Parameters vs hyperparameters
•Parameters are the configuration model, which are internal to the model.
• These are the parameters in the model that must be determined using the training data set.
• The weights in an artificial neural network.
• The coefficients in a linear regression or logistic regress
• Hyperparameters are adjustable parameters that must be tuned in order to
obtain a model with optimal performance.
• These are the parameters in the model that must be determined using the validation
data set.
• The learning rate for training a neural network.
• Max_depth in decision tree.
• Parameters are essential for making predictions. Accuracy is important.
• Hyperparameters are essential for optimizing the model. Cost of running is
important.
2
3.
Hyperparameter tuning
• Hyperparametertuning is a process of selecting the optimal values
for hyperparameters of the machine learning model.
• It is an important step in the model development process, as the
choice of hyperparameters can have a significant impact on the
model's performance.
4.
Model Generalization
• Generalizationthe ability of the model to accurately predict outputs
from unseen data or real-time data.
• Overfitting occurs when the model learns too many specifics from the
training dataset and can't generalize for testing or validation
datasets.
• Underfitting occurs when the model doesn't learn from the data
enough and doesn't accurately understand the patterns from the
training data
5.
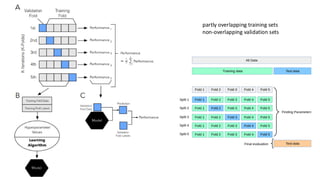
Cross-validation (CV)
• isa technique used in machine learning to assess the generalization
capability and performance of a machine learning model.
• This involves creating multiple subsets of datasets called folds and
iteratively performing training and evaluation of models on different
training and testing datasets each time.
▪ Holdout
▪ Cross-validation
▪ K-fold
▪ Leave-one-out
▪ Stratified k-fold
6.
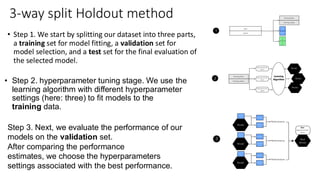
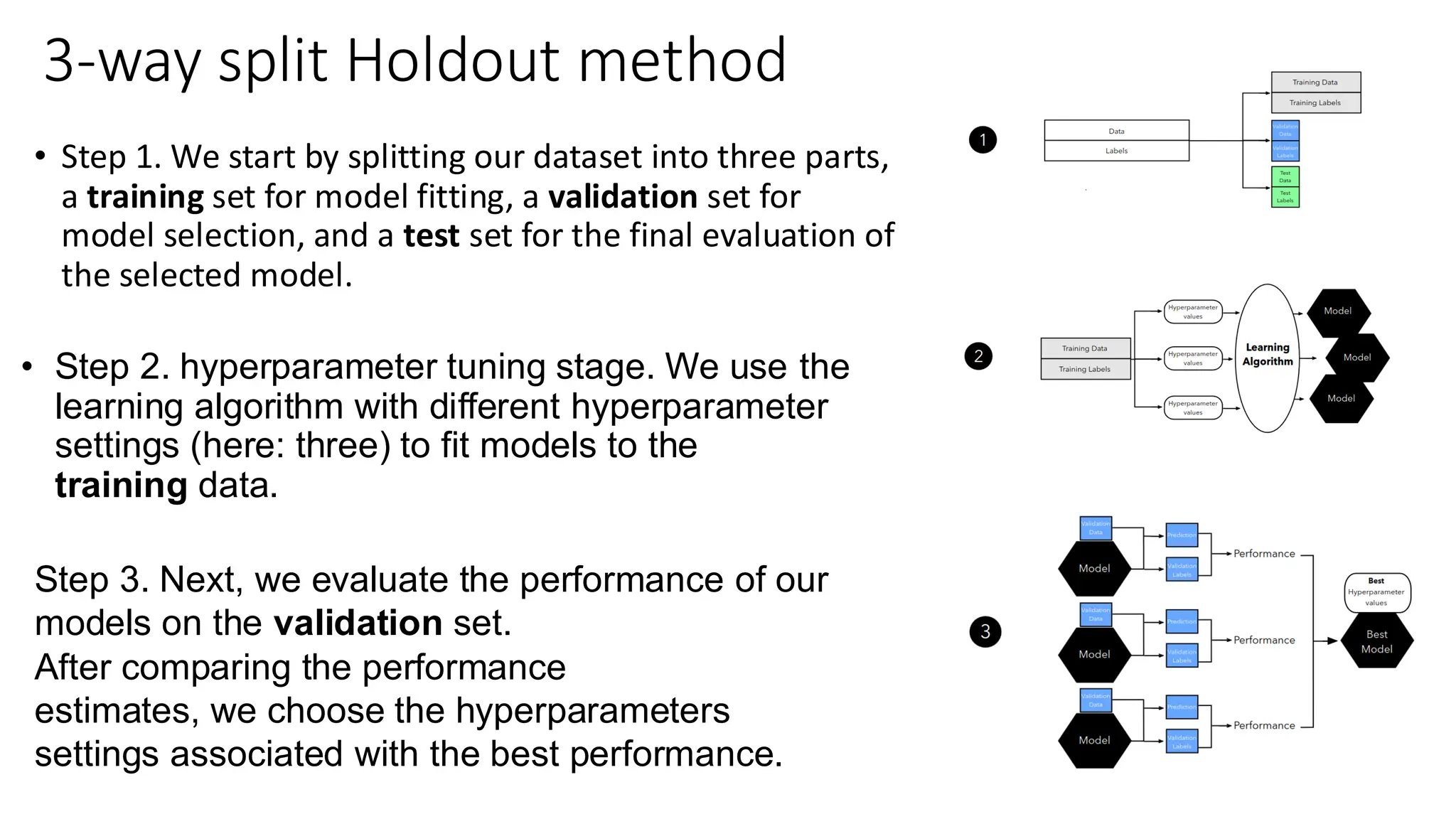
• Step 1.We start by splitting our dataset into three parts,
a training set for model fitting, a validation set for
model selection, and a test set for the final evaluation of
the selected model.
3-way split Holdout method
• Step 2. hyperparameter tuning stage. We use the
learning algorithm with different hyperparameter
settings (here: three) to fit models to the
training data.
Step 3. Next, we evaluate the performance of our
models on the validation set.
After comparing the performance
estimates, we choose the hyperparameters
settings associated with the best performance.
7.
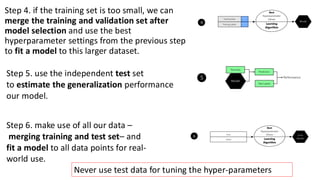
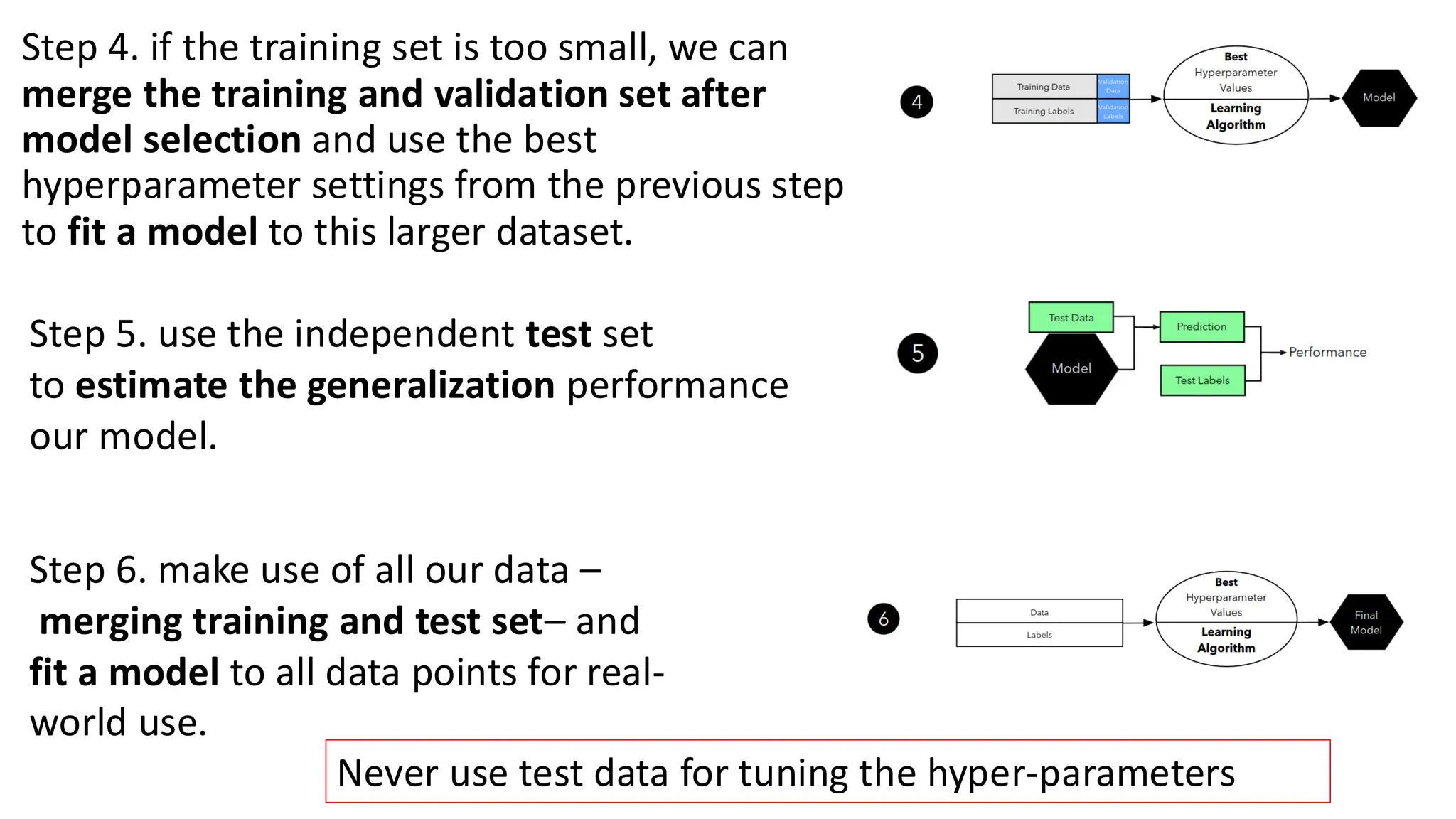
Step 4. ifthe training set is too small, we can
merge the training and validation set after
model selection and use the best
hyperparameter settings from the previous step
to fit a model to this larger dataset.
Step 5. use the independent test set
to estimate the generalization performance
our model.
Step 6. make use of all our data –
merging training and test set– and
fit a model to all data points for real-
world use.
Never use test data for tuning the hyper-parameters
8.
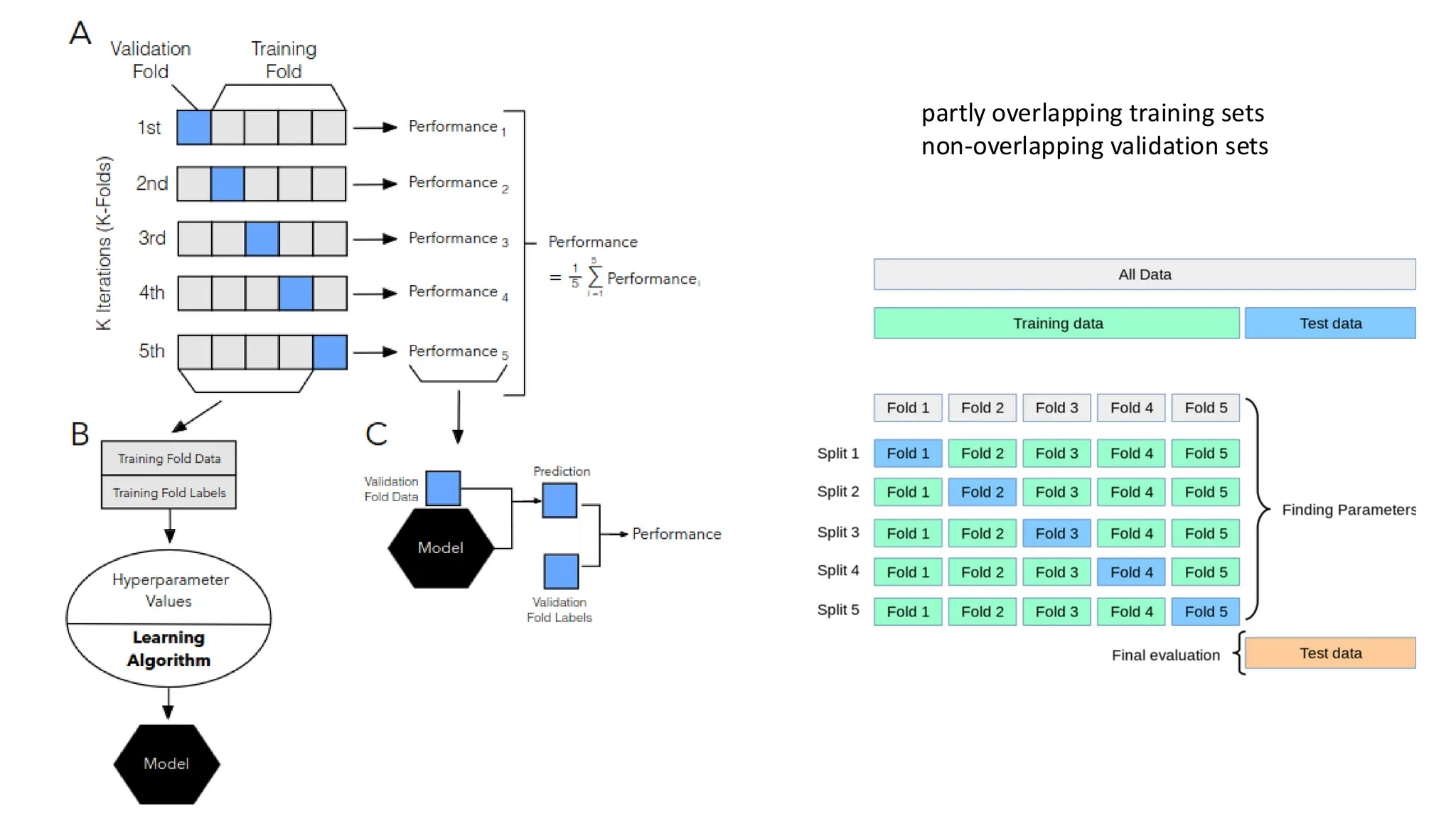
K-fold cross validation
•the main idea behind cross-validation is that each sample in our
dataset has the opportunity of being tested
• the total dataset is split into k-folds or subsets of equal sizes, and the kth
fold is used for testing while the remaining k-1 folds are used as the
training dataset.
• we iterate over a dataset set k times.
• In each round, we split the dataset into k parts: one part is used for validation, and
the remaining k − 1 parts are merged into a training subset for model
• we use a learning algorithm with fixed hyperparameter settings to fit
models to the training folds in each iteration when we use the k-fold cross-
validation method for model evaluation.
• we compute the cross-validation performance as the arithmetic
mean (average) over the k performance estimates from the validation sets.
• A common choice for k = 5, 10
Stratified K-Fold
• StratifiedK-Fold is an extended version of the K-Fold technique that
considers the class imbalance present in the dataset.
• It ensures that every fold of the dataset contains the same proportion
of each class, thereby maintaining the class distribution in both the
training and testing datasets.
11.
Leave-One-Out Cross-Validation (LOOCV)
•fit a model to n − 1 samples of the dataset and
evaluate it on the single, remaining data point.
• Although this process is computationally
expensive, given that we have n iterations, it can
be useful for small datasets, cases where
withholding data from the training set would be
too wasteful.
• We can think of the LOOCV estimate as being
approximately unbiased
• While LOOCV is almost unbiased, one downside
of using LOOCV over k-fold cross-validation with k
< n is the large variance of the LOOCV estimate.
12.
Which method isuseful for deep learning?
• the three-way holdout may be preferred over k-fold cross-validation
since the former is computationally cheap in comparison.
• we only use deep learning algorithms when we have relatively large
sample sizes anyway, scenarios where we do not have to worry about
high variance – the sensitivity of our estimates towards how we split
the dataset for training, validation, and testing – so much.
• it is fine to use the holdout method with a training, validation, and
test split over the k-fold cross-validation for model selection if the
dataset is relatively large
13.
The Law ofParsimony
• also known as Occam’s Razor:
”Among competing hypotheses, the one with the fewest assumptions should be selected.”
If all else is equal, the simplest solution is correct.
•First razor: Given two models with the same generalization error, the simpler one should be
preferred because simplicity is desirable in itself.
•Second razor: Given two models with the same training-set error, the simpler one should be
preferred because it is likely to have lower generalization error
Grid search
• Thetraditional way of performing hyperparameter optimization has
been grid search, or a parameter sweep, which is simply an
exhaustive searching through a manually specified subset of the
hyperparameter space of a learning algorithm.
• Since the parameter space of a machine learner may include real-
valued or unbounded value spaces for certain parameters, manually
set bounds and discretization may be necessary before applying grid
search.
Blue contours indicate
regions with strong results,
whereas red ones show
regions with poor results.
16.
Pros and cons
•The grid search method is computationally intensive, as it requires
training a separate model for each combination of hyperparameters.
• It is also limited by the predefined set of possible values for each
hyperparameter, which may not include the optimal values.
• Despite these limitations, the grid search method is widely used due
to its simplicity and effectiveness, particularly for smaller and less
complex models.
17.
How can wemake grid search fast?
• Early stopping. Can abort some of the runs in the grid early if it
becomes clear that they will be suboptimal.
• Parallelism. Grid search is a parallel method.
• We can evaluate the grid points independently on parallel machines and get
near-linear speedup.
18.
Random search
• RandomSearch replaces the exhaustive
enumeration of all combinations by
selecting them randomly.
• Combine grid search with subsampling.
19.
Random search vsGrid search
• Upside: Solves the curse of dimensionality. We often don’t need to
increase the number of sample points exponentially as the number of
dimensions increases.
• Downside: Not as replicable. Results depend on a random seed.
• Downside: Suboptimal. Not necessarily going to go anywhere near
the optimal parameters in a finite sample.
• Same downsides as grid search: needing to choose the search space
and no way of taking advantage of insight about the system
20.
Evolutionary optimization
• Inhyperparameter optimization, evolutionary optimization uses
evolutionary algorithms to search the space of hyperparameters for a
given algorithm.
• Evolutionary hyperparameter optimization follows a process inspired
by the biological concept of evolution:
• Genetic algorithms
• Particle Swarm Optimization
21.
1.Create an initialpopulation of random solutions (i.e., randomly generate
tuples of hyperparameters, typically 100+)
2.Evaluate the hyperparameters tuples and acquire their fitness function
(e.g., 10-fold cross-validation accuracy of the machine learning algorithm
with those hyperparameters)
3.Rank the hyperparameter tuples by their relative fitness
4.Replace the worst-performing hyperparameter tuples with new
hyperparameter tuples generated through crossover and mutation
5.Repeat steps 2-4 until satisfactory algorithm performance is reached or
algorithm performance is no longer improving
Genetic algorithm for HP tuning
22.
Crossover
• Combine twoparents to generate new offspring
• One-point crossover
• the tails of its two parents are swapped to get new off-springs.
• Multi Point Crossover
• alternating segments are swapped to get new off-springs.
23.
Mutation
• mutation maybe defined as a small random tweak in the
chromosome, to get a new solution.
• Bit Flip Mutation
• we select one or more random bits and flip them
• Swap Mutation
• we select two positions on the chromosome at random, and interchange the
values.
24.
Bayesian optimization
• Analysisof hyperparameter combinations happens in sequence, with
previous results informing the refinements in the next experiment.
• works by building a probabilistic model of the objective function
• is a more complex method of hyperparameter tuning than grid search
or random search, and it requires more computational resources.
• However, it can be more effective at finding the optimal set of
hyperparameters, particularly for larger and more complex models.





































































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=600ounds&width=560&fit=bounds)























![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)










![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




