Download as PDF, PPTX















![Spark’s shuffle code today
private[spark] trait ShuffleManager {
def registerShuffle[K, V, C](shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V,
C]): ShuffleHandle
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext, metrics:
ShuffleWriteMetricsReporter): ShuffleWriter[K, V]
def getReader[K, C](handle: ShuffleHandle, startPartition: Int, endPartition: Int, context:
TaskContext, metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]
def unregisterShuffle(shuffleId: Int): Boolean
def shuffleBlockResolver: ShuffleBlockResolver
def stop(): Unit
}
24#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/85/Improving-Apache-Spark-Downscaling-24-320.jpg)
![Continued..
/**
* Obtained inside a map task to write out records to the shuffle system.
*/
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
def stop(success: Boolean): Option[MapStatus]
}
25#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/85/Improving-Apache-Spark-Downscaling-25-320.jpg)
![Continued..
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we
don't
// care whether the keys get sorted in each partition; that will be done on the reduce
side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
...
26#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/85/Improving-Apache-Spark-Downscaling-26-320.jpg)

![Continued..
/ Note: Changes to the format in this file should be kept in sync with
//
org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getSortBasedShuffleBlockData().
private[spark] class IndexShuffleBlockResolver(
conf: SparkConf,
_blockManager: BlockManager = null)
extends ShuffleBlockResolver
………..
28#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/85/Improving-Apache-Spark-Downscaling-28-320.jpg)




![Where we started
class HcfsShuffleWriter[K, V, C] extends ShuffleWriter[K, V] {
override def write(records: Iterator[Product2[K, V]]): Unit = {
val sorter = new ExternalSorter[K, V, C/V](...)
sorter.insertAll(records)
val partitionIter = sorter.partitionedIter
val hcfsStream = …
val countingStream = new CountingOutputStream(hcfsStream)
val framedOutput = new FramingOutputStream(countingStream)
try {
for ((partition, iter) <- partitionIter) {
// Write partition to external storage
}
} finally {
framedOutput.closeUnderlying()
}
}
34#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/85/Improving-Apache-Spark-Downscaling-34-320.jpg)



















![Spark’s shuffle code today
private[spark] trait ShuffleManager {
def registerShuffle[K, V, C](shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V,
C]): ShuffleHandle
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext, metrics:
ShuffleWriteMetricsReporter): ShuffleWriter[K, V]
def getReader[K, C](handle: ShuffleHandle, startPartition: Int, endPartition: Int, context:
TaskContext, metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]
def unregisterShuffle(shuffleId: Int): Boolean
def shuffleBlockResolver: ShuffleBlockResolver
def stop(): Unit
}
24#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/75/Improving-Apache-Spark-Downscaling-24-2048.jpg)
![Continued..
/**
* Obtained inside a map task to write out records to the shuffle system.
*/
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
def stop(success: Boolean): Option[MapStatus]
}
25#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/75/Improving-Apache-Spark-Downscaling-25-2048.jpg)
![Continued..
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we
don't
// care whether the keys get sorted in each partition; that will be done on the reduce
side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
...
26#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/75/Improving-Apache-Spark-Downscaling-26-2048.jpg)

![Continued..
/ Note: Changes to the format in this file should be kept in sync with
//
org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getSortBasedShuffleBlockData().
private[spark] class IndexShuffleBlockResolver(
conf: SparkConf,
_blockManager: BlockManager = null)
extends ShuffleBlockResolver
………..
28#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/75/Improving-Apache-Spark-Downscaling-28-2048.jpg)




![Where we started
class HcfsShuffleWriter[K, V, C] extends ShuffleWriter[K, V] {
override def write(records: Iterator[Product2[K, V]]): Unit = {
val sorter = new ExternalSorter[K, V, C/V](...)
sorter.insertAll(records)
val partitionIter = sorter.partitionedIter
val hcfsStream = …
val countingStream = new CountingOutputStream(hcfsStream)
val framedOutput = new FramingOutputStream(countingStream)
try {
for ((partition, iter) <- partitionIter) {
// Write partition to external storage
}
} finally {
framedOutput.closeUnderlying()
}
}
34#UnifiedDataAnalytics #SparkAISummit](https://image.slidesharecdn.com/christophercrosbiebensidhom-191031204703/75/Improving-Apache-Spark-Downscaling-34-2048.jpg)








The document discusses Google's Cloud Dataproc, a fully-managed service for Apache Spark and Hadoop, detailing its integration with various Google Cloud products and the management of cluster resources through autoscaling. It addresses the complexities and challenges of optimizing Spark jobs, particularly focusing on shuffle processing, data management, and the transition to Kubernetes for enhanced control and performance. Additionally, it highlights advancements in external shuffling mechanisms to improve efficiency and reduce the impact of scaling operations.
WiFi SSID and password information for attendees at the Spark AI Summit.
Introduces speakers Christopher Crosbie and Ben Sidhom from Google, focusing on improving Spark.
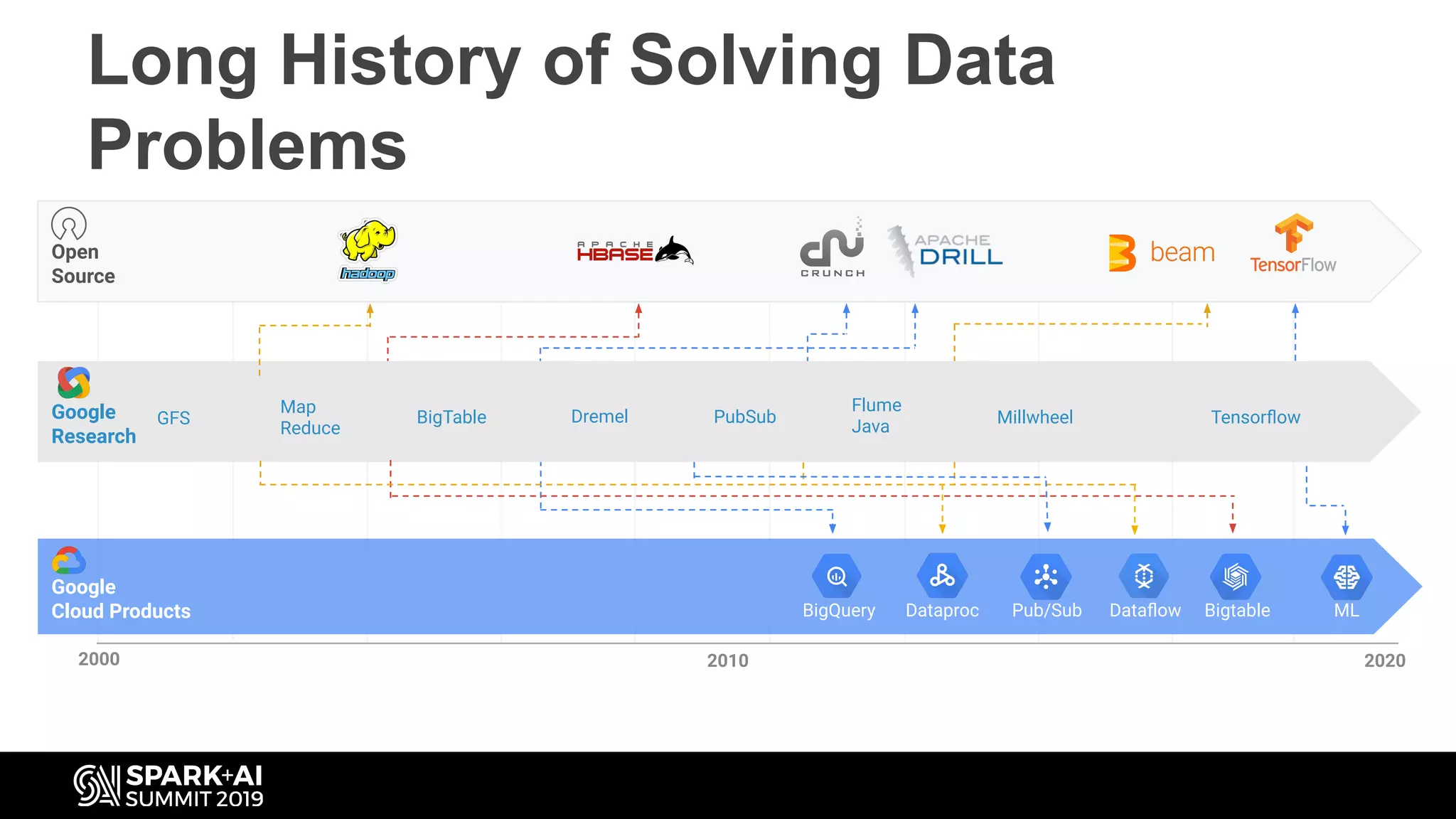
Timeline showing evolution of Google cloud products like GFS, MapReduce, BigQuery, and Tensorflow from 2000 to 2020.
Overview of Google Cloud services related to ML and data processing including Apache Airflow and Cloud ML Engine.
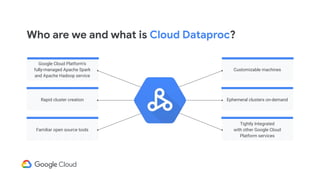
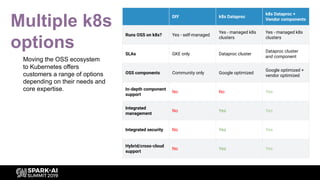
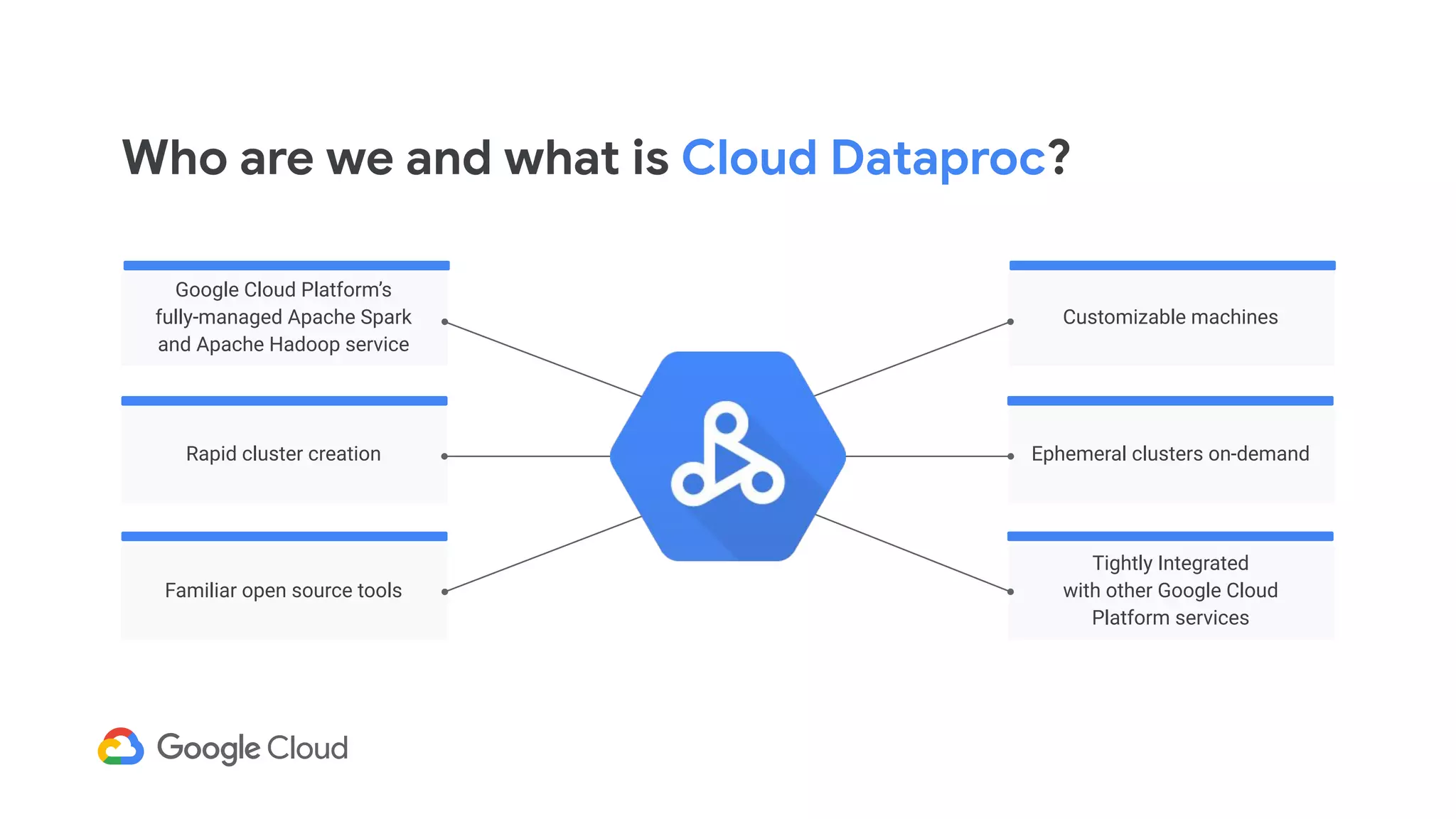
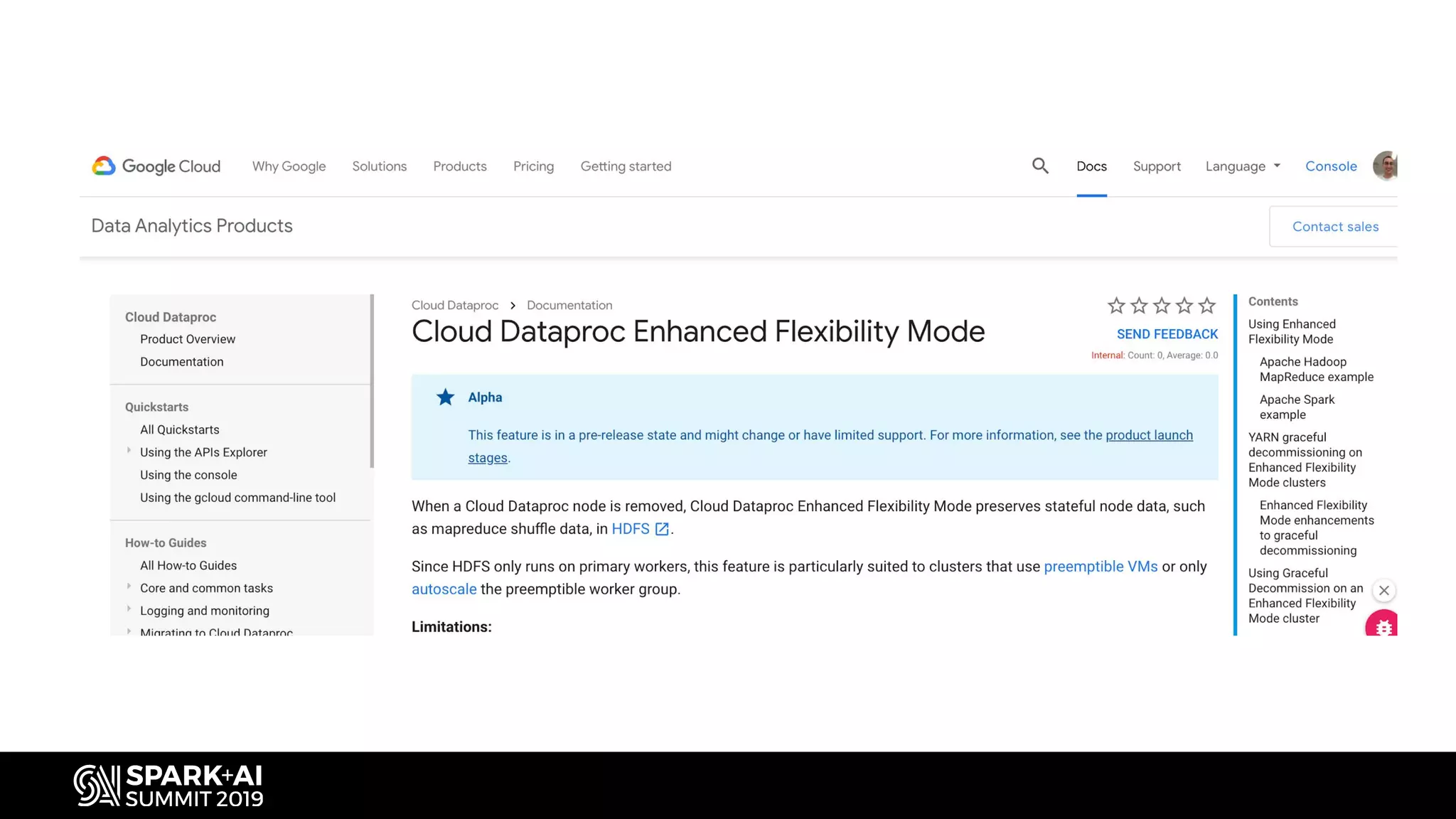
Description of Cloud Dataproc as a fully-managed service for Apache Spark and Hadoop with rapid cluster creation.
Highlights the integration of Cloud Dataproc with various Google Cloud services to enhance capabilities.
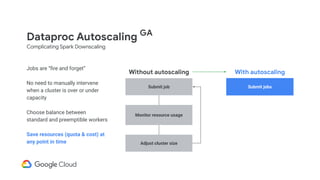
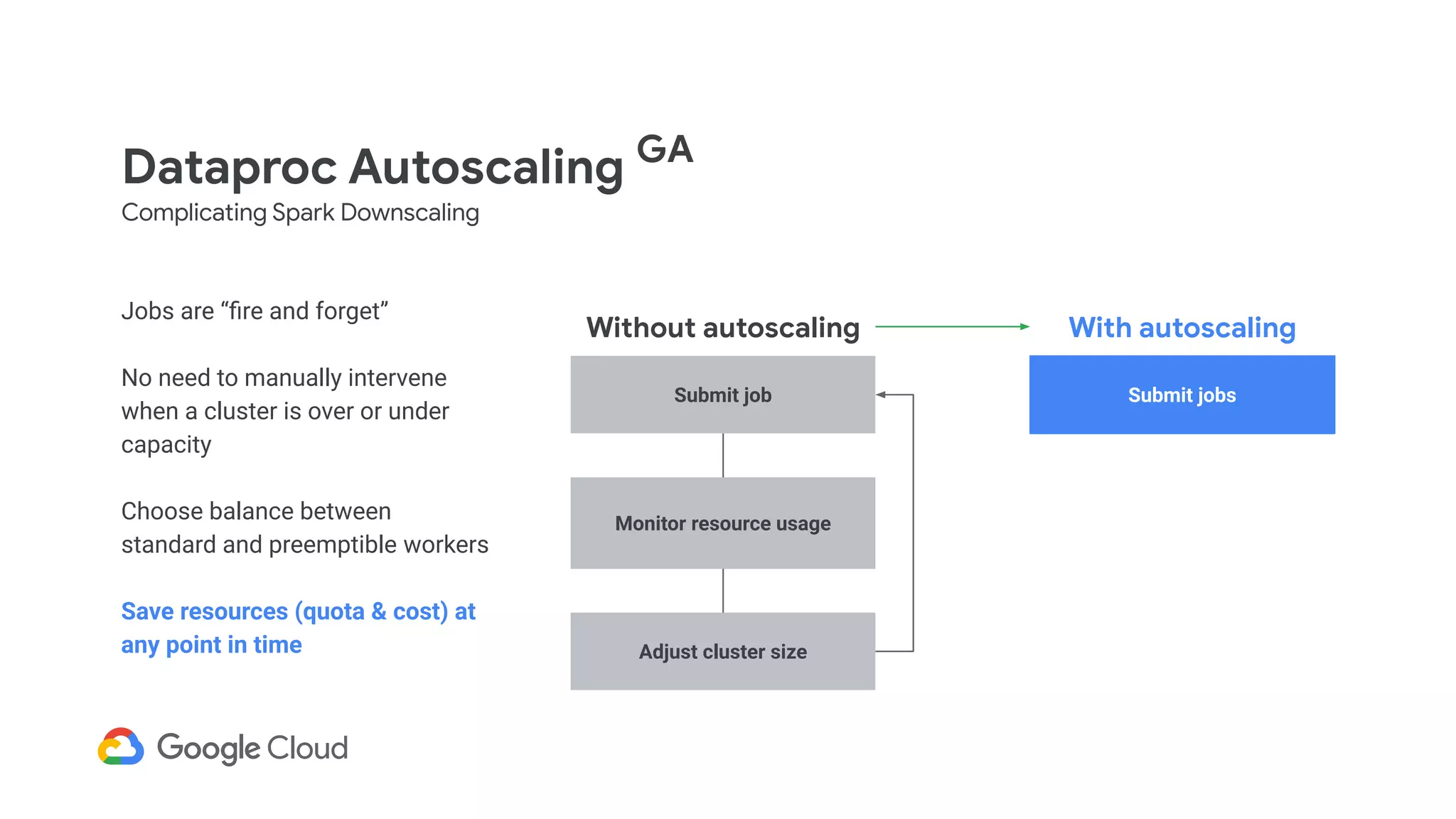
Explains how Dataproc allows for autoscaling of clusters to balance resources efficiently.
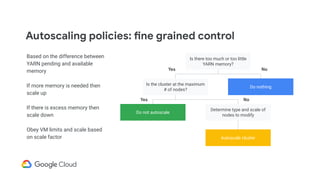
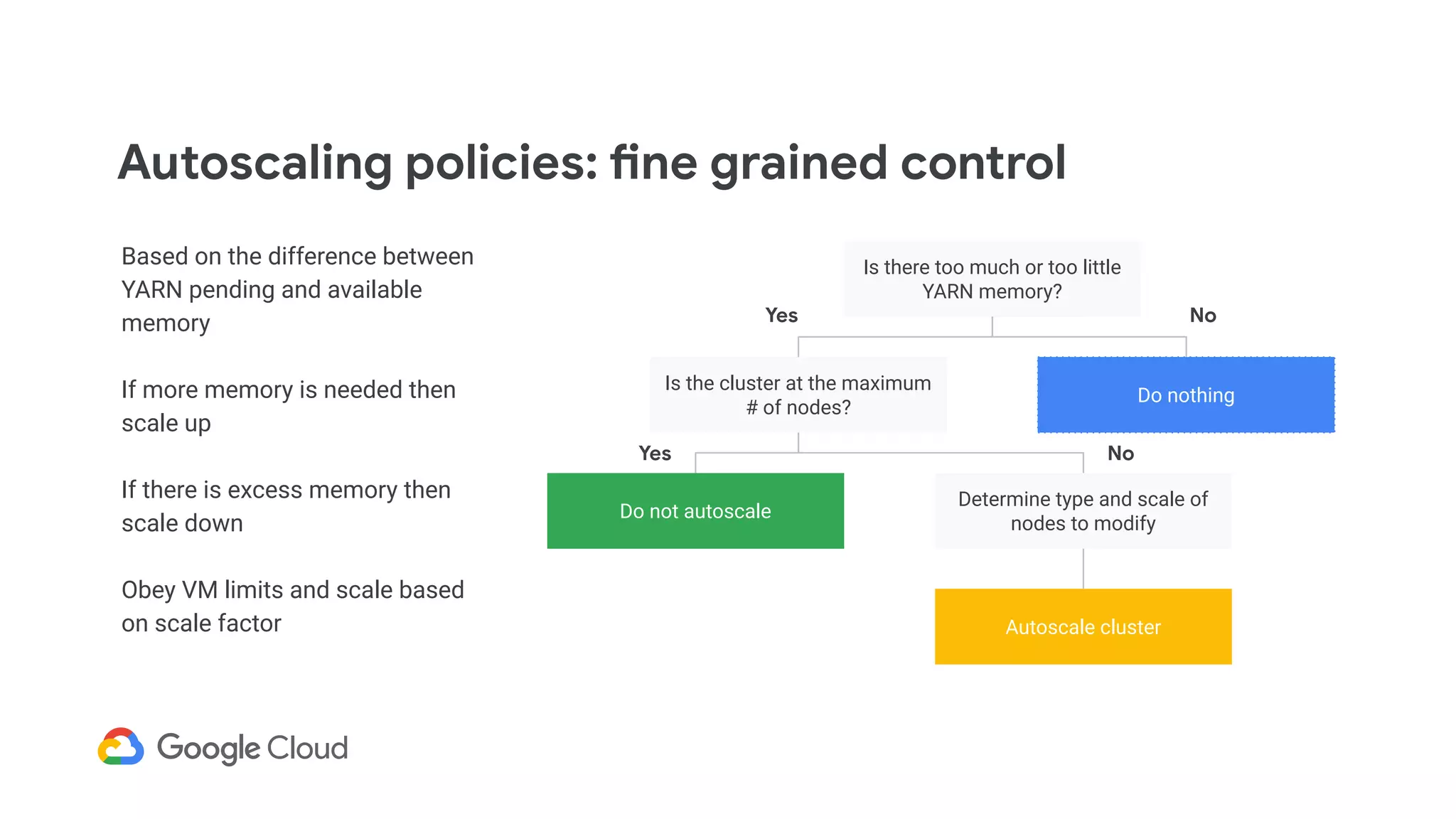
Details the criteria for scaling clusters up or down based on YARN memory availability and usage.
Discusses complexities in YARN's infrastructure regarding resource management and optimization in Spark.
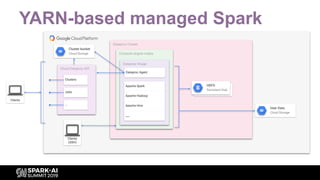
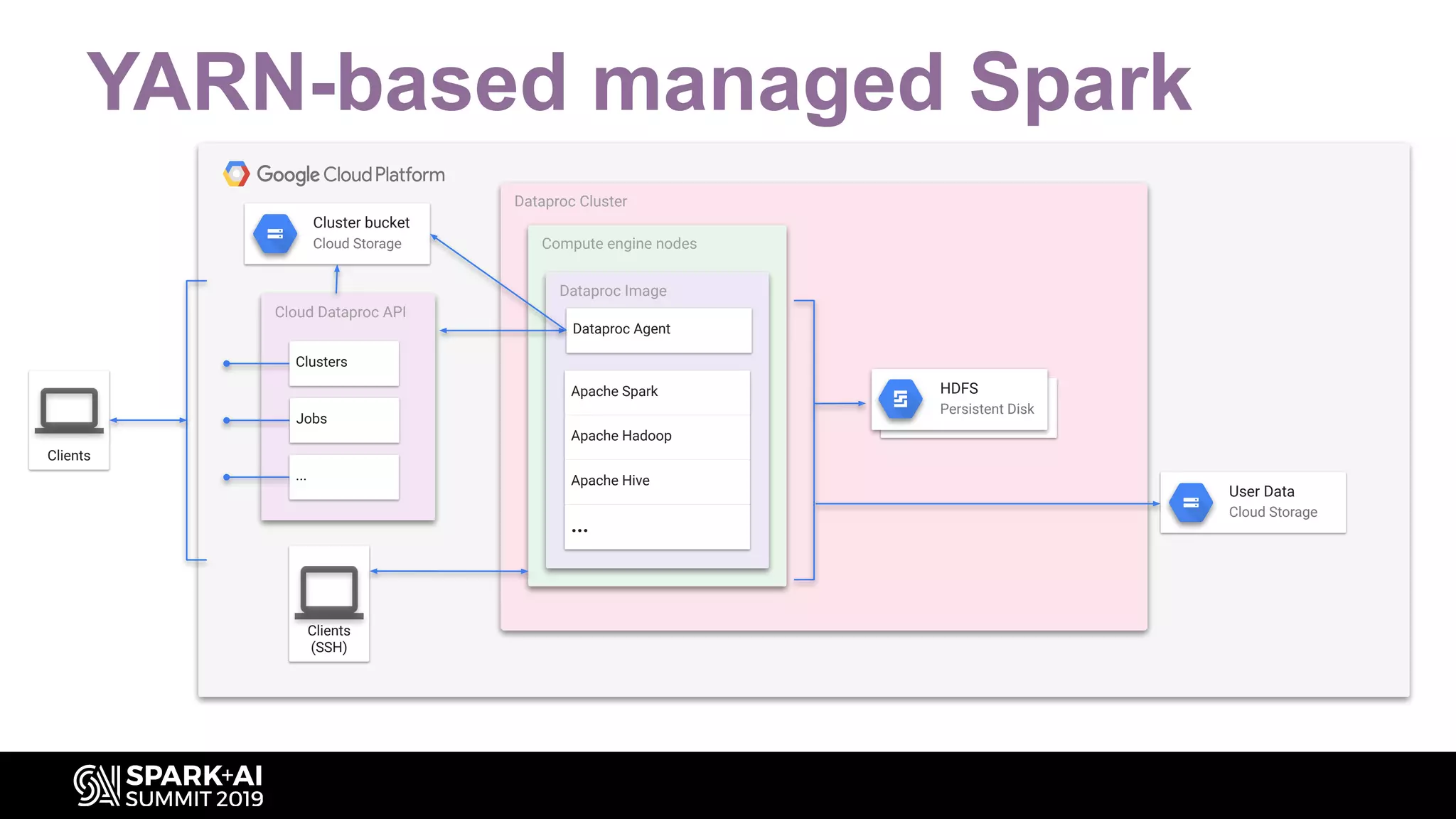
Focus on YARN, a key resource management layer for Hadoop and Spark's back-end.
Illustrates the architecture of a YARN-based managed Spark cluster with various components.
Discusses the difficult management and complexity associated with YARN in managing clusters and dependencies.
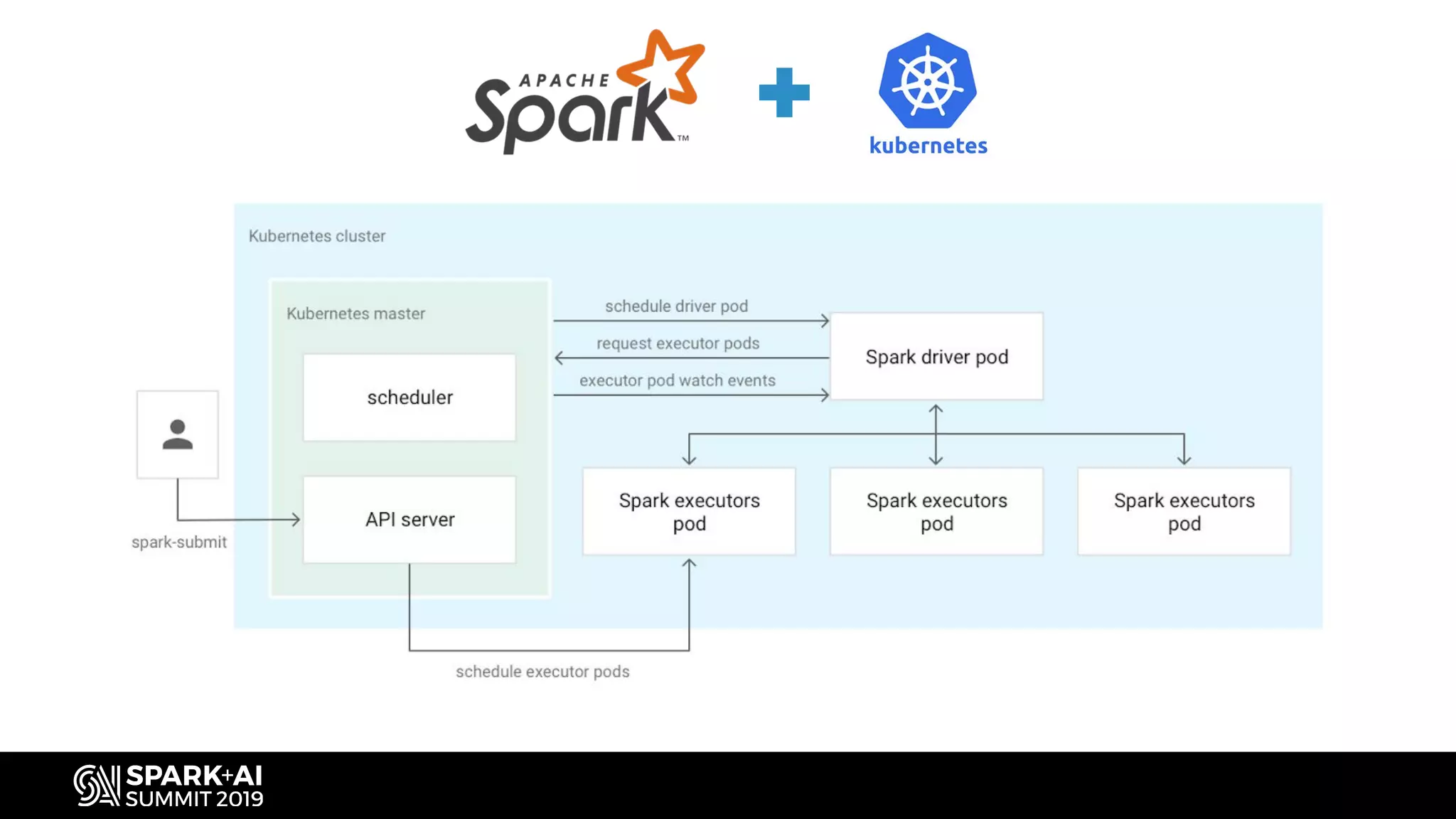
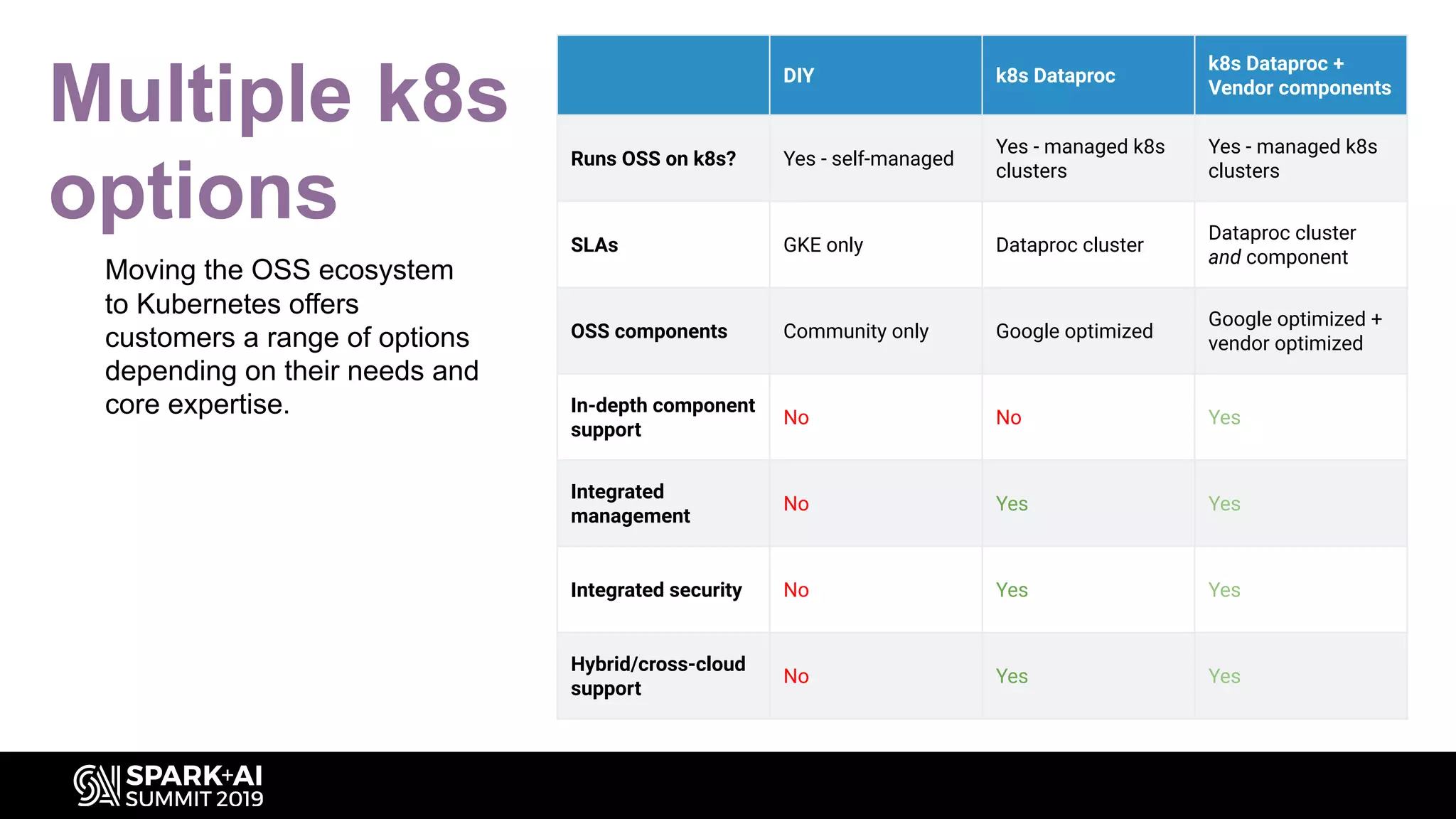
Explores multiple options for Kubernetes and how it benefits the open-source ecosystem for Dataproc.
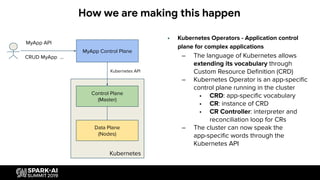
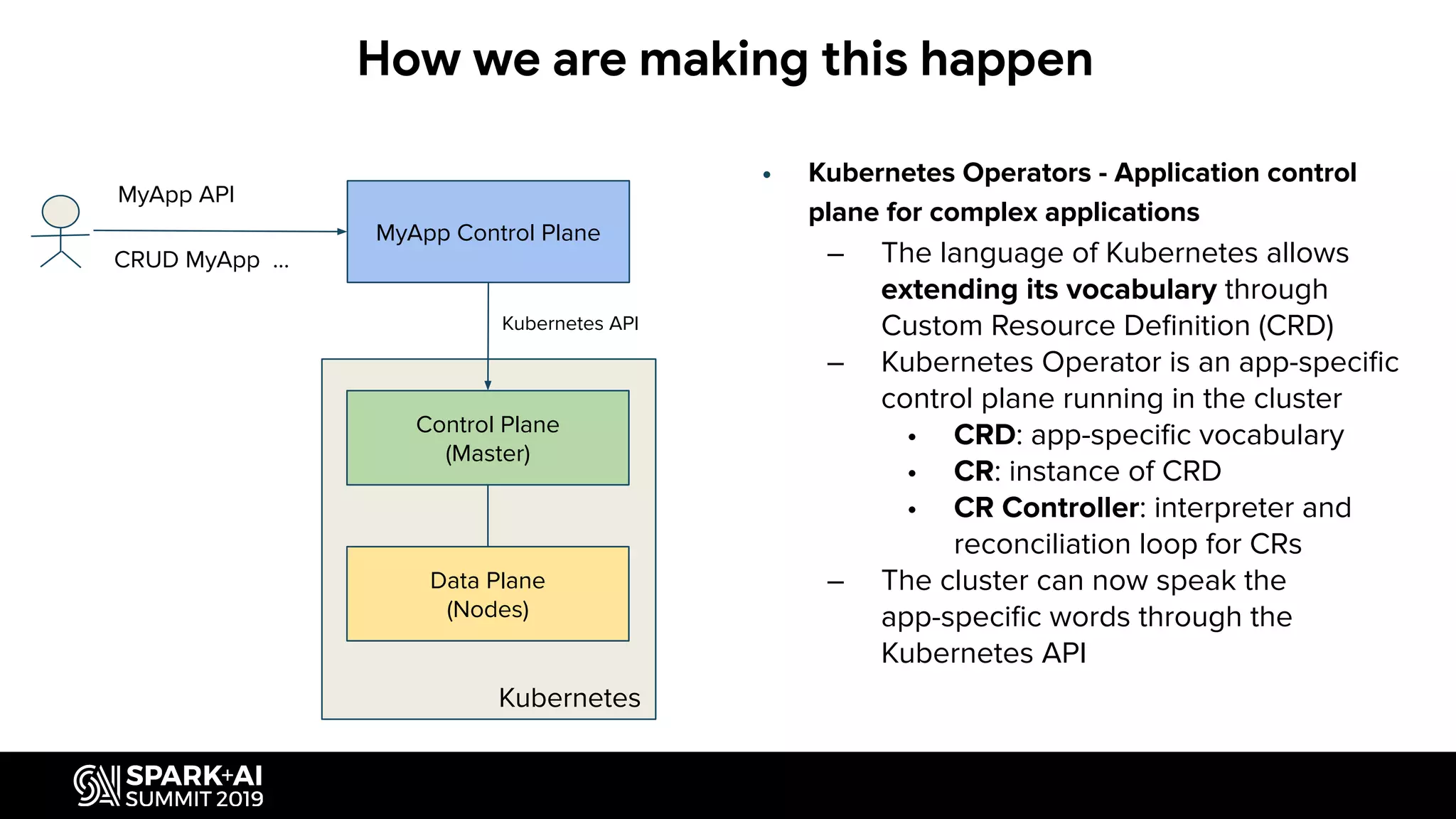
Describes how Kubernetes Operators enable application control and customization in clusters.
Details the integration of Dataproc with BigQuery, Google Cloud Storage, and monitoring via Stackdriver.
Discusses various deployment options available for users of Cloud Dataproc.
Outlines the advantages of unified resource management in simplifying Spark job management.
Highlights existing issues that remain unaddressed in current data processing setups.
Discusses the challenges of locating and processing data efficiently in distributed systems.
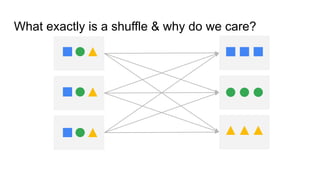
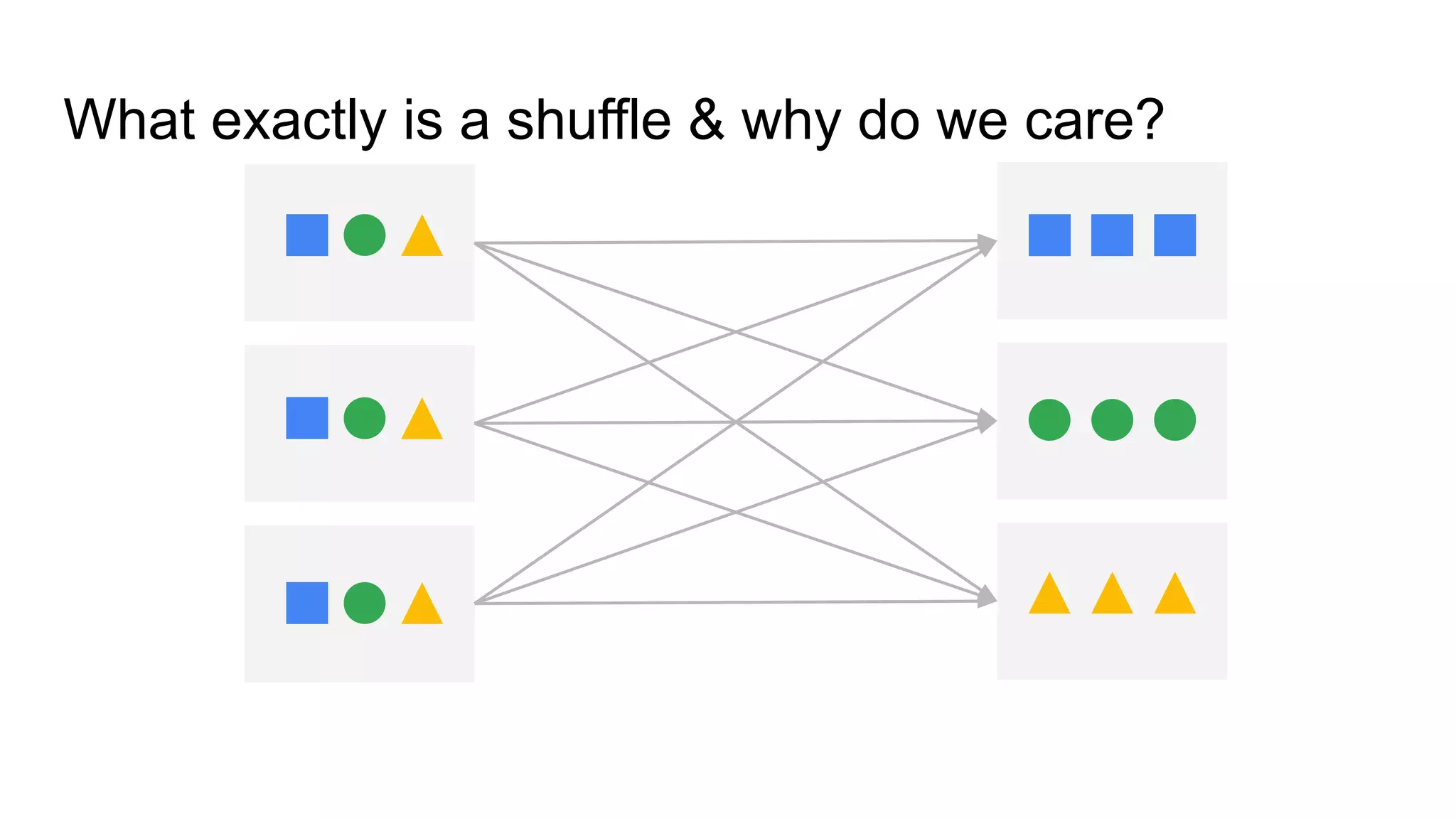
Explains the concept of shuffle in Spark and its importance for data processing.
Overview of how Spark handled shuffle files in the past and the issues that arose from it.
Examines the improvements in Spark's shuffle mechanism with dynamic allocation.
Technical overview of Spark's shuffle code and its functionality within the framework.
Technical insights into the ShuffleWriter class used in Spark for managing shuffle operations.
Continues technical explanation of how Spark writes records to shuffle storage.
Continues detailed coding mechanics related to managing shuffle files efficiently.
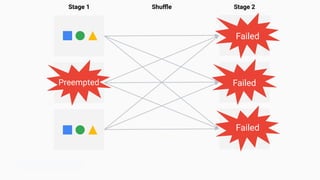
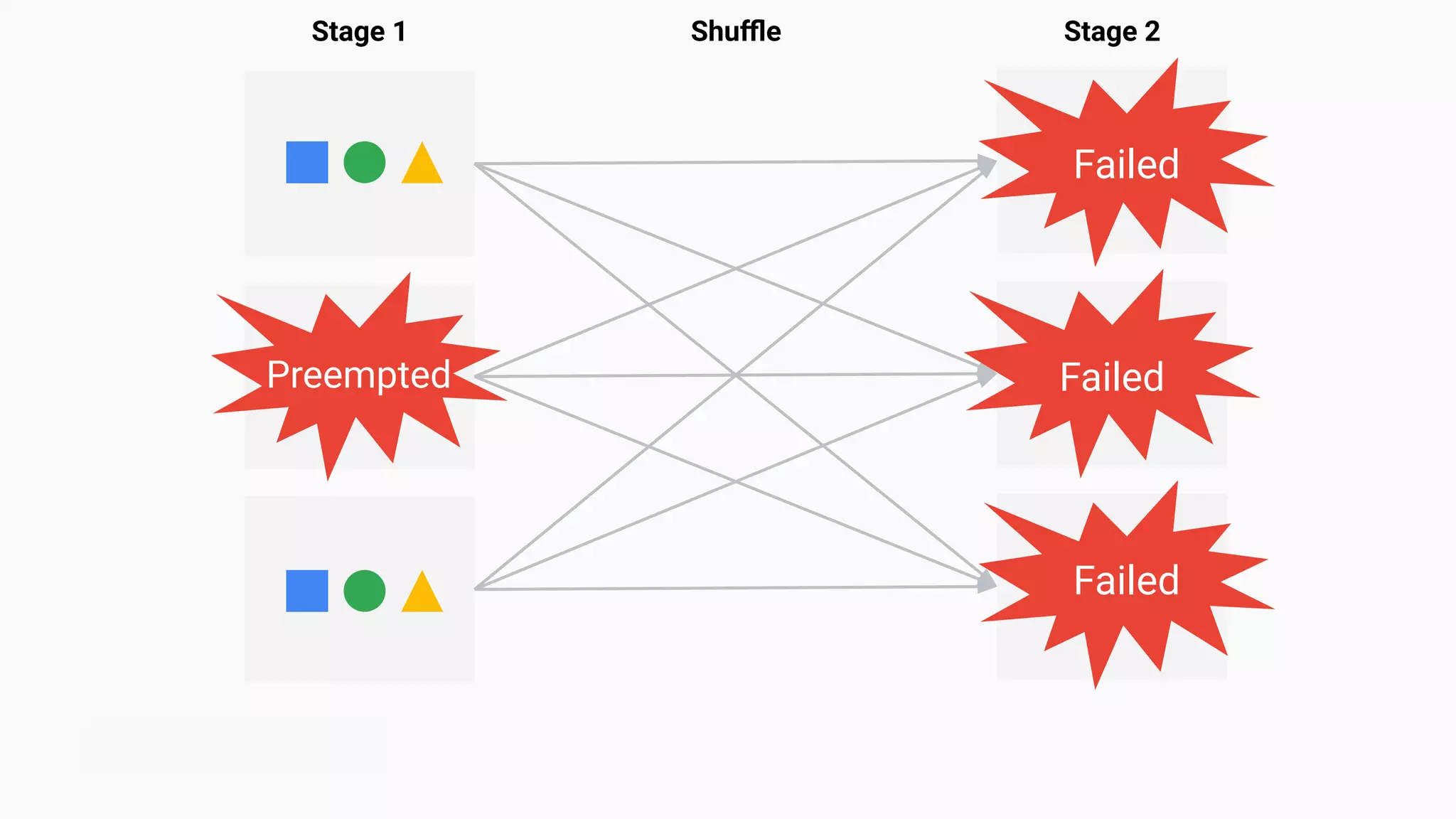
Discusses the complications encountered while rapidly downscaling in cloud environments.
Overview of strategies for optimizing costs in cloud processing environments.
Discusses preemptible VMs and Spot Instances and their cost benefits for cloud services.
Illustrates the multiple stages involved in the shuffle process within Spark.
Proposes solutions for making intermediate shuffle data external to enhance storage management.
Describes the initial approach to implementing external shuffle management.
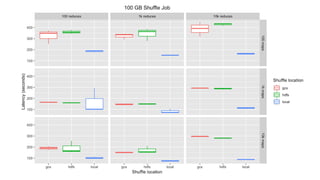
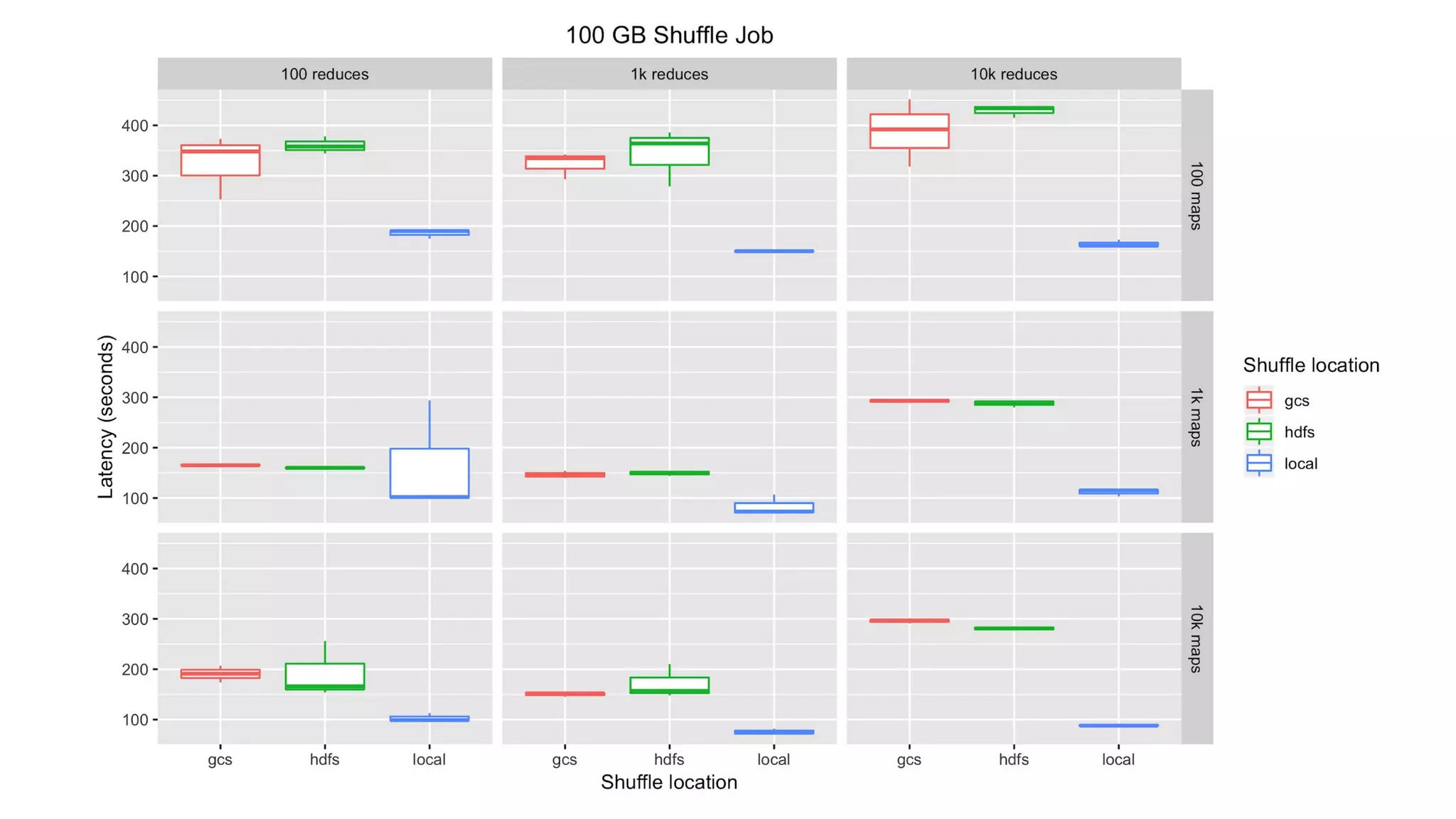
Identifies performance limitations of HDFS in data processing tasks and potential solutions.
Ponders the implications of using object storage solutions for cloud-based data management.
Explains Apache Crail as a solution for high-speed sharing of ephemeral data.
Highlights the features and benefits of using Google Cloud Bigtable for data processing.
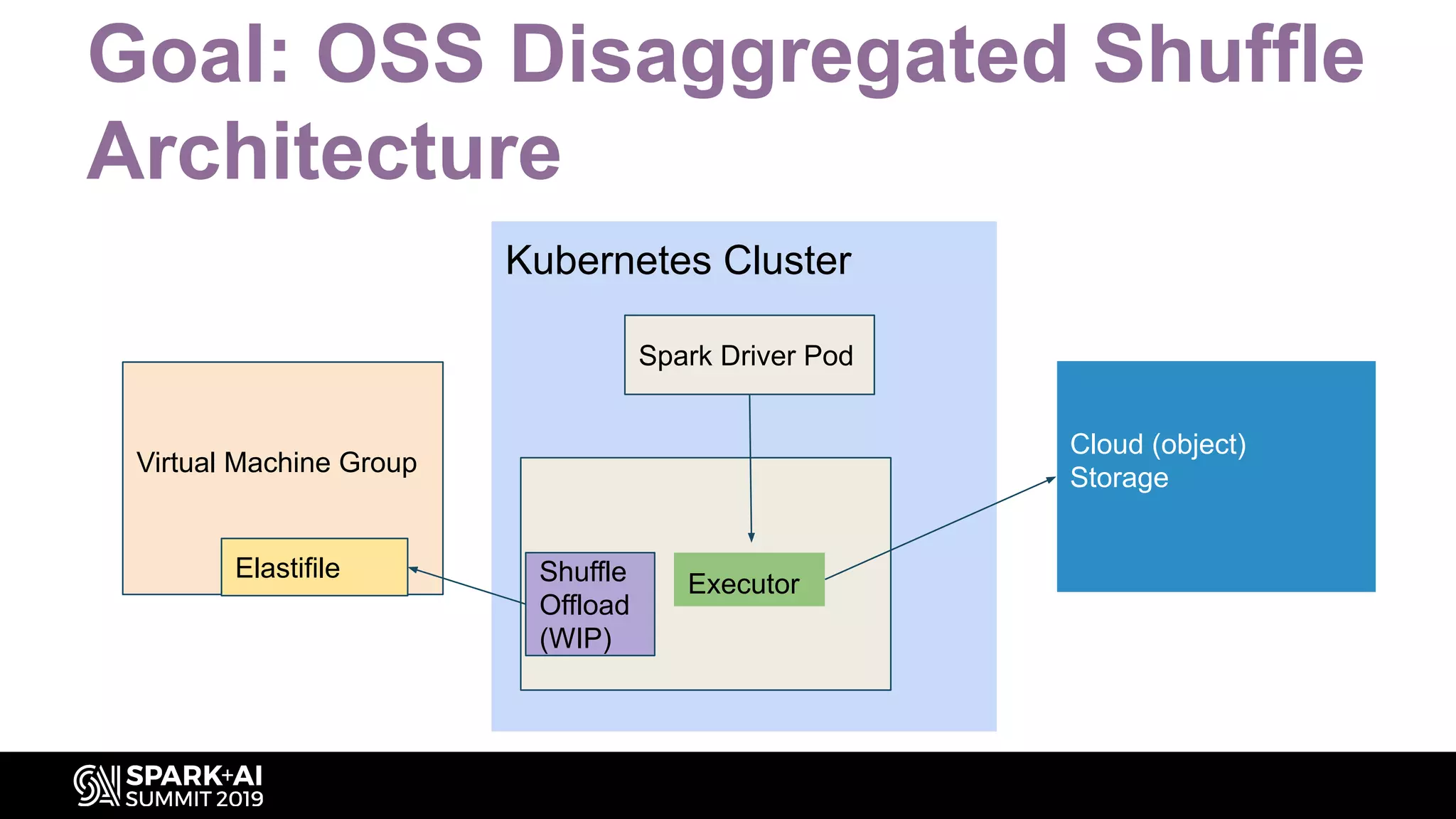
Discusses the use of NFS, specifically Elastifile, for managing shuffle data in the cloud.
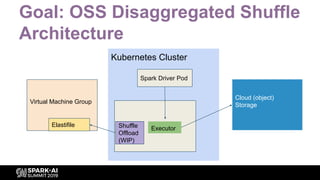
Articulates the vision for a disaggregated shuffle architecture leveraging cloud capabilities.
Questions whether current cloud solutions can be optimized further with innovative strategies.
Encourages participants to rate and review the sessions at the Spark AI Summit.







































































![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)















