Downloaded 23 times


![Complexities?
• Nested Fields
• a.b.c.d[*].e nested hairiness!
• Arrays!
• MapType
• Every Tenant has a different Schema!
• Schema evolves constantly
• Fields can get deleted, updated.
• Multiple Sources
• Streaming
• Batch](https://image.slidesharecdn.com/276yeshwanthvijayakumar-210616155242/85/Massive-Data-Processing-in-Adobe-Using-Delta-Lake-8-320.jpg)















![Complexities?
• Nested Fields
• a.b.c.d[*].e nested hairiness!
• Arrays!
• MapType
• Every Tenant has a different Schema!
• Schema evolves constantly
• Fields can get deleted, updated.
• Multiple Sources
• Streaming
• Batch](https://image.slidesharecdn.com/276yeshwanthvijayakumar-210616155242/75/Massive-Data-Processing-in-Adobe-Using-Delta-Lake-8-2048.jpg)













The document discusses massive data processing at Adobe using Delta Lake, highlighting various aspects such as data representation, schema evolution, and challenges in data ingestion. It emphasizes the performance benefits of utilizing Delta Lake for handling large-scale data efficiently, while considering issues like schema management and replication lag. Key features like ACID transactions and lazy schema on-read approaches are also outlined to address the complexities of multi-tenant data architecture.
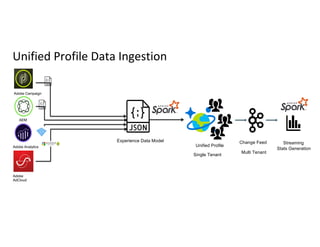
Introduction to processing large data with Delta Lake at Adobe. Agenda covers topics from data storage to performance tracking.
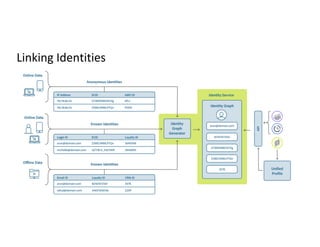
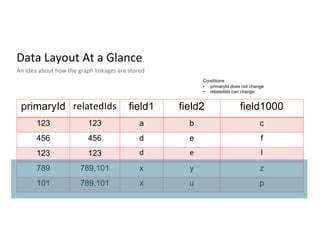
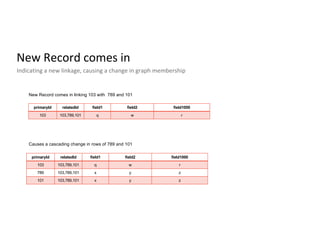
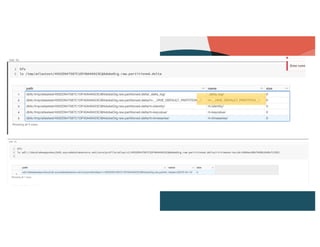
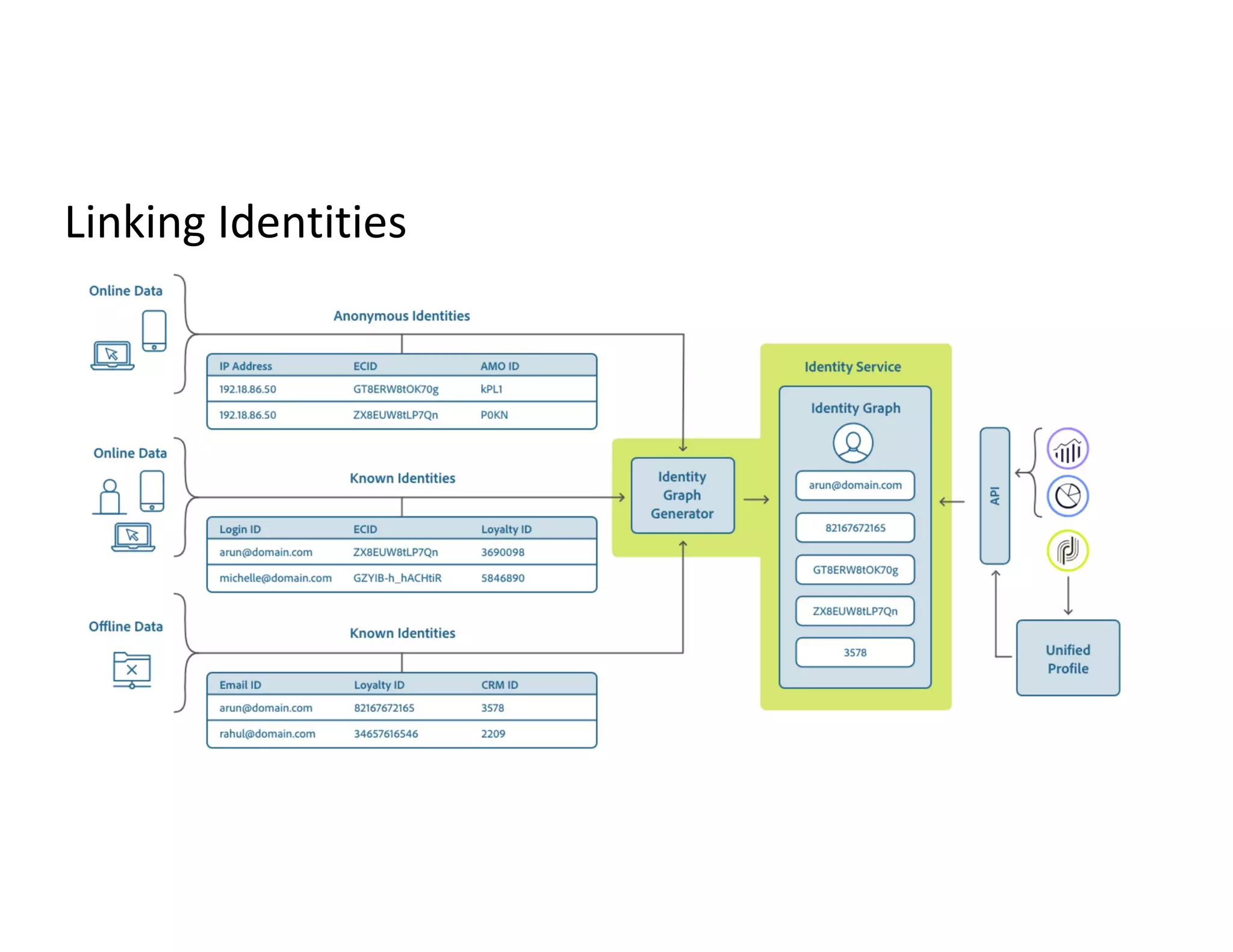
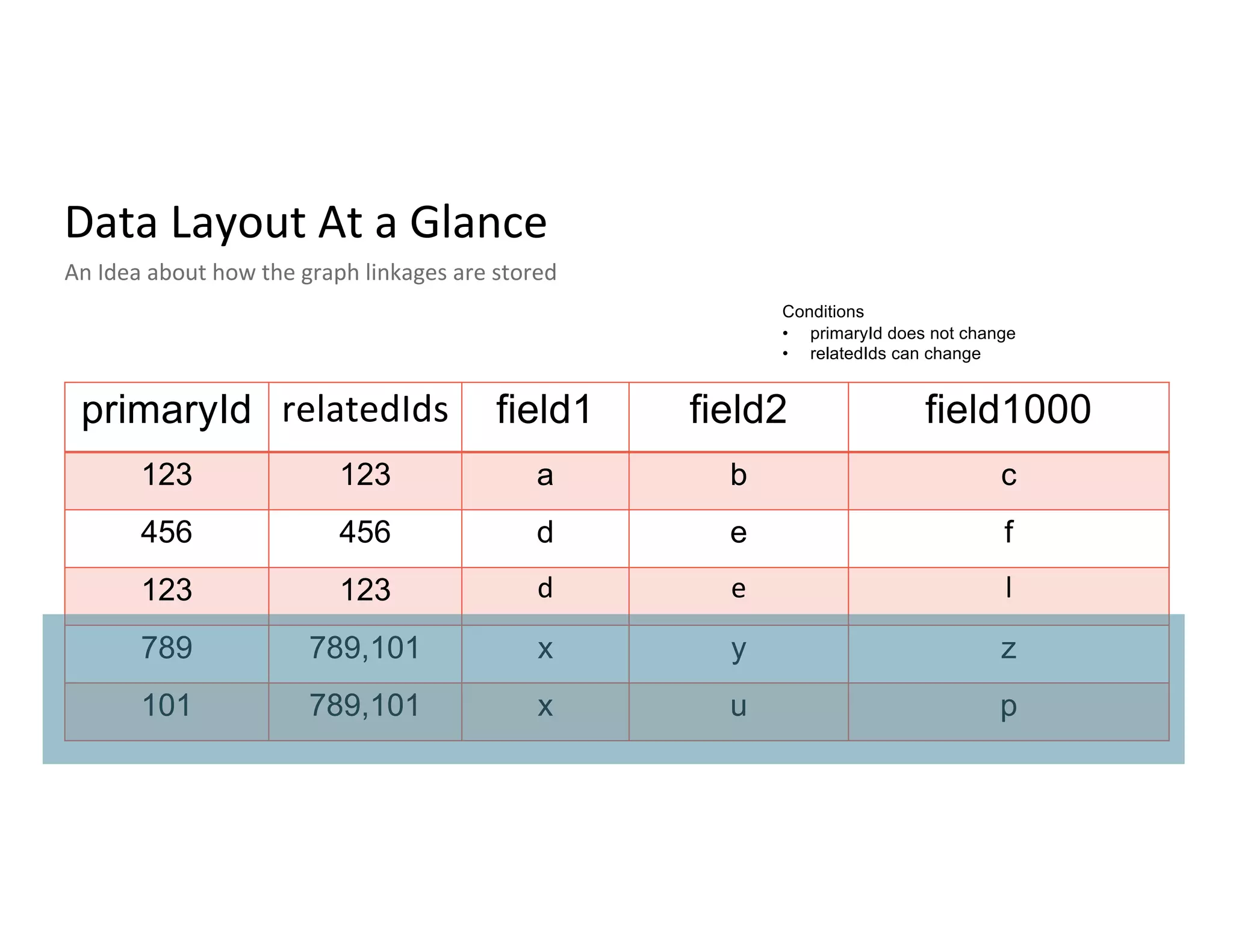
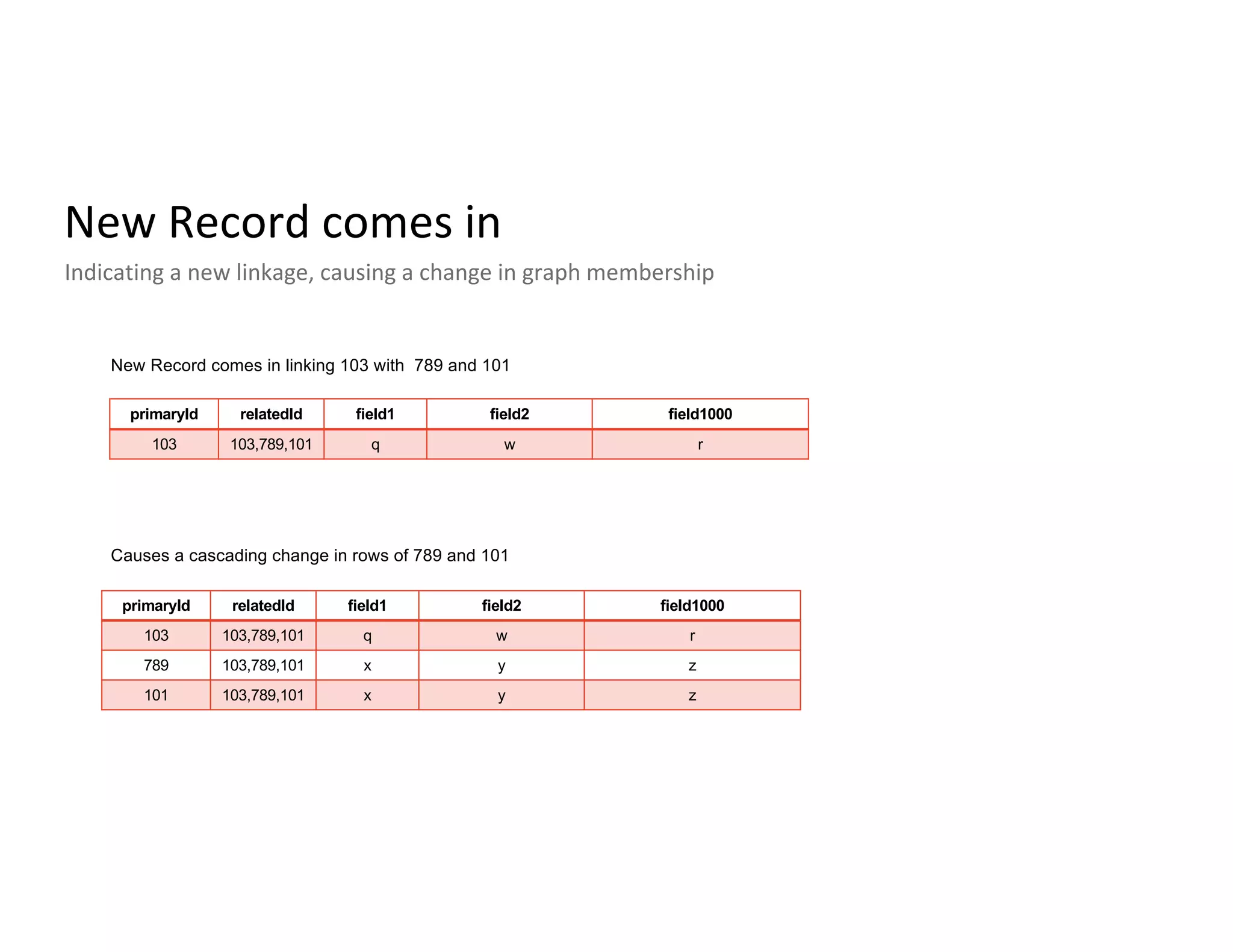
Description of unified profile ingestion and linkage of identities using a nested schema with examples of records.
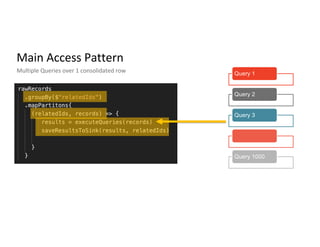
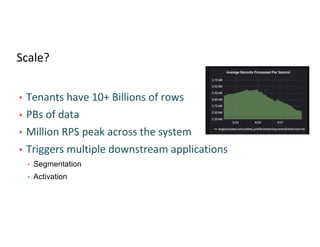
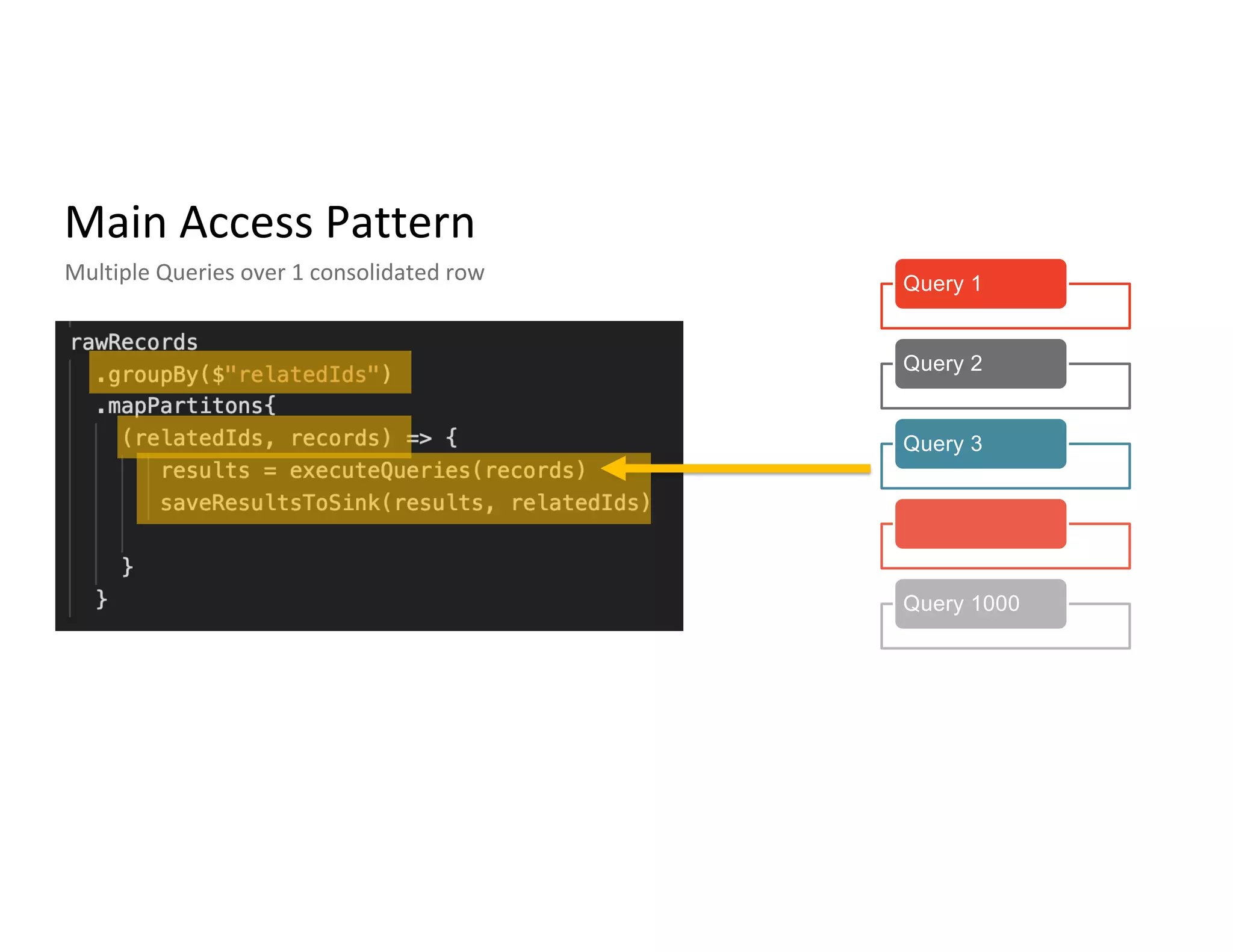
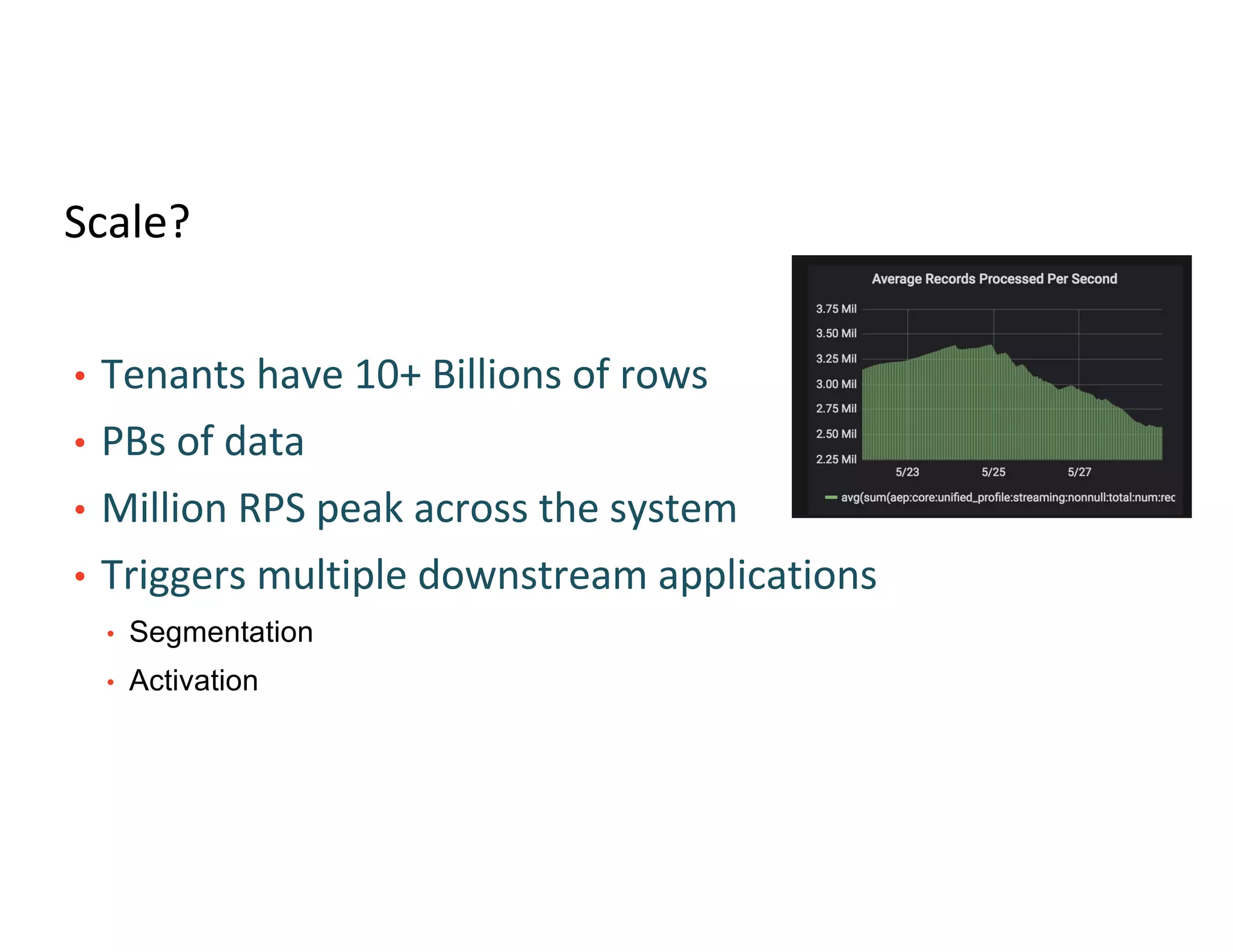
Main access patterns for queries, complexities from nested fields, and scale metrics like billions of rows.
Overview of Delta Lake as a Lakehouse architecture, highlighting key features such as ACID transactions and schema enforcement.
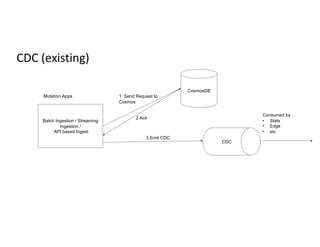
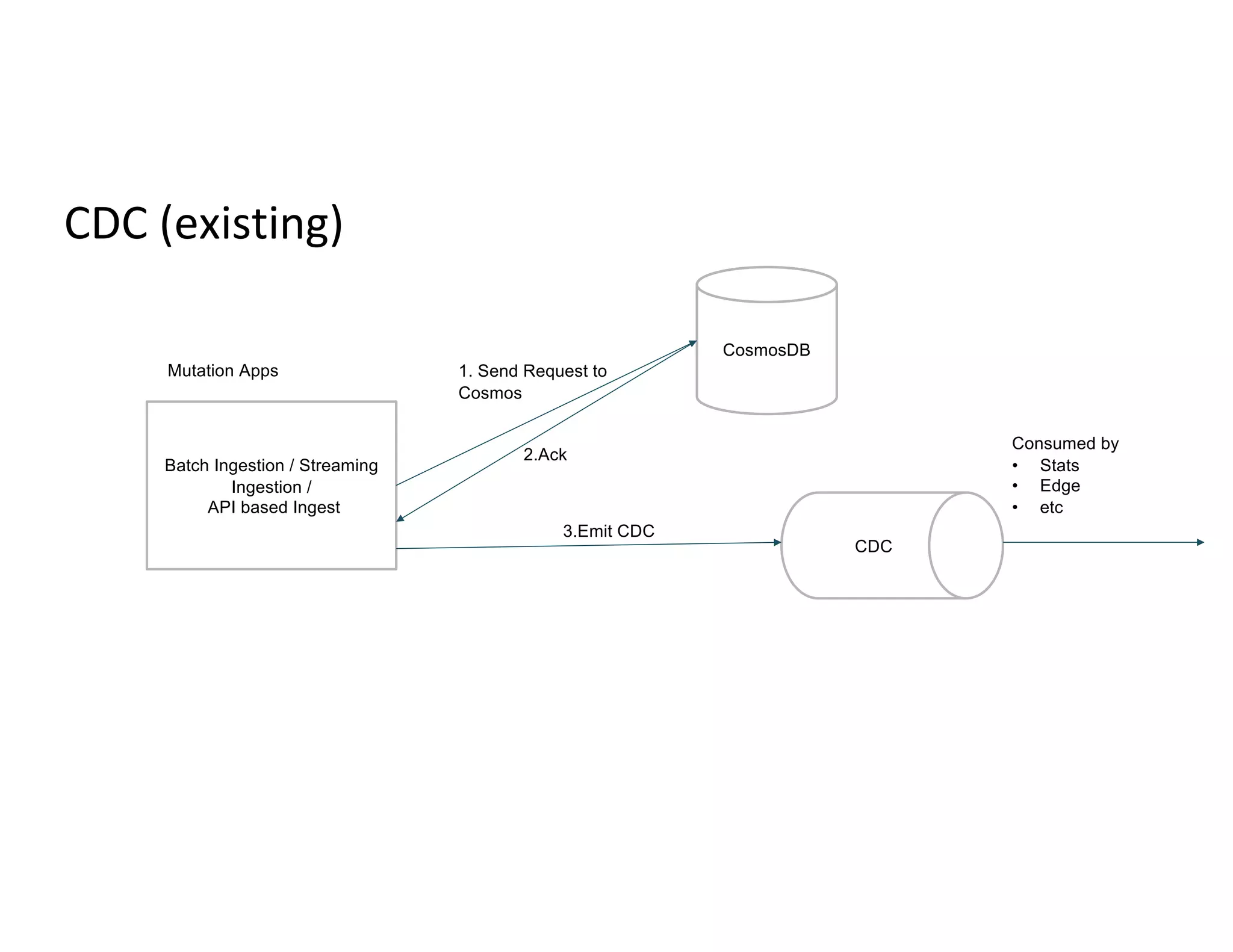
Addressing concurrency issues and challenges in data ingestion, including CDC strategies for mutation apps.
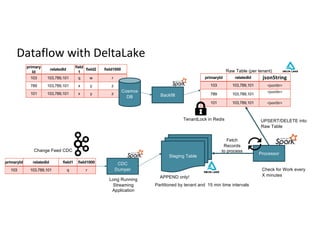
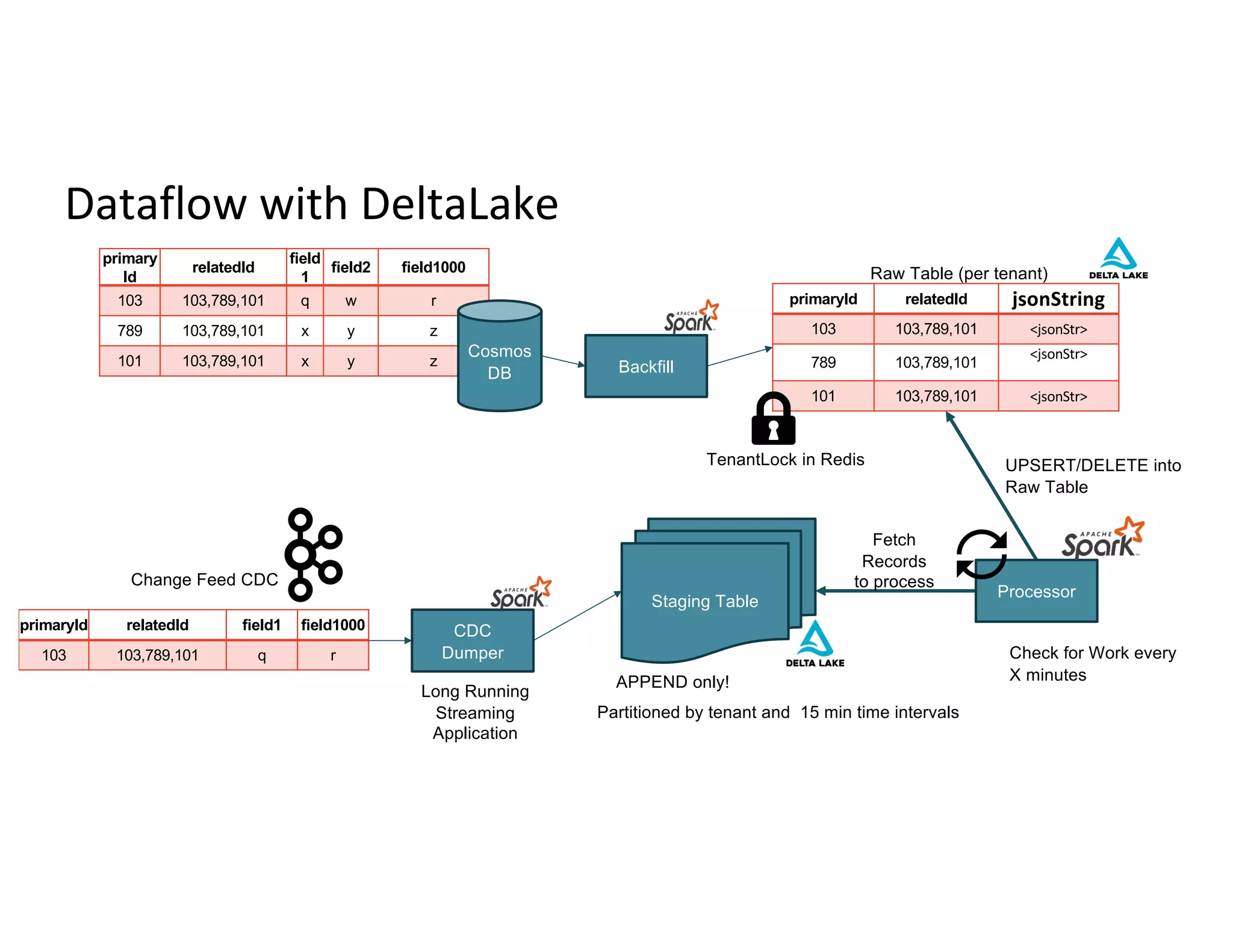
Detailed flow of data through Delta Lake with emphasis on staging tables to manage data efficiently.
Reasons for using JSON for lazy schema on-read and tackling schema evolution challenges.
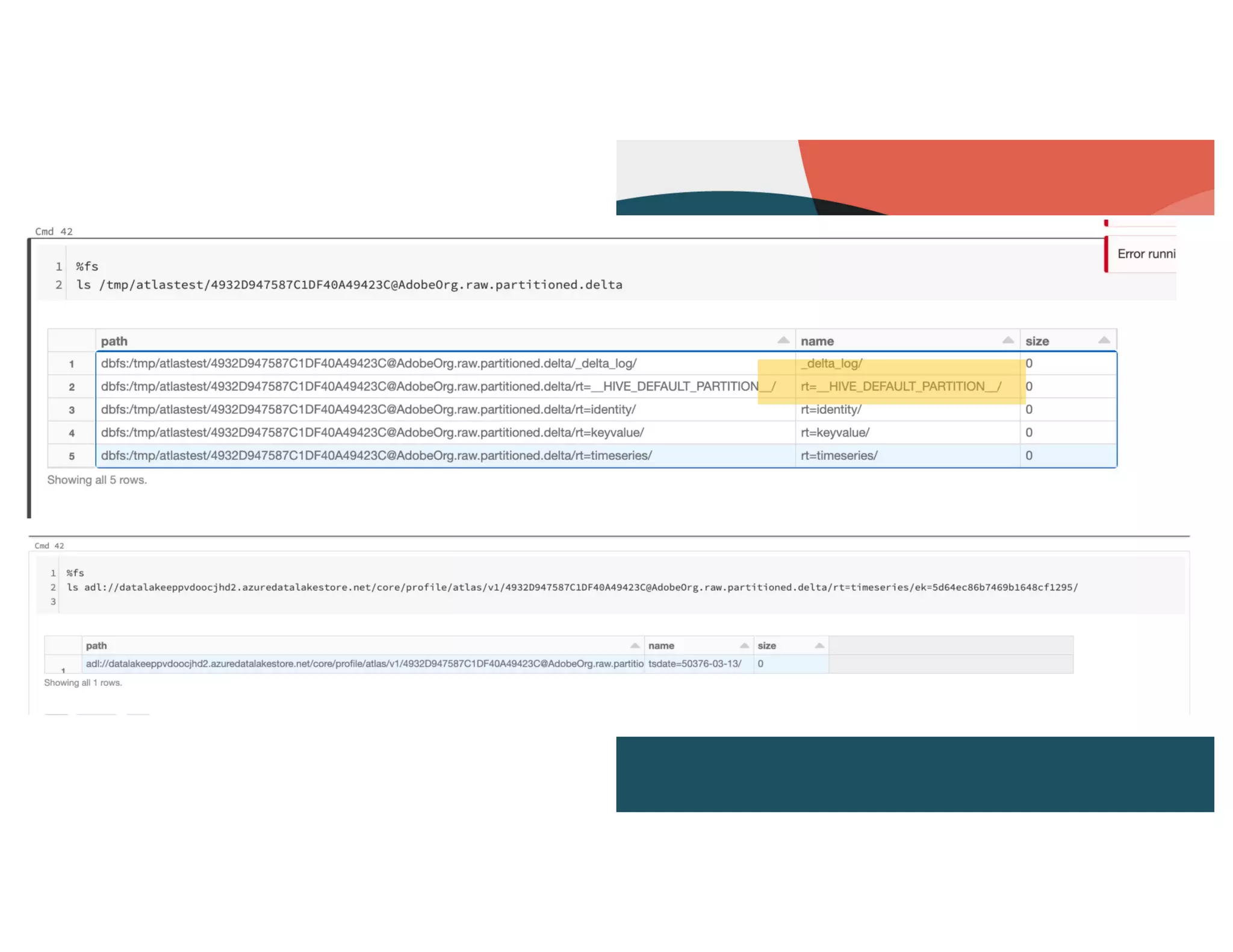
Partitioning strategies for raw records and types of replication lag in tracking data readiness.
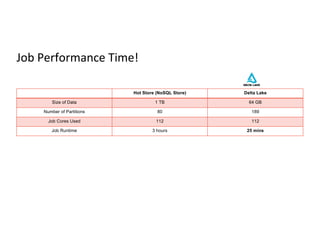
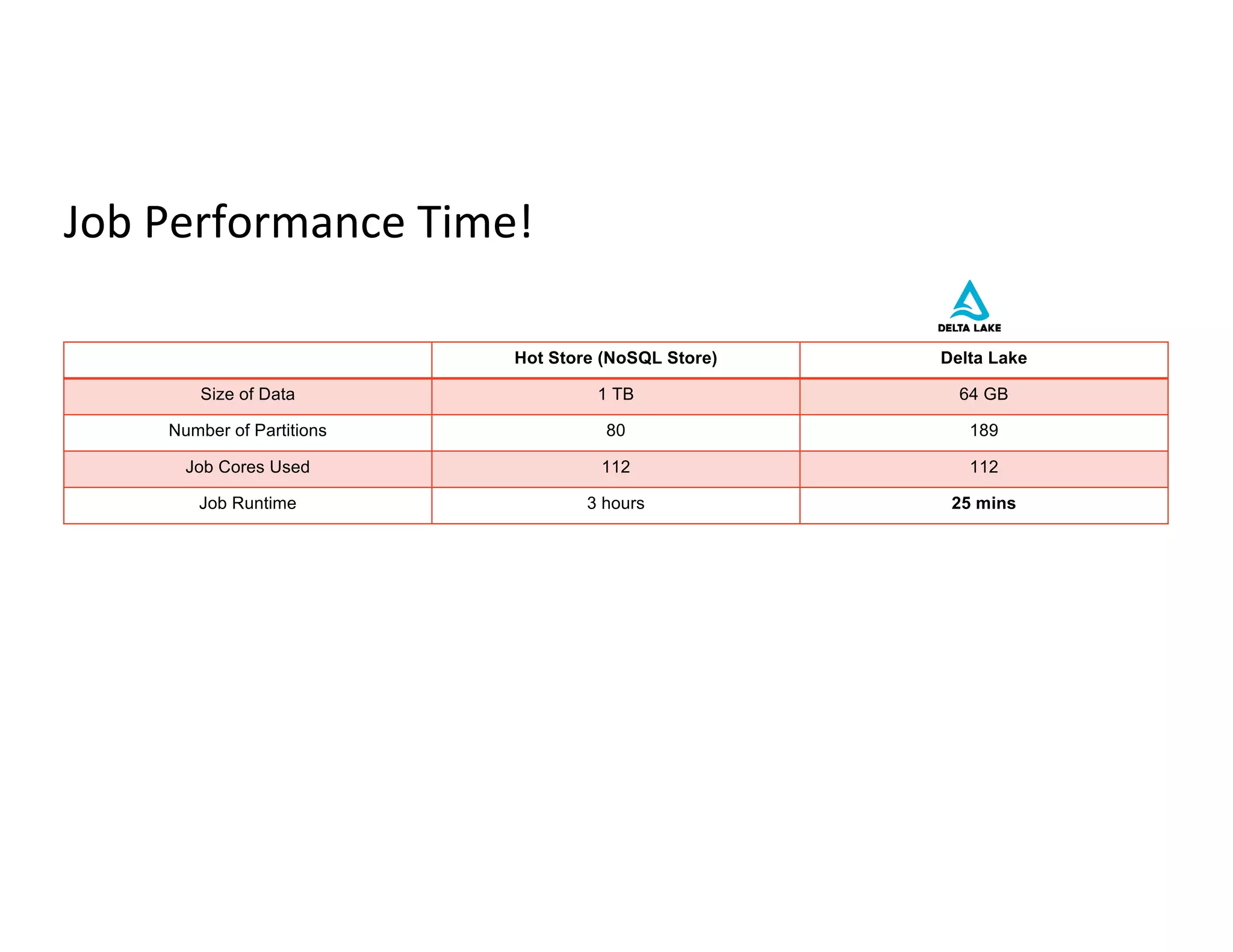
Performance metrics including UPSERT timings and comparisons between Delta Lake and NoSQL store efficiency.
Encouragement for feedback and session review, highlighting the importance of user input.











































![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
























![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
