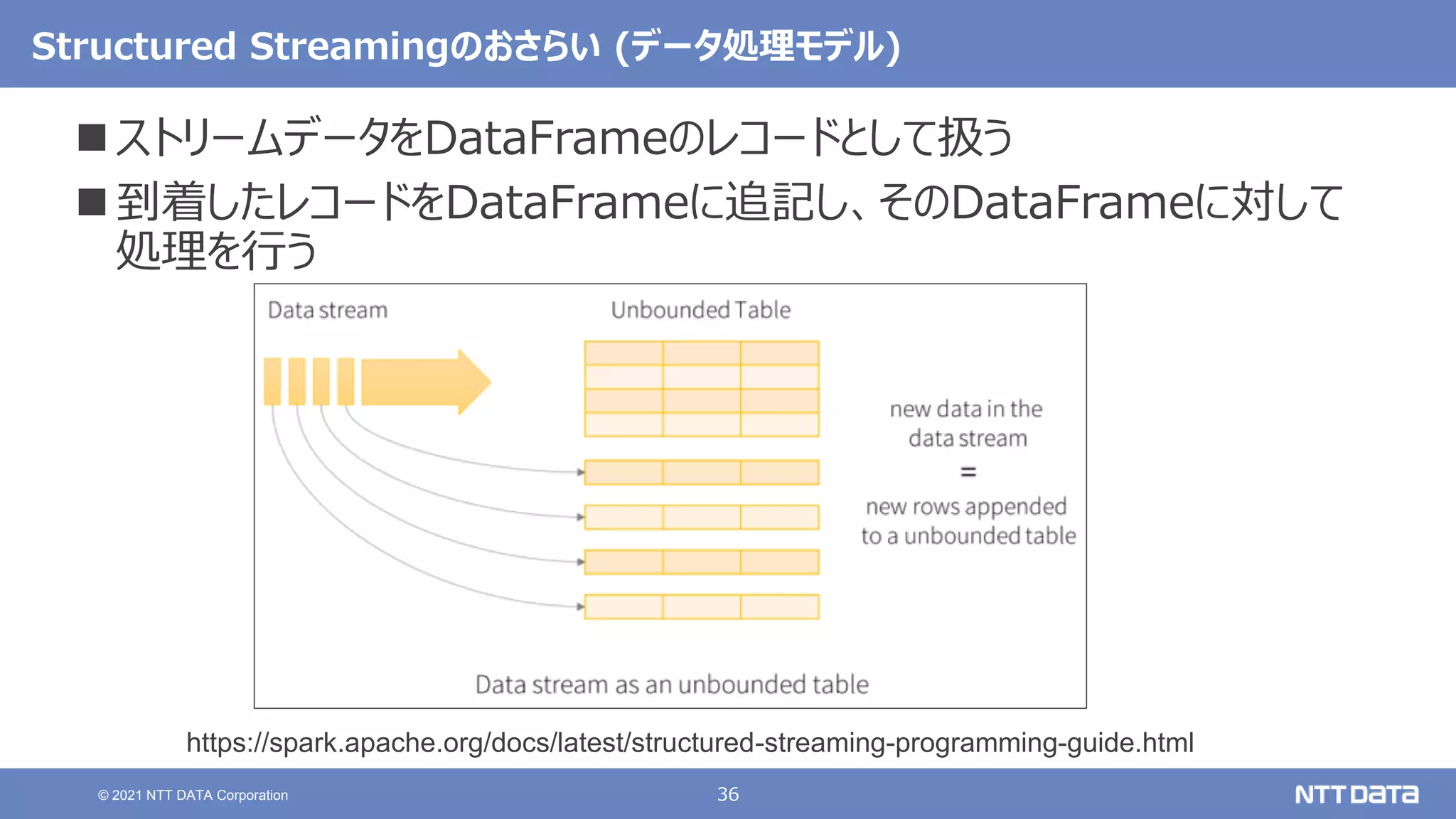
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import pyspark.pandas as ps
df = ps.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas
pandas API on Spark(Spark 3.2)](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/85/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-31-320.jpg)


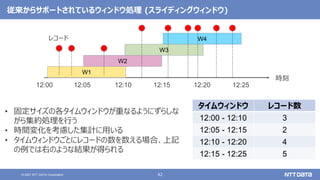


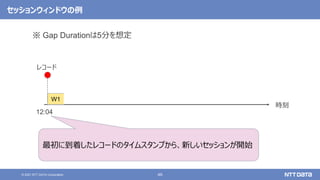

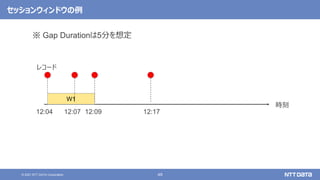















![12
© 2021 NTT DATA Corporation
メーリングリスト
• 正式な意思決定はメーリングリストで行うポリシー
http://www.apache.org/theapacheway/
• [DISCUSS]スレッドで議論してから[VOTE]スレッドで投票する
https://www.apache.org/foundation/voting.html
• MLも4つ(common, hdfs, mapreduce, yarn)に分かれている...
• User MLとDeveloper MLがあるが、動向を知りたい場合はDeveloper MLを見るとよい](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/75/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-12-2048.jpg)














![29
© 2021 NTT DATA Corporation
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/75/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-29-2048.jpg)
![30
© 2021 NTT DATA Corporation
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/75/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-30-2048.jpg)
![31
© 2021 NTT DATA Corporation
pandas API on Sparkを用いたSparkアプリケーション記述例
import pandas as pd
df = pd.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import databricks.koalas as ks
df = ks.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
import pyspark.pandas as ps
df = ps.read_csv(file)
df['x'] = df.y * df.z
df.describe()
df.plot.line(...)
Pandas Koalas
pandas API on Spark(Spark 3.2)](https://image.slidesharecdn.com/dbtechshowcase2021-211129150922/75/OSS-Hadoop-Spark-2021-db-tech-showcase-2021-ONLINE-31-2048.jpg)