KEMBAR78
Daftar
Login
あなたの知らないPostgreSQL監視の世界 | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yoshinori Nakanishi
19,881 views
あなたの知らないPostgreSQL監視の世界
PostgreSQLカンファレンス2015の講演資料
Technology
◦
Read more
15
Save
Share
Embed
Download
Downloaded 145 times
1
/ 79
2
/ 79
3
/ 79
4
/ 79
5
/ 79
6
/ 79
7
/ 79
8
/ 79
9
/ 79
10
/ 79
11
/ 79
12
/ 79
13
/ 79
14
/ 79
15
/ 79
16
/ 79
17
/ 79
18
/ 79
19
/ 79
20
/ 79
21
/ 79
22
/ 79
Most read
23
/ 79
Most read
24
/ 79
25
/ 79
26
/ 79
27
/ 79
28
/ 79
29
/ 79
30
/ 79
31
/ 79
32
/ 79
33
/ 79
Most read
34
/ 79
35
/ 79
36
/ 79
37
/ 79
38
/ 79
39
/ 79
40
/ 79
41
/ 79
42
/ 79
43
/ 79
44
/ 79
45
/ 79
46
/ 79
47
/ 79
48
/ 79
49
/ 79
50
/ 79
51
/ 79
52
/ 79
53
/ 79
54
/ 79
55
/ 79
56
/ 79
57
/ 79
58
/ 79
59
/ 79
60
/ 79
61
/ 79
62
/ 79
63
/ 79
64
/ 79
65
/ 79
66
/ 79
67
/ 79
68
/ 79
69
/ 79
70
/ 79
71
/ 79
72
/ 79
73
/ 79
74
/ 79
75
/ 79
76
/ 79
77
/ 79
78
/ 79
79
/ 79
More Related Content
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
PDF
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
PPTX
PostgreSQL開発コミュニティに参加しよう!(PostgreSQL Conference Japan 2021 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQLのトラブルシューティング@第5回中国地方DB勉強会
by
Shigeru Hanada
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
PostgreSQL開発コミュニティに参加しよう!(PostgreSQL Conference Japan 2021 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのトラブルシューティング@第5回中国地方DB勉強会
by
Shigeru Hanada
What's hot
PPTX
CloudNativePGを動かしてみた! ~PostgreSQL on Kubernetes~(第34回PostgreSQLアンカンファレンス@オンライ...
by
NTT DATA Technology & Innovation
PPTX
iostat await svctm の 見かた、考え方
by
歩 柴田
PDF
PostgreSQLの関数属性を知ろう
by
kasaharatt
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
PDF
PostgreSQLアーキテクチャ入門
by
Uptime Technologies LLC (JP)
PDF
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
PostgreSQLアンチパターン
by
Soudai Sone
PDF
PostgreSQL 13でのpg_stat_statementsの改善について(第12回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会
by
Masahiko Sawada
PPTX
祝!PostgreSQLレプリケーション10周年!徹底紹介!!
by
NTT DATA Technology & Innovation
PDF
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
PDF
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
PPTX
PostgreSQL開発コミュニティに参加しよう! ~2022年版~(Open Source Conference 2022 Online/Kyoto 発...
by
NTT DATA Technology & Innovation
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PDF
JVMのGCアルゴリズムとチューニング
by
佑哉 廣岡
PDF
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
オンライン物理バックアップの排他モードと非排他モードについて(第15回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
CloudNativePGを動かしてみた! ~PostgreSQL on Kubernetes~(第34回PostgreSQLアンカンファレンス@オンライ...
by
NTT DATA Technology & Innovation
iostat await svctm の 見かた、考え方
by
歩 柴田
PostgreSQLの関数属性を知ろう
by
kasaharatt
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
PostgreSQLアーキテクチャ入門
by
Uptime Technologies LLC (JP)
Fluentdのお勧めシステム構成パターン
by
Kentaro Yoshida
Vacuum徹底解説
by
Masahiko Sawada
PostgreSQLアンチパターン
by
Soudai Sone
PostgreSQL 13でのpg_stat_statementsの改善について(第12回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Inside vacuum - 第一回PostgreSQLプレ勉強会
by
Masahiko Sawada
祝!PostgreSQLレプリケーション10周年!徹底紹介!!
by
NTT DATA Technology & Innovation
PostgreSQLバックアップの基本
by
Uptime Technologies LLC (JP)
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
PostgreSQL開発コミュニティに参加しよう! ~2022年版~(Open Source Conference 2022 Online/Kyoto 発...
by
NTT DATA Technology & Innovation
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
JVMのGCアルゴリズムとチューニング
by
佑哉 廣岡
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLの統計情報について(第26回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
オンライン物理バックアップの排他モードと非排他モードについて(第15回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Viewers also liked
PDF
【17-E-3】 オンライン機械学習で実現する大規模データ処理
by
Developers Summit
PDF
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
PDF
並列データベースシステムの概念と原理
by
Makoto Yui
PPTX
Writing Yarn Applications Hadoop Summit 2012
by
Hortonworks
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
ODP
Data analytics with hadoop hive on multiple data centers
by
Hirotaka Niisato
PPTX
Future of HCatalog - Hadoop Summit 2012
by
Hortonworks
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PDF
Database smells
by
Mikiya Okuno
PDF
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
PDF
【SQLインジェクション対策】徳丸先生に怒られない、動的SQLの安全な組み立て方
by
kwatch
KEY
Hadoop Summit 2012 - Hadoop and Vertica: The Data Analytics Platform at Twitter
by
Bill Graham
PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012)
by
Uptime Technologies LLC (JP)
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PDF
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
PPTX
ならば(その弐)
by
Tomoaki Hiramoto
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
【17-E-3】 オンライン機械学習で実現する大規模データ処理
by
Developers Summit
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
並列データベースシステムの概念と原理
by
Makoto Yui
Writing Yarn Applications Hadoop Summit 2012
by
Hortonworks
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
Data analytics with hadoop hive on multiple data centers
by
Hirotaka Niisato
Future of HCatalog - Hadoop Summit 2012
by
Hortonworks
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
Database smells
by
Mikiya Okuno
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
【SQLインジェクション対策】徳丸先生に怒られない、動的SQLの安全な組み立て方
by
kwatch
Hadoop Summit 2012 - Hadoop and Vertica: The Data Analytics Platform at Twitter
by
Bill Graham
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012)
by
Uptime Technologies LLC (JP)
SQLチューニング入門 入門編
by
Miki Shimogai
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
ならば(その弐)
by
Tomoaki Hiramoto
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
Similar to あなたの知らないPostgreSQL監視の世界
PDF
新しくなったPg monzでpostgre sqlのクラスタを監視しよう
by
Yoshinori Nakanishi
PDF
明日から使えるPostgre sql運用管理テクニック(監視編)
by
kasaharatt
PDF
PostgreSQL9.3新機能紹介
by
NTT DATA OSS Professional Services
PDF
OSC沖縄2014_JPUG資料
by
kasaharatt
PDF
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
PDF
Kof2016 postgresql-9.6
by
Toshi Harada
PPTX
PostgreSQLモニタリング機能の現状とこれから(Open Developers Conference 2020 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
pg_walinspectについて調べてみた!(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
いまさら聞けないPostgreSQL運用管理
by
Uptime Technologies LLC (JP)
PDF
PostgreSQL 9.6 新機能紹介
by
Masahiko Sawada
PDF
PostgreSQL on Amazon EC2の可能性
by
Serverworks Co.,Ltd.
PDF
Hackers Champloo 2016 postgresql-9.6
by
Toshi Harada
PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
PDF
Chugoku db 17th-postgresql-9.6
by
Toshi Harada
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PDF
PostgreSQLの新バージョン -PostgreSQL9.4- のご紹介
by
Insight Technology, Inc.
PDF
5ステップで始めるPostgreSQLレプリケーション@hbstudy#13
by
Uptime Technologies LLC (JP)
PDF
[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告
by
Amazon Web Services Japan
PDF
位置情報を使ったサービス「スマポ」をPostgreSQLで作ってみた db tech showcase 2013 Tokyo
by
Yoshiyuki Asaba
PDF
PostgreSQL運用管理入門
by
Yoshiyuki Asaba
新しくなったPg monzでpostgre sqlのクラスタを監視しよう
by
Yoshinori Nakanishi
明日から使えるPostgre sql運用管理テクニック(監視編)
by
kasaharatt
PostgreSQL9.3新機能紹介
by
NTT DATA OSS Professional Services
OSC沖縄2014_JPUG資料
by
kasaharatt
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
Kof2016 postgresql-9.6
by
Toshi Harada
PostgreSQLモニタリング機能の現状とこれから(Open Developers Conference 2020 Online 発表資料)
by
NTT DATA Technology & Innovation
pg_walinspectについて調べてみた!(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
いまさら聞けないPostgreSQL運用管理
by
Uptime Technologies LLC (JP)
PostgreSQL 9.6 新機能紹介
by
Masahiko Sawada
PostgreSQL on Amazon EC2の可能性
by
Serverworks Co.,Ltd.
Hackers Champloo 2016 postgresql-9.6
by
Toshi Harada
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み)
by
Hironobu Suzuki
Chugoku db 17th-postgresql-9.6
by
Toshi Harada
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PostgreSQLの新バージョン -PostgreSQL9.4- のご紹介
by
Insight Technology, Inc.
5ステップで始めるPostgreSQLレプリケーション@hbstudy#13
by
Uptime Technologies LLC (JP)
[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告
by
Amazon Web Services Japan
位置情報を使ったサービス「スマポ」をPostgreSQLで作ってみた db tech showcase 2013 Tokyo
by
Yoshiyuki Asaba
PostgreSQL運用管理入門
by
Yoshiyuki Asaba
More from Yoshinori Nakanishi
PDF
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10-
by
Yoshinori Nakanishi
PDF
Vagrant - 最近流行ってるらしいけど何者?
by
Yoshinori Nakanishi
PDF
JPUGしくみ+アプリケーション勉強会(第28回)
by
Yoshinori Nakanishi
PDF
JPUGしくみ+アプリケーション勉強会(第20回)
by
Yoshinori Nakanishi
PDF
JPUGしくみ+アプリケーション勉強会(第25回)
by
Yoshinori Nakanishi
PDF
Chef社内勉強会(第1回)
by
Yoshinori Nakanishi
各スペシャリストがお届け!データベース最新情報セミナー -PostgreSQL10-
by
Yoshinori Nakanishi
Vagrant - 最近流行ってるらしいけど何者?
by
Yoshinori Nakanishi
JPUGしくみ+アプリケーション勉強会(第28回)
by
Yoshinori Nakanishi
JPUGしくみ+アプリケーション勉強会(第20回)
by
Yoshinori Nakanishi
JPUGしくみ+アプリケーション勉強会(第25回)
by
Yoshinori Nakanishi
Chef社内勉強会(第1回)
by
Yoshinori Nakanishi
Recently uploaded
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
あなたの知らないPostgreSQL監視の世界
1.
あなたの知らない PostgreSQL 監視の世界 中西 剛紀
2.
2 自己紹介 • 氏名 :
中西 剛紀 (なかにし よしのり) • 所属 : TIS株式会社 OSS推進室 • お仕事 : OSSのサポート, 技術支援 • 主な活動領域 : PostgreSQL全般 – 日本PostgreSQLユーザ会(JPUG)でたまに講演 http://www.slideshare.net/naka24nori/pg-monzpostgre-sql – PostgreSQLエンタープライズコンソーシアム (PGECons)で技術検証活動 http://itpro.nikkeibp.co.jp/atcl/column/15/052800134/052900004/? ST=oss&a • pg_monzの開発メンバー
3.
3 AGENDA • PostgreSQLの監視に使える情報 • PostgreSQLの監視に使えるツール •
PostgreSQLの監視パターン • PostgreSQLのログについて考える
4.
4 PostgreSQLの運用でやるべきこと • データベース運用の目的 – DBの状態を把握して健全な状態に保つ • データベース運用の種類 – 死活監視 – リソース監視 – 性能分析/チューニング – バックアップ/リストア •
監視が運用管理の基本 – 正しく現状を把握しなければ何もできない
5.
5 PostgreSQLの運用でやるべきこと • データベース運用の目的 – DBの状態を把握して健全な状態に保つ • データベース運用の種類 – 死活監視 – リソース監視 – 性能分析/チューニング – バックアップ/リストア •
監視が運用管理の基本 – 正しく現状を把握しなければ何もできない 今回お話する範囲
6.
6 PostgreSQLの監視に使える情報
7.
7 PostgreSQLの監視に使える情報 • PostgreSQLの標準機能 – コマンド – 関数 – 稼働統計情報 – ログ
8.
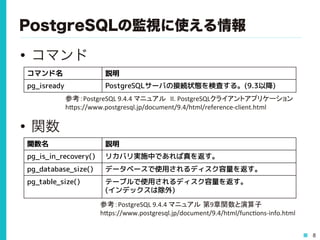
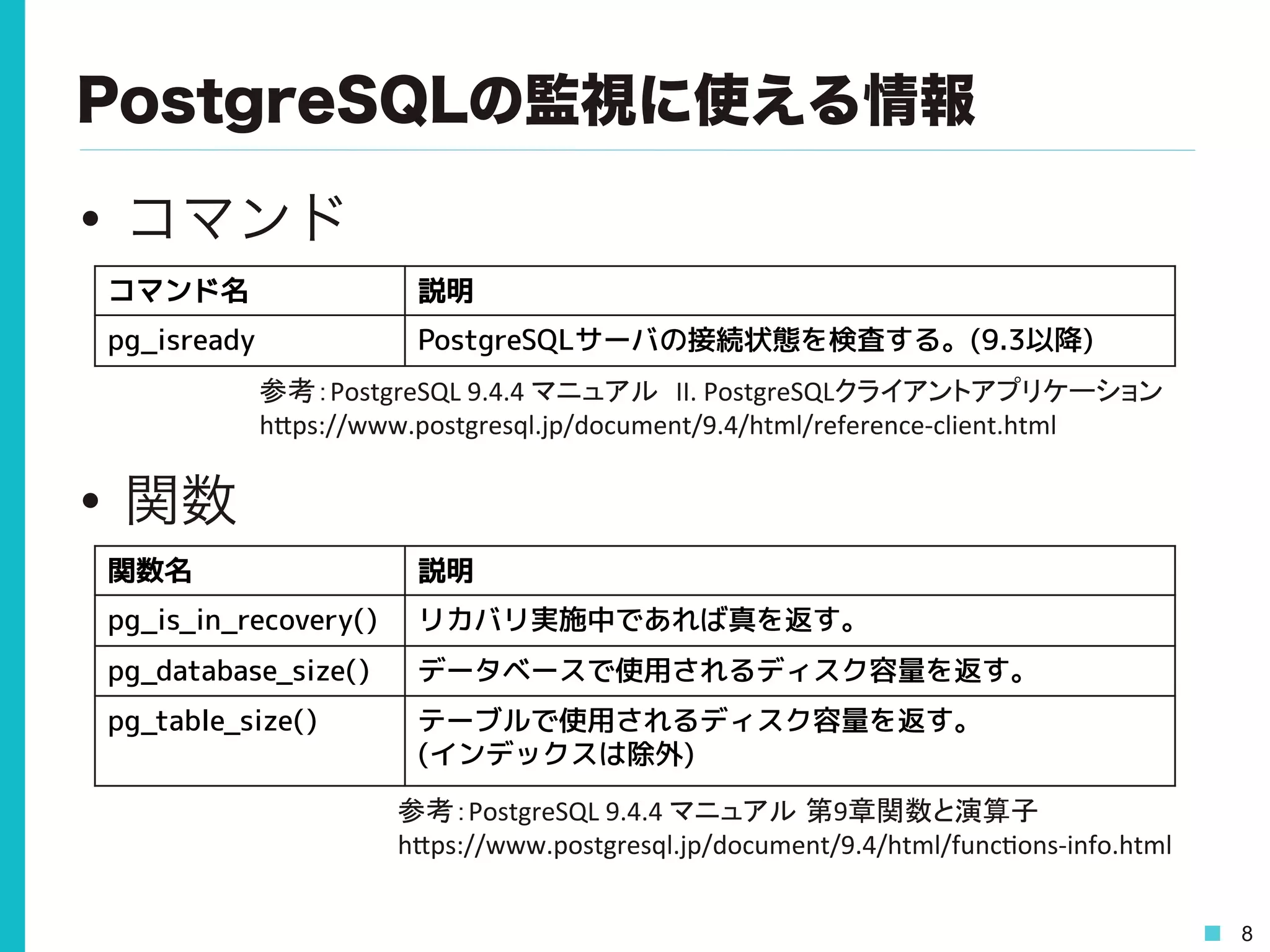
8 PostgreSQLの監視に使える情報 • コマンド • 関数 参考:PostgreSQL
9.4.4 マニュアル 第9章関数と演算子 h0ps://www.postgresql.jp/document/9.4/html/func>ons-‐info.html コマンド名 説明 pg_isready PostgreSQLサーバの接続状態を検査する。(9.3以降) 参考:PostgreSQL 9.4.4 マニュアル II. PostgreSQLクライアントアプリケーション h0ps://www.postgresql.jp/document/9.4/html/reference-‐client.html 関数名 説明 pg_is_in_recovery() リカバリ実施中であれば真を返す。 pg_database_size() データベースで使用されるディスク容量を返す。 pg_table_size() テーブルで使用されるディスク容量を返す。 (インデックスは除外)
9.
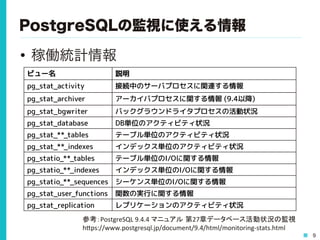
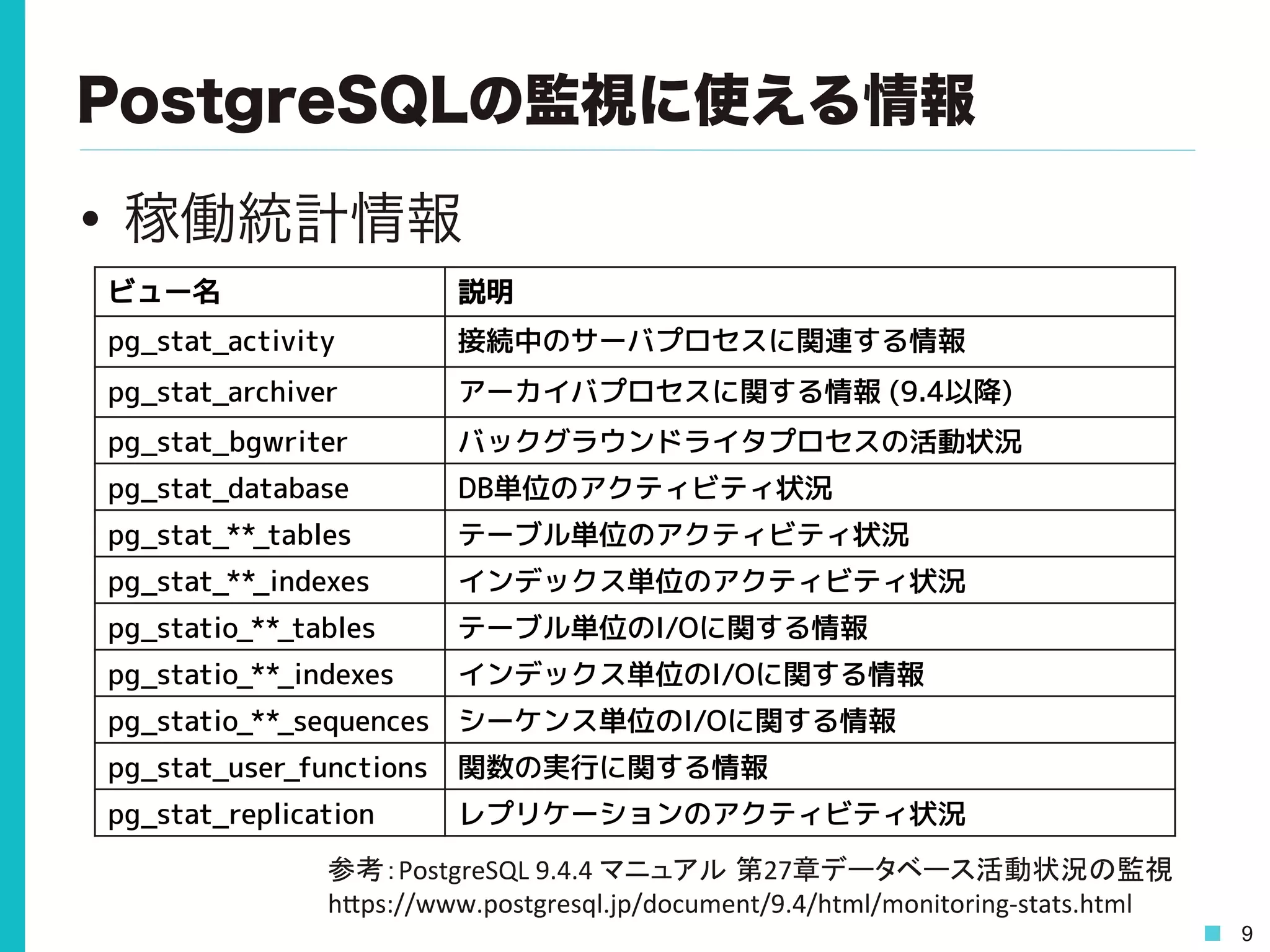
9 PostgreSQLの監視に使える情報 • 稼働統計情報 ビュー名 説明 pg_stat_activity
接続中のサーバプロセスに関連する情報 pg_stat_archiver アーカイバプロセスに関する情報 (9.4以降) pg_stat_bgwriter バックグラウンドライタプロセスの活動状況 pg_stat_database DB単位のアクティビティ状況 pg_stat_**_tables テーブル単位のアクティビティ状況 pg_stat_**_indexes インデックス単位のアクティビティ状況 pg_statio_**_tables テーブル単位のI/Oに関する情報 pg_statio_**_indexes インデックス単位のI/Oに関する情報 pg_statio_**_sequences シーケンス単位のI/Oに関する情報 pg_stat_user_functions 関数の実行に関する情報 pg_stat_replication レプリケーションのアクティビティ状況 参考:PostgreSQL 9.4.4 マニュアル 第27章データベース活動状況の監視 h0ps://www.postgresql.jp/document/9.4/html/monitoring-‐stats.html
10.
10 PostgreSQLの監視に使える情報 • ログ – 何らかの事象が発生したことを出力 • 深刻なレベル(PANIC,FATAL,ERROR)から、 特に影響ないレベル(INFO)まで – 処理されたSQL •
設定時間を超過したSQL(スロークエリ) • 監査目的で全てのSQLを出力することも可能 – チェックポイント、自動VACUUMの実行 – デッドロックの発生 – 出力形式 • テキスト(プレーン、CSV) • syslog • イベントログ
11.
11 PostgreSQLの監視に使えるツール
12.
12 PostgreSQLの監視に使えるツール • contrib – pg_stat_statements – file_fdw • サードパーティ – pg_statsinfo – pg_monz – pgBadger – Fluentd
13.
13 pg_stat_statements • PostgreSQLサーバで実行された クエリの情報を収集する共有ライブラリ – 8.4からcontribとして配布されている。 – クエリ種別、実行回数、総実行時間を収集 – 稼働統計情報と同様のビューを提供 – 永安さんの資料が詳しい • 「今そこにある危機」を捉える
∼ pg_stat_statements revisited http://www.slideshare.net/uptimejp/pgstatstatements-revisited
14.
14 pg_statsinfo • PostgreSQLサーバの稼働統計情報(+α) を定期的に収集・蓄積するツール – http://pgstatsinfo.sourceforge.net/pg_statsinfo-ja.html •
pg_stats_reporterで蓄積した統計情報 からグラフィカルなレポートを出力可能 • NTTさんが開発しているOSS • PostgreSQLの性能管理ツールとしては 一番知名度が高い。
15.
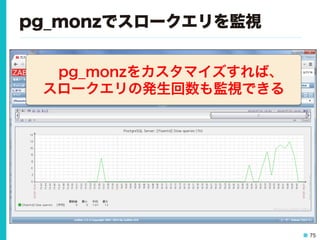
15 pg_monz(ぴーじーもんず) • ZabbixにPostgreSQLの監視機能を 追加するテンプレート&スクリプト – http://pg-monz.github.io/pg_monz/ •
TISとSRA OSS, Inc.日本支社で共同開発 • Apache License Version 2.0で公開 • 2015年 4月 Version 2.0 リリース
16.
16 Zabbixについて少々 • オープンソースの統合監視ソフトウェア • 監視ツールに必要な機能を網羅 – いろんな機器(NW,サーバ,MW,アプリ)に対応 – 対応プラットフォーム(OS)も多い – 収集データの蓄積、傾向分析 – メール等での障害通知 – WebインタフェースによるGUIで操作可 •
ラトビアのZabbix SIAが開発元 – 国内の導入事例が増加しています。 – クラウドでの引き合い多数(¥的な面で)
17.
17 PostgreSQLの監視パターン
18.
18 救急患者レベル • 事象を検知したら即座に対応しよう。 • 死活監視 •
ログ監視 • レプリケーション監視
19.
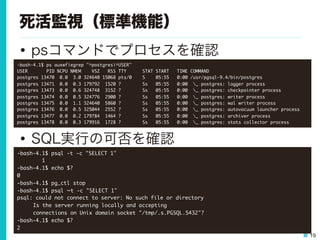
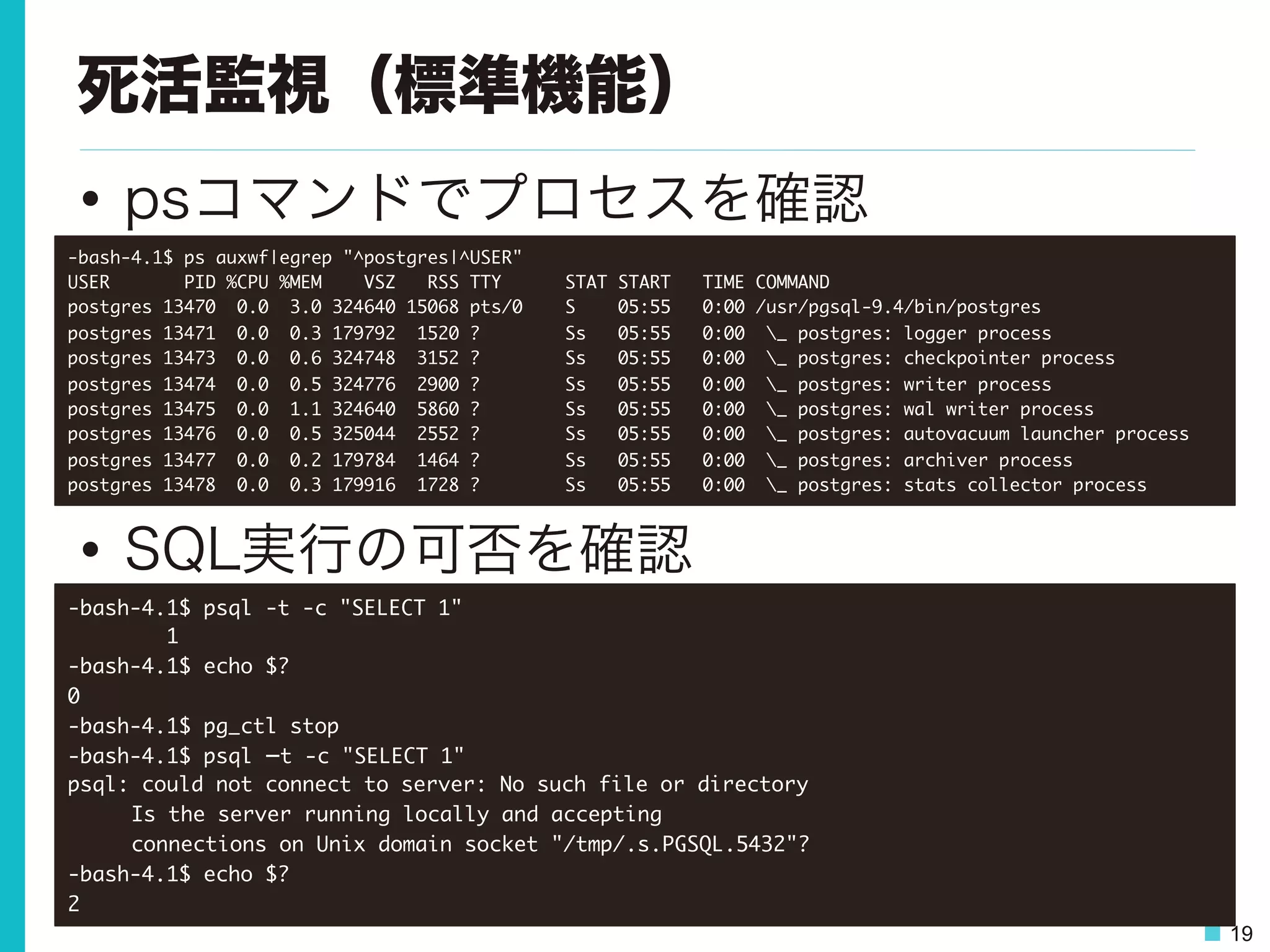
19 死活監視(標準機能) • psコマンドでプロセスを確認 • SQL実行の可否を確認 -bash-4.1$
ps auxwf|egrep "^postgres|^USER" USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND postgres 13470 0.0 3.0 324640 15068 pts/0 S 05:55 0:00 /usr/pgsql-9.4/bin/postgres postgres 13471 0.0 0.3 179792 1520 ? Ss 05:55 0:00 _ postgres: logger process postgres 13473 0.0 0.6 324748 3152 ? Ss 05:55 0:00 _ postgres: checkpointer process postgres 13474 0.0 0.5 324776 2900 ? Ss 05:55 0:00 _ postgres: writer process postgres 13475 0.0 1.1 324640 5860 ? Ss 05:55 0:00 _ postgres: wal writer process postgres 13476 0.0 0.5 325044 2552 ? Ss 05:55 0:00 _ postgres: autovacuum launcher process postgres 13477 0.0 0.2 179784 1464 ? Ss 05:55 0:00 _ postgres: archiver process postgres 13478 0.0 0.3 179916 1728 ? Ss 05:55 0:00 _ postgres: stats collector process -bash-4.1$ psql -t -c "SELECT 1" 1 -bash-4.1$ echo $? 0 -bash-4.1$ pg_ctl stop -bash-4.1$ psql –t -c "SELECT 1" psql: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/tmp/.s.PGSQL.5432"? -bash-4.1$ echo $? 2
20.
20 死活監視(標準機能) • pg_ctl statusコマンドで確認 •
pg_isreadyコマンドで確認(9.3以降) -bash-4.1$ pg_ctl status pg_ctl: server is running (PID: 13616) /usr/pgsql-9.4/bin/postgres -bash-4.1$ echo $? 0 -bash-4.1$ pg_ctl stop -bash-4.1$ pg_ctl status pg_ctl: no server running -bash-4.1$ echo $? 3 -bash-4.1$ pg_isready /tmp:5432 - accepting connections -bash-4.1$ echo $? 0 -bash-4.1$ pg_ctl stop -bash-4.1$ pg_isready /tmp:5432 - no response -bash-4.1$ echo $? 2
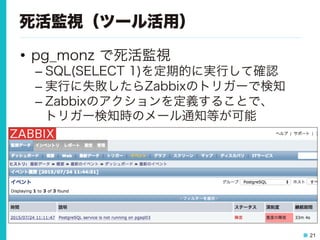
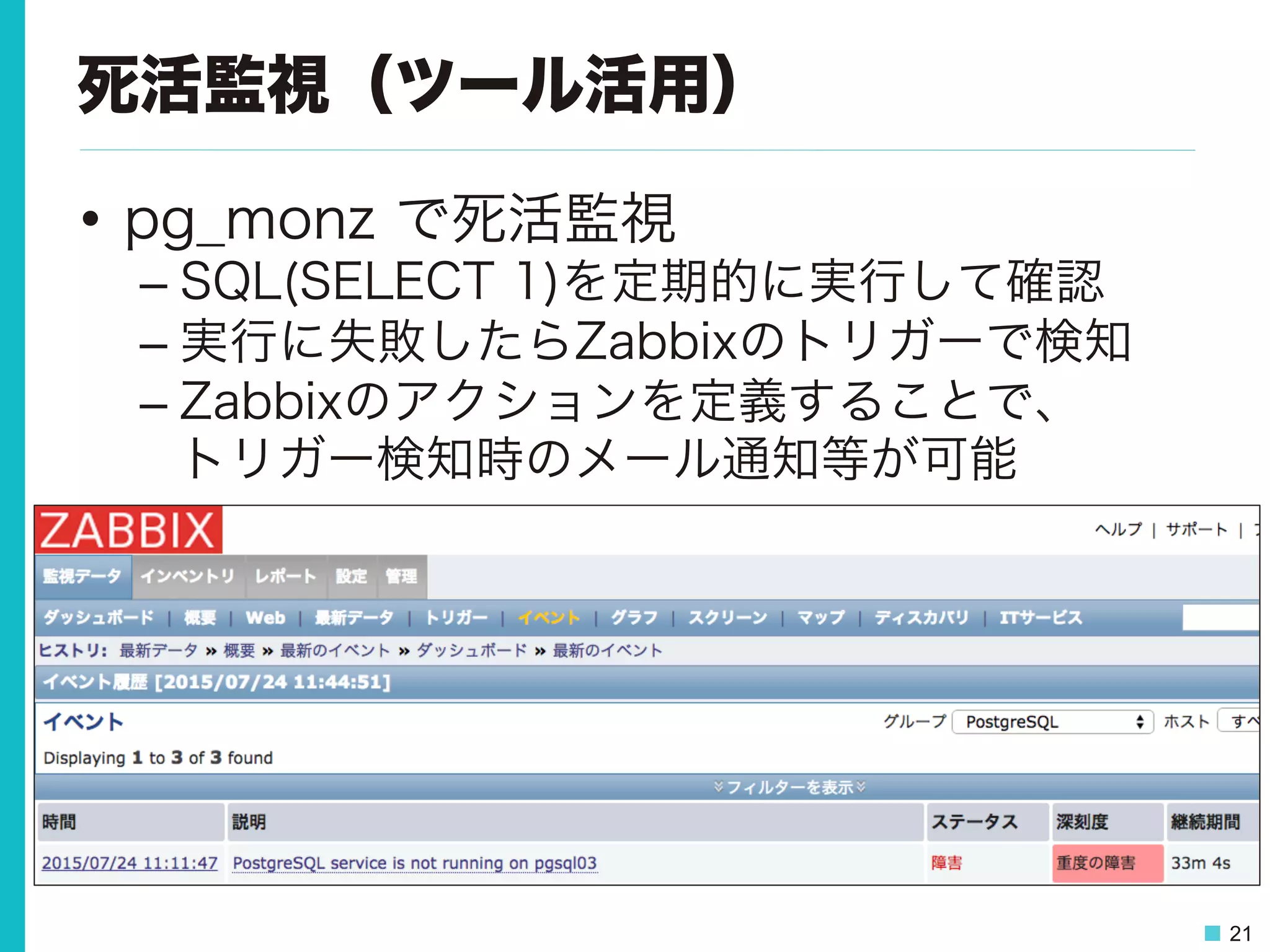
21.
21 死活監視(ツール活用) • pg_monz で死活監視 – SQL(SELECT
1)を定期的に実行して確認 – 実行に失敗したらZabbixのトリガーで検知 – Zabbixのアクションを定義することで、 トリガー検知時のメール通知等が可能
22.
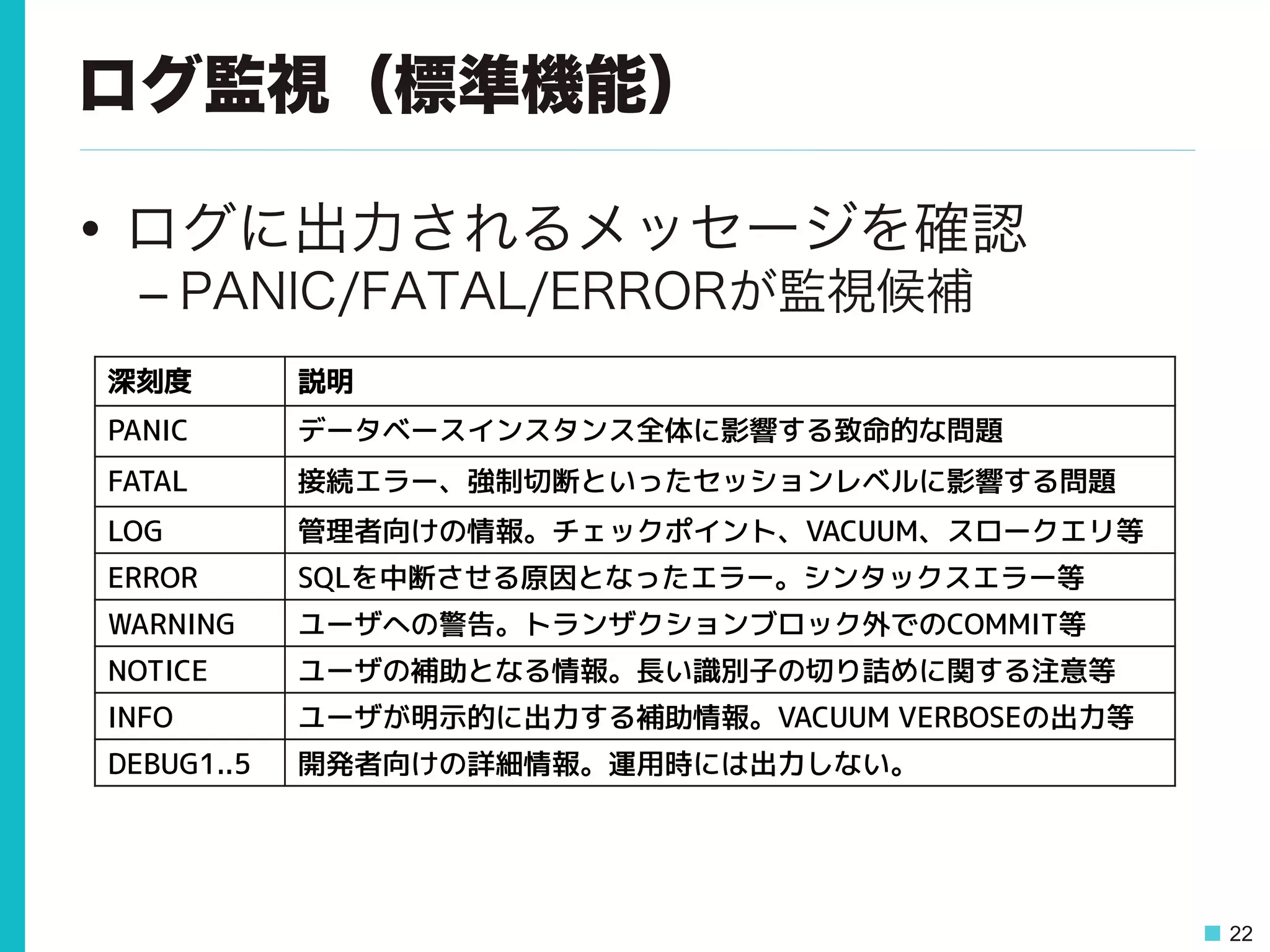
22 ログ監視(標準機能) • ログに出力されるメッセージを確認 – PANIC/FATAL/ERRORが監視候補 深刻度 説明 PANIC
データベースインスタンス全体に影響する致命的な問題 FATAL 接続エラー、強制切断といったセッションレベルに影響する問題 LOG 管理者向けの情報。チェックポイント、VACUUM、スロークエリ等 ERROR SQLを中断させる原因となったエラー。シンタックスエラー等 WARNING ユーザへの警告。トランザクションブロック外でのCOMMIT等 NOTICE ユーザの補助となる情報。長い識別子の切り詰めに関する注意等 INFO ユーザが明示的に出力する補助情報。VACUUM VERBOSEの出力等 DEBUG1..5 開発者向けの詳細情報。運用時には出力しない。
23.
23 ログ監視(ツール活用) • pg_monzでログ監視 – ログファイルの内容を定期的に確認 – PANIC/FATAL/ERRORを含むメッセージを 検出したらZabbixのトリガーで検知 – Zabbixのアクションを定義することで、 トリガー検知時のメール通知等が可能
24.
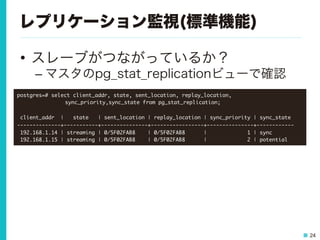
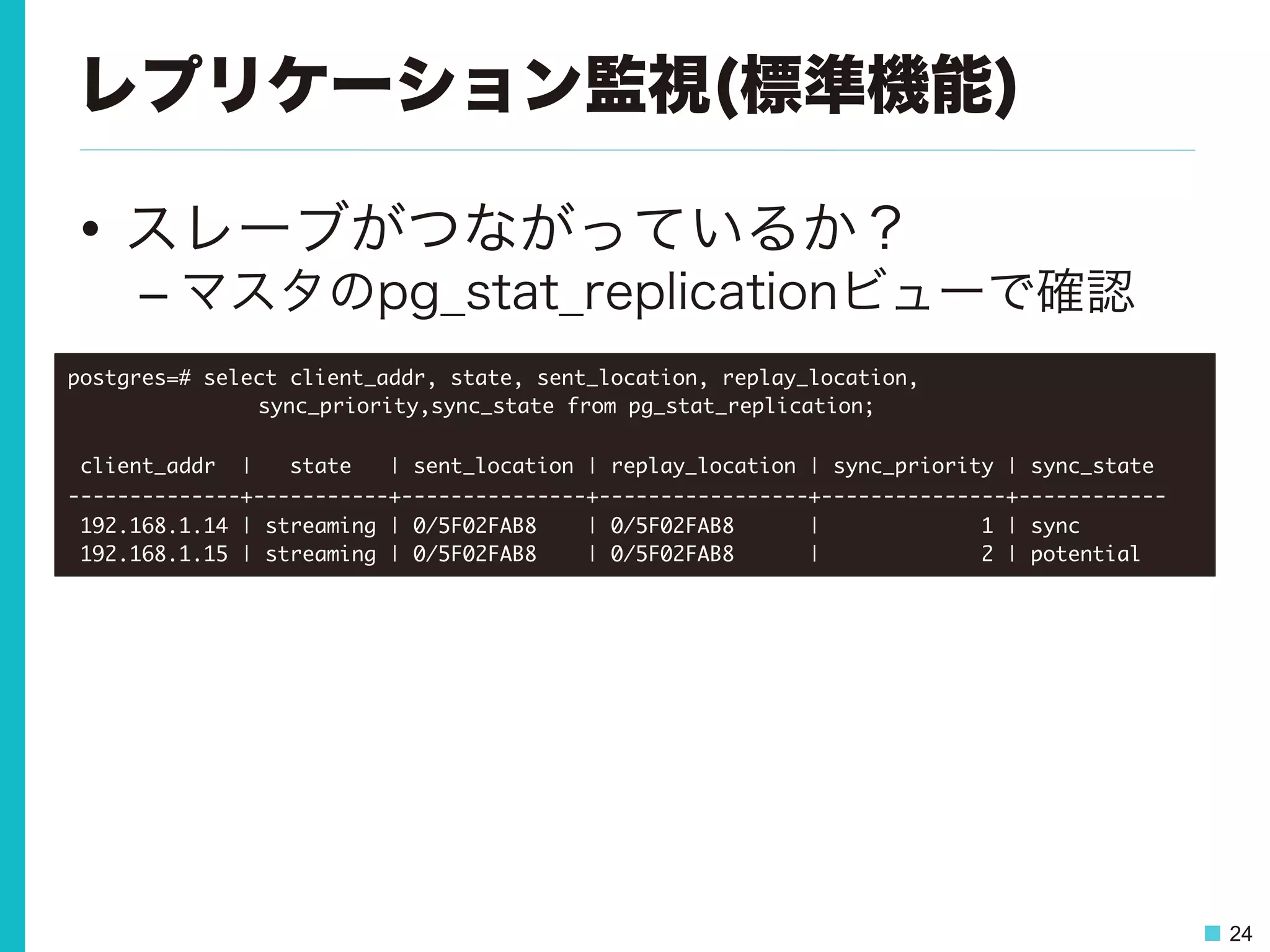
24 レプリケーション監視(標準機能) • スレーブがつながっているか? – マスタのpg_stat_replicationビューで確認 postgres=# select
client_addr, state, sent_location, replay_location, sync_priority,sync_state from pg_stat_replication; client_addr | state | sent_location | replay_location | sync_priority | sync_state --------------+-----------+---------------+-----------------+---------------+------------ 192.168.1.14 | streaming | 0/5F02FAB8 | 0/5F02FAB8 | 1 | sync 192.168.1.15 | streaming | 0/5F02FAB8 | 0/5F02FAB8 | 2 | potential
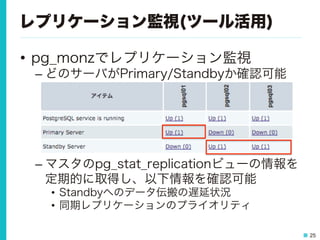
25.
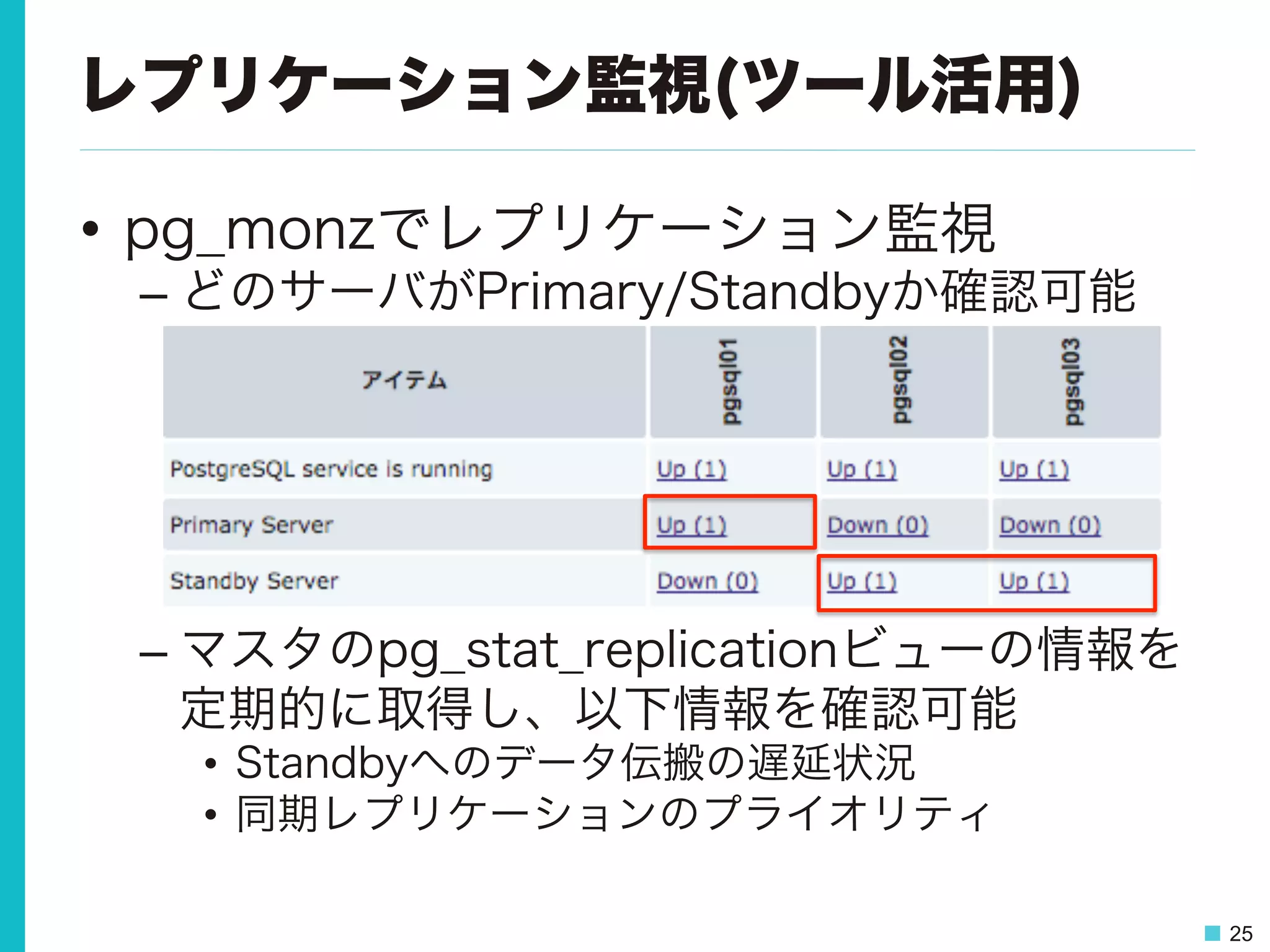
25 レプリケーション監視(ツール活用) • pg_monzでレプリケーション監視 – どのサーバがPrimary/Standbyか確認可能 – マスタのpg_stat_replicationビューの情報を 定期的に取得し、以下情報を確認可能 • Standbyへのデータ伝搬の遅延状況 •
同期レプリケーションのプライオリティ
26.
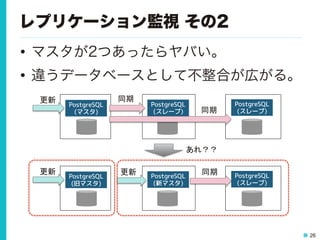
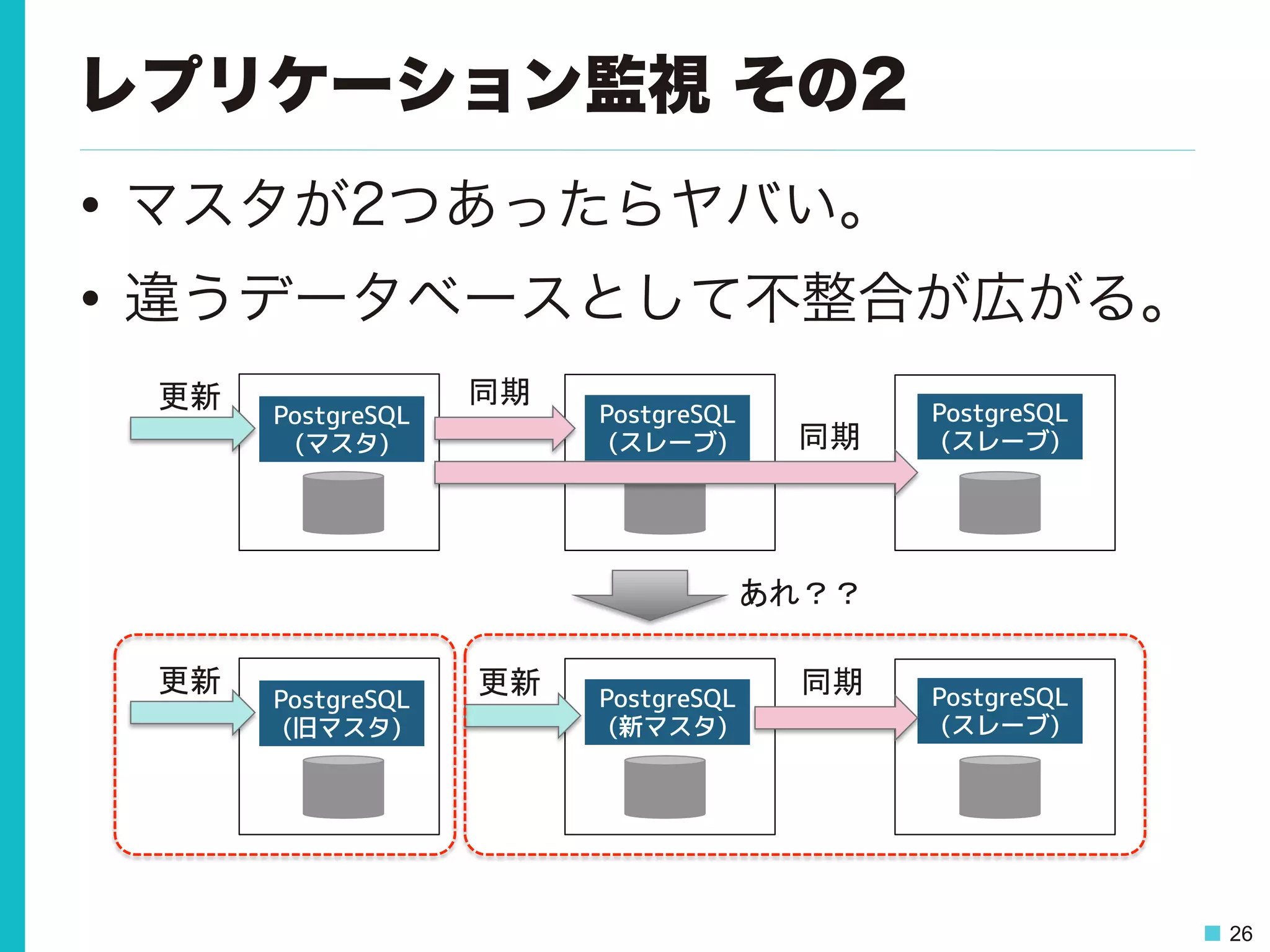
26 レプリケーション監視 その2 • マスタが2つあったらヤバい。 •
違うデータベースとして不整合が広がる。 PostgreSQL (スレーブ) PostgreSQL (スレーブ) PostgreSQL (マスタ) 更新 同期 同期 PostgreSQL (スレーブ) PostgreSQL (新マスタ) PostgreSQL (旧マスタ) 更新 同期 あれ?? 更新
27.
27 レプリケーション監視(標準機能) • pg_is_in_recovery関数で確認 • pg_stat_replicationビューで確認 postgres=#
SELECT pg_is_in_recovery(); ★マスタで実行 pg_is_in_recovery ------------------- f postgres=# SELECT pg_is_in_recovery(); ★スレーブで実行 pg_is_in_recovery ------------------- t postgres=# SELECT COUNT(*) FROM pg_stat_replication; ★マスタで実行 count ------- 2 postgres=# SELECT COUNT(*) FROM pg_stat_replication; ★スレーブで実行 count ------- 0
28.
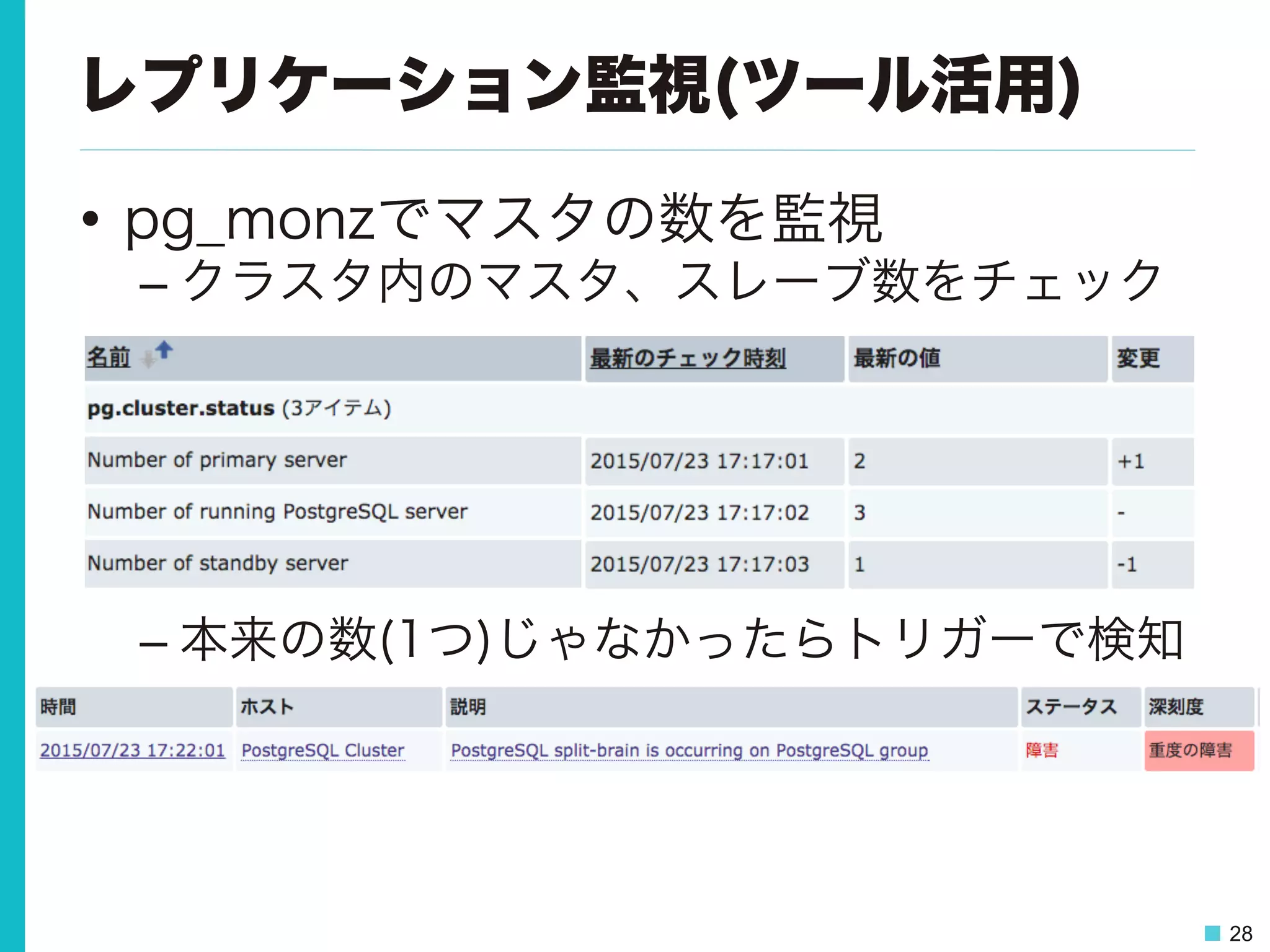
28 レプリケーション監視(ツール活用) • pg_monzでマスタの数を監視 – クラスタ内のマスタ、スレーブ数をチェック – 本来の数(1つ)じゃなかったらトリガーで検知
29.
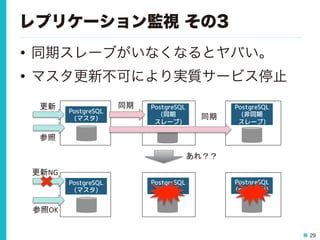
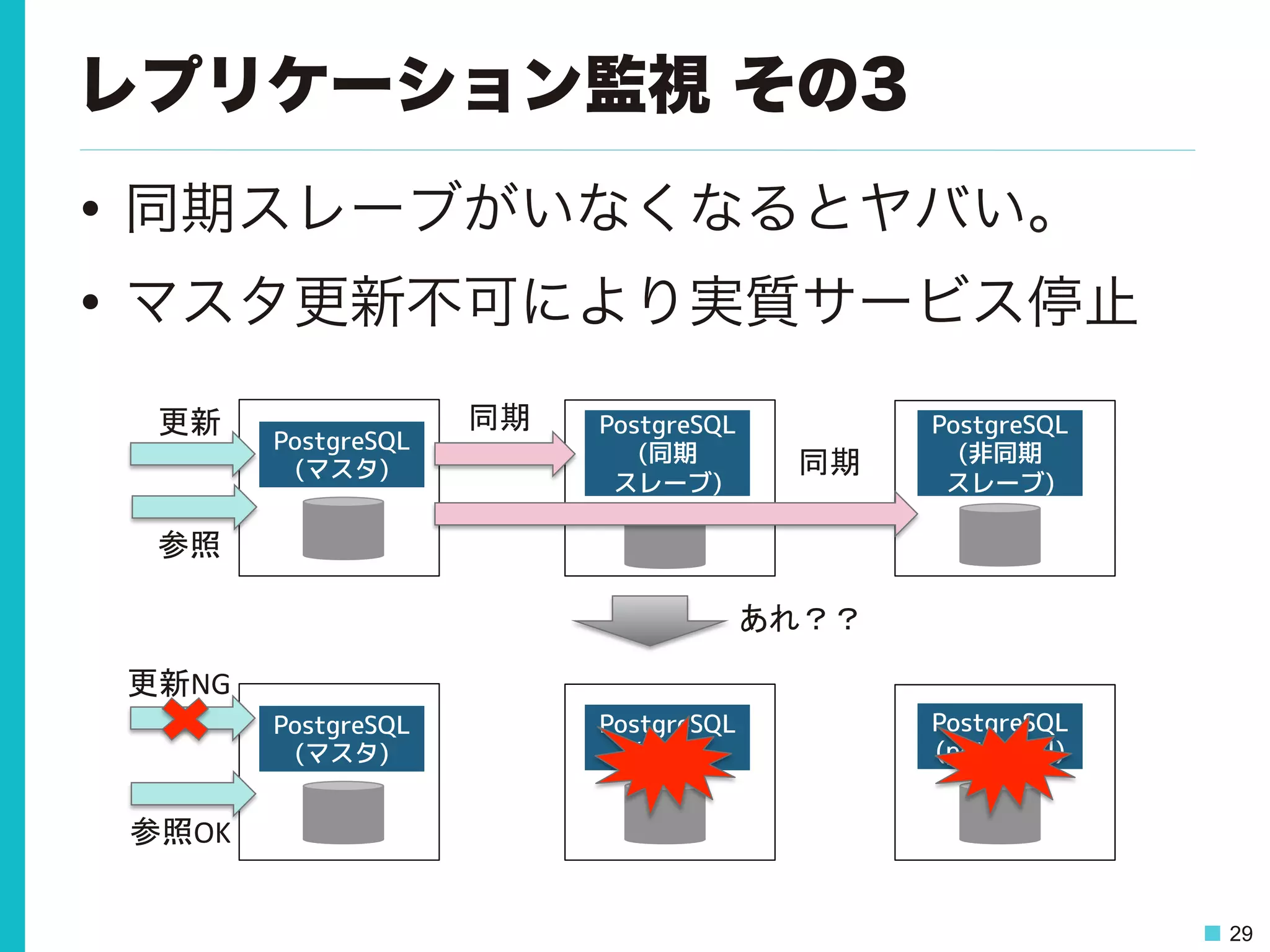
29 レプリケーション監視 その3 • 同期スレーブがいなくなるとヤバい。 •
マスタ更新不可により実質サービス停止 PostgreSQL (非同期 スレーブ) PostgreSQL (同期 スレーブ) PostgreSQL (マスタ) 更新 同期 同期 PostgreSQL (potential) PostgreSQL (sync) PostgreSQL (マスタ) 更新NG あれ?? 参照OK 参照
30.
30 レプリケーション監視(標準機能) • pg_stat_replicationビューで確認 postgres=# SELECT
COUNT(*) FROM pg_stat_replication; ★マスタで実行 count ------- 2 ⇒ 問題なし postgres=# SELECT COUNT(*) FROM pg_stat_replication; ★マスタで実行 count ------- 0 ⇒ スレーブが1つもいないので問題あり
31.
31 レプリケーション監視(ツール活用) • pg_monzで同期スレーブの数を監視 – 同期レプリケーションを設定している場合、 スレーブがいなくなったらトリガーで検知
32.
32 レントゲンに怪しい影が、、レベル • 事態が深刻化する前に手を打とう。 • データベース容量 •
WALアーカイブ • デッドロック • 長時間かかっている処理
33.
33 データベース容量(標準機能) • データベースクラスタのディレクトリを duコマンドで確認 • 関数で確認 [postgres@pgsql01
9.4]$ du -sh data 611M data postgres=# select pg_size_pretty(pg_database_size(‘testdb’)); ★データベース pg_size_pretty ---------------- 171 MB testdb=# select pg_size_pretty(pg_table_size(‘pgbench_accounts’)); ★テーブル pg_size_pretty ---------------- 130 MB
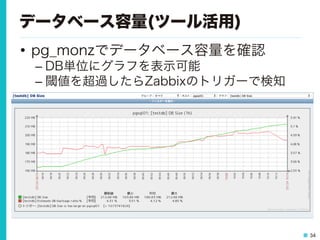
34.
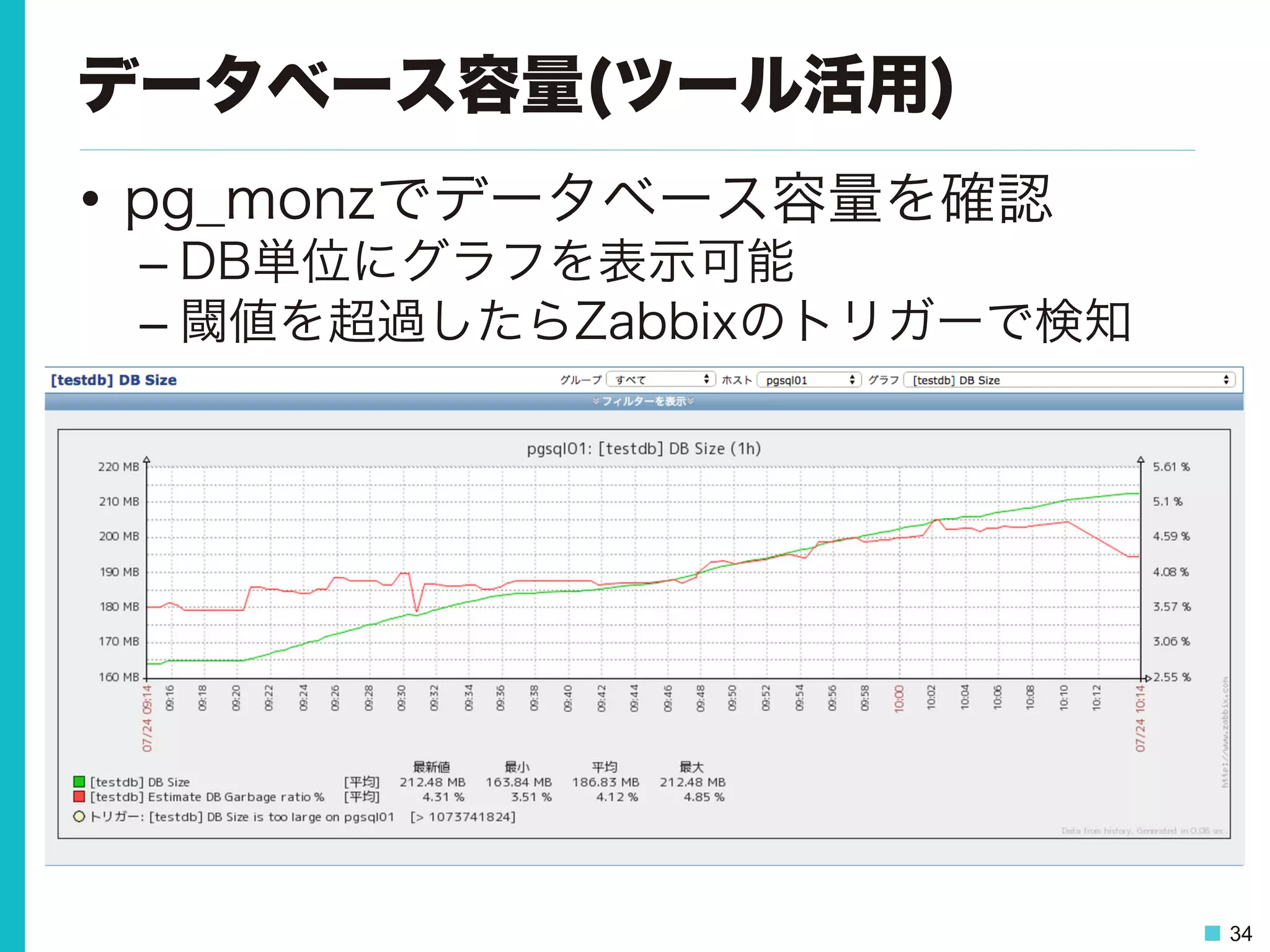
34 データベース容量(ツール活用) • pg_monzでデータベース容量を確認 – DB単位にグラフを表示可能 – 閾値を超過したらZabbixのトリガーで検知
35.
35 WALアーカイブ(標準機能) • PITRでの復旧にWALアーカイブが必要 • WALアーカイブに失敗したログを確認 – 深刻度がLOG,WARNINGなので注意 cp:
cannot create regular file `/var/lib/pgsql/9.4/archive_bad/ 000000010000000000000008': No such file or directory < 2015-11-11 10:04:50.609 UTC >LOG: archive command failed with exit code 1 < 2015-11-11 10:04:50.609 UTC >DETAIL: The failed archive command was: cp pg_xlog/ 000000010000000000000008 /var/lib/pgsql/9.4/archive_bad/000000010000000000000008 cp: cannot create regular file `/var/lib/pgsql/9.4/archive_bad/ 000000010000000000000008': No such file or directory < 2015-11-11 10:04:51.614 UTC >LOG: archive command failed with exit code 1 < 2015-11-11 10:04:51.614 UTC >DETAIL: The failed archive command was: cp pg_xlog/ 000000010000000000000008 /var/lib/pgsql/9.4/archive_bad/000000010000000000000008 cp: cannot create regular file `/var/lib/pgsql/9.4/archive_bad/ 000000010000000000000008': No such file or directory < 2015-11-11 10:04:52.618 UTC >LOG: archive command failed with exit code 1 < 2015-11-11 10:04:52.618 UTC >DETAIL: The failed archive command was: cp pg_xlog/ 000000010000000000000008 /var/lib/pgsql/9.4/archive_bad/000000010000000000000008 < 2015-11-11 10:04:52.619 UTC >WARNING: archiving transaction log file "000000010000000000000008" failed too many times, will try again later
36.
36 WALアーカイブ(標準機能) • pg_stat_archiverビューで確認(9.4以降) postgres=# select
* from pg_stat_archiver; -[ RECORD 1 ]------+------------------------------ archived_count | 12 last_archived_wal | 00000001000000000000000E last_archived_time | 2015-11-11 10:10:50.629021+00 failed_count | 6 last_failed_wal | 000000010000000000000008 last_failed_time | 2015-11-11 10:05:52.719825+00 stats_reset | 2015-11-06 08:10:16.027035+00
37.
37 デッドロック(標準機能) • デッドロック発生をログで確認 – log_lock_waitsパラメータを設定して出力 • pg_stat_databaseビューで確認 2015-11-12
14:52:07 JST [10382] LOG: process 10382 detected deadlock while waiting for AccessExclusiveLock on relation 16420 of database 16400 after 1000.088 ms postgres=# SELECT datname,deadlocks FROM pg_stat_database where datname = 'testdb'; datname | deadlocks ---------+----------- testdb | 2
38.
38 デッドロック(ツール活用) • pg_monzでデッドロック監視 – DB単位のデッドロック発生数を定期的に確認 – 一定時間内の発生数が閾値を超過したら Zabbixのトリガーで検知 • pg_statsinfoでデッドロック監視 – DB単位のデッドロック発生数を収集
39.
39 長時間かかっている処理 • ロングクエリ – 開始されてから長時間終了していないクエリ • ロングトランザクション – BEGIN∼COMMITまでが長時間の処理 – VACUUMやHOTによるガベージ回収処理を 妨げ、DBの肥大化を起こす要因
40.
40 長時間かかっている処理(標準機能) • pg_stat_activityビューで確認 – xact_start: トランザクション開始時刻 – query_start:
現在のクエリ開始時刻 postgres=# SELECT pid, state, waiting, (now() - xact_start)::interval(3) AS tx_duration, (now() - query_start)::interval(3) AS sql_duration, query FROM pg_stat_activity WHERE pid <> pg_backend_pid(); pid | state | waiting | tx_duration | sql_duration | query -------+--------+---------+--------------+--------------+---------------------- 10266 | active | f | 00:02:00.303 | 00:00:14.175 | SELECT pg_sleep(60);
41.
41 長時間かかっている処理(ツール活用) • pg_monzでロングクエリを確認 – 一定時間以上かかっているクエリの数を 定期的に確認 – 閾値を超過したらZabbixのトリガーで検知
42.
42 体力測定レベル • データベースの稼働状況を把握しよう。 • データベースのスループット •
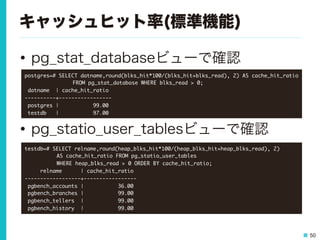
データベースの接続数 • キャッシュヒット率 • チェックポイント、VACUUMの実行状況 • 一時ファイルの書き出し • 実行されたSQLの実行時間
43.
43 データベースのスループット • 日頃の処理量を知っておこう。 – 平常時、ピーク時のトランザクション量 – 性能問題の原因切り分けの基礎情報
44.
44 データベースのスループット(標準機能) • pg_stat_databaseビューで確認 – 取得できるのは累積値 – 実際に利用するには単位秒あたりの 差分値を計算する等の工夫が必要 postgres=# select
datname,xact_commit,xact_rollback from pg_stat_database where datname = 'testdb'; -[ RECORD 1 ]-+------- datname | testdb xact_commit | 17727 xact_rollback | 4
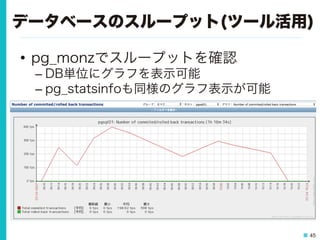
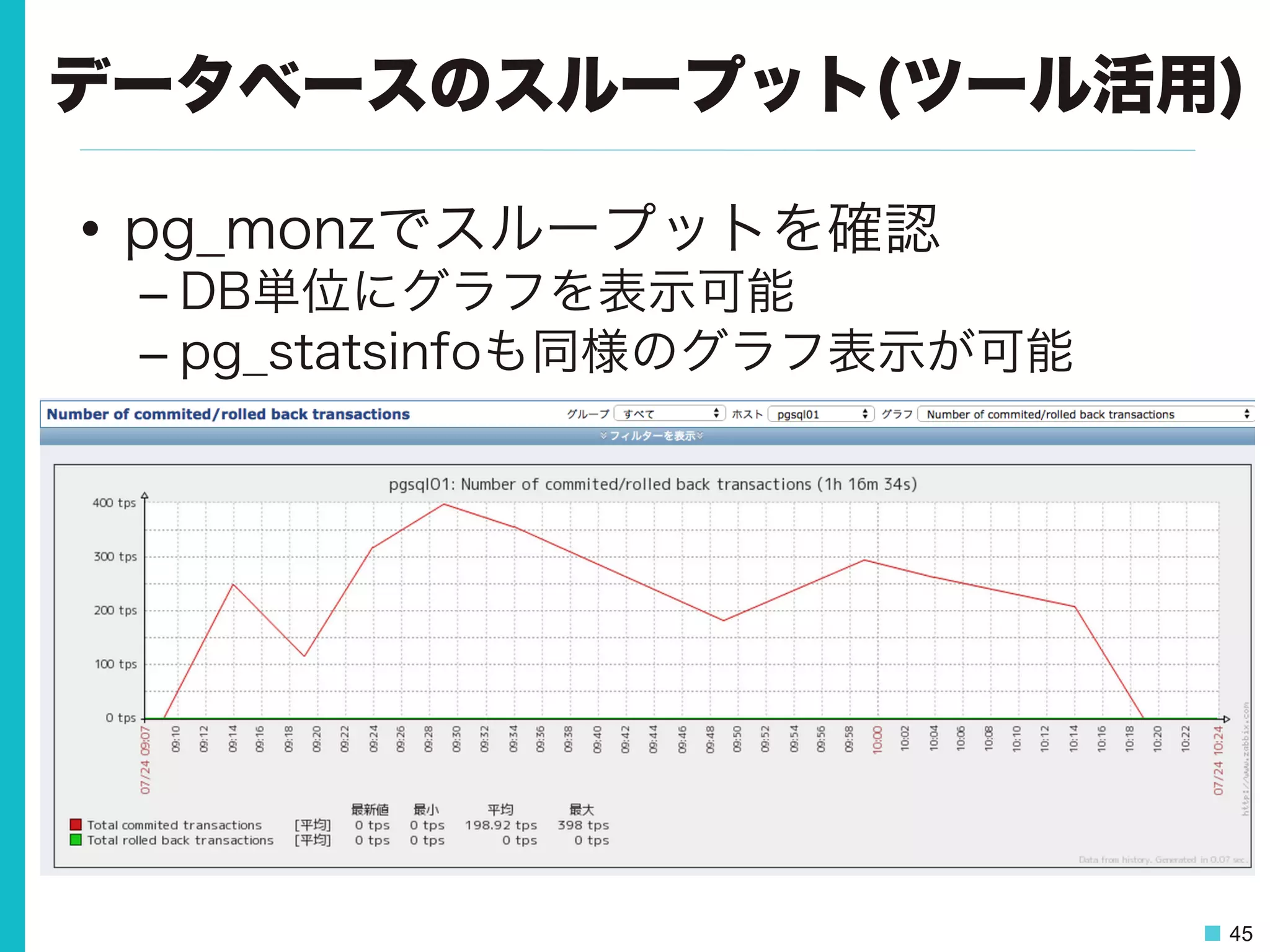
45.
45 データベースのスループット(ツール活用) • pg_monzでスループットを確認 – DB単位にグラフを表示可能 – pg_statsinfoも同様のグラフ表示が可能
46.
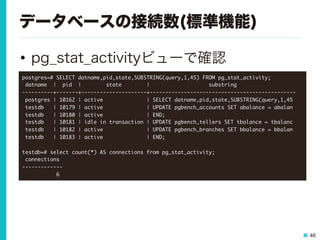
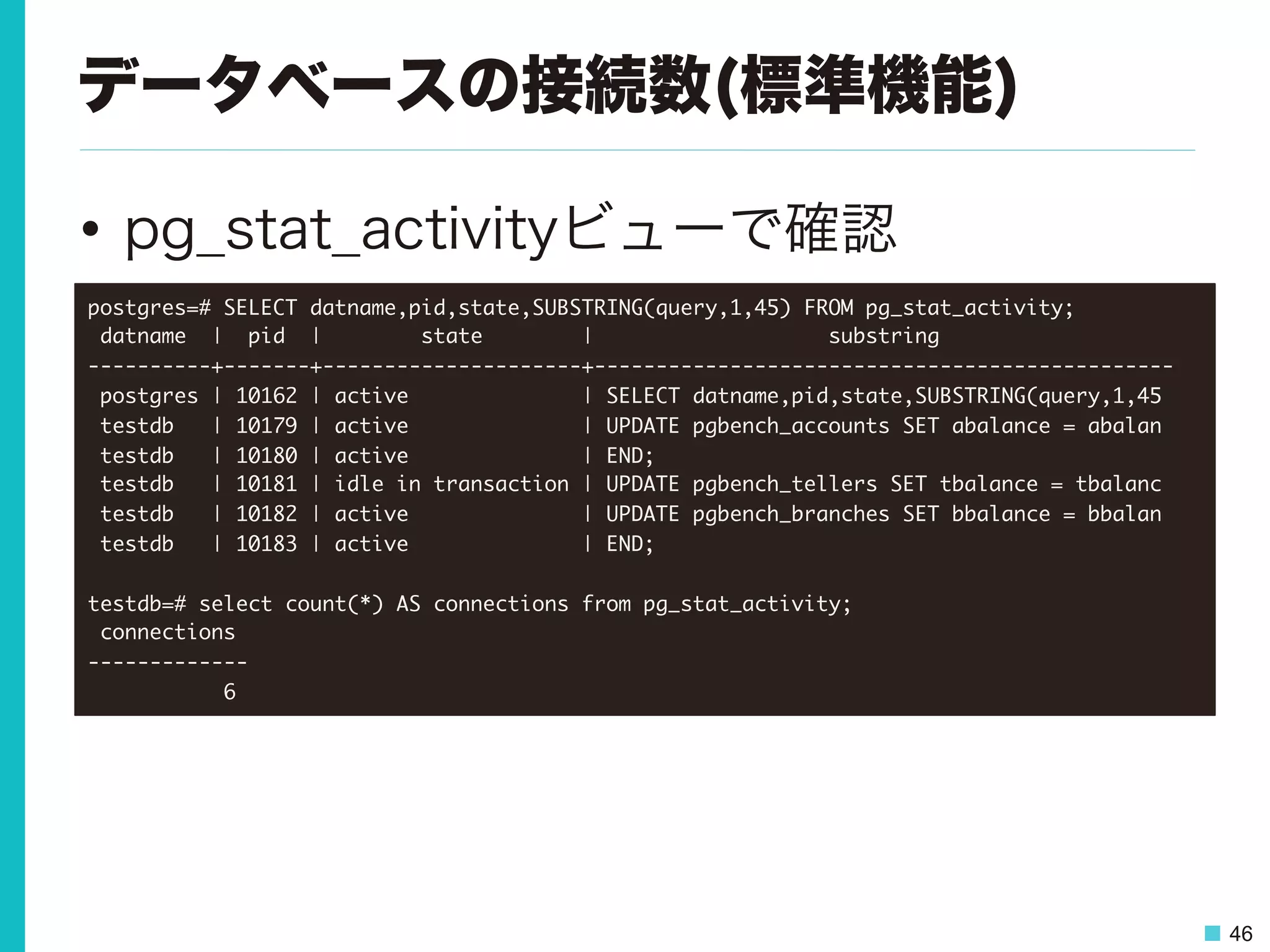
46 データベースの接続数(標準機能) • pg_stat_activityビューで確認 postgres=# SELECT
datname,pid,state,SUBSTRING(query,1,45) FROM pg_stat_activity; datname | pid | state | substring ----------+-------+---------------------+----------------------------------------------- postgres | 10162 | active | SELECT datname,pid,state,SUBSTRING(query,1,45 testdb | 10179 | active | UPDATE pgbench_accounts SET abalance = abalan testdb | 10180 | active | END; testdb | 10181 | idle in transaction | UPDATE pgbench_tellers SET tbalance = tbalanc testdb | 10182 | active | UPDATE pgbench_branches SET bbalance = bbalan testdb | 10183 | active | END; testdb=# select count(*) AS connections from pg_stat_activity; connections ------------- 6
47.
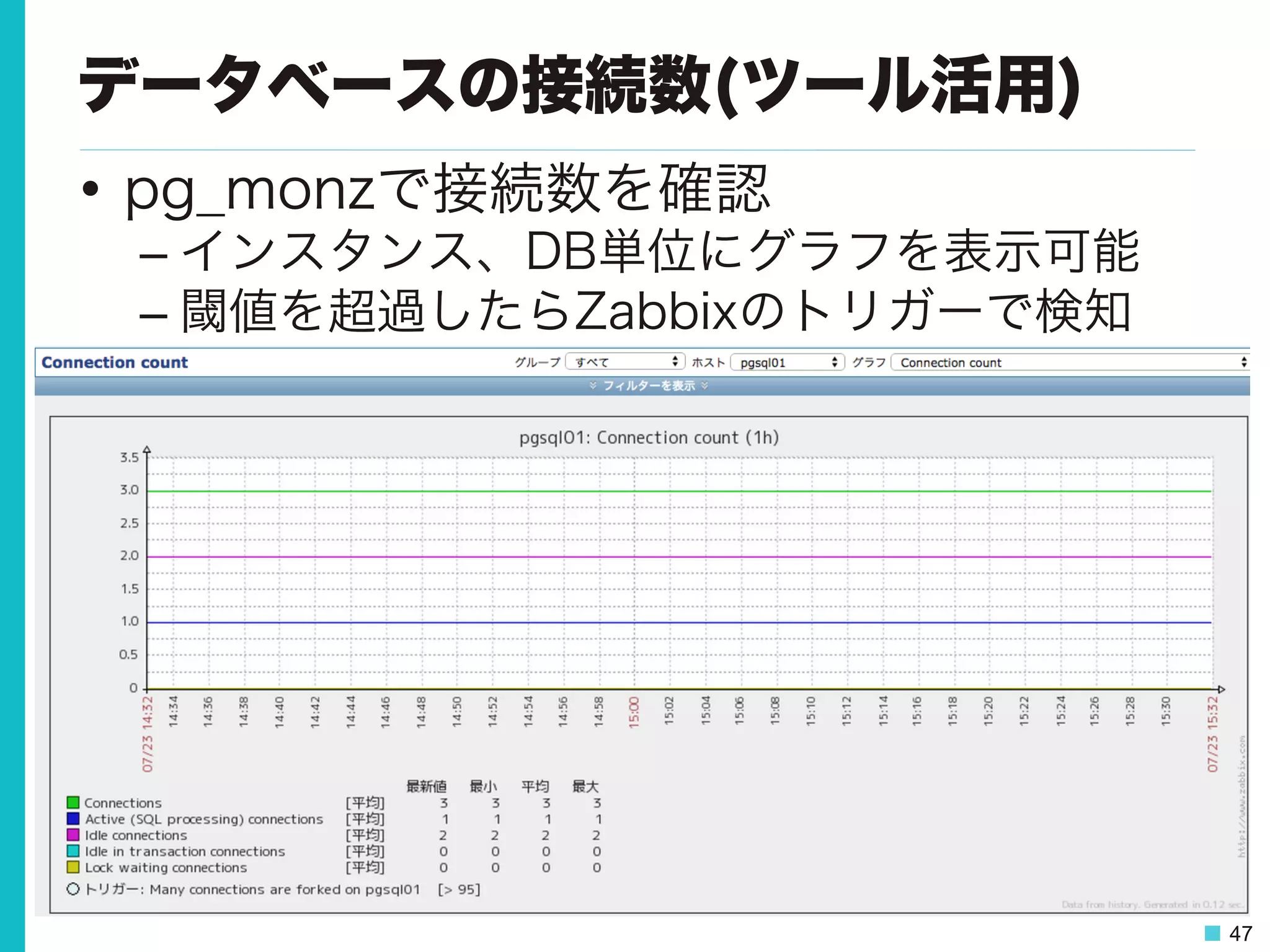
47 データベースの接続数(ツール活用) • pg_monzで接続数を確認 – インスタンス、DB単位にグラフを表示可能 – 閾値を超過したらZabbixのトリガーで検知
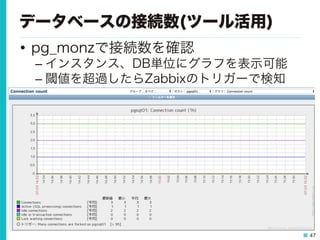
48.
48 データベースの接続数(ツール活用) • pg_statsinfoで接続数を確認 – インスタンス単位の情報、グラフを表示可能
49.
49 キャッシュヒット率 • DBはディスクにアクセスしない方が速い。 – どれだけメモリだけで処理できたか? = キャッシュヒット率 – 一般的に90%以上を維持するのが目標
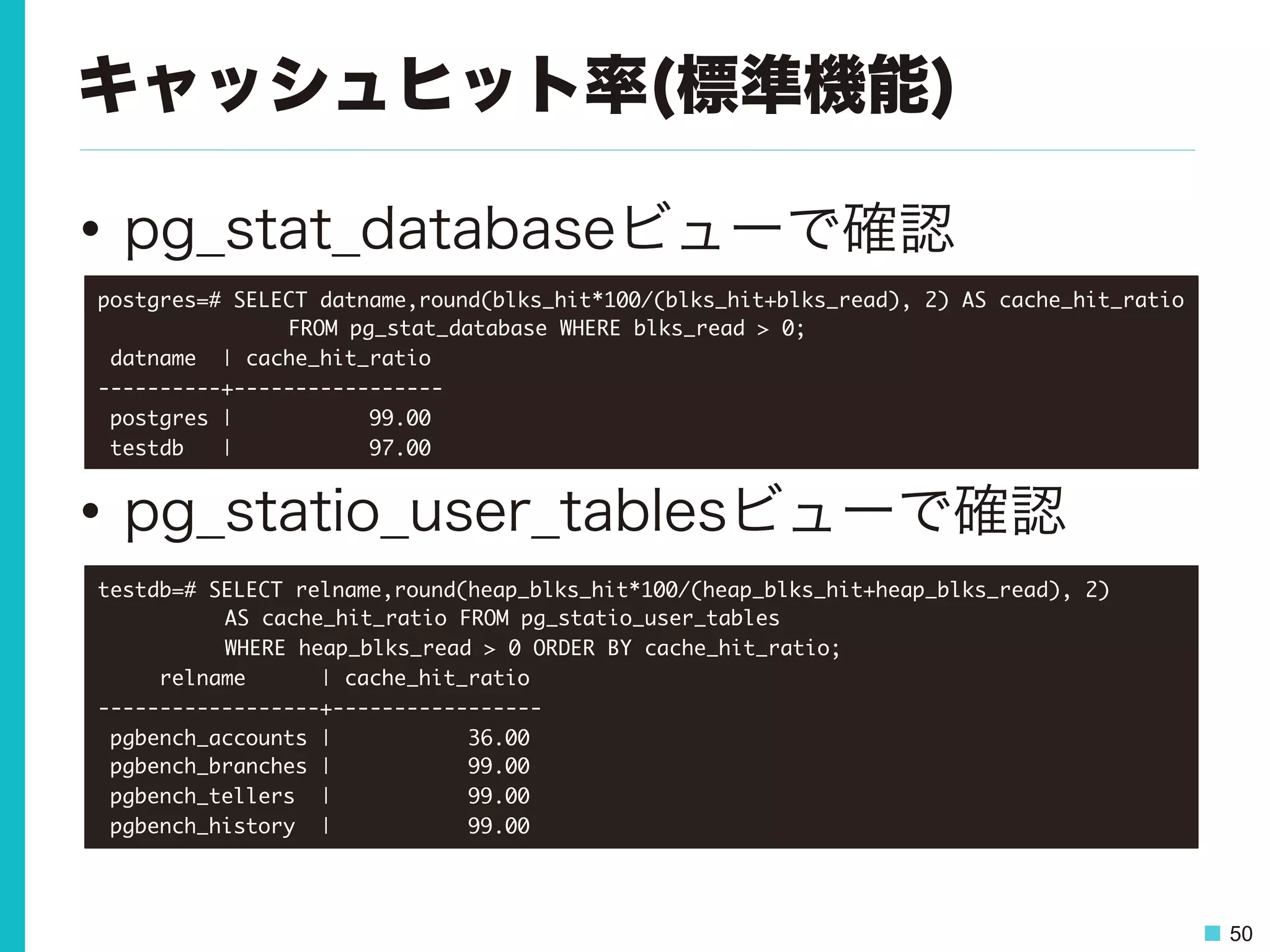
50.
50 キャッシュヒット率(標準機能) • pg_stat_databaseビューで確認 • pg_statio_user_tablesビューで確認 postgres=#
SELECT datname,round(blks_hit*100/(blks_hit+blks_read), 2) AS cache_hit_ratio FROM pg_stat_database WHERE blks_read > 0; datname | cache_hit_ratio ----------+----------------- postgres | 99.00 testdb | 97.00 testdb=# SELECT relname,round(heap_blks_hit*100/(heap_blks_hit+heap_blks_read), 2) AS cache_hit_ratio FROM pg_statio_user_tables WHERE heap_blks_read > 0 ORDER BY cache_hit_ratio; relname | cache_hit_ratio ------------------+----------------- pgbench_accounts | 36.00 pgbench_branches | 99.00 pgbench_tellers | 99.00 pgbench_history | 99.00
51.
51 キャッシュヒット率(ツール活用) • pg_monzでキャッシュヒット率を確認 – DB単位にグラフを表示可能 – 閾値を下回ったらZabbixのトリガーで検知 – テーブル単位のキャッシュヒット率も収集 • pg_statsinfoでキャッシュヒット率を確認 – DB単位に表示可能
52.
52 チェックポイント • 更新されたメモリ上のページをディスク に書き出す処理 • チェックポイント実行中に行われている 処理の性能に影響をおよぼすことがある。 – チェックポイントを頻繁に実行している? – サーバ負荷が高い時間帯にチェックポイント が行われている?
53.
53 チェックポイント(標準機能) • ログを確認 – log_checkpointsパラメータを設定して出力 • pg_stat_bgwriterビューで確認 testdb=#
SELECT checkpoints_timed,checkpoints_req,checkpoint_write_time, checkpoint_sync_time,buffers_checkpoint from pg_stat_bgwriter; -[ RECORD 1 ]---------+-------- checkpoints_timed | 568 checkpoints_req | 0 checkpoint_write_time | 1343894 checkpoint_sync_time | 2062 buffers_checkpoint | 38659 2015-11-12 13:37:53 JST [7602] LOG: checkpoint starting: time 2015-11-12 13:42:23 JST [7602] LOG: checkpoint complete: wrote 7418 buffers (45.3%); 0 transaction log file(s) added, 0 removed, 0 recycled; write=269.201 s, sync=0.421 s, total=269.685 s; sync files=17, longest=0.418 s, average=0.024 s 2015-11-12 17:49:22 JST [10679] LOG: checkpoints are occurring too frequently (25 seconds apart)
54.
54 チェックポイント(ツール活用) • pg_monzでチェックポイントを確認 – checkpoint_timeouts/segments契機で 実行されたチェックポイント実行回数を収集 – 一定期間のチェックポイント発生回数が 閾値を超過したらZabbixのトリガーで検知 • pg_statsinfoでチェックポイントを確認 – checkpoint_timeouts/segments契機で 実行されたチェックポイント実行回数を収集 – 平均および最大の処理時間を表示可能 – チェックポイントが走った時間帯をレポート の各種グラフに重ね合わせることも可能
55.
55 VACUUM • 不要なレコードを回収する処理 – ちゃんと実行されないとDBが肥大化する。
56.
56 VACUUM(標準機能) • ログを確認 – log_autovacuum_min_durationパラメータ を設定して出力 • pg_stat_user_tablesビューで確認 2015-11-12
13:36:30 JST [10188] LOG: automatic vacuum of table "testdb.public.pgbench_tellers": index scans: 0 pages: 0 removed, 25 remain tuples: 533 removed, 100 remain, 0 are dead but not yet removable buffer usage: 86 hits, 0 misses, 0 dirtied avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s system usage: CPU 0.00s/0.00u sec elapsed 0.00 sec testdb=# SELECT relname,n_live_tup,n_dead_tup,last_autovacuum,autovacuum_count FROM pg_stat_user_tables where relname = 'pgbench_accounts'; -[ RECORD 1 ]----+------------------------------ relname | pgbench_accounts n_live_tup | 1002477 n_dead_tup | 0 last_autovacuum | 2015-11-12 17:50:26.224429+09 autovacuum_count | 1
57.
57 VACUUM(ツール活用) • pg_monzでVACUUMを確認 – テーブル単位にVACUUMが実行された回数、 不要領域の割合を収集 • pg_statsinfoでVACUUMを確認 – テーブル単位にVACUUMが実行された回数、 不要領域の割合を収集 – 平均および最大の処理時間を表示可能
58.
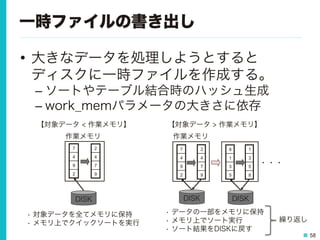
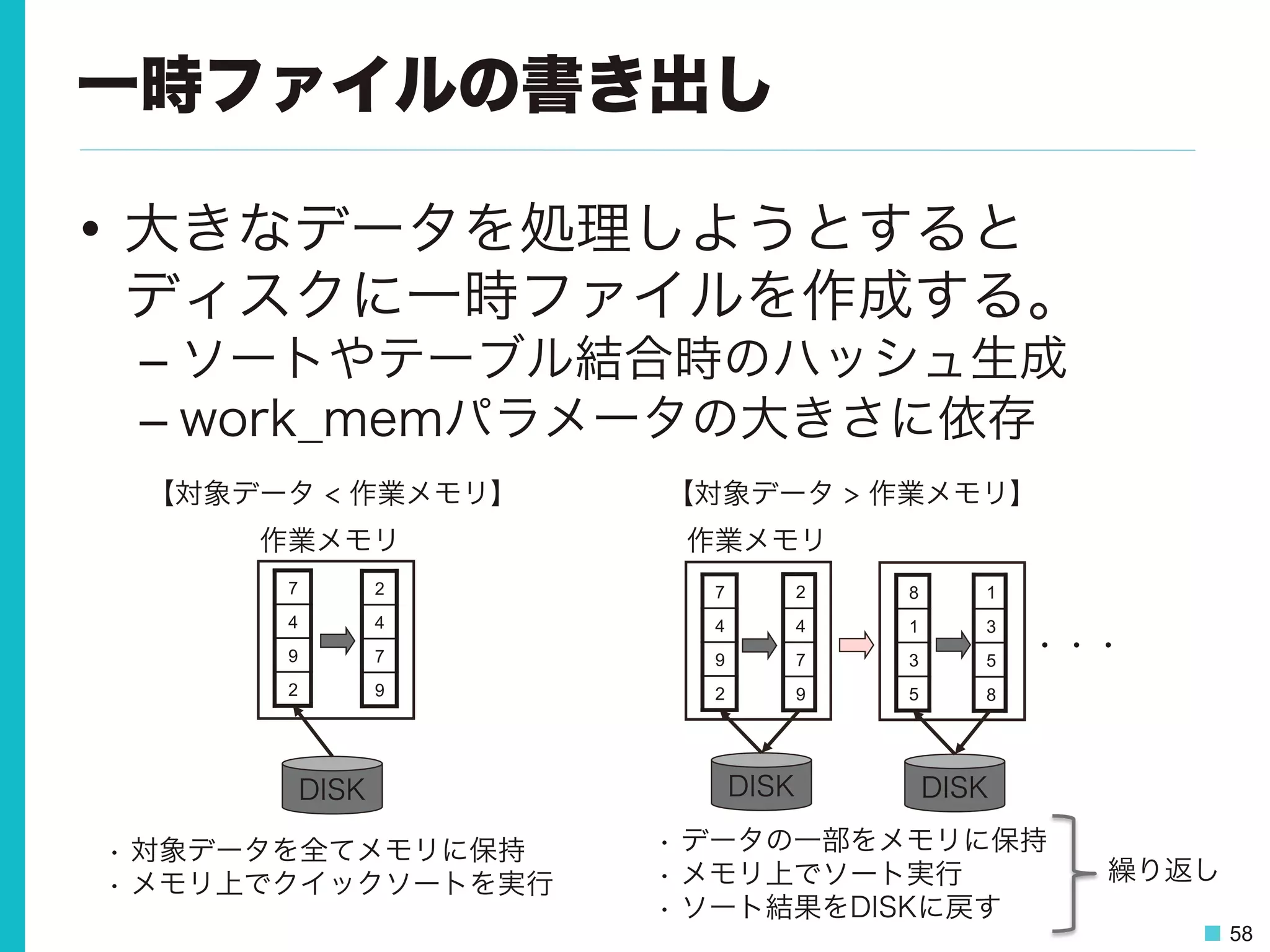
58 一時ファイルの書き出し • 大きなデータを処理しようとすると ディスクに一時ファイルを作成する。 – ソートやテーブル結合時のハッシュ生成 – work_memパラメータの大きさに依存 7 4 9 2 DISK • 対象データを全てメモリに保持 •
メモリ上でクイックソートを実行 7 4 9 2 2 4 7 9 2 4 7 9 8 1 3 5 1 3 5 8 DISK DISK ・・・ 【対象データ < 作業メモリ】 作業メモリ 【対象データ > 作業メモリ】 作業メモリ • データの一部をメモリに保持 • メモリ上でソート実行 • ソート結果をDISKに戻す 繰り返し
59.
59 一時ファイルの書き出し(標準機能) • ログを確認 – log_temp_filesパラメータを設定して出力 • pg_stat_databaseビューで確認 2015-11-11
20:52:33 JST [7801] LOG: temporary file: path "base/pgsql_tmp/ pgsql_tmp7801.1", size 53157 2015-11-11 20:52:33 JST [7801] STATEMENT: select * from pg_settings where name = 'log_temp_files'; postgres=# select datname,temp_files,temp_bytes from pg_stat_database where datname = 'testdb'; -[ RECORD 1 ]-------- datname | testdb temp_files | 1 temp_bytes | 14016512
60.
60 一時ファイルの書き出し(ツール活用) • pg_monzで一時ファイル書き出しを確認 – DB単位に書きだされたデータ量を収集 – 閾値を超過したらZabbixのトリガーで検知 • pg_statsinfoで一時ファイル書き出しを 確認 – DB単位に書きだされたファイル数、 データ量を収集
61.
61 腐ったミカンは除去しよう • 一握りの悪者が全体の足を引っ張る。 • 遅いSQLは早く見つけて撲滅しよう。
62.
62 遅いSQL(標準機能) • スロークエリをログで確認 2015-11-11 19:47:48
JST [7619] LOG: duration: 145.893 ms statement: select count(*) from pgbench_accounts;
63.
63 遅いSQL(ツール活用) • auto_explainで遅いSQLの実行計画を 自動でログ記録 2015-11-11 19:47:48
JST [7619] LOG: duration: 92.204 ms plan: Query Text: select count(*) from pgbench_accounts; Aggregate (cost=29182.66..29182.67 rows=1 width=0) -> Seq Scan on pgbench_accounts (cost=0.00..26681.53 rows=1000453 width=0)
64.
64 遅いSQL(ツール活用) • pg_stat_statementsでデータベース全体 への影響が大きいSQLを確認 – トータルの実行時間が長いSQL – 実行回数が多いSQL postgres=# SELECT
datname,SUBSTRING(query,1,40) AS query,calls, TRUNC(total_time::numeric,3) AS total_time FROM pg_stat_statements LEFT OUTER JOIN pg_database ON pg_stat_statements.dbid = pg_database.oid WHERE datname = 'testdb' ORDER BY total_time DESC LIMIT 5; datname | query | calls | total_time ---------+-------------------------------------------------+-------+------------ testdb | UPDATE pgbench_accounts SET abalance = a | 12755 | 14088.258 testdb | select count(*) from pgbench_accounts; | 3 | 5740.594 testdb | SELECT c.oid AS relid, c.relnamespace, | 53 | 642.248 testdb | UPDATE pgbench_tellers SET tbalance = tb | 12755 | 386.210 testdb | UPDATE pgbench_branches SET bbalance = b | 12755 | 248.036
65.
65 遅いSQL(ツール活用) • サーバログをpgBadgerで集計 – Perlスクリプトとして実装 – サーバログを指定して実行すると、ログを 分析したレポートをHTMLファイルで作成 – 永安さんの資料が詳しい。 • pgBadgerでSQLログを分析する http://pgsqldeepdive.blogspot.jp/2012/12/pgbadgersql.html
66.
66 PostgreSQLのログについて考える
67.
67 なぜそのままではダメか? • ログをルーティングする機能がない。 – なんでも1つのログファイルに吐き出す。 – PostgreSQLサーバが起動できないような 深刻なエラーメッセージとスロークエリログ が混在する。 • 深刻度/使い道が異なるものがごちゃまぜ。 – エラーレベルやカテゴリで分けられないので、 ログから見たい情報を探すのが面倒 – grepするのが関の山。。。
68.
68 file_fdw • FDW: 外部データラッパ – DB外部のデータへ通常の表と同様にアクセス – 花田さんの資料が詳しい。 •
外部データラッパによるPostgreSQLの拡張 http://www.slideshare.net/babystarmonja/postgre-sql-11764943 • file_fdw: 外部ファイルをテーブル化 – サーバのファイルシステムにある データファイルにアクセス – COPY FROMで読み込み可能なフォーマット に対応(CSV、タブ区切り等) – 9.1からcontribとして配布されている。
69.
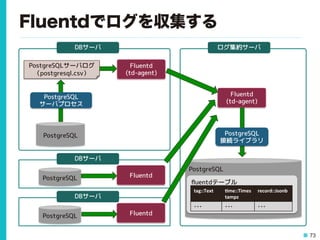
69 file_fdwでログを外部テーブル化 • CSVログを外部テーブル化してアクセス testdb=# CREATE
EXTENSION file_fdw; testdb=# CREATE SERVER pglog FOREIGN DATA WRAPPER file_fdw; testdb=# CREATE FOREIGN TABLE pglog (log_time timestamp(3) with time zone, testdb(# user_name text, database_name text, process_id integer, testdb(# connection_from text, session_id text, session_line_num bigint, testdb(# command_tag text, session_start_time timestamp with time zone, testdb(# virtual_transaction_id text, transaction_id bigint, error_severity text, testdb(# sql_state_code text, message text,detail text, hint text, testdb(# internal_query text, internal_query_pos integer, context text, testdb(# query text,query_pos integer, location text,application_name text testdb(# ) SERVER pglog testdb-# OPTIONS (filename '/var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.csv', format 'csv'); testdb=# select log_time,user_name,database_name,process_id,error_severity, message,application_name from pglog where message like 'duration%'; -[ RECORD 1 ]-------+------------------------------------------------------ log_time | 2015-11-06 08:33:31.528+00 user_name | postgres database_name | testdb process_id | 8962 error_severity | LOG message | duration: 5006.931 ms statement: select pg_sleep(5); application_name | psql
70.
70 file_fdwでログを外部テーブル化 • サーバログをSQL文で検索 – 絞込みや並べ替えが可能 • 深刻度,発生時刻,データベース,プロセスNo
etc – テーブルへのロード不要 • 最新のログデータにアクセスが可能 • データベースのサイズが膨らむ心配なし • 複数ログファイルの検索は工夫が必要 – ローテーションによるログファイルの切替 – ファイル名を固定化(例:曜日単位) • postgresql-Sun.csv,postgresql-Mon.csv ... – 9.5から外部テーブルの継承をサポート • 複数ログテーブルのパーティション化も可能に
71.
71 Fluentdで加工したログを収集 • file_fdwで検索するにはこんな点が不足 – ログの種別を持っていない • スロークエリ,チェックポイント,デッドロックetc – ログファイル毎に1テーブル •
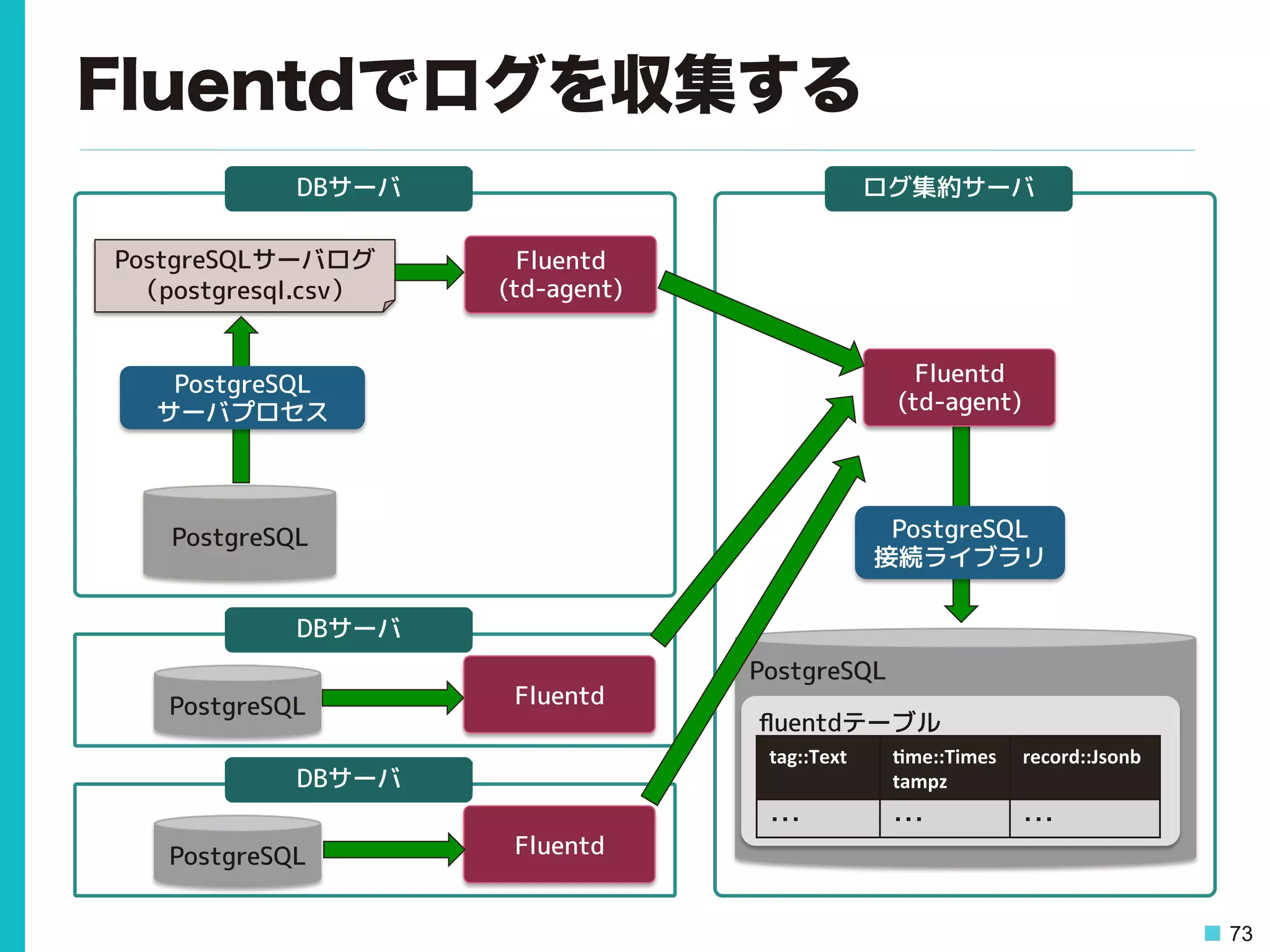
複数サーバのログをまとめたい • 種別が違うログは分けて管理したい – ログメッセージに含まれる値を使いたい • スロークエリのduration、statement • Fluentdで検索しやすい形にログを加工 – 詳しくはOSC 2015 Hokkaidoの資料を参照 http://www.ospn.jp/osc2015-do/pdf/OSC2015_do_tis.pdf
72.
72 Fluentd • Fluentdとは – http://www.fluentd.org/ – 軽量でプラガブルなログ収集ツール – Apache
License Version 2.0 • Fluentdの特徴 – ログ管理を3つの層に分けて管理 • インプット、バッファ、アウトプット – 各層がプラガブルなアーキテクチャ • 用途に応じたプラグインを追加するだけで使える
73.
73 Fluentdでログを収集する PostgreSQL Fluentd (td-agent) DBサーバ PostgreSQL サーバプロセス PostgreSQLサーバログ (postgresql.csv) PostgreSQL 接続ライブラリ DBサーバ PostgreSQL DBサーバ Fluentd PostgreSQL Fluentd ログ集約サーバ Fluentd (td-agent) PostgreSQL fluentdテーブル tag::Text (me::Times tampz record::Jsonb ・・・
・・・ ・・・
74.
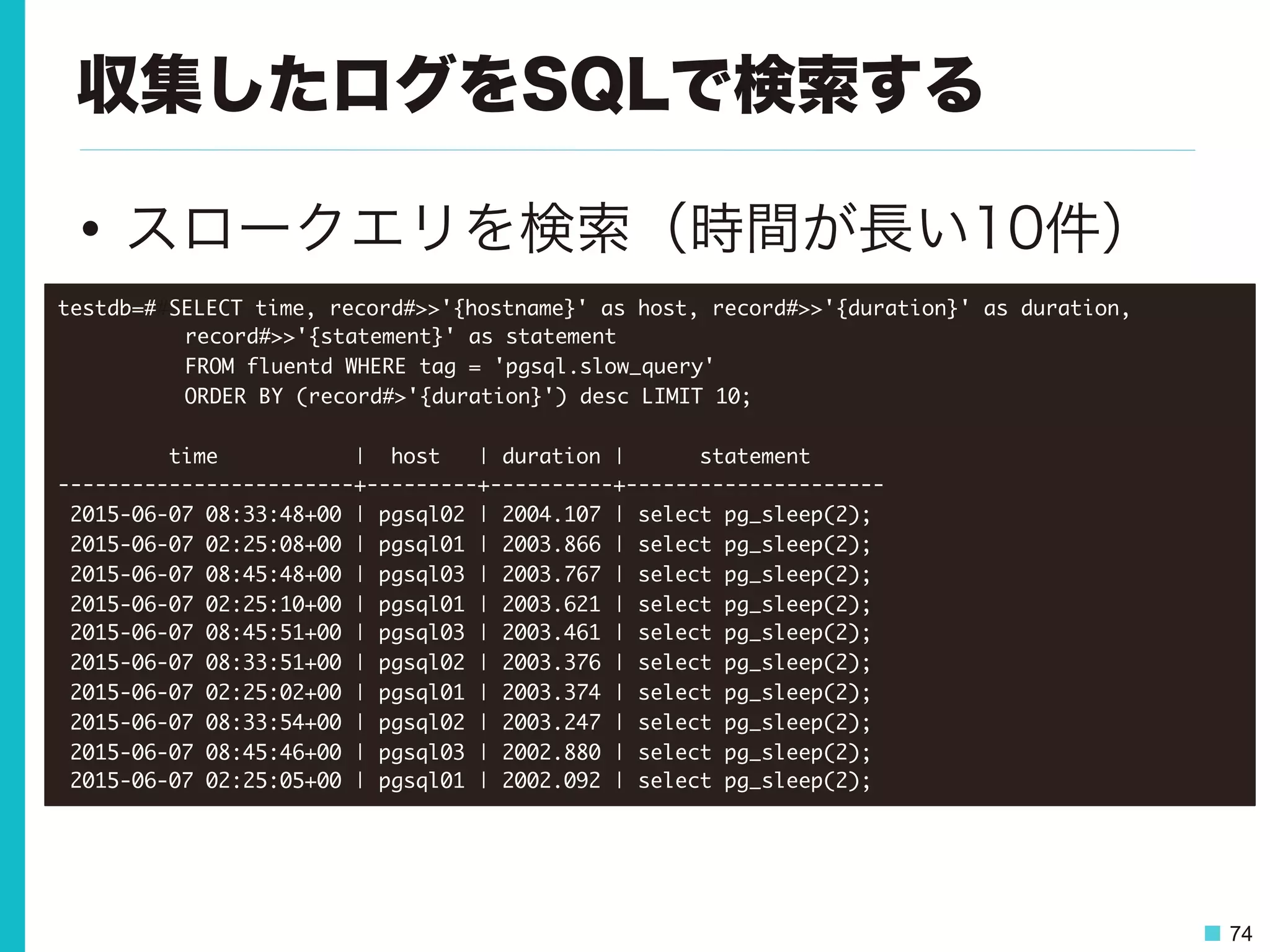
74 収集したログをSQLで検索する • スロークエリを検索(時間が長い10件) testdb=##SELECT time,
record#>>'{hostname}' as host, record#>>'{duration}' as duration, record#>>'{statement}' as statement FROM fluentd WHERE tag = 'pgsql.slow_query' ORDER BY (record#>'{duration}') desc LIMIT 10; time | host | duration | statement ------------------------+---------+----------+--------------------- 2015-06-07 08:33:48+00 | pgsql02 | 2004.107 | select pg_sleep(2); 2015-06-07 02:25:08+00 | pgsql01 | 2003.866 | select pg_sleep(2); 2015-06-07 08:45:48+00 | pgsql03 | 2003.767 | select pg_sleep(2); 2015-06-07 02:25:10+00 | pgsql01 | 2003.621 | select pg_sleep(2); 2015-06-07 08:45:51+00 | pgsql03 | 2003.461 | select pg_sleep(2); 2015-06-07 08:33:51+00 | pgsql02 | 2003.376 | select pg_sleep(2); 2015-06-07 02:25:02+00 | pgsql01 | 2003.374 | select pg_sleep(2); 2015-06-07 08:33:54+00 | pgsql02 | 2003.247 | select pg_sleep(2); 2015-06-07 08:45:46+00 | pgsql03 | 2002.880 | select pg_sleep(2); 2015-06-07 02:25:05+00 | pgsql01 | 2002.092 | select pg_sleep(2);
75.
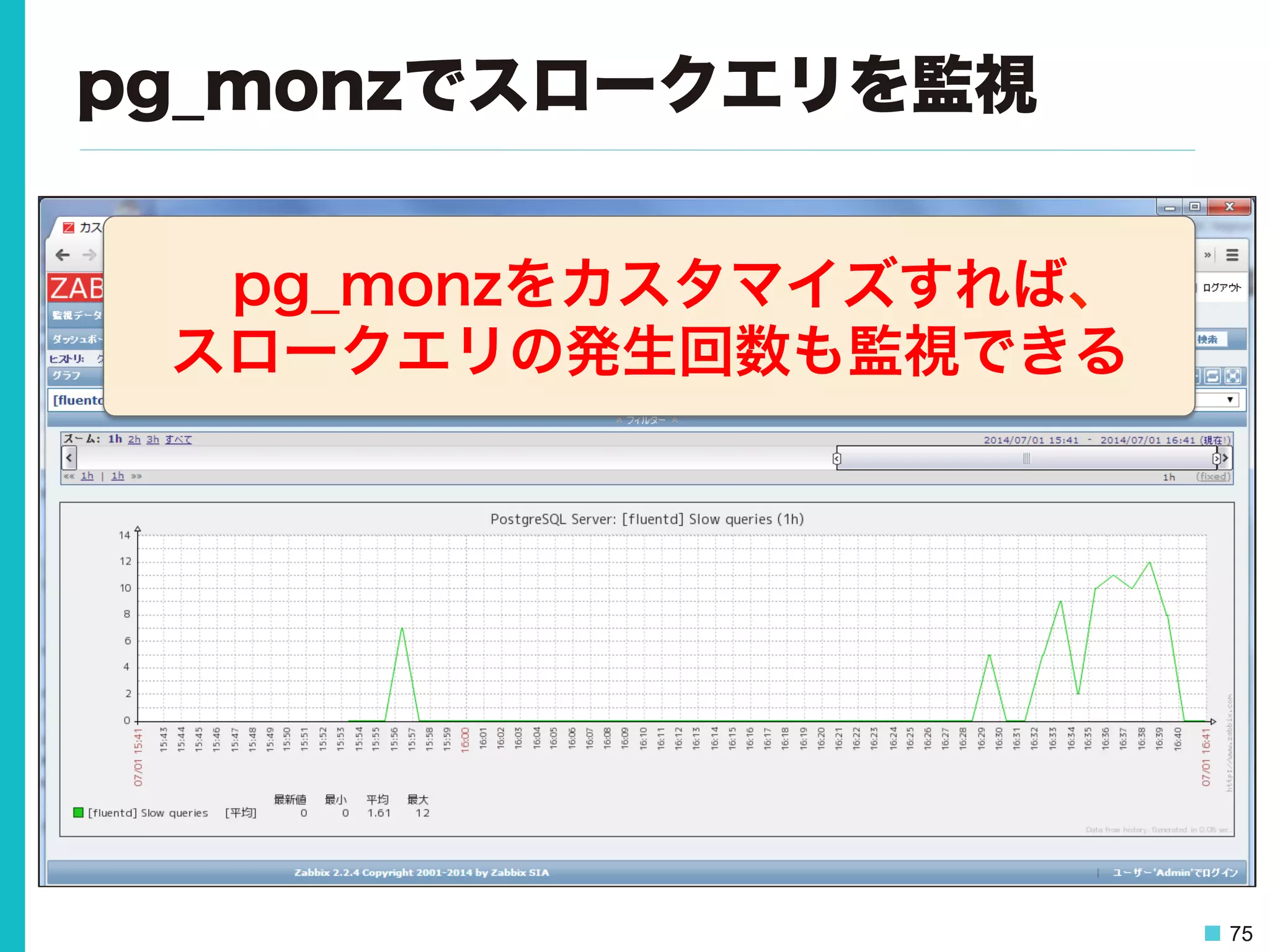
75 pg_monzでスロークエリを監視 pg_monzをカスタマイズすれば、 スロークエリの発生回数も監視できる
76.
76 まとめ
77.
77 監視の観点を理解しよう • 救急患者レベル • レントゲンに怪しい影が、、レベル •
体力測定レベル • 腐ったミカン = 遅いSQL
78.
78 ツールをうまく組み合わせよう • pg_monzは「監視」ツール – 発生した問題に即座にアクションを起こす。 – 性能分析に使う情報「も」集められる。 • pg_statsinfoは「性能分析」ツール – 過去時点の情報をひとまず保管しておき、 後でゆっくりと問題を分析する。 – 発生した問題に対するアクションは、 別の監視ツールに任せる。 •
PostgreSQLのサーバログ – 障害メッセージは監視ツールで素早く検出 – 後で分析するログはFluentdで収集
79.
79 pg_monz をよろしくおねがいします • 入手先や使い方 http://pg-monz.github.io/pg_monz/ •
問い合わせ – pg_monz ユーザーグループ pg_monz@googlegroups.com • 試行環境を自動構築するAnsible Playbook等をGitHubから入手できます。 https://github.com/tech-sketch/pg_monz-trial • フィードバックをお待ちしています。
Download

























![33
データベース容量(標準機能)
• データベースクラスタのディレクトリを
duコマンドで確認
• 関数で確認
[postgres@pgsql01 9.4]$ du -sh data
611M
data
postgres=# select pg_size_pretty(pg_database_size(‘testdb’)); ★データベース
pg_size_pretty
----------------
171 MB
testdb=# select pg_size_pretty(pg_table_size(‘pgbench_accounts’)); ★テーブル
pg_size_pretty
----------------
130 MB](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-33-320.jpg)

![36
WALアーカイブ(標準機能)
• pg_stat_archiverビューで確認(9.4以降)
postgres=# select * from pg_stat_archiver;
-[ RECORD 1 ]------+------------------------------
archived_count | 12
last_archived_wal | 00000001000000000000000E
last_archived_time | 2015-11-11 10:10:50.629021+00
failed_count | 6
last_failed_wal | 000000010000000000000008
last_failed_time | 2015-11-11 10:05:52.719825+00
stats_reset | 2015-11-06 08:10:16.027035+00](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-36-320.jpg)
![37
デッドロック(標準機能)
• デッドロック発生をログで確認
– log_lock_waitsパラメータを設定して出力
• pg_stat_databaseビューで確認
2015-11-12 14:52:07 JST [10382] LOG: process 10382 detected deadlock while waiting for
AccessExclusiveLock on relation 16420 of database 16400 after 1000.088 ms
postgres=# SELECT datname,deadlocks FROM pg_stat_database where datname = 'testdb';
datname | deadlocks
---------+-----------
testdb | 2](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-37-320.jpg)






![44
データベースのスループット(標準機能)
• pg_stat_databaseビューで確認
– 取得できるのは累積値
– 実際に利用するには単位秒あたりの
差分値を計算する等の工夫が必要
postgres=# select datname,xact_commit,xact_rollback
from pg_stat_database where datname = 'testdb';
-[ RECORD 1 ]-+-------
datname | testdb
xact_commit | 17727
xact_rollback | 4](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-44-320.jpg)




![53
チェックポイント(標準機能)
• ログを確認
– log_checkpointsパラメータを設定して出力
• pg_stat_bgwriterビューで確認
testdb=# SELECT checkpoints_timed,checkpoints_req,checkpoint_write_time,
checkpoint_sync_time,buffers_checkpoint from pg_stat_bgwriter;
-[ RECORD 1 ]---------+--------
checkpoints_timed | 568
checkpoints_req | 0
checkpoint_write_time | 1343894
checkpoint_sync_time | 2062
buffers_checkpoint | 38659
2015-11-12 13:37:53 JST [7602] LOG: checkpoint starting: time
2015-11-12 13:42:23 JST [7602] LOG: checkpoint complete: wrote 7418 buffers (45.3%);
0 transaction log file(s) added, 0 removed, 0 recycled;
write=269.201 s, sync=0.421 s, total=269.685 s; sync files=17, longest=0.418 s,
average=0.024 s
2015-11-12 17:49:22 JST [10679] LOG: checkpoints are occurring too frequently (25
seconds apart)](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-53-320.jpg)


![56
VACUUM(標準機能)
• ログを確認
– log_autovacuum_min_durationパラメータ
を設定して出力
• pg_stat_user_tablesビューで確認
2015-11-12 13:36:30 JST [10188] LOG: automatic vacuum of table
"testdb.public.pgbench_tellers": index scans: 0 pages: 0 removed, 25 remain
tuples: 533 removed, 100 remain, 0 are dead but not yet removable
buffer usage: 86 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU 0.00s/0.00u sec elapsed 0.00 sec
testdb=# SELECT relname,n_live_tup,n_dead_tup,last_autovacuum,autovacuum_count
FROM pg_stat_user_tables where relname = 'pgbench_accounts';
-[ RECORD 1 ]----+------------------------------
relname | pgbench_accounts
n_live_tup | 1002477
n_dead_tup | 0
last_autovacuum | 2015-11-12 17:50:26.224429+09
autovacuum_count | 1](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-56-320.jpg)

![59
一時ファイルの書き出し(標準機能)
• ログを確認
– log_temp_filesパラメータを設定して出力
• pg_stat_databaseビューで確認
2015-11-11 20:52:33 JST [7801] LOG: temporary file: path "base/pgsql_tmp/
pgsql_tmp7801.1", size 53157
2015-11-11 20:52:33 JST [7801] STATEMENT: select * from pg_settings where
name = 'log_temp_files';
postgres=# select datname,temp_files,temp_bytes from pg_stat_database
where datname = 'testdb';
-[ RECORD 1 ]--------
datname | testdb
temp_files | 1
temp_bytes | 14016512](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-59-320.jpg)


![62
遅いSQL(標準機能)
• スロークエリをログで確認
2015-11-11 19:47:48 JST [7619] LOG: duration: 145.893 ms statement:
select count(*) from pgbench_accounts;](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-62-320.jpg)
![63
遅いSQL(ツール活用)
• auto_explainで遅いSQLの実行計画を
自動でログ記録
2015-11-11 19:47:48 JST [7619] LOG: duration: 92.204 ms plan:
Query Text: select count(*) from pgbench_accounts;
Aggregate (cost=29182.66..29182.67 rows=1 width=0)
-> Seq Scan on pgbench_accounts (cost=0.00..26681.53
rows=1000453 width=0)](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-63-320.jpg)





![69
file_fdwでログを外部テーブル化
• CSVログを外部テーブル化してアクセス
testdb=# CREATE EXTENSION file_fdw;
testdb=# CREATE SERVER pglog FOREIGN DATA WRAPPER file_fdw;
testdb=# CREATE FOREIGN TABLE pglog (log_time timestamp(3) with time zone,
testdb(# user_name text, database_name text, process_id integer,
testdb(# connection_from text, session_id text, session_line_num bigint,
testdb(# command_tag text, session_start_time timestamp with time zone,
testdb(# virtual_transaction_id text, transaction_id bigint, error_severity text,
testdb(# sql_state_code text, message text,detail text, hint text,
testdb(# internal_query text, internal_query_pos integer, context text,
testdb(# query text,query_pos integer, location text,application_name text
testdb(# ) SERVER pglog
testdb-# OPTIONS (filename '/var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.csv',
format 'csv');
testdb=# select log_time,user_name,database_name,process_id,error_severity,
message,application_name from pglog where message like 'duration%';
-[ RECORD 1 ]-------+------------------------------------------------------
log_time
| 2015-11-06 08:33:31.528+00
user_name
| postgres
database_name
| testdb
process_id
| 8962
error_severity
| LOG
message
| duration: 5006.931 ms statement: select pg_sleep(5);
application_name
| psql](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/85/PostgreSQL-69-320.jpg)





























![33
データベース容量(標準機能)
• データベースクラスタのディレクトリを
duコマンドで確認
• 関数で確認
[postgres@pgsql01 9.4]$ du -sh data
611M
data
postgres=# select pg_size_pretty(pg_database_size(‘testdb’)); ★データベース
pg_size_pretty
----------------
171 MB
testdb=# select pg_size_pretty(pg_table_size(‘pgbench_accounts’)); ★テーブル
pg_size_pretty
----------------
130 MB](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-33-2048.jpg)

![36
WALアーカイブ(標準機能)
• pg_stat_archiverビューで確認(9.4以降)
postgres=# select * from pg_stat_archiver;
-[ RECORD 1 ]------+------------------------------
archived_count | 12
last_archived_wal | 00000001000000000000000E
last_archived_time | 2015-11-11 10:10:50.629021+00
failed_count | 6
last_failed_wal | 000000010000000000000008
last_failed_time | 2015-11-11 10:05:52.719825+00
stats_reset | 2015-11-06 08:10:16.027035+00](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-36-2048.jpg)
![37
デッドロック(標準機能)
• デッドロック発生をログで確認
– log_lock_waitsパラメータを設定して出力
• pg_stat_databaseビューで確認
2015-11-12 14:52:07 JST [10382] LOG: process 10382 detected deadlock while waiting for
AccessExclusiveLock on relation 16420 of database 16400 after 1000.088 ms
postgres=# SELECT datname,deadlocks FROM pg_stat_database where datname = 'testdb';
datname | deadlocks
---------+-----------
testdb | 2](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-37-2048.jpg)






![44
データベースのスループット(標準機能)
• pg_stat_databaseビューで確認
– 取得できるのは累積値
– 実際に利用するには単位秒あたりの
差分値を計算する等の工夫が必要
postgres=# select datname,xact_commit,xact_rollback
from pg_stat_database where datname = 'testdb';
-[ RECORD 1 ]-+-------
datname | testdb
xact_commit | 17727
xact_rollback | 4](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-44-2048.jpg)




![53
チェックポイント(標準機能)
• ログを確認
– log_checkpointsパラメータを設定して出力
• pg_stat_bgwriterビューで確認
testdb=# SELECT checkpoints_timed,checkpoints_req,checkpoint_write_time,
checkpoint_sync_time,buffers_checkpoint from pg_stat_bgwriter;
-[ RECORD 1 ]---------+--------
checkpoints_timed | 568
checkpoints_req | 0
checkpoint_write_time | 1343894
checkpoint_sync_time | 2062
buffers_checkpoint | 38659
2015-11-12 13:37:53 JST [7602] LOG: checkpoint starting: time
2015-11-12 13:42:23 JST [7602] LOG: checkpoint complete: wrote 7418 buffers (45.3%);
0 transaction log file(s) added, 0 removed, 0 recycled;
write=269.201 s, sync=0.421 s, total=269.685 s; sync files=17, longest=0.418 s,
average=0.024 s
2015-11-12 17:49:22 JST [10679] LOG: checkpoints are occurring too frequently (25
seconds apart)](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-53-2048.jpg)


![56
VACUUM(標準機能)
• ログを確認
– log_autovacuum_min_durationパラメータ
を設定して出力
• pg_stat_user_tablesビューで確認
2015-11-12 13:36:30 JST [10188] LOG: automatic vacuum of table
"testdb.public.pgbench_tellers": index scans: 0 pages: 0 removed, 25 remain
tuples: 533 removed, 100 remain, 0 are dead but not yet removable
buffer usage: 86 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU 0.00s/0.00u sec elapsed 0.00 sec
testdb=# SELECT relname,n_live_tup,n_dead_tup,last_autovacuum,autovacuum_count
FROM pg_stat_user_tables where relname = 'pgbench_accounts';
-[ RECORD 1 ]----+------------------------------
relname | pgbench_accounts
n_live_tup | 1002477
n_dead_tup | 0
last_autovacuum | 2015-11-12 17:50:26.224429+09
autovacuum_count | 1](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-56-2048.jpg)

![59
一時ファイルの書き出し(標準機能)
• ログを確認
– log_temp_filesパラメータを設定して出力
• pg_stat_databaseビューで確認
2015-11-11 20:52:33 JST [7801] LOG: temporary file: path "base/pgsql_tmp/
pgsql_tmp7801.1", size 53157
2015-11-11 20:52:33 JST [7801] STATEMENT: select * from pg_settings where
name = 'log_temp_files';
postgres=# select datname,temp_files,temp_bytes from pg_stat_database
where datname = 'testdb';
-[ RECORD 1 ]--------
datname | testdb
temp_files | 1
temp_bytes | 14016512](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-59-2048.jpg)


![62
遅いSQL(標準機能)
• スロークエリをログで確認
2015-11-11 19:47:48 JST [7619] LOG: duration: 145.893 ms statement:
select count(*) from pgbench_accounts;](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-62-2048.jpg)
![63
遅いSQL(ツール活用)
• auto_explainで遅いSQLの実行計画を
自動でログ記録
2015-11-11 19:47:48 JST [7619] LOG: duration: 92.204 ms plan:
Query Text: select count(*) from pgbench_accounts;
Aggregate (cost=29182.66..29182.67 rows=1 width=0)
-> Seq Scan on pgbench_accounts (cost=0.00..26681.53
rows=1000453 width=0)](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-63-2048.jpg)





![69
file_fdwでログを外部テーブル化
• CSVログを外部テーブル化してアクセス
testdb=# CREATE EXTENSION file_fdw;
testdb=# CREATE SERVER pglog FOREIGN DATA WRAPPER file_fdw;
testdb=# CREATE FOREIGN TABLE pglog (log_time timestamp(3) with time zone,
testdb(# user_name text, database_name text, process_id integer,
testdb(# connection_from text, session_id text, session_line_num bigint,
testdb(# command_tag text, session_start_time timestamp with time zone,
testdb(# virtual_transaction_id text, transaction_id bigint, error_severity text,
testdb(# sql_state_code text, message text,detail text, hint text,
testdb(# internal_query text, internal_query_pos integer, context text,
testdb(# query text,query_pos integer, location text,application_name text
testdb(# ) SERVER pglog
testdb-# OPTIONS (filename '/var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.csv',
format 'csv');
testdb=# select log_time,user_name,database_name,process_id,error_severity,
message,application_name from pglog where message like 'duration%';
-[ RECORD 1 ]-------+------------------------------------------------------
log_time
| 2015-11-06 08:33:31.528+00
user_name
| postgres
database_name
| testdb
process_id
| 8962
error_severity
| LOG
message
| duration: 5006.931 ms statement: select pg_sleep(5);
application_name
| psql](https://image.slidesharecdn.com/jwdzcysbsdq7u9rproal-signature-14bf6cbc45ac7063e72309c1d4f4025b443768b11490bf1700e3b050e9dfb932-poli-151128001859-lva1-app6891/75/PostgreSQL-69-2048.jpg)





































































![[よくわかるクラウドデータベース] Amazon RDS for PostgreSQL検証報告](https://cdn.slidesharecdn.com/ss_thumbnails/20140117rdsforpgsqlbenchreport-140216194106-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














