Downloaded 26 times

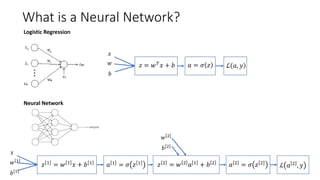
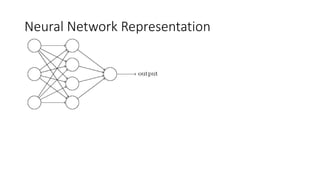
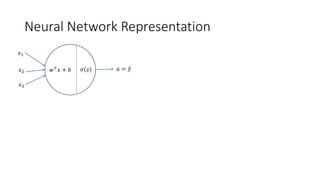
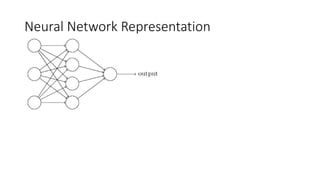
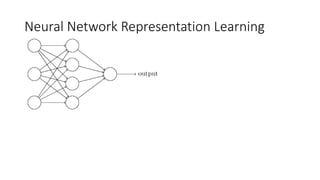
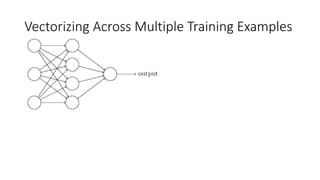










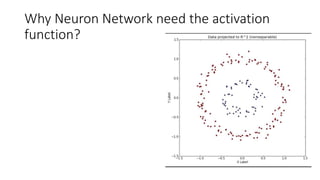






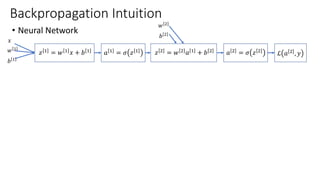


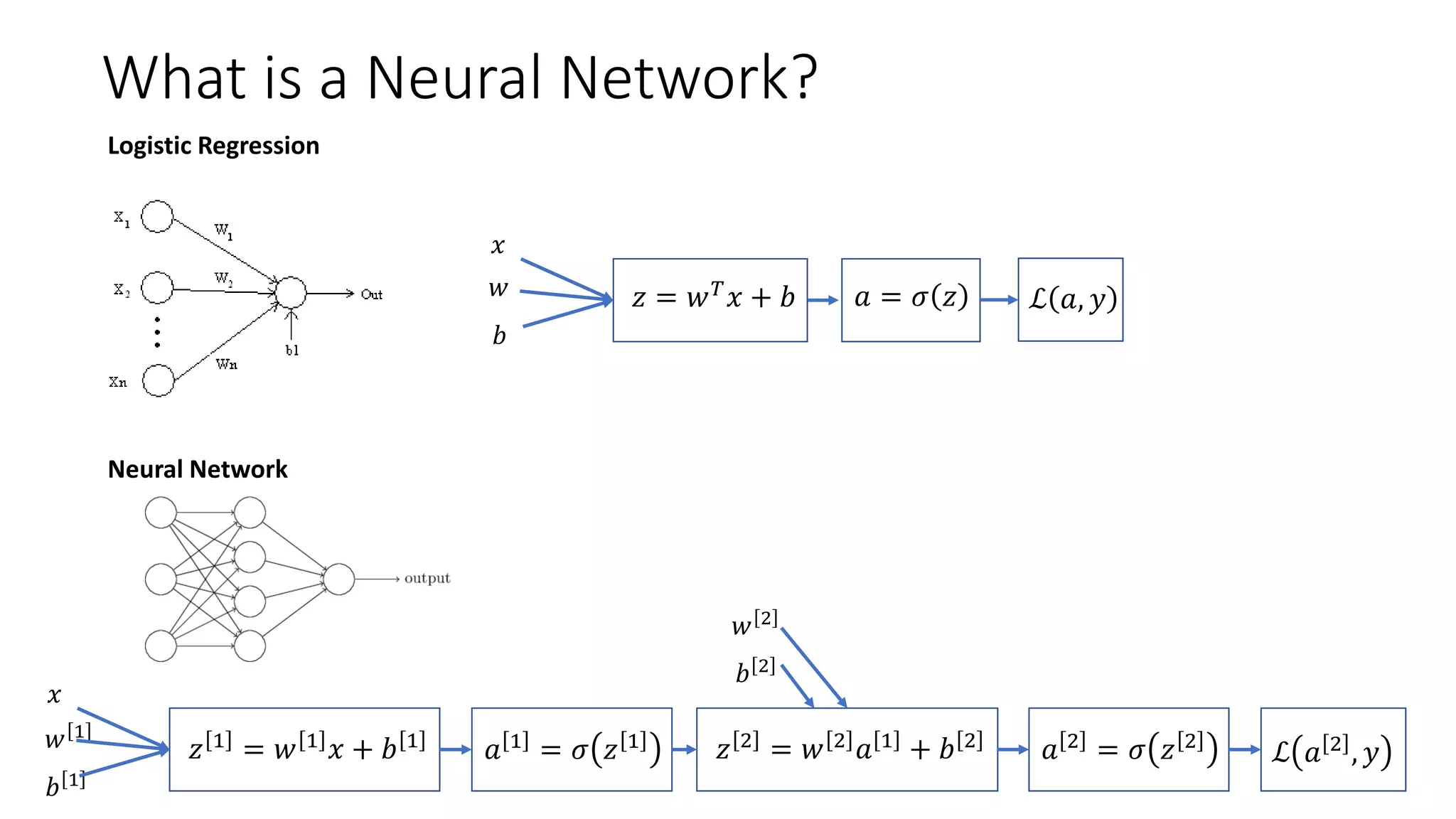
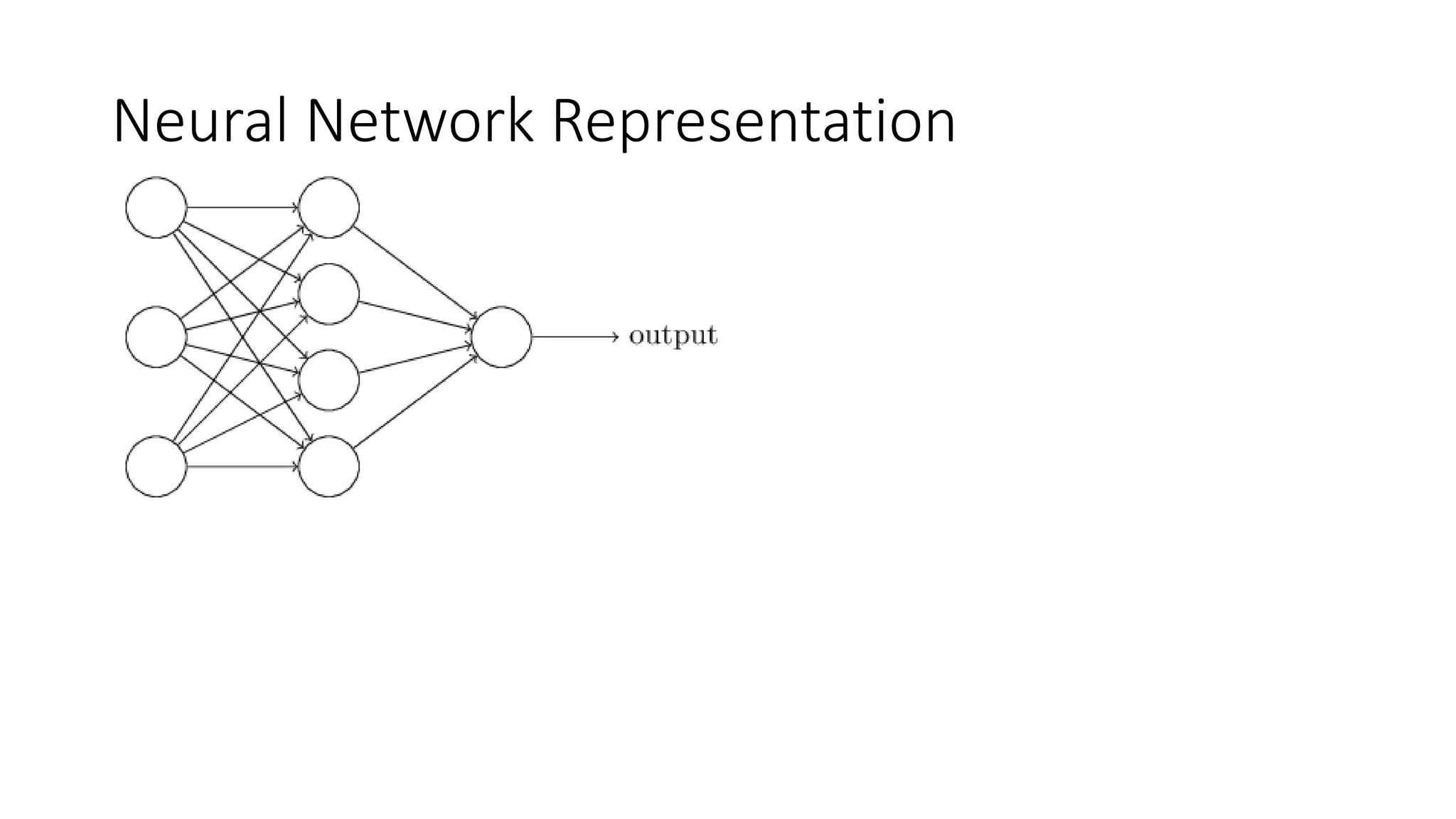
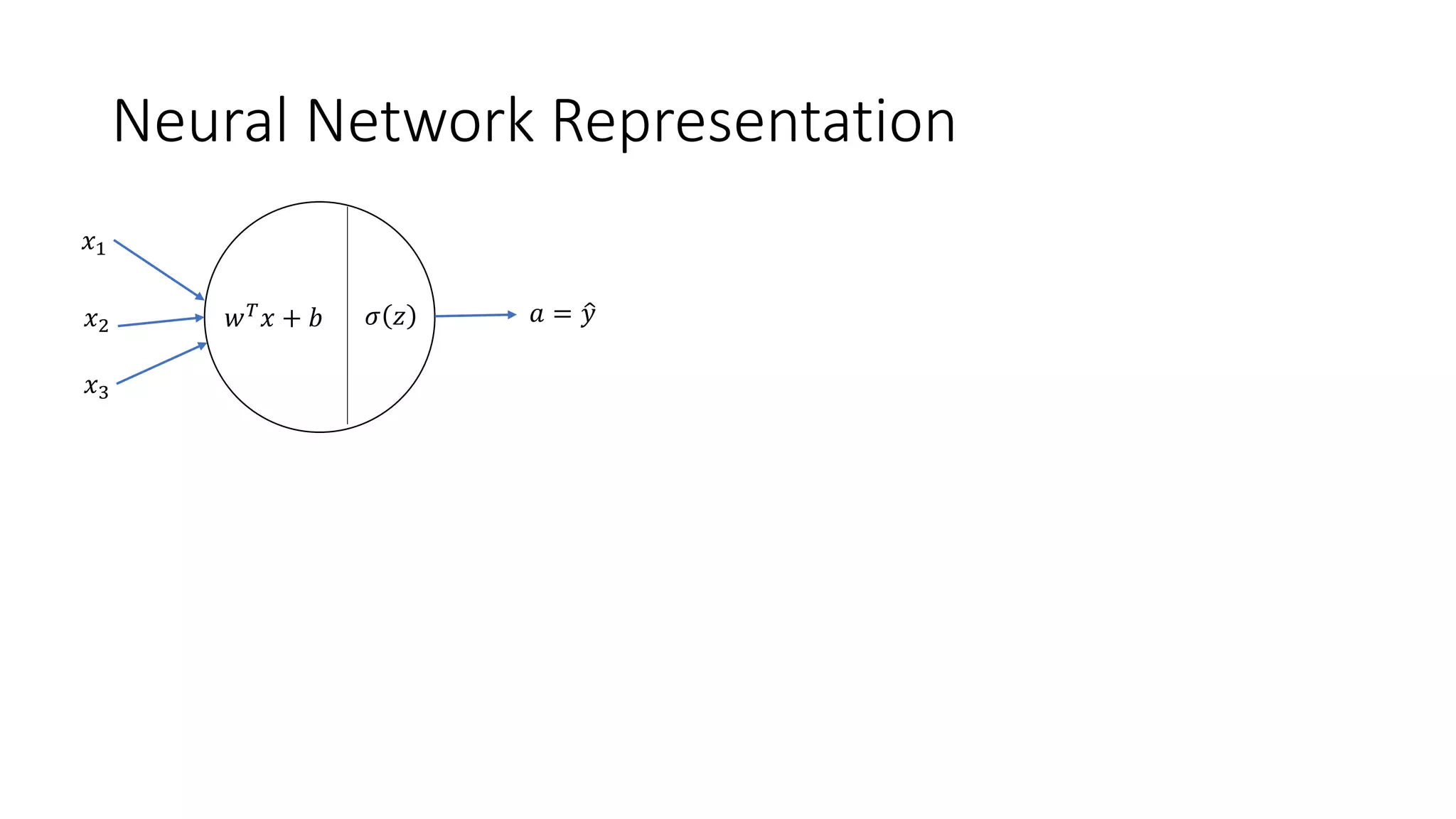
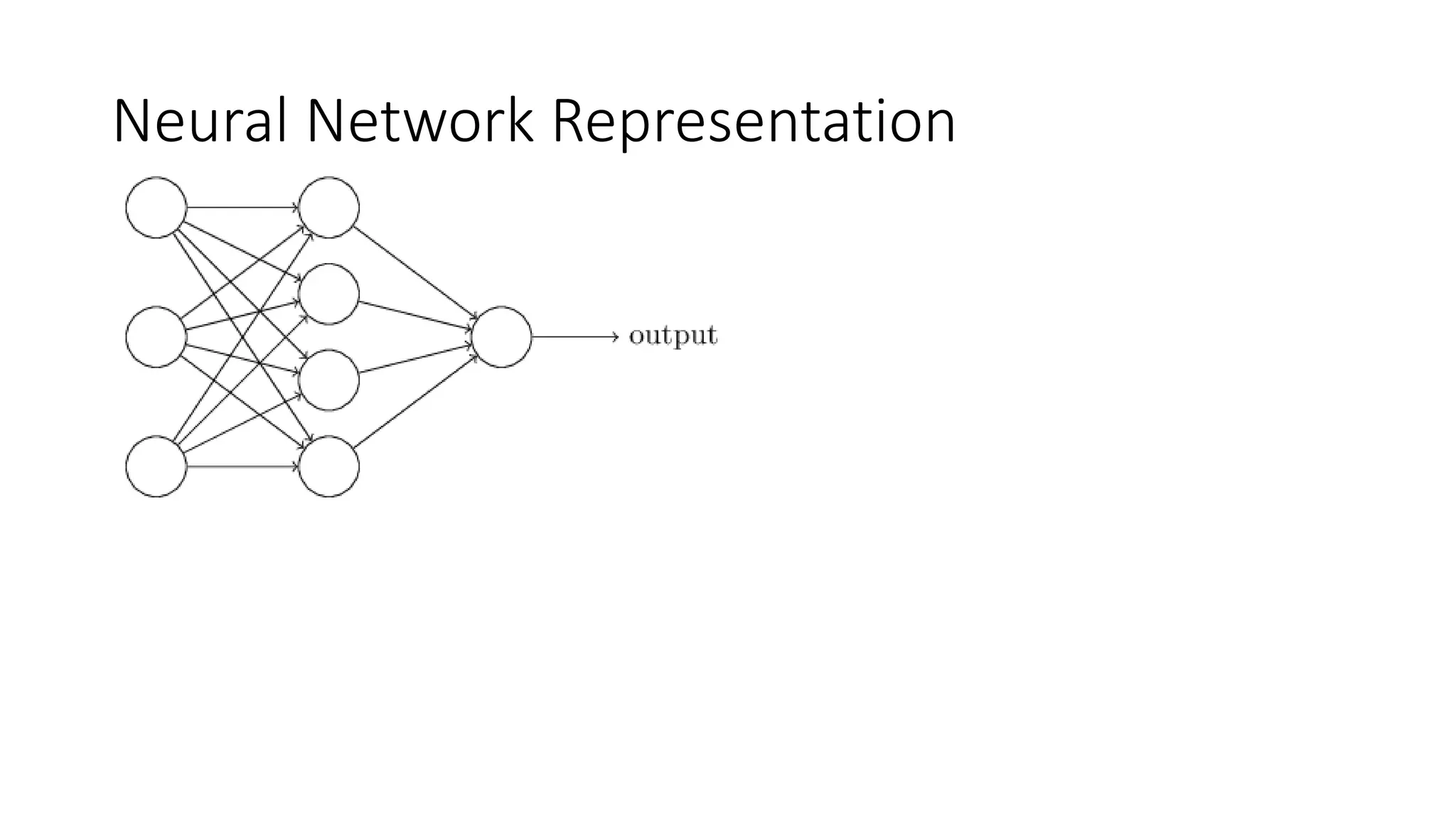
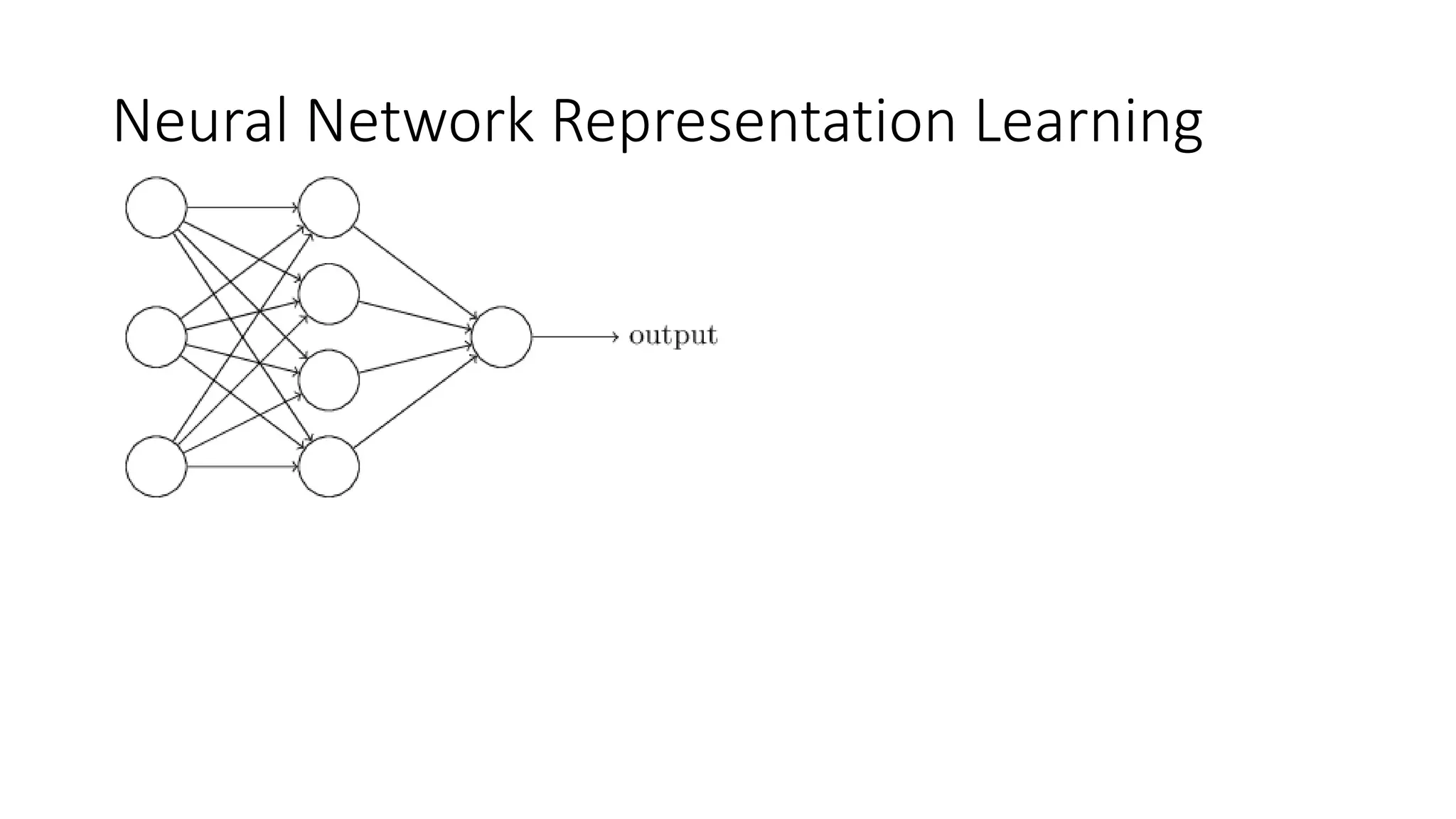
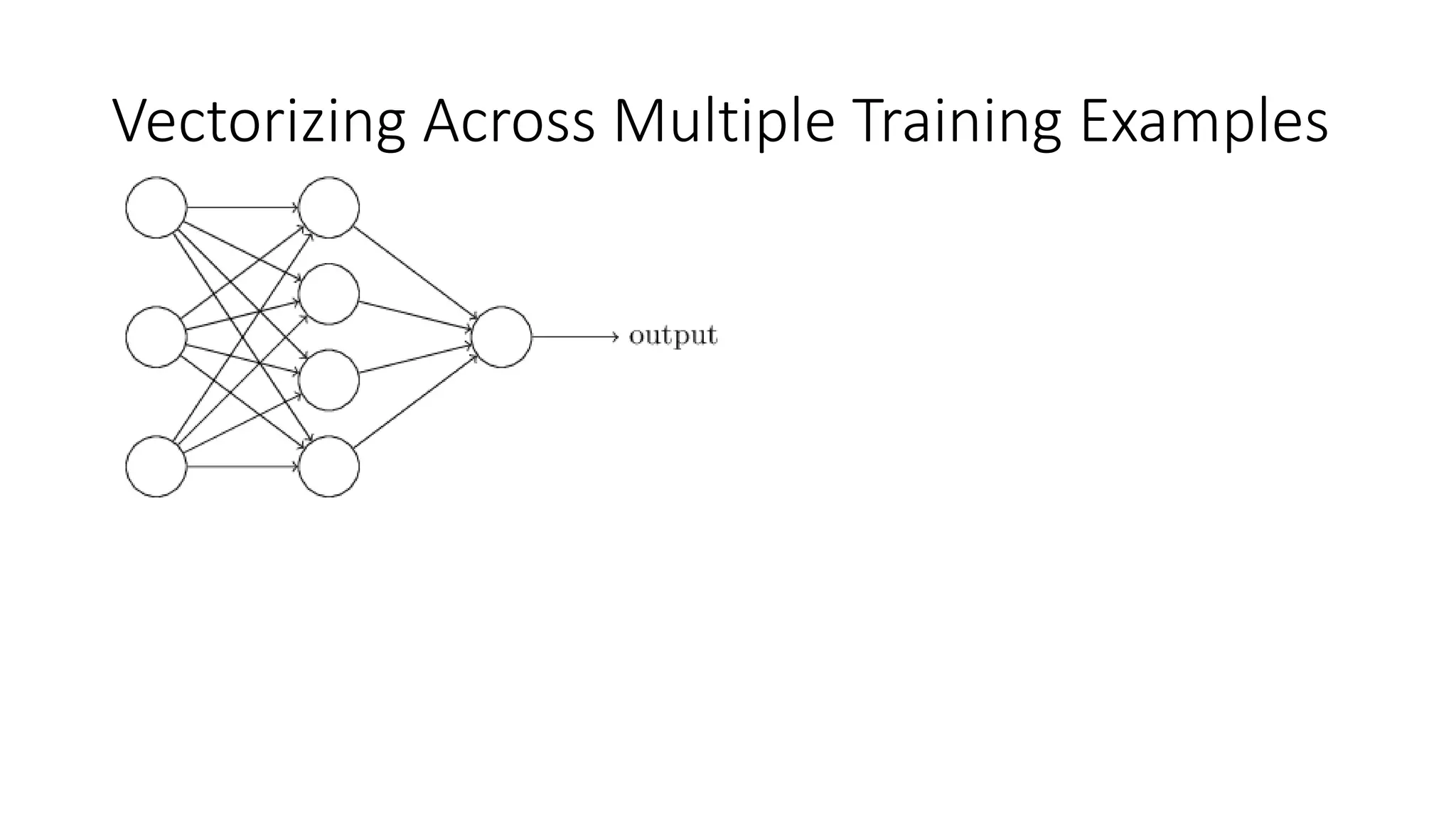










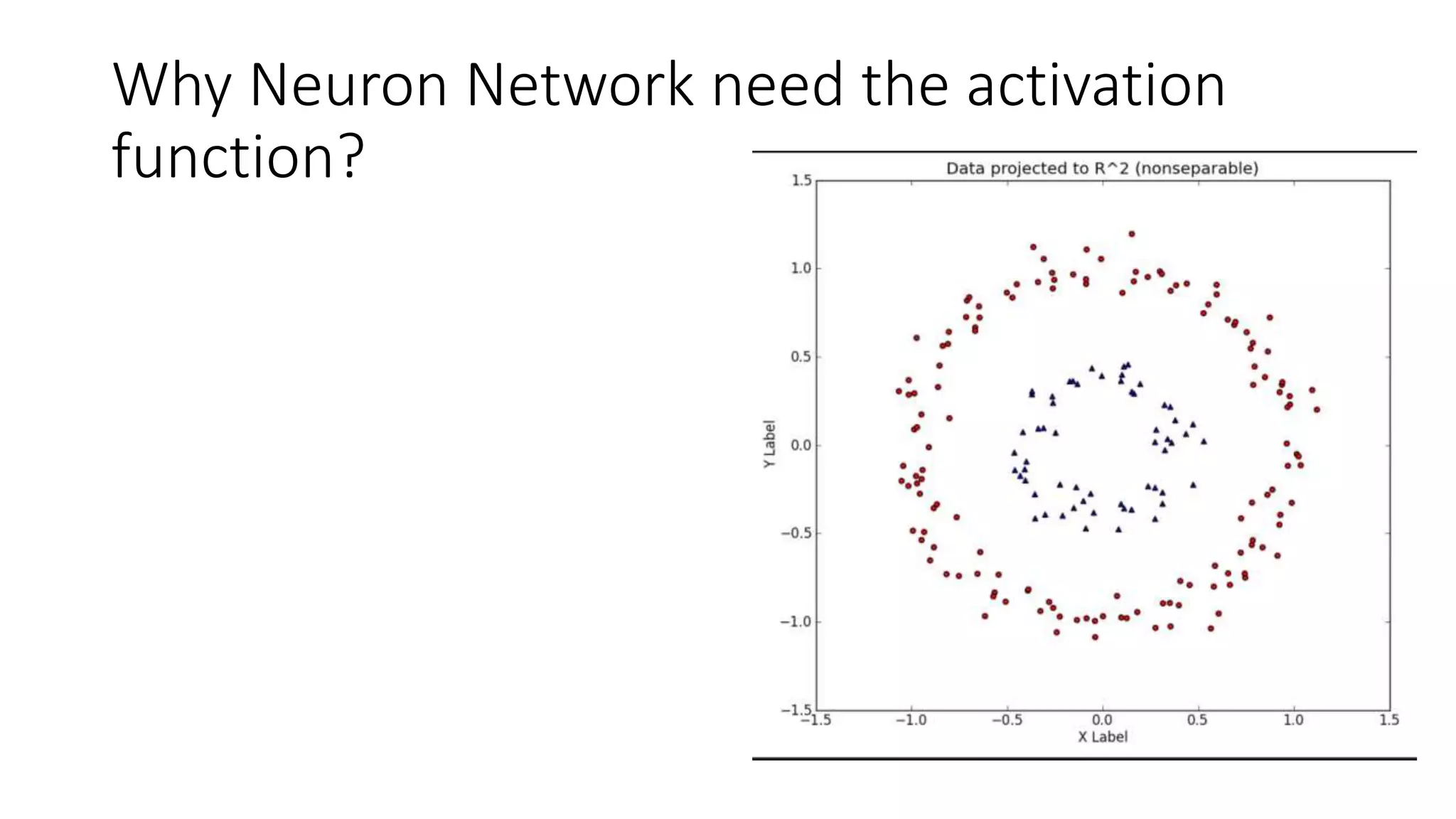






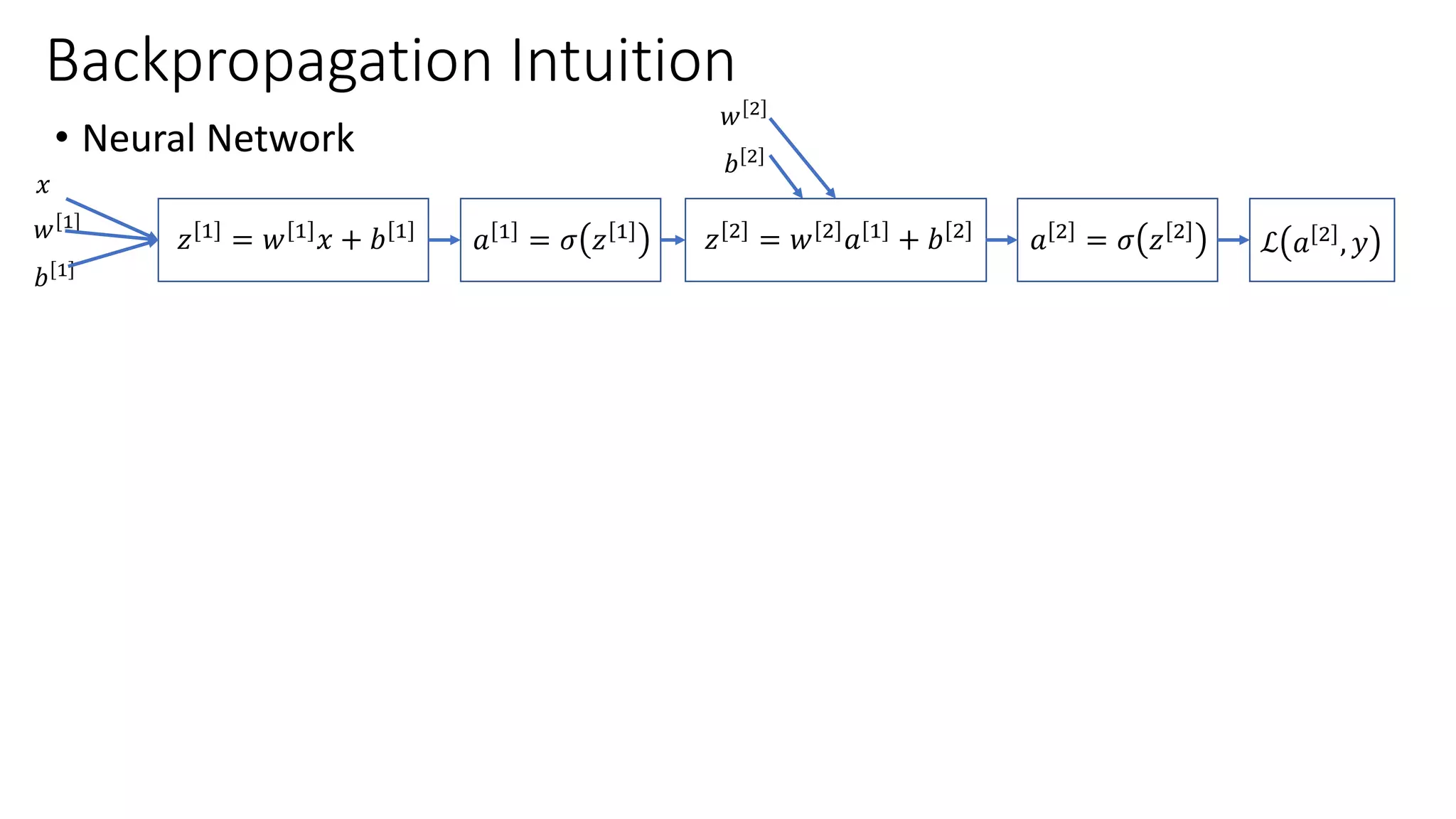

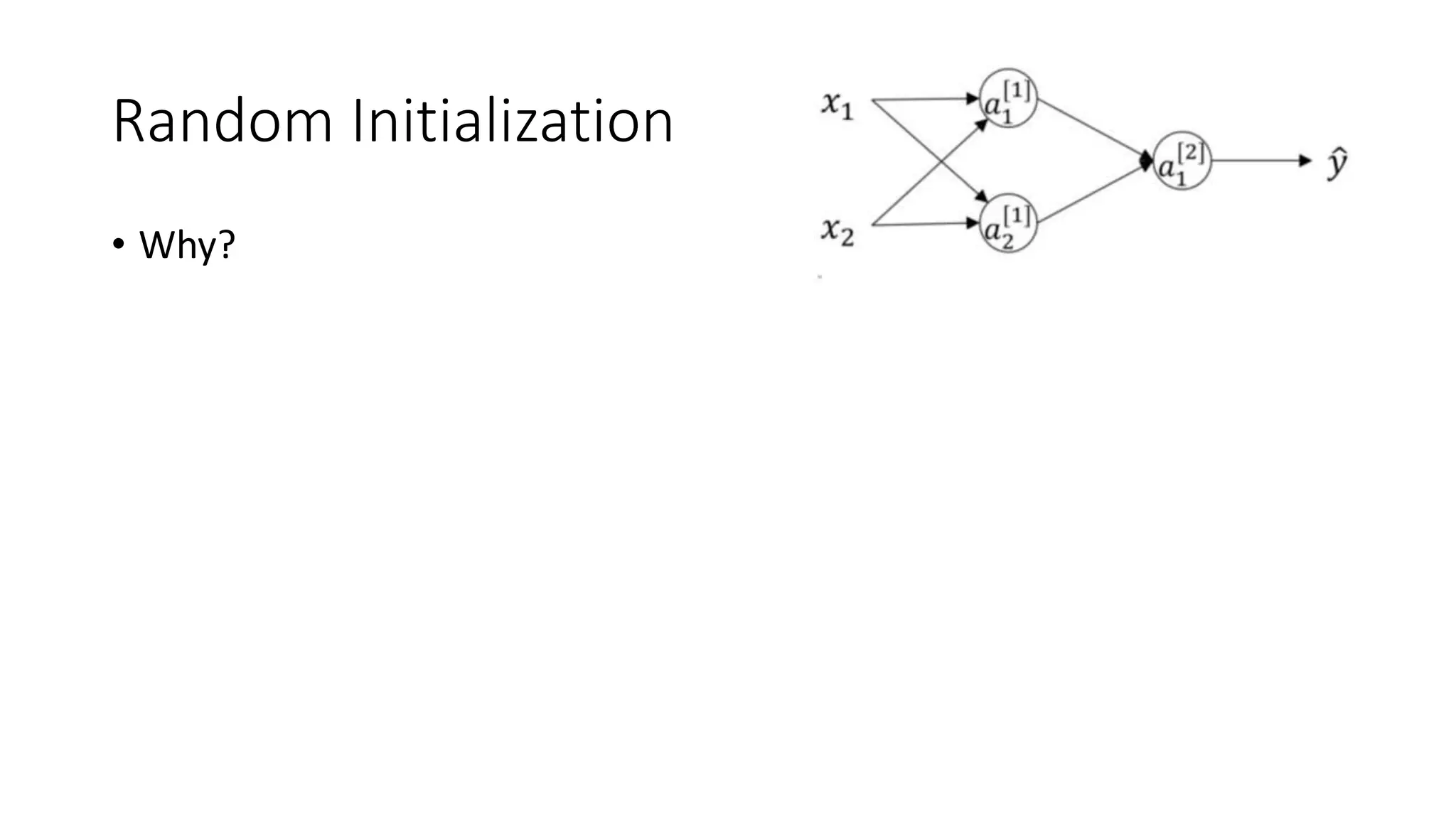
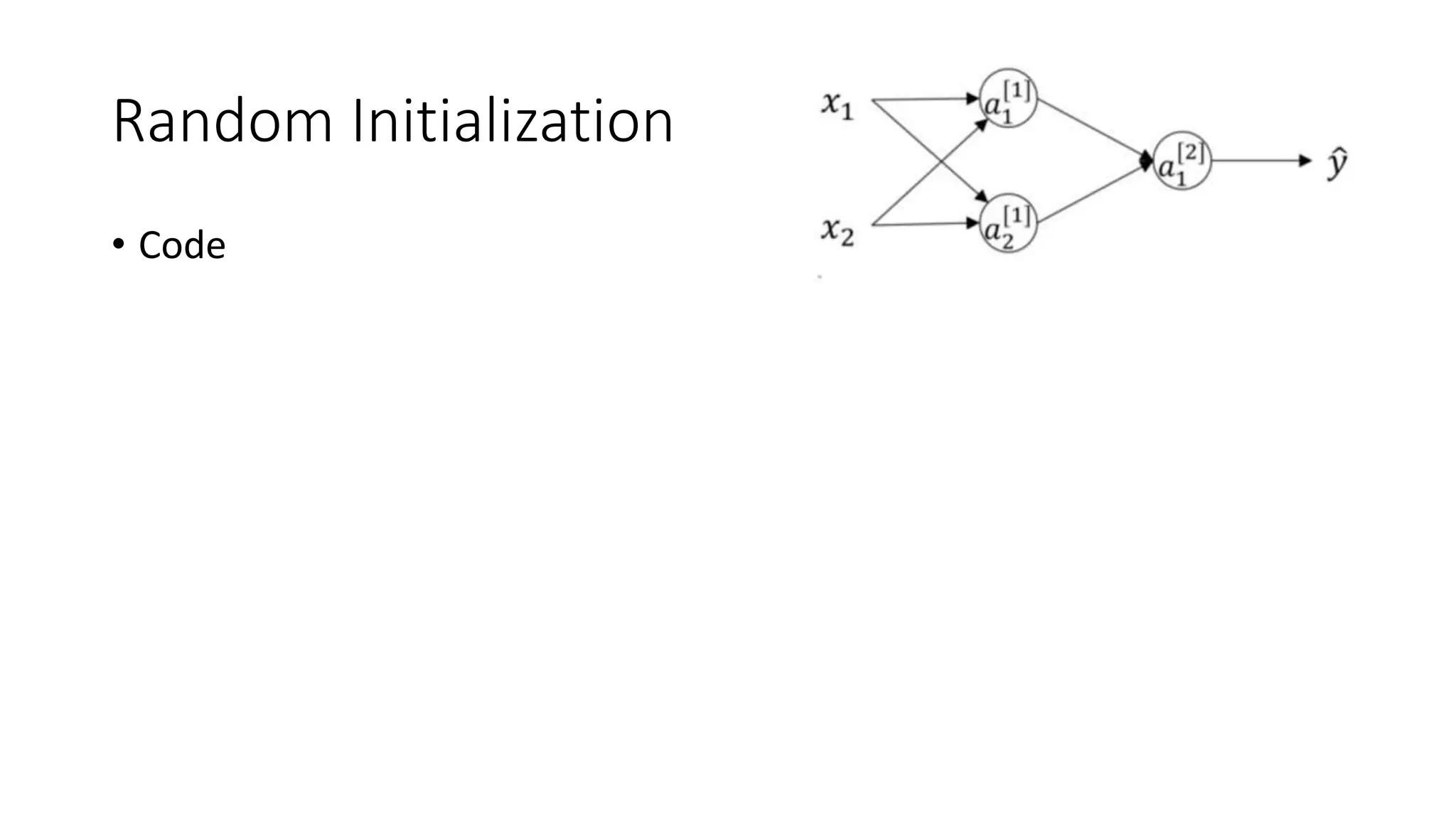

This lecture discusses shallow neural networks. It introduces neural network concepts like network representation, vectorizing training examples, and activation functions such as sigmoid, tanh, and ReLU. It explains that activation functions introduce non-linearity crucial for neural networks. The lecture also covers backpropagation for computing gradients in neural networks and updating weights with gradient descent. Random initialization is discussed as important for breaking symmetry in networks.




































![[Lecture 3] AI and Deep Learning: Logistic Regression (Coding)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture3empty-180216132805-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[Lecture 2] AI and Deep Learning: Logistic Regression (Theory)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture2-ink-180216131533-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





























