Downloaded 14 times



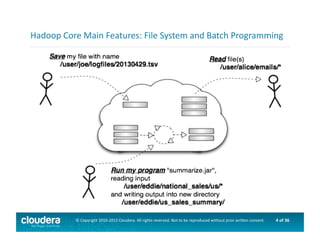

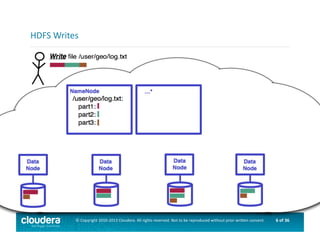
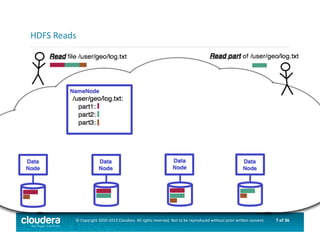

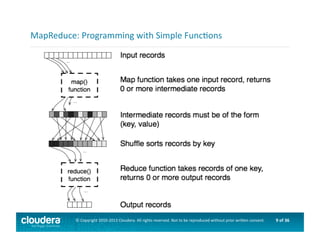
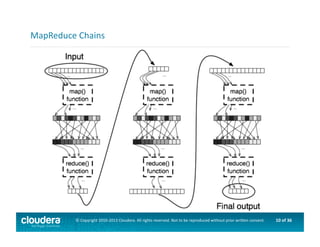
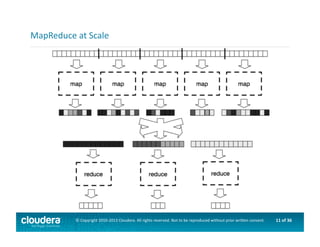
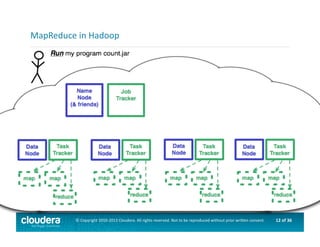

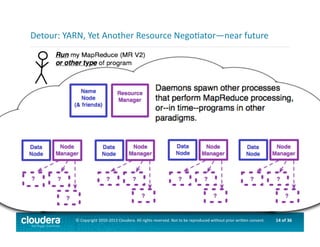

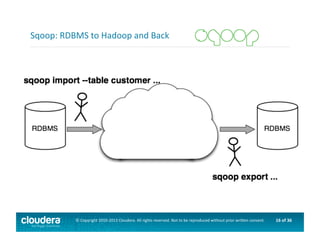
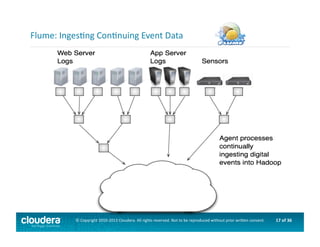
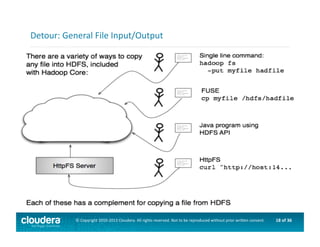
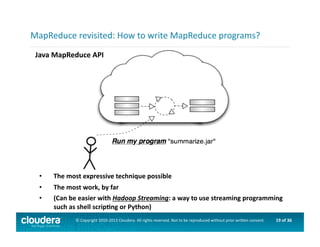
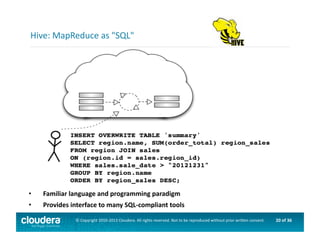

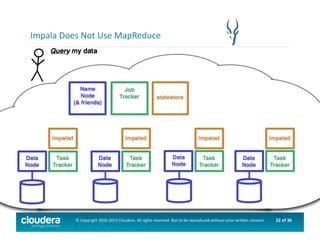





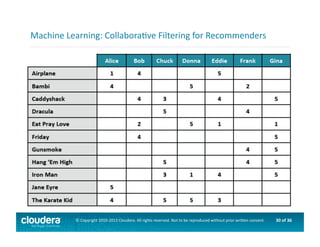
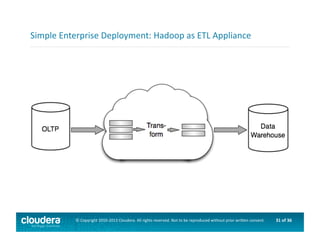
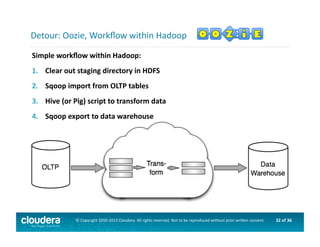
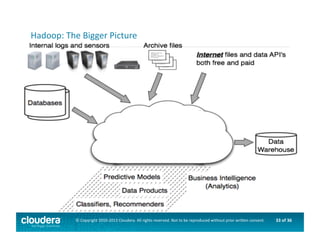






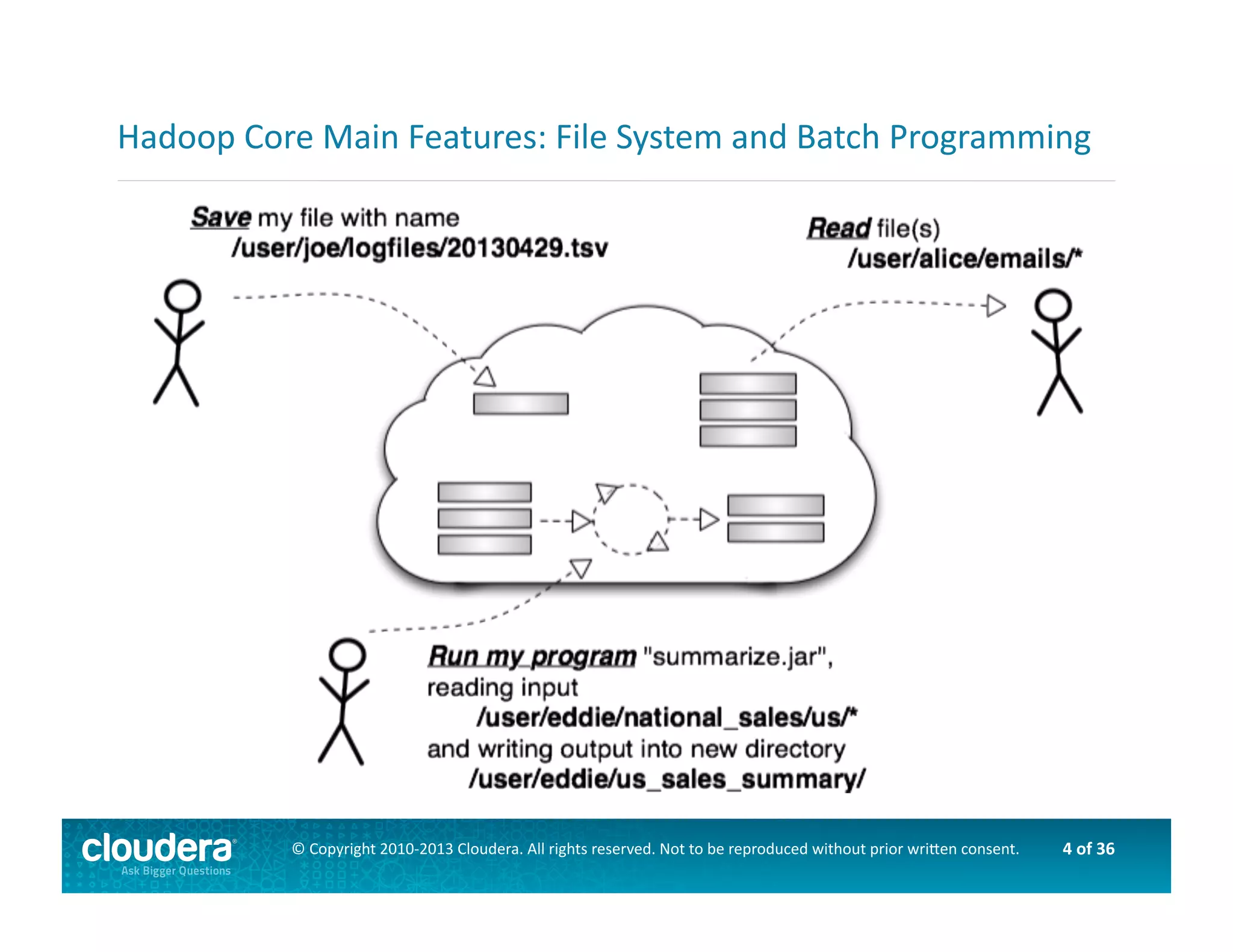

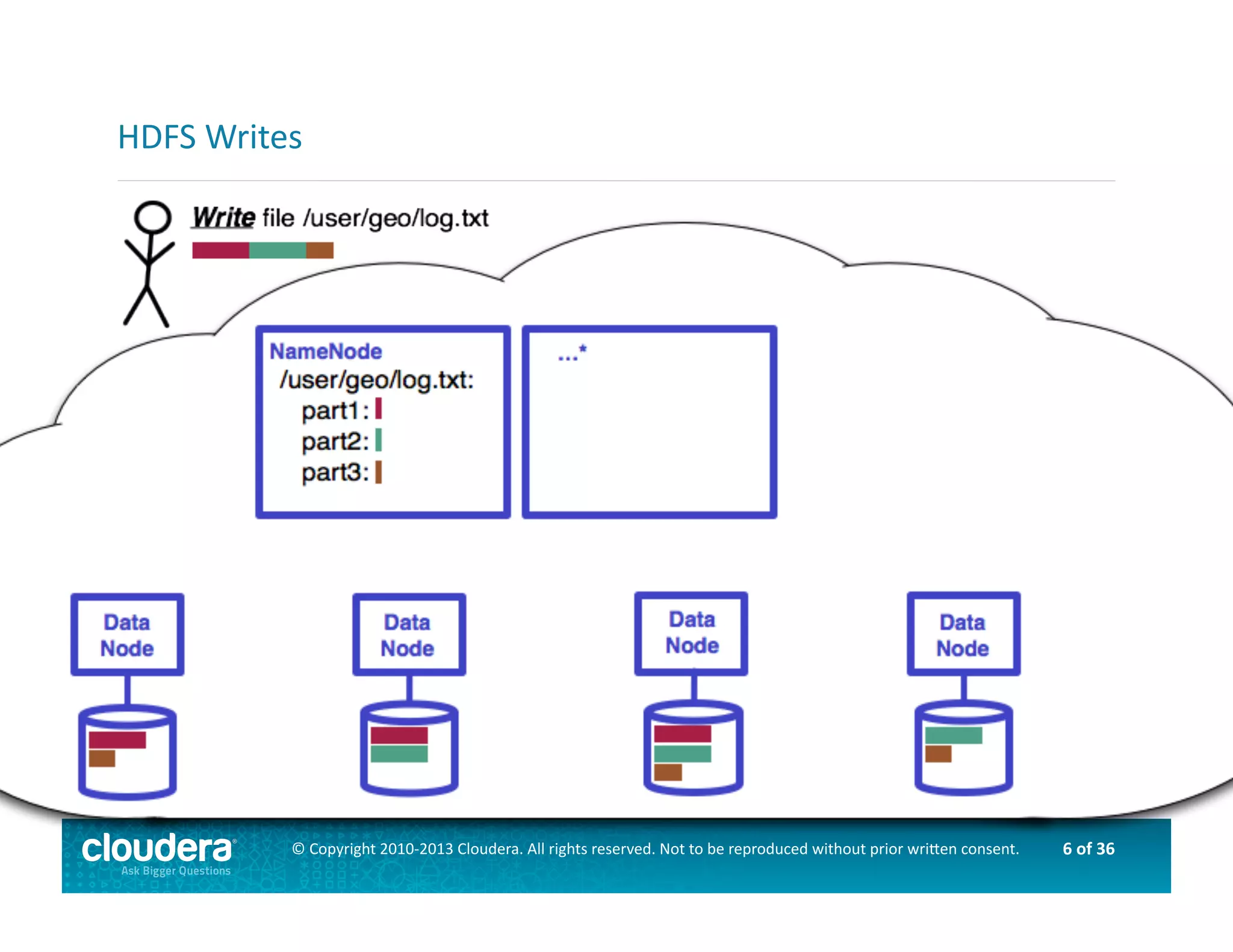
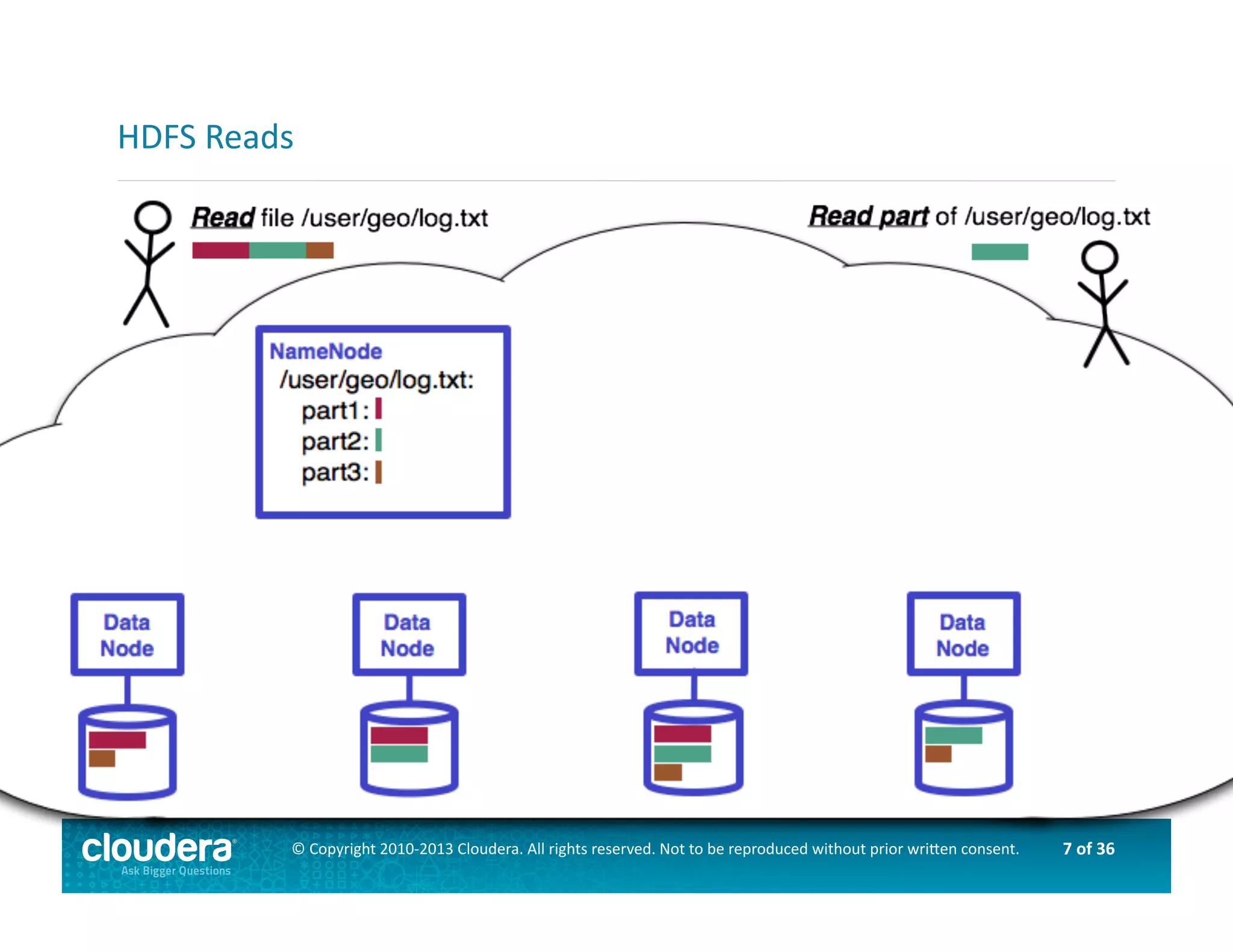

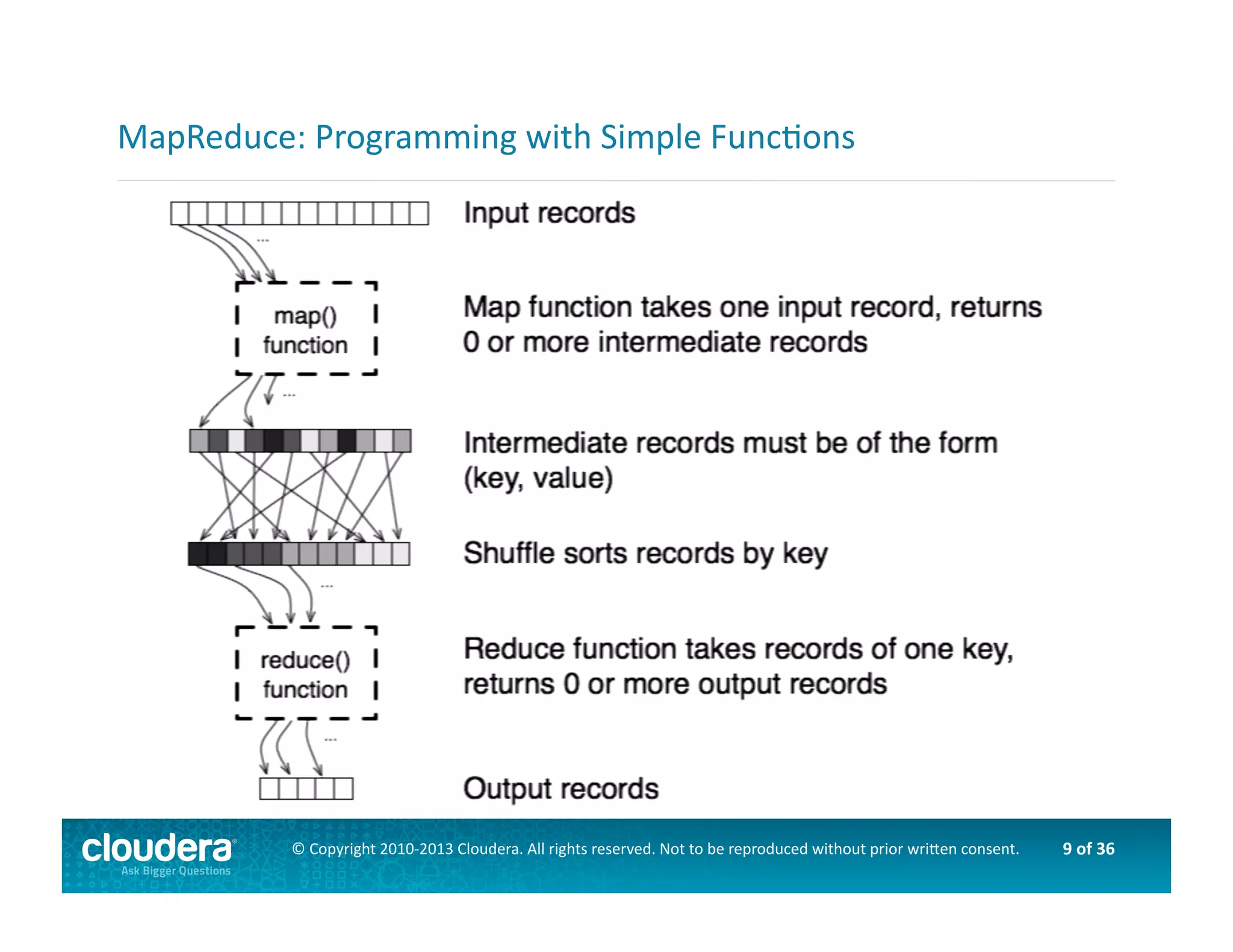
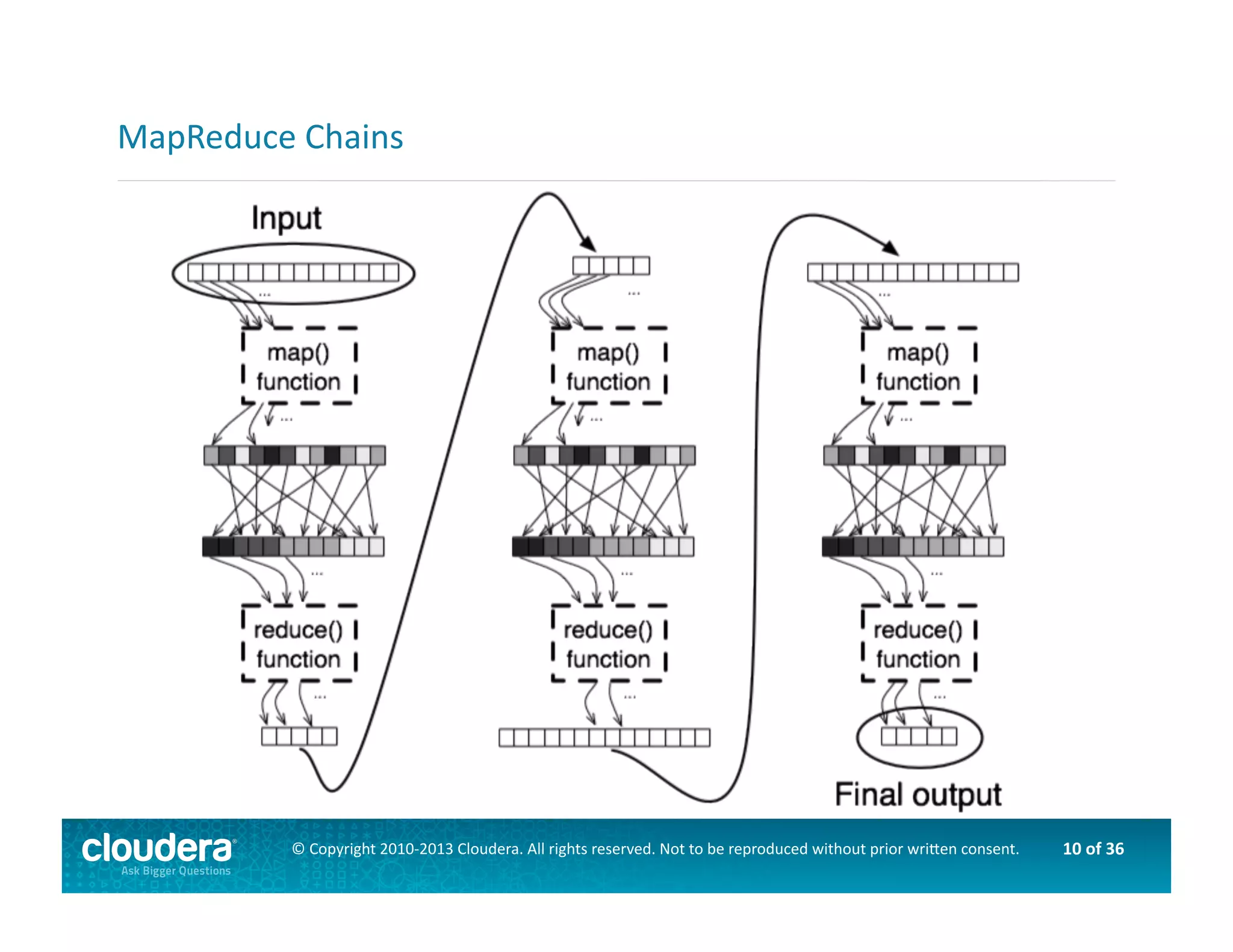
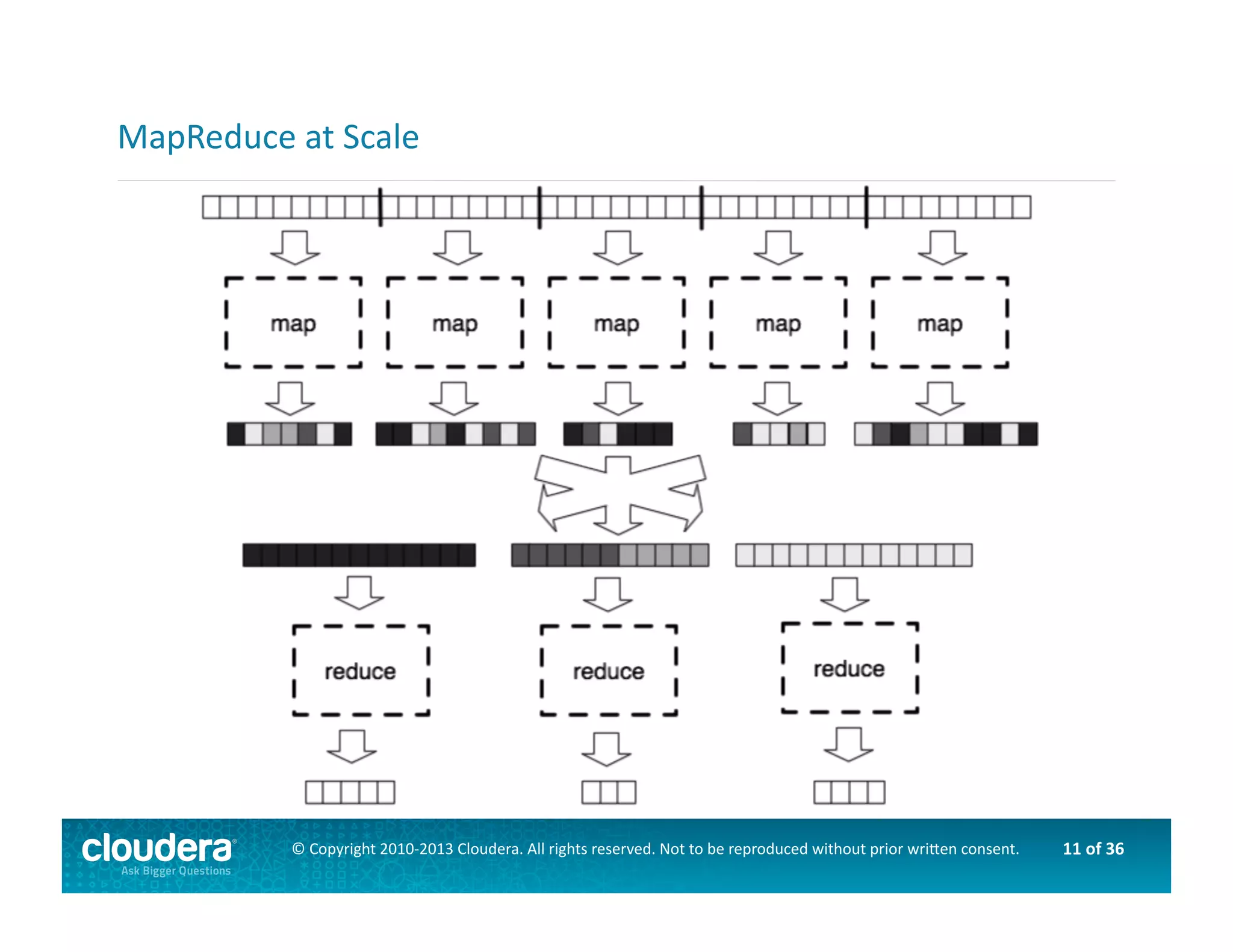
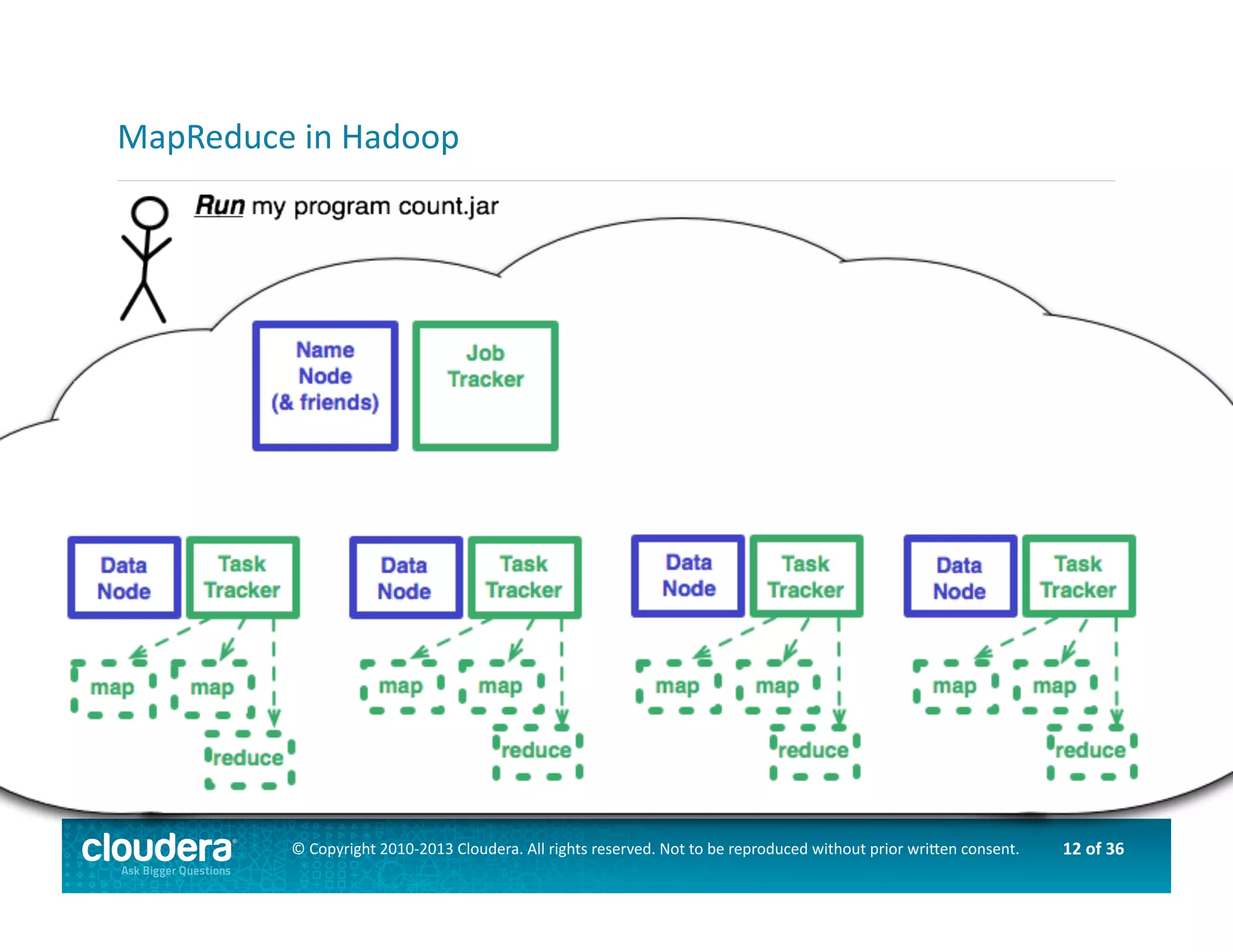

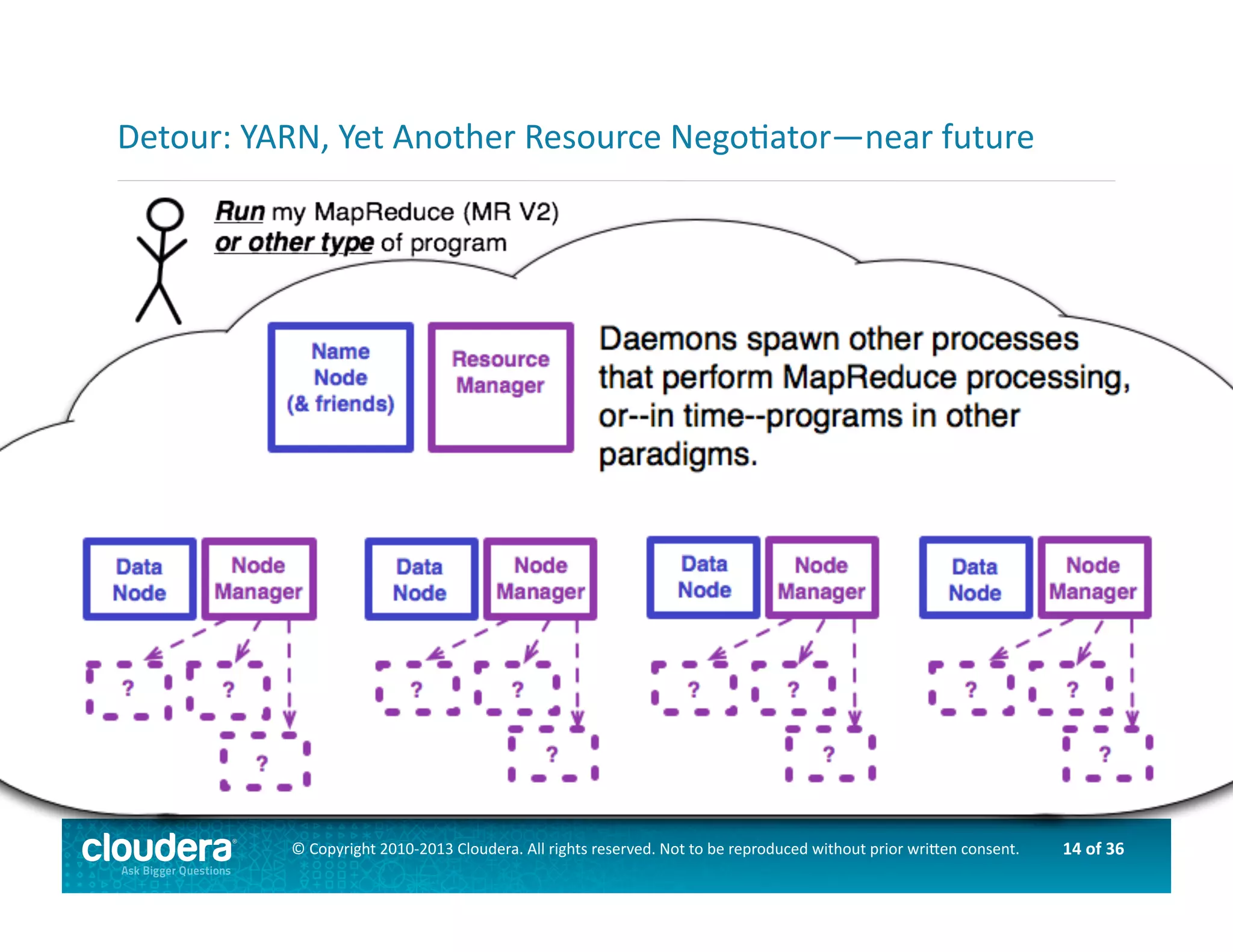

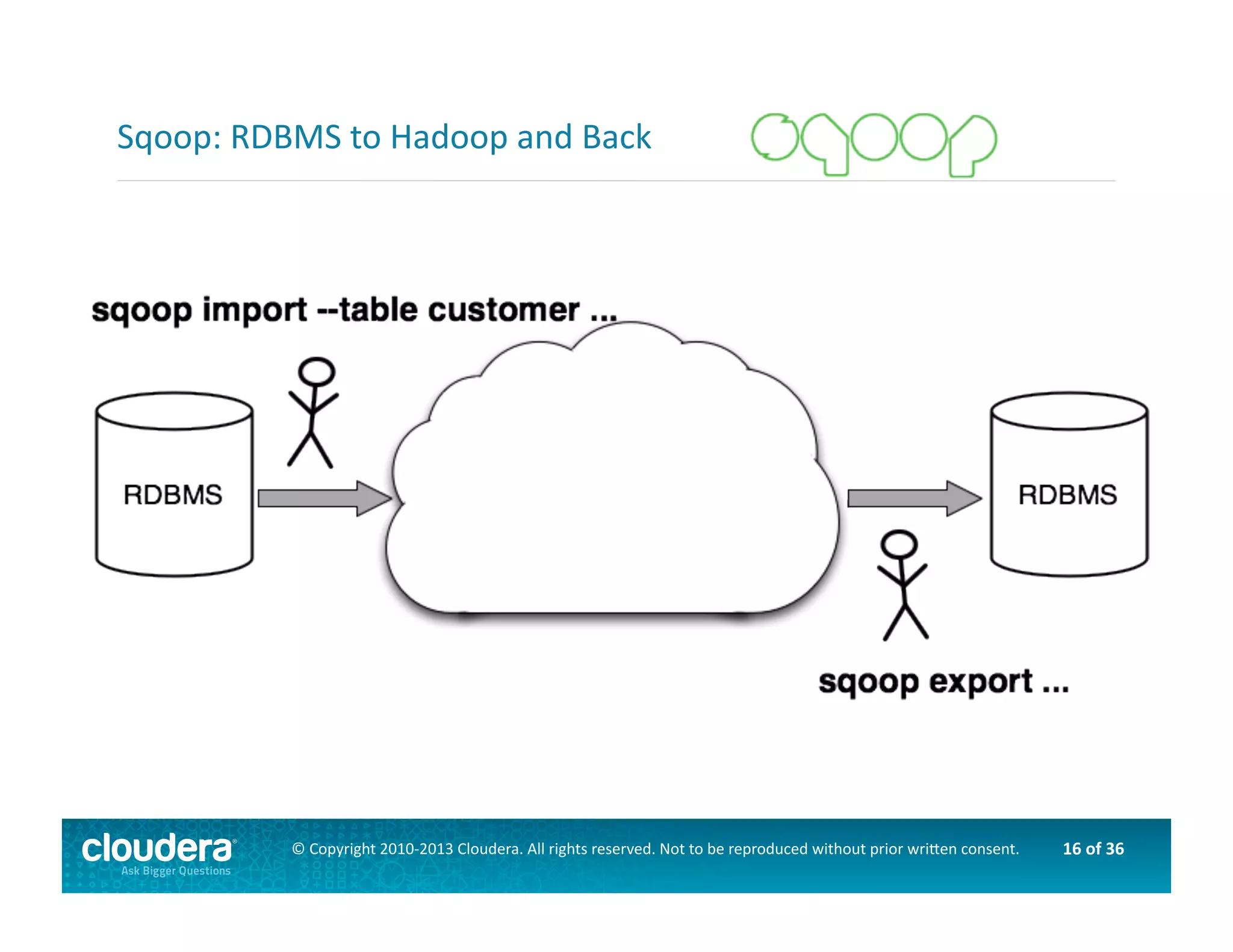
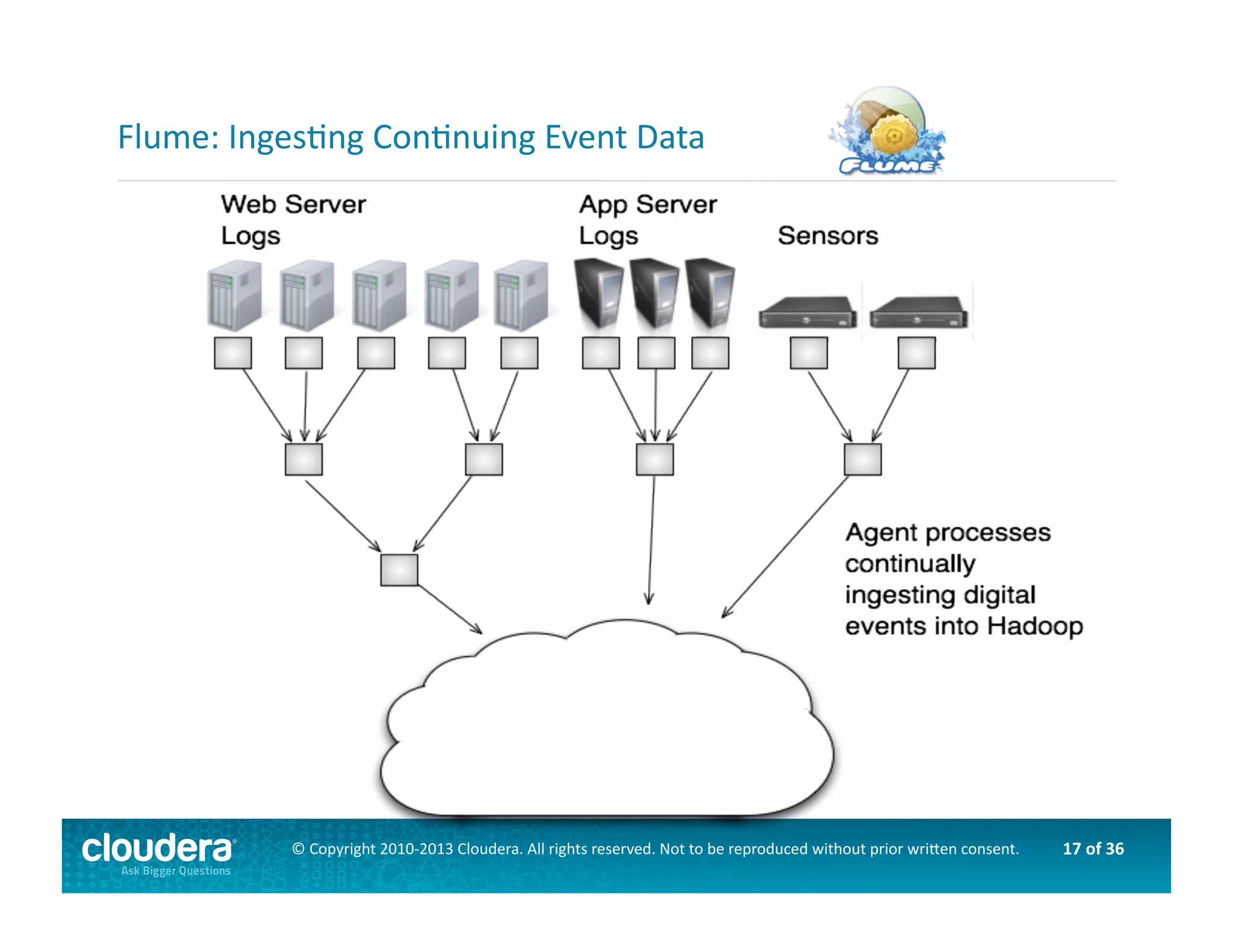
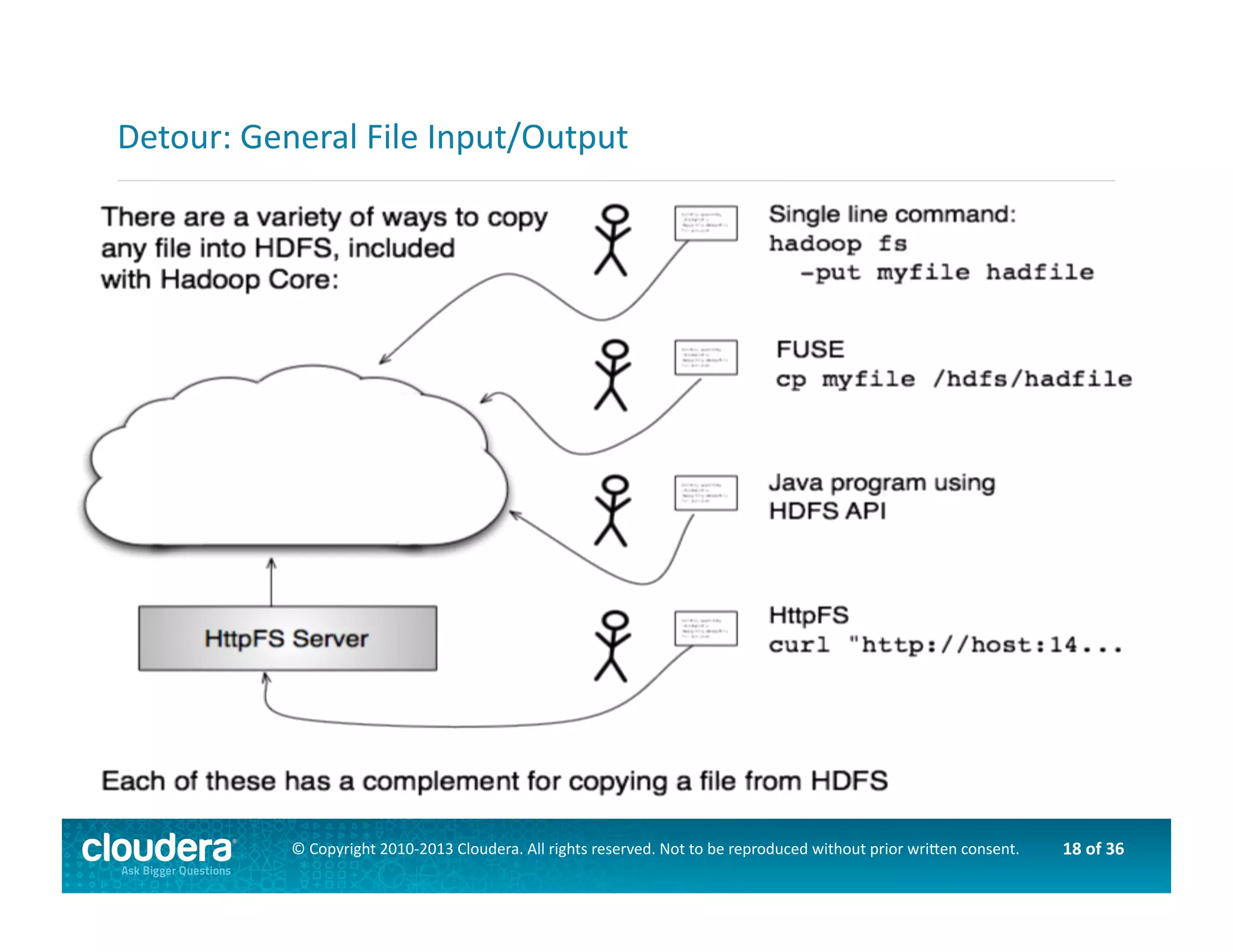
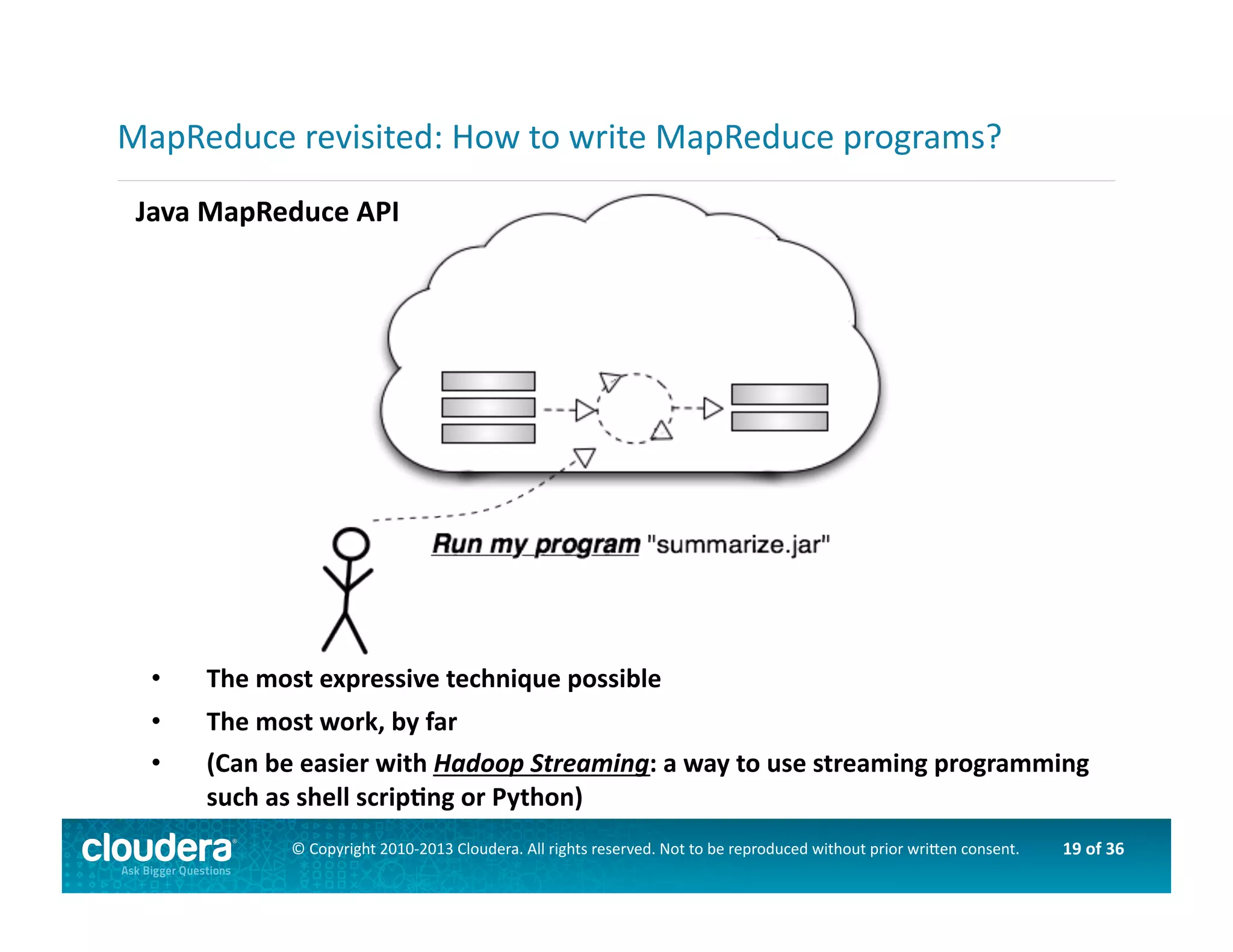
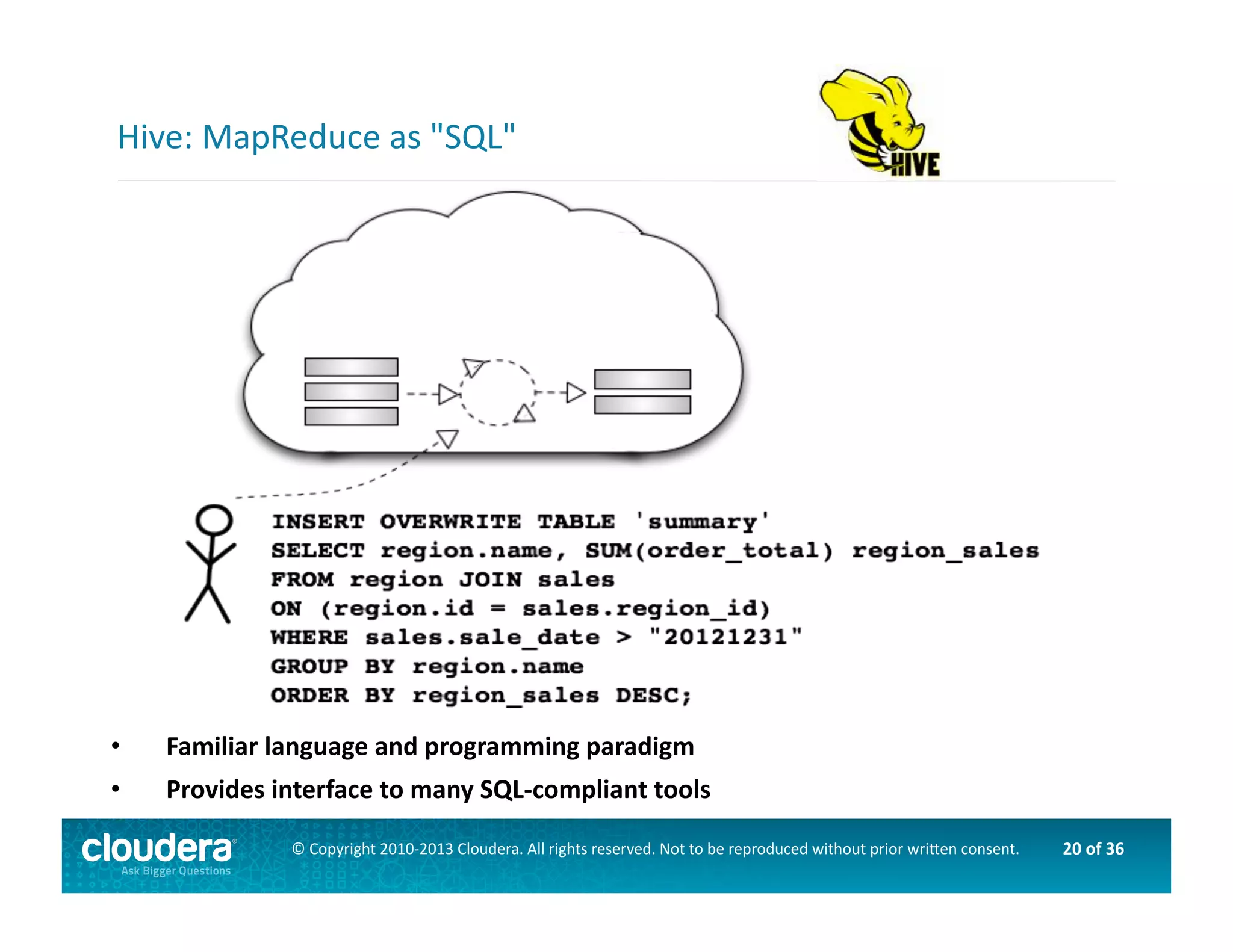

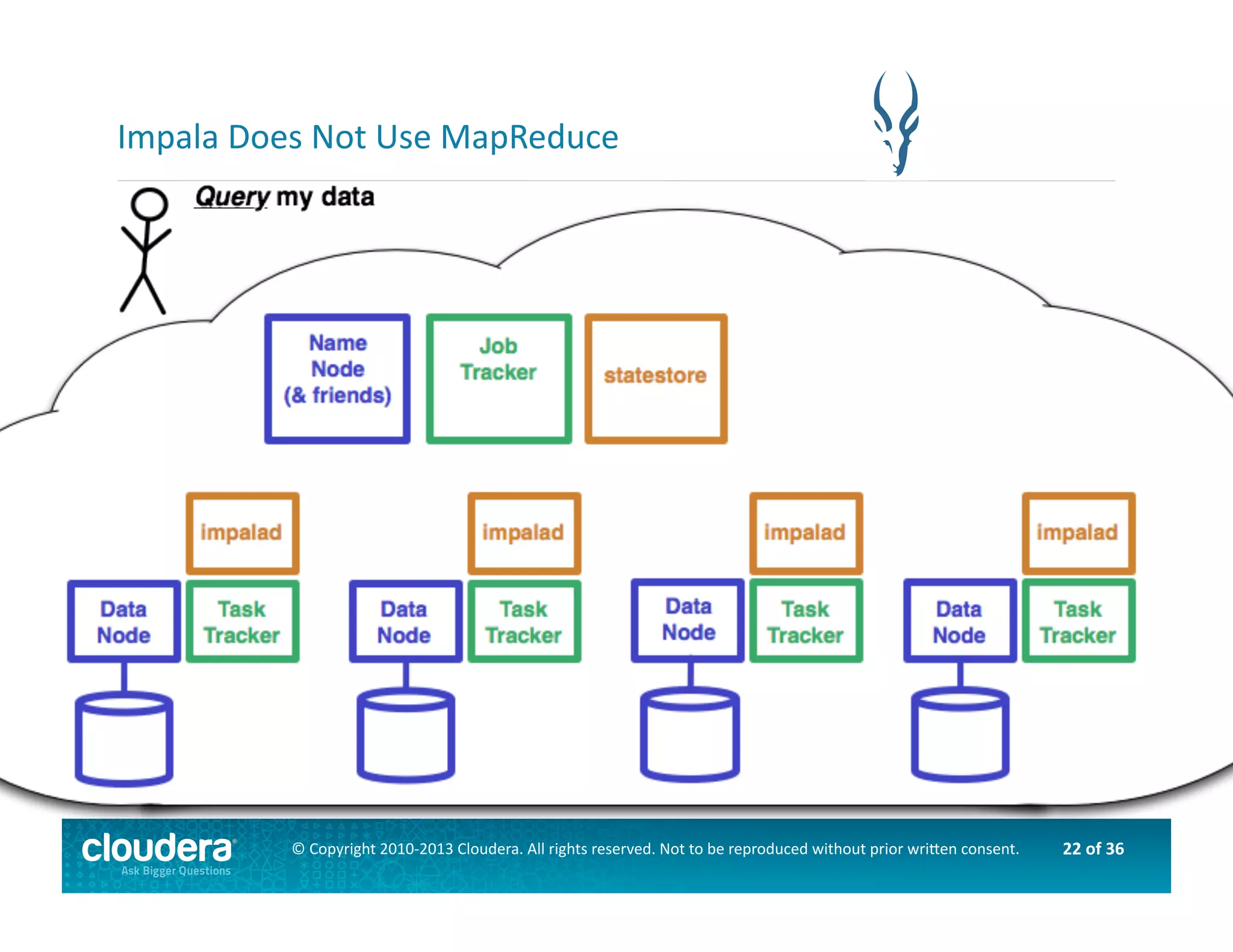
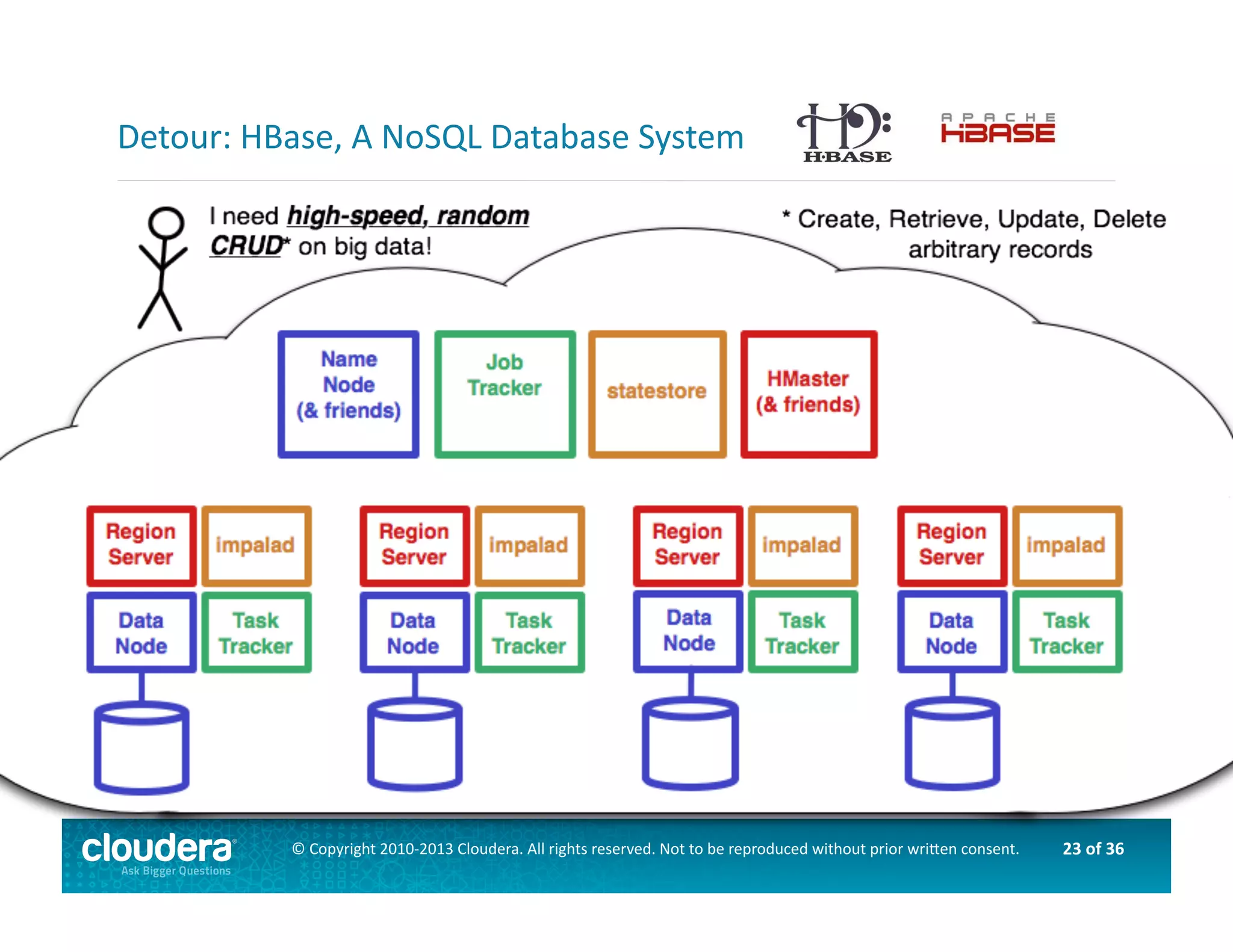



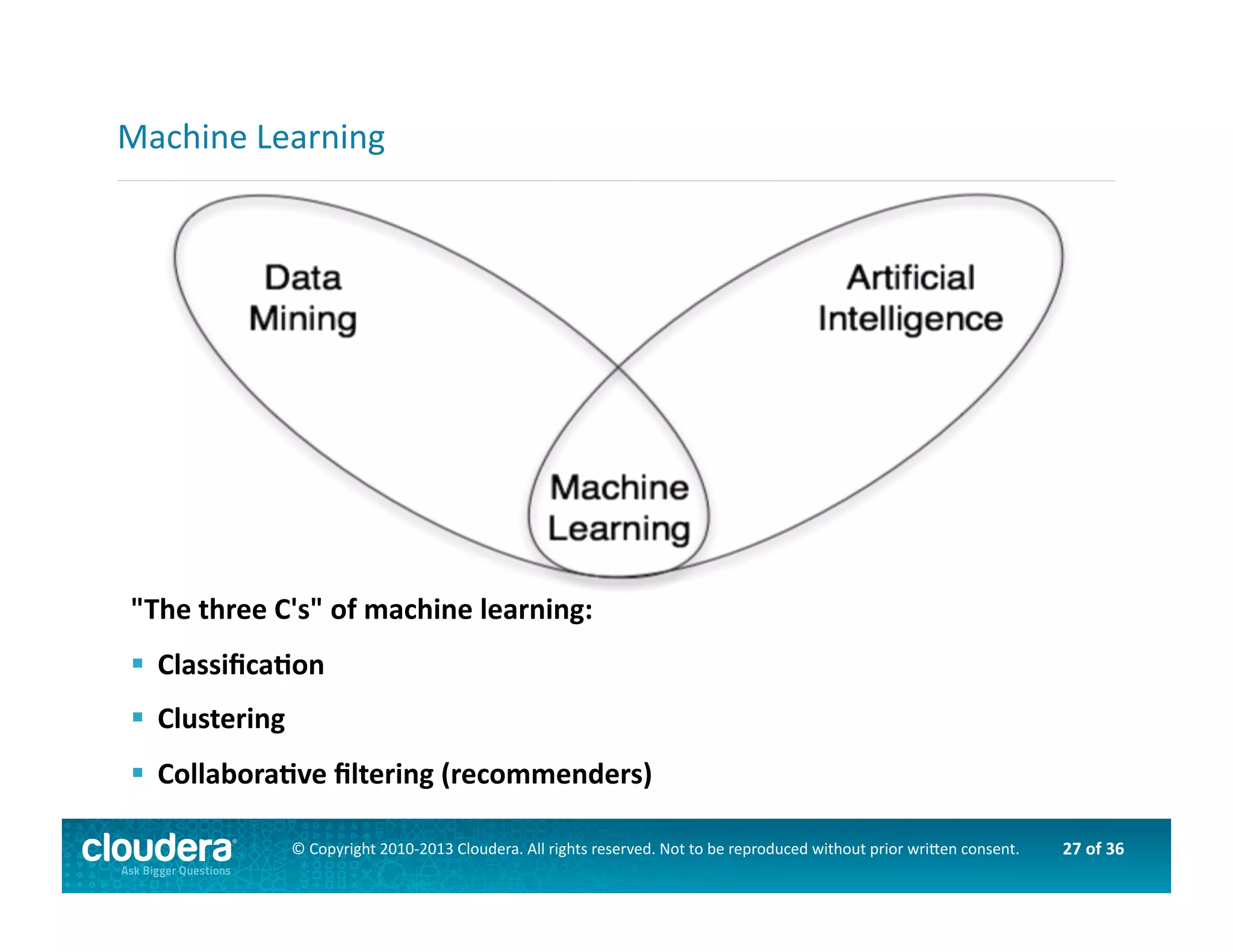

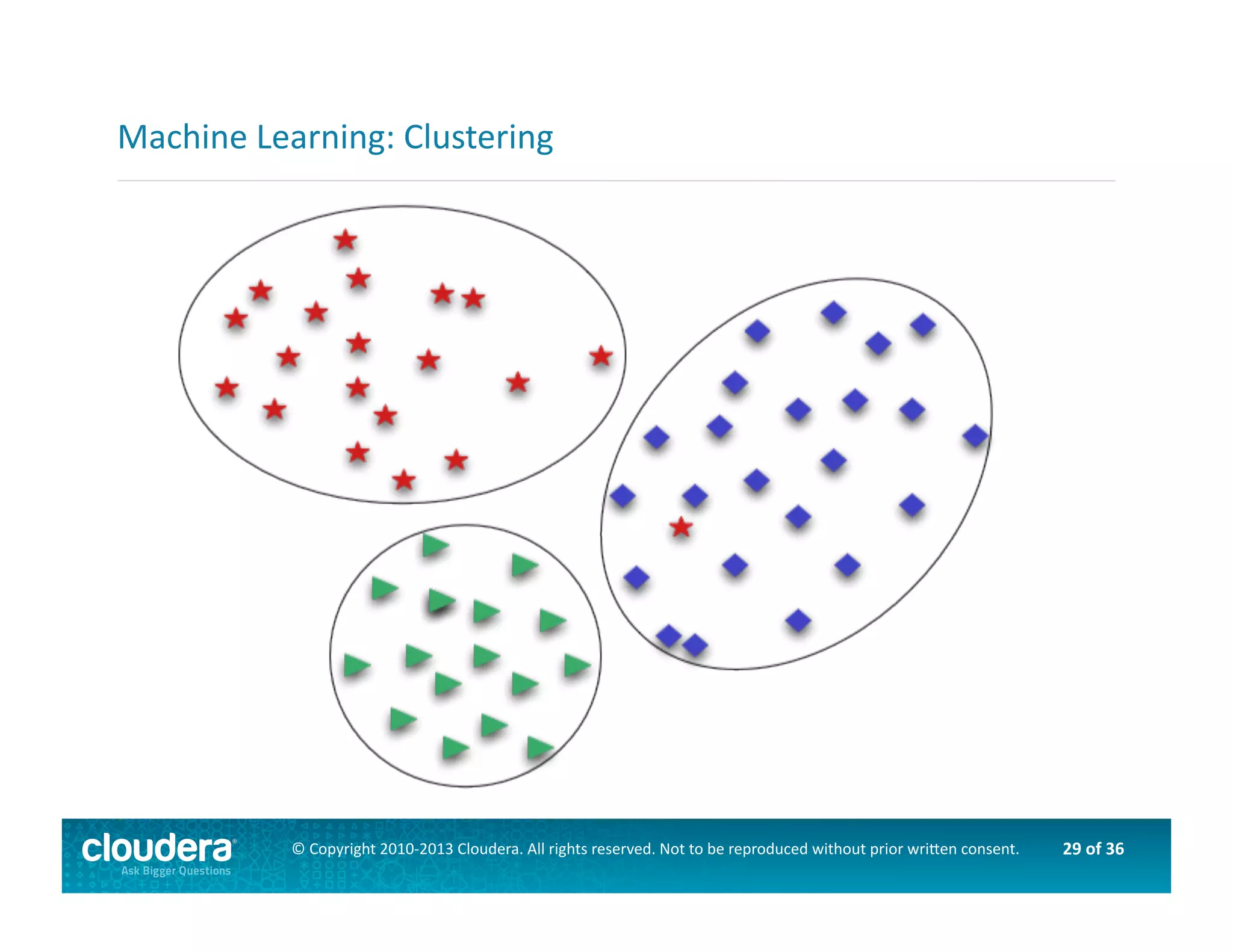
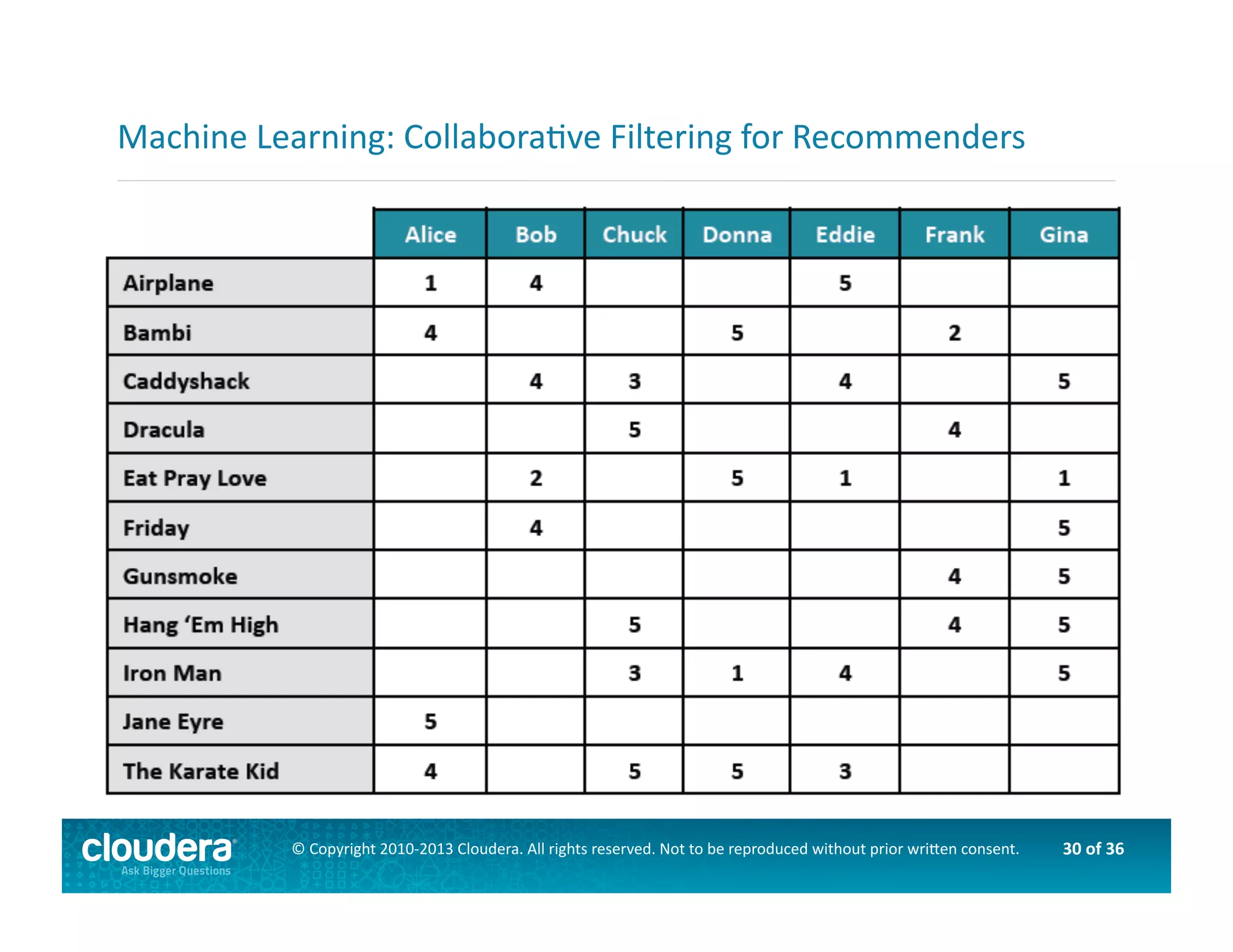
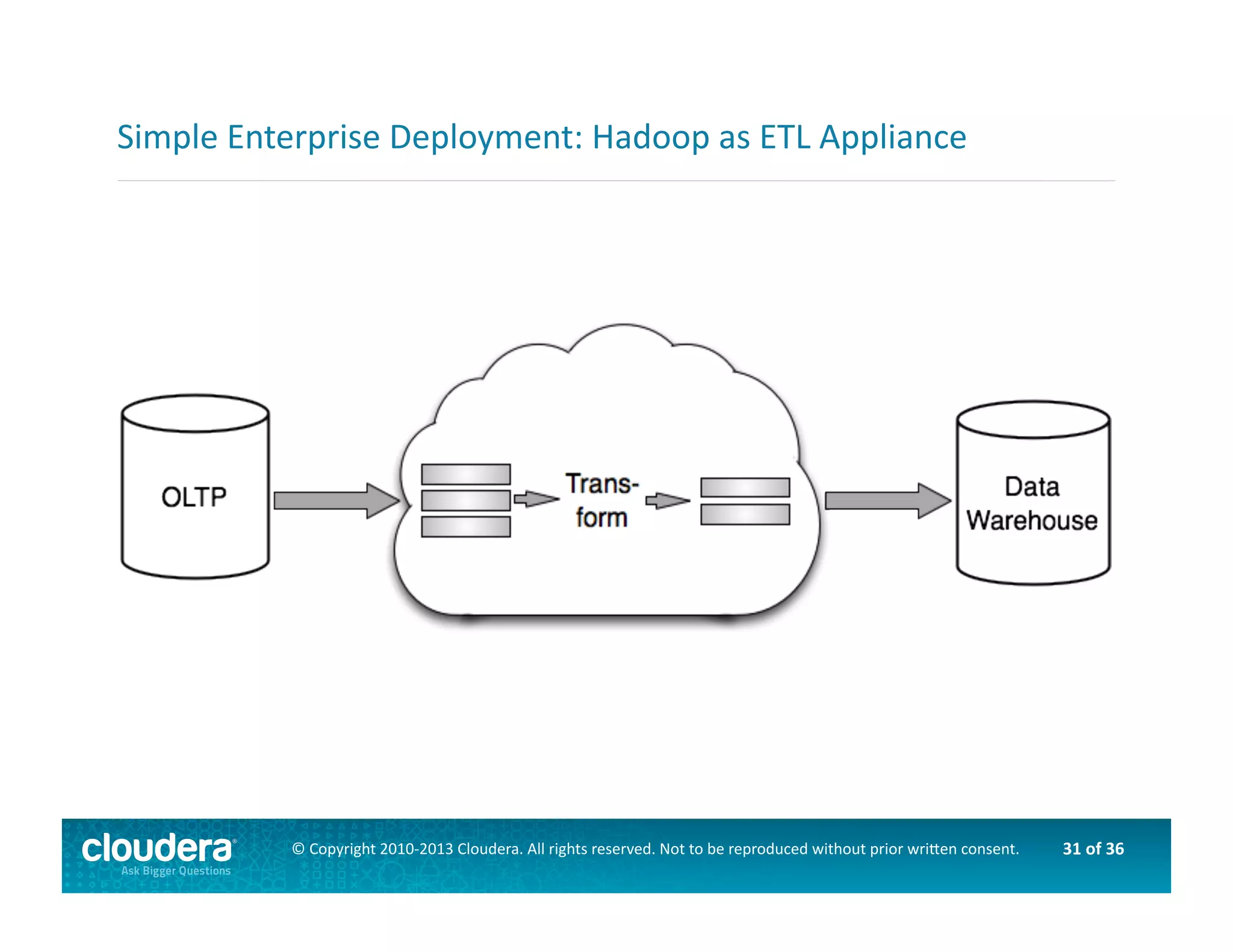
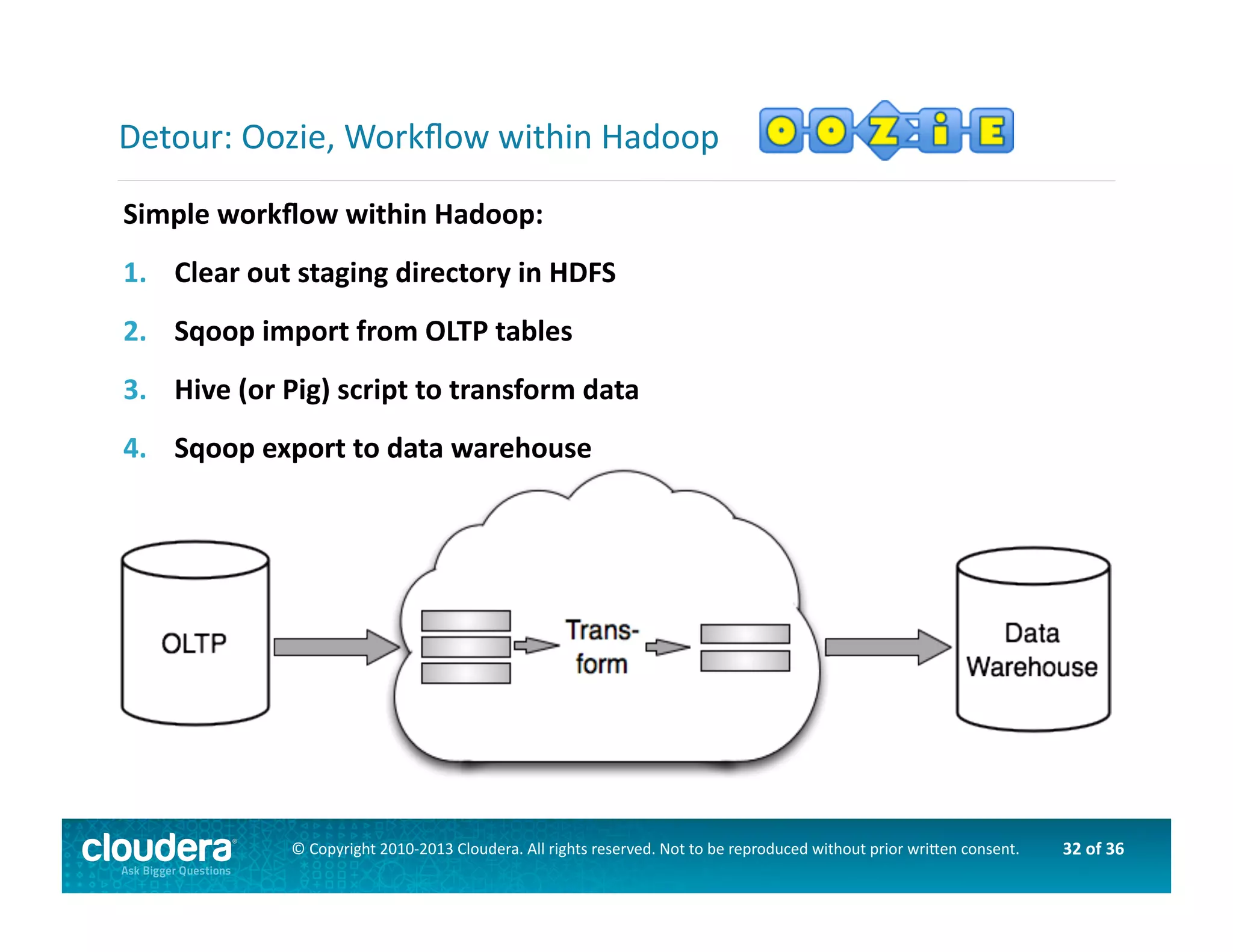
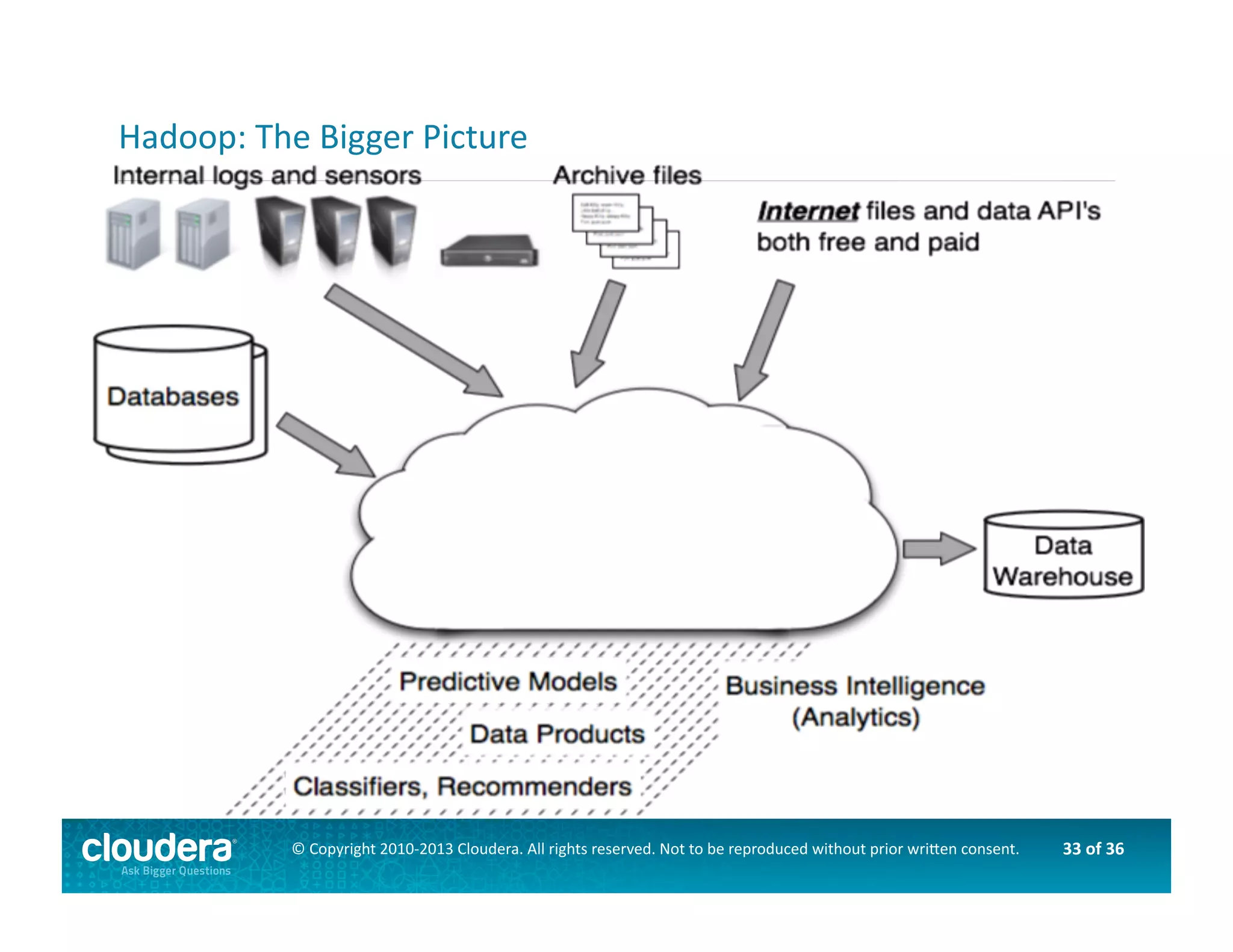




This document provides an introduction to data science using Hadoop, covering its core components like HDFS and MapReduce, as well as various ecosystem tools such as Sqoop, Flume, Hive, and Mahout. It explains the strengths and weaknesses of Hadoop's core features and describes the role of data scientists in data wrangling, exploration, modeling, and product development. Additionally, it touches upon high-level programming languages and frameworks that enhance Hadoop's functionality for data analysis.



















































































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)













![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


