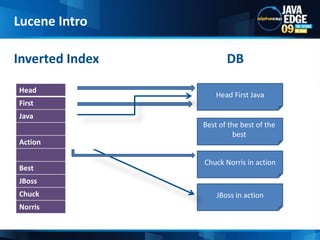
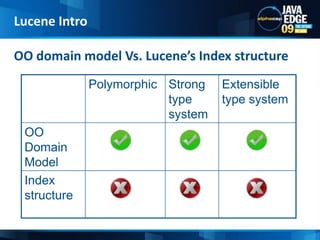
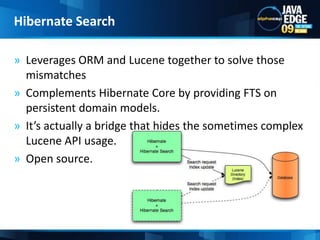
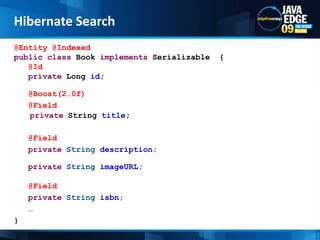
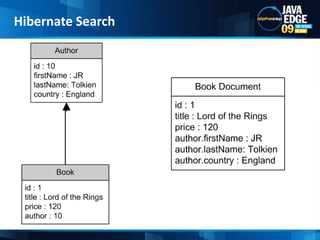
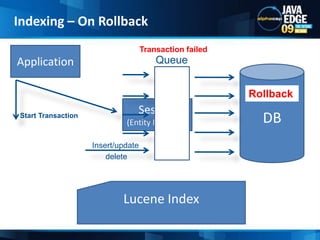
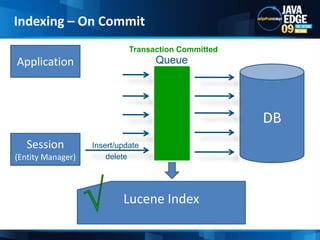
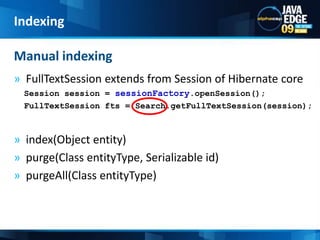
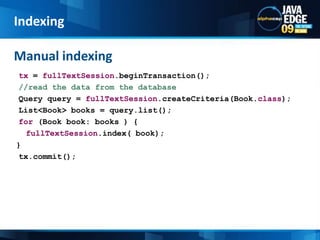
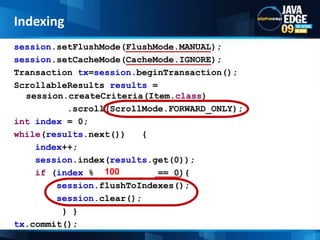
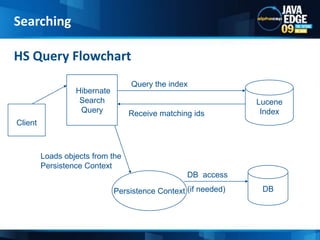
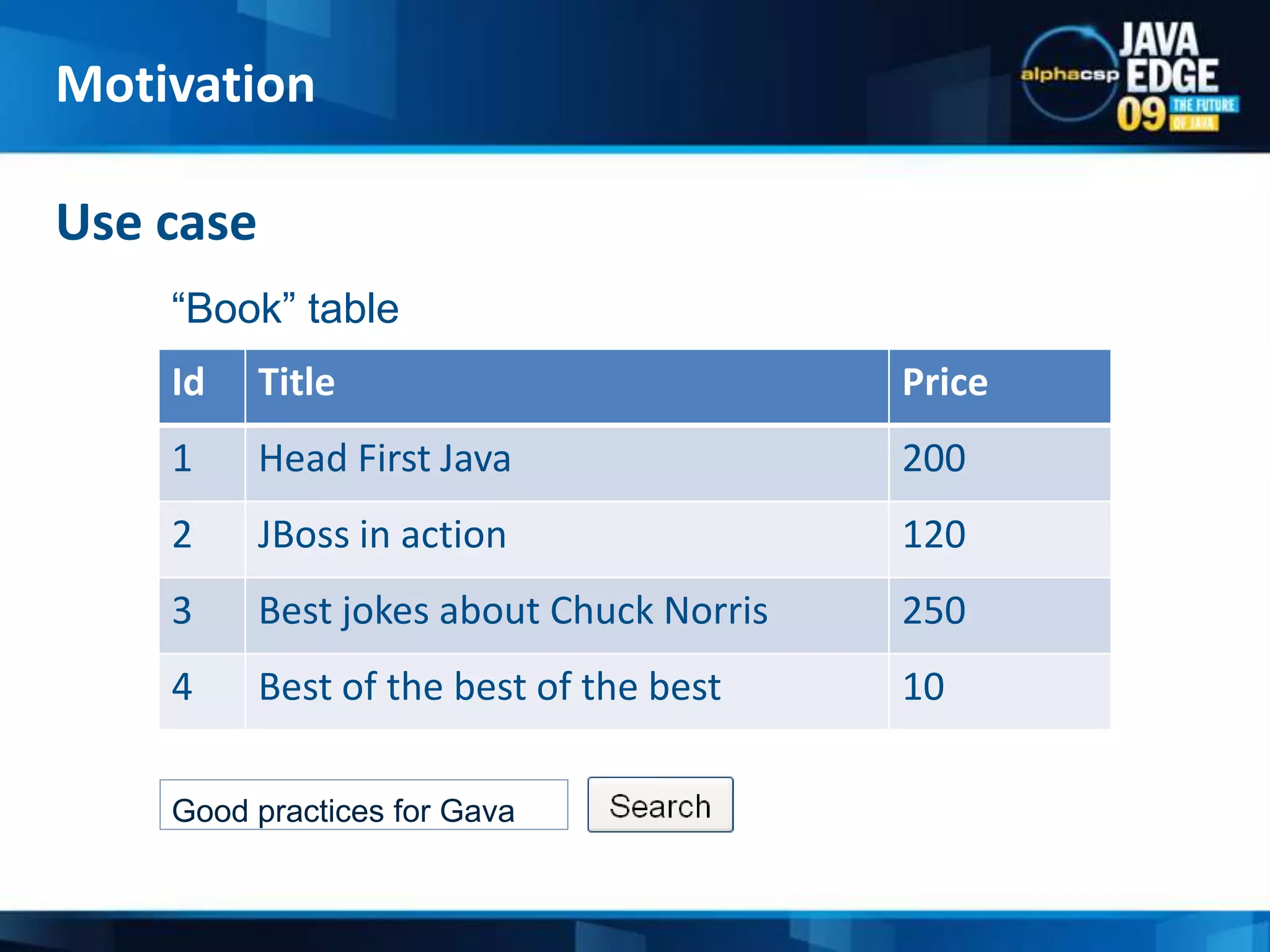
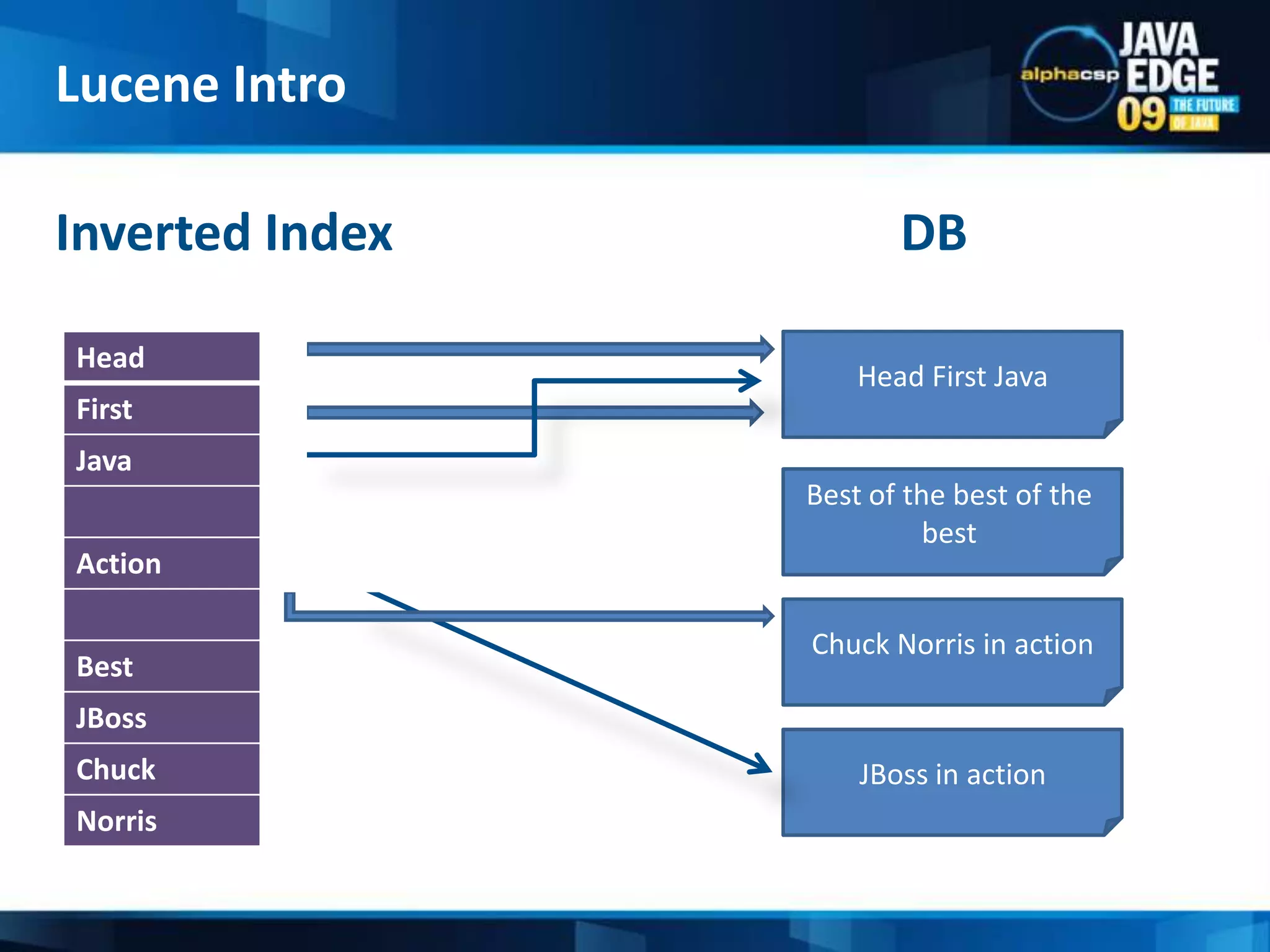
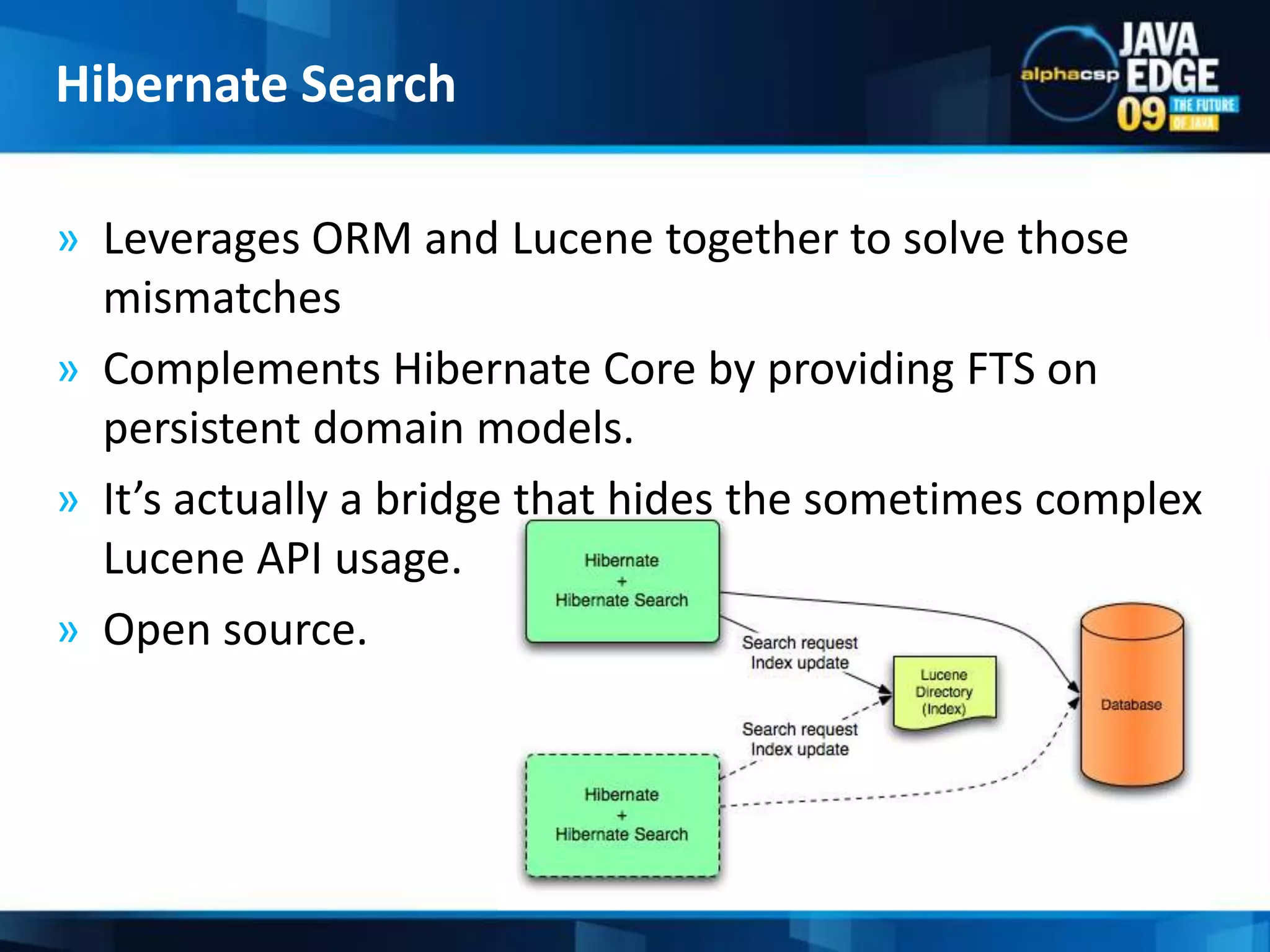
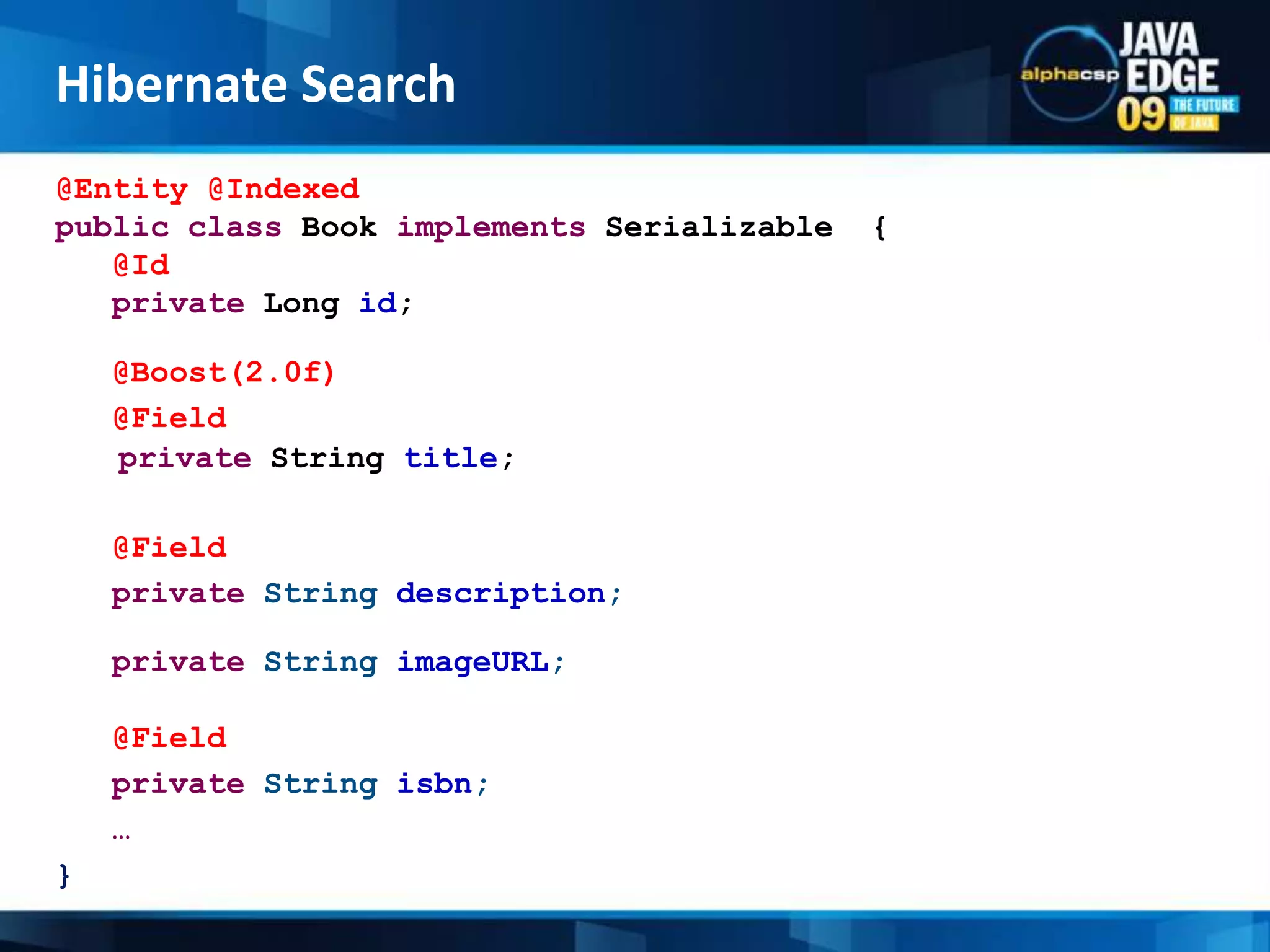
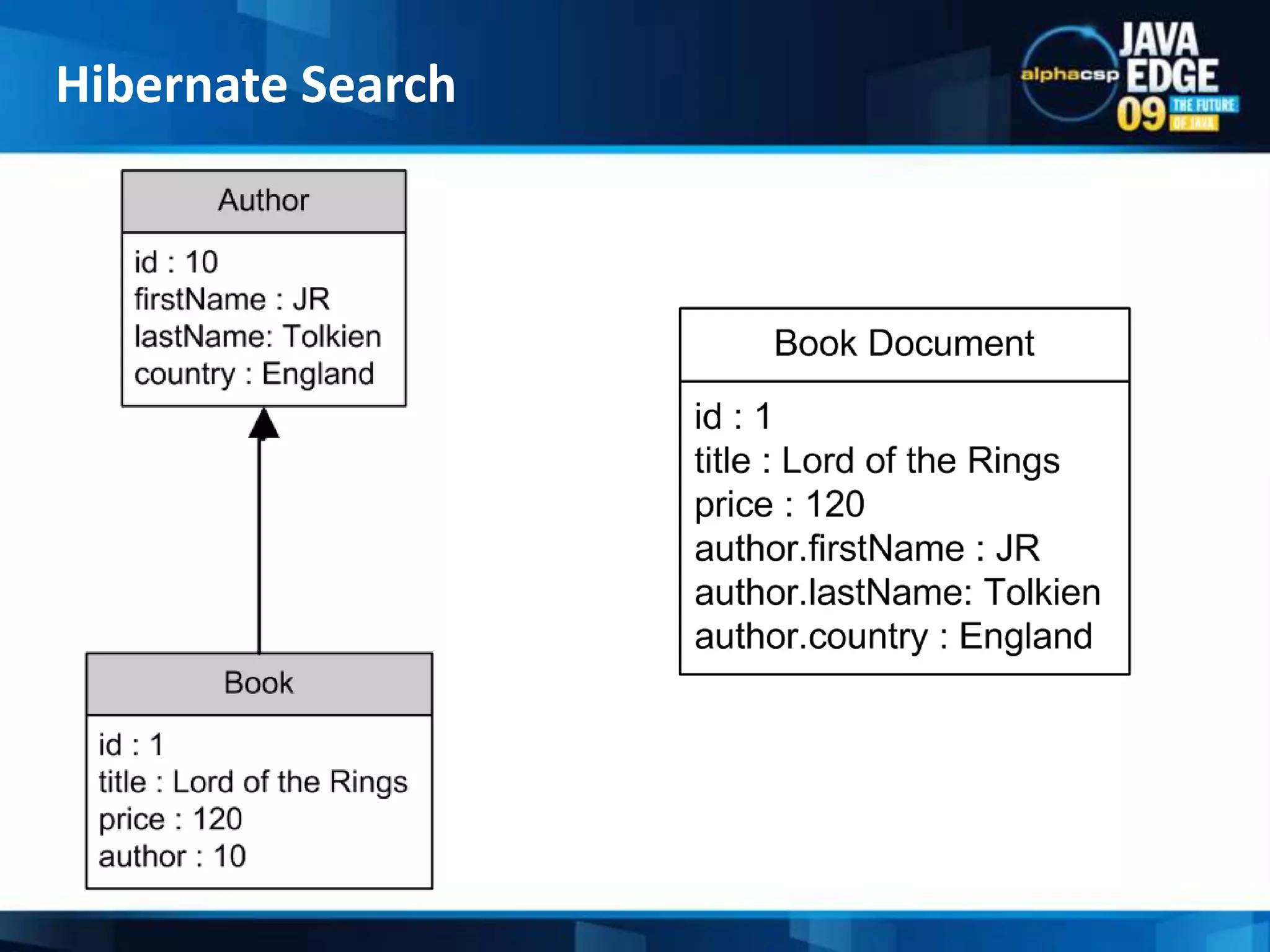
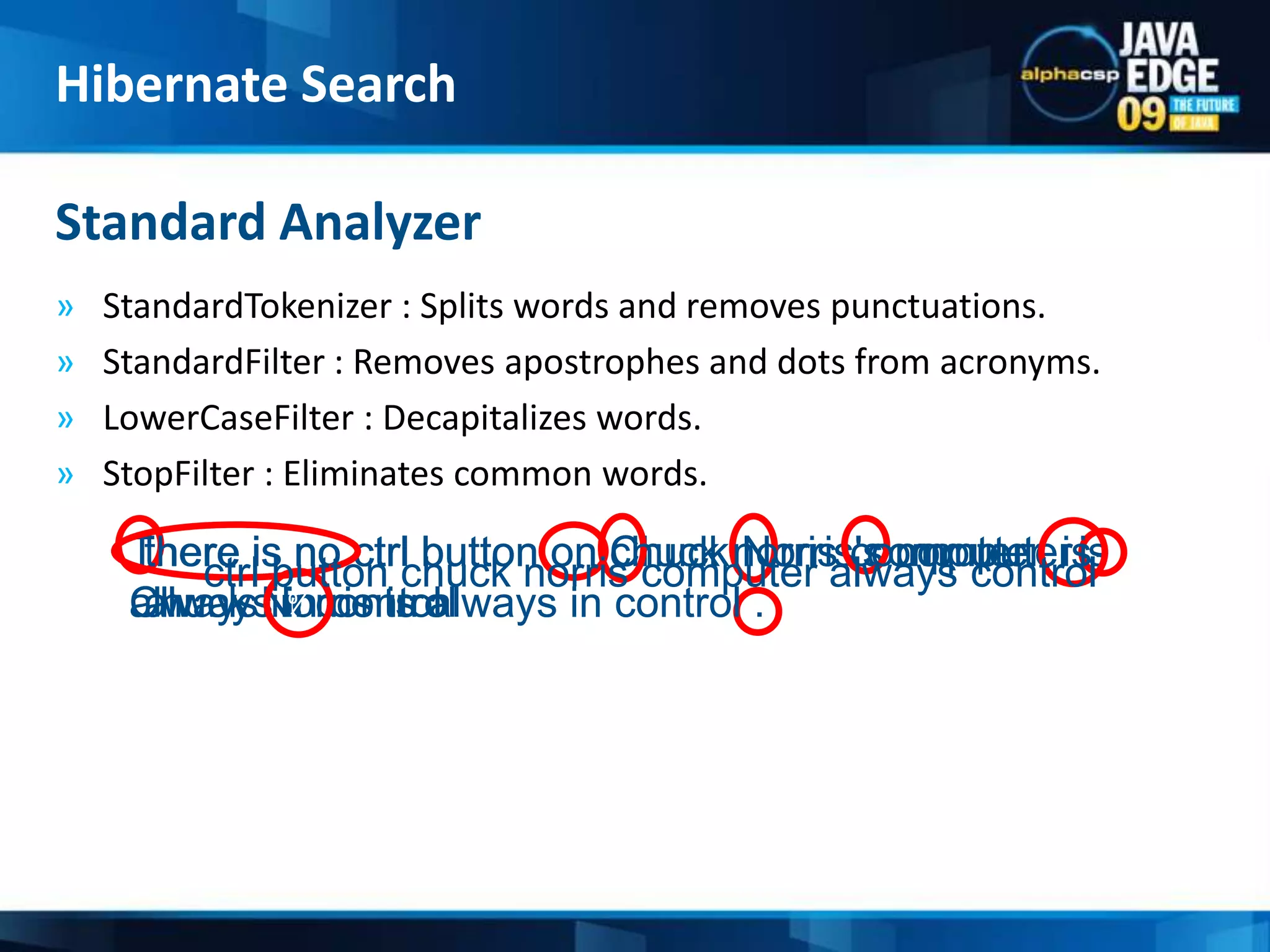
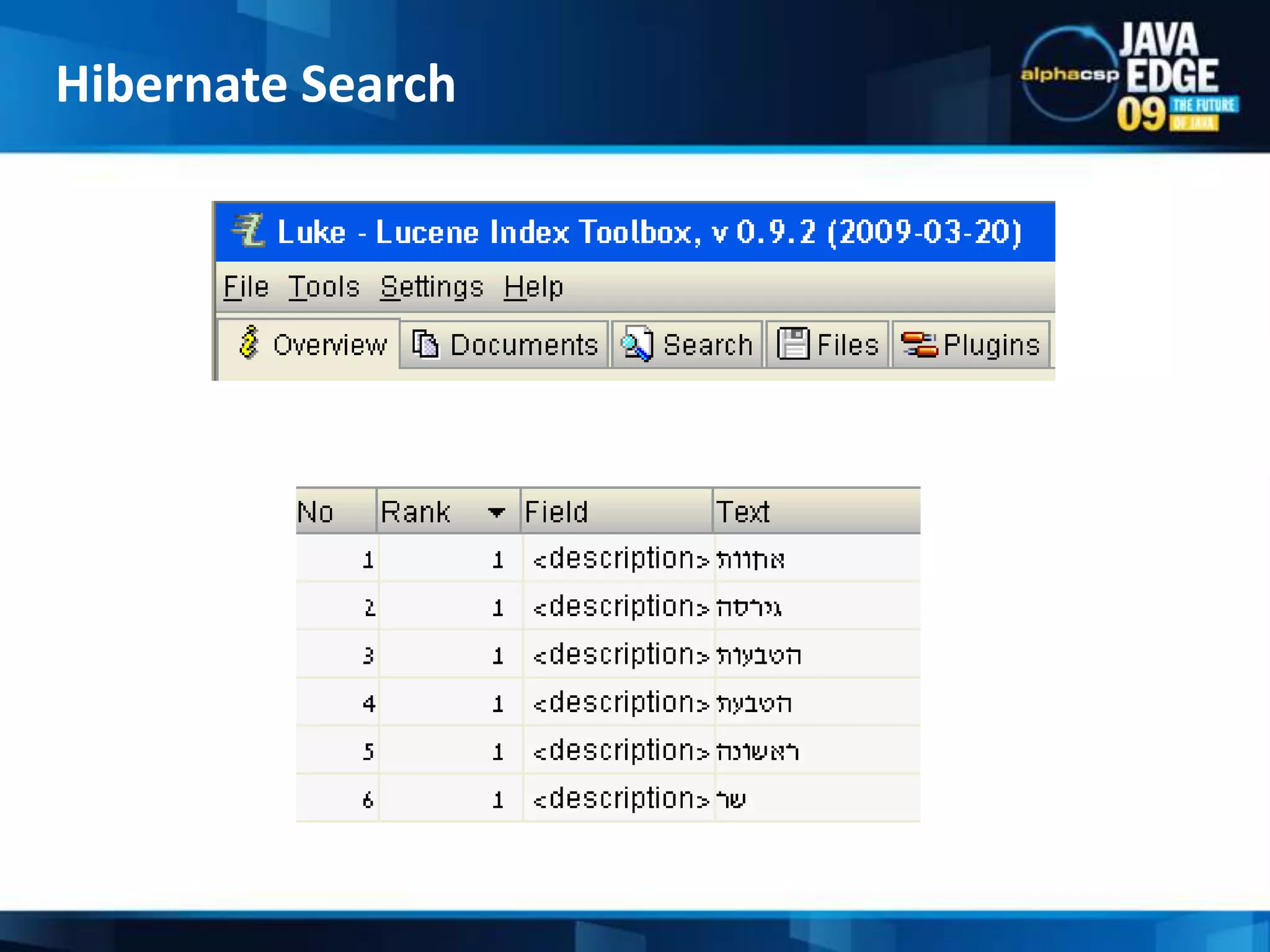
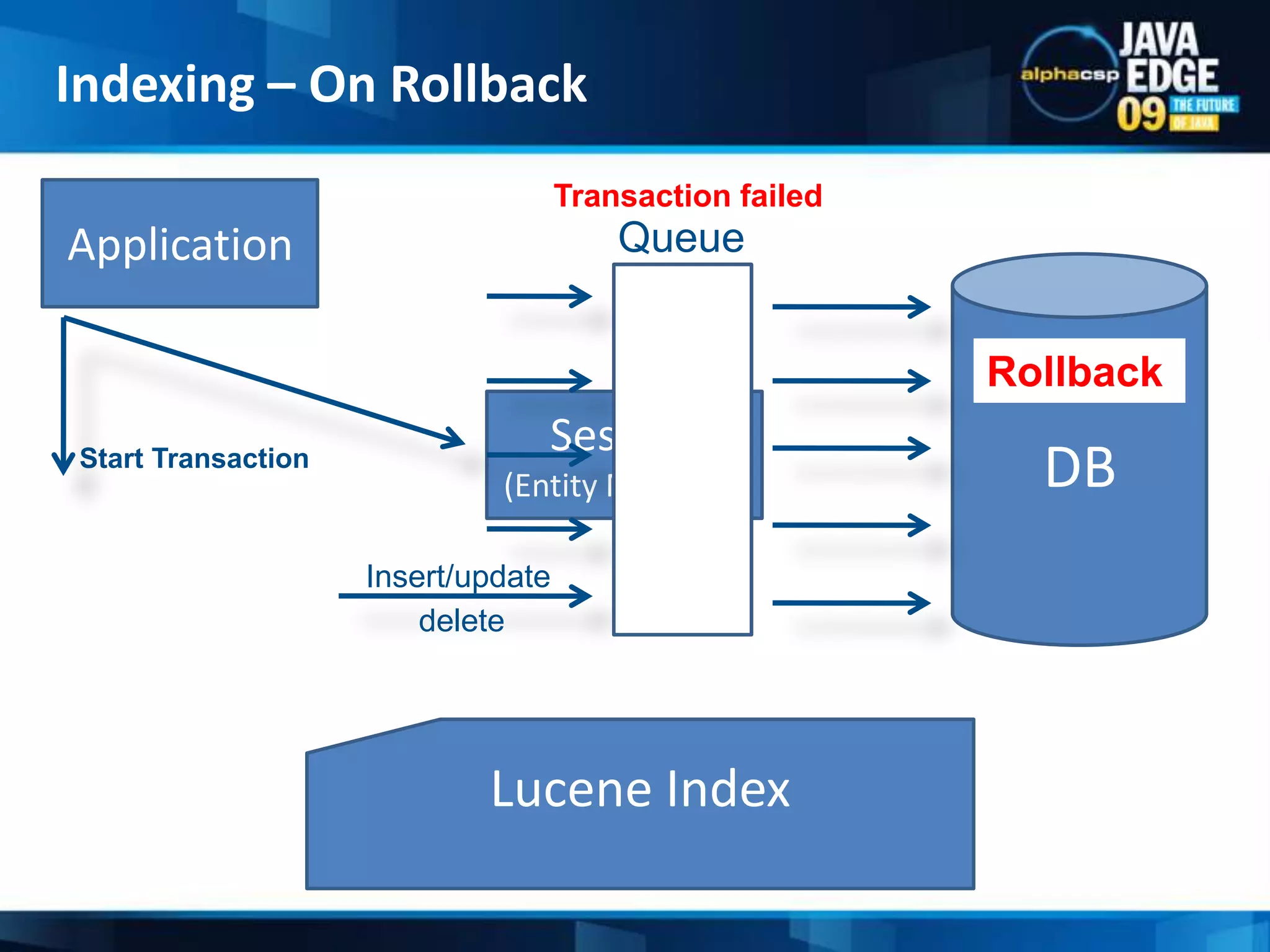
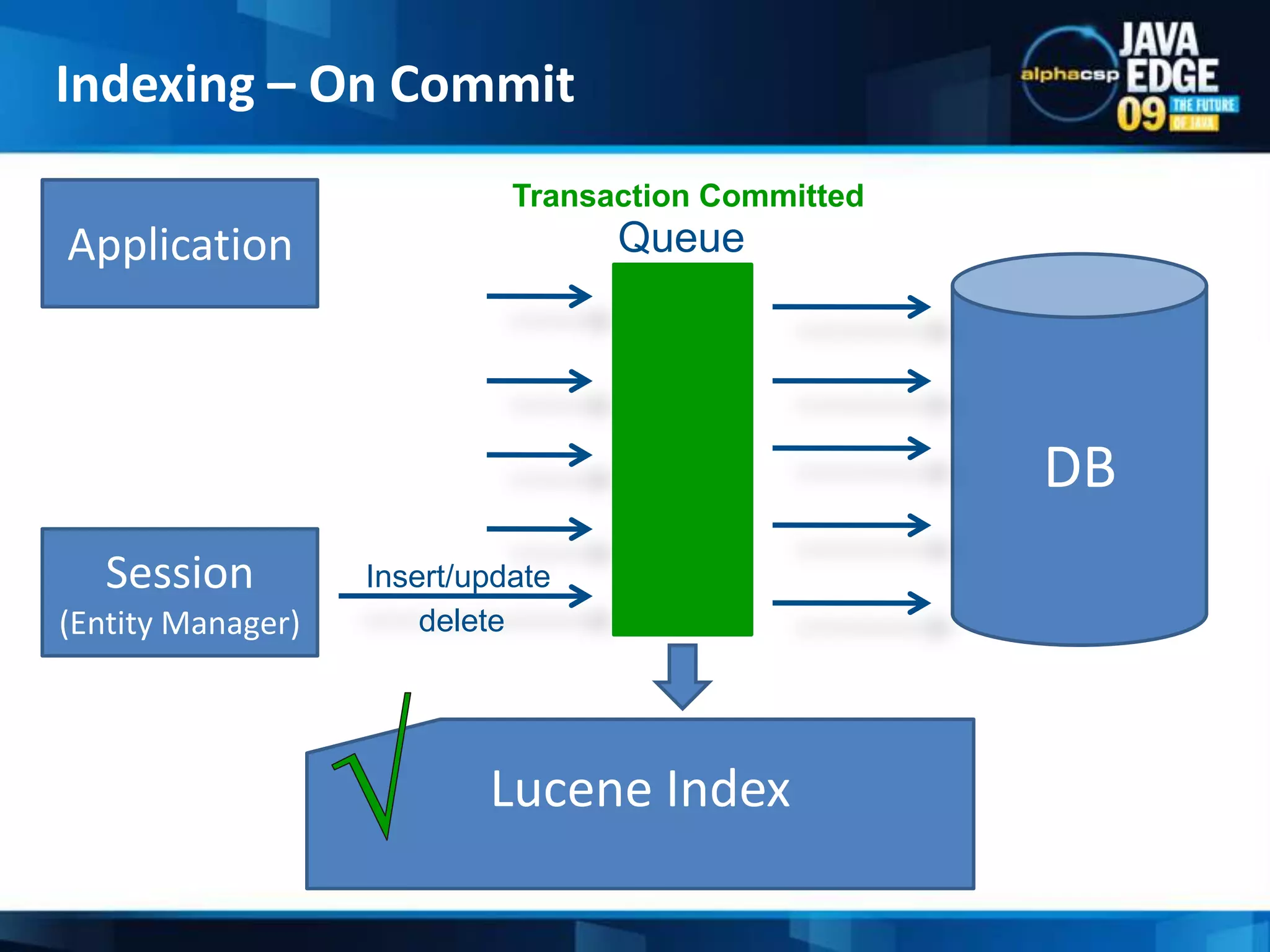
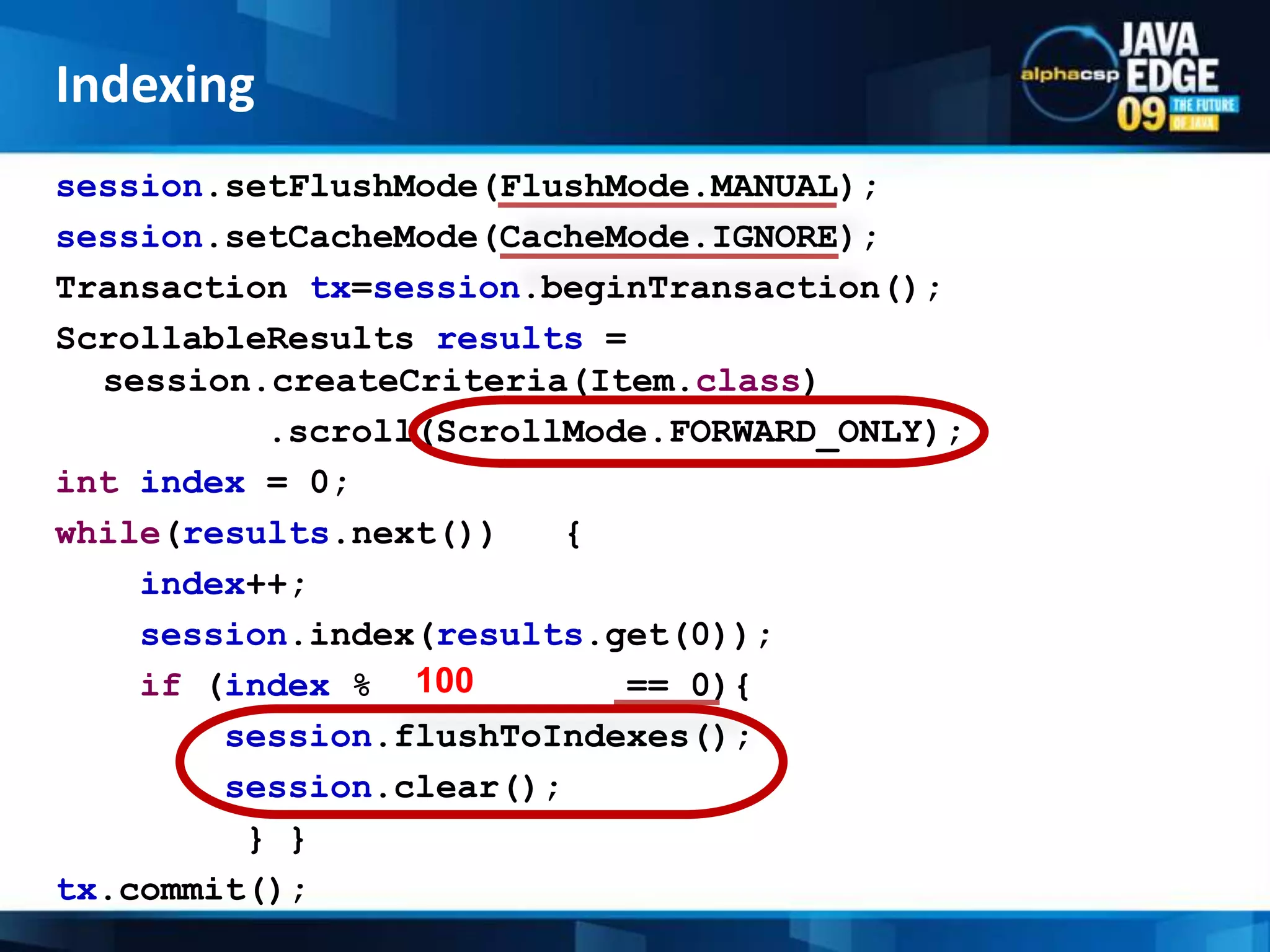
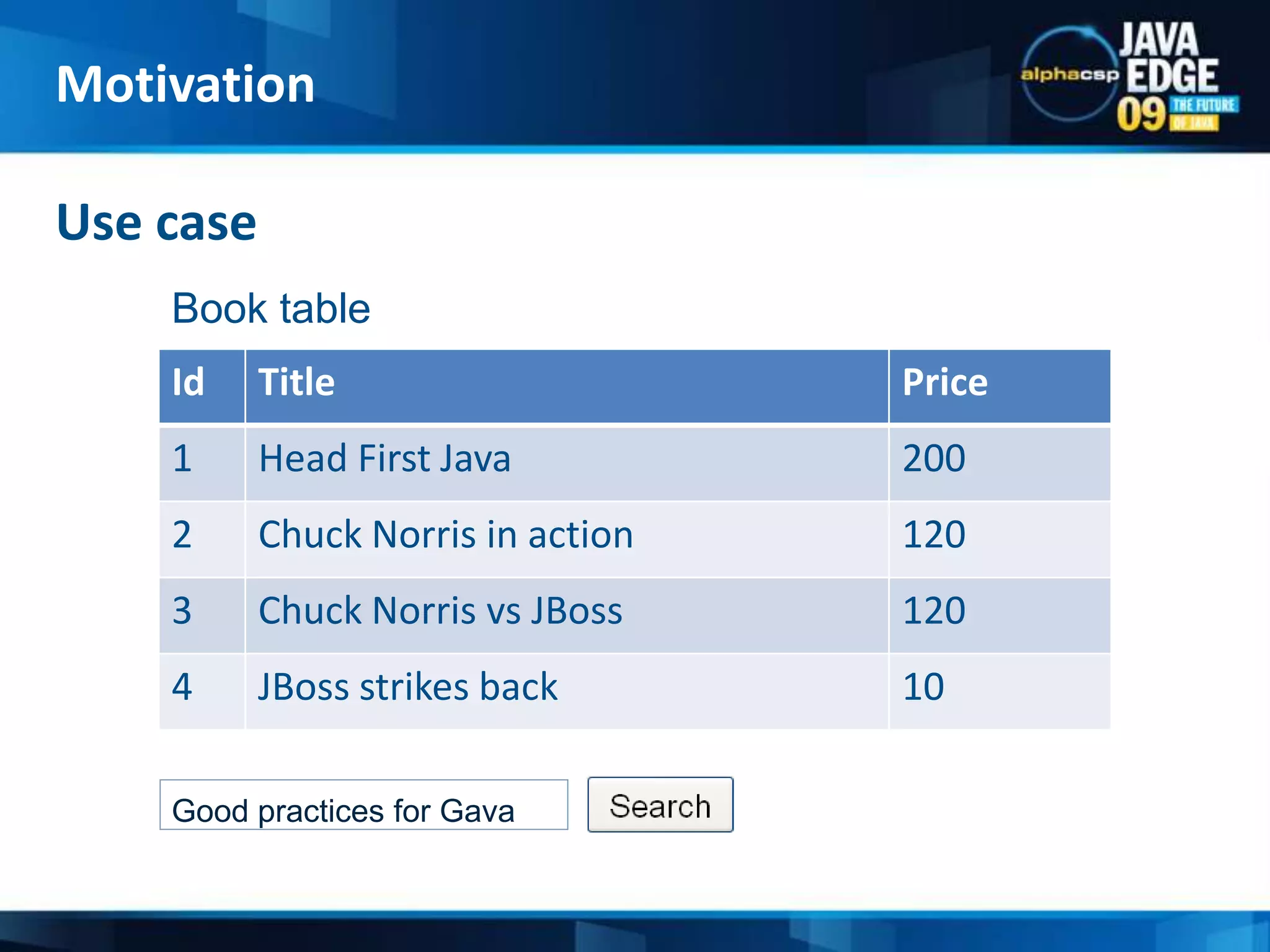
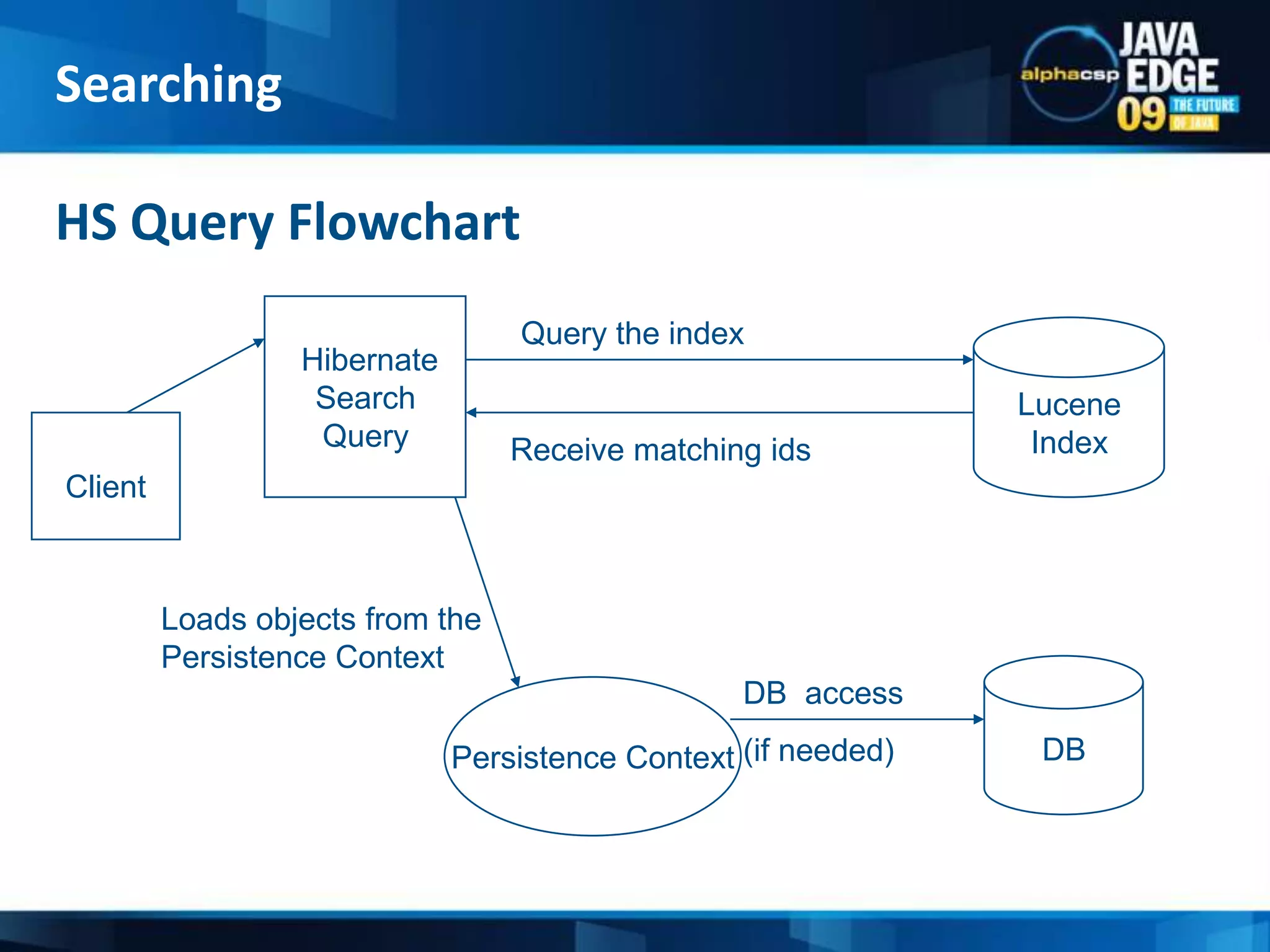
The document discusses the implementation of full-text search using Lucene and Hibernate Search, detailing key features, configurations, and best practices. It covers the indexing process, retrieval of documents, and addresses potential challenges like object and index synchronization. Additionally, it explores the use of custom bridges and analyzers to optimize search capabilities in Java applications.