Downloaded 25 times








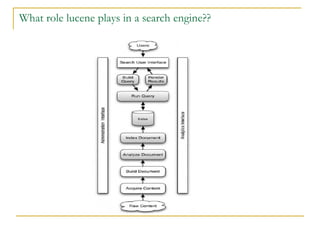


![Types of Analyzer WhitespaceAnalyzer , as the name implies, simply splits text into tokens on whitespace characters and makes no other effort to normalize the tokens. "XY&Z Corporation - xyz@example.com“ [XY&Z] [Corporation] [-] [xyz@example.com] SimpleAnalyzer first splits tokens at non-letter characters, then lowercases each token. Be careful! This analyzer quietly discards numeric characters. [xy] [z] [corporation] [xyz] [example] [com] StopAnalyzer is the same as SimpleAnalyzer, except it removes common words. By default it removes common words in the English language (the, a, etc.), though you can pass in your own set. [xy] [z] [corporation] [xyz] [example] [com] StandardAnalyzer is Lucene’s most sophisticated core analyzer. It has quite a bit of logic to identify certain kinds of tokens, such as company names, email addresses, and host names. It also lowercases each token and removes stop words. [xy&z] [corporation] [xyz@example.com]](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/85/Advanced-full-text-searching-techniques-using-Lucene-14-320.jpg)
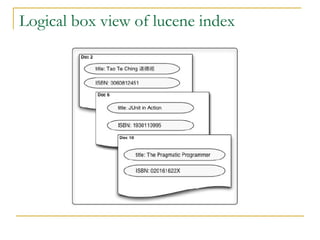
![Types of Query Query ( Abstract Parent Class ) TermQuery ( For single term query ) RangeQuery( For ranges eg, updatedate:[20040101 TO 20050101]) PrefixQuery ( search for prefix ) BooleanQuery ( Multiple queries ) WildcardQuery ( wildcard search ) FuzzyQuery ( near/close words eg for query wazza we can get wazzu fazzu etc )](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/85/Advanced-full-text-searching-techniques-using-Lucene-15-320.jpg)





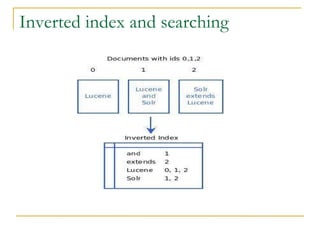
![Hello Lucene Code Query TermQuery t1 = new TermQuery( new Term("title","art")); TermQuery t2 = new TermQuery( new Term("text","art")); BooleanQuery bq = new BooleanQuery(); bq.add(t1,Occur. MUST ); bq.add(t2,Occur. MUST ); OR Query q = new QueryParser(Version.LUCENE_CURRENT, "title", analyzer).parse(“title:art AND text:art”); Search int hitsPerPage = 10; IndexSearcher searcher = new IndexSearcher(index, true); TopScoreDocCollector collector = TopScoreDocCollector. create (hitsPerPage, true); searcher.search(bq, collector); ScoreDoc[] hits = collector.topDocs().scoreDocs;](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/85/Advanced-full-text-searching-techniques-using-Lucene-21-320.jpg)
![Hello Lucene Code Finally Display results System. out .println("Found " + hits.length + " hits."); for ( int i=0;i<hits.length;++i) { int docId = hits[i].doc; Document d = searcher.doc(docId); System. out .println((i + 1) + ". " + d.get("title") + " : " + d.get("text") ); }](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/85/Advanced-full-text-searching-techniques-using-Lucene-22-320.jpg)


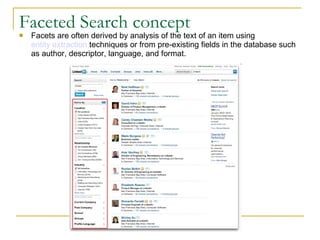













![Types of Analyzer WhitespaceAnalyzer , as the name implies, simply splits text into tokens on whitespace characters and makes no other effort to normalize the tokens. "XY&Z Corporation - xyz@example.com“ [XY&Z] [Corporation] [-] [xyz@example.com] SimpleAnalyzer first splits tokens at non-letter characters, then lowercases each token. Be careful! This analyzer quietly discards numeric characters. [xy] [z] [corporation] [xyz] [example] [com] StopAnalyzer is the same as SimpleAnalyzer, except it removes common words. By default it removes common words in the English language (the, a, etc.), though you can pass in your own set. [xy] [z] [corporation] [xyz] [example] [com] StandardAnalyzer is Lucene’s most sophisticated core analyzer. It has quite a bit of logic to identify certain kinds of tokens, such as company names, email addresses, and host names. It also lowercases each token and removes stop words. [xy&z] [corporation] [xyz@example.com]](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/75/Advanced-full-text-searching-techniques-using-Lucene-14-2048.jpg)
![Types of Query Query ( Abstract Parent Class ) TermQuery ( For single term query ) RangeQuery( For ranges eg, updatedate:[20040101 TO 20050101]) PrefixQuery ( search for prefix ) BooleanQuery ( Multiple queries ) WildcardQuery ( wildcard search ) FuzzyQuery ( near/close words eg for query wazza we can get wazzu fazzu etc )](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/75/Advanced-full-text-searching-techniques-using-Lucene-15-2048.jpg)





![Hello Lucene Code Query TermQuery t1 = new TermQuery( new Term("title","art")); TermQuery t2 = new TermQuery( new Term("text","art")); BooleanQuery bq = new BooleanQuery(); bq.add(t1,Occur. MUST ); bq.add(t2,Occur. MUST ); OR Query q = new QueryParser(Version.LUCENE_CURRENT, "title", analyzer).parse(“title:art AND text:art”); Search int hitsPerPage = 10; IndexSearcher searcher = new IndexSearcher(index, true); TopScoreDocCollector collector = TopScoreDocCollector. create (hitsPerPage, true); searcher.search(bq, collector); ScoreDoc[] hits = collector.topDocs().scoreDocs;](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/75/Advanced-full-text-searching-techniques-using-Lucene-21-2048.jpg)
![Hello Lucene Code Finally Display results System. out .println("Found " + hits.length + " hits."); for ( int i=0;i<hits.length;++i) { int docId = hits[i].doc; Document d = searcher.doc(docId); System. out .println((i + 1) + ". " + d.get("title") + " : " + d.get("text") ); }](https://image.slidesharecdn.com/etilizelucenepresentation2-12866147772578-phpapp02/75/Advanced-full-text-searching-techniques-using-Lucene-22-2048.jpg)






The document discusses efficient text searching techniques using Java, comparing MySQL's full-text search with Lucene, an advanced, scalable information retrieval library. It details differences in performance, indexing, and query capabilities, highlighting Lucene's advantages in speed and complexity, as well as its support for various types of queries and analyzers. Additionally, it emphasizes the importance of implementing effective search functionalities in modern applications for enhanced user experience.












































































