KEMBAR78
Daftar
Login
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集 | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
matsu_chara
13,729 views
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集
@matsu_chara 2016/5/31 Apache Kafka Meetup Japan #1 at Yahoo! JAPAN
Technology
◦
Read more
19
Save
Share
Embed
Download
Downloaded 56 times
1
/ 39
2
/ 39
3
/ 39
4
/ 39
5
/ 39
6
/ 39
7
/ 39
8
/ 39
9
/ 39
10
/ 39
11
/ 39
12
/ 39
13
/ 39
14
/ 39
15
/ 39
16
/ 39
17
/ 39
18
/ 39
19
/ 39
20
/ 39
21
/ 39
22
/ 39
23
/ 39
24
/ 39
25
/ 39
26
/ 39
27
/ 39
28
/ 39
29
/ 39
30
/ 39
31
/ 39
32
/ 39
33
/ 39
34
/ 39
35
/ 39
36
/ 39
37
/ 39
38
/ 39
39
/ 39
More Related Content
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
マイクロサービス化デザインパターン - #AWSDevDay Tokyo 2018
by
Yusuke Suzuki
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
LINE LIVE のチャットが 30,000+/min のコメント投稿を捌くようになるまで
by
LINE Corporation
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
マイクロサービス化デザインパターン - #AWSDevDay Tokyo 2018
by
Yusuke Suzuki
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
LINE LIVE のチャットが 30,000+/min のコメント投稿を捌くようになるまで
by
LINE Corporation
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
What's hot
PPTX
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
PDF
JCBの Payment as a Service 実現にむけたゼロベースの組織変革とテクニカル・イネーブラー(NTTデータ テクノロジーカンファレンス ...
by
NTT DATA Technology & Innovation
PPTX
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
PDF
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PDF
20190806 AWS Black Belt Online Seminar AWS Glue
by
Amazon Web Services Japan
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PPTX
Helidon 概要
by
オラクルエンジニア通信
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PDF
Akkaとは。アクターモデル とは。
by
Kenjiro Kubota
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PPTX
ぱぱっと理解するSpring Cloudの基本
by
kazuki kumagai
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
OSS+AWSでここまでできるDevSecOps (Security-JAWS第24回)
by
Masaya Tahara
PDF
DockerとPodmanの比較
by
Akihiro Suda
PDF
こわくない Git
by
Kota Saito
PDF
5分で分かるgitのrefspec
by
ikdysfm
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
今こそ知りたいSpring Batch(Spring Fest 2020講演資料)
by
NTT DATA Technology & Innovation
JCBの Payment as a Service 実現にむけたゼロベースの組織変革とテクニカル・イネーブラー(NTTデータ テクノロジーカンファレンス ...
by
NTT DATA Technology & Innovation
Hive on Spark の設計指針を読んでみた
by
Recruit Technologies
ストリーム処理を支えるキューイングシステムの選び方
by
Yoshiyasu SAEKI
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
20190806 AWS Black Belt Online Seminar AWS Glue
by
Amazon Web Services Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Helidon 概要
by
オラクルエンジニア通信
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
Akkaとは。アクターモデル とは。
by
Kenjiro Kubota
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
ぱぱっと理解するSpring Cloudの基本
by
kazuki kumagai
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
OSS+AWSでここまでできるDevSecOps (Security-JAWS第24回)
by
Masaya Tahara
DockerとPodmanの比較
by
Akihiro Suda
こわくない Git
by
Kota Saito
5分で分かるgitのrefspec
by
ikdysfm
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
Viewers also liked
PPTX
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
PPTX
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
PDF
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PDF
Treasure Data and AWS - Developers.io 2015
by
N Masahiro
PDF
Developers Summit 2014 「Play2/Scalaでドメイン駆動設計を利用した大規模Webアプリケーションのスクラム開発の勘所」
by
Yoshimura Soichiro
PDF
Kafkaによるリアルタイム処理
by
Naoki Yanai
PDF
Fluentd v0.12 master guide
by
N Masahiro
PDF
Javaエンジニアに知ってほしい、Springの教科書「TERASOLUNA」 #jjug_ccc #ccc_f3
by
日本Javaユーザーグループ
PPTX
Top 5 Deep Learning and AI Stories - October 6, 2017
by
NVIDIA
リクルートライフスタイルの考える ストリームデータの活かし方(Hadoop Spark Conference2016)
by
Atsushi Kurumada
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
KafkaとAWS Kinesisの比較
by
Yoshiyasu SAEKI
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
Treasure Data and AWS - Developers.io 2015
by
N Masahiro
Developers Summit 2014 「Play2/Scalaでドメイン駆動設計を利用した大規模Webアプリケーションのスクラム開発の勘所」
by
Yoshimura Soichiro
Kafkaによるリアルタイム処理
by
Naoki Yanai
Fluentd v0.12 master guide
by
N Masahiro
Javaエンジニアに知ってほしい、Springの教科書「TERASOLUNA」 #jjug_ccc #ccc_f3
by
日本Javaユーザーグループ
Top 5 Deep Learning and AI Stories - October 6, 2017
by
NVIDIA
Recently uploaded
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集
1.
Kafkaを使った マイクロサービス基盤 part2 +運用して起きたトラブル集 @matsu_chara 2016/5/31 Apache
Kafka Meetup Japan #1 at Yahoo! JAPAN
2.
今日のスライド http://www.slideshare.net/matsu_chara/kafka-part2
3.
part1のスライド http://xuwei-k.github.io/slides/kafka-matsuri/#1
4.
自己紹介 • @matsu_chara • Ponylang非公式エバンジェリスト活動 •
Scala新卒研修用テキスト
5.
話すこと • Kafkaを使ったイベントハブについて • イベントハブとしてのKafka •
現在のシステム構成 • Kafkaの設定 • Kafka運用時辛かった事例 • TopicとPartition数増大による性能劣化 • FullGC発生によるPublish失敗 • Raidコントローラエラー発生事件
6.
• 利用用途の違いでKafkaのチューニングは どう変わるのか • 運用・性能面で困ったことを共有 話すこと
7.
Kafkaを使ったEventHubについて
8.
よくあるKafkaの使われ方 • ユーザーアクティビティログ・メトリクスの集約 => availability重視 •
イベントハブ(受け取ったデータをロストしないこと が最重要) => durabilityを重視
9.
よくあるKafkaの使われ方 • ユーザーアクティビティログ・メトリクスの集約 => availability重視 •
イベントハブ(受け取ったデータをロストしないこと が最重要) => durabilityを重視
10.
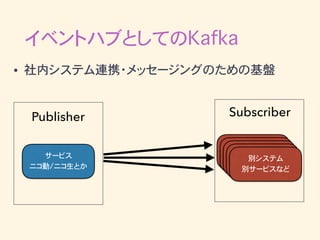
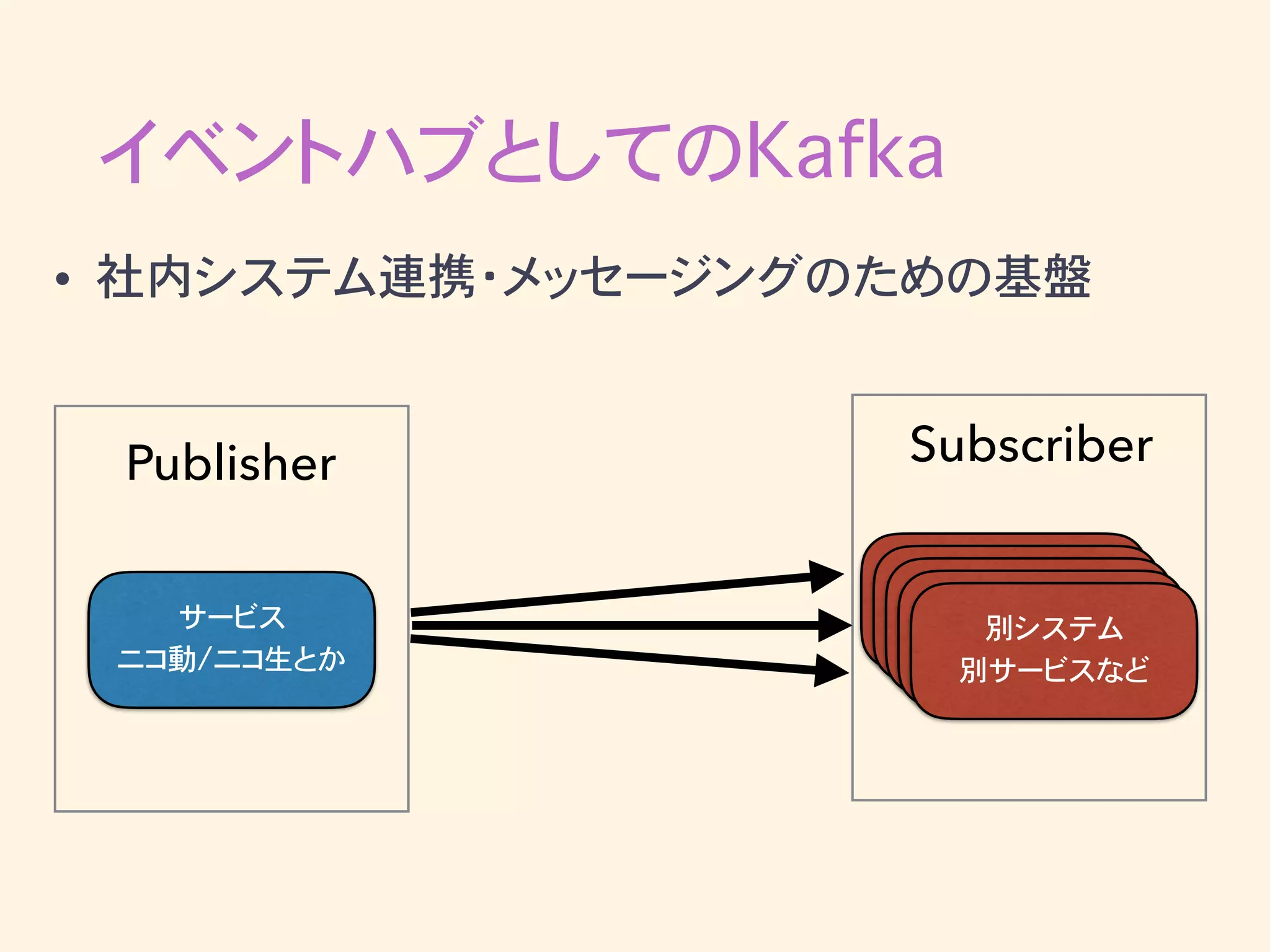
イベントハブとしてのKafka • 社内システム連携・メッセージングのための基盤
11.
イベントハブとしてのKafka • 社内システム連携・メッセージングのための基盤 サービス ニコ動/ニコ生とか Publisher 別システム 別サービスなど Subscriber
12.
イベントハブとしてのKafka • Publisherが直接1:Nで配信するのは大変 • 様々な温かみが生まれた歴史… •
各種サービスから情報を集約したいチームが出てきた 時に対応するコスト • 性能を各サービスでスケールさせるコスト
13.
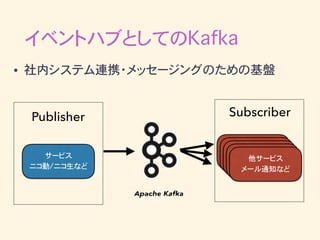
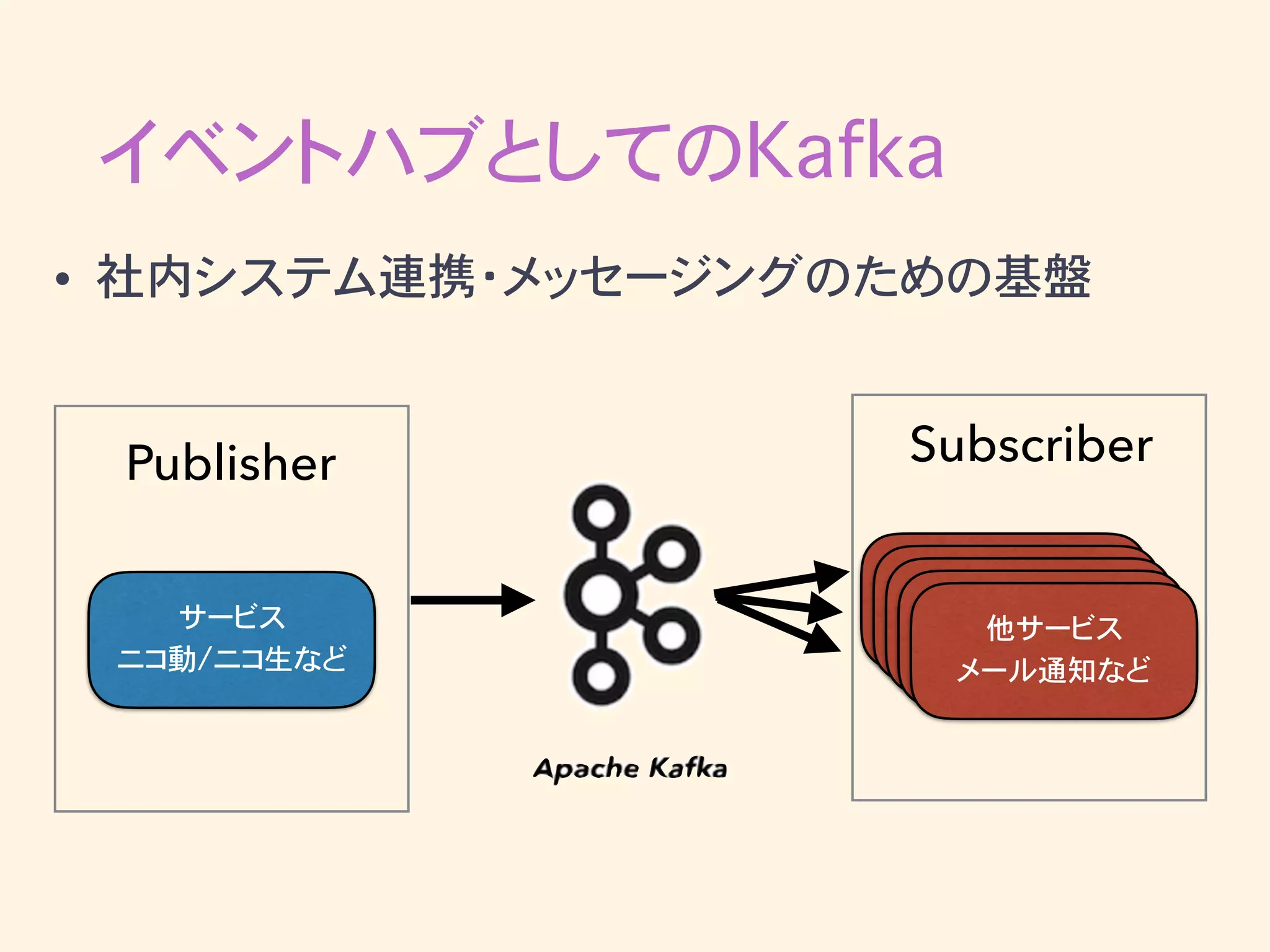
イベントハブとしてのKafka • 社内システム連携・メッセージングのための基盤 サービス ニコ動/ニコ生など Publisher 他サービス メール通知など Subscriber
14.
イベントハブとしてのKafka • Kafkaを中心にしてデータを集約 • Kafkaのスケーラビリティにより、色々なサービスが情報 をsubscribe可能になる •
publisherのシステム的な都合にsubscriberが影響さ れない(密結合を防ぐ)
15.
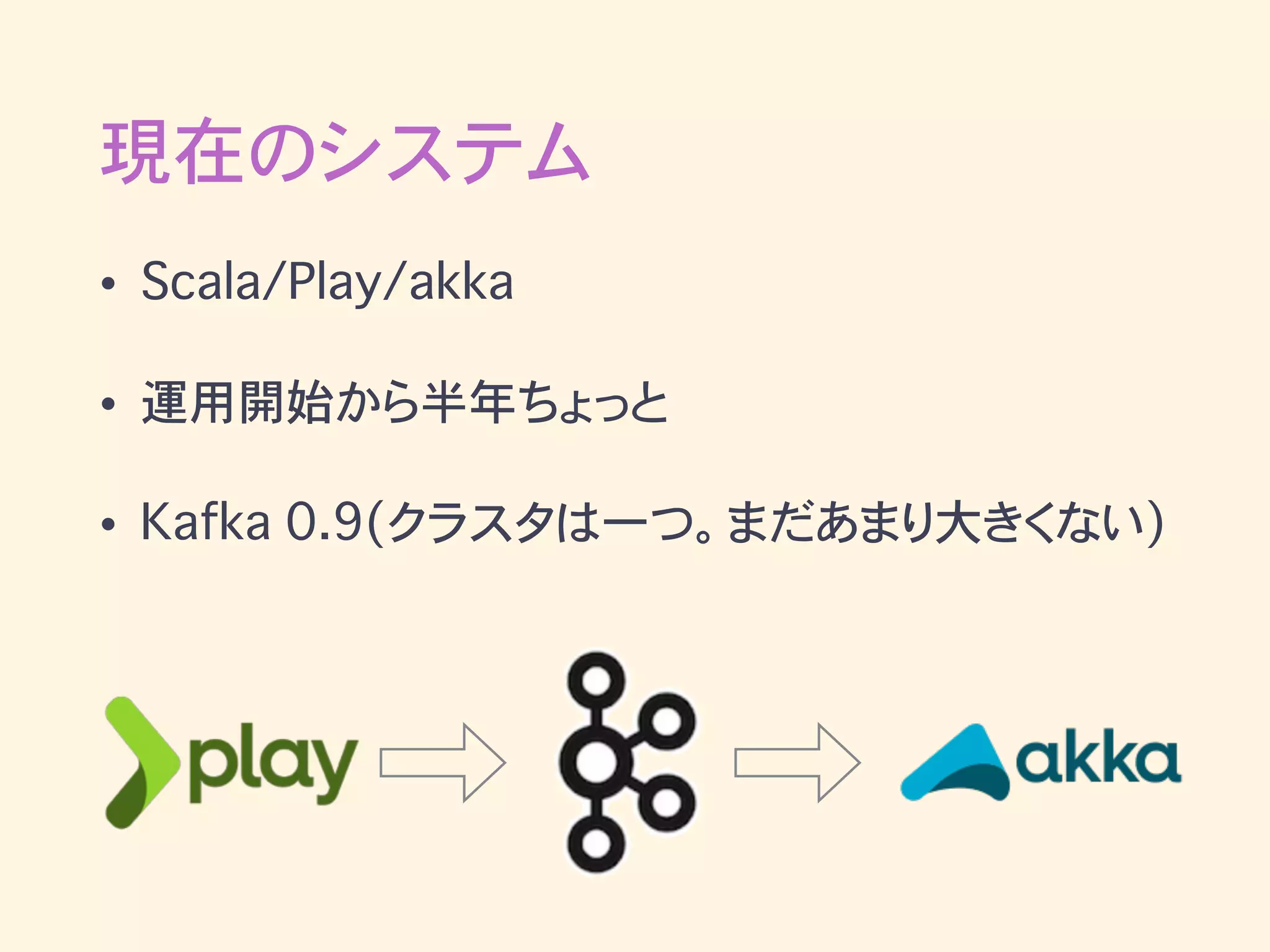
現在のシステム • Scala/Play/akka • 運用開始から半年ちょっと •
Kafka 0.9(クラスタは一つ。まだあまり大きくない)
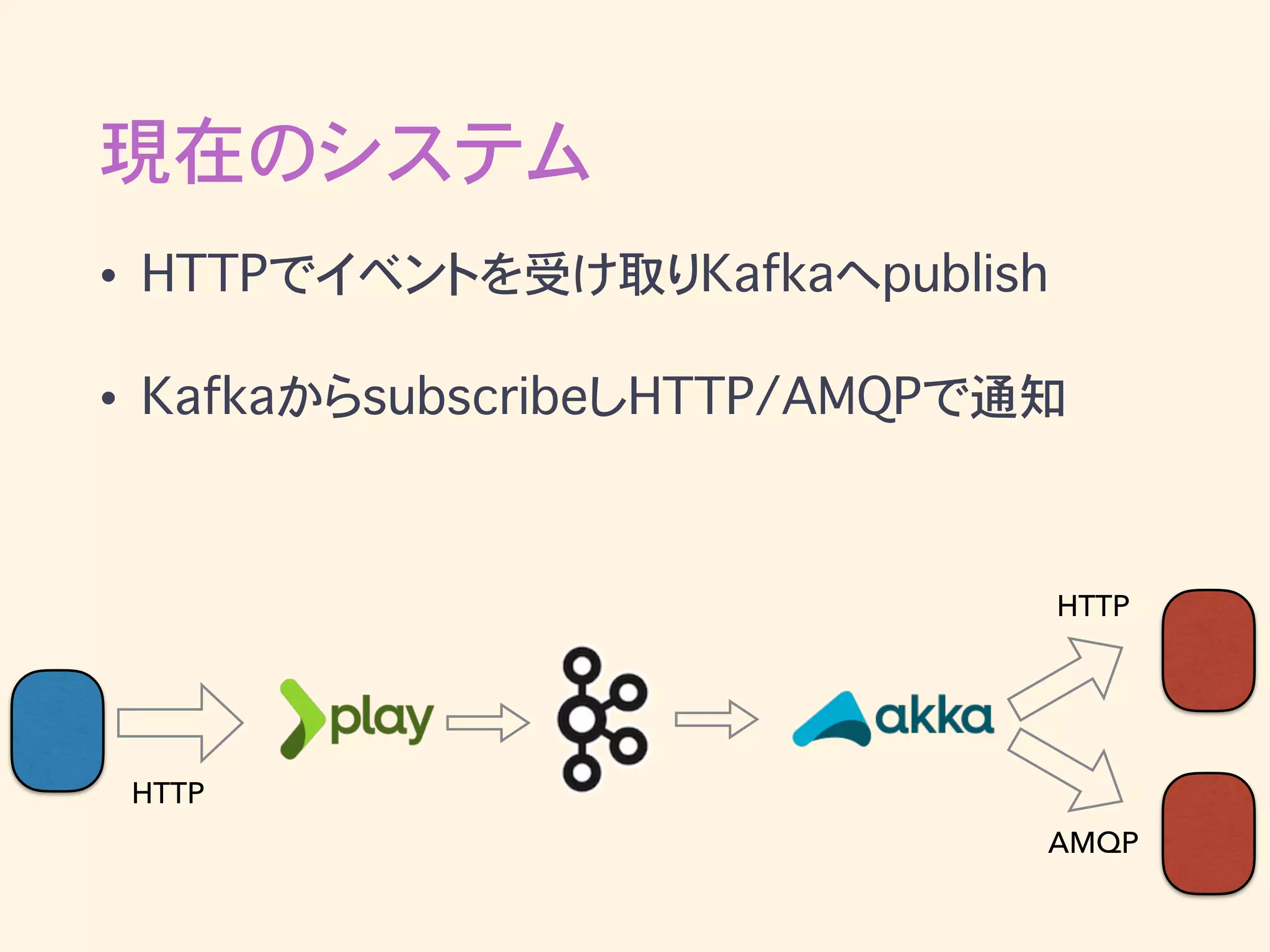
16.
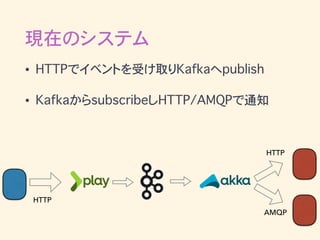
現在のシステム • HTTPでイベントを受け取りKafkaへpublish • KafkaからsubscribeしHTTP/AMQPで通知 HTTP AMQP HTTP
17.
Protocol Buffers on
Kafka • イベントのシリアライザは • 社内システム間連携の基盤として、メッセージの 互換性を保障・調整する役割も担いたい • 互換性維持のやりやすさを考慮して採用 • grpcも併せて社内のデータ交換形式の統一をし ていきたい
18.
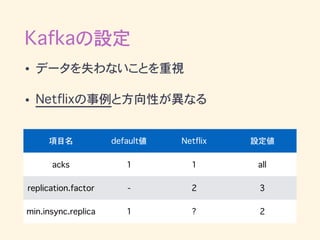
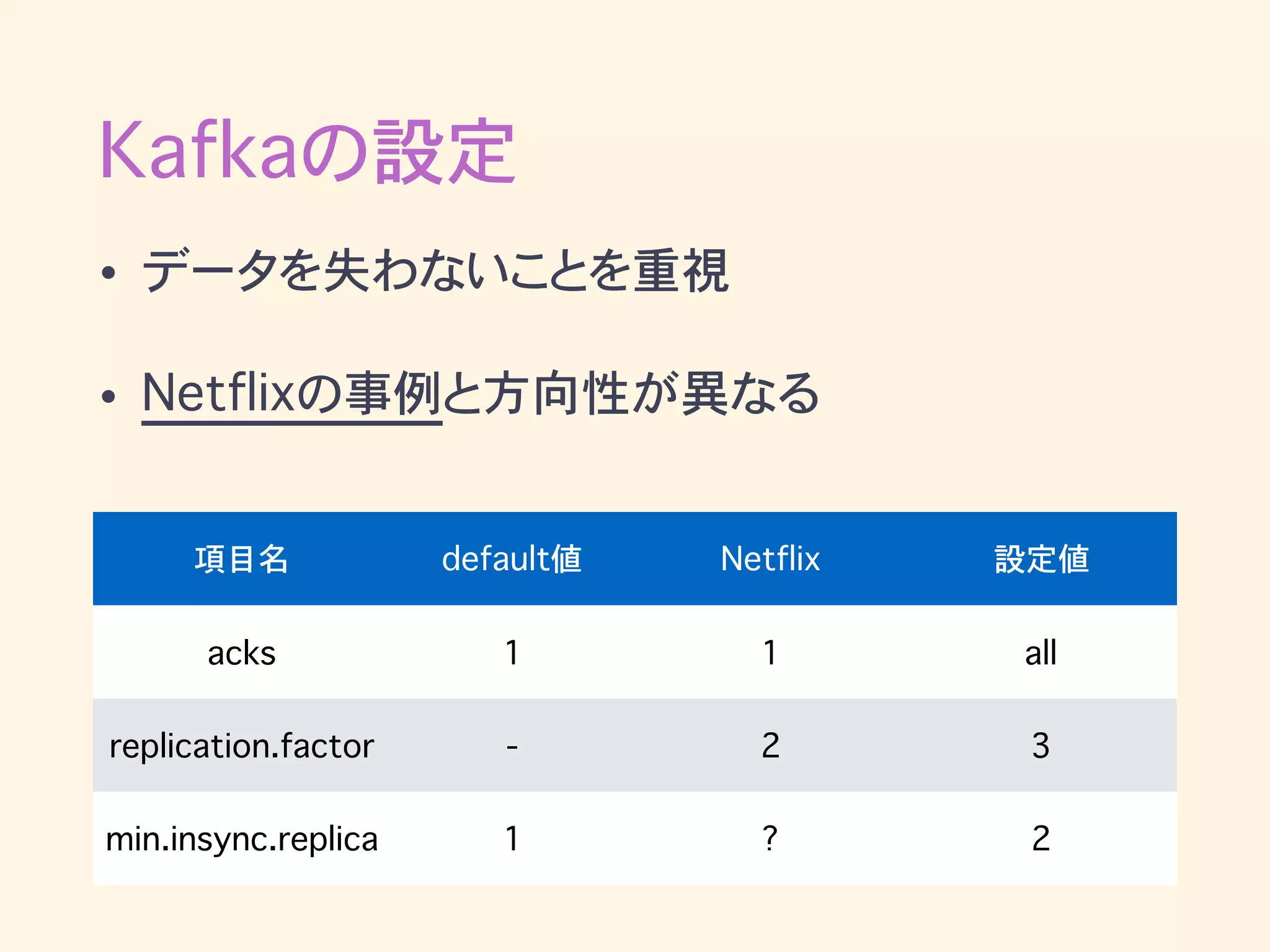
Kafkaの設定 • データを失わないことを重視 • Netflixの事例と方向性が異なる 項目名
default値 Netflix 設定値 acks 1 1 all replication.factor - 2 3 min.insync.replica 1 ? 2
19.
Kafkaの設定 その他の設定はpart1で紹介。 もっとチューニングしたいけど機能追加の兼ね合いがあるので隙を見てやっ ていきたい もっと詳細な情報 http://xuwei-k.github.io/slides/ kafka-matsuri/#34 clouderaの資料 http://www.cloudera.com/ documentation/kafka/latest/topics/ kafka_ha.html
20.
Kafka運用辛かった事例
21.
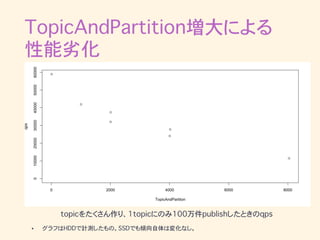
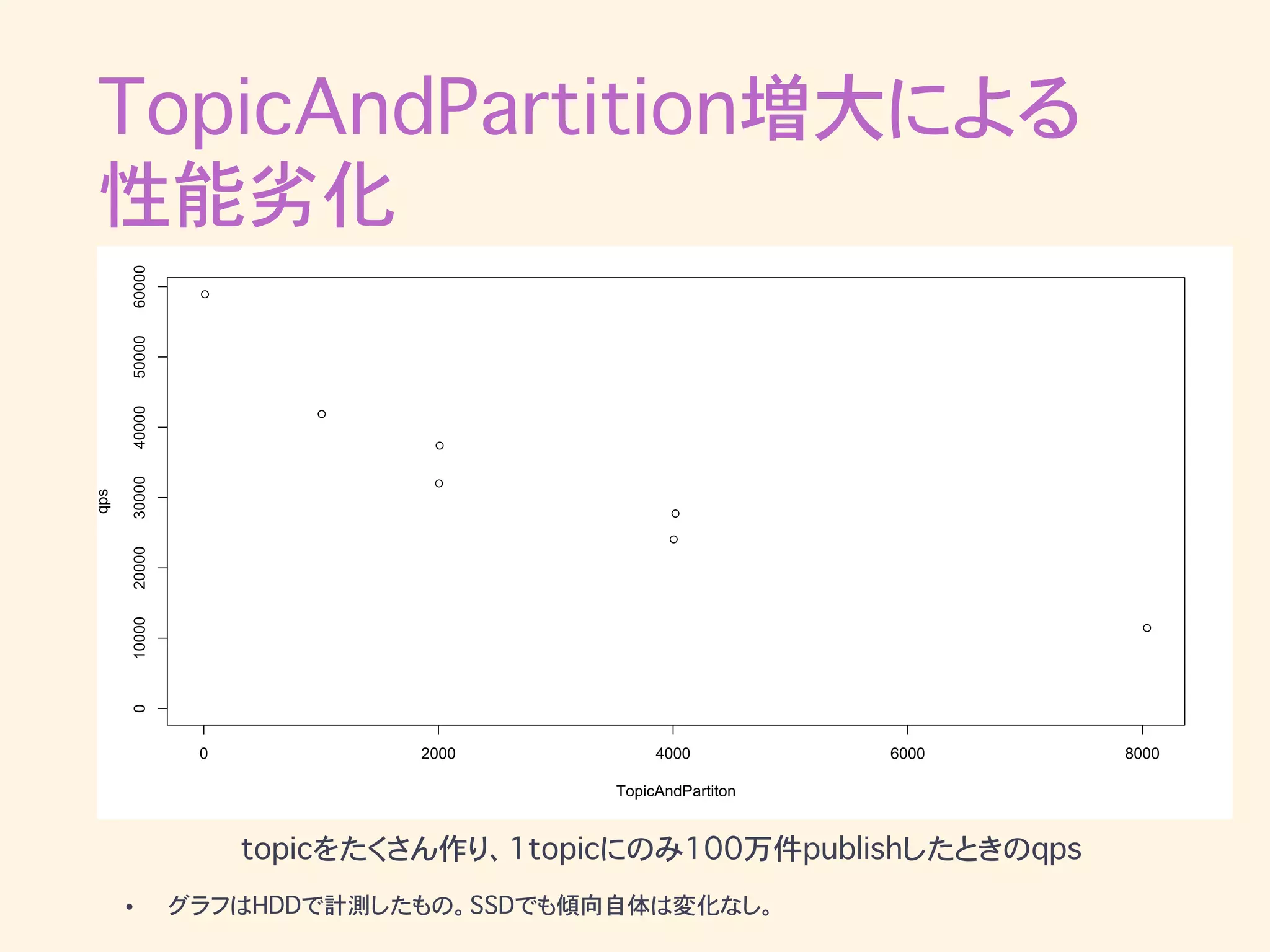
TopicAndPartition増大による 性能劣化 • partitionが増えるとPublish完了までの時間が悪化 • replication
factorにも依存 • レプリケーションが主な原因のようなので num.replica.fetchers などをチューニングする
22.
TopicAndPartition増大による 性能劣化 topicをたくさん作り、1topicにのみ100万件publishしたときのqps • グラフはHDDで計測したもの。SSDでも傾向自体は変化なし。 0 2000
4000 6000 8000 0100002000030000400005000060000 TopicAndPartiton qps
23.
TopicAndPartition増大による 性能劣化 • 現在はイベント頻度が高すぎないものに関しては partition数を1にして対処(必要に応じて増やす) • partition数の目安は1brokerあたり (100
* broker台数 * replication factor) 程度? (記事参照) 詳細 http://www.confluent.io/blog/how-to- choose-the-number-of-topicspartitions- in-a-kafka-cluster/
24.
TopicAndPartition増大による 性能劣化 • Netflixも抑えているが、そちらは可用性に関するチューニング? • 故障時のオーバーヘッドを減らす 企業
目安 参考元 confluent 2000~4000 partitions/broker 10K~ partitions/cluster http://www.confluent.io/blog/ how-to-choose-the-number-of- topicspartitions-in-a-kafka- cluster/ Netflix 200 broker/cluster 以下 10K partition/custer 以下 http://techblog.netflix.com/ 2016/04/kafka-inside- keystone-pipeline.html
25.
FullGC発生によるPublish失敗 • 負荷試験中に発生。 • メッセージサイズによる。(Kafka的には1KB程度が最も 性能がでてGCにも優しいらしい) •
Javaパフォーマンスに書いてあるようなことをひたすら やっていく。 clouderaの資料 http://www.cloudera.com/documentation/kafka/latest/ topics/kafka_performance.html 実際にやったチューニング http://xuwei-k.github.io/slides/kafka-matsuri/ #61
26.
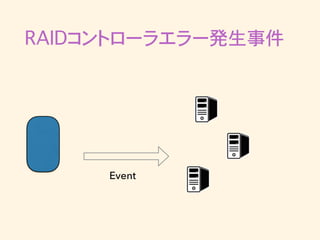
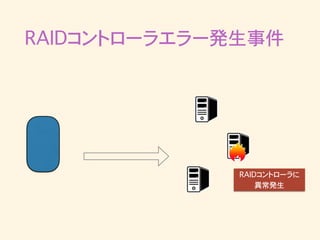
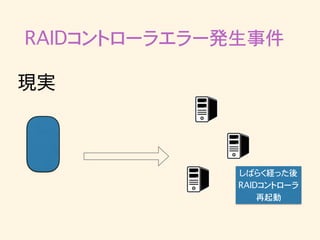
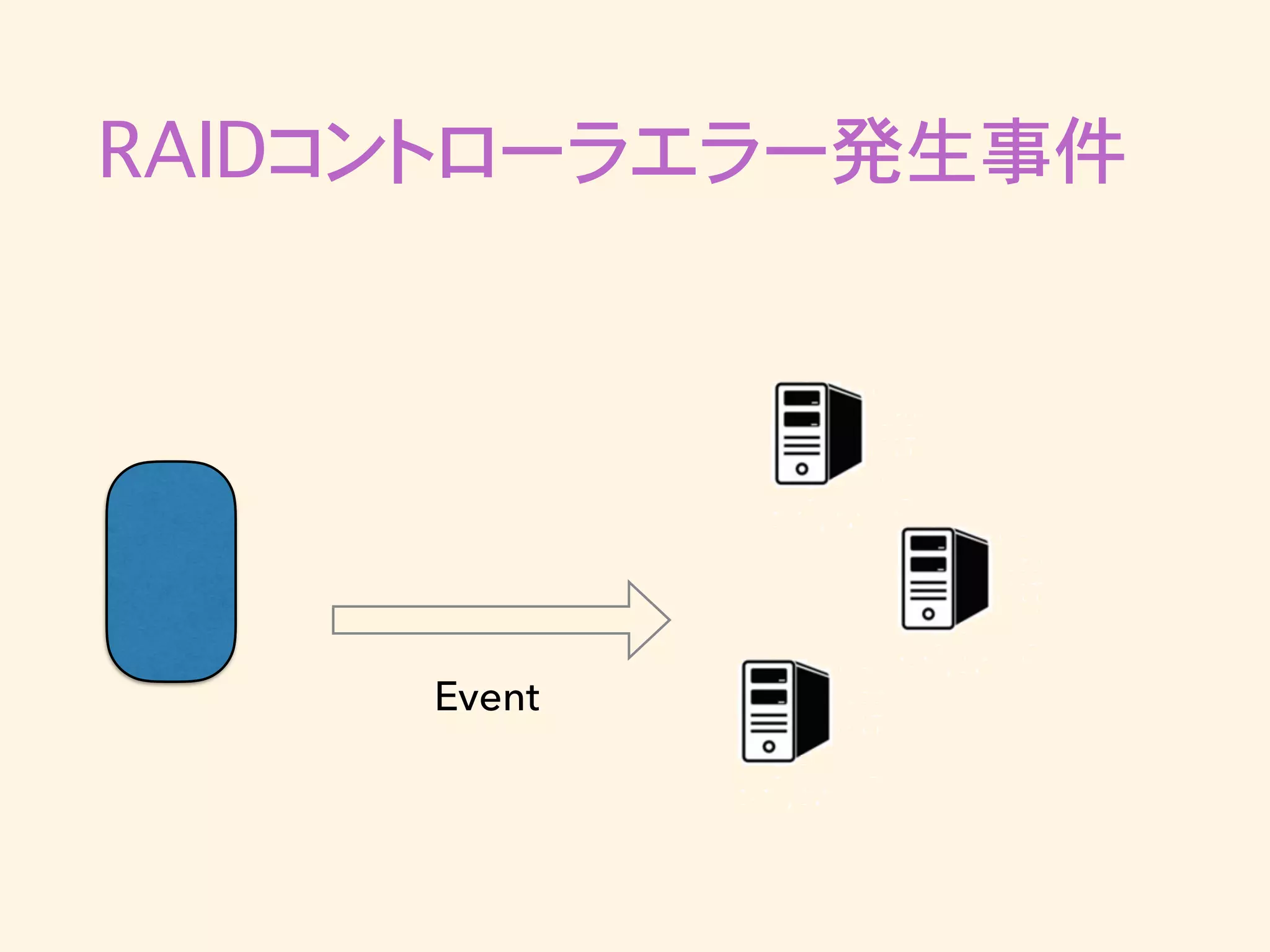
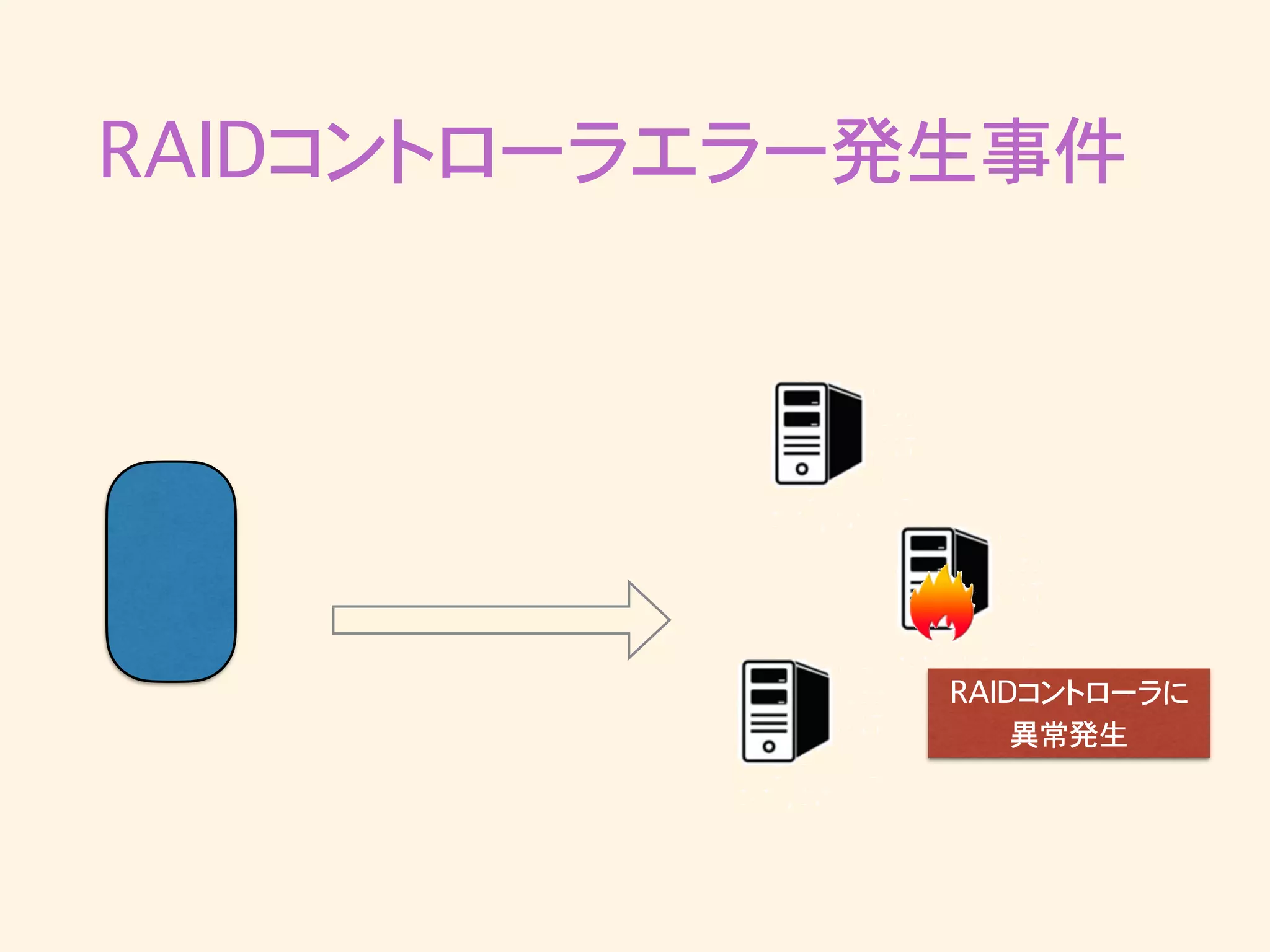
RAIDコントローラエラー発生事件 • 突然Kafkaへのpublishがタイムアウトし始める • ログを見るとRAIDコントローラが再起動していた •
RAIDコントローラ再起動後のbrokerは正常に動作 • 最近の出来事で調査・対策の方針がまだ立ってい ない
27.
RAIDコントローラエラー発生事件 Event
28.
RAIDコントローラエラー発生事件 RAIDコントローラに 異常発生
29.
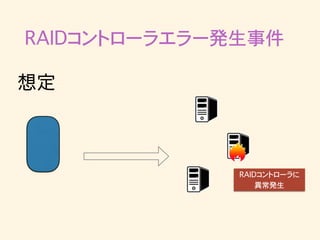
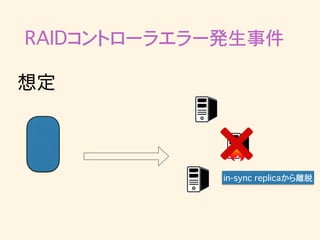
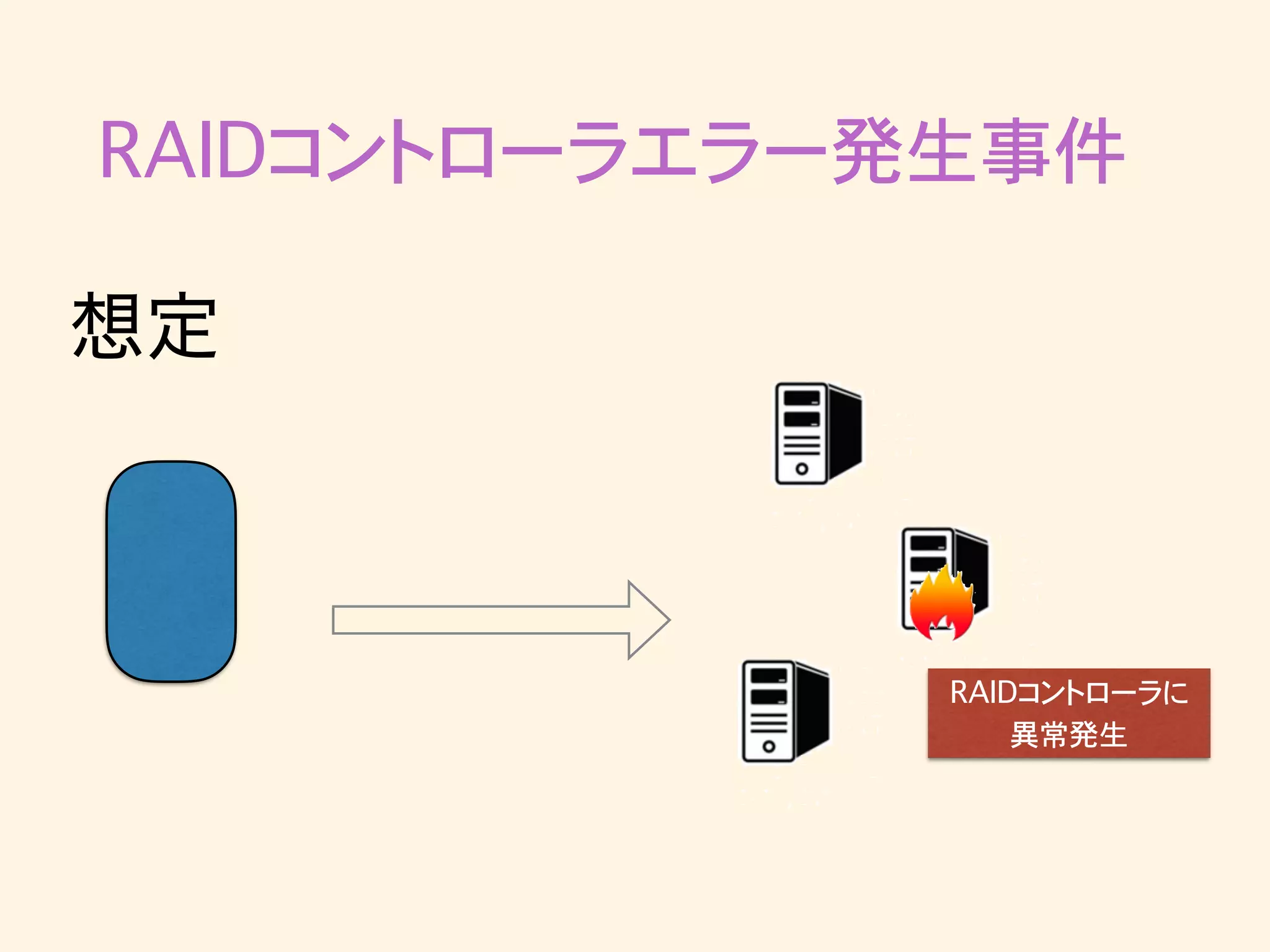
RAIDコントローラエラー発生事件 想定 RAIDコントローラに 異常発生
30.
RAIDコントローラエラー発生事件 in-sync replicaから離脱 想定
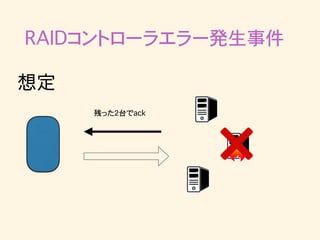
31.
RAIDコントローラエラー発生事件 残った2台でack 想定
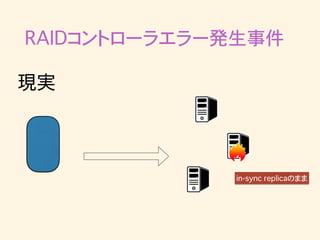
32.
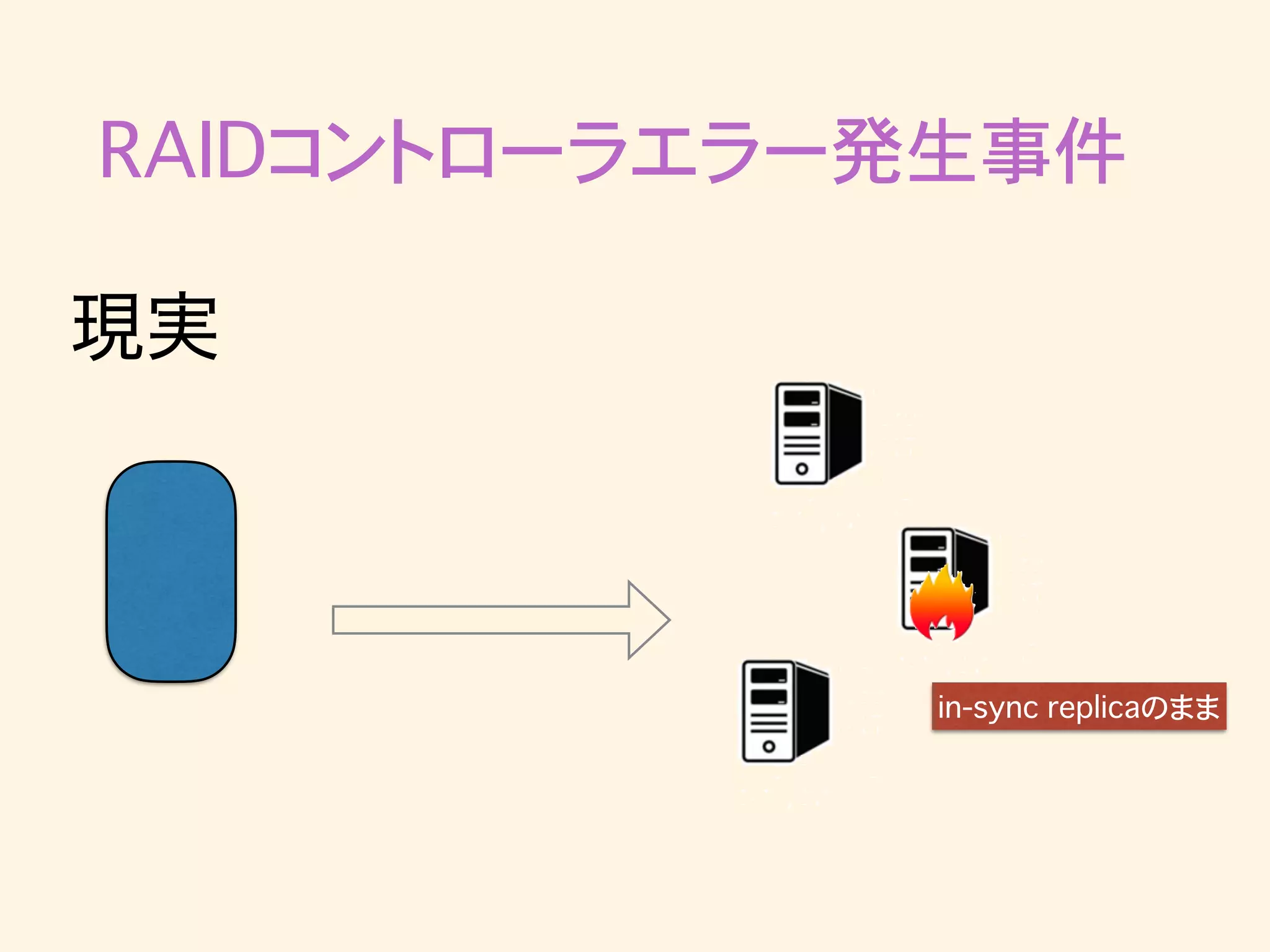
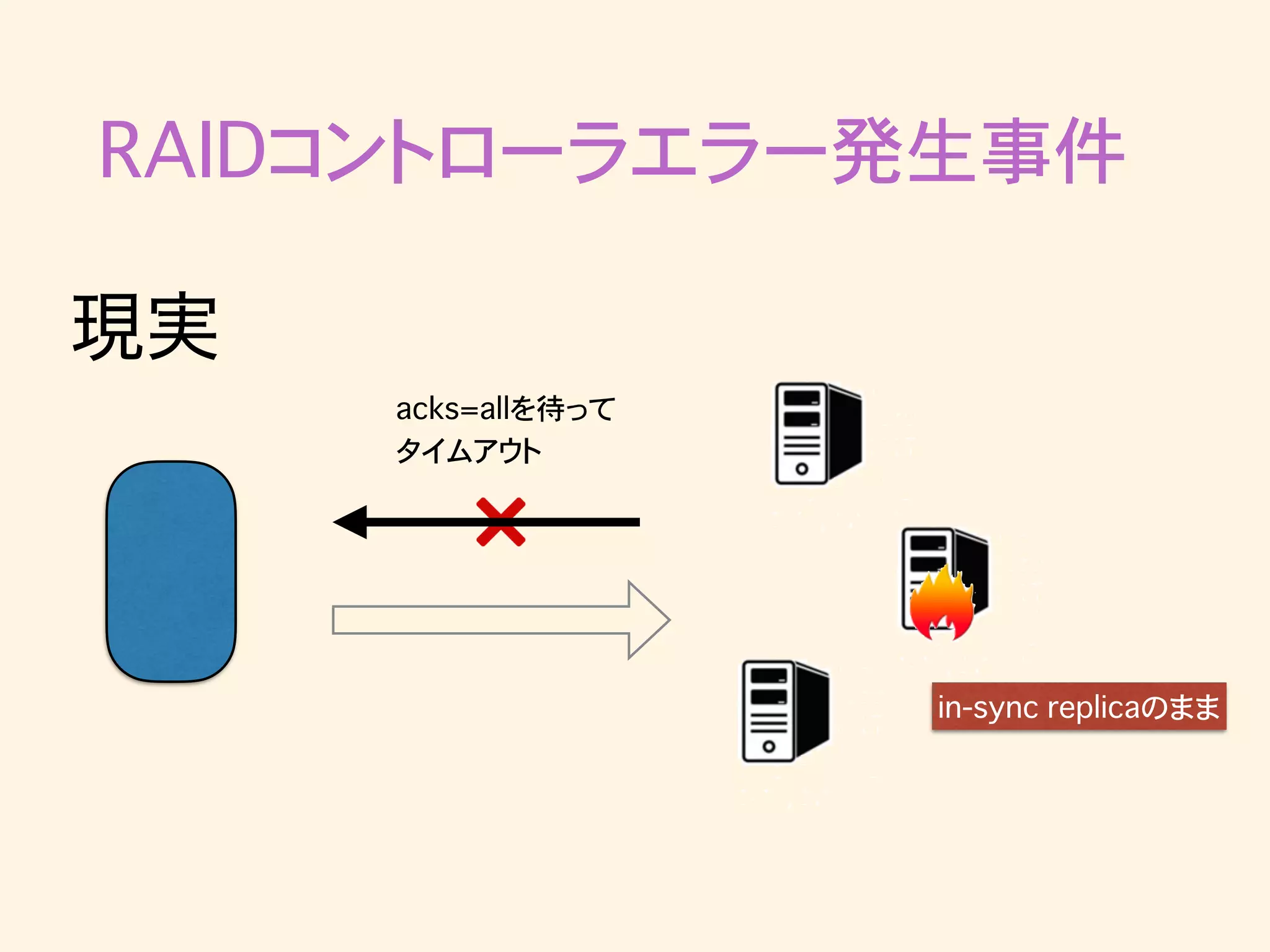
RAIDコントローラエラー発生事件 in-sync replicaのまま 現実
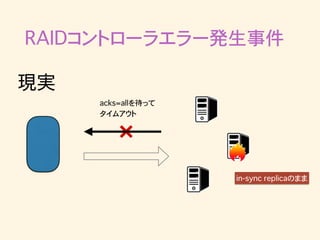
33.
RAIDコントローラエラー発生事件 in-sync replicaのまま 現実 acks=allを待って タイムアウト
34.
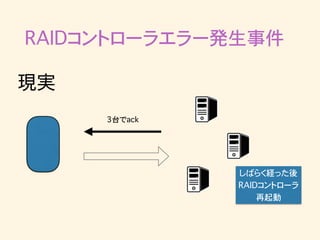
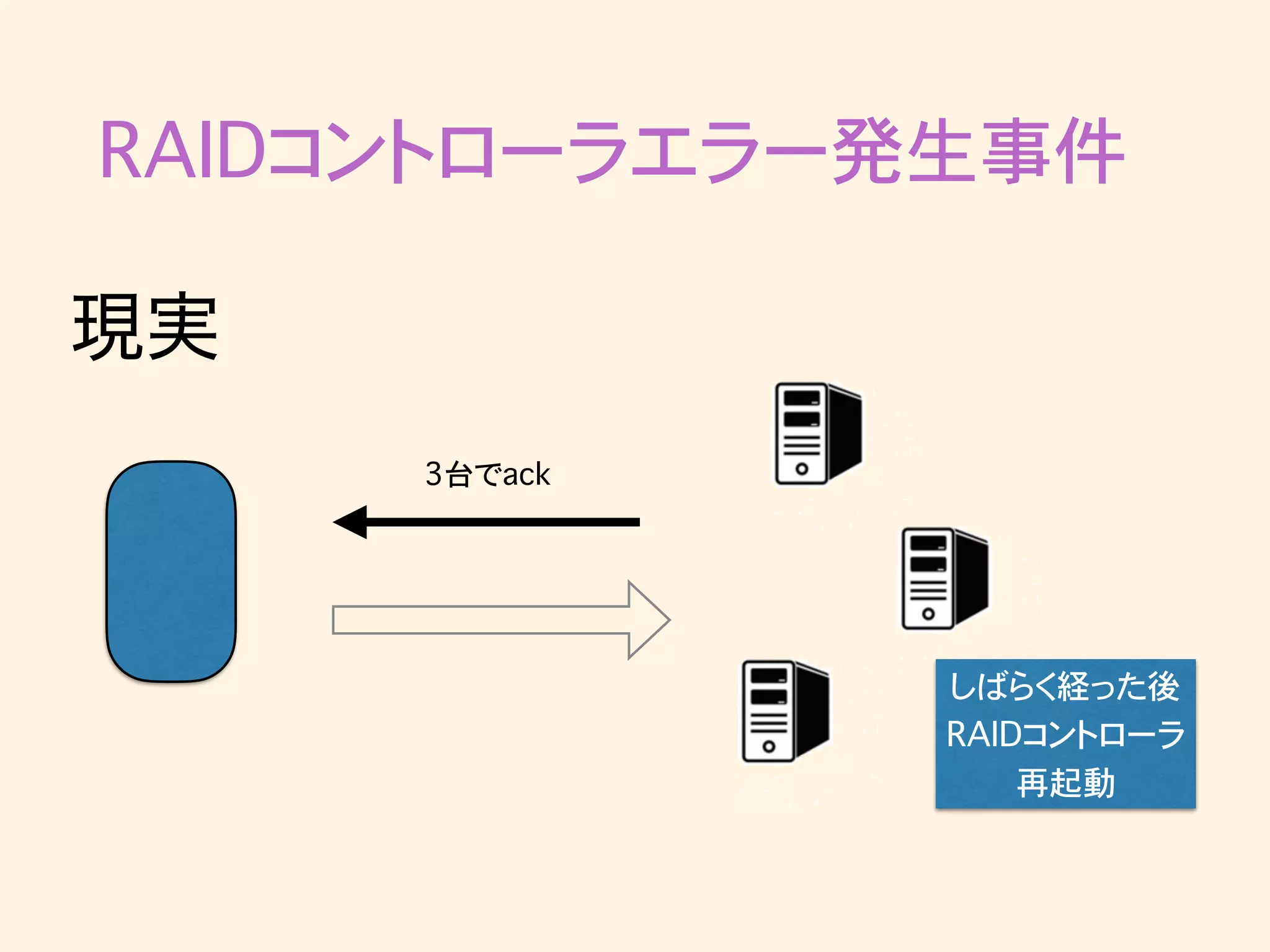
RAIDコントローラエラー発生事件 現実 しばらく経った後 RAIDコントローラ 再起動
35.
RAIDコントローラエラー発生事件 現実 3台でack しばらく経った後 RAIDコントローラ 再起動
36.
RAIDコントローラエラー発生事件 • min.insync.replica=2なので1台落ちてもpublish できるという想定だった。 • しかし「brokerがackを返せない状態」で「クラスタ から離脱しなかった」ため、「acks=all」の設定により publishできなかったと思われる •
brokerはzookeeperのハートビートには応答するが、 ackは返せないという状態になりうる?
37.
RAIDコントローラエラー発生事件 • acks=2はkafka 0.9からは出来なくなっている •
RAIDを使わない方針も考えられる? • RAID以外のエラーでも同じような現象は起きうる のか? • 自動で離脱しないなら、brokerを停止させる外部 機構が必要?
38.
RAIDコントローラエラー発生事件 • Netflixのようにcold standbyなクラスタを用意 するのはどうなのか、調子の悪いbrokerを停止さ せるだけでは不十分? •
再現できていないので仮説ベースな部分あり • 意見募集
39.
まとめ • 事例紹介 • 用途の違いを意識したチューニングが必要になる •
Netflixのようなavailabilityを重視 • イベントバスとしてdurabilityを重視 • 運用トラブルが起きる前に、confluent/linkedin/clouderaなど の資料は一通り目を通しておくと後悔が少ない。 • 実際の運用時の環境を想定した負荷試験をしてみる
Download