Download as PDF, PPTX














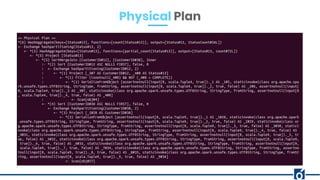
![map vs mapPartitions
- Map works the function being utilized at a per element level while mapPartitions
exercises the function at the partition level.
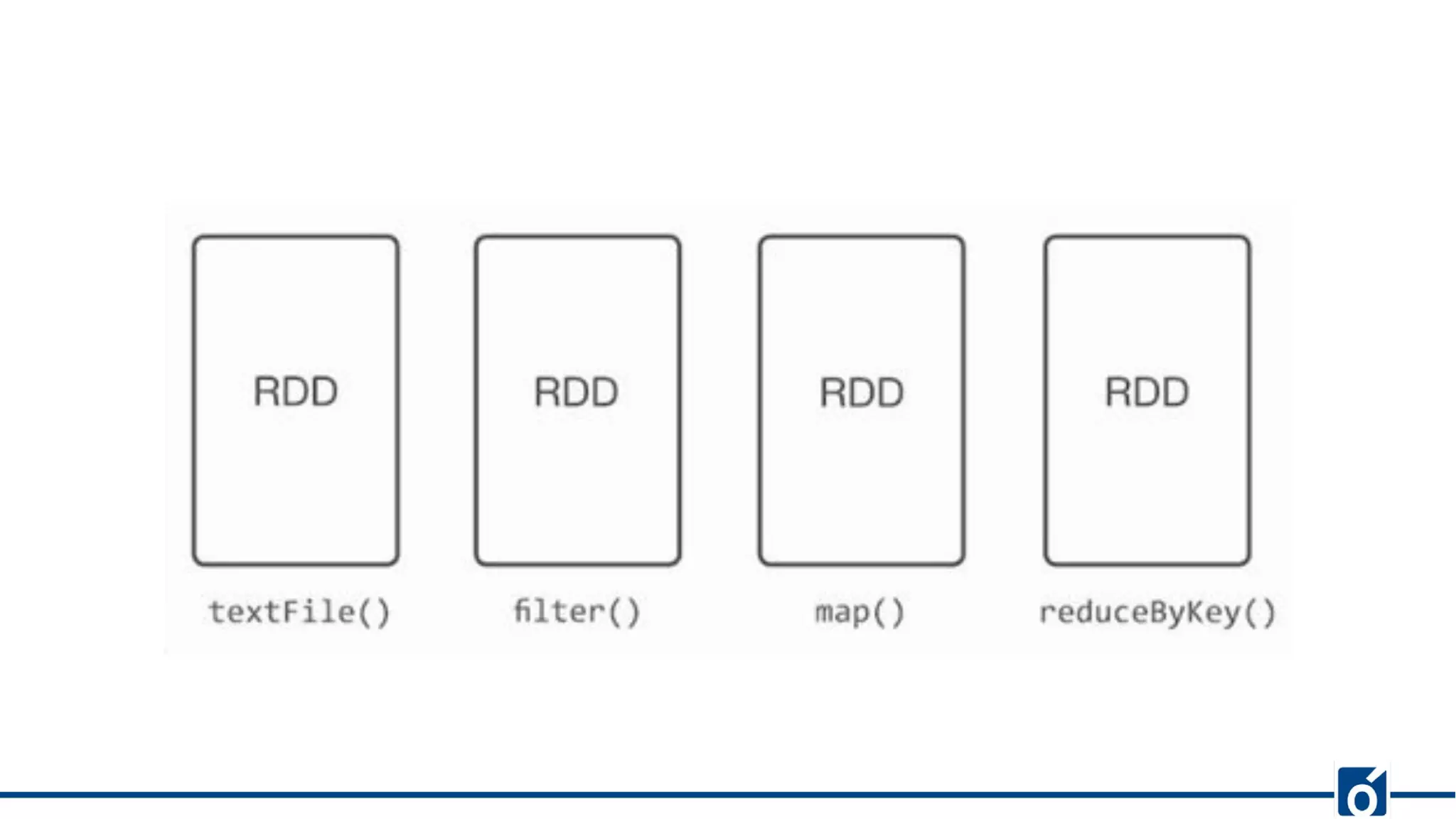
- map: Applies a transformation function on each item of the RDD and returns the result
as a new RDD.
- mapPartition: It is called only once for each partition. The entire content of the
respective partitions is available as a sequential stream of values via the input
argument (Iterarator[T]).
- https://stackoverflow.com/questions/21185092/apache-spark-map-vs-mappartitions](https://image.slidesharecdn.com/webinaroptimizationsinspark-200317080627/85/Optimizations-in-Spark-RDD-DataFrame-24-320.jpg)






























![map vs mapPartitions
- Map works the function being utilized at a per element level while mapPartitions
exercises the function at the partition level.
- map: Applies a transformation function on each item of the RDD and returns the result
as a new RDD.
- mapPartition: It is called only once for each partition. The entire content of the
respective partitions is available as a sequential stream of values via the input
argument (Iterarator[T]).
- https://stackoverflow.com/questions/21185092/apache-spark-map-vs-mappartitions](https://image.slidesharecdn.com/webinaroptimizationsinspark-200317080627/75/Optimizations-in-Spark-RDD-DataFrame-24-2048.jpg)





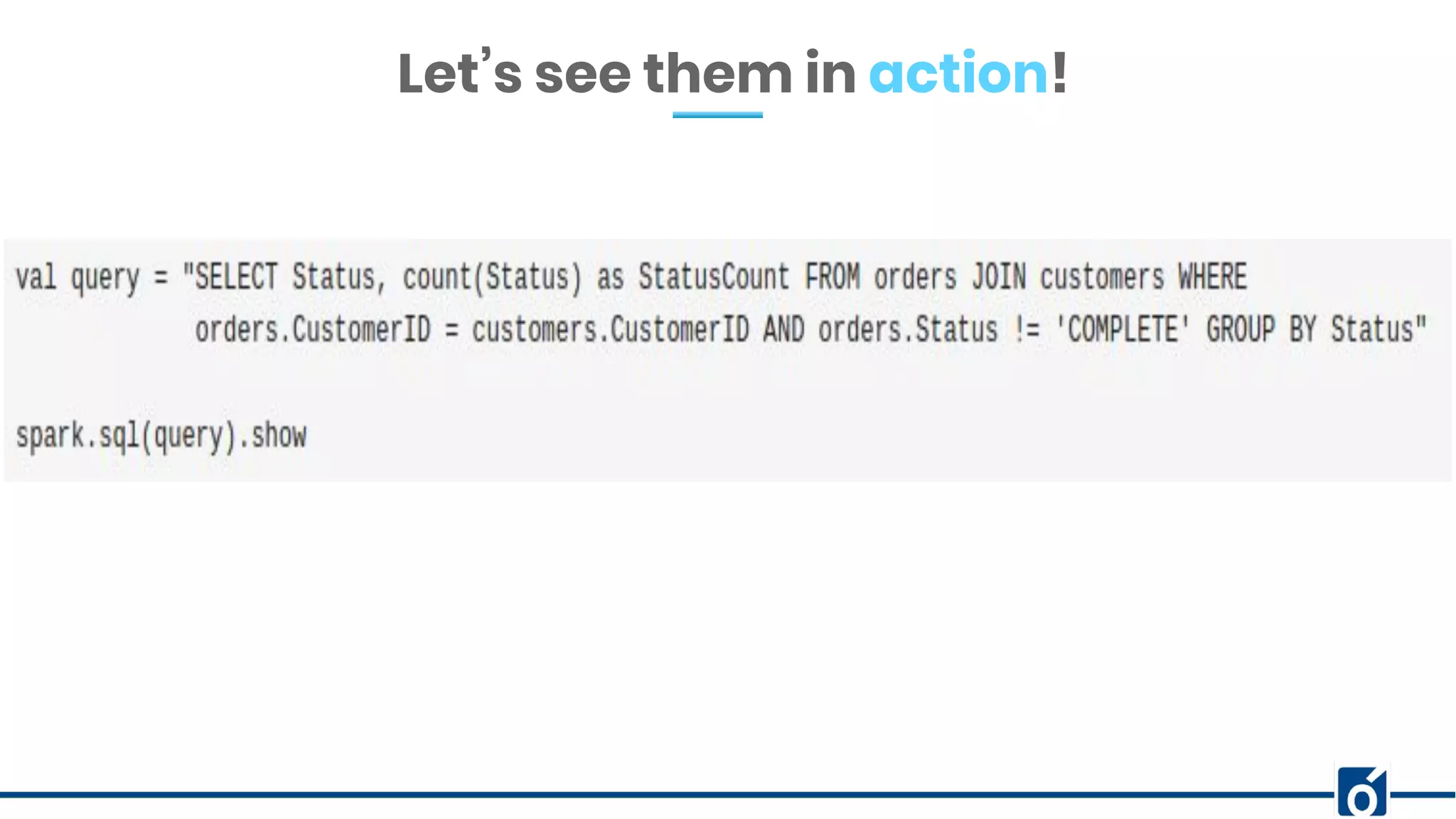
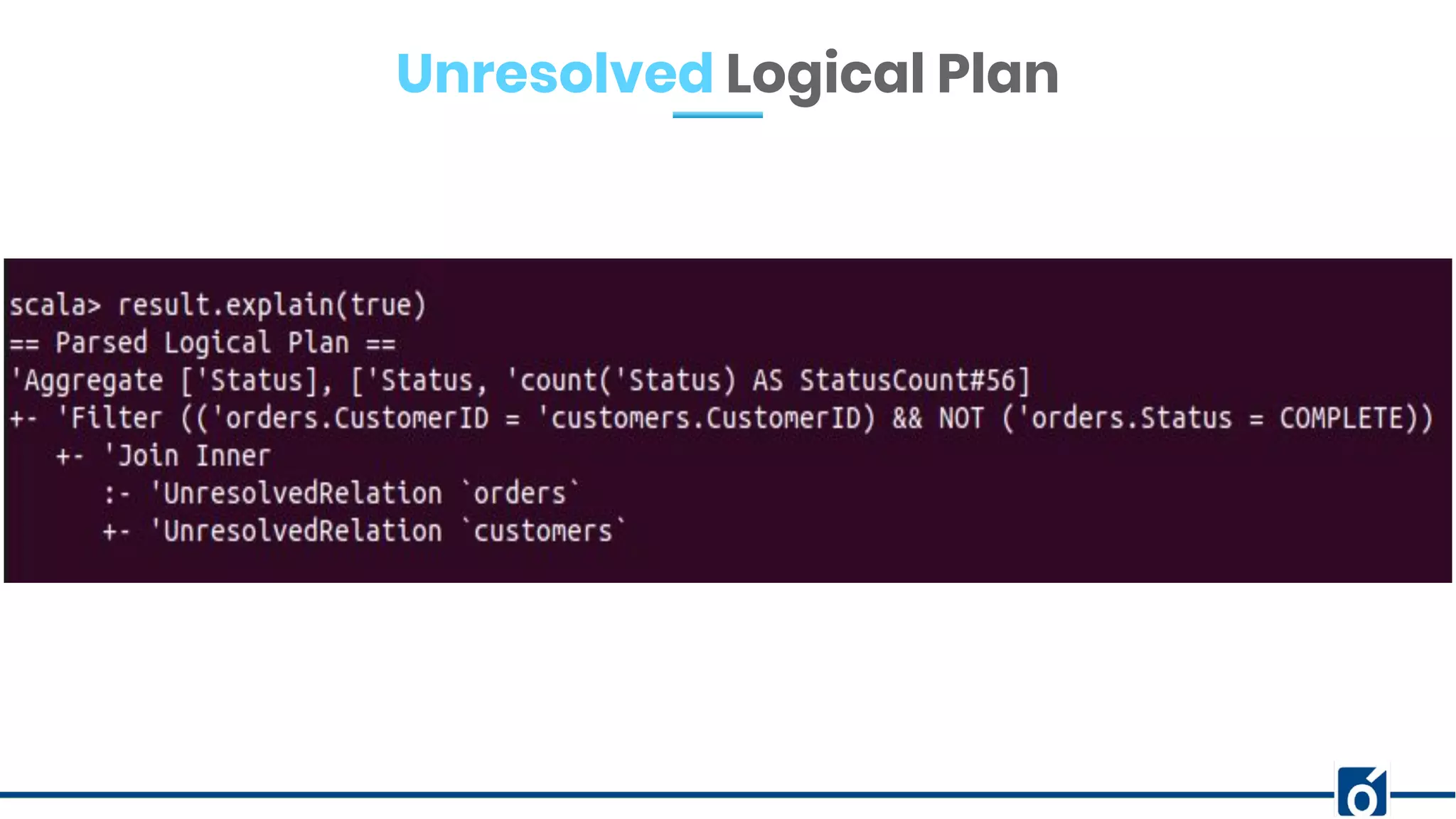
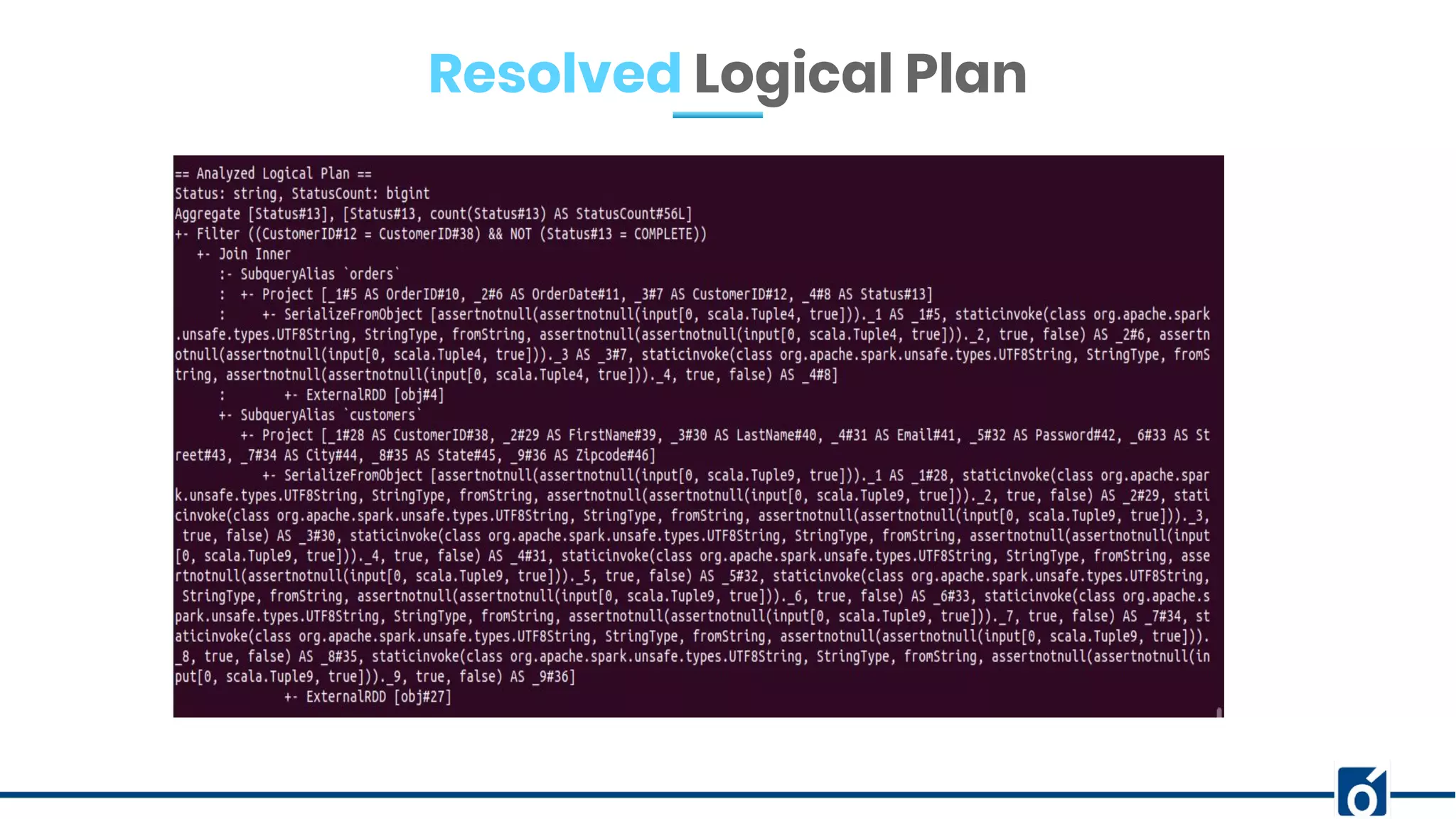

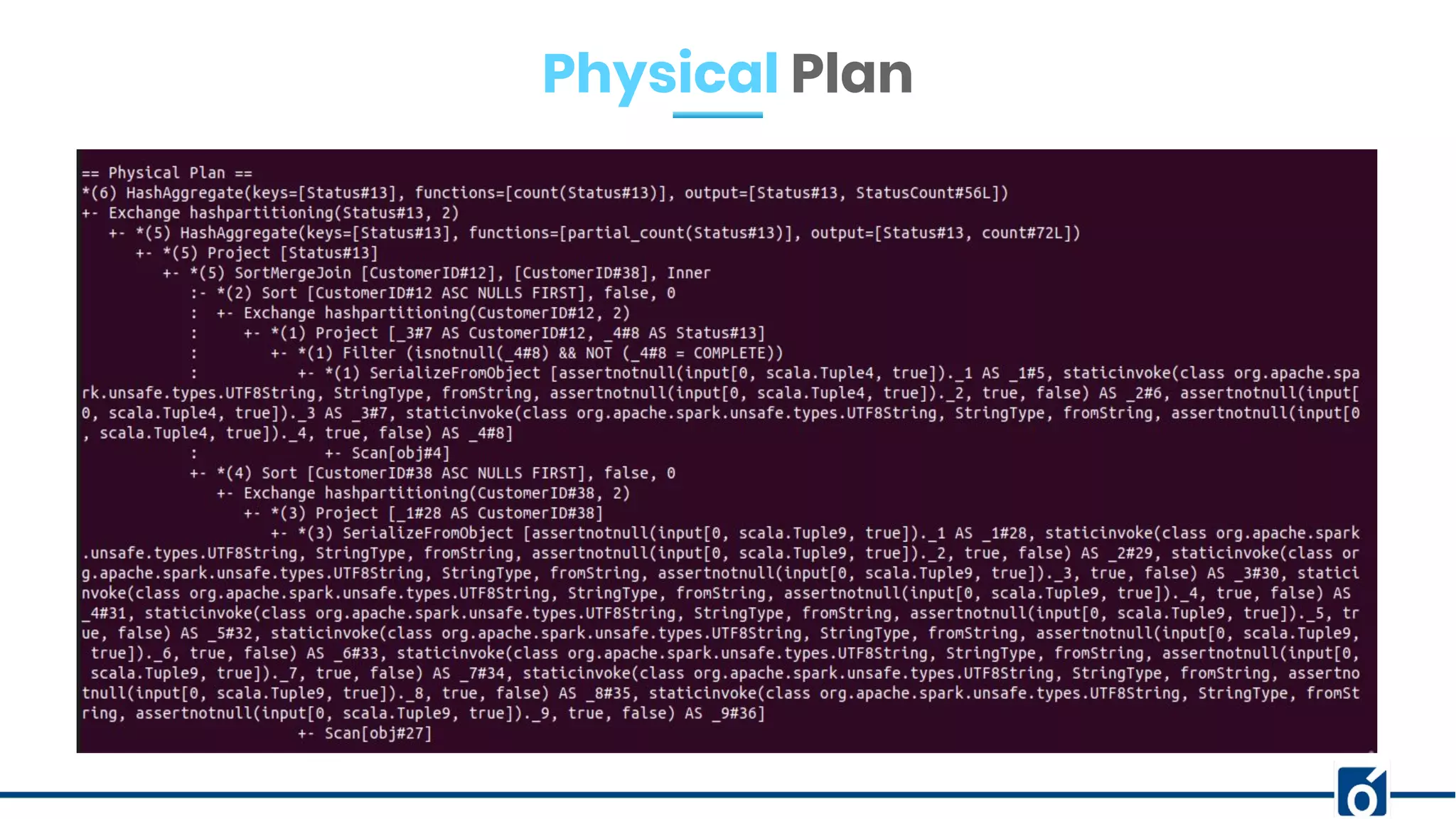





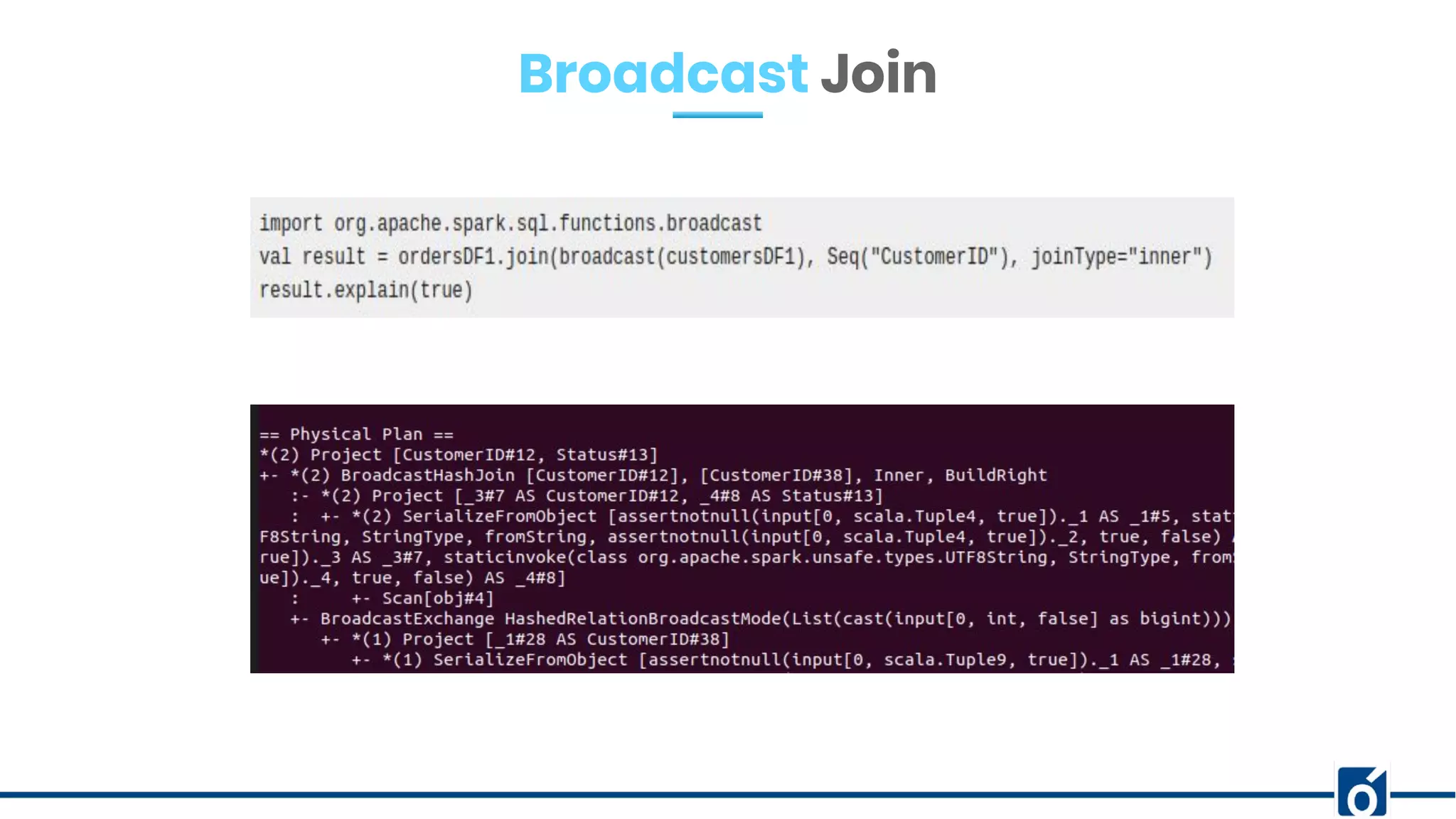
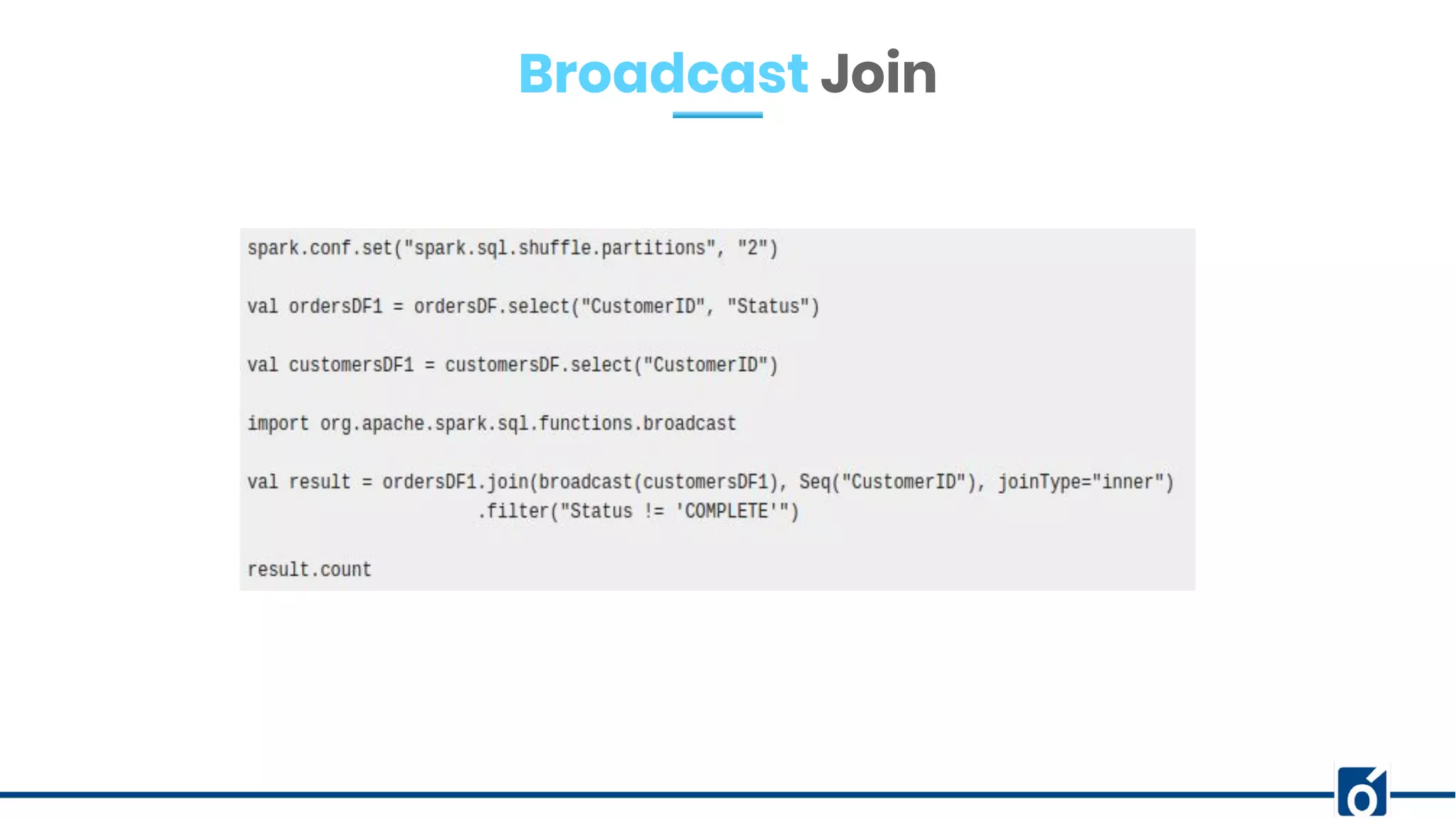
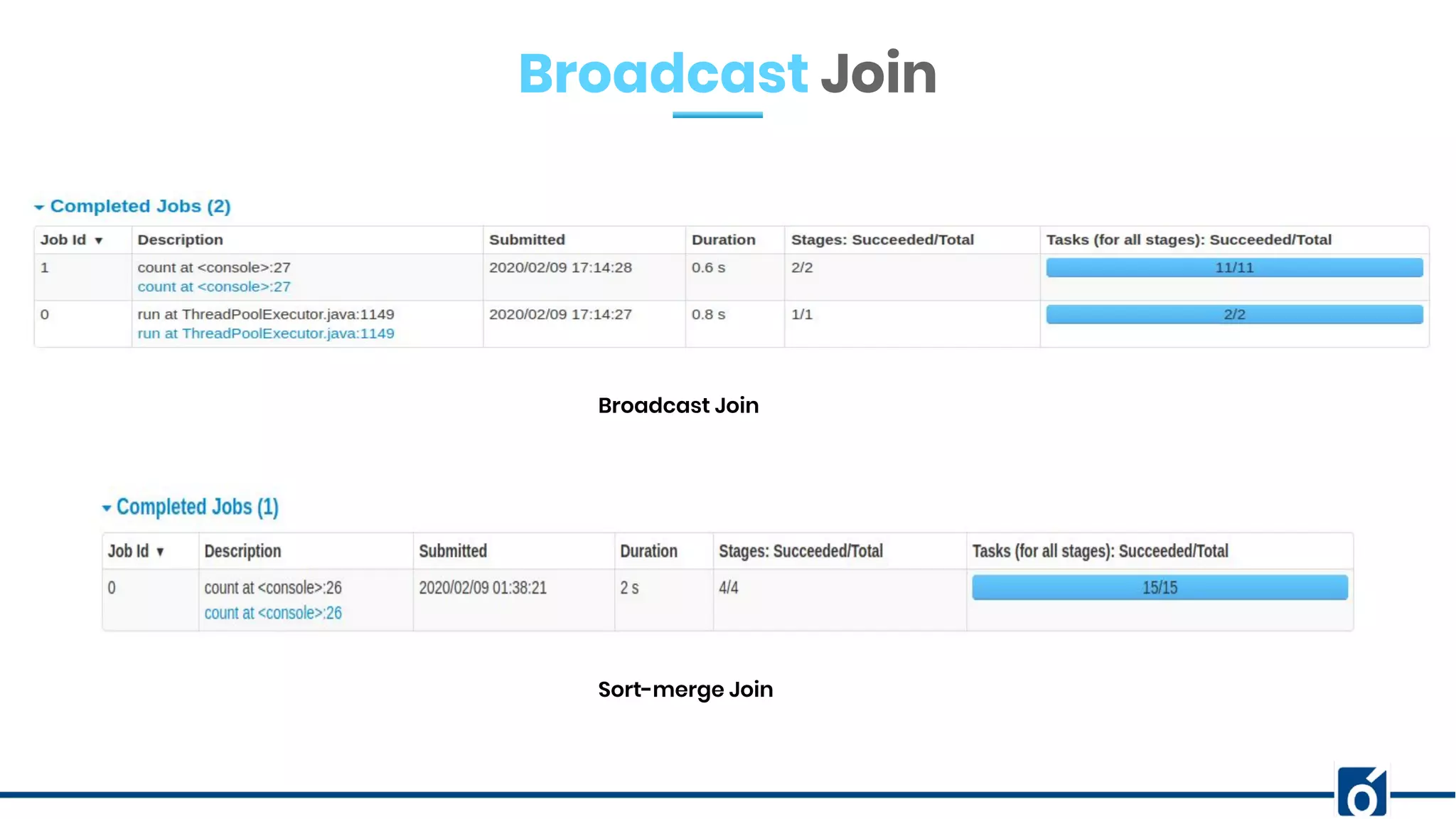





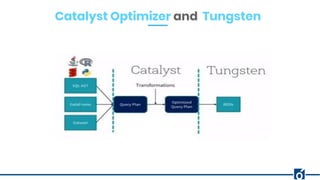
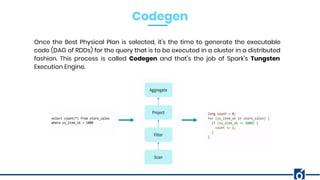
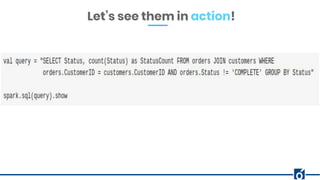
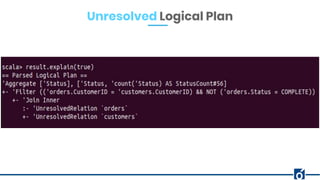
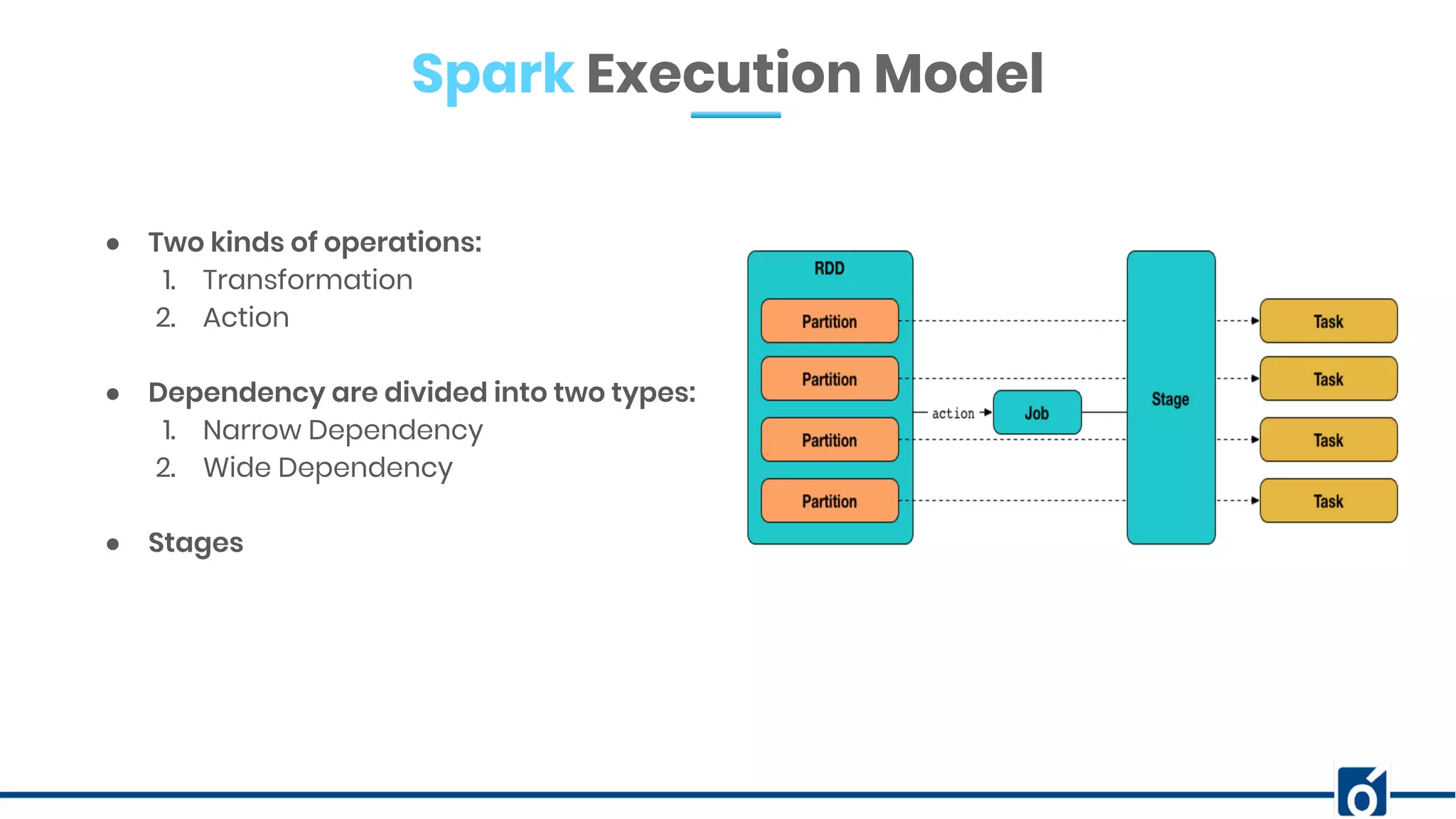
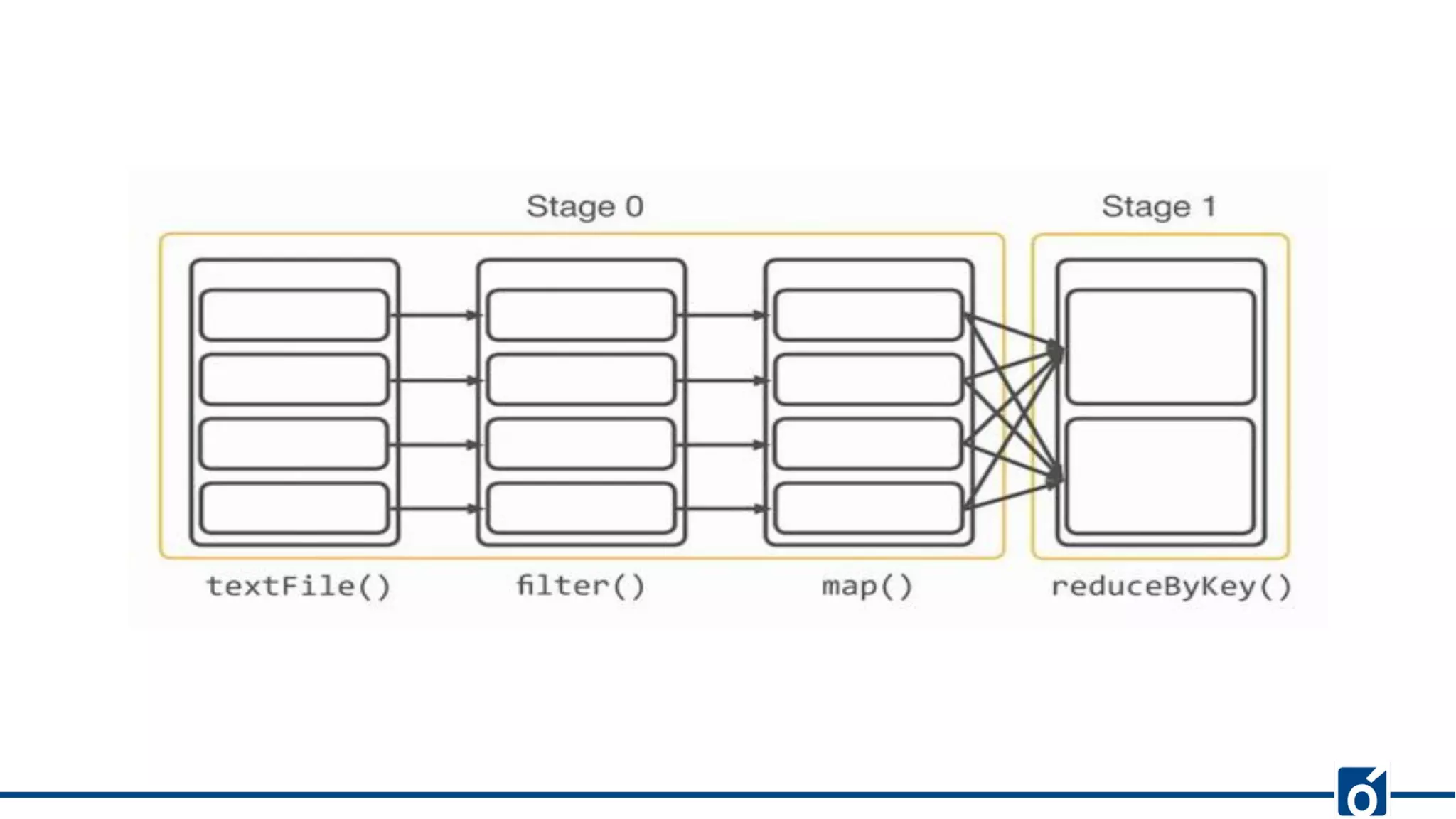
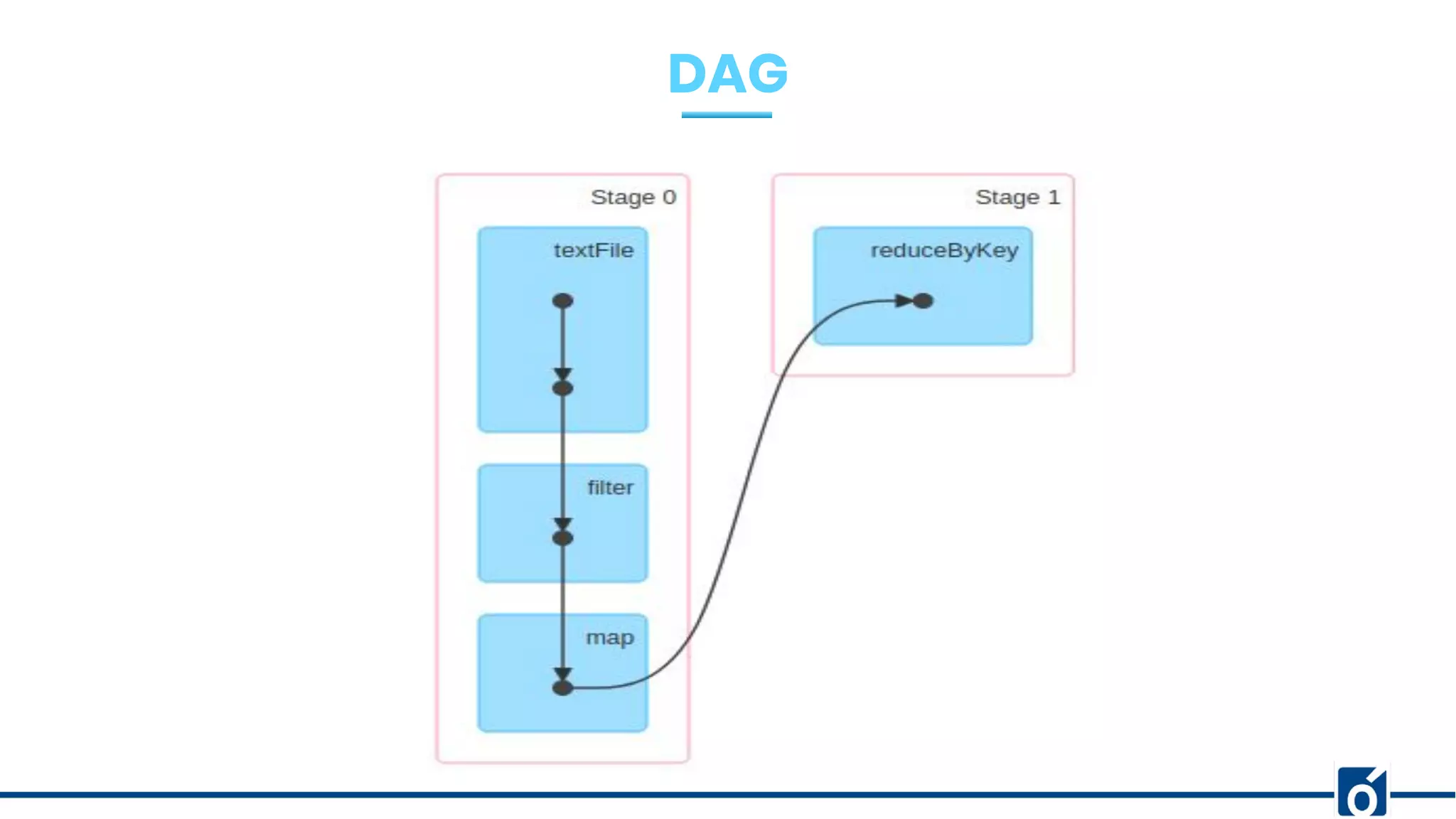
The document presents optimizations in Apache Spark, covering key concepts such as the Spark execution model, shuffle operations, and the differences between SQL and RDDs. It discusses partitioning strategies, optimizing transformations, and various types of joins while highlighting the importance of caching and checkpointing for performance. Additionally, it provides references for further reading on these topics.























































































