Downloaded 18 times







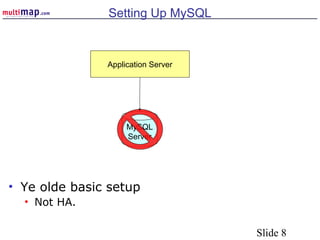
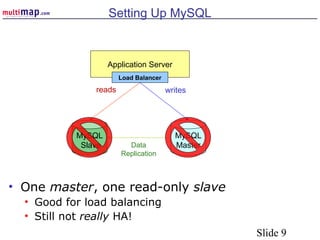
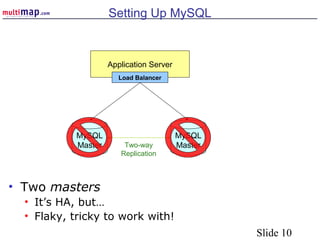


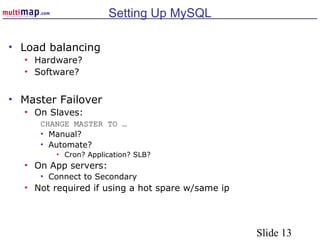




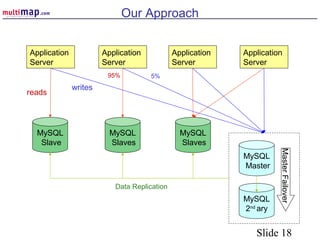
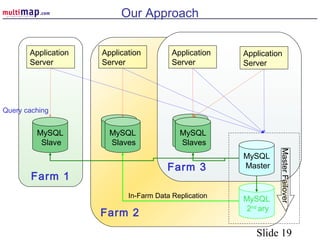

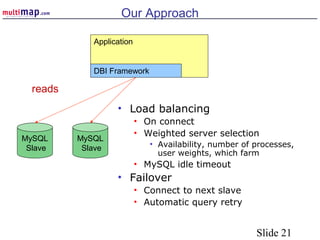
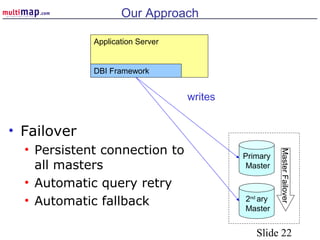























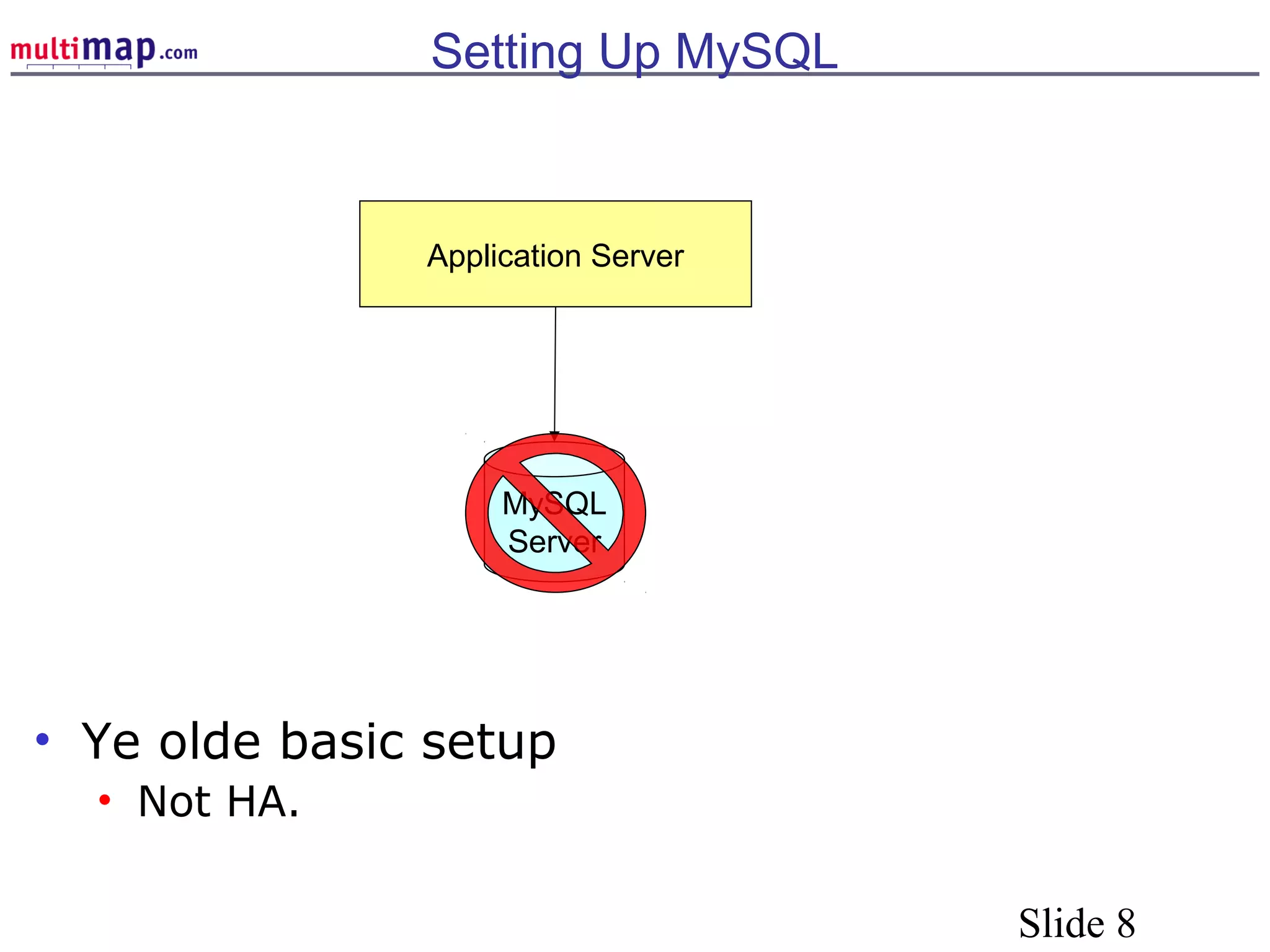
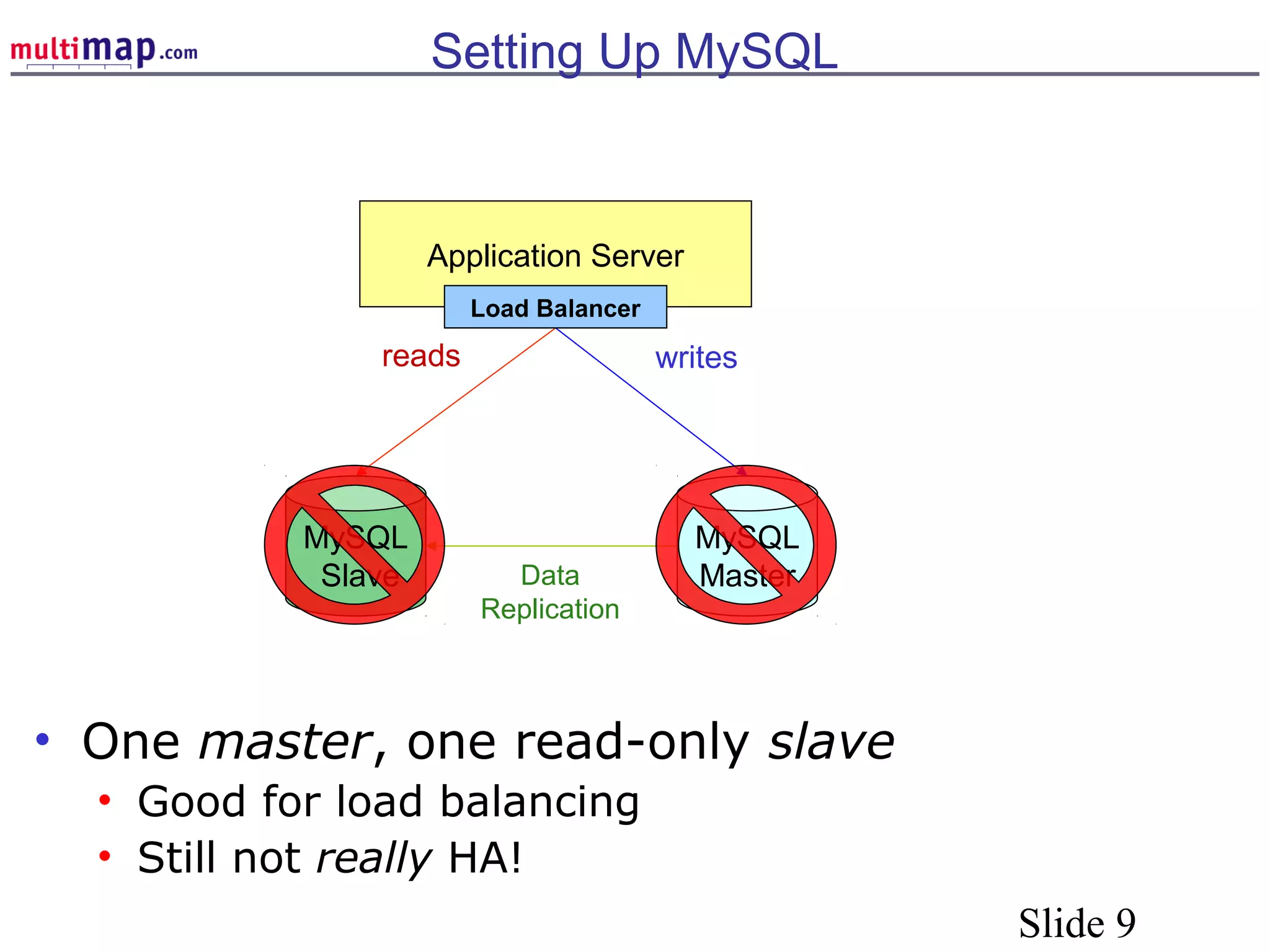
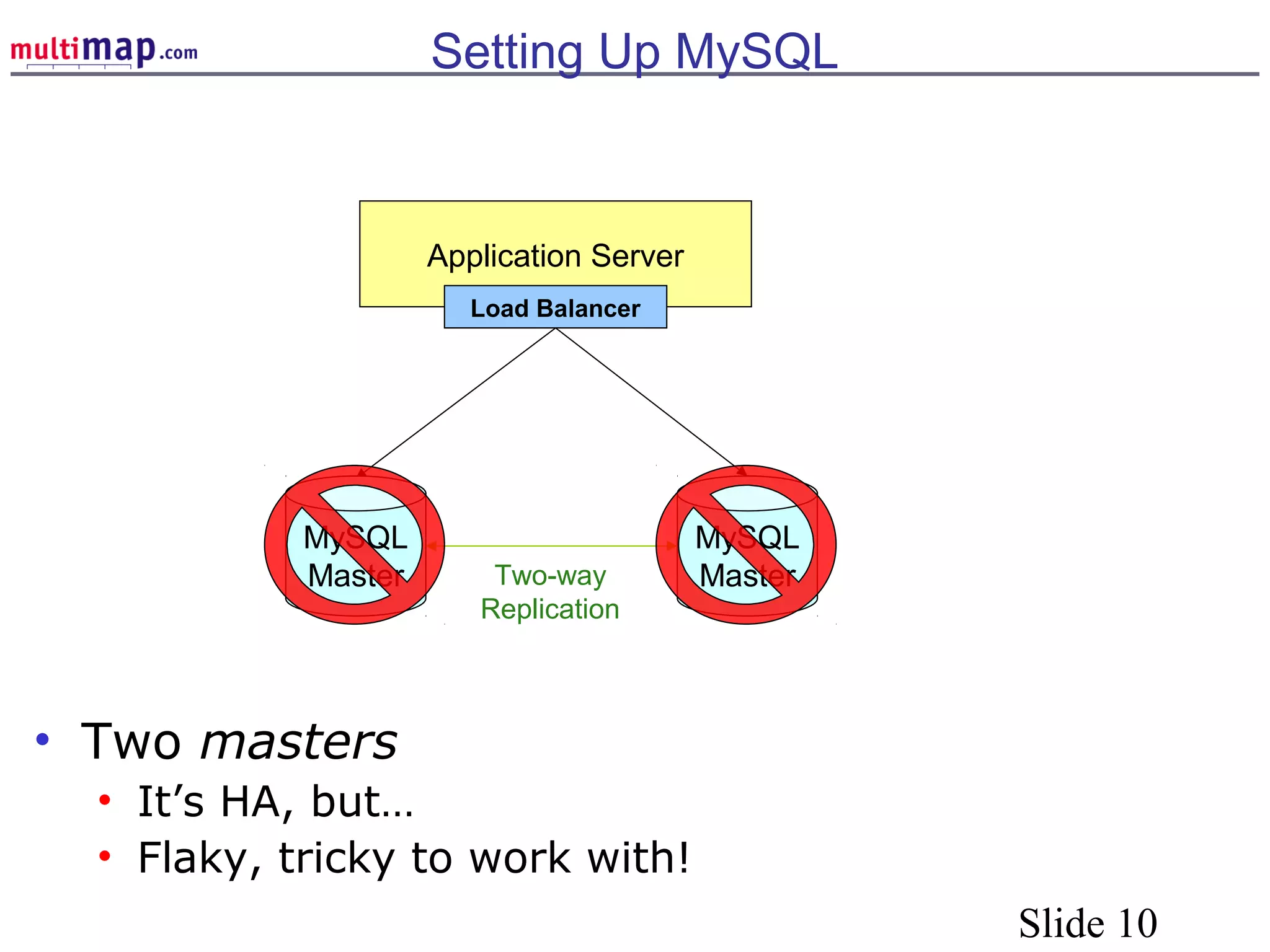


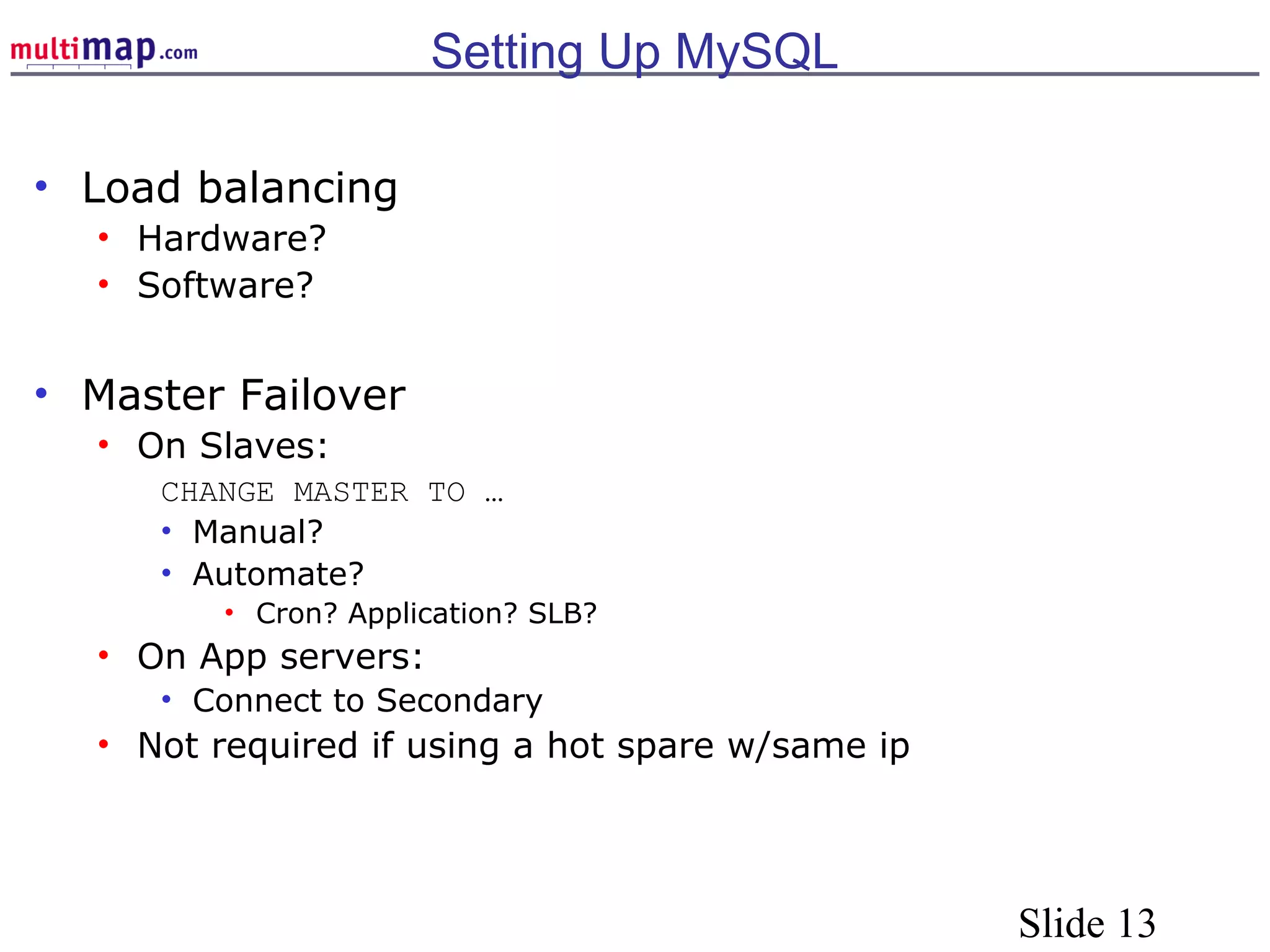




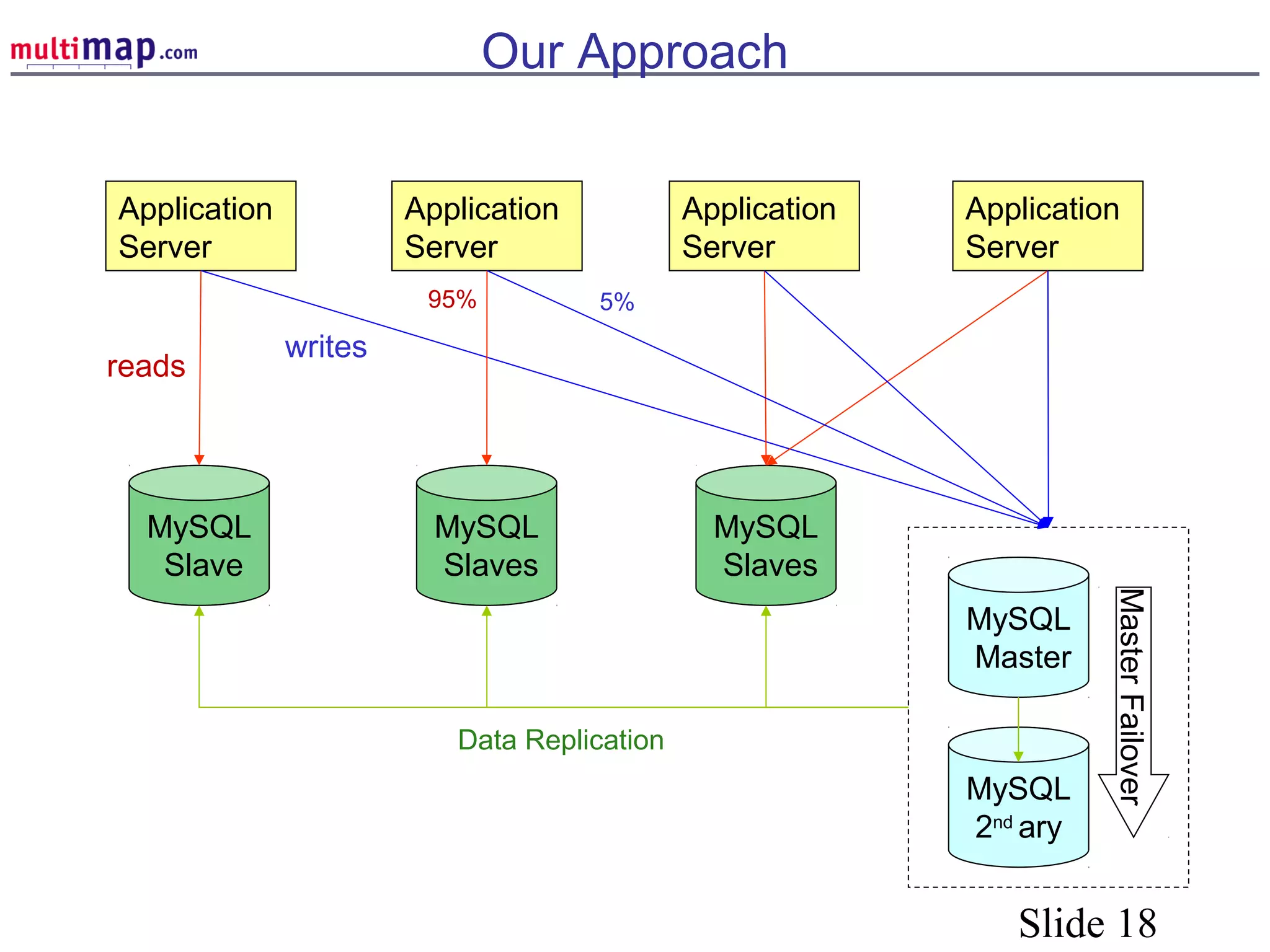
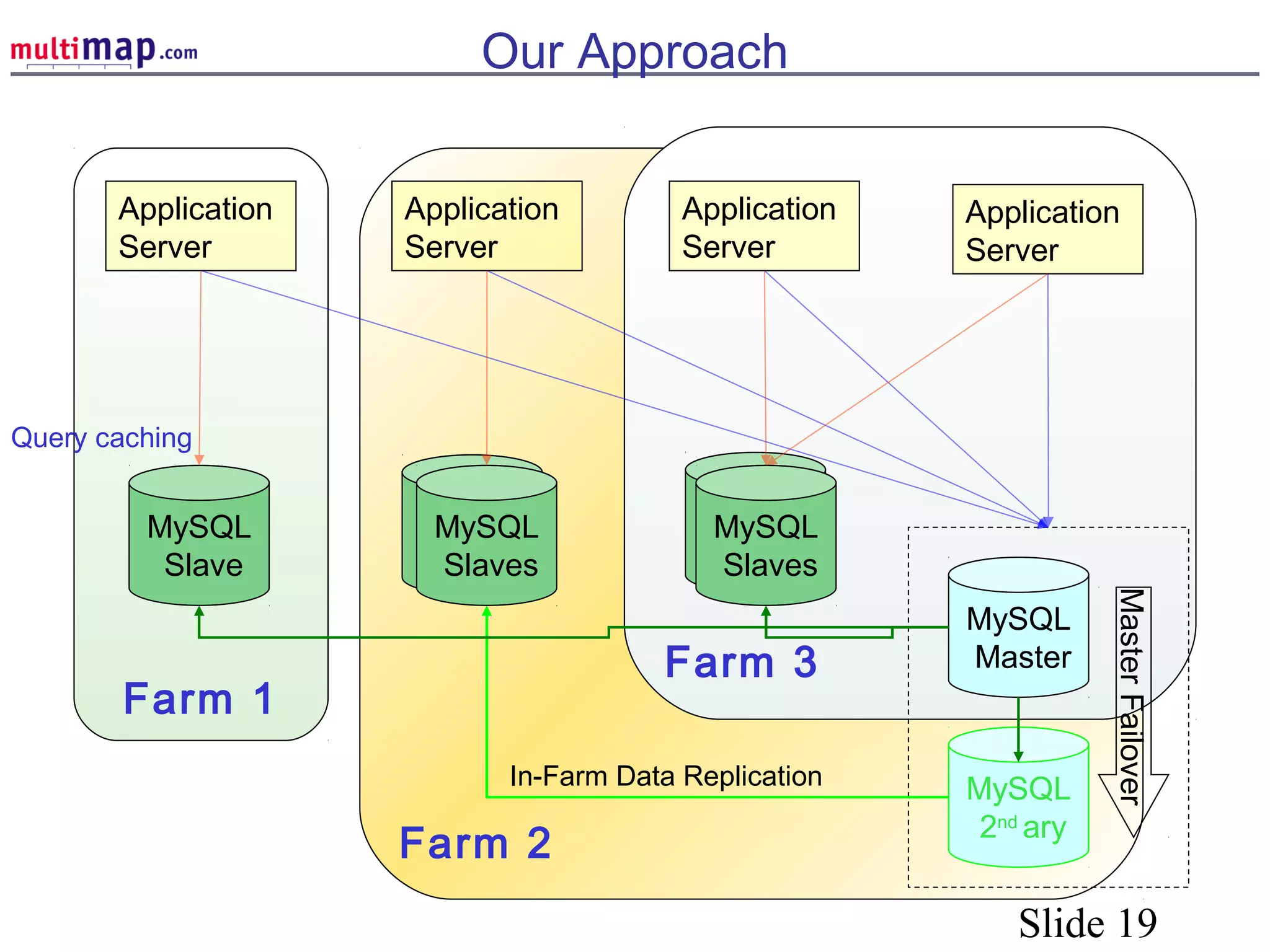

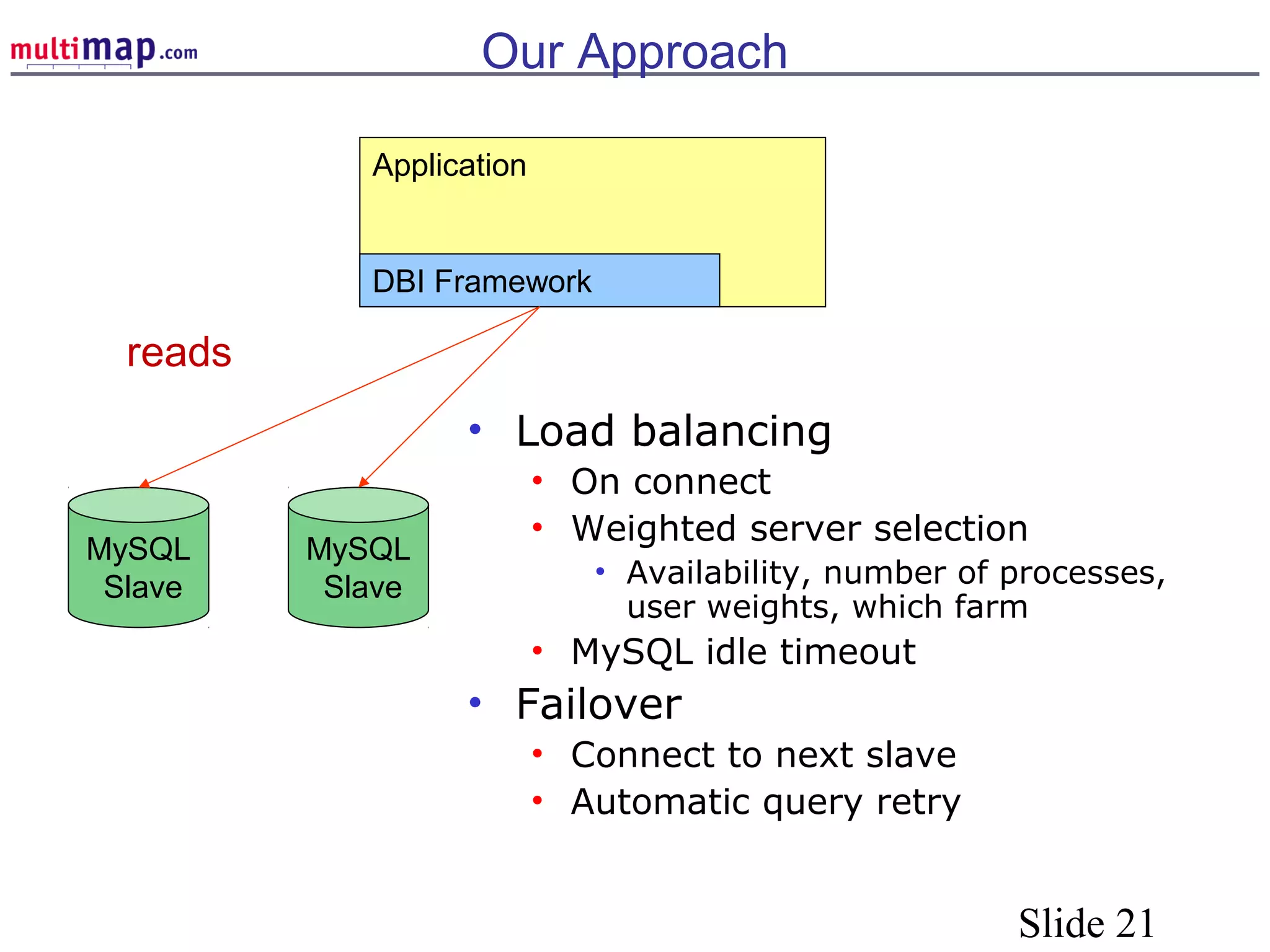


















The document discusses high availability (HA) solutions for MySQL, focusing on minimizing downtime for critical applications through strategies like redundancy, data replication, and load balancing. It presents various architectures for setting up MySQL, including setups with multiple masters and slaves, and highlights the importance of analyzing application needs when designing HA systems. The talk also introduces a DBI framework for managing connections, failover, and load balancing, while suggesting upcoming technologies and frameworks for better HA implementation.



![Java script nirvana in netbeans [con5679]](https://cdn.slidesharecdn.com/ss_thumbnails/javascriptnirvanainnetbeanscon5679-160927041807-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



























































































