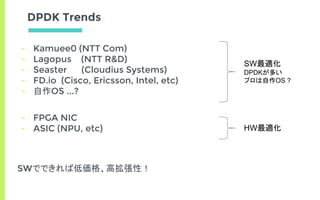
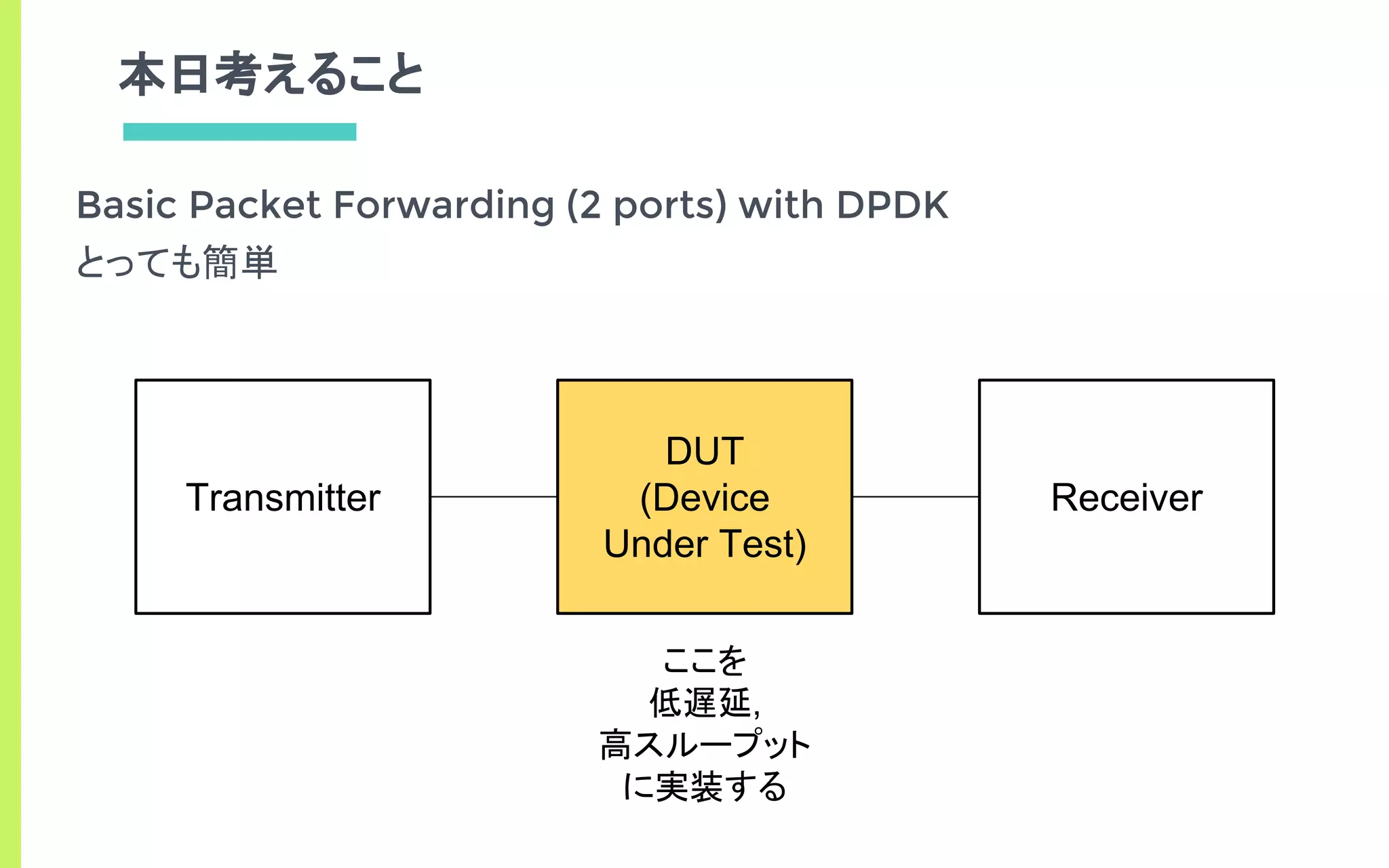
What is DPDK…?
Hardware
User Land
Kernel Land
APP
低
速
Hardware
User Land
Kernel Land
APP
DPDK
超
高
速
DPDKを使用 Linuxを使用カーネル経由で遅い
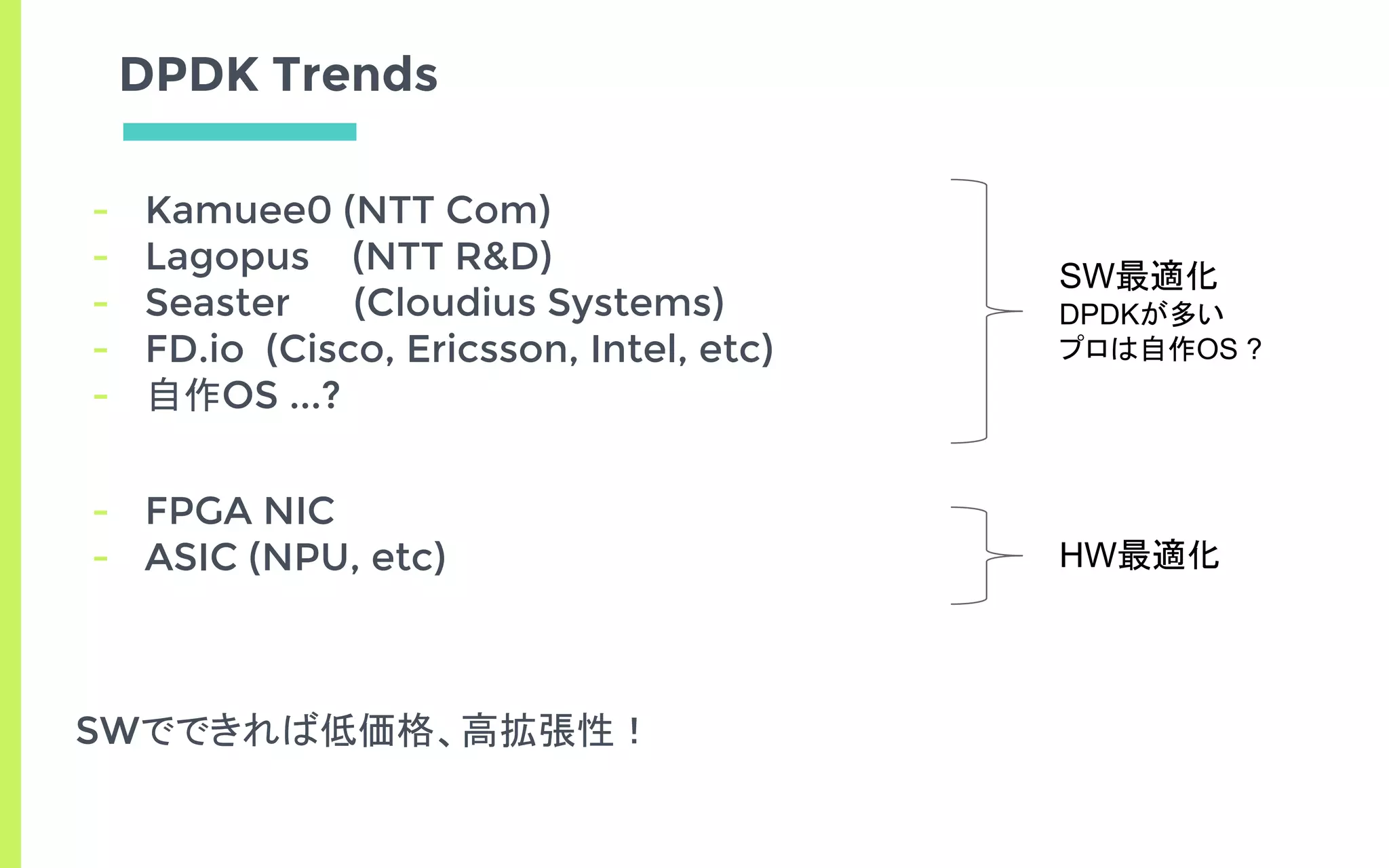
(Intel) DataPlane Developing Kit
▣ SWによる高速NW処理を実現するライブラリ
▣ ユーザランドからカーネルをバイパスして高速に動作
▣ Openflowスイッチとかソフトルータとか
9.
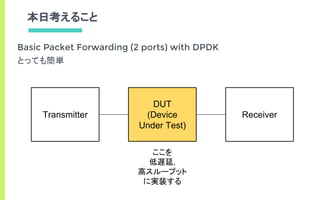
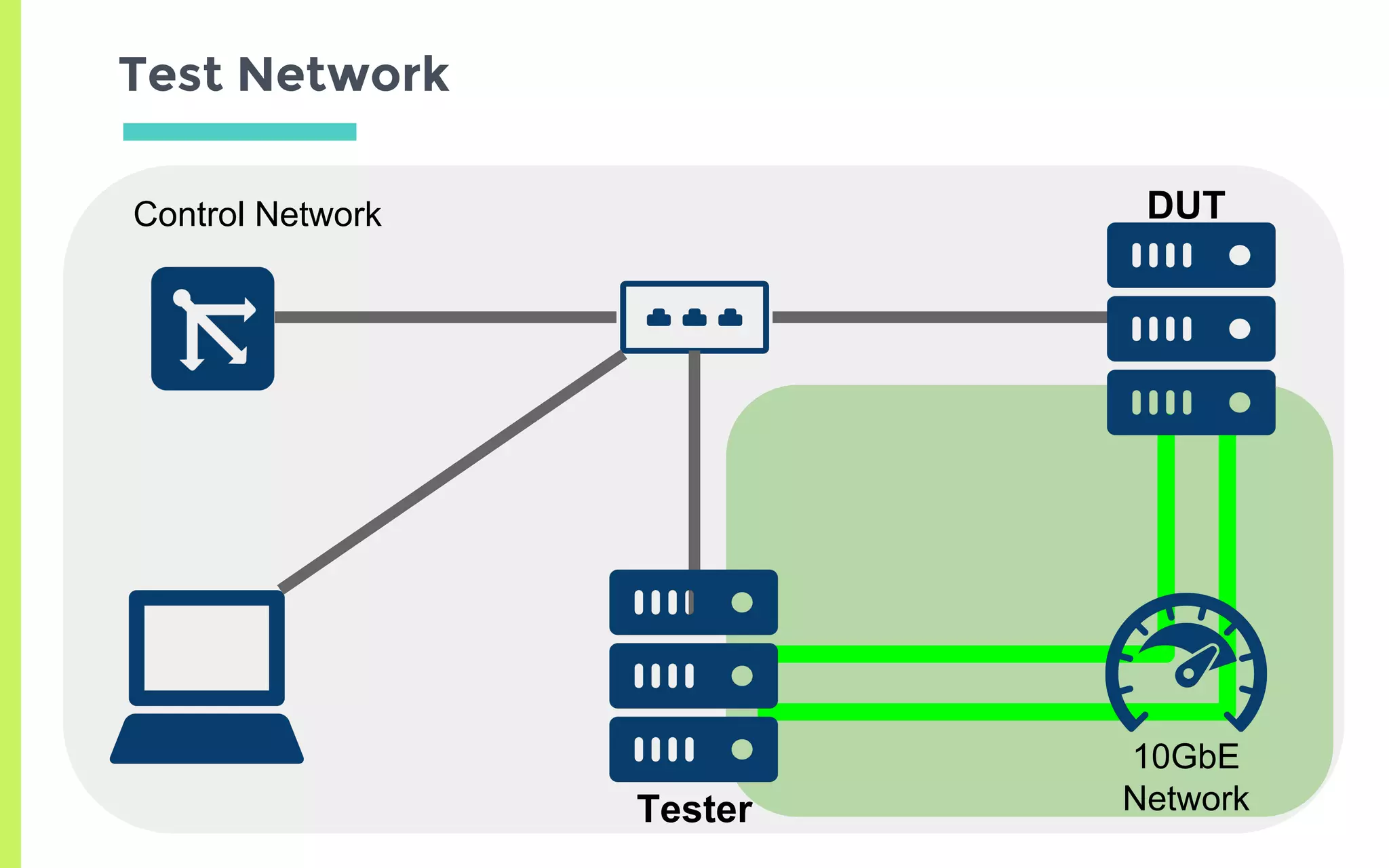
What is DPDK…?
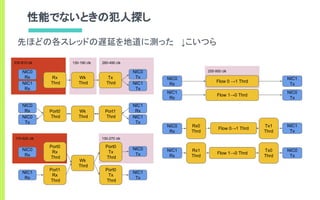
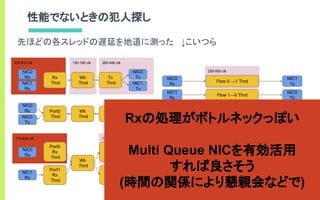
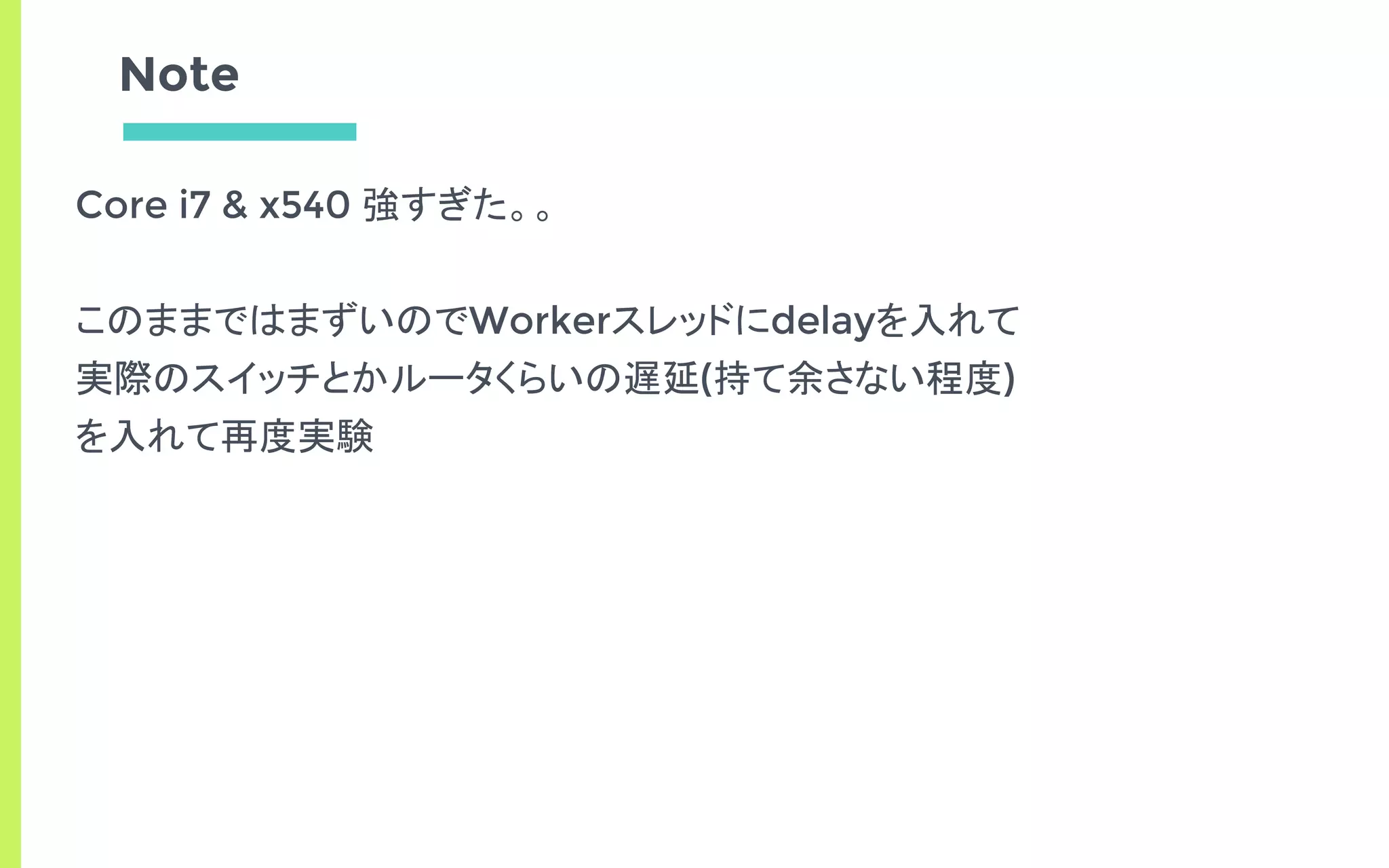
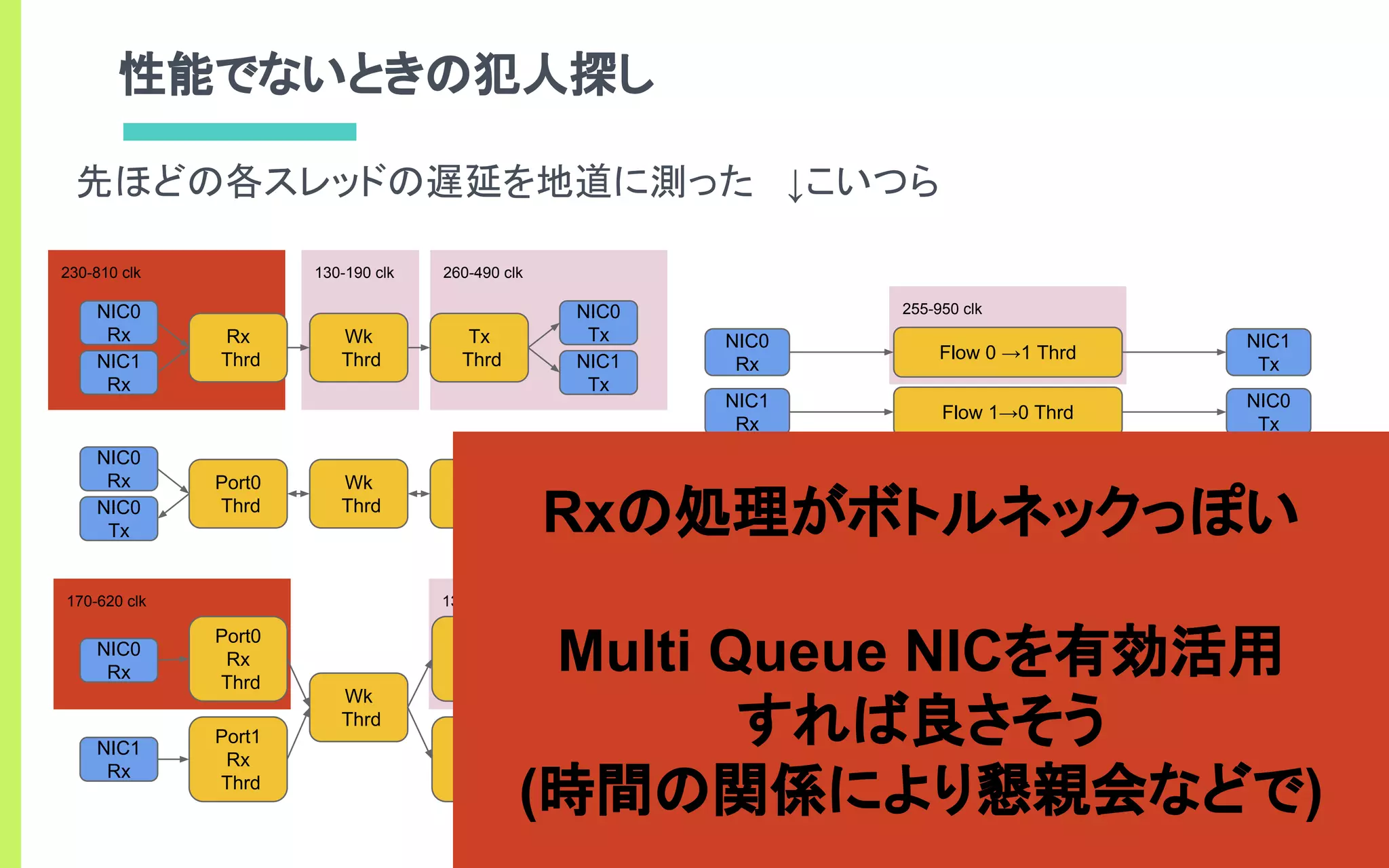
- CPU100%のbusy-loopでポートを監視して
低遅延にパケットIOを行う
- ユーザランドからデバイスを直接制御
- 詳しくはdpdk.orgを見ましょう










![DPDK Usecase [ex]: Lagopus (Openflow Switch)
引
用:http://www.slideshare.net/jstleger/dpdk-summit-08-sept-
2014-ntt-high-performance-vswitch](https://image.slidesharecdn.com/edomaesec-open-170122085307/85/High-Performance-Networking-with-DPDK-Multi-Many-Core-13-320.jpg)




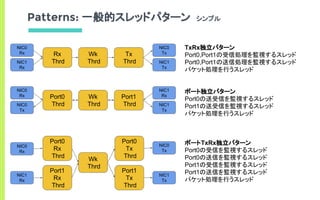
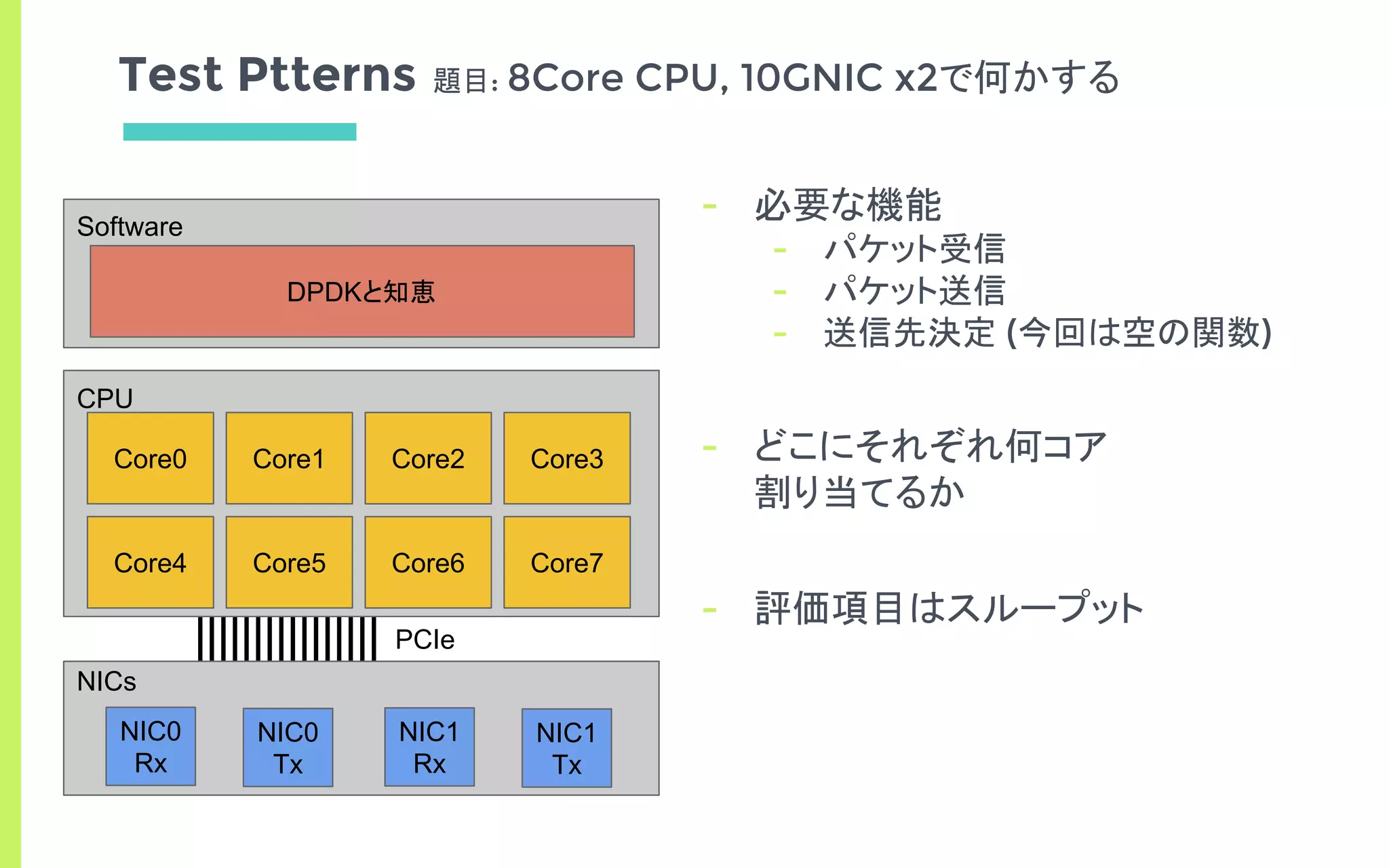
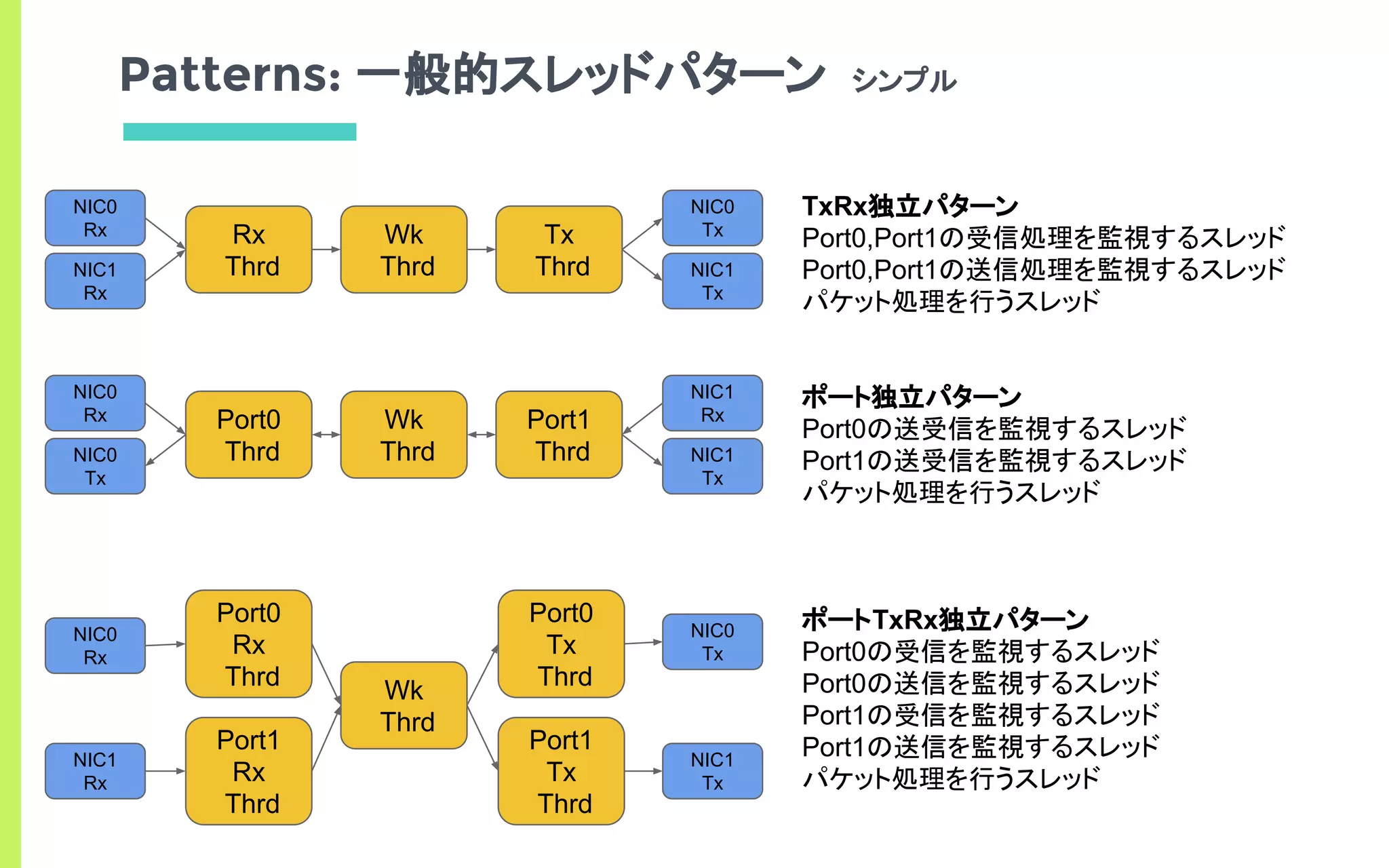
![TxRx独立パターン
ポート独立パターン
ポートTxRx独立パターン
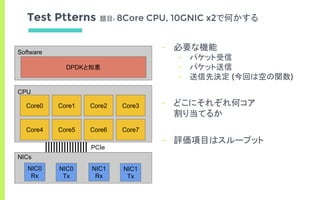
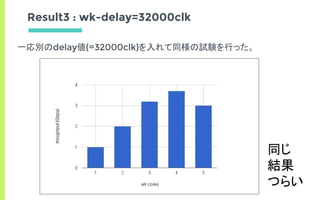
Result
Num Cores 4 5 6 7 8
Thoughput [bps] 8.4 8.4 8.4 8.4 8.4
Num Cores 4 5 6 7 8
Thoughput [bps] - - 8.4 8.4 8.4
Num Cores 4 5 6 7 8
Thoughput [bps] 8.4 8.4 8.4 8.4 8.4
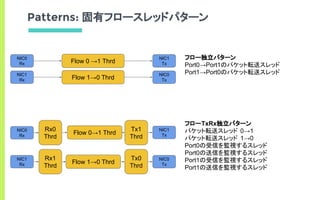
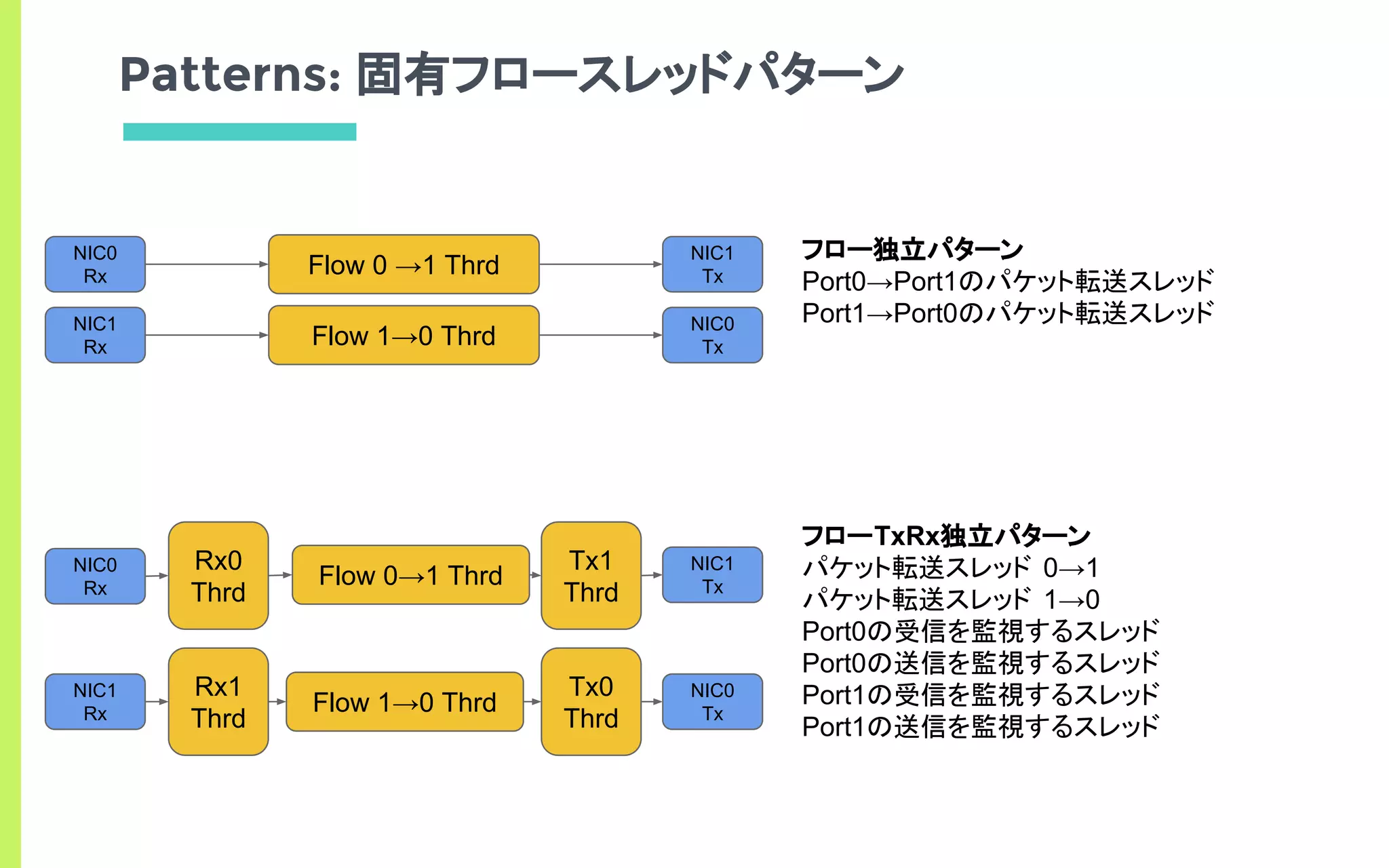
フロー独立パターン
フローTxRx独立パターン
※ pkt size = 64byte
Wirerate ≒ 8.4Gbps
Num cores 3~
Thoughput [bps] 8.4
Num cores 7~
Thoughput [bps] 8.4
どのパターンでもwirerate](https://image.slidesharecdn.com/edomaesec-open-170122085307/85/High-Performance-Networking-with-DPDK-Multi-Many-Core-23-320.jpg)
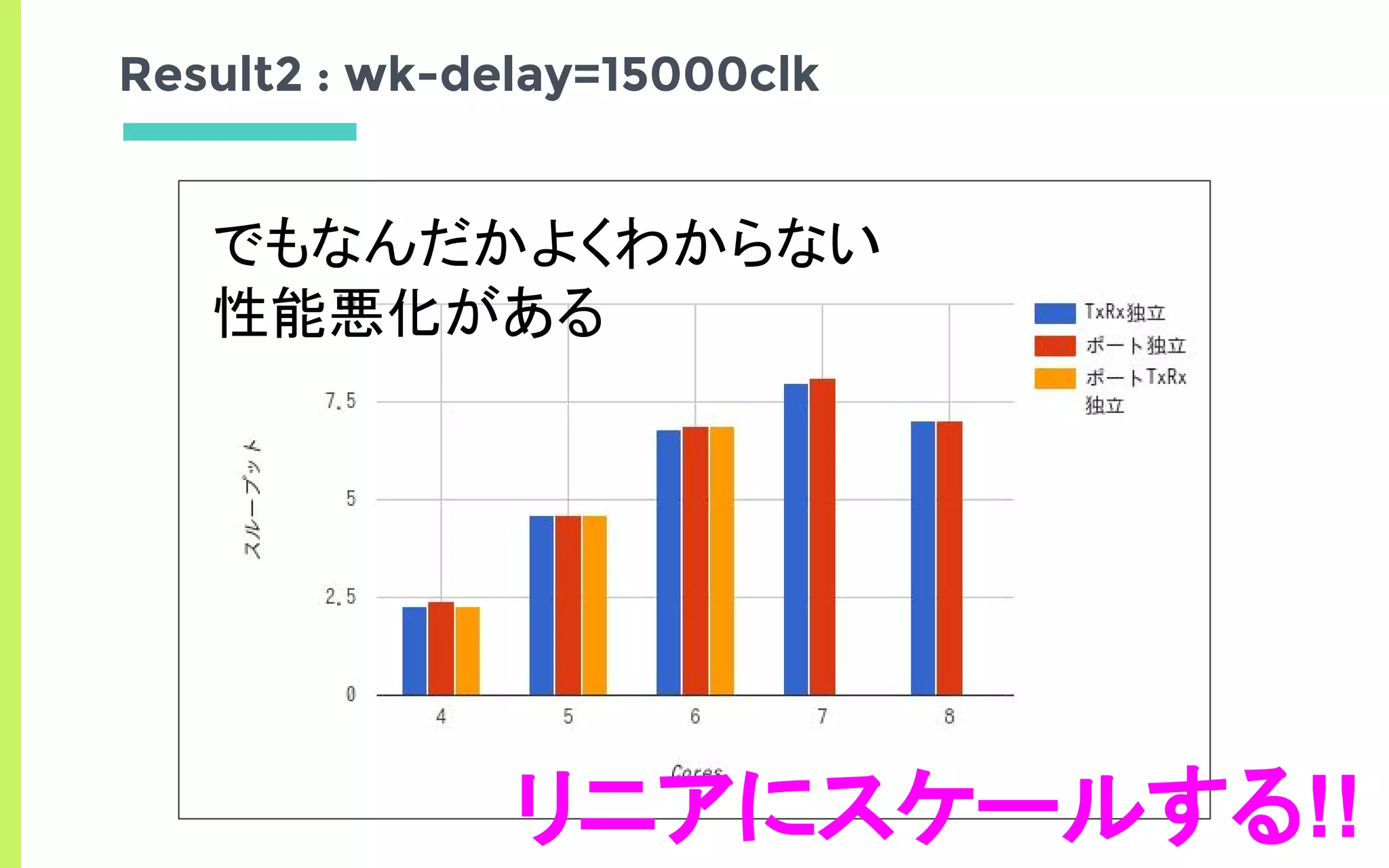
![TxRx独立パターン
ポート独立パターン
ポートTxRx独立パターン
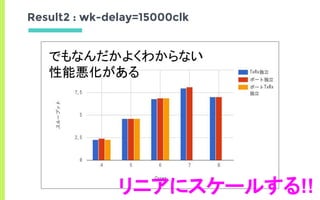
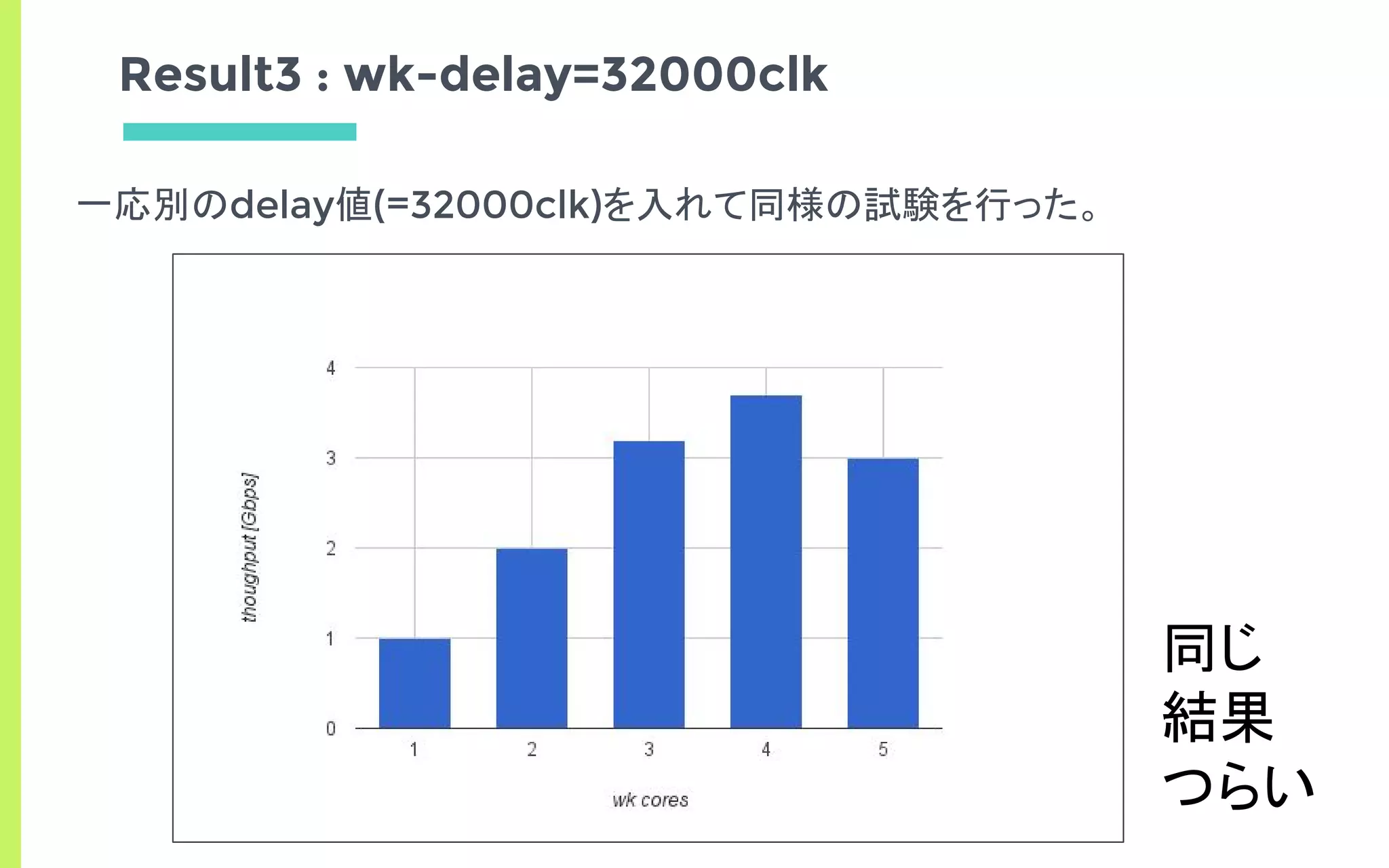
Result2 : wk-delay=15000clk
Num Cores 4 5 6 7 8
Thoughput [bps] 2.3 4.6 6.8 8 7
Num Cores 4 5 6 7 8
Thoughput [bps] - - 2.3 4.6 6.9
Num Cores 4 5 6 7 8
Thoughput [bps] 2.4 4.6 6.9 8.1 7](https://image.slidesharecdn.com/edomaesec-open-170122085307/85/High-Performance-Networking-with-DPDK-Multi-Many-Core-25-320.jpg)
















![DPDK Usecase [ex]: Lagopus (Openflow Switch)
引
用:http://www.slideshare.net/jstleger/dpdk-summit-08-sept-
2014-ntt-high-performance-vswitch](https://image.slidesharecdn.com/edomaesec-open-170122085307/75/High-Performance-Networking-with-DPDK-Multi-Many-Core-13-2048.jpg)




![TxRx独立パターン
ポート独立パターン
ポートTxRx独立パターン
Result
Num Cores 4 5 6 7 8
Thoughput [bps] 8.4 8.4 8.4 8.4 8.4
Num Cores 4 5 6 7 8
Thoughput [bps] - - 8.4 8.4 8.4
Num Cores 4 5 6 7 8
Thoughput [bps] 8.4 8.4 8.4 8.4 8.4
フロー独立パターン
フローTxRx独立パターン
※ pkt size = 64byte
Wirerate ≒ 8.4Gbps
Num cores 3~
Thoughput [bps] 8.4
Num cores 7~
Thoughput [bps] 8.4
どのパターンでもwirerate](https://image.slidesharecdn.com/edomaesec-open-170122085307/75/High-Performance-Networking-with-DPDK-Multi-Many-Core-23-2048.jpg)
![TxRx独立パターン
ポート独立パターン
ポートTxRx独立パターン
Result2 : wk-delay=15000clk
Num Cores 4 5 6 7 8
Thoughput [bps] 2.3 4.6 6.8 8 7
Num Cores 4 5 6 7 8
Thoughput [bps] - - 2.3 4.6 6.9
Num Cores 4 5 6 7 8
Thoughput [bps] 2.4 4.6 6.9 8.1 7](https://image.slidesharecdn.com/edomaesec-open-170122085307/75/High-Performance-Networking-with-DPDK-Multi-Many-Core-25-2048.jpg)





















































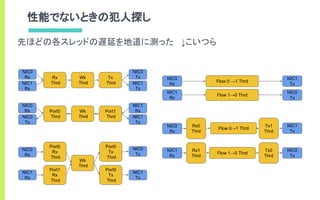
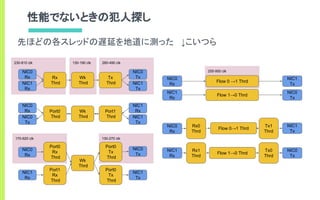
![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=600ounds&width=560&fit=bounds)















