Downloaded 24 times


































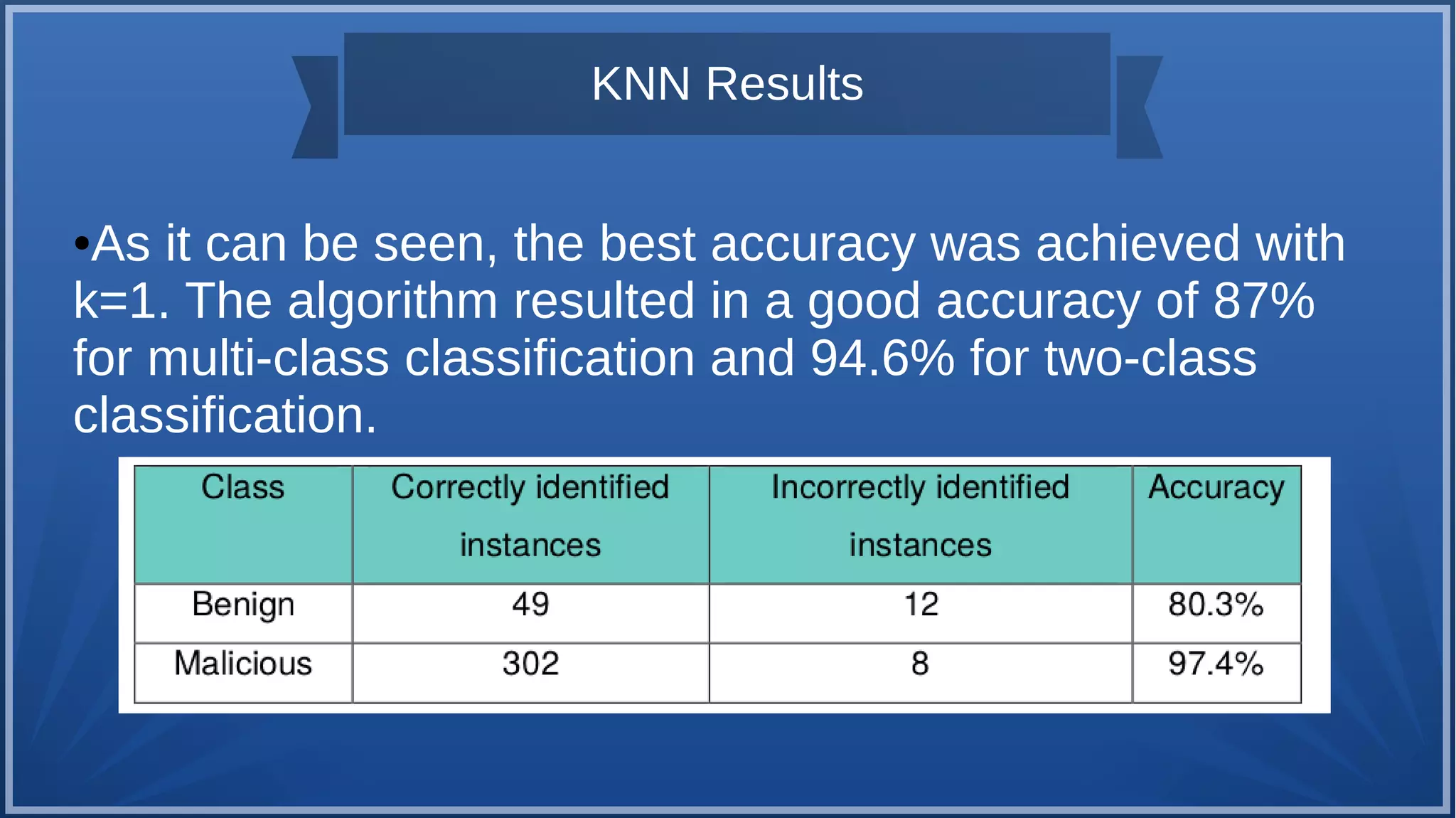




The document discusses malware detection using machine learning, highlighting the limitations of traditional signature-based methods in identifying polymorphic malware. It presents a solution that utilizes API sequence features and outlines the use of Cuckoo Sandbox for analysis, followed by feature extraction and machine learning algorithms like Random Forest and Support Vector Machines. Ultimately, the experiments demonstrate that integrated machine learning classifiers outperform traditional methods, with Random Forest achieving the highest accuracy at 95.69% for multi-class classification.


































































