Downloaded 708 times









![Analysis Process - Tokenizer
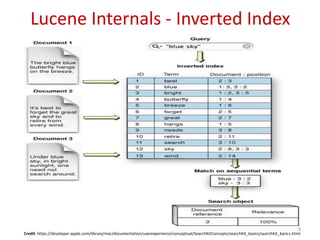
WhitespaceAnalyzer
Simplest built-in analyzer
The quick brown fox jumps over the lazy dog.
[The] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog.]
Tokens](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/85/Introduction-to-Elasticsearch-with-basics-of-Lucene-12-320.jpg)
![Analysis Process - Tokenizer
SimpleAnalyzer
Lowercases, split at non-letter boundaries
The quick brown fox jumps over the lazy dog.
[the] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog]
Tokens](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/85/Introduction-to-Elasticsearch-with-basics-of-Lucene-13-320.jpg)






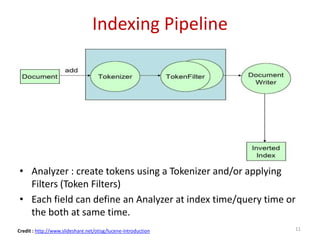
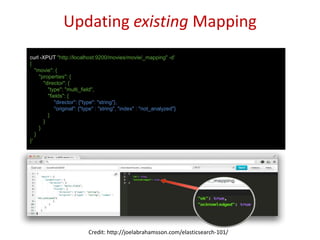
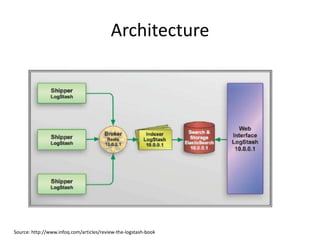
![INDEX CREATION
curl -XPUT "http://localhost:9200/movies/movie/1" -d‘ {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}'
http://localhost:9200/<index>/<type>/[<id>]
Credit: http://joelabrahamsson.com/elasticsearch-101/](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/85/Introduction-to-Elasticsearch-with-basics-of-Lucene-21-320.jpg)

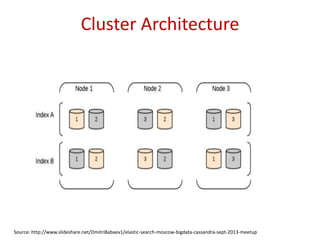
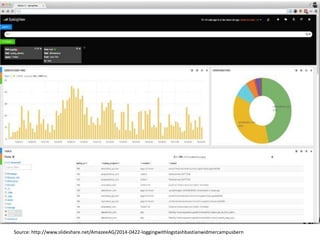
![UPDATE
curl -XPUT "http://localhost:9200/movies/movie/1" -d' {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
Updated Version
Credit: http://joelabrahamsson.com/elasticsearch-101/
New field](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/85/Introduction-to-Elasticsearch-with-basics-of-Lucene-23-320.jpg)



















![Analysis Process - Tokenizer
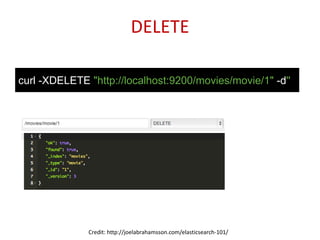
WhitespaceAnalyzer
Simplest built-in analyzer
The quick brown fox jumps over the lazy dog.
[The] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog.]
Tokens](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/75/Introduction-to-Elasticsearch-with-basics-of-Lucene-12-2048.jpg)
![Analysis Process - Tokenizer
SimpleAnalyzer
Lowercases, split at non-letter boundaries
The quick brown fox jumps over the lazy dog.
[the] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog]
Tokens](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/75/Introduction-to-Elasticsearch-with-basics-of-Lucene-13-2048.jpg)






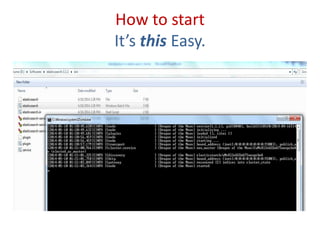
![INDEX CREATION
curl -XPUT "http://localhost:9200/movies/movie/1" -d‘ {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972
}'
http://localhost:9200/<index>/<type>/[<id>]
Credit: http://joelabrahamsson.com/elasticsearch-101/](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/75/Introduction-to-Elasticsearch-with-basics-of-Lucene-21-2048.jpg)

![UPDATE
curl -XPUT "http://localhost:9200/movies/movie/1" -d' {
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year": 1972,
"genres": ["Crime", "Drama"]
}'
Updated Version
Credit: http://joelabrahamsson.com/elasticsearch-101/
New field](https://image.slidesharecdn.com/introductiontoelasticsearchwithbasicsoflucene-140512000323-phpapp02/75/Introduction-to-Elasticsearch-with-basics-of-Lucene-23-2048.jpg)












Rahul Jain gives an introduction to Elasticsearch and its basic concepts like term frequency, inverse document frequency, and boosting. He describes Lucene as a fast, scalable search library that uses inverted indexes. Elasticsearch is introduced as an open source search platform built on Lucene that provides distributed indexing, replication, and load balancing. Logstash and Kibana are also briefly described as tools for collecting, parsing, and visualizing logs in Elasticsearch.
Overview of the presentation and background of the speaker, highlighting experience in software engineering and information retrieval.
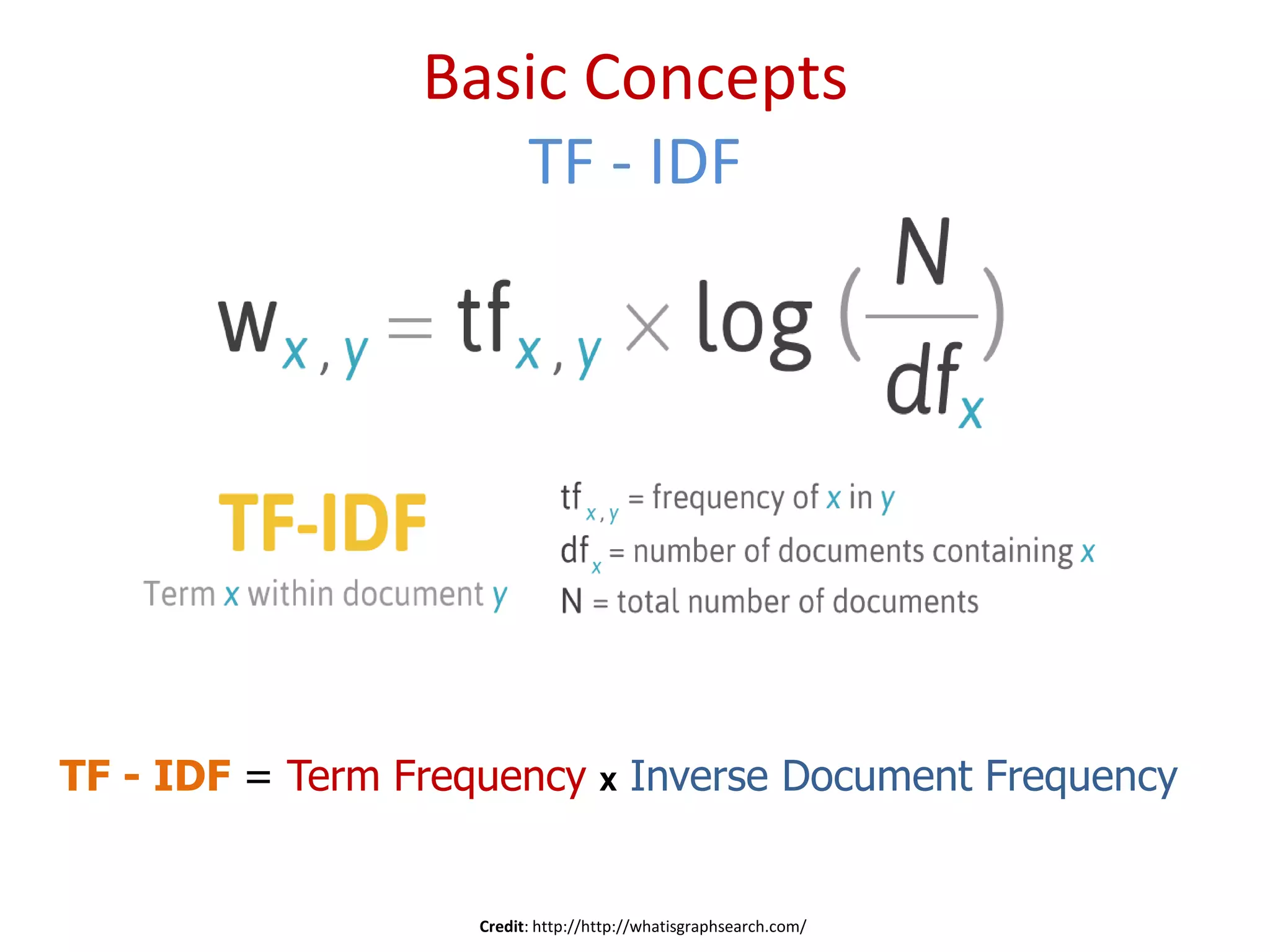
Definition and essential concepts of Information Retrieval (IR), including term frequency and inverse document frequency.
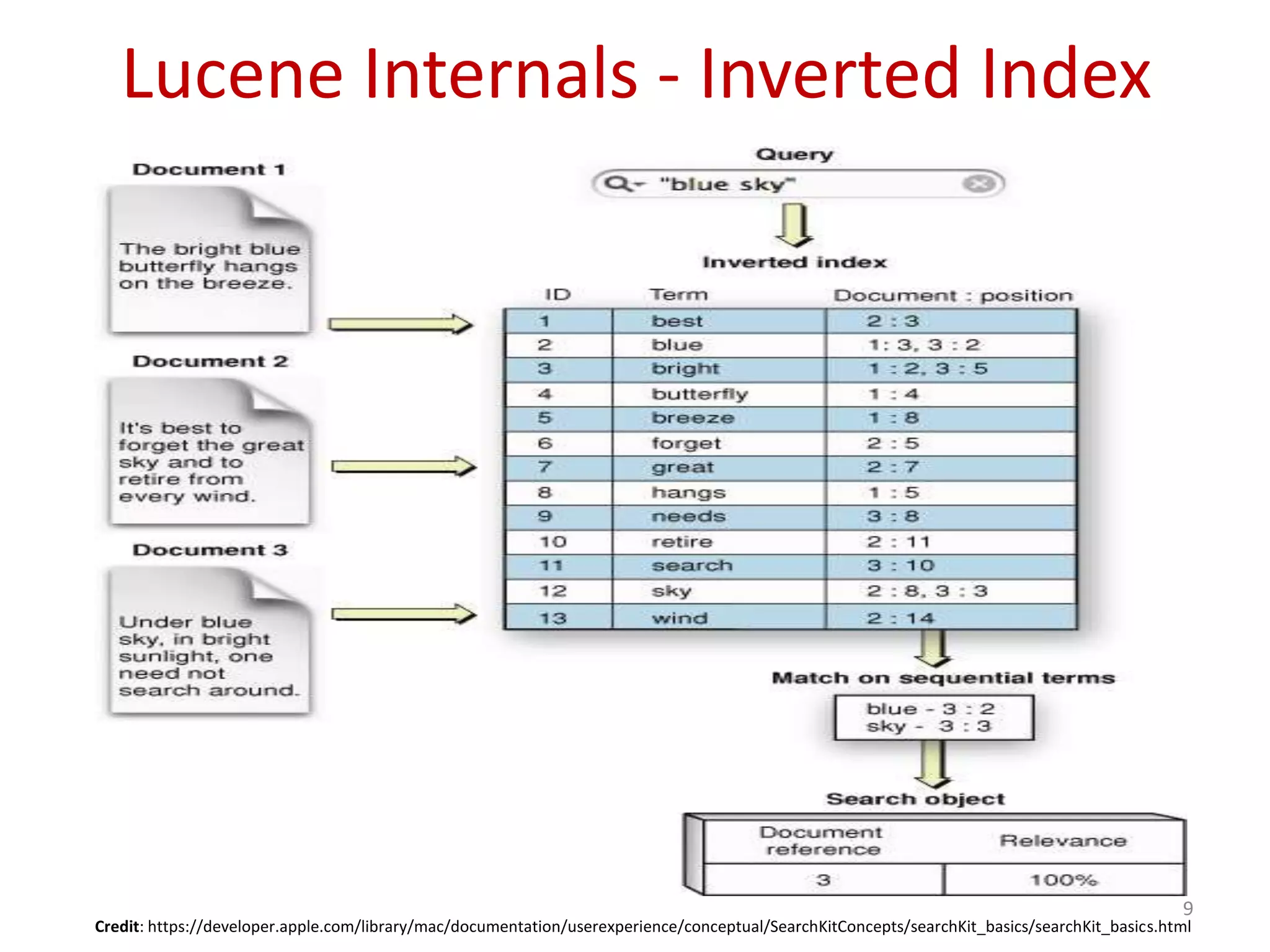
Introduction to Apache Lucene as a search library, discussing its features, internal structure, and the concept of inverted indexing.
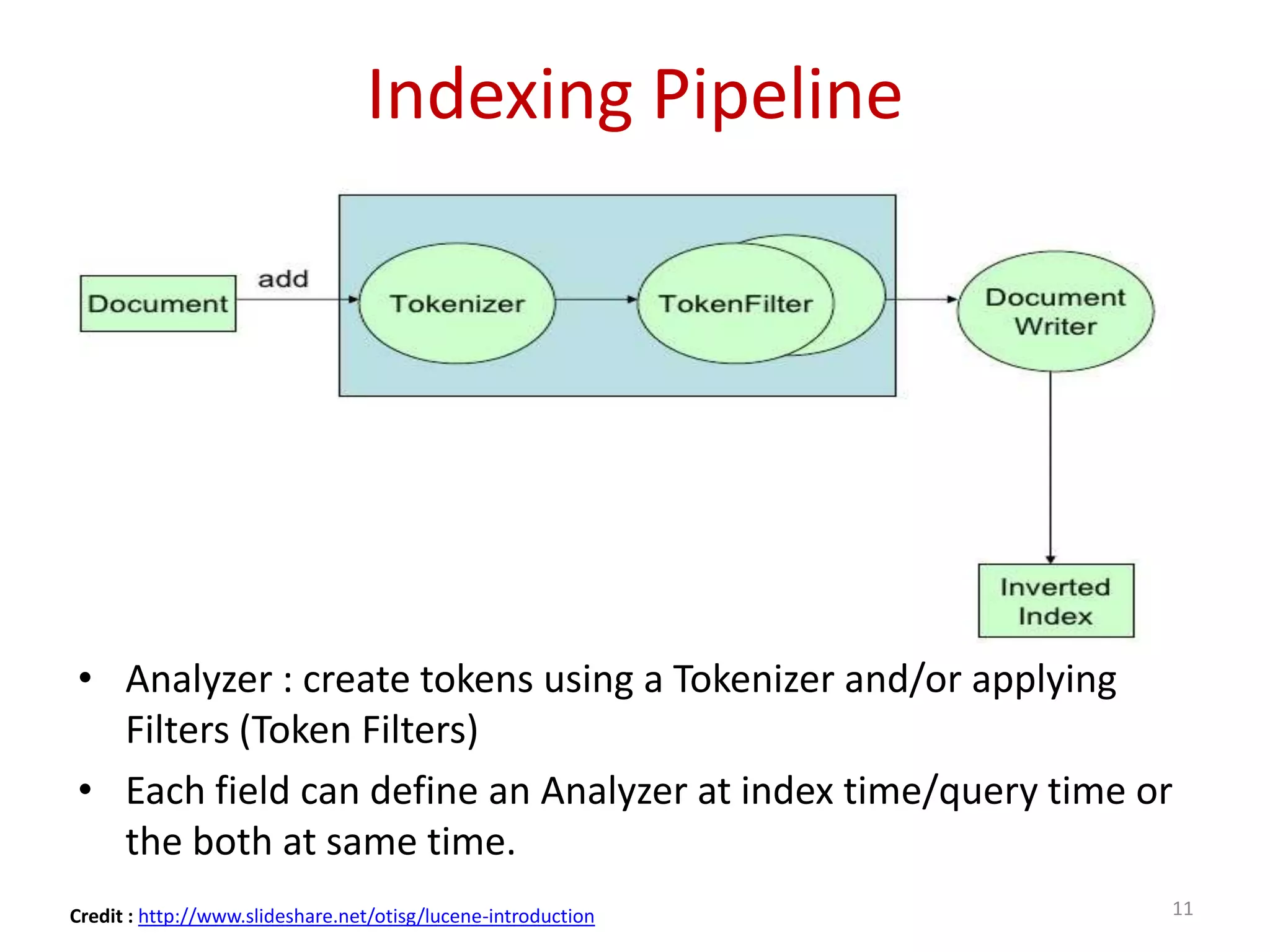
Details on the indexing pipeline and tokenization process in Lucene, showcasing analysis through different built-in analyzers.
Explanation of Elasticsearch as a distributed search and analytics engine with features like schema less design and RESTful API.
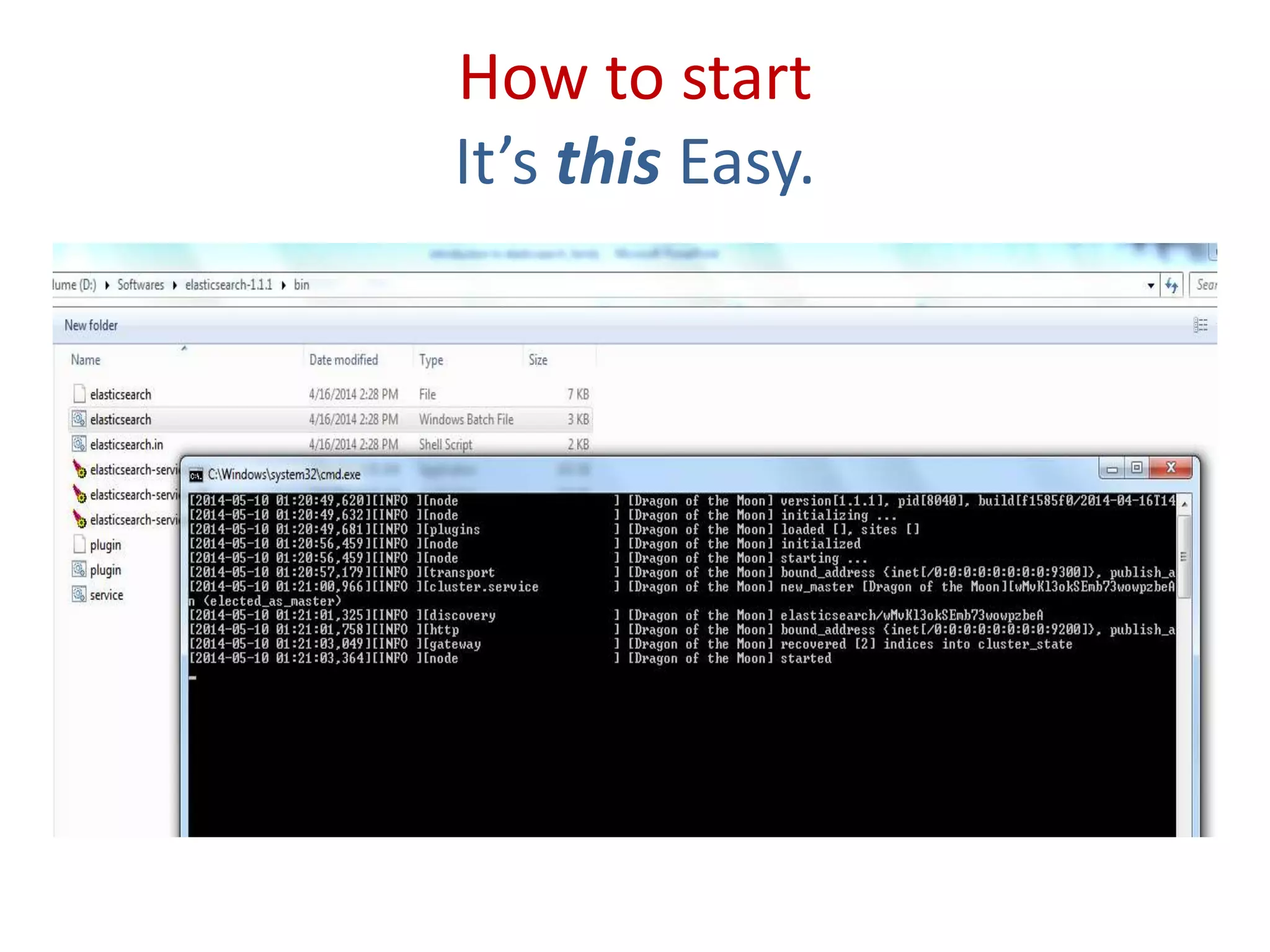
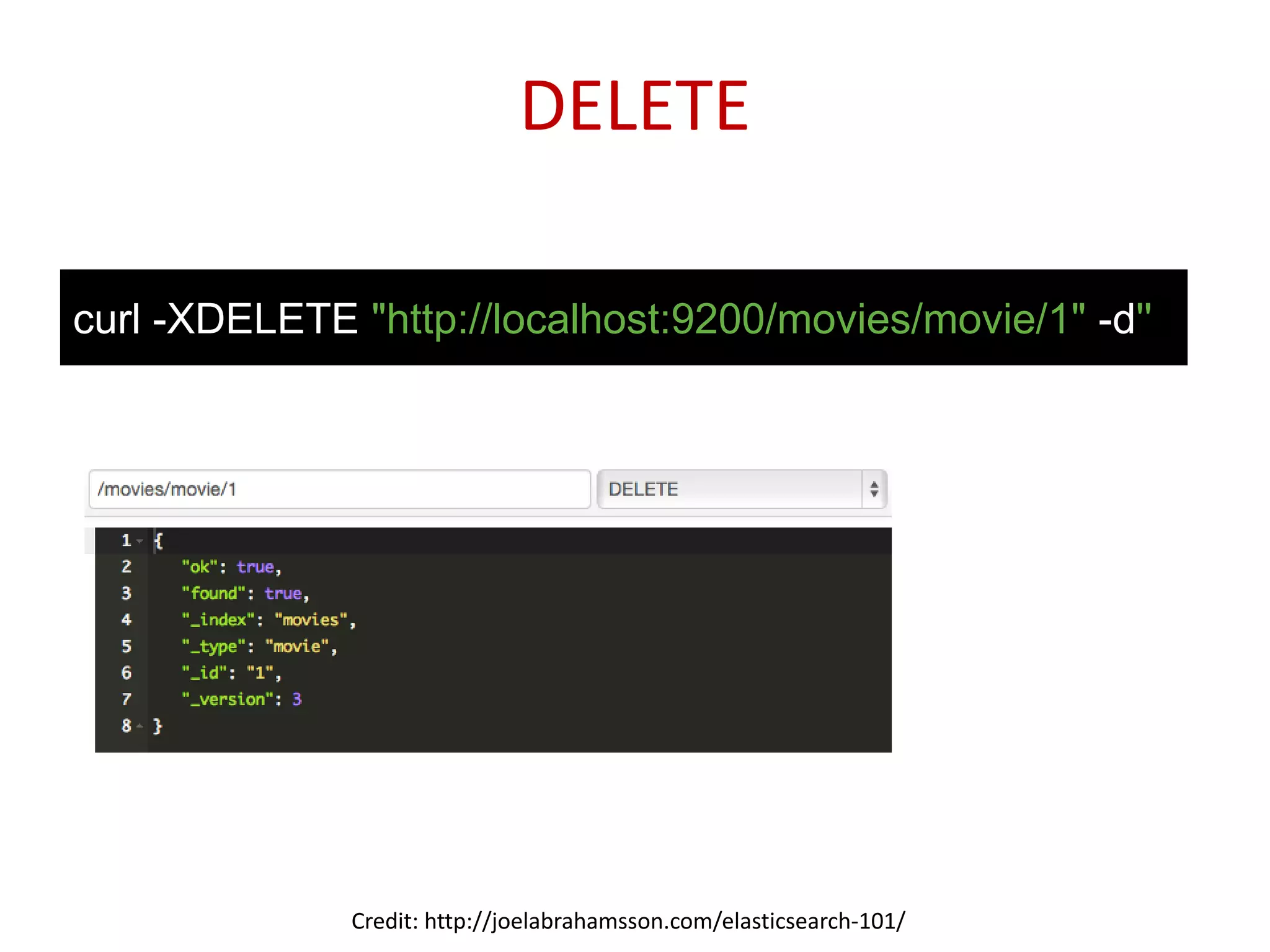
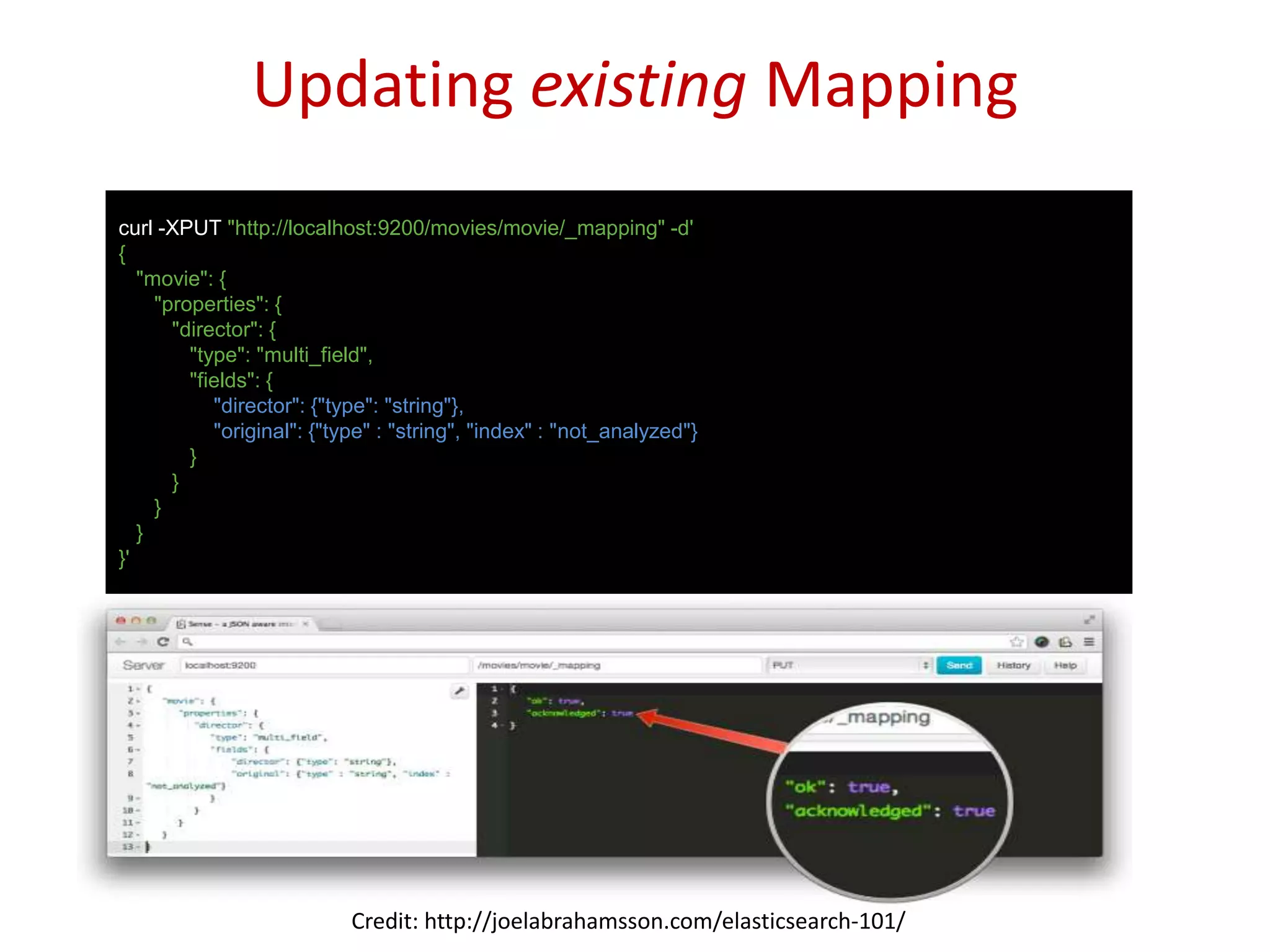
Practical commands for index creation, updating documents, and executing search functions within Elasticsearch.
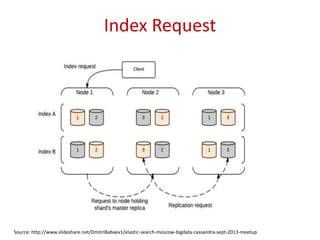
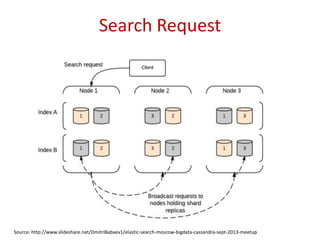
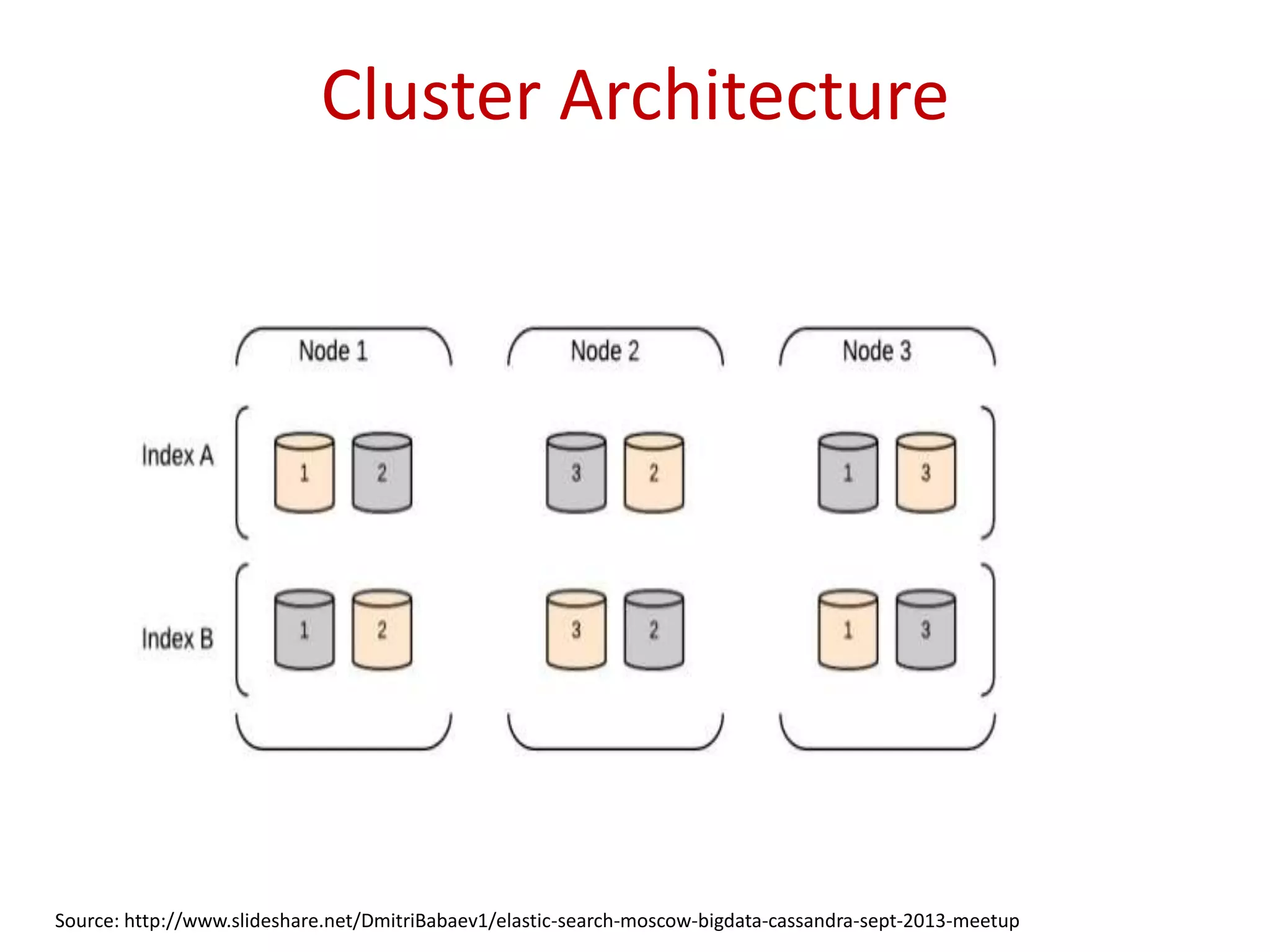
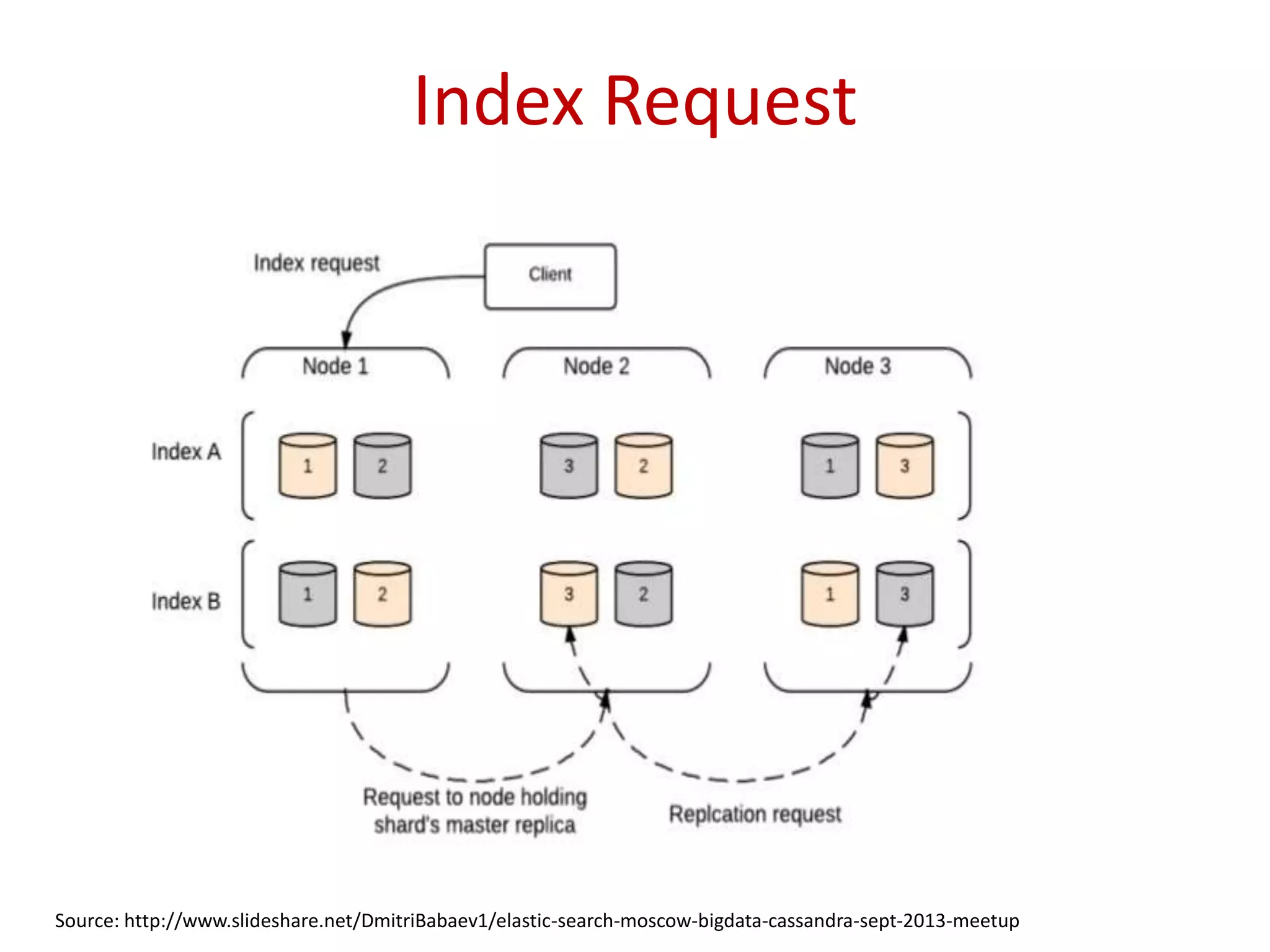
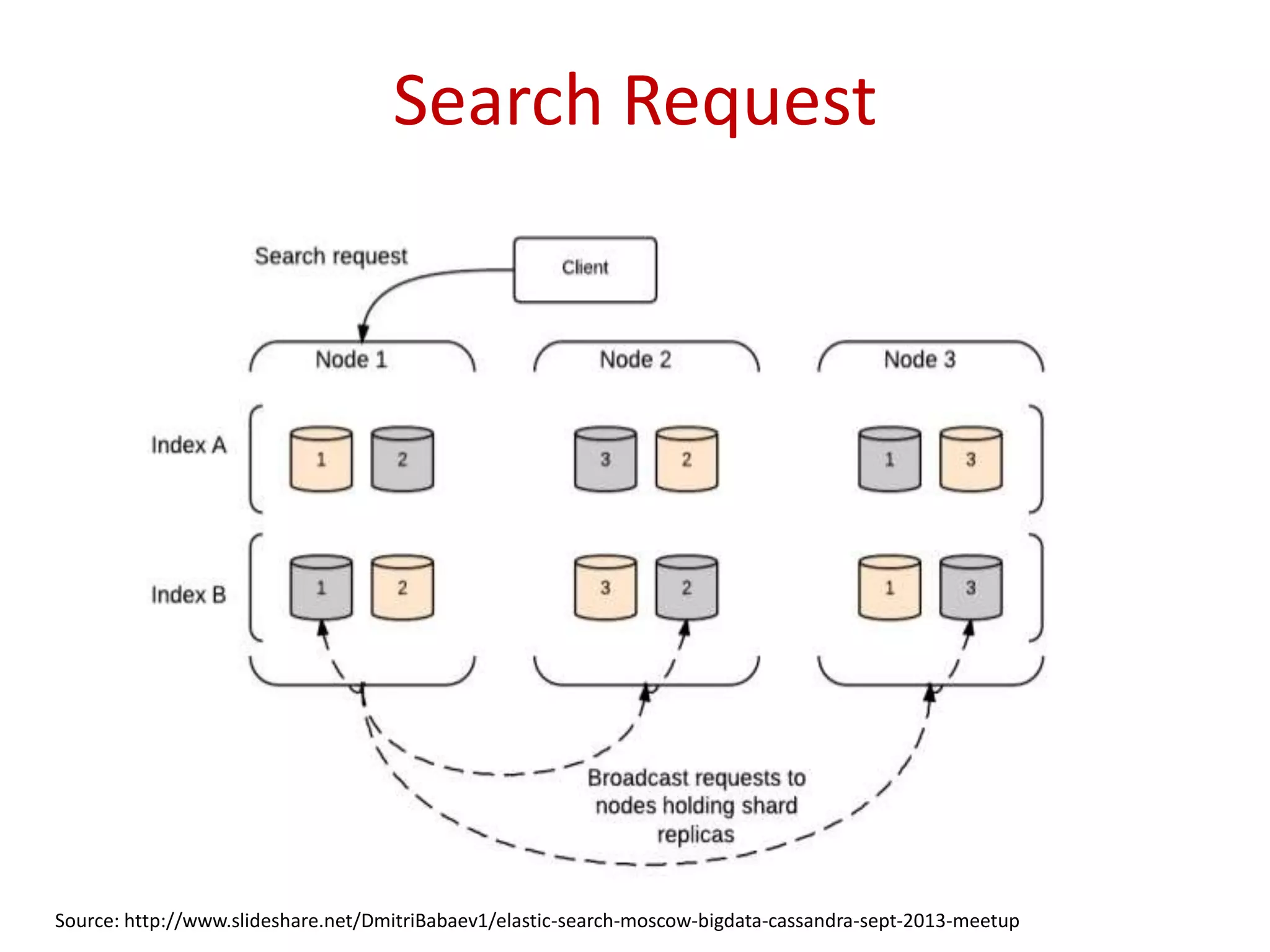
Insights on the architecture of Elasticsearch clusters and the requests made for indexing and searching data.
Prominent companies and organizations utilizing Elasticsearch for their search and analytics requirements.
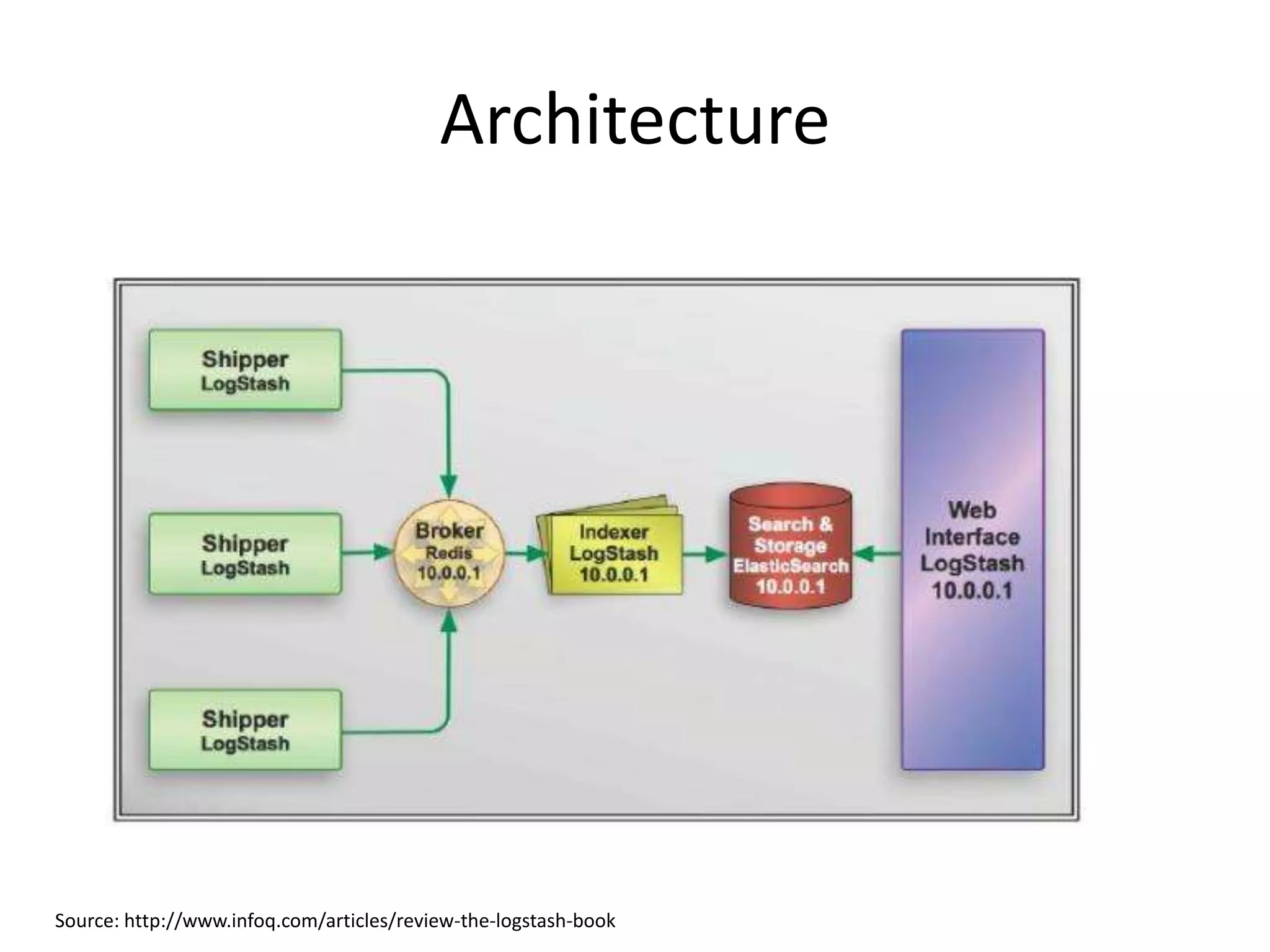
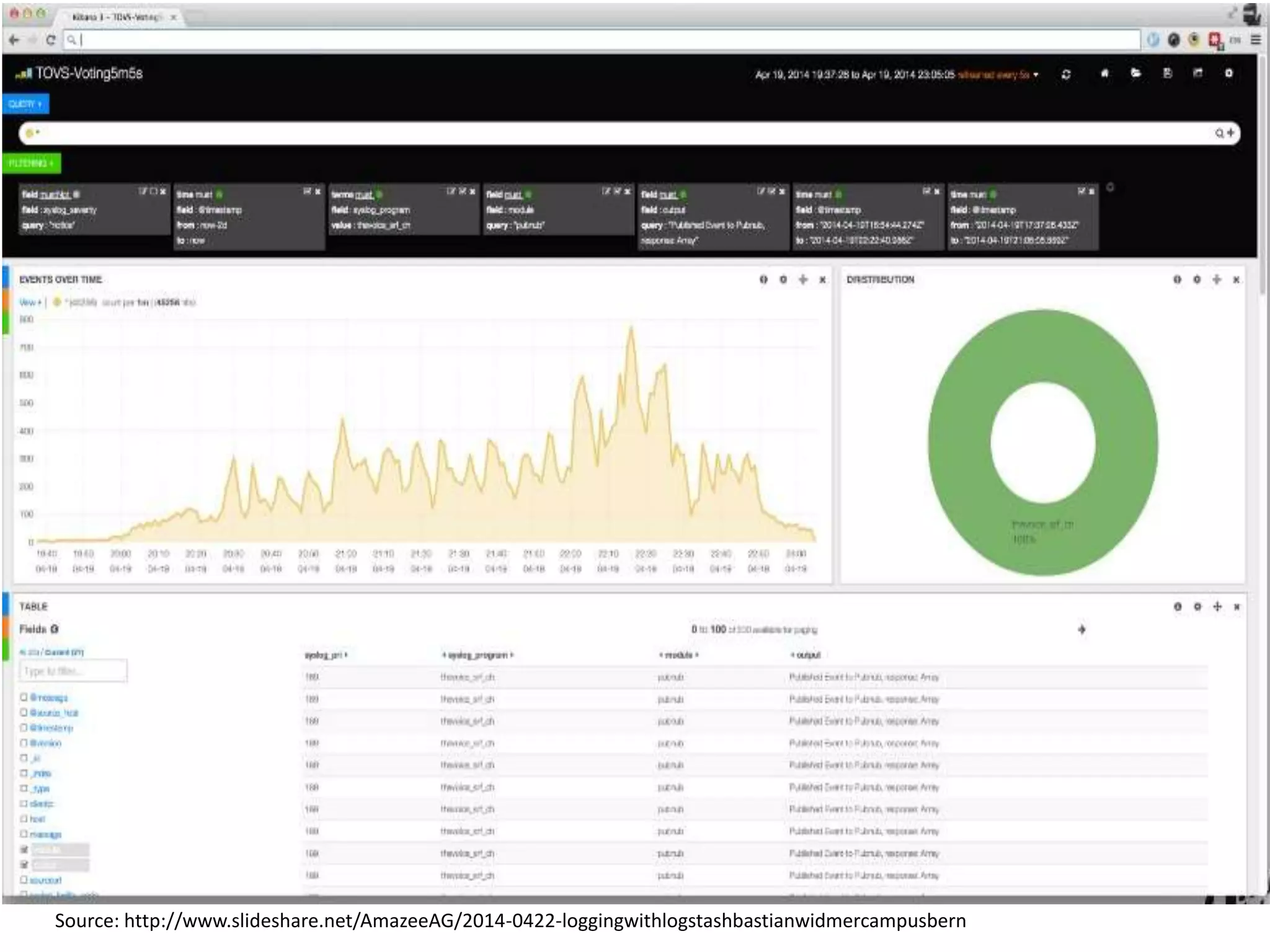
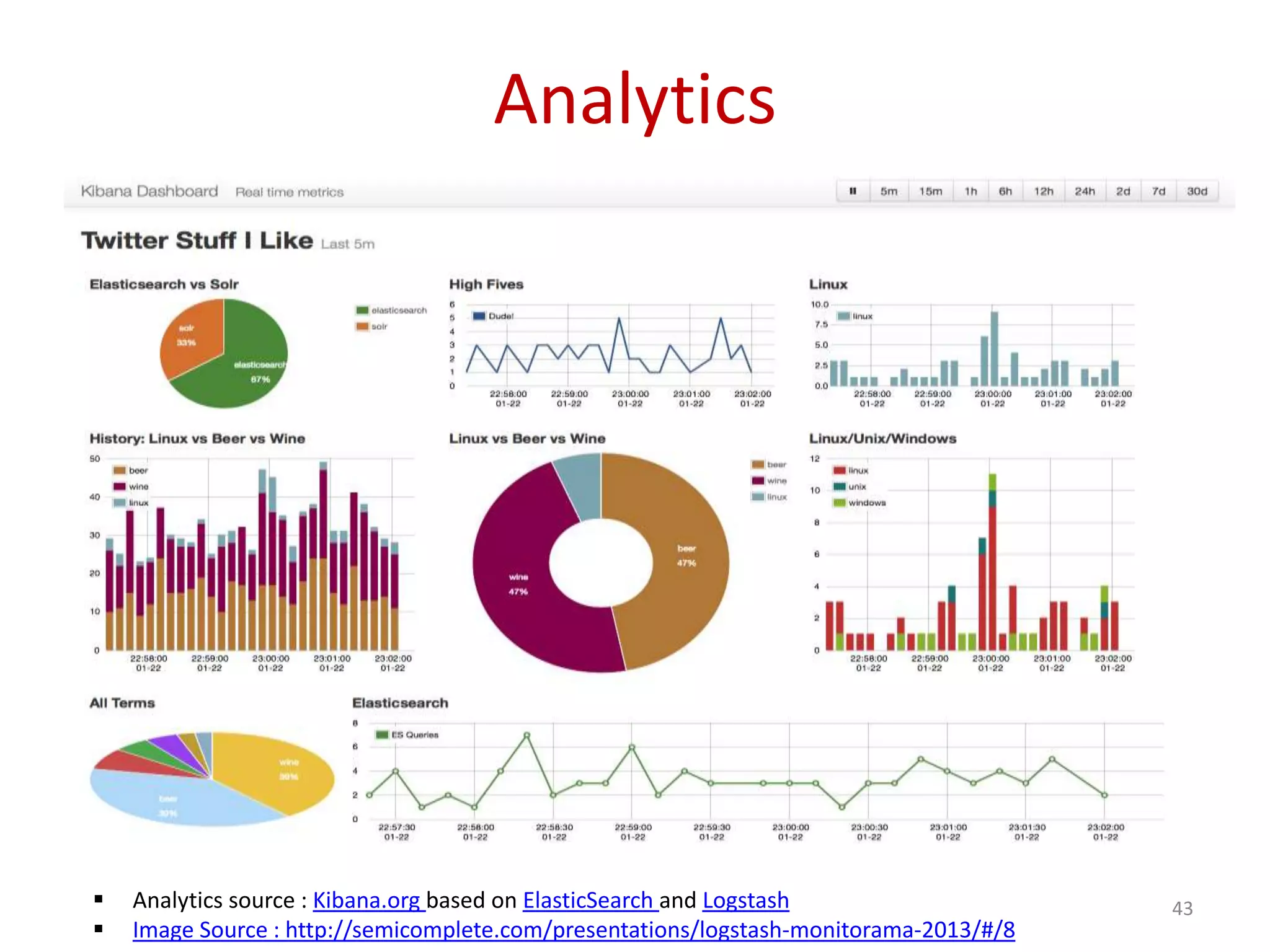
Overview of Logstash, its role in data processing (input, filters, output), and its integration with Elasticsearch.
Introduction to Kibana as an analytics tool that works with Elasticsearch and Logstash, concluding with contact information.





































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











