Download as PDF, PPTX


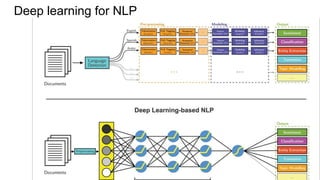





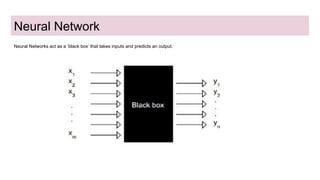

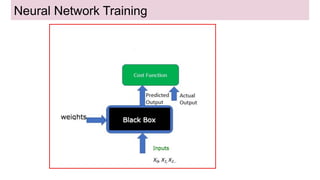

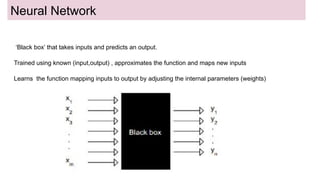
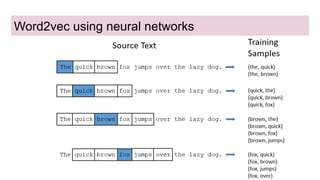
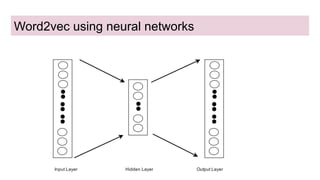
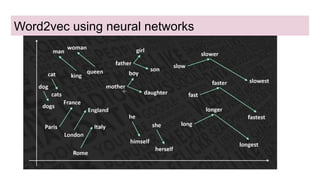



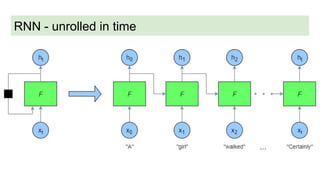
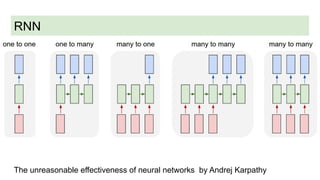

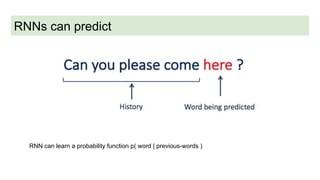
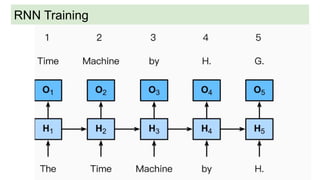

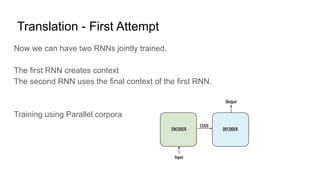

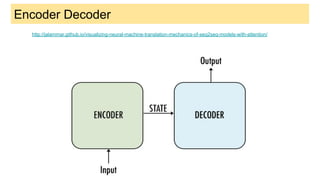
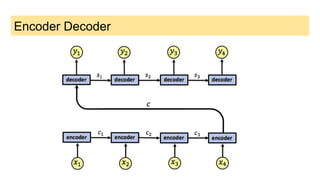
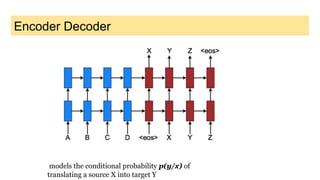
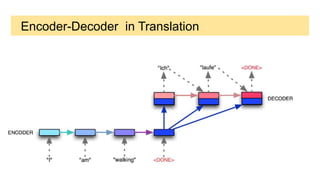



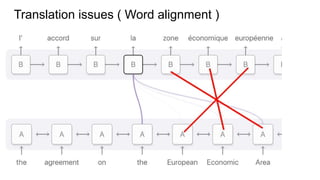

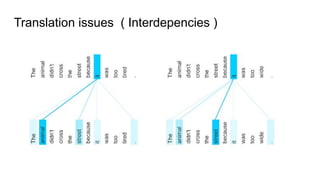




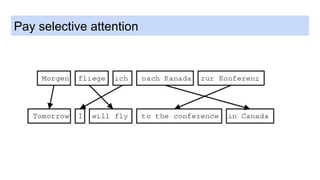

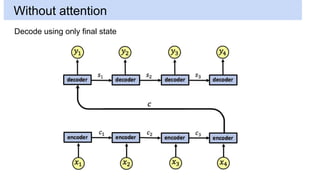
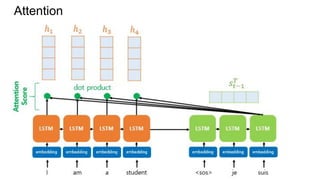
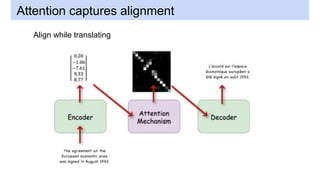



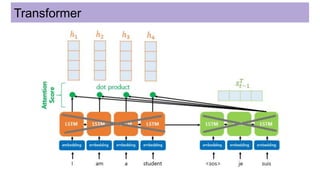
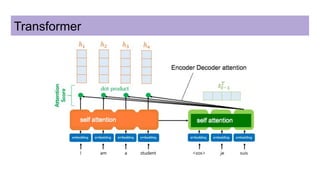


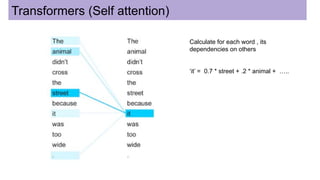

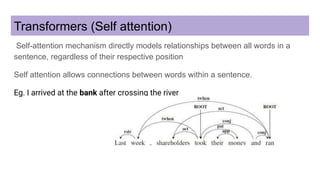

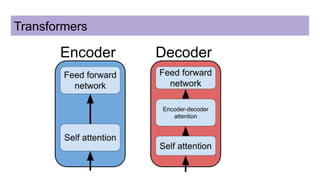
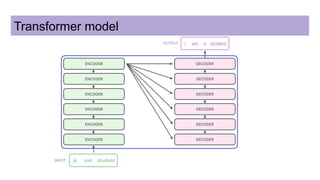
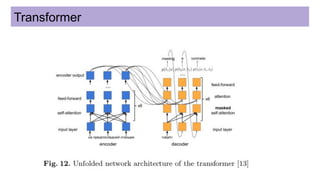
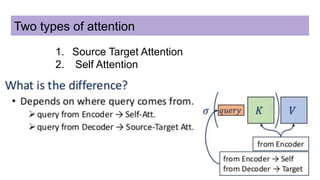




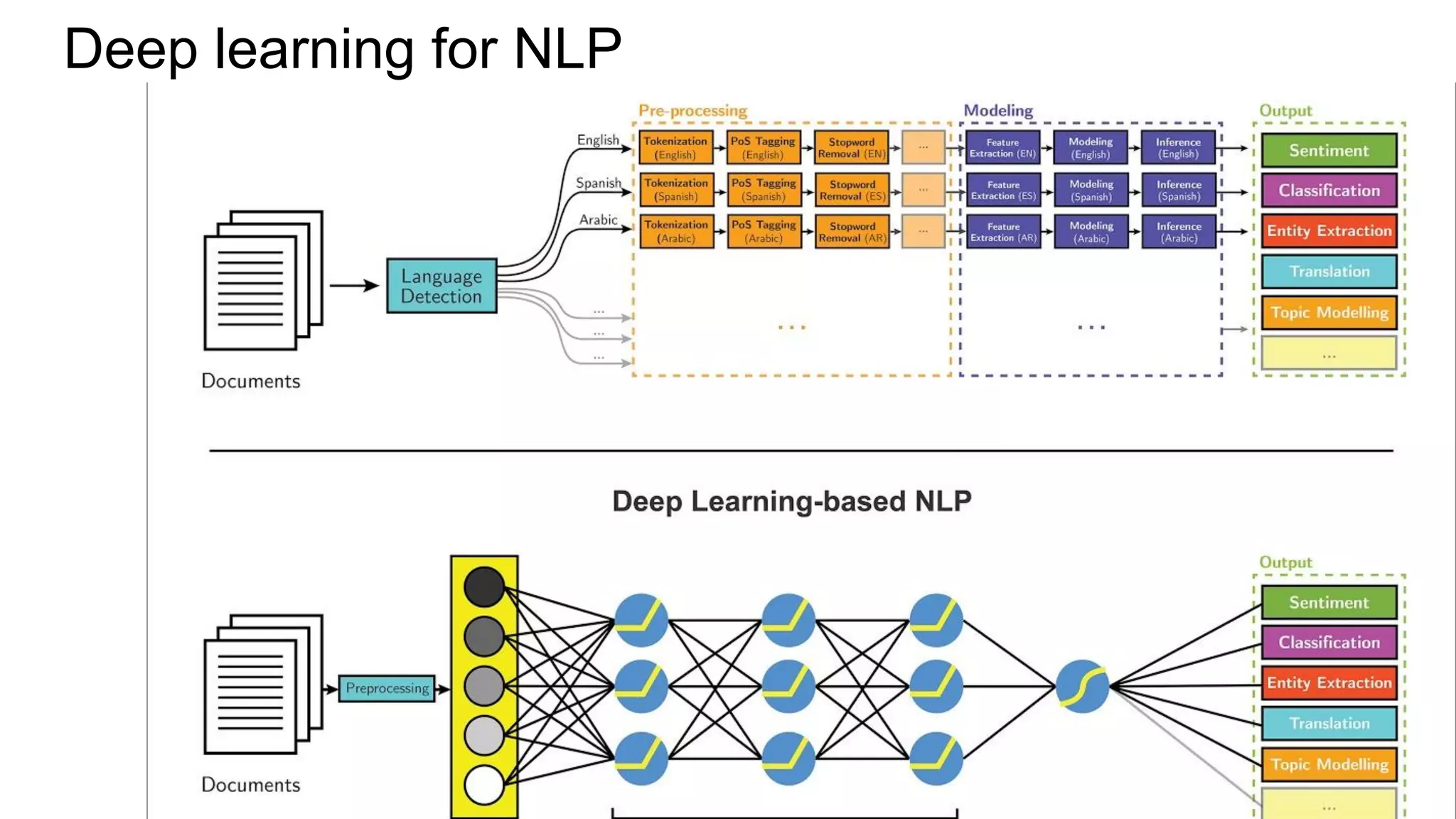





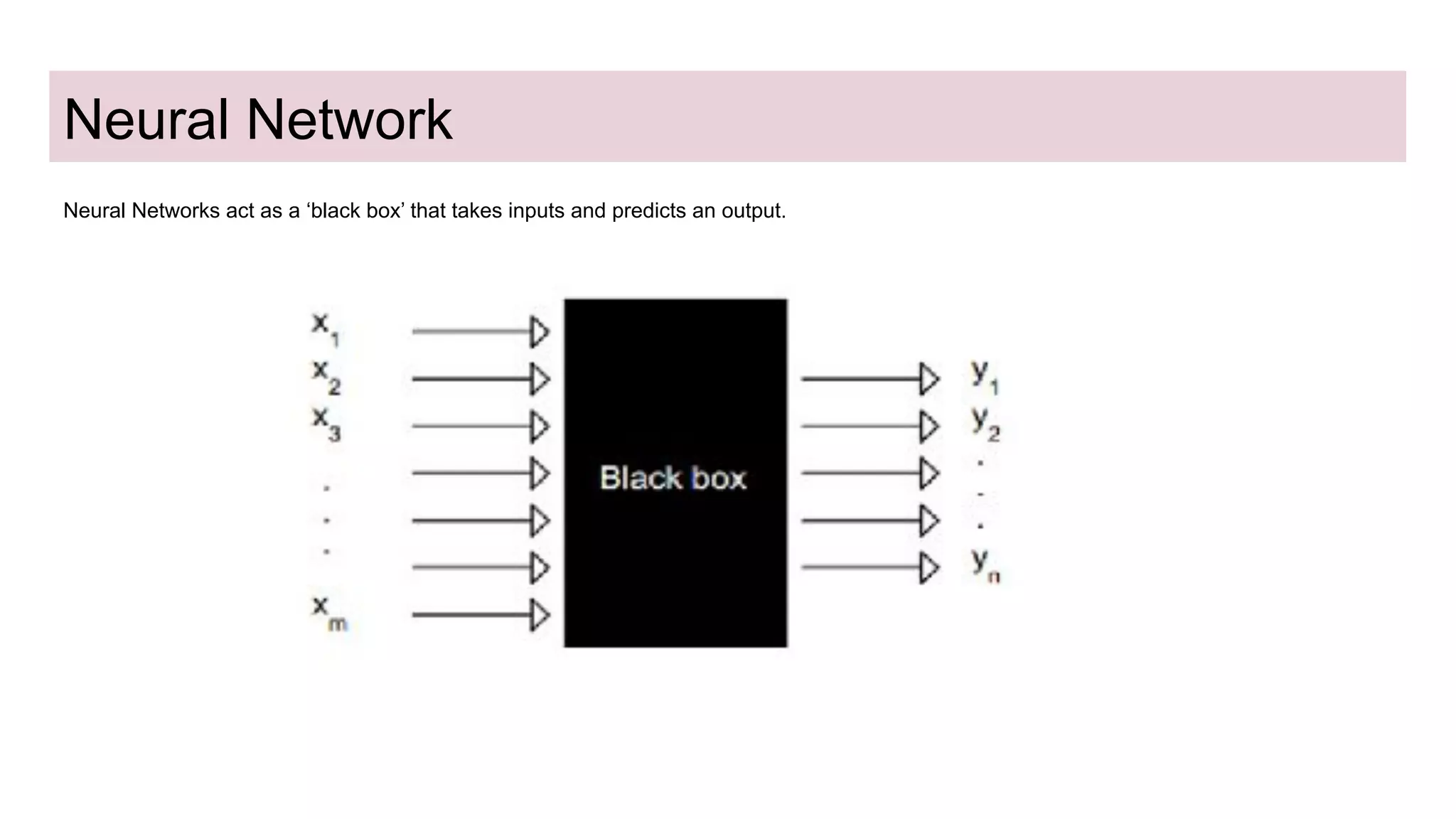
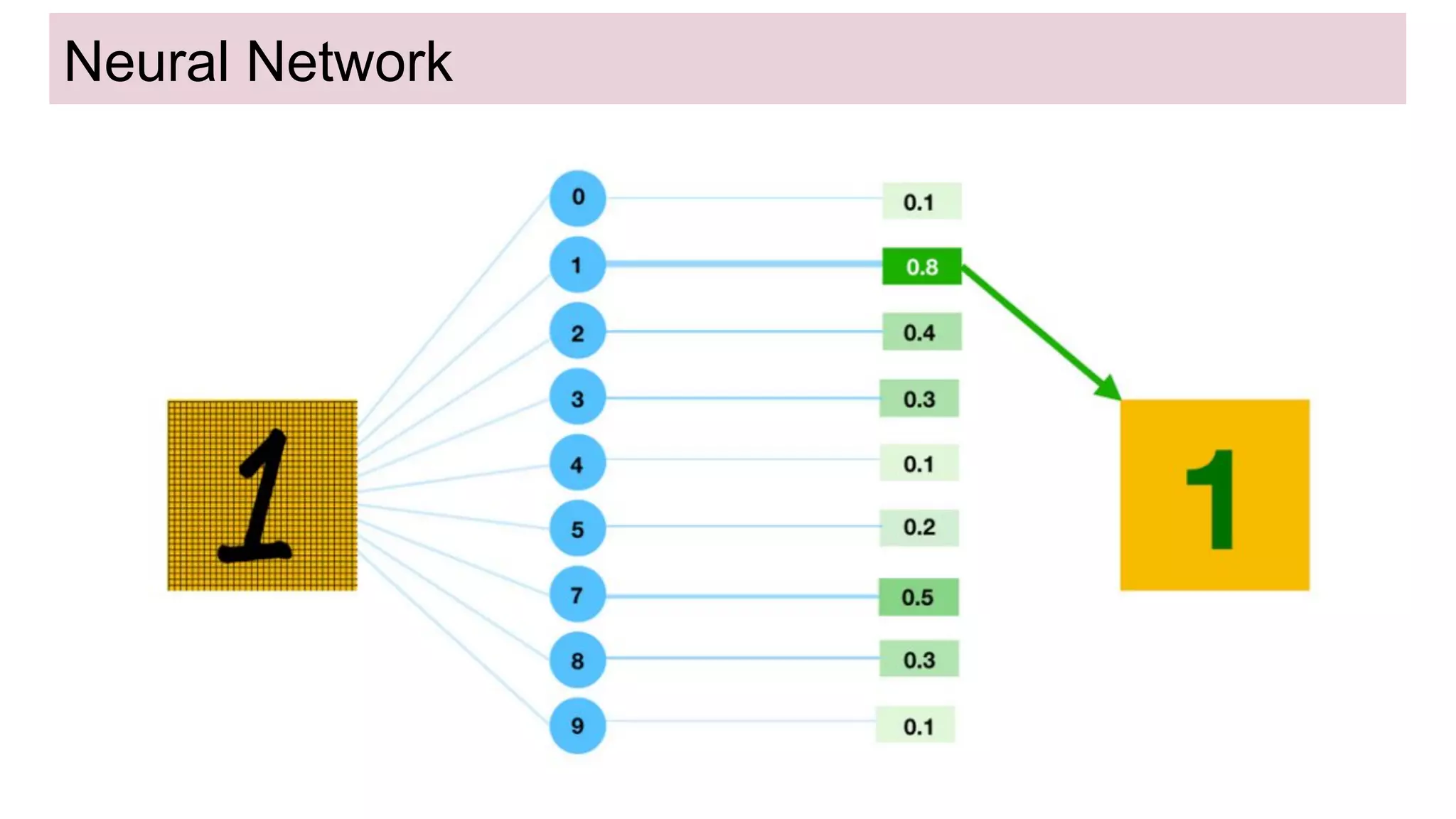
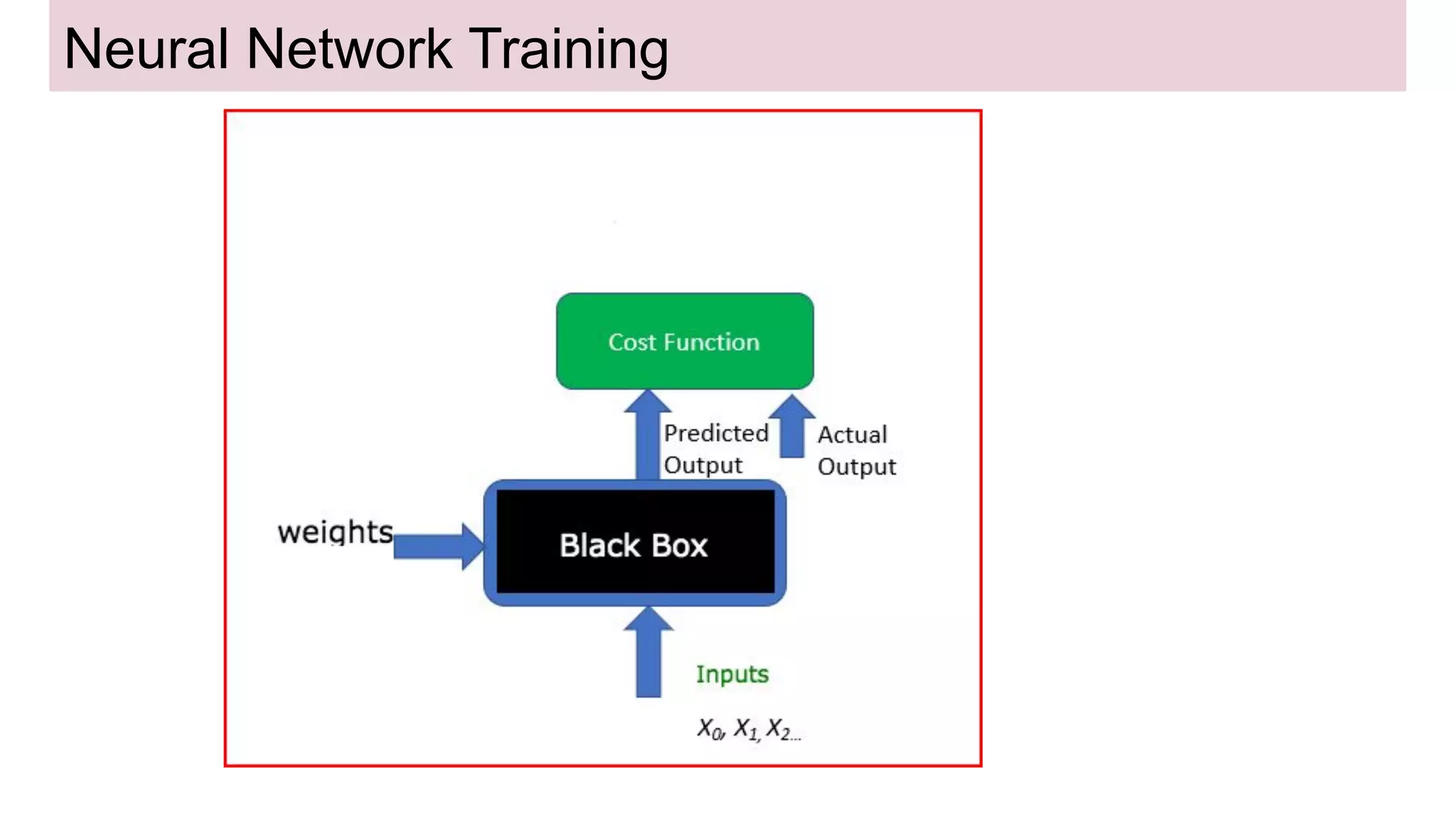
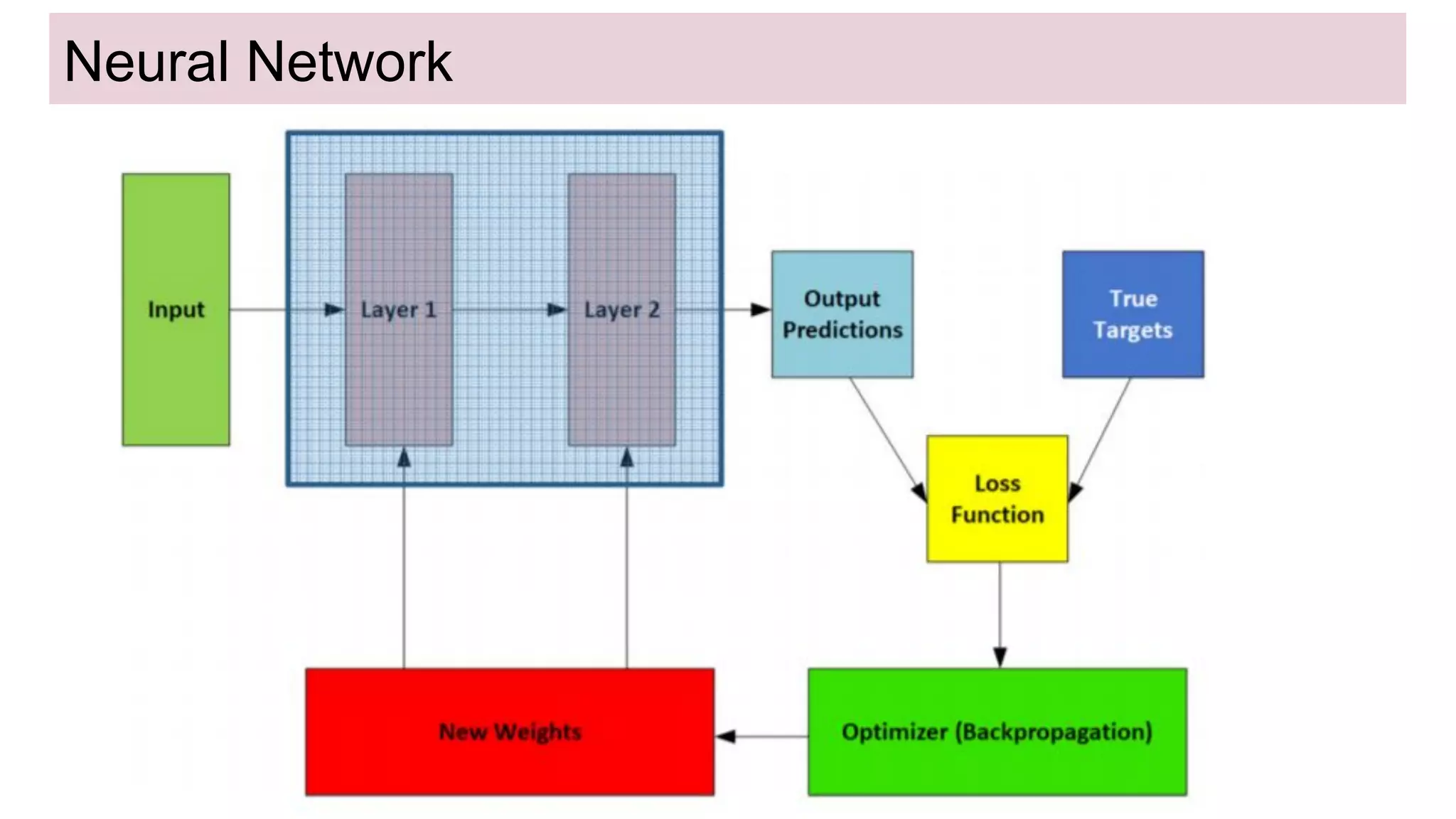
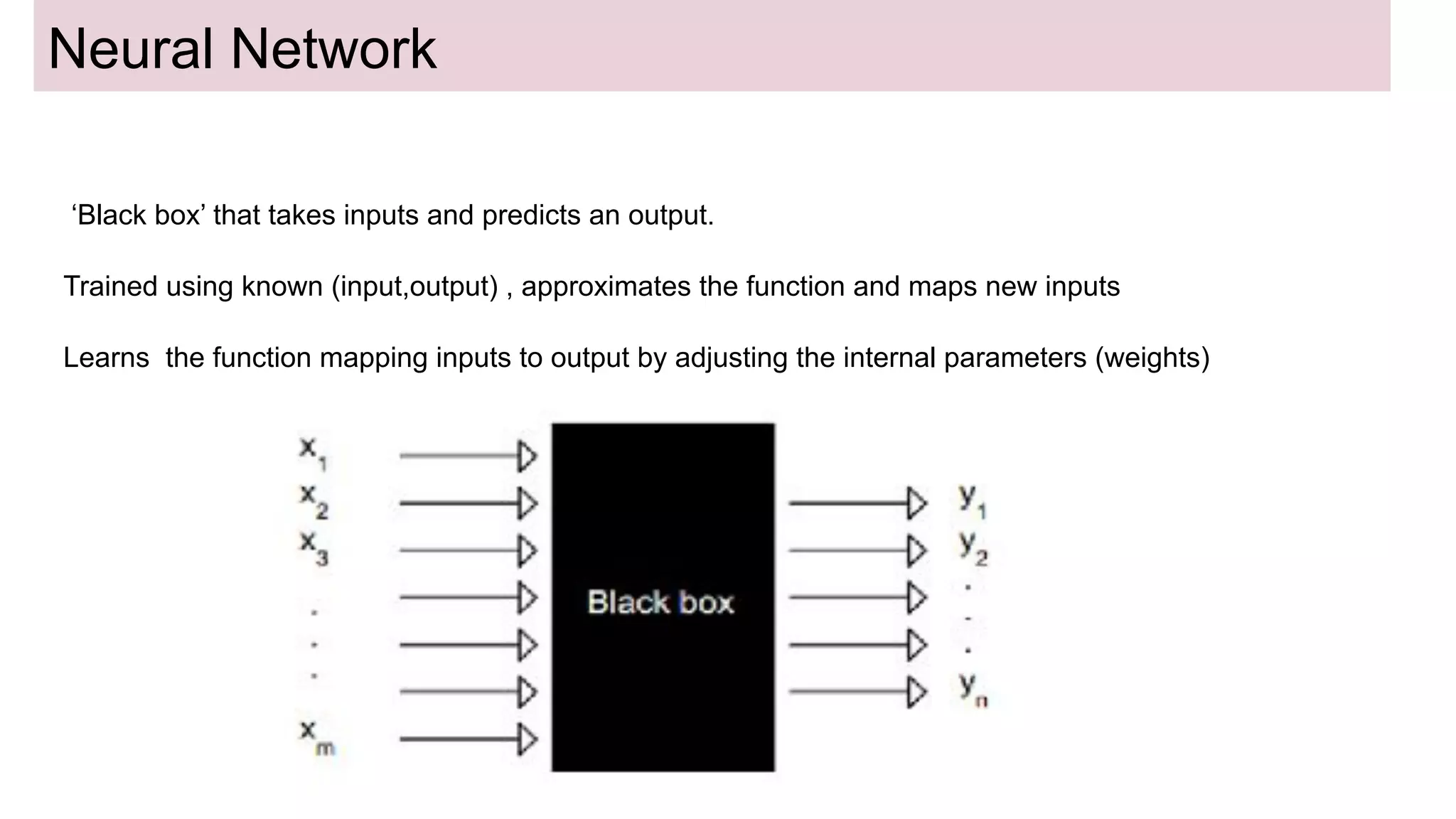
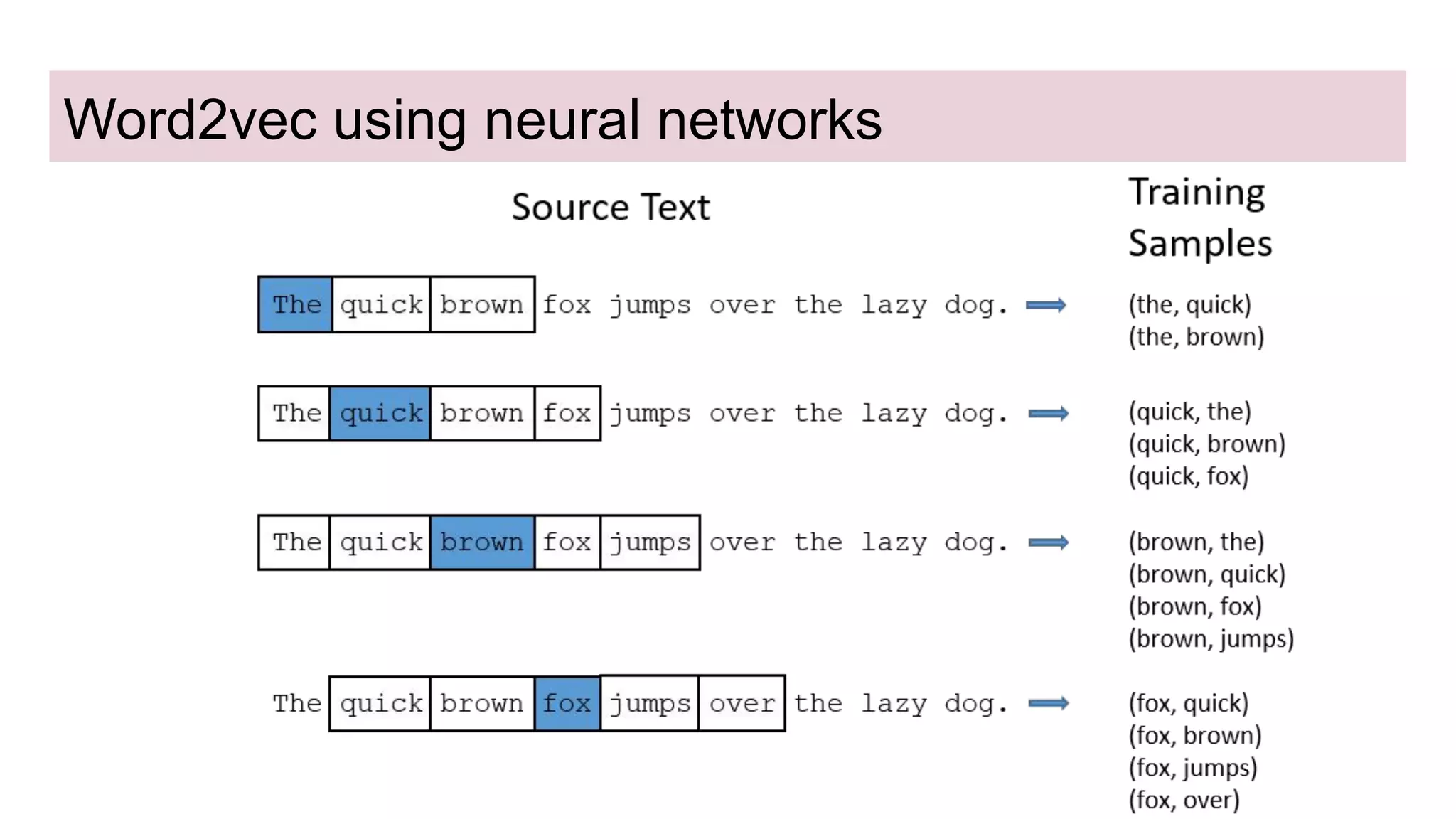
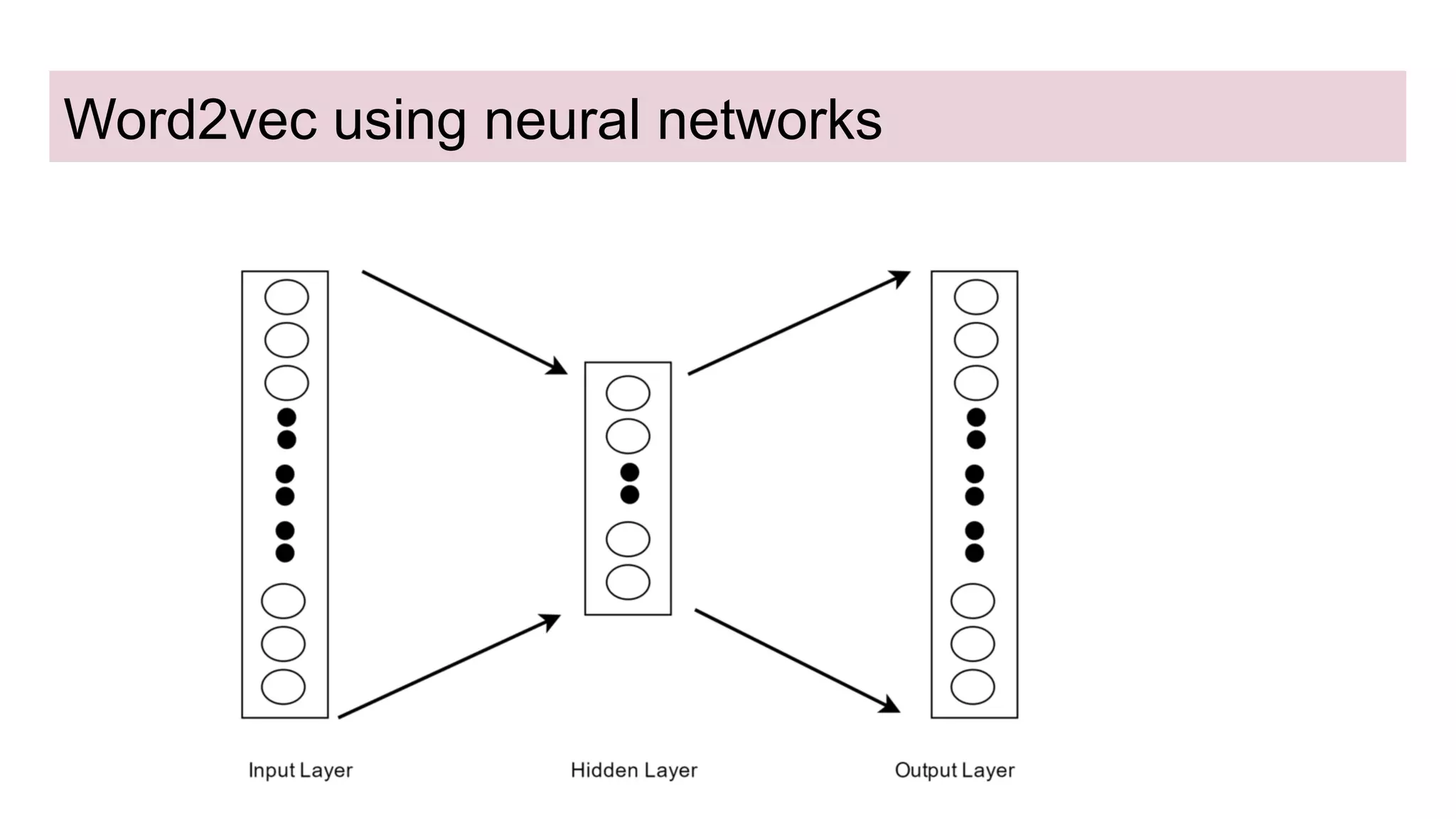




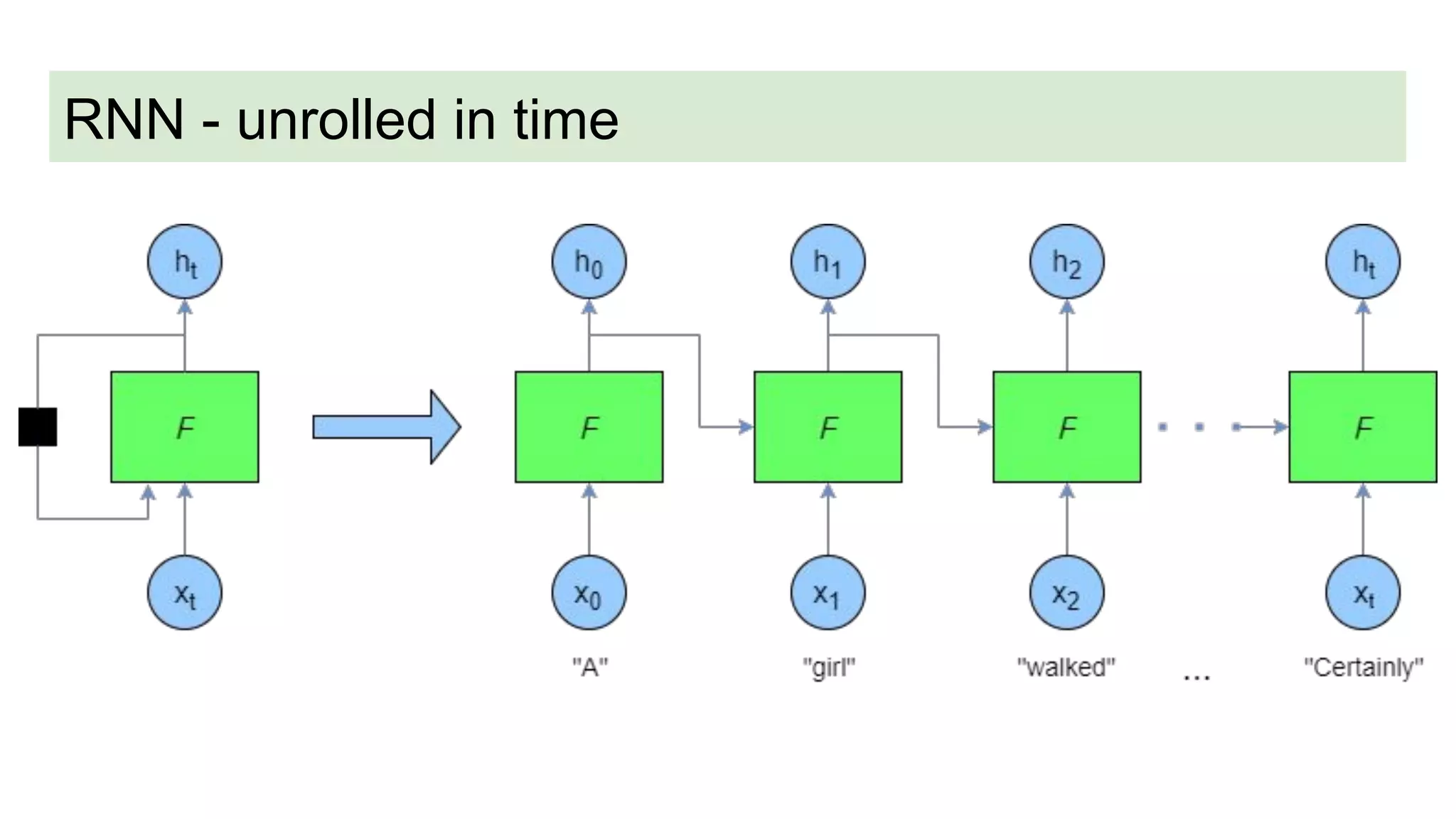


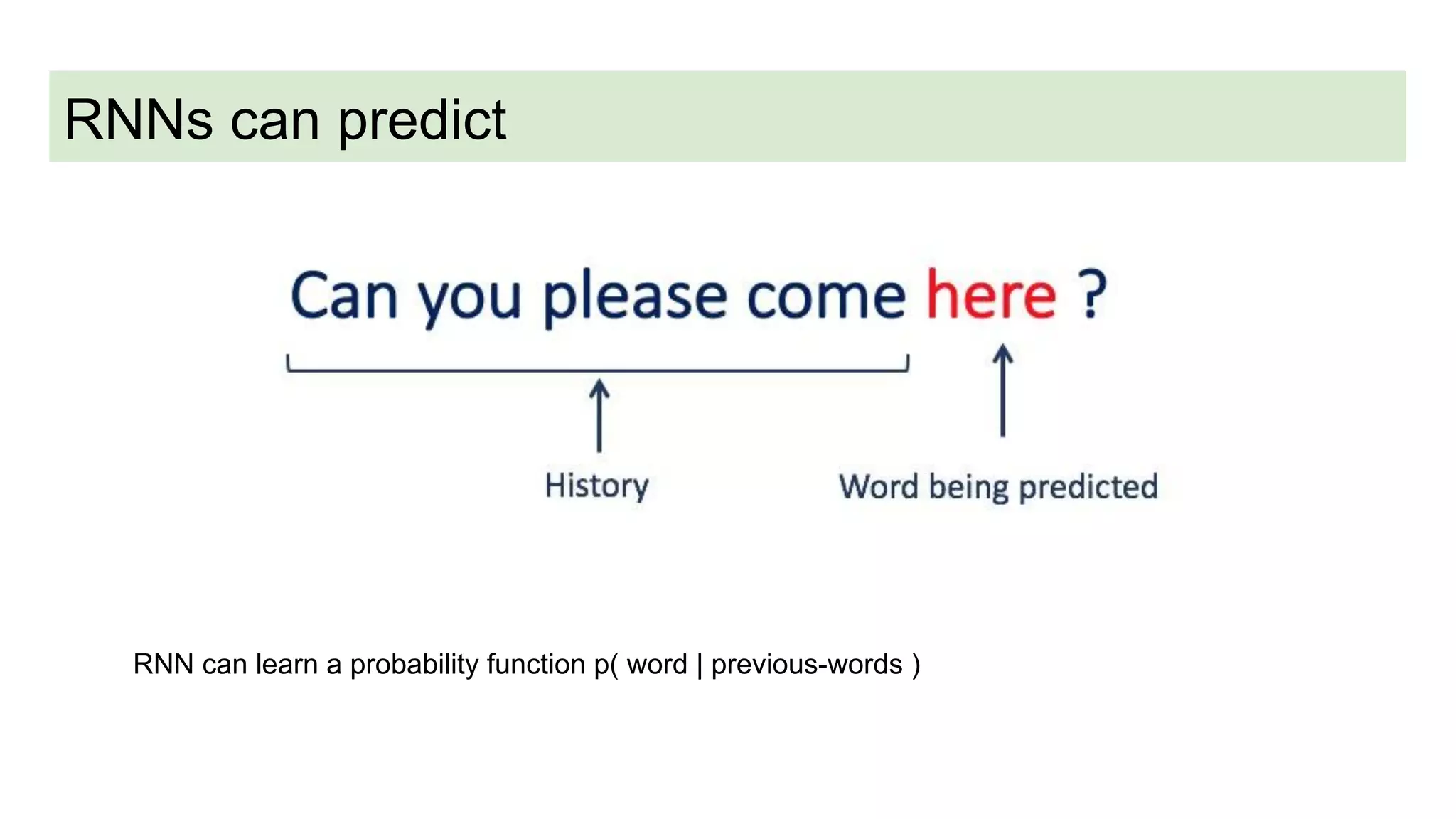
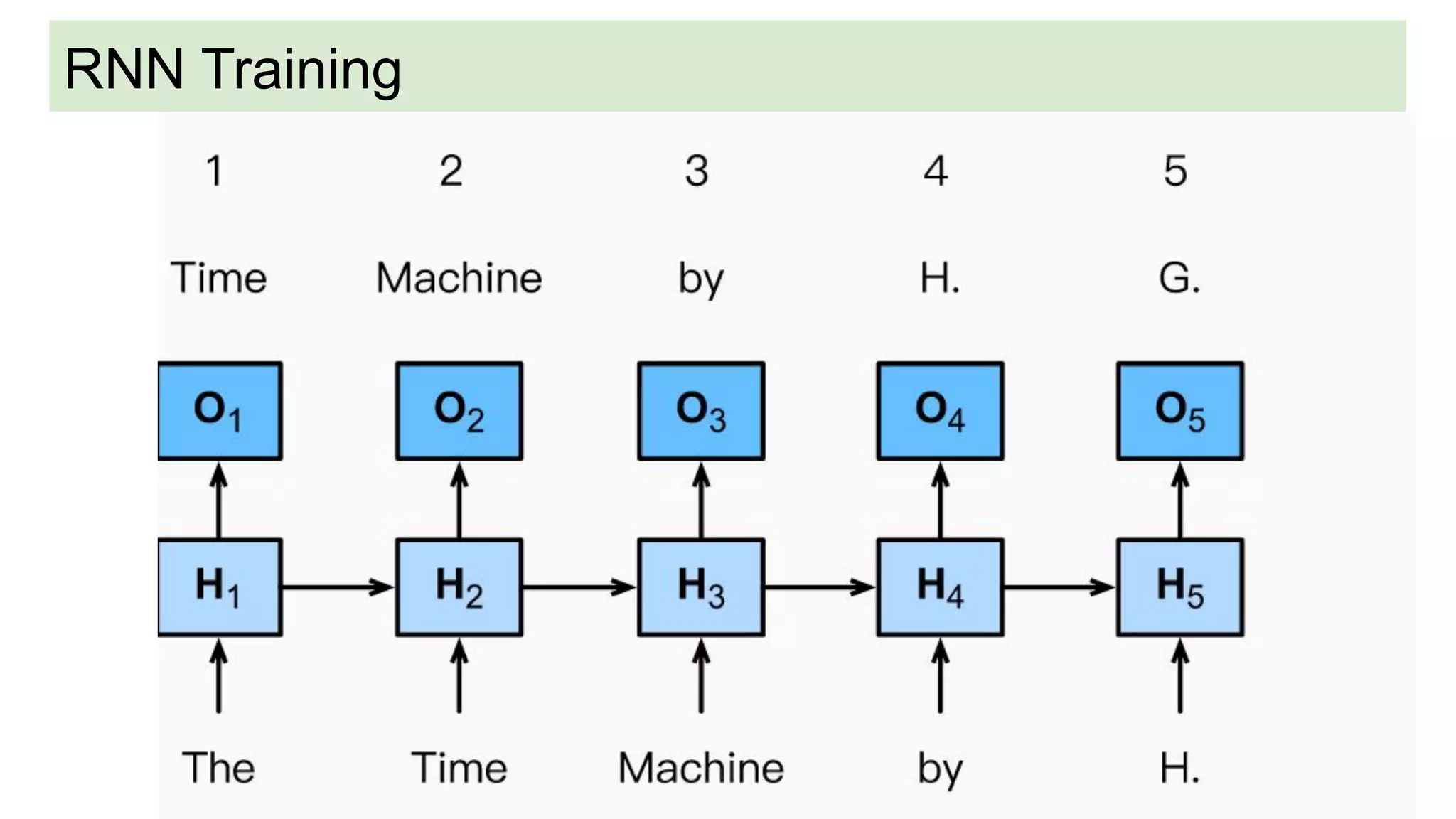


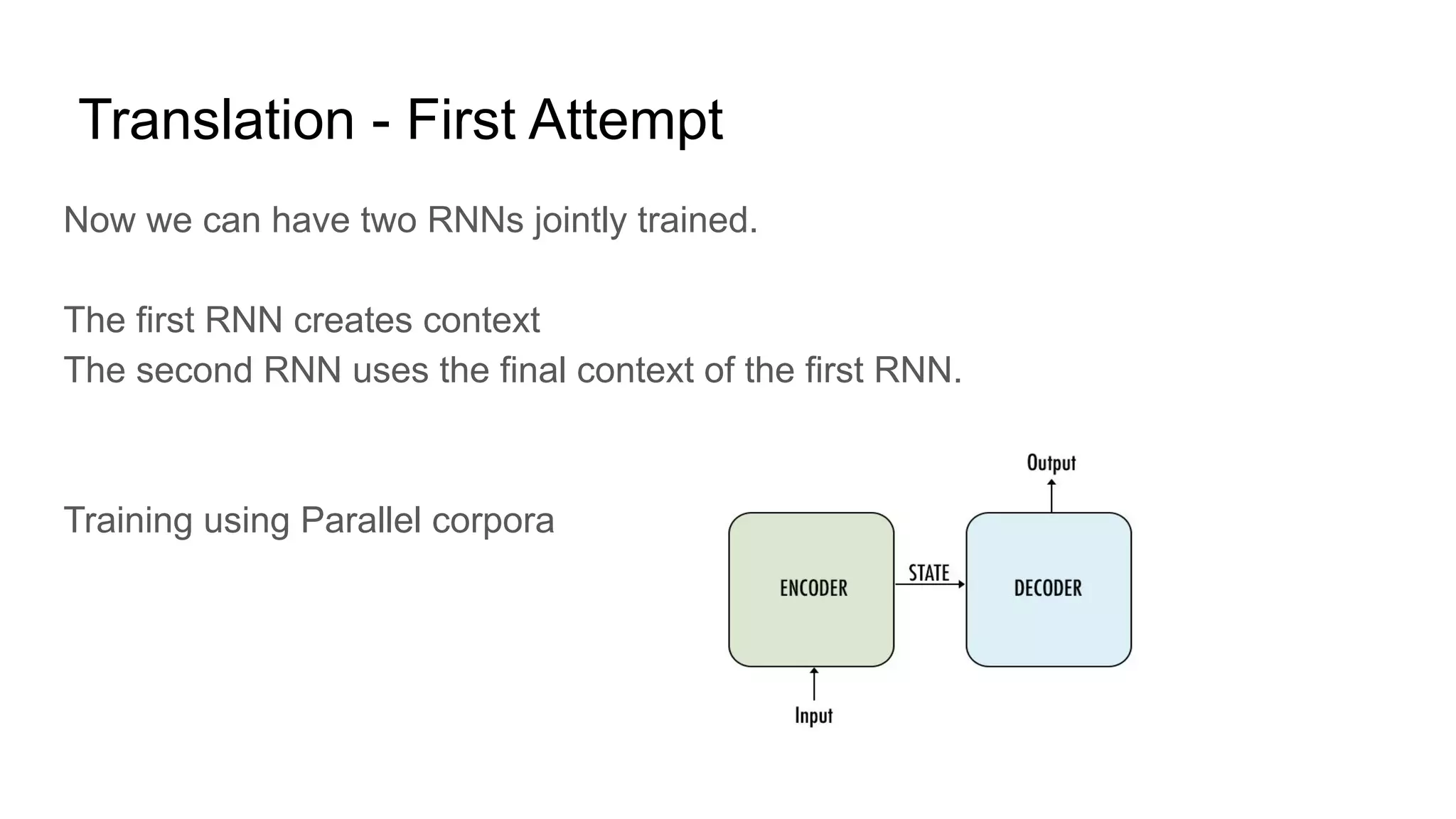

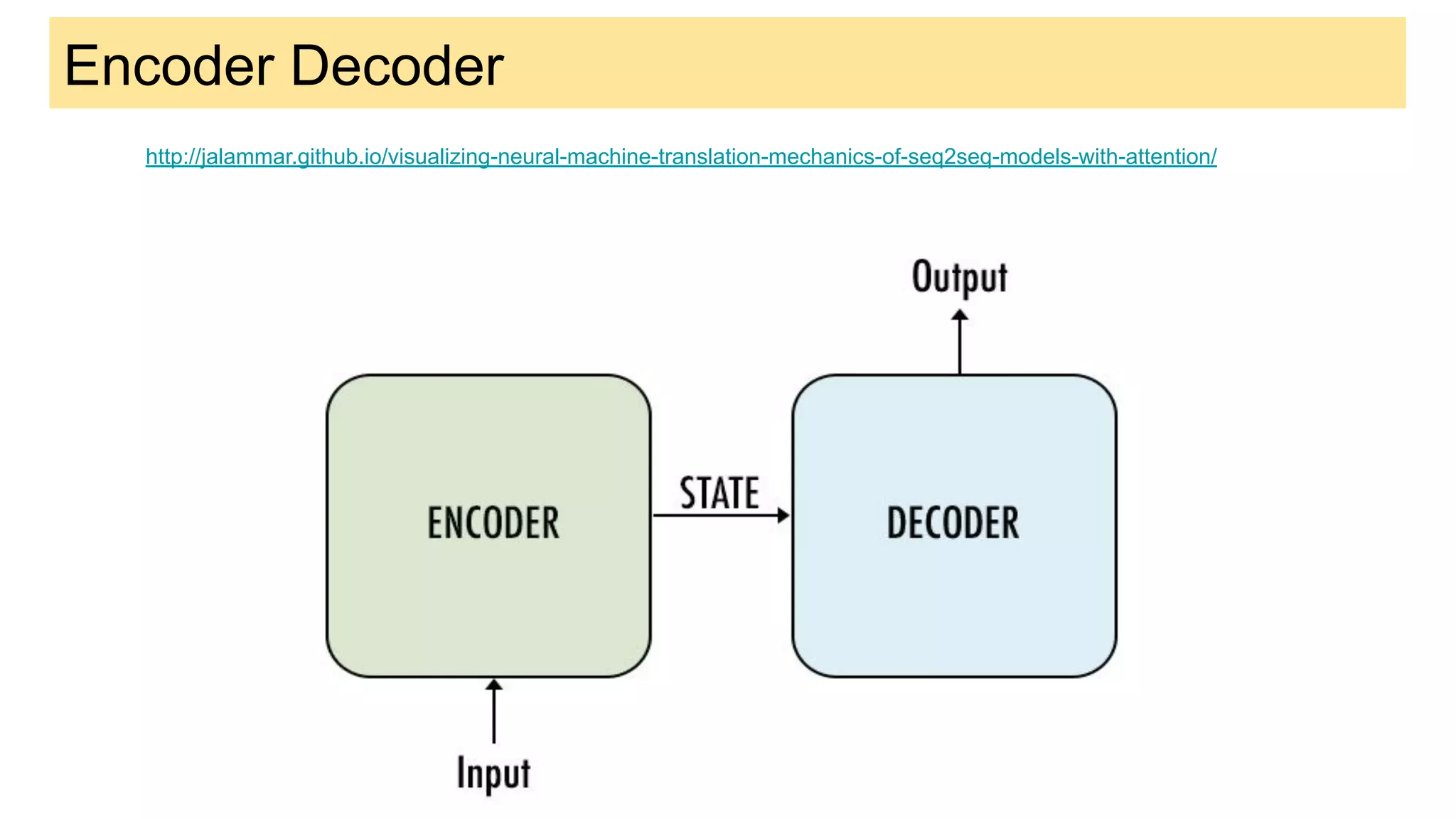
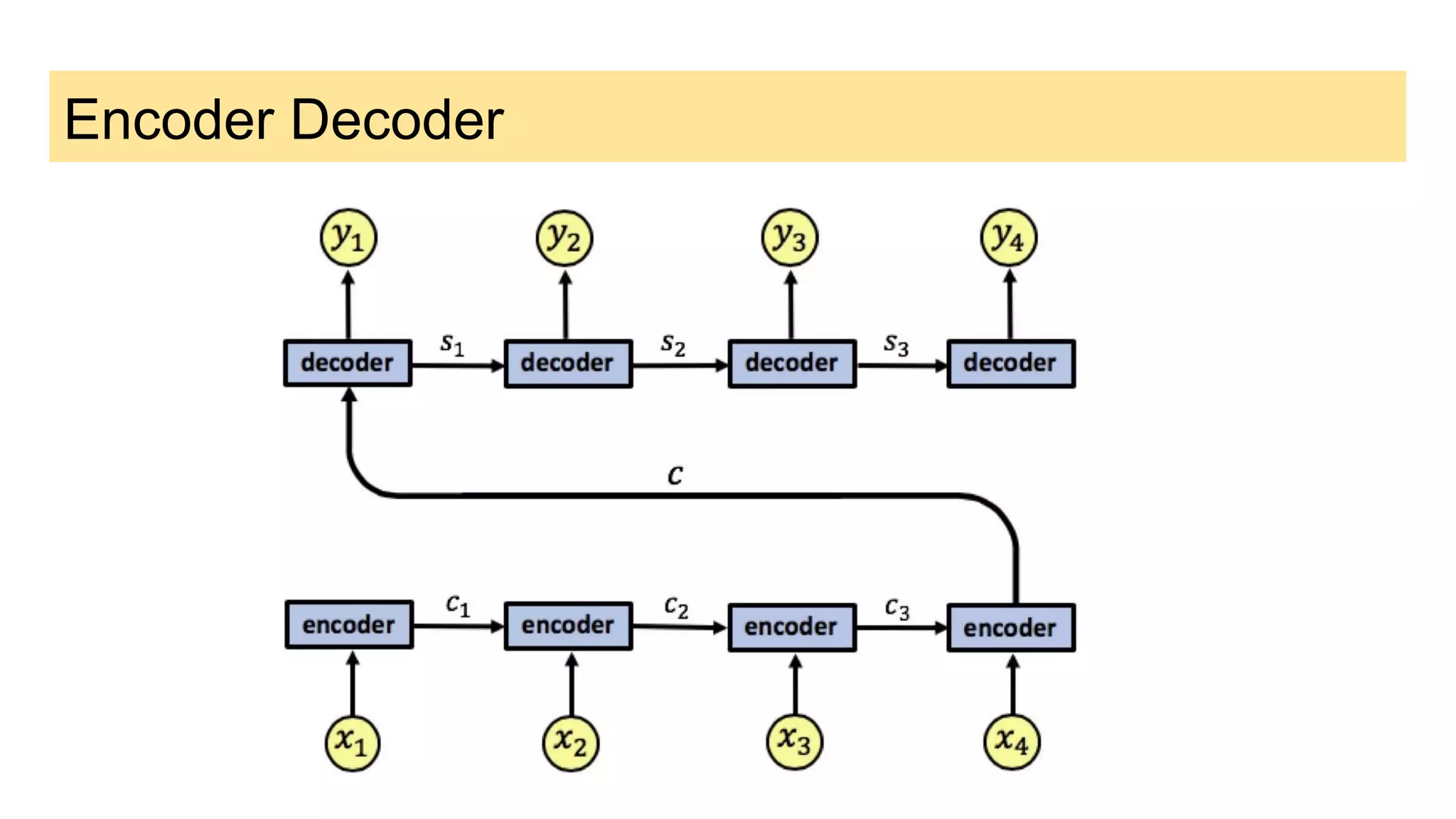

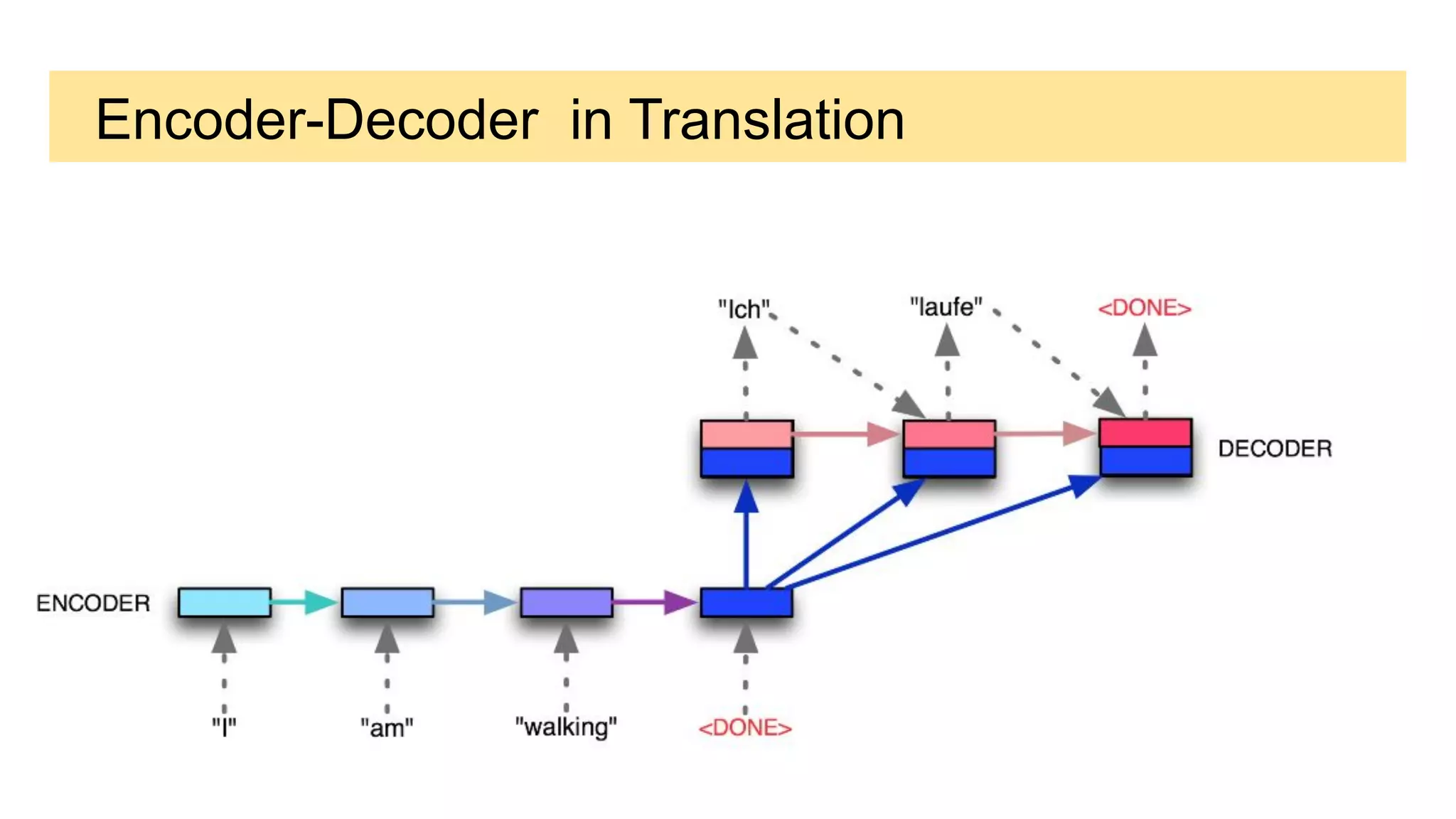



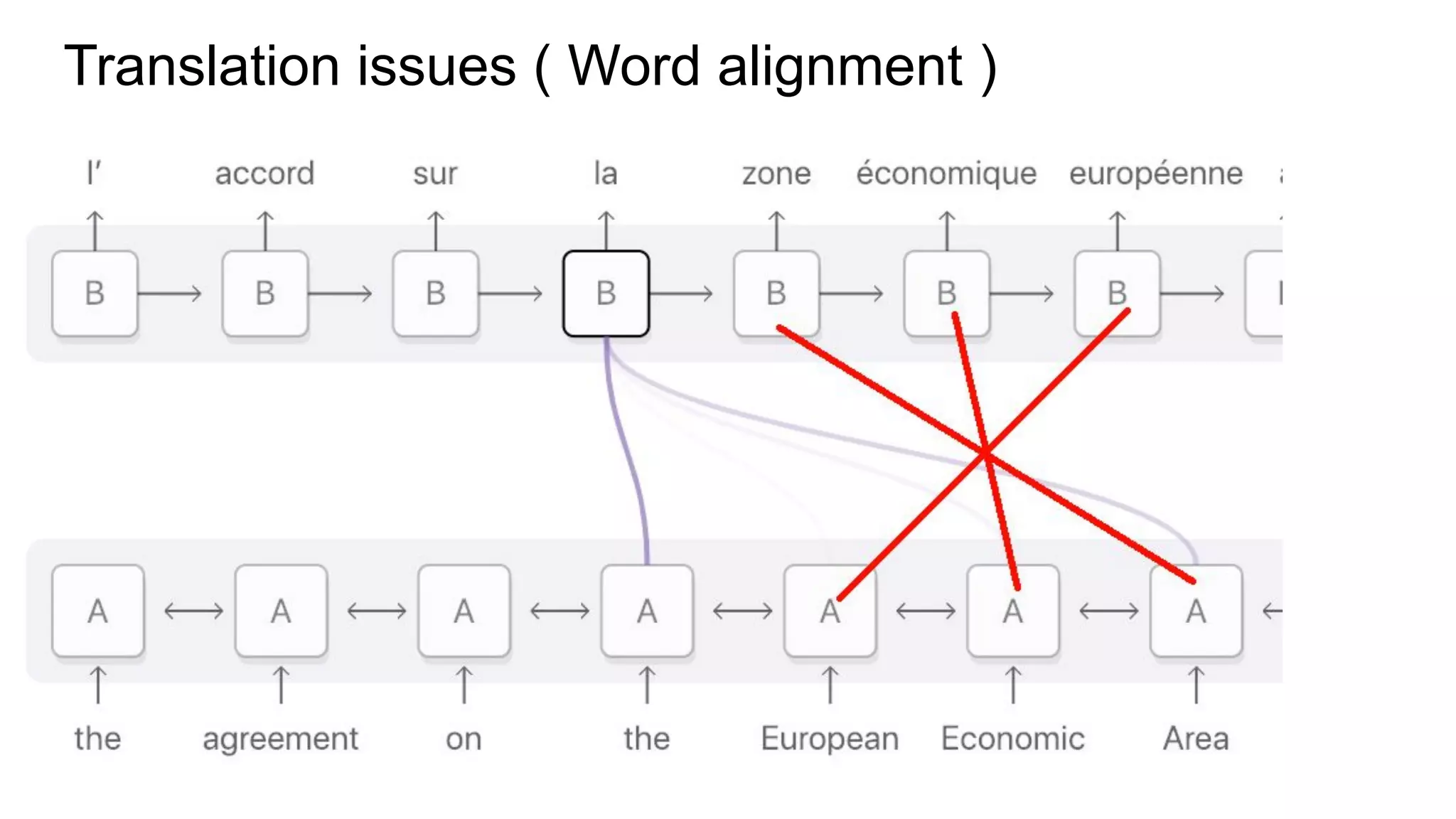






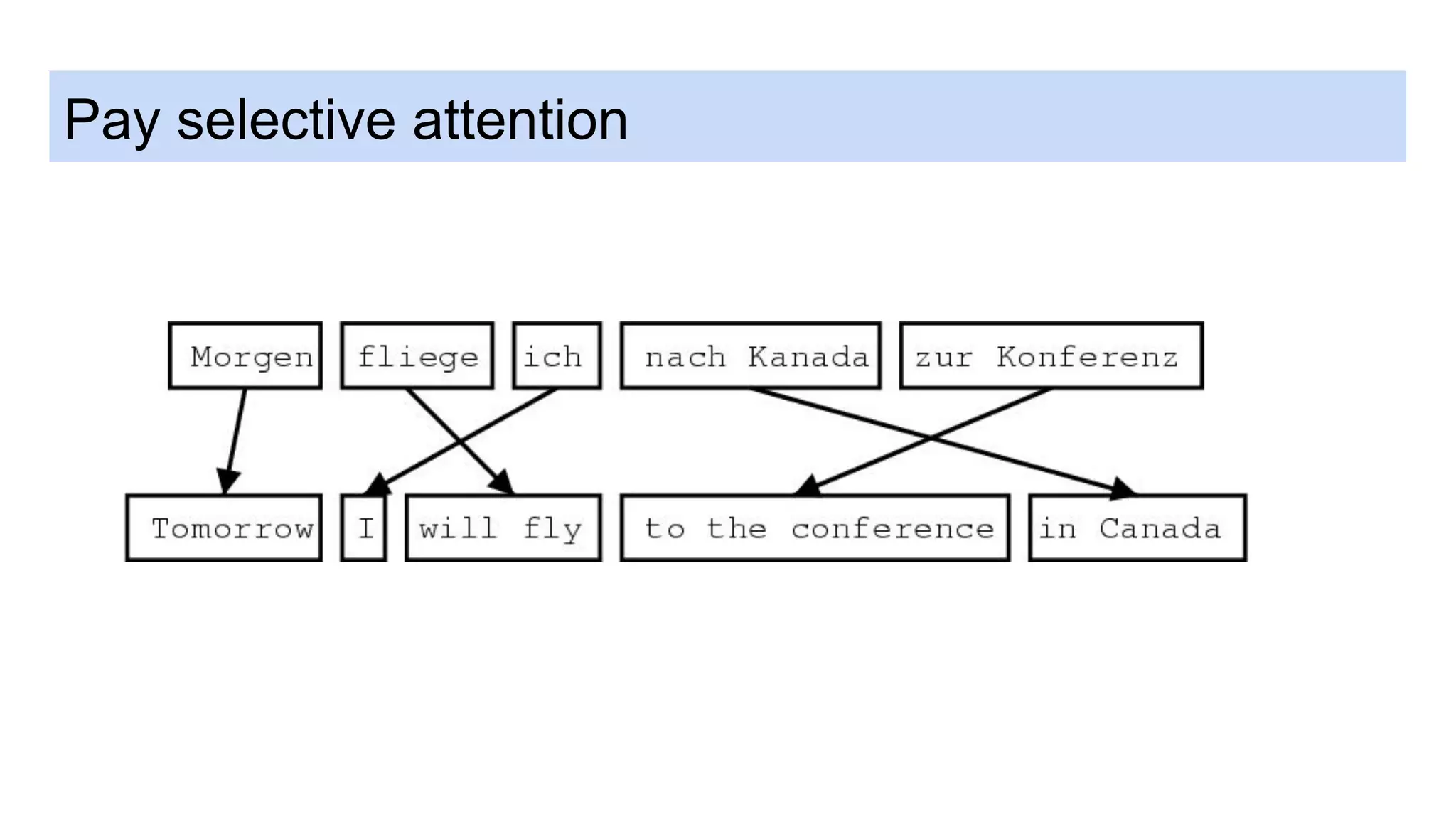


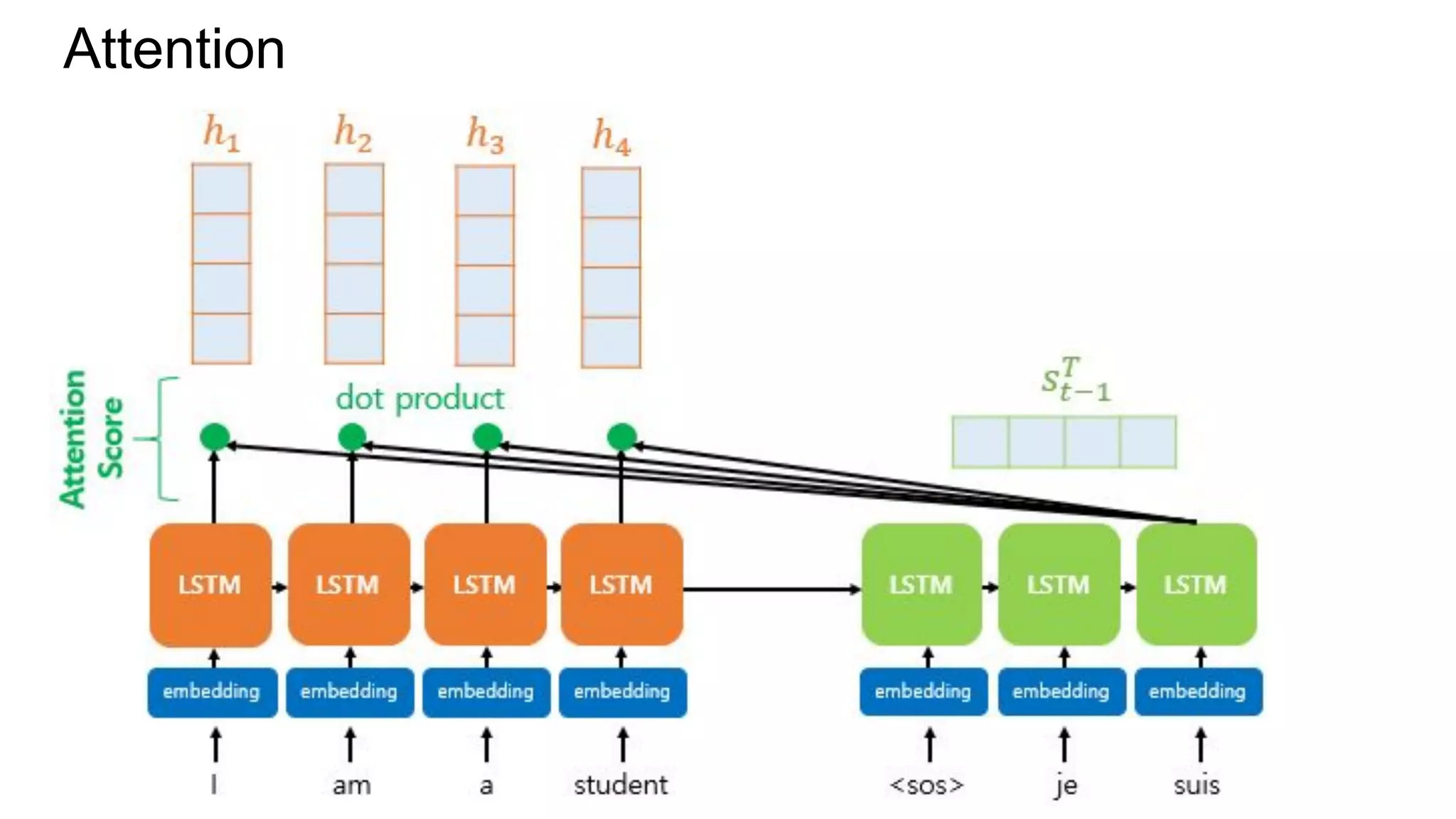
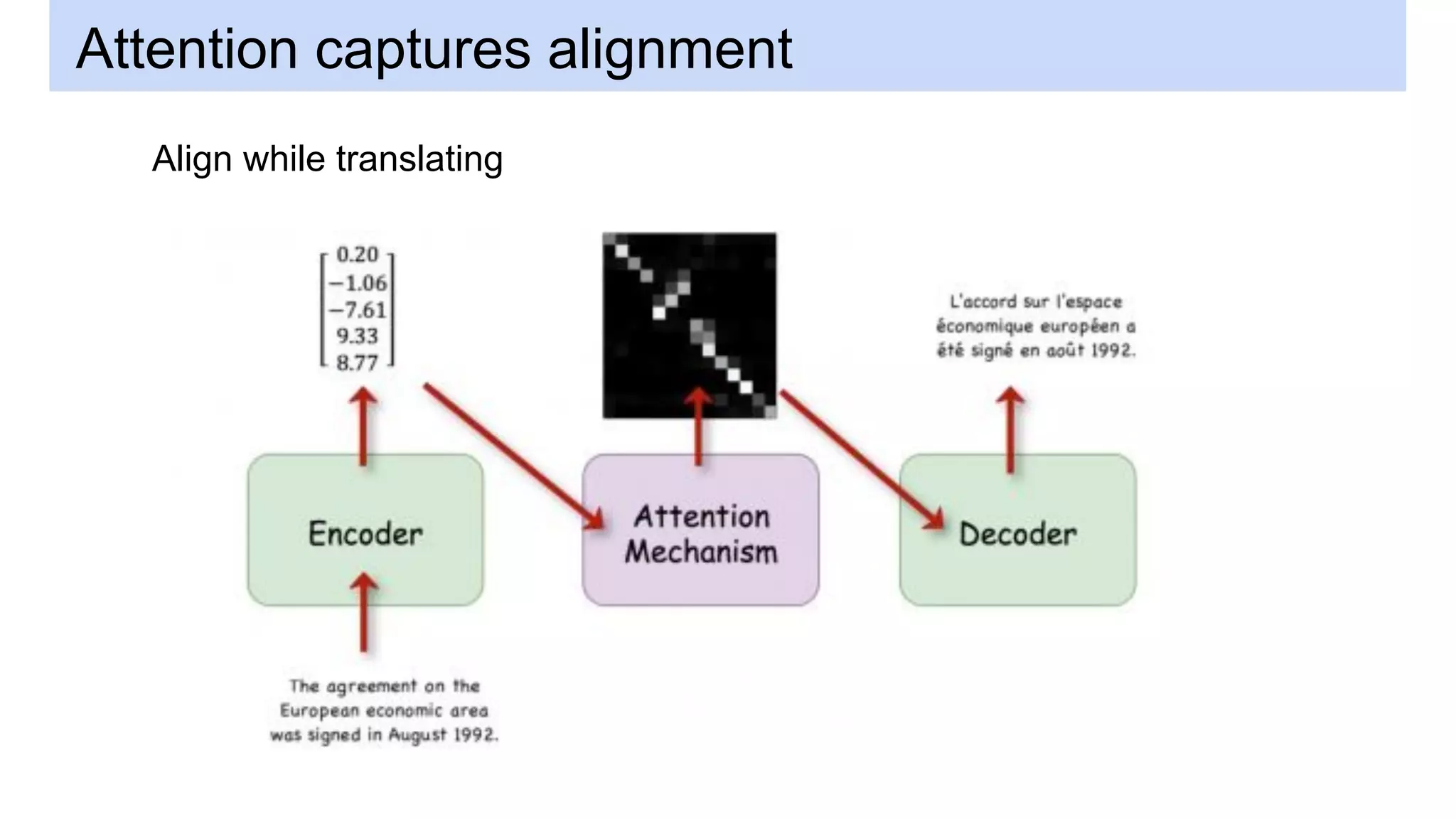



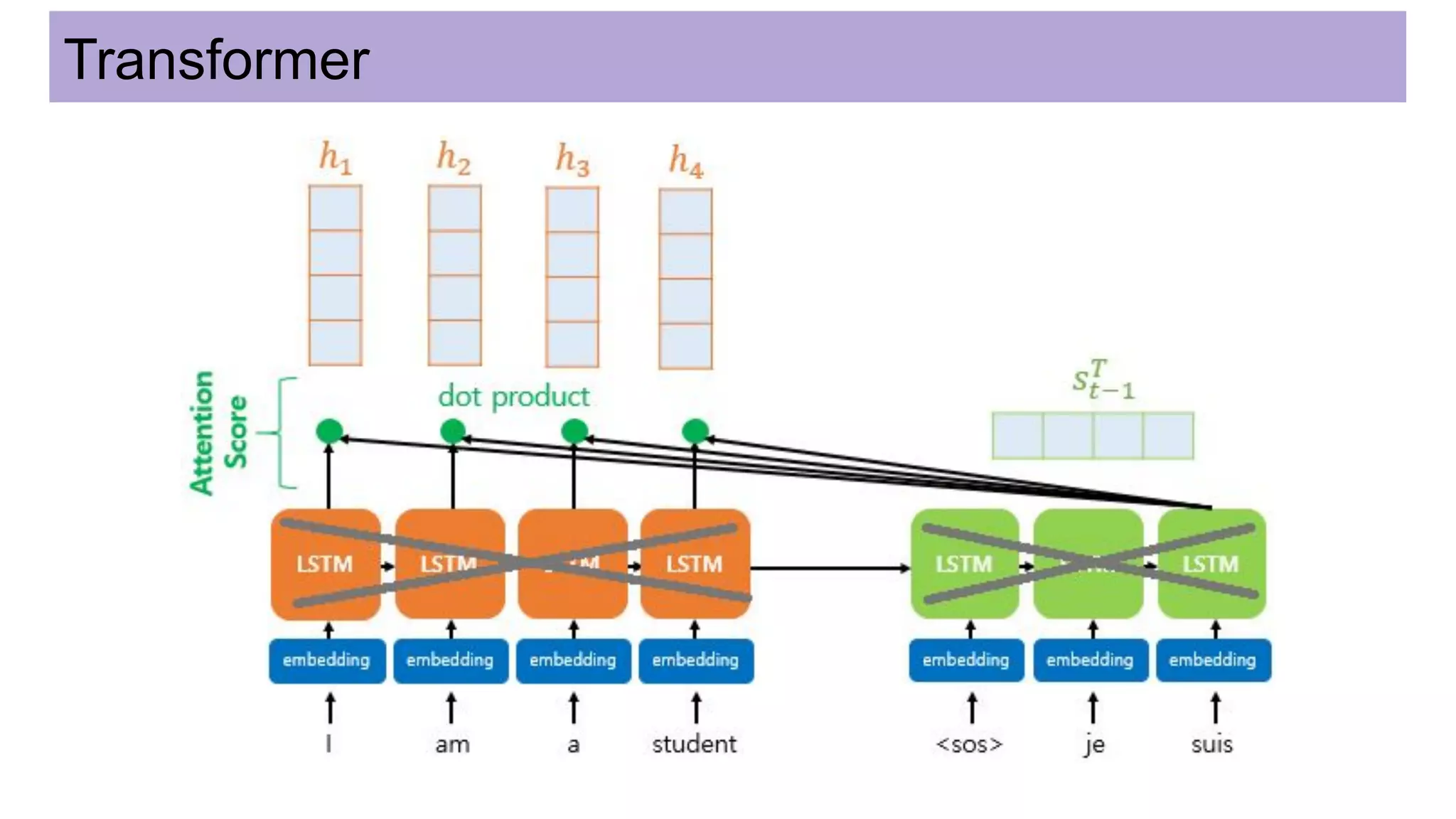
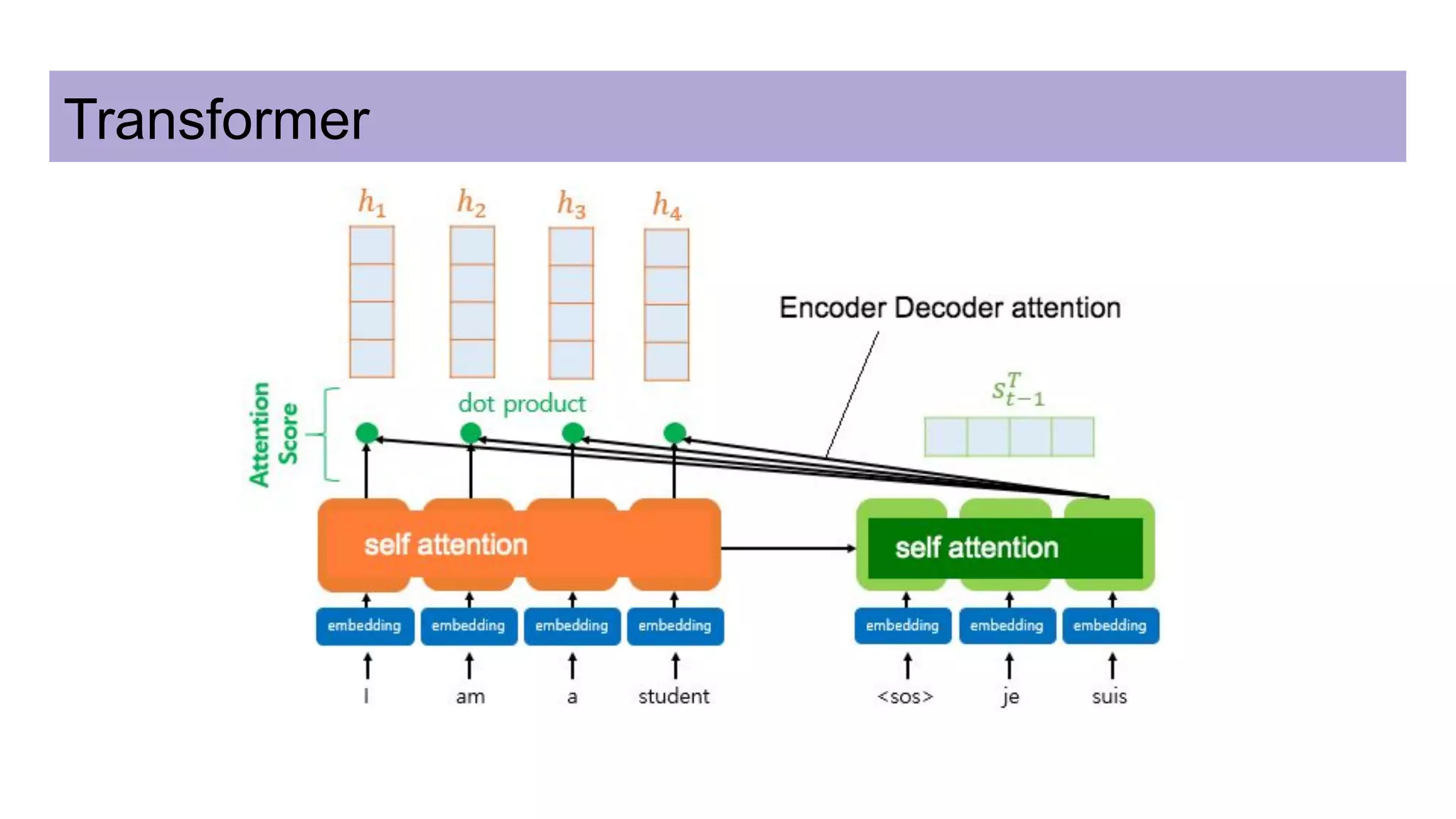

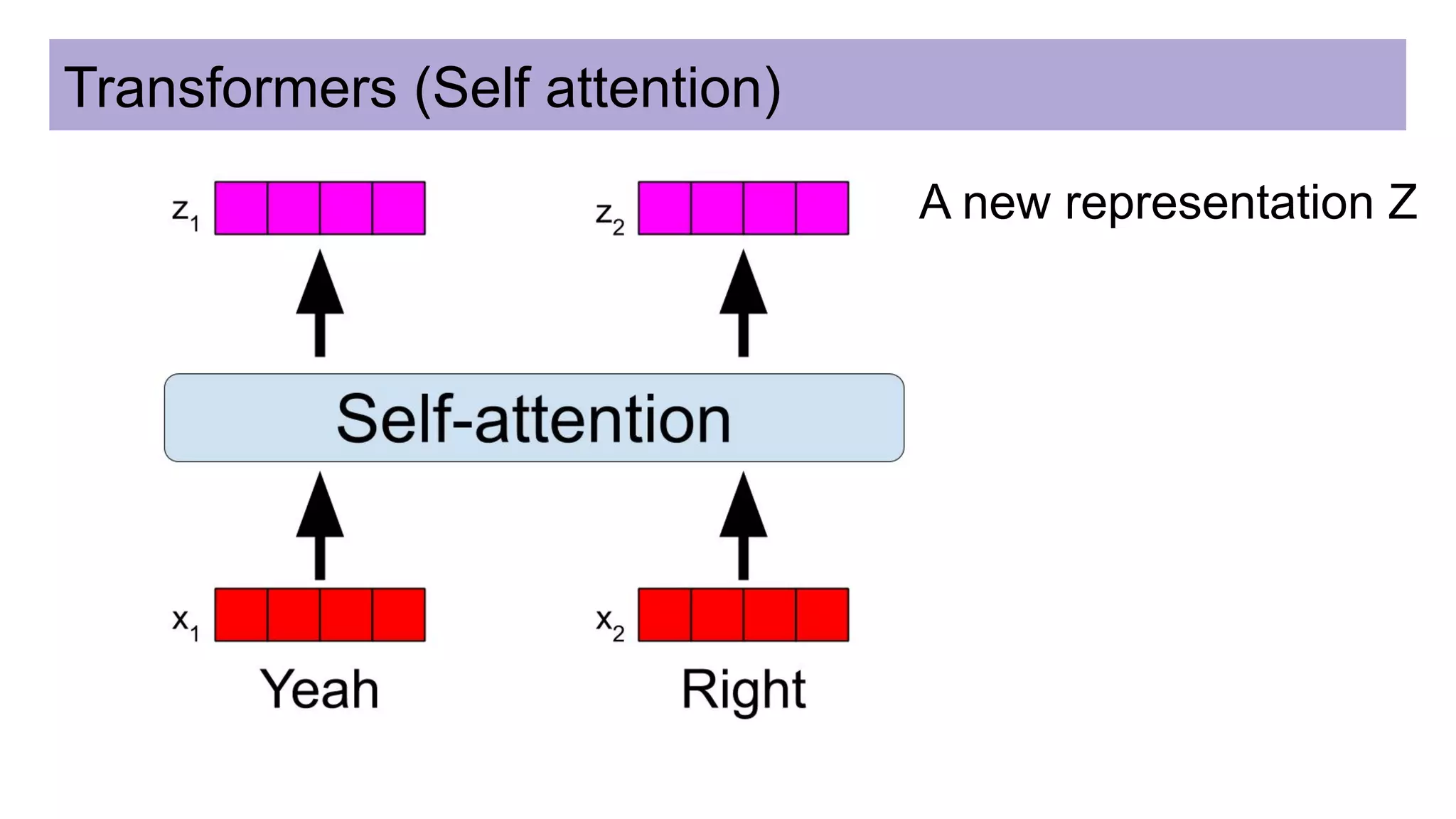
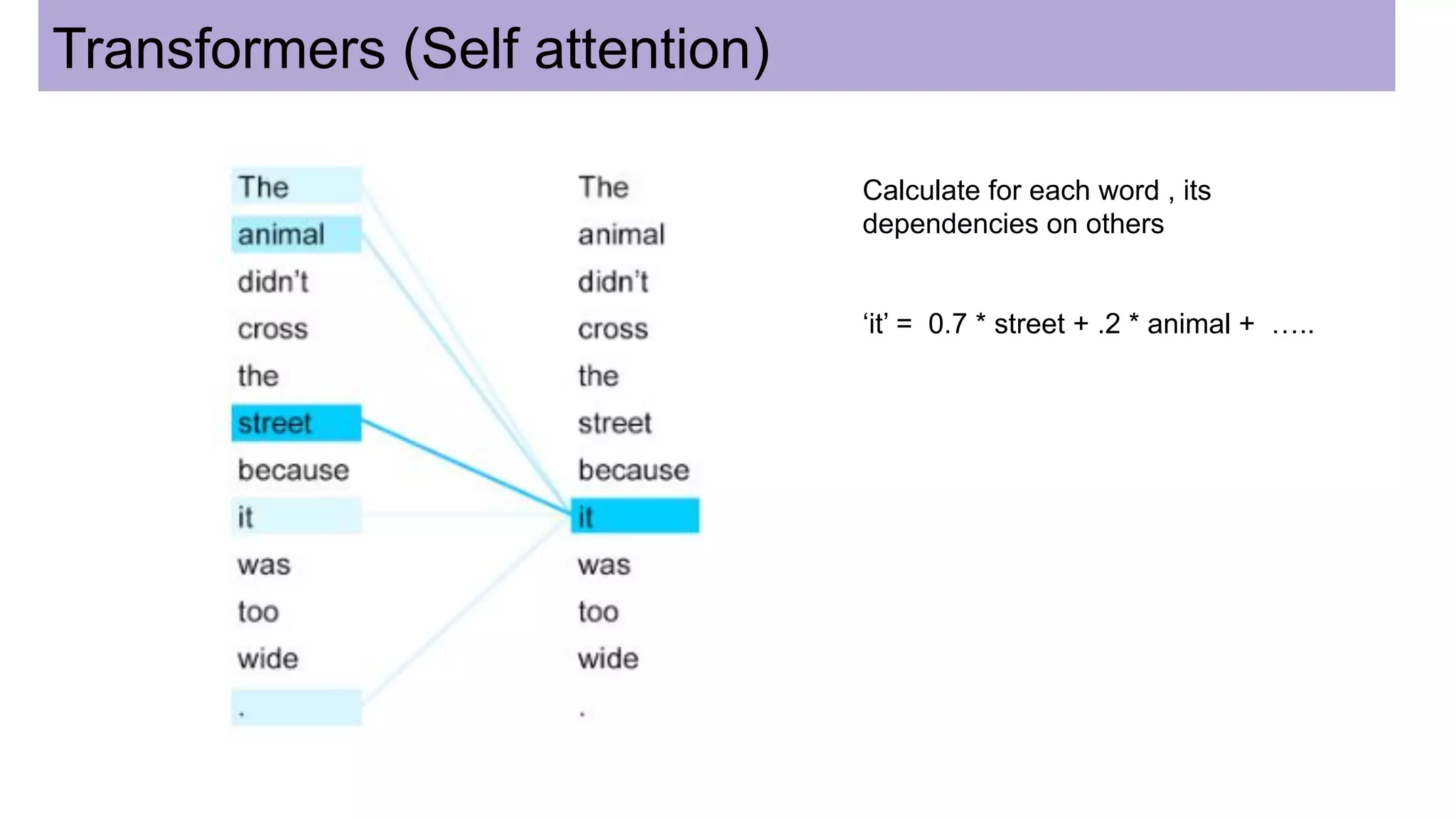

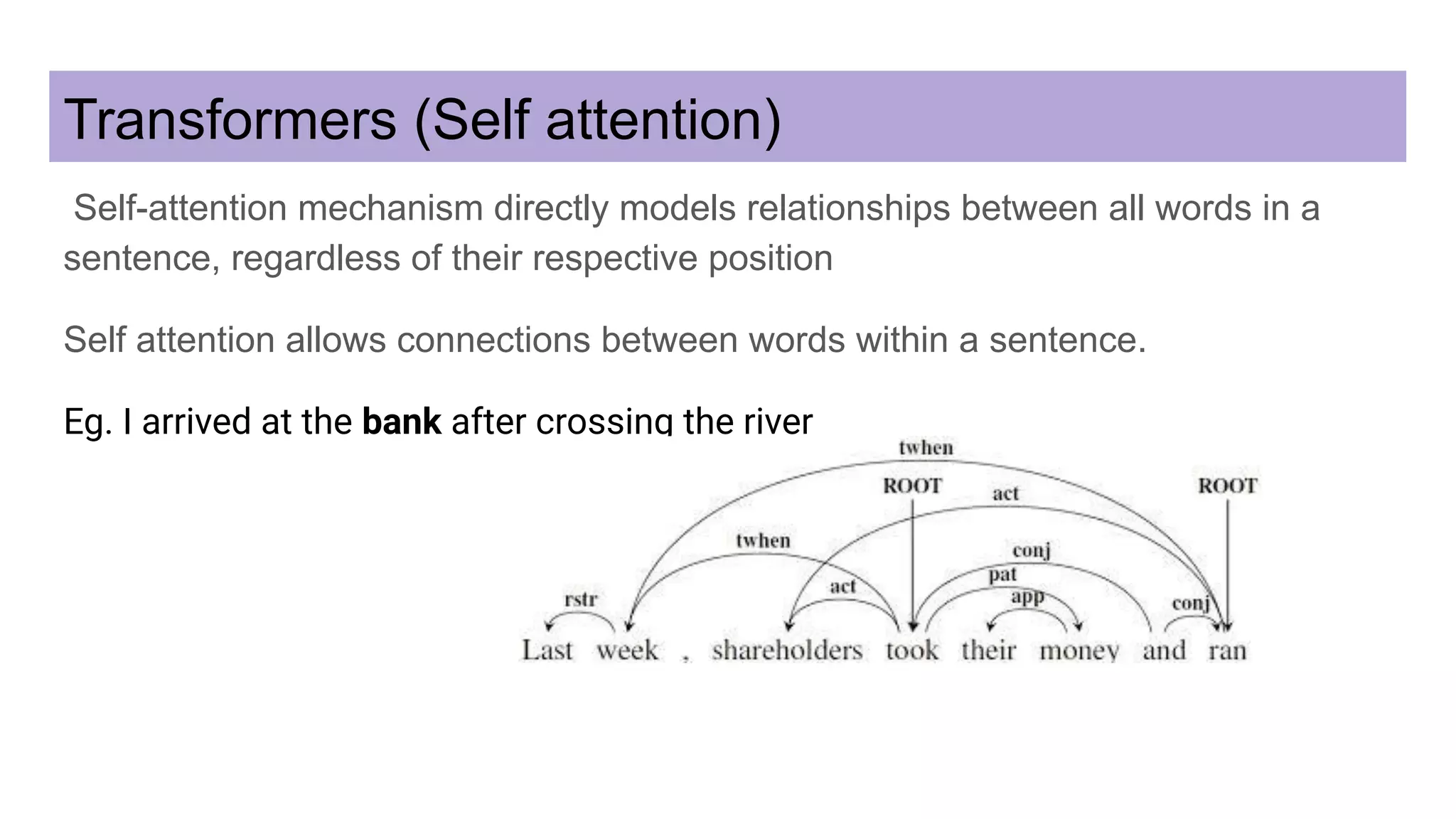

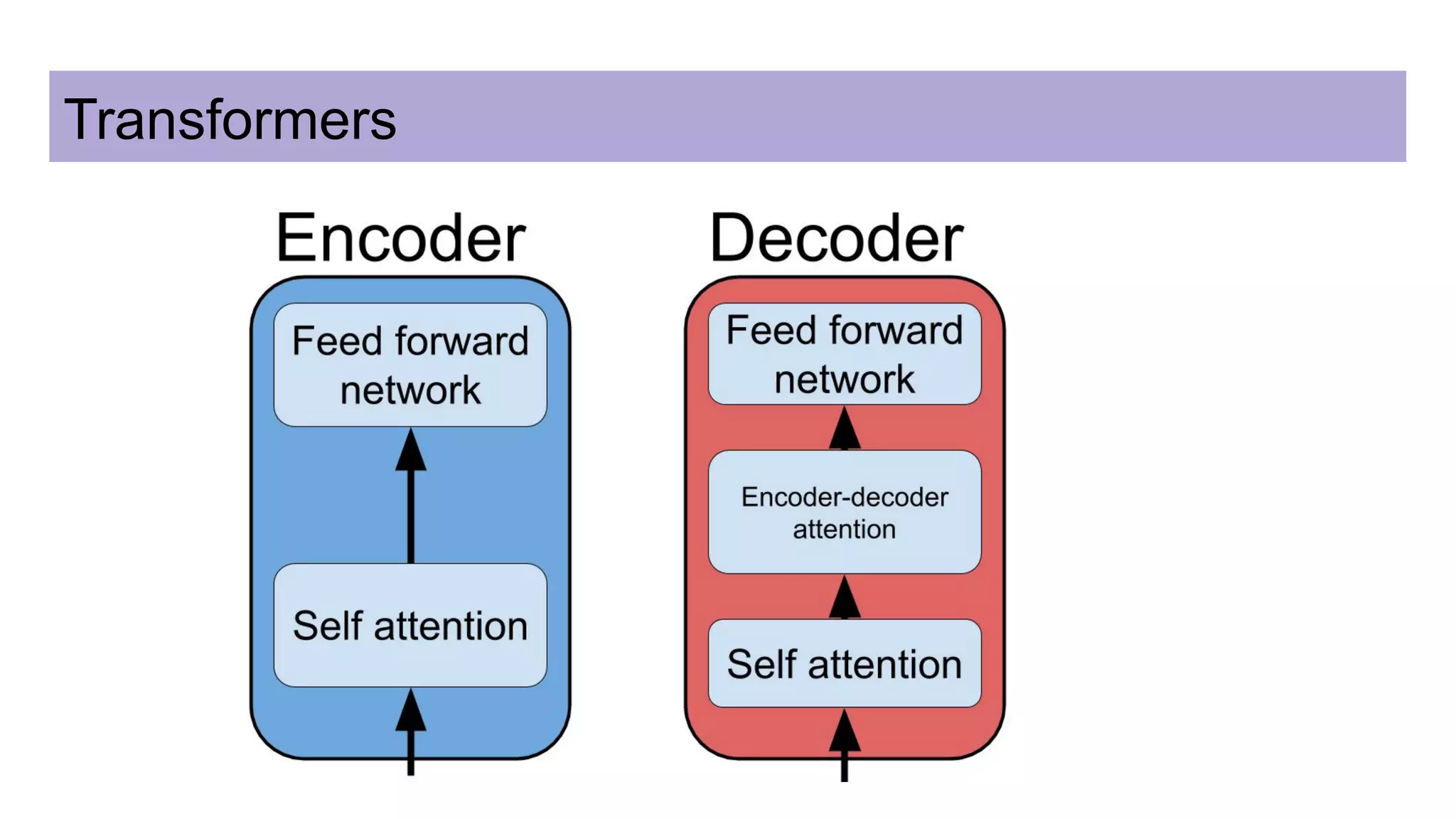
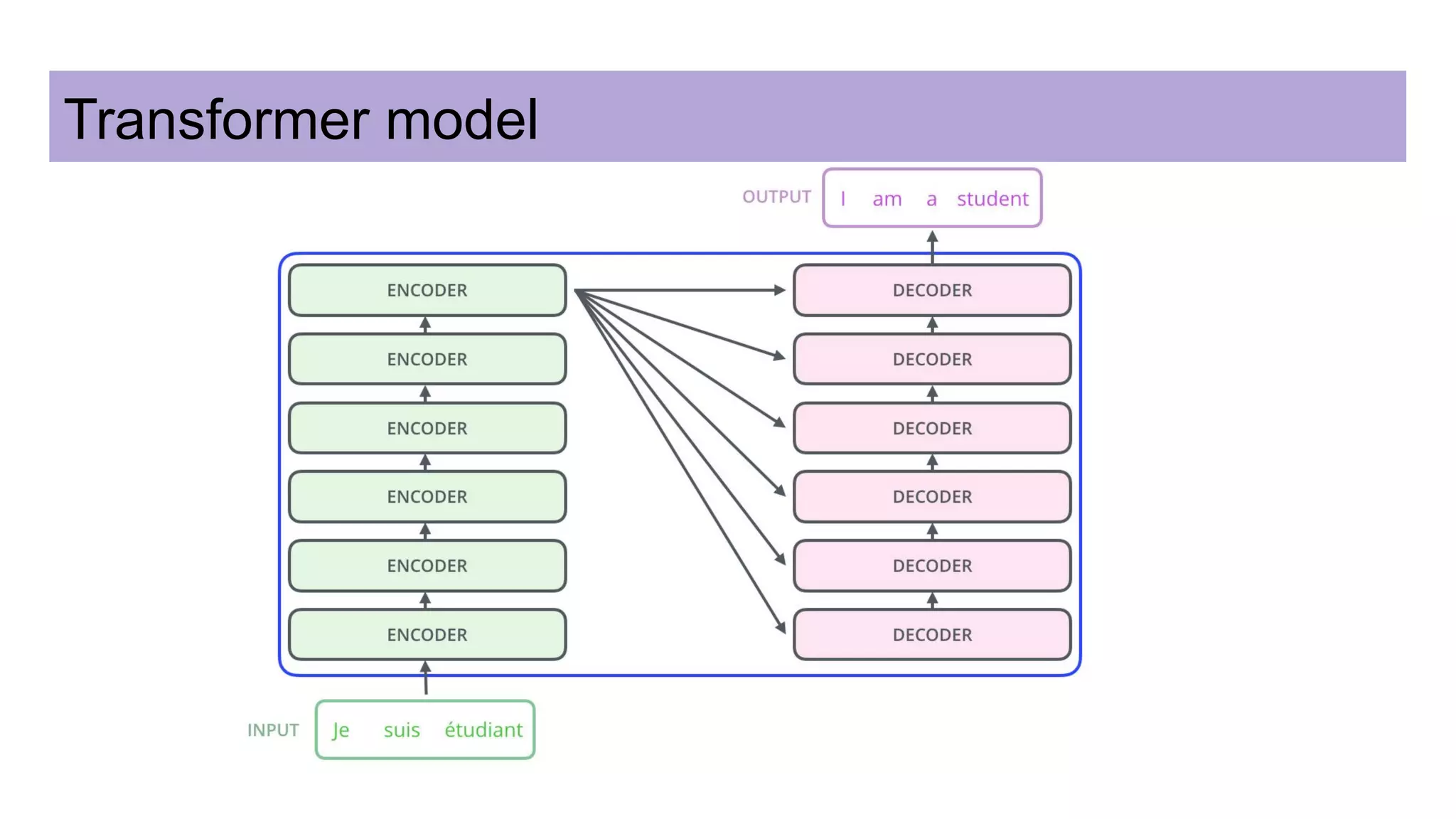
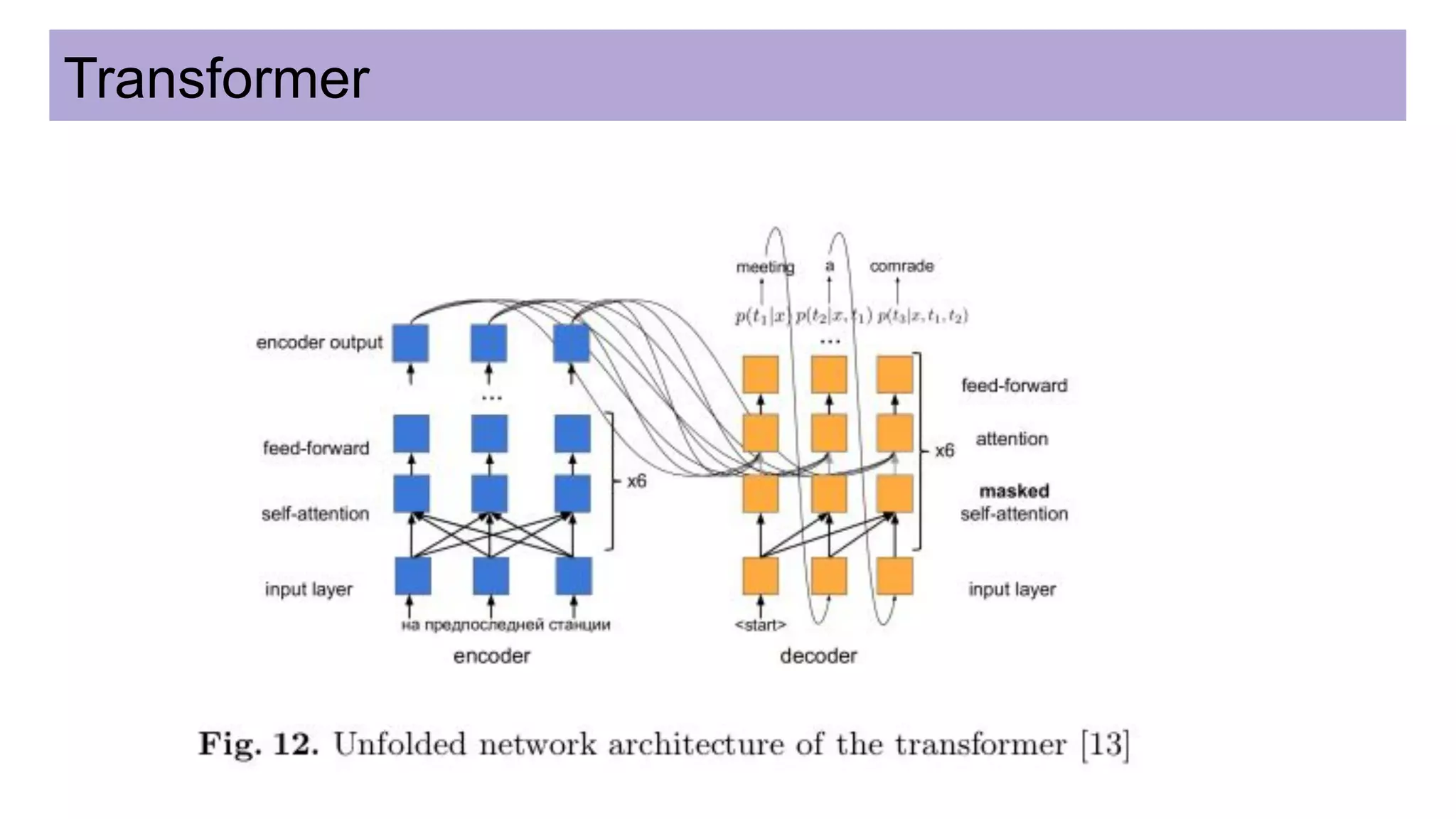
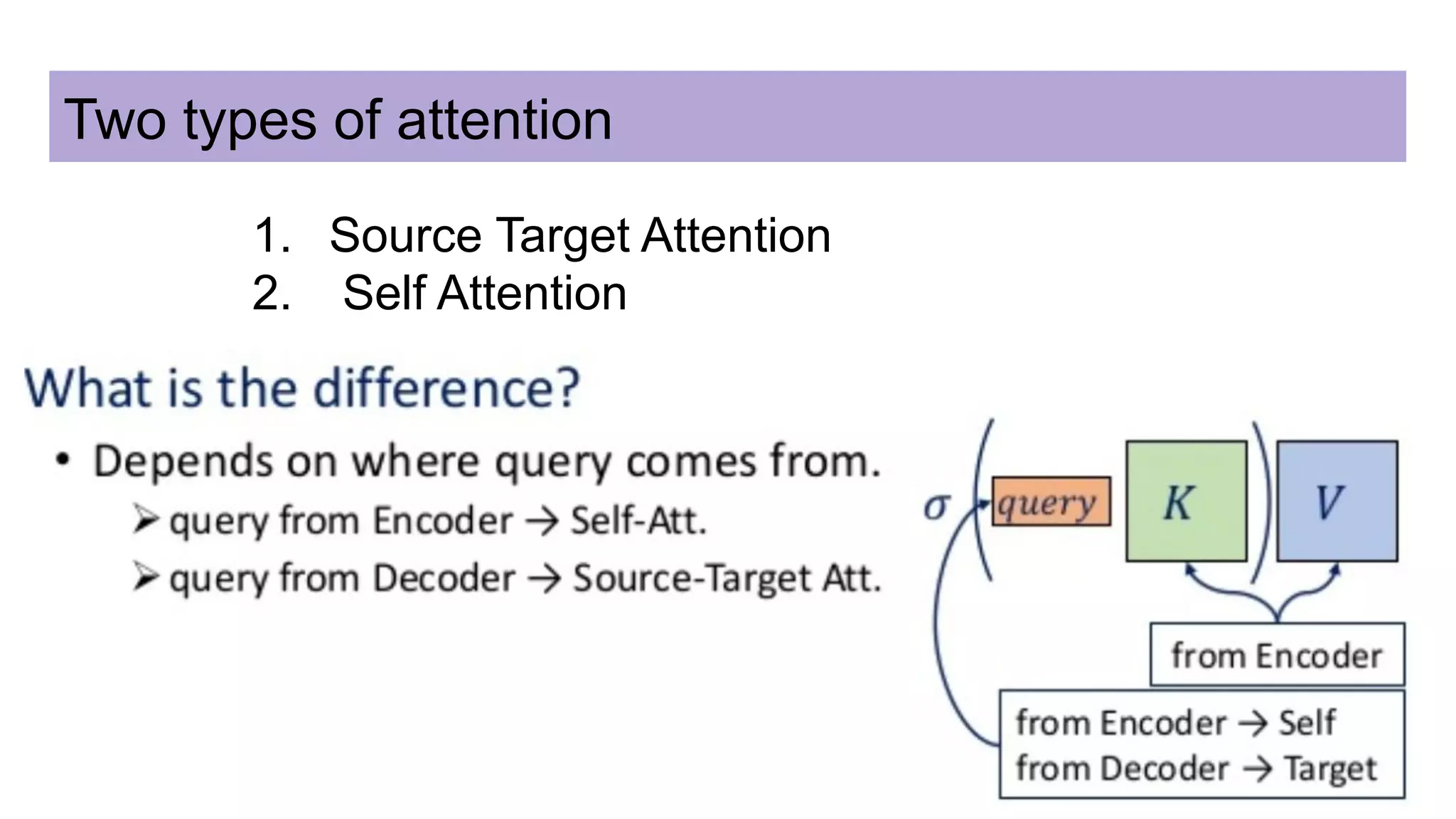



This document discusses neural network models for natural language processing tasks like machine translation. It describes how recurrent neural networks (RNNs) were used initially but had limitations in capturing long-term dependencies and parallelization. The encoder-decoder framework addressed some issues but still lost context. Attention mechanisms allowed focusing on relevant parts of the input and using all encoded states. Transformers replaced RNNs entirely with self-attention and encoder-decoder attention, allowing parallelization while generating a richer representation capturing word relationships. This revolutionized NLP tasks like machine translation.







![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=600ounds&width=560&fit=bounds)















































































