Downloaded 156 times





![How does ML work – continued?
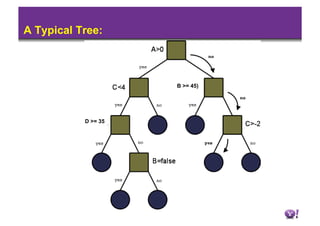
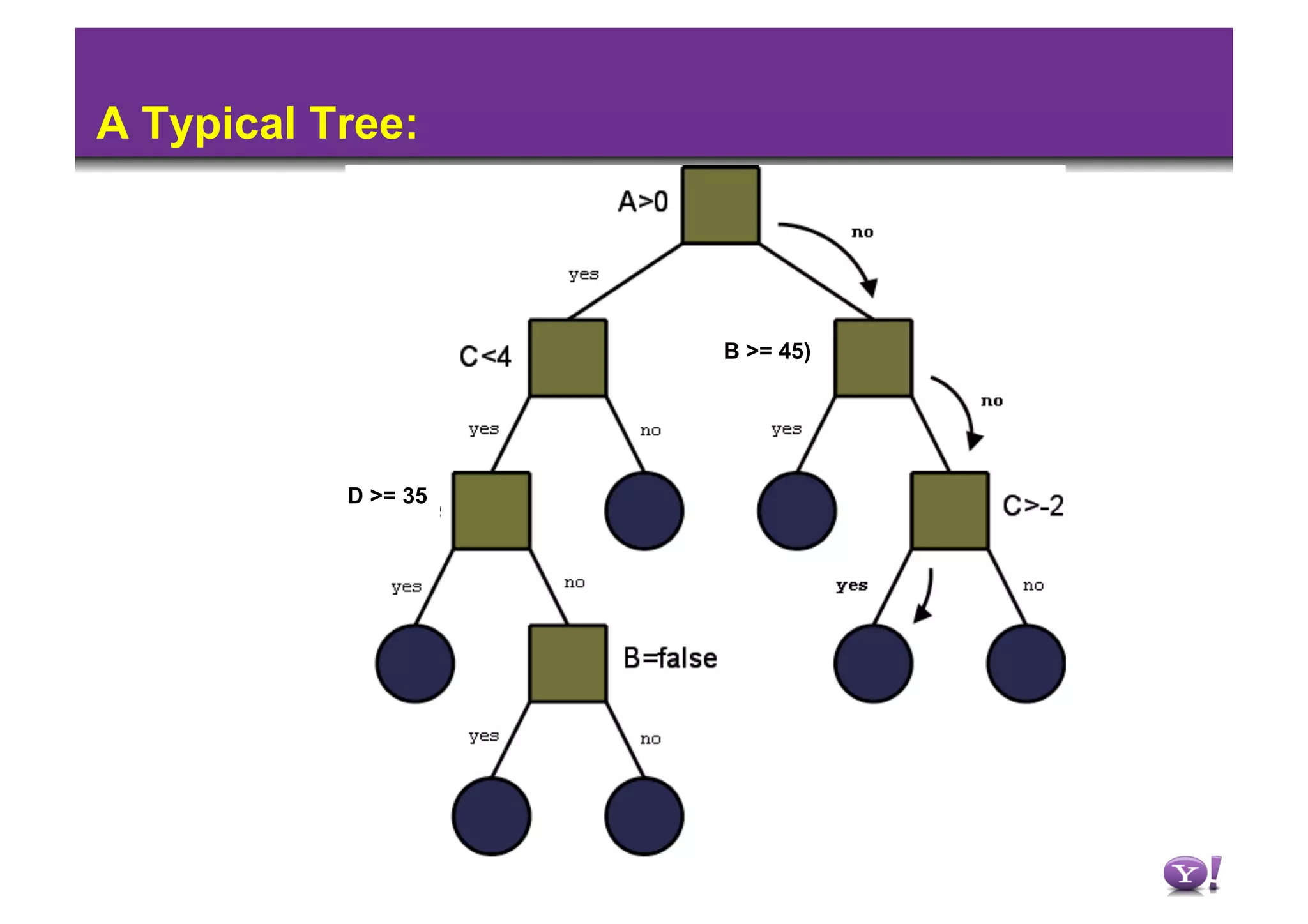
• An Old class of learners – Tree induction.
– [Split] Choose attribute (subject) which can best describe the final
class with least encoding.
If the {attribute {=,≤,≥} value} can homogeneously describe the
outcome you are done.
Else for each {attribute {=,≤,≥} value} group choose another
attribute and iterate from above.
– Intuition: Look at the toughest course– who got low marks here
also fails the exam. Amongst the one who passed this course look
at which course they have failed and split on that (so on..).
– When do we stop? What do we mean by homogeneous?
– What is over-fit? How do we prune?](https://image.slidesharecdn.com/hadoopsummit2010machinelearningusinghadoop-100305131603-phpapp01/85/Hadoop-Summit-2010-Machine-Learning-Using-Hadoop-7-320.jpg)








![How does ML work – continued?
• An Old class of learners – Tree induction.
– [Split] Choose attribute (subject) which can best describe the final
class with least encoding.
If the {attribute {=,≤,≥} value} can homogeneously describe the
outcome you are done.
Else for each {attribute {=,≤,≥} value} group choose another
attribute and iterate from above.
– Intuition: Look at the toughest course– who got low marks here
also fails the exam. Amongst the one who passed this course look
at which course they have failed and split on that (so on..).
– When do we stop? What do we mean by homogeneous?
– What is over-fit? How do we prune?](https://image.slidesharecdn.com/hadoopsummit2010machinelearningusinghadoop-100305131603-phpapp01/75/Hadoop-Summit-2010-Machine-Learning-Using-Hadoop-7-2048.jpg)

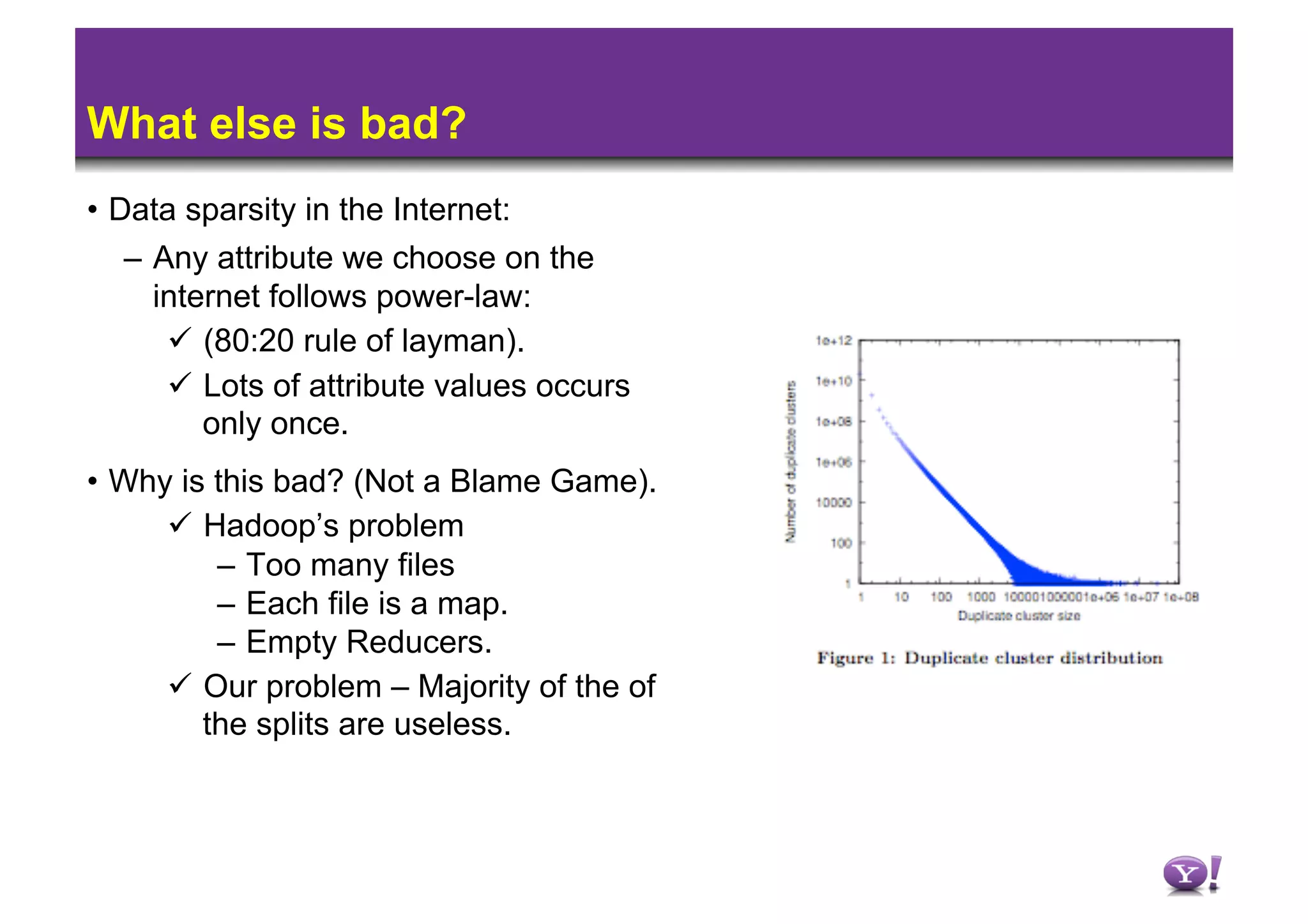

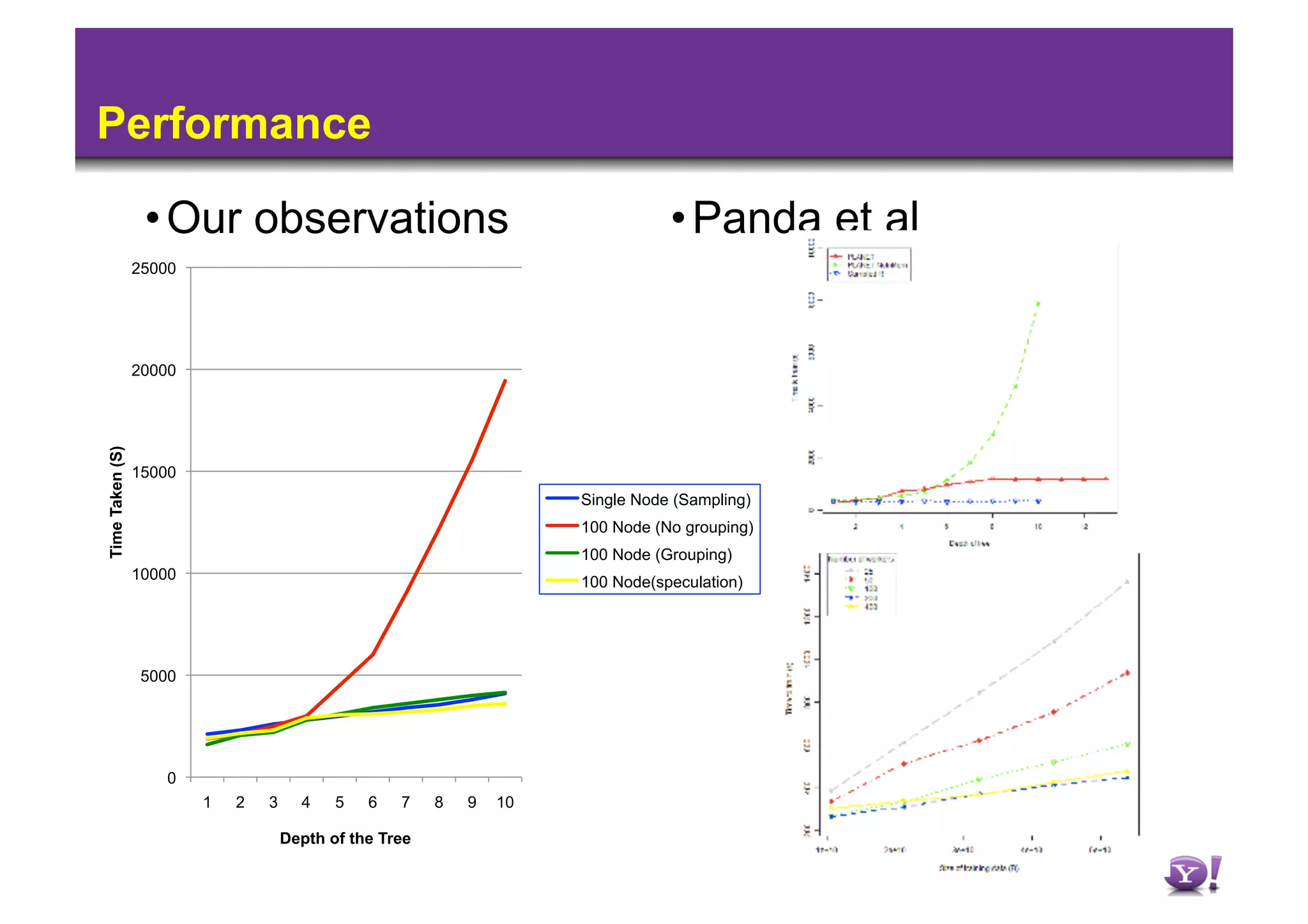


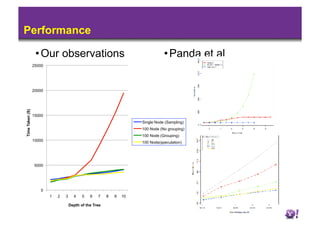
1) Machine learning algorithms aim to learn patterns in labeled data to predict labels for new data, while data mining describes patterns without guaranteed generalization. 2) Running machine learning on Hadoop has issues with iterations and data sparsity causing many small, empty files. 3) Techniques like speculation, grouping rare values, and sampling can improve performance by reducing iterations and sparsity when learning decision trees on Hadoop.























































































