Lock-based Concurrent Datastructure
Adding locks to a data structure makes the structure thread safe.
How locks are added determine both the correctness and performance
of the data structure.
2
Youjip Won
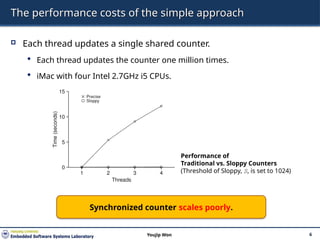
The performance costsof the simple approach
Each thread updates a single shared counter.
Each thread updates the counter one million times.
iMac with four Intel 2.7GHz i5 CPUs.
6
Youjip Won
Performance of
Traditional vs. Sloppy Counters
(Threshold of Sloppy, S, is set to 1024)
Synchronized counter scales poorly.
7.
Perfect Scaling
Eventhough more work is done, it is done in parallel.
The time taken to complete the task is not increased.
7
Youjip Won
8.
Sloppy counter
Thesloppy counter works by representing …
A single logical counter via numerous local physical counters, on per
CPU core
A single global counter
There are locks:
One fore each local counter and one for the global counter
Example: on a machine with four CPUs
Four local counters
One global counter
8
Youjip Won
9.
The basic ideaof sloppy counting
When a thread running on a core wishes to increment the counter.
It increment its local counter.
Each CPU has its own local counter:
Threads across CPUs can update local counters without contention.
Thus counter updates are scalable.
The local values are periodically transferred to the global counter.
Acquire the global lock
Increment it by the local counter’s value
The local counter is then reset to zero.
9
Youjip Won
10.
The basic ideaof sloppy counting (Cont.)
How often the local-to-global transfer occurs is determined by a
threshold, S (sloppiness).
The smaller S:
The more the counter behaves like the non-scalable counter.
The bigger S:
The more scalable the counter.
The further off the global value might be from the actual count.
10
Youjip Won
11.
Sloppy counter example
Tracing the Sloppy Counters
The threshold S is set to 5.
There are threads on each of four CPUs
Each thread updates their local counters … .
11
Youjip Won
Time G
0 0 0 0 0 0
1 0 0 1 1 0
2 1 0 2 1 0
3 2 0 3 1 0
4 3 0 3 2 0
5 4 1 3 3 0
6 5 0 1 3 4 5 (from )
7 0 2 4 5 0 10 (from )
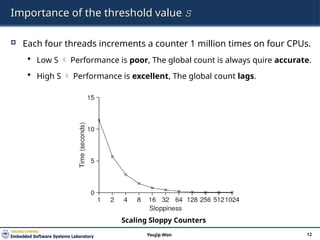
12.
Importance of thethreshold value S
Each four threads increments a counter 1 million times on four CPUs.
Low S Performance is poor, The global count is always quire accurate.
High S Performance is excellent, The global count lags.
12
Youjip Won
Scaling Sloppy Counters
13.
Sloppy Counter Implementation
13
YoujipWon
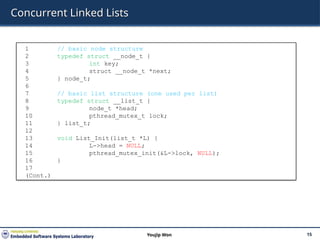
1 typedef struct __counter_t {
2 int global; // global count
3 pthread_mutex_t glock; // global lock
4 int local[NUMCPUS]; // local count (per cpu)
5 pthread_mutex_t llock[NUMCPUS]; // ... and locks
6 int threshold; // update frequency
7 } counter_t;
8
9 // init: record threshold, init locks, init values
10 // of all local counts and global count
11 void init(counter_t *c, int threshold) {
12 c->thres hold = threshold;
13
14 c->global = 0;
15 pthread_mutex_init(&c->glock, NULL);
16
17 int i;
18 for (i = 0; i < NUMCPUS; i++) {
19 c->local[i] = 0;
20 pthread_mutex_init(&c->llock[i], NULL);
21 }
22 }
23
14.
Sloppy Counter Implementation(Cont.)
14
Youjip Won
(Cont.)
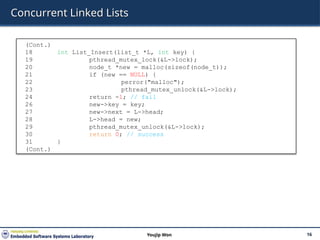
24 // update: usually, just grab local lock and update local amount
25 // once local count has risen by ’threshold’, grab global
26 // lock and transfer local values to it
27 void update(counter_t *c, int threadID, int amt) {
28 pthread_mutex_lock(&c->llock[threadID]);
29 c->local[threadID] += amt; // assumes amt > 0
30 if (c->local[threadID] >= c->threshold) { // transfer to global
31 pthread_mutex_lock(&c->glock);
32 c->global += c->local[threadID];
33 pthread_mutex_unlock(&c->glock);
34 c->local[threadID] = 0;
35 }
36 pthread_mutex_unlock(&c->llock[threadID]);
37 }
38
39 // get: just return global amount (which may not be perfect)
40 int get(counter_t *c) {
41 pthread_mutex_lock(&c->glock);
42 int val = c->global;
43 pthread_mutex_unlock(&c->glock);
44 return val; // only approximate!
45 }
Concurrent Linked Lists(Cont.)
The code acquires a lock in the insert routine upon entry.
The code releases the lock upon exit.
If malloc() happens to fail, the code must also release the lock before
failing the insert.
This kind of exceptional control flow has been shown to be quite error
prone.
Solution: The lock and release only surround the actual critical section in
the insert code
18
Youjip Won
Concurrent Linked List:Rewritten (Cont.)
20
Youjip Won
(Cont.)
22 int List_Lookup(list_t *L, int key) {
23 int rv = -1;
24 pthread_mutex_lock(&L->lock);
25 node_t *curr = L->head;
26 while (curr) {
27 if (curr->key == key) {
28 rv = 0;
29 break;
30 }
31 curr = curr->next;
32 }
33 pthread_mutex_unlock(&L->lock);
34 return rv; // now both success and failure
35 }
21.
Scaling Linked List
Hand-over-hand locking (lock coupling)
Add a lock per node of the list instead of having a single lock for the
entire list.
When traversing the list,
First grabs the next node’s lock.
And then releases the current node’s lock.
Enable a high degree of concurrency in list operations.
However, in practice, the overheads of acquiring and releasing locks for each
node of a list traversal is prohibitive.
21
Youjip Won
22.
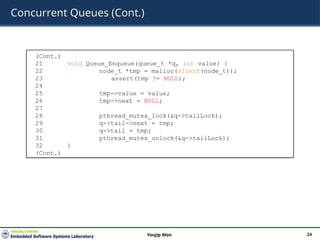
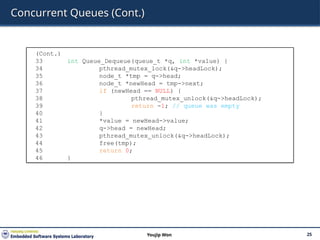
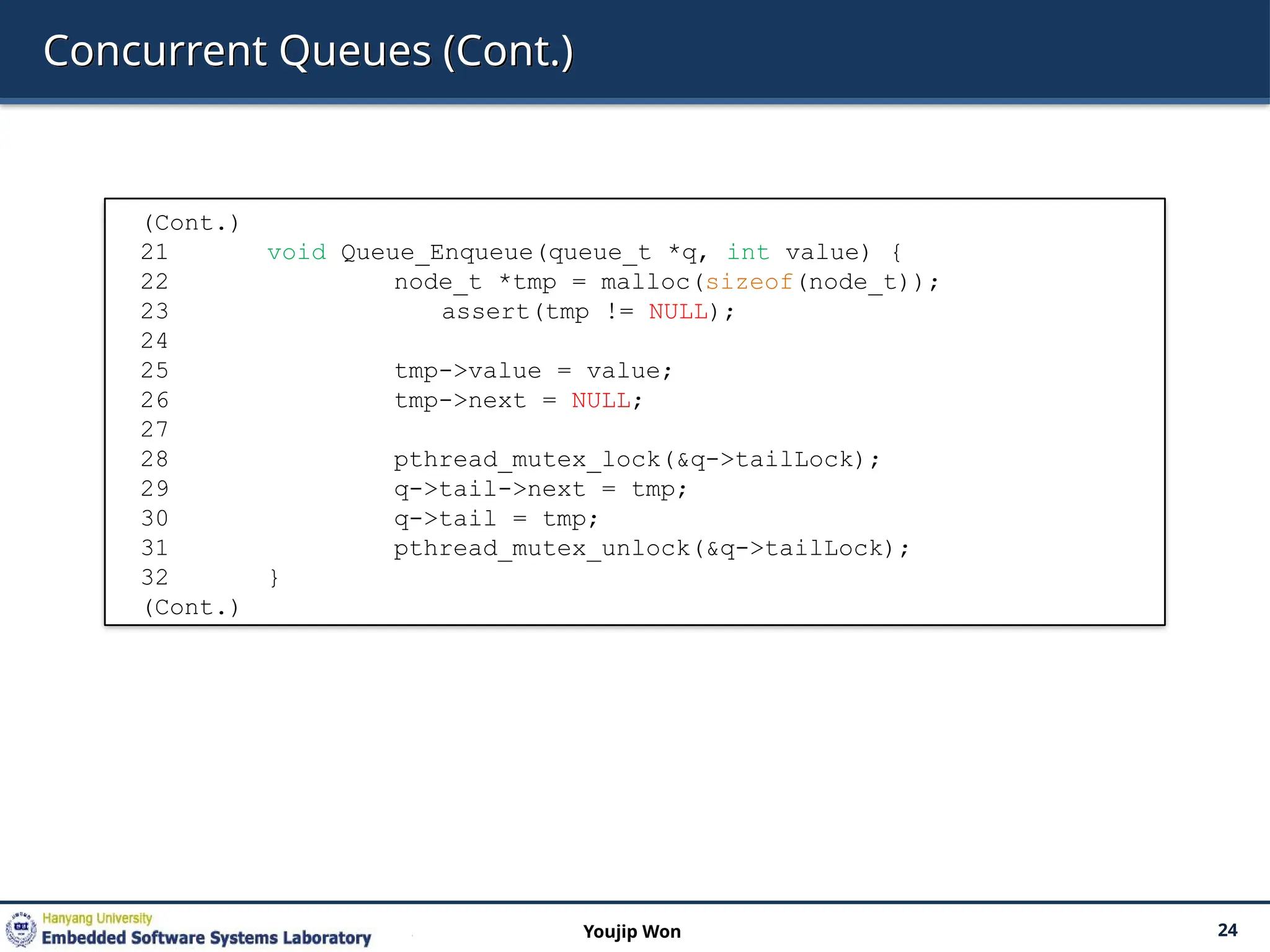
Michael and ScottConcurrent Queues
There are two locks.
One for the head of the queue.
One for the tail.
The goal of these two locks is to enable concurrency of enqueue and
dequeue operations.
Add a dummy node
Allocated in the queue initialization code
Enable the separation of head and tail operations
22
Youjip Won
Concurrent Hash Table
Focus on a simple hash table
The hash table does not resize.
Built using the concurrent lists
It uses a lock per hash bucket each of which is represented by a list.
26
Youjip Won
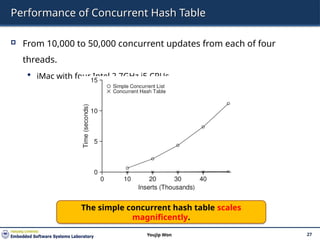
27.
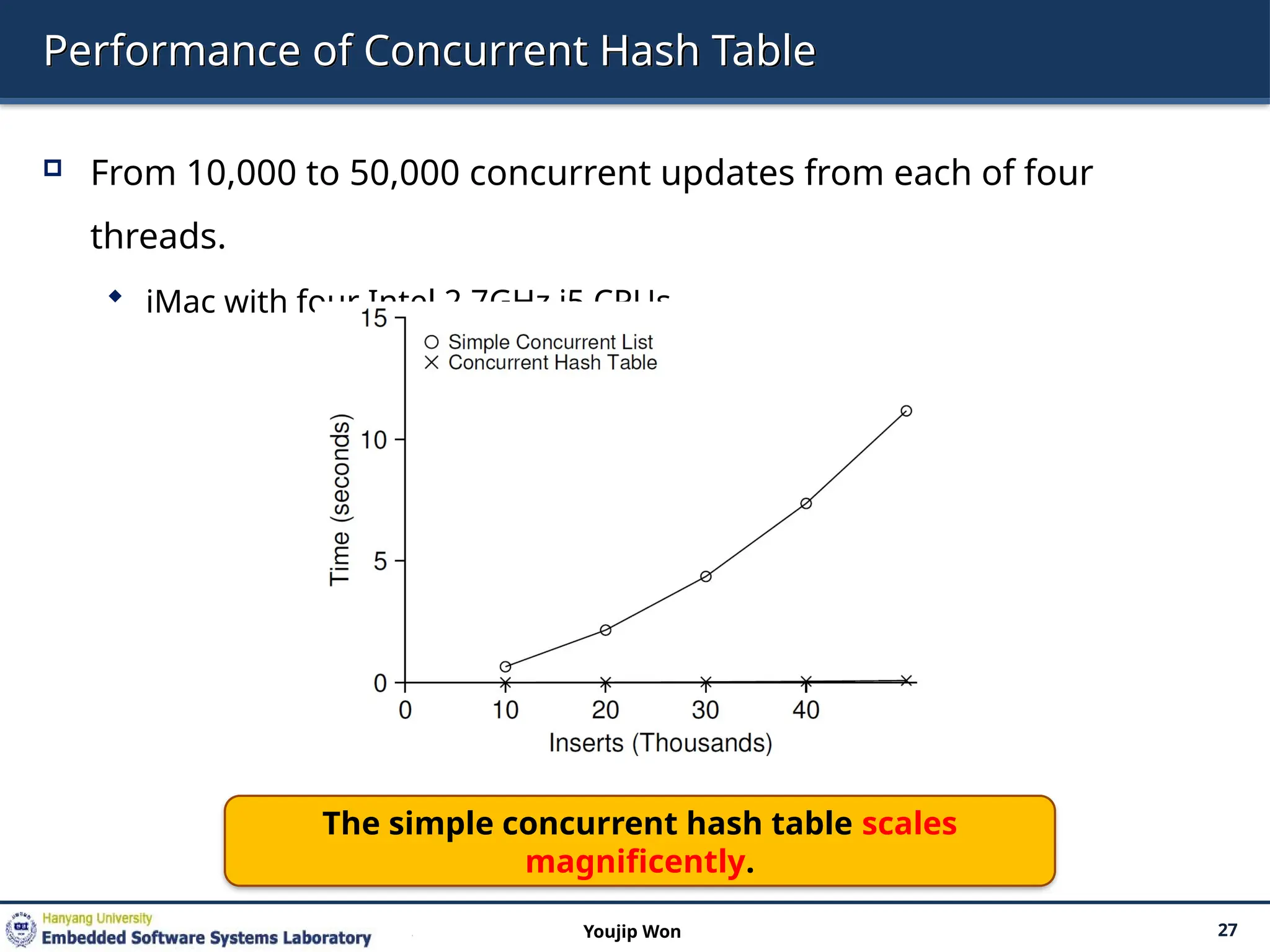
Performance of ConcurrentHash Table
From 10,000 to 50,000 concurrent updates from each of four
threads.
iMac with four Intel 2.7GHz i5 CPUs.
27
Youjip Won
The simple concurrent hash table scales
magnificently.
28.
Concurrent Hash Table
28
YoujipWon
1 #define BUCKETS (101)
2
3 typedef struct __hash_t {
4 list_t lists[BUCKETS];
5 } hash_t;
6
7 void Hash_Init(hash_t *H) {
8 int i;
9 for (i = 0; i < BUCKETS; i++) {
10 List_Init(&H->lists[i]);
11 }
12 }
13
14 int Hash_Insert(hash_t *H, int key) {
15 int bucket = key % BUCKETS;
16 return List_Insert(&H->lists[bucket], key);
17 }
18
19 int Hash_Lookup(hash_t *H, int key) {
20 int bucket = key % BUCKETS;
21 return List_Lookup(&H->lists[bucket], key);
22 }
29.
Disclaimer: Thislecture slide set was initially developed for Operating System course in
Computer Science Dept. at Hanyang University. This lecture slide set is for OSTEP book
written by Remzi and Andrea at University of Wisconsin.
29
Youjip Won










![Sloppy Counter Implementation
13
Youjip Won
1 typedef struct __counter_t {
2 int global; // global count
3 pthread_mutex_t glock; // global lock
4 int local[NUMCPUS]; // local count (per cpu)
5 pthread_mutex_t llock[NUMCPUS]; // ... and locks
6 int threshold; // update frequency
7 } counter_t;
8
9 // init: record threshold, init locks, init values
10 // of all local counts and global count
11 void init(counter_t *c, int threshold) {
12 c->thres hold = threshold;
13
14 c->global = 0;
15 pthread_mutex_init(&c->glock, NULL);
16
17 int i;
18 for (i = 0; i < NUMCPUS; i++) {
19 c->local[i] = 0;
20 pthread_mutex_init(&c->llock[i], NULL);
21 }
22 }
23](https://image.slidesharecdn.com/29-250817165311-06e7c24c/85/Lock-based_Concurrent_Data_Structures-in-13-320.jpg)
![Sloppy Counter Implementation (Cont.)
14
Youjip Won
(Cont.)
24 // update: usually, just grab local lock and update local amount
25 // once local count has risen by ’threshold’, grab global
26 // lock and transfer local values to it
27 void update(counter_t *c, int threadID, int amt) {
28 pthread_mutex_lock(&c->llock[threadID]);
29 c->local[threadID] += amt; // assumes amt > 0
30 if (c->local[threadID] >= c->threshold) { // transfer to global
31 pthread_mutex_lock(&c->glock);
32 c->global += c->local[threadID];
33 pthread_mutex_unlock(&c->glock);
34 c->local[threadID] = 0;
35 }
36 pthread_mutex_unlock(&c->llock[threadID]);
37 }
38
39 // get: just return global amount (which may not be perfect)
40 int get(counter_t *c) {
41 pthread_mutex_lock(&c->glock);
42 int val = c->global;
43 pthread_mutex_unlock(&c->glock);
44 return val; // only approximate!
45 }](https://image.slidesharecdn.com/29-250817165311-06e7c24c/85/Lock-based_Concurrent_Data_Structures-in-14-320.jpg)








![Concurrent Hash Table
28
Youjip Won
1 #define BUCKETS (101)
2
3 typedef struct __hash_t {
4 list_t lists[BUCKETS];
5 } hash_t;
6
7 void Hash_Init(hash_t *H) {
8 int i;
9 for (i = 0; i < BUCKETS; i++) {
10 List_Init(&H->lists[i]);
11 }
12 }
13
14 int Hash_Insert(hash_t *H, int key) {
15 int bucket = key % BUCKETS;
16 return List_Insert(&H->lists[bucket], key);
17 }
18
19 int Hash_Lookup(hash_t *H, int key) {
20 int bucket = key % BUCKETS;
21 return List_Lookup(&H->lists[bucket], key);
22 }](https://image.slidesharecdn.com/29-250817165311-06e7c24c/85/Lock-based_Concurrent_Data_Structures-in-28-320.jpg)













![Sloppy Counter Implementation
13
Youjip Won
1 typedef struct __counter_t {
2 int global; // global count
3 pthread_mutex_t glock; // global lock
4 int local[NUMCPUS]; // local count (per cpu)
5 pthread_mutex_t llock[NUMCPUS]; // ... and locks
6 int threshold; // update frequency
7 } counter_t;
8
9 // init: record threshold, init locks, init values
10 // of all local counts and global count
11 void init(counter_t *c, int threshold) {
12 c->thres hold = threshold;
13
14 c->global = 0;
15 pthread_mutex_init(&c->glock, NULL);
16
17 int i;
18 for (i = 0; i < NUMCPUS; i++) {
19 c->local[i] = 0;
20 pthread_mutex_init(&c->llock[i], NULL);
21 }
22 }
23](https://image.slidesharecdn.com/29-250817165311-06e7c24c/75/Lock-based_Concurrent_Data_Structures-in-13-2048.jpg)
![Sloppy Counter Implementation (Cont.)
14
Youjip Won
(Cont.)
24 // update: usually, just grab local lock and update local amount
25 // once local count has risen by ’threshold’, grab global
26 // lock and transfer local values to it
27 void update(counter_t *c, int threadID, int amt) {
28 pthread_mutex_lock(&c->llock[threadID]);
29 c->local[threadID] += amt; // assumes amt > 0
30 if (c->local[threadID] >= c->threshold) { // transfer to global
31 pthread_mutex_lock(&c->glock);
32 c->global += c->local[threadID];
33 pthread_mutex_unlock(&c->glock);
34 c->local[threadID] = 0;
35 }
36 pthread_mutex_unlock(&c->llock[threadID]);
37 }
38
39 // get: just return global amount (which may not be perfect)
40 int get(counter_t *c) {
41 pthread_mutex_lock(&c->glock);
42 int val = c->global;
43 pthread_mutex_unlock(&c->glock);
44 return val; // only approximate!
45 }](https://image.slidesharecdn.com/29-250817165311-06e7c24c/75/Lock-based_Concurrent_Data_Structures-in-14-2048.jpg)











![Concurrent Hash Table
28
Youjip Won
1 #define BUCKETS (101)
2
3 typedef struct __hash_t {
4 list_t lists[BUCKETS];
5 } hash_t;
6
7 void Hash_Init(hash_t *H) {
8 int i;
9 for (i = 0; i < BUCKETS; i++) {
10 List_Init(&H->lists[i]);
11 }
12 }
13
14 int Hash_Insert(hash_t *H, int key) {
15 int bucket = key % BUCKETS;
16 return List_Insert(&H->lists[bucket], key);
17 }
18
19 int Hash_Lookup(hash_t *H, int key) {
20 int bucket = key % BUCKETS;
21 return List_Lookup(&H->lists[bucket], key);
22 }](https://image.slidesharecdn.com/29-250817165311-06e7c24c/75/Lock-based_Concurrent_Data_Structures-in-28-2048.jpg)



























































