Download to read offline


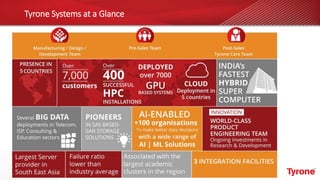



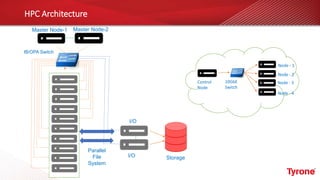
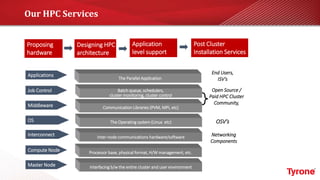



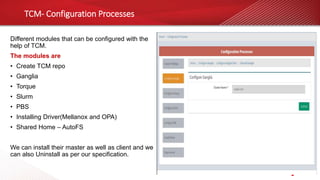







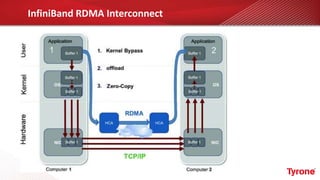







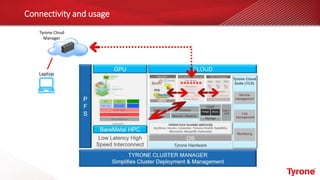
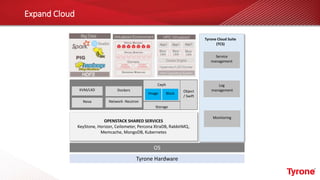
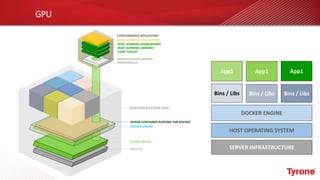


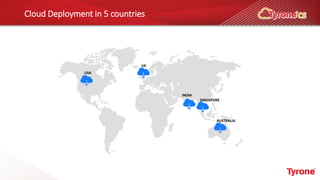
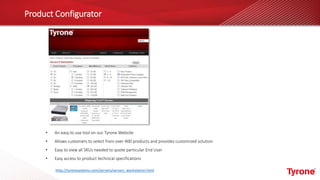



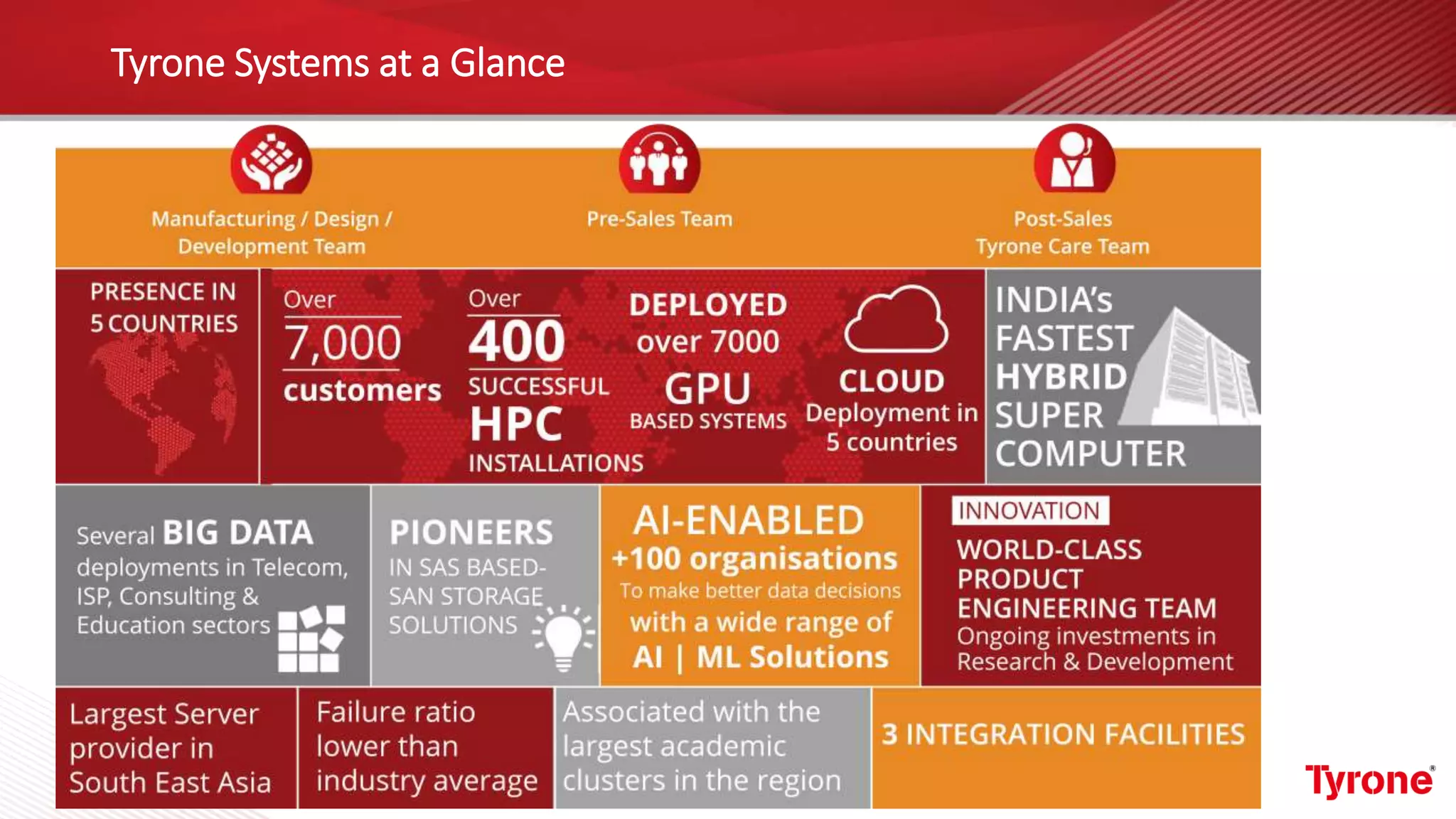

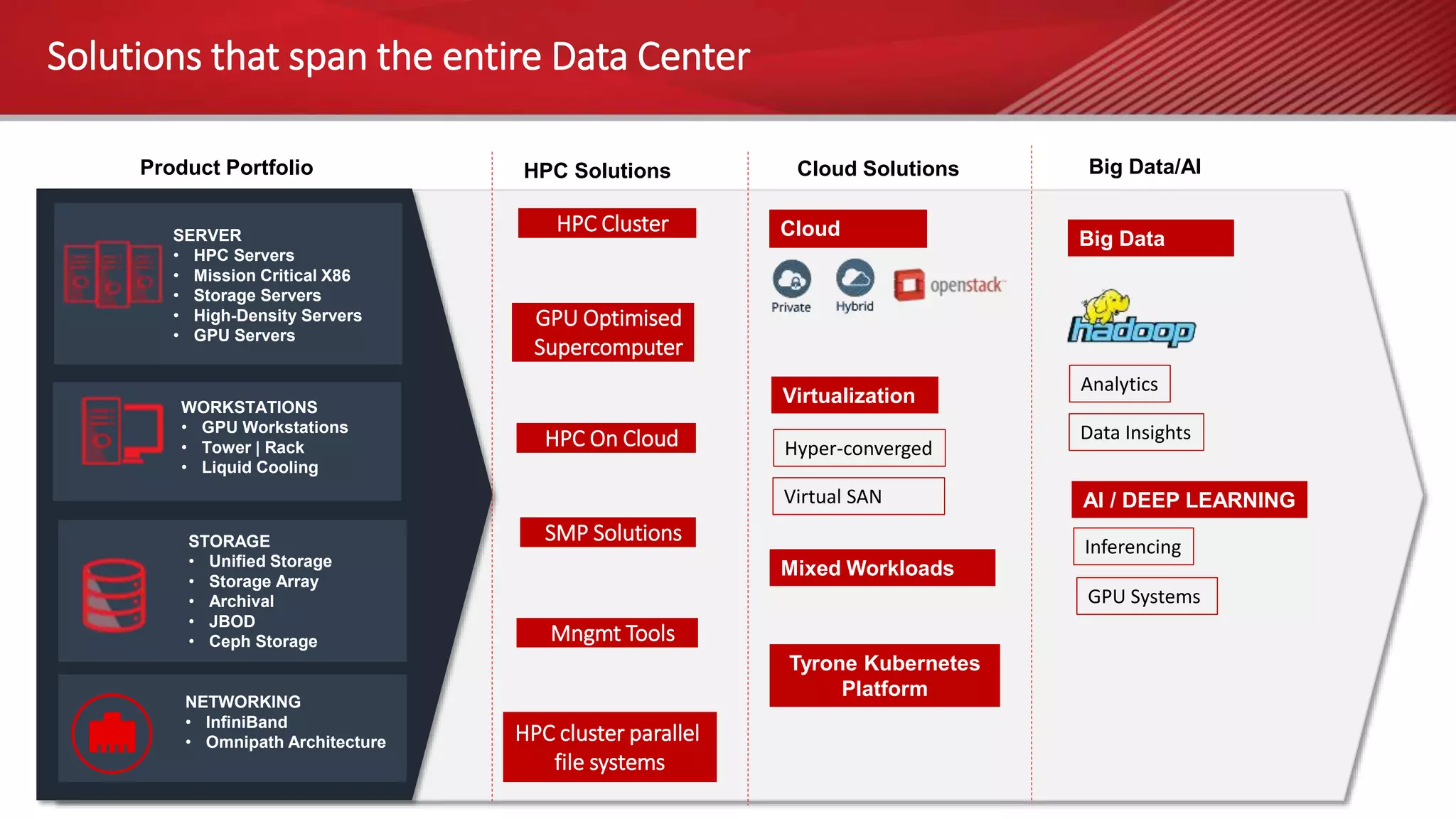

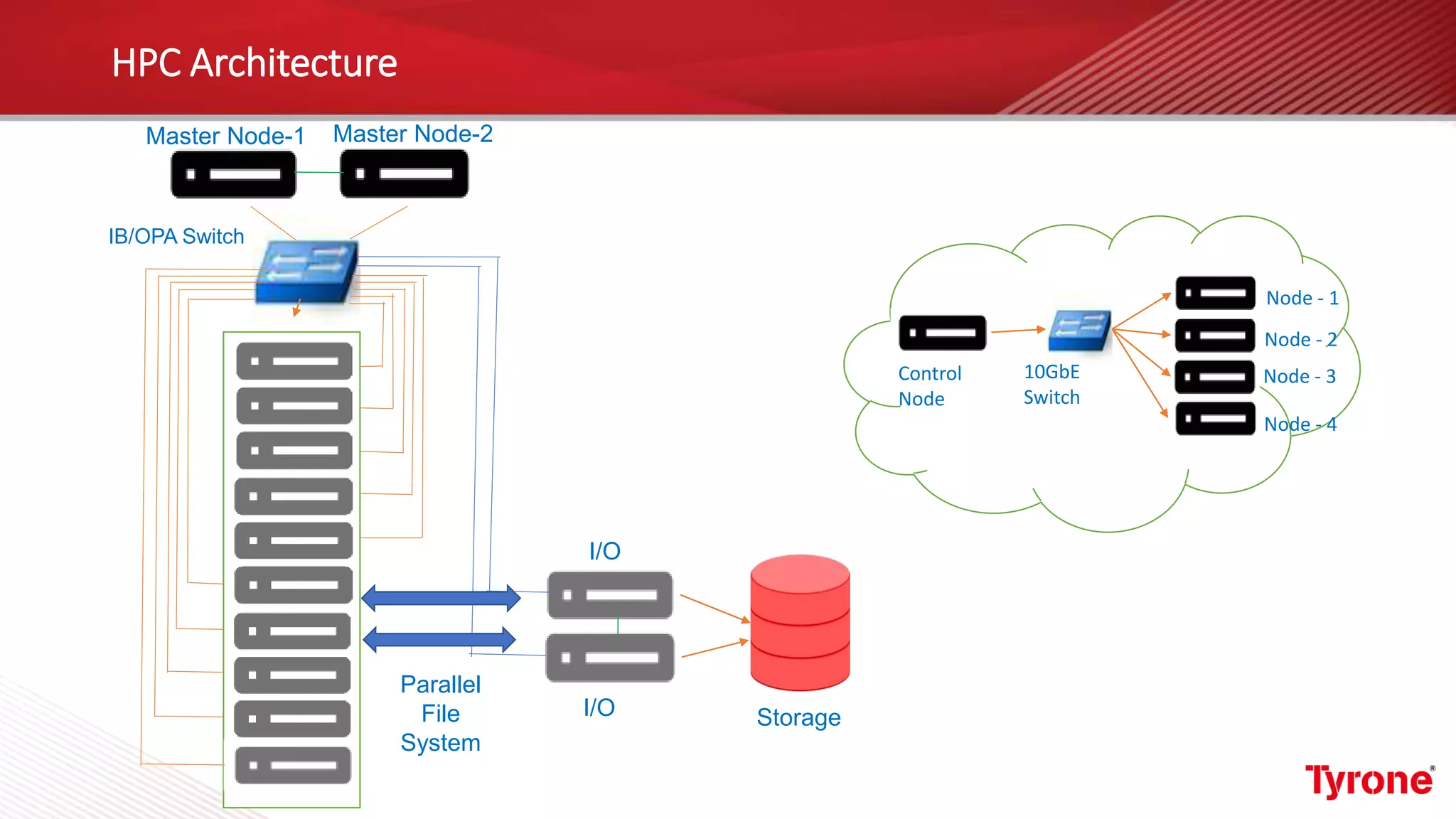
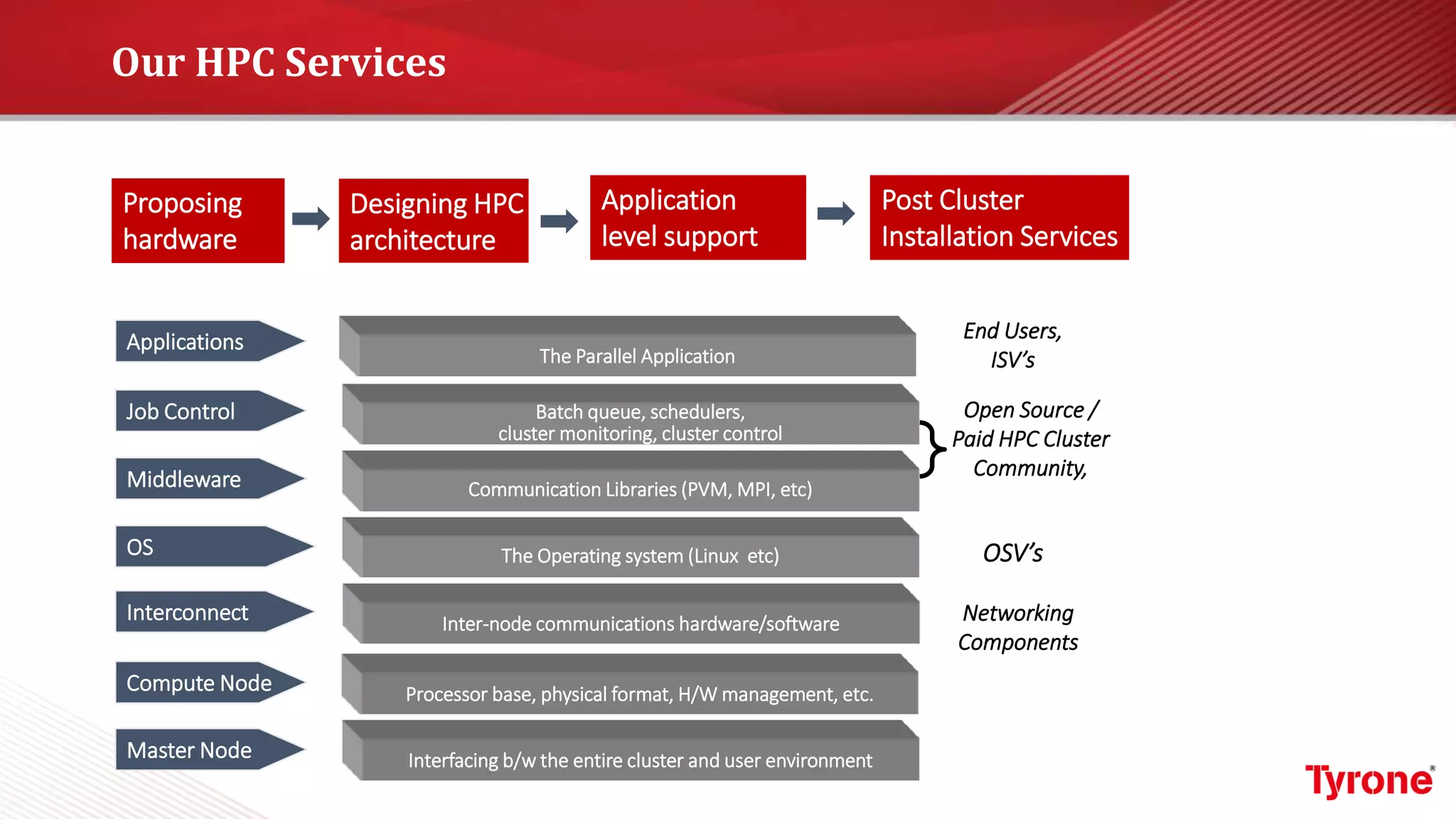



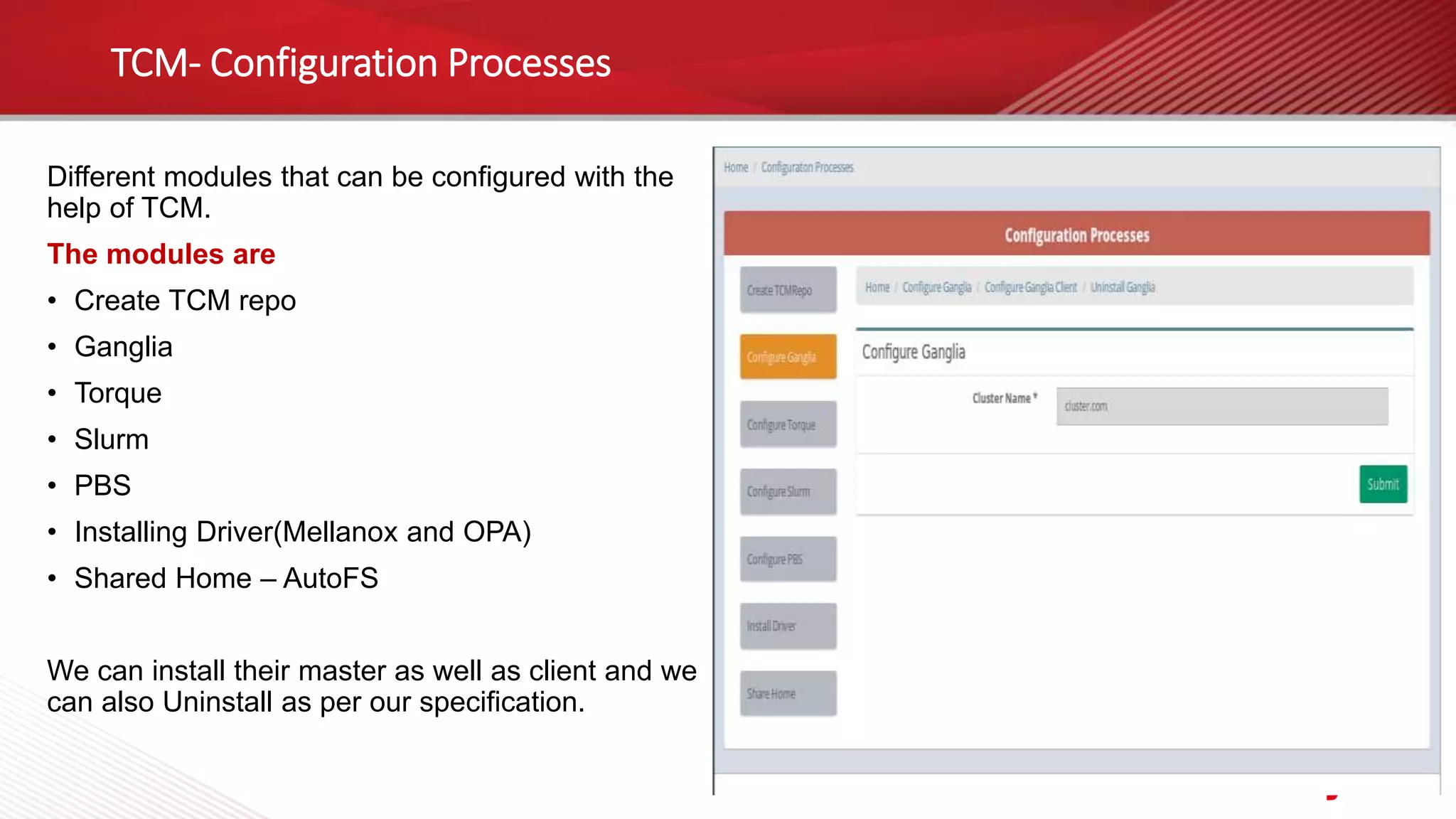







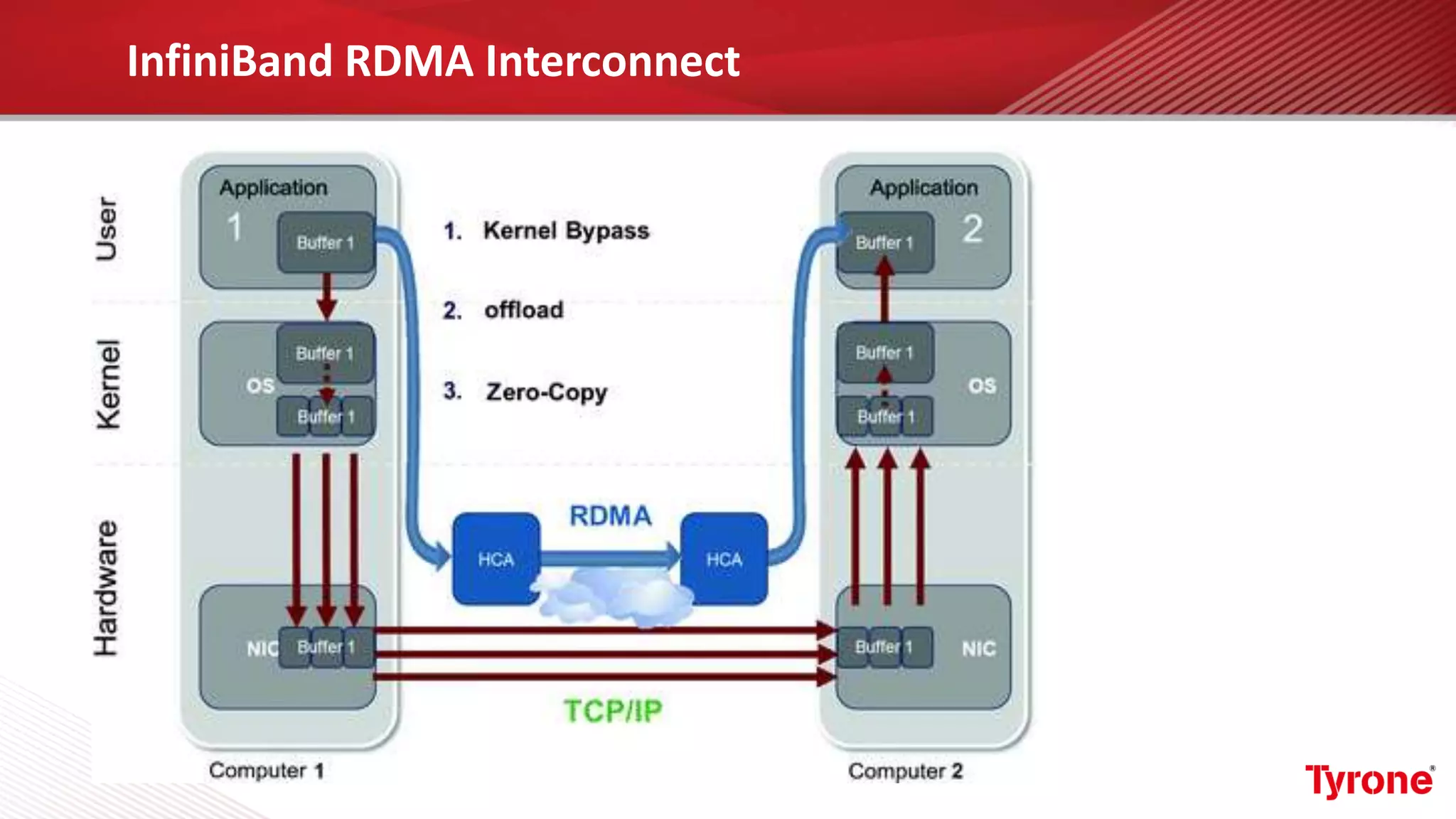







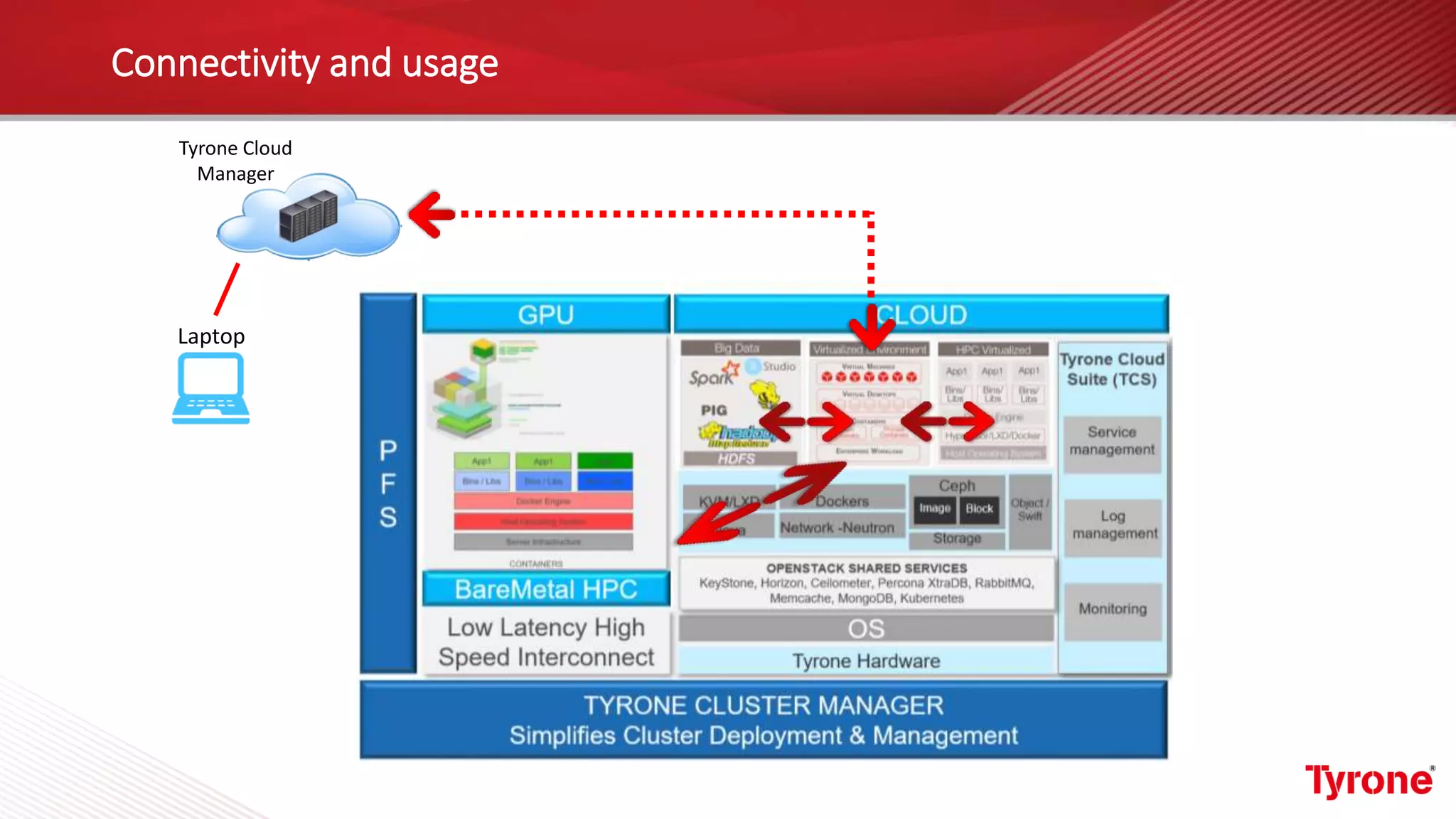
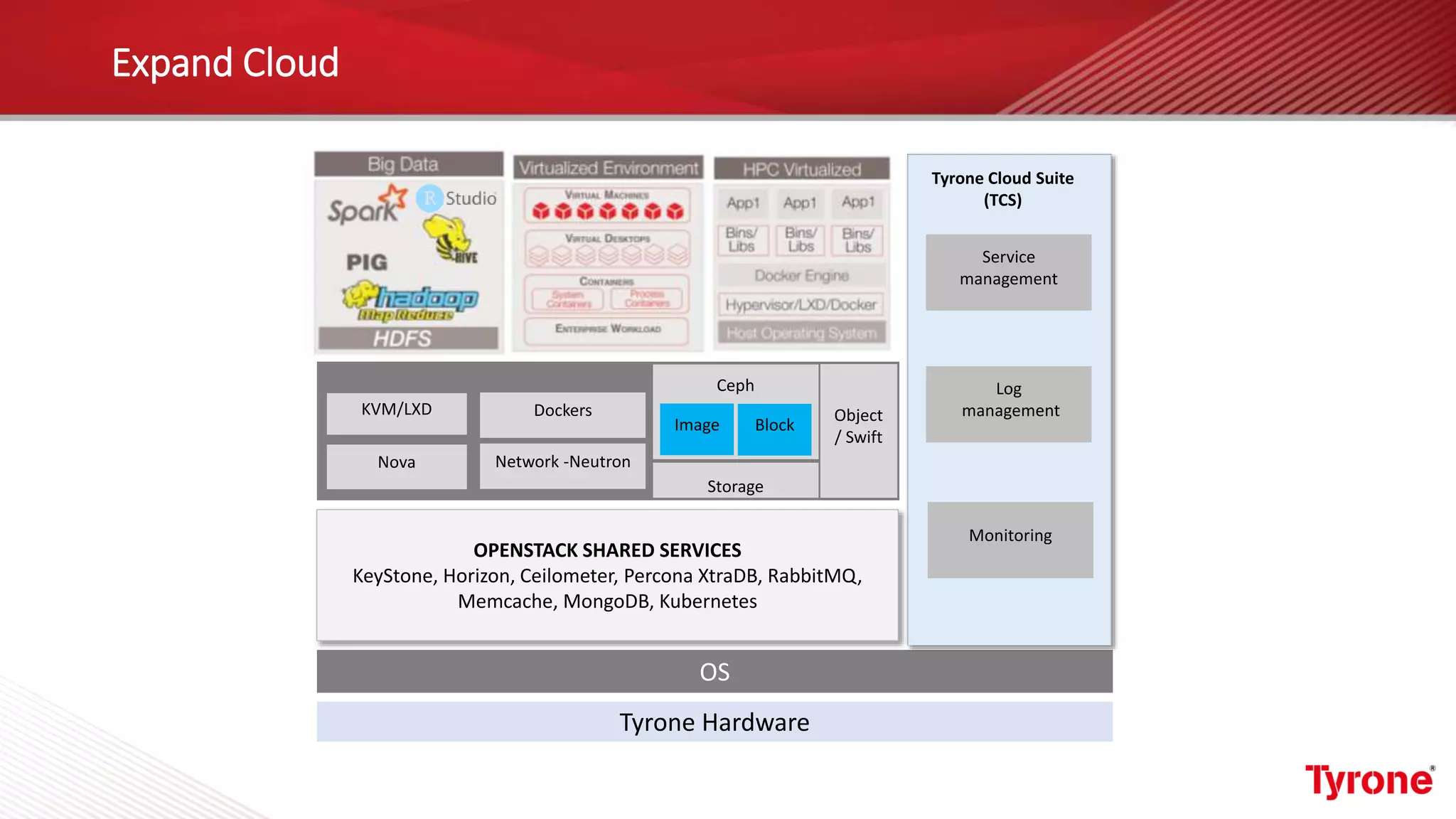
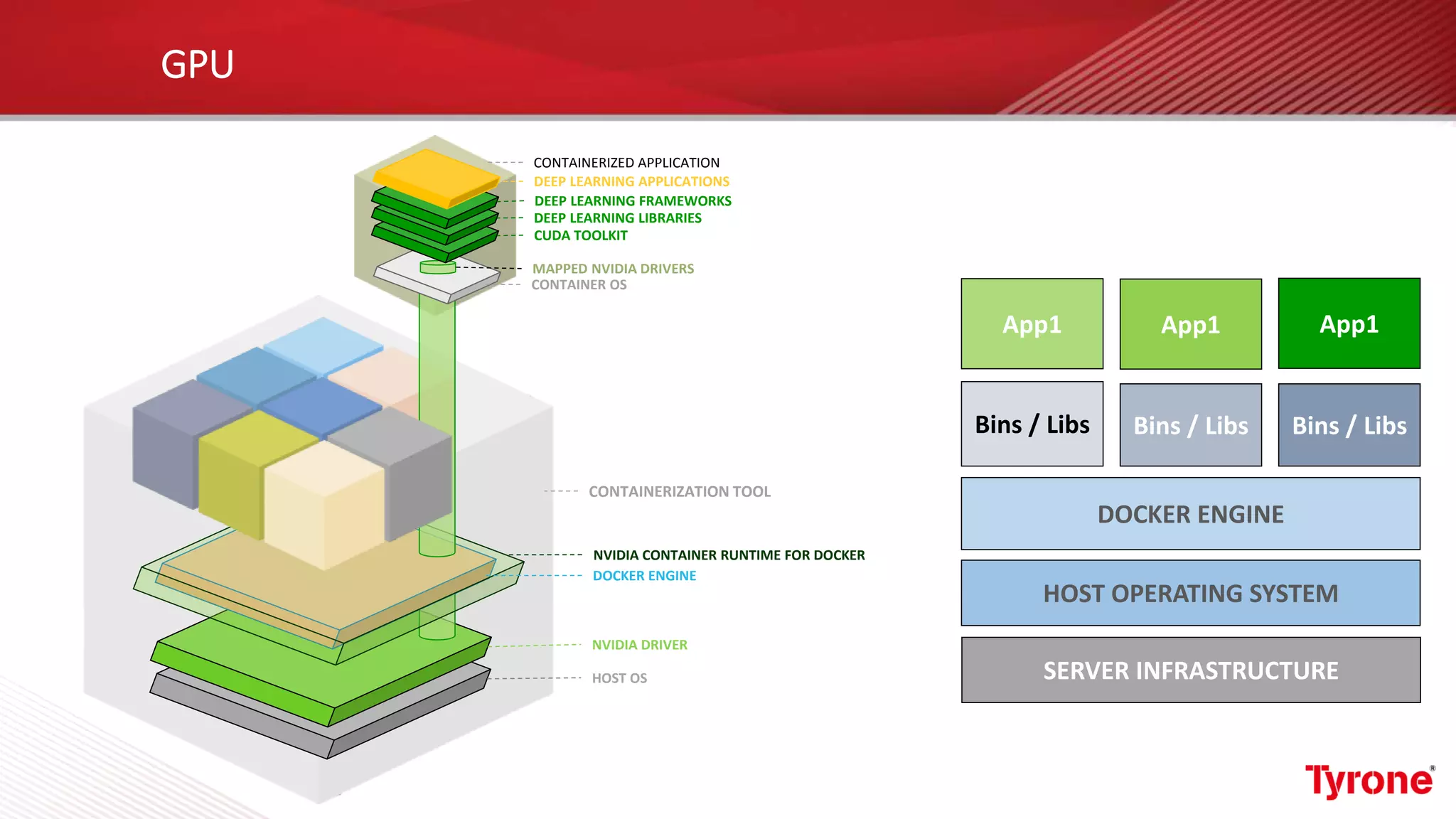
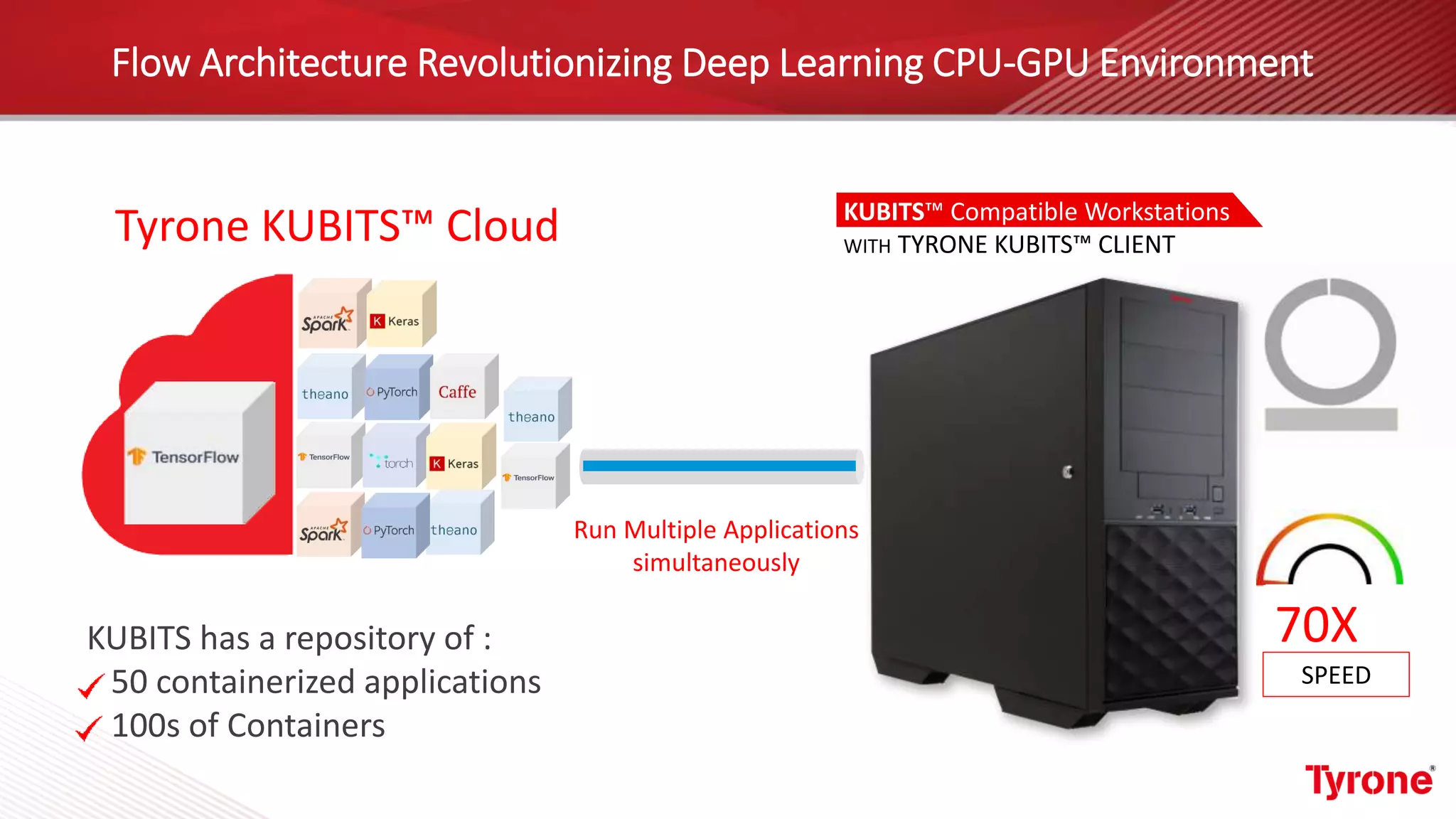
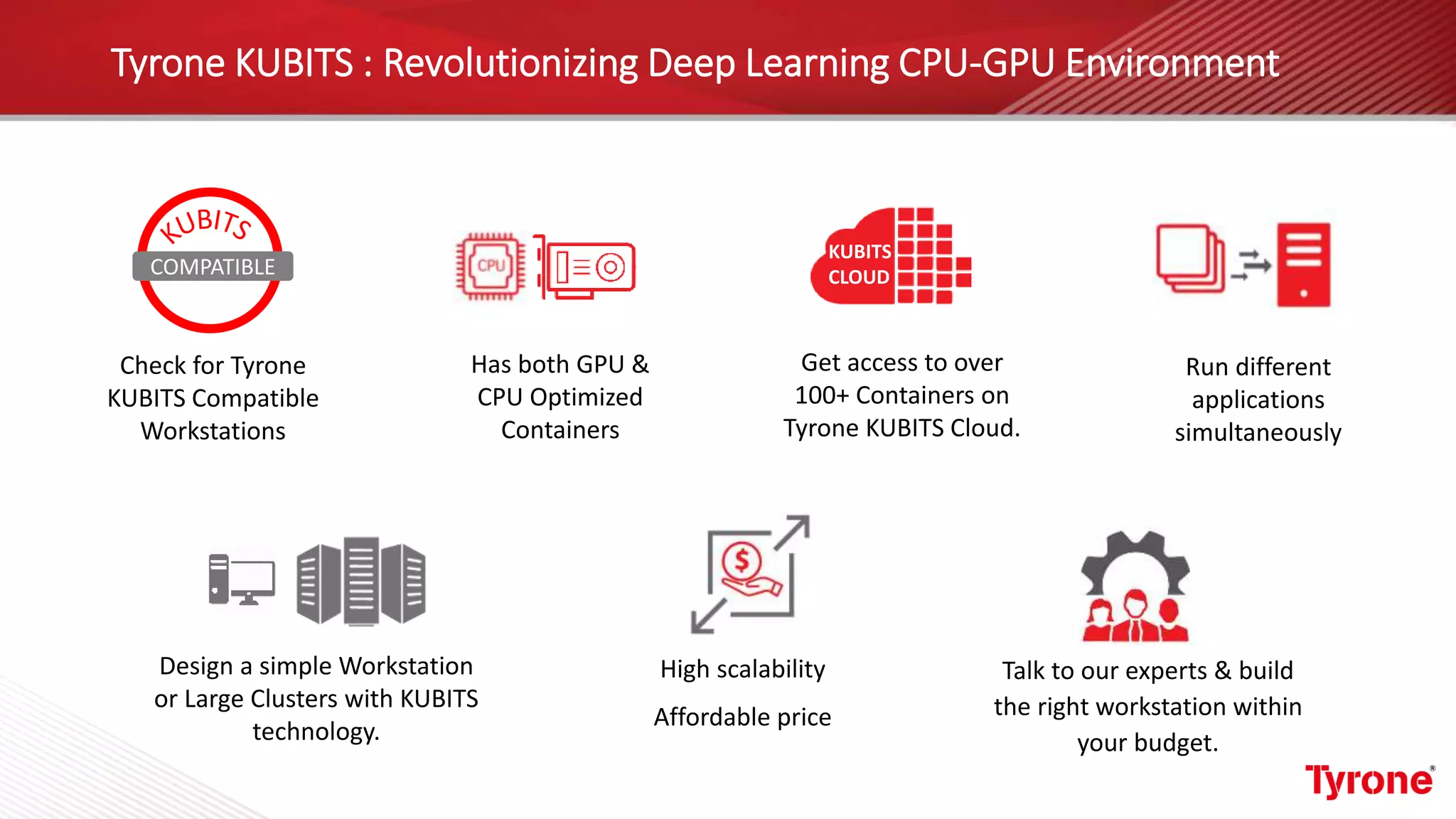

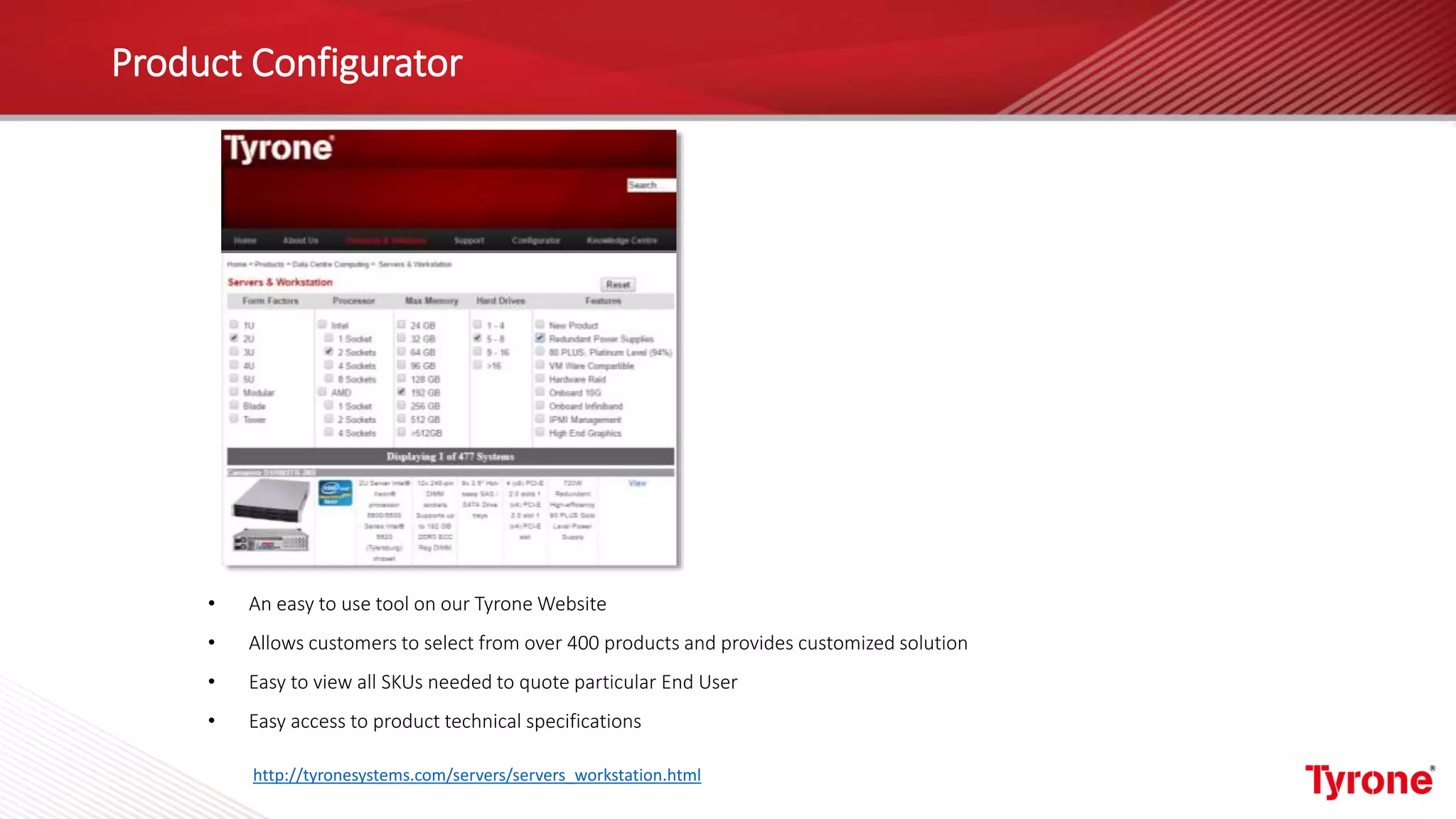


The document outlines a webinar on High-Performance Computing (HPC) hosted by Netweb, detailing their systems, services, and solutions for HPC workloads, including GPU optimized AI/ML solutions and unified storage options. It introduces the Tyrone Cluster Manager (TCM) that facilitates management of HPC clusters and discusses various applications supported by their hardware. Key services include scalable storage solutions, deep learning capabilities, and customization through an online product configurator.























































































