Hyperparameters Parameters
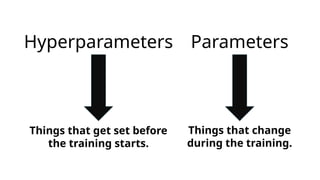
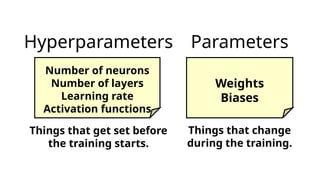
Things thatget set before
the training starts.
Things that change
during the training.
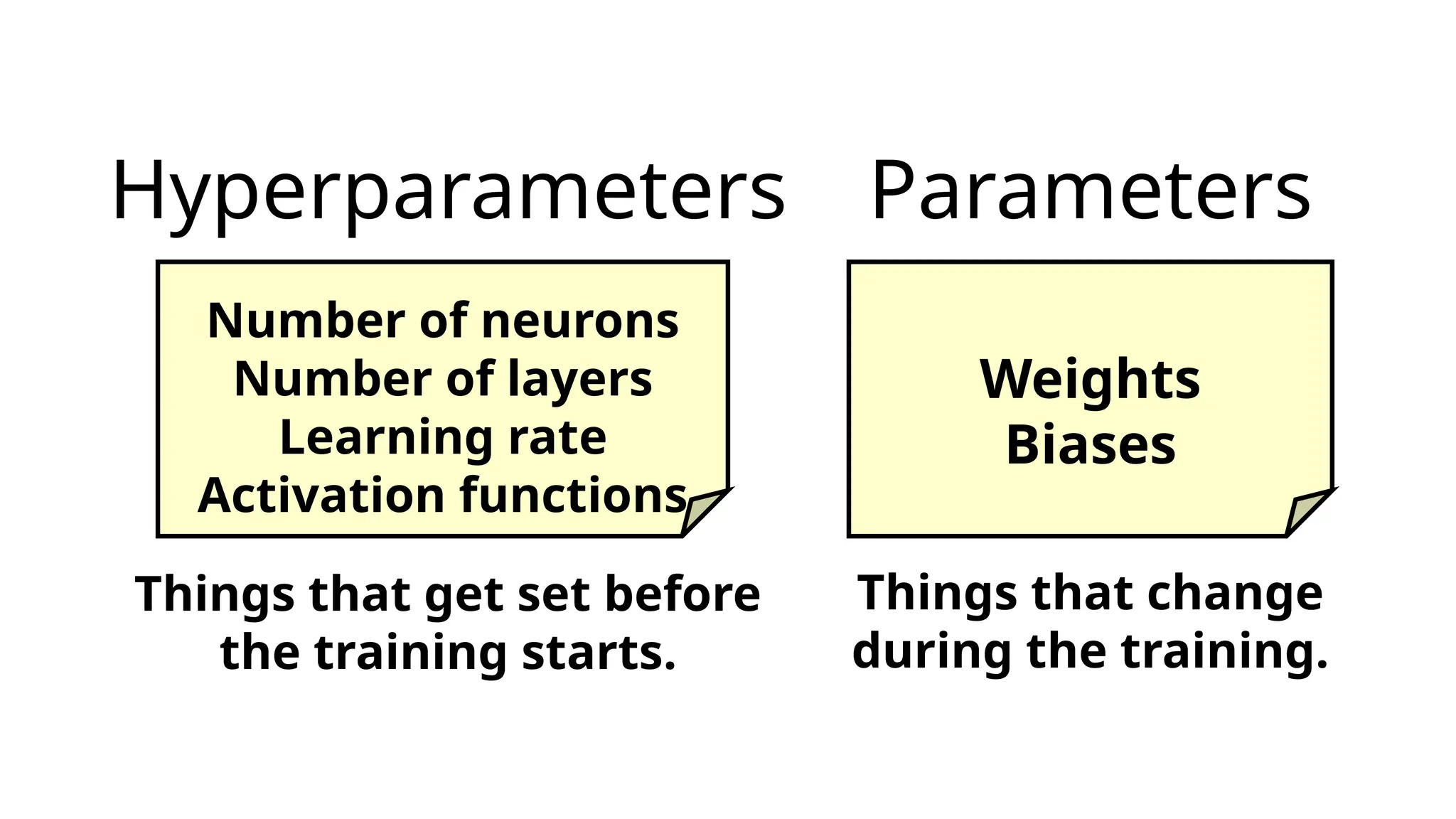
Number of neurons
Number of layers
Learning rate
Activation functions
Weights
Biases
10.
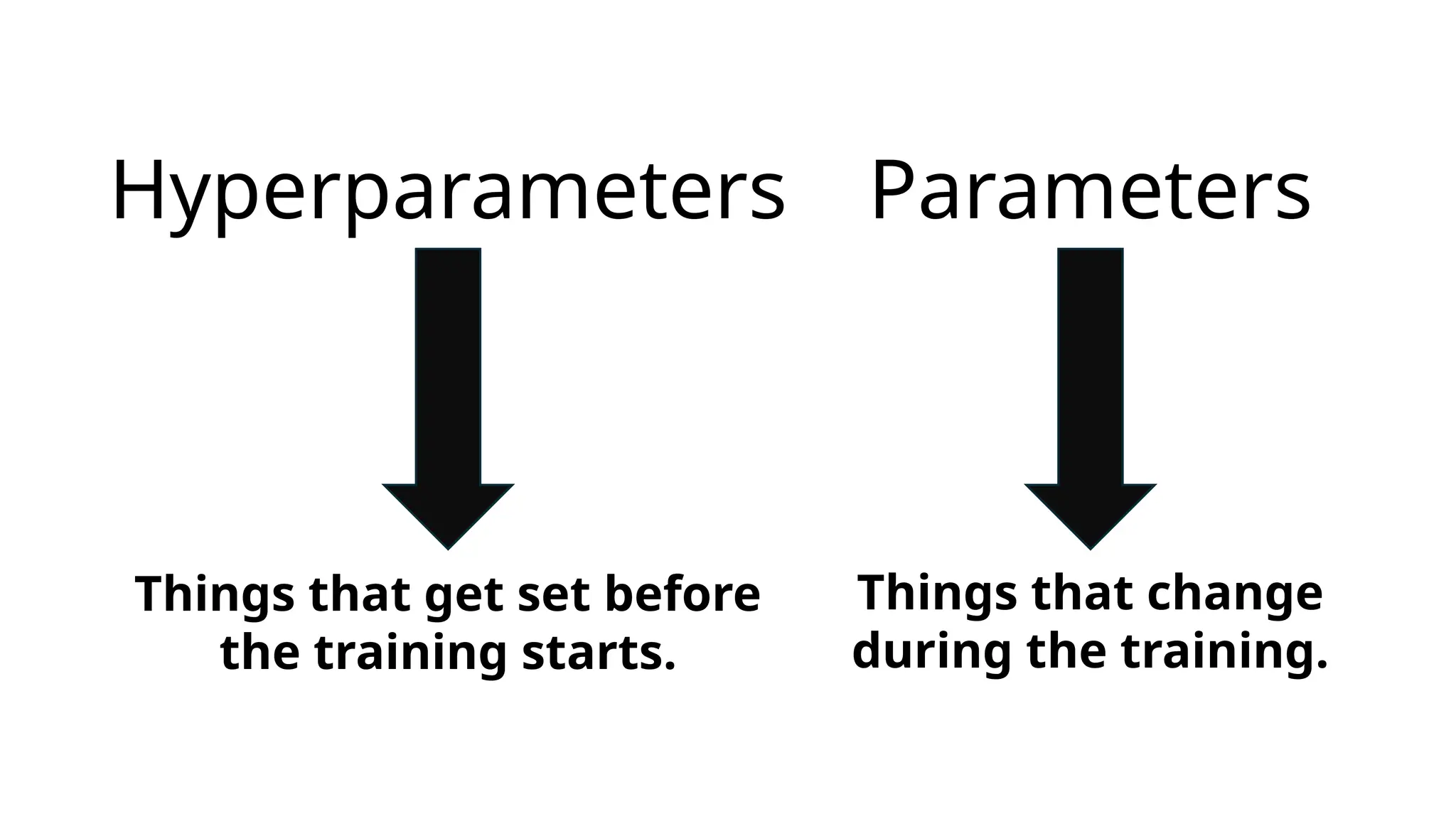
Hyperparameters vs. Parameters
•Hyperparameters:Manually set;
control how the model learns
•Parameters: Weights and biases
learned during training
•Crucial for convergence, performance,
and generalization
11.
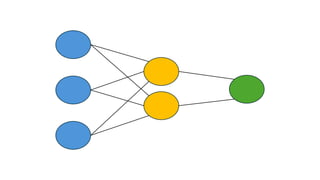
What Are Hyperparameters?
•Hyperparametersare the settings
chosen before training of a neural
network begins learning.
•So, they are not learned by the model
during training (like Weights and Biases)
•They help control the learning process
and model structure
Hyperparameters: Examples
•And othersinclude:
•Batch size - we can process the training
examples in batches.
•Dropout rate - the fraction of neurons to
randomly deactivate during each training
step to prevent overfitting.
•Optimizer type – the rate at which the
weights get adjusted
15.
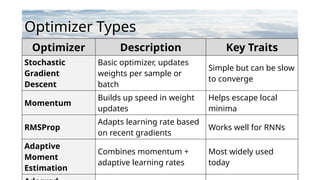
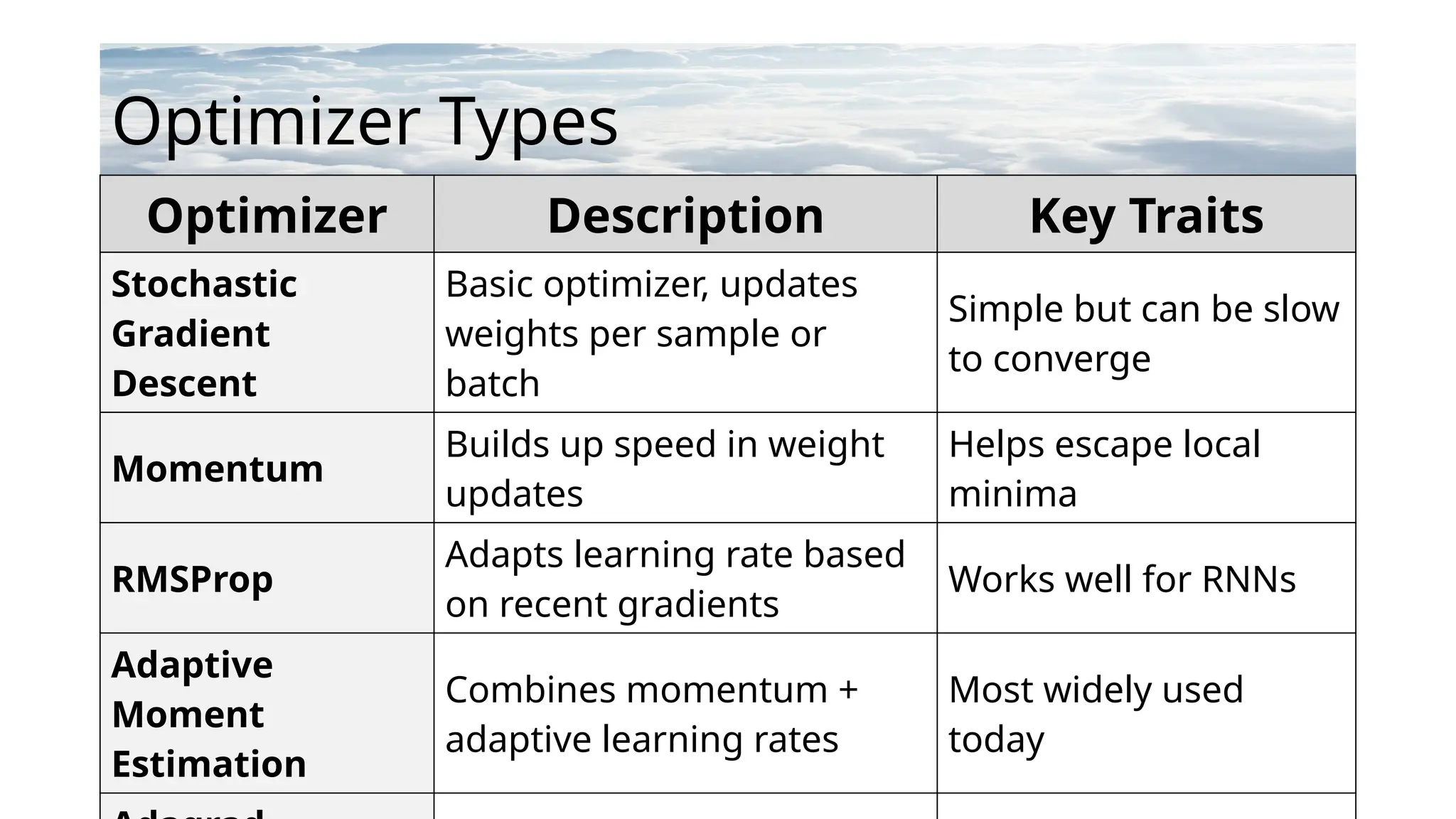
Optimizer Description KeyTraits
Stochastic
Gradient
Descent
Basic optimizer, updates
weights per sample or
batch
Simple but can be slow
to converge
Momentum
Builds up speed in weight
updates
Helps escape local
minima
RMSProp
Adapts learning rate based
on recent gradients
Works well for RNNs
Adaptive
Moment
Estimation
Combines momentum +
adaptive learning rates
Most widely used
today
Optimizer Types
16.
What Are Hyperparameters?
•Moreformally:
•A hyperparameter is a configuration that is set
before the training process begins and influences
how a neural network learns. Unlike parameters
(like weights and biases, which the model learns
automatically), hyperparameters are manually
defined by the user and are crucial in shaping
the training dynamics and model performance.
17.
Why Hyperparameter TuningMatters
•A good model can perform poorly with
bad hyperparameters
•Prevents overfitting or underfitting
•Improves accuracy, loss, convergence
time
•Essential in real-world deployments for
optimal results
Hyperparameter Tuning Methods
•ManualSearch: Trial and error, intuition-driven
•Grid Search: Try all combinations from a set of
values
•Random Search: Sample values randomly from
the search space
•Bayesian Optimization: Model the performance
function and update with new data
•Automated Tuning Tools (e.g., Optuna, Ray Tune)
Grid Search
•Try allcombinations from a set of
values
•Exhaustive, easy to parallelize
•Computationally expensive
22.
Random Search
• Samplevalues randomly from the
search space
• More efficient in high-dimensional
spaces
• Often finds good results faster
23.
Bayesian Optimization
•Model theperformance function and update
with new data
•Models the objective function (e.g., accuracy)
with a surrogate (e.g., Gaussian Process)
•Chooses next hyperparameter set based on
expected improvement
•More efficient but more complex
Other Techniques
•Hyperband /Successive Halving: Early
stopping of poor configurations
•Genetic Algorithms: Evolutionary search
•Neural Architecture Search (NAS):
Explore both architecture and
hyperparameters
Best Practices
•Start withcoarse tuning, then fine-tune
•Monitor validation loss/accuracy
•Use cross-validation
•Track experiments (e.g., with W&B or
MLflow)
•Set realistic compute and time budgets
28.
Summary & Takeaways
•Hyperparametersstrongly influence
model performance
•Tuning is a mix of science and art
•Tools and strategies exist to automate the
process
•Experimentation and tracking are key to
success