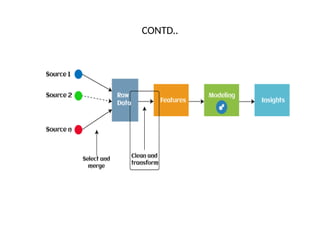
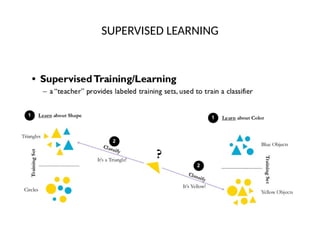
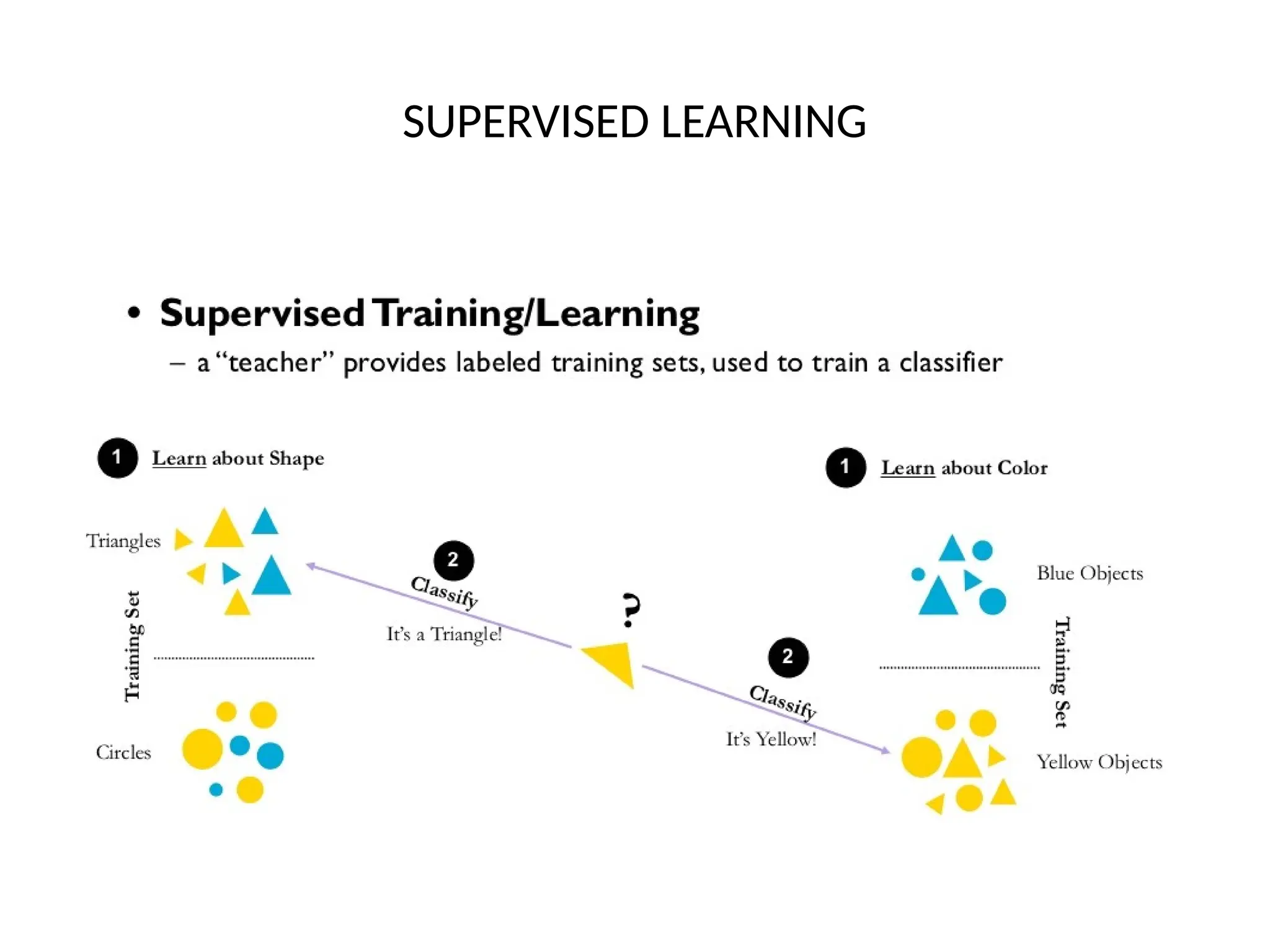
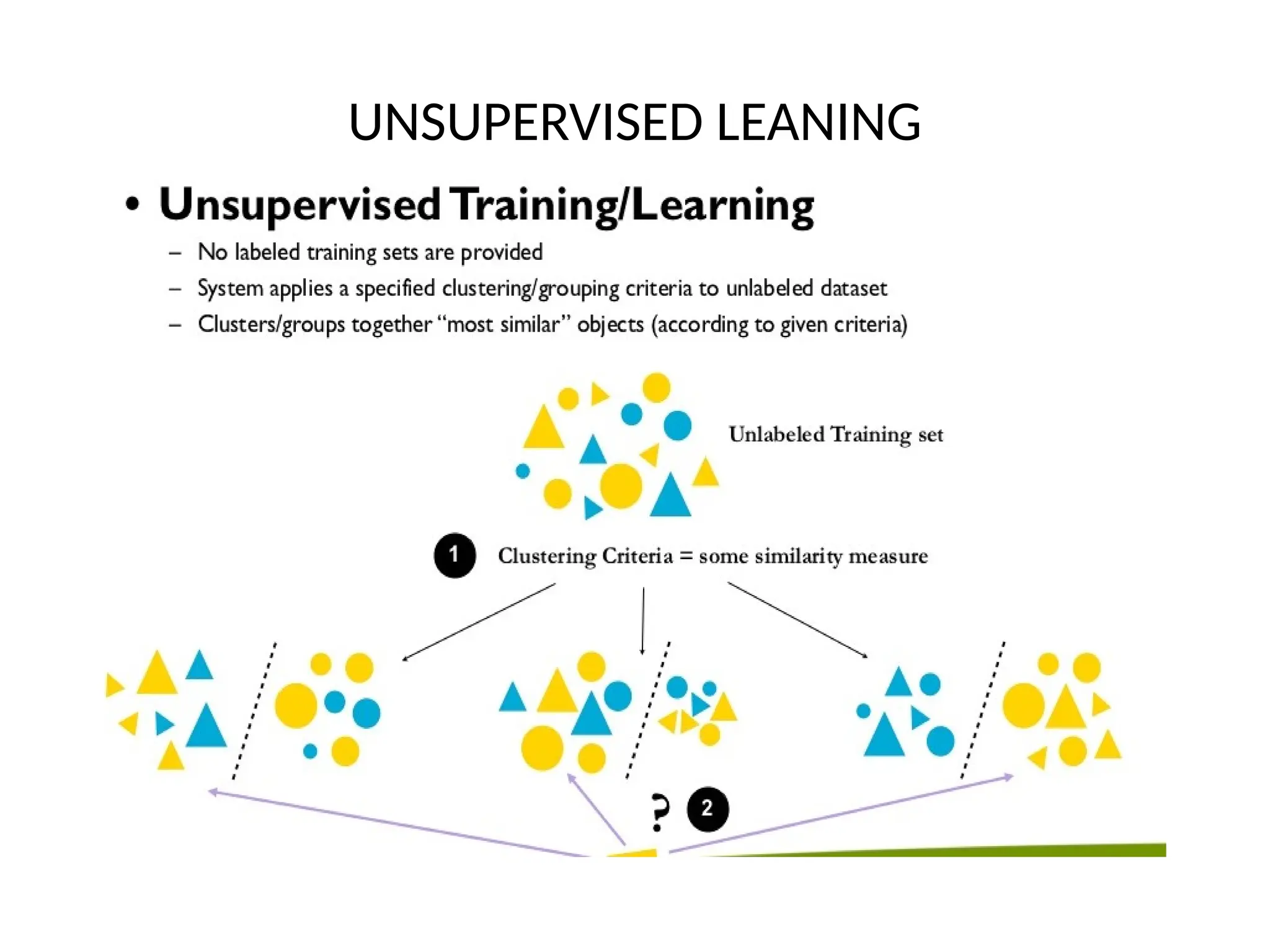
The document discusses feature engineering, a crucial pre-processing step in machine learning that transforms raw data into useful features for predictive models. It outlines four main processes of feature engineering: feature creation, transformations, feature extraction, and feature selection, which increase model performance. Additionally, it describes the three main paradigms of machine learning: supervised, unsupervised, and reinforcement learning, highlighting their roles and distinctions.








![CONTD..
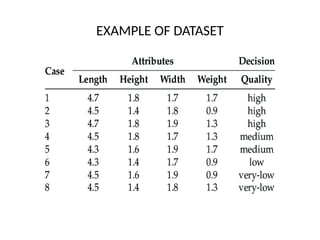
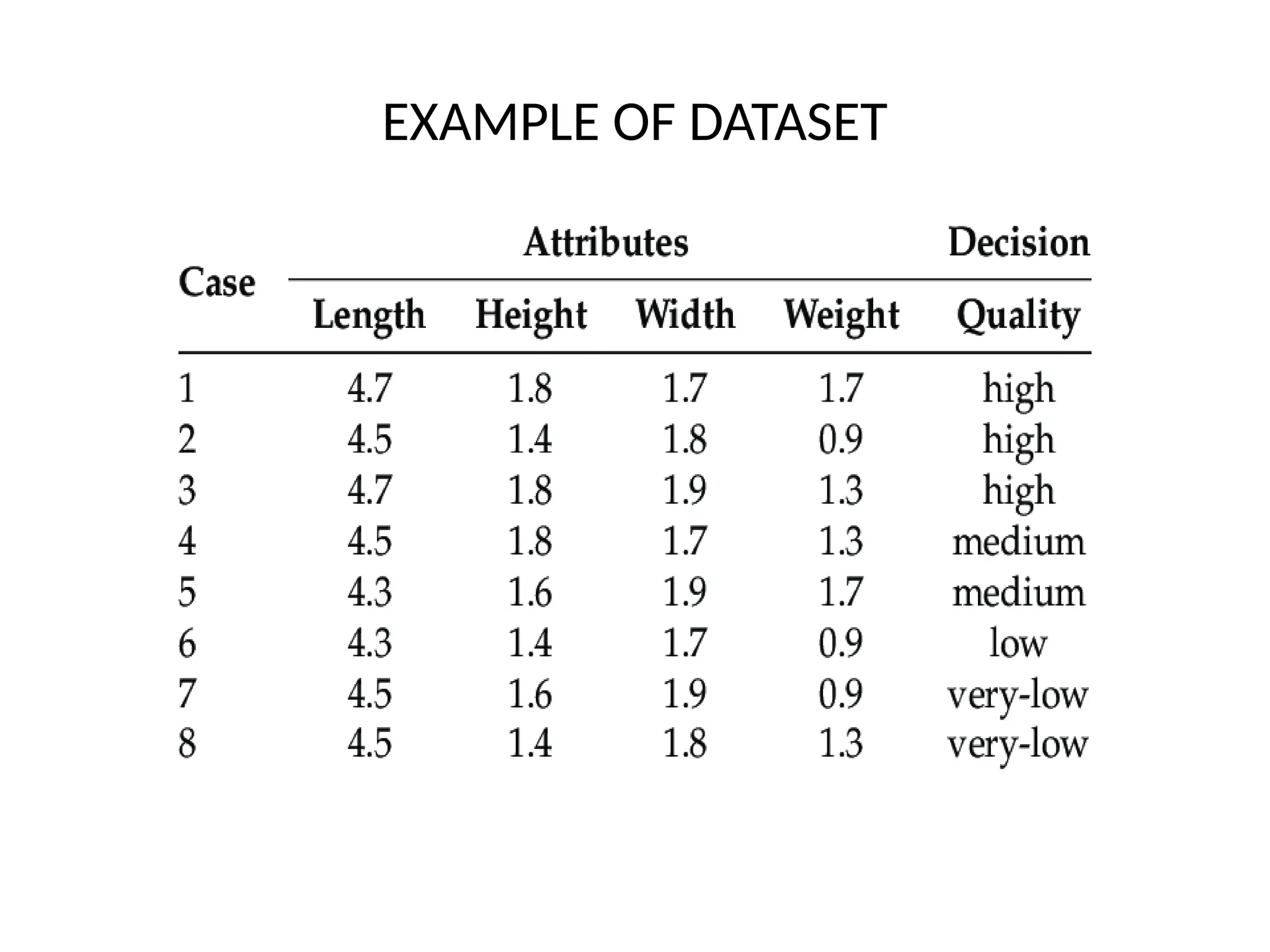
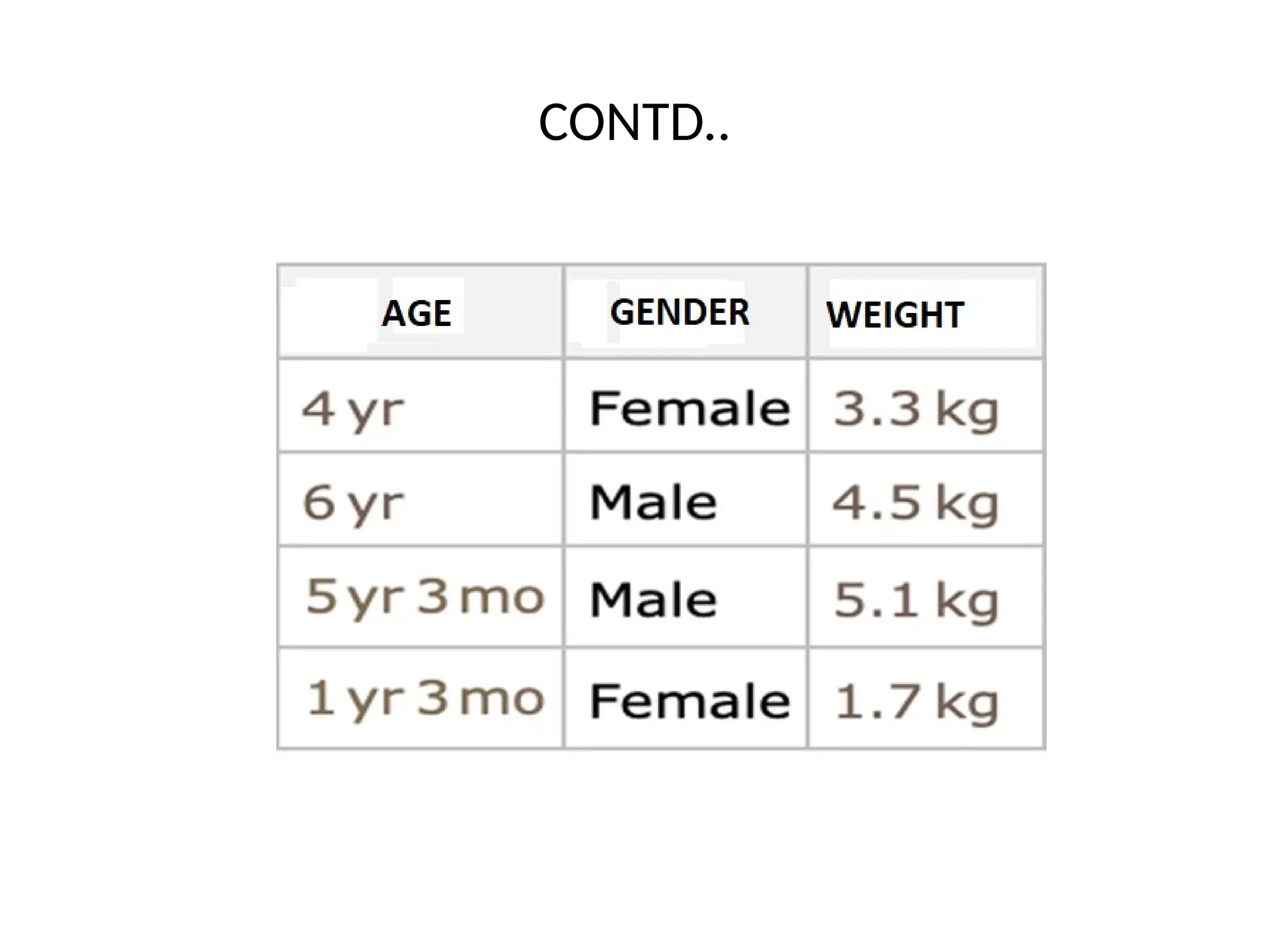
• The input variables (here, age and gender) are generally
called features, and the set of features representing an
example is called a feature vector. From this dataset, we can
learn a predictor in a supervised way.
Out[•]=
OUT = 3.65KG](https://image.slidesharecdn.com/lec-2-featureengineering-250107115457-1049f8cb/85/LECTURE-2-INTRO-FEATURE-ENGINEERING-pptx-12-320.jpg)











![CONTD..
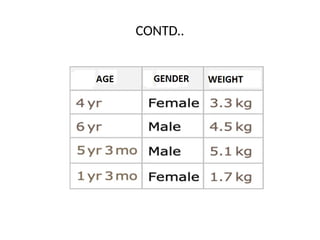
• The input variables (here, age and gender) are generally
called features, and the set of features representing an
example is called a feature vector. From this dataset, we can
learn a predictor in a supervised way.
Out[•]=
OUT = 3.65KG](https://image.slidesharecdn.com/lec-2-featureengineering-250107115457-1049f8cb/75/LECTURE-2-INTRO-FEATURE-ENGINEERING-pptx-12-2048.jpg)




























![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















