2
Two Types ofHashing
1.Static Hashing .
2.Dynamic Hashing .
Static Hashing :
•It is the hash function maps search key value to
a fixed set of locations.
Dynamic Hashing :
•The Hash Table can grow to handle more
Items.The associated Hash Function must
Change as the table grows.
3.
Hash
Table :
• TheHash Table data structure is a array
of some fixed size table containing the
Keys.
• A Key is a values associated with each record.
• A Hash table is partition into array of size.
• Each Bucket has many slots and
eachslots holds one records.
Hash Function :
• A Hashing Function is a key to address
Transformation which acts upon a given Key
to complete the Relative Position of the Key
arra 4
4.
• A Keycan be a member of a String etc..
• A Hash Function Formula is
• Hash (Key Value ) =(Key Values % Table
Size)
• Hash (Key Value)=Key Values % Table
Size
• Hash(10) =10 % 5=0
• Hash(33) =33 % 5 =3
• Hash(11)=11 % 5=1
Hash(21)= 21 % 5=1
4
5.
5
A Good Hashingconsist of
•Minimum Collision.
•Be easy and quick to complete.
•Distribute Key Value Every in the Hash Table.
•Use all the Information Provided in the Key.
Application of Hash Table:
•Database Systems
•Symbol Tables .
•Data Dictionaries
•Network Processing Algorithm
•Browse Casher.
6.
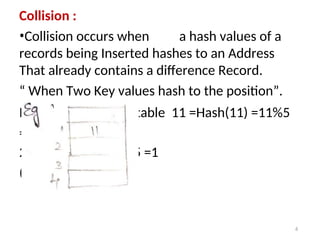
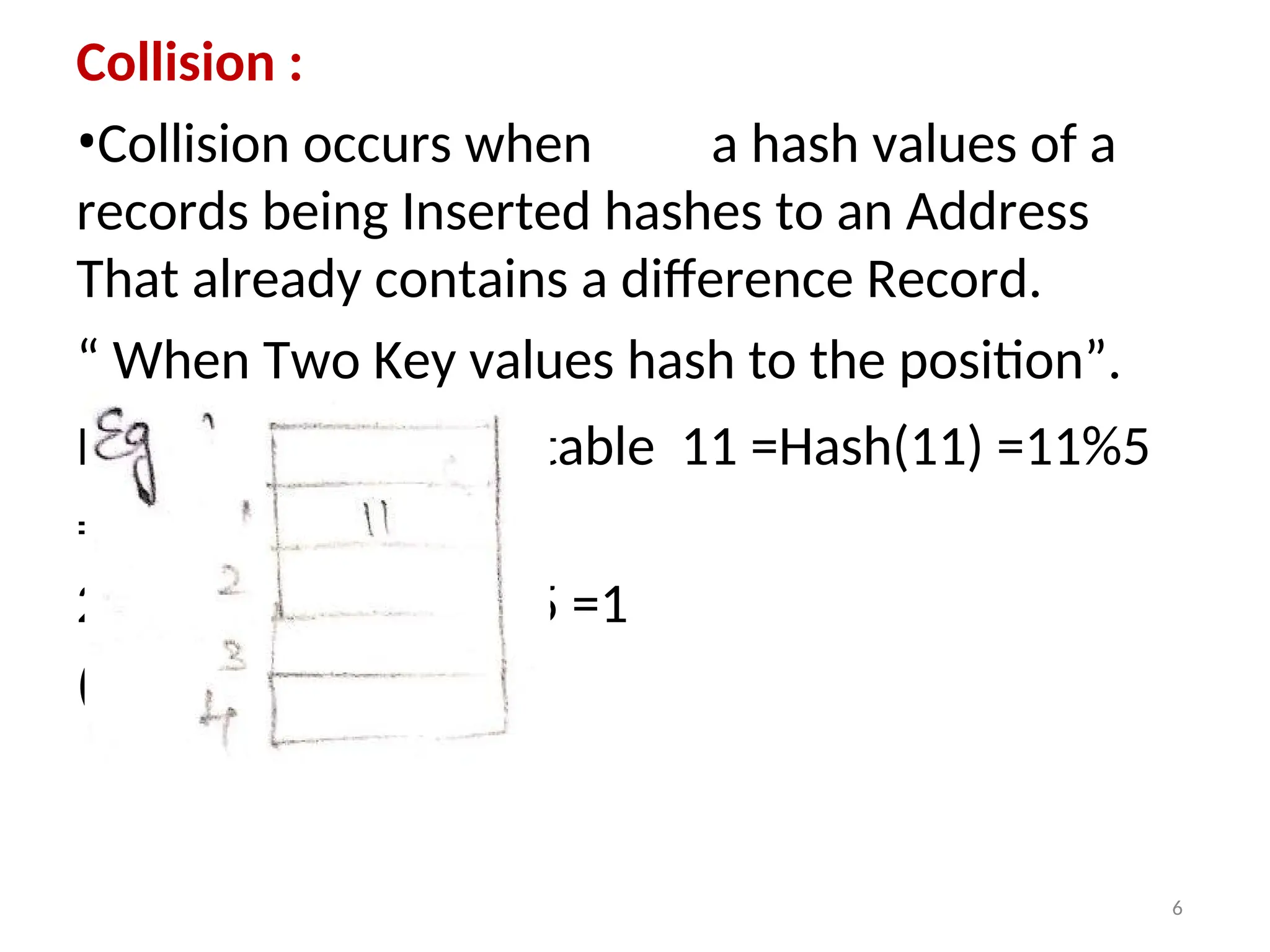
Collision :
•Collision occurswhen a hash values of a
records being Inserted hashes to an Address
That already contains a difference Record.
“ When Two Key values hash to the position”.
Insert 11,21 in hash table 11 =Hash(11) =11%5
=1
21= Hash (21) =21%5 =1
(collision occur)
6
7.
7
Collision Resolution :
•TheProcess of finding another Position for
The Collide Record Is said to be collision
Resolution Strategy.
Two categories of Hashing .
1.Open Hashing
eg: Separate Chaining.
2.Closed Hashing .
eg : Open Addressing ,Rehashing and
Extendable hashing.
8.
8
Open Hashing :
•EachBucket in the Hash table is the head of a
Linked List.
•All Elements that hash to a Particular Bucket
are Placed on the Buckets Linked List .
Closed Hashing:
•Ensures that all elements are stored directly in
to the Hash Table.
9.
9
Separate Chaining :
•SeparateChaining is an open hashing
Technique
•A Pointer fields is added to each record
Location.
•In this method the table can never overflow
since the linked are only extended upon or
New Keys.
Example:
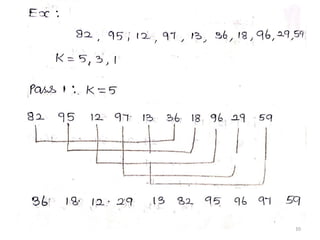
10 , 11 , 81 , 10 , 7 , 34 , 94 , 17 , 29 , 89 , 99
11
The element 81collides to the same of the hash
value to place the value 81 at this position perform
the following.
1.Traverse the list to check whether
it is already present.
2.Since, it is not already present, insert at end of
the list similarly, the rest of the elements are
inserted.
Advantages:
More number of elements can be inserted as it
uses of linked list.
Collision resolution is simple and efficient.
12.
12
Disadvantages:
It requires pointers,which occupies
more memory space.
Closed hashing:
•Collide elements are stored at another slot in
the table. Ensures that all elements stored
directly in the hash table.
Eg: Open addressing
Rehashing and extendable hashing.
13.
2
Open Addressing:
•
• Openaddressing also called closed
hashing which is an attentive to resolve the
collision with linked list.
If a collision occurs, alternative cells are tried until
an empty cell is found (i.e) cells ho(x), h1(x),
h2(x) are tried in succession.
There are three common collision strategies, there
are
1. Linear Probing
2. Quadratic Probing
3. Double Hashing
6
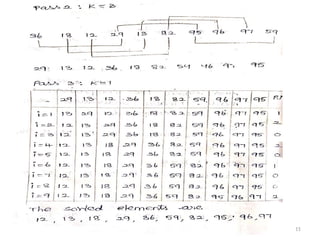
Rehashing:
•
• If thetable get’s to full. Then the rehashing
method new tables that is about twice as with and
scan down the entire original hash table.
The entire original hash table, computing the new hash
value for each element and in sorting it in the new
table.
• Rehashing is very expensive operations, the
running time is O(N), Rehashing can be implements
is several ways with Quadratic probing such as
i). Rehash as soon as the table is half full.
18.
7
• A newtable is created as table so full. The size of the
table so full. The size of the table is 17, as this to the
first prime (i.e) a) twice as large as the old table size.
• The new hash function is h(x) = Xmod 17 the old
table is scanned and the elements, 6,15,24,23 and 13
are inserted into the new table.
9
Advantages
:
Programmer does notabout the table size.
Simple to implement.
It can be used in order data structure as well.
ii) Rehash only when an insertion fails.
Suppose the elements 13,15 ,23 ,24 & 6
are insert into an open addressing hash
table of size.
Hash function h(x) = x mod 7
If 23 isinserted into the Table ,the
Resulting Table Will be over 70% Full.
1) Insert 23:
Hash(23)=23%7
=2
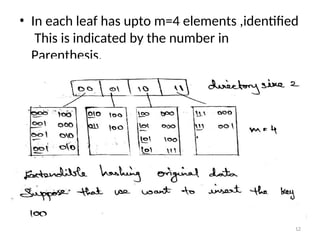
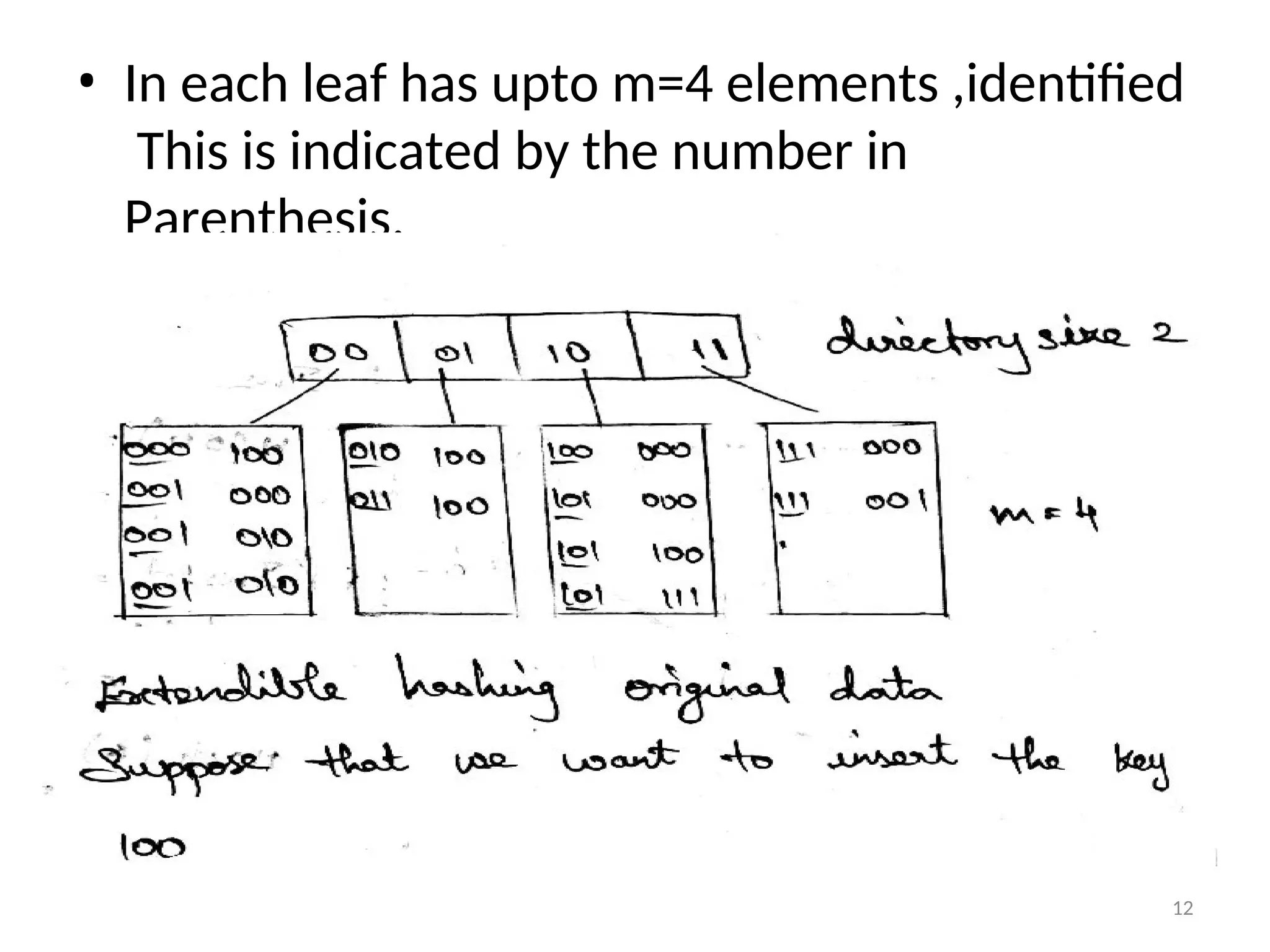
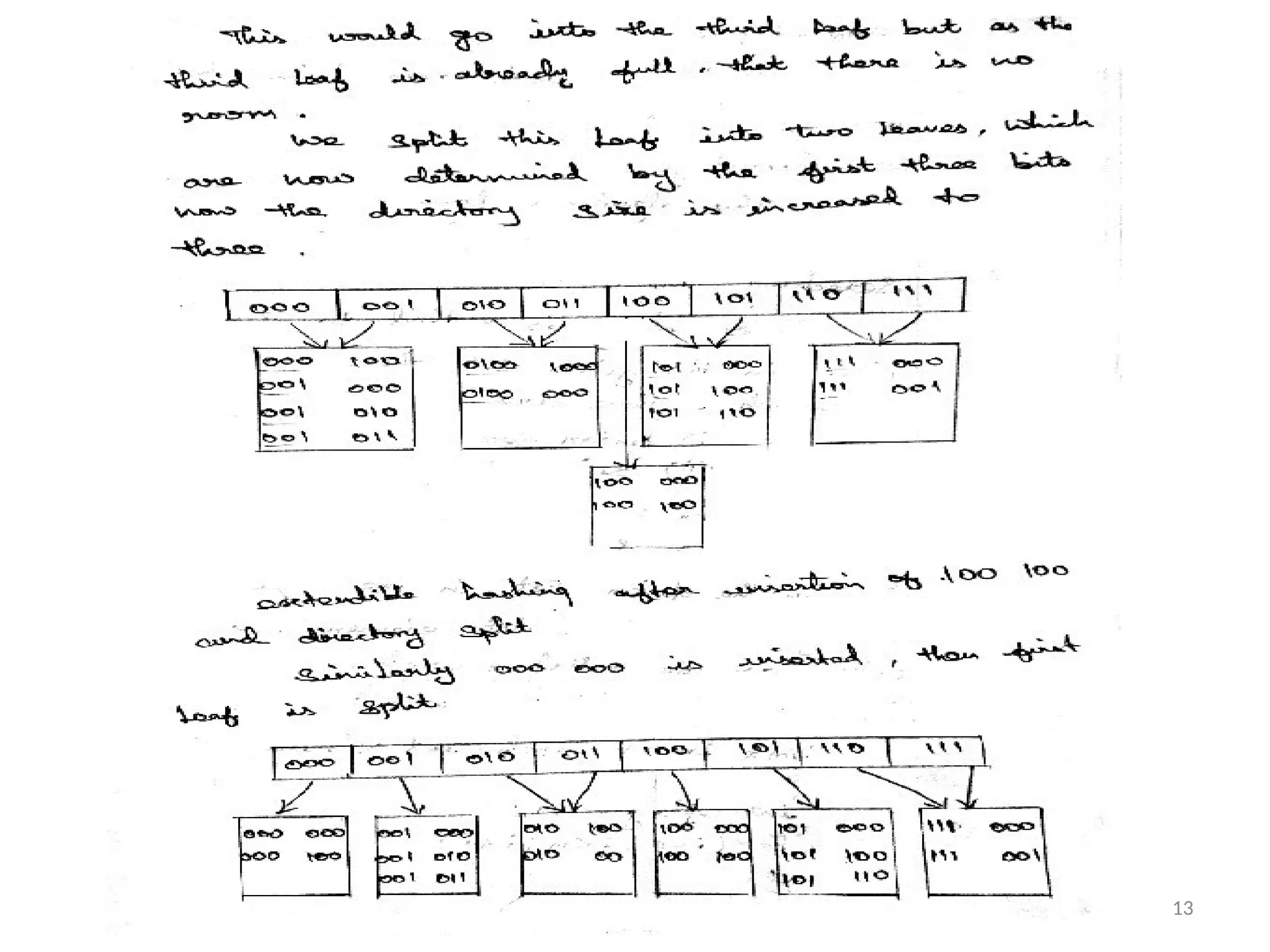
Extendable Hashing:
•Extendable Hashing Allows a find to be
Performed in two disk accesses. Insertion Also
Requires few Disk accesses.
•Let us support consider our data consist of
determined by the leading two bits are the
data . 11
23.
• In eachleaf has upto m=4 elements ,identified
This is indicated by the number in
Parenthesis.
12
14
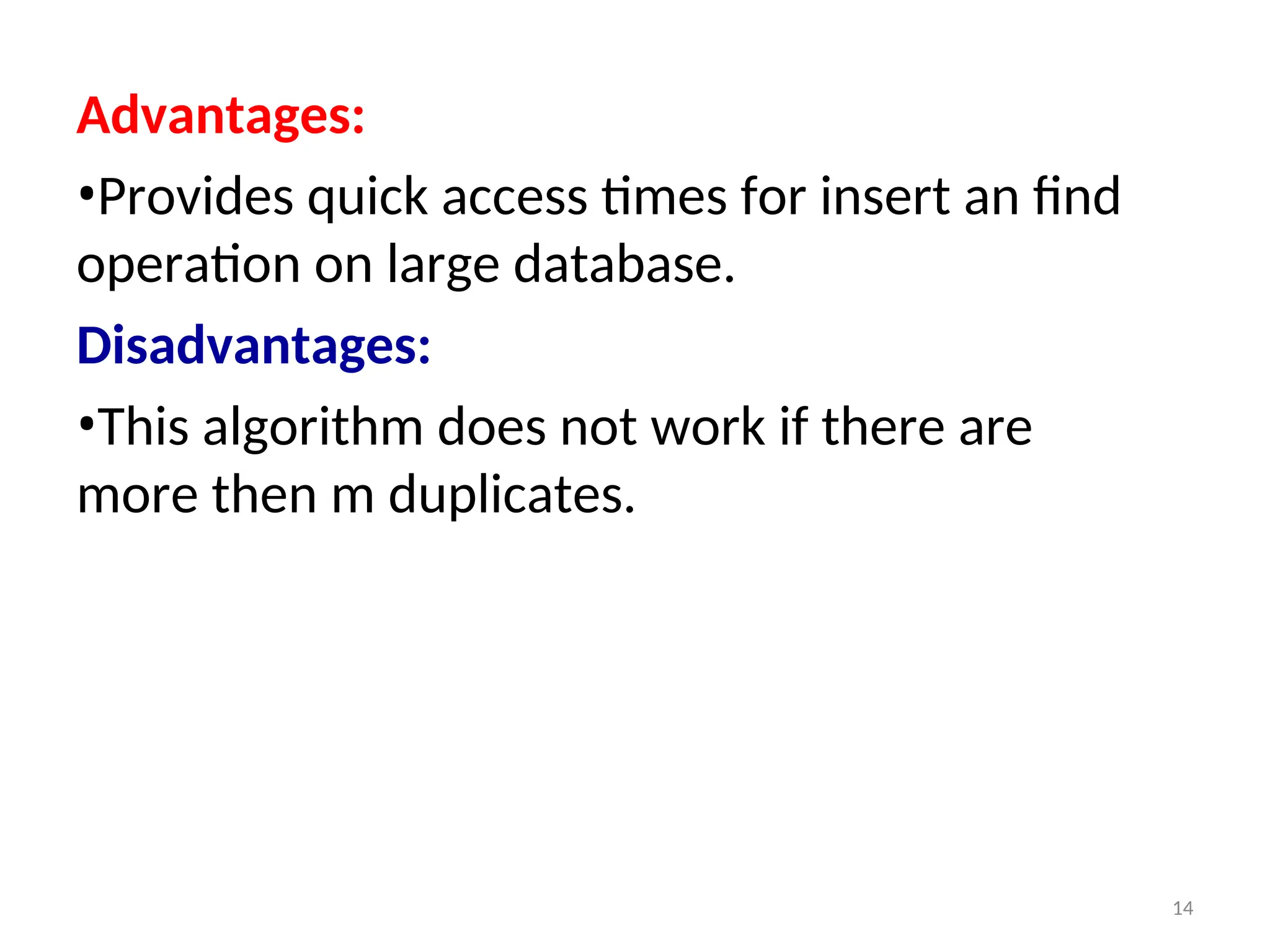
Advantages:
•Provides quick accesstimes for insert an find
operation on large database.
Disadvantages:
•This algorithm does not work if there are
more then m duplicates.
What is Searching?
Searchingis the process of finding the occurrence of a particular element in a list.
If Element which to be searched is found in the list then search is said to be
successful otherwise unsuccessful .
There are two types of searching technique.
Linear / Sequential Search
Binary Search
28.
Linear Search
It isone of the simplest searching technique. In this technique, the Array is traversed
sequentially from the first element until the element is found or end of the array is
reached.
This technique is suitable for performing a search in a small array or in
an unsorted array.
Unsorted means element may or may not be in ascending or descending order.
29.
C++ Program torepresent Linear Search
int linear(int ar[],int size,int item)
{
int i; for(i=0;i<size;i++)
{
if(ar[i]==item)
return i;
}
return -1;
}
30.
Linear Search withoutfunction
#include<iostream>
using namespace std;
int main()
{
int ar[50],size,item,i,j;
cout<<"Enter number of elements=";
cin>>size;
cout<<"Enter Array's Elements=";
for(i=0;i<size;i++)
cin>>ar[i];
cout<<"Enter element which to be searched=";
cin>>item;
for(i=0;i<size;i++)
{
if(ar[i]==item)
{
j=1;
break;
} }
if(j==1)
cout<<"Element Found at="<<(i+1);
else
cout<<"Element not Found";
return 0;
}
31.
Analysis of Linear
Search:
• BEST CASE ANALYSIS:0(1)
• AVERAGE CASE ANALYSIS:0(N)
• WORST CASE ANALYSIS: 0(N)
Binary Search:
• Binary Search is used to Search an Item in a
Sorted list . In this Method ,Initialize the lower
Limit as 1 And Upper Limit as N(N-1)
• The middle position is computed as (Lower
+Upper)/2 and check the element in the Middle
Position with the Data item to be
Searched. 5
32.
• If thedata item is greater then are Middle
Value then the Lower limit Is adjusted to
one Greater then the middle value.
• Otherwise , The Upper Limit is adjusted to
One Less then the Middle Value Ex: X=25.
6
33.
Binary Search
The Binarysearch technique is used to search in a sorted array. Sorted array
means the elements should be Ascending to Descending order.
In this technique , the element which to be searched is compared with the middle
element of the array. If it matches then search is said to be successful.
If the element which to be searched is less than middle element then search operation
is performed before the middle element.
If the element which to be searched is greater than the middle element then search
operation is performed after the middle element.
This process continues until the element is found or end of the array segment reduced
to a single element i.e not equal to item.
34.
C++ Program toRepresent Binary Search
int Binary(int ar[],int size,int item)
{
int low,high,mid;
low=0;
high=size-1;
while(low<=high)
{
mid=(low+high)/2;
if(item==ar[mid])
return mid;
else if(item<ar[mid])
high=mid-1;
else low=mid+1;
}
return -1;
}
2
Def: Sorting isa
SORTING
Process (or) Technique
of
Arranging a group or a Sequence of Data
Elements in an order either in ascending or
descending.
Two Types of Sorting: 1.Internal Sorting
2.External Sorting.
37.
3
Internal Sorting:
•A sortingin which all records of the file to be
sorted should be within the main memory at
the time of sorting.
External Sorting:
•Sorting is which at the time of Sorting Some
Record of the file to be Sorted can be in the
secondary memory.
Internal Sorting:
1.Insertion Sort 2.Shell sort
5
Insertion Sort:
•Insertion SortWorks by tasking element from
the list one by one and inserting them in their
current position into a new sorted list.
•Insertion sort consists of N-1 Passes Where N is
the number of element to be sorted .
•The ith Pass of insertion sort will insert the ith
•Element A*1+ , A*2+ ,….A*i-1] .After Doing this
Insertion the Record occupying A*1+,….A*i+ are
in sorted order.
40.
Insertion and Routine:
voidinsertion sort (element type a[], int N )
{
int j, p ;
element type tmp ; for(p=1; p<N ; p++)
{
tmp =a[p];
for (j=p ; j>0&& a[j-1]>tmp ;j--) a[j] =a[j-1];
a[j]=tmp ;
} }
6
8
Analysis of insertionSort :
•WORST CASE ANALYSIS -
O(N^2)
•BEST CASE ANALYSIS - O(N)
•AVERAGE CASE ANALYSIS -O(N^2)
43.
9
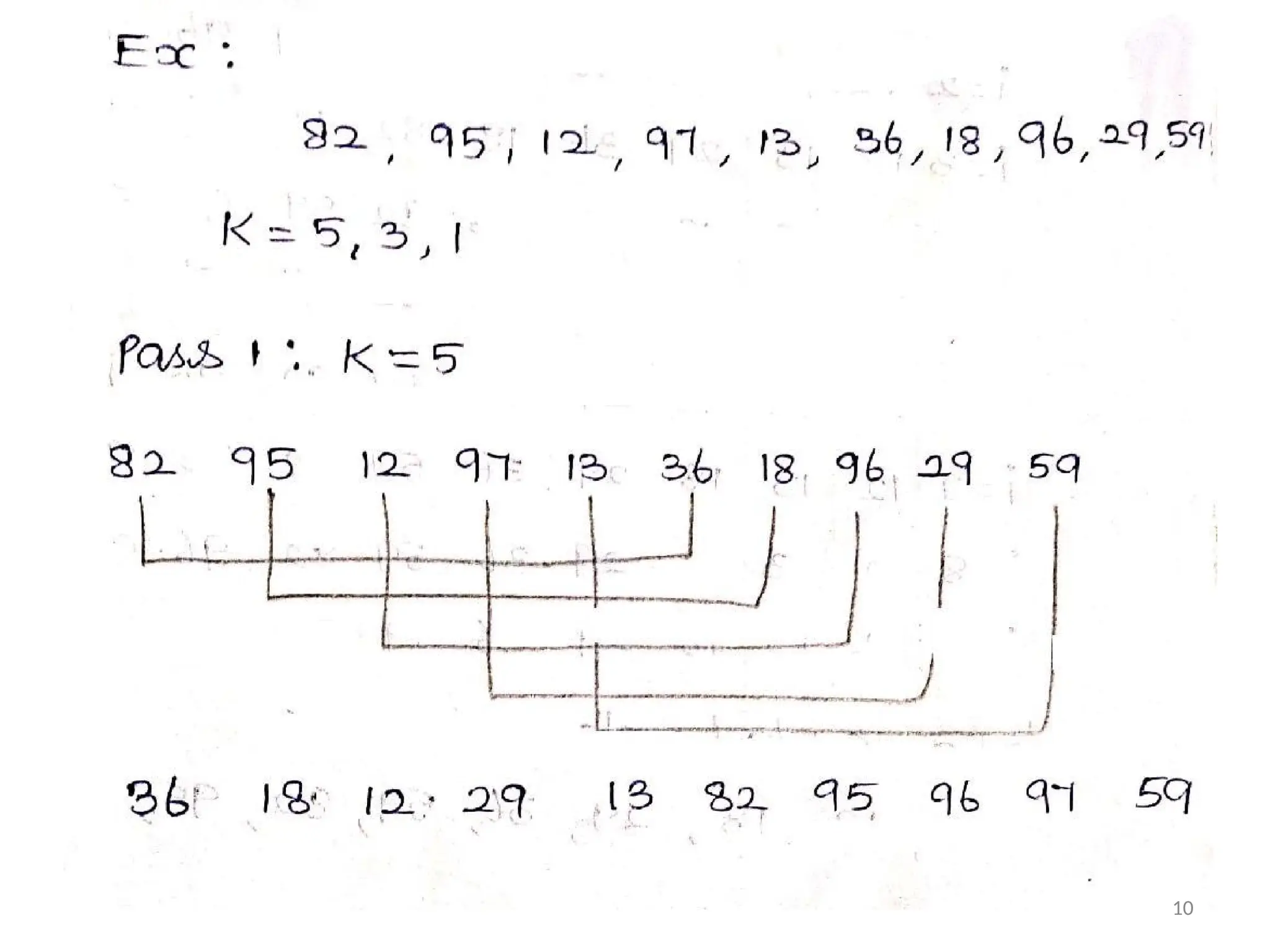
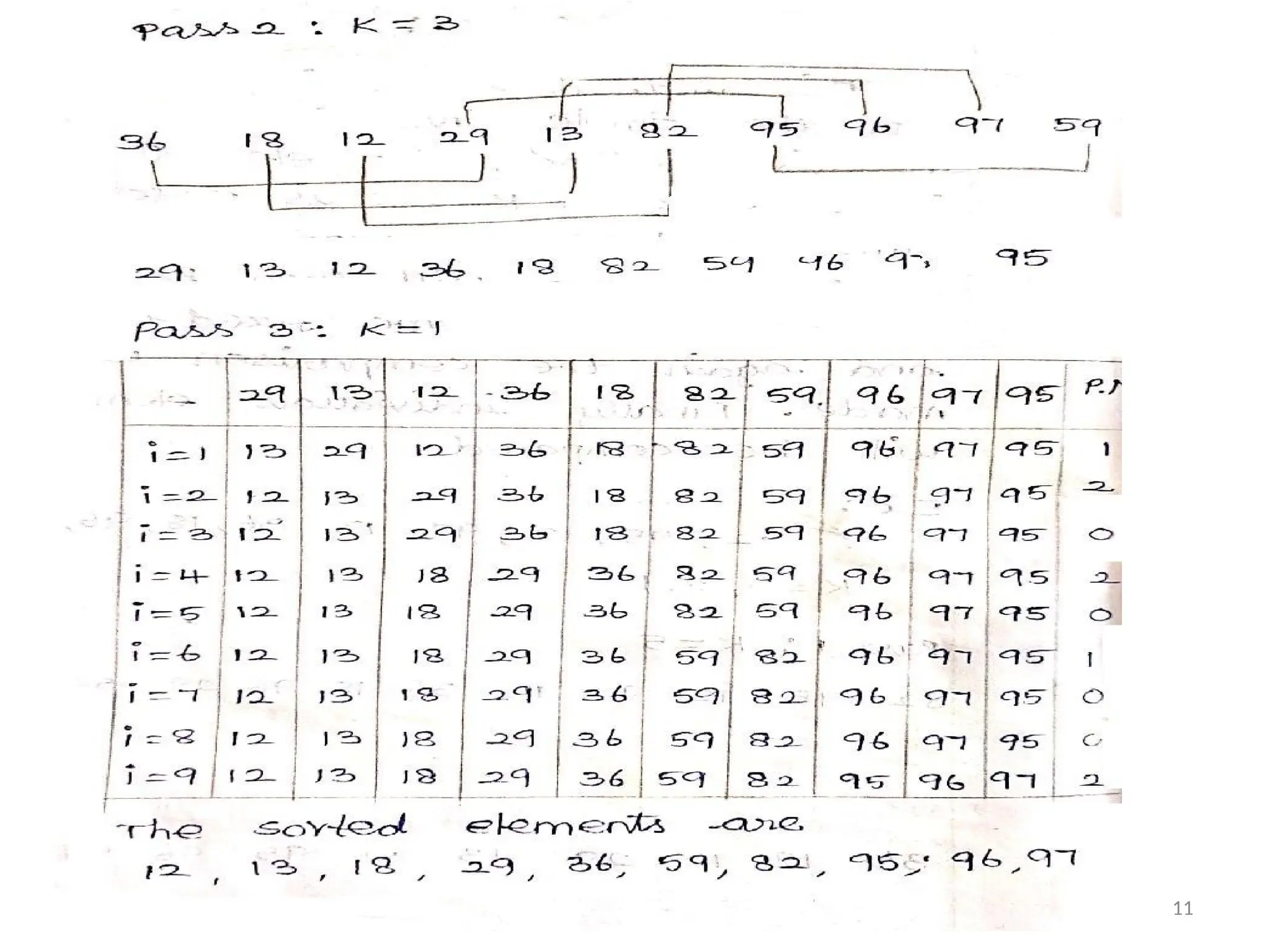
Shell Sort :
•This
method
is an Improvement over
the
Simple Insertion Sort .In this Method The
Element at Fixed Distance K (K is Preferably
prime Number ) or compared .
•The distance will then be decremented by
Some fixed amount and again the
Comparison will be made . Finally Individuals
elements will be compared.
18
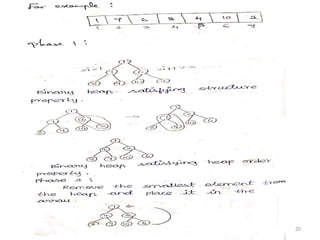
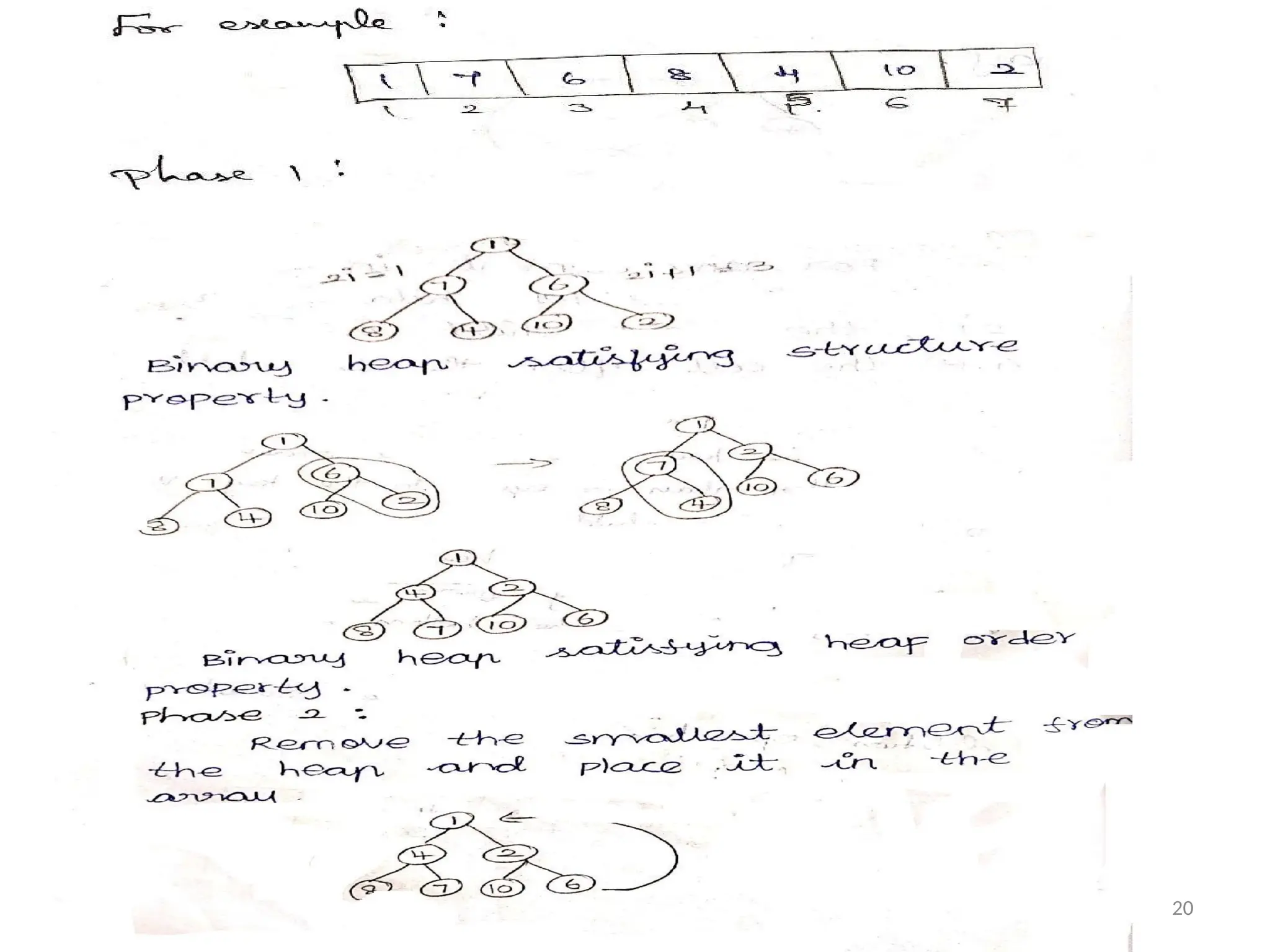
Heap Sort :
•Inheap sort the array of Interpret as a binary
Tree. This Method pass 2 Phases.
•In Phase 1: Binary heap is Constructed.
•In Phase 2: Delete min Routine is Performed.
Phase 1: Two Properties of Binary Heap :
Structure Property .
Heap order Property.
Structure Property :
•For Any Element in Array Position i , The Left
child is in 2i+1 (i.e) The Cell after the Left Child
47.
19
Heap Order Property:
•Thekey Values in the parent Node is Smaller
then or equal to the key Value of any in its
Child node.
•To Build the Heap , apply the heap order
Property Starting from the Right Most Non –
Leaf Node at the Bottom level.
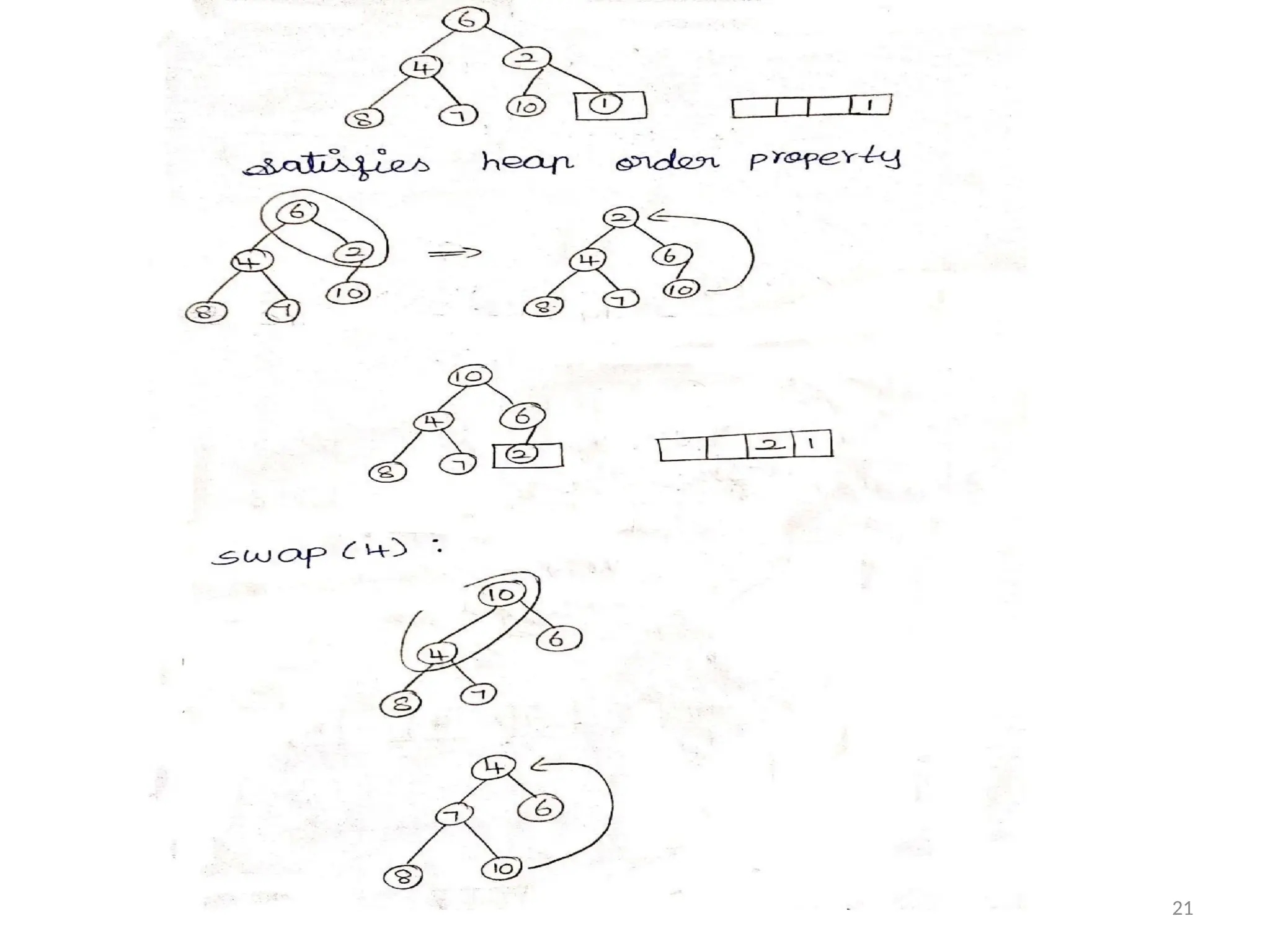
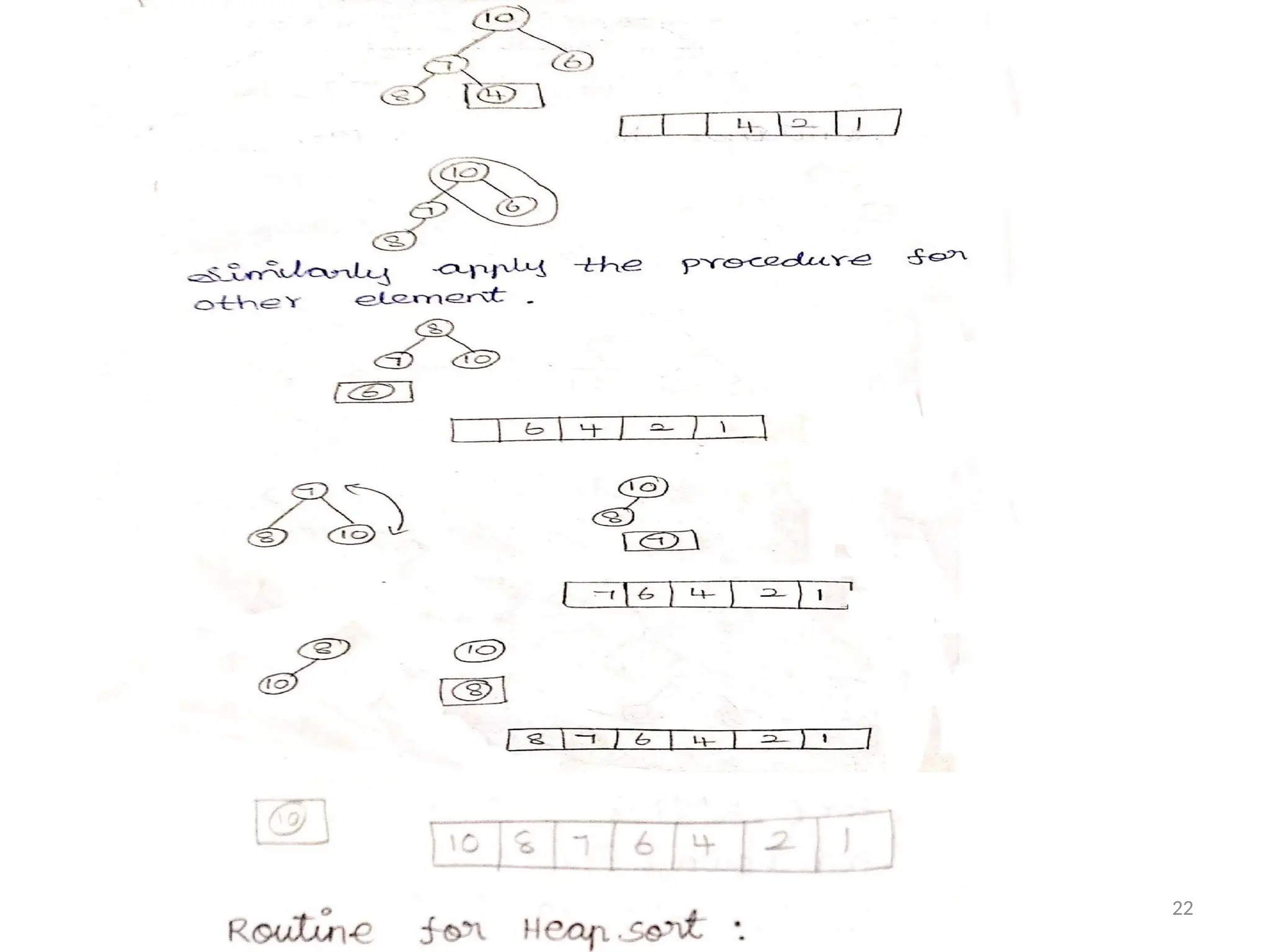
Phase 2:
The Array Element are Stored using Deletion
Operation.
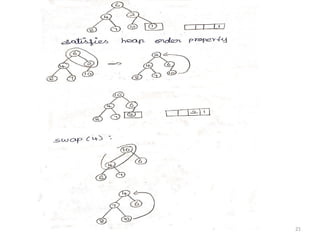
Example :
23
Routine for HeapSort :
#define left child [i] (2*(i)+1)
void perdown (element type A[] , int i , int N)
{
int child ;
element type tmp ;
for(tmp =A[i] , left child (i)<N , i=child)
{
child =left child (i);
if (child!=N-1&&A[child +]>A[child]) child ++ ;
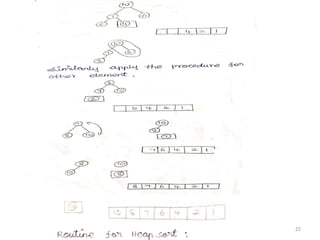
25
perdown (A ,i, N);
for(i=N-1; i>0; i--)
{
swap (&A[0] ,&A[i]);
per down (A,o,i);
}
}
}
54.
Analysis of HeapSort :
Worst Case Analysis =O(N log N)
Best case Analysis = O(N log N)
Arg Case Analysis = O(N log N)
Advantages:
•It is efficient for Sorting Large
number of Element.
•It has the Add of Worst case.
Limitation :
•It is Not a stable Sort .
•It Require Most Processing Time .
55.
27
Radix Sort :
•RadixSort is one of
the Linear Sorting
algorithm for Integers.
•It is
generated from radix
Sort.
•It can be performed
using Bucket 0 to 9.
56.
• It isalso called as Binsort.
• In First Pass all element arranged according to
the least Significant digit. In Second Pass ,the
element are arranged according to the next
least significant digit and so on.
28
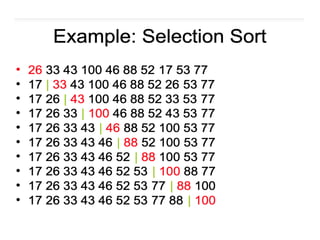
void selectionSort(int *array,int size)
{
int i, j, imin;
for(i = 0; i<size-1; i++)
{
imin = i; //get index of minimum data
for(j = i+1; j<size; j++)
if(array[j] < array[imin])
imin = j; //placing in correct position
swap(array[i], array[imin]);
}
}
void swap(int &a, int &b)
{ //swap the content of a and b
int temp;
temp = a;
a = b;
b = temp;
}
61.
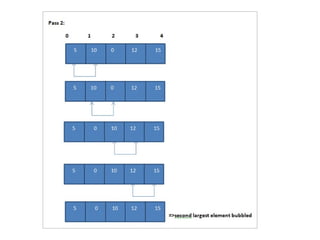
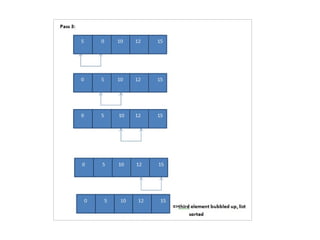
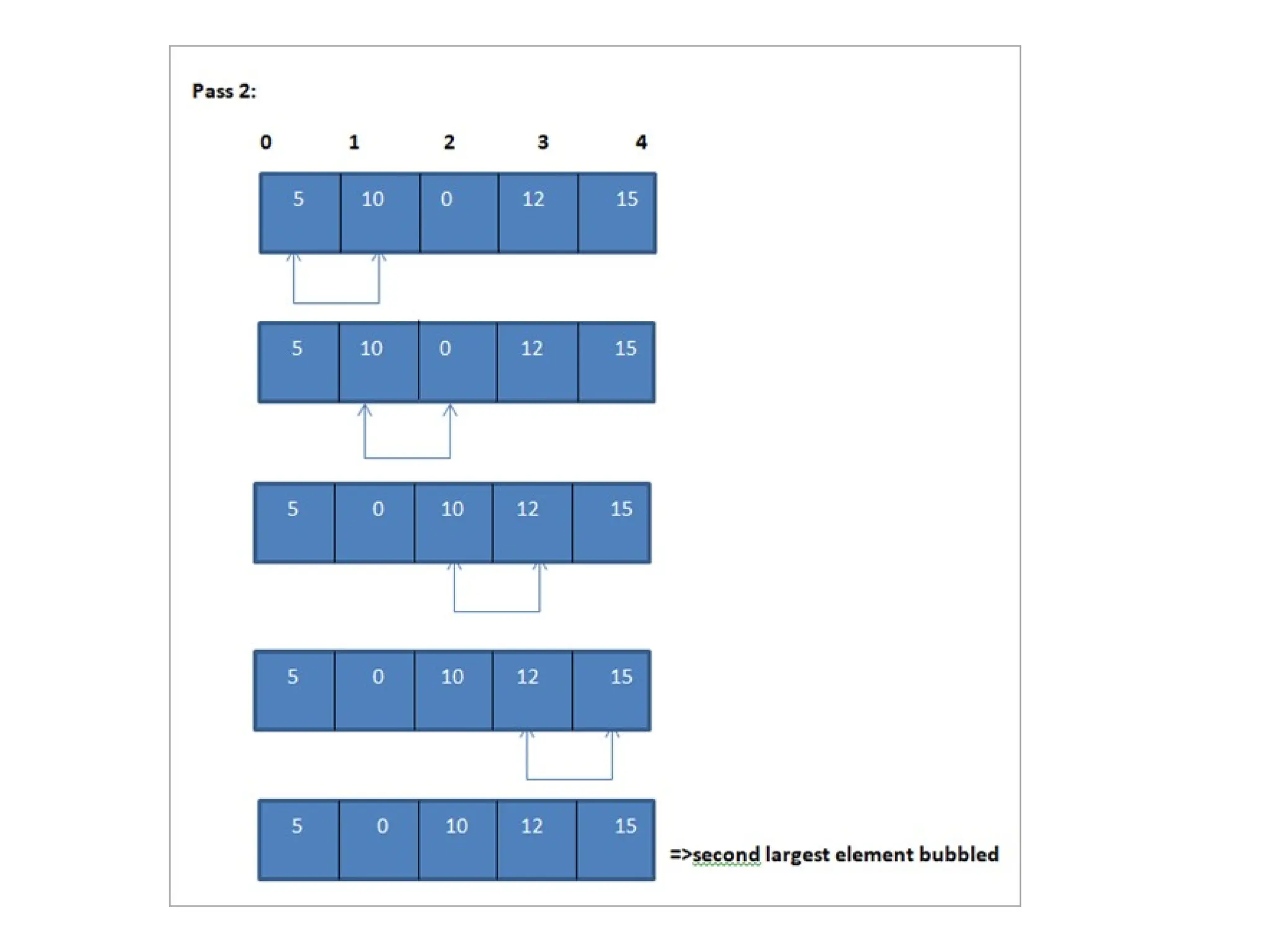
Bubble Sort
Bubble Sortis the simplest of the sorting techniques.
In the bubble sort technique, each of the elements in
the list is compared to its adjacent element.
Thus if there are n elements in list A, then A[0] is
compared to A[1], A[1] is compared to A[2] and so
on.
After comparing if the first element is greater than the
second, the two elements are swapped then.
62.
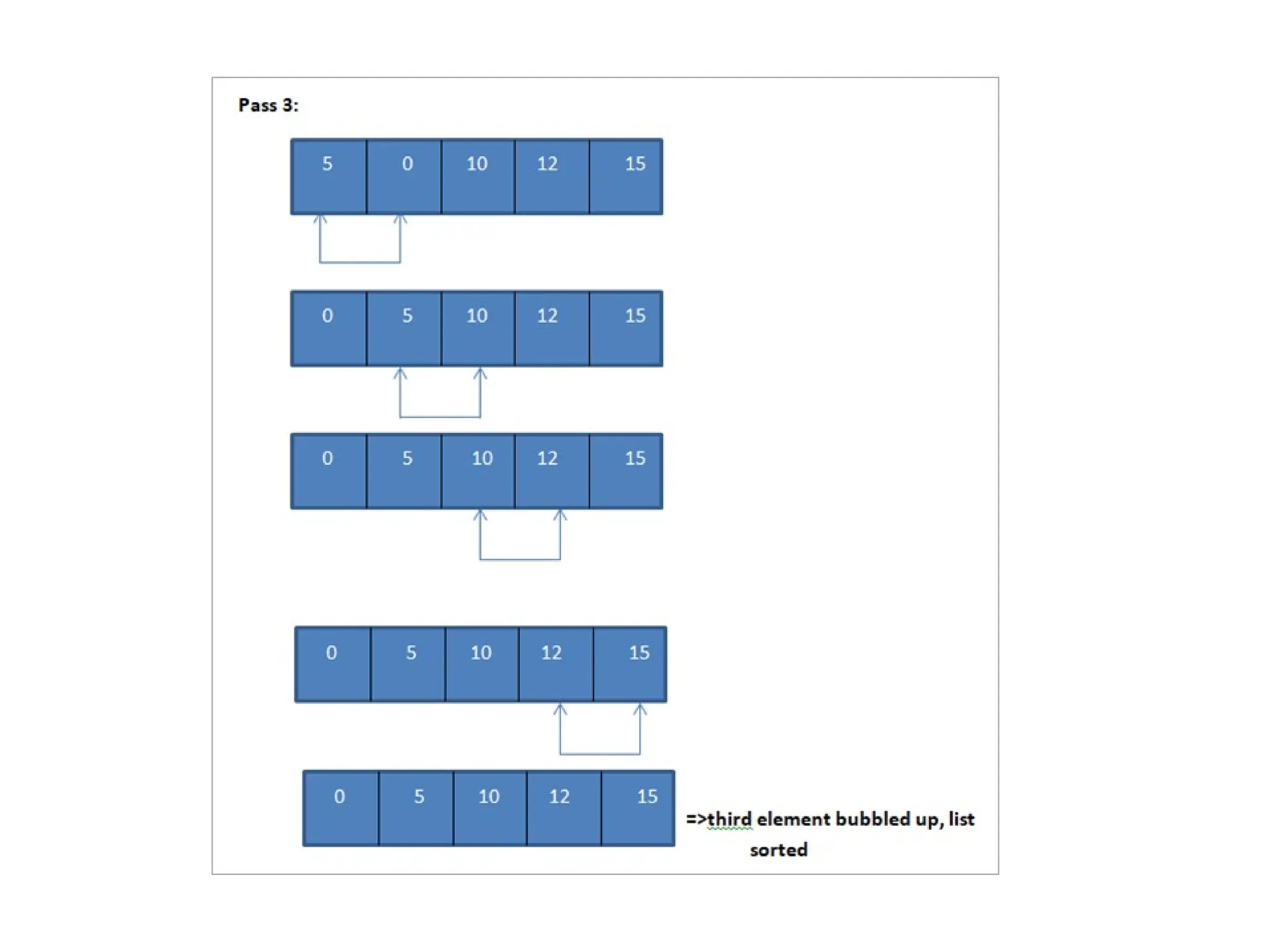
We take anarray of size 5 and illustrate the bubble sort algorithm.
65.
void bubble(int a[],int n) // function to implement bubble sort
{
int i, j, temp;
for(i = 0; i < n; i++)
{
for(j = i+1; j < n; j++)
{
if(a[j] < a[i])
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
}


























![C++ Program to represent Linear Search
int linear(int ar[],int size,int item)
{
int i; for(i=0;i<size;i++)
{
if(ar[i]==item)
return i;
}
return -1;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-29-320.jpg)
![Linear Search without function
#include<iostream>
using namespace std;
int main()
{
int ar[50],size,item,i,j;
cout<<"Enter number of elements=";
cin>>size;
cout<<"Enter Array's Elements=";
for(i=0;i<size;i++)
cin>>ar[i];
cout<<"Enter element which to be searched=";
cin>>item;
for(i=0;i<size;i++)
{
if(ar[i]==item)
{
j=1;
break;
} }
if(j==1)
cout<<"Element Found at="<<(i+1);
else
cout<<"Element not Found";
return 0;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-30-320.jpg)



![C++ Program to Represent Binary Search
int Binary(int ar[],int size,int item)
{
int low,high,mid;
low=0;
high=size-1;
while(low<=high)
{
mid=(low+high)/2;
if(item==ar[mid])
return mid;
else if(item<ar[mid])
high=mid-1;
else low=mid+1;
}
return -1;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-34-320.jpg)




![5
Insertion Sort:
•Insertion Sort Works by tasking element from
the list one by one and inserting them in their
current position into a new sorted list.
•Insertion sort consists of N-1 Passes Where N is
the number of element to be sorted .
•The ith Pass of insertion sort will insert the ith
•Element A*1+ , A*2+ ,….A*i-1] .After Doing this
Insertion the Record occupying A*1+,….A*i+ are
in sorted order.](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-39-320.jpg)
![Insertion and Routine:
void insertion sort (element type a[], int N )
{
int j, p ;
element type tmp ; for(p=1; p<N ; p++)
{
tmp =a[p];
for (j=p ; j>0&& a[j-1]>tmp ;j--) a[j] =a[j-1];
a[j]=tmp ;
} }
6](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-40-320.jpg)





![23
Routine for Heap Sort :
#define left child [i] (2*(i)+1)
void perdown (element type A[] , int i , int N)
{
int child ;
element type tmp ;
for(tmp =A[i] , left child (i)<N , i=child)
{
child =left child (i);
if (child!=N-1&&A[child +]>A[child]) child ++ ;](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-51-320.jpg)
![24
if (tmp<A[child]) A[i]=A[child]);
else Break ;
}
A[i] =tmp;
}
void heap sort(element type a[],int N)
{
int I; for(i=N/2;i>=0 ; i--)](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-52-320.jpg)
![25
perdown (A ,i , N);
for(i=N-1; i>0; i--)
{
swap (&A[0] ,&A[i]);
per down (A,o,i);
}
}
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-53-320.jpg)





![void selectionSort(int *array, int size)
{
int i, j, imin;
for(i = 0; i<size-1; i++)
{
imin = i; //get index of minimum data
for(j = i+1; j<size; j++)
if(array[j] < array[imin])
imin = j; //placing in correct position
swap(array[i], array[imin]);
}
}
void swap(int &a, int &b)
{ //swap the content of a and b
int temp;
temp = a;
a = b;
b = temp;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-60-320.jpg)
![Bubble Sort
Bubble Sort is the simplest of the sorting techniques.
In the bubble sort technique, each of the elements in
the list is compared to its adjacent element.
Thus if there are n elements in list A, then A[0] is
compared to A[1], A[1] is compared to A[2] and so
on.
After comparing if the first element is greater than the
second, the two elements are swapped then.](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-61-320.jpg)

![void bubble(int a[], int n) // function to implement bubble sort
{
int i, j, temp;
for(i = 0; i < n; i++)
{
for(j = i+1; j < n; j++)
{
if(a[j] < a[i])
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/85/Hashing-in-Data-structures-and-Algorithms-65-320.jpg)
























![C++ Program to represent Linear Search
int linear(int ar[],int size,int item)
{
int i; for(i=0;i<size;i++)
{
if(ar[i]==item)
return i;
}
return -1;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-29-2048.jpg)
![Linear Search without function
#include<iostream>
using namespace std;
int main()
{
int ar[50],size,item,i,j;
cout<<"Enter number of elements=";
cin>>size;
cout<<"Enter Array's Elements=";
for(i=0;i<size;i++)
cin>>ar[i];
cout<<"Enter element which to be searched=";
cin>>item;
for(i=0;i<size;i++)
{
if(ar[i]==item)
{
j=1;
break;
} }
if(j==1)
cout<<"Element Found at="<<(i+1);
else
cout<<"Element not Found";
return 0;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-30-2048.jpg)



![C++ Program to Represent Binary Search
int Binary(int ar[],int size,int item)
{
int low,high,mid;
low=0;
high=size-1;
while(low<=high)
{
mid=(low+high)/2;
if(item==ar[mid])
return mid;
else if(item<ar[mid])
high=mid-1;
else low=mid+1;
}
return -1;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-34-2048.jpg)




![5
Insertion Sort:
•Insertion Sort Works by tasking element from
the list one by one and inserting them in their
current position into a new sorted list.
•Insertion sort consists of N-1 Passes Where N is
the number of element to be sorted .
•The ith Pass of insertion sort will insert the ith
•Element A*1+ , A*2+ ,….A*i-1] .After Doing this
Insertion the Record occupying A*1+,….A*i+ are
in sorted order.](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-39-2048.jpg)
![Insertion and Routine:
void insertion sort (element type a[], int N )
{
int j, p ;
element type tmp ; for(p=1; p<N ; p++)
{
tmp =a[p];
for (j=p ; j>0&& a[j-1]>tmp ;j--) a[j] =a[j-1];
a[j]=tmp ;
} }
6](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-40-2048.jpg)





![23
Routine for Heap Sort :
#define left child [i] (2*(i)+1)
void perdown (element type A[] , int i , int N)
{
int child ;
element type tmp ;
for(tmp =A[i] , left child (i)<N , i=child)
{
child =left child (i);
if (child!=N-1&&A[child +]>A[child]) child ++ ;](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-51-2048.jpg)
![24
if (tmp<A[child]) A[i]=A[child]);
else Break ;
}
A[i] =tmp;
}
void heap sort(element type a[],int N)
{
int I; for(i=N/2;i>=0 ; i--)](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-52-2048.jpg)
![25
perdown (A ,i , N);
for(i=N-1; i>0; i--)
{
swap (&A[0] ,&A[i]);
per down (A,o,i);
}
}
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-53-2048.jpg)






![void selectionSort(int *array, int size)
{
int i, j, imin;
for(i = 0; i<size-1; i++)
{
imin = i; //get index of minimum data
for(j = i+1; j<size; j++)
if(array[j] < array[imin])
imin = j; //placing in correct position
swap(array[i], array[imin]);
}
}
void swap(int &a, int &b)
{ //swap the content of a and b
int temp;
temp = a;
a = b;
b = temp;
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-60-2048.jpg)
![Bubble Sort
Bubble Sort is the simplest of the sorting techniques.
In the bubble sort technique, each of the elements in
the list is compared to its adjacent element.
Thus if there are n elements in list A, then A[0] is
compared to A[1], A[1] is compared to A[2] and so
on.
After comparing if the first element is greater than the
second, the two elements are swapped then.](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-61-2048.jpg)

![void bubble(int a[], int n) // function to implement bubble sort
{
int i, j, temp;
for(i = 0; i < n; i++)
{
for(j = i+1; j < n; j++)
{
if(a[j] < a[i])
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
}](https://image.slidesharecdn.com/unit4-250831171923-24097b25/75/Hashing-in-Data-structures-and-Algorithms-65-2048.jpg)





























































