The document discusses the use of machine learning in intrusion detection systems (IDS), highlighting the growing need for automated detection due to increasing cyberattacks. It reviews various methodologies, including signature-based detection, anomaly-based detection, and hybrid systems, while addressing challenges such as defining normal behavior and managing high error costs. The paper emphasizes the importance of feature selection and robust statistics in enhancing the effectiveness of machine learning-based IDS.







![Pros and cons of Intrusion Detection Methods
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 9
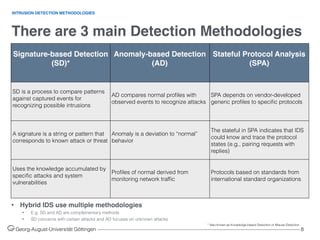
INTRUSION DETECTION METHODOLOGIES
Table 1: Pros and Cons of intrusion detection methodologies. Source [2]
Signature-based Detection
(SD)
Anomaly-based Detection
(AD)
Stateful Protocol Analysis
(SPA)
• Simplest and effective method to
detect attacks
• Detail contextual analysis
• Effective to detect new and
unforeseen vulnerabilities
• Less dependent on OS
• Facilitate detections of privilege
abuse
• Know and trace protocol states
• Distinguish unexpected sequences
of commands
• Ineffective with unknown attacks
and variants of known attacks
• Little understanding to states and
protocols
• Hard to keep signatures/patterns up
to date
• Time consuming to maintain the
knowledge
• Weak profiles accuracy due to
observed events
• Unavailable during rebuilding of
behavior profiles
• Difficult to trigger alerts in right time
• Resource consuming to protocol
state tracing and examination
• Unable to inspect attacks looking
like benign protocol behaviors
• Might be incompatible to dedicated
OSs or APs
PROSCONS](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-9-320.jpg)




![Robust Feature Selection and Robust PCA for Internet
Traffic Anomaly Detection
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 14
A MACHINE LEARNING BASED IDS
• Robust statistics
• Reliable results even in the
presence of outliers
Example:
• In normal distribution, the inner 95%
are in “center ± 1.96 X spread”
• Center: instead of mean,
take the median
• Spread: instead of SD (standard
deviation), take the MAD (median
absolute deviation)
Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-14-320.jpg)

![Dataset creation for training and testing (2/2)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 16
• Customer usage profiles
• (a) Soft browsing (HTTP only)
• (b) File sharing machine (BitTorrent only)
• (c) File sharing user (BitTorrent and HTTP)
• (d) Heavy user (HTTP, BitTorrent, and
Streaming)
• Network scenarios
• (B) Business user
• 100% (a)
• (R) Residential user
• 30% (b), 40% (c), 30% (d)
• Attack intensities
• (1) 6% (5% snapshot, 1% port-scan)
• (2) 20% (15% snapshot, 5% port-scan)
• (3) 35% (30% snapshot, 5% port-scan)
A MACHINE LEARNING BASED IDS
Table 2. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-16-320.jpg)
![Results (1/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 17
A MACHINE LEARNING BASED IDS
• 6 types of anomaly detectors A-B
• A: feature selection method, B Outlier
detection method
• R (robust)
• NR (non-robust)
• ∅ (no-method)
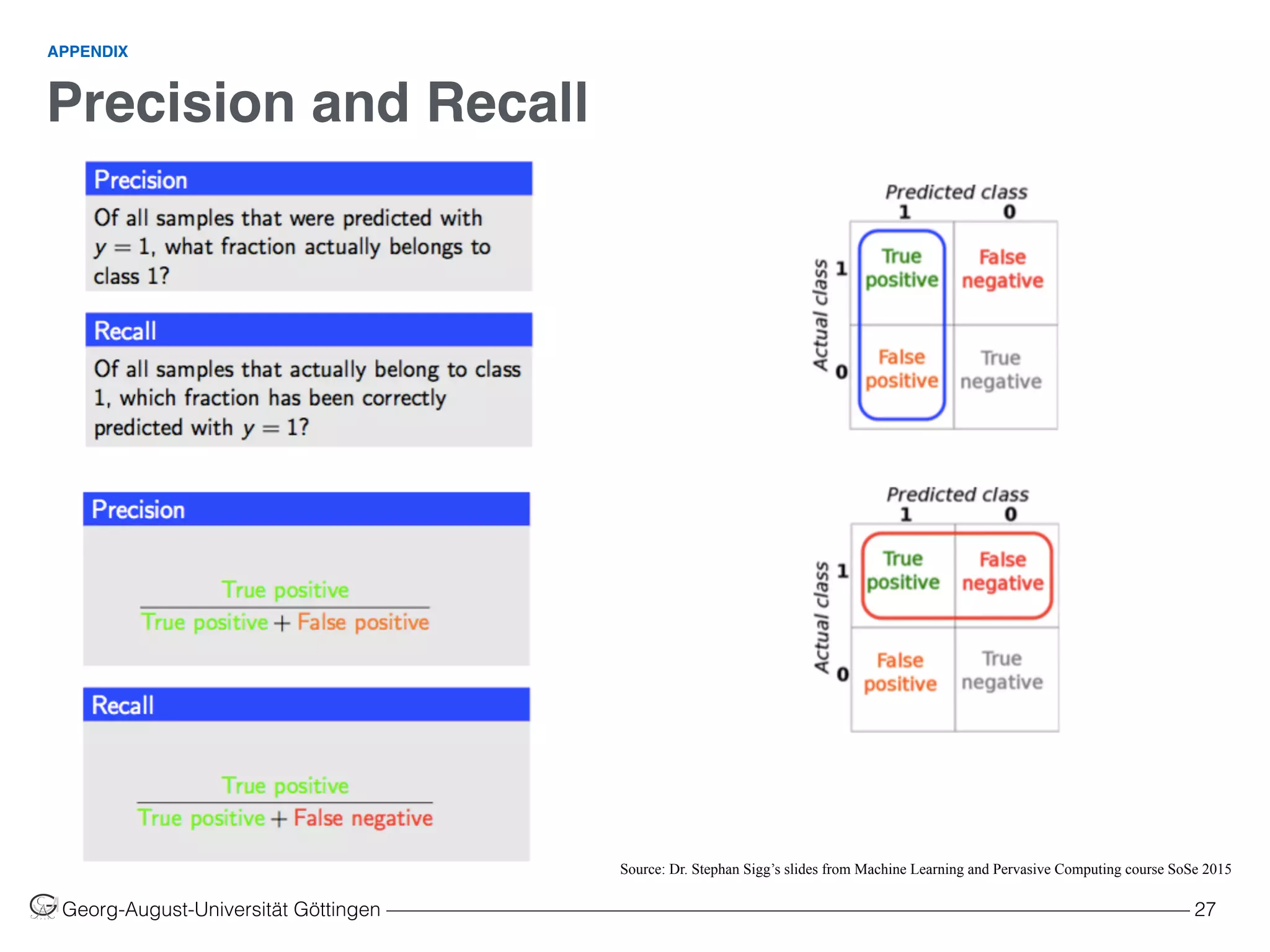
• Performance measures
• Nr Ftrs: number of selected features
• Recall: probability that an observation is
classified as anomaly when in fact it is an
anomaly
• False positive rate (FPR): probability that an
observation is classified as an anomaly when
in fact it is a regular observation
• Precision: probability of having an anomalous
observation given that it is classified as an
anomaly
Table 3. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-17-320.jpg)
![Results (2/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 18
• R-R detector achieved the best
results
• Recall is always 1
• B1, B2, B3, R3 performance is maximum
• FPR and Precision are close to their optimal
• Improvement over non-robust
version is high
• Low recall means large percentage of
anomalies are not correctly identified
• B2, B3, R3 recall improved from 0.167,
0.273, and 0.125 to 1
• Feature selection
• Feature selection reduces Nr Ftrs, improves
performance
• B3 and R3: no feature selection sometimes
better than non-robust feature selection
A MACHINE LEARNING BASED IDS
Table 3. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-18-320.jpg)
![Results (3/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 19
A MACHINE LEARNING BASED IDS
• Compare R-NR (top) and R-R
(bottom)
• Any point with score or distance
larger than a threshold (the lines) is
considered an anomaly
• R-NR case there is confusion
around snapshots
• thus poor recall value 0.125
• proximity in behavior between snapshots and
some HTTP and BitTorrent fools the non-robust
outlier detector
• All consist of small file uploads
Source [1]
Fig. 2.](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-19-320.jpg)





![Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 26
References
[1] C. Pasocal, M. Oliveira, R. Valdas, P. Filzmoser, P. Salvador and A. Pacheco. Robust Feature Selection and
Robust PCA for Internet Traffic Anomaly Detection. In Proceedings IEEE INFOCOM, pages 1755-1763, 2012
[2] H. Liao, C. Lin, Y. Lin and K. Tung. Intrusion Detection System: A Comprehensive Review. In Journal of
Network and Computer Applications, pages 16-24, 2013
[3] R. Sommer and V. Paxson. Outside the Closed World: On Using Machine Learning For Network Intrusion
Detection. In IEEE Symposium on Security and Privacy, pages 305-316, 2010
[4] Feature Selection. https://en.wikipedia.org/wiki/Feature_selection on 6 August 2015
[5] Outlier. https://en.wikipedia.org/wiki/Outlier on 6 August 2015
[6] Anomaly Detection – Using Machine Learning to Detect Abnormalities in Time Series Data. http://
blogs.technet.com/b/machinelearning/archive/2014/11/05/anomaly-detection-using-machine-learning-to-
detect-abnormalities-in-time-series-data.aspx on 6 August 2015
REFERENCES](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/85/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-26-320.jpg)







![Pros and cons of Intrusion Detection Methods
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 9
INTRUSION DETECTION METHODOLOGIES
Table 1: Pros and Cons of intrusion detection methodologies. Source [2]
Signature-based Detection
(SD)
Anomaly-based Detection
(AD)
Stateful Protocol Analysis
(SPA)
• Simplest and effective method to
detect attacks
• Detail contextual analysis
• Effective to detect new and
unforeseen vulnerabilities
• Less dependent on OS
• Facilitate detections of privilege
abuse
• Know and trace protocol states
• Distinguish unexpected sequences
of commands
• Ineffective with unknown attacks
and variants of known attacks
• Little understanding to states and
protocols
• Hard to keep signatures/patterns up
to date
• Time consuming to maintain the
knowledge
• Weak profiles accuracy due to
observed events
• Unavailable during rebuilding of
behavior profiles
• Difficult to trigger alerts in right time
• Resource consuming to protocol
state tracing and examination
• Unable to inspect attacks looking
like benign protocol behaviors
• Might be incompatible to dedicated
OSs or APs
PROSCONS](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-9-2048.jpg)




![Robust Feature Selection and Robust PCA for Internet
Traffic Anomaly Detection
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 14
A MACHINE LEARNING BASED IDS
• Robust statistics
• Reliable results even in the
presence of outliers
Example:
• In normal distribution, the inner 95%
are in “center ± 1.96 X spread”
• Center: instead of mean,
take the median
• Spread: instead of SD (standard
deviation), take the MAD (median
absolute deviation)
Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-14-2048.jpg)

![Dataset creation for training and testing (2/2)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 16
• Customer usage profiles
• (a) Soft browsing (HTTP only)
• (b) File sharing machine (BitTorrent only)
• (c) File sharing user (BitTorrent and HTTP)
• (d) Heavy user (HTTP, BitTorrent, and
Streaming)
• Network scenarios
• (B) Business user
• 100% (a)
• (R) Residential user
• 30% (b), 40% (c), 30% (d)
• Attack intensities
• (1) 6% (5% snapshot, 1% port-scan)
• (2) 20% (15% snapshot, 5% port-scan)
• (3) 35% (30% snapshot, 5% port-scan)
A MACHINE LEARNING BASED IDS
Table 2. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-16-2048.jpg)
![Results (1/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 17
A MACHINE LEARNING BASED IDS
• 6 types of anomaly detectors A-B
• A: feature selection method, B Outlier
detection method
• R (robust)
• NR (non-robust)
• ∅ (no-method)
• Performance measures
• Nr Ftrs: number of selected features
• Recall: probability that an observation is
classified as anomaly when in fact it is an
anomaly
• False positive rate (FPR): probability that an
observation is classified as an anomaly when
in fact it is a regular observation
• Precision: probability of having an anomalous
observation given that it is classified as an
anomaly
Table 3. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-17-2048.jpg)
![Results (2/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 18
• R-R detector achieved the best
results
• Recall is always 1
• B1, B2, B3, R3 performance is maximum
• FPR and Precision are close to their optimal
• Improvement over non-robust
version is high
• Low recall means large percentage of
anomalies are not correctly identified
• B2, B3, R3 recall improved from 0.167,
0.273, and 0.125 to 1
• Feature selection
• Feature selection reduces Nr Ftrs, improves
performance
• B3 and R3: no feature selection sometimes
better than non-robust feature selection
A MACHINE LEARNING BASED IDS
Table 3. Source [1]](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-18-2048.jpg)
![Results (3/3)
Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 19
A MACHINE LEARNING BASED IDS
• Compare R-NR (top) and R-R
(bottom)
• Any point with score or distance
larger than a threshold (the lines) is
considered an anomaly
• R-NR case there is confusion
around snapshots
• thus poor recall value 0.125
• proximity in behavior between snapshots and
some HTTP and BitTorrent fools the non-robust
outlier detector
• All consist of small file uploads
Source [1]
Fig. 2.](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-19-2048.jpg)





![Georg-August-Universität Göttingen ––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– 26
References
[1] C. Pasocal, M. Oliveira, R. Valdas, P. Filzmoser, P. Salvador and A. Pacheco. Robust Feature Selection and
Robust PCA for Internet Traffic Anomaly Detection. In Proceedings IEEE INFOCOM, pages 1755-1763, 2012
[2] H. Liao, C. Lin, Y. Lin and K. Tung. Intrusion Detection System: A Comprehensive Review. In Journal of
Network and Computer Applications, pages 16-24, 2013
[3] R. Sommer and V. Paxson. Outside the Closed World: On Using Machine Learning For Network Intrusion
Detection. In IEEE Symposium on Security and Privacy, pages 305-316, 2010
[4] Feature Selection. https://en.wikipedia.org/wiki/Feature_selection on 6 August 2015
[5] Outlier. https://en.wikipedia.org/wiki/Outlier on 6 August 2015
[6] Anomaly Detection – Using Machine Learning to Detect Abnormalities in Time Series Data. http://
blogs.technet.com/b/machinelearning/archive/2014/11/05/anomaly-detection-using-machine-learning-to-
detect-abnormalities-in-time-series-data.aspx on 6 August 2015
REFERENCES](https://image.slidesharecdn.com/machinelearninginnetworksintrusiondetection-160110182506/75/Using-Machine-Learning-in-Networks-Intrusion-Detection-Systems-26-2048.jpg)















































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















