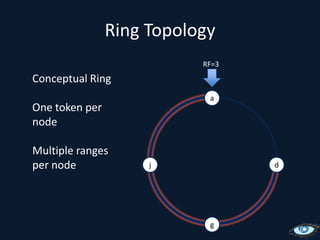
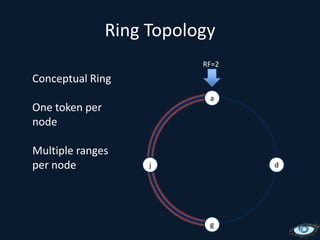
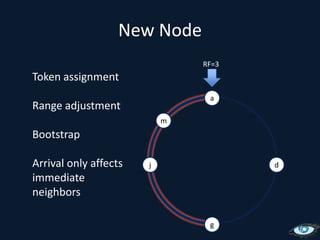
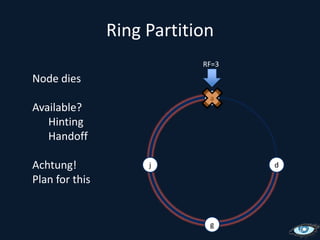
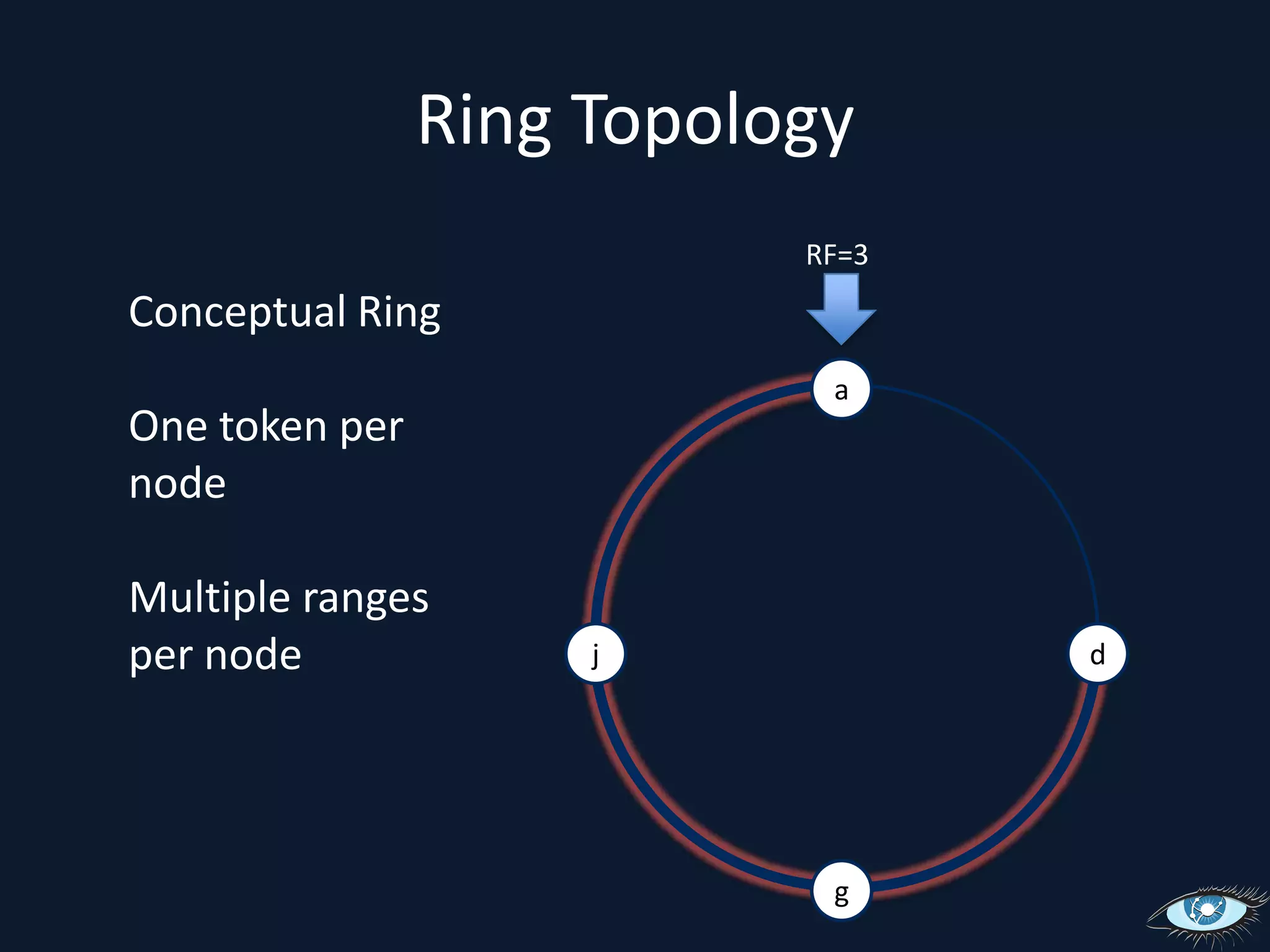
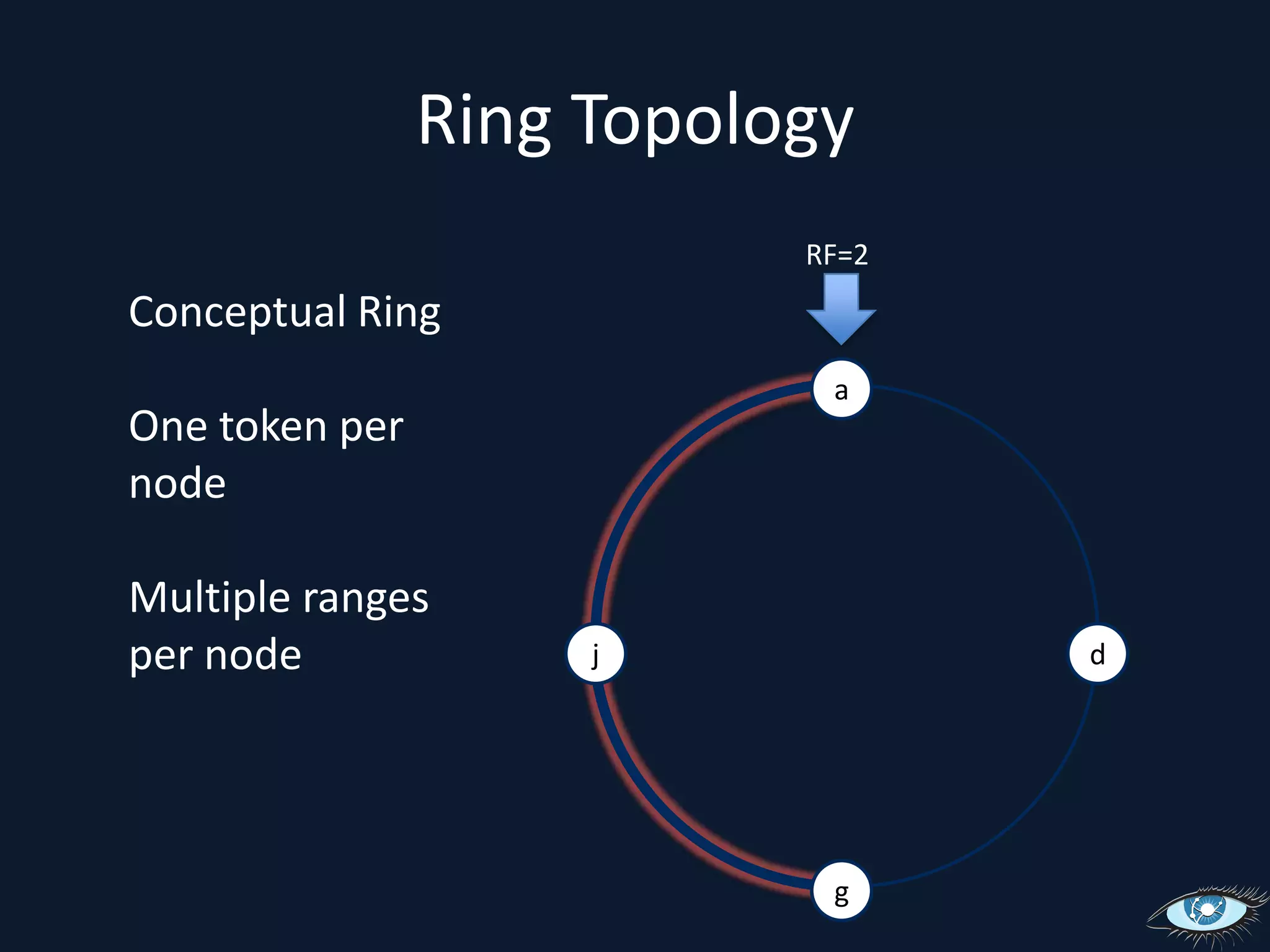
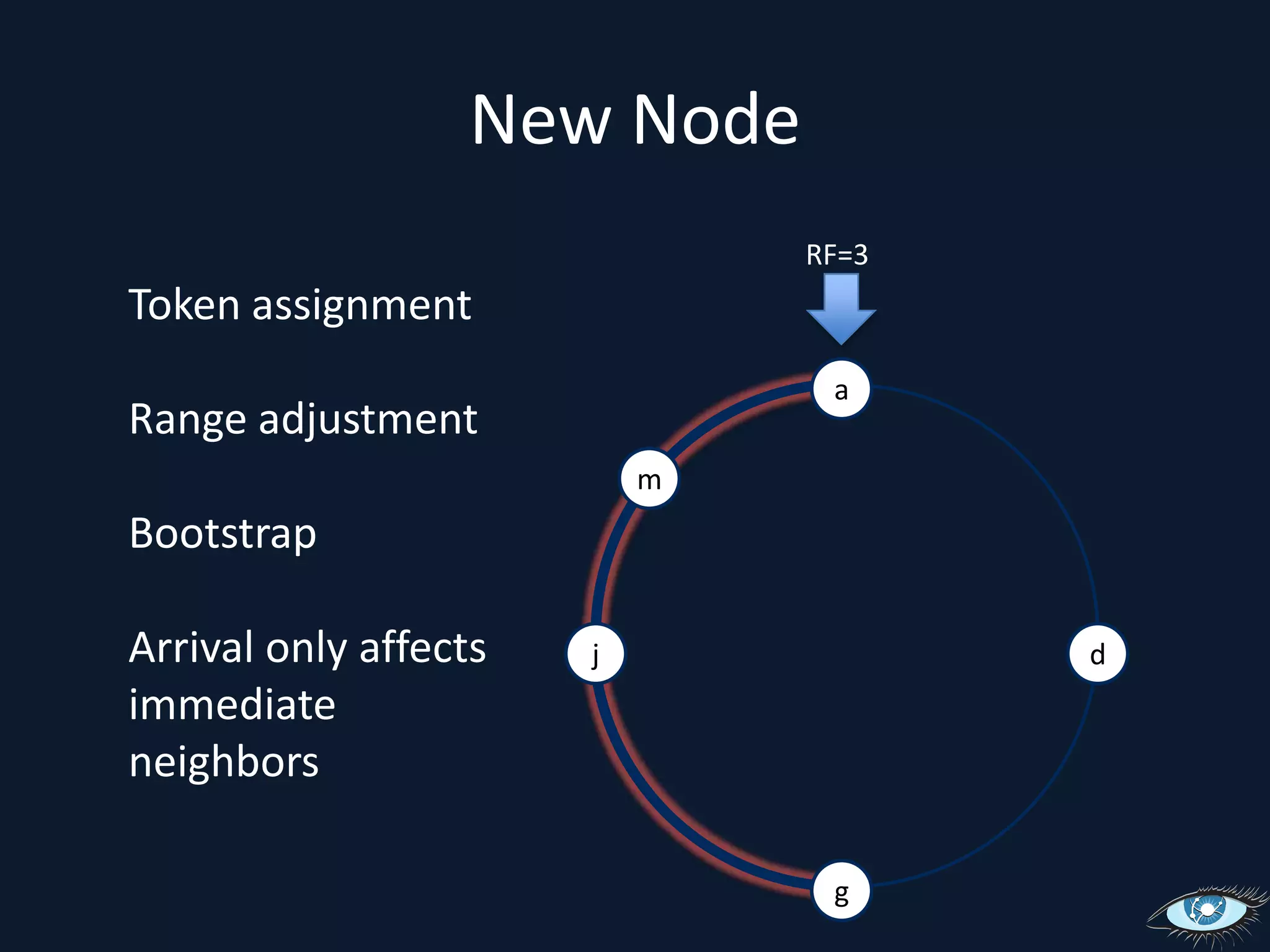
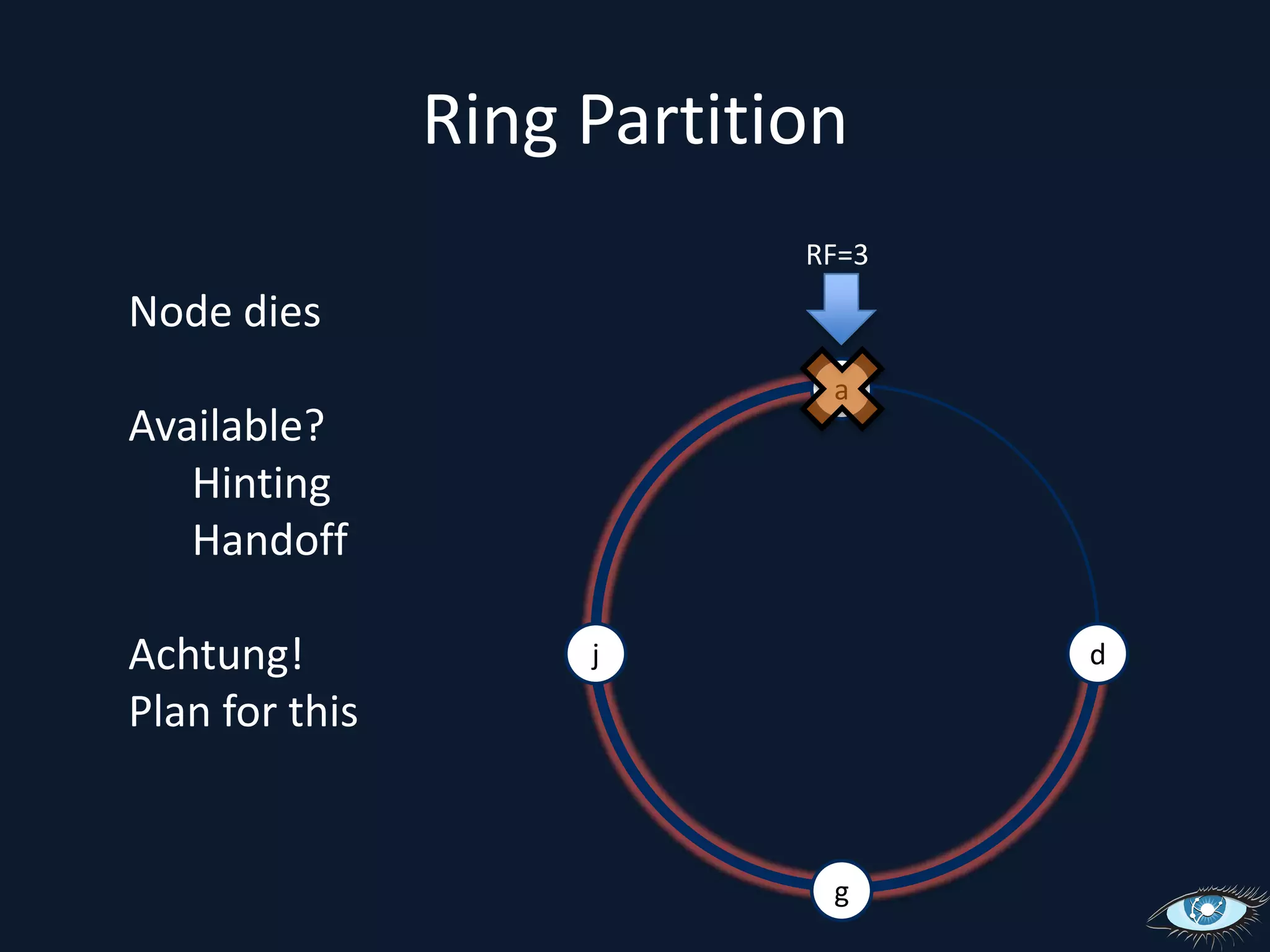
This document provides an overview of Apache Cassandra, including its origins from Amazon Dynamo and Google BigTable, its data model using a ring topology and column families, and how it provides horizontal scalability and eventual consistency through replication. It discusses Cassandra's write path using commit logs and memtables as well as its read path involving caching. It also covers client access, practical considerations, and Cassandra's future direction.























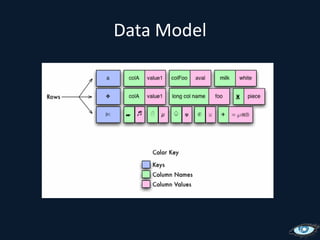






![Inserting: OverviewSimple: put(key, col, value) Complex: put(key, [col:value, …, col:value]) Batch: multi key.](https://image.slidesharecdn.com/cassandrasvccg10june2010-100618145003-phpapp02/85/Introduction-to-Cassandra-June-2010-36-320.jpg)

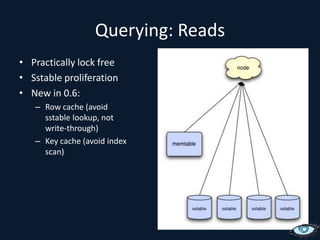































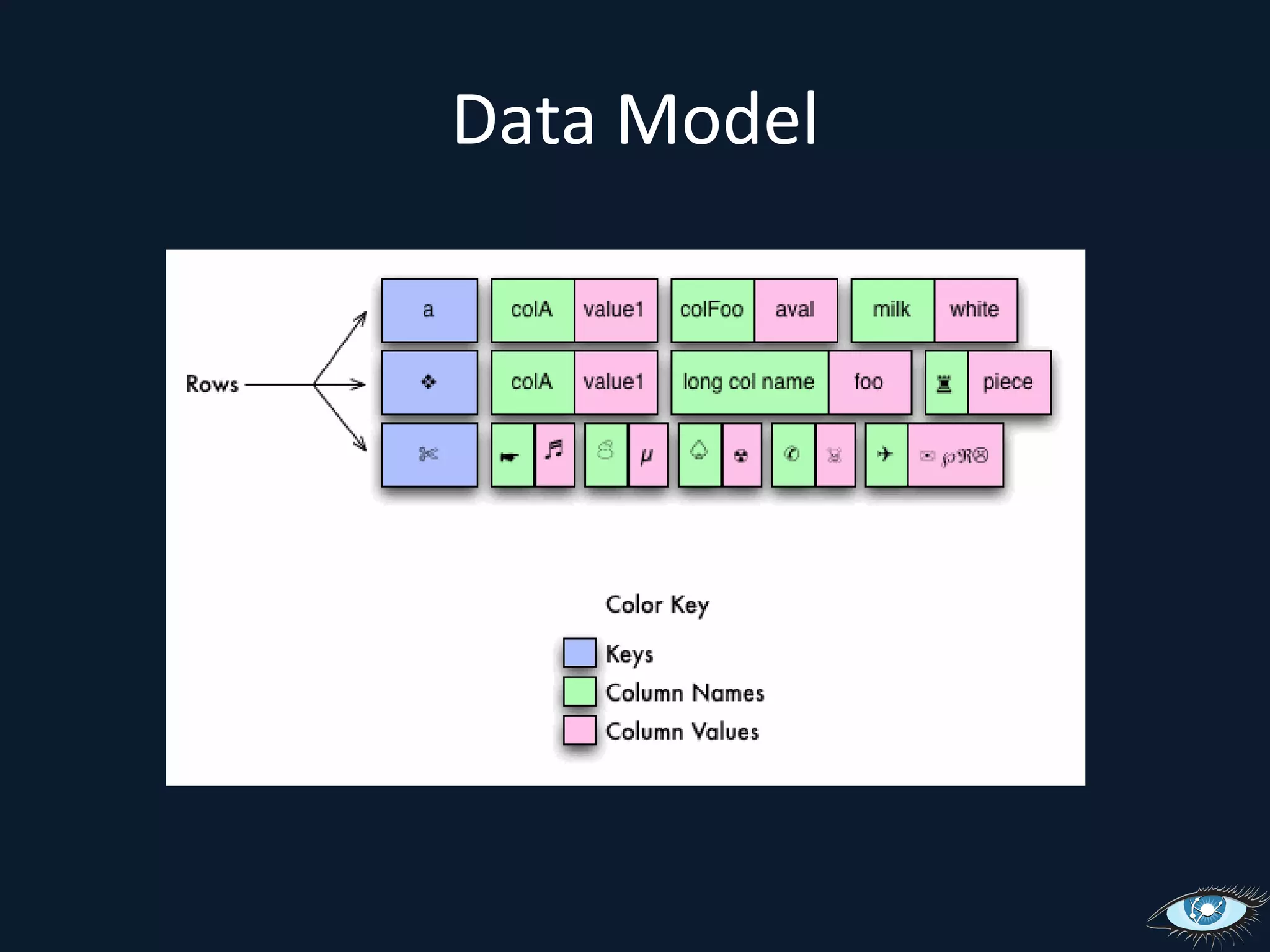






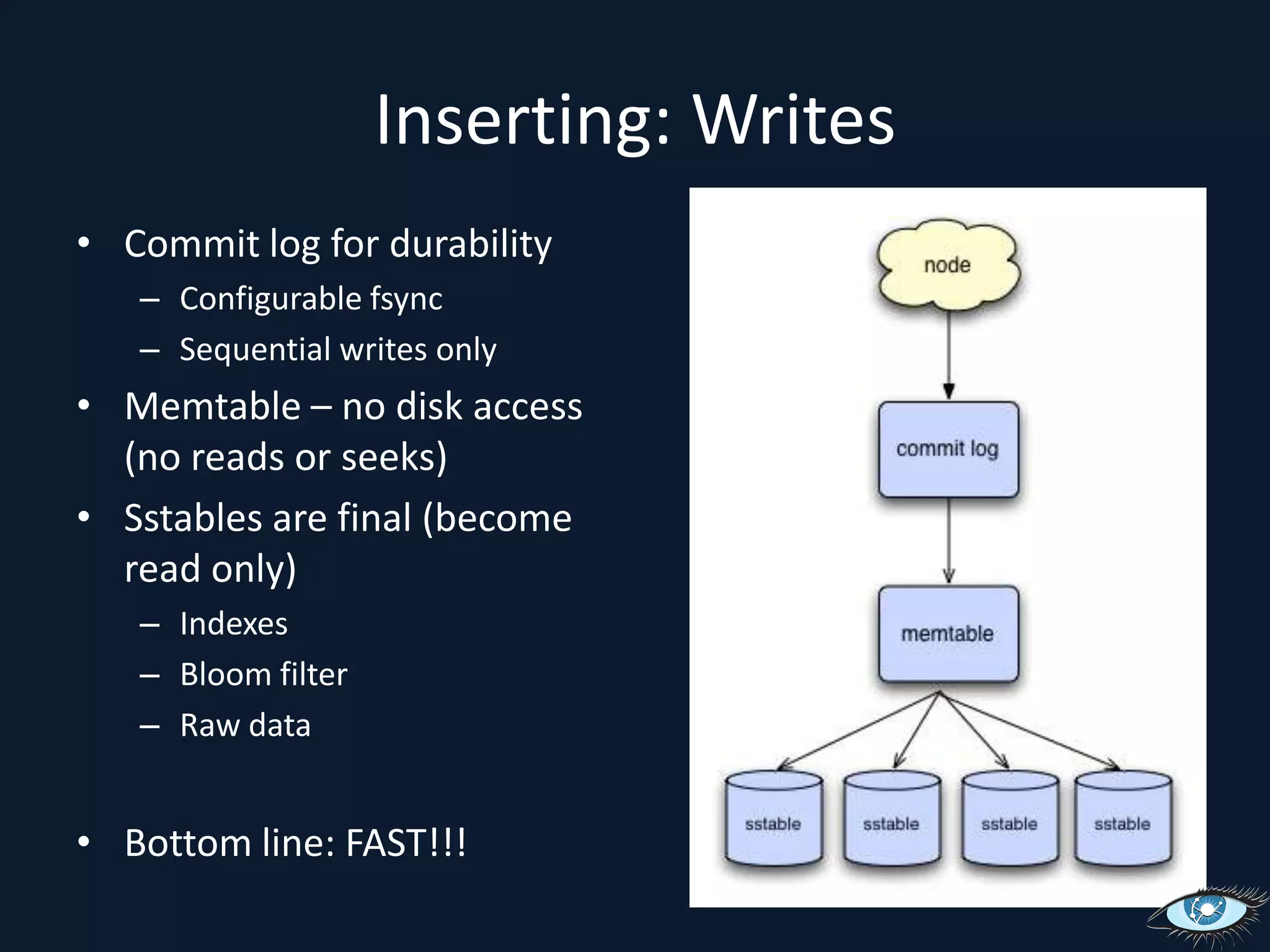
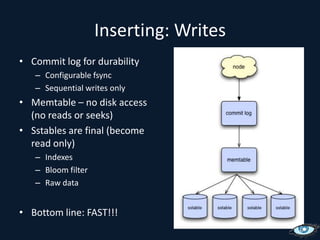
![Inserting: OverviewSimple: put(key, col, value) Complex: put(key, [col:value, …, col:value]) Batch: multi key.](https://image.slidesharecdn.com/cassandrasvccg10june2010-100618145003-phpapp02/75/Introduction-to-Cassandra-June-2010-36-2048.jpg)






































![[PASS Summit 2016] Azure DocumentDB: A Deep Dive into Advanced Features](https://cdn.slidesharecdn.com/ss_thumbnails/passdocdbadvfeatures-161029023827-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














































