Downloaded 112 times


![Instruction Set Architecture
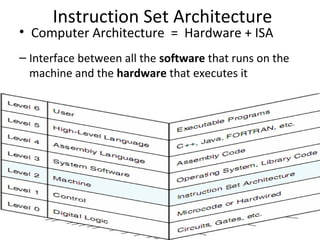
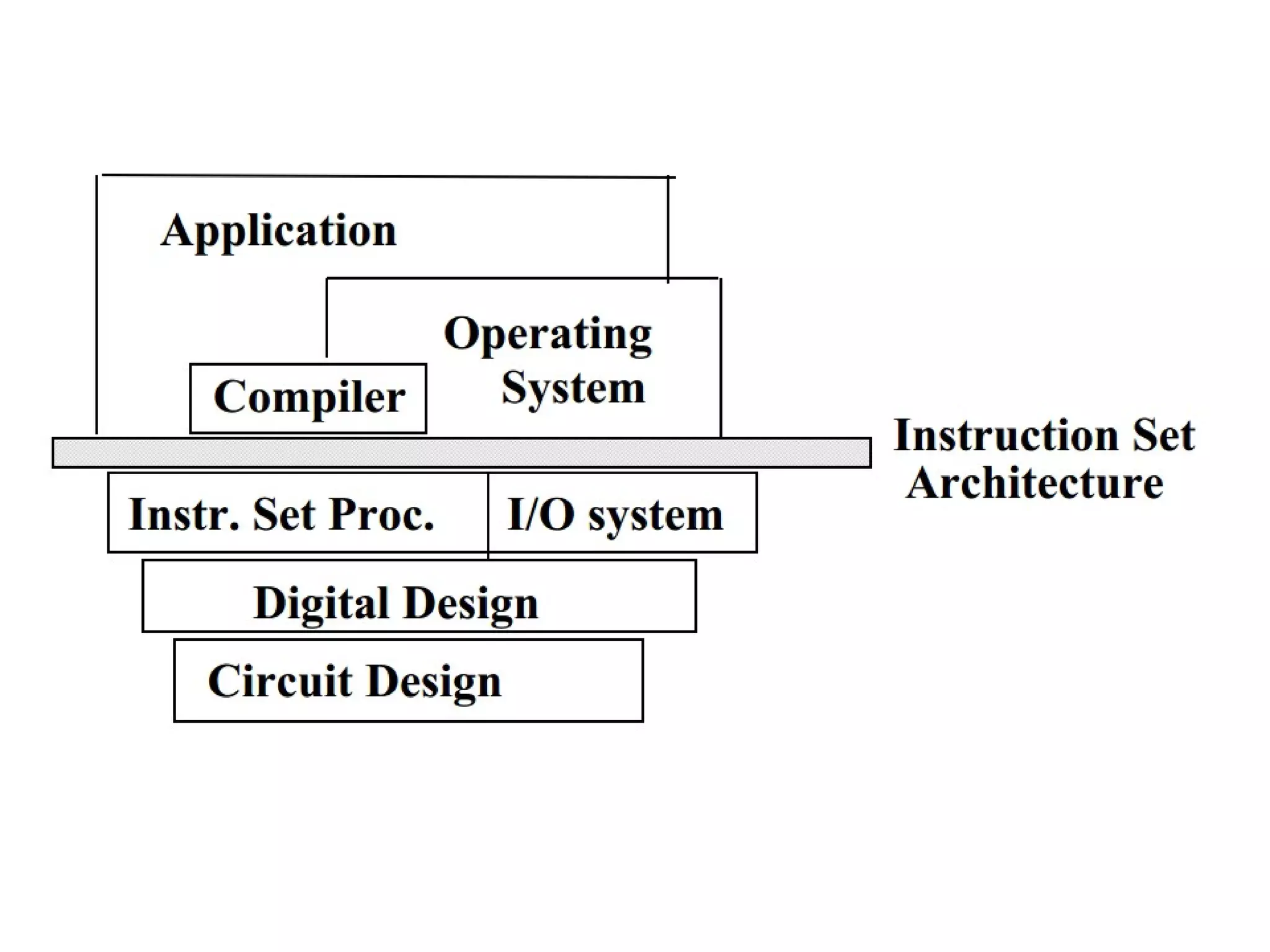
Computer Architecture =
Instruction Set Architecture
+ Machine Organization
• “... the attributes of a [computing] system as seen by
the programmer, i.e. the conceptual structure and
functional behavior …”](https://image.slidesharecdn.com/isa1-150210012211-conversion-gate01/85/isa-architecture-3-320.jpg)







































































![Instruction Set Architecture
Computer Architecture =
Instruction Set Architecture
+ Machine Organization
• “... the attributes of a [computing] system as seen by
the programmer, i.e. the conceptual structure and
functional behavior …”](https://image.slidesharecdn.com/isa1-150210012211-conversion-gate01/75/isa-architecture-3-2048.jpg)




































































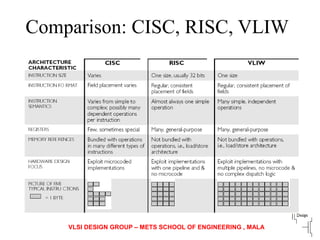
The document discusses instruction set architecture (ISA), describing it as the interface between software and hardware that defines the programming model and machine language instructions. It provides details on RISC ISAs like MIPS and how they aim to have simpler instructions, more registers, load/store architectures, and pipelining to improve performance compared to CISC ISAs. The document also discusses different types of ISA designs including stack-based, accumulator-based, and register-to-register architectures.
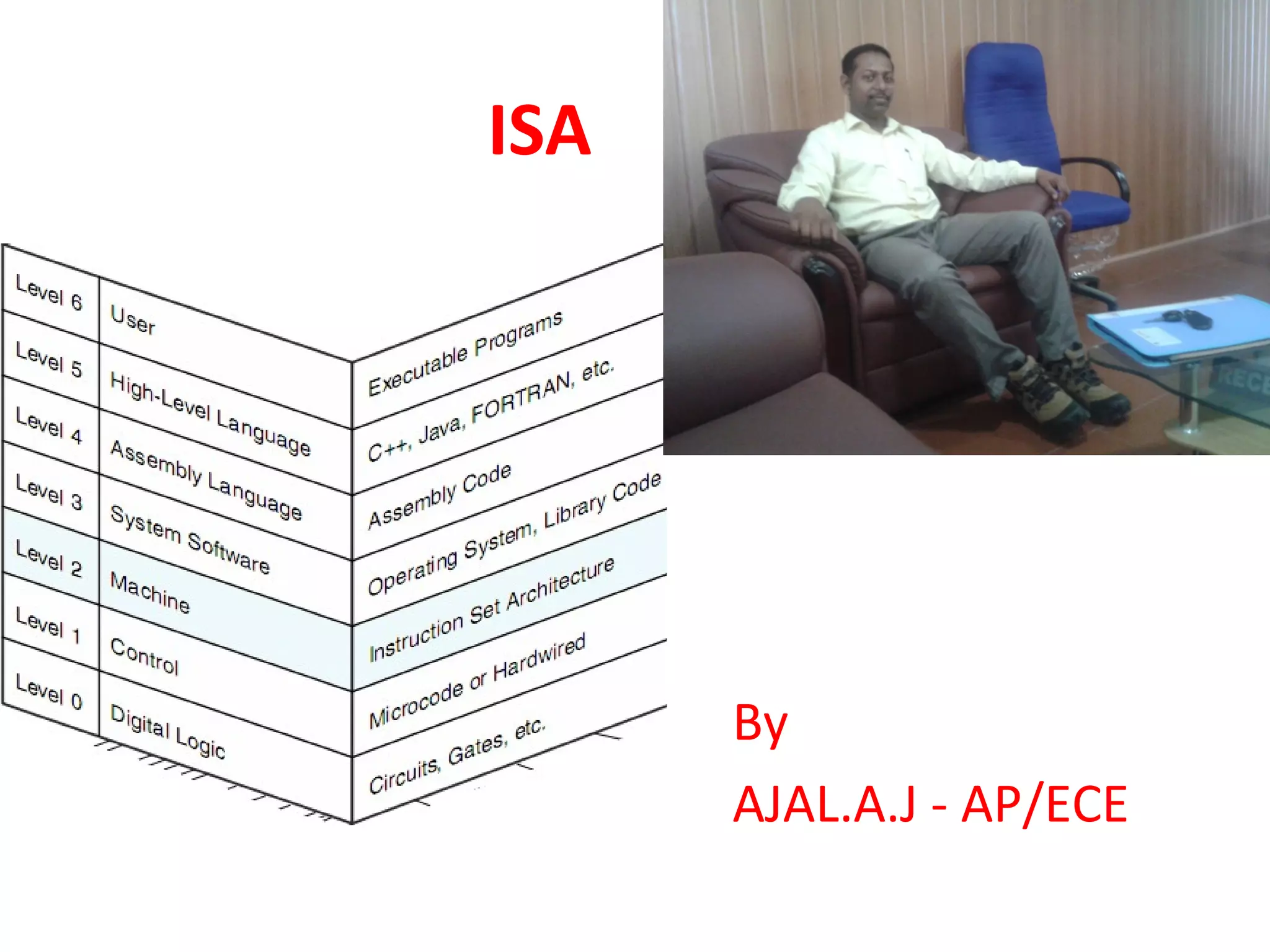
Introduction to the presentation on Instruction Set Architecture (ISA) by Ajal A.J.
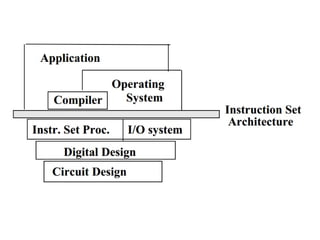
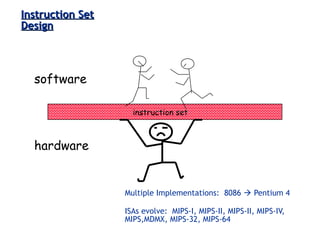
Definition of ISA as the structure essential for programming and hardware design; includes data types, operations, and machine language.
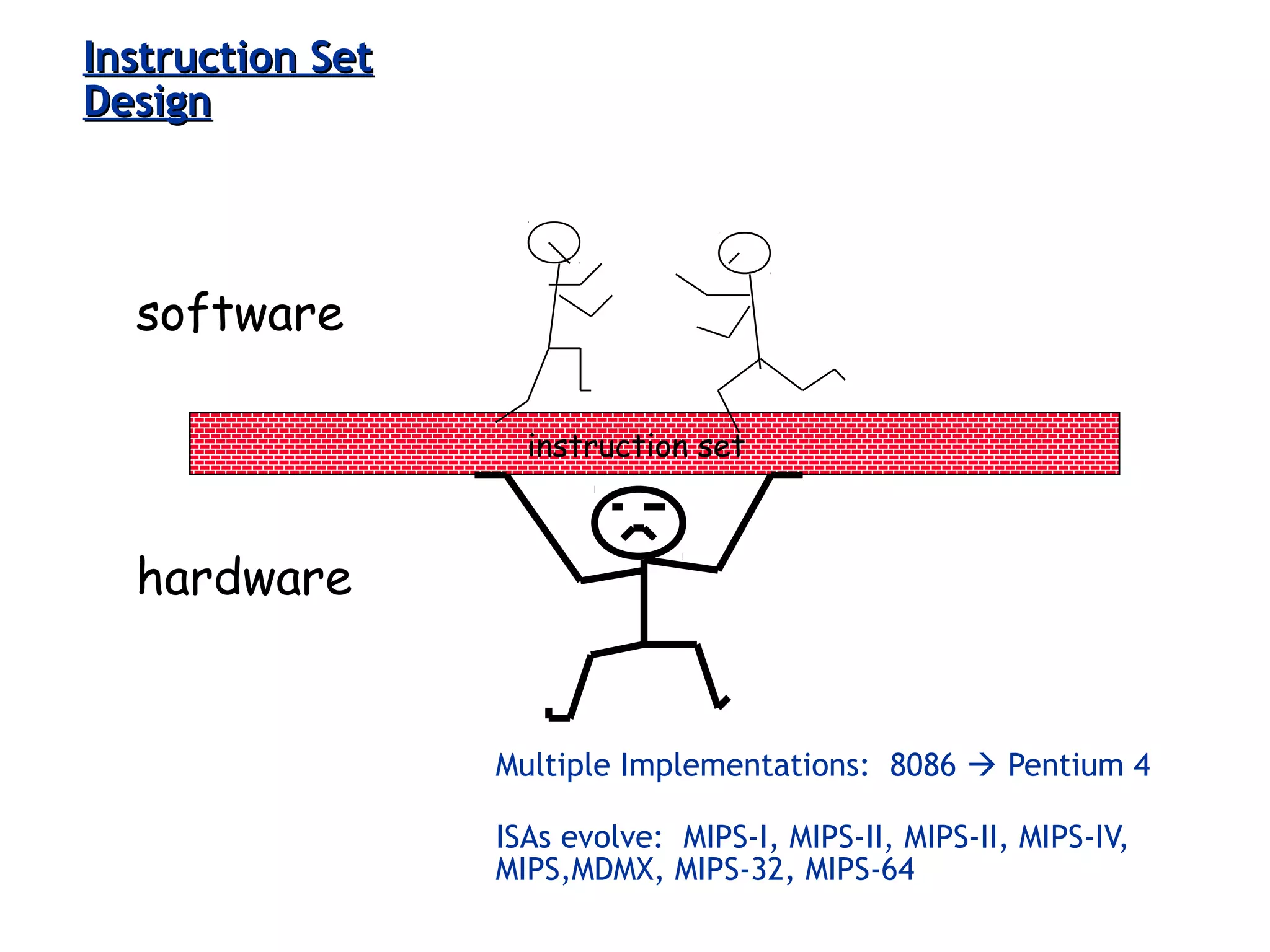
Differentiates microarchitecture from ISA; examples like Intel Pentium vs. AMD Athlon illustrate varied internal designs with the same ISA.
Explains Unit Assumed Latency (UAL) and Non-Unit Assumed Latency (NUAL) concepts crucial for understanding performance in instruction processing.
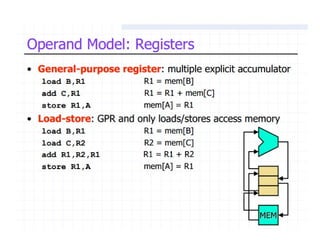
Summary of RISC principles: single-size instructions, use of registers, and minimal addressing modes leading to efficient performance.
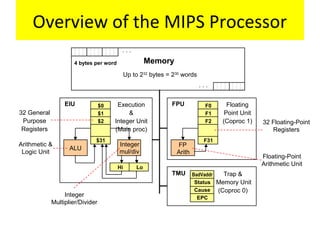
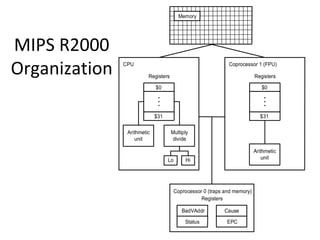
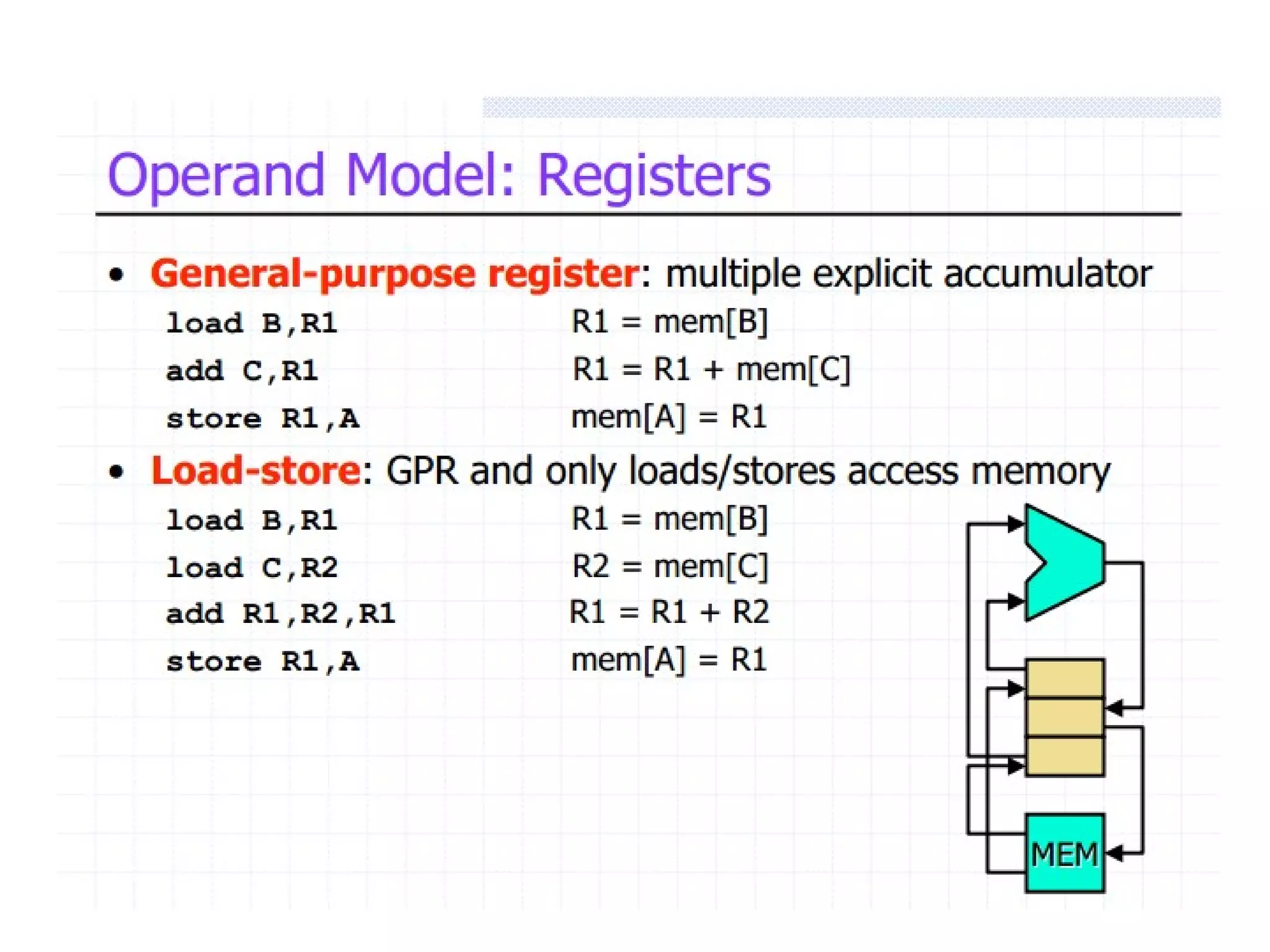
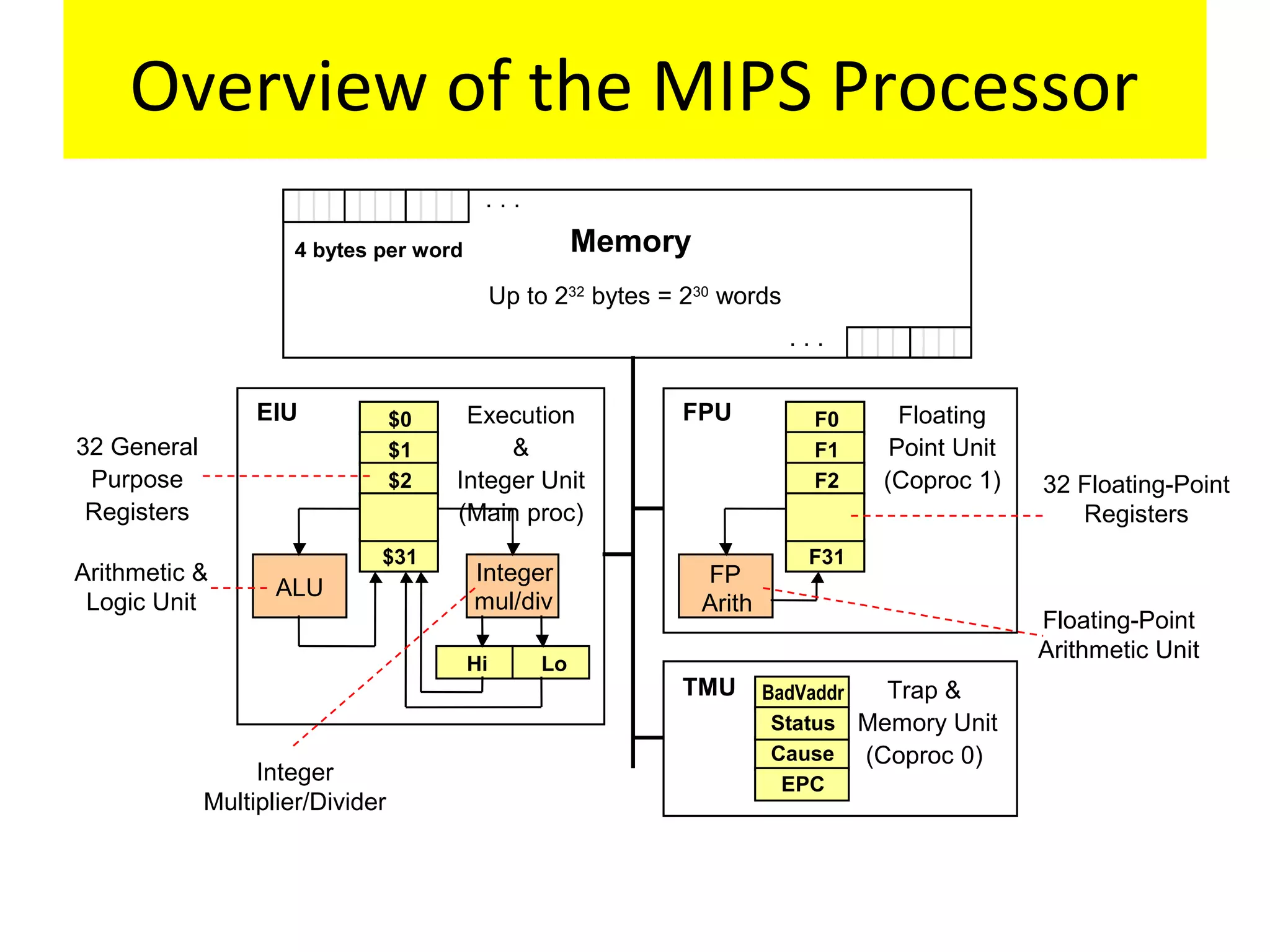
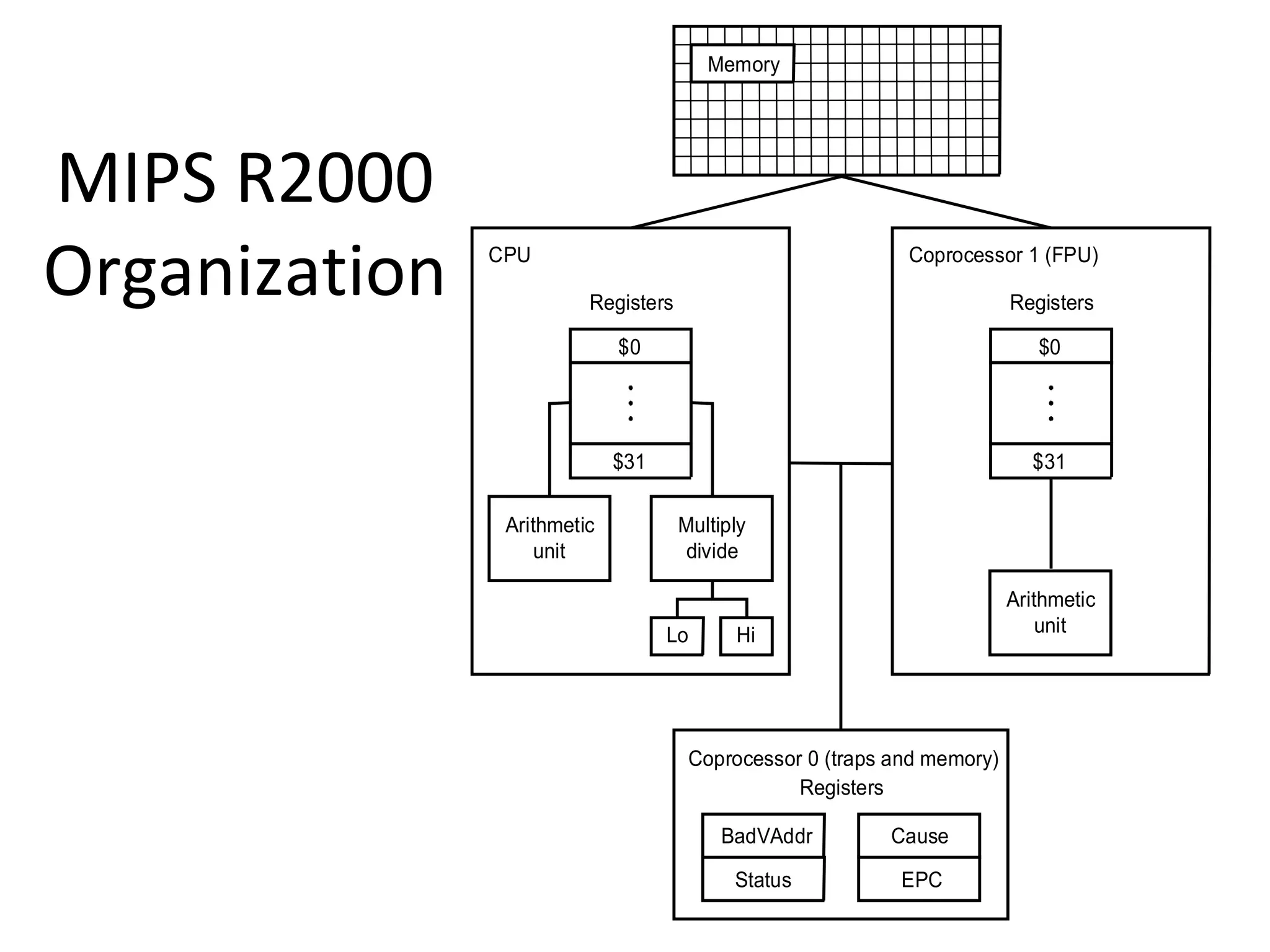
Focus on MIPS as a RISC example, detailing its instruction set, register structure, and overall organization.
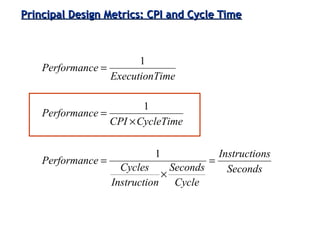
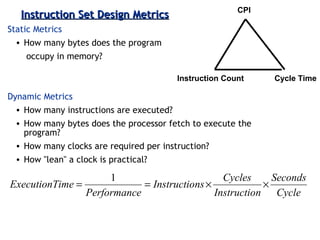
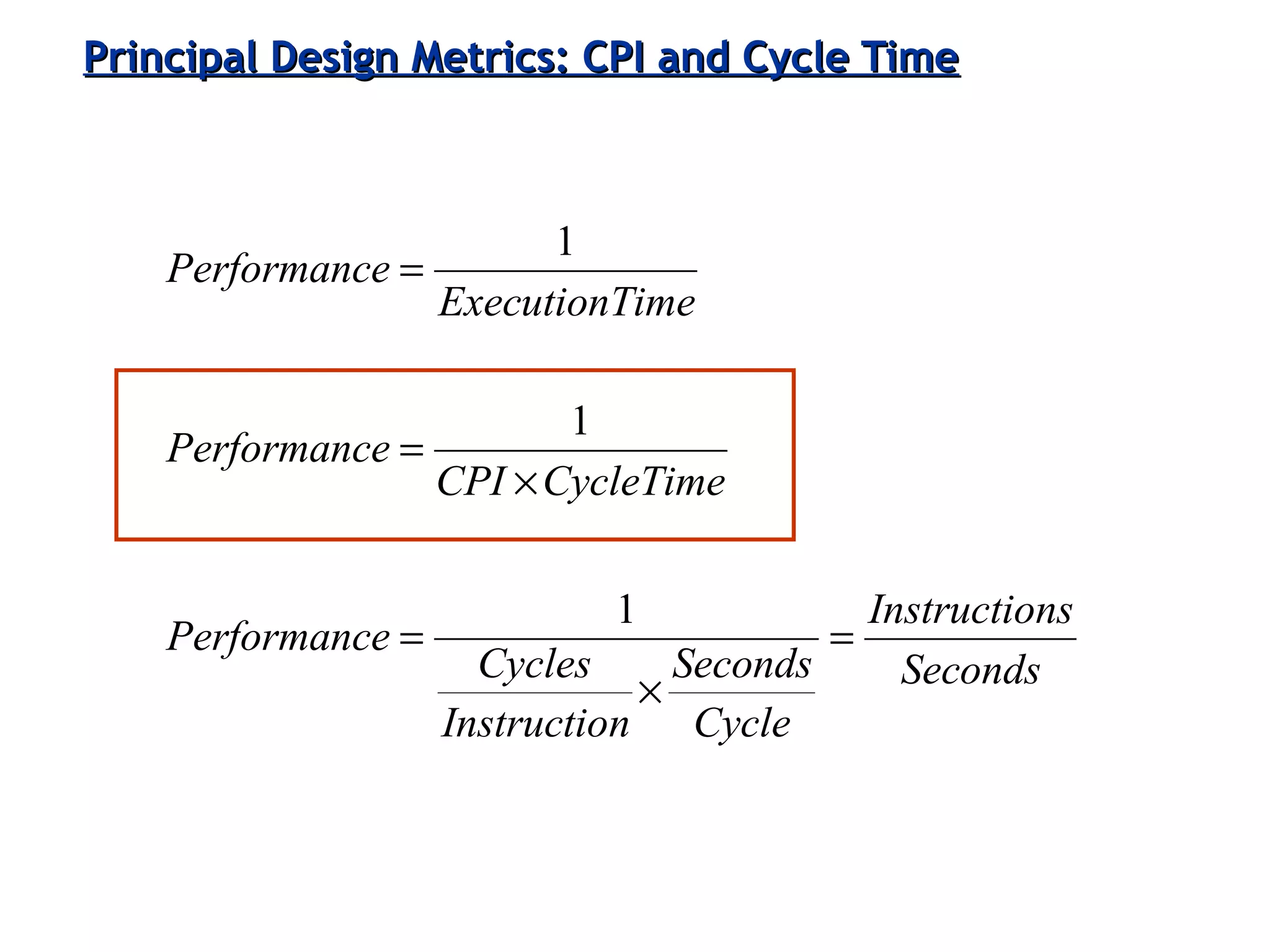
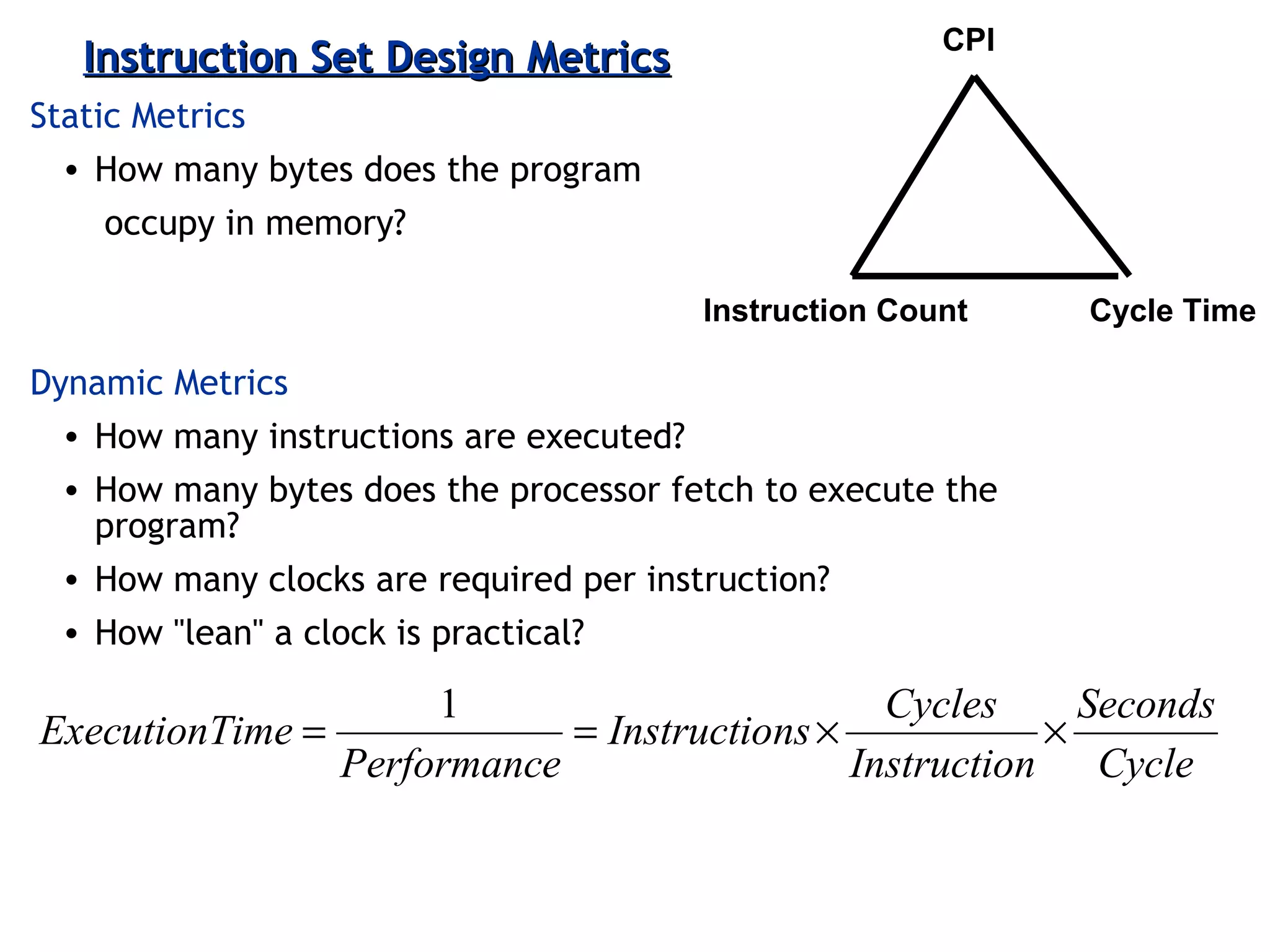
Discussion on performance metrics like CPI (Cycles Per Instruction) and execution time, as well as trade-offs in architectural design.
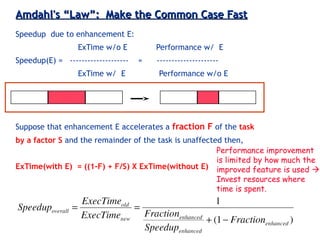
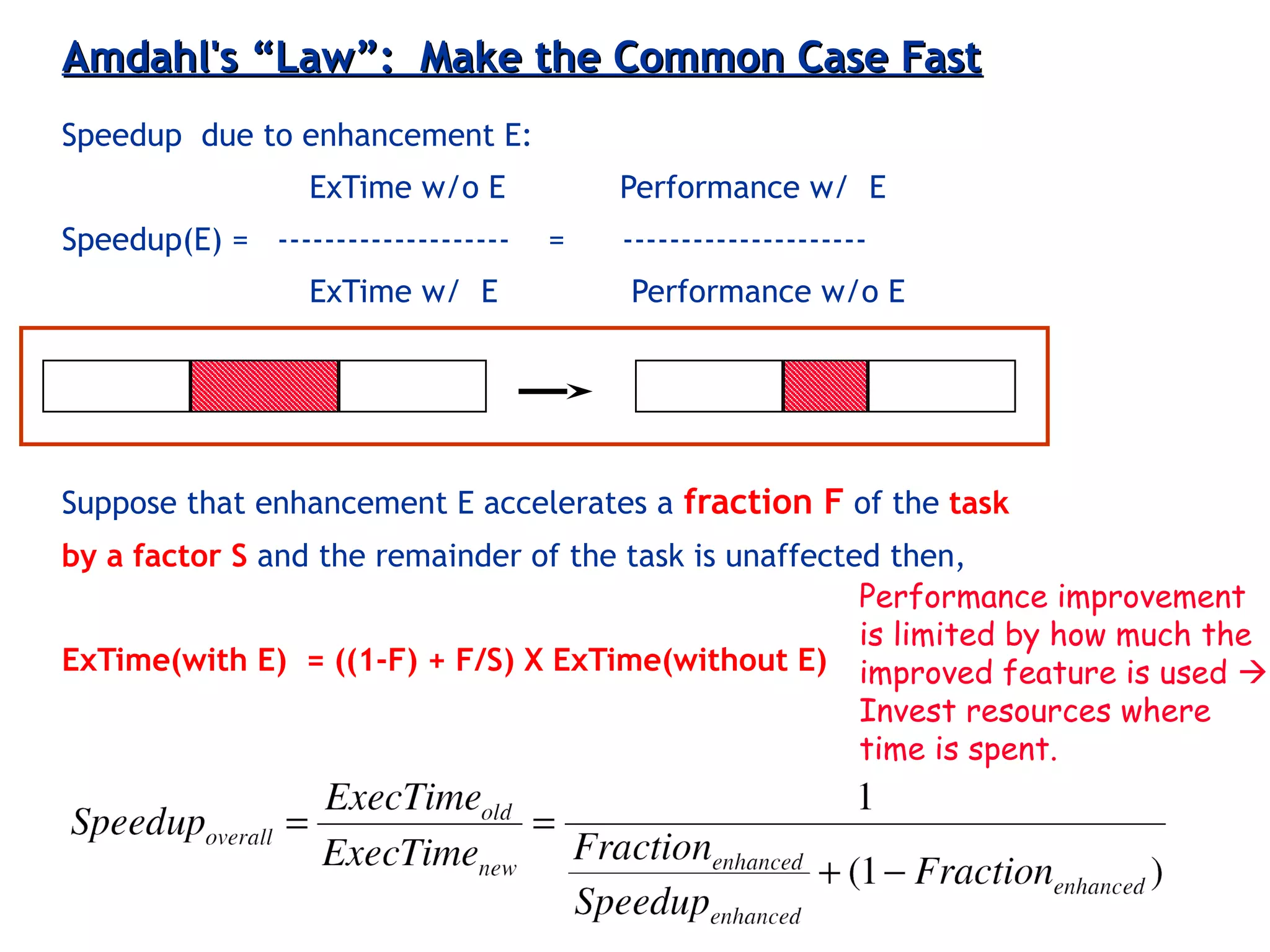
Introduces Amdahl's Law in the context of performance enhancements, illustrating limitations and optimal resource allocation.
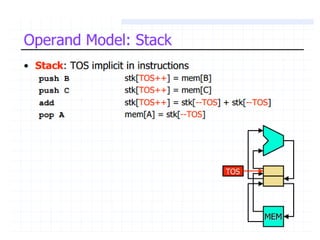
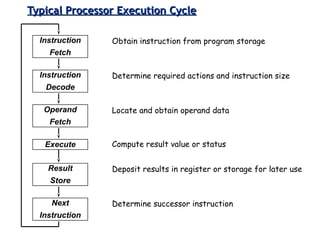
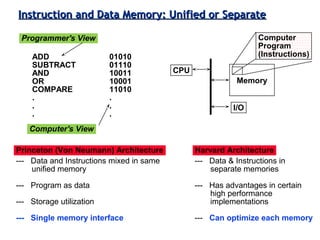
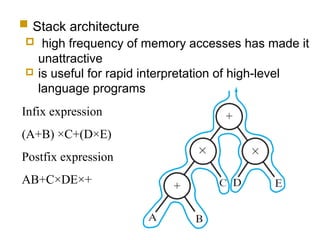
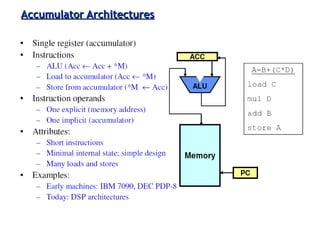
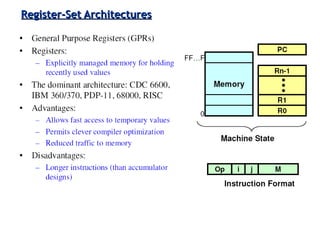
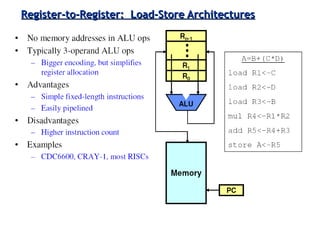
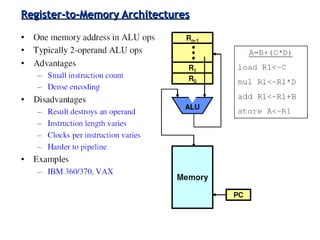
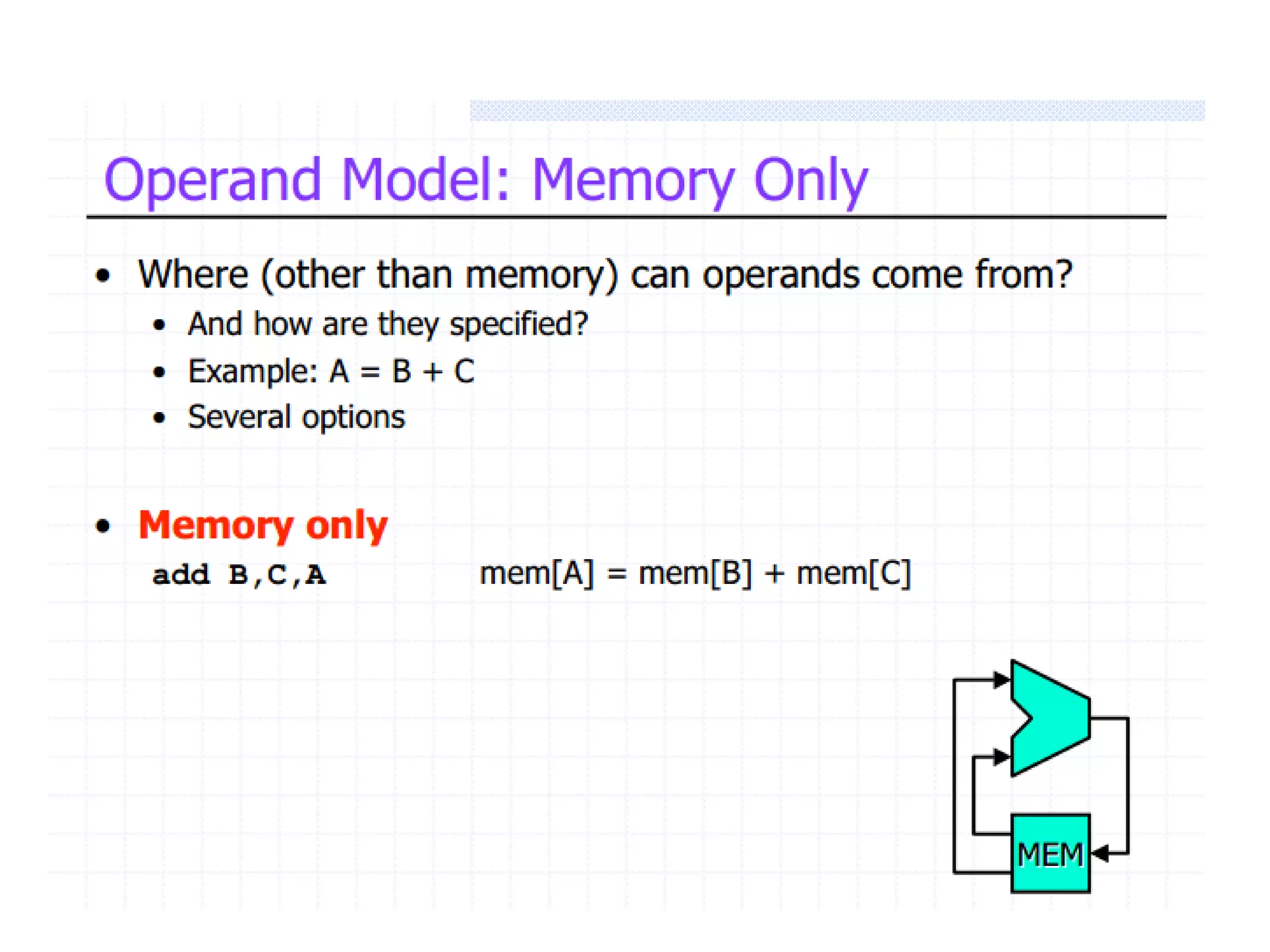
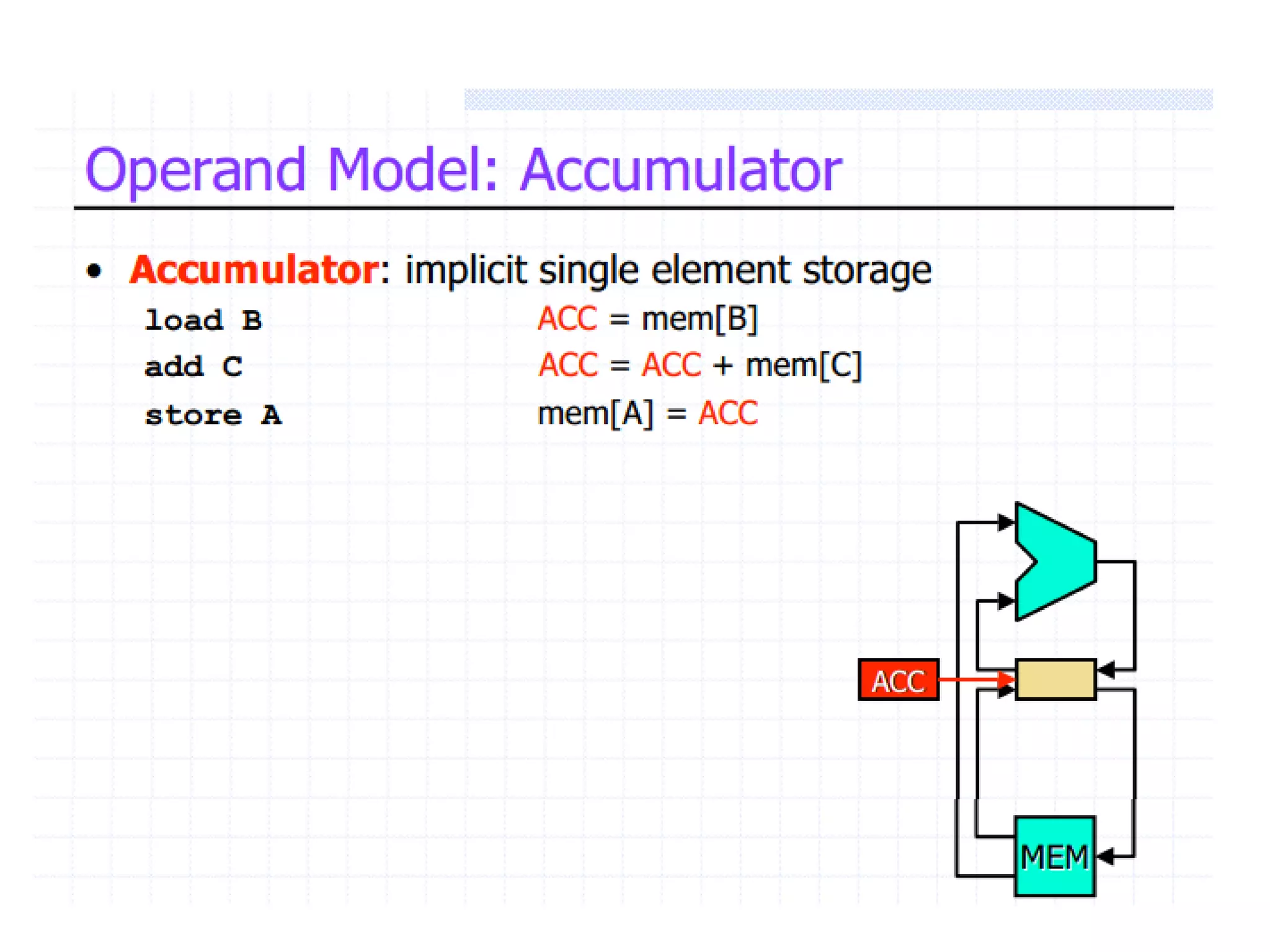
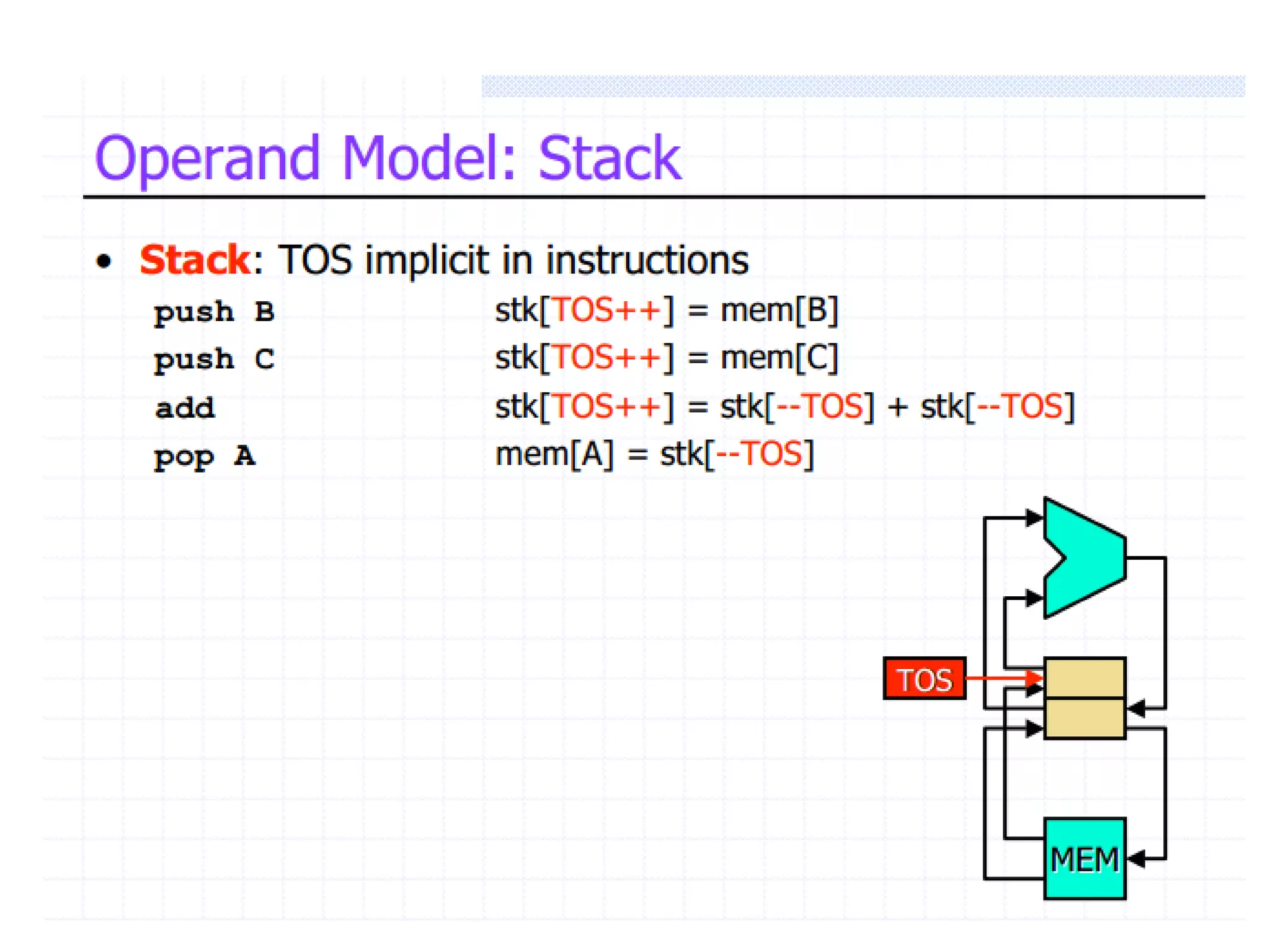
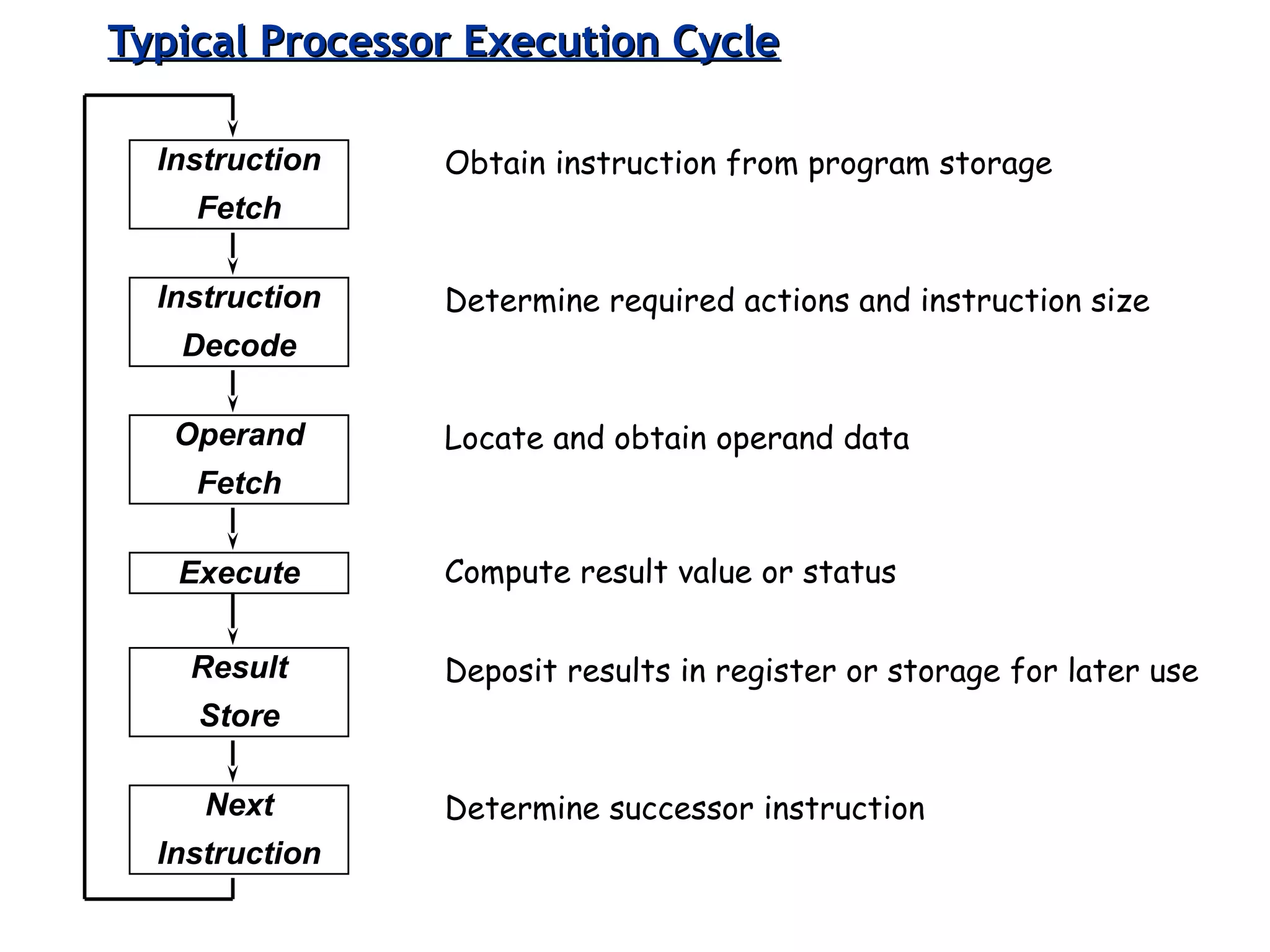
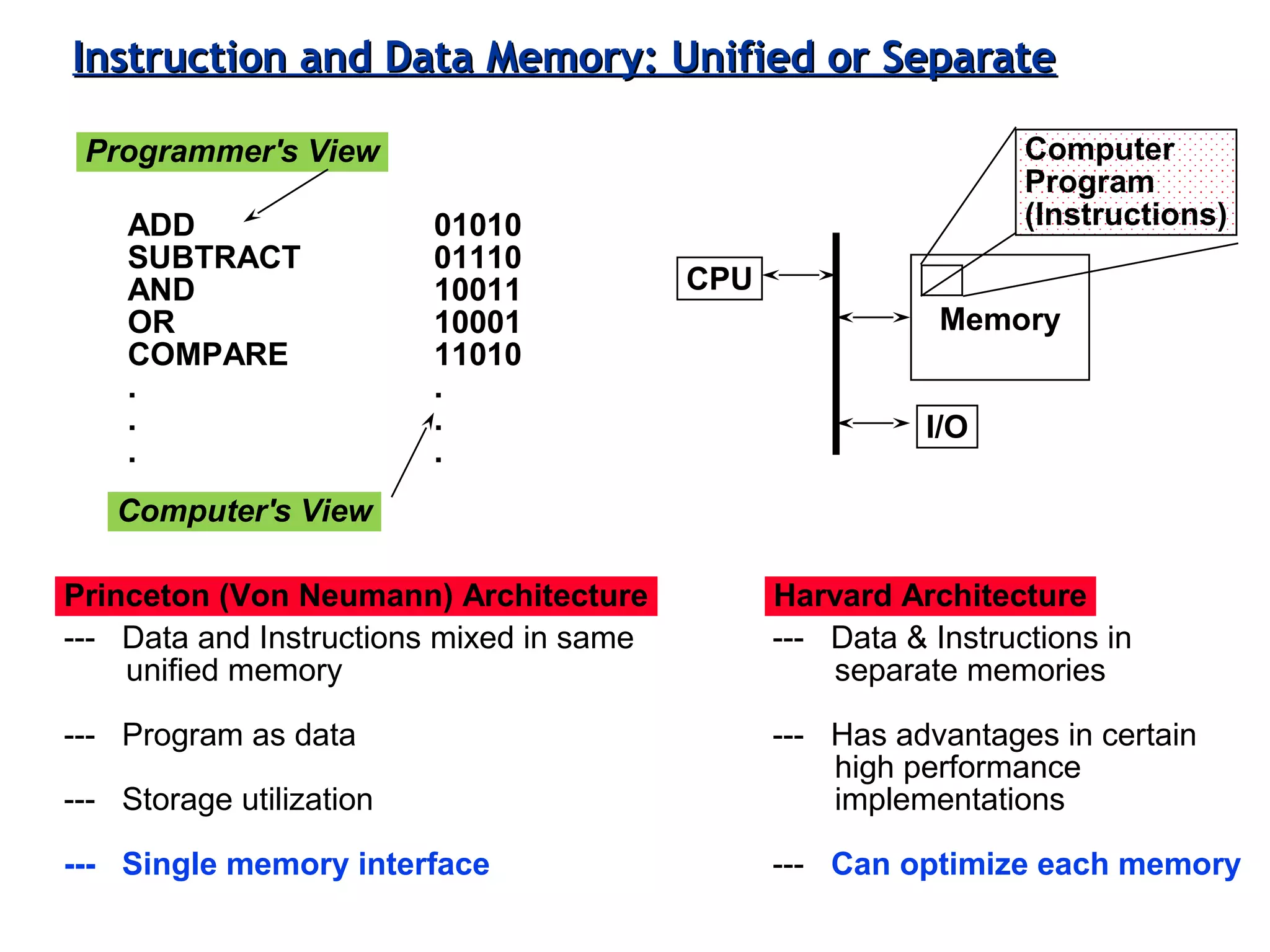
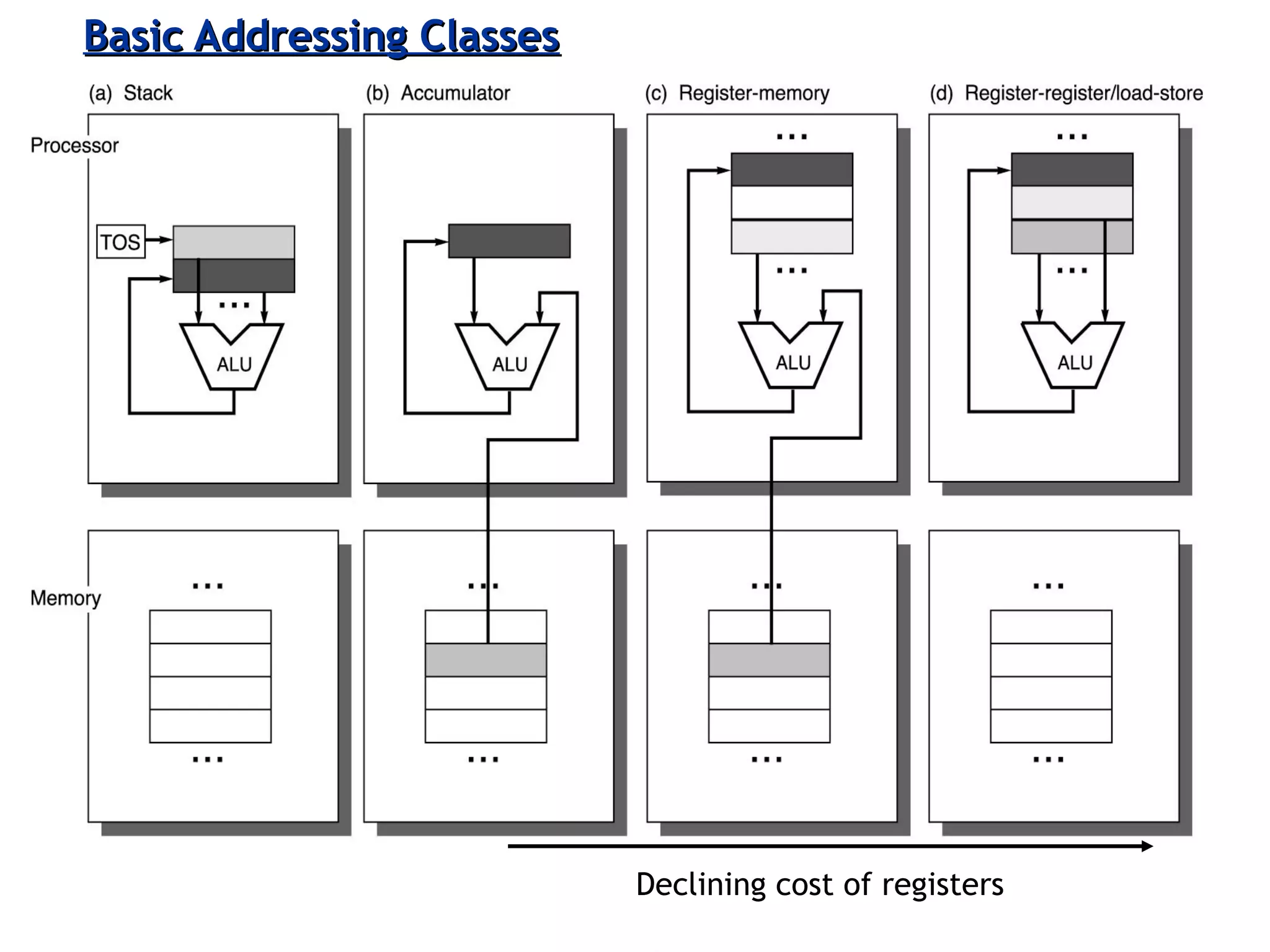
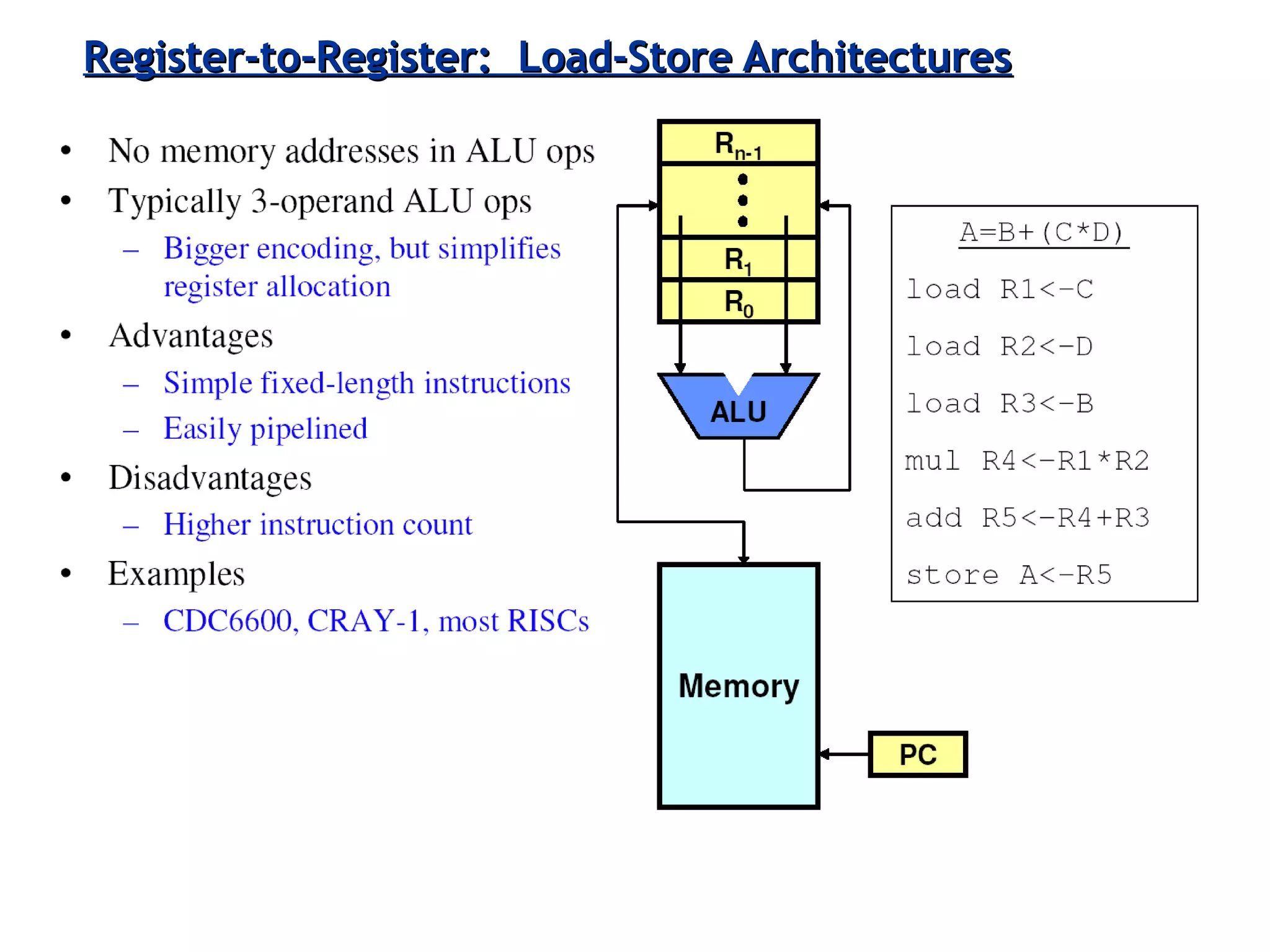
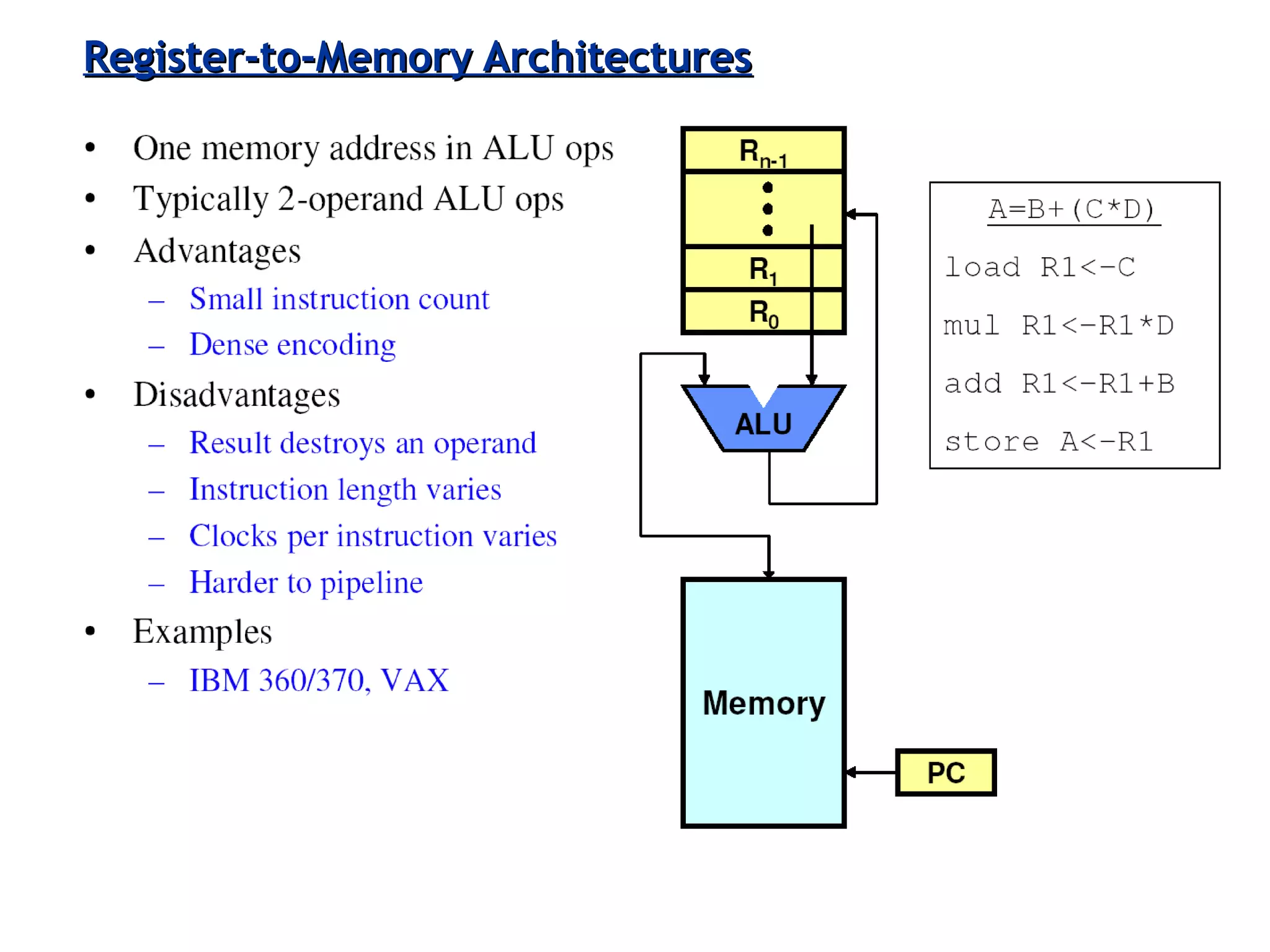
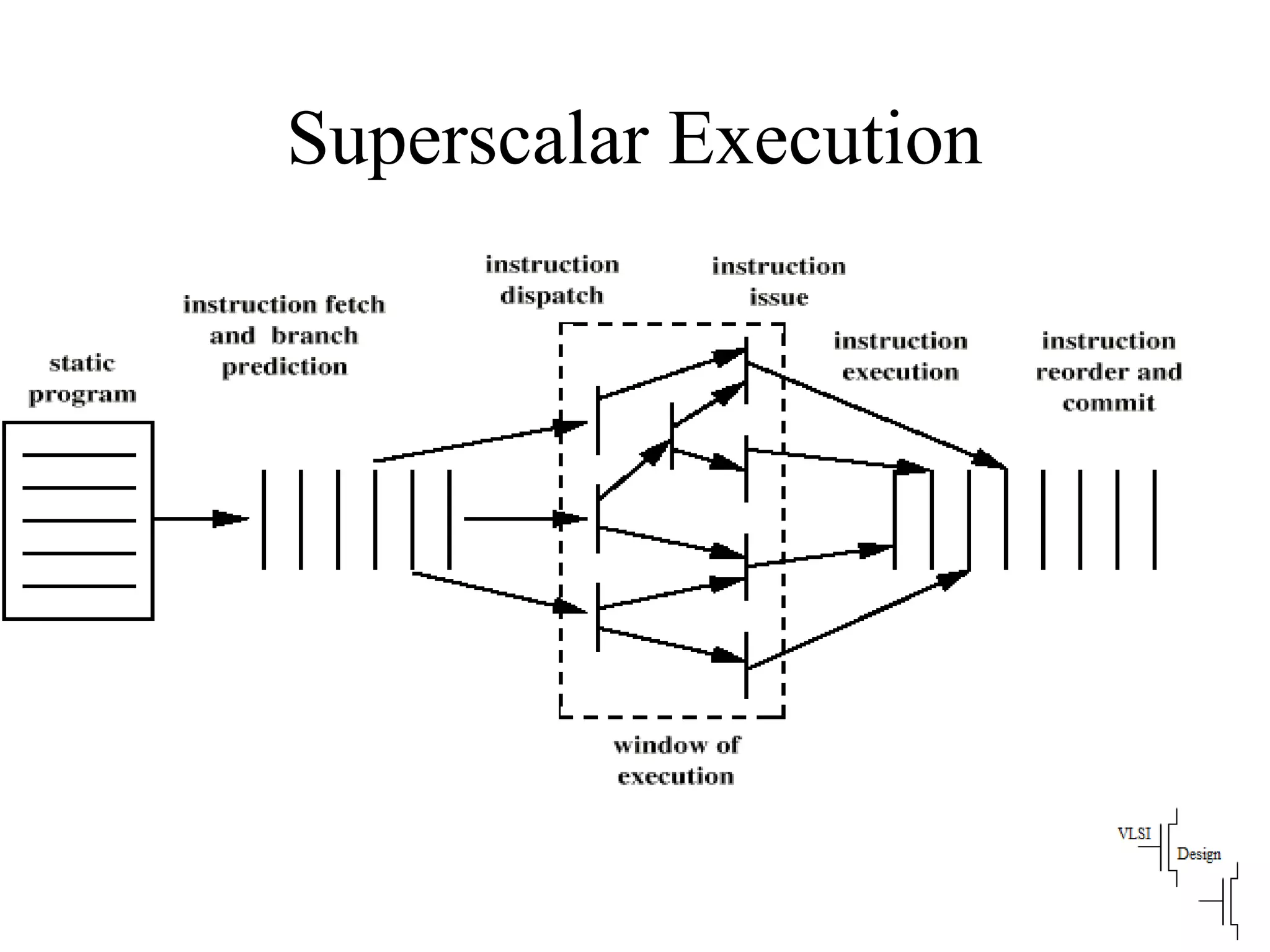
Classifies ISAs into types and details execution process from fetching to storing results, explaining unified vs. separate memory structures.
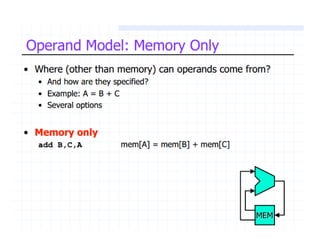
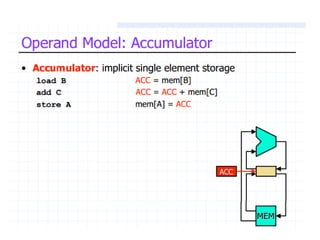
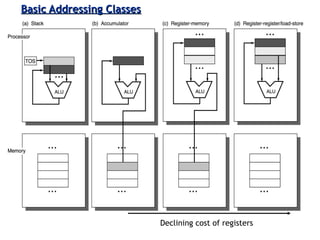
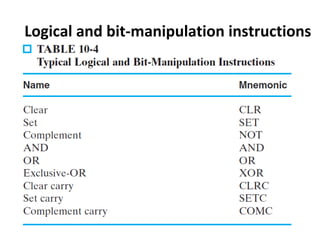
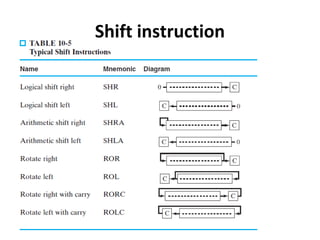
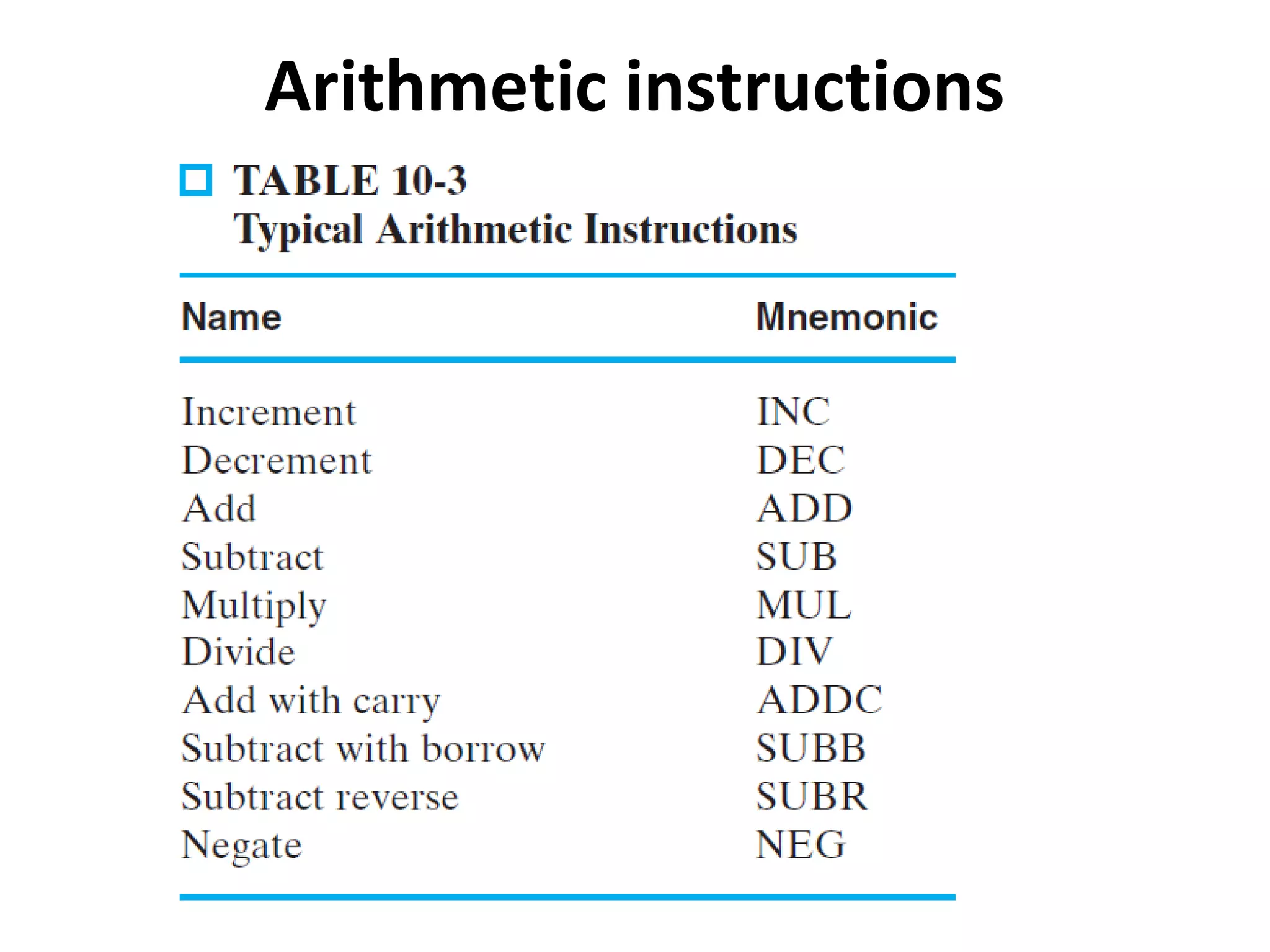
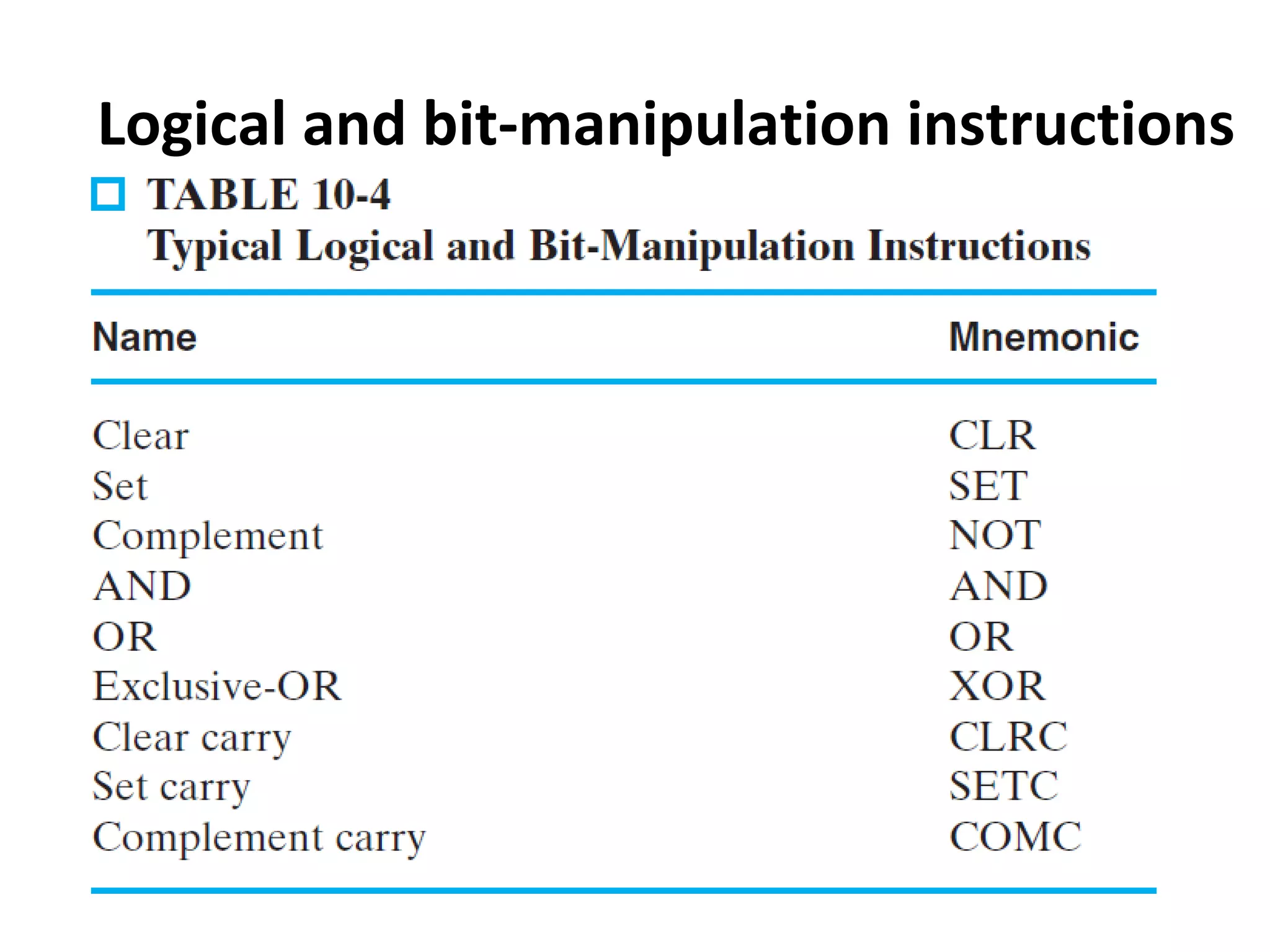
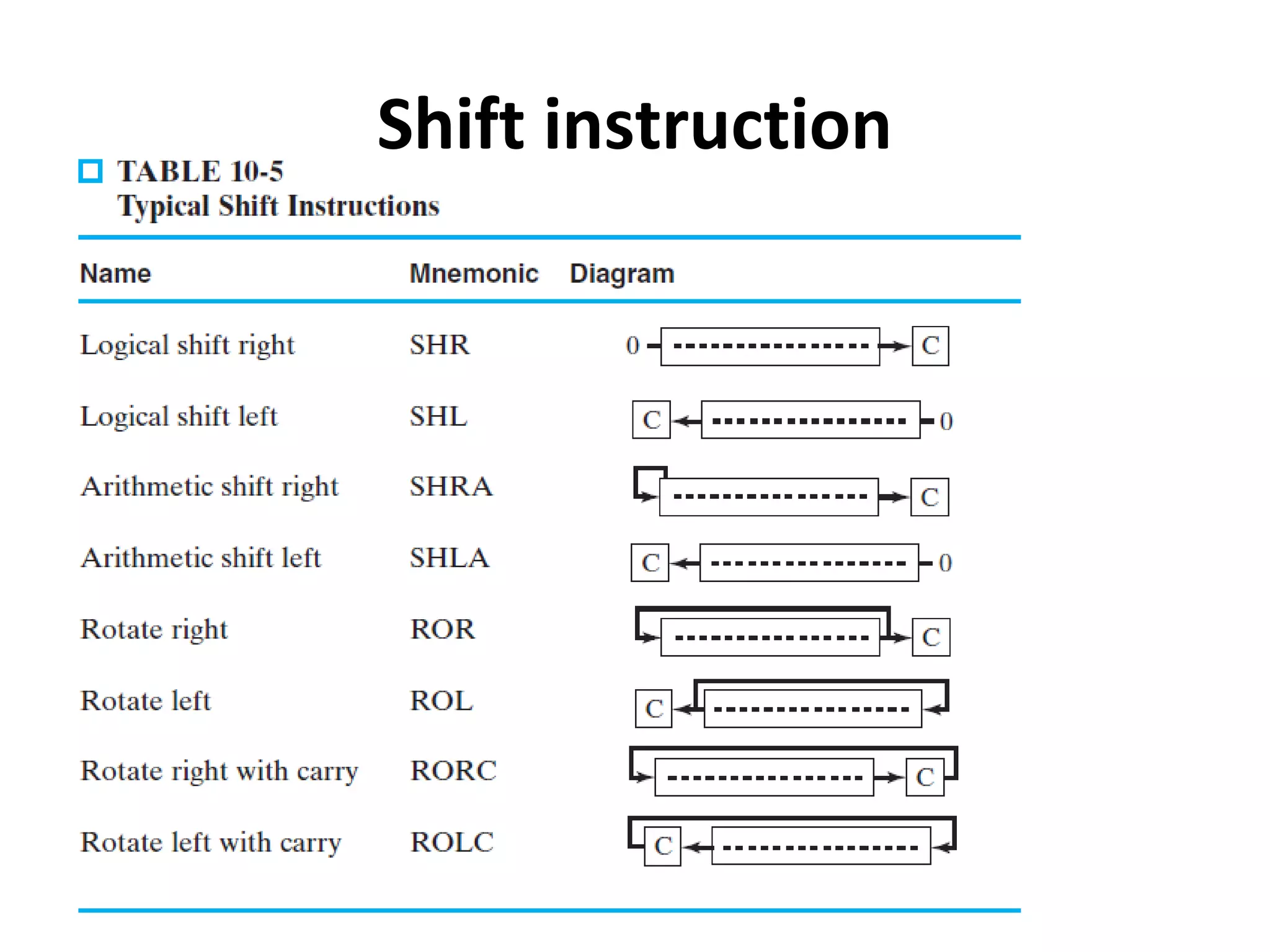
Explains addressing modes in instruction design and metrics related to program size and instruction execution.
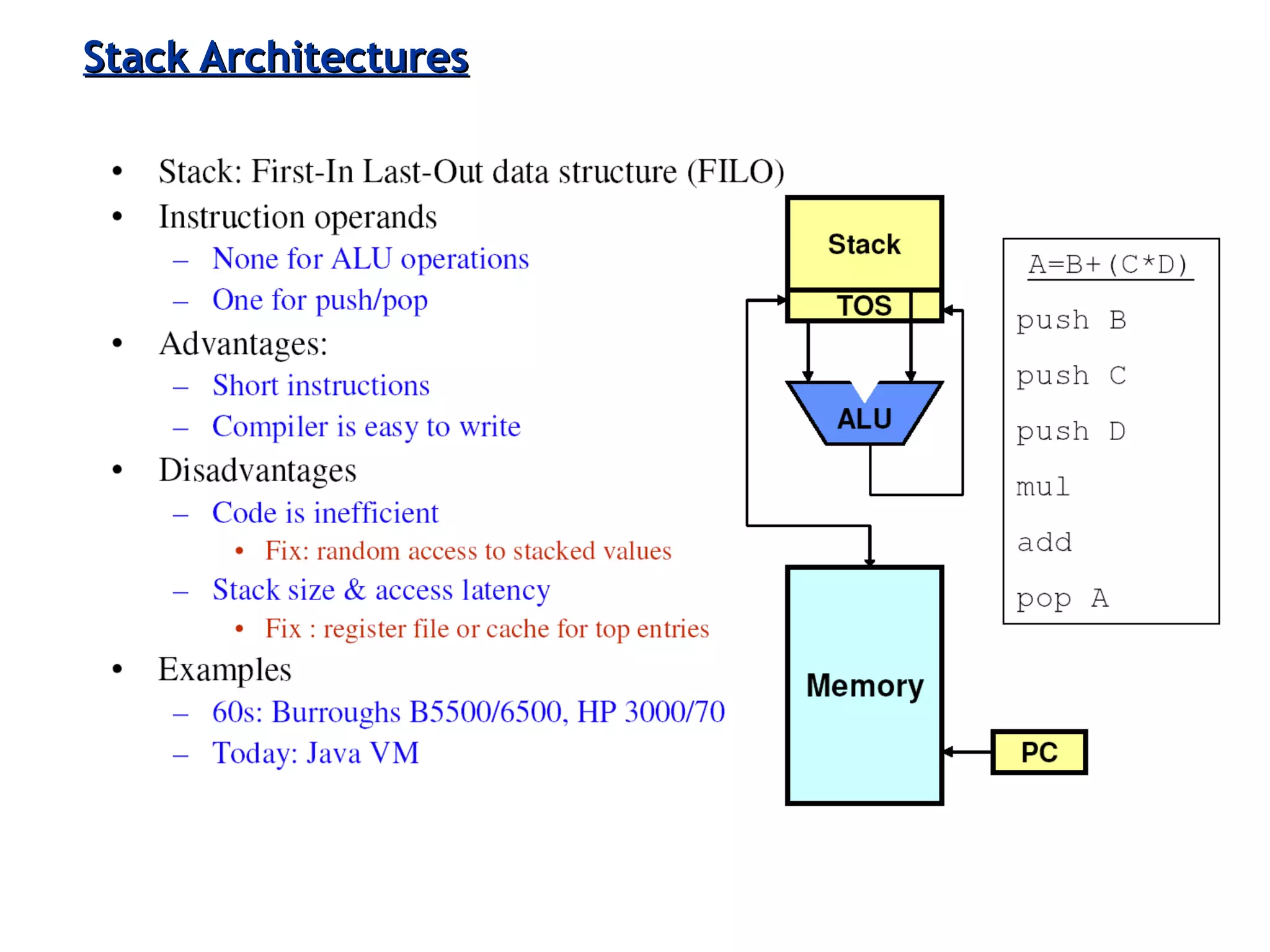
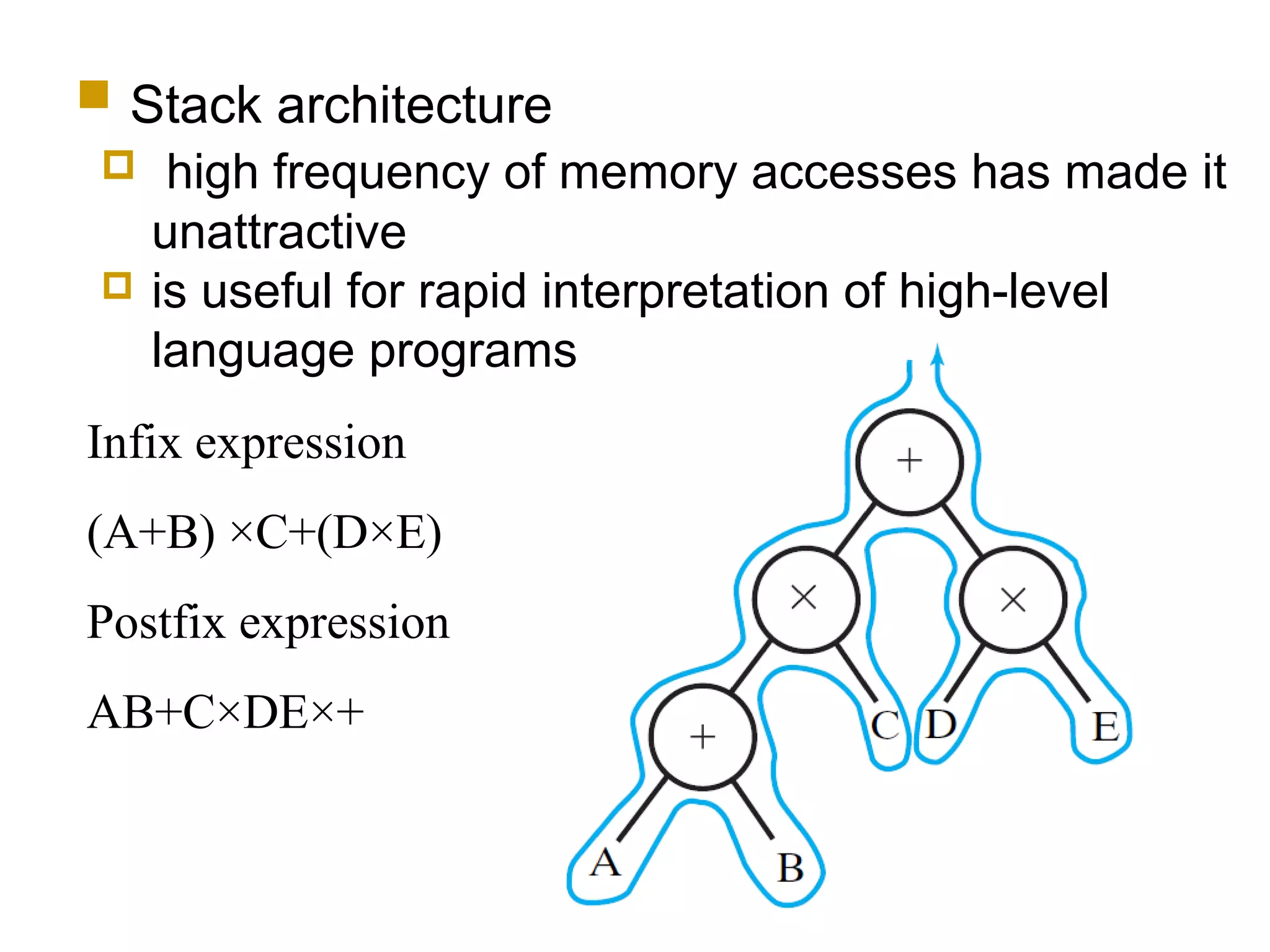
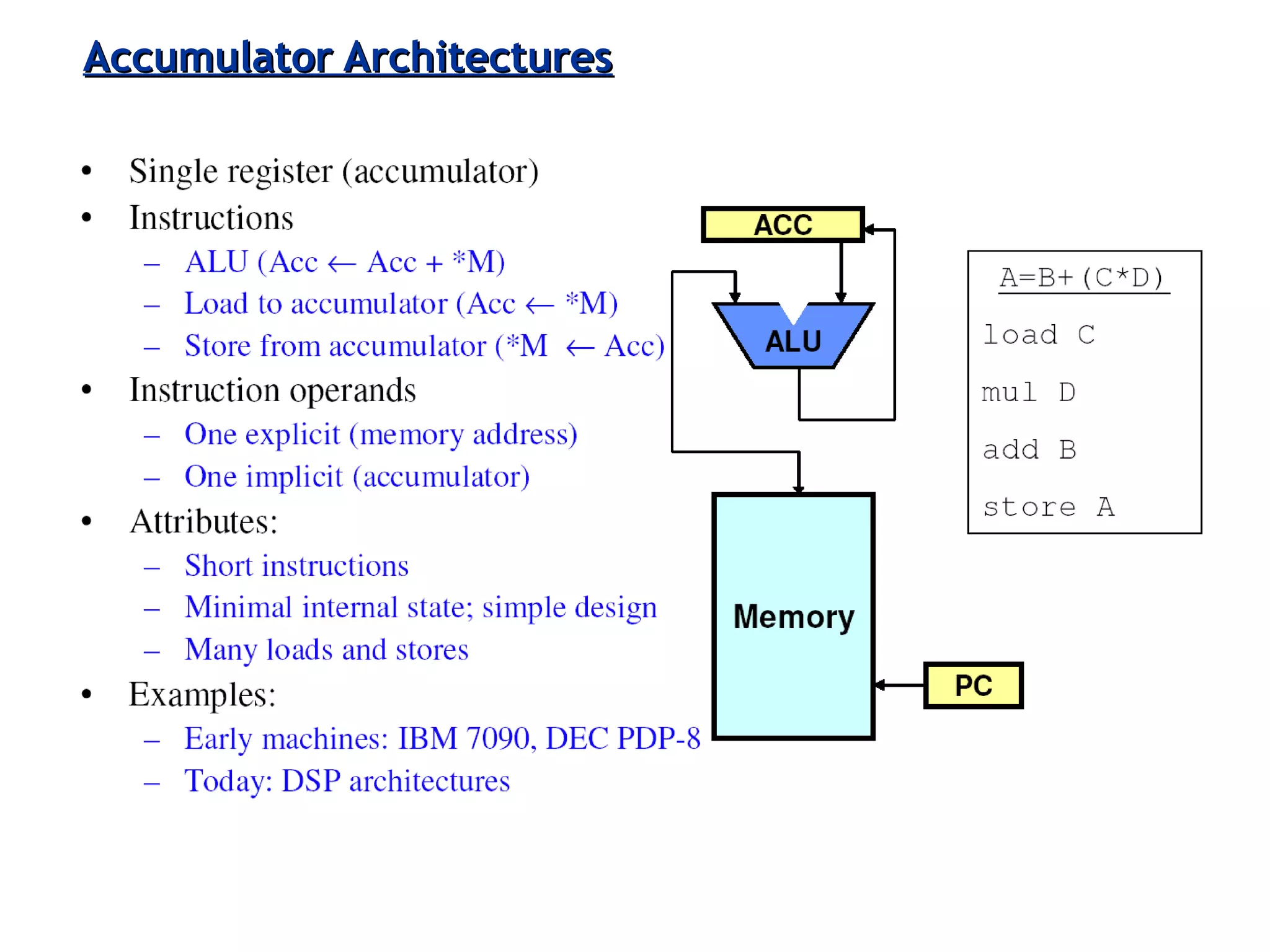
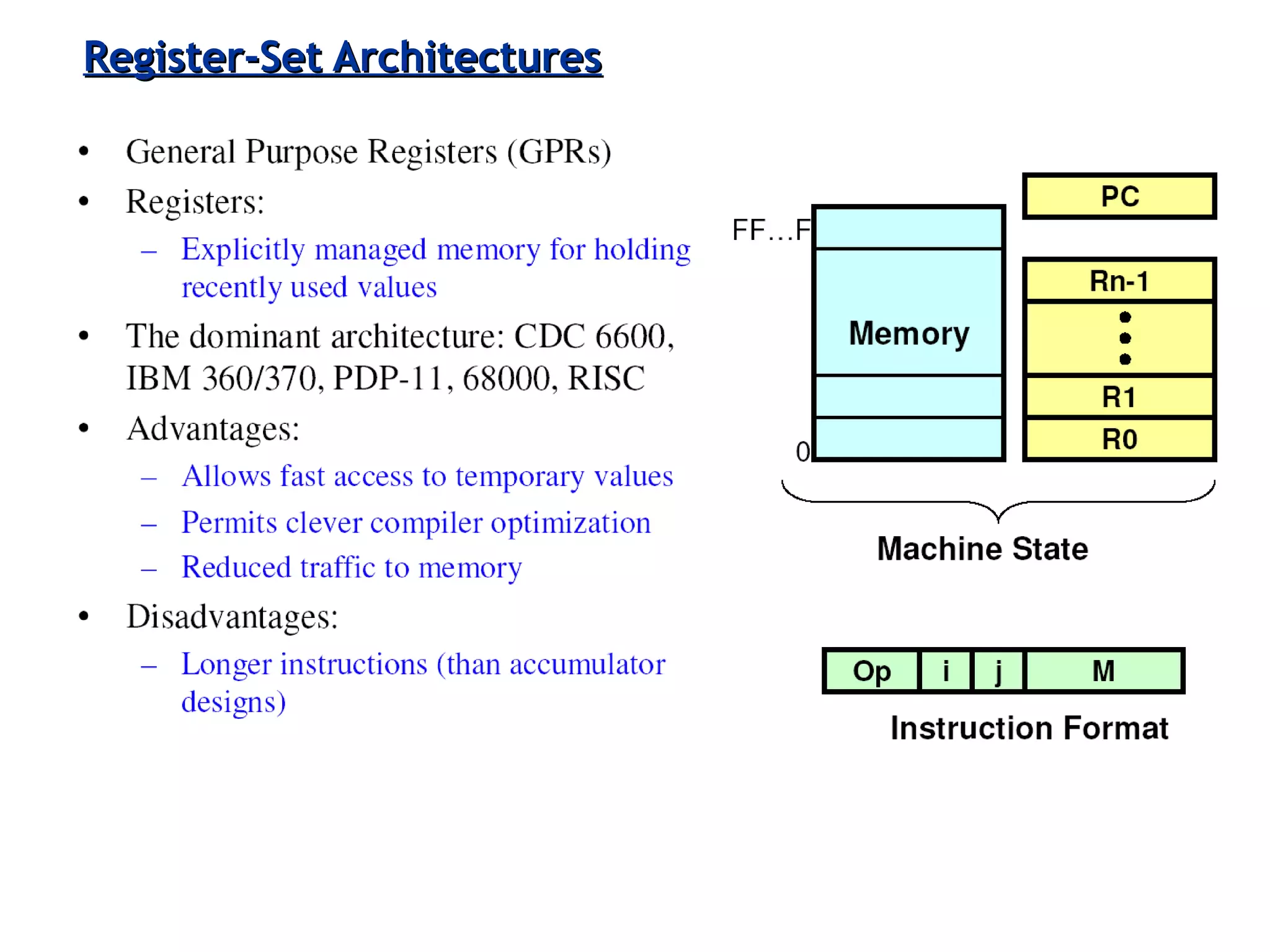
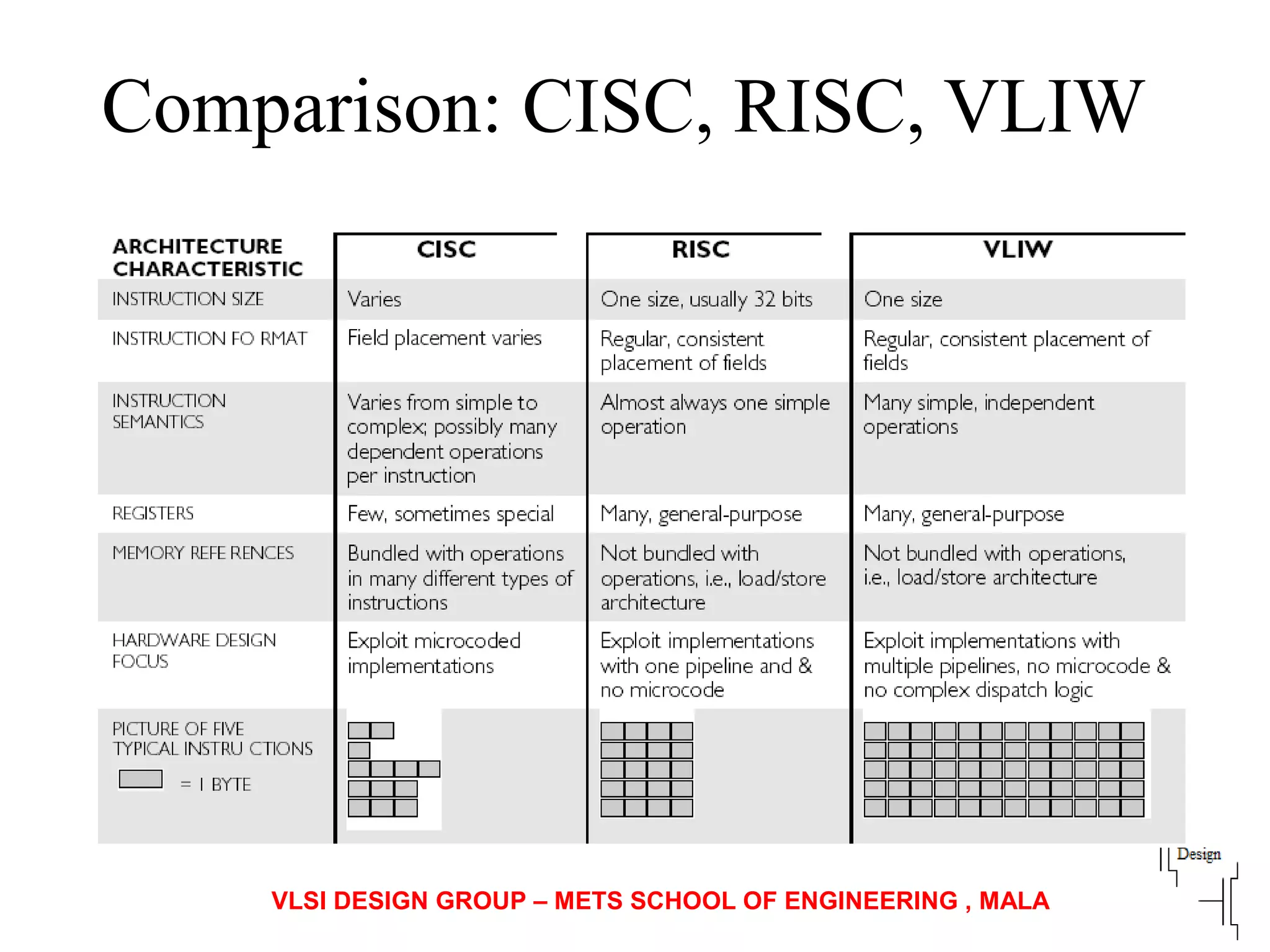
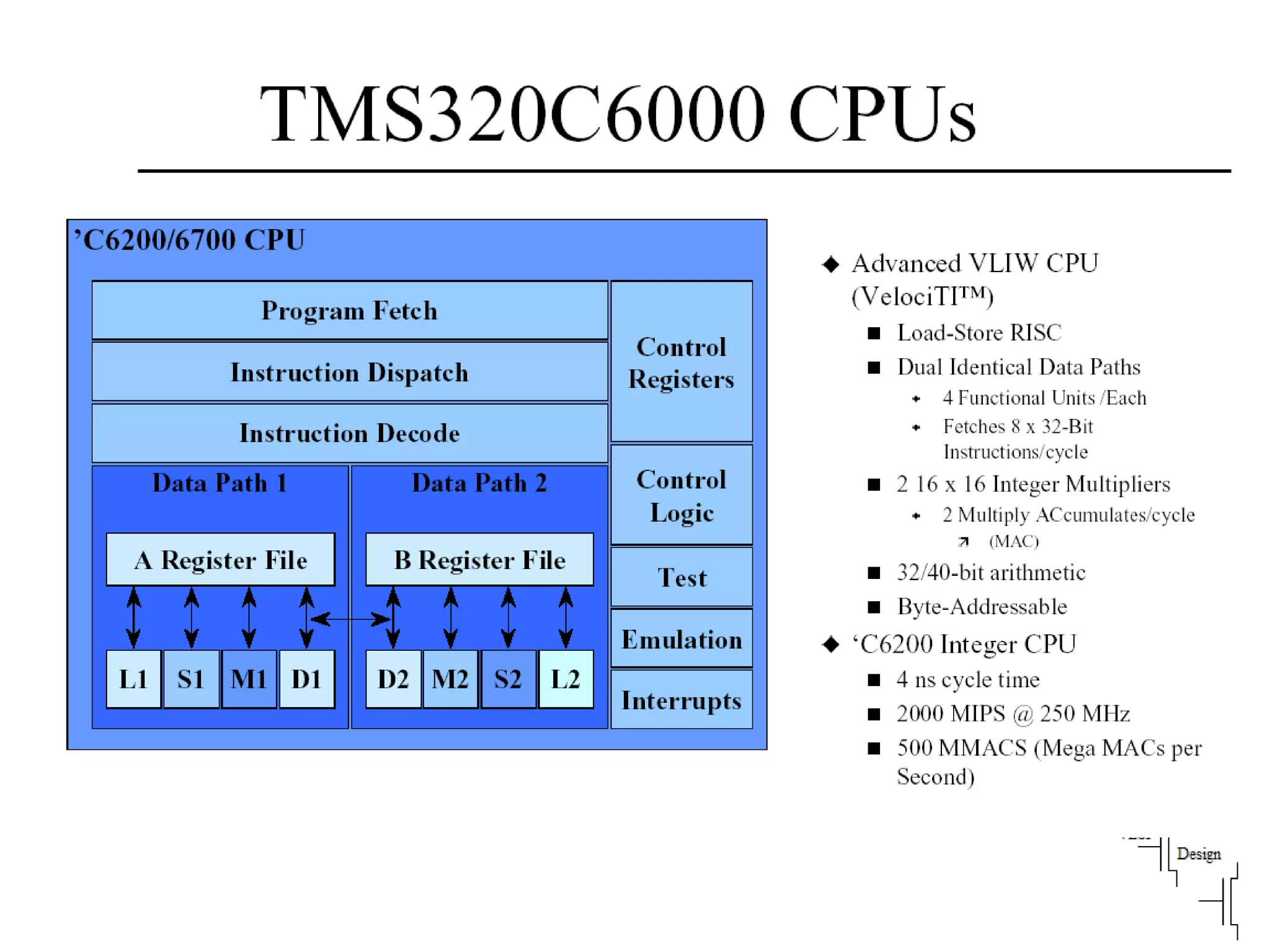
Various instruction set architectures; historical challenges in design leading to the adoption of RISC methodologies.
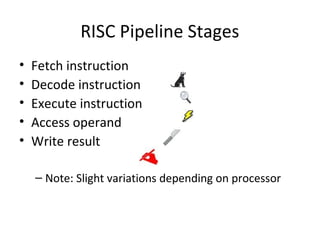
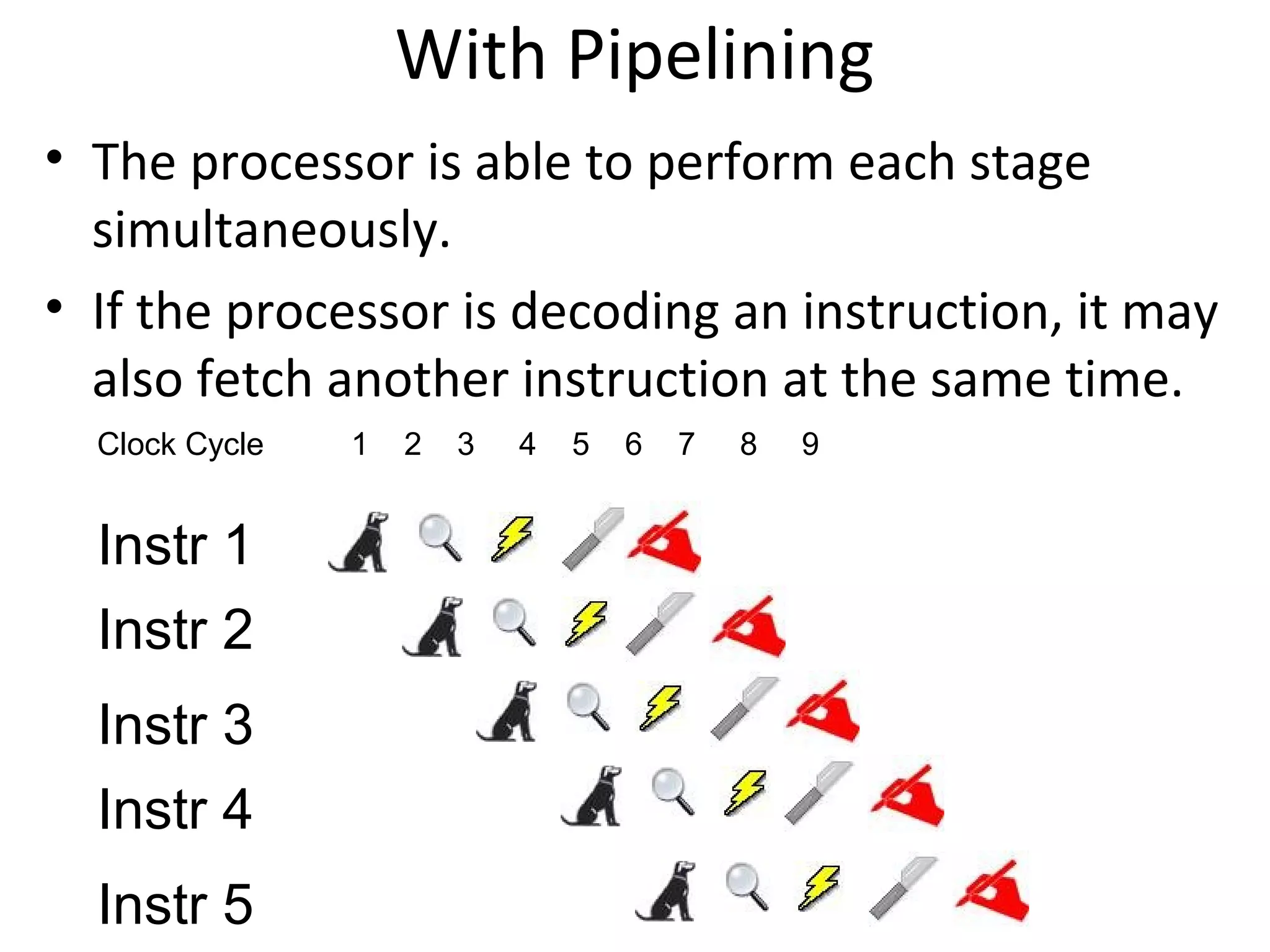
Focuses on RISC features like a load-store architecture and pipelining for efficiency in execution.
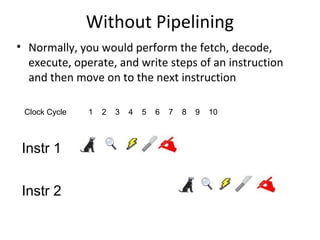
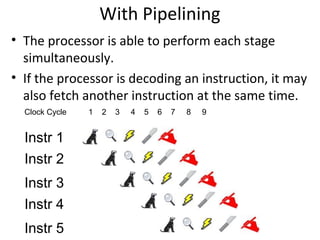
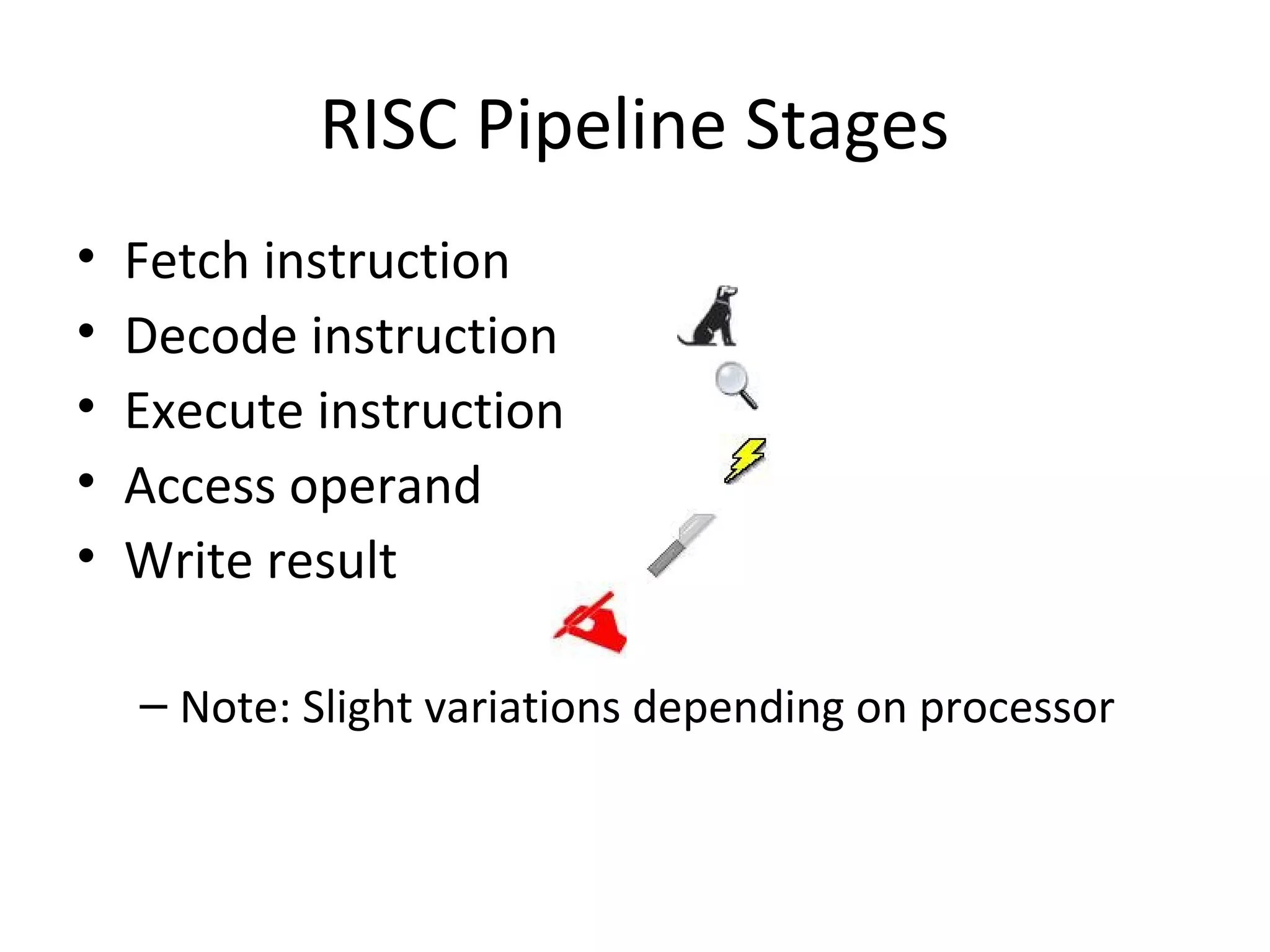
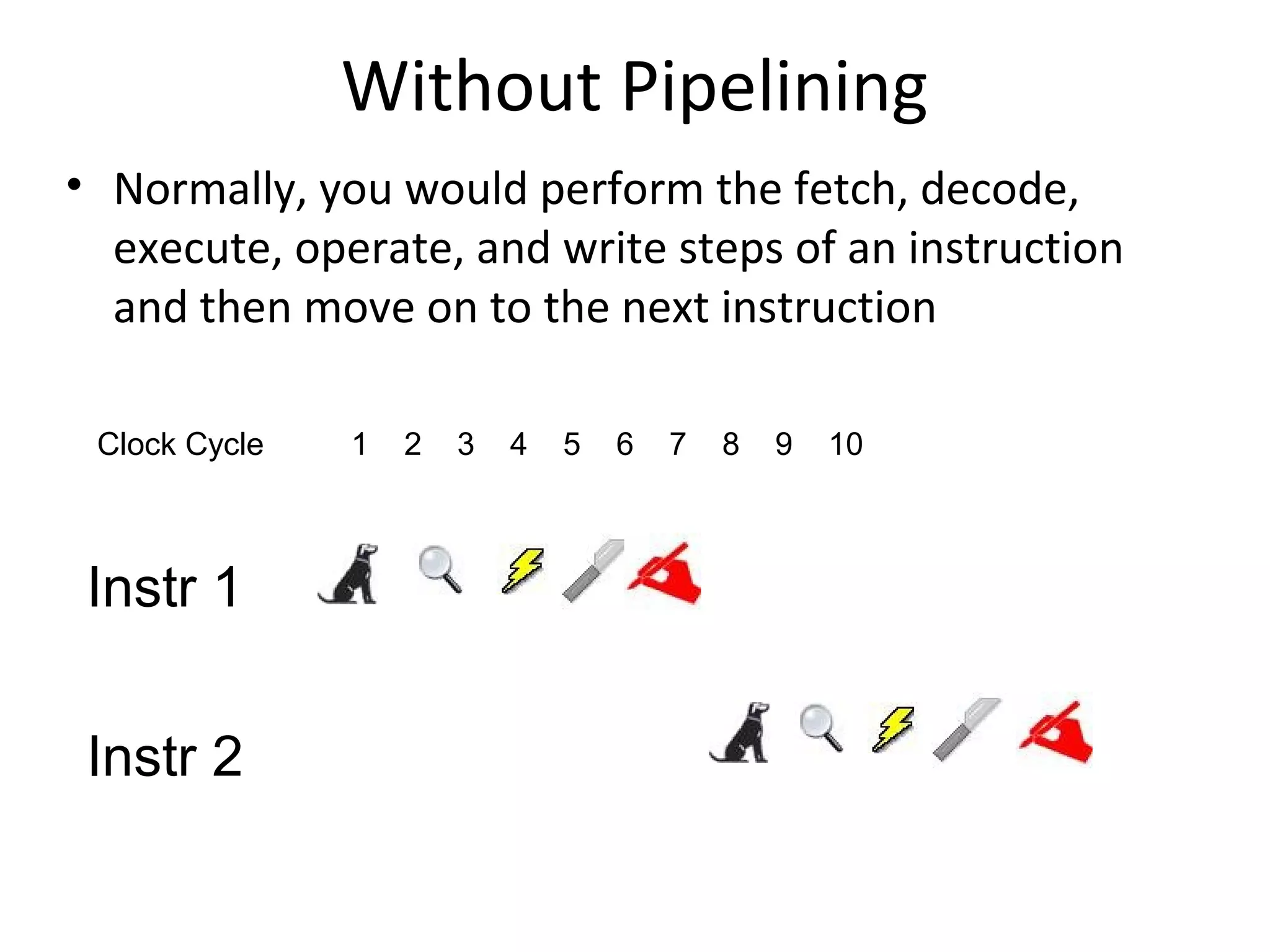
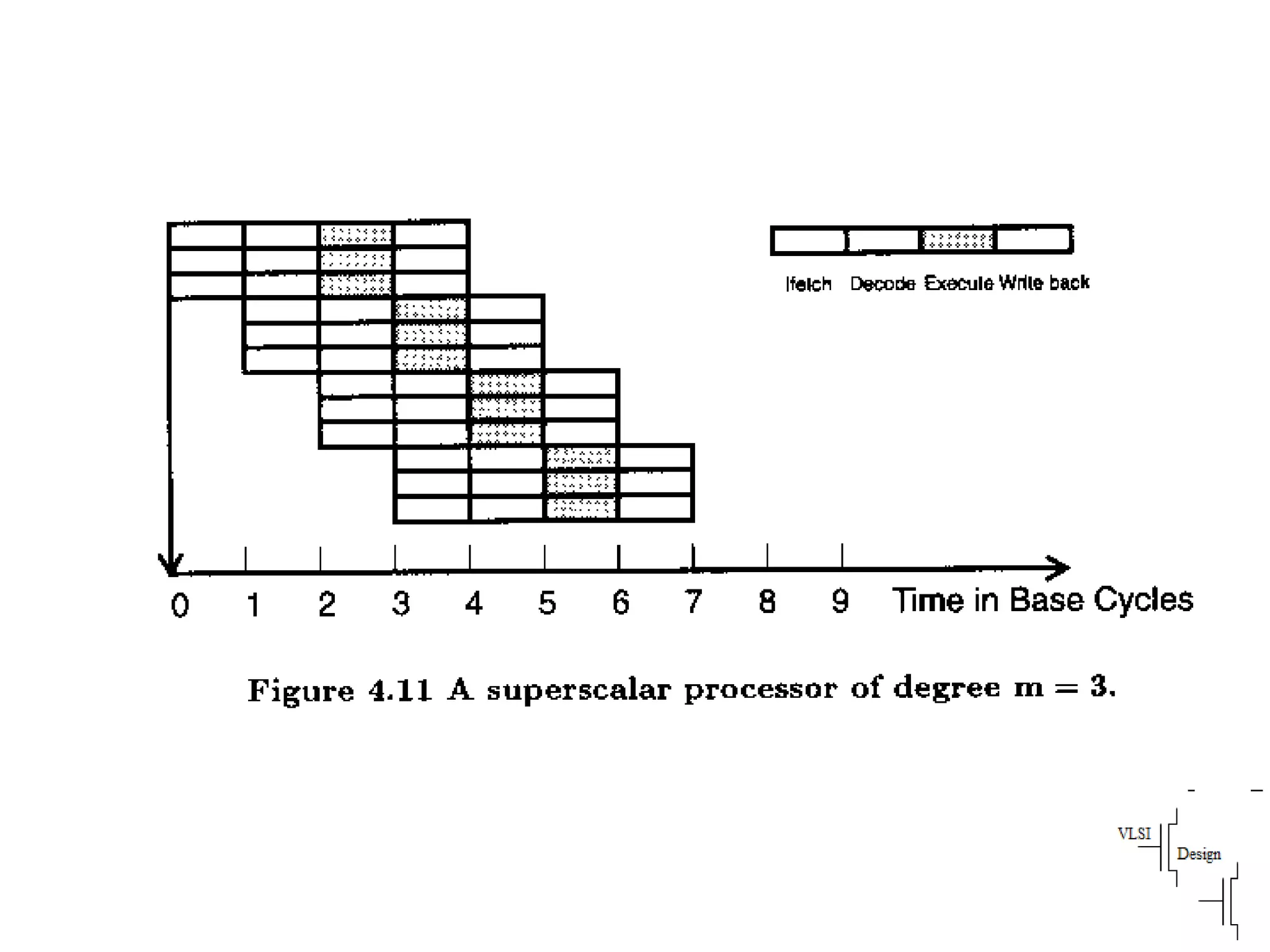
Details stages of pipelining in RISC architecture, addressing potential issues and solutions in instruction execution.
Explains the ongoing relevance of CISC architectures, highlighting their widespread adoption and enhancements through pipelining.
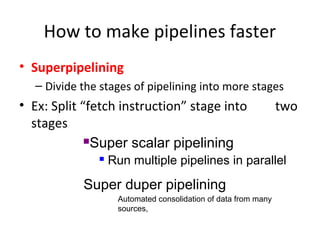
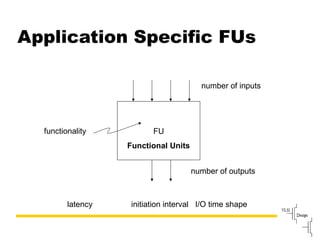
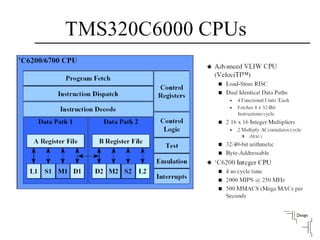
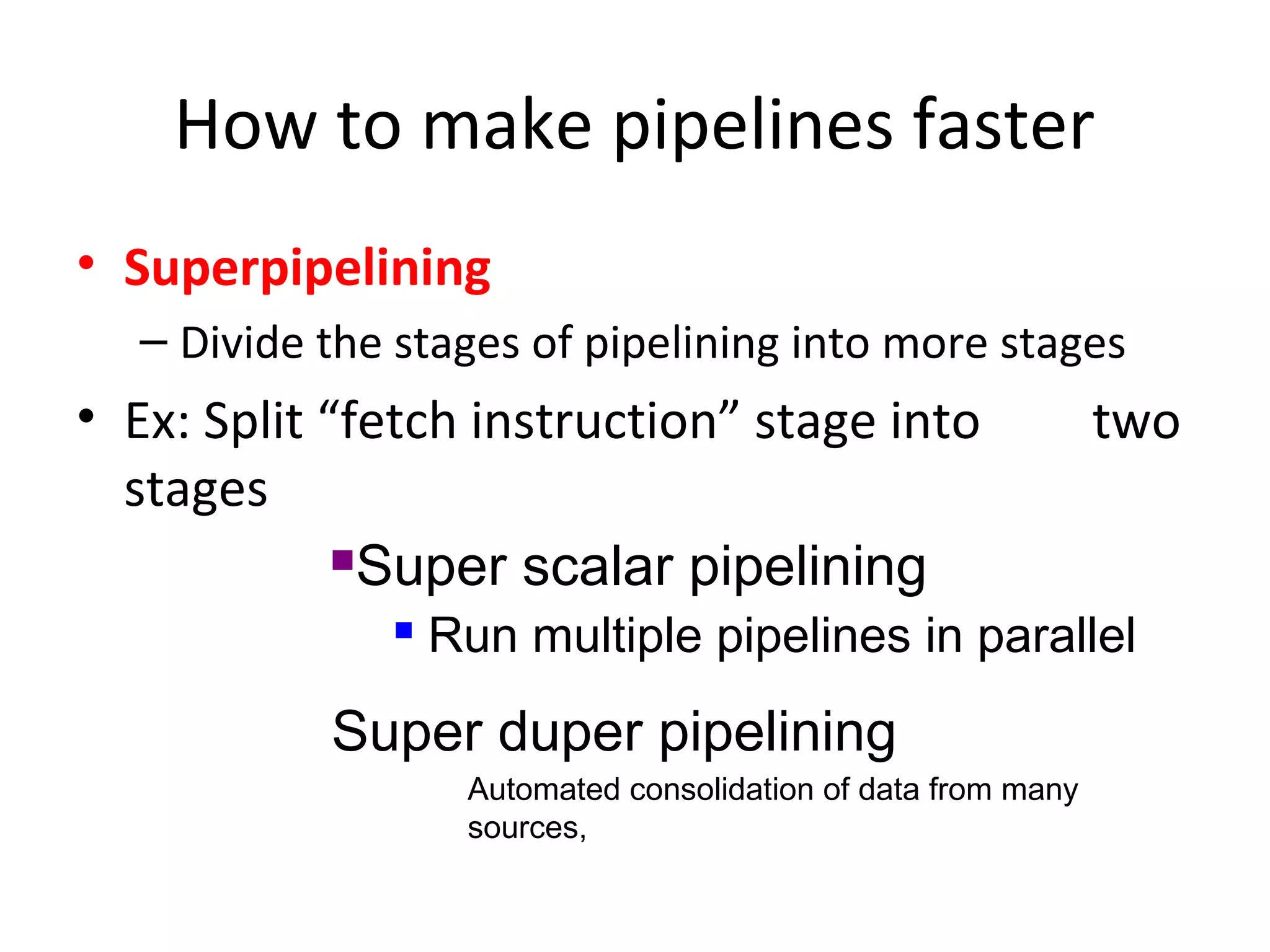
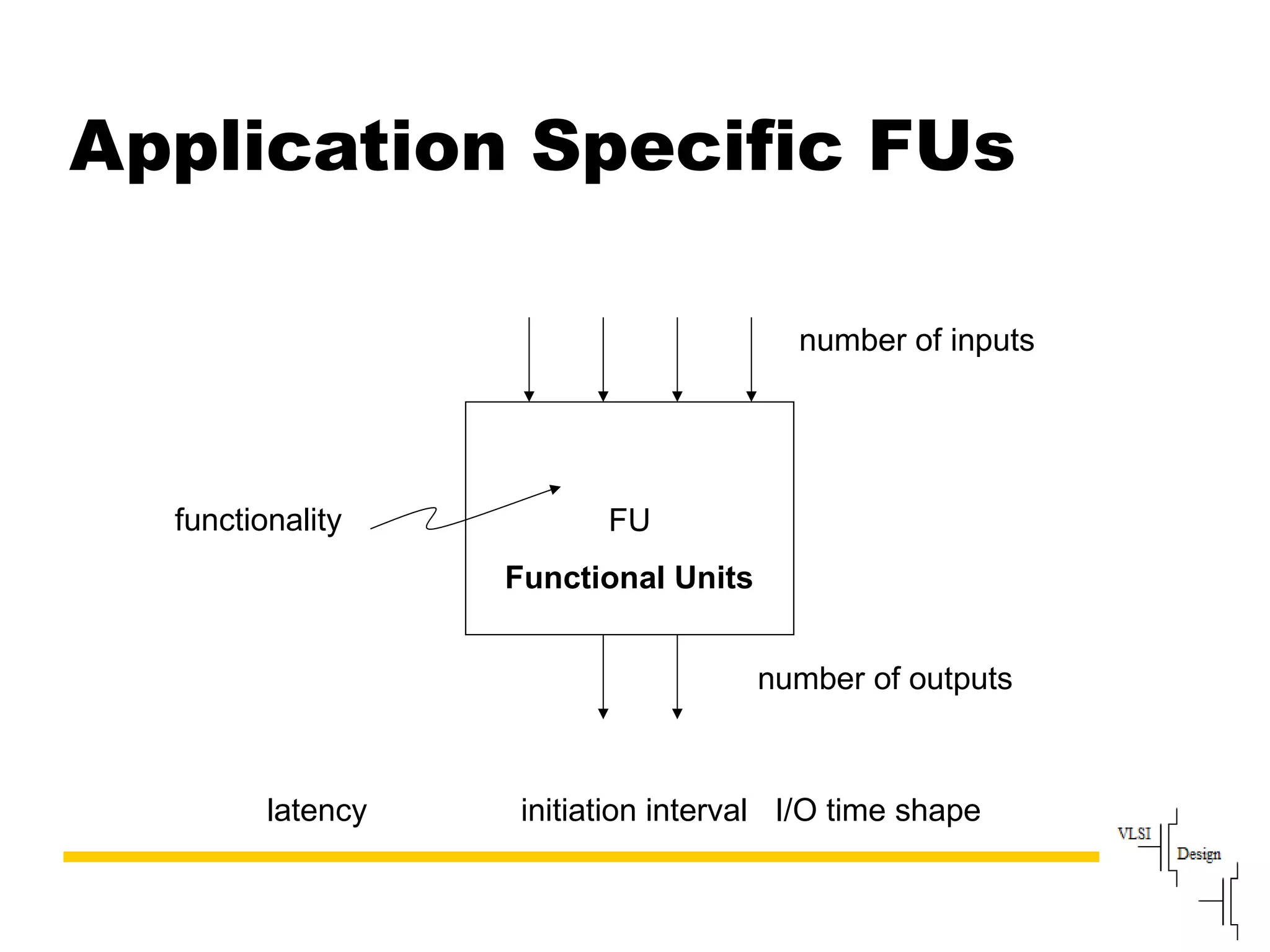
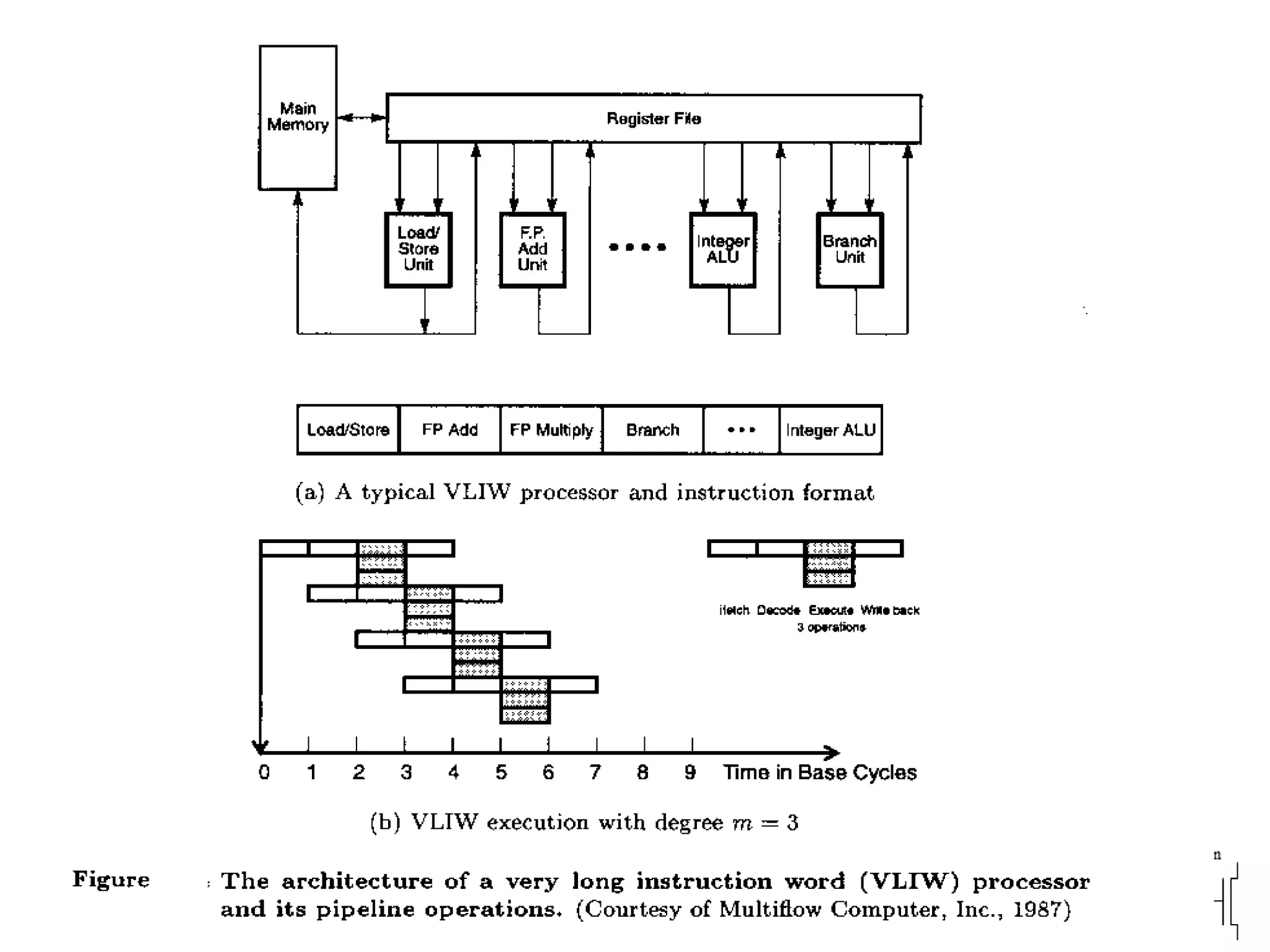
Describes VLIW design goals focusing on reducing hardware complexity while enhancing instruction-level parallelism.
Discusses the role of the compiler in scheduling instructions for VLIW architectures, enhancing instruction-level parallelism.
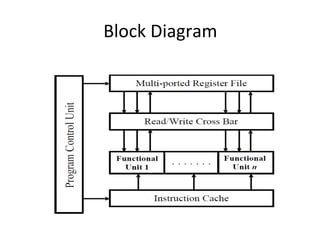
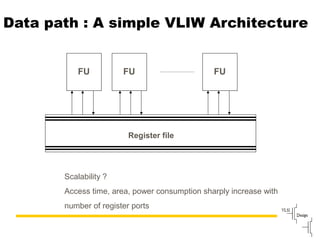
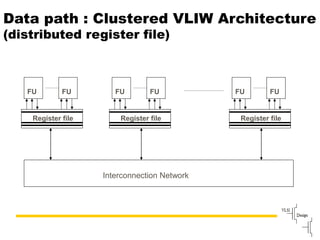
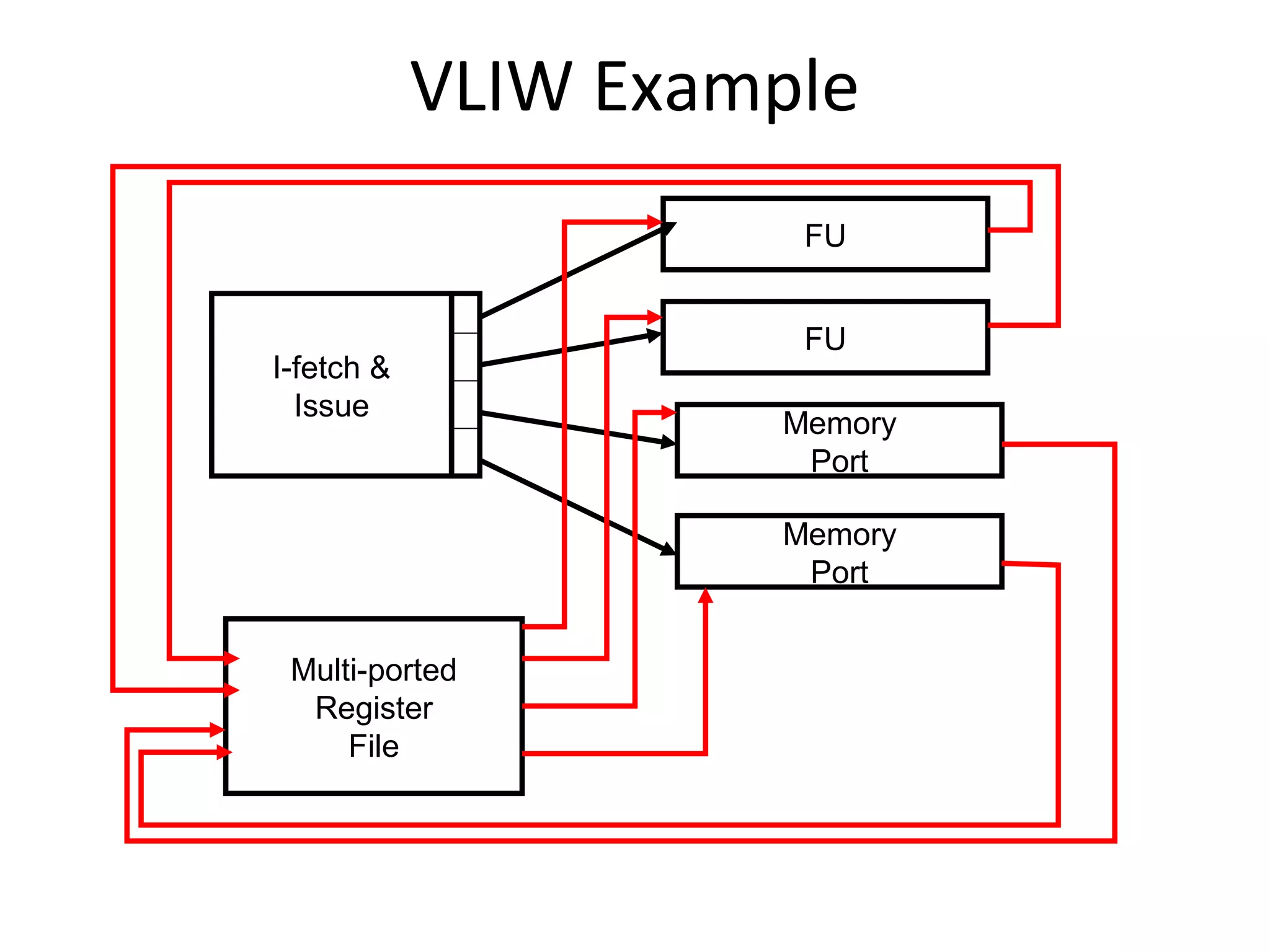
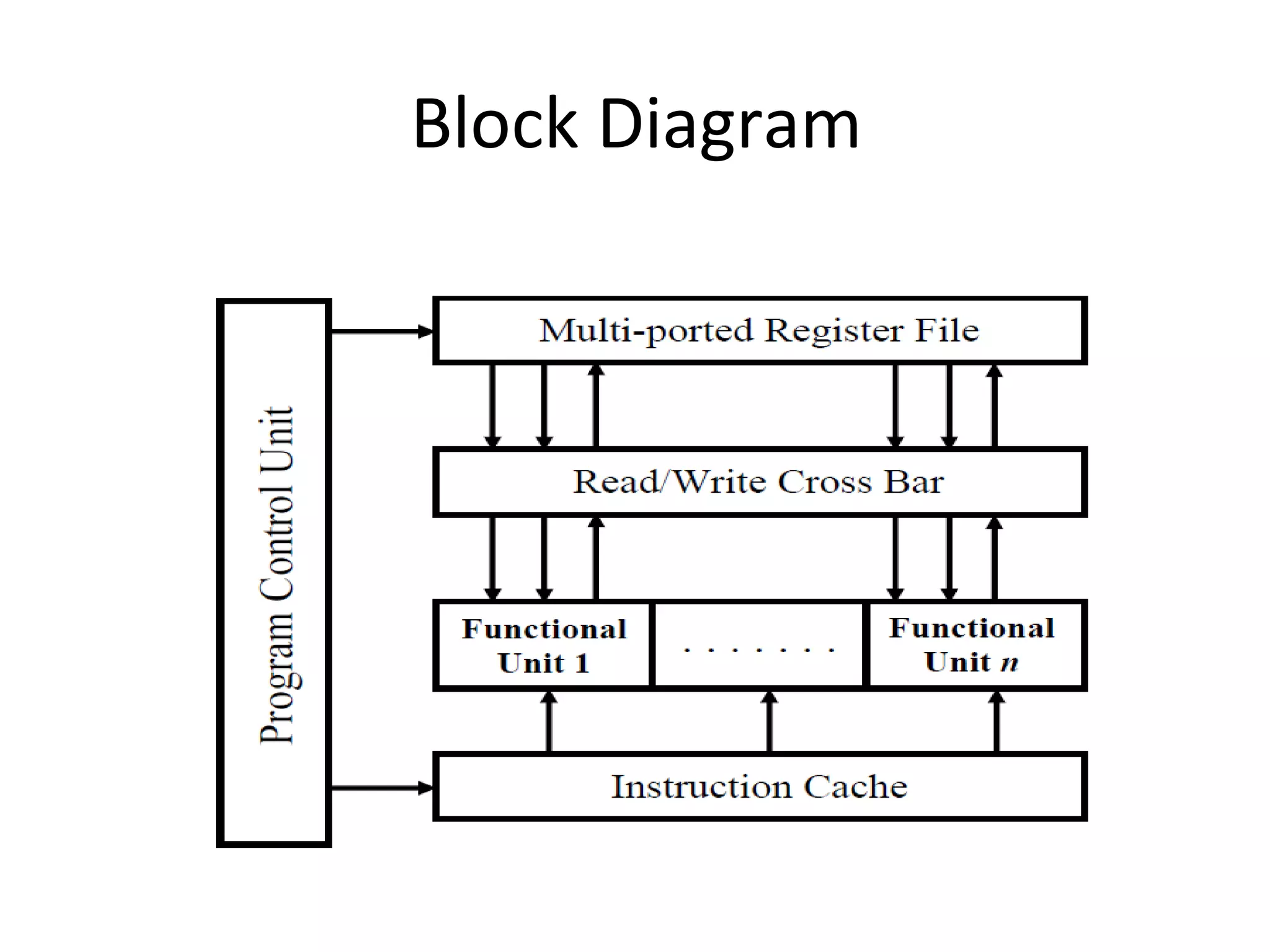
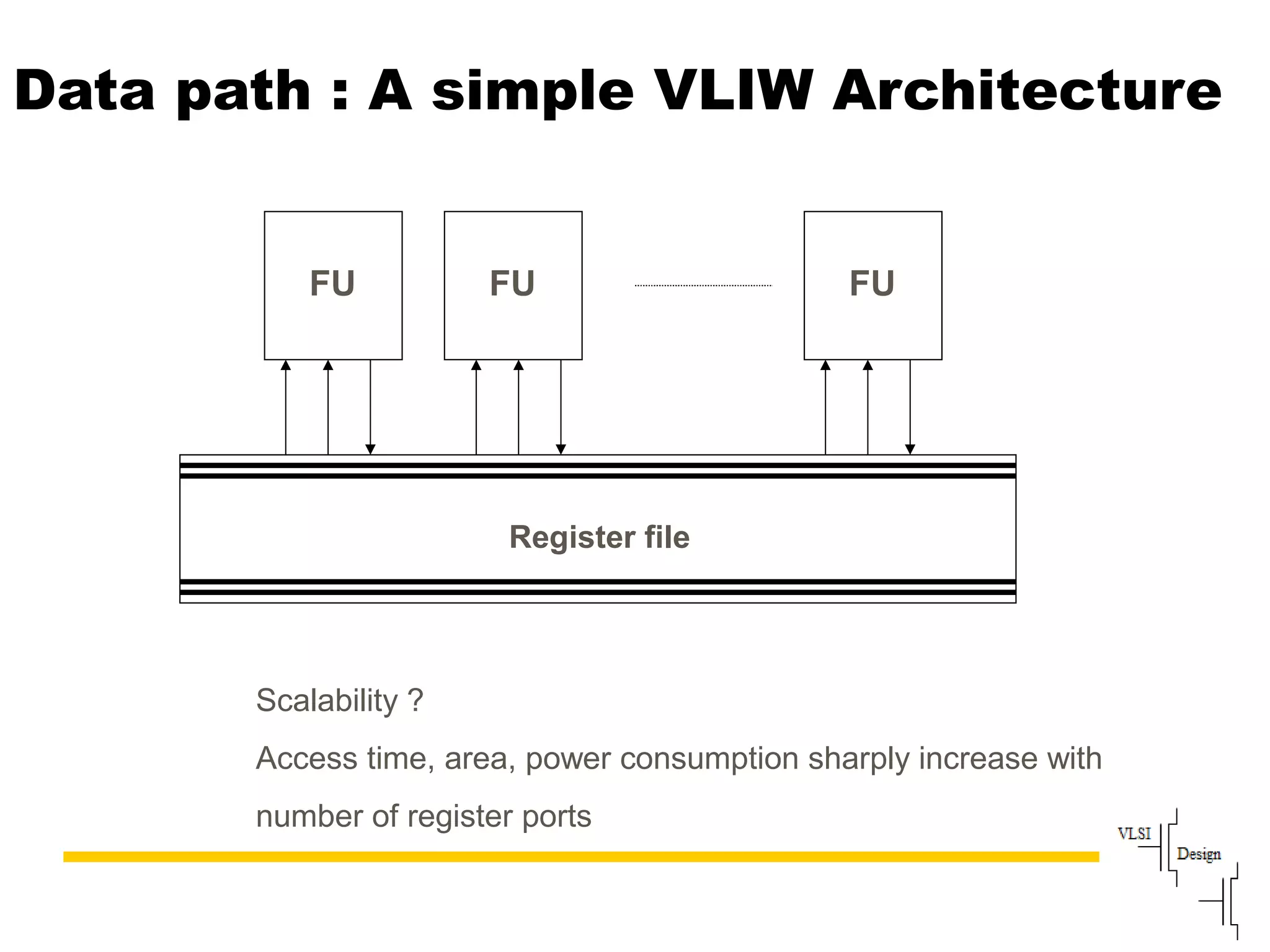
Explains the workings of VLIW processors including instruction fetching, execution units, and register file management.
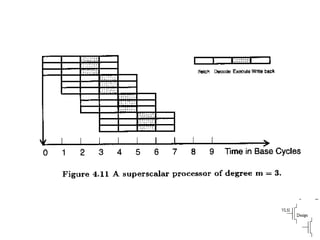
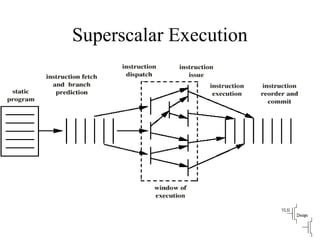
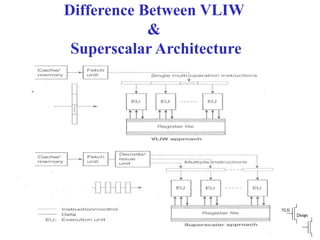
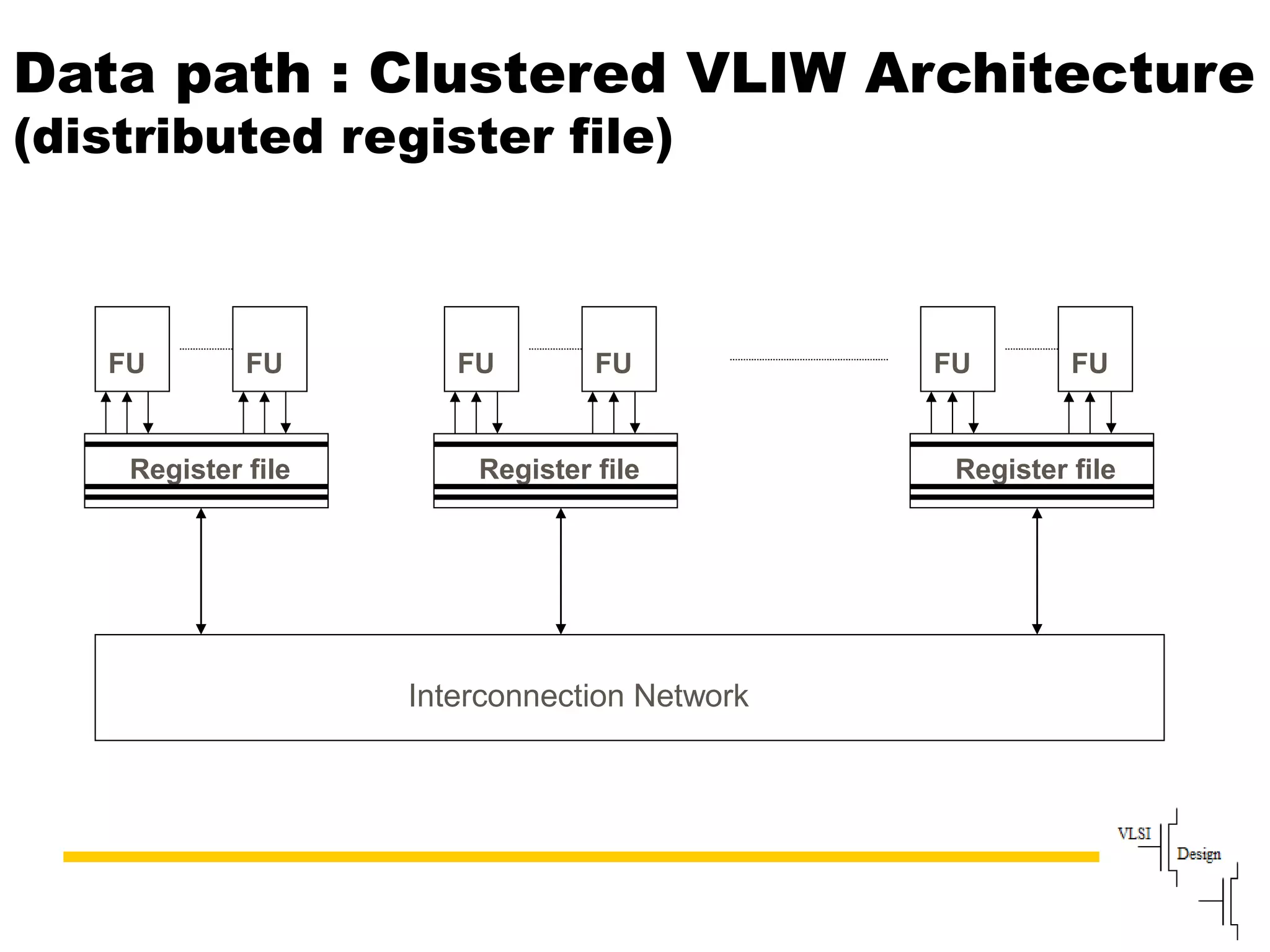
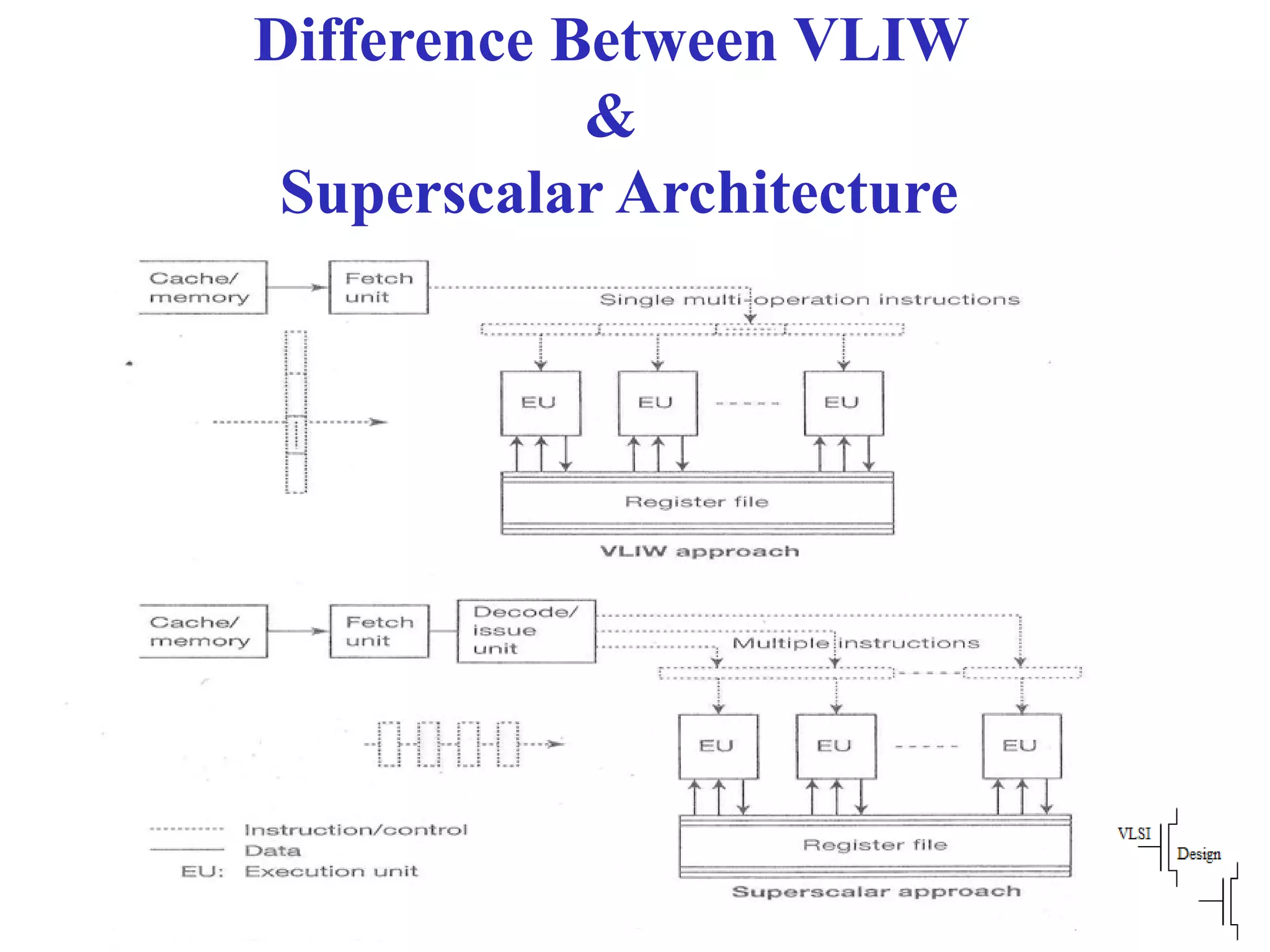
Compares VLIW and superscalar architectures, emphasizing VLIW's complexity and efficiencies in code execution.
Advantages of VLIW like efficient scheduling contrasted with drawbacks such as compatibility issues and code density.
List of references for further study, thanking the audience for their attention.























































































