




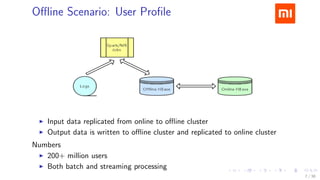





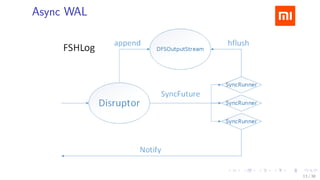

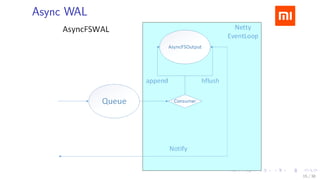





























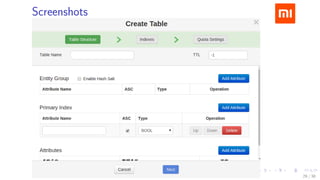
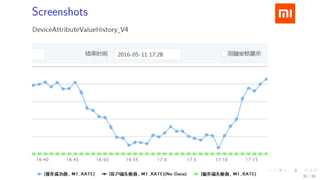
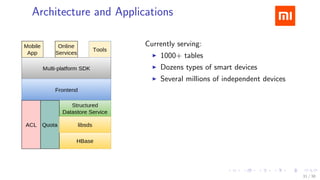
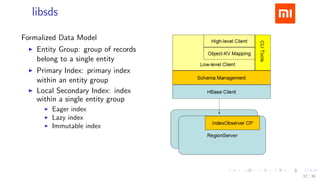


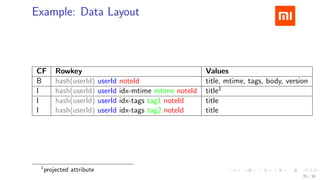
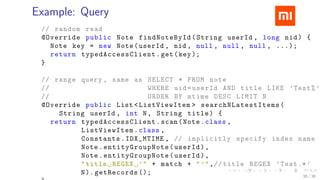













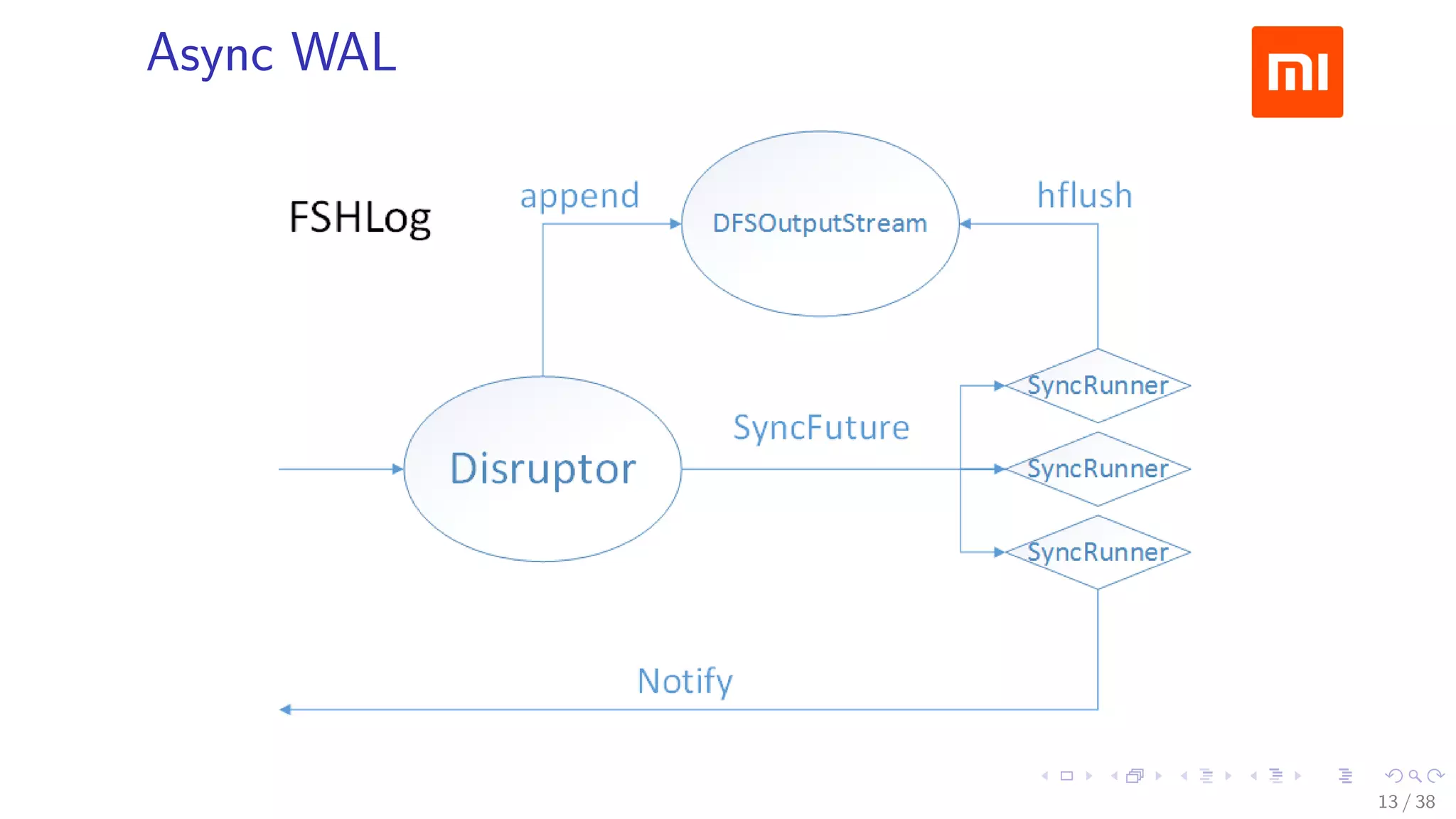

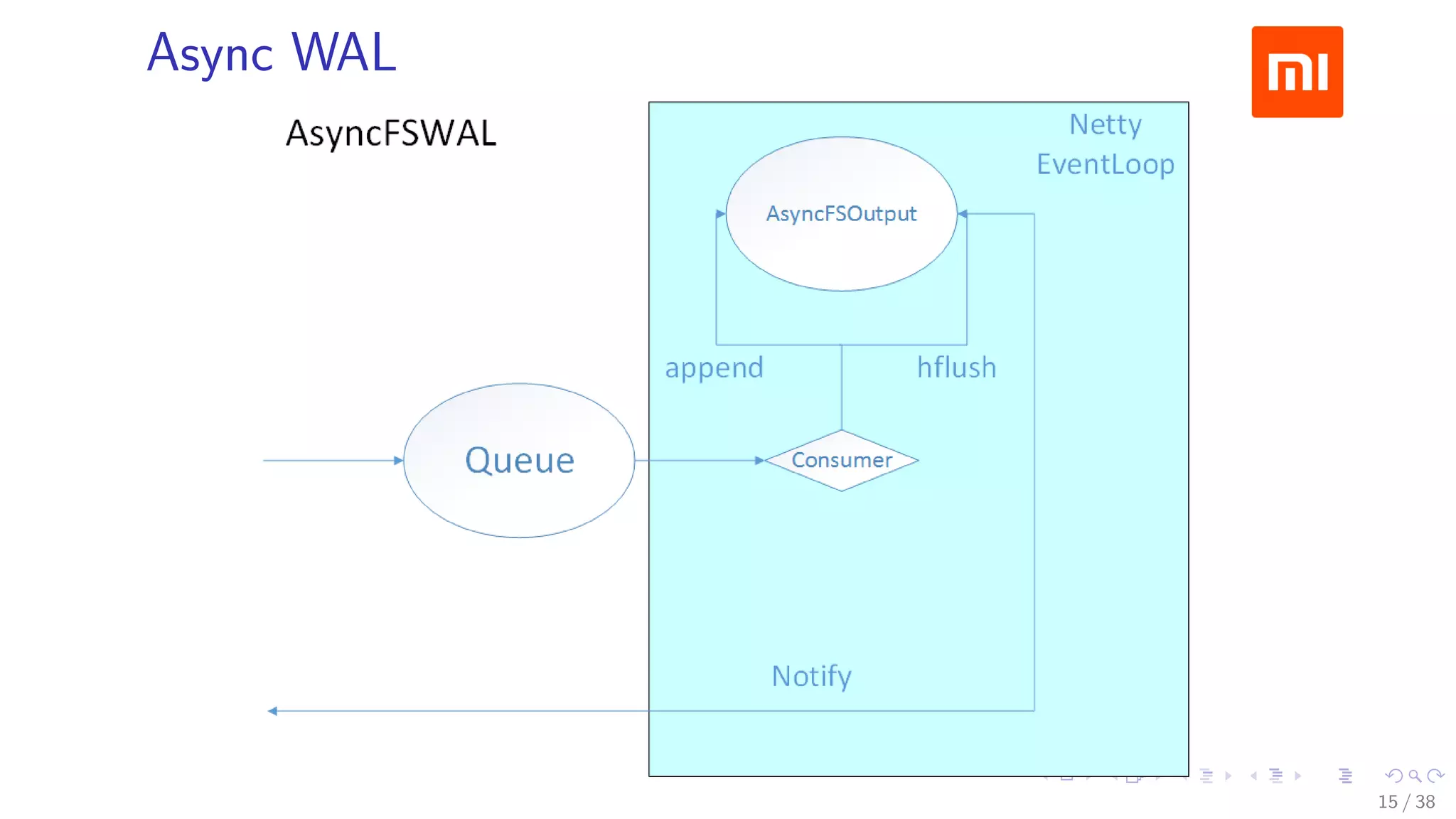



















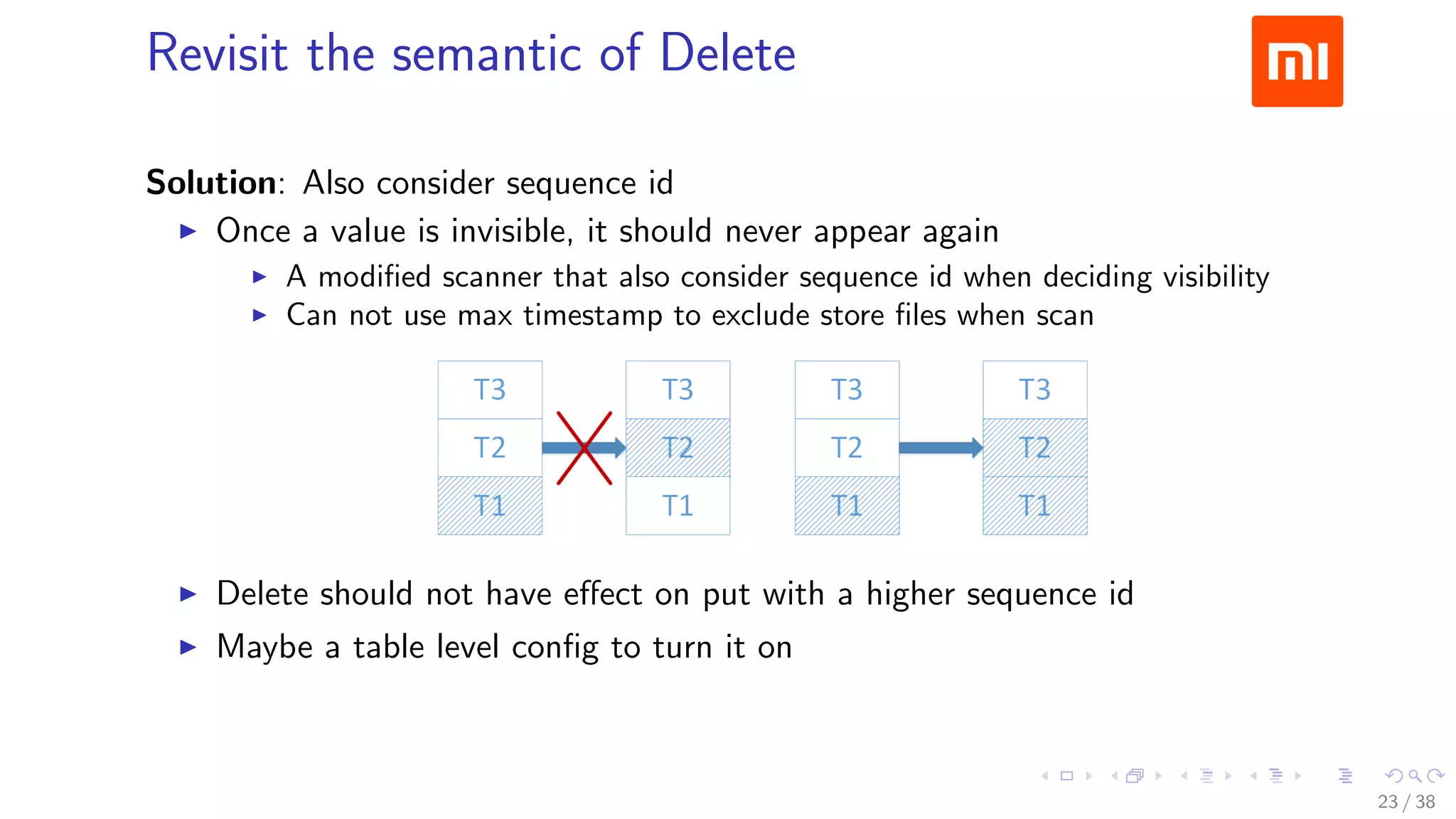










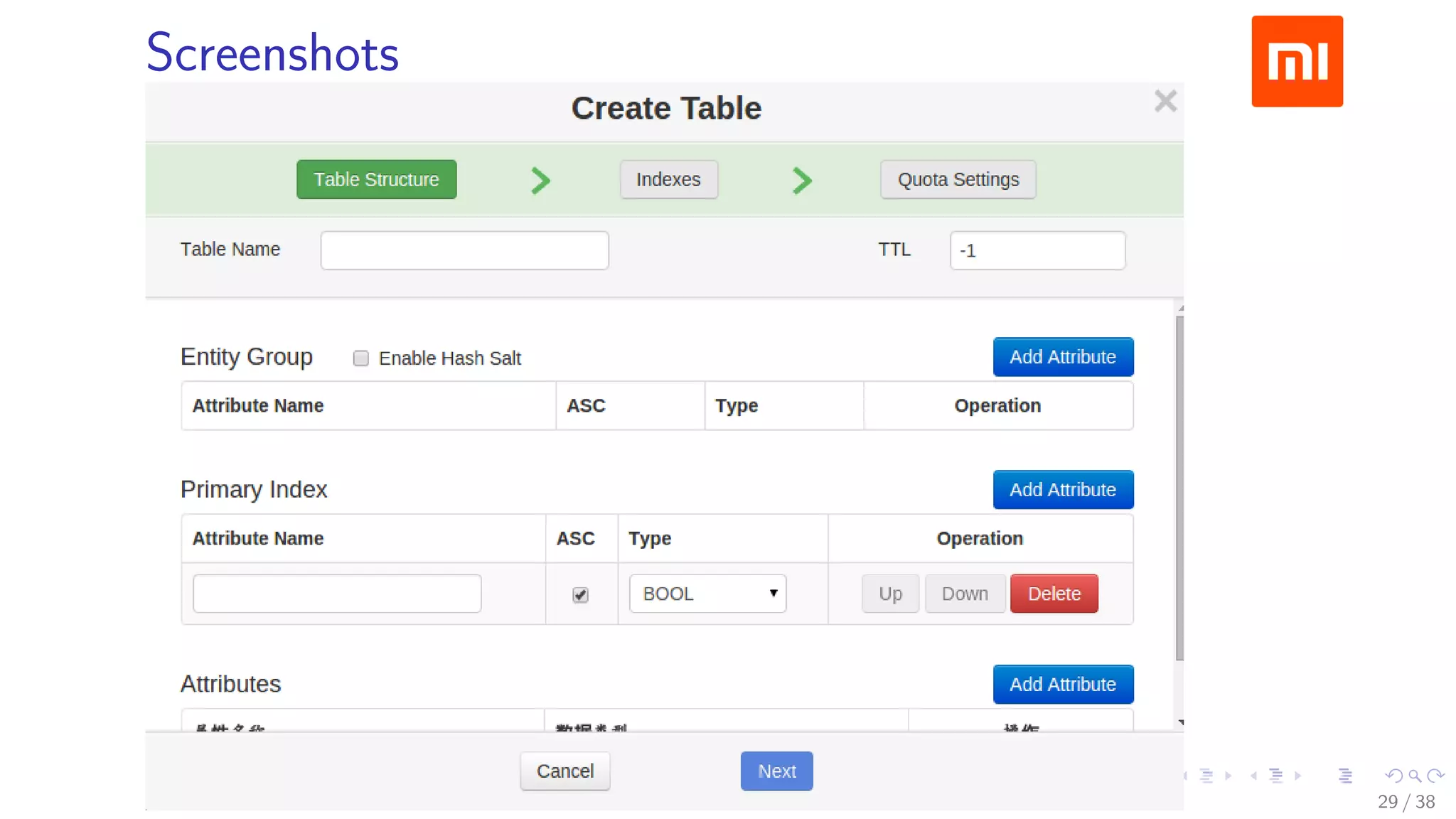
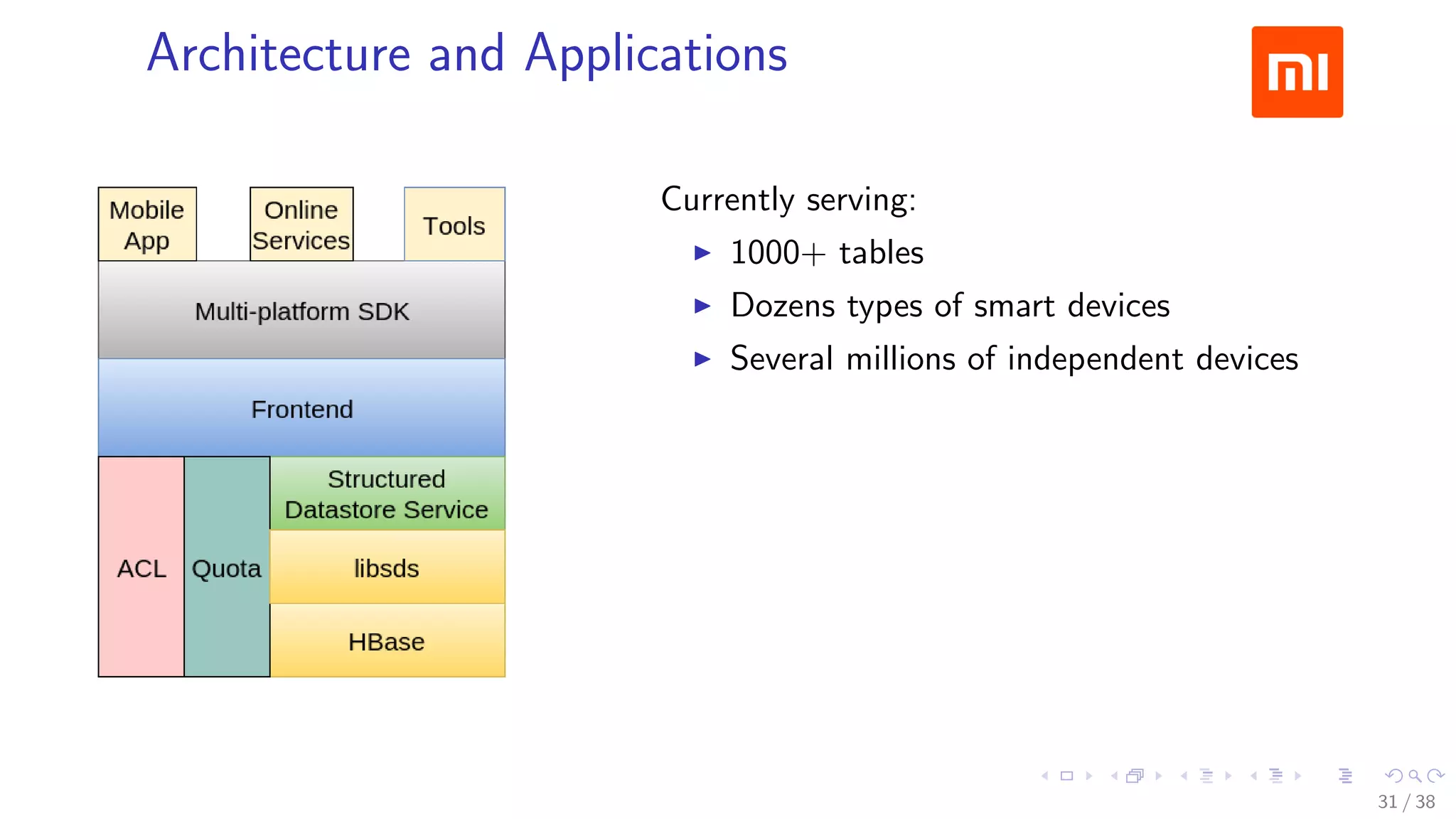
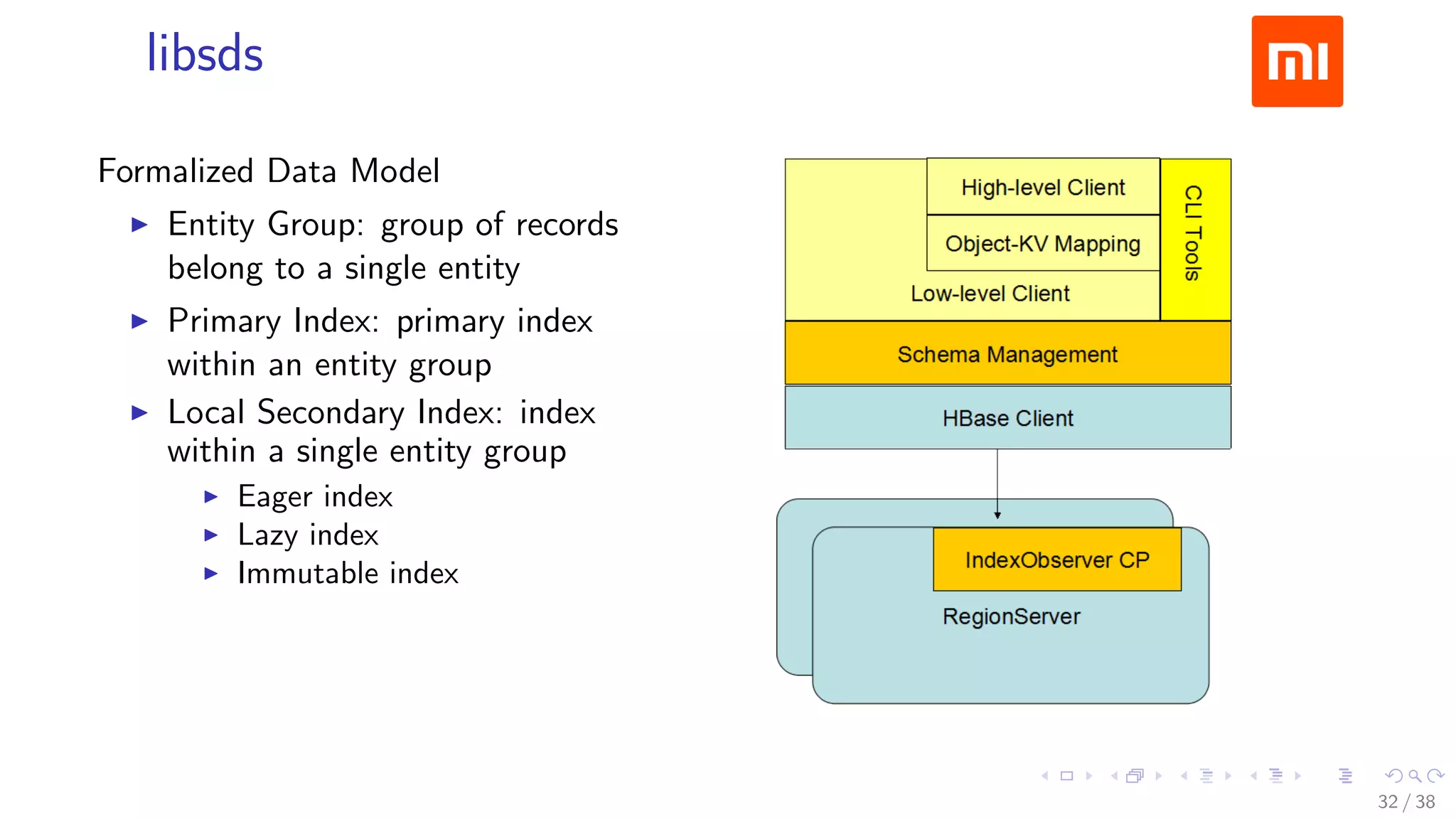


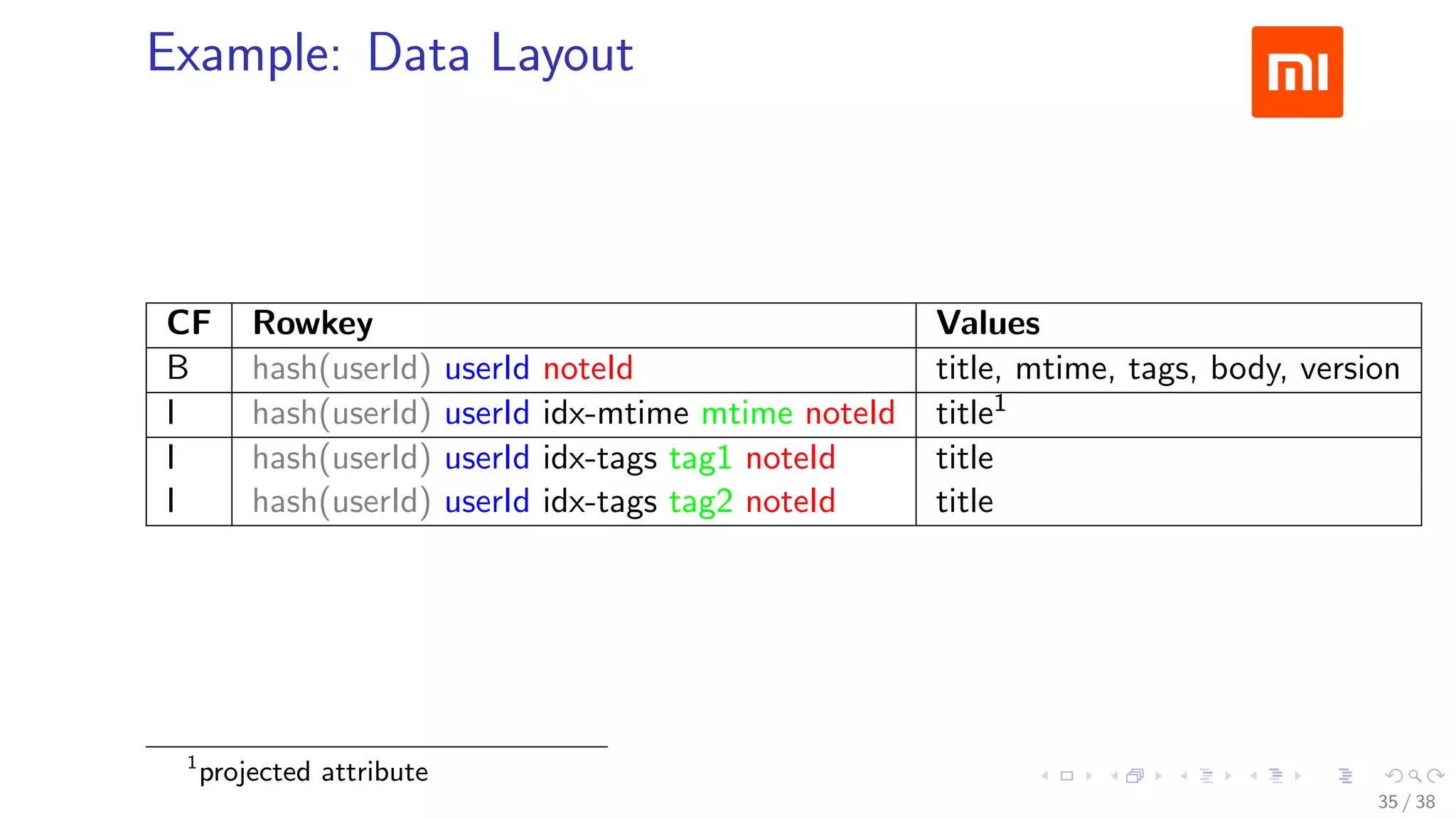
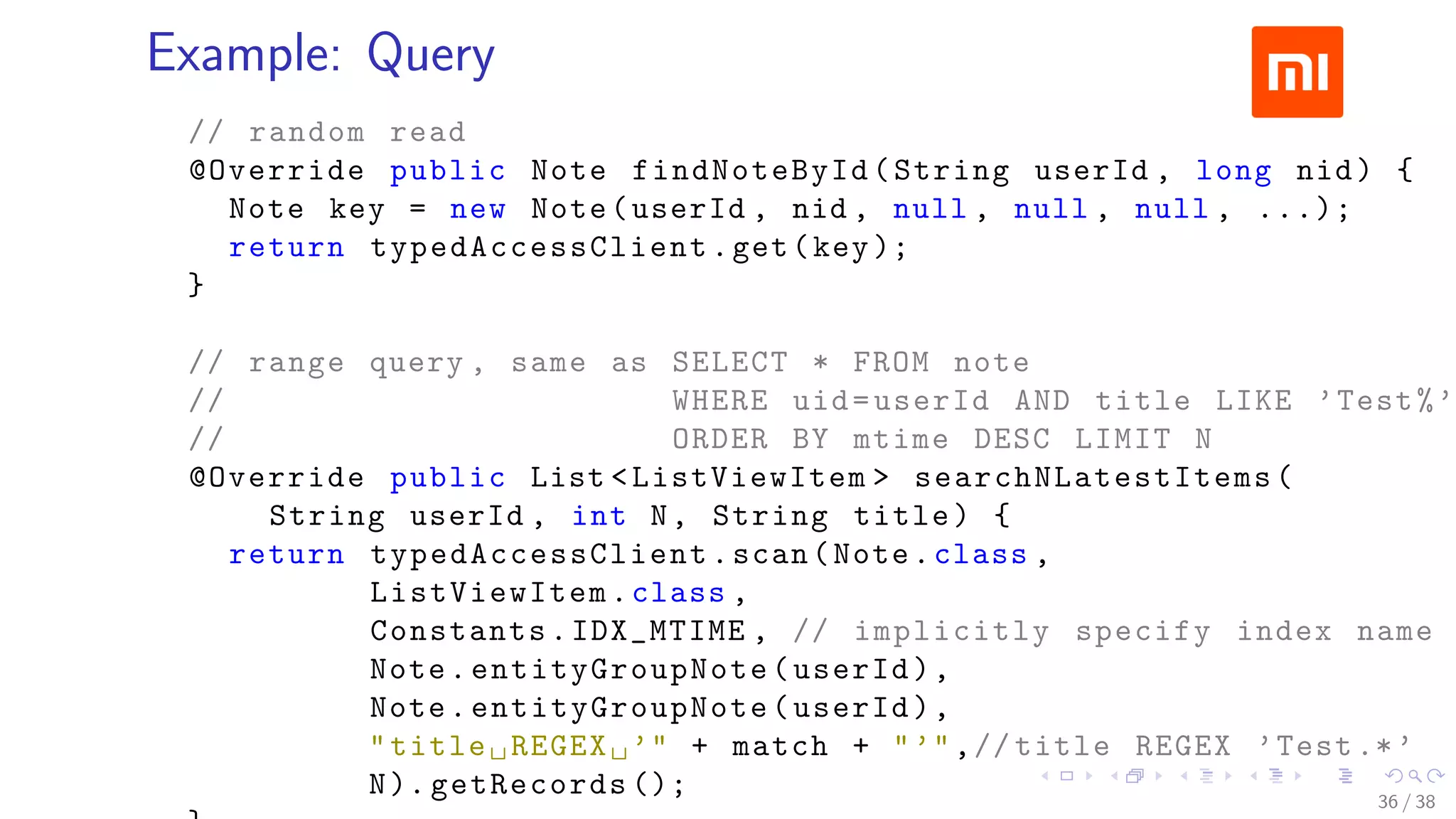



The document discusses HBase improvements and practices at Xiaomi, focusing on their HDFS/HBase team's structure and the challenges they face. Key topics include online and offline cluster scenarios, enhancing HBase performance through per-column family flushes, and the implementation of async Write Ahead Logs (WAL) to optimize data write operations. Additionally, it addresses the complexities surrounding data deletion semantics and their effects on data integrity and replication.











































































































