KEMBAR78
Daftar
Login
Spark SQL - The internal - | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
NS
Uploaded by
NTT DATA OSS Professional Services
5,310 views
Spark SQL - The internal -
2018年10月31日に開催されたNTTデータ テクノロジーカンファレンス2018での講演資料です。
Technology
◦
Related topics:
Apache Spark
•
Read more
5
Save
Share
Embed
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
NTT DATA と PostgreSQL が挑んだ総力戦
by
NTT DATA OSS Professional Services
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
What's hot
PDF
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
PDF
Pacemakerを使いこなそう
by
Takatoshi Matsuo
PDF
Pacemaker + PostgreSQL レプリケーション構成(PG-REX)のフェイルオーバー高速化
by
kazuhcurry
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PPTX
iostat await svctm の 見かた、考え方
by
歩 柴田
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PPTX
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PPTX
スケールアウトするPostgreSQLを目指して!その第一歩!(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
祝!PostgreSQLレプリケーション10周年!徹底紹介!!
by
NTT DATA Technology & Innovation
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache NiFi の紹介 #streamctjp
by
Yahoo!デベロッパーネットワーク
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
Pacemakerを使いこなそう
by
Takatoshi Matsuo
Pacemaker + PostgreSQL レプリケーション構成(PG-REX)のフェイルオーバー高速化
by
kazuhcurry
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
iostat await svctm の 見かた、考え方
by
歩 柴田
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
事例で学ぶApache Cassandra
by
Yuki Morishita
スケールアウトするPostgreSQLを目指して!その第一歩!(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
祝!PostgreSQLレプリケーション10周年!徹底紹介!!
by
NTT DATA Technology & Innovation
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Apache NiFi の紹介 #streamctjp
by
Yahoo!デベロッパーネットワーク
Similar to Spark SQL - The internal -
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
PDF
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
DAIS2024参加報告 ~Spark中心にしらべてみた~ (JEDAI DAIS Recap 講演資料)
by
NTT DATA Technology & Innovation
PDF
The Future of Apache Spark
by
Hadoop / Spark Conference Japan
PPTX
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
PDF
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PPT
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PPTX
20180627 databricks ver1.1
by
Hirono Jumpei
PPTX
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
PDF
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
PDF
SAIS/SIGMOD参加報告 in SAIS/DWS2018報告会@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
PDF
Spark Analytics - スケーラブルな分散処理
by
Tusyoshi Matsuzaki
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
大量のデータ処理や分析に使えるOSS Apache Spark入門 - Open Source Conference2020 Online/Fukuoka...
by
NTT DATA Technology & Innovation
Apache spark 2.3 and beyond
by
NTT DATA Technology & Innovation
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
DAIS2024参加報告 ~Spark中心にしらべてみた~ (JEDAI DAIS Recap 講演資料)
by
NTT DATA Technology & Innovation
The Future of Apache Spark
by
Hadoop / Spark Conference Japan
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
Spark + AI Summit 2020セッションのハイライト(Spark Meetup Tokyo #3 Online発表資料)
by
NTT DATA Technology & Innovation
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
Quick Overview of Upcoming Spark 3.0 + α
by
Takeshi Yamamuro
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
20180627 databricks ver1.1
by
Hirono Jumpei
Spark+AI Summit Europe 2019 セッションハイライト(Spark Meetup Tokyo #2 講演資料)
by
NTT DATA Technology & Innovation
Sparkによる GISデータを題材とした時系列データ処理 (Hadoop / Spark Conference Japan 2016 講演資料)
by
Hadoop / Spark Conference Japan
SAIS/SIGMOD参加報告 in SAIS/DWS2018報告会@Yahoo! JAPAN
by
Yahoo!デベロッパーネットワーク
Spark Analytics - スケーラブルな分散処理
by
Tusyoshi Matsuzaki
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
More from NTT DATA OSS Professional Services
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
PDF
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
PPTX
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
PPTX
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Recently uploaded
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
Spark SQL - The internal -
1.
NTTデータ テクノロジーカンファレンス 2018 ©
2018 NTT DATA Corporation Spark SQL - The internal - 2018/10/31 NTT ソフトウェアイノベーションセンタ 山室 健 NTTデータシステム技術本部 土橋 昌
2.
© 2018 NTT
DATA Corporation 2 本日のアジェンダ 自己紹介 Apache Sparkの注目したい最近の動向 Spark SQL Deep Dive Data Source API Code generation
3.
© 2018 NTT
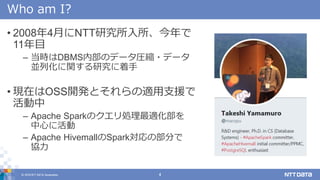
DATA Corporation 3 Who am I? • 所属 – NTTデータ 技術革新統括本部 システム技術本部 方式技術部 • 業務経歴 – 入社以来OSSを用いたシステム開発、研究開発に従事 – 近年は大規模データ処理のための技術を主担当とし、企業の 研究者と連携しながら新しい技術をエンタープライズで用い られるようにする取り組みに多数携わってきた • 登壇・執筆 – Spark Summit、Kafka Summit、 Strata Data Conference、 DataWorks Summit、 Developer Summitなど。 土橋 昌
4.
© 2018 NTT
DATA Corporation 4 Who am I? • 2008年4月にNTT研究所入所、今年で 11年目 – 当時はDBMS内部のデータ圧縮・データ 並列化に関する研究に着手 • 現在はOSS開発とそれらの適用支援で 活動中 – Apache Sparkのクエリ処理最適化部を 中心に活動 – Apache HivemallのSpark対応の部分で 協力
5.
© 2018 NTT
DATA Corporation 6 本セッションでの共同登壇に関して
6.
© 2018 NTT
DATA Corporation 7 (準備)Apache Sparkとは?
7.
© 2018 NTT
DATA Corporation 8 Apache Spark(以降Spark)概要 • Apache Spark is a unified analytics engine for large-scale data processing(https://spark.apache.org/) • 2014年にtop-level Apacheプロジェクトになった。2018/10/31 時点の最新バージョンは2.3.2である。 昨年のMatei Zaharia (Sparkの生みの親) の講演より https://www.slideshare.net/databricks/deep- learning-and-streaming-in-apache-spark-2x- with-matei-zaharia- 81232855?from_action=save
8.
© 2018 NTT
DATA Corporation 9 Sparkのコンポーネント Spark Summit Europe 2018にて紹介された2015年当時の定義 https://www.slideshare.net/databricks/unifying-stateoftheart-ai-and-big-data-in-apache-spark-with-reynold-xin
9.
© 2018 NTT
DATA Corporation 10 Sparkとは?に関する参考情報 • Unifying State-of-the-Art AI and Big Data in Apache Spark with Reynold Xin – https://www.slideshare.net/databricks/unifying-stateoftheart-ai-and- big-data-in-apache-spark-with-reynold-xin – 前半に簡単な歴史も記載されているので、誰かに紹介するときに 便利
10.
© 2018 NTT
DATA Corporation 11 Sparkの注目したい最近の動向
11.
© 2018 NTT
DATA Corporation 12 本枠の内容について • Spark2.3.0以降の議論の中で注目すべきトピックを(主観的 に…)抽出し、簡単に紹介します。 1. Project Hydrogen ★ 2. Kubernetes対応 ★ 3. Python周りの改善 ★ 4. Data Source周りの対応改善 →主に山室氏の講演参照 5. Structured Streaming関連 →主に昨年度テクノロジカンファレンス猿田氏の講演参照 • https://www.slideshare.net/hadoopxnttdata/structured-streaming- the-internal
12.
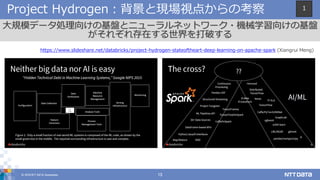
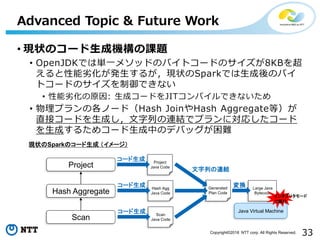
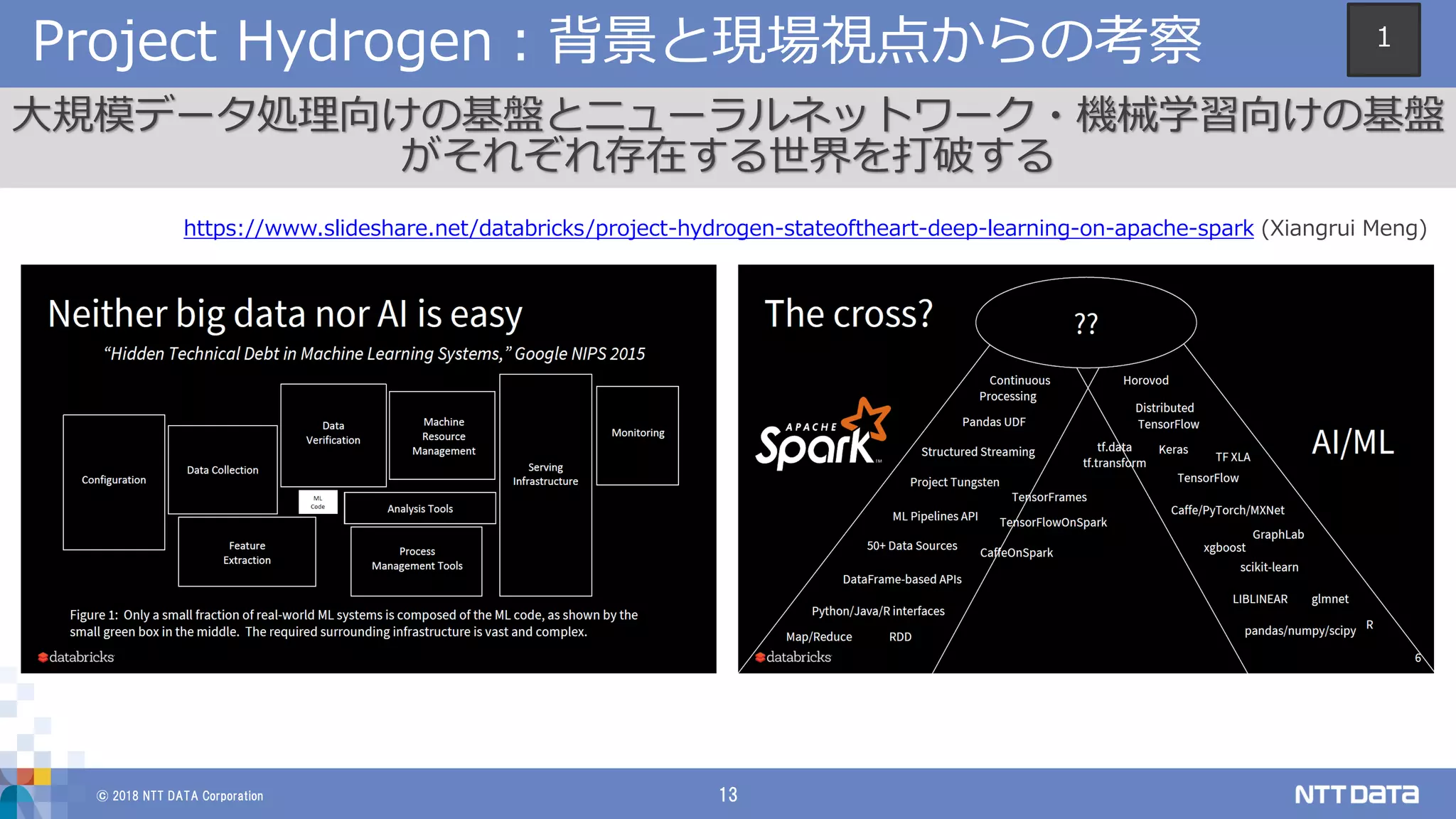
© 2018 NTT
DATA Corporation 13 Project Hydrogen:背景と現場視点からの考察 大規模データ処理向けの基盤とニューラルネットワーク・機械学習向けの基盤 がそれぞれ存在する世界を打破する https://www.slideshare.net/databricks/project-hydrogen-stateoftheart-deep-learning-on-apache-spark (Xiangrui Meng) 1
13.
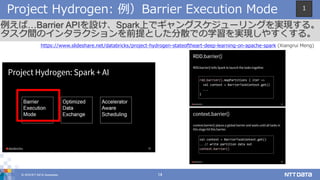
© 2018 NTT
DATA Corporation 14 Project Hydrogen: 例)Barrier Execution Mode 例えば…Barrier APIを設け、Spark上でギャングスケジューリングを実現する。 タスク間のインタラクションを前提とした分散での学習を実現しやすくする。 https://www.slideshare.net/databricks/project-hydrogen-stateoftheart-deep-learning-on-apache-spark (Xiangrui Meng) 1
14.
© 2018 NTT
DATA Corporation 15 Project Hydrogen: 例)Barrier Execution Mode https://jira.apache.org/jira/browse/SPARK-24374 1
15.
© 2018 NTT
DATA Corporation 16 Project Hydrogen:参考情報 • Xiangrui Meng による概要説明 – https://www.slideshare.net/databricks/project-hydrogen-stateoftheart- deep-learning-on-apache-spark • SPIP: Barrier Execution Mode – https://jira.apache.org/jira/browse/SPARK-24374 • Barrier Executionのデザインドキュメント – https://jira.apache.org/jira/browse/SPARK-24582 • BarrierTaskContextのデザインドキュメント – https://issues.apache.org/jira/browse/SPARK-24581 1
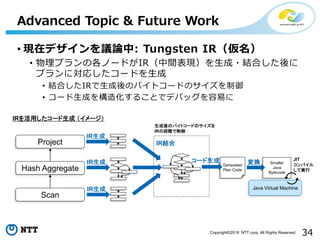
16.
© 2018 NTT
DATA Corporation 17 Kubernetes対応:背景と現場視点からの考察 KubernetesのエコシステムやKubernetes上の異なるワークロードと共存させ る。開発の分断を減らす、オペレーションコストを減らす。 https://issues.apache.org/jira/secure/attachment/12881586/SPARK- 18278%20Spark%20on%20Kubernetes%20Design%20Proposal%20Revisi on%202%20%281%29.pdf https://www.slideshare.net/databricks/apache-spark-on-kubernetes- anirudh-ramanathan-and-tim-chen (Anirudh Ramananathan et al.) https://www.slideshare.net/databricks/apache-spark-on-kubernetes- anirudh-ramanathan-and-tim-chen (Anirudh Ramananathan et al.) 2
17.
© 2018 NTT
DATA Corporation 18 Kubernetes対応:スケジューラバックエンドの拡張に関する議論 https://issues.apache.org/jira/browse/SPARK-18278 by Seon Owen by Matt Cheah https://issues.apache.org/jira/browse/SPARK-18278 private[spark] class KubernetesClusterSchedulerBackend( scheduler: TaskSchedulerImpl, rpcEnv: RpcEnv, kubernetesClient: KubernetesClient, requestExecutorsService: ExecutorService, snapshotsStore: ExecutorPodsSnapshotsStore, podAllocator: ExecutorPodsAllocator, lifecycleEventHandler: ExecutorPodsLifecycleManager, watchEvents: ExecutorPodsWatchSnapshotSource, pollEvents: ExecutorPodsPollingSnapshotSource) extends CoarseGrainedSchedulerBackend(scheduler, rpcEnv) { (snip) private[spark] // Yarn only OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.queue"), OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES, confKey = "spark.executor.instances"), OptionAssigner(args.pyFiles, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.pyFiles"), OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.jars"), OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.files"), OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, confKey = "spark.yarn.dist.archives"), 2
18.
© 2018 NTT
DATA Corporation 19 Kubernetes対応:参考情報 • SPIP: Support native submission of spark jobs to a kubernetes cluster – https://issues.apache.org/jira/browse/SPARK-18278 • Apache Spark on Kubernetes, Anirudh Ramanathan and Tim Chen – https://www.slideshare.net/databricks/apache-spark-on-kubernetes- anirudh-ramanathan-and-tim-chen 2
19.
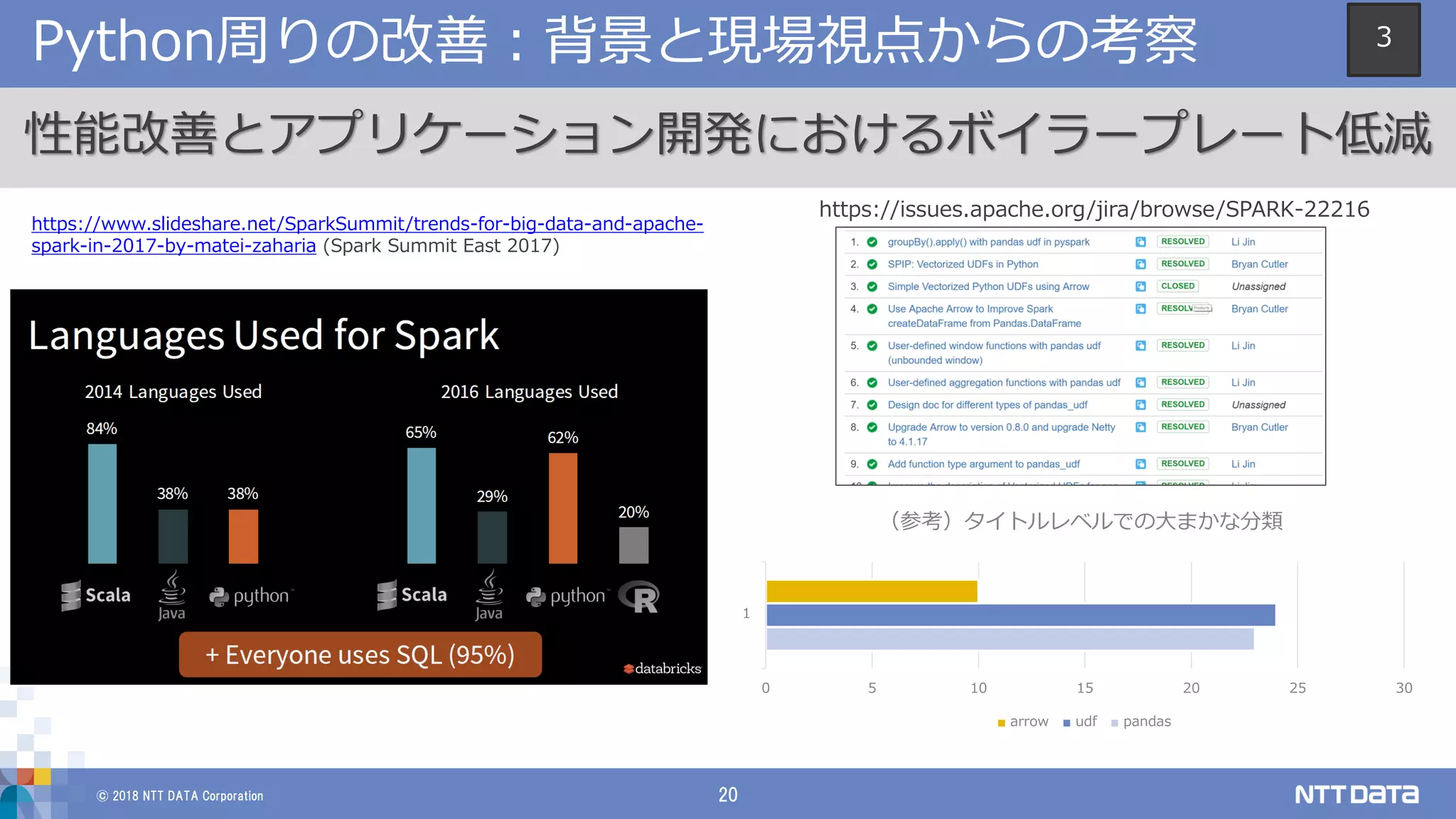
© 2018 NTT
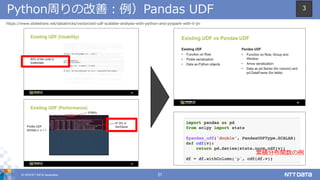
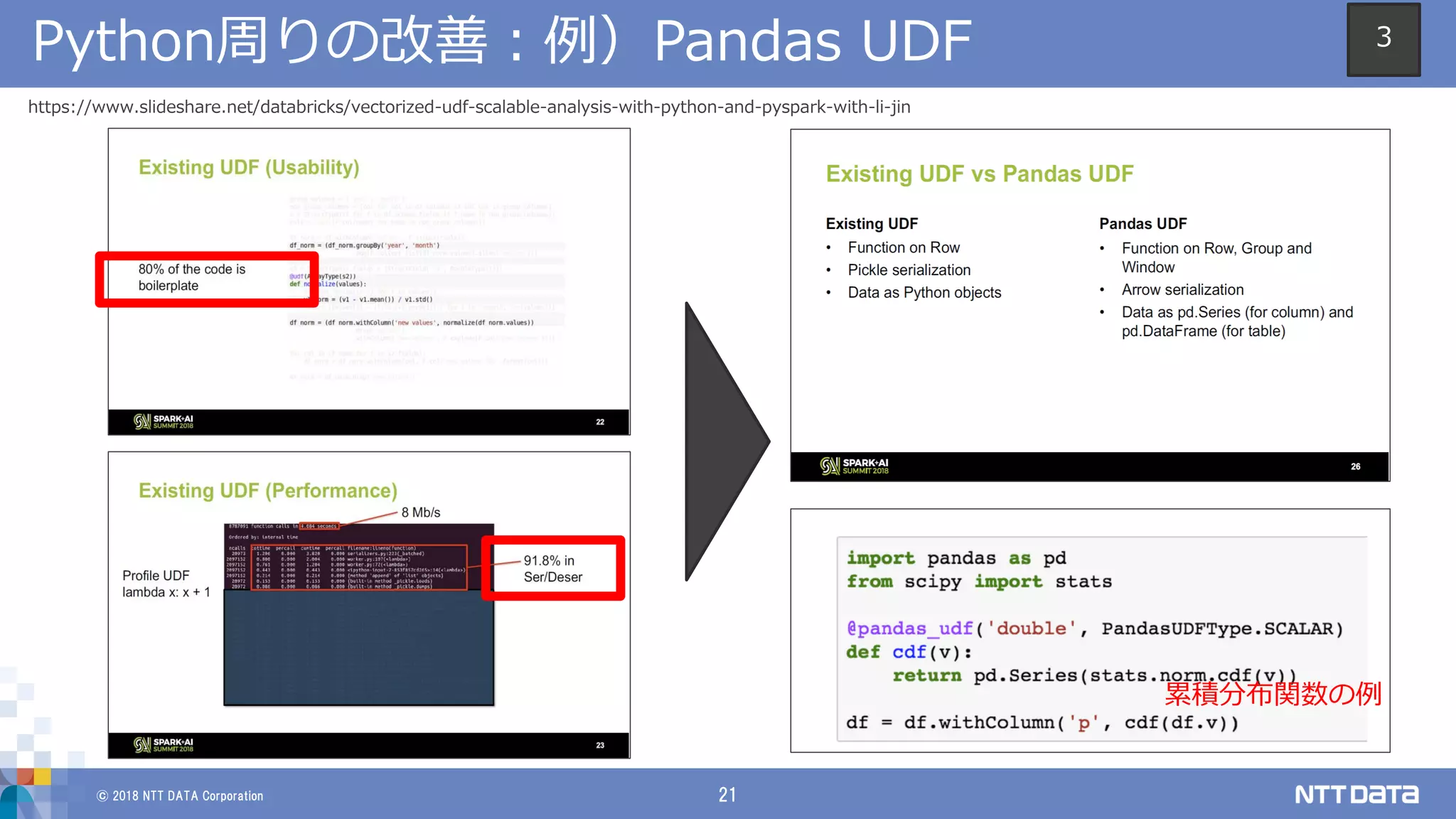
DATA Corporation 20 Python周りの改善:背景と現場視点からの考察 1 0 5 10 15 20 25 30 (参考)タイトルレベルでの大まかな分類 arrow udf pandas 性能改善とアプリケーション開発におけるボイラープレート低減 https://www.slideshare.net/SparkSummit/trends-for-big-data-and-apache- spark-in-2017-by-matei-zaharia (Spark Summit East 2017) https://issues.apache.org/jira/browse/SPARK-22216 3
20.
© 2018 NTT
DATA Corporation 21 Python周りの改善:例)Pandas UDF https://www.slideshare.net/databricks/vectorized-udf-scalable-analysis-with-python-and-pyspark-with-li-jin 累積分布関数の例 3
21.
© 2018 NTT
DATA Corporation 22 Python周りの改善:参考情報 • Improving PySpark/Pandas interoperability – https://issues.apache.org/jira/browse/SPARK-22216 • Complete support for remaining Spark data types in Arrow Converters – https://issues.apache.org/jira/browse/SPARK-21187 • Vectorized UDF: Scalable Analysis with Python and PySpark with Li Jin – https://www.slideshare.net/databricks/vectorized-udf-scalable- analysis-with-python-and-pyspark-with-li-jin 3
22.
© 2018 NTT
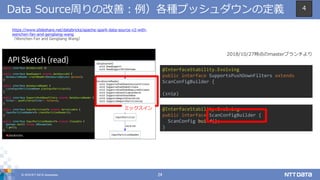
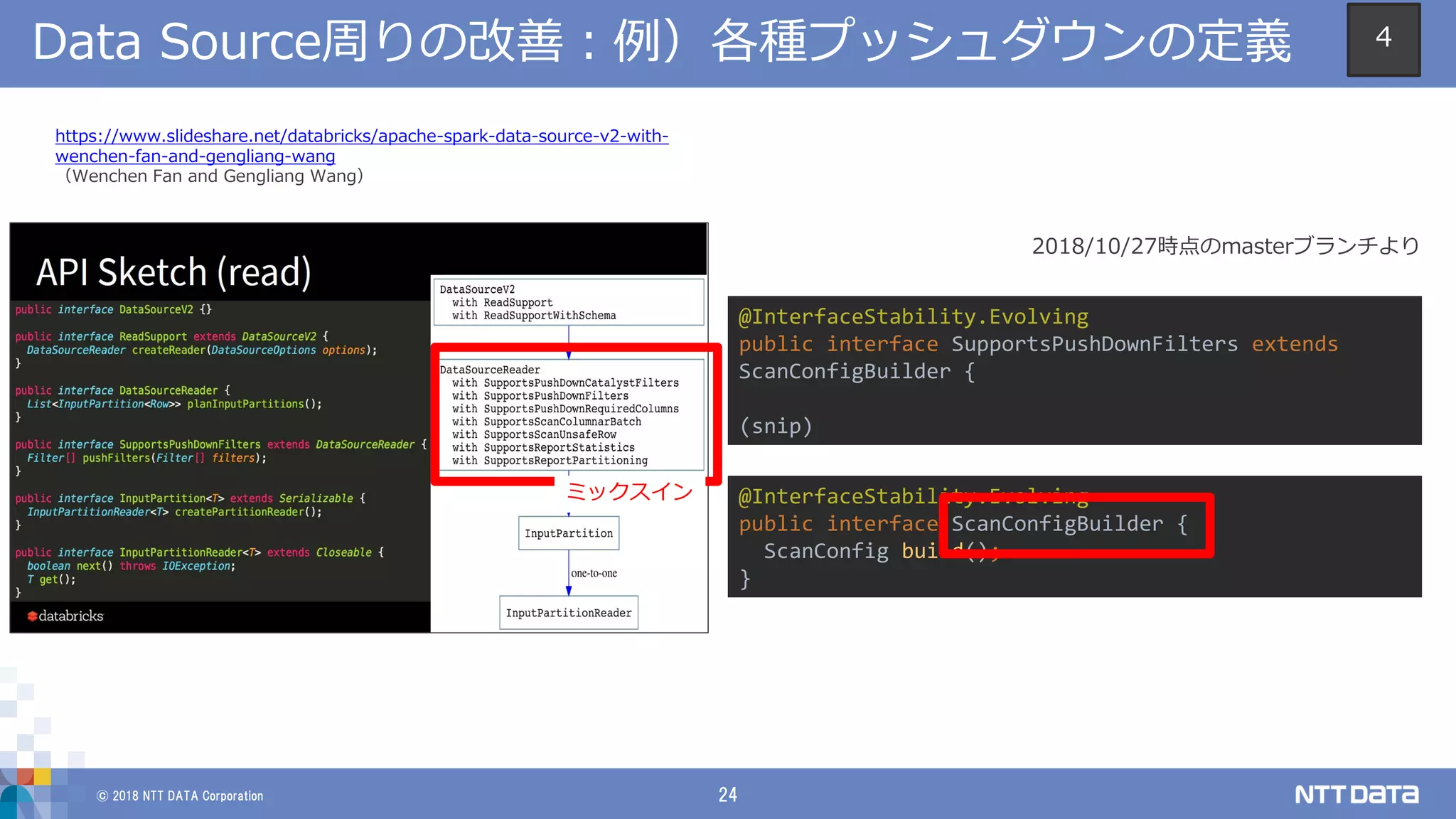
DATA Corporation 23 Data Source周りの改善:背景と現場視点からの考察 https://issues.apache.org/jira/browse/SPARK-15689 ⇒小さなサーフェースの実現 ⇒カラム型対応の改善 ⇒既存のプッシュダウンは存続 ⇒さらに新しいオペレーションにも対応 4
23.
© 2018 NTT
DATA Corporation 24 Data Source周りの改善:例)各種プッシュダウンの定義 https://www.slideshare.net/databricks/apache-spark-data-source-v2-with- wenchen-fan-and-gengliang-wang (Wenchen Fan and Gengliang Wang) @InterfaceStability.Evolving public interface SupportsPushDownFilters extends ScanConfigBuilder { (snip) @InterfaceStability.Evolving public interface ScanConfigBuilder { ScanConfig build(); } ミックスイン 2018/10/27時点のmasterブランチより 4
24.
© 2018 NTT
DATA Corporation 25 Data Source周りの改善:参考情報 • SPIP: Standardize SQL logical plans with DataSourceV2 – https://issues.apache.org/jira/browse/SPARK-23521 • Data source API v2 – https://issues.apache.org/jira/browse/SPARK-15689 • Data Source V2 improvements – https://issues.apache.org/jira/browse/SPARK-22386 • Apache Spark Data Source V2 with Wenchen Fan and Gengliang Wang – https://www.slideshare.net/databricks/apache-spark-data-source-v2- with-wenchen-fan-and-gengliang-wang 4
25.
© 2018 NTT
DATA Corporation 26 Structured Streaming関連(今回は省略) • SPIP: Continuous Processing Mode for Structured Streaming – https://issues.apache.org/jira/browse/SPARK-20928 • Introducing Low-latency Continuous Processing Mode in Structured Streaming in Apache Spark 2.3 – https://databricks.com/blog/2018/03/20/low-latency-continuous- processing-mode-in-structured-streaming-in-apache-spark-2-3- 0.html 5
26.
© 2018 NTT
DATA Corporation 27 続いて山室氏講演
27.
Copyright©2018 NTT corp.
All Rights Reserved. SQL - The Internal Takeshi Yamamuro NTT Software Innovation Center Copyright(c)2018 NTT Corp. All Rights Reserved.
28.
2Copyright©2018 NTT corp.
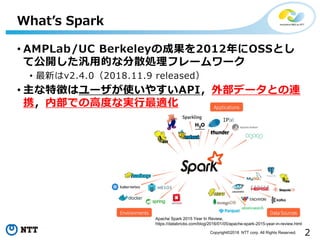
All Rights Reserved. What’s Spark Apache Spark 2015 Year In Review, https://databricks.com/blog/2016/01/05/apache-spark-2015-year-in-review.html • AMPLab/UC Berkeleyの成果を2012年にOSSとし て公開した汎用的な分散処理フレームワーク • 最新はv2.4.0(2018.11.9 released) • 主な特徴はユーザが使いやすいAPI,外部データとの連 携,内部での高度な実行最適化
29.
3Copyright©2018 NTT corp.
All Rights Reserved. • 外部データとの連携 • Sparkが外部データ(CSV/Parquetなどのストレージフォーマ ットやPostgreSQLなどのRDBMS)に対して読み書き・最適化 (e.g., 不要なIOの除去) を実施 • これらを効率的に行うために外部データに対する操作をData Source APIとして抽象化 • 内部での高度な実行最適化 • ユーザやライブラリからの入力(SQL/DataFrame/Dataset) に関係代数的な最適化を行った後,コード生成・実行 • Catalystが一連の実行最適化を担当 What’s Spark
30.
4Copyright©2018 NTT corp.
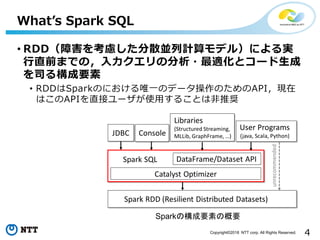
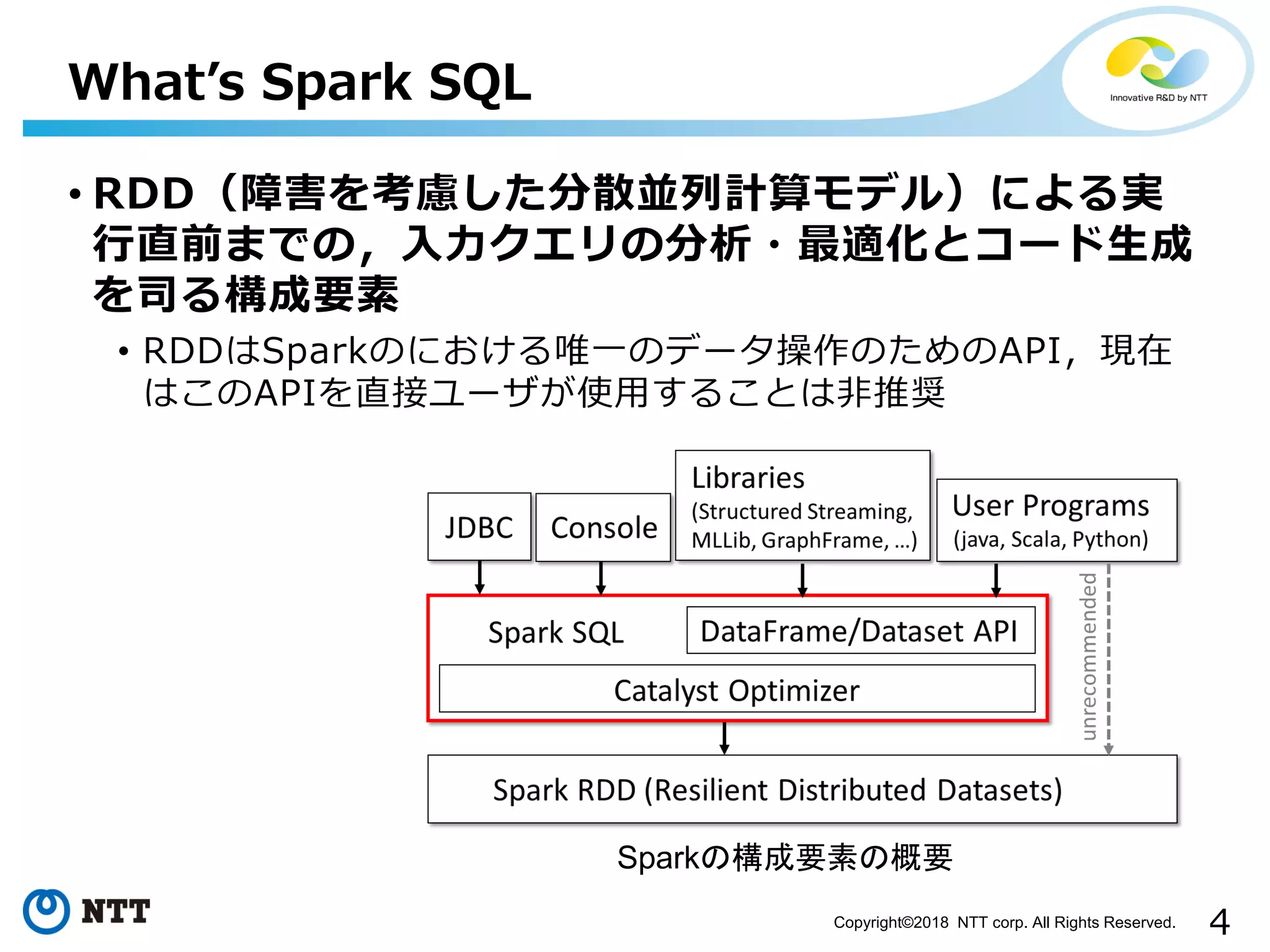
All Rights Reserved. What’s Spark SQL • RDD(障害を考慮した分散並列計算モデル)による実 行直前までの,入力クエリの分析・最適化とコード生成 を司る構成要素 • RDDはSparkのにおける唯一のデータ操作のためのAPI,現在 はこのAPIを直接ユーザが使用することは非推奨 Sparkの構成要素の概要
31.
5Copyright©2018 NTT corp.
All Rights Reserved. • 前半: Data Source APIに関して • 読み込み処理の具体例を示しながら,Data Sourceの各実装で どのような最適化が内部で実施されているかを俯瞰 • 後半: Catalystでの実行最適化に関して • Catalystの特徴と最適化の具体的な方法,またコード生成によ る高速化に関して俯瞰 Today’s Agenda
32.
6Copyright©2018 NTT corp.
All Rights Reserved. Data Sources API
33.
7Copyright©2018 NTT corp.
All Rights Reserved. • 外部データへの読み書きを抽象化したAPI • 本発表では特に読み込みのみに焦点を当てて紹介 • Spark Built-in Data Source • CSV, JSON, JDBC, Parquet, ORC, and Hive Tables • AVROはv2.4.0からサポート • 3rd Party Data Source • 比較的容易に新規に追加可能 • 実装例: https://github.com/databricks/spark-xml Data Source API
34.
8Copyright©2018 NTT corp.
All Rights Reserved. • シンプル&大半のケースでうまく動くように設計 • Data Source実装に最適化情報(条件句と参照カラム列)を提供 • 結果は行の集合(RDD[Row])として返却 A Design of the API 条件句のCatalyst内部表現参照カラム列 Data Source APIの一部 結果の行集合
35.
9Copyright©2018 NTT corp.
All Rights Reserved. An Example - CSV scala> val df = spark.read.option("inferSchema", true).csv(”/tmp/test.csv”) scala> df.show +---+----+-----+ |_c0| _c1|_c2| +---+----+-----+ | 1| abc| 3.8| +---+----+-----+ scala> df.explain == Physical Plan == *(1) FileScan csv [_c0#39,_c1#40,_c2#41] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<_c0:int,_c1:string,_c2:double> scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Project [_c0#39, _c1#40] +- *(1) Filter (isnotnull(_c0#39) && (_c0#39 = 1)) +- *(1) FileScan csv [_c0#39,_c1#40] Batched: false, DataFilters: [isnotnull(_c0#39), (_c0#39 = 1)], Format: CSV, Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string> 1, abc, 3.8
36.
10Copyright©2018 NTT corp.
All Rights Reserved. An Example - Parquet scala> val df = spark.read.parquet("/tmp/test.parquet") scala> df.show +---+----+-----+ |_c0| _c1|_c2| +---+----+-----+ | 1| abc| 3.8| +---+----+-----+ scala> df.explain == Physical Plan == *(1) FileScan parquet [_c0#103,_c1#104,_c2#105] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<_c0:int,_c1:string,_c2:double> scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Project [_c0#103, _c1#104] +- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1)) +- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true, DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
37.
11Copyright©2018 NTT corp.
All Rights Reserved. An Example - JDBC scala> val df = spark.read.jdbc("jdbc:postgresql:postgres", "test", options) scala> df.show +---+----+-----+ |_c0| _c1|_c2| +---+----+-----+ | 1| abc| 3.8| +---+----+-----+ scala> df.explain == Physical Plan == *(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23,_c2#24] PushedFilters: [], ReadSchema: struct<_c0:int,_c1:string,_c2:double> scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23] PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
38.
12Copyright©2018 NTT corp.
All Rights Reserved. • 1. Pushed Filters • 2. Read Schema • 3. Filter/Project Plan Pruning • 4. Partition Listing & Filters To Understand Data Source scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Project [_c0#103, _c1#104] +- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1)) +- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true, DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
39.
13Copyright©2018 NTT corp.
All Rights Reserved. • Data SourceへPush Downされた条件句 • この条件句自体はCatalystの内部表現 • このCatalystの内部表現で表された条件句を活用して 最適化を行うかは実装依存 • CSVは未使用 • ParquetはParquetの内部表現に変換して活用 • JDBCは内部でSQL文のWHERE句にコンパイルして活用 1. Pushed Filters scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Project [_c0#103, _c1#104] +- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1)) +- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true, DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
40.
14Copyright©2018 NTT corp.
All Rights Reserved. • JDBCRDD#compileFilterがWHERE句に変換 • WHERE ("_c0" IS NOT NULL) AND ("_c0" = 1) 1. Pushed Filters - JDBC scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23] PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
41.
15Copyright©2018 NTT corp.
All Rights Reserved. • 上位の物理プランで参照されるカラム列 • PushedFiltersと同様でこの情報を活用した最適化を 行うかは実装依存 • CSVは内部のパーサ(Univocity)が不要なカラムの処理をバ イパスしてCPU時間を節約するために活用 • Parquetはカラムナ構造であるため不要なIOを除去 • JDBCはSELECT文に参照するカラムを指定 2. Read Schema scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == *(1) Project [_c0#103, _c1#104] +- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1)) +- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true, DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string>
42.
16Copyright©2018 NTT corp.
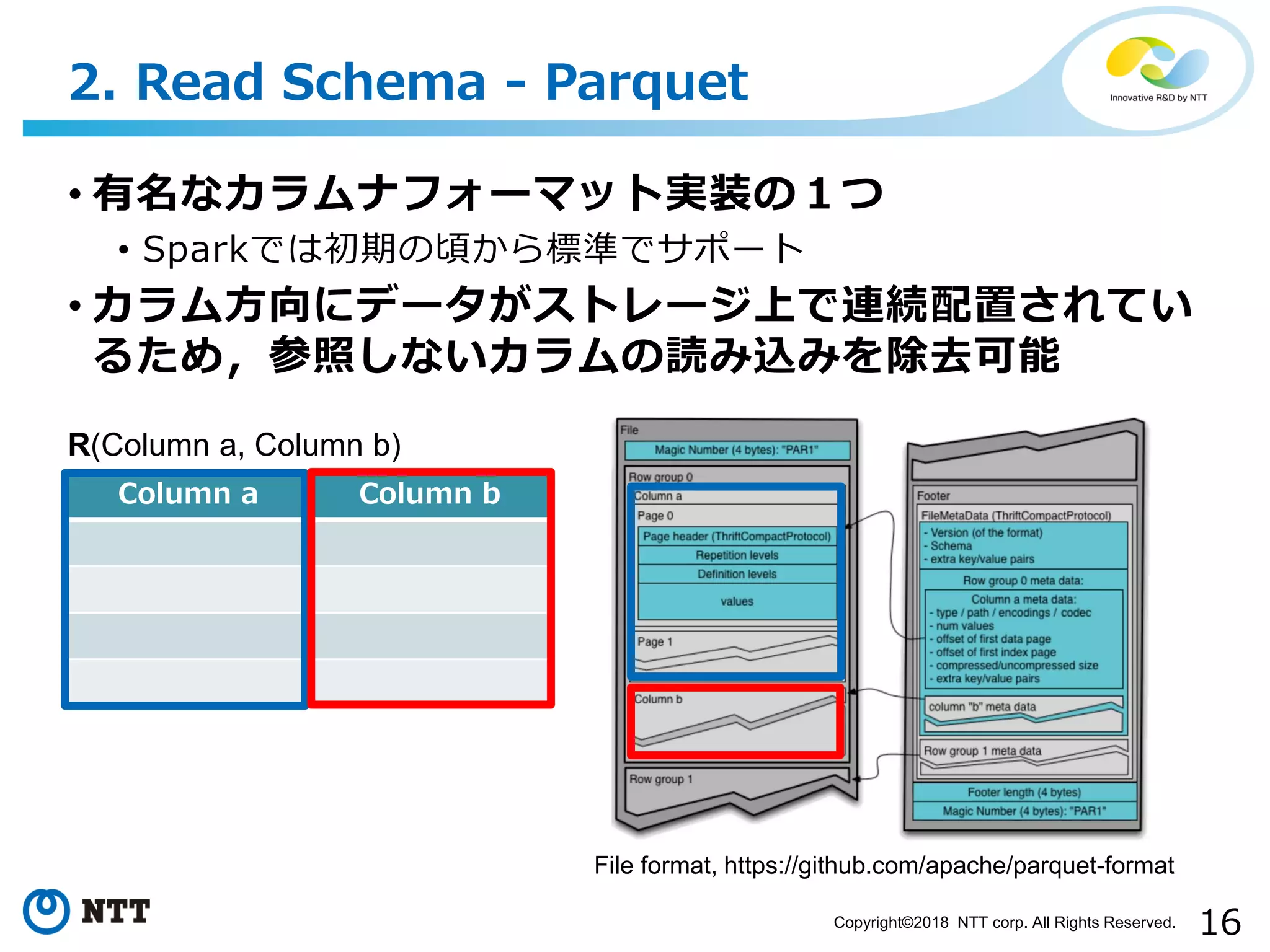
All Rights Reserved. • 有名なカラムナフォーマット実装の1つ • Sparkでは初期の頃から標準でサポート • カラム方向にデータがストレージ上で連続配置されてい るため,参照しないカラムの読み込みを除去可能 2. Read Schema - Parquet File format, https://github.com/apache/parquet-format Column a Column b R(Column a, Column b)
43.
17Copyright©2018 NTT corp.
All Rights Reserved. • 現状ではJDBCのみが不要な物理ノードを除去 • この最適化がCSV/Parquetで適用されていないのはFileFormat API(Data Source APIの一部)の制約 3. Filter/Project Plan Pruning scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain == Physical Plan == // Parquet *(1) Project [_c0#103, _c1#104] +- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1)) +- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true, DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [], PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string> == Physical Plan ==. // JDBC *(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23] PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)], ReadSchema: struct<_c0:int,_c1:string> ProjectとFilterが除去
44.
18Copyright©2018 NTT corp.
All Rights Reserved. • CSVやParquetはパーティション分割が可能で,読み 込み時に対象ファイルの列挙が必要 • また読み込みに不要なファイルの除去も可能 4. Partition Listing & Filters scala> val df = spark.range(100).selectExpr("id % 3 AS p", "id”) scala> df.write.partitionBy("p").parquet("/tmp/test.parquet”) scala> df.show(5) +---+---+ | p| id| +---+---+ | 0| 0| | 1| 1| | 2| 2| | 0| 3| | 1| 4| +---+---+ Data Source Table Format
45.
19Copyright©2018 NTT corp.
All Rights Reserved. • CSVやParquetはパーティション分割が可能で,読み 込み時に対象ファイルの列挙が必要 • また読み込みに不要なディレクトリのスキップが可能 4. Partition Listing & Filters scala> spark.read.parquet("/tmp/test.parquet").where("p = 0").explain == Physical Plan == *(1) FileScan parquet [id#45L,p#46] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionCount: 1, PartitionFilters: [isnotnull(p#46), (p#46 = 0)], PushedFilters: [], ReadSchema: struct<id:bigint> このフォルダ以下のファイルのみ読み込み Data Source Table Format
46.
20Copyright©2018 NTT corp.
All Rights Reserved. • Scalable File Listing (v2.1+) • ファイルの列挙処理をSparkクラスタで分散並列化 • v2.0まではドライバで逐次列挙していたため,パーティション が数万以上になるとオーバヘッドが顕在化 • パーティション数が異常に多い場合は,Sparkクラスタ のリソースを食いつぶさないように並列数を制御 4. Partition Listing & Filters Scalable Partition Handling for Cloud-Native Architecture in Apache Spark 2.1, https://databricks.com/blog/2016/12/15/scalable-partition-handling-for- cloud-native-architecture-in-apache-spark-2-1.html
47.
21Copyright©2018 NTT corp.
All Rights Reserved. • 現在コミュニティで開発中のData Source向けの新し いAPI,現状(V1)のAPIの問題点を解決 • org.apache.spark.sql.execution.datasources.v2 • 開発の過程で一貫性がなくなってきたAPIの整理 • FilterだけではなくLimitやAggregateなどの他のプランの Push Downを可能に • 行以外の(e.g., 列)読み込みパタンを考慮した設計 • ... • Iceberg: A fast table format for S3 • https://github.com/Netflix/iceberg • Data Source V2を活用した高速なテーブル表現 • HiveテーブルのO(n)のパーティション列挙を,Icebergテーブ ルではO(1)のメタデータ読み込みに • ここでのnはクエリの処理に必要なパーティション数 WIP: Data Source V2
48.
22Copyright©2018 NTT corp.
All Rights Reserved. Catalyst Optimization
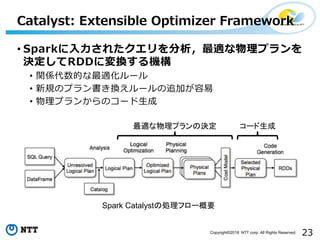
49.
23Copyright©2018 NTT corp.
All Rights Reserved. • Sparkに入力されたクエリを分析,最適な物理プランを 決定してRDDに変換する機構 • 関係代数的な最適化ルール • 新規のプラン書き換えルールの追加が容易 • 物理プランからのコード生成 Catalyst: Extensible Optimizer Framework Spark Catalystの処理フロー概要 最適な物理プランの決定 コード生成
50.
24Copyright©2018 NTT corp.
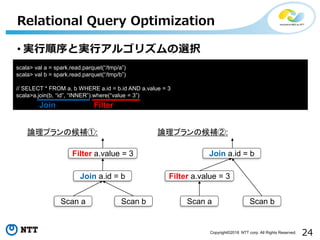
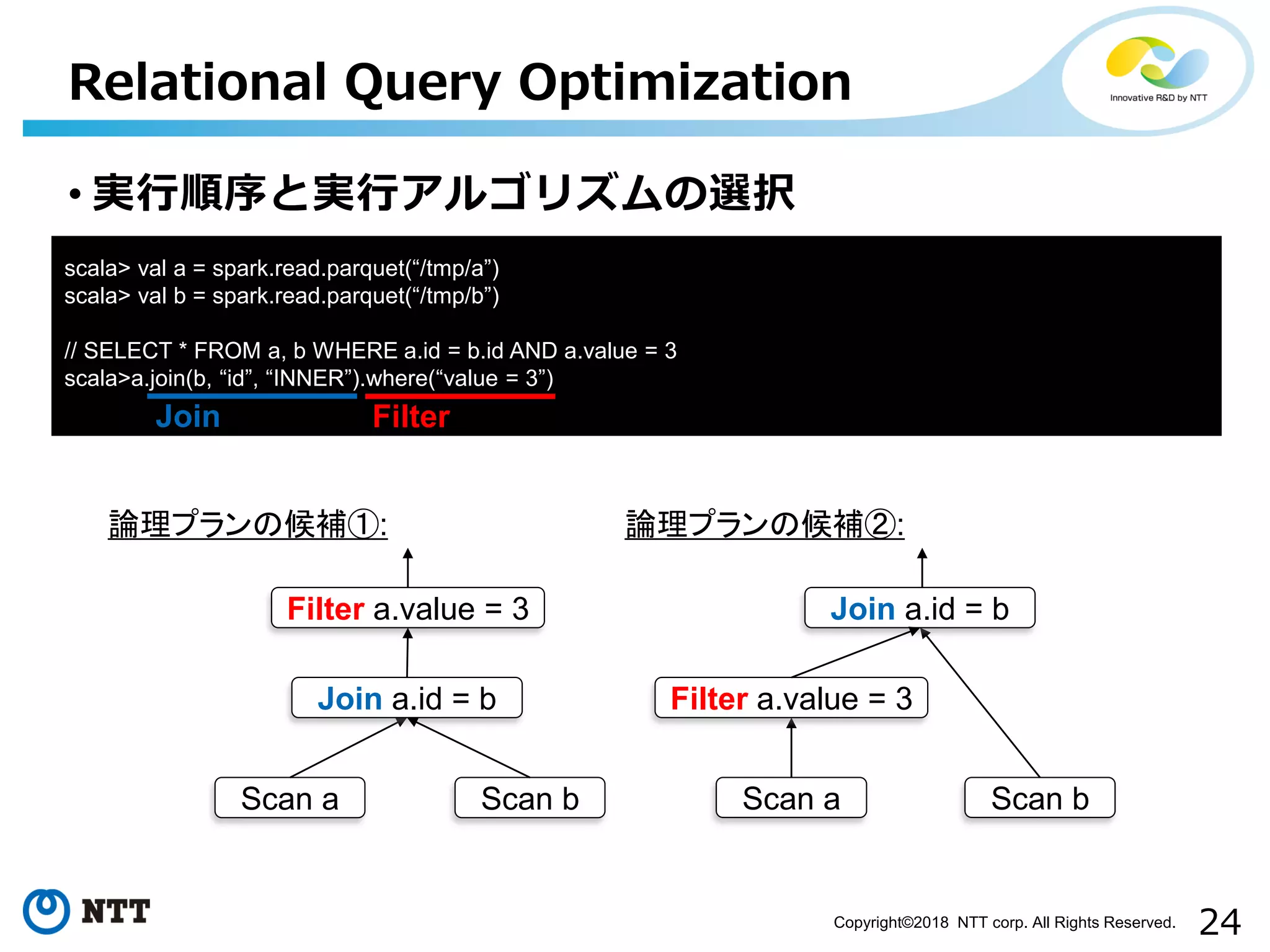
All Rights Reserved. • 実行順序と実行アルゴリズムの選択 Relational Query Optimization scala> val a = spark.read.parquet(“/tmp/a”) scala> val b = spark.read.parquet(“/tmp/b”) // SELECT * FROM a, b WHERE a.id = b.id AND a.value = 3 scala>a.join(b, “id”, “INNER”).where(“value = 3”) Join Filter 論理プランの候補①: Scan a Scan b Join a.id = b Filter a.value = 3 Scan a Scan b Filter a.value = 3 Join a.id = b 論理プランの候補②:
51.
25Copyright©2018 NTT corp.
All Rights Reserved. • 実行順序と実行アルゴリズムの選択 Relational Query Optimization Scan a Scan b Filter a.value = 3 Join a.id = b 選択された論理プラン: scala> val a = spark.read.parquet(“/tmp/a”) scala> val b = spark.read.parquet(“/tmp/b”) // SELECT * FROM a, b WHERE a.id = b.id AND a.value = 3 scala>a.join(b, “id”, “INNER”).where(“value = 3”) Join Filter
52.
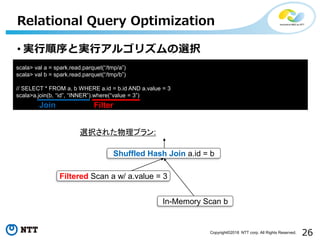
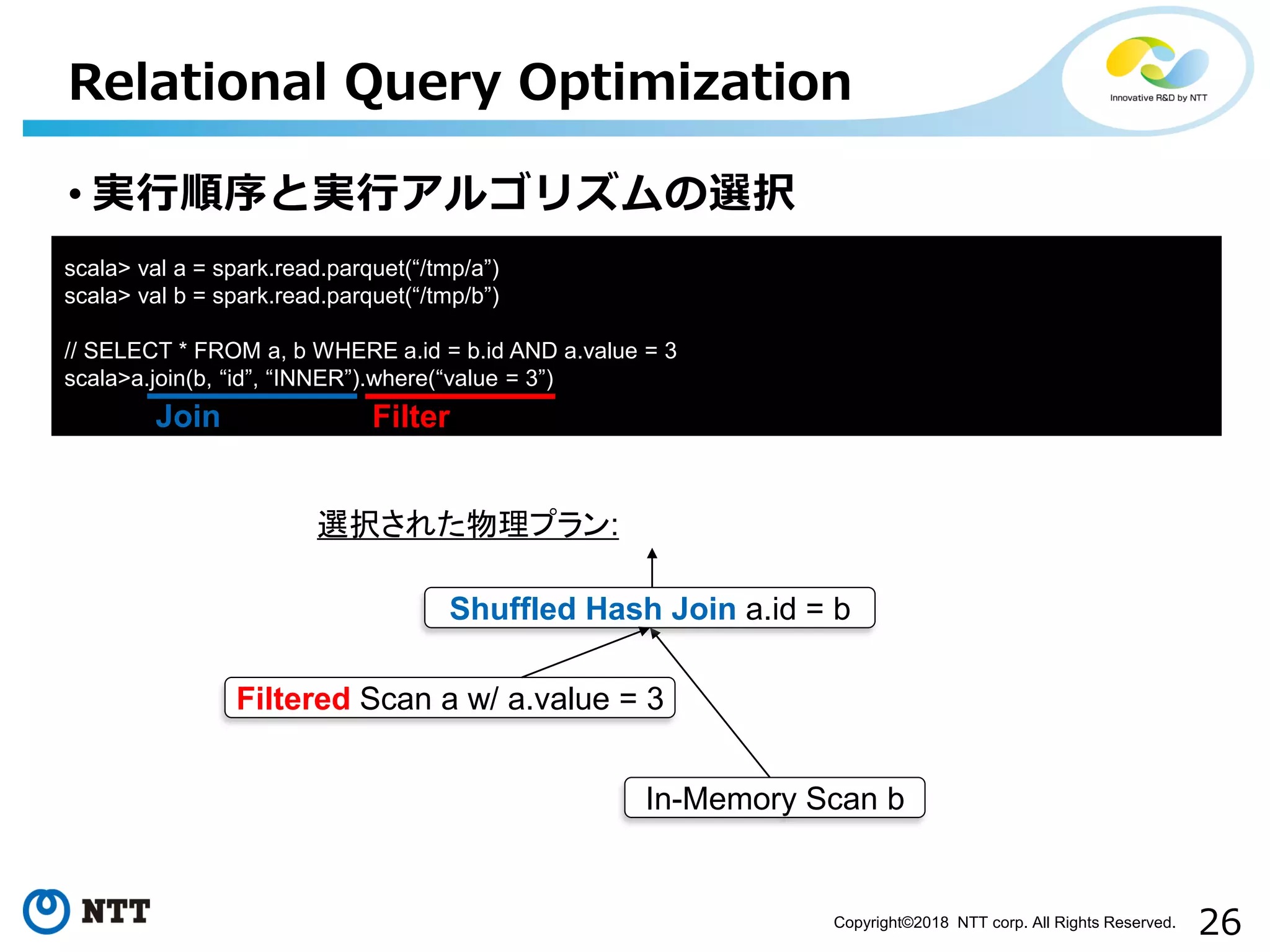
26Copyright©2018 NTT corp.
All Rights Reserved. • 実行順序と実行アルゴリズムの選択 Relational Query Optimization In-Memory Scan b Filtered Scan a w/ a.value = 3 Shuffled Hash Join a.id = b 選択された物理プラン: scala> val a = spark.read.parquet(“/tmp/a”) scala> val b = spark.read.parquet(“/tmp/b”) // SELECT * FROM a, b WHERE a.id = b.id AND a.value = 3 scala>a.join(b, “id”, “INNER”).where(“value = 3”) Join Filter
53.
27Copyright©2018 NTT corp.
All Rights Reserved. • Sparkは内部で関係代数的な評価を行うため,Pandas のDataFrameとNULLの扱いが異なる • Sparkは3値理論におけるNULL NULL Behavior Difference in DataFrame scala> val df = spark.read.option("inferSchema", true).csv("/tmp/test.csv") scala> df.where("_c0 != 1").explain == Physical Plan == *(1) Project [_c0#76, _c1#77, _c2#78] +- *(1) Filter (isnotnull(_c0#76) && NOT (_c0#76 = 1)) +- *(1) FileScan csv [_c0#76,_c1#77,_c2#78] … Isnotnullが自動で挿入
54.
28Copyright©2018 NTT corp.
All Rights Reserved. • Sparkは内部で関係代数的な評価を行うため,Pandas のDataFrameとNULLの扱いが異なる • Sparkは3値理論におけるNULL NULL Behavior Difference in DataFrame scala> sdf.show +----+----+ | _c0| _c1| +----+----+ | 1| a| | 2| b| | | c| +----+----+ scala> sdf.where("_c0 != 1").show +----+----+ | _c0| _c1| +----+----+ | 2| b| +----+----+ null >>> pdf _c0 _c1 0 1.0 a 1 2.0 b 2 NaN c >>> pdf[pdf['_c0'] != 1] 1 2.0 b 2 NaN c Spark DataFrame Pandas DataFrame NULLを含む行は除去
55.
29Copyright©2018 NTT corp.
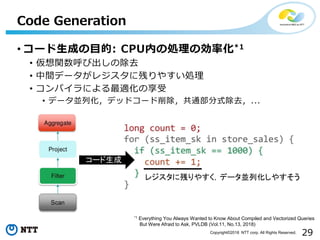
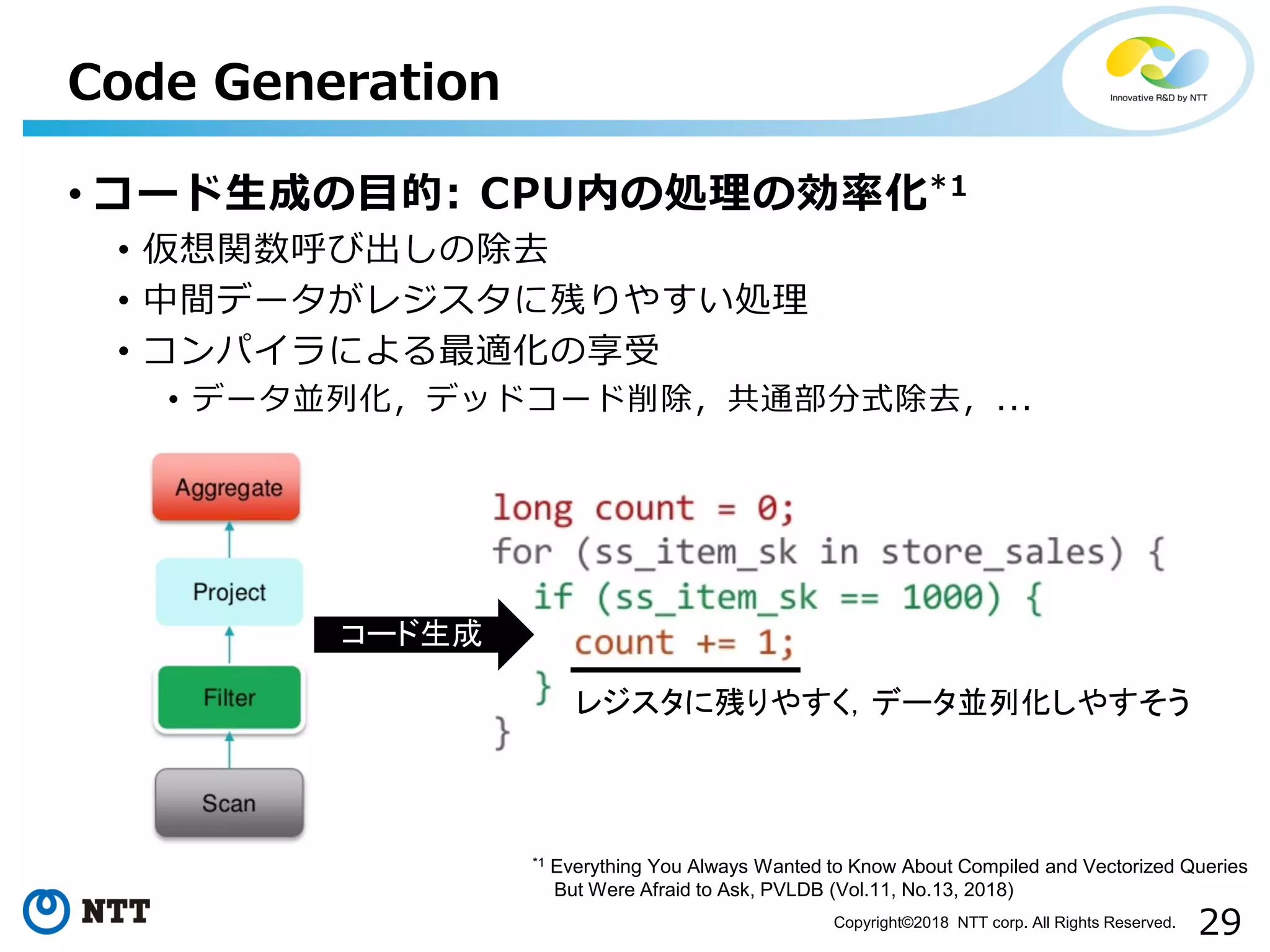
All Rights Reserved. • コード生成の目的: CPU内の処理の効率化*1 • 仮想関数呼び出しの除去 • 中間データがレジスタに残りやすい処理 • コンパイラによる最適化の享受 • データ並列化,デッドコード削除,共通部分式除去,... Code Generation *1 Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask, PVLDB (Vol.11, No.13, 2018) コード生成 レジスタに残りやすく,データ並列化しやすそう
56.
30Copyright©2018 NTT corp.
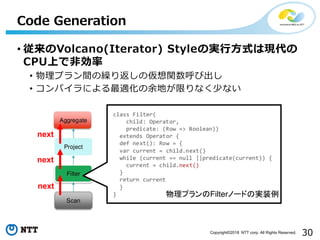
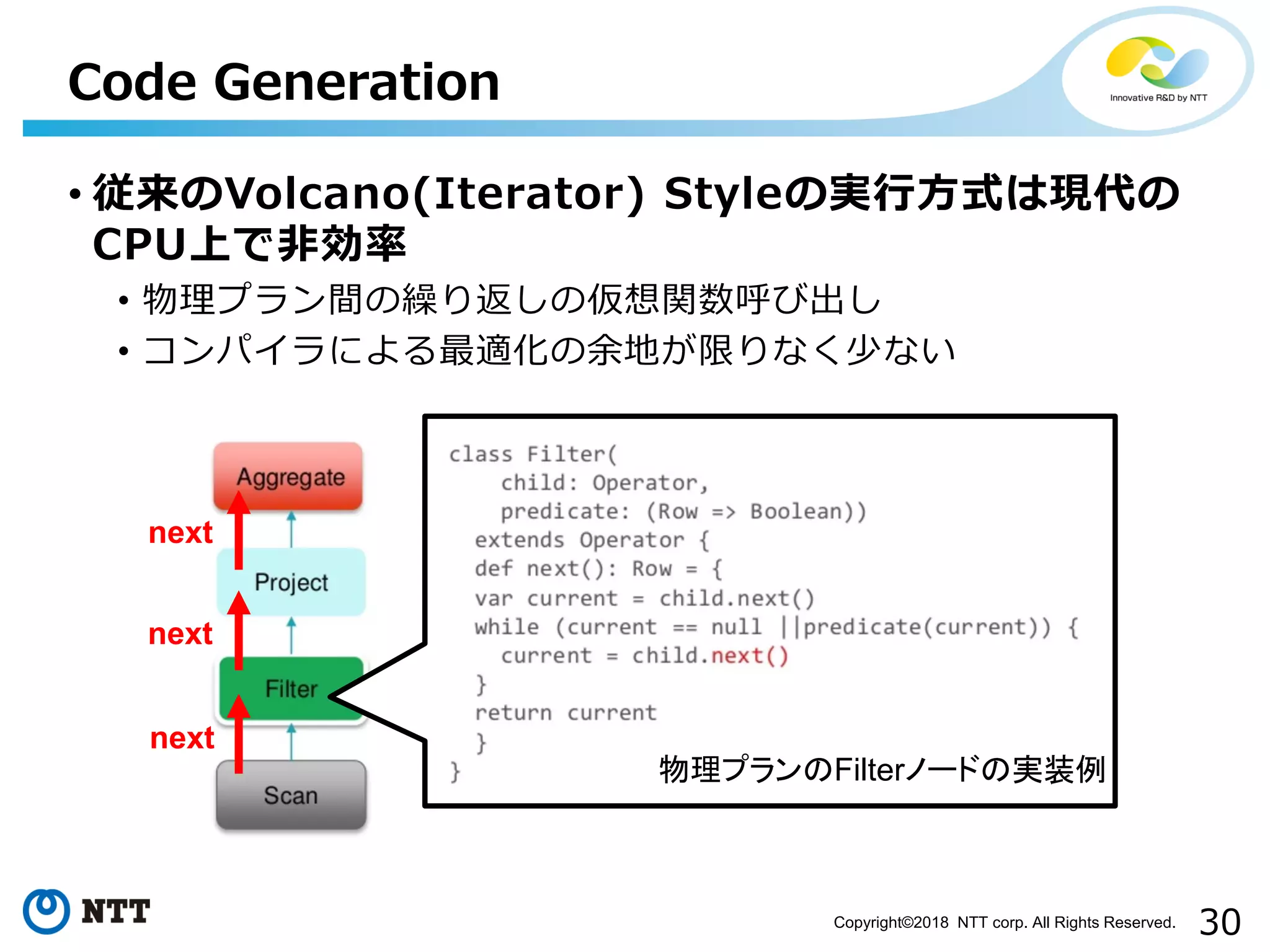
All Rights Reserved. • 従来のVolcano(Iterator) Styleの実行方式は現代の CPU上で非効率 • 物理プラン間の繰り返しの仮想関数呼び出し • コンパイラによる最適化の余地が限りなく少ない Code Generation 物理プランのFilterノードの実装例 next next next
57.
31Copyright©2018 NTT corp.
All Rights Reserved. • 性能改善の例: Broadcast Hash Join Code Generation
58.
32Copyright©2018 NTT corp.
All Rights Reserved. Future Work & Wrap Up
59.
33Copyright©2018 NTT corp.
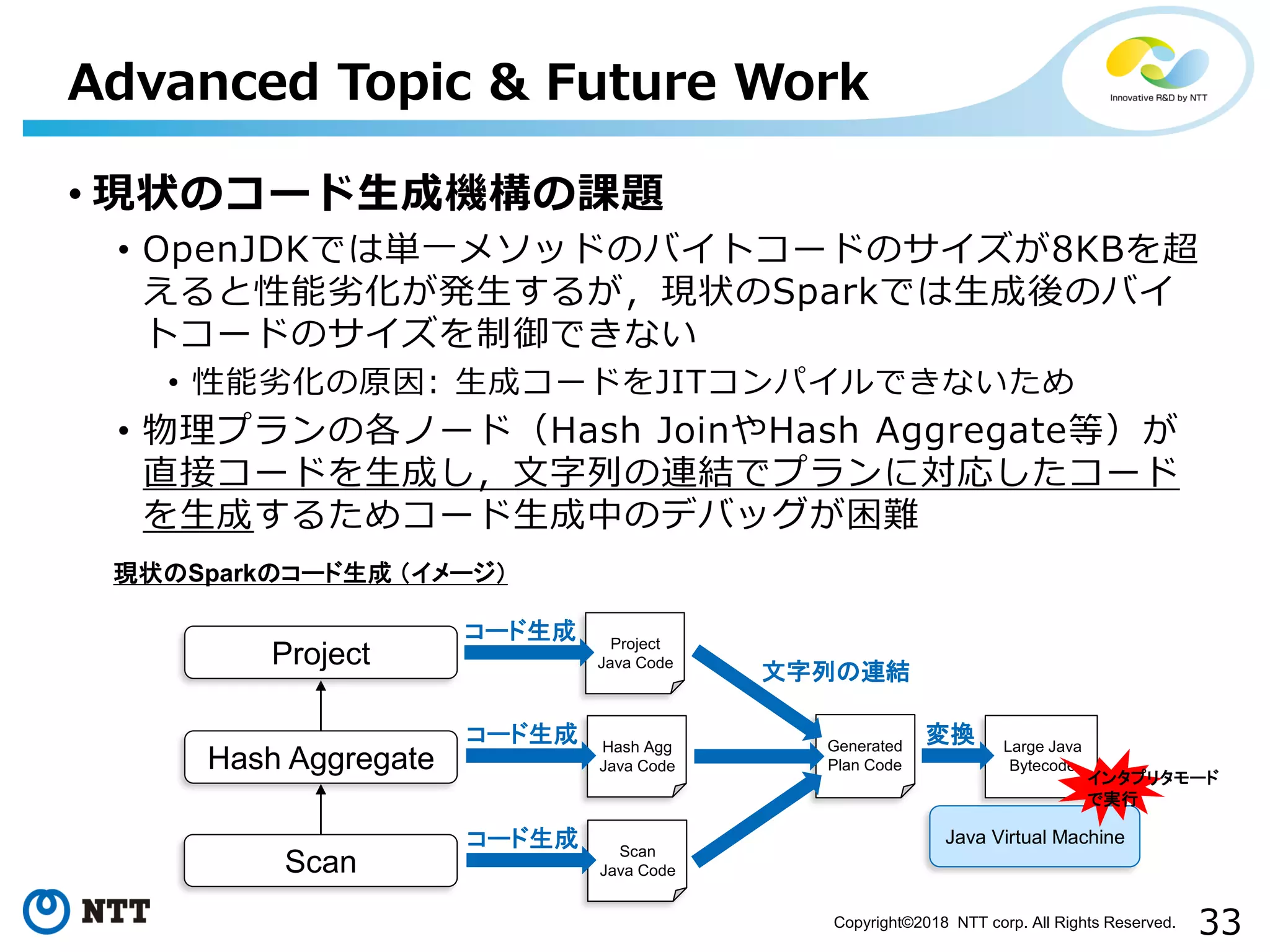
All Rights Reserved. • 現状のコード生成機構の課題 • OpenJDKでは単一メソッドのバイトコードのサイズが8KBを超 えると性能劣化が発生するが,現状のSparkでは生成後のバイ トコードのサイズを制御できない • 性能劣化の原因: 生成コードをJITコンパイルできないため • 物理プランの各ノード(Hash JoinやHash Aggregate等)が 直接コードを生成し,文字列の連結でプランに対応したコード を生成するためコード生成中のデバッグが困難 Advanced Topic & Future Work Hash Aggregate Scan Project 現状のSparkのコード生成 (イメージ) Project Java Code コード生成 Hash Agg Java Code コード生成 Scan Java Code コード生成 Generated Plan Code Java Virtual Machine 文字列の連結 Large Java Bytecode 変換 インタプリタモード で実行
60.
34Copyright©2018 NTT corp.
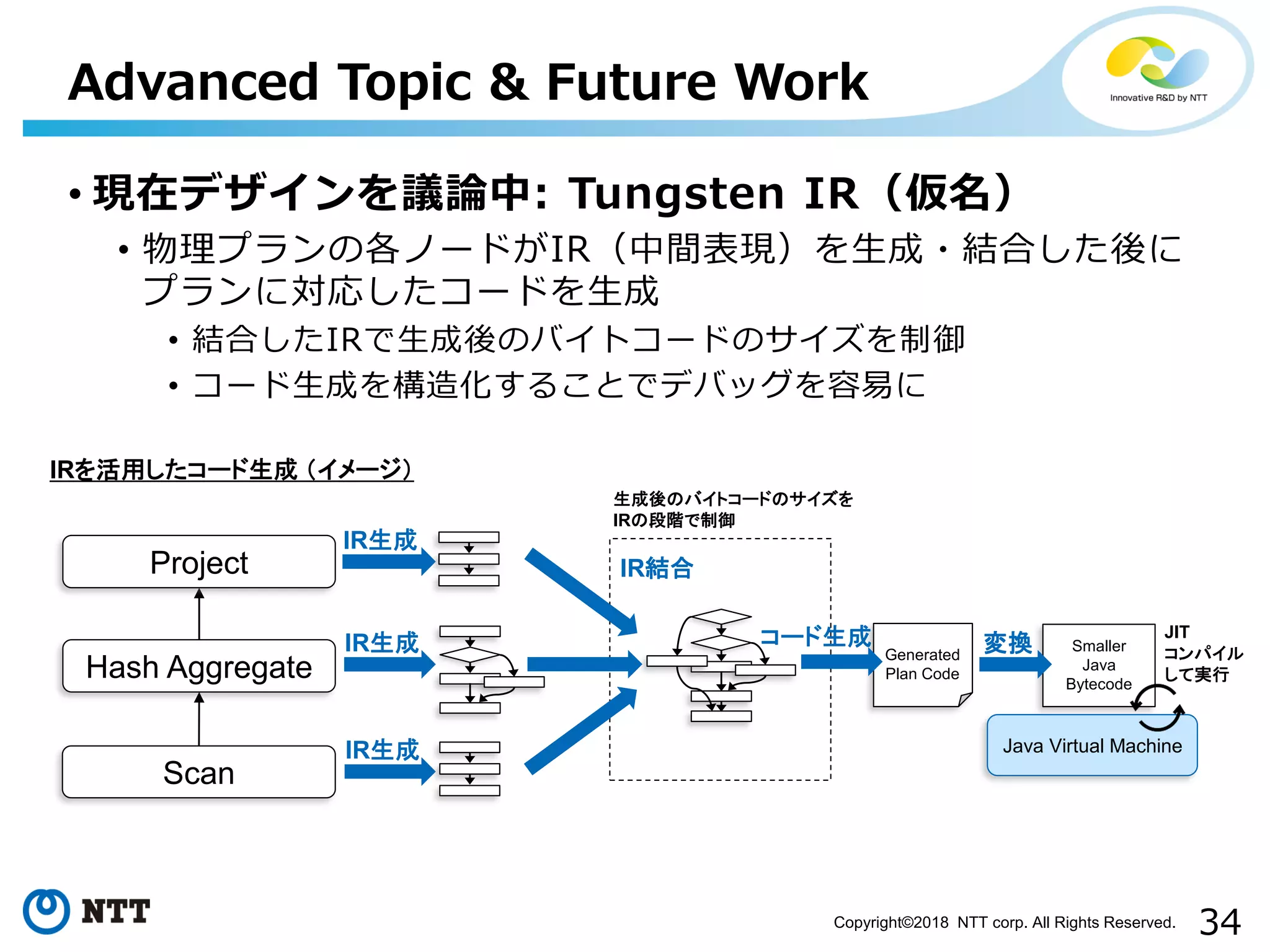
All Rights Reserved. • 現在デザインを議論中: Tungsten IR(仮名) • 物理プランの各ノードがIR(中間表現)を生成・結合した後に プランに対応したコードを生成 • 結合したIRで生成後のバイトコードのサイズを制御 • コード生成を構造化することでデバッグを容易に Advanced Topic & Future Work Hash Aggregate Scan Project IRを活用したコード生成 (イメージ) IR生成 IR生成 IR生成 Generated Plan Code Java Virtual Machine Smaller Java Bytecode 変換 IR結合 コード生成 JIT コンパイル して実行 生成後のバイトコードのサイズを IRの段階で制御
61.
35Copyright©2018 NTT corp.
All Rights Reserved. • Spark SQLは入力されたクエリの実行最適化を行う Sparkにおいて非常に重要な構成要素 • Data Source API • 外部データに対して読み書きと必要な最適化情報を提供するた めのAPI,実際の最適化内容は実装依存 • Catalyst • 関係代数的な最適化,拡張が容易な構造,コード生成などを特 徴とするSpark SQLの心臓部 Wrap Up
62.
© 2018 NTT
DATA Corporation 28 本講演のまとめ • Apache Sparkの注目したい最近の動向 – Project Hydrogen、Kubernetes対応、Python周りの改善、Data Source周りの対応改善 – エントリポイントとなる情報の紹介 • Spark SQL Deep Dive – Data Source API – Code generation
63.
© 2018 NTT
DATA Corporation













![© 2018 NTT DATA Corporation 18
Kubernetes対応:スケジューラバックエンドの拡張に関する議論
https://issues.apache.org/jira/browse/SPARK-18278
by Seon Owen
by Matt Cheah
https://issues.apache.org/jira/browse/SPARK-18278
private[spark] class KubernetesClusterSchedulerBackend(
scheduler: TaskSchedulerImpl,
rpcEnv: RpcEnv,
kubernetesClient: KubernetesClient,
requestExecutorsService: ExecutorService,
snapshotsStore: ExecutorPodsSnapshotsStore,
podAllocator: ExecutorPodsAllocator,
lifecycleEventHandler: ExecutorPodsLifecycleManager,
watchEvents: ExecutorPodsWatchSnapshotSource,
pollEvents: ExecutorPodsPollingSnapshotSource)
extends CoarseGrainedSchedulerBackend(scheduler, rpcEnv) {
(snip) private[spark]
// Yarn only
OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.queue"),
OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES,
confKey = "spark.executor.instances"),
OptionAssigner(args.pyFiles, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.pyFiles"),
OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.jars"),
OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.files"),
OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.archives"),
2](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-17-320.jpg)












![8Copyright©2018 NTT corp. All Rights Reserved.
• シンプル&大半のケースでうまく動くように設計
• Data Source実装に最適化情報(条件句と参照カラム列)を提供
• 結果は行の集合(RDD[Row])として返却
A Design of the API
条件句のCatalyst内部表現参照カラム列
Data Source APIの一部 結果の行集合](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-34-320.jpg)
![9Copyright©2018 NTT corp. All Rights Reserved.
An Example - CSV
scala> val df = spark.read.option("inferSchema", true).csv(”/tmp/test.csv”)
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) FileScan csv [_c0#39,_c1#40,_c2#41] Batched: false, DataFilters: [], Format: CSV,
Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [],
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#39, _c1#40]
+- *(1) Filter (isnotnull(_c0#39) && (_c0#39 = 1))
+- *(1) FileScan csv [_c0#39,_c1#40] Batched: false, DataFilters: [isnotnull(_c0#39), (_c0#39 = 1)],
Format: CSV, Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
1, abc, 3.8](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-35-320.jpg)
![10Copyright©2018 NTT corp. All Rights Reserved.
An Example - Parquet
scala> val df = spark.read.parquet("/tmp/test.parquet")
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) FileScan parquet [_c0#103,_c1#104,_c2#105] Batched: true, DataFilters: [], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-36-320.jpg)
![11Copyright©2018 NTT corp. All Rights Reserved.
An Example - JDBC
scala> val df = spark.read.jdbc("jdbc:postgresql:postgres", "test", options)
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23,_c2#24]
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-37-320.jpg)
![12Copyright©2018 NTT corp. All Rights Reserved.
• 1. Pushed Filters
• 2. Read Schema
• 3. Filter/Project Plan Pruning
• 4. Partition Listing & Filters
To Understand Data Source
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-38-320.jpg)
![13Copyright©2018 NTT corp. All Rights Reserved.
• Data SourceへPush Downされた条件句
• この条件句自体はCatalystの内部表現
• このCatalystの内部表現で表された条件句を活用して
最適化を行うかは実装依存
• CSVは未使用
• ParquetはParquetの内部表現に変換して活用
• JDBCは内部でSQL文のWHERE句にコンパイルして活用
1. Pushed Filters
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-39-320.jpg)
![14Copyright©2018 NTT corp. All Rights Reserved.
• JDBCRDD#compileFilterがWHERE句に変換
• WHERE ("_c0" IS NOT NULL) AND ("_c0" = 1)
1. Pushed Filters - JDBC
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-40-320.jpg)
![15Copyright©2018 NTT corp. All Rights Reserved.
• 上位の物理プランで参照されるカラム列
• PushedFiltersと同様でこの情報を活用した最適化を
行うかは実装依存
• CSVは内部のパーサ(Univocity)が不要なカラムの処理をバ
イパスしてCPU時間を節約するために活用
• Parquetはカラムナ構造であるため不要なIOを除去
• JDBCはSELECT文に参照するカラムを指定
2. Read Schema
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-41-320.jpg)

![17Copyright©2018 NTT corp. All Rights Reserved.
• 現状ではJDBCのみが不要な物理ノードを除去
• この最適化がCSV/Parquetで適用されていないのはFileFormat
API(Data Source APIの一部)の制約
3. Filter/Project Plan Pruning
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan == // Parquet
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
== Physical Plan ==. // JDBC
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
ProjectとFilterが除去](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-43-320.jpg)

![19Copyright©2018 NTT corp. All Rights Reserved.
• CSVやParquetはパーティション分割が可能で,読み
込み時に対象ファイルの列挙が必要
• また読み込みに不要なディレクトリのスキップが可能
4. Partition Listing & Filters
scala> spark.read.parquet("/tmp/test.parquet").where("p = 0").explain
== Physical Plan ==
*(1) FileScan parquet [id#45L,p#46] Batched: true, DataFilters: [], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionCount: 1,
PartitionFilters: [isnotnull(p#46), (p#46 = 0)],
PushedFilters: [],
ReadSchema: struct<id:bigint>
このフォルダ以下のファイルのみ読み込み
Data Source Table Format](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-45-320.jpg)




![27Copyright©2018 NTT corp. All Rights Reserved.
• Sparkは内部で関係代数的な評価を行うため,Pandas
のDataFrameとNULLの扱いが異なる
• Sparkは3値理論におけるNULL
NULL Behavior Difference in DataFrame
scala> val df = spark.read.option("inferSchema", true).csv("/tmp/test.csv")
scala> df.where("_c0 != 1").explain
== Physical Plan ==
*(1) Project [_c0#76, _c1#77, _c2#78]
+- *(1) Filter (isnotnull(_c0#76) && NOT (_c0#76 = 1))
+- *(1) FileScan csv [_c0#76,_c1#77,_c2#78] …
Isnotnullが自動で挿入](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-53-320.jpg)
![28Copyright©2018 NTT corp. All Rights Reserved.
• Sparkは内部で関係代数的な評価を行うため,Pandas
のDataFrameとNULLの扱いが異なる
• Sparkは3値理論におけるNULL
NULL Behavior Difference in DataFrame
scala> sdf.show
+----+----+
| _c0| _c1|
+----+----+
| 1| a|
| 2| b|
| | c|
+----+----+
scala> sdf.where("_c0 != 1").show
+----+----+
| _c0| _c1|
+----+----+
| 2| b|
+----+----+
null
>>> pdf
_c0 _c1
0 1.0 a
1 2.0 b
2 NaN c
>>> pdf[pdf['_c0'] != 1]
1 2.0 b
2 NaN c
Spark DataFrame Pandas DataFrame
NULLを含む行は除去](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/85/Spark-SQL-The-internal-54-320.jpg)




















![© 2018 NTT DATA Corporation 18
Kubernetes対応:スケジューラバックエンドの拡張に関する議論
https://issues.apache.org/jira/browse/SPARK-18278
by Seon Owen
by Matt Cheah
https://issues.apache.org/jira/browse/SPARK-18278
private[spark] class KubernetesClusterSchedulerBackend(
scheduler: TaskSchedulerImpl,
rpcEnv: RpcEnv,
kubernetesClient: KubernetesClient,
requestExecutorsService: ExecutorService,
snapshotsStore: ExecutorPodsSnapshotsStore,
podAllocator: ExecutorPodsAllocator,
lifecycleEventHandler: ExecutorPodsLifecycleManager,
watchEvents: ExecutorPodsWatchSnapshotSource,
pollEvents: ExecutorPodsPollingSnapshotSource)
extends CoarseGrainedSchedulerBackend(scheduler, rpcEnv) {
(snip) private[spark]
// Yarn only
OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.queue"),
OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES,
confKey = "spark.executor.instances"),
OptionAssigner(args.pyFiles, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.pyFiles"),
OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.jars"),
OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.files"),
OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, confKey =
"spark.yarn.dist.archives"),
2](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-17-2048.jpg)












![8Copyright©2018 NTT corp. All Rights Reserved.
• シンプル&大半のケースでうまく動くように設計
• Data Source実装に最適化情報(条件句と参照カラム列)を提供
• 結果は行の集合(RDD[Row])として返却
A Design of the API
条件句のCatalyst内部表現参照カラム列
Data Source APIの一部 結果の行集合](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-34-2048.jpg)
![9Copyright©2018 NTT corp. All Rights Reserved.
An Example - CSV
scala> val df = spark.read.option("inferSchema", true).csv(”/tmp/test.csv”)
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) FileScan csv [_c0#39,_c1#40,_c2#41] Batched: false, DataFilters: [], Format: CSV,
Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [],
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#39, _c1#40]
+- *(1) Filter (isnotnull(_c0#39) && (_c0#39 = 1))
+- *(1) FileScan csv [_c0#39,_c1#40] Batched: false, DataFilters: [isnotnull(_c0#39), (_c0#39 = 1)],
Format: CSV, Location: InMemoryFileIndex[file:/tmp/test.csv], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
1, abc, 3.8](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-35-2048.jpg)
![10Copyright©2018 NTT corp. All Rights Reserved.
An Example - Parquet
scala> val df = spark.read.parquet("/tmp/test.parquet")
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) FileScan parquet [_c0#103,_c1#104,_c2#105] Batched: true, DataFilters: [], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-36-2048.jpg)
![11Copyright©2018 NTT corp. All Rights Reserved.
An Example - JDBC
scala> val df = spark.read.jdbc("jdbc:postgresql:postgres", "test", options)
scala> df.show
+---+----+-----+
|_c0| _c1|_c2|
+---+----+-----+
| 1| abc| 3.8|
+---+----+-----+
scala> df.explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23,_c2#24]
PushedFilters: [],
ReadSchema: struct<_c0:int,_c1:string,_c2:double>
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-37-2048.jpg)
![12Copyright©2018 NTT corp. All Rights Reserved.
• 1. Pushed Filters
• 2. Read Schema
• 3. Filter/Project Plan Pruning
• 4. Partition Listing & Filters
To Understand Data Source
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-38-2048.jpg)
![13Copyright©2018 NTT corp. All Rights Reserved.
• Data SourceへPush Downされた条件句
• この条件句自体はCatalystの内部表現
• このCatalystの内部表現で表された条件句を活用して
最適化を行うかは実装依存
• CSVは未使用
• ParquetはParquetの内部表現に変換して活用
• JDBCは内部でSQL文のWHERE句にコンパイルして活用
1. Pushed Filters
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-39-2048.jpg)
![14Copyright©2018 NTT corp. All Rights Reserved.
• JDBCRDD#compileFilterがWHERE句に変換
• WHERE ("_c0" IS NOT NULL) AND ("_c0" = 1)
1. Pushed Filters - JDBC
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-40-2048.jpg)
![15Copyright©2018 NTT corp. All Rights Reserved.
• 上位の物理プランで参照されるカラム列
• PushedFiltersと同様でこの情報を活用した最適化を
行うかは実装依存
• CSVは内部のパーサ(Univocity)が不要なカラムの処理をバ
イパスしてCPU時間を節約するために活用
• Parquetはカラムナ構造であるため不要なIOを除去
• JDBCはSELECT文に参照するカラムを指定
2. Read Schema
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan ==
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-41-2048.jpg)
![17Copyright©2018 NTT corp. All Rights Reserved.
• 現状ではJDBCのみが不要な物理ノードを除去
• この最適化がCSV/Parquetで適用されていないのはFileFormat
API(Data Source APIの一部)の制約
3. Filter/Project Plan Pruning
scala> df.selectExpr("_c0", "_c1").where("_c0 = 1").explain
== Physical Plan == // Parquet
*(1) Project [_c0#103, _c1#104]
+- *(1) Filter (isnotnull(_c0#103) && (_c0#103 = 1))
+- *(1) FileScan parquet [_c0#103,_c1#104] Batched: true,
DataFilters: [isnotnull(_c0#103), (_c0#103 = 1)], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionFilters: [],
PushedFilters: [IsNotNull(_c0), EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
== Physical Plan ==. // JDBC
*(1) Scan JDBCRelation(test) [numPartitions=1] [_c0#22,_c1#23]
PushedFilters: [*IsNotNull(_c0), *EqualTo(_c0,1)],
ReadSchema: struct<_c0:int,_c1:string>
ProjectとFilterが除去](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-43-2048.jpg)

![19Copyright©2018 NTT corp. All Rights Reserved.
• CSVやParquetはパーティション分割が可能で,読み
込み時に対象ファイルの列挙が必要
• また読み込みに不要なディレクトリのスキップが可能
4. Partition Listing & Filters
scala> spark.read.parquet("/tmp/test.parquet").where("p = 0").explain
== Physical Plan ==
*(1) FileScan parquet [id#45L,p#46] Batched: true, DataFilters: [], Format: Parquet,
Location: InMemoryFileIndex[file:/tmp/test.parquet], PartitionCount: 1,
PartitionFilters: [isnotnull(p#46), (p#46 = 0)],
PushedFilters: [],
ReadSchema: struct<id:bigint>
このフォルダ以下のファイルのみ読み込み
Data Source Table Format](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-45-2048.jpg)





![27Copyright©2018 NTT corp. All Rights Reserved.
• Sparkは内部で関係代数的な評価を行うため,Pandas
のDataFrameとNULLの扱いが異なる
• Sparkは3値理論におけるNULL
NULL Behavior Difference in DataFrame
scala> val df = spark.read.option("inferSchema", true).csv("/tmp/test.csv")
scala> df.where("_c0 != 1").explain
== Physical Plan ==
*(1) Project [_c0#76, _c1#77, _c2#78]
+- *(1) Filter (isnotnull(_c0#76) && NOT (_c0#76 = 1))
+- *(1) FileScan csv [_c0#76,_c1#77,_c2#78] …
Isnotnullが自動で挿入](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-53-2048.jpg)
![28Copyright©2018 NTT corp. All Rights Reserved.
• Sparkは内部で関係代数的な評価を行うため,Pandas
のDataFrameとNULLの扱いが異なる
• Sparkは3値理論におけるNULL
NULL Behavior Difference in DataFrame
scala> sdf.show
+----+----+
| _c0| _c1|
+----+----+
| 1| a|
| 2| b|
| | c|
+----+----+
scala> sdf.where("_c0 != 1").show
+----+----+
| _c0| _c1|
+----+----+
| 2| b|
+----+----+
null
>>> pdf
_c0 _c1
0 1.0 a
1 2.0 b
2 NaN c
>>> pdf[pdf['_c0'] != 1]
1 2.0 b
2 NaN c
Spark DataFrame Pandas DataFrame
NULLを含む行は除去](https://image.slidesharecdn.com/20181031ntc2018c3sparksqltheinternal-190327093851/75/Spark-SQL-The-internal-54-2048.jpg)



































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=600ounds&width=560&fit=bounds)












































