Spark Day 2017 Machine Learning & Deep Learning With Spark
1.
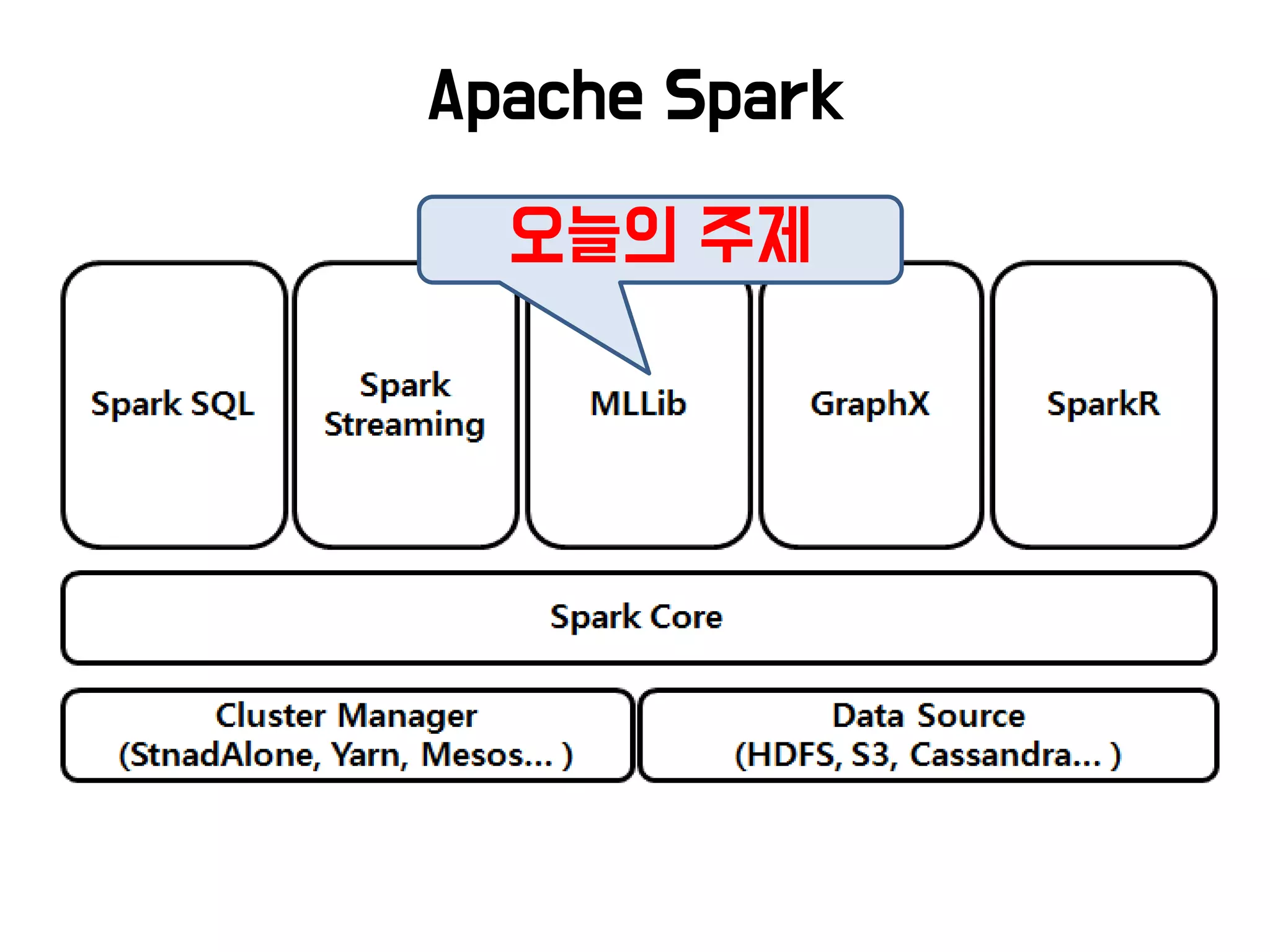
Machine Learning &Deep Learnig
With Spark
SK 주식회사 DataScience 팀
스파크 사용자 모임 운영자
이상훈
2.
Who am I?
•패턴인식, 머신러닝 전공
• 전) KIST 인지로봇 연구단
• SK 주식회사 Data Science 팀
• 스파크 사용자 모임 운영자
• Streaming, DW, Machine Learning,
Deep Learning, AutoML 관심 많음
• 빅데이터 실무 기술 가이드 공저, 실시간 분석의 모든것
번역
• phoenixlee1@gmail.com
• www.facebook.com/phoenixlee.sh
머신러닝을 처음 시작할때 배우는 것
• 머신러닝은 크게 2가지 종류로 나눌 수 있음
• Supervised Learning
– 훈련 데이터(Training Data)로부터 하나의 함수를 유추
• Unsupervised Learning
– 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주에 속
함
– Supervised Learning 입력값에 대한 목표치가 주어지지
않음
• 참고 : Reinforcement Learning
Labeled Data
유무!
보상과 환경
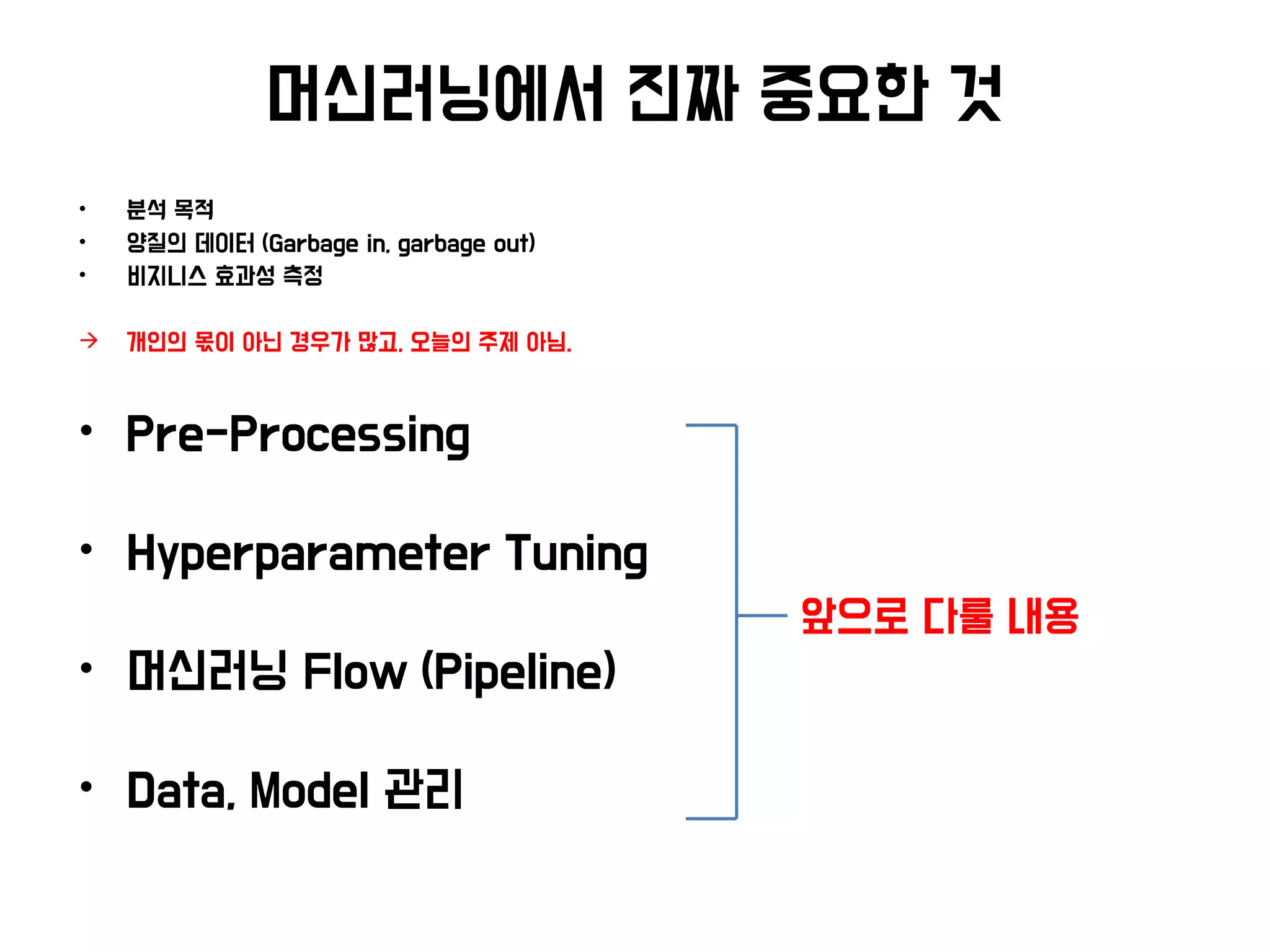
머신러닝에서 진짜 중요한것
• 분석 목적
• 양질의 데이터 (Garbage in, garbage out)
• 비지니스 효과성 측정
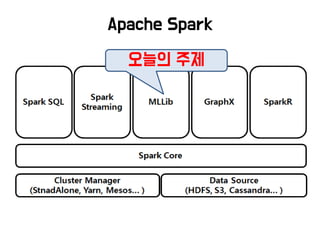
개인의 몫이 아닌 경우가 많고, 오늘의 주제 아님.
9.
머신러닝에서 진짜 중요한것
• 분석 목적
• 양질의 데이터 (Garbage in, garbage out)
• 비지니스 효과성 측정
개인의 몫이 아닌 경우가 많고, 오늘의 주제 아님.
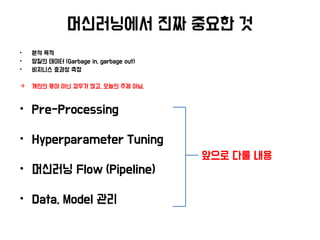
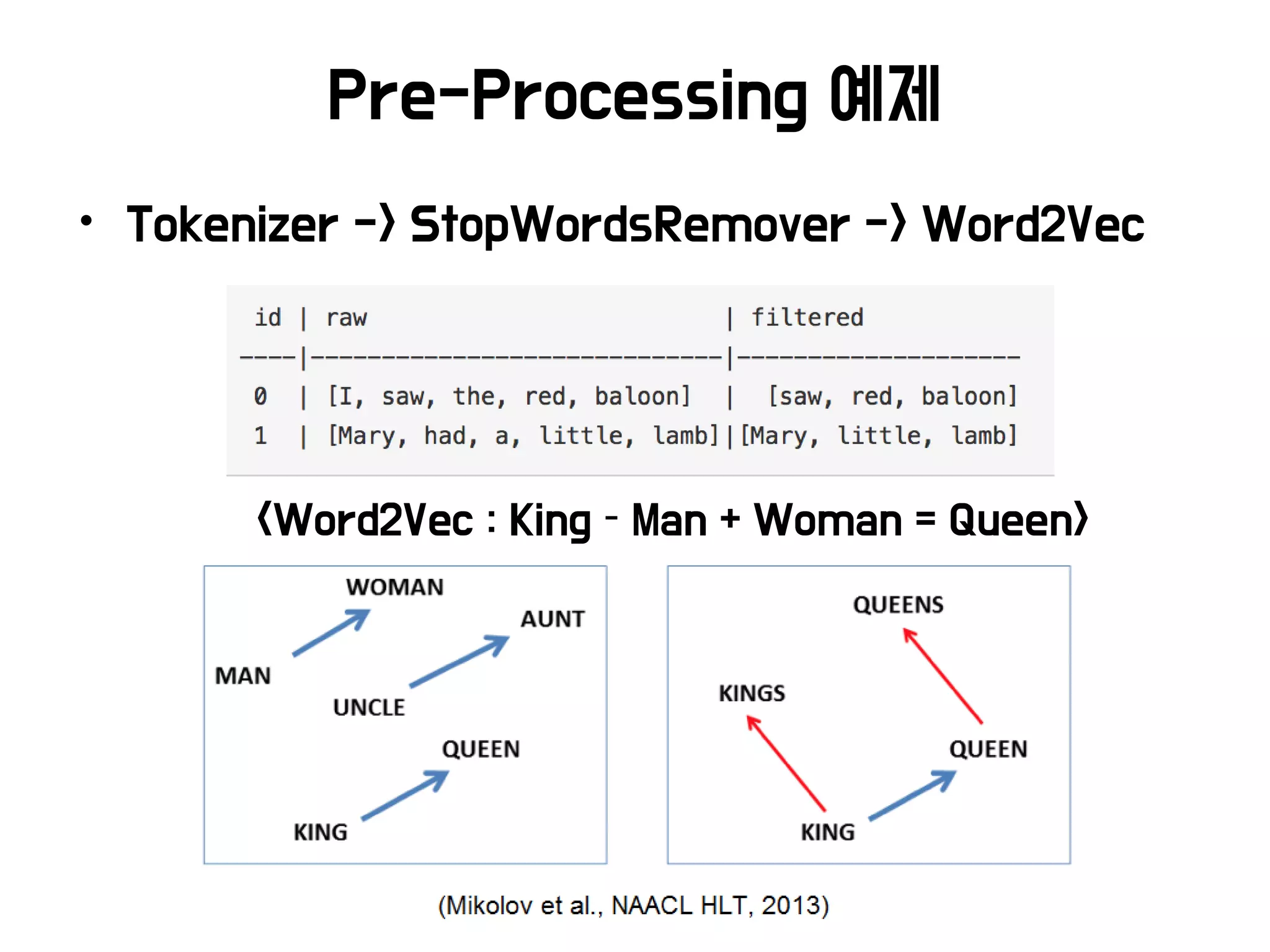
• Pre-Processing
• Hyperparameter Tuning
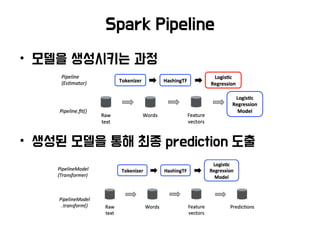
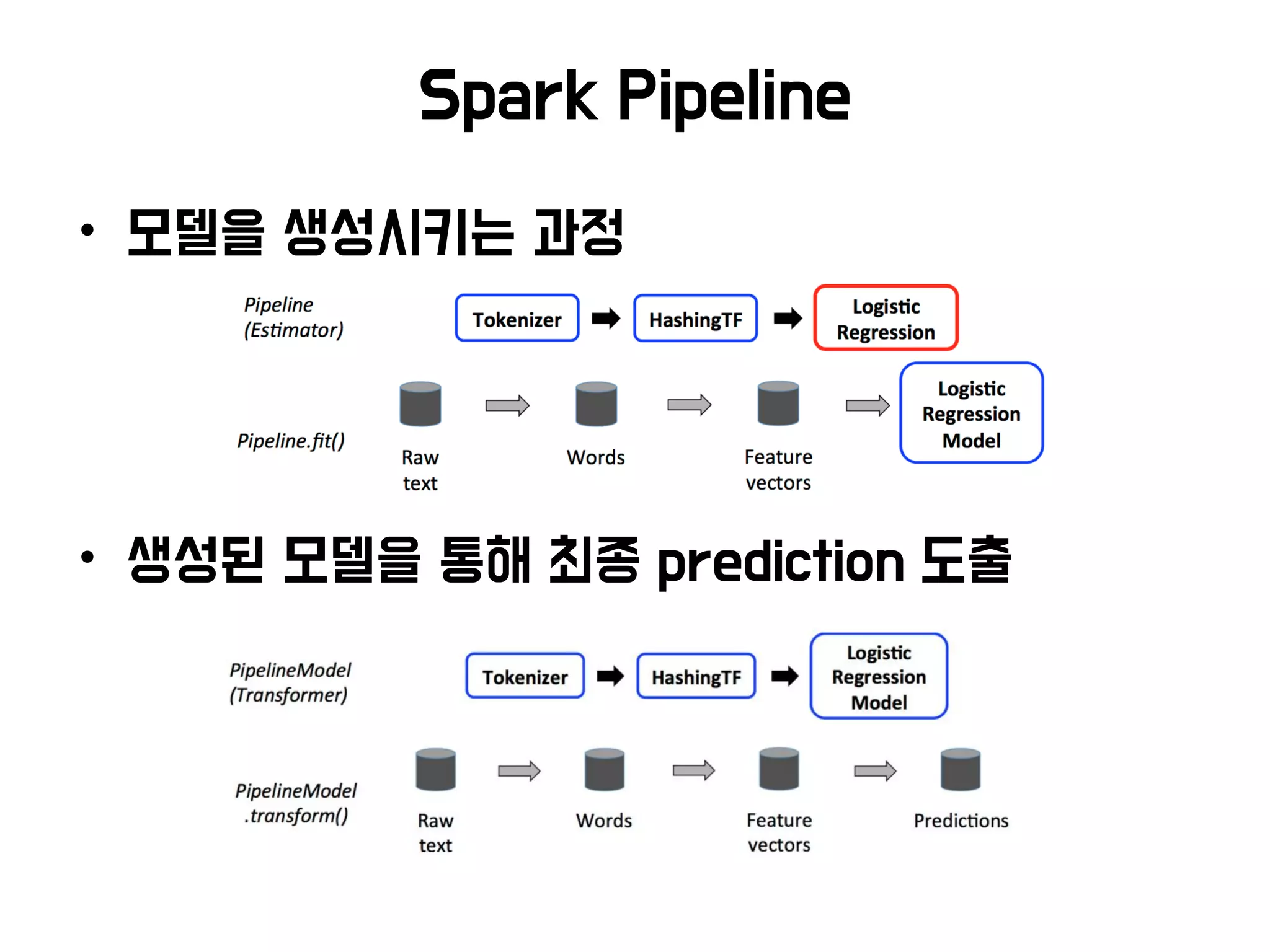
• 머신러닝 Flow (Pipeline)
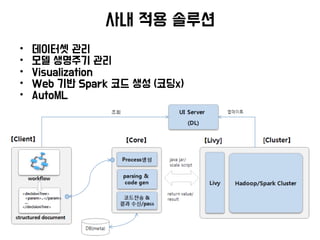
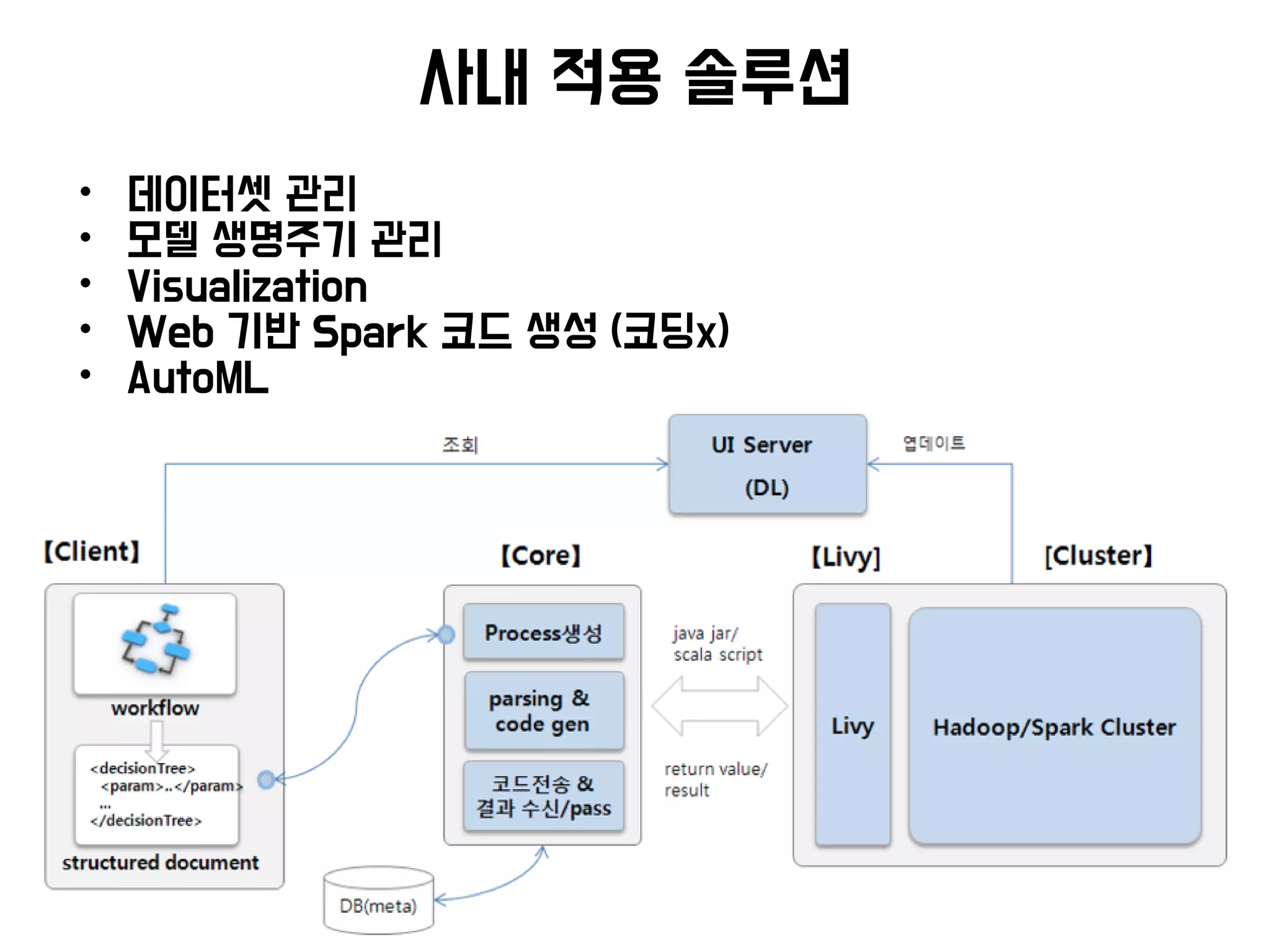
• Data, Model 관리
앞으로 다룰 내용
1. 전처리 (General)
•특징 추출 및 일반화
• 적용: 텍스트와 같은 입력
데이터를 머신러닝
알고리즘에 활용할 수
있도록 변화
• 구성: 데이터 전처리, 특징
추출
2. 차원 축소
(Dimensionality
Reduction)
• 결정해야 할 확률변수의
개수를 줄이는 방법
• 적용: Visualization,
Increased efficiency
• 알고리즘: PCA, feature
selection, non-negative
matrix factorization.
전처리(Pre-processing)
• 파라미터와 모델의 비교
및 평가를 통한 선택
• 목적 : 파라미터 조정을
통한 정확도 향상
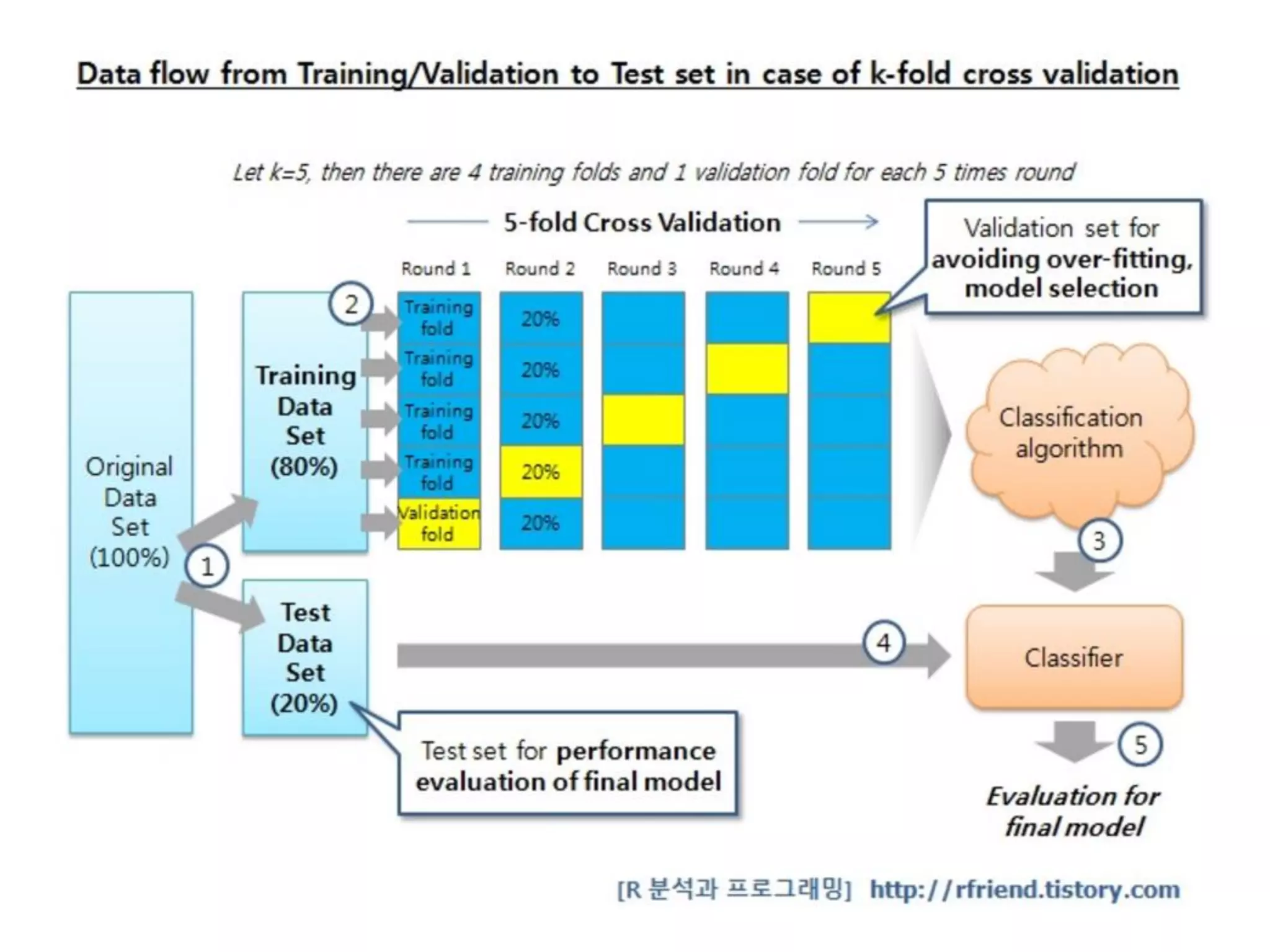
• 구성 : grid search, cross
validation,metrics , …
모델 선택(Model Selection)
• 해당 객체가 어느
카테고리에 속하는지
확인하여 구분 짓는 방법
• 적용 : 스팸 메일 탐지,
이미지 인식 등
• 알고리즘 : SVM, ANN,
random forest, ...
분류(Classification)
• 유사성이 존재하는
객체들끼리 묶어주는 방법
• 적용 : 고객 세분화,
실험결과 grouping
• 알고리즘: k-Means, spectral
clustering,mean-shift, ...
군집(Clustring)
• 변수 간의 이론적 의존
관계를 해석하는 방법
• 적용 : 약물 반응, 주식 가격
예측 등
• 알고리즘: SVR, ridge
regression, Lasso, ...
회귀(Regression)
• 상품이나 서비스 등을
제안하기 위한 분석 기법
• 적용: 미디어, 소셜 태그 등
추천
• 알고리즘 : Content Based
Recommendation,
Collaborative filtering
추천(Recommendation)
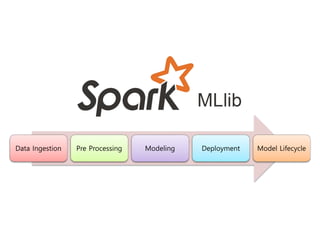
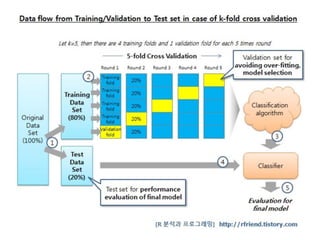
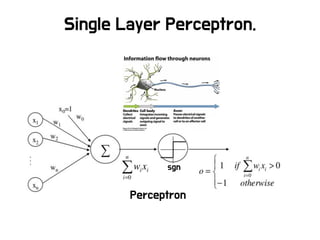
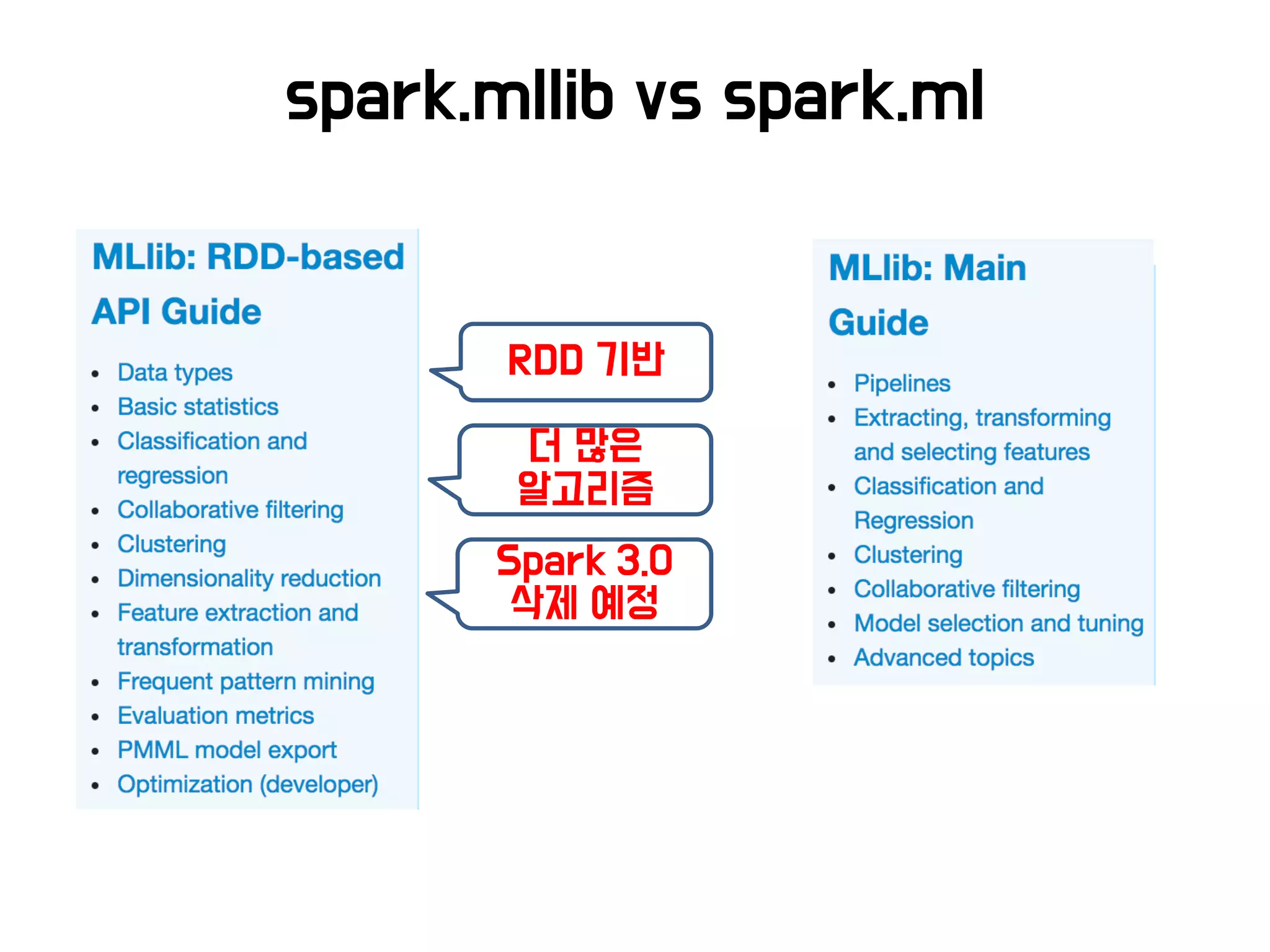
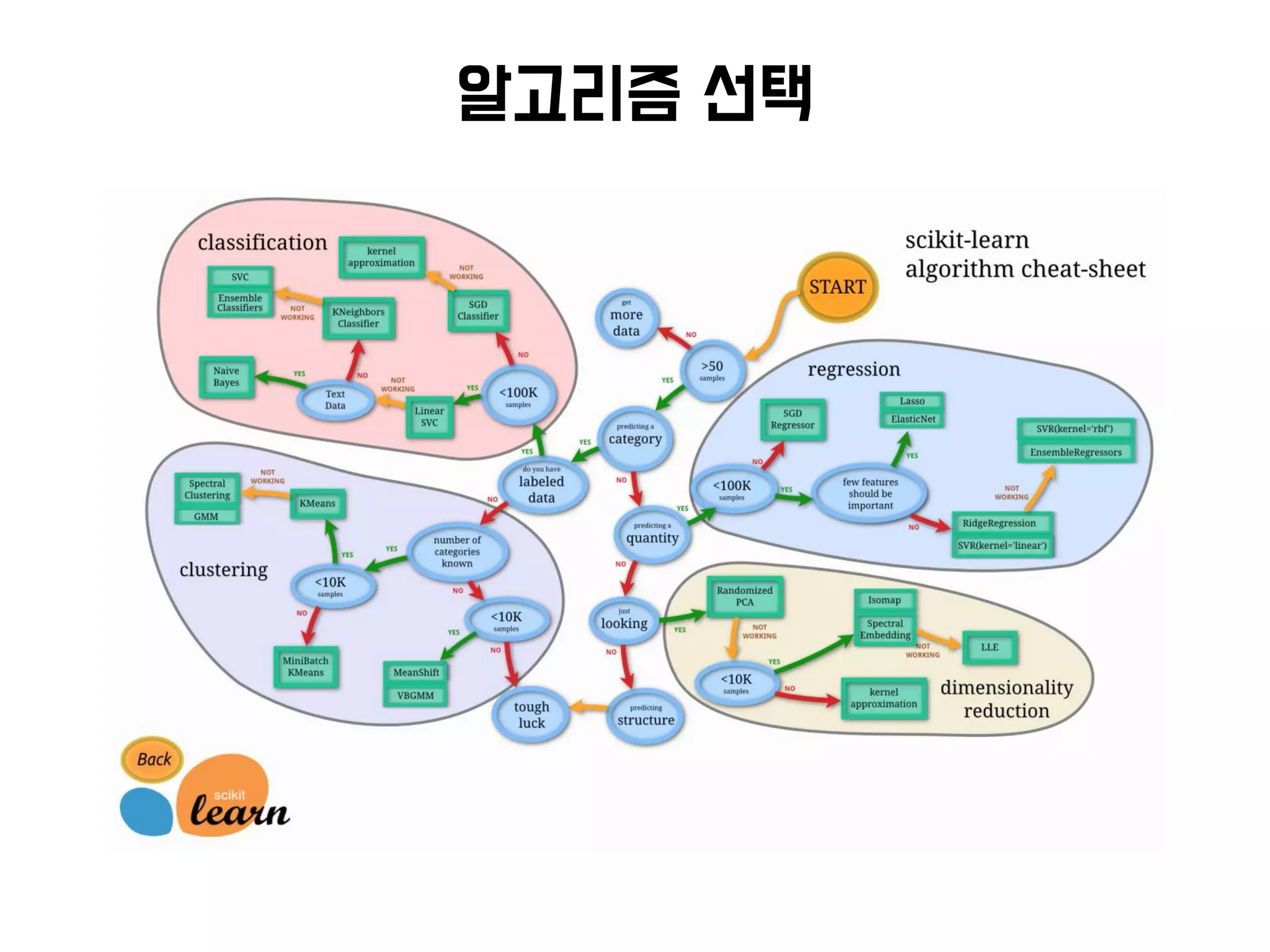
머신러닝 처리과정
R
• 가장 다양하고 최신의
알고리즘 패키지 제공
• 분산처리 취약하고 주로 모델
분석용으로 사용
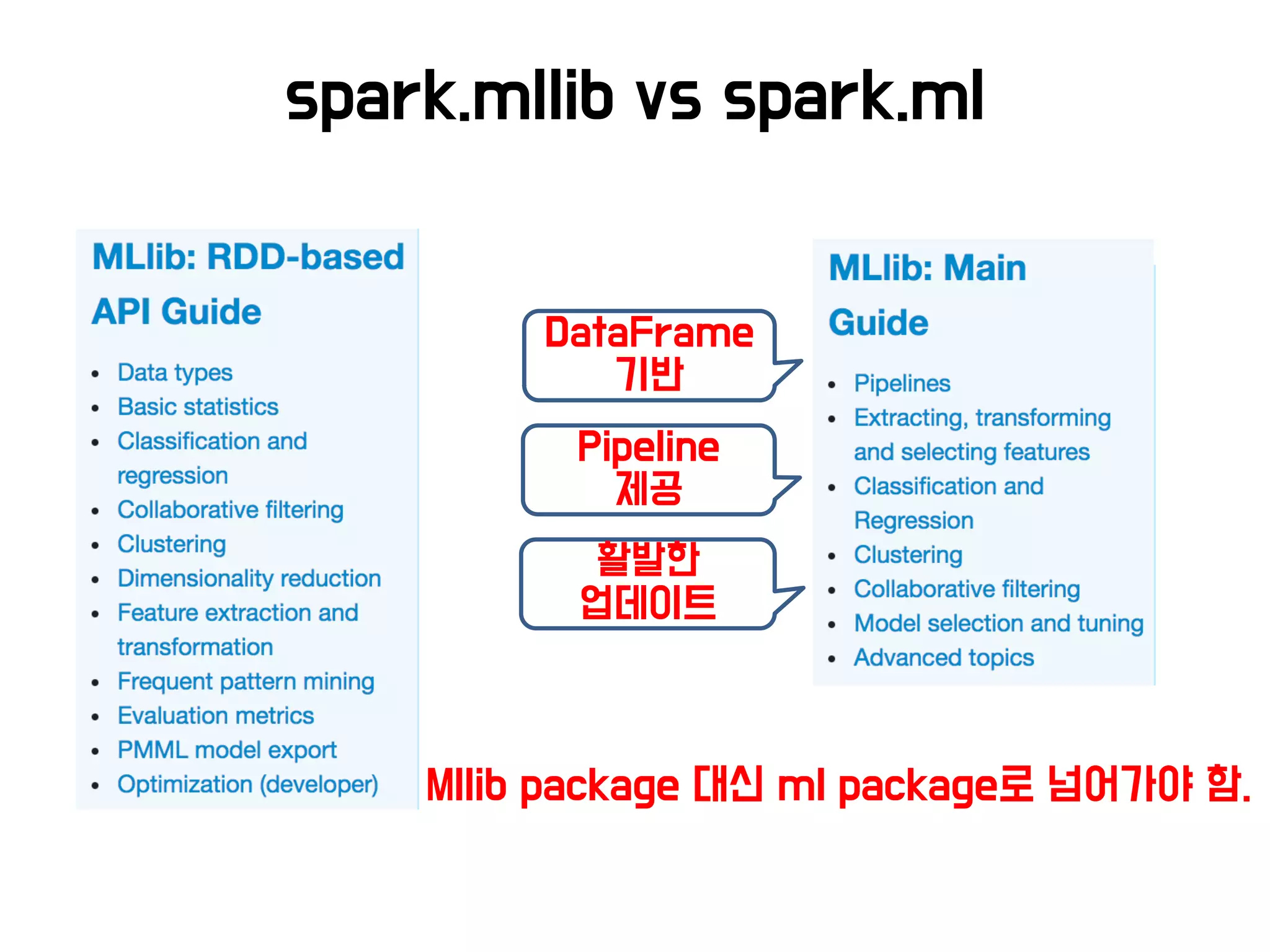
Spark ML
• 분산처리 및 스트리밍 SQL
연동 등 쉬움 (Spark 기반)
• 최근 많이 사용하고 있지만
적용사례 찾기 어려움
Scikit-Learn
• 프로그래밍 언어(Python)
기반이기 때문에 편리함
• 분산처리 취약하고 R 대비
알고리즘 少
Mahout
• 하둡과 연동이 쉬우며 적용
사례 가장 多
• 맵리듀스 기반이라 느리며,
지원 알고리즘 少
…
오픈소스
적용 및
알고리즘
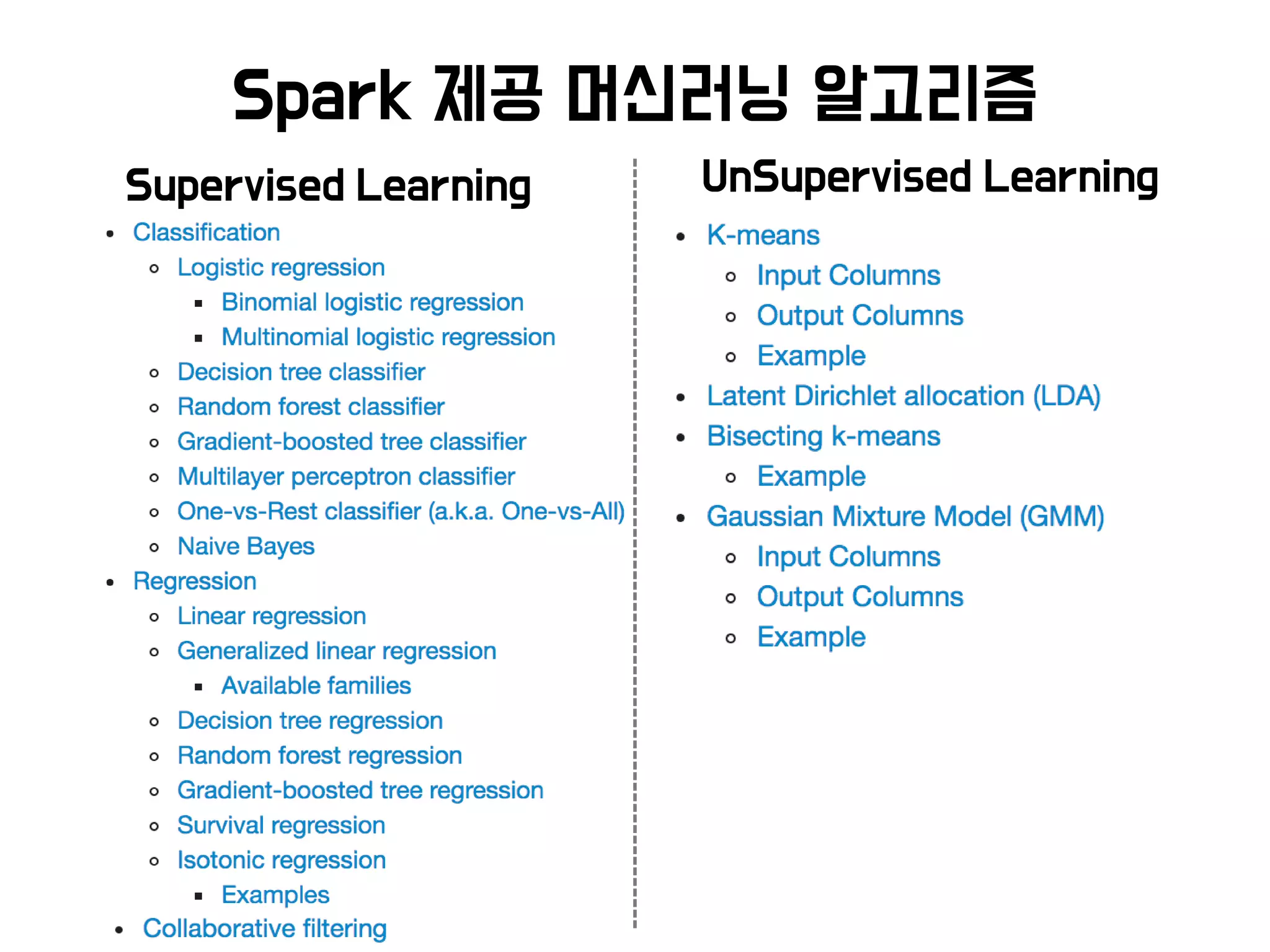
머신러닝 알고리즘 및 오픈소스
Thanks to 서진철, 이은지
12.
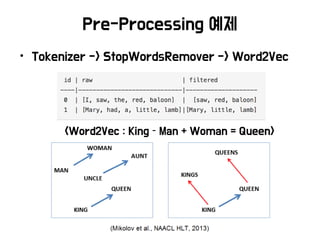
Pre-Processing
• Data Cleaning
•Instance selection (Dataset reduction)
• Normalization
• Transformation
• Feature extraction and selection
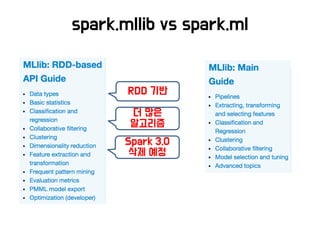
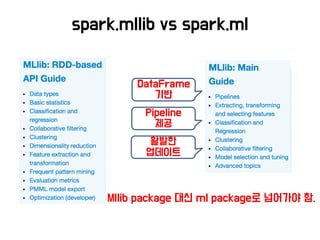
Spark Ml package
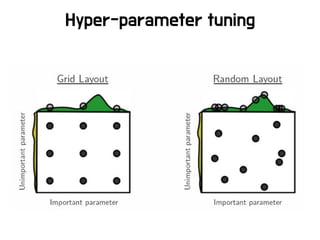
HyperParameters
Randomforest
classifier
• setFeaturescol
• setPredictioncol
• setImpurity(String) : gain 계산시 사용할 수식 (대소문
자 구분함).
• setMaxBins(Int) : 최대 bin(몇 개로 나눌지) 수
• setMaxDepth(Int) : 최대 트리의 깊이
• setMinInfoGain(Double) : 트리를 분류할 때 최소한의 inf
omation gain.
• setMinInstancesPerNode(Int) : 각 노드당 최소한의 인
스턴스 수.
• setNumTrees(Int) : 학습할 트리 수. 1보다 같거나 커야
함
• setSeed(Long) : 랜덤 시드
• setSubsampleingRate(Double) : 각 결정 트리에서 사용
할 데이터 크기. 0초과부터 1까지.
• setThresholds(Array[Double]) : Multi-class Classifi
cation 임계치로 각 클래스의 예상 확률값.
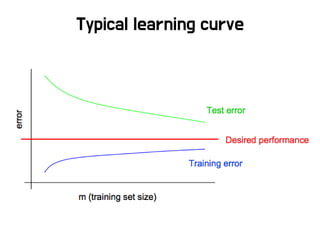
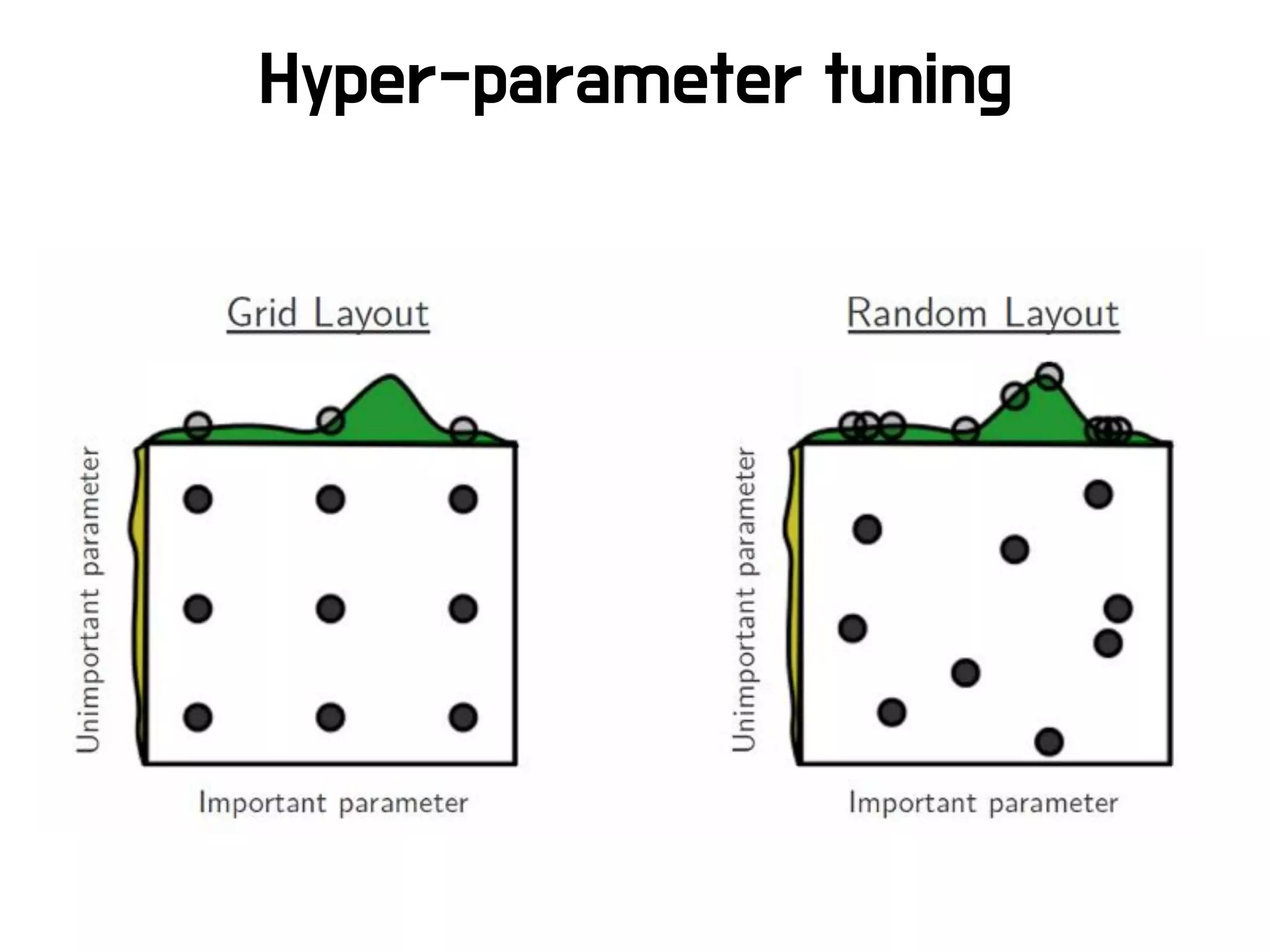
• 너무 많은 파라미터들!
Advanced Hyperparameter tunning
Practical Bayesian Optimization of MachineLearning Algorithms
− http://papers.nips.cc/paper/4522-practical-bayesian-optimization-of-
machine-learning-algorithms.pdf
− 위 논문이랑 비슷하게 bayseian 기반의 탐색이 종종 보임.
Sequential Model-Based Optimization for General Algorithm Configuration
− http://www.cs.ubc.ca/~hutter/papers/11-LION5-SMAC.pdf
− Auto weka 참고 논문으로 SMBO이긴 한데 random forest를 사용하고 있음.
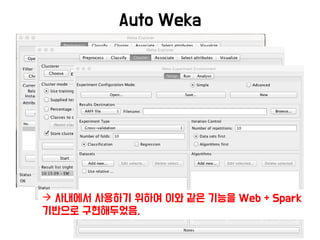
Auto Weka
− http://www.cs.ubc.ca/labs/beta/Projects/autoweka/papers/au
toweka.pdf
− 기본적으로 위의 SMBO(Sequential Model-based Bayesian Optimization)이라
는 방법으로 최적의 값을 찾아냄.
− SMAC이라는 알고리즘을 기반으로 Hyper Parameter의 loss function을 구함
기계학습 추가이론
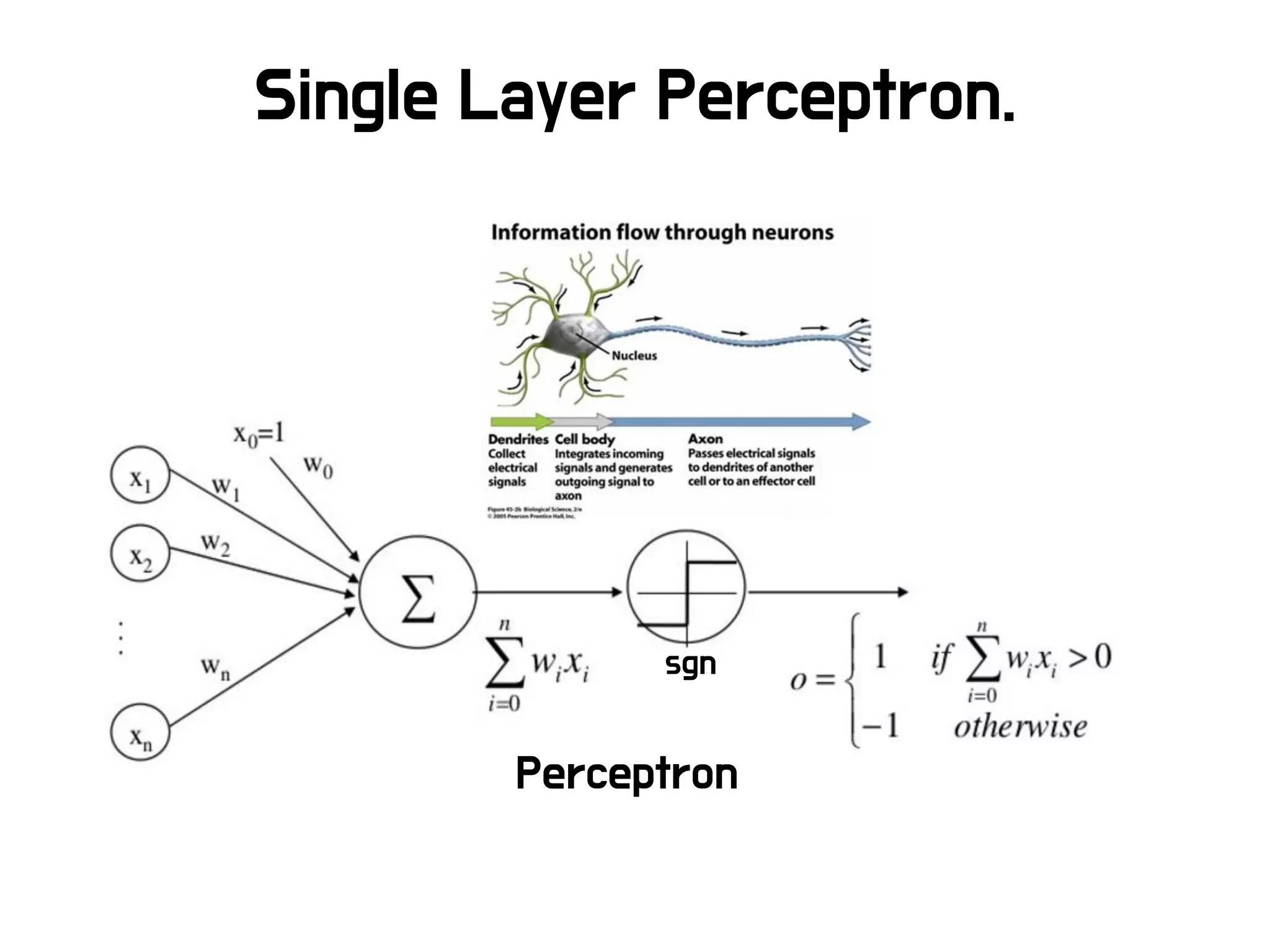
딥러닝
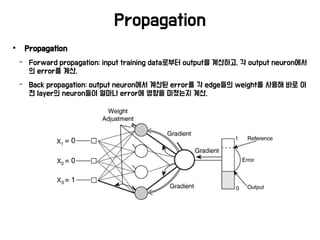
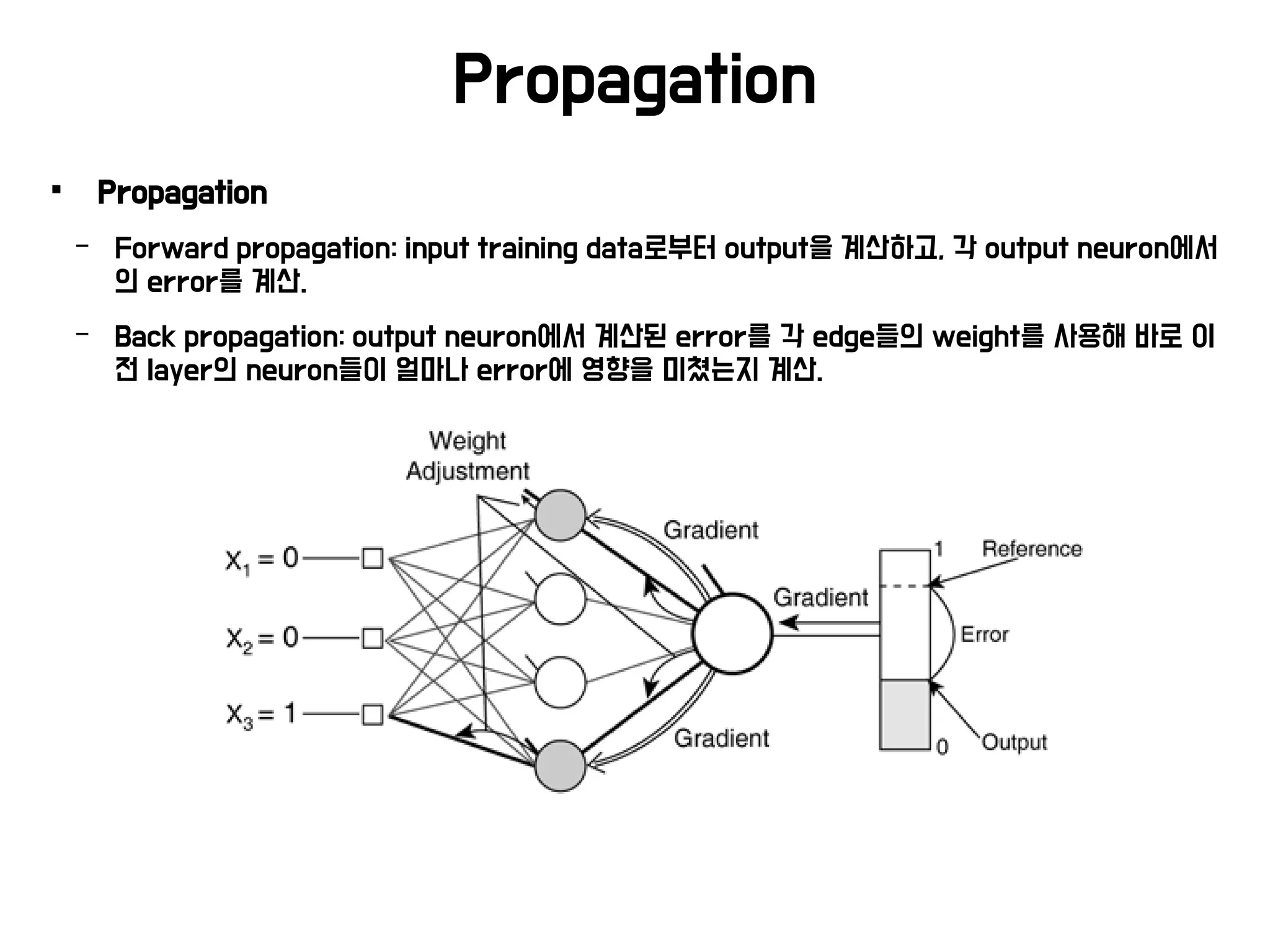
Propagation
Propagation
− Forwardpropagation: input training data로부터 output을 계산하고, 각 output neuron에서
의 error를 계산.
− Back propagation: output neuron에서 계산된 error를 각 edge들의 weight를 사용해 바로 이
전 layer의 neuron들이 얼마나 error에 영향을 미쳤는지 계산.
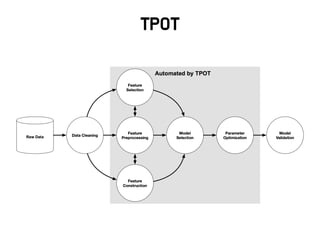
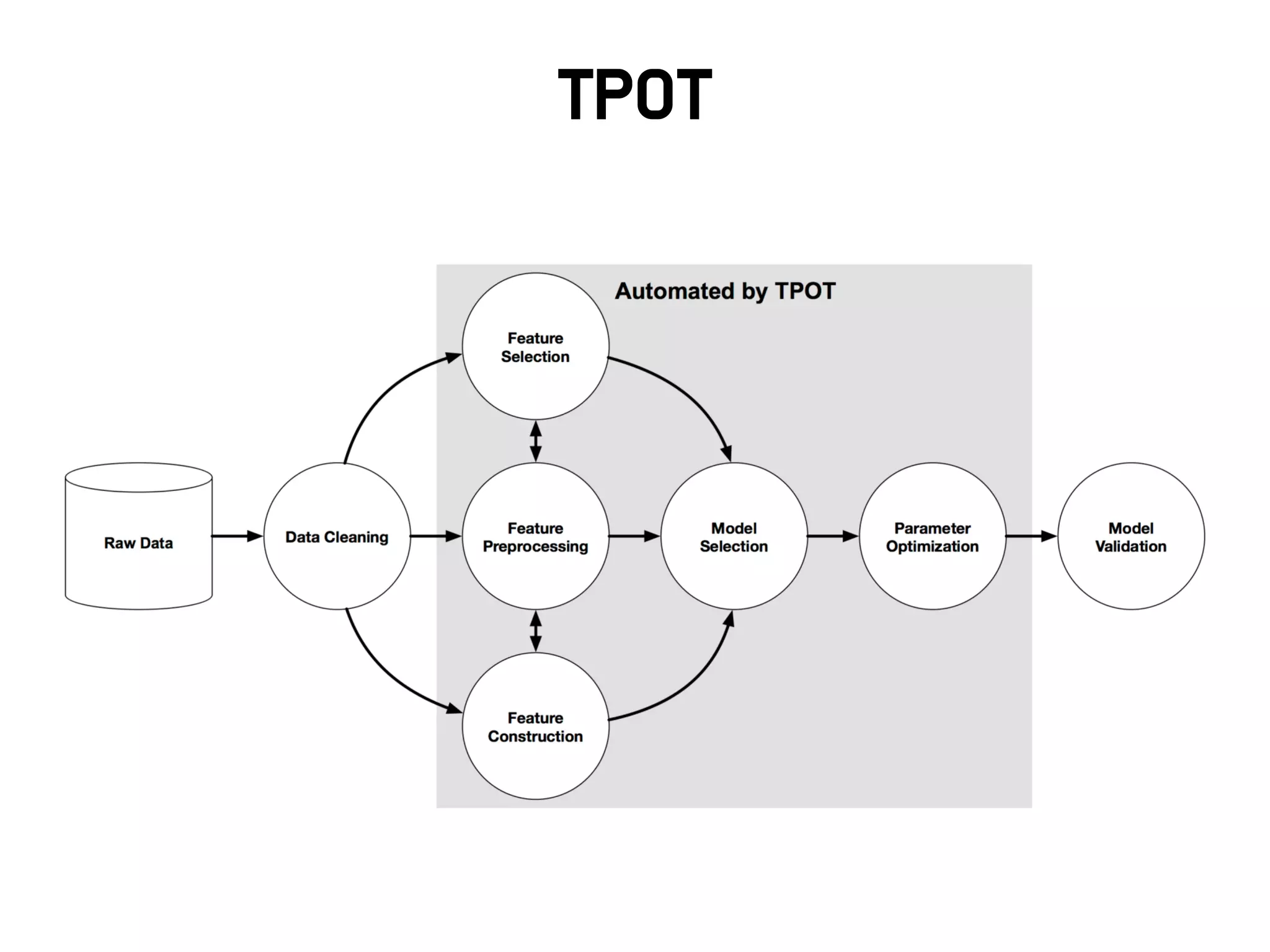
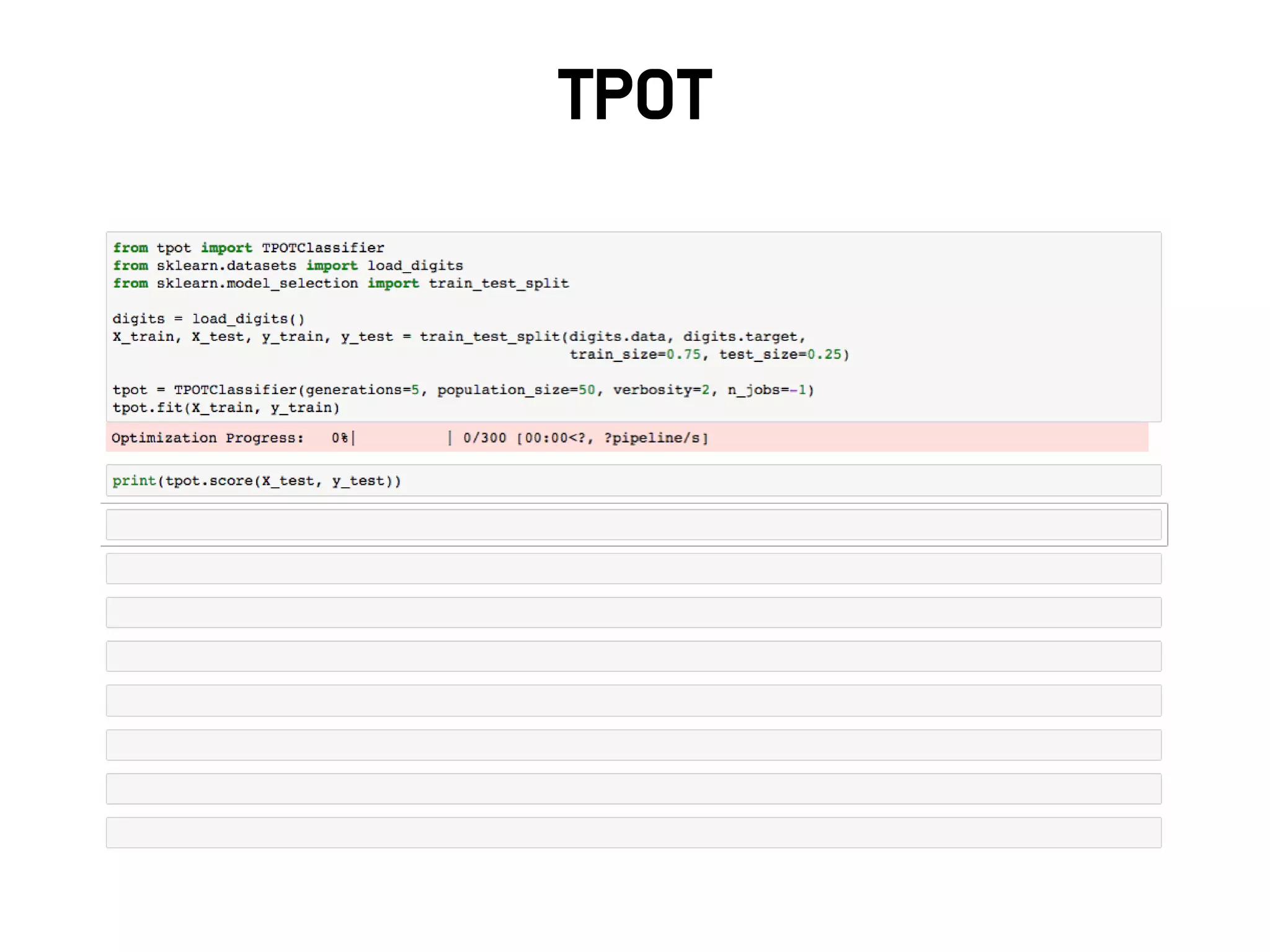
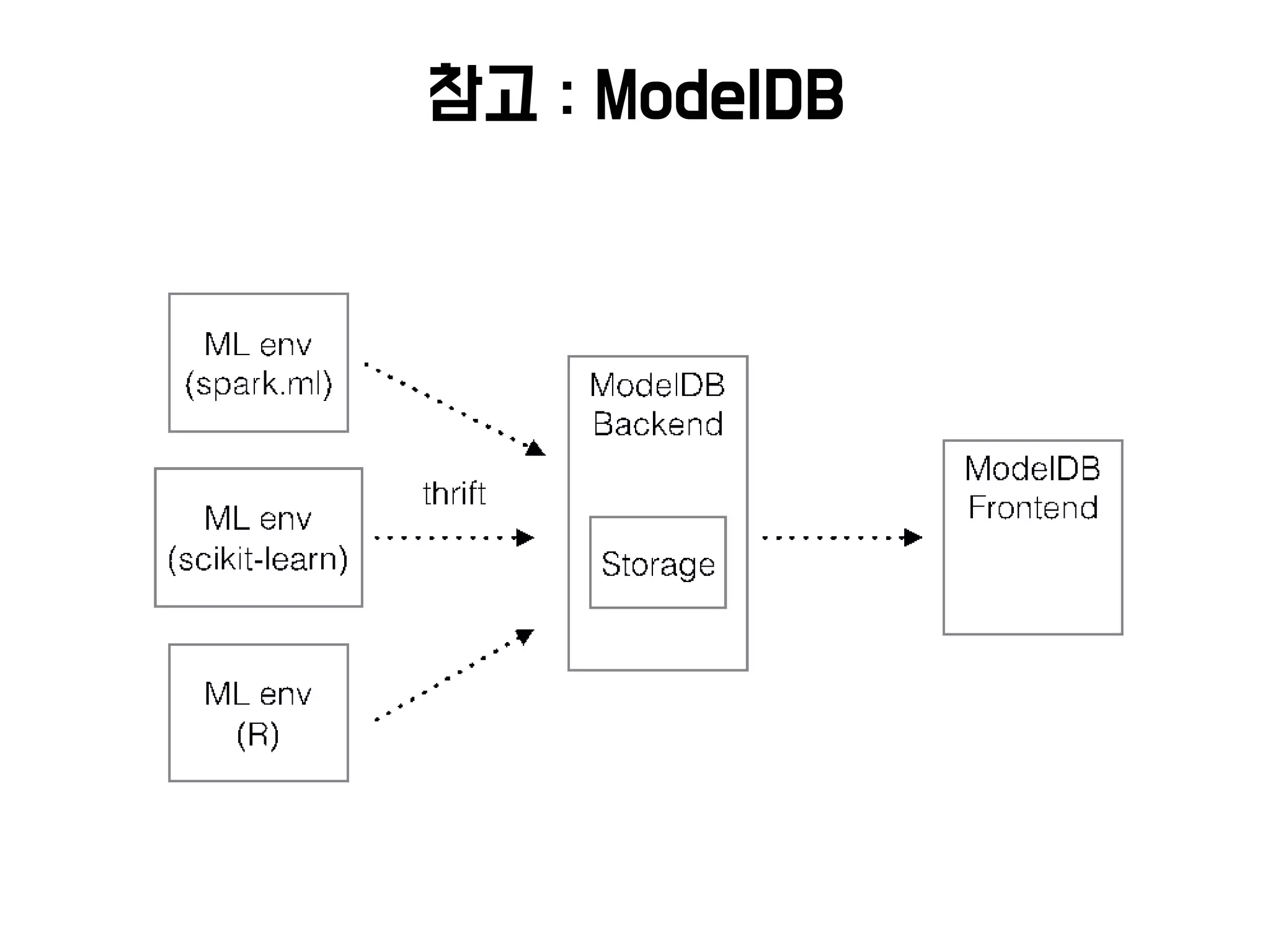
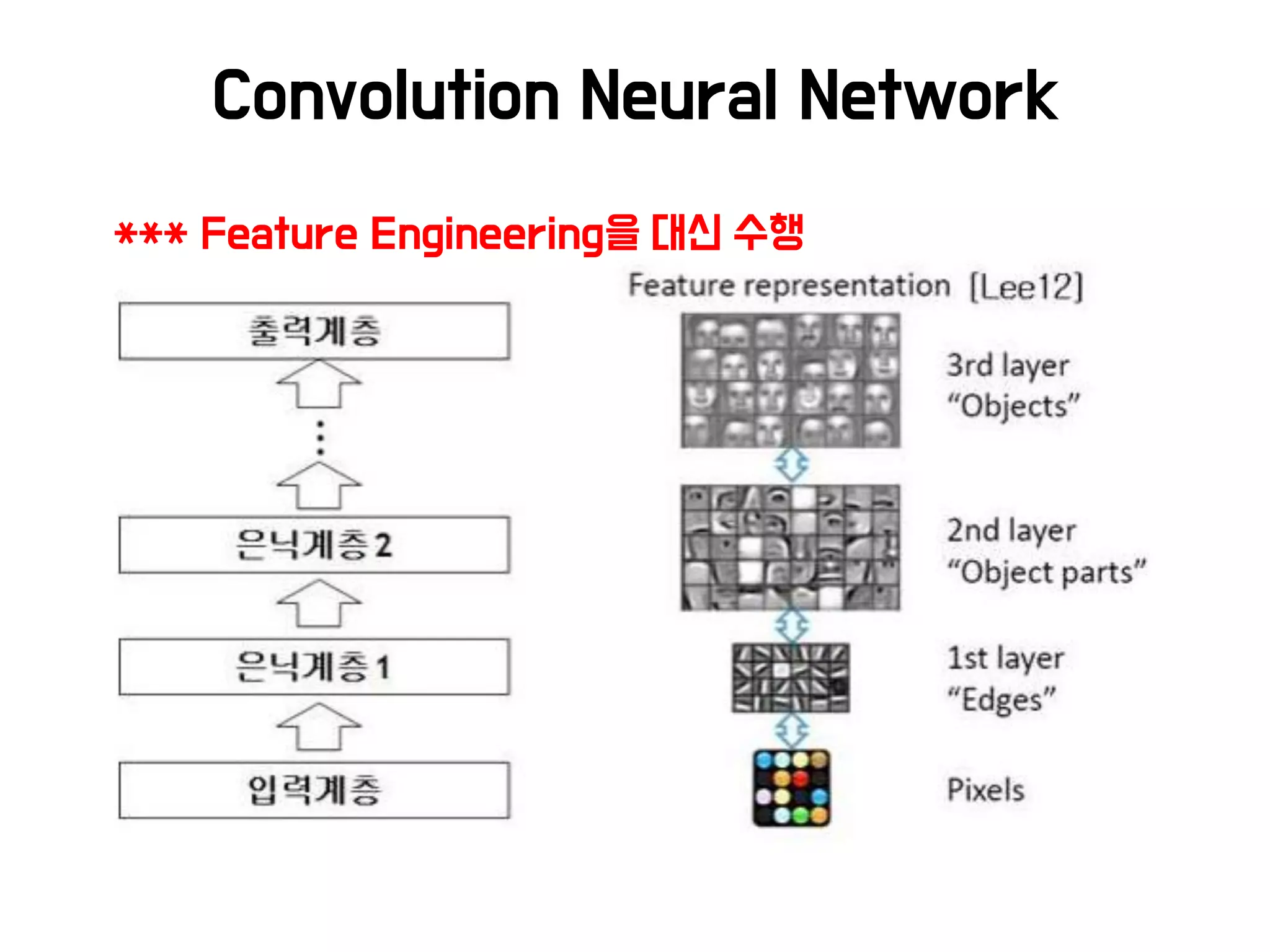
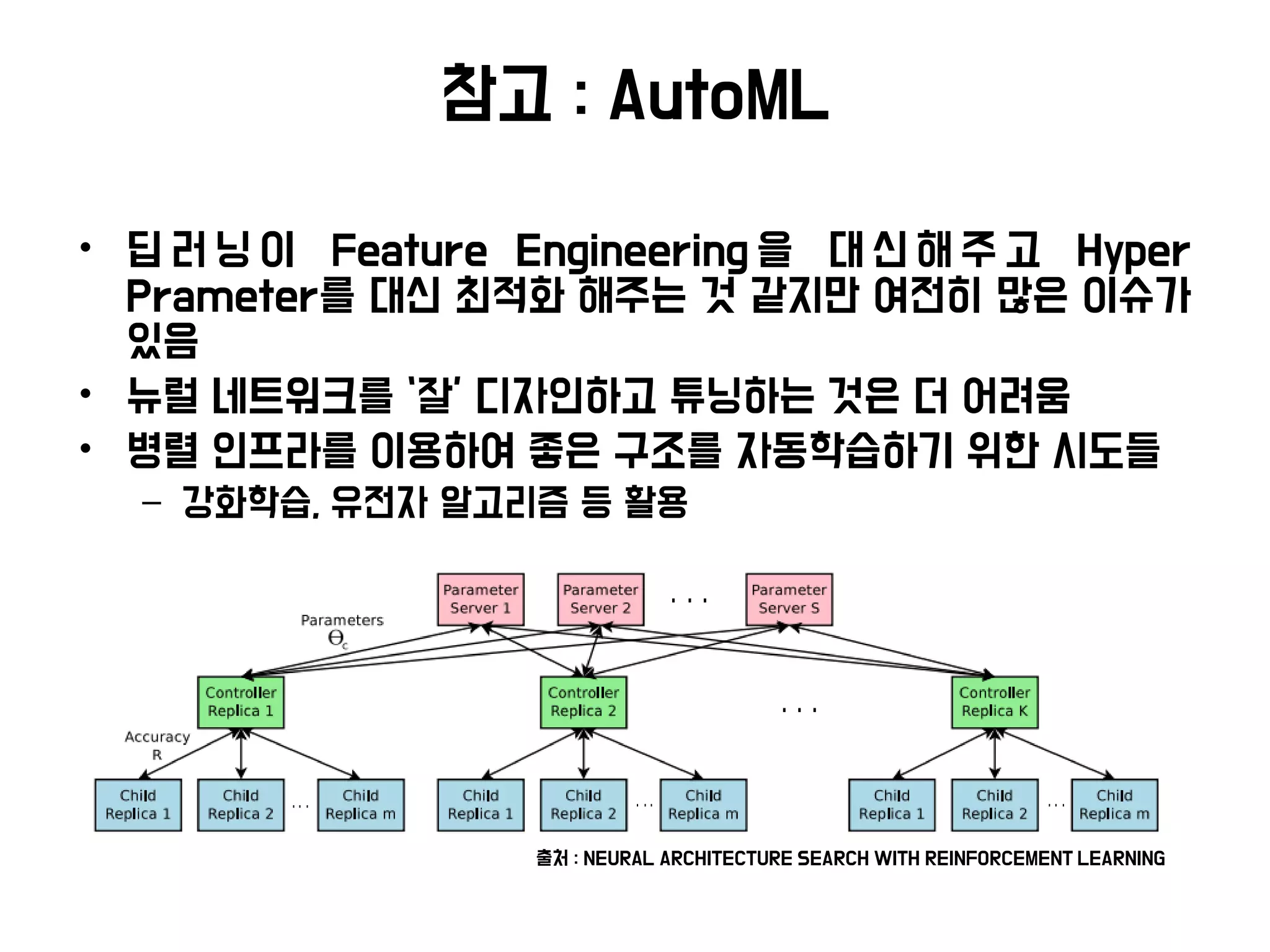
참고 : AutoML
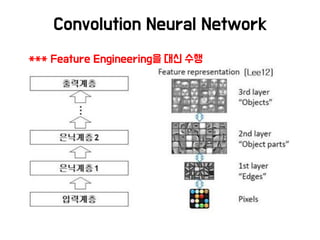
•딥 러 닝 이 Feature Engineering 을 대 신 해 주 고 Hyper
Prameter를 대신 최적화 해주는 것 같지만 여전히 많은 이슈가
있음
• 뉴럴 네트워크를 ‘잘’ 디자인하고 튜닝하는 것은 더 어려움
• 병렬 인프라를 이용하여 좋은 구조를 자동학습하기 위한 시도들
– 강화학습, 유전자 알고리즘 등 활용
출처 : NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
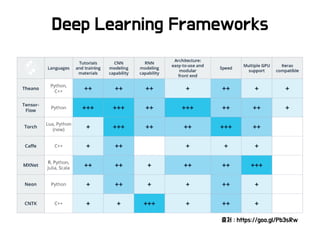
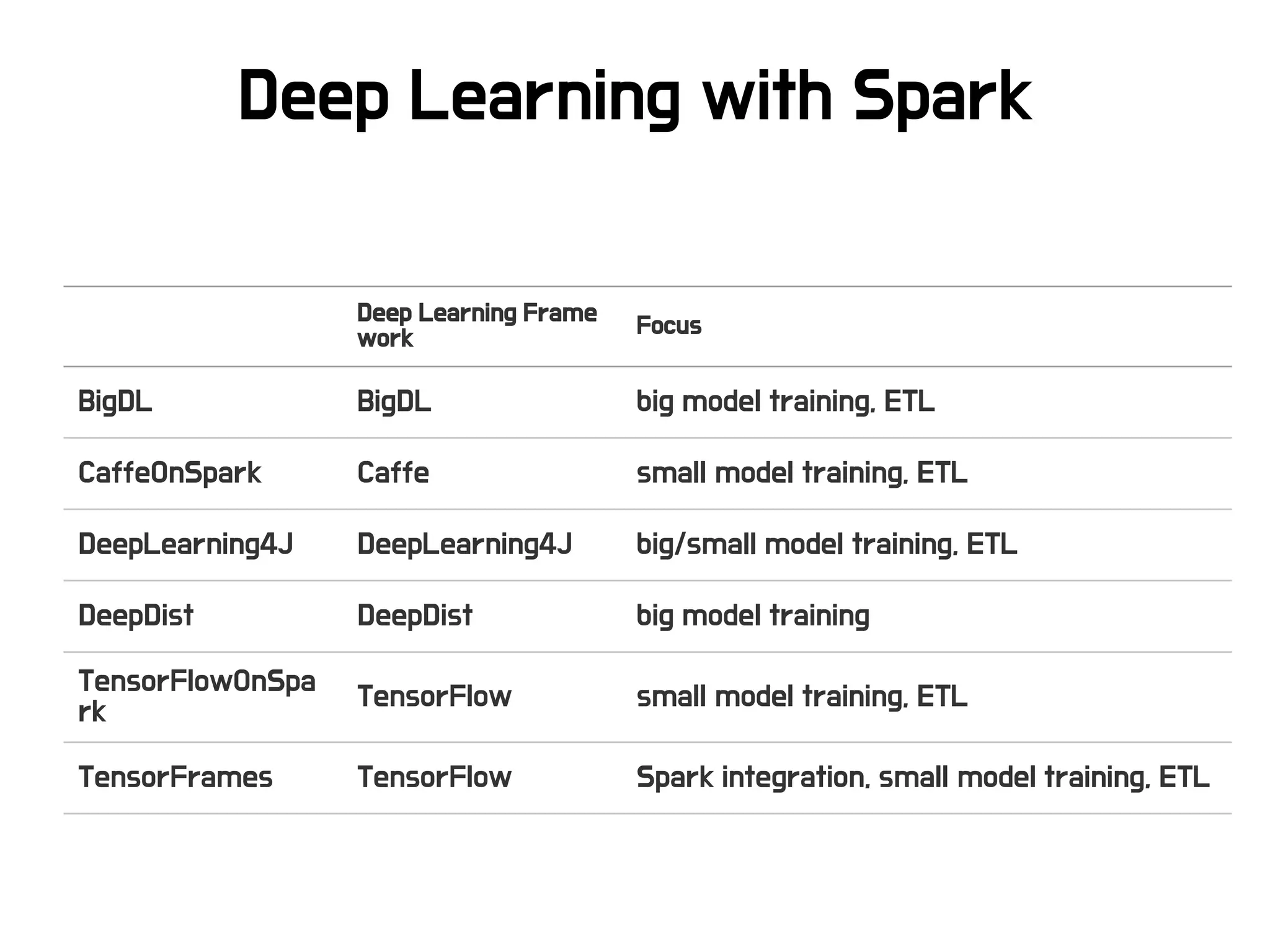
Deep Learning withSpark
Deep Learning Frame
work
Focus
BigDL BigDL big model training, ETL
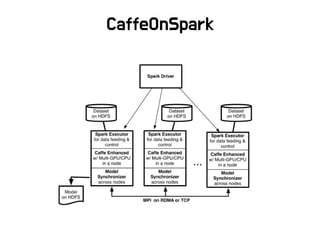
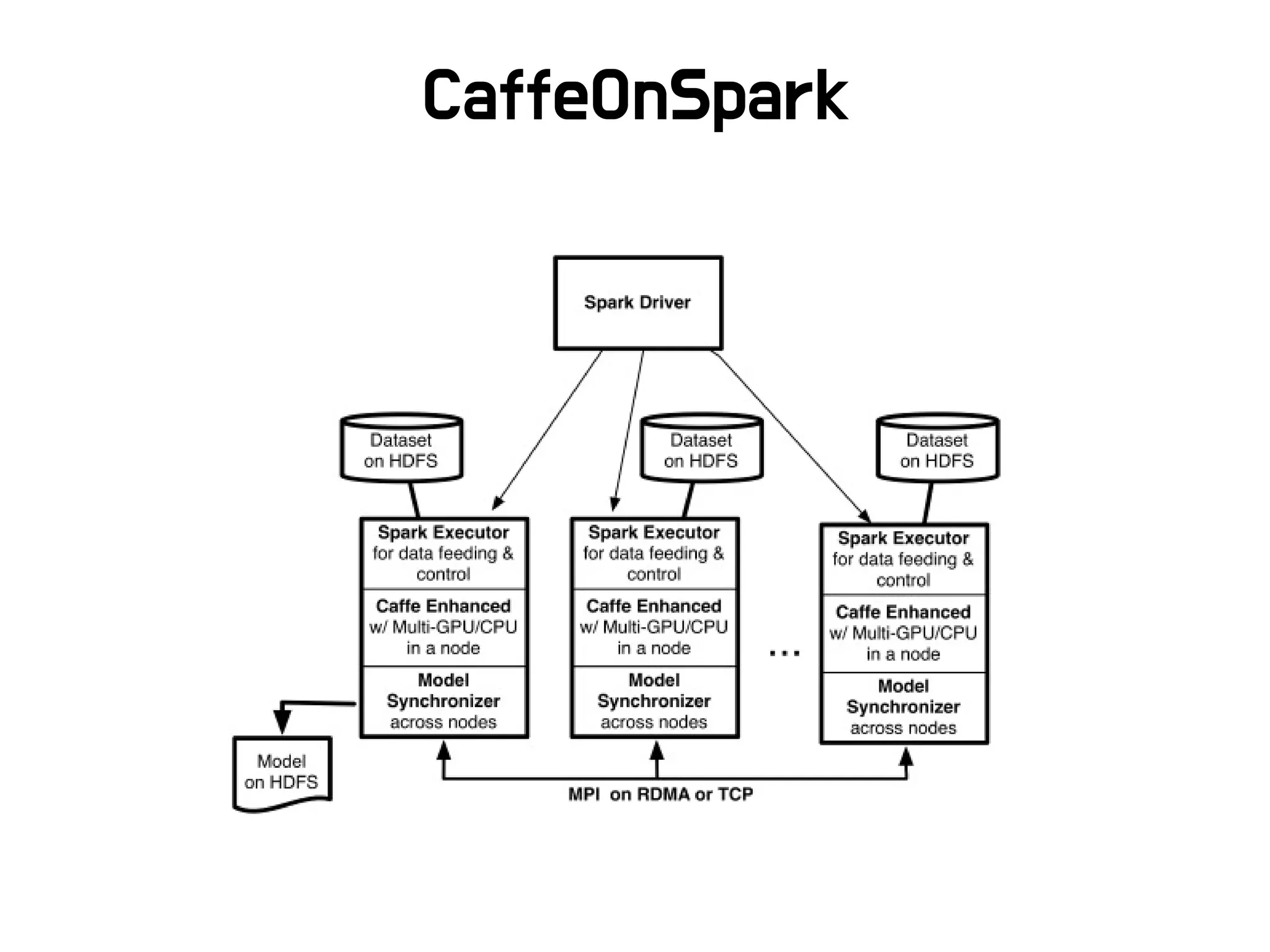
CaffeOnSpark Caffe small model training, ETL
DeepLearning4J DeepLearning4J big/small model training, ETL
DeepDist DeepDist big model training
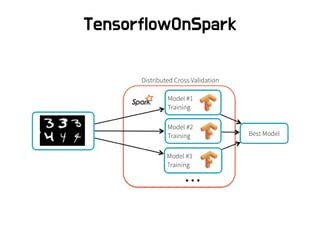
TensorFlowOnSpa
rk
TensorFlow small model training, ETL
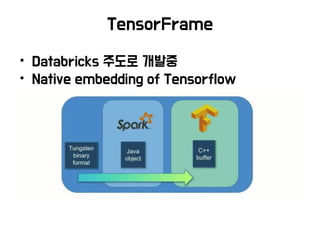
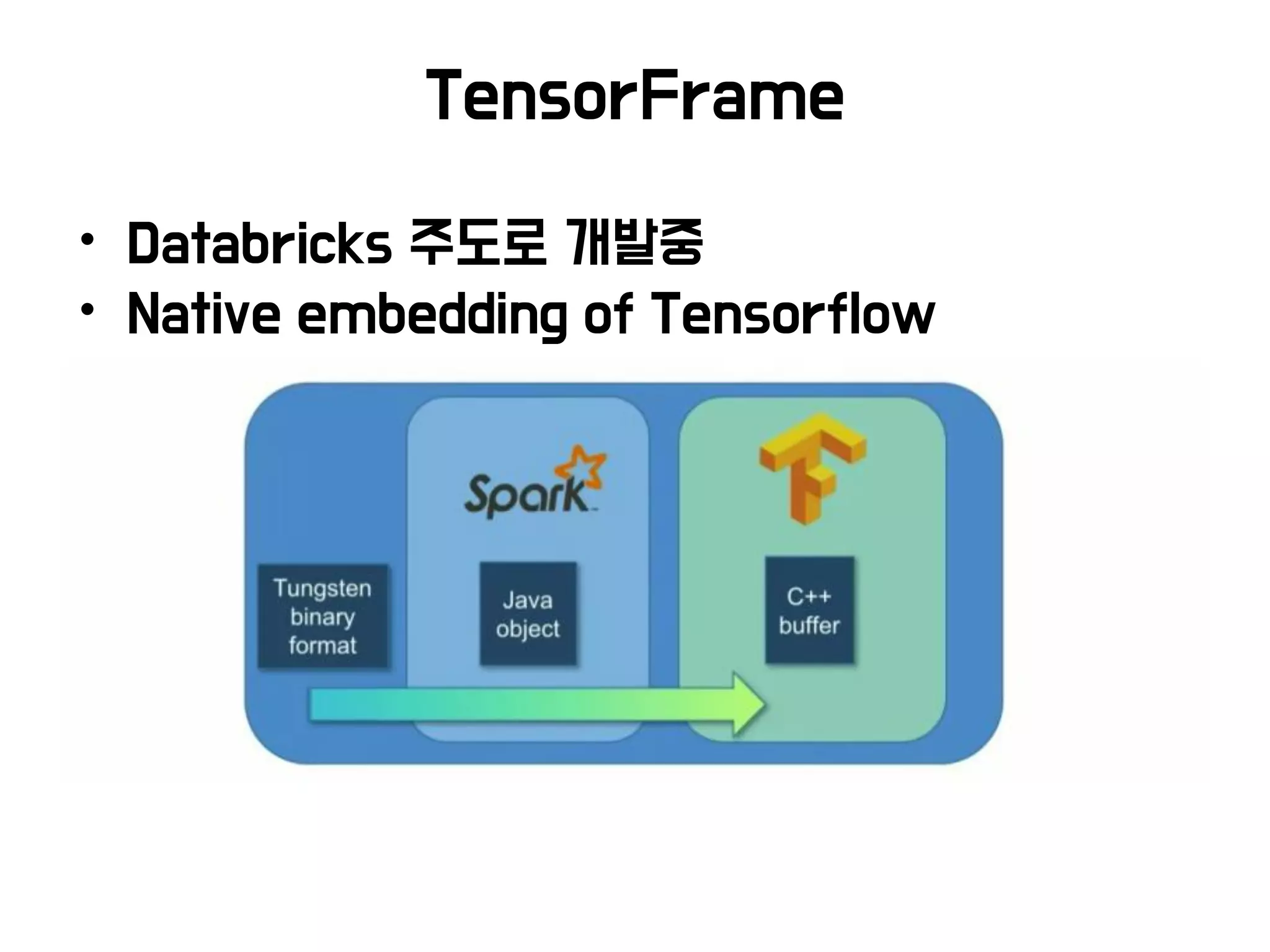
TensorFrames TensorFlow Spark integration, small model training, ETL
DL4J
• History
– 2014년첫 릴리즈
– Skymind를 주도로 만들어진 오픈소스로 Skymind가 상업적 지원도 병행하고
있음
– 다른 딥러닝 프레임워크와 달리 Java를 메인 언어로 지원
– 연구용 보다는 Spark를 기반으로 엔터프라이즈를 추구
• 장점
– 엔터프라이즈에 적용이 상대적으로 쉬우며 컨설팅 가능
– Skymind(아담 깁슨) 등 주요 개발자가 채팅 등을 통해 적극적으로 이슈해결에
도움을 줌
– 빅데이터 시스템과의 연동이 쉬움
• 단점
– 사용자 층이 얇음
– 개발자 수가 적어서 이슈 처리가 상대적으로 느림
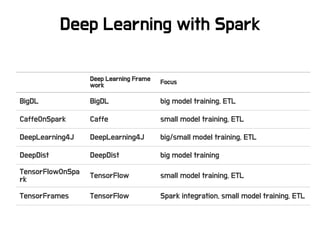
분산 기계학습
49.
분산 기계학습
BigDL
• Intel의주도로 개발되고 있으며 Xeon과 같은 서버 CPU 활용에
초점을 맞췄음
• MKL와 멀티쓰레딩을 이용하여 큰 모델에서의 뛰어난 성능
• Production ML/DL system is complex
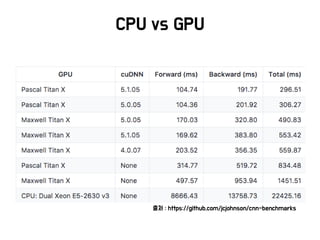
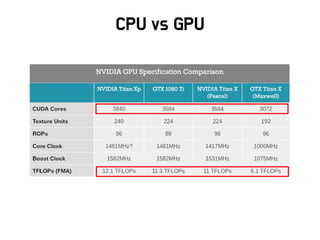
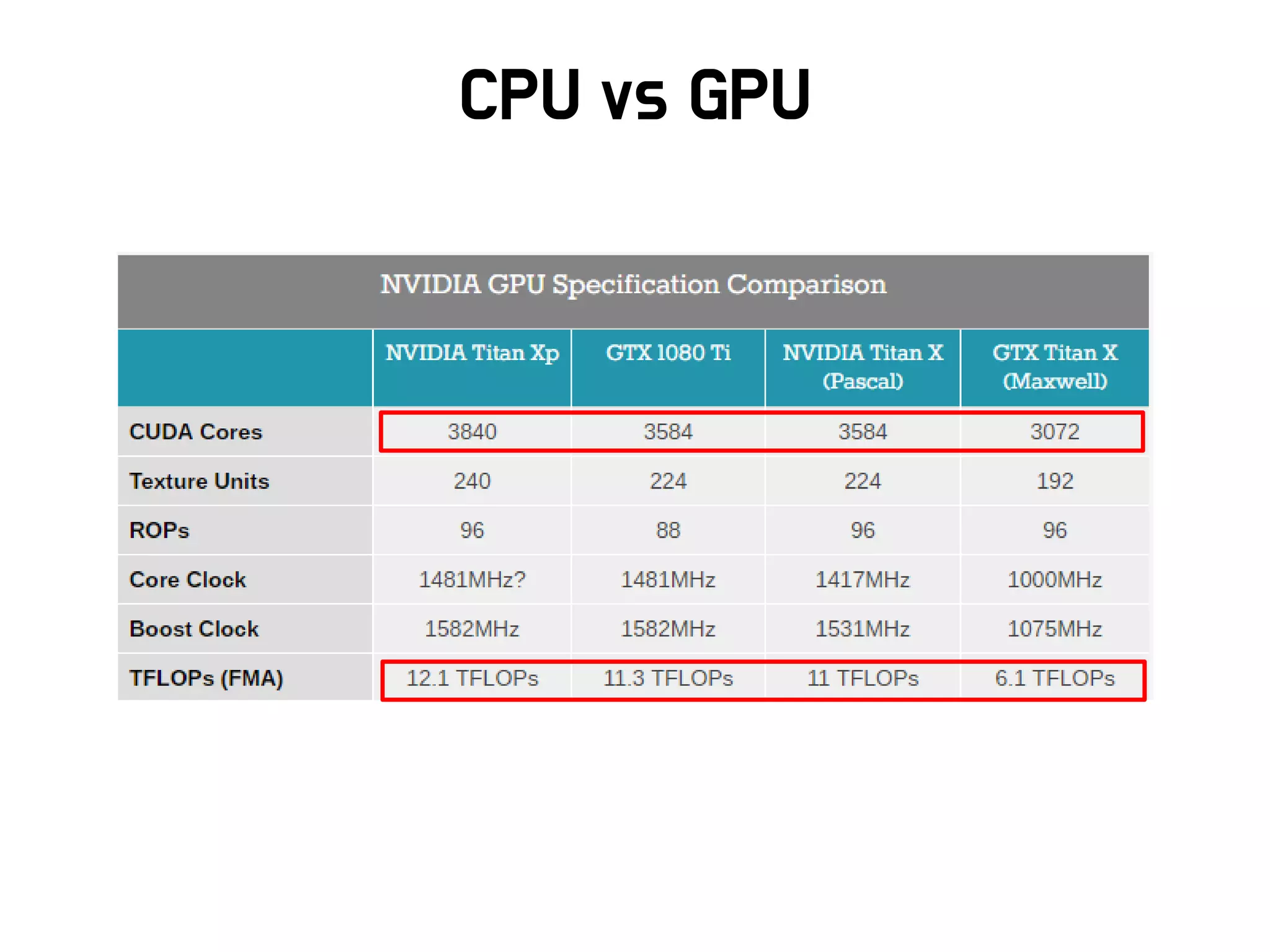
Google TPU
Infra
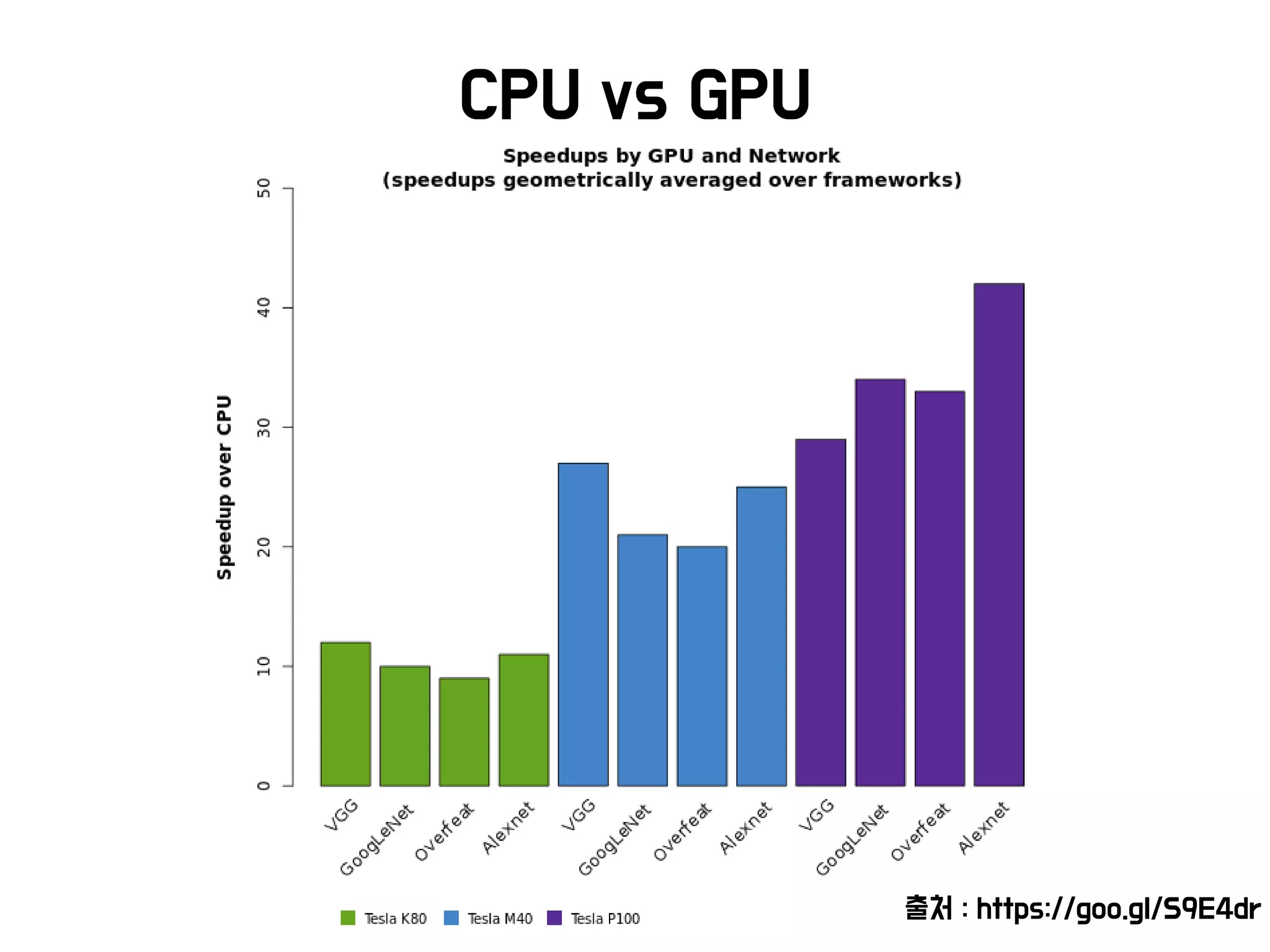
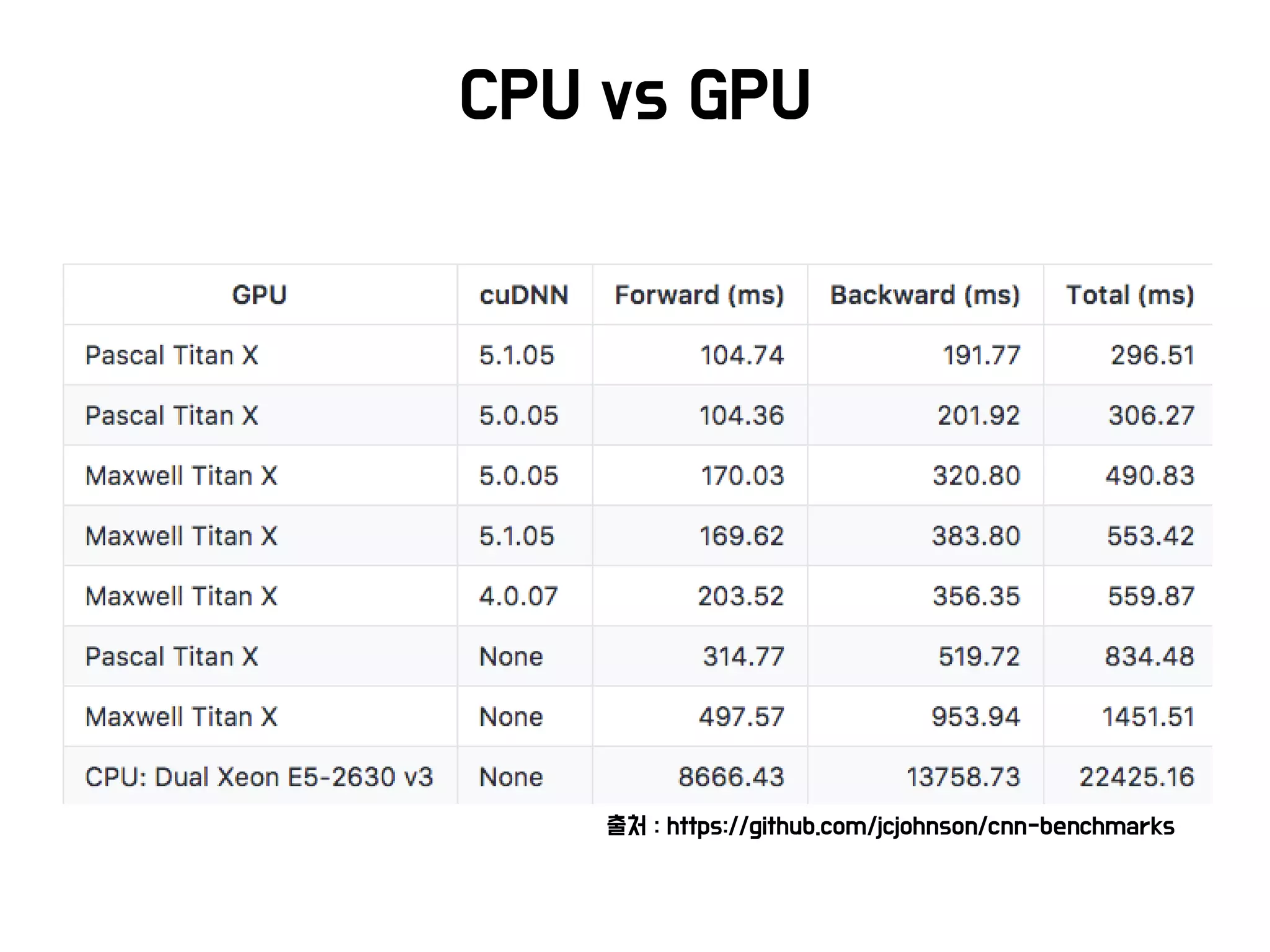
• (’16)이세돌과 싸웠던 알파고는 1202개 CPU와 176개 GPU를
활용
• (’17) 커제와 싸운 알파고는 수 개의 Google TPU를 활용하였음
• 2세대 Google TPU
– 최대 180 Teraflops에 달하는 부동 소수점 연산기능
– TPU Pod을 이용하면 11.5 Petaflops까지도 가능함
• 단점 : Google 클라우드에서만 사용가능하고 비쌈
54.
결론
• 머신러닝
– 머신러닝은알고리즘이 전부가 아니다.
– Pre-Processing, Hyperparameter Tuning, Pipeline, Data,
Model 관리 및 서빙이 필요하다.
– Spark는 위 프로세스에 최적의 OpenSource이다.
• 딥러닝
– Spark에 딥러닝을 접목하기 위한 시도가 많이 이루어지고 있다.
– GPU와 딥러닝 프레임워크의 대체보다는 시너지를 가지는 방향으로
발전 될 것이다.
• AutoML
분산 기계학습









![Spark Ml package
HyperParameters
Random forest
classifier
• setFeaturescol
• setPredictioncol
• setImpurity(String) : gain 계산시 사용할 수식 (대소문
자 구분함).
• setMaxBins(Int) : 최대 bin(몇 개로 나눌지) 수
• setMaxDepth(Int) : 최대 트리의 깊이
• setMinInfoGain(Double) : 트리를 분류할 때 최소한의 inf
omation gain.
• setMinInstancesPerNode(Int) : 각 노드당 최소한의 인
스턴스 수.
• setNumTrees(Int) : 학습할 트리 수. 1보다 같거나 커야
함
• setSeed(Long) : 랜덤 시드
• setSubsampleingRate(Double) : 각 결정 트리에서 사용
할 데이터 크기. 0초과부터 1까지.
• setThresholds(Array[Double]) : Multi-class Classifi
cation 임계치로 각 클래스의 예상 확률값.
• 너무 많은 파라미터들!](https://image.slidesharecdn.com/sparkday20170627-170626154524/85/Spark-Day-2017-Machine-Learning-Deep-Learning-With-Spark-17-320.jpg)























![Spark Ml package
HyperParameters
Random forest
classifier
• setFeaturescol
• setPredictioncol
• setImpurity(String) : gain 계산시 사용할 수식 (대소문
자 구분함).
• setMaxBins(Int) : 최대 bin(몇 개로 나눌지) 수
• setMaxDepth(Int) : 최대 트리의 깊이
• setMinInfoGain(Double) : 트리를 분류할 때 최소한의 inf
omation gain.
• setMinInstancesPerNode(Int) : 각 노드당 최소한의 인
스턴스 수.
• setNumTrees(Int) : 학습할 트리 수. 1보다 같거나 커야
함
• setSeed(Long) : 랜덤 시드
• setSubsampleingRate(Double) : 각 결정 트리에서 사용
할 데이터 크기. 0초과부터 1까지.
• setThresholds(Array[Double]) : Multi-class Classifi
cation 임계치로 각 클래스의 예상 확률값.
• 너무 많은 파라미터들!](https://image.slidesharecdn.com/sparkday20170627-170626154524/75/Spark-Day-2017-Machine-Learning-Deep-Learning-With-Spark-17-2048.jpg)





























![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


