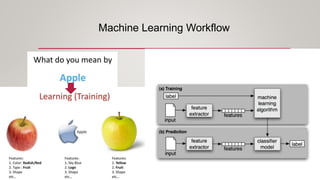
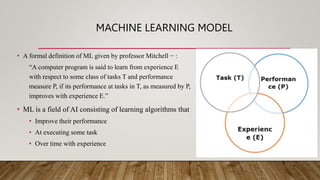
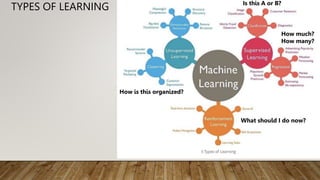
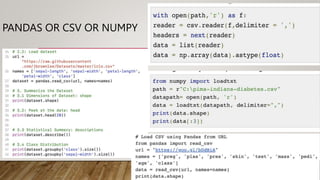
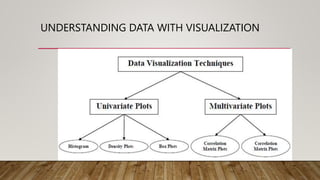
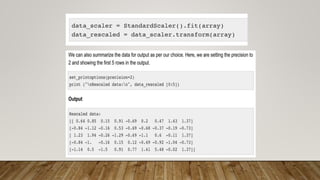
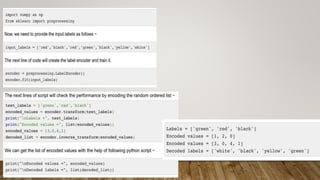
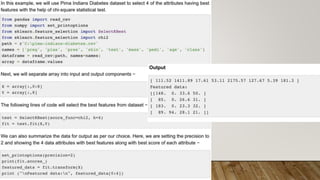
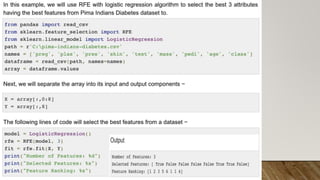
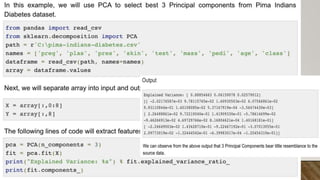
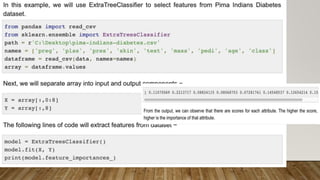
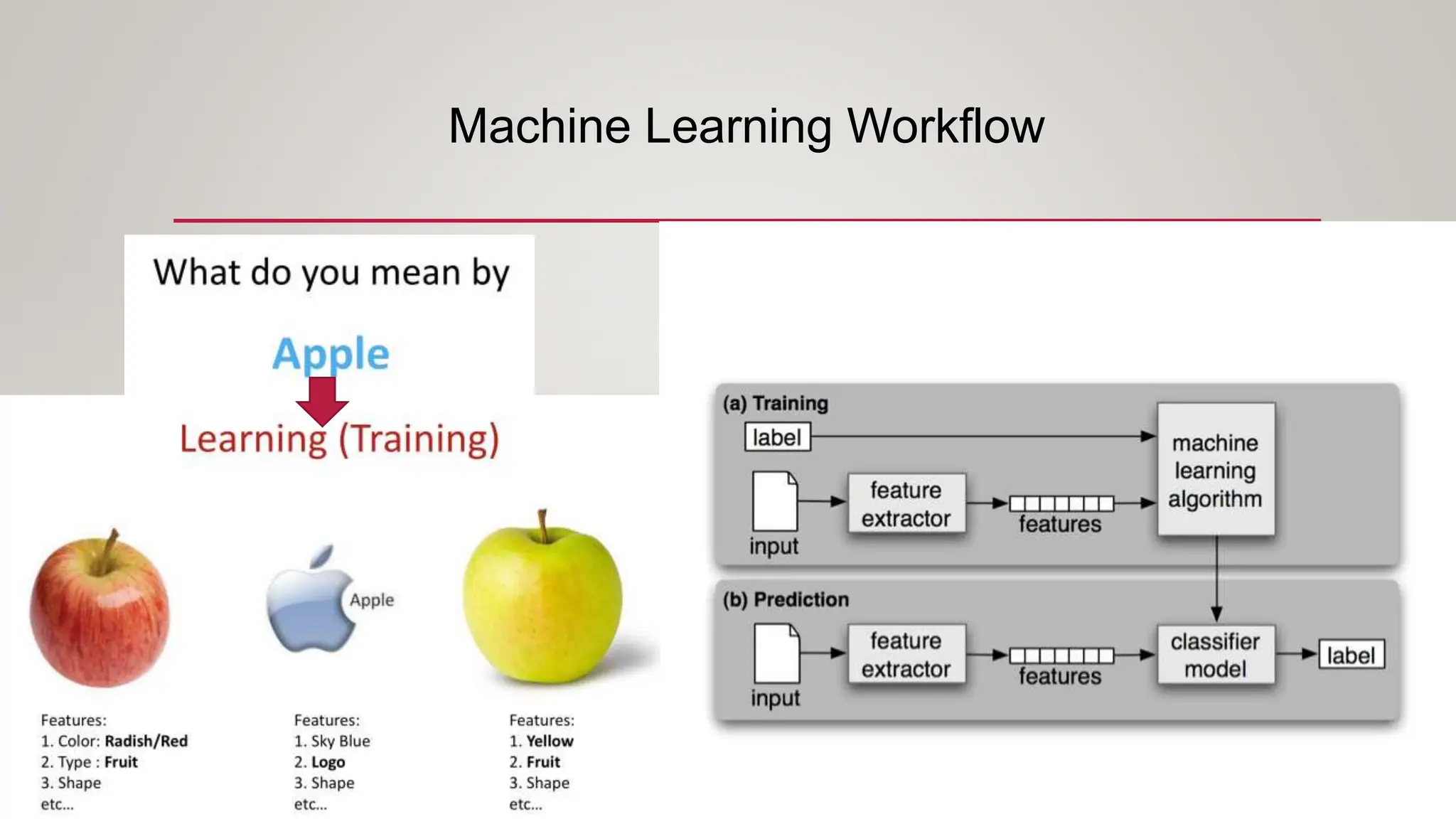
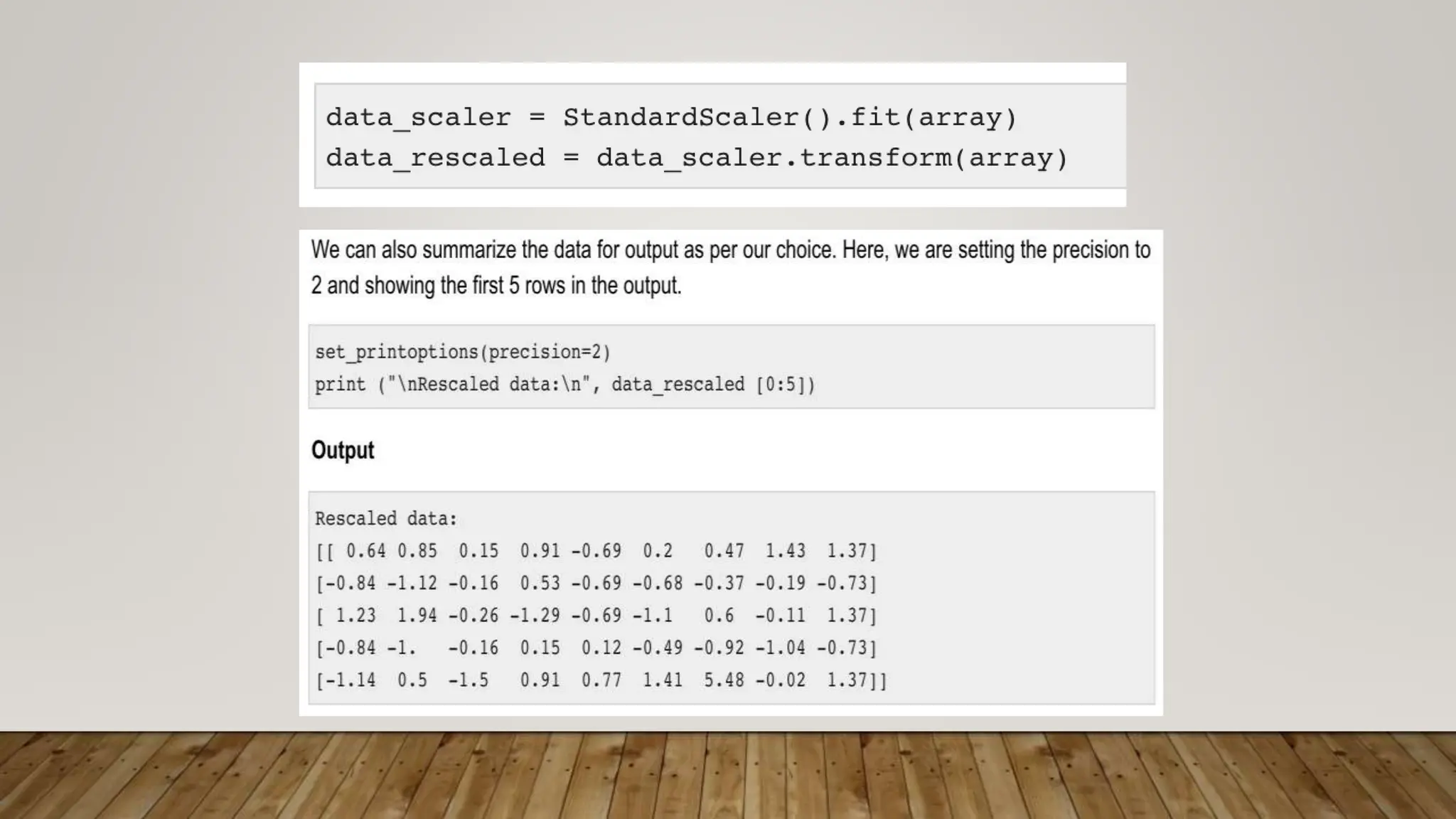
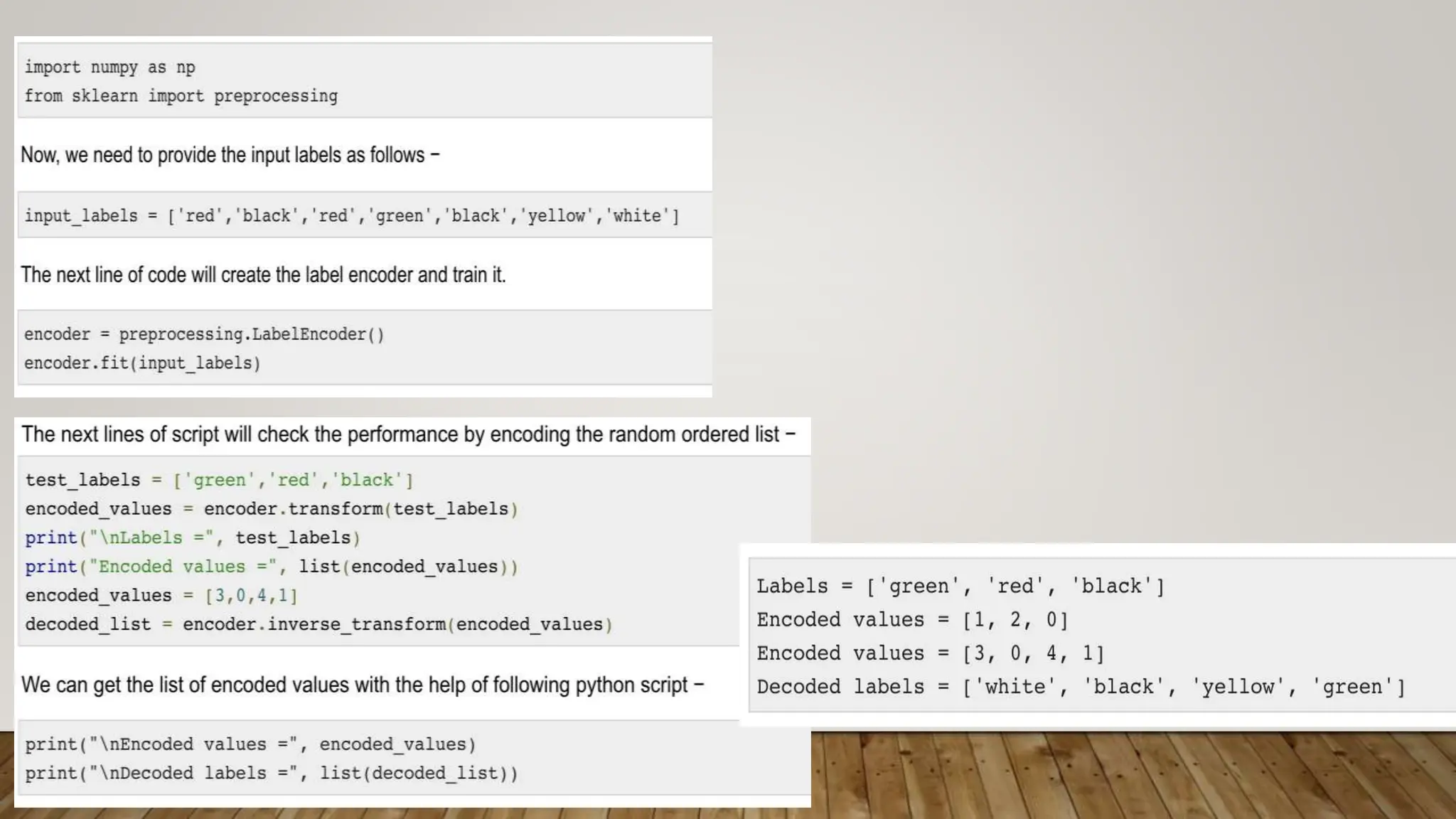
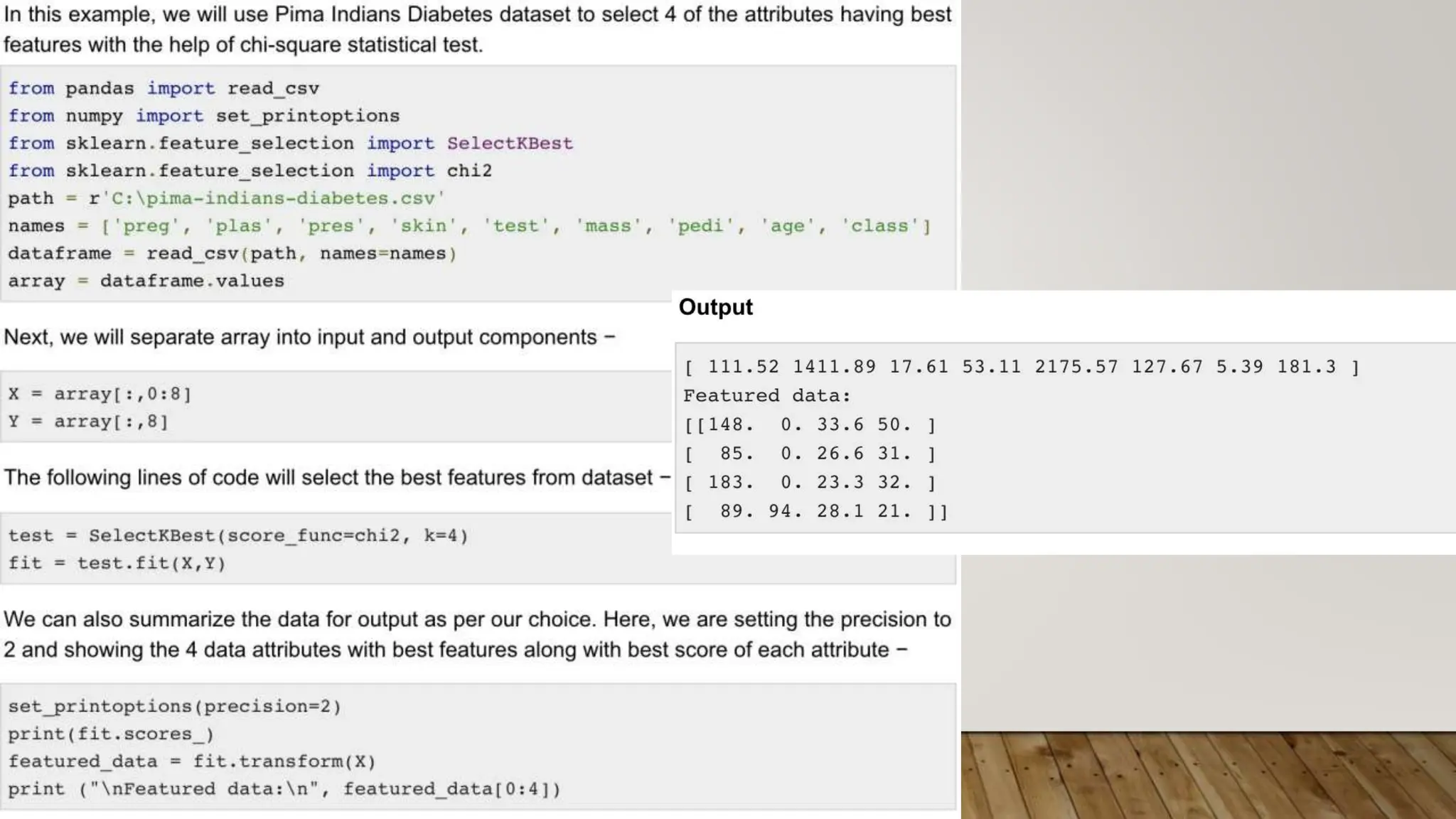
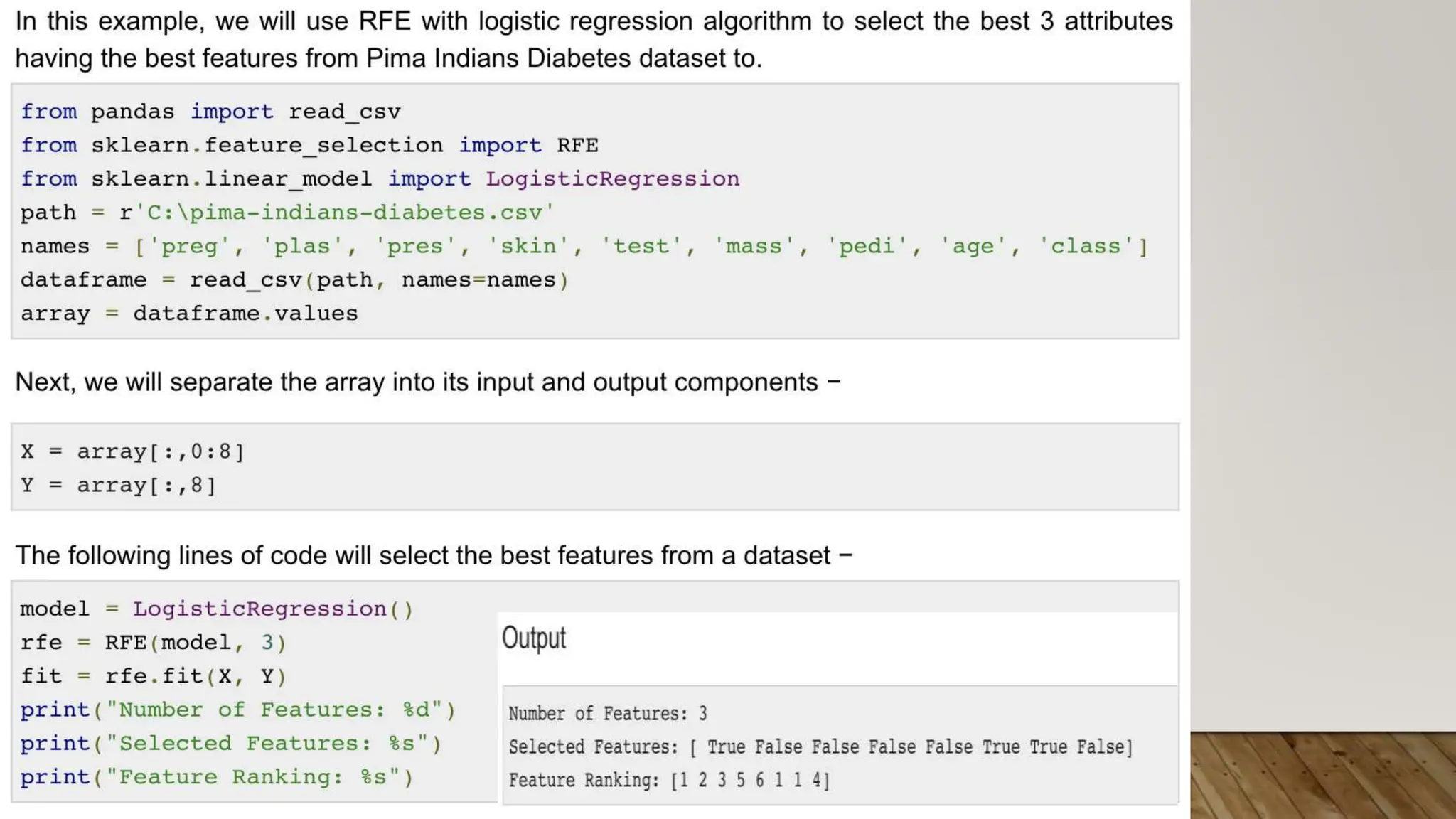
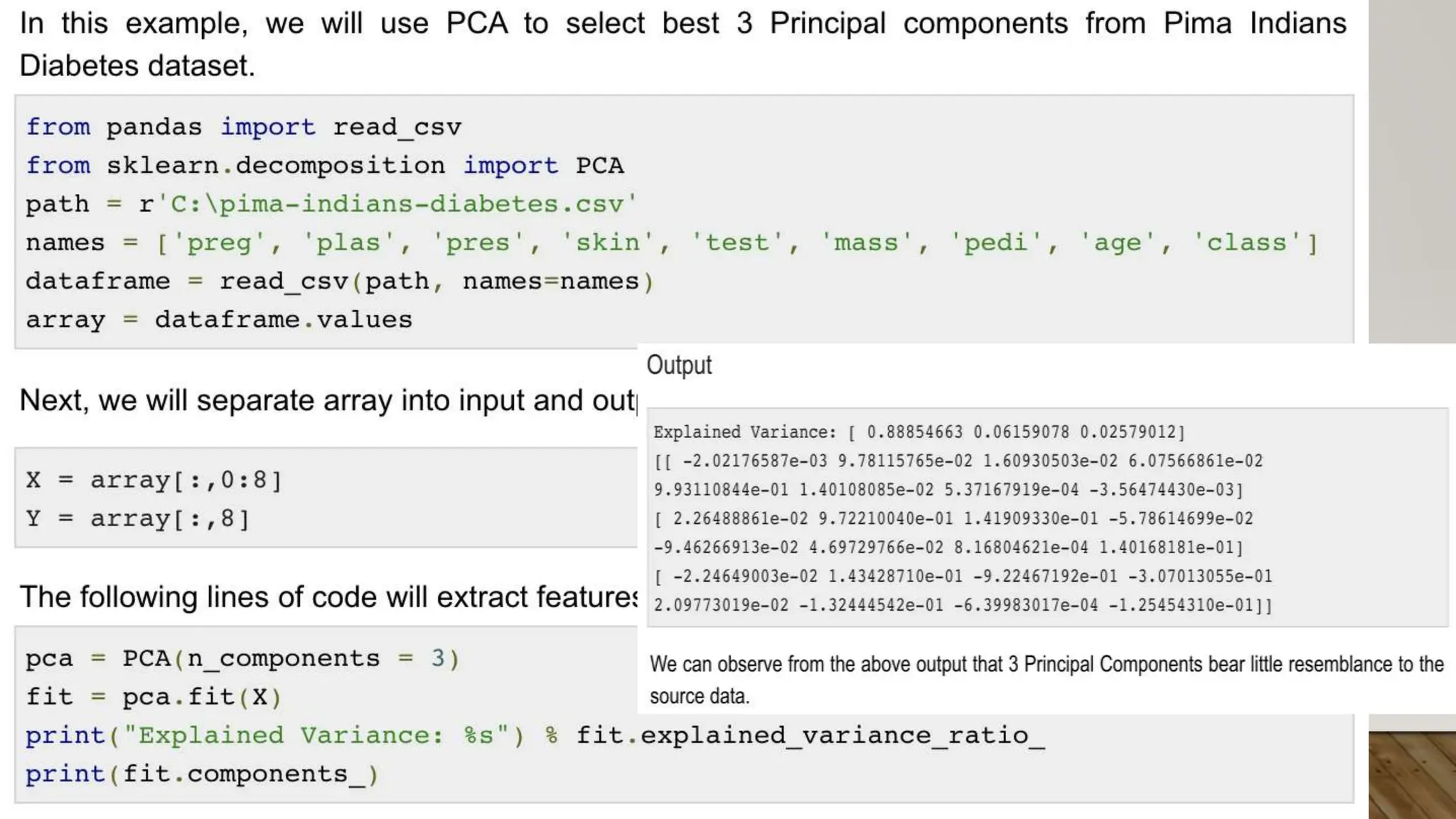
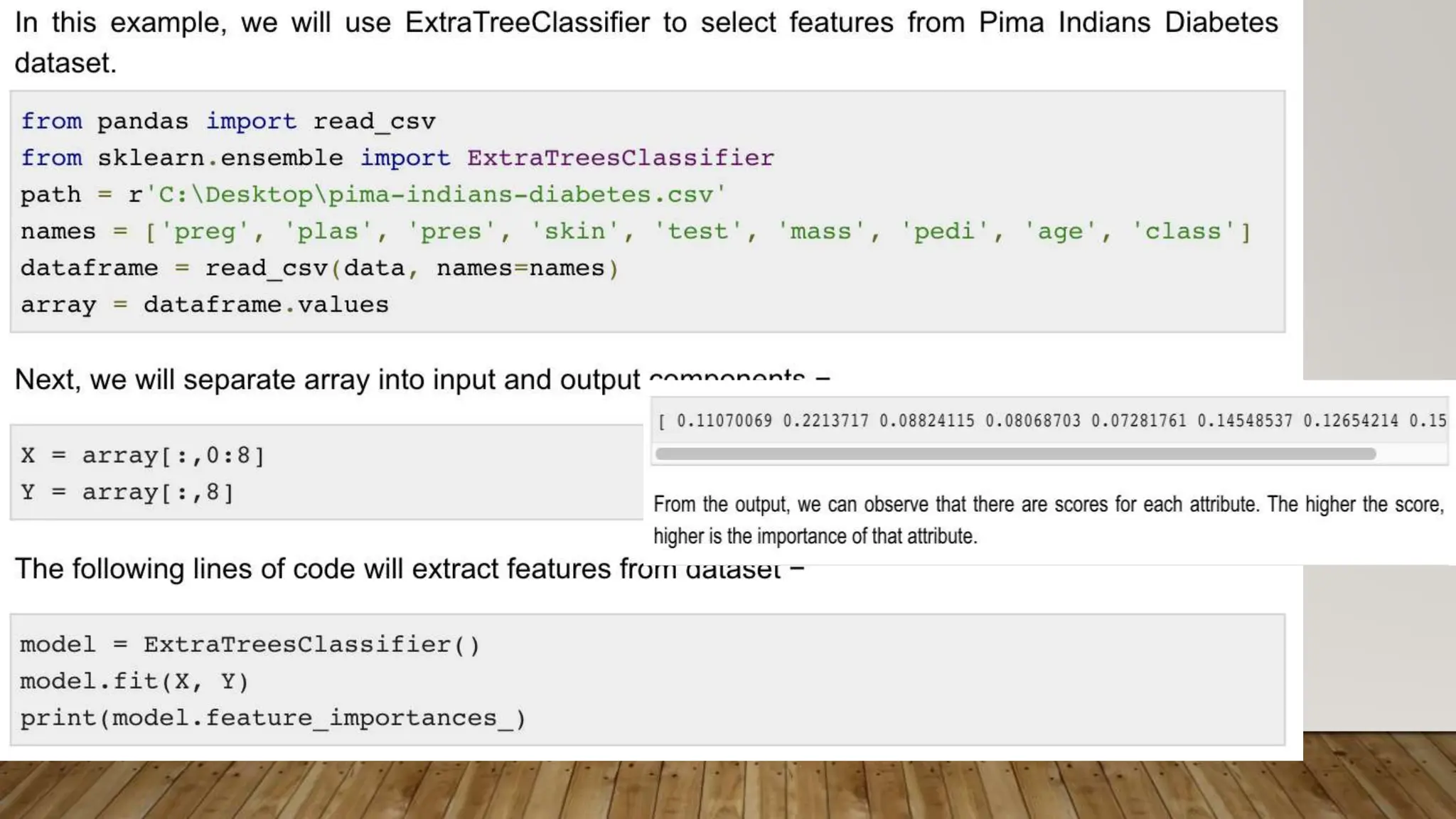
This document provides an overview of machine learning, including definitions of key concepts like tasks, experience, and performance in machine learning. It also discusses common machine learning workflows like data loading, understanding data through statistics and visualization, preparing data through techniques like scaling and normalization, selecting features, and discussing applications and types of machine learning. It provides examples of challenges in machine learning and techniques for data preparation and feature selection.

































































































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






