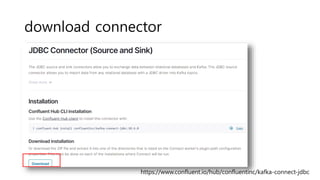
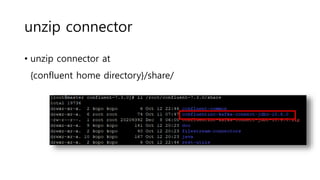
Download to read offline







![Execution
• sh bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka/sink-postgres.properties
[2022-12-08 07:42:54,056] INFO [employee-sink|task-0] [Consumer clientId=connector-consumer-employee-sink-0, groupId=connect-employee-sink] Resetting offset for partition employee-0 to
position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[slave2.kopo:9092 (id: 3 rack: null)], epoch=0}}.
(org.apache.kafka.clients.consumer.internals.SubscriptionState:399)
[2022-12-08 07:47:56,035] INFO [employee-sink|task-0] Attempting to open connection #1 to PostgreSql (io.confluent.connect.jdbc.util.CachedConnectionProvider:79)
[2022-12-08 07:47:56,456] INFO [employee-sink|task-0] Maximum table name length for database is 63 bytes (io.confluent.connect.jdbc.dialect.PostgreSqlDatabaseDialect:130)
[2022-12-08 07:47:56,456] INFO [employee-sink|task-0] JdbcDbWriter Connected (io.confluent.connect.jdbc.sink.JdbcDbWriter:56)
[2022-12-08 07:47:56,531] INFO [employee-sink|task-0] Checking PostgreSql dialect for existence of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:586)
[2022-12-08 07:47:56,548] INFO [employee-sink|task-0] Using PostgreSql dialect TABLE "employee" present (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:594)
[2022-12-08 07:47:56,578] INFO [employee-sink|task-0] Checking PostgreSql dialect for type of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:880)
[2022-12-08 07:47:56,589] INFO [employee-sink|task-0] Setting metadata for table "employee" to Table{name='"employee"', type=TABLE columns=[Column{'idx', isPrimaryKey=false, allowsNull=true,
sqlType=int4}, Column{'name', isPrimaryKey=false, allowsNull=true, sqlType=varchar}]} (io.confluent.connect.jdbc.util.TableDefinitions:64)
[2022-12-08 07:51:53,759] INFO [employee-sink|task-0] [Consumer clientId=connector-consumer-employee-sink-0, groupId=connect-employee-sink] Node -1 disconnected.
(org.apache.kafka.clients.NetworkClient:937)](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-10-320.jpg)
![Test
• consumer shell ({confluent home dir}/bin)
./kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic employee
• Producer shell ({confluent home dir}/bin)
./kafka-avro-console-producer --broker-list localhost:9092 --topic employee --property
value.schema='{"type":"record","name":"kafka_employee","fields":[{"name":"idx","type":"in
t"},{"name":"name","type":"string"}]}’
{"idx":1,"name":"hwang"}
{"idx":2,"name":"kim"} DB](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-11-320.jpg)


![Execution
• sh bin/connect-distributed etc/kafka/connect-distributed.properties
[2022-12-08 08:09:53,943] INFO REST resources initialized; server is started and ready to handle requests (org.apache.kafka.connect.runtime.rest.RestServer:312)
[2022-12-08 08:09:53,944] INFO Kafka Connect started (org.apache.kafka.connect.runtime.Connect:56)
[2022-12-08 08:09:54,419] INFO [sink-jdbc-postgre|task-0] Attempting to open connection #1 to PostgreSql (io.confluent.connect.jdbc.util.CachedConnectionProvider:79)
[2022-12-08 08:09:55,020] INFO [sink-jdbc-postgre|task-0] Maximum table name length for database is 63 bytes (io.confluent.connect.jdbc.dialect.PostgreSqlDatabaseDialect:130)
[2022-12-08 08:09:55,020] INFO [sink-jdbc-postgre|task-0] JdbcDbWriter Connected (io.confluent.connect.jdbc.sink.JdbcDbWriter:56)
[2022-12-08 08:09:55,142] INFO [sink-jdbc-postgre|task-0] Checking PostgreSql dialect for existence of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:586)
[2022-12-08 08:09:55,168] INFO [sink-jdbc-postgre|task-0] Using PostgreSql dialect TABLE "employee" present (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:594)
[2022-12-08 08:09:55,201] INFO [sink-jdbc-postgre|task-0] Checking PostgreSql dialect for type of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:880)
[2022-12-08 08:09:55,216] INFO [sink-jdbc-postgre|task-0] Setting metadata for table "employee" to Table{name='"employee"', type=TABLE columns=[Column{'idx', isPrimaryKey=false,
allowsNull=true, sqlType=int4}, Column{'name', isPrimaryKey=false, allowsNull=true, sqlType=varchar}]} (io.confluent.connect.jdbc.util.TableDefinitions:64)](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-14-320.jpg)
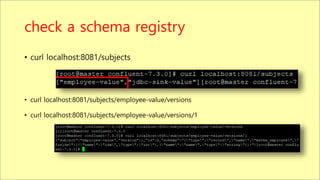
![check a registered connector
• curl --location --request GET 'localhost:8083/connector-plugins'
[{"class":"io.confluent.connect.jdbc.JdbcSinkConnector","type":"sink","version":"10.6.0"},{"class":"io.confluent.c
onnect.jdbc.JdbcSourceConnector","type":"source","version":"10.6.0"},{"class":"org.apache.kafka.connect.mirror.
MirrorCheckpointConnector","type":"source","version":"7.3.0-
ccs"},{"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"7.3.0-
ccs"},{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"7.3.0-ccs"}]](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-15-320.jpg)

![query a connector
• curl -s localhost:8083/connectors/sink-jdbc-postgre
{"name":"sink-jdbc-postgre","config":{"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector","table.name.format":"employee","connection.password":“{db
pwd}","tasks.max":"1","topics":"employee","connection.user":“{db id}","name":"sink-jdbc-postgre","auto.create":"true","connection.url":"jdbc:postgresql://{db ip}:{dp port}/{db
name}","insert.mode":"insert","pk.mode":"none","pk.fields":"none"},"tasks":[{"connector":"sink-jdbc-postgre","task":0}],"type":"sink"}
[FYI] connector delete command
curl -X DELETE "http://localhost:8083/connectors/sink-jdbc-postgre"](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-17-320.jpg)
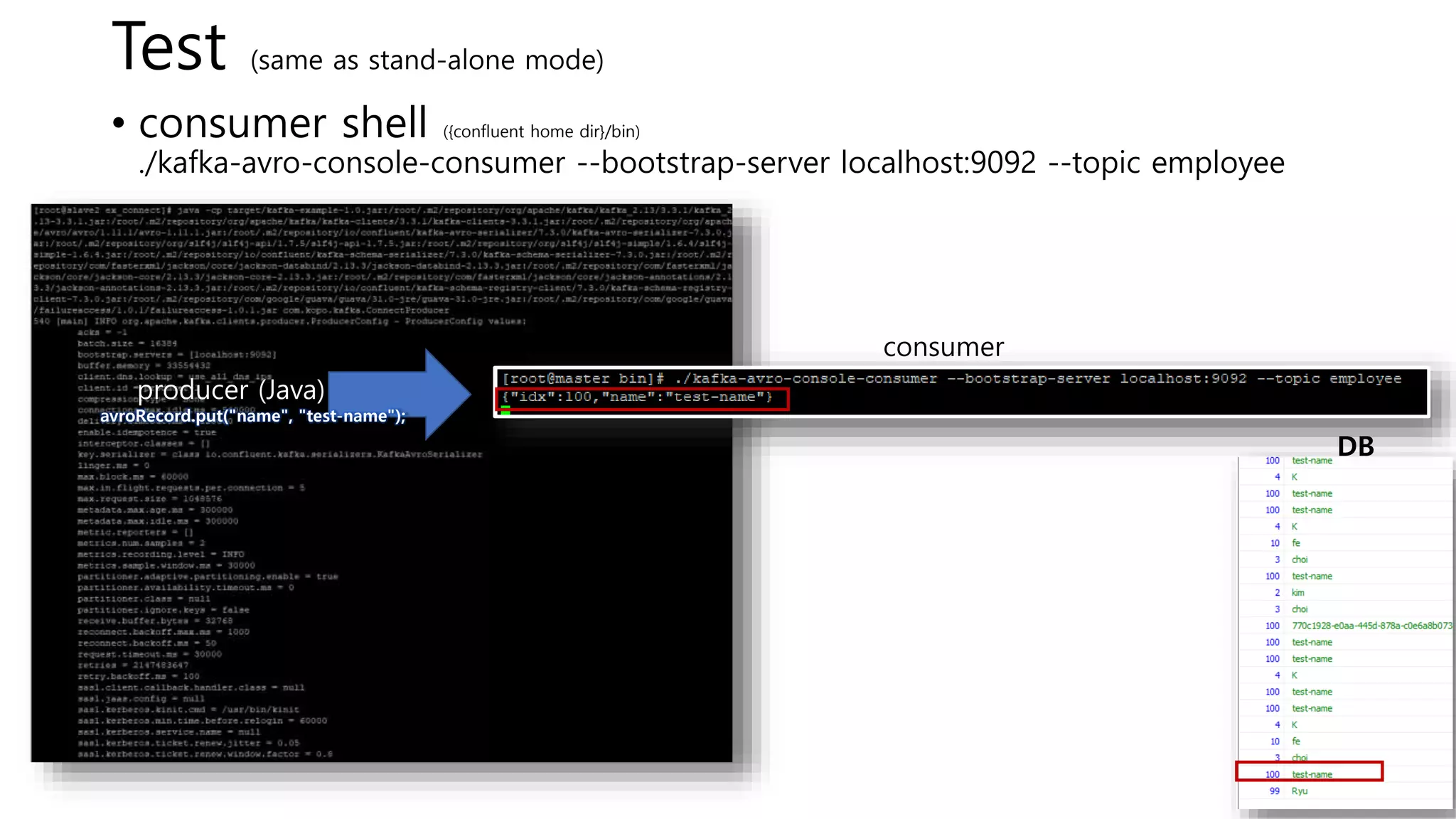
![Test (same as stand-alone mode)
• consumer shell ({confluent home dir}/bin)
./kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic employee
• Producer shell ({confluent home dir}/bin)
./kafka-avro-console-producer --broker-list localhost:9092 --topic employee --property
value.schema='{"type":"record","name":"kafka_employee","fields":[{"name":"idx","type":"in
t"},{"name":"name","type":"string"}]}’
{"idx":1,"name":"hwang"}
{"idx":2,"name":"kim"} DB](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-19-320.jpg)

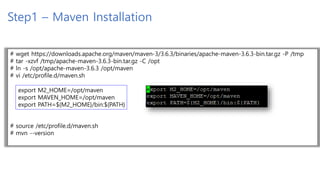

![Step3 – Implementation
mkdir -p src/main/java/com/kopo/kafka
vi src/main/java/com/kopo/kafka/ConnectProducer.java
package com.kopo.kafka;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import org.apache.avro.Schema;
import java.util.Properties;
import java.util.Random;
import java.util.UUID;
public class ConnectProducer {
private final static String TOPIC_NAME = "employee";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.setProperty("key.serializer", KafkaAvroSerializer.class.getName());
configs.setProperty("value.serializer", KafkaAvroSerializer.class.getName());
configs.setProperty("schema.registry.url", "http://192.168.56.30:8081");
String schema = "{"
// + ""namespace": "myrecord","
+ " "name": "kafka_employee","
+ " "type": "record","
+ " "fields": ["
+ " {"name": "idx", "type": "int"},"
+ " {"name": "name", "type": "string"}"
+ " ]"
+ "}";
Schema.Parser parser = new Schema.Parser();
Schema avroSchema1 = parser.parse(schema);
// generate avro generic record
GenericRecord avroRecord = new GenericData.Record(avroSchema1);
avroRecord.put("idx", 100);
avroRecord.put("name", "test-name");
KafkaProducer<String, GenericRecord> producer = new KafkaProducer<>(configs);
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>(TOPIC_NAME, avroRecord);
producer.send(record);
producer.flush();
producer.close();
}
}
schema registry running server](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/85/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-23-320.jpg)











![Execution
• sh bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka/sink-postgres.properties
[2022-12-08 07:42:54,056] INFO [employee-sink|task-0] [Consumer clientId=connector-consumer-employee-sink-0, groupId=connect-employee-sink] Resetting offset for partition employee-0 to
position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[slave2.kopo:9092 (id: 3 rack: null)], epoch=0}}.
(org.apache.kafka.clients.consumer.internals.SubscriptionState:399)
[2022-12-08 07:47:56,035] INFO [employee-sink|task-0] Attempting to open connection #1 to PostgreSql (io.confluent.connect.jdbc.util.CachedConnectionProvider:79)
[2022-12-08 07:47:56,456] INFO [employee-sink|task-0] Maximum table name length for database is 63 bytes (io.confluent.connect.jdbc.dialect.PostgreSqlDatabaseDialect:130)
[2022-12-08 07:47:56,456] INFO [employee-sink|task-0] JdbcDbWriter Connected (io.confluent.connect.jdbc.sink.JdbcDbWriter:56)
[2022-12-08 07:47:56,531] INFO [employee-sink|task-0] Checking PostgreSql dialect for existence of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:586)
[2022-12-08 07:47:56,548] INFO [employee-sink|task-0] Using PostgreSql dialect TABLE "employee" present (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:594)
[2022-12-08 07:47:56,578] INFO [employee-sink|task-0] Checking PostgreSql dialect for type of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:880)
[2022-12-08 07:47:56,589] INFO [employee-sink|task-0] Setting metadata for table "employee" to Table{name='"employee"', type=TABLE columns=[Column{'idx', isPrimaryKey=false, allowsNull=true,
sqlType=int4}, Column{'name', isPrimaryKey=false, allowsNull=true, sqlType=varchar}]} (io.confluent.connect.jdbc.util.TableDefinitions:64)
[2022-12-08 07:51:53,759] INFO [employee-sink|task-0] [Consumer clientId=connector-consumer-employee-sink-0, groupId=connect-employee-sink] Node -1 disconnected.
(org.apache.kafka.clients.NetworkClient:937)](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-10-2048.jpg)
![Test
• consumer shell ({confluent home dir}/bin)
./kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic employee
• Producer shell ({confluent home dir}/bin)
./kafka-avro-console-producer --broker-list localhost:9092 --topic employee --property
value.schema='{"type":"record","name":"kafka_employee","fields":[{"name":"idx","type":"in
t"},{"name":"name","type":"string"}]}’
{"idx":1,"name":"hwang"}
{"idx":2,"name":"kim"} DB](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-11-2048.jpg)


![Execution
• sh bin/connect-distributed etc/kafka/connect-distributed.properties
[2022-12-08 08:09:53,943] INFO REST resources initialized; server is started and ready to handle requests (org.apache.kafka.connect.runtime.rest.RestServer:312)
[2022-12-08 08:09:53,944] INFO Kafka Connect started (org.apache.kafka.connect.runtime.Connect:56)
[2022-12-08 08:09:54,419] INFO [sink-jdbc-postgre|task-0] Attempting to open connection #1 to PostgreSql (io.confluent.connect.jdbc.util.CachedConnectionProvider:79)
[2022-12-08 08:09:55,020] INFO [sink-jdbc-postgre|task-0] Maximum table name length for database is 63 bytes (io.confluent.connect.jdbc.dialect.PostgreSqlDatabaseDialect:130)
[2022-12-08 08:09:55,020] INFO [sink-jdbc-postgre|task-0] JdbcDbWriter Connected (io.confluent.connect.jdbc.sink.JdbcDbWriter:56)
[2022-12-08 08:09:55,142] INFO [sink-jdbc-postgre|task-0] Checking PostgreSql dialect for existence of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:586)
[2022-12-08 08:09:55,168] INFO [sink-jdbc-postgre|task-0] Using PostgreSql dialect TABLE "employee" present (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:594)
[2022-12-08 08:09:55,201] INFO [sink-jdbc-postgre|task-0] Checking PostgreSql dialect for type of TABLE "employee" (io.confluent.connect.jdbc.dialect.GenericDatabaseDialect:880)
[2022-12-08 08:09:55,216] INFO [sink-jdbc-postgre|task-0] Setting metadata for table "employee" to Table{name='"employee"', type=TABLE columns=[Column{'idx', isPrimaryKey=false,
allowsNull=true, sqlType=int4}, Column{'name', isPrimaryKey=false, allowsNull=true, sqlType=varchar}]} (io.confluent.connect.jdbc.util.TableDefinitions:64)](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-14-2048.jpg)
![check a registered connector
• curl --location --request GET 'localhost:8083/connector-plugins'
[{"class":"io.confluent.connect.jdbc.JdbcSinkConnector","type":"sink","version":"10.6.0"},{"class":"io.confluent.c
onnect.jdbc.JdbcSourceConnector","type":"source","version":"10.6.0"},{"class":"org.apache.kafka.connect.mirror.
MirrorCheckpointConnector","type":"source","version":"7.3.0-
ccs"},{"class":"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector","type":"source","version":"7.3.0-
ccs"},{"class":"org.apache.kafka.connect.mirror.MirrorSourceConnector","type":"source","version":"7.3.0-ccs"}]](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-15-2048.jpg)

![query a connector
• curl -s localhost:8083/connectors/sink-jdbc-postgre
{"name":"sink-jdbc-postgre","config":{"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector","table.name.format":"employee","connection.password":“{db
pwd}","tasks.max":"1","topics":"employee","connection.user":“{db id}","name":"sink-jdbc-postgre","auto.create":"true","connection.url":"jdbc:postgresql://{db ip}:{dp port}/{db
name}","insert.mode":"insert","pk.mode":"none","pk.fields":"none"},"tasks":[{"connector":"sink-jdbc-postgre","task":0}],"type":"sink"}
[FYI] connector delete command
curl -X DELETE "http://localhost:8083/connectors/sink-jdbc-postgre"](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-17-2048.jpg)
![Test (same as stand-alone mode)
• consumer shell ({confluent home dir}/bin)
./kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic employee
• Producer shell ({confluent home dir}/bin)
./kafka-avro-console-producer --broker-list localhost:9092 --topic employee --property
value.schema='{"type":"record","name":"kafka_employee","fields":[{"name":"idx","type":"in
t"},{"name":"name","type":"string"}]}’
{"idx":1,"name":"hwang"}
{"idx":2,"name":"kim"} DB](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-19-2048.jpg)


![Step3 – Implementation
mkdir -p src/main/java/com/kopo/kafka
vi src/main/java/com/kopo/kafka/ConnectProducer.java
package com.kopo.kafka;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import org.apache.avro.Schema;
import java.util.Properties;
import java.util.Random;
import java.util.UUID;
public class ConnectProducer {
private final static String TOPIC_NAME = "employee";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.setProperty("key.serializer", KafkaAvroSerializer.class.getName());
configs.setProperty("value.serializer", KafkaAvroSerializer.class.getName());
configs.setProperty("schema.registry.url", "http://192.168.56.30:8081");
String schema = "{"
// + ""namespace": "myrecord","
+ " "name": "kafka_employee","
+ " "type": "record","
+ " "fields": ["
+ " {"name": "idx", "type": "int"},"
+ " {"name": "name", "type": "string"}"
+ " ]"
+ "}";
Schema.Parser parser = new Schema.Parser();
Schema avroSchema1 = parser.parse(schema);
// generate avro generic record
GenericRecord avroRecord = new GenericData.Record(avroSchema1);
avroRecord.put("idx", 100);
avroRecord.put("name", "test-name");
KafkaProducer<String, GenericRecord> producer = new KafkaProducer<>(configs);
ProducerRecord<String, GenericRecord> record = new ProducerRecord<>(TOPIC_NAME, avroRecord);
producer.send(record);
producer.flush();
producer.close();
}
}
schema registry running server](https://image.slidesharecdn.com/kafkajdbcconnectguidepostgressink-221208164254-838cea0d/75/Kafka-JDBC-Connect-Guide-Postgres-Sink-pptx-23-2048.jpg)




The document outlines the steps for setting up a Kafka connector to integrate PostgreSQL with Kafka in both standalone and distributed modes. It includes commands for creating a topic, configuring properties for connectors, executing connector tasks, and providing examples of consumer and producer shell commands to test functionality. Additionally, it details producer implementation using Java with Maven, including dependencies and schemas required for integration.















































